8월부터 9월 초 사이 클로드 응답 품질을 간헐적으로 떨어뜨린 세 가지 인프라 버그의 원인, 영향, 해결 과정과 재발 방지 대책을 공유합니다.
최근 8월부터 9월 초 사이, 세 가지 인프라 버그가 간헐적으로 클로드의 응답 품질을 저하시켰습니다. 현재는 모두 해결되었으며, 무엇이 있었는지 설명드립니다.
8월 초, 일부 사용자들이 클로드의 응답 품질 저하를 보고하기 시작했습니다. 초기 보고들은 사용자 피드백의 정상적인 변동성과 구분하기 어려웠습니다. 하지만 8월 말에는 보고 빈도와 지속성이 높아져 조사를 시작했고, 그 과정에서 서로 다른 세 가지 인프라 버그를 발견했습니다.
명확히 말씀드리면: 저희는 수요, 시간대, 서버 부하 때문에 모델 품질을 낮추지 않습니다. 사용자들이 보고한 문제는 전적으로 인프라 버그 때문이었습니다.
사용자들은 클로드가 일관된 품질을 제공하기를 기대하며, 저희는 인프라 변경이 모델 출력에 영향을 주지 않도록 매우 높은 기준을 유지합니다. 이번 사건들에서는 그 기준에 미치지 못했습니다. 아래 포스트모템에서는 무엇이 잘못되었는지, 탐지와 해결이 기대보다 오래 걸린 이유, 그리고 유사한 사건을 방지하기 위해 무엇을 바꾸고 있는지를 설명합니다.
평소에는 인프라에 대한 이 정도의 기술적 세부사항을 공유하지 않지만, 이번 이슈들의 범위와 복잡성은 보다 포괄적인 설명을 정당화했습니다.
클로드는 자사 API, Amazon Bedrock, Google Cloud의 Vertex AI를 통해 수백만 사용자에게 제공됩니다. AWS Trainium, NVIDIA GPU, Google TPU 등 복수의 하드웨어 플랫폼에 배포합니다. 이 접근법은 전 세계 사용자에게 서비스를 제공하는 데 필요한 용량과 지리적 분산을 보장합니다.
각 하드웨어 플랫폼은 특성이 달라 특정 최적화가 필요합니다. 그럼에도 저희는 모델 구현에 대해 엄격한 동등성 기준을 둡니다. 어떤 플랫폼이 요청을 처리하더라도 사용자가 동일한 품질의 응답을 받도록 하는 것이 목표입니다. 이러한 복잡성 때문에 인프라 변경 시 모든 플랫폼과 구성에서 주의 깊은 검증이 필요합니다.
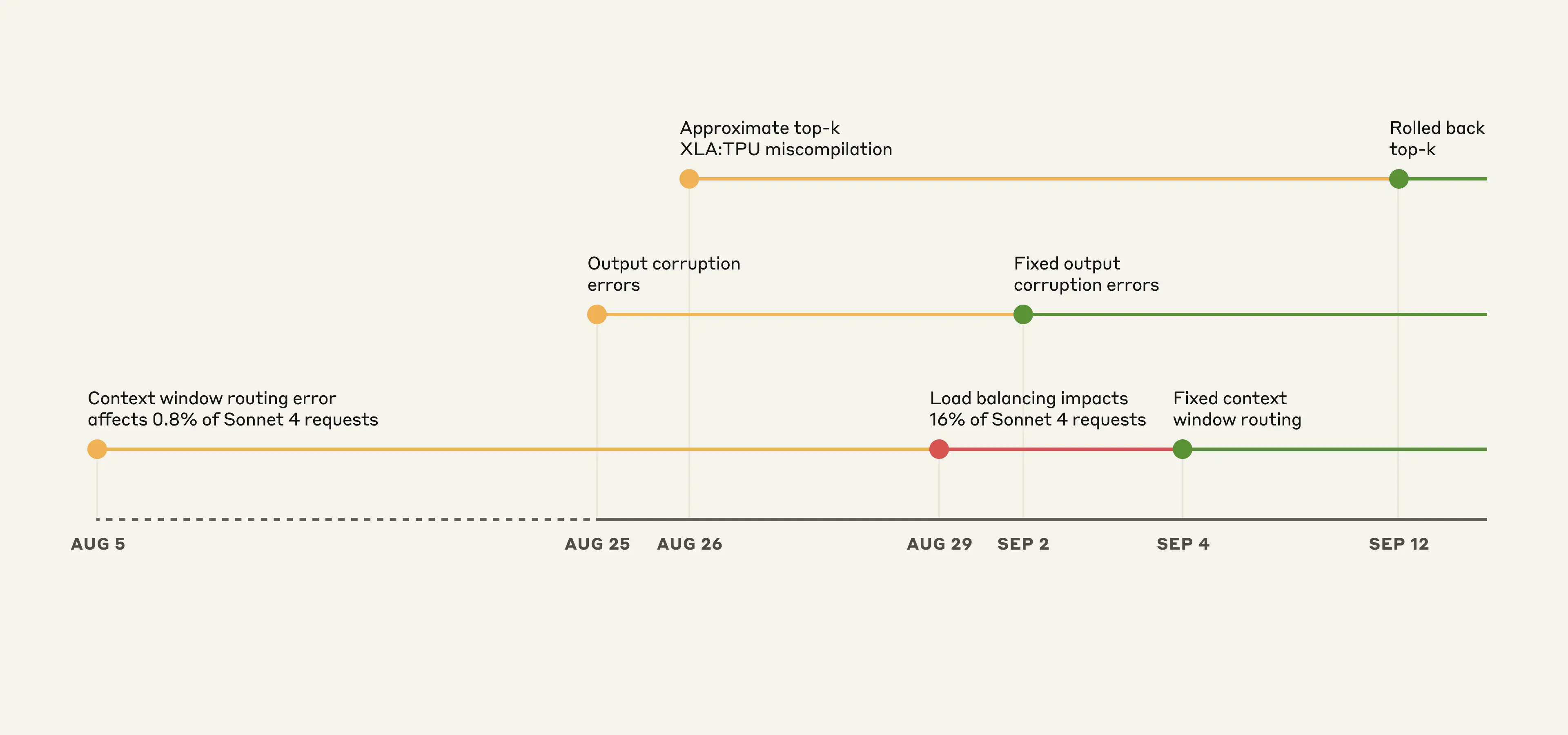
Claude API에서의 사건 타임라인 예시. 노란색: 문제 탐지, 빨간색: 품질 저하 심화, 초록색: 수정 배포.
이 버그들이 서로 겹쳐 나타나 진단이 특히 어려웠습니다. 첫 번째 버그는 8월 5일에 도입되어 Sonnet 4 요청의 약 0.8%에 영향을 주었습니다. 이후 8월 25일과 26일의 배포로 두 개의 버그가 추가로 발생했습니다.
초기 영향은 제한적이었지만, 8월 29일의 부하 분산 변경으로 영향받는 트래픽이 증가하기 시작했습니다. 그 결과 더 많은 사용자가 문제를 겪는 한편, 다른 사용자들은 정상적인 성능을 계속 경험하며 혼란스럽고 상반된 보고가 생성되었습니다.
아래는 품질 저하를 유발한 세 가지 버그, 발생 시점, 해결 방법입니다.
8월 5일, 일부 Sonnet 4 요청이 예정 중이던 1M 토큰컨텍스트 윈도우용 서버로 잘못 라우팅되었습니다. 이 버그는 처음에는 요청의 0.8%에 영향을 주었습니다. 8월 29일의 일상적인 부하 분산 변경으로 인해 단기 컨텍스트 요청이 1M 컨텍스트 서버로 더 많이 라우팅되는 문제가 생겼습니다. 8월 31일 가장 영향이 컸던 시간대에는 Sonnet 4 요청의 16%가 영향을 받았습니다.
해당 기간 동안 요청을 보낸 Claude Code 사용자 중 약 30%는 최소 한 번 이상 잘못된 서버 유형으로 라우팅되어 열화된 응답을 받았습니다. Amazon Bedrock에서는 8월 12일부터 Sonnet 4 전체 요청의 0.18%에서 오라우팅이 정점에 달했습니다. Google Cloud의 Vertex AI에서는 8월 27일부터 9월 16일 사이 전체 요청의 0.0004% 미만에만 잘못된 라우팅이 발생했습니다.
다만, 라우팅이 "스티키(sticky)"하게 동작하기 때문에 일부 사용자는 더 심각한 영향을 받았습니다. 한 번 잘못된 서버가 요청을 처리하면, 이후 후속 요청도 같은 잘못된 서버로 전달될 가능성이 높았습니다.
해결: 단기/장기 컨텍스트 요청이 올바른 서버 풀로 전달되도록 라우팅 로직을 수정했습니다. 수정은 9월 4일 배포했으며, 자사 플랫폼과 Google Cloud의 Vertex에는 9월 16일까지 롤아웃을 완료했습니다. Bedrock에는 현재 롤아웃 중입니다.
8월 25일, Claude API의 TPU 서버에 잘못 구성된 설정이 배포되어 토큰 생성 중 오류가 발생했습니다. 런타임 성능 최적화로 인한 이슈로, 맥락상 거의 등장하지 않아야 할 토큰에 높은 확률이 부여되는 경우가 간헐적으로 발생했습니다. 예를 들어 영어 프롬프트에 태국어나 중국어 문자가 출력되거나, 코드에서 명백한 구문 오류가 발생하는 식입니다. 영어로 질문한 일부 사용자는 응답 중간에 예컨대 "สวัสดี" 같은 문자열을 봤을 수도 있습니다.
이 손상은 8월 25–28일에는 Opus 4.1과 Opus 4 요청에, 8월 25일–9월 2일에는 Sonnet 4 요청에 영향을 주었습니다. 서드파티 플랫폼에는 영향을 주지 않았습니다.
해결: 문제를 확인하고 9월 2일 해당 변경을 롤백했습니다. 배포 과정에 예상치 못한 문자 출력에 대한 감지 테스트를 추가했습니다.
8월 25일, 텍스트 생성 중 토큰 선택 방식을 개선하는 코드를 배포했습니다. 이 변경이 XLA:TPU[1] 컴파일러의 잠재 버그를 우발적으로 촉발했고, Claude Haiku 3.5 요청에 영향을 준 것이 확인되었습니다.
또한 Claude API의 Sonnet 4와 Opus 3 일부에도 영향을 주었을 가능성이 있다고 판단했습니다. 서드파티 플랫폼에는 영향을 주지 않았습니다.
해결: 먼저 Haiku 3.5에서 영향을 관측하고 9월 4일 롤백했습니다. 이후 사용자 보고 중 Opus 3에서 해당 버그와 양상이 일치하는 사례를 확인해 9월 12일 롤백했습니다. 장기간 조사했지만 Sonnet 4에서는 재현하지 못했으나, 예방적 차원에서 동일 변경을 롤백했습니다.
동시에 (a) XLA:TPU 팀과 협력해 컴파일러 버그 수정에 참여하고, (b) 향상된 정밀도의 정확한 top-k를 사용하도록 수정사항을 롤아웃했습니다. 자세한 내용은 아래 심층 설명을 참고하세요.
이슈의 복잡성을 보여주기 위해, XLA 컴파일러 버그가 어떻게 나타났고 왜 진단이 특히 어려웠는지 설명합니다.
클로드가 텍스트를 생성할 때, 가능한 다음 단어 각각에 대한 확률을 계산한 뒤 이 확률 분포에서 무작위로 샘플을 선택합니다. 비상식적인 출력을 피하기 위해 "top-p 샘플링"을 사용합니다. 누적 확률이 특정 임계치(보통 0.99 또는 0.999)에 도달할 때까지의 단어만 고려합니다. TPU에서는 모델이 여러 칩에 걸쳐 실행되며, 확률 계산도 서로 다른 위치에서 이루어집니다. 이 확률을 정렬하려면 칩 간 데이터를 조율해야 하는데, 이 과정이 복잡합니다.[2]
2024년 12월, TPU 구현에서 온도(temperature)가 0일 때 최확률 토큰이 간헐적으로 누락되는 현상을 발견했습니다. 이 경우를 해결하기 위한 우회책을 배포했습니다.

temperature = 0일 때 예기치 않게 토큰이 누락되는 버그를 우회하기 위한 2024년 12월 패치의 코드 스니펫.
근본 원인은 혼합 정밀도 산술에 있었습니다. 다음 토큰 확률은 bf16 (16비트 부동소수점)로 계산합니다. 하지만 벡터 프로세서는 fp32-native이므로, TPU 컴파일러(XLA)는 일부 연산을 fp32(32비트)로 변환해 런타임을 최적화할 수 있습니다. 이 최적화 패스는 기본값이 true인 xla_allow_excess_precision 플래그에 의해 보호됩니다.
이로 인해 불일치가 발생했습니다. 동일한 최확률 토큰에 합의해야 하는 연산들이 서로 다른 정밀도로 수행된 것입니다. 정밀도 불일치 때문에 어떤 토큰이 가장 높은 확률인지에 대해 합의하지 못했고, 그 결과 최확률 토큰이 고려 대상에서 통째로 사라지는 일이 생겼습니다.
8월 26일, 정밀도 문제를 해결하고 top-p 임계치 경계에서 확률을 더 잘 처리하도록 샘플링 코드를 재작성해 배포했습니다. 하지만 이를 고치면서 더 까다로운 문제가 드러났습니다.

8월 11일 변경에 포함된 최소 재현 코드 스니펫으로, 2024년 12월 우회책이 다루던 "버그"의 근본을 보여줍니다. 실제로는 xla_allow_excess_precision 플래그의 기대 동작입니다.
저희 수정으로 12월 우회책을 제거했는데, 근본 원인을 해결했다고 판단했기 때문입니다. 하지만 이로 인해 approximate top-k 연산에서 더 깊은 버그가 노출되었습니다. 이는 가장 높은 확률의 토큰을 빠르게 찾기 위한 성능 최적화입니다.[3] 이 근사 연산은 특정 배치 크기와 모델 구성에서만 완전히 잘못된 결과를 돌려주는 일이 있었습니다. 12월 우회책이 우연히 이 문제를 가리고 있었던 것입니다.
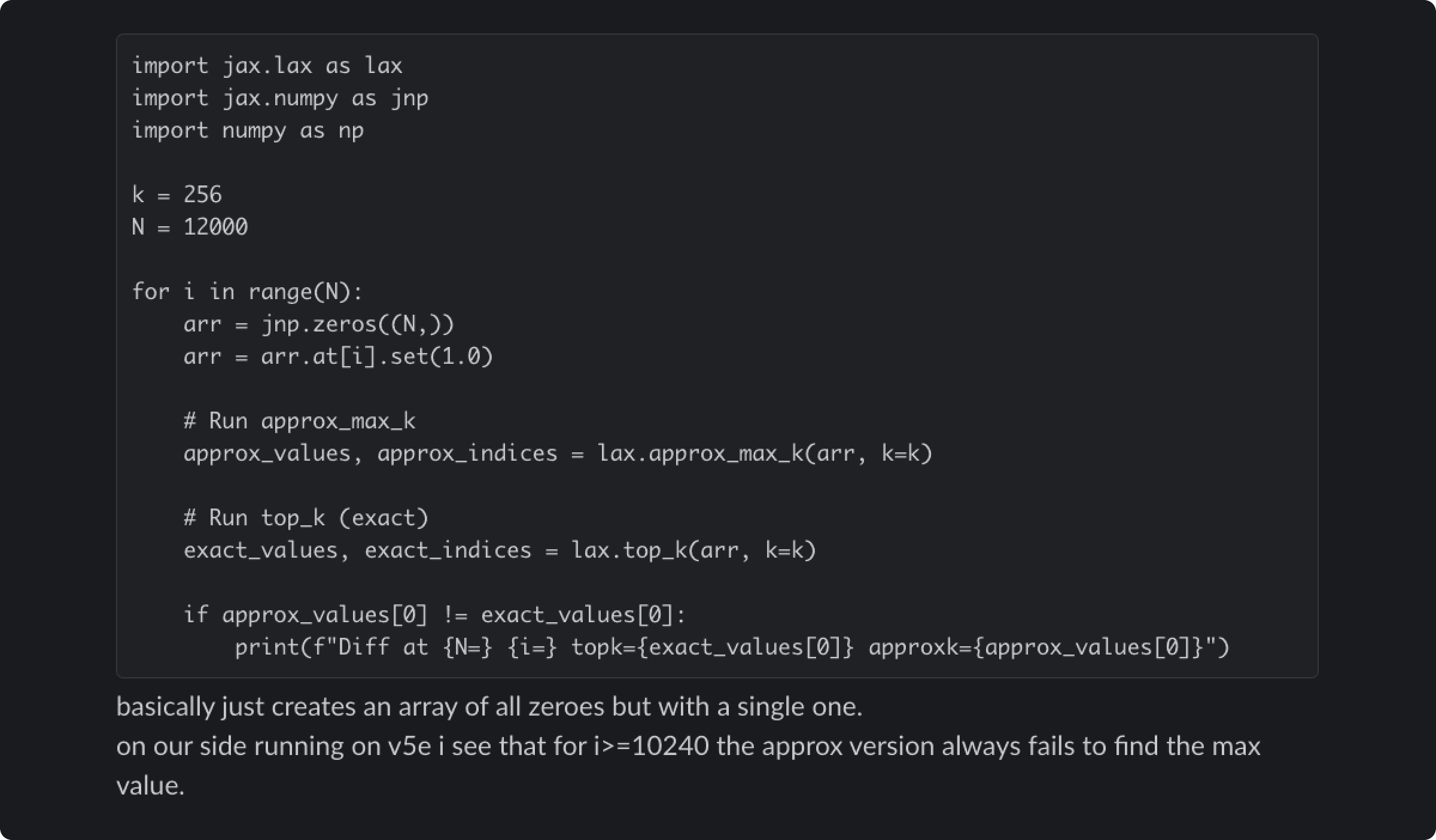
해당 알고리즘을 개발한 XLA:TPU 엔지니어들과 공유한 근본적인 approximate top-k 버그의 재현 코드. CPU에서는 올바른 결과가 나옵니다.
이 버그의 동작은 성가실 만큼 일관성이 없었습니다. 앞뒤로 어떤 연산이 실행되었는지, 디버깅 도구가 활성화되어 있는지 같은 무관해 보이는 요소에 따라 달라졌습니다. 동일한 프롬프트가 한 번의 요청에서는 완벽히 동작하고 다음 요청에서는 실패할 수 있었습니다.
조사 과정에서 정확한 top-k 연산의 성능 페널티가 예전만큼 크지 않다는 것도 확인했습니다. approximate에서 exact top-k로 전환하고, 일부 추가 연산을 fp32 정밀도로 표준화했습니다.[4] 모델 품질은 타협할 수 없기에, 소폭의 효율 저하는 수용했습니다.
저희의 통상적 검증 프로세스는 벤치마크와 안전성 평가, 성능 지표에 의존합니다. 엔지니어링 팀은 수시 점검을 수행하고, 먼저 소규모 "카나리아" 그룹에 배포합니다.
하지만 이번 이슈들은 더 일찍 파악했어야 할 중요한 빈틈을 드러냈습니다. 실행한 평가가 사용자들이 보고한 열화를 충분히 포착하지 못했습니다. 그 이유 중 하나는 클로드가 단발성 오류에서 대체로 잘 회복한다는 점입니다. 또한 저희 자체 프라이버시 관행 때문에 조사에 어려움이 있었습니다. 내부 프라이버시 및 보안 통제는, 특히 피드백으로 신고되지 않은 상호작용에 대해, 엔지니어가 사용자와 클로드 간 상호작용에 접근하는 방식과 시기를 제한합니다. 이는 사용자 프라이버시를 보호하지만, 문제를 파악하거나 재현하는 데 필요한 문제 사례를 엔지니어가 들여다보는 것을 방해합니다.
각 버그가 플랫폼마다, 그리고 서로 다른 속도로 서로 다른 증상을 만들었습니다. 단일 원인을 가리키지 않는 혼란스러운 보고가 섞여 들어왔고, 무작위적이고 일관성 없는 열화처럼 보였습니다.
더 근본적으로는, 잡음이 많은 평가에 과도하게 의존했습니다. 온라인에서 부정적 보고가 늘고 있다는 사실은 인지하고 있었지만, 이를 최근 변경사항 각각과 연결할 명확한 방법이 부족했습니다. 8월 29일 부정적 보고가 급증했을 때에도, 통상적인 부하 분산 변경과 즉시 연결하지 못했습니다.
인프라를 개선해 나가면서, 클로드를 제공하는 모든 플랫폼에서 이번과 같은 버그를 평가하고 예방하는 방식도 개선하고 있습니다. 다음과 같은 변화가 있습니다.
평가와 모니터링은 중요합니다. 하지만 이번 사건은, 클로드의 응답이 평소 수준에 미치지 못할 때 사용자들로부터 지속적인 신호를 받는 것 또한 필요함을 보여줬습니다. 관측된 구체적 변화에 대한 보고, 예상치 못한 행동의 예시, 다양한 사용 사례 전반의 패턴은 저희가 문제를 분리해내는 데 큰 도움이 되었습니다.
사용자 여러분이 계속 직접 피드백을 보내주시면 특히 도움이 됩니다. Claude Code에서는 "/bug" 명령을, 클로드 앱에서는 "엄지손가락 아래(thumbs down)" 버튼을 사용해 주십시오. 개발자와 연구자들은 내부 테스트를 보완하는 새롭고 흥미로운 모델 품질 평가 방법을 종종 고안하곤 합니다. 공유하고 싶으시다면 feedback@anthropic.com으로 연락해 주세요.
커뮤니티의 기여에 깊이 감사드립니다.
[1] XLA:TPU는 XLA 고수준 최적화 언어(보통 JAX로 작성됨)를 TPU 기계어로 변환하는 최적화 컴파일러입니다.
[2] 저희 모델은 단일 칩에 담기에는 너무 커서 수십 개 이상의 칩에 파티셔닝되어, 정렬 연산이 분산 정렬이 됩니다. TPU(및 GPU와 Trainium)는 CPU와 성능 특성이 달라, 직렬 알고리즘 대신 벡터화 연산을 사용하는 다른 구현 기법이 필요합니다.
[3] 이 근사 연산은 상당한 성능 향상을 제공해 사용해 왔습니다. 근사는 가장 낮은 확률 토큰에서의 잠재적 부정확성을 허용하는데, 이는 품질에 영향을 주지 않아야 합니다—버그로 최확률 토큰을 떨어뜨리는 상황만 아니라면.
[4] 현재 올바르게 동작하는 top-k 구현으로 인해 top-p 임계치 부근 토큰의 포함 여부가 약간 달라질 수 있으며, 드물게는 사용자가 top-p 값을 재조정해 이득을 볼 수도 있습니다.