부동소수점에 대한 두려움에서 출발해, 직접 가산기와 하드웨어 구현까지 파고들며 bfloat16 기반 FPU를 설계하고 테이프아웃한 여정을 다룬다.
부동소수점에 대해 고백할 것이 있다. 부동소수점은 나를 무섭게 한다.
반십 년 전, 나는 어떤 부동소수점 산술을 구현해보겠다고 결심했다. 그때는 꽤 해볼 만해 보였다. 부동소수점은 어디에나 있으니까. 도대체 얼마나 어렵겠는가? 그때까지 내 경험은 이랬다. 문제에 충분한 시간과 노력을 들이부어 머리를 박아대면, 대체로 결국은 알아낼 수 있다는 것이었다.
그렇게 나는 내 인생에서 가장 완전한 기술적 패배를 맞이했다. 그 철저한 전멸 속에서 지금의 부동소수점 공포가 탄생했다.
반십 년이 지나고, 나는 재대결할 때가 되었다고 결심했다. 내 드래곤들과 맞설 시간이다!
하지만 이번에는 단지 겉핥기 수준의 이해를 목표로 하지 않을 것이다. 이번에는 부동소수점 표현을 깊이 있게 파악하는 것을 목표로 할 것이다.
이 성전에 나설 때, 나는 부동소수점을 진정으로 이해하는 사람은 단 세 부류뿐이라고 믿었다.
2라운드에 오신 것을 환영한다!
돌이켜보면, 과거의 패배를 불러온 주된 이유 중 하나는 내가 부동소수점을 사용할 수 있다는 사실을 이해의 지표로 착각했다는 점이다. 그래서 부동소수점을 공부하는 데 시간을 투자할 필요가 없다고 여겼고, 마치 하다 보면 자연스럽게 익히게 될 것처럼 생각했다.
그러니 이제 컴퓨터는 잠시 치워두고, 종이와 함께 10일을 보내야 할 때다. ( 기억하는가, 그 하얀 것 말이다 )
독자들이 이미 부동소수점이 무엇인지에 대해 어느 정도는 알고 있다고 가정하겠다. 그러니 기본적인 입문 설명은 생략하겠다.
우선 몇 가지 정의만 하자. 이 논의의 맥락에서 정규 부동소수점 수는 다음과 같이 정의한다.
여기서 , , 의 값은 부동소수점 필드에 저장된 값들이다.

부동소수점 레이아웃 - IEEE 754-2019, section 3
이 필드들의 크기와 (지수 바이어스), (정밀도)의 값은 부동소수점 포맷에 따라 달라진다.
예를 들어 IEEE 754 단정밀도(float32_t)의 경우 다음과 같다.
따라서 다음이 된다.
이 글에서는 다음과 같이 부르겠다.
사실 우리가 관심 있는 것은 추상적인 의미의 부동소수점이 아니라, 프로그램에서 흔히 “float”라고 부르는 것이다.
가능한 모든 부동소수점 타입의 세계에서 이것들은 바닐라에 해당한다. 그런데 이 세계에서는 모두가 항상 바닐라만 원한다!
이 float 포맷은 IEEE 754 명세를 통해 IEEE에 의해 정전화되어 있다. 이 성배 안에는 기대되는 동작이 숨 막히도록 세세하게 정의되어 있어서, 사용자는 서로 다른 플랫폼에서도 동일한 부동소수점 연산에 대해 동일한 동작을 기대할 수 있다. 이것이 float를 이식 가능하게 만드는 초석이다.
그리고 바로 여기서 지옥이 시작된다!
천천히 하강을 시작해보자.
가장 눈썰미 좋은 독자라면 이미 표현 형식을 보며 눈치챘겠지만 (칭찬한다), 우리에게는 진짜 부호 비트가 있다. 이는 곧 0에 대해 실제로 2개의 표현이 있다는 뜻이다: +0.0 과 −0.0.
이제 재미있어지는 부분은 어느 0을 써야 하는지에 대한 규칙이 있다는 점이다. 예를 들어 두 부동소수점 수의 동등성을 어떻게 판정할지 생각해보자. 예를 들어 X == Y 는?
이 비교를 하려면 일반적으로 가산기를 재사용해 X - Y 를 수행한 뒤 결과의 모든 비트가 0인지 확인하면 된다. 문제는 −0.0 은 부호 비트에 1이 들어간다는 점이다.
그래서 결과가 언제 +0.0 을 써야 하고 언제 −0.0 을 써야 하는지에 대한 규칙이 있으며, 같은 두 부동소수점 수를 빼는 경우가 바로 그 규칙의 한 예다.
NaN 은 Not A Number의 약자다.
우리가 숫자에 대해 이야기하고 있다고 생각했던 모든 분들에게, 바로 이 지점에서 숫자와 표현 형식의 차이를 이해하기 시작하게 된다.
그러니 재미있는 부분부터 시작하자. 사실 NaN 에도 여러 종류가 있다.
quiet NaN (qNaN)signaling NaN (sNaN). 대부분의 사람은 이것을 마주치지 않는다.그렇다면 “qNaN 은 산술 연산의 결과를 표현할 수 없을 때 이를 나타내기 위해 사용된다” 는 말은 무슨 뜻일까?
몇 가지 예를 보자.
qNaN 이 된다. 왜냐하면 이고, 는 복소수 표기 없이는 표현할 수 없는 허수이기 때문이다.qNaN 이 된다. 왜냐하면: 지금 뭘 하고 있는가?qNaN 이 된다. 왜냐하면 는 사실 숫자가 아니라 극한이기 때문이다. 한 극한에서 다른 극한 를 빼는 것은 의미가 없다.qNaN 에 대한 또 다른 재미있는 사실을 알고 싶은가?
전염된다.
피연산자 중 하나가 qNaN 인 산술 연산의 결과는 qNaN 이 된다.
생각해보라. 결과를 표현할 수 없는 연산에 대해 무슨 결과를 내놓아야 하겠는가?
메모리에서 NaN 은 지수 비트가 모두 1이고, 가수 비트 중 적어도 하나가 1인 형태로 표현된다. 어떤 가수 비트가 설정되어 있는지에 따라 서로 다른 NaN 을 구분할 수 있으며, 그 인코딩은 구현자 재량에 맡겨져 있다.
이미 NaN 을 설명하며 이것들을 도입하기 시작했지만, 부동소수점 표현에는 두 개의 무한대 표기 공간이 있다. +∞ 를 위한 하나와 그 거울상인 −∞ 를 위한 하나다. 이것들은 숫자가 아니다. 무한대는 숫자가 아니라 극한이다!
IEEE를 준수하는 경우 특정한 무한대는 산술 연산에 사용될 수 있고, 불리언 연산의 입력이 될 수 있으며, 계산 결과로 생성될 수도 있다.
메모리에서 무한대는 지수 비트가 모두 1이고, NaN 과 구분하기 위해 가수 비트는 모두 0이다.
잠시 무한대와 NaN 은 옆으로 치워두고, 다시 숫자 자체에 대해서만 이야기해보자.
서두에서 나는 정규 부동소수점 수를 다음과 같이 정의했다.
이것을 더 일반적으로 쓰면 다음과 같다.
여기서 은 형태의 비트열로 표현되는 수이며, 길이는 이다. (여기서 는 정밀도, 즉 가수 비트 수 + 1이다.)
예를 들어 1.5는 다음과 같이 쓴다.
그리고 3은 이므로 다음과 같다.
우리의 정규 부동소수점 표현에서 의 1은 바로 이며 항상 로 설정된다.
그런데 재미있는 점은, 실제 가수 필드는 비트만 가지고 있고, 는 실제로 추론되는 비트라는 것이다. 우리는 이것을 hidden bit 라고 부른다.
충분히 단순해 보이는가? 드디어 부동소수점에서 뭔가 단순한 것이 나온 걸까?!
걱정하지 말라. 부동소수점은 이런 식으로 실망시키지 않는다. 왜냐하면 또 다른 범주의 수가 있기 때문이다!
이들은 암묵적인 hidden bit 가 으로 설정되며 subnormal numbers (또는 denormal numbers) 라고 불린다. 만세 🥳
이들은 표현 가능한 가장 작은 부동소수점 수들을 인코딩하는 데 사용되며, IEEE 574 명세 제정 과정에서 가장 논쟁적이었던 부분이었다.
그리고 구현하기는 엄청나게 귀찮다. 초기 FPU들 중 상당수는 subnormal 수가 나오면 trap을 걸고 소프트웨어로 처리했는데… 아주 느리게…
그렇다면 몇 비트 아끼는 것 말고 왜 굳이 이것들을 감수하는가?
범인은 바로: gradual underflow 다.
gradual underflow의 핵심은 표현 가능한 가장 작은 정규수 이후에 정밀도가 갑자기 사라지지 않도록, 그 손실을 완만하게 만드는 것이다. 이는 수치적 안정성에 도움을 준다.
무슨 뜻인지 설명하기 위해, subnormal 이 없다고 상상해보자. 와 가 인 부동소수점 수라고 하자. 만약 가 0.0과 가장 작은 표현 가능 부동소수점 수 사이 범위에 떨어지면, 그 범위에는 표현 가능한 수가 없으므로 0.0으로 언더플로된다.
예를 들어 subnormal 이 없는 float16에서는:
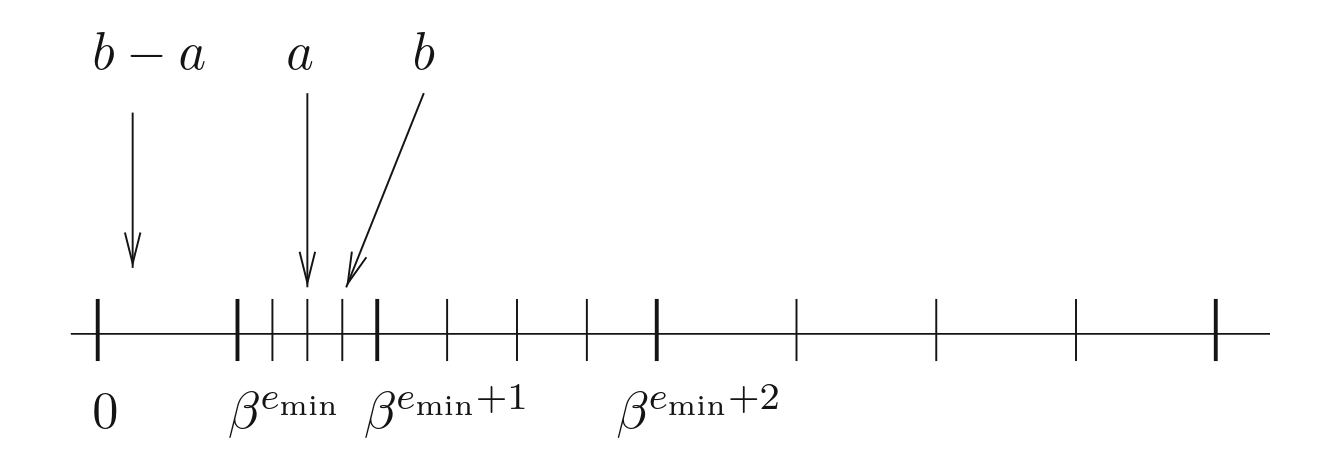
출처: Handbook of Floating-Point Arithmetic, Second Edition
이제 subnormal 을 추가하면 사실상 이 틈을 메우게 된다.
예를 들어 subnormal 이 있는 float16에서는:
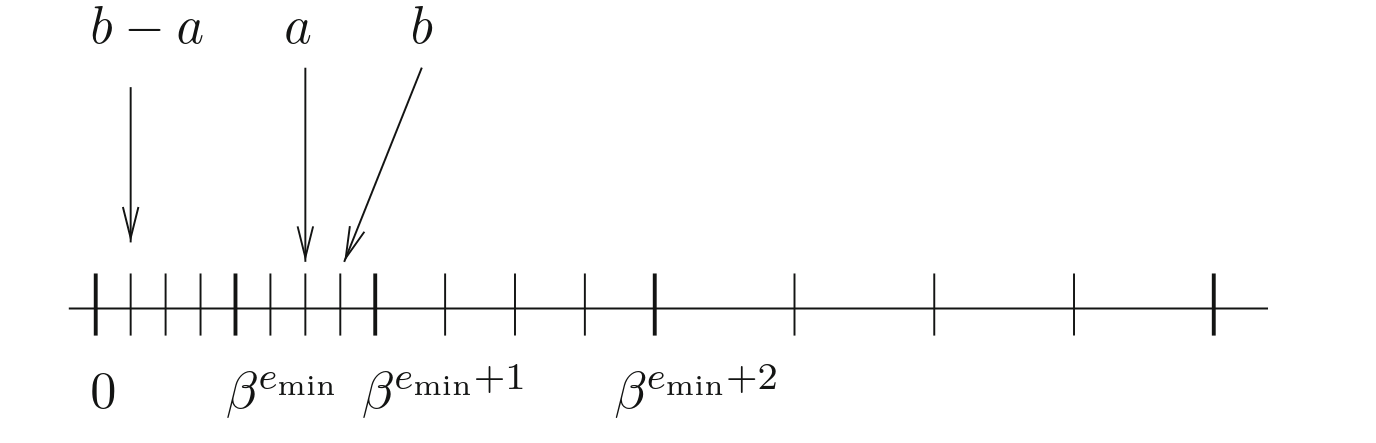
출처: Handbook of Floating-Point Arithmetic, Second Edition
이제 시스템에 subnormal 이 들어오면 다음과 같은 흥미로운 성질을 얻게 된다. 어떤 부동소수점 수 와 에 대해 라면, 는 반드시 0이 아니다.
보너스: 이제 0으로 나누기에 대한 추가 방어막도 얻는다.
if ( x != y ) z = 1.0 / ( x - y );
무엇을 표현할 수 있고 무엇을 표현할 수 없는지는 타입마다 다르다. 비트가 많을수록 표현 가능한 값의 공간은 넓어지고, 반대로 작은 타입일수록 가능한 값의 수는 줄어든다.
IEEE 16비트 half float float16_t 를 생각해보자. 이 타입은 지수 비트 5개와 가수 비트 10개를 가지는데, 놀랍게도 15359 를 표현할 수 없다!
그렇다면 여기에 15359 를 넣으려 하면 어떻게 될까?
float16_t e = 15359.0;
cout << e << endl;
정답은 42다.
좀 더 진지하게 말하면, 경우에 따라 다르다. 어떤 반올림 모드를 쓰고 있는가?
IEEE 명세는 준수 하드웨어가 지원해야 할 5가지 반올림 모드를 정의한다.
RD 아래쪽인 방향으로 반올림: 결과는 정확한 결과 이하인 가장 큰 표현 가능 부동소수점 수RU 방향으로 반올림: 결과는 정확한 결과 이상인 가장 작은 표현 가능 부동소수점 수RZ 모든 경우에 0.0 방향으로 반올림RN_even/RN_away 최근접 반올림: 결과는 가장 가까운 가능한 값이며, 정확히 중간값일 때는 타이브레이크 규칙을 적용한다.
even (짝수로 반올림) 은 가수의 최하위 비트가 0인 수를 선택한다.away (바깥쪽으로 반올림) 은 다음 연속 부동소수점 수를 선택한다.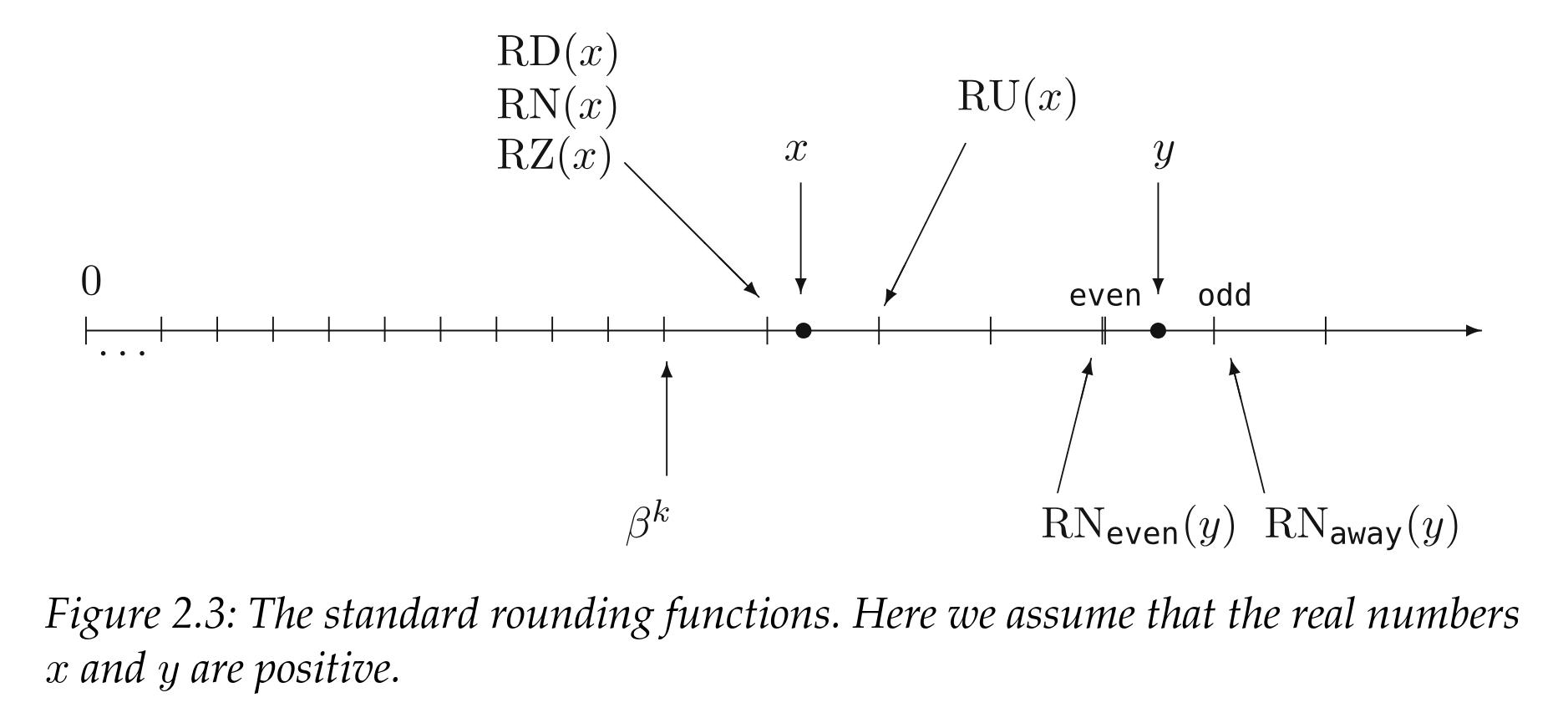
출처 : Handbook of Floating-Point Arithmetic, Second Edition 2장
다시 예제로 돌아가 보자. 15359 는 float16_t 로 표현할 수 없고, 가장 가까운 두 수는 15352 와 15360 이다.
따라서 어떤 반올림 모드를 쓰느냐에 따라 다음과 같은 결과를 얻는다.
| rounding mode | result |
|---|---|
| RD | 15352 |
| RZ | 15352 |
| RU | 15360 |
| RN (even) | 15360 |
RN_even 은 현대 시스템에서 기본 IEEE 반올림 모드이며, C++ FE_TONEAREST 반올림 모드가 지정하는 동작이기도 하다.
반올림 모드의 동작을 설명할 때 내가 결과를 일관되게 “숫자”라고 부르지 않았던 이유를 기억하는가? 일부 반올림 모드는 결과를 로 반올림하게 만들기 때문이다.
예를 들어 float16_t 에서 RU 반올림을 사용하면:
float16_t x, y, z;
x = 65504;
y = 1;
fesetround(FE_UPWARD);
z = x + y;
cout << x << " + " << y << " = " << z << endl;
결과는 다음과 같다.
65504 + 1 = inf
비슷하게:
float16_t x, y, z;
x = -65504;
y = 1;
fesetround(FE_DOWNWARD);
z = x - y;
cout << x << " - " << y << " = " << z << endl;
이 경우 로 반올림된다.
-65504 - 1 = -inf
이 정의들을 함께 보면, RU 를 사용하는 연산은 에 도달하지 않고, RD 를 사용하는 연산은 에 도달하지 않는다는 뜻이 된다.
float16_t x, y, zsub, zadd;
x = 65504;
y = 1;
fesetround(FE_UPWARD);
zsub = -x - y;
cout << -x << " - " << y << " = " << zsub << endl;
fesetround(FE_DOWNWARD);
zadd = x + y;
cout << x << " + " << y << " = " << zadd << endl;
결과:
-65504 - 1 = -65504
65504 + 1 = 65504
여기서 RZ 가 재미있어지는 이유는, 양수에 대해서는 RD 처럼 동작하고 음수에 대해서는 RU 처럼 동작하기 때문이다. 즉 이 반올림 모드를 사용하는 연산은 에 도달할 수 없다.
이 시점에서 내가 반올림 모드의 극한 동작에 갑자기 집착하는 것이 다소 뜬금없어 보일 수 있다. 지금은 그냥 조금만 참아 달라. 이 글 뒤에서 이 동작을 활용하게 된다.
코드에서 부동소수점 값을 비교하는 일은 꽤 흔하며, 기본적인 불리언 비교 연산은 IEEE 754 명세에 정의되어 있다. 두 수는 서로에 대해 작거나, 같거나, 크다.
그런데 비교의 한쪽이 NaN 이라면 어떻게 될까? 예를 들어 x 가 NaN 일 때 x > y 를 비교할 수 있을까? 가능하다면 결과는 무엇일까?
가능한 관계는 네 가지이며 서로 배타적이다: less than, equal, greater than, unordered. unordered 는 적어도 한 피연산자가 NaN일 때 발생한다. 모든 NaN은 자기 자신을 포함한 모든 것과 unordered 로 비교된다.
즉 NaN 과의 모든 비교는 unordered 가 된다. 이는 NaN 이 개입하면 문자 그대로 순서 관계가 존재하지 않는다는 꽤 흥미로운 성질이다.
이 관계가 실제로 어떻게 드러나는지 보자.
float16_t x, y;
x = NAN;
y = 1.0;
cout << "x =/= x: " << ((x=x) ? "true" : "false") << endl;
cout << "x > x: " << ((x>x) ? "true" : "false") << endl;
cout << "x <= x: " << ((x<=x) ? "true" : "false") << endl;
cout << "x > y: " << ((x>y) ? "true" : "false") << endl;
cout << "x <= y: " << ((x<=y) ? "true" : "false") << endl;
결과:
x =/= x: true
x > x: false
x <= x: false
x > y: false
x <= y: false
이것의 부작용 중 하나는 비교 관계가 어떻게 작동해야 한다는 우리의 기본 가정 중 일부가 무너지기 시작한다는 것이다. 가장 악명 높은 예는 다음이다.
삼분법칙이 무너졌다. 우리는 이제 이것을 본 적 없다고 할 수 없다!

부동소수점 K.O
좋다. 그렇다면 실제로는 어떻게 동작할까? 예제 하나가 천 마디 말보다 낫다. (분명히 이 글은 그 속담을 그다지 잘 따르지 않지만) 그러니 코드로 보자!
다음은 부동소수점 덧셈을 수행하는 단계들을 보여주는 C 예제다. 이 코드는 설명 목적일 뿐이며, 일부 코너 케이스는 빠져 있다.
bfloat16 타입을 사용한 C에서의 부동소수점 덧셈:
#include <stdint.h>
#include <stddef.h>
#include <stdfloat>
#include <stdbool.h>
#include <stdlib.h>
#include <stdio.h>
/*******
* Env *
*******/
/* Assert. */
#define assert(cdt) ({if (!(cdt)) {printf("%s:%s : assert(%s) failed.\n", __FILE__, __LINE__, #cdt); abort();}})
#ifdef DEBUG
#define check(cdt) ({if (!(cdt)) {printf("%s:%s : check(%s) failed.\n", __FILE__, __LINE__, #cdt); abort();}})
#else
#define check(cdt) ({;})
#endif
#define swap(a, b) ({auto _ = b; b = a; a = _;})
typedef bool u1;
typedef uint8_t u8;
typedef uint16_t u16;
typedef uint64_t u64;
typedef std::bfloat16_t bfloat16_t;
/*********
* Types *
*********/
typedef struct bf16 bf16;
/**************
* Structures *
**************/
/*
* Bfloat 16.
*/
struct bf16 {
union {
struct {
u16 frc:7;
u16 exp:8;
u16 sig:1;
};
u16 raw;
};
};
/*
* Special values.
*/
/* Special exponent. */
#define BF16_EXP_SPC 0xff
/* Special nummber : infinity frac. */
#define BF16_SPC_FRC_INF 0
/*************
* Utilities *
*************/
/*
* If @val is special, return 1.
* Otherwise, return 0.
*/
static inline u1 bf16_is_spc(
bf16 val
)
{
return val.exp == BF16_EXP_SPC;
}
/*
* If @val is an infinity, return 1.
* Otherwise, return 0.
*/
static inline u1 bf16_is_inf(
bf16 val
)
{
return bf16_is_spc(val) && (val.frc == BF16_SPC_FRC_INF);
}
/*
* If @val is a nan, return 1.
* Otherwise, return 0.
*/
static inline u1 bf16_is_nan(
bf16 val
)
{
return bf16_is_spc(val) && (val.frc != BF16_SPC_FRC_INF);
}
/*
* If @val is negative, return 1.
* Otherwise, return 0.
*/
static inline u1 bf16_is_neg(
bf16 val
)
{
return val.sig;
}
/*
* If @val is 0 or a subnormal, return 1.
* Otherwise, return 0.
*/
static inline u1 bf16_is_nul_or_sub(
bf16 val
)
{
return val.exp == 0;
}
/*
* If @val is a subnormal, return 1.
* Otherwise, return 0.
*/
static inline u1 bf16_is_sub(
bf16 val
)
{
return bf16_is_nul_or_sub(val) && val.frc != 0;
}
/*
* If @val is zero (plus or minus) return 1.
* Otherwise, return 0.
*/
static inline u1 bf16_is_nul(
bf16 val
)
{
return (val.exp == 0) && (val.frc == 0);
}
/*
* If @val is regular (not inf, not nan, not subnormal), return 1.
* Otherwise, return 0.
*/
static inline u1 bf16_is_reg(
bf16 val
)
{
return (!bf16_is_spc(val)) && (!bf16_is_sub(val));
}
/*
* Get @val's complete mantissa with bit 1 placed at offset 31.
*/
static inline u64 bf16_frc_to_arr(
bf16 val
)
{
check((1 << 7) == 0x80);
check(bf16_is_reg(val));
const u64 arr = (1 << 31) | (((u64) val.frc) << 24);
check(((arr >> 24) & 0x7f) == val.frc);
check(((arr >> 24) & 0x80) == 0x80);
check((arr >> 32) == 0);
check(arr & 0xffffff == 0);
return arr;
}
/*
* Return the opposite of @val.
*/
static inline bf16 bf16_opp(
bf16 val
)
{
val.sig = val.sig ? 0 : 1;
return val;
}
/*******
* API *
*******/
/*
* Addition.
*/
static inline bf16 bf16_add(
bf16 src0,
bf16 src1
)
{
/* Check regularity. */
assert(bf16_is_reg(src0));
assert(bf16_is_reg(src1));
/* If both are null, return 0. We have a lookup table for the sign.
* If one is null, return the other. */
{
const u1 nul0 = bf16_is_nul(src0);
const u1 nul1 = bf16_is_nul(src1);
if (nul0 && nul1) {
return (bf16) {.frc = 0, .exp = 0, .sig = (u16) (src0.sig & src1.sig)};
} else if (nul0 || nul1) {
return (nul0) ? src1 : src0;
}
}
/* Ensure that abs(src0) >= abs(src1). */
const u1 swp = (
(src1.exp > src0.exp) ||
((src1.exp == src0.exp) && (src1.frc > src0.frc))
);
if (swp) {
swap(src0, src1);
}
/* Ensure src0 is positive. */
const u1 neg = bf16_is_neg(src0);
if (neg) {
src0 = bf16_opp(src0);
src1 = bf16_opp(src1);
}
check(src0.exp >= src1.exp);
check(src0.sig == 0);
/* Get exponents. */
const u16 exp0 = src0.exp;
const u16 exp1 = src1.exp;
check(exp0 > 0);
check(exp1 > 0);
check(exp0 < 255);
check(exp1 < 255);
/* Get the mantissa shift amount. */
check(exp0 >= exp1);
const u16 shf = exp0 - exp1;
check(shf <= 253);
/* Generate mantissas with the shadow 1 bit placed at offset 31.
* Everything on range [32, 63] is null.
* Everything on range [0, 23] is null. */
const u64 mnt0 = bf16_frc_to_arr(src0);
u64 mnt1 = bf16_frc_to_arr(src1);
/* Shift @mnt1 to match @src0's exponent.
* There are only 32 meaningful bits.
* If right shift more (>=) than 32, @src0 is effectively
* null. */
mnt1 = (shf >= 32) ? 0 : (mnt1 >> shf);
/* After shift, mnt0 shoudl be greater than mnt1. */
check(mnt0 >= mnt1);
/* Do the required operation. */
const u1 sub = (bf16_is_neg(src1));
const u64 mntr = sub ? mnt0 - mnt1 : mnt0 + mnt1;
/* Initialize the sign part of the result. */
bf16 res;
res.sig = neg;
/* If there are bits in the [32, 63] range (overflow), right shift and update the exponent. */
if (mntr >> 32) {
/* Only a single bit overflow is meaningful. */
check(!(mntr >> 33));
/* Only happens after sub. */
check(!sub);
/* The exponent of src0 is used. Increment it. */
check(exp0 < 255);
u16 expr = exp0 + 1;
check(expr > exp0);
/* If infinity, round down. */
if (expr == 255) {
res.frc = 0x7f;
res.exp = 254;
}
/* Otherwise, just use this exponent and right shift the mantissa of 1. */
else {
res.frc = ((mntr >> 1) >> 24) & 0x7f;
res.exp = expr;
}
}
/* If there are no bits in the [32, 63] range, left shift and update the exponent. */
else {
/* If bit 31 is not set, check that a subtraction was performed. */
check((mntr & (1 << 31)) || sub);
/* Determine the index of the first set bit and the shift count.
* We shift at most of 31. */
u64 mnt_shf = 0;
u8 shf_cnt = 0;
for (shf_cnt = 0; shf_cnt <= 31; shf_cnt++) {
const u64 mnt_shf = mntr << shf_cnt;
if (mnt_shf & (1 << 31)) {
goto found;
}
}
/* If not found, default to 0. */
goto zero;
found:;
/* If the shift count leaves an exponent > 0,
* compute the result. */
if (exp0 > shf_cnt) {
check(mnt_shf & (1 << 31));
res.frc = (mnt_shf >> 24) & 0x7f;
res.exp = exp0 - shf_cnt;
}
/* Zero case.
* Hit if set bit not found or if shift count
* is greater than the exponent. */
else {
zero:;
res.frc = 0;
res.exp = 0;
}
}
/* Swap doesn't matter as we're doing a sum.
* neg already handled when initializing the sign. */
/* Complete. */
return res;
}
int main() {
bf16 f0 = {.frc = 0, .exp = 1, .sig = 0};
bf16 r = bf16_add(f0, f0);
return 0;
}⚠ 이 코드는 충분히 테스트되지 않았으니, 프로덕션에서 사용하지 말라!
당신이 무슨 생각을 하는지 안다. C 구현이 있고, 동작도 하는데, 왜 이 글은 아직도 이렇게 긴가? 댓글란이 그렇게 생산적인가?
이제 집에 가도 되는가?
우리가 처음부터 부동소수점을 만든다고 했던 것, 기억하는가?
그렇지!?
코드만으로는 부족하다. 더 깊이 들어가야 한다!
그렇다면 C 코드보다 더 처음부터인 것은 무엇일까?
어셈블리로 코딩하면서 책에 나오는 온갖 비트 트위들링 최적화 기법을 총동원할 수도 있다. 물론 그동안 ISA 너머에서 우리를 노려보는 아름다운 fadd 명령어들은 못 본 척하면서 말이다.
그런데 놀랍게도, 우리는 여전히 더 깊이 내려갈 수 있다. 그리고 슬프게도 세계에서 가장 정교하게 손으로 다듬은 어셈블리라고 해도, 전용 floating point addition 명령 하나가 할 일을 내 할머니 컴퓨터보다도 훨씬 느리게 수행할 것이다.
아니다. 우리는 트랜지스터로 직접 FPU 하드웨어를 만들고, 미친 듯이 최적화하고, 그걸 칩에 올려 테이프아웃할 것이다!
다음 섹션은 하드웨어 설계에 익숙하지 않은 독자들에게, 하드웨어 설계의 제약을 이해하는 데 필요한 바탕을 제공하기 위한 단순화된 개요다.
이미 심연을 들여다본 적이 있다면 이 섹션은 건너뛰어도 된다.
디지털 하드웨어는 셀이라고 불리는, 미리 배치된 트랜지스터 묶음을 연결해서 만든다. 이 셀은 기본 논리 연산에 해당할 수도 있다. 다음은 2입력 or 의 결과를 또 다른 입력과 and 하는 예다.
이 논리는 다음과 같이 쓸 수 있다.
X = ((A1 | A2) & B1)
또는 다음 회로도로 표현할 수 있다.

이 게이트들은 트랜지스터로 만들어지므로 node 라고 알려진 제조 공정에 종속적이다. 다음은 Skywater 130nm A node 에서 이 함수가 어떻게 생겼는지다.

sky130_fd_sc_hd__o21a_1 셀 플로어플랜. 각 색은 칩 샌드위치의 특정 레이어에 대응한다.
이 셀들은 이를 구성하는 데 필요한 트랜지스터 수에 비례하는 칩 면적을 차지한다. 트랜지스터가 많을수록 면적도 커진다. 칩을 만들 때 더 큰 면적이 필요할수록 제조 비용도 더 많이 든다. 또한 어떤 기능이 차지하는 면적이 클수록 논리가 더 멀리 퍼지고, 와이어는 더 길어지며, 와이어 지연도 커진다. 이는 타이밍에 영향을 준다.
무슨 타이밍?
전하 운반자가 물처럼 퍼져나가는 세계를 상상해보자. 운반자가 논리 게이트와 와이어를 통과해 전파되는 데는 시간이 걸린다. 경로 상의 논리 게이트가 많을수록, 지나야 할 와이어가 길수록, 시간은 더 오래 걸린다. 이 운반자의 밀도가 0 또는 1이라는 이진 상태를 나타내며, 칩이 예측 가능하게 동작하려면 가장 긴 경로를 따라 이 흐름이 완전히 전파될 충분한 시간을 남겨두어야 한다.
얼마나 많은 시간을 남기느냐는 하드웨어를 얼마나 빠르게 클록할 수 있는지, 따라서 설계에서 얼마나 많은 성능을 끌어낼 수 있는지에 직접 영향을 준다.
좋다. 우리는 그저 FPU를 만들려는 것이 아니다. 최적화된 버전을 만들려는 것이다.
왜 굳이 최적화라는 제약을 더하느냐고 궁금할 수 있다. 그것은 어떤 것이든 단지 동작하게 만드는 것보다, 최적화된 버전을 만드는 것이 훨씬 더 미묘하고 깊은 이해를 요구하기 때문이다. 최적화에는 여러 차원이 있지만, 이 프로젝트에서 나는 “최적화”를 주어진 기능에 대해 가능한 한 가장 낮은 면적으로, 가능한 한 가장 높은 주파수를 달성하는 것으로 정의하겠다. 이것이 최고의 가성비다.
정리하자면, 우리는 하드웨어를 만들고 있으며 하드웨어에서 모든 논리는 면적과 타이밍 양쪽 모두에서 비싸다. 그리고 우리는 바로 그 지표들에 비추어 가장 최적화된 버전을 만들고자 한다.
좋군… 내가 또 뭘 시작한 거지?
추가하는 모든 논리에는 비용이 따르므로, 1단계는 한걸음 물러서서 실제로 무엇을 필요로 하는지 먼저 생각하는 것이다.
부동소수점 포맷은 아주 다양하다. 표준 IEEE 타입부터 Pixar float 같은 더 기묘한 애플리케이션 특화 포맷까지 있다.
이 모든 포맷을 경기장에 집어넣고 끝까지 싸우게 할 수 있는 차원에 살고 있다면 좋았겠지만, 안타깝게도 추상 개념으로는 그렇게 할 수 없다. 그러니 이제 앉아서 생각해야 한다… 아
맞다, 제대로 읽은 것이다. 이것은 어떤 AI 환각도 아니고, 2019년 단편 영화를 말하는 것도 아니다.
Pixar 에는 자기들의 용도에 맞춘 24비트 부동소수점 타입이 있다는 사실을 알고 있었는가? Pixar 는 아마도 가장 과소평가된 기술 기업 중 하나일 것이다. 과거에 그들의 렌더링 하드웨어가 얼마나 맞춤화되었는지 대부분의 사람은 전혀 모른다. 또 Pixar Image Computers 에 대해 들어본 적 있는가?
주의하라. 이 토끼굴은 깊다.
한쪽에는 IEEE float 가 있다. 이것은 업계 표준 float 다. 이를 준수하면 같은 부동소수점 연산이 어느 하드웨어에서 실행되든 같은 동작을 보장할 수 있고, 이는 구매자들이 정말 원한다. (물론 하드웨어에 버그가 있다면 얘기가 다르다. 그 경우 당신은 준수하려고 시도한 셈이다. 안녕 intel 👋 인터넷은 아직 잊지 않았다.) 하지만 준수는 subnormal, NaN, , 그리고 5가지 반올림 모드를 모두 지원해야 함을 뜻한다.
그다음은 크기의 문제다. 메모리 풋프린트는 어느 정도인가? 그리고 지수 필드와 가수 필드에 비트를 어떻게 배분할 것인가?
몇 가지 선택지는 다음과 같다.
float16, IEEE 754 half-precision: 지수 5비트, 가수 10비트float32, IEEE 754 single precision: 지수 8비트, 가수 23비트float64, IEEE 754 double precision: 지수 11비트, 가수 52비트tf32, Nvidia 의 TensorFloat-32. 19비트 포맷이다. 정말이다. 왜 이름 짓기를 마케팅 부서에 맡겼는지 모르겠다. 지수 8비트, 가수 10비트bfloat16, Google 의 brain float 포맷: 지수 8비트, 가수 7비트최종적으로 어떤 크기를 선택할지는 워크로드의 요구에 달려 있다. 어떤 워크로드는 더 많은 정밀도가 필요하므로 더 많은 가수 비트를 원하고, 다른 워크로드는 더 작은 포맷을 통해 메모리 대역폭 병목을 우회하는 편이 유리하다.
그러니 다시 한 번, 답은 이것이다: 경우에 따라 다르다! 읽어줘서 고맙다!
좀 더 진지하게 말하면, 우리가 실제로 무엇을 만들고 있는지 분명히 하자. 이 부동소수점 산술은 더 큰 프로젝트의 일부가 될 것이다. 그렇지 않다면 재미가 없지 않겠는가. 그리고 재미를 극대화하려면 부동소수점 연산이 아주 많이 필요한 프로젝트가 필요하다.
다행히도, 그 작업에 딱 맞는 가속기 아키텍처를 내가 하나 알고 있다. 바로 행렬-행렬 곱셈용 systolic array 다! 이런 가속기는 학습과 추론을 모두 겨냥한 머신러닝 가속기에서 널리 쓰인다. (양자화가 정확도를 너무 깎아먹을 때를 대비해서다.) 내가 AI 가속기를 만들겠다는 것은 아니고, 단지 실리콘 위에 지나치게 많은 부동소수점 산술을 올릴 그럴듯한 핑계가 필요했을 뿐이다.
훌륭하다. 이제 우리의 핑계가 생겼으니 어떤 애플리케이션을 겨냥하는지 알았으니, 이 워크로드의 제약을 살펴보자.
첫째, 우리는 외부 클라이언트를 가진 CPU용 FPU 유닛을 만드는 것이 아니다. 우리는 커스텀으로 갈 수 있다. 그러면 편리하게도 IEEE 754 호환성과 5가지 반올림 모드를 그것이 기어 나온 지옥 구덩이로 다시 던져버릴 수 있다. 그렇다고 해도, 부동소수점 산술 구현을 테스트하기 위한 테스트 벡터를 만들려면 덜 비밀스러운 포맷을 고르는 것이 좋다. 또한 널리 지원되는 IEEE 타입 중 하나와 쉽게 상호 변환할 수 있는 포맷이라면 가산점이다. 그러면 가속기와 이를 구동하는 펌웨어 사이의 상호운용성이 쉬워진다.
둘째, 내 칩은 IO 병목에 걸릴 것이다. (이 블로그를 계속 보고 있던 분들은 알 것이다. 맞다, 또다시다 🔥) 그래서 내 선택은 minifloat 중 하나가 된다. 이 용어는 폭이 32비트보다 작은 float 를 가리킨다. 보라. 이름이 귀엽기 때문만은 아니다. 기술적인 이유도 있다.
우리는 더 작은 포맷을 목표로 하므로, 지수/가수 분할을 더 신중히 결정해야 한다. 지수 비트를 줄이면 표현 범위가 줄고, 가수 쪽을 너무 줄이면 숫자의 표현 정밀도가 떨어진다. 또 하드웨어 관점에서도 이 분할이 곱셈과 덧셈 구현에 어떤 영향을 미칠지 생각해볼 수 있다.
곱셈을 생각해보자. 부동소수점 곱셈에서 가장 비싼 연산은 가수의 곱셈이다. 이는 폭이 <significand bits> + 1 인 부호 없는 곱셈을 포함하며, 곱셈의 하드웨어 비용은 선형으로는 전혀 스케일되지 않는다. 8비트 bfloat16 가수 곱셈의 하드웨어 비용은 11비트 float16 가수 곱셈 비용의 대략 절반 정도다.
작은 가수가 점점 더 매력적으로 들리기 시작한다.
다시 애플리케이션 요구로 돌아가 보자. AI 워크로드는 정밀도 손실에 비교적 둔감하다는 흥미로운 특성이 있다. 양자화가 가능하다는 사실이 이를 보여준다. 반면 더 넓은 범위를 가지는 편이 유리하다.
이 모든 이유로, 나는 이제 bfloat16을 우리의 승자로 선포한다. 축하한다. 공식적으로 네가 내가 가장 좋아하는 minifloat 다! 🏆
왜 bfloat16 이 우주 역사상 최고의 포맷인지 정리해보자.
float32 로의 변환이 쉬움: 가수 비트만 잘라내면 된다 (물론 나중에 다룰 몇 가지 주의점은 있다)bfloat16 의 훌륭한 점은 명세가 없다는 것이다. 그래서 원하는 대로 구현할 수 있다!
bfloat16 의 끔찍한 점도 명세가 없다는 것이다. 그래서 원하는 대로 구현할 수 있다!
이 프로젝트는 왜 우리에게 IEEE가 필요한지에 대한 훌륭한 교훈이었다. 무료 도넛으로 엔지니어를 유인해서 명세가 나올 때까지 방에 가둬두는 유구한 전통을 지켜야 하는 이유 말이다!
명세가 없으면 원하는 대로 구현할 수 있고, 그러면 자연스럽게 모두가 다르게 구현한다!
우리는 커스텀 가속기를 만들고 있으니 bfloat16 연산 호환성 자체는 큰 문제가 아니다. 문제는 이제 내 부동소수점 수학 맛에 어떤 아이스크림 토핑을 올릴지 스스로 정해야 한다는 점이다.
가장 먼저 결정해야 할 것은 반올림 모드다.
적어도 하나는 골라야 하고, 알려진 테스트 벡터와 대조하려면 IEEE 모드 중 하나여야 한다. 명세의 5개 모드 중 0 방향 반올림이 하드웨어에서 구현하기에 단연 가장 편하고 저렴하다. 다른 모드들과 달리 다음 부동소수점 값으로 올림할 필요가 전혀 없어서, 덧셈의 맨 마지막에 있는 16비트 덧셈을 생략할 수 있다. (최대의 타이밍 압박을 위해 치명 경로 한복판에 절묘하게 놓여 있는 바로 그 연산 말이다.)
하지만 RZ (0 방향 반올림) 에는 또 하나의 엄청난 장점이 있다. 바로 오버플로 시의 동작이다.
RZ 는 로 오버플로하지 않는다. clamp 한다!
즉, 내 덧셈과 곱셈 연산의 입력으로 가 주어지지만 않는다면, 이 연산들은 절대로 를 생성하지 않는다. 따라서 를 입력으로 금지하면 지원 전체를 제거하고 하드웨어를 절약할 수 있다.
그런데 더 좋다. 덧셈과 곱셈 연산에서 자연스럽게 NaN 을 만들어내는 유일한 경우는 와의 연산이다. 따라서 NaN 역시 입력으로 금지하면, 그것을 지원하는 하드웨어 비용도 제거할 수 있다.
마지막으로 denormal 지원 여부가 남는다. 아마 bfloat16 설계에서 가장 덜 논쟁적인 질문일 것이다. denormal 로 얻는 추가 126개의 값은 그 하드웨어 번거로움을 감수할 가치가 전혀 없다. 삭제.
정리하자면, 우리의 아이스크림 주문은 🍨 이다.
bfloat16: 부호 1비트, 지수 8비트, 가수 7비트NaN 지원 없음이제 무엇을 만들지 결정하는 첫 번째 어려운 부분을 끝냈으니, 두 번째 어려운 부분, 즉 이를 아키텍처화해야 한다.
행렬-행렬 연산을 위해서는 가산기와 곱셈기가 모두 필요하다.
이 글이 이미 꽤 길어졌고, 곱셈기는 가수 곱셈을 효율적으로 설계하는 법만 알아내면 사실 꽤 만들기 쉽다. (스포일러: 부호 없는 booth radix-4 multiplier) 따라서 이제부터는 더 복잡하고 더 정교한 가산기 설계에 집중하겠다.
가산기를 설계하는 순진한 방법은 single path adder 를 만드는 것이다. 즉 C 코드 예제처럼 모든 단계를 같은 경로에서 수행하는 구조다. 개념적으로는 단순하고 논리 중복이 없기 때문에 면적 측면에서는 효율적이지만, 이 단일 경로의 깊이 때문에 성능 측면에서는 매우 비싸다.
나쁜 설계라는 뜻은 아니다. 면적만 최적화하려는 상황이었다면 충분히 괜찮은 후보였을 수도 있다. 하지만 우리는 면적과 성능이라는 이중의 의무를 지고 있으므로, 더 잘해야 한다.
덧셈 알고리즘을 다시 보면, 대규모 cancellation 과 가수 시프트는 사실 서로 배타적이라는 것을 알 수 있다. 즉 가수 차이의 leading zero 를 세고 정규화 전에 지수에서 1보다 큰 값을 빼야 하는 cancellation 은 두 피연산자의 지수 차이가 2 미만이면서, 동시에 실효적으로는 뺄셈을 수행하는 경우에만 발생한다.
이를 바탕으로, 약간의 기능 중복을 감수하는 대가로 가산기를 2개의 경로로 나눌 수 있다.
이 분할 구조를 dual path architecture 라고 하며, 1980년대 이후 고성능 FPU의 사실상 표준 가산기 구조였다.
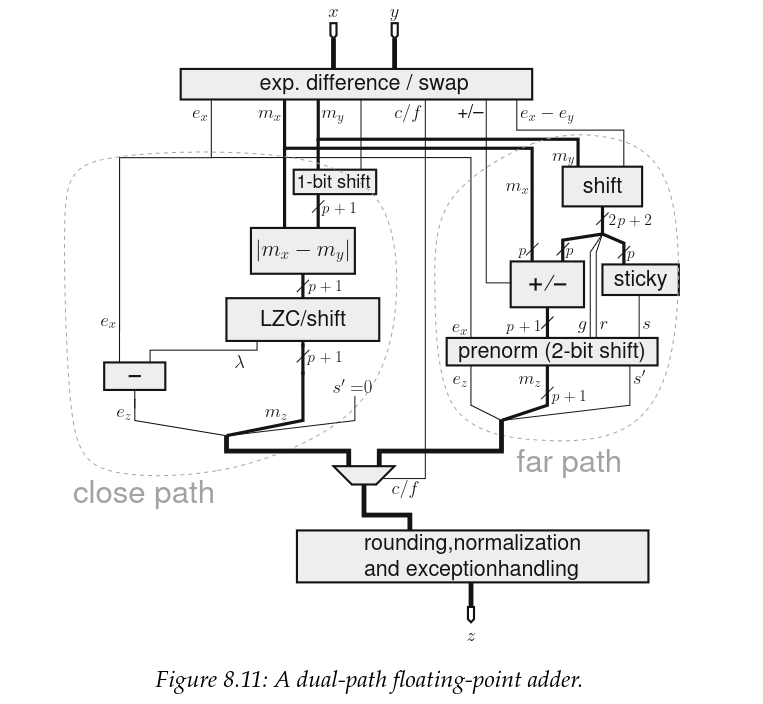
Dual path adder architecture schematic.
출처: Handbook of Floating-Point Arithmetic, Second edition
그런데 이 회로도는 IEEE 준수 float 용이고, 우리는 일반적인 경우를 설계하는 것이 아니다. 그렇다면 우리에게는 무엇이 달라질까?
우리가 RZ 반올림만 사용하기로 했던 것을 떠올려보자. RZ 는 반올림이 필요한 경우 사실상 가수를 clamp 하는 것과 같고, 이는 결코 다음 값으로 올림할 필요가 없음을 뜻한다. 따라서 그 효과를 위한 논리를 전부 잘라낼 수 있다.
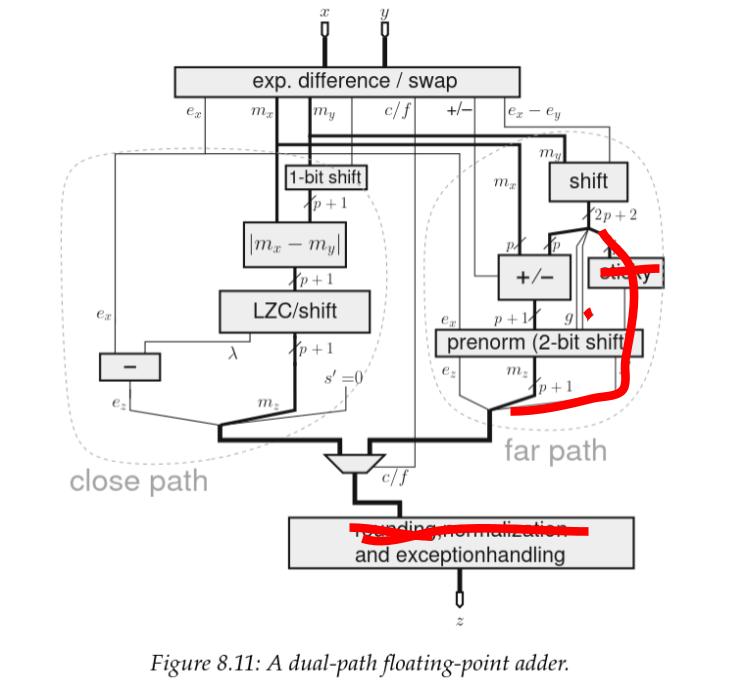
올림 반올림 때문에 필요한 논리를 색으로 표시해두었고, 우리는 그것을 전부 제거한다. (🔥 w 🔥)
다음으로, NaN 이나 를 피연산자로 허용하지 않으므로 예외를 발생시킬 방법도 없다. 따라서 이것 역시 제거된다.
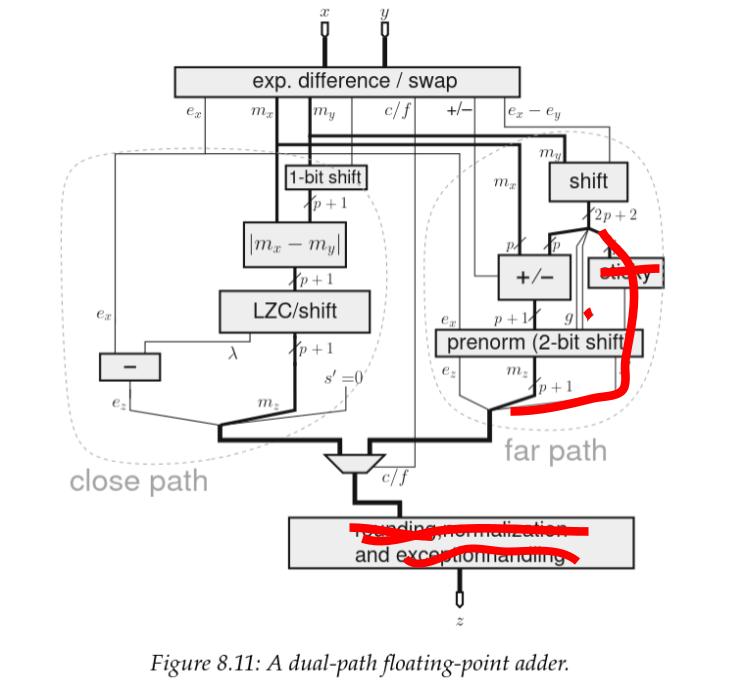
더 많은 것들을 도려내는 중 🪓
이 회로도는 subnormal 처리 방식을 보여주지는 않지만, 우리 구현은 그 부분에서도 논리를 절약한다. 그렇다고 해도 subnormal 이 발생했는지 검출하고 이를 0으로 clamp 하는 약간의 논리는 여전히 필요하다. close path 에서는 이 기능이 내가 “normalize” 라고 부를 블록에 통합되어 있으며, 이는 다비트 가수 시프트와 지수 감산 뒤의 치명 경로 위에 놓인다.
최종 설계는 대략 다음과 같은 모습이다.
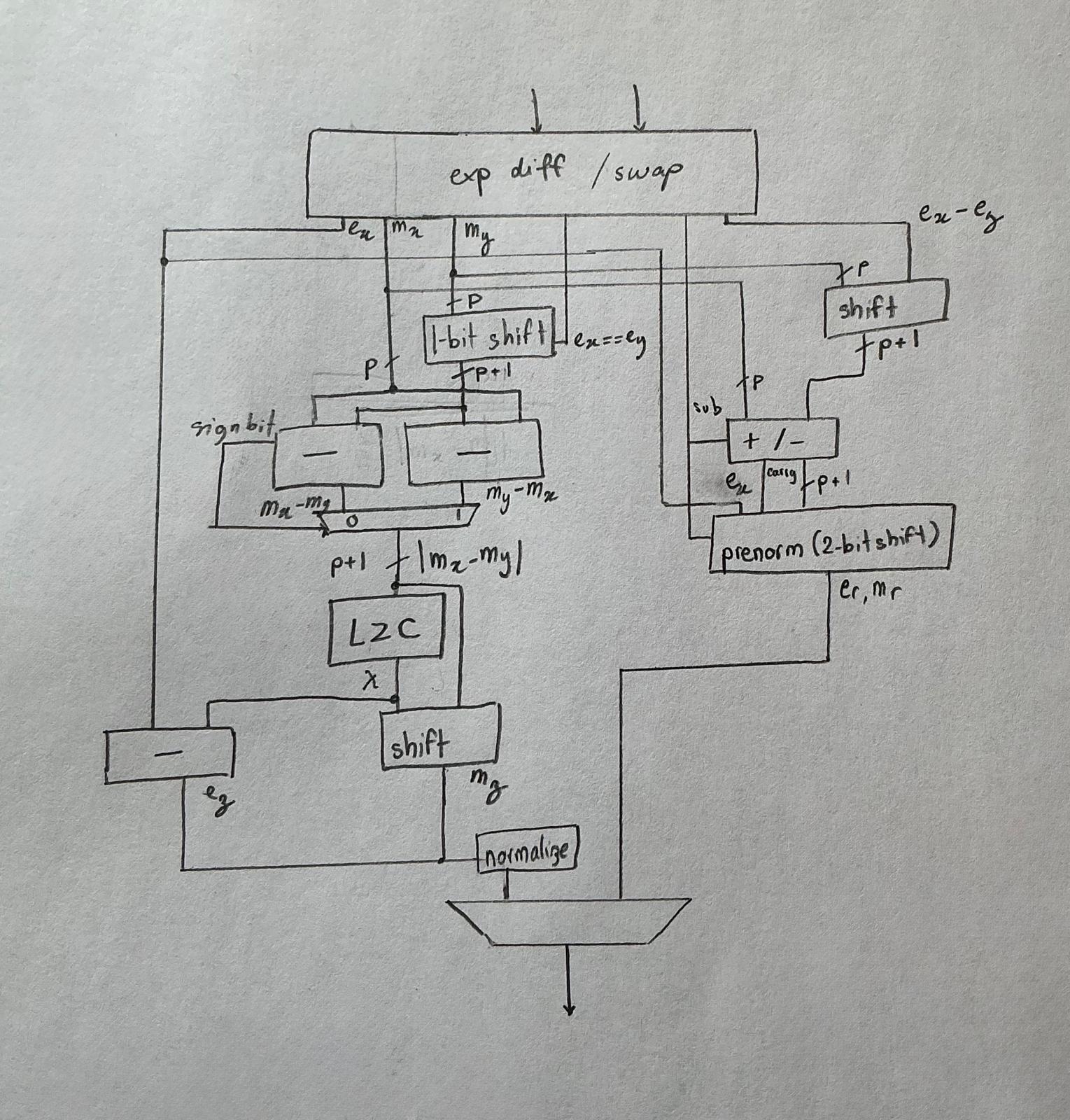
내가 구현 중인 bfloat16 덧셈 버전의 회로도.
이론은 즐겁지만, 현실에 맞서 버텨낼 수 있다는 것이 증명되기 전까지는 아무것도 그것을 참이라고 보장하지 않는다. 그러니 자신의 이해를 검증하는 가장 좋은 방법은 차갑고 냉혹한 현실에 던져보는 것이다.
그리고 이것은 단순한 사고 실험이 아니다. 우리는 실제 실리콘으로 실제 테이프아웃을 하고 있다. 그리고 과거의 하드웨어 트라우마가 내 머리에 단 하나의 교훈만 새겨놓았다면, 그것은 이것이다. 작동함이 증명되기 전까지는, 그것은 고장난 것이다!
테스트를 돌릴 시간이다!
부동소수점 산술 하드웨어를 테스트하는 일은 흥미로운 도전이다. 코너 케이스가 너무 많기 때문이다. 100개의 무작위 값을 넣고 하루를 끝낼 수 있는 문제가 아니다. 아니다. 이런 모든 모서리에 대해 exhaustive coverage 가 필요하며, 그 대부분은 당신이 존재조차 몰랐던 것들이다. 이건 전형적인 “무엇을 모르는지도 모른다” 문제다. 그렇다면 계획은 무엇일까?
바로 여기서 내가 검증에 대한 죄를 저질렀다. directed simulation 기반 테스트는 입력 공간의 크기에 따라 스케일되는데, 그럴듯하게 표현하면 선형적으로 스케일되지 않는다는 뜻이다. 그래서 형식 기법이 부동소수점 검증에서 점점 더 널리 쓰이고 있다. 이걸 directed testing 으로 테스트하려면 모든 입력 조합을 시험해야 하는데, 끔찍한 생각처럼 들린다…
… 그리고 나는 바로 그것을 하려고 한다. 사전에 모든 함정을 정확히 아는 상태가 아니라면, 모든 코너 케이스를 빠짐없이 확인하는 유일한 방법이기 때문이다.
그러면 다음 문제가 생긴다. 테스트 시간이다. 40억 개가 넘는 조합을 테스트하는 데 대체 얼마나 걸릴까? 빠른 반복 시간이 일을 해내는 데 가장 중요하다고 믿기 때문에, 이 테스트벤치는 빨라야 하고, 따라서 빠른 시뮬레이터와 golden model 이 필요하다.
여기서 verilator 가 등장한다. Synopsis vcs 와 비슷하게 시뮬레이션을 네이티브 실행 파일로 컴파일해 주므로, 오픈소스 진영에서 가장 빠른 시뮬레이터라 할 수 있다.
다음은 golden model 이다. 마침 우리가 살고 있는 2026년에는 C++23 표준 라이브러리에 stdfloat 안의 bfloat16 타입이 추가되어 있다.
마지막으로, DPI-C interface 를 사용하면 (더 느린 VPI 인터페이스 대신) C++로 작성한 커스텀 golden model 을 테스트벤치 안으로 호출할 수 있다.
완벽한 계획처럼 들린다… C++가 나를 배신하기 전까지는.
하지만 내 golden model 이 그렇게 golden 하지 않았던 이유로 들어가기 전에, stdfloat 의 bfloat16 타입이 내부적으로 실제로 어떻게 동작하는지 이해해야 한다.
중요한 점은 내 컴퓨터에는 실제 bfloat16 네이티브 하드웨어가 없다는 것이다. 그런데도 대체 어떻게 계산하고 있는 걸까?
간단한 덧셈으로 시험해보자.
#include <stdfloat>
int main(){
bfloat16_t a,b,c;
a = 1.0;
b = 1.0;
c = a + b;
return 0;
}이 테스트 프로그램의 디스어셈블리를 보면 gcc 가 bfloat16 덧셈을 soft bfloat16 부동소수점 함수 대체(__extendbfsf2, __truncsfbf2 + wrapper code) 를 사용해 처리하는 것을 볼 수 있다.
이는 현재 내 하드웨어가 bfloat16 하드웨어 지원이 없거나, 지원이 있더라도 컴파일러에 광고되지 않고 있음을 시사한다.
4 int main(){
0x0000000000001119 <+0>: push %rbp
0x000000000000111a <+1>: mov %rsp,%rbp
0x000000000000111d <+4>: sub $0x20,%rsp
5 bfloat16_t a, b, c;
6
7 a = 1.0;
0x0000000000001121 <+8>: movzwl 0xee4(%rip),%eax # 0x200c
0x0000000000001128 <+15>: mov %ax,-0x6(%rbp)
8 b = 1.0;
0x000000000000112c <+19>: movzwl 0xed9(%rip),%eax # 0x200c
0x0000000000001133 <+26>: mov %ax,-0x4(%rbp)
9 c = a+b;
0x0000000000001137 <+30>: pinsrw $0x0,-0x6(%rbp),%xmm0
0x000000000000113d <+36>: call 0x1180 <__extendbfsf2>
0x0000000000001142 <+41>: movss %xmm0,-0x14(%rbp)
0x0000000000001147 <+46>: pinsrw $0x0,-0x4(%rbp),%xmm0
0x000000000000114d <+52>: call 0x1180 <__extendbfsf2>
0x0000000000001152 <+57>: movaps %xmm0,%xmm1
0x0000000000001155 <+60>: addss -0x14(%rbp),%xmm1
0x000000000000115a <+65>: movd %xmm1,%eax
0x000000000000115e <+69>: movd %eax,%xmm0
0x0000000000001162 <+73>: call 0x1250 <__truncsfbf2>
0x0000000000001167 <+78>: movd %xmm0,%eax
0x000000000000116b <+82>: mov %ax,-0x2(%rbp)
10
11 return 0;
0x000000000000116f <+86>: mov $0x0,%eax
12 }
0x0000000000001174 <+91>: leave
0x0000000000001175 <+92>: ret이 어셈블리를 보면 bfloat16_t 의 기대 동작은
clamp 된 float32_t 와 비슷하다고 볼 수 있다.
그리고 이는 완전히 합법적이다. bfloat16 동작은 어떤 명세로도 완전히 정의되어 있지 않으므로 구현 정의 사항이기 때문이다. 🌈
bfloat16_t 구현 탐사#나는 x86 어셈블리에 완전히 능숙하지는 않기 때문에, 내 soft bfloat16_t 의 동작을 파악하기 위해 간단한 테스트 프로그램 을 작성했다.
이를 통해 나는 다음을 알게 되었다.
NaN 지원이 있다그래서 순진한 나는 이것을 하드웨어의 golden model 로 쓰려면, subnormal 을 0으로 수동 clamp 하고 NaN 과 를 입력으로 넣지 않기만 하면 된다고 생각했다.
#define IS_SUBNORMAL(x) ((isnormal(x) | isnan(x) | isinf(x) | (x == 0e0bf16)))
그래서 나는 subnormal 을 clamp 하고 신나게 앞으로 나아갔다.
그런데 가능한 모든 피연산자 조합을 테스트하면서 행복하게 작업하던 중, 재앙이 닥쳤다.
C++ 2022 공표 제안서 “Extended floating-point types and standard names” 에서 인용하겠다.
7.2. Supported formats
We propose aliases for the following layouts:
- [IEEE-754-2008] binary16 - IEEE 16-bit.
- [IEEE-754-2008] binary32 - IEEE 32-bit.
- [IEEE-754-2008] binary64 - IEEE 64-bit.
- [IEEE-754-2008] binary128 - IEEE 128-bit.
- bfloat16, which is binary32 with 16 bits of precision truncated; see [bfloat16]. <–
본질적으로 이것은, 바이너리 분석에서 드러난 그대로 bfloat16_t 가 truncation 된 float32_t 라는 뜻이다. (IEEE 명세에서는 binary32 라고 부른다.)
문제는 이 접근에서 float32_t 의 내부 정밀도 가 bfloat16_t 에 비해 훨씬 크다는 점이다.
float32_t bfloat16_t 실제로는 이것이 뜻하는 바는, 내 하드웨어가 C++ 표준 라이브러리에 명시된 golden model 과 정확히 일치하려면, 를 지원해야 한다는 것이다. 그리고 그것은 곧 모든 곳의 가수 경로가 훨씬 더 넓어져야 함을 의미한다… 그리고 그건 어느 우주에서도 내가 원하는 결과가 아니다.
C++ 표준 라이브러리의 bfloat16_t 구현은 내부적으로 float32_t 를 사용하므로, golden model 의 결과와 기대 RTL 출력을 깔끔하게 일치시킬 수 없다.
이는 float32_t 가 내부 정밀도 비트를 가지는 반면, bloat16_t 는 8비트이기 때문이다. 따라서 같은 입력값이 주어졌을 때, 입력 사이의 지수 차이가 ] 범위 안에 있다면, 같은 반올림 모드와 같은 피연산자를 사용하더라도 반올림 동작에서 차이를 관찰하게 된다.
이것의 또 다른 성질은, 그 차이가 다음 연속 부동소수점 수까지의 범위 안에 갇혀 있다는 점이다.
다음 섹션을 단순하게 하기 위해, 를 “unit of last place” 라고 정의하겠다. 더 공식적으로는 다음과 같다.
는 에 가장 가까운 두 부동소수점 수 사이의 간격이며, 심지어 가 그중 하나일 때도 마찬가지다.
따라서 내 golden model 의 bfloat16_t 와 내 구현 사이의 상대 오차는 최대 이다.
는 다음과 같이 정의된다.
내 bfloat16 구현에서는 이므로 이고, 상대 오차는 다음과 같이 계산한다.
이제 불평을 끝내고 golden model 을 제대로 동작하게 만든 뒤에는, float32 로부터 bfloat16 을 에뮬레이션하는 것이 표준 라이브러리에는 더 우수한 접근이라는 점을 인정하고 싶다. 이렇게 하면 대부분의 계산을 CPU의 FPU에 넘길 수 있어, 완전히 소프트웨어로 구현하는 것보다 훨씬 더 높은 성능을 얻을 수 있다.
물론 결과가 다를 수는 있다. 하지만 우리가 bfloat16 을 쓰기 시작했을 때 이미 감수한 것이 바로 그것이다.
이제 동작하는 bfloat16 산술이 생겼으니, 내가 가장 좋아하는 부분이 온다. 이것을 비싼 수정 반도체로 만드는 것이다.
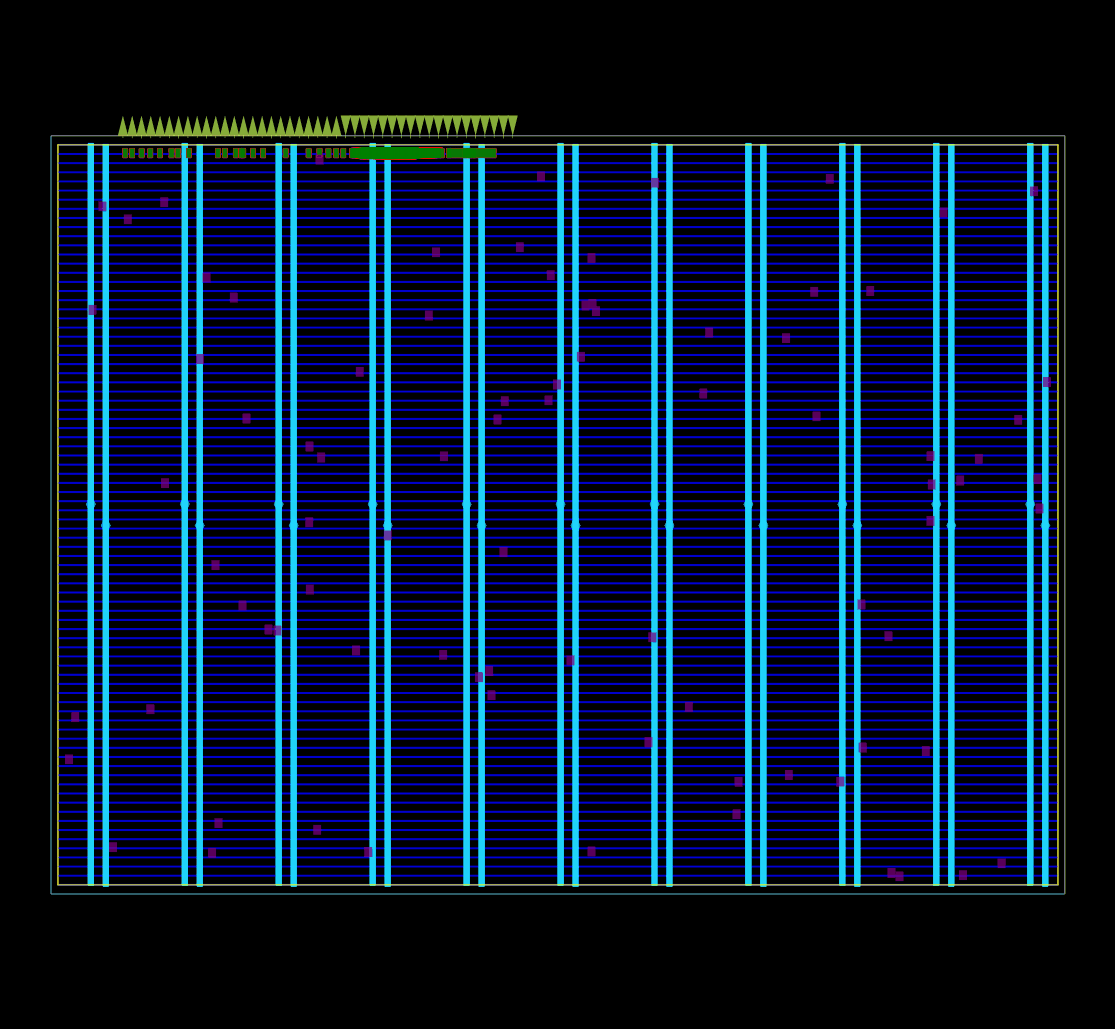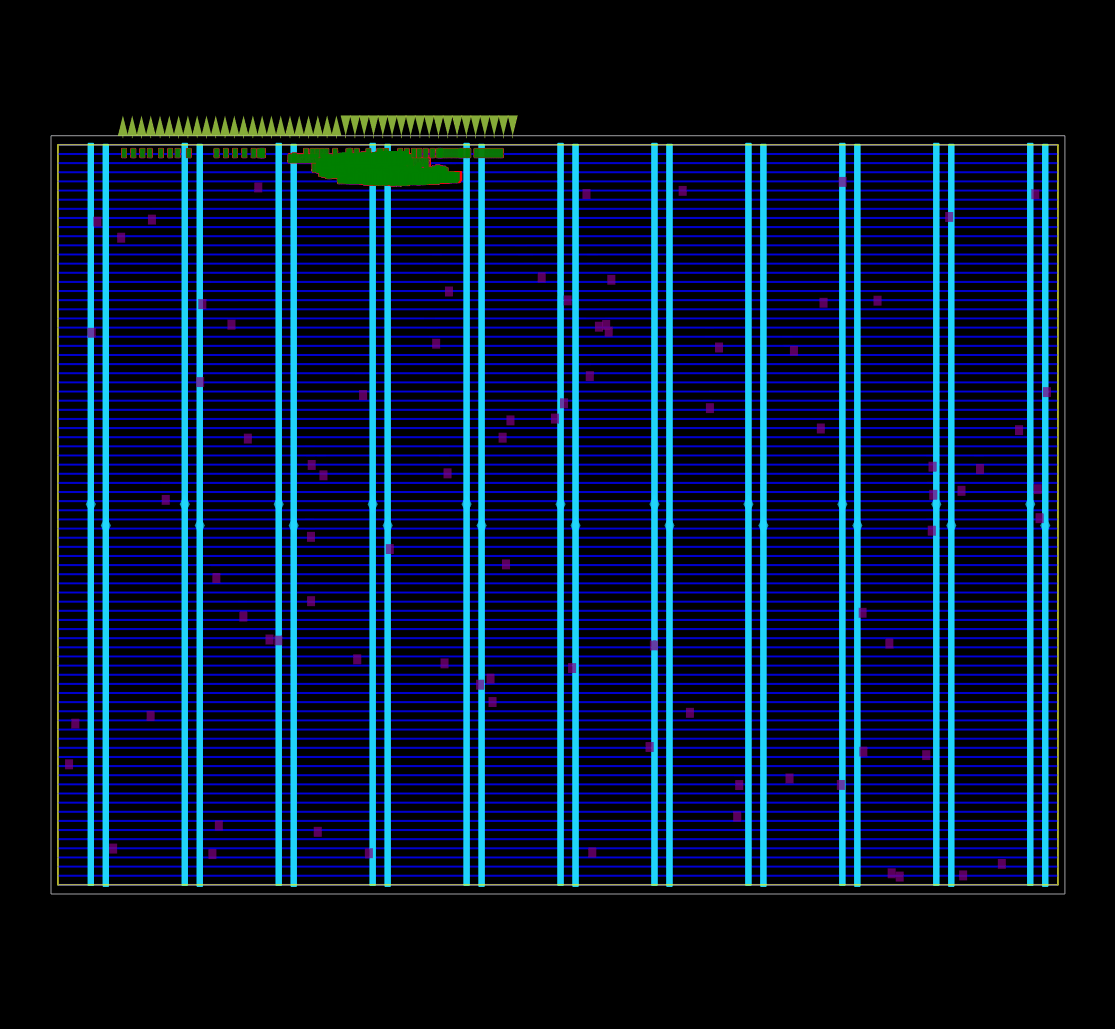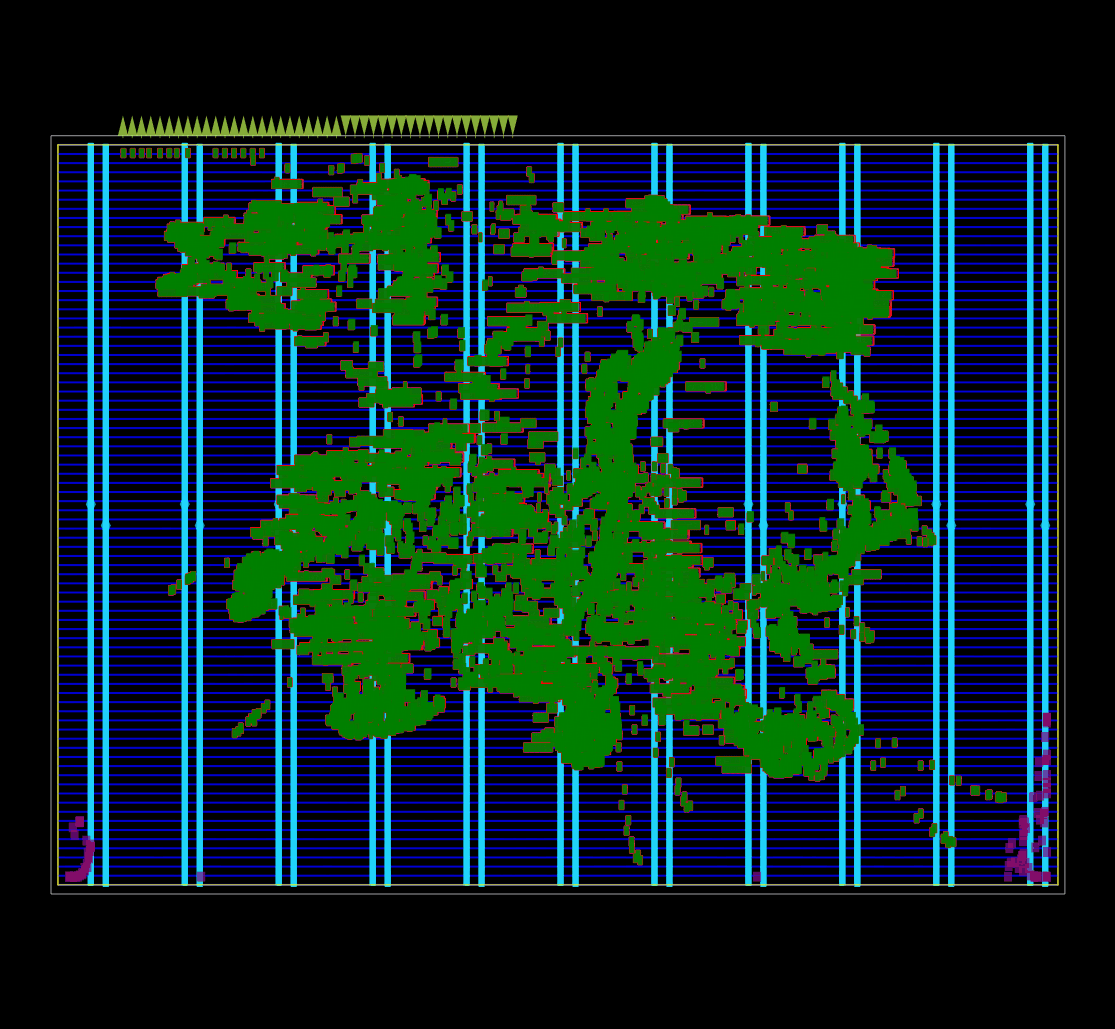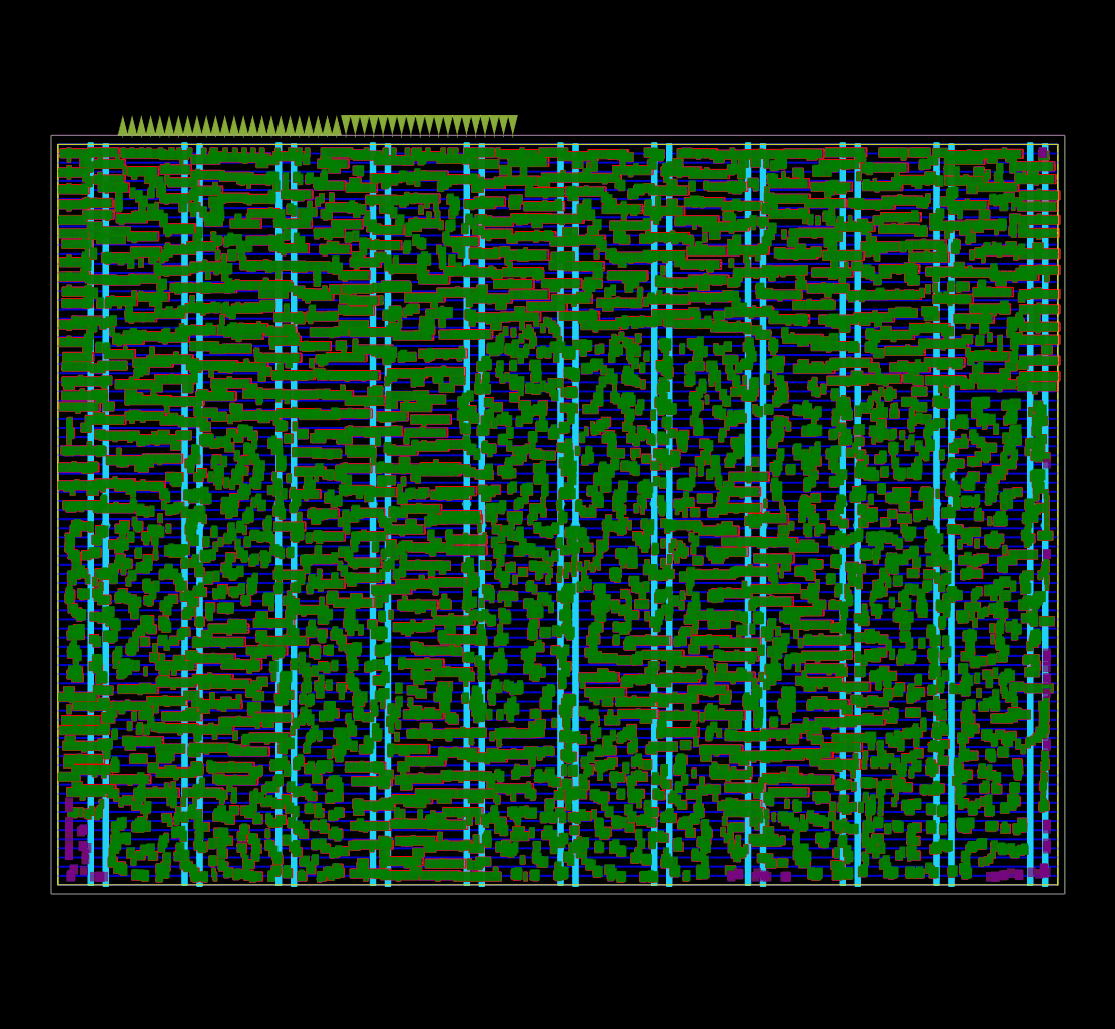
ASIC 플로어플랜의 모든 논리 셀에 대한 초기 global placement 가 동작 중인 모습.
OpenROAD global placement 의 debug mode 로 캡처했다.
이 글은 부동소수점 산술에 초점을 맞추고 있으므로, 가속기의 나머지 부분에 대해 떠들고 싶은 내 욕망은 ASIC 저장소 안에 가둬두겠다.
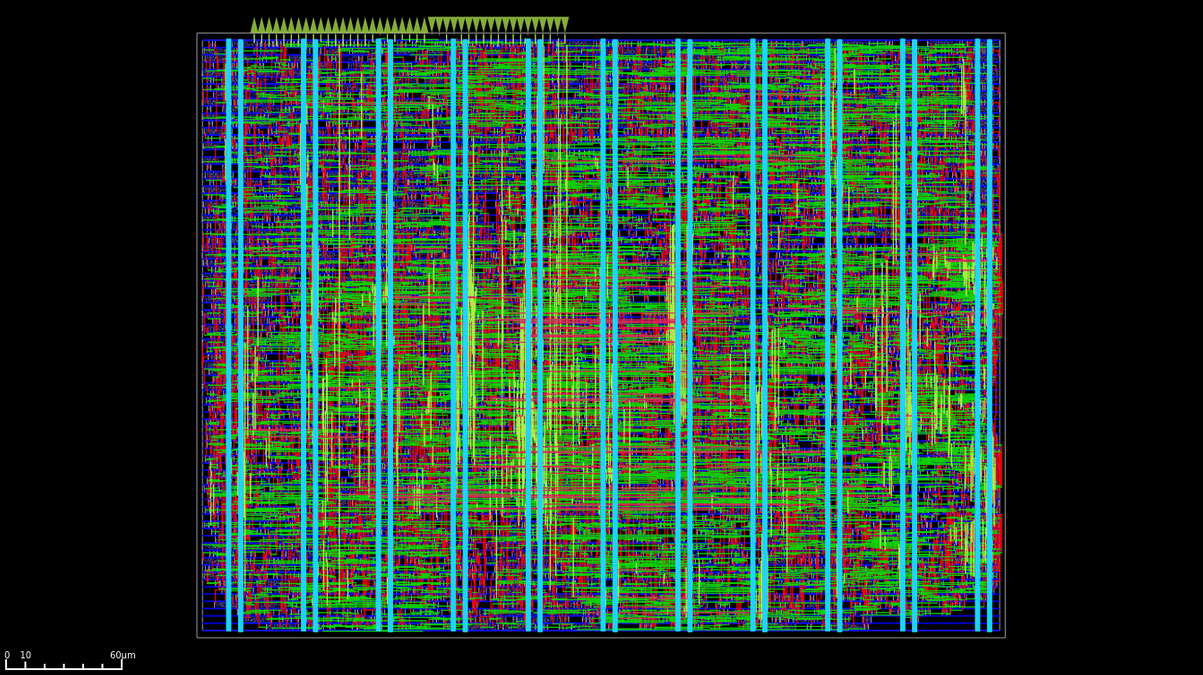
sg13g2 PDK 를 사용해 IHP 130nm node 용으로 설계한 2세대 Systolic Array 의 플로어플랜. 다이 면적은 126,685 µm² 이고, 목표 전형 동작 전압은 25°C 에서 1.2V 다.
이 설계에는 두 개의 clock tree 가 있다. 하나는 MAC 용이고 다른 하나는 JTAG TAP 용이다. MAC 클록은 최대 100 MHz 동작을 목표로 하지만, 현재 출력 GPIO 주파수 실험은 최대 75 MHz 정도를 시사하고, JTAG 는 2 MHz 다.
이번에는 IHP의 멋진 130nm sg13g2 node 에서 Tiny Tapeout 의 ihp26a 칩 을 shuttle 로 사용해 칩을 테이프아웃한다. 그리고 완전한 투명성을 위해 말하자면, Tiny Tapout 팀이 내가 이 프로젝트에 쓰는 면적(그리고 devboard 하나)을 위해 교환한 쿠폰을 제공해 주었다. 그러니 기술적으로 이 테이프아웃은 Tiny Tapeout 의 후원을 받는 셈이며, 그 사실이 내가 그들을 덜 찬양하게 만들지는 않을 것이다!
고맙다 여러분!
Tiny Tapeout shuttle chip ihp26a 렌더.
출처: https://github.com/TinyTapeout/tinytapeout-chip-renders
이번에 사용하는 IHP 130nm 셀 라이브러리는 특별하다. 다른 두 오픈소스 PDK 와 비교해 엄청나게 빠르기 때문에, 정말 인상적인 fmax 에 도달할 수 있다. (이는 자매 IHP sg13cmos5l node 를 사용한 우리 fmax 경쟁 에서도 드러난다.)
하지만 또다시 IO 문제가 있다. 최대 GPIO 안정 동작 주파수는 입력에서 대략 100MHz, 출력 경로에서 75MHz 정도일 것으로 예상되므로, 이 systolic array 는 사실상 75MHz 에서 병목된다. 그런데 sg13g2 PDK 가 너무 빠르고, 75MHz 에서 타이밍을 맞추는 것이 충분히 도전적이지 않았기 때문에, 나는 정상 동작 주파수를 100MHz 로 목표로 삼아 스스로를 더 괴롭히기로 했다. 게다가 bfloat16 덧셈과 곱셈 전부를 단일 사이클로 처리 하기로 했다.
물론 이 연산들을 파이프라인할 수도 있었다. 하지만 그러면 구현 성능을 끌어올릴 기회를 낭비하는 셈이었다.
구현 도중 있었던 흥미로운 이야기를 하나 들려주겠다.
하지만 먼저 배경을 깔자. 치명 경로는 정확히 예상한 곳을 지난다. 곱셈기의 가수 곱셈을 통과한 뒤 가산기의 close path 로 이어지고, 바로 LZC (leading zero count) 를 통과한다.
이 시점에서 나는 이미 RTL 타이밍 최적화의 꽤 고전적인 몇 가지 트릭을 적용한 상태였고, slow corner 에서 +0.6ns 의 slack, nominal corner 에서 +3.9ns 의 slack 을 확보한 상태였다. 나는 일이 끝났다고 생각했는데, 한 친구가 내 LZC 설계 선택을 문제 삼기 시작했다.
이 숫자들은 systolic array 의 제어 논리를 전부 다시 설계하고, 모든 플롭을 DFT scan chain 의 일부로 연결하기 전 타이밍 결과였다.
나는 tree based LZC 를 구현하기로 했는데, 논문에서 볼 수 있는 바로 그 방식이다. verilog 코드가 너무 읽기 어렵고 RTL 스러워서 전용 테스트벤치 가 따로 필요할 정도였지만, 그 기반 아이디어가 너무 우아해서 포기할 수가 없었다.
이미 타이밍이 잘 나오고 있었기 때문에, 더 최적화된 leading zero anticipation 을 나중의 백업 옵션으로 남겨두기로 했다.
그런데 친구가 와서 다른 것을 하자고 제안했다. tree based LZC 는 잊고, 그냥 priority mux 를 써서 synthesizer 에 맡기자는 것이다.
always @(*) begin
casez (in)
9'b1????????: shift_amt = 4'd0;
9'b01???????: shift_amt = 4'd1;
9'b001??????: shift_amt = 4'd2;
9'b0001?????: shift_amt = 4'd3;
9'b00001????: shift_amt = 4'd4;
9'b000001???: shift_amt = 4'd5;
9'b0000001??: shift_amt = 4'd6;
9'b00000001?: shift_amt = 4'd7;
9'b000000001: shift_amt = 4'd8;
default: shift_amt = 4'd0;
endcase
end솔직히 말해, 나는 이것이 tree based LZC 보다 더 나은 타이밍을 낼 거라고는 전혀 생각하지 않았다. 그러나 RTL 과 타이밍 사이에는 124단계 최적화를 가진 yosys 가 있고, yosys 는 techmap 을 이해한다.
참고로, 이것이 원래 모듈의 코드다. 구현 시 hierarchy 를 유지하면서 추적할 수 있도록 별도 모듈로 분리했다.
module pmux(
input wire [8:0] data_i,
output reg [3:0] zero_cnt
);
always @(*) begin
casez (data_i)
9'b1????????: zero_cnt = 4'd0;
9'b01???????: zero_cnt = 4'd1;
9'b001??????: zero_cnt = 4'd2;
9'b0001?????: zero_cnt = 4'd3;
9'b00001????: zero_cnt = 4'd4;
9'b000001???: zero_cnt = 4'd5;
9'b0000001??: zero_cnt = 4'd6;
9'b00000001?: zero_cnt = 4'd7;
9'b000000001: zero_cnt = 4'd8;
default: zero_cnt = 4'd0;
endcase
end
endmodule이 모듈은 19셀 구현으로 합성되며, 치명 경로 깊이가 단 3 개의 논리 레벨에 불과해서 더 나은 타이밍을 낸다.
최종 flattened 버전에서는 slow path 에서 +0.05ns 의 개선을 가져왔다. 한편으로는 큰 향상은 아니다. 하지만 다른 한편으로는, 이 경험은 툴이 얼마나 성능 좋은 로직을 만들어낼 수 있는지 인정하게 만든다.
이 casez LZC 설계는 약간 더 빠를 뿐 아니라, 가장 큰 장점은 이해하기 훨씬 쉽다는 점이다. 그 덕분에 유지보수도 더 쉬워지고, 장기적으로 버그가 들어갈 가능성도 직접적으로 줄어든다.
때로 좋은 설계란 성능만의 문제가 아니다.
그런데 잠깐! 두 번째 테이프아웃이 있었다고?!
이 글을 기획했을 때, 내 바람은 bfloat16 산술을 IHP 130 nm 위의 2세대 systolic array 의 일부로 테이프아웃하는 것이었다.
그런데 이 글을 쓰는 도중 Tiny Tapeout 커뮤니티는 IHP 130 nm 에서 두 번째 테이프아웃을 할 기회를 얻었고, 이번에는 IHP의 더 새로운 sg13cmos5l node 를 목표로 했다.
1세대 systolic array 를 위해 GF180 테이프아웃 기회를 얻었던 때와 마찬가지로, 이것 역시 비공개 실험 셔틀이었고, 그래서 우리는 다시 출발점으로 돌아오게 되었다.

Tiny Tapeout shuttle ihp0p4 칩 렌더.
크레딧: Luis Eduardo Ledoux Pardo
나는 테이프아웃에 대해 약간 독특한 규칙이 하나 있다. 같은 설계를 두 번 테이프아웃하지 않는다는 것이다.
그래서 ihp0p4 셔틀 칩에 제출하려면 기존 IP 를 그대로 재사용할 수 없었다. 아니다. 새로운 것이 필요했다.
그렇게 fmax 챌린지! 가 등장했다.
내가 IHP 셀이 얼마나 빠른지, 그리고 덧셈과 곱셈 전체를 단일 사이클에서 수행하고 있다고 말했던 것을 기억하는가? 내 안의 일부는 IO 제한을 무시하고 최대 주파수를 목표로 삼는다면 얼마나 높이 갈 수 있을지 죽도록 궁금했다!
다행히도 다른 커뮤니티 구성원도 비슷한 설계 를 테이프아웃하고 있었고, 그래서 우리는 경쟁했다!
주파수를 더 높이기 위해 bfloat16 곱셈은 2사이클로 쪼갰다. 예상대로 주요 치명 경로는 가수 곱셈을 통과했다. 원래 곱셈 구현에서는 synthesizer implementation directive 를 사용해 부호 없는 Booth radix-4 multiplier 를 추론하게 했다.
LZC 경험이 보여주었듯, yosys 는 최적화된 로직 생성에서 결코 가벼운 상대가 아니다. 하지만 그 대가로 netlist 에 대한 제어력을 일부 잃게 되며, 이 경우에는 곱셈을 정확히 어디에서 분할할지 선택할 수 없게 된다.
그래서 이 경로를 파이프라인하는 데 도움을 주기 위해, 나는 커스텀 8비트 부호 없는 Booth radix-4 multiplier 를 처음부터 다시 구현해야 했다.
이 커스텀 곱셈 스테이지 안에서는 encoding stage 뒤, compression stage 중간에 플롭이 하나 추가된다. 첫 두 partial product 와 마지막 3개의 부분 압축 결과를 저장하고, 다음 사이클에서 그것들을 함께 압축해 최종 가수 곱셈 결과를 얻는다.
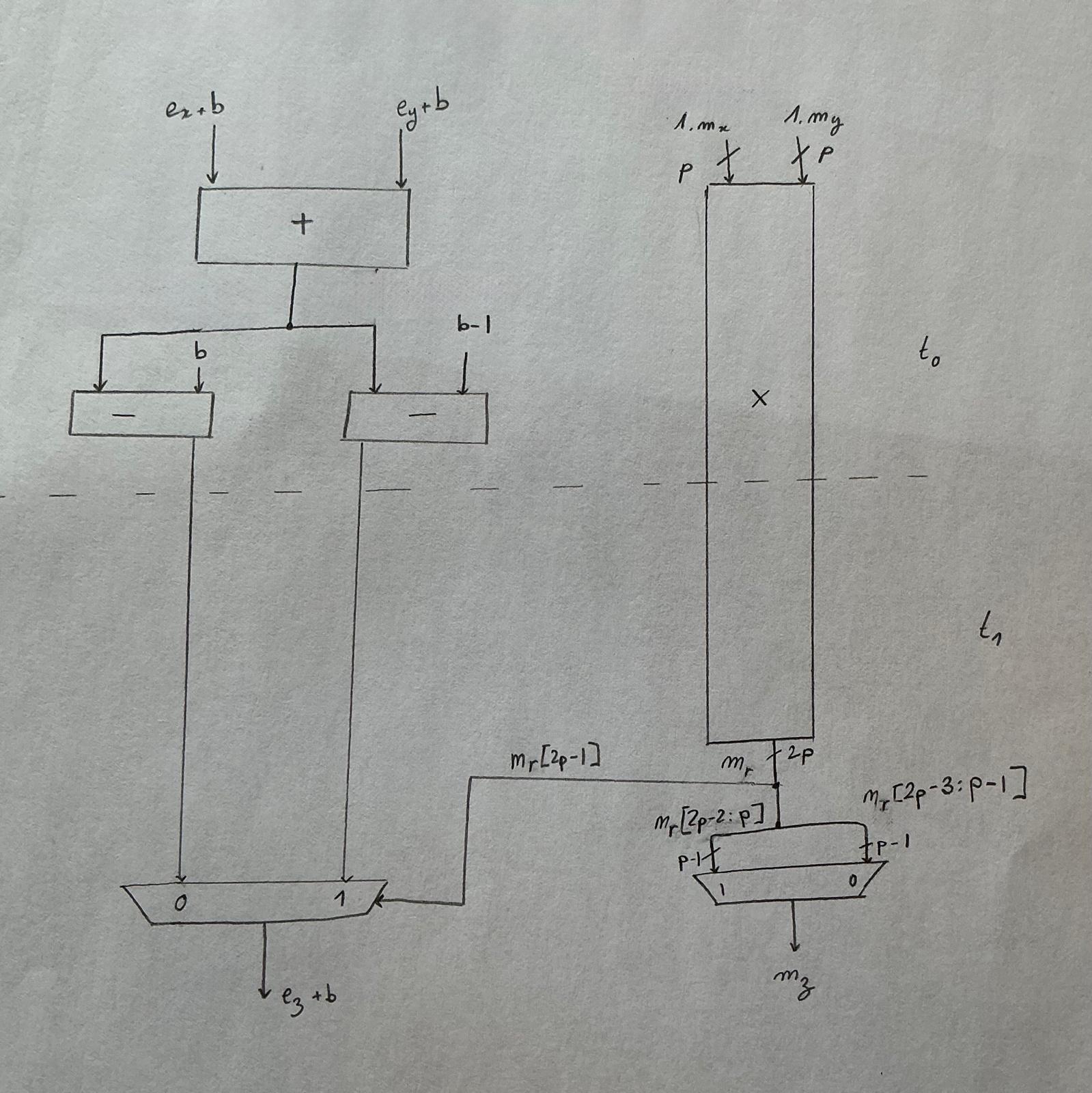
내가 구현 중인 고속 곱셈기의 회로도. 분리선은 어떤 연산이 에서 일어나고 어떤 연산이 에서 일어나는지 나타낸다.
곱셈기 전반에 걸쳐 몇 가지 추가 최적화도 수행되어, 이 설계는 최대 동작 주파수 454.545 MHz 에 도달했다.
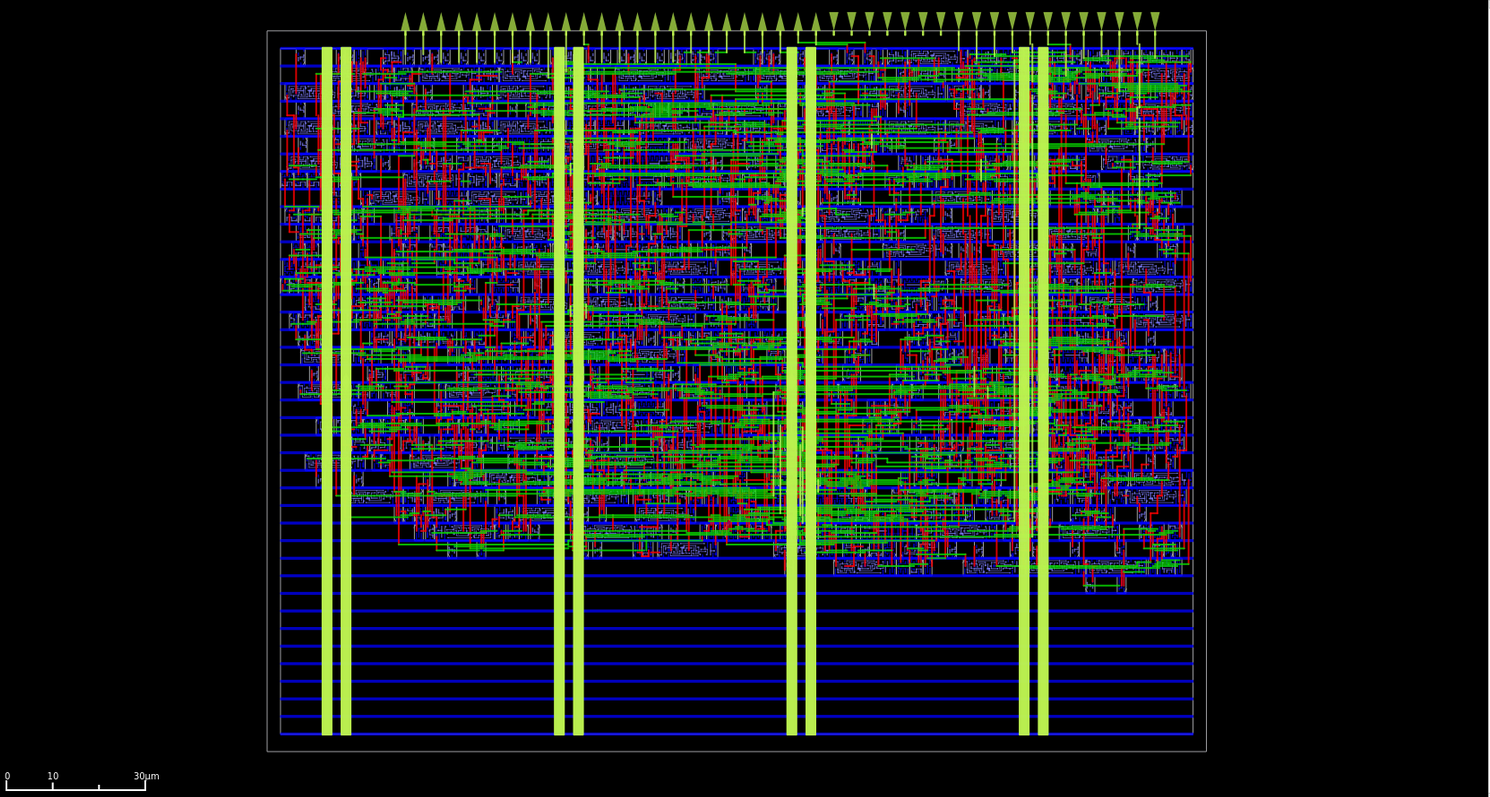
쓸데없이 빠른 곱셈기의 플로어플랜 렌더. 25°C 에서 1.20 V nominal operating corner 기준 최대 454.545 MHz 까지 동작하며, 202.08x154.98 um 크기의 단일 타일 면적을 차지한다.
반십 년이 넘는 시간이 지난 끝에, 나는 마침내 내 드래곤을 쓰러뜨리고 부동소수점 수학에게 복수했다!
처음부터 직접 부동소수점 산술을 만들어본 뒤, 나는 이제 부동소수점을 진정으로 이해하는 사람은 다음 두 부류뿐이라고 믿게 되었다.
부동소수점 산술을 다시 구현하고 그것을 두 번이나 테이프아웃한 지금, 나는 내가 부동소수점 산술을 깊이 이해한다고는 자신 있게 말할 수 없다. 하지만 적어도 이제 그 토끼굴이 얼마나 깊은지, 그리고 진정으로 그것을 마스터하려면 무엇을 해야 하는지는 정확히 안다.
하지만 내 부동소수점 IP 가 들어간 130nm 테이프아웃 두 번을 해낸 지금, 다른 minifloat 탐험과 더 복잡한 연산의 구현은 언젠가 다른 날로 미뤄둘 수 있다.
왜냐하면 지금 내게는 훨씬 더 중요한 일이 있기 때문이다!
이제 자기 전에, 문서를 다 쓰기 전에, 테이프아웃 이후 절대 빼먹어서는 안 되는 전통이 하나 있다.

Waffle House! ❤
부동소수점이라는 질문에 대한 600페이지 버전을 원하는 독자에게는 훌륭한 책 “Handbook of Floating-Point Arithmetic, Second edition” 을 강력히 추천한다.
이 글의 검토를 도와준 내 최고의 절반, yg, Prawnzz, 그리고 Erstfeld 에게 특별한 감사를 전한다.