개발자들이 자주 오해하여 버그로 이어지는 직관적이지 않은 함정들을 폭넓게 정리했습니다. 오류나 제안이 있다면 메일로 알려주세요.
개발자들에게 존재하는 몇 가지 함정을 요약한 글입니다. 이들 함정은 직관적이지 않아 쉽게 오해되고 버그의 원인이 됩니다.
이 글은 폭넓은 분야를 아우릅니다. 오류를 발견하거나 제안이 있다면 qouteall@163.com 으로 피드백을 보내주세요.
min-width의 기본값은 auto입니다. 플렉스박스나 그리드 내부에서는 min-width: auto가 종종 콘텐츠에 의해 최소 너비가 결정되게 만듭니다. 이 값은 flex-shrink, width: 0, max-width: 100% 등 많은 다른 CSS 속성보다 우선합니다. min-width: 0을 지정하는 것이 권장됩니다. 참고
CSS에서 가로와 세로는 다릅니다:
width: auto는 부모의 가용 공간을 채우려고 합니다. 하지만 height: auto는 보통 콘텐츠를 담을 수 있을 만큼만 확장됩니다.width: auto가 확장하려 들지 않습니다.margin: 0 auto는 가로 정렬을 중앙으로 합니다. 그러나 margin: auto 0는 보통 margin: 0 0이 되어 세로 중앙 정렬을 하지 않습니다. 플렉스박스에서 flex-direction: column인 경우 margin: auto 0로 세로 중앙 정렬이 가능합니다.writing-mode: vertical-rl).블록 포매팅 컨텍스트(BFC):
display: flow-root는 BFC를 생성합니다. (그 외에도 overflow: hidden, overflow: auto, overflow: scroll, display: table 등이 BFC를 만들지만 부작용이 있을 수 있습니다)border나 padding이 지정되어 있으면 마진 겹침이 일어나지 않습니다.다음과 같은 경우 새 스태킹 컨텍스트가 시작됩니다:
* 특수 렌더링 효과를 주는 속성들(`transform`, `filter`, `perspective`, `mask`, `opacity` 등)을 지정하면 새로운 스태킹 컨텍스트가 생성됩니다.
* `position: fixed` 또는 `position: sticky`는 스태킹 컨텍스트를 생성합니다.
* `position`이 `absolute` 또는 `relative`일 때 `z-index`를 지정한 경우
* 요소가 플렉스박스나 그리드 안에 있고 `z-index`를 지정한 경우
* `isolation: isolate`
* ...
스태킹 컨텍스트는 다음과 같은 동작을 유발할 수 있습니다:
* `z-index`는 스태킹 컨텍스트를 넘어 작동하지 않습니다. 동일한 스태킹 컨텍스트 내에서만 유효합니다.
* 스태킹 컨텍스트는 `position: absolute`나 `fixed`의 좌표에 영향을 줄 수 있습니다. (내부 로직은 복잡합니다. [참고](https://developer.mozilla.org/en-US/docs/Web/CSS/position))
* `position: sticky`는 스태킹 컨텍스트를 가로질러서는 동작하지 않습니다.
* `overflow: visible`이어도 스태킹 컨텍스트에 의해 잘릴 수 있습니다.
* `background-attachment: fixed`의 기준도 스태킹 컨텍스트가 됩니다.
모바일 브라우저에서는 스크롤을 내리면 상단 주소 표시줄과 하단 네비게이션 바가 화면 밖으로 사라질 수 있습니다. 100vh는 두 바가 사라진 상태의 높이를 기준으로 하므로, 바들이 보이는 상태의 실제 높이보다 큽니다. 현대적인 해법은 100dvh입니다.
width: 100vw는 스크롤바를 제외한 너비를 100vw로 만들기 때문에, 스크롤바까지 포함한 전체 너비가 가로로 넘칠 수 있습니다. width: 100%를 사용하면 이 문제를 피할 수 있습니다.
position: absolute는 부모를 기준으로 하지 않습니다. 가장 가까운 "포지셔닝된 조상"(즉, position이 relative나 absolute이거나 스태킹 컨텍스트를 생성하는 가장 가까운 조상)을 기준으로 합니다.
부모의 display가 flex나 grid이면 자식의 float는 효과가 없습니다.
부모의 너비/높이가 사전에 결정되어 있지 않으면, 퍼센트 너비/높이(width: 50%, height: 100% 등)는 동작하지 않습니다. (부모 높이는 콘텐츠 높이에 의해 결정되는데, 콘텐츠 높이가 다시 부모 높이에 의해 결정되는 순환 의존을 피하기 위해서입니다.)
display: inline에서는 width``height와 margin-top``margin-bottom이 무시됩니다.
공백 접힘(whitespace collapse). 참고
<pre>는 공백 접힘을 방지할 수 있으나, 콘텐츠의 시작과 끝 부분에서 다소 특이한 동작을 보입니다.<a>에서는 그렇지 않습니다.display: inline-block 요소 사이에 있는 공백이나 줄바꿈은 실제 간격으로 렌더링됩니다. 이는 플렉스박스나 그리드에서는 발생하지 않습니다.text-align은 텍스트와 인라인 요소들을 정렬하지만, 블록 요소(예: 일반 div)는 정렬하지 않습니다.
기본적으로 width와 height는 패딩과 보더를 포함하지 않습니다. width: 100%와 padding: 10px를 함께 쓰면 부모를 넘칠 수 있습니다. box-sizing: border-box를 사용하면 너비/높이에 보더와 패딩이 포함됩니다.
누적 레이아웃 이동(CLS). 이미지 로딩 지연으로 인한 레이아웃 흔들림을 막기 위해 <img>에 width와 height 속성을 지정하는 것이 좋습니다.
파일 다운로드 요청은 Chrome DevTools에 표시되지 않습니다. DevTools는 현재 탭의 네트워킹만 보여주는데, 파일 다운로드는 다른 탭에서의 네트워킹으로 취급되기 때문입니다. 파일 다운로드 요청을 점검하려면 chrome://net-export/를 사용하세요.
HTML 안의 JS는 HTML 파싱을 방해할 수 있습니다. 예를 들어 <script>console.log('</script>')</script>는 브라우저가 첫 번째 </script>를 닫는 태그로 인식하게 만듭니다. 참고
두 가지 개념: 코드 포인트(code point), 그래프림 클러스터(grapheme cluster):
\u 이스케이프는 서로게이트 페어를 사용합니다. JSON의 "\uD83D\uDE00"는 코드 포인트 하나만을 나타냅니다.언어별 문자열:
s.len()은 바이트 수를 반환합니다. Rust는 str에 대해 직접 인덱싱을 허용하지 않습니다(슬라이스 추출은 가능). s.chars().count()는 코드 포인트 수를 반환합니다. Rust는 UTF-8 코드 포인트의 유효성에 엄격합니다(예: 잘못된 코드 포인트 경계에서 슬라이스를 자를 수 없음).len(s)는 코드 포인트 수를 반환합니다. 인덱싱은 코드 포인트 하나를 담은 문자열을 반환합니다.std::string은 인코딩 제약이 없고 바이트 배열과 유사합니다. 길이와 인덱싱은 바이트 기준입니다.varchar(100)은 100개의 코드 포인트(바이트가 아님)로 제한합니다.일부 텍스트 파일은 시작 부분에 바이트 순서 표시(BOM)가 있습니다. 예를 들어 FE FF는 파일이 빅 엔디언 UTF-16임을 의미합니다. EF BB BF는 UTF-8을 의미합니다. 주로 Windows에서 사용됩니다. 일부 비-Windows 소프트웨어는 BOM을 처리하지 못합니다.
바이너리 데이터를 문자열로 변환할 때, 유효하지 않은 위치는 종종 �(U+FFFD)로 대체됩니다.
정규화. 예를 들어 é는 U+00E9(한 개의 코드 포인트) 또는 U+0065 U+0301(두 개의 코드 포인트)일 수 있습니다. 문자열 비교는 바이너리 데이터 기준으로 동작하며 정규화를 고려하지 않습니다.
줄바꿈. Windows는 종종 CRLF \r\n을 사용하고, Linux와 macOS는 LF \n을 사용합니다.
로케일(아래에서 자세히).
NaN. 부동소수점의 NaN은 자기 자신을 포함해 어떤 값과도 같지 않습니다. NaN == NaN은 항상 거짓입니다(비트가 같아도). NaN != NaN은 항상 참입니다. NaN으로 연산하면 보통 NaN이 나오며(계산을 "오염"시킵니다),
+Inf와 -Inf가 있습니다. 이들은 NaN이 아닙니다.
-0.0이라는 음의 0이 있으며 일반 0과 다릅니다. 부동소수점 비교에서는 음의 0이 0과 같다고 간주됩니다. 일반 0은 "양의 0"으로 취급됩니다. 두 0은 일부 연산에서 다르게 동작합니다(예: 1.0 / 0.0 == Inf, 1.0 / -0.0 == -Inf, log(0.0) == -Inf, log(-0.0)은 NaN).
JSON 표준은 NaN이나 Inf를 허용하지 않습니다:
JSON.stringify는 NaN과 Inf를 null로 바꿉니다.json.dumps(...)는 결과에 NaN, Infinity를 그대로 씁니다. 이는 JSON 표준을 준수하지 않습니다. json.dumps(..., allow_nan=False)는 NaN이나 Inf가 있으면 ValueError를 발생시킵니다.json.Marshal은 NaN이나 Inf가 있으면 에러를 반환합니다.부동소수점에서 값을 직접 동등 비교하면 정밀도 손실 때문에 실패할 수 있습니다. abs(a - b) < 0.00001 같은 방식으로 비교하세요.
JS는 모든 수를 부동소수점으로 표현합니다. "안전한" 최대 정수는 2^53−1입니다. 여기서 "안전"이란 범위 내의 모든 정수를 정확히 표현할 수 있음을 의미합니다. 안전 범위를 벗어나면 대부분의 정수가 부정확해집니다. 큰 정수에는 BigInt 사용을 권장합니다.
JSON에 그보다 큰 정수가 들어 있고 JS가 JSON.parse로 역직렬화하면, 결과의 숫자는 부정확할 가능성이 큽니다. 해결책은 다른 방식으로 JSON을 역직렬화하거나, 큰 정수는 문자열로 전송하는 것입니다.
(밀리초 타임스탬프 정수를 JSON에 넣는 것은 괜찮습니다. 밀리초 타임스탬프가 한계를 넘는 시점은 서기 287396년입니다. 하지만 나노초 타임스탬프는 이 문제에 걸립니다.)
결합법칙과 분배법칙은 정밀도 손실 때문에 엄밀히 성립하지 않습니다. 이 법칙을 근거로 행렬 곱셈과 합을 병렬화하면 결과가 비결정적일 수 있습니다. 참고: Defeating Nondeterminism in LLM Inference
나눗셈은 곱셈보다 훨씬 느립니다(근사치를 쓰지 않는다면). 하나의 수로 많은 수를 나눠야 한다면, 먼저 역수를 구한 뒤 곱하는 방식으로 최적화할 수 있습니다.
다음 요인들로 인해 하드웨어에 따라 부동소수점 결과가 달라질 수 있습니다:
하드웨어 FMA(fused multiply-add) 지원. fma(a, b, c) = a * b + c(어떤 곳에선 a + b * c). 대부분의 현대 하드웨어는 FMA의 중간 결과를 더 높은 정밀도로 처리합니다. 오래된 하드웨어나 임베디드 프로세서는 이를 일반 곱셈+덧셈으로 취급할 수 있습니다.
부동소수점에는 서브노멀 범위가 있어 0에 아주 가까운 값을 더 정확히 표현합니다. 대부분의 현대 하드웨어는 이를 처리하지만, 일부 오래된/임베디드 하드웨어는 서브노멀을 0으로 취급합니다.
반올림 모드. 표준은 "가장 가까운 짝수로"(RNTE)나 0 방향으로(RTZ) 같은 다양한 반올림 모드를 허용합니다.
삼각함수, 로그 같은 수학 함수는 일부 임베디드/구형 하드웨어에서 덜 정확할 수 있습니다.
x86에는 80비트 부동소수점 레지스터와 코어 단위 반올림 모드 상태를 가진 레거시 FPU가 있습니다. 사용하지 않는 것이 권장됩니다.
......
절대값이 매우 크거나 0에 매우 가까운 값에서는 부동소수점 정밀도가 낮습니다. 중간 계산 결과가 매우 큰 절대값이나 0 근처가 되지 않도록 피하는 것이 좋습니다.
반복 연산은 오차 누적을 일으킬 수 있습니다. 예를 들어 어떤 것을 매 프레임 1도씩 회전시켜야 한다면, 행렬을 캐시해 매 프레임 1도 회전 행렬을 곱하는 대신, 시간으로부터 각도를 계산해 매번 새로 회전 행렬을 만드는 것이 좋습니다.
==는 객체 참조를 비교합니다. 객체 내용을 비교하려면 .equals를 사용하세요.equals와 hashCode 오버라이드를 잊는 문제. 맵 키나 셋에서는 기본적으로 객체 동일성(참조)으로 비교합니다.List<T>를 반환하는 메서드가 때로는 변경 가능한 ArrayList를, 때로는 변경 불가능한 Collections.emptyList()를 반환할 수 있습니다. Collections.emptyList()를 변경하려 하면 UnsupportedOperationException이 발생합니다.Optional<T>를 반환하는 메서드가 null을 반환하기도 합니다(권장되지 않지만 실제 코드베이스에 존재합니다).get()이 null을 반환하면, 값이 없어서일 수도 있고 값은 있지만 그 값이 null일 수도 있습니다(containsKey로 구분 가능). JSON의 null 필드와 누락된 필드는 모두 Java 객체에서 null로 매핑됩니다. 참고Integer``Long``Double 등을 int``long``double 등으로 암묵 변환할 때 NullPointerException이 날 수 있습니다.finally 블록에서 return을 하면, try나 catch에서 던진 예외가 삼켜집니다. 메서드는 finally의 반환값을 반환합니다..submit()으로 보낸 작업의 예외를 로그하지 않습니다. 예외는 .submit()이 반환한 Future에서만 얻을 수 있습니다. Future를 버리지 마세요. 또한 scheduleAtFixedRate 작업은 예외가 발생해도 조용히 멈춥니다.0123은 83).toString()을 호출합니다. 일부 클래스의 .toString()에 부작용이 있어, 디버거에서 코드가 다르게 동작할 수 있습니다. IDE에서 비활성화할 수 있습니다.synchronized 락에서 블로킹될 때 "고정(pinned)"되어 교착의 원인이 될 수 있었습니다. 가상 스레드를 사용한다면 Java 24로 업그레이드를 권장합니다.finalize() 오버라이드는 권장되지 않습니다. finalize()가 너무 느리면 GC를 막을 수 있습니다. finalize() 밖으로 던진 예외는 로그되지 않습니다. 죽은 객체가 finalize()에서 되살아날 수 있으며, 되살아난 객체가 다시 죽어도 finalize()는 다시 호출되지 않습니다. GC 주도의 해제를 위해 Cleaner를 사용하세요.append()는 용량이 허용되면 메모리 영역을 재사용합니다. 부모 슬라이스와 메모리를 공유한 하위 슬라이스에 대해 append하면 부모가 덮어써질 수 있습니다.
defer는 렉시컬 스코프가 끝날 때가 아니라, 함수가 반환될 때 실행됩니다.
defer는 변경 가능한 변수를 캡처합니다.
nil 관련:
nil은 특이한 동작이 있습니다. 인터페이스 포인터는 타입 정보와 데이터 포인터를 담은 두꺼운 포인터입니다. 데이터 포인터가 null이어도 타입 정보가 null이 아니면 nil과 같지 않습니다.Go 1.22 이전에는 루프 변수 캡처 문제가 있었습니다.
데드 웨이트(Dead Wait). Understanding Real-World Concurrency Bugs in Go
다양한 종류의 타임아웃. The complete guide to Go net/http timeouts
객체의 내부 포인터가 존재하면 객체 전체의 수명이 유지됩니다. 이로 인해 메모리 누수가 발생할 수 있습니다.
std::vector 내부 원소의 포인터를 보관한 뒤 벡터를 성장시키면, vector가 내용을 재할당하여 원소 포인터가 무효가 될 수 있습니다.
리터럴 문자열에서 만든 std::string이 일시 객체일 수 있습니다. 일시 문자열에서 c_str()을 가져오는 것은 잘못입니다.
이터레이터 무효화. 순회 중인 컨테이너를 수정하는 문제.
std::views::filter는 다중 패스 반복에서 요소를 변경해 조건 결과가 바뀌면 오작동할 수 있습니다. 참고. std::views::as_rvalue와 std::ranges::to의 조합은 요소를 변경하여 이 문제를 유발할 수 있습니다. 참고
std::remove는 실제로 제거하지 않고 요소를 재배열만 합니다. 실제 제거는 erase가 수행합니다.
0으로 시작하는 리터럴 수는 8진수로 해석됩니다. (0123은 83)
깊은 트리 구조를 파괴(소멸)할 때 스택 오버플로가 날 수 있습니다. 해결책은 소멸자에서 재귀를 루프로 바꾸는 것입니다.
std::shared_ptr 자체는 원자적이지 않습니다(참조 카운트는 원자적임). shared_ptr 자체를 변경하는 것은 스레드 안전하지 않습니다. std::atomic<std::shared_ptr<...>>는 원자적입니다.
미정의 동작(Undefined behavior). 컴파일러 최적화는 정의된 동작은 유지하지만, 미정의 동작은 자유롭게 바꿀 수 있습니다. 미정의 동작에 의존하면 최적화에서 프로그램이 망가질 수 있습니다. 참고
char*를 구조체 포인터로 변환하면, 객체 수명이 시작되지 않았기에 초기화되지 않은 메모리에 접근하는 것으로 볼 수 있습니다. 구조체를 다른 곳에 두고 memcpy로 초기화하는 것이 권장됩니다.A*와 B* 타입의 두 포인터가 있으면, 컴파일러는 두 포인터가 같지 않다고 가정합니다. 만약 같다면 미정의 동작입니다. 예외는 두 가지: 1. A와 B가 서브타입 관계일 때 2. 포인터를 바이트 포인터(char*, unsigned char*, std::byte*)로 변환할 때(역방향은 적용되지 않음).정렬(Alignment).
전역 변수 초기화는 main 이전에 실행됩니다. 정적 초기화 순서 대참사(SIOF).
Null은 특별합니다.
x = null은 동작하지 않습니다. x is null은 동작합니다. Null은 NaN처럼 자기 자신과도 같지 않습니다.select distinct는 null을 동일하게 취급할 수 있습니다(데이터베이스별 동작).count(x)와 count(distinct x)는 x가 null인 행을 무시합니다.날짜의 암묵적 변환은 시간대에 의존적일 수 있습니다.
distinct가 있는 복잡한 조인은 중첩 쿼리보다 느릴 수 있습니다. 참고
MySQL(InnoDB)에서 문자열 필드에 character set utf8mb4가 없으면 4바이트 UTF-8 코드 포인트가 포함된 텍스트를 넣을 때 에러가 납니다.
MySQL(InnoDB)은 기본적으로 대소문자를 구분하지 않습니다.
MySQL(InnoDB)은 기본적으로 암묵적 변환을 수행합니다. select '123abc' + 1;의 결과는 124입니다.
MySQL(InnoDB)의 갭 락(gap lock)은 교착을 유발할 수 있습니다.
MySQL(InnoDB)에서는 한 필드를 선택하고 다른 필드로 그룹화할 수 있으며, 그 결과는 비결정적일 수 있습니다.
SQLite에서는 테이블이 strict가 아닌 한 필드 타입이 중요하지 않습니다.
SQLite는 기본적으로 vacuum을 수행하지 않습니다. 파일 크기는 증가만 하고 줄어들지 않습니다. 줄이려면 수동으로 vacuum;을 실행하거나 auto_vacuum을 활성화해야 합니다.
외래 키는 암묵적 락을 유발할 수 있으며, 이는 교착으로 이어질 수 있습니다.
락킹이 반복 가능 읽기 격리 수준을 깨뜨릴 수 있습니다(데이터베이스에 따라 다름).
분산 SQL 데이터베이스는 락킹을 지원하지 않거나 특이하게 동작할 수 있습니다. 데이터베이스별로 상이합니다.
백엔드에 N+1 쿼리 문제가 있을 때, 느림이 슬로우 쿼리 로그에 드러나지 않을 수 있습니다. 백엔드가 많은 작은 쿼리를 직렬로 실행하고 각 쿼리는 빠르기 때문입니다.
장기 실행 트랜잭션은 문제(예: 락)를 유발할 수 있습니다. 모든 트랜잭션을 빠르게 끝내는 것이 권장됩니다.
문자열 컬럼이 인덱스나 기본 키에 사용되면 길이 제한이 생깁니다. MySQL은 테이블 스키마 변경 시 제한을 적용합니다. PostgreSQL은 삽입/갱신 시 에러로 제한을 적용합니다.
서비스가 일시적으로 불가용해질 수 있는 전체 테이블 락:
mysqldump를 --single-transaction 없이 사용하면 전체 테이블 읽기 락이 걸립니다.create unique index나 alter table ... add foreign key가 전체 테이블 읽기 락을 유발합니다. 이를 피하려면 유니크 인덱스는 create unique index concurrently를 사용하세요. 외래 키는 alter table ... add foreign key ... not valid; 후 alter table ... validate constraint ...를 사용하세요.범위에 관하여:
select ... from ranges where p >= start and p <= end로 조회하는 것은 비효율적입니다(심지어 (start, end) 복합 인덱스가 있어도). 효율적인 방법: select * from (select ... from ranges where start <= p order by start desc limit 1) where end >= p (열 start에 대한 인덱스만 필요).volatile:
volatile 하나만으로 락을 대체할 수 없습니다. volatile 자체는 원자성을 제공하지 않습니다.volatile이 필요 없습니다. 락은 이미 메모리 순서를 정립하고 잘못된 최적화를 방지합니다.volatile은 일부 잘못된 최적화를 피하게 해줄 뿐이며, volatile 접근에 자동으로 메모리 배리어 명령을 추가하지 않습니다.volatile 접근은 순차적 일관성(Sequential Consistency)을 가집니다(JVM이 필요 시 메모리 배리어를 사용).volatile 값에 대한 접근은 릴리스-획득(Release-Acquire) 순서를 가집니다(CLR이 필요 시 메모리 배리어를 사용).volatile은 읽기/쓰기를 재배열하거나 병합하는 잘못된 최적화를 방지할 수 있습니다. (컴파일러가 레지스터에 값을 캐시하여 읽기를 병합할 수 있고, 레지스터에만 쓰다가 메모리에 늦게 쓰며 쓰기를 병합할 수 있습니다. 쓰기 직후의 읽기를 제거하기도 합니다.)검사-사용 시간차(TOCTOU, Time-of-check to time-of-use).
SQL 데이터베이스에서 간단한 유니크 인덱스로 표현하기 어려운 특수 고유 제약(예: 두 테이블에 걸친 고유성, 조건부 고유성, 시간 범위 내 고유성)을 애플리케이션 단에서 강제하려는 경우:
select ... for update로 확인한 뒤 삽입하며, 고유성 확인 대상 컬럼에 인덱스가 있다면 갭 락 덕분에 동작합니다. (동시성이 높으면 갭 락이 교착을 유발할 수 있으니, 교착 감지를 켜고 재시도를 구현하세요.)select ... for update 후 삽입하는 방식은 동시성 하에서 제약을 보장하기에 충분하지 않습니다(쓰기 치우침, write skew). 몇 가지 해결책:
원자적 참조 카운팅(Arc, shared_ptr)은 많은 스레드가 같은 카운터를 자주 변경하면 느려질 수 있습니다. 참고
읽기-쓰기 락: 읽기 락을 들고 있는 상태에서 쓰기 락을 시도하면 교착됩니다. 올바른 방법은 먼저 읽기 락을 풀고, 그다음 쓰기 락을 획득하며, 읽기 락에서 확인했던 조건들을 다시 확인하는 것입니다.
재진입 가능 락:
synchronized와 ReentrantLock은 재진입 가능합니다.Mutex와 Golang의 sync.Mutex는 비재진입입니다.동일 캐시 라인에 대한 거짓 공유(False sharing)는 성능을 떨어뜨립니다.
[[0] * 10] * 10은 올바른 2차원 배열을 만들지 않습니다.(low + high) / 2는 오버플로될 수 있습니다. 더 안전한 방법은 low + (high - low) / 2입니다.a() || b()에서 a()가 true면 b()는 실행되지 않습니다. a() && b()에서 a()가 false면 b()는 실행되지 않습니다.현재 디렉터리가 이동되면 pwd는 여전히 원래 경로를 보여줍니다. pwd -P는 실제 경로를 보여줍니다.
cmd > file 2>&1은 stdout과 stderr를 모두 파일로 보냅니다. 하지만 cmd 2>&1 > file은 stdout만 파일로 보내고 stderr는 리다이렉트하지 않습니다.
파일 이름은 대소문자를 구분합니다(Windows와 다름).
실행 파일에는 파일 권한 시스템과 별개로 capability 시스템이 있습니다. getcap으로 capability를 확인하세요.
설정되지 않은 변수. DIR이 설정되지 않았다면 rm -rf $DIR/는 rm -rf /가 됩니다. set -u를 사용하면 bash가 설정되지 않은 변수를 만나면 에러를 내도록 할 수 있습니다.
bash는 명령 이름과 명령 파일 경로 간에 캐시가 있습니다. $PATH 안의 파일을 옮긴 뒤 해당 명령을 실행하면 ENOENT가 날 수 있습니다. hash -r로 캐시를 갱신하세요.
변수를 따옴표 없이 사용하면 줄바꿈이 공백으로 취급됩니다.
set -e는 하위 명령이 실패하면 스크립트를 즉시 종료시킬 수 있으나, 결과를 조건으로 검사하는 함수 내부(예: ||, &&의 좌항, if의 조건)에서는 동작하지 않습니다. 참고
K8s의 livenessProbe와 디버거. 브레이크포인트 디버거는 보통 애플리케이션 전체를 멈추게 하여 헬스 체크 요청에 응답하지 못하게 만들고, 그 결과 K8s livenessProbe에 의해 종료될 수 있습니다.
:latest 이미지는 사용하지 마세요. 언제든 바뀔 수 있습니다.
Redis에서 접두사로 키를 조회하는 KEYS prefix-*는 모든 키를 순회하는 느린 연산입니다. 그런 용도에는 Redis 해시 맵을 사용하세요.
렌더링 코드에서 state를 변경.
React는 내용 동등이 아니라 참조 동등으로 비교합니다.
useMemo로 해결하세요.useCallback을 사용하세요.useEffect 의존성 배열에 넣으면, 매 렌더마다 effect가 실행됩니다. Cloudflare 2025-09-12 사건 참고.setInterval``removeInterval을 effect로 관리할 때, effect에 의존 값이 있으면 값이 바뀔 때마다 타이머를 제거하고 다시 추가하여 타이밍이 꼬일 수 있습니다.
state 값 자체는 불변이어야 합니다. state 객체의 필드를 직접 바꾸지 마세요. 항상 전체 객체를 재생성하세요.
useEffect 의존성 배열에 값을 빠뜨림.
useEffect에서 정리(clean-up)를 빼먹음.
클로저 함정. 클로저가 어떤 state를 캡처하면, state가 바뀌어도 클로저는 이전 state를 캡처한 상태로 남습니다.
useReducer 내에서 state에 접근하게 하는 것입니다.useRef에 넣는 것입니다(단, ref 내부 값을 바꿔도 리렌더링은 발생하지 않으므로, 리렌더링을 원하면 state나 prop을 변경해야 합니다).useEffect는 브라우저가 웹페이지를 렌더링한 3 뒤, 이벤트 루프의 다음 턴에서 처음 실행됩니다. 초기화를 useEffect에서 하면 너무 늦어 시각적 깜빡임이 생길 수 있습니다. 조기 초기화에는 useLayoutEffect를 사용하세요(같은 이벤트 루프 턴에서 실행). DOM 객체를 ref로 얻는 경우, 첫 렌더링(컴포넌트 함수 호출) 중에는 접근할 수 없고 useLayoutEffect에서 접근할 수 있습니다.
리베이스는 히스토리를 다시 쓸 수 있습니다. 히스토리가 변경되면 일반 push에서 충돌이 발생합니다. 히스토리를 다시 쓴 후에는 강제 푸시가 필요합니다. 원격 브랜치의 히스토리가 다시 쓰인 경우, pull은 --rebase를 사용해야 합니다.
--force-with-lease로 강제 푸시하면 다른 개발자의 커밋을 덮어쓰는 일을 때로는 피할 수 있습니다. 하지만 fetch만 하고 pull을 하지 않았다면 --force-with-lease가 보호해주지 못합니다.머지를 되돌려도 머지의 부작용을 완전히 취소하지 못합니다. B를 A에 머지했다가 되돌린 뒤 B를 다시 A에 머지하면 효과가 없습니다. 한 가지 해결책은 머지 되돌리기를 다시 되돌리는 것입니다. (머지를 취소하는 더 깔끔한 방법은, 브랜치를 백업하고 머지 전 커밋으로 하드 리셋한 다음 머지 이후의 커밋을 체리픽하고 강제 푸시하는 것입니다.)
GitHub에서 비밀(예: API 키)을 실수로 커밋해 퍼블릭으로 푸시했다면, 강제 푸시로 덮어써도 GitHub는 그 비밀을 기록으로 남깁니다. 참고예시 activity 탭
GitHub에서 비공개 저장소 A를 포크해 비공개 B를 만들었는데, A가 공개가 되면 비공개 B의 콘텐츠도 공개적으로 접근 가능해집니다. B를 삭제한 뒤에도 그렇습니다. 참고.
GitHub는 기본적으로 릴리스 태그 삭제 후 같은 이름으로 다른 커밋을 가리키는 새 태그를 추가하는 것을 허용합니다. 이는 권장되지 않습니다. 많은 빌드 시스템이 릴리스 태그를 기준으로 캐시하고 있어 문제가 됩니다. 규칙셋 설정에서 비활성화할 수 있습니다.
git stash pop은 충돌이 발생하면 stash를 드롭하지 않습니다.
Windows에서 Git은 클론한 텍스트 파일을 CRLF 줄바꿈으로 자동 변환하는 경우가 많습니다. 하지만 WSL에서는 bash 같은 많은 소프트웨어가 CRLF 줄바꿈 파일에서 제대로 동작하지 않습니다. git clone --config core.autocrlf=false -c core.eol=lf ...로 LF로 클론하도록 설정할 수 있습니다.
macOS는 모든 폴더에 .DS_Store 파일을 자동으로 추가합니다. .gitignore에 **/.DS_Store를 추가하는 것이 좋습니다.
일부 라우터와 방화벽은 애플리케이션에 알리지 않고 유휴 TCP 연결을 무 silently kill 합니다. 일부 코드(HTTP 클라이언트 라이브러리, 데이터베이스 클라이언트 등)는 재사용을 위해 TCP 연결 풀을 유지하는데, 이 연결들이 조용히 무효화될 수 있습니다(사용 시 RST). 해결하려면 시스템 TCP keepalive를 구성하세요. 참고
traceroute 결과는 신뢰성이 낮습니다. 참고. 때로는 tcptraceroute가 유용합니다.
TCP 슬로 스타트는 지연을 늘릴 수 있습니다. tcp_slow_start_after_idle을 비활성화하여 해결할 수 있습니다. 참고
TCP 스티키 패킷. 네이글 알고리즘은 패킷 전송을 지연시켜 지연시간을 늘립니다. TCP_NODELAY를 활성화하여 해결할 수 있습니다. 참고
백엔드를 Nginx 뒤에 둘 경우, 연결 재사용을 구성해야 합니다. 그렇지 않으면 높은 동시성에서 Nginx와 백엔드 간 연결이 내부 포트 부족으로 실패할 수 있습니다.
Nginx의 proxy_buffering은 SSE를 지연시킵니다.
HTTP 프로토콜은 GET과 DELETE 요청에 바디가 있는 것을 명시적으로 금지하지 않습니다. 일부 환경에서는 GET/DELETE의 바디를 사용합니다. 하지만 많은 라이브러리와 HTTP 서버는 이를 지원하지 않습니다.
하나의 IP에 여러 웹사이트가 존재할 수 있으며, 도메인 이름으로 구분합니다. HTTP 헤더의 Host와 TLS 핸드셰이크의 SNI가 도메인 이름을 전달하는데 중요합니다. 일부 웹사이트는 IP 주소로는 접근할 수 없습니다.
CORS(교차 출처 리소스 공유). 다른 웹사이트(오리진)로의 요청에 대해, 서버 응답에 Access-Control-Allow-Origin 헤더가 있고 클라이언트 웹사이트와 일치하지 않으면 브라우저는 JS에서 응답을 읽지 못하게 합니다. 이는 백엔드 구성 변경을 요구합니다. 다른 웹사이트로 쿠키를 전송하려면 추가 설정이 필요합니다.
일반적으로 프런트엔드와 백엔드가 같은 웹사이트(같은 도메인과 포트)라면 CORS 문제는 없습니다.
역방향 경로 필터링(Reverse path filtering). 라우팅이 비대칭적이라 A→B와 B→A가 다른 인터페이스를 사용할 때, 역방향 경로 필터링이 유효한 패킷을 거부할 수 있습니다.
구버전 Linux에서 tcp_tw_recycle이 활성화되면, TCP 타임스탬프 기반으로 연결을 공격적으로 재활용합니다. NAT와 로드밸런서는 TCP 타임스탬프를 단조롭게 만들지 않으므로, 이 기능이 정상 연결도 드롭시킬 수 있습니다.
I의 소문자가 ı이고, i의 대문자가 İ입니다. 정규표현식의 \w(단어 문자)는 로케일 의존적일 수 있습니다.[a-z]는 다른 로케일에서 오작동할 수 있습니다.1,234.56은 독일에선 1.234,56에 해당합니다.,를 구분자로 쓰지만, 독일 로케일에서는 ;를 사용합니다.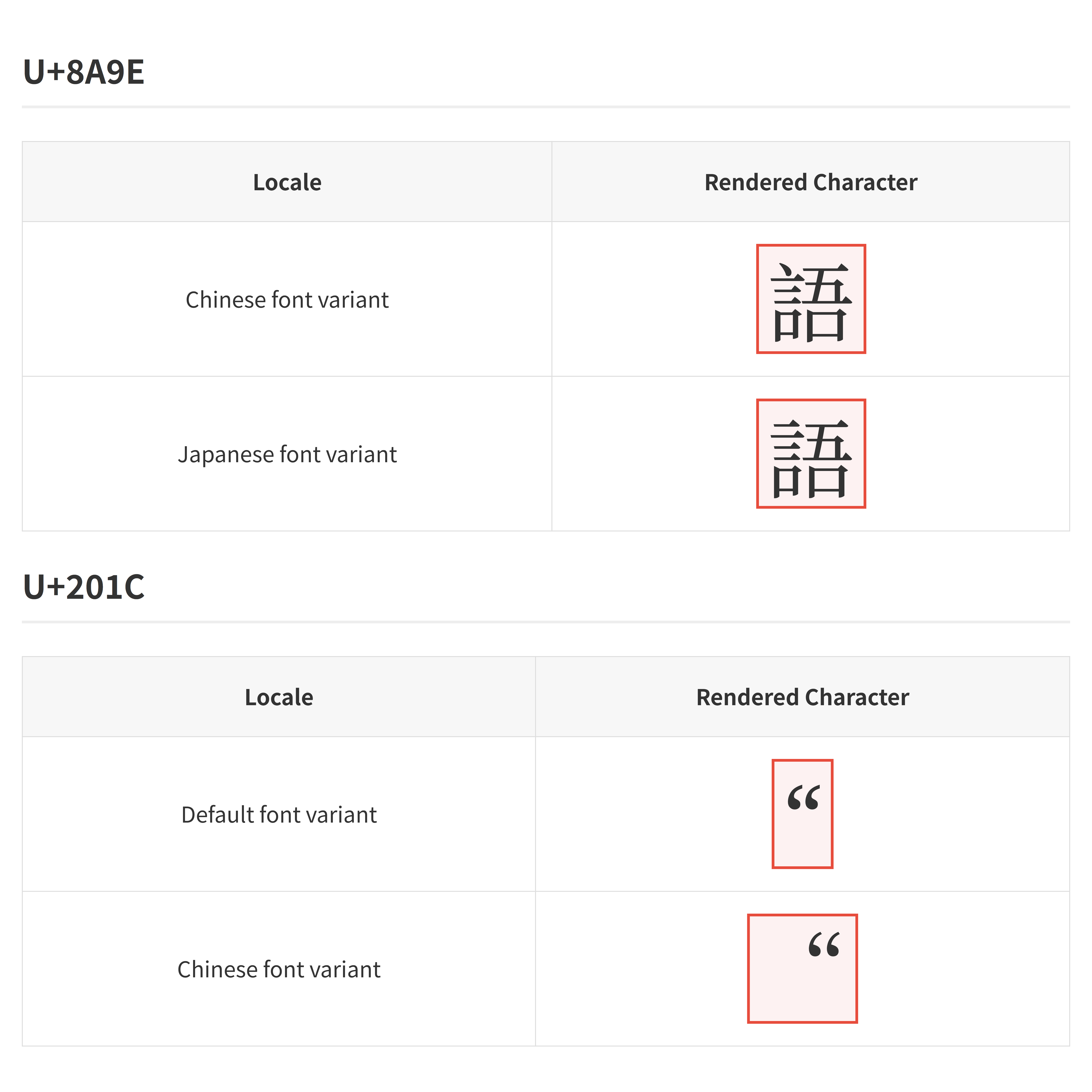
YAML:
key:value는 잘못이고 key: value가 맞습니다.NO는 따옴표로 감싸지 않으면 false가 됩니다.Microsoft Excel로 CSV 파일을 열면, Excel은 날짜 변환(예: 1/2, 1-2를 2-Jan으로 바꿈) 등 많은 변환을 수행하며 원래 문자열을 보여주지 않습니다. 유전자 SEPT1은 이 Excel 문제 때문에 이름이 바뀌었습니다. Excel은 큰 숫자도 부정확하게 만듭니다(예: 12345678901234567890을 12345678901234500000으로 바꿈) 그리고 원래의 정확한 숫자를 보여주지 않습니다. Excel은 내부적으로 숫자에 부동소수점을 사용하기 때문입니다.
클라우드 서비스를 사용할 때, 특히 서버리스에서는 과금 한도를 설정하는 것이 권장됩니다. 참고: ServerlessHorrors
바이너리 파일과 네트워크 패킷의 빅 엔디언/리틀 엔디언.
엄밀히 말하면, 이들 언어는 UTF-16과 유사하지만 잘못된 서로게이트 페어를 허용하는 WTF-16 인코딩을 사용합니다. 또한 Java는 가능한 경우 메모리 내 문자열에 Latin-1 인코딩(코드 포인트당 1바이트)을 사용하는 최적화가 있습니다. 그러나 String의 API는 여전히 WTF-16 코드 유닛을 기준으로 동작합니다. 유사한 일이 C#과 JS에서도 일어날 수 있습니다. ↩
기존 바이너리 데이터를 곧바로 구조체로 취급하는 것은 객체 수명이 시작되지 않았기 때문에 미정의 동작입니다. 하지만 memcpy로 구조체를 초기화하는 것은 괜찮습니다. ↩
웹 개발에서 "render"라는 단어는 모호합니다. 브라우저가 "렌더링"한다는 것은 화면에 표시하기 위해 그리는 것을 뜻합니다. React 컴포넌트가 "렌더링"된다는 것은 컴포넌트 함수가 호출되는 것이지 화면에 무언가를 그리는 것이 아닙니다. ↩