LLM 시대에 데이터 사이언스의 핵심 역량이 왜 여전히 중요하며, 평가·실험 설계·레이블링·프로덕션 모니터링에서 데이터 사이언티스트가 어떤 차이를 만드는지 설명한다.
21세기의 데이터 사이언티스트 전성기는 끝난 것일까? Harvard Business Review는 한때 이를 “21세기 가장 섹시한 직업”이라고 불렀다.1 기술 업계에서 데이터 사이언티스트 역할은 종종 가장 높은 보수를 받는 직군에 속했다.2 이 직업은 또한 드문 기술 조합을 요구했다:
높은 진입 장벽을 만드는 것에 더해, 이러한 기술은 데이터 사이언티스트가 예측 모델을 구축하고, 인과관계를 측정하며, 데이터에서 패턴을 찾을 수 있게 했다. 이 가운데 예측 모델링의 보상이 가장 컸다. 이후 기업들은 이 업무를 떼어내 새로운 직함으로 분리했다: Machine Learning Engineer(“MLE”).3
오랫동안 AI를 실제로 배포하려면 데이터 사이언티스트와 MLE가 반드시 핵심 경로에 있어야 했다. LLM이 등장하면서 이것은 더 이상 기본값이 아니게 되었다. 이제 파운데이션 모델 API를 통해 팀들이 독립적으로 AI를 통합할 수 있다.
이 과정에서 배제되는 경험은 내가 아는 데이터 사이언티스트와 MLE들을 불안하게 만들었다. 회사가 더 이상 AI를 출시하기 위해 당신을 필요로 하지 않는다면, 그 직업이 여전히 같은 상승 여력을 갖는지 의문을 품는 것은 당연하다. 사람들이 스스로에게 들려주는 더 냉혹한 이야기는 이렇다. 파운데이션 모델 연구소에서 사전학습을 하고 있지 않다면, 진짜 일이 벌어지는 곳에 있지 않다는 것이다.
나는 이것을 다르게 읽는다. 모델 학습은 애초에 직무의 대부분이 아니었다. 일의 대부분은 AI가 보지 못한 데이터에 얼마나 잘 일반화하는지 시험하기 위한 실험을 설계하고, 확률적 시스템을 디버깅하고, 좋은 메트릭을 설계하는 데 있다. API로 LLM을 호출한다고 해서 이 일이 사라지지는 않는다.
나는 최근 PyAI Conf에서 “데이터 사이언티스트의 복수”라는 제목으로 발표를 했고, 단순한 주장 대신 사례를 통해 이 점을 설명하려 했다. 아래는 그 발표에 주석을 덧붙인 버전이다.

OpenAI는 harness engineering에 관한 블로그 글을 공개했는데, 읽어보길 권한다. 그들은 Codex가 테스트와 명세로 둘러싸인 하네스 안에서 에이전트가 코드를 개발하며, 몇 달 동안 자율적으로 소프트웨어 프로젝트를 진행한 방식을 설명한다.

그 블로그 글에서 놓치기 쉬운 한 가지 디테일이 있다. 하네스에는 관측 가능성 스택이 포함되어 있다. 즉, 로그, 메트릭, 트레이스가 에이전트에게 노출되어 있어서 스스로 경로를 벗어나고 있는지를 알 수 있다. 테스트와 명세에 더해 메트릭이 있다. 이것이 시스템의 핵심 구성 요소다.
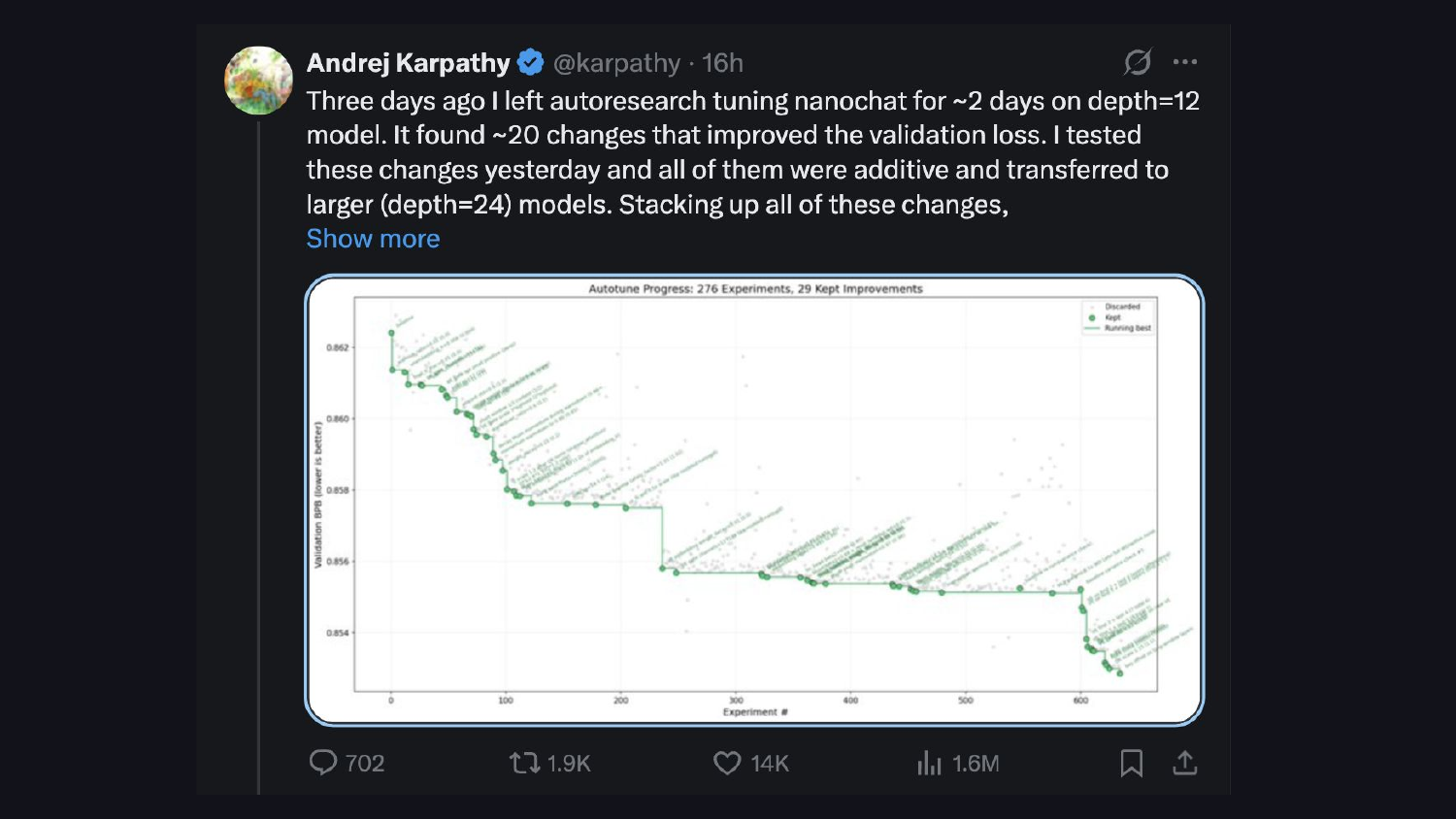
Andrej Karpathy의 auto-research project도 같은 패턴을 보여준다. 모델은 검증 손실 메트릭에 맞춰 반복적으로 최적화된다. 아이디어는 같고, 하네스만 다르다.

내가 여러분을 설득하고 싶은 핵심은 하네스의 상당 부분이 데이터 사이언스라는 점이다.
잠시 한 걸음 물러서서 우리가 지금 어디에 있는지 점검해 보자.

몇 년 전만 해도 실무자들은 데이터를 들여다보고, 레이블 정렬을 확인하고, 메트릭을 설계하는 데 몇 시간을 썼다. 오늘날 우리는 “감”에 기대어 시스템을 만들고, 모델에게 스스로 잘했는지 묻고, 데이터를 보지도 않은 채 기성 메트릭 라이브러리를 가져다 쓴다.

이 현상은 특히 검색과 평가 주변에서 두드러진다. 데이터 배경이 없는 엔지니어들은 자신이 이해하지 못하는 것을 두려워한다. 그래서 “RAG는 죽었다”거나 “평가는 죽었다”고 말하면서도, 실제로는 그런 개념들에 의존하는 시스템을 구축한다.
이 글의 나머지 부분에서는 내가 반복해서 보는 다섯 가지 평가 함정을 살펴보고, 각 경우에 데이터 사이언티스트라면 무엇을 다르게 했을지 설명한다.
첫 번째 함정은 범용 메트릭이다.

평가 프레임워크를 집어 들고 거기 있는 메트릭을 그대로 사용하는 것은 매우 유혹적이다. 문제는 실제로 무엇이 망가졌는지 전혀 모른다는 점이다. 대부분의 팀은 helpfulness 점수, coherence 점수, hallucination 점수 같은 것이 있는 대시보드를 띄운다. 그럴듯하게 들린다. 하지만 동시에 너무 범용적이어서 애플리케이션의 실패를 진단하는 데는 쓸모가 없다.
데이터 사이언티스트는 기성 메트릭을 그대로 채택하지 않는다. 데이터를 탐색하고, 트레이스를 탐색하고, “여기서 실제로 무엇이 깨지고 있지?”라고 묻고, 측정을 시작했을 때 가장 가치가 큰 것이 무엇인지 찾아낸다. 측정할 수 있는 것은 무한하다. 가설을 세우고 반복해야 한다.
이 함정에 대한 최고의 처방은 데이터를 보는 것이다.
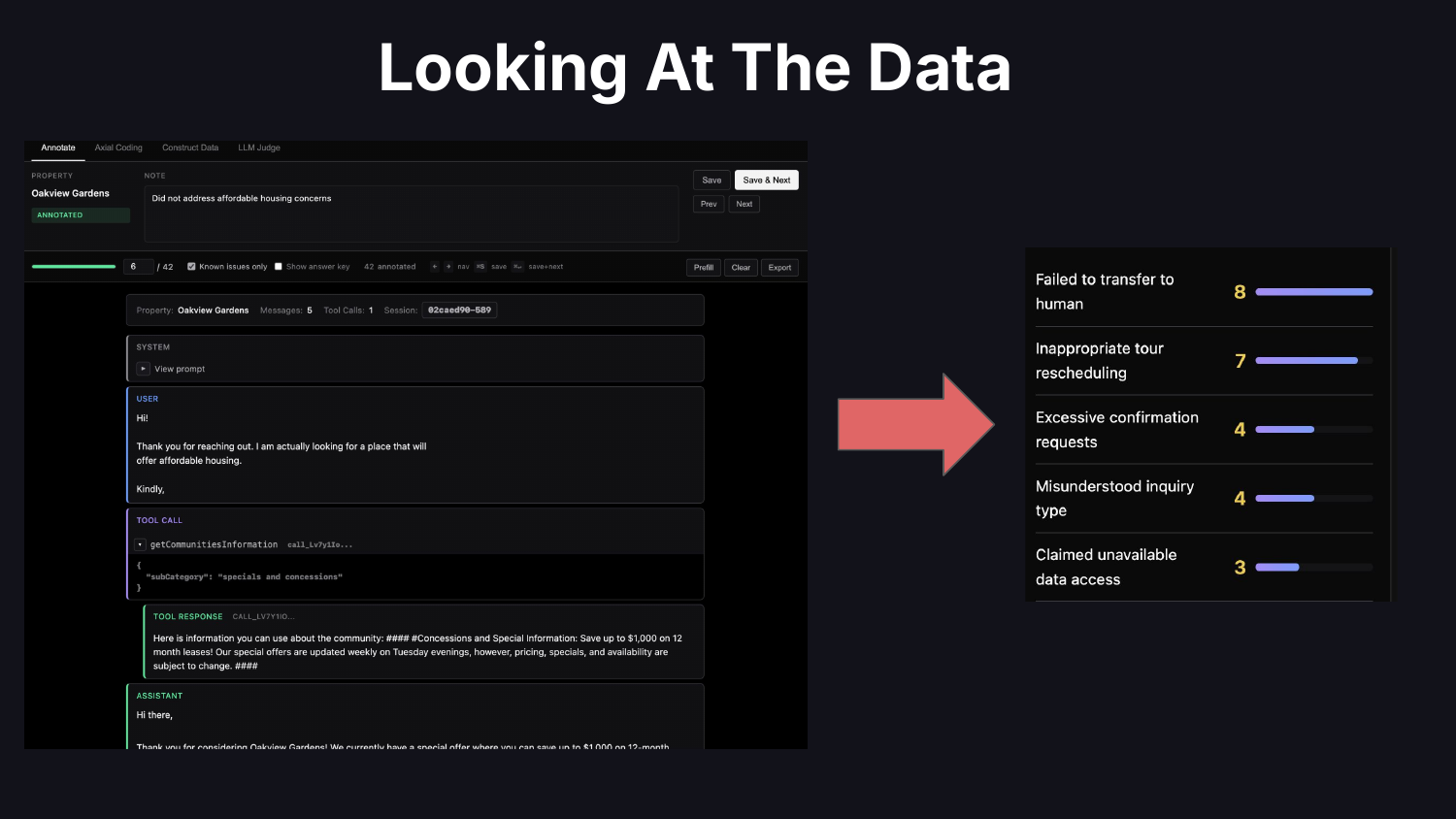
실제로 “데이터를 본다”는 것은 무엇을 뜻할까? 트레이스를 읽는다는 뜻이다. 마찰을 줄이고 도메인의 특수성을 반영해 화면을 맞춤화할 수 있도록, 직접 커스텀 트레이스 뷰어를 코딩하라. 발견한 문제에 대해 메모하라. 오류 분석을 하라. 실패를 분류하고, 무엇을 우선순위에 둘지 파악하고, 무엇을 작업할지 결정하라.
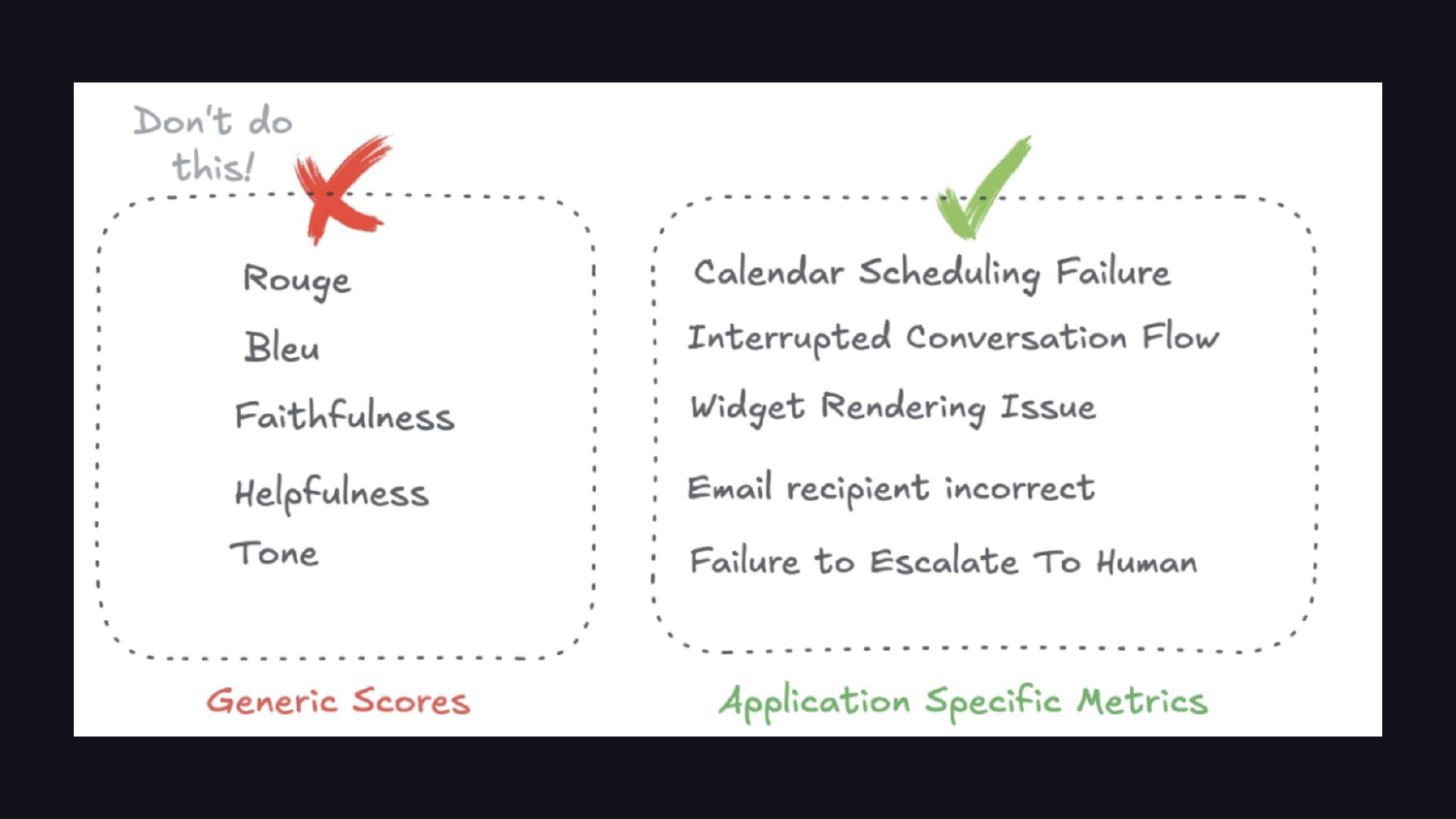
데이터를 들여다보면 결국 애플리케이션 특화 메트릭으로 나아가게 된다. ROUGE나 BLEU 같은 기성 유사도 메트릭은 LLM 출력에 거의 맞지 않는다. 정말 중요한 메트릭은 “캘린더 일정 조율 실패”나 “사람에게 에스컬레이션하지 못함” 같은 것들이다.

이 글에서 단 한 가지만 가져가야 한다면 이것이다. 데이터를 보라. 어떻게 봐야 하는지는 별개의 질문이며 연습이 필요하다. 이것은 당신이 할 수 있는 활동 중 ROI가 가장 높은 편에 속하지만, 자주 건너뛰어진다.
두 번째 함정은 검증되지 않은 판정자다. 많은 팀이 자신의 AI가 잘 작동하는지 알아보기 위해 LLM을 판정자로 사용한다. 그런데 대부분의 경우 “그 판정자를 어떻게 신뢰하나요?”라는 질문에 누구도 제대로 답하지 못한다.

기본 방식은 이렇다. LLM에게 출력을 척도로 평가하게 하고, 그 숫자를 사용한다. 데이터 사이언티스트는 판정자를 분류기처럼 다룬다. 예측값을 내놓는 블랙박스가 있다. 이것을 어떻게 신뢰할 것인가? 사람 레이블을 수집하고, 데이터를 train/dev/test로 분할하고, 그 분류기가 신뢰할 만한지 측정하라.
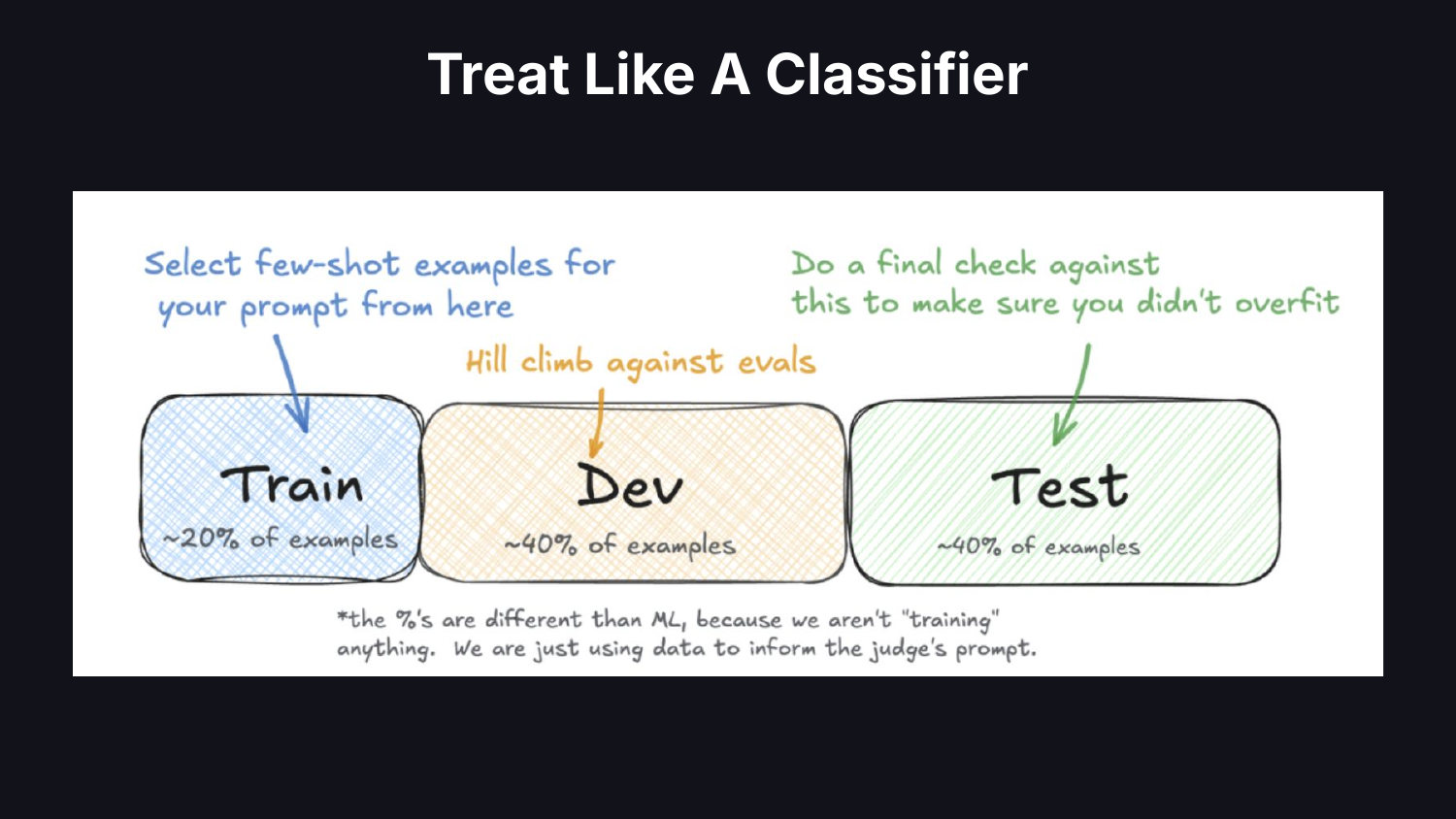
few-shot 예시는 학습 세트에서 가져와라. dev 세트를 상대로 판정자 프롬프트를 점진적으로 개선하라. 과적합하지 않았음을 확인하기 위해 test 세트는 따로 남겨 두어라. 이전에 머신러닝을 해본 적이 있다면 이 모든 것은 지루할 정도로 익숙한 이야기다. 하지만 사람들은 이것을 하지 않고 있다. 분류기를 검증하는 일은 현대 AI에서 잃어버린 기술이 되었다.

결과를 보고할 때도 판정자를 분류기처럼 다뤄라. 내가 가는 곳마다 accuracy만 보고된다. 실패 모드가 5%의 빈도로 발생한다면 accuracy는 시스템의 실제 성능을 가려버린다. precision과 recall을 사용하라.
세 번째 함정은 실험 설계다. 여기에는 여러 차원이 있지만, 가장 자주 등장하는 두 가지를 보자.

첫 번째는 테스트 세트 구성이다. 대부분의 팀은 LLM에 “테스트 질의 50개를 줘”라고 프롬프트해서 합성 데이터를 만든다. 그러면 일반적이고 대표성이 없는 데이터가 나온다. 데이터 사이언티스트라면 먼저 실제 프로덕션 데이터를 보고, 어떤 차원이 중요한지 가설로 판단한 다음, 그 차원들을 따라 합성 예시를 생성할 것이다.

합성 데이터는 실제 로그나 트레이스에 기반을 두어라. 무엇을 변화시킬 차원으로 삼을지 파악하라. 엣지 케이스를 주입하라. 실제 데이터를 바탕으로 합성 데이터를 만들어라.
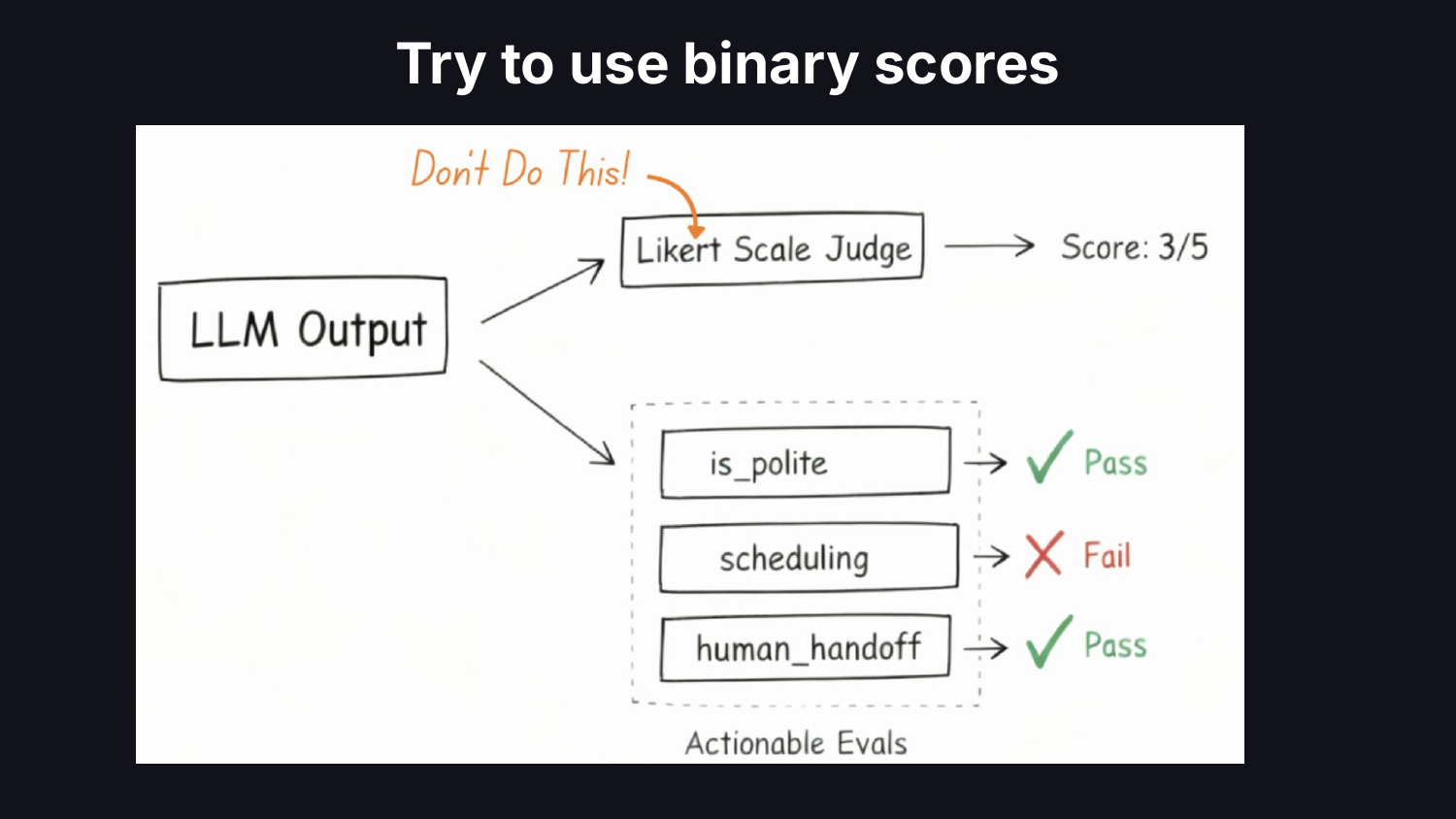
두 번째는 메트릭 설계다. 팀들은 전체 평가 기준표를 하나의 LLM 호출에 묶어 넣고, 기본적으로 1-5 리커트 척도를 사용한다. 데이터 사이언티스트라면 복잡성을 줄이고, 각 메트릭이 행동 가능한 것이 되게 만들며, 그것을 비즈니스 성과와 연결할 것이다. 주관적인 척도 대신 범위가 명확한 기준에 대한 이진 pass/fail을 사용하라. 리커트 척도는 모호성을 감추고, 시스템 성능에 대한 어려운 결정을 나중으로 미루게 만든다.
네 번째 함정은 나쁜 데이터와 레이블이다. 데이터 사이언티스트는 데이터를 신뢰하지 않는다. 레이블도 신뢰하지 않는다. 아무것도 쉽게 믿지 않는다. 그들은 훈련을 통해 회의적인 태도를 갖게 된다. 반면 대다수 AI 엔지니어들은 아직 이 근육을 키우지 못했다.

레이블링에 관해서라면 대부분의 팀은 그것을 다른 사람의 문제로 만든다. 레이블링은 화려해 보이지 않기 때문에 개발팀에 떠넘겨지거나 외주로 나간다. 데이터 사이언티스트라면 도메인 전문가가 데이터를 레이블링해야 한다고 insist할 것이고, 레이블을 계속 의심하며, 데이터를 직접 들여다볼 것이다.

하지만 레이블링이 중요한 이유는 단지 레이블 품질 때문만은 아니다. 데이터를 보지 않고는 자신이 원하는 것이 무엇인지 알 수 없다. Shreya Shankar와 동료들의 논문에서 검증된 “criteria drift”라는 개념이 있다. 사용자는 출력을 채점하기 위한 기준이 필요하지만, 출력을 채점하는 과정 자체가 사용자가 자신의 기준을 정의하도록 돕는다. 사람들은 LLM의 출력을 보기 전까지 자신이 원하는 것을 모른다. 레이블링 과정 그 자체가 무엇이 중요한지를 드러낸다.

데이터 사이언티스트는 바로 이것을 옹호한다. 도메인 전문가와 프로덕트 매니저를 요약 점수 앞이 아니라 원시 데이터 앞에 세워라.
다섯 번째 함정은 지나친 자동화다. 이 모든 것은 인간의 일이다. 유혹은 이것마저 자동화로 없애버리는 것이다.


LLM은 연결 작업을 돕고, 배관 코드를 쓰고, 평가용 보일러플레이트를 생성하는 데 도움이 될 수 있다. 그러나 여러분을 대신해 데이터를 봐줄 수는 없다. 바로 방금 논의한 이유 때문이다. 출력을 보기 전까지는 자신이 원하는 것이 무엇인지 모르기 때문이다.
모든 함정을 다 다룰 시간은 없었다. 나머지는 빠르게 훑어보자.

유사도 점수 오용. 판정자에게 “도움이 되나요?” 같은 모호한 질문을 던지는 것. 주석자에게 원시 JSON을 읽게 하는 것. 신뢰 구간 없이 보정되지 않은 점수를 보고하는 것. 데이터 드리프트, 과적합, 잘못된 샘플링, 말이 안 되는 대시보드.
한 걸음 물러나 보면, 위의 모든 함정은 같은 근본 원인을 가진다. 데이터 사이언스의 기초를 놓치고 있다는 점이다.

트레이스를 읽고 실패를 분류하는 것은 탐색적 데이터 분석이다. LLM 판정자를 사람 레이블에 대해 검증하는 것은 모델 평가다. 프로덕션 데이터에서 대표성 있는 테스트 세트를 만드는 것은 실험 설계다. 도메인 전문가가 출력을 레이블링하게 하는 것은 데이터 수집이다. 프로덕션에서 제품이 제대로 작동하는지 모니터링하는 것은 프로덕션 ML이다. 이 중 새로운 것은 없다. 이름이 바뀌었을 뿐, 일은 바뀌지 않았다.
이곳은 Python 컨퍼런스이니, 이렇게 말해두자. Python은 여전히 데이터를 들여다보고 데이터를 다루기에 가장 좋은 도구 집합이다.

나는 더 깊은 내용을 다루는 오픈소스 플러그인을 만들었다. 여러분의 평가 파이프라인을 가리키면 무엇을 잘못하고 있는지 말해주거나, 적어도 최선을 다해 그렇게 하려 할 것이다.

항상 데이터를 보라.
이 발표의 밈이 즐거웠다면, 내 웹사이트에 더 많은 밈이 있다.
이 주제들 중 어떤 것이든 더 깊이 들어가고 싶다면, 아래의 슬라이드와 영상을 보라.
Shreya Shankar와 Bryan Bischof에게 감사드린다. 이 발표를 빚어내는 데 많은 대화가 도움이 되었다.
https://hbr.org/2012/10/data-scientist-the-sexiest-job-of-the-21st-century[↩︎](https://hamel.dev/blog/posts/revenge/#fnref1)
https://www.forbes.com/sites/louiscolumbus/2018/01/29/data-scientist-is-the-best-job-in-america-according-glassdoors-2018-rankings/[↩︎](https://hamel.dev/blog/posts/revenge/#fnref2)
https://www.mckinsey.com/about-us/new-at-mckinsey-blog/ai-reinvents-tech-talent-opportunities[↩︎](https://hamel.dev/blog/posts/revenge/#fnref3)