DuckDB 쿼리가 엔진에 들어온 순간부터 스토리지 레이어까지, DuckDB의 속도를 만드는 핵심 설계를 살펴봅니다.
DuckDB는 2019년 암스테르담 CWI의 연구 프로젝트에서 지난 10년 사이 가장 널리 채택된 데이터베이스 중 하나로 성장했습니다. 등장하는 곳도 매우 많습니다. 노트북, ETL 파이프라인, 대시보드, CI 테스트 러너, SaaS 제품 내부의 임베디드 분석, 심지어 스케일 팩터 100으로 TPC-H를 실행하는 iPhone까지 있습니다.

드라이아이스 상자 안의 iPhone에서 TPC-H를 실행하는 모습입니다. (source)
기업들도 이를 중심으로 실제 제품을 만들기 시작했습니다. MotherDuck은 DuckDB를 클라우드 데이터 웨어하우스로 감싸고 있습니다. Hex, Omni, Evidence 같은 BI 및 데이터 앱 플랫폼은 이를 앱 내 실행 엔진이자 캐시로 사용합니다. Fivetran의 Managed Data Lake Service는 병합과 컴팩션을 위해 데이터 레이크 라이터 내부에 DuckDB를 사용합니다. Rill은 이를 기반으로 오픈소스 BI 도구를 구축합니다. Greybeam에서도 이를 사용하며, BI와 분석 워크로드를 위해 수백만 건의 쿼리를 구동하고 있습니다.
DuckDB는 인프로세스 분석용 SQL 데이터베이스입니다. _분석용_이라는 말은 수백만 행을 스캔해 필터링, 집계, 조인을 수행하는 종류의 쿼리에 최적화되어 있다는 뜻입니다. 기본 키로 단일 레코드를 조회하는 종류의 쿼리가 아닙니다. _인프로세스_라는 말은 서버가 없다는 뜻입니다. DuckDB에 연결하는 것이 아니라, NumPy나 Polars를 로드하듯 프로그램 안에서 라이브러리로 로드합니다.
DuckDB가 널리 채택된 이유는 정말 말도 안 되게 사용하기 쉽기 때문입니다. 20 MB 미만의 단일 바이너리로 제공되며 외부 의존성이 없습니다. pip install duckdb, brew install duckdb로 설치하거나, C++ 프로젝트에 libduckdb를 링크하면 됩니다. Parquet, CSV, JSON 파일이 있는 어떤 디렉터리든 이미 SQL 데이터베이스인 것처럼 열 수 있습니다.
또한 DuckDB는 사용 가능한 가장 빠른 단일 노드 분석 엔진 중 하나이기도 하며, 연간 수백만 달러가 드는 전체 클러스터와도 정기적으로 대등하게 경쟁합니다.
이 글은 DuckDB 내부를 깊이 파헤치는 3부작의 첫 번째 글입니다. 쿼리가 엔진에 들어오는 순간부터 결과가 반환되는 순간까지 따라가며, 각 단계에서 무엇이 DuckDB를 빠르게 만드는지 살펴보겠습니다.
DuckDB의 속도는 몇 가지 설계 선택에서 나옵니다.
이 글은 SQL이 입력된 뒤 엔진이 쿼리 실행 준비를 마칠 때까지의 경로와, 쿼리가 읽게 될 스토리지 레이어를 다룹니다. 글을 다 읽고 나면 DuckDB의 준비 작업과 스토리지 레이아웃에 대한 명확한 정신 모델을 갖게 될 것입니다. 쿼리 실행은 2부에서 다루니 꼭 구독해 주세요!
노트북에 있는 6 GB Parquet 파일을 DuckDB에 지정합니다. 결과는 1초도 안 되어 돌아옵니다. 클러스터도 없고, 설정도 없고, 마이그레이션도 없고, CREATE TABLE도 없습니다. 이게 어떻게 가능한 걸까요?
SELECT
*
FROM 'orders.parquet';
대부분의 분석용 데이터베이스는 서버입니다. Snowflake, Postgres, BigQuery, Redshift가 그렇습니다. 연결을 열고, TCP를 통해 SQL을 전송한 다음, 결과가 돌아오기를 기다립니다. 그 과정에서 결과의 모든 레코드는 wire protocol로 _직렬화_되고, 네트워크를 통해 전송되며, 반대편에서 다시 _역직렬화_됩니다.
데이터베이스 내부에서 쿼리 결과는 특정 메모리 주소에 놓인 타입이 있는 값들로 존재합니다. 여기에는 64비트 정수가 하나 있고, 저기에는 문자열을 가리키는 포인터가 있습니다. 그런 주소들은 그 프로세스 안에서만 존재합니다. 다른 머신의 클라이언트로 결과를 보내려면, 데이터베이스는 모든 값을 합의된 바이트 형식으로 다시 써야 합니다. Postgres는 자체 형식이 있고, MySQL도 또 다른 형식이 있으며, ODBC와 JDBC는 드라이버가 그 위에 노출하는 클라이언트 측 API입니다. 그래야 TCP 소켓을 통해 밀어 넣을 수 있습니다. 그런 다음 클라이언트는 그 바이트를 다시 자신의 네이티브 타입으로 파싱합니다. 각 값은 인코딩할 때 한 번, 디코딩할 때 한 번, 여러 번 건드려질 수 있으며, 큰 결과 집합에서는 이런 작업이 쿼리 자체보다 더 오래 걸리는 경우가 많습니다.
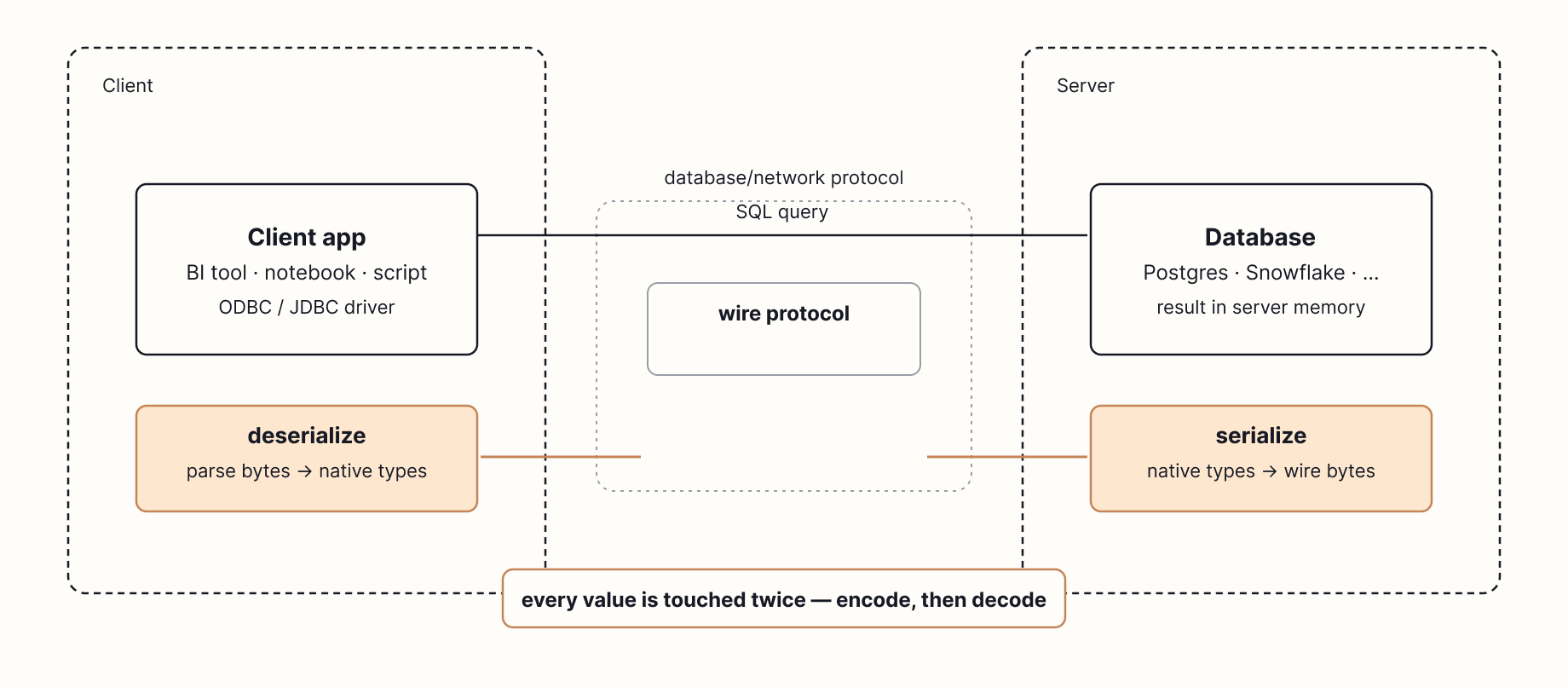 DuckDB는 서버가 아닙니다. 라이브러리입니다. DuckDB 데몬도 없고, 포트도 없고, 클러스터도 없습니다.
DuckDB는 서버가 아닙니다. 라이브러리입니다. DuckDB 데몬도 없고, 포트도 없고, 클러스터도 없습니다. libduckdb를 프로그램 안에 로드하고 직접 함수 호출을 수행합니다.
2017년 Mark Raasveldt와 Hannes Mühleisen은 Don't Hold My Data Hostage라는 논문을 발표해, 웨어하우스에서 결과 집합을 끌어낼 때 실제로 무슨 일이 일어나는지 측정했습니다. 그들은 클라이언트 프로토콜 자체, 즉 ODBC, JDBC, 그리고 이와 유사한 행 단위 값 API가 전체 쿼리에서 가장 느린 단일 단계인 경우가 많다는 것을 발견했습니다. 때로는 데이터베이스가 답을 계산하는 데 쓴 시간을 압도하기도 했습니다.
이 비용은 두 가지에서 비롯됩니다. 첫째는 순수 대역폭입니다. 일반적인 기가비트 이더넷 링크는 대략 125 MB/s 정도에서 한계에 도달하며, 큰 결과 집합은 계산하는 데 걸린 시간보다 전송하는 데 더 오래 걸릴 수 있습니다. 둘째는 값별 오버헤드입니다. ODBC와 JDBC는 결과를 한 번에 한 행, 한 값씩 돌려주므로, 클라이언트는 모든 행의 모든 필드마다 별도의 함수 호출을 해야 합니다. 1억 행 결과라면 수억 번의 함수 호출이 생기고, 각 호출은 저마다 작은 메모리 복사, 타입 검사, 문자열 할당을 수행합니다.
ADBC는 시스템 간 데이터를 컬럼형 Arrow 형식으로 전송하므로 ODBC와 JDBC가 요구하는 행 단위 직렬화/역직렬화를 피할 수 있습니다. 우리의 친구들인 Columnar가 이것을 일상적인 것으로 만들고 있습니다.
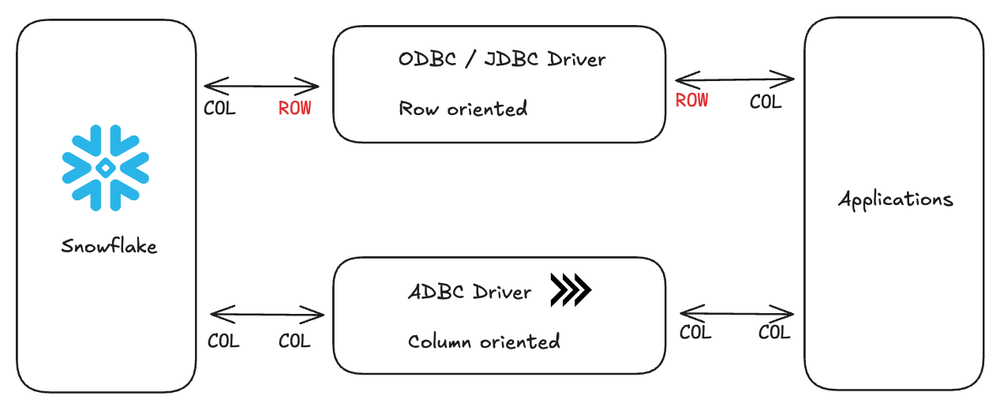
Snowflake에 연결할 때 ODBC와 ADBC의 차이.
DuckDB는 클라이언트와 같은 프로세스 안에서 실행됨으로써 이 두 병목을 모두 피합니다.
Python 스크립트가 pandas dataframe에 대해 con.sql("SELECT ... FROM my_df")를 실행하면, DuckDB는 replacement scan이라는 기능을 사용할 수 있습니다. 먼저 dataframe을 내부 테이블로 복사하는 대신, DuckDB는 테이블 참조를 쿼리 실행 시 dataframe에서 읽는 함수로 대체합니다.
가장 이상적인 경우 DuckDB는 Python 프로세스가 이미 소유한 동일한 기본 버퍼를 읽을 수 있으므로, 데이터의 두 번째 전체 복사본을 물질화하지 않아도 됩니다. 이것이 zero-copy입니다! NumPy가 “여기 int64 값 100만 개가 담긴 버퍼(연속된 메모리 청크)가 있다”고 말하면, DuckDB는 동일한 물리적 레이아웃을 이해하기 때문에 종종 그 동일한 버퍼를 직접 읽을 수 있습니다.
실제로 이 경로가 진정한 zero-copy인지 여부는 dataframe의 물리적 레이아웃, 컬럼 타입, null 표현, 문자열 저장 방식에 달려 있습니다. 타입이나 레이아웃이 맞지 않으면, DuckDB는 일부 컬럼에 대해 변환된 버퍼를 할당할 수 있습니다.
Arrow는 이 이야기의 가장 깔끔한 버전입니다. Arrow는 이미 시스템 간 데이터 공유를 위해 설계된 컬럼형의 타입 있는 메모리 형식이기 때문입니다. 그래서 DuckDB 결과를 Arrow로 반환하거나 Arrow 기반 데이터를 질의할 때, 기존 API가 강제하는 행 단위 변환 오버헤드의 상당 부분을 피할 수 있습니다.
SQL이 DuckDB에 도달하면 일반적인 단계를 거칩니다. 파싱, 바인딩, 계획 수립, 최적화입니다.
첫 단계는 SQL을 AST(추상 구문 트리)로 파싱하는 것입니다. DuckDB는 Postgres parser의 포크를 사용하며, 이것이 DuckDB 방언이 매우 친숙하게 느껴지는 이유 중 하나입니다.
AST는 쿼리를 트리 구조로 표현한 것으로, 각 노드는 SELECT 문, 컬럼 참조, 함수 호출, 조인, 리터럴 같은 구문적 구성 요소입니다. 파싱은 평평한 문자열 SELECT sum(l_quantity) FROM lineitem WHERE l_shipdate > '2024-01-01'를 엔진이 실제로 추론할 수 있는 구조화된 객체로 바꿉니다.
Select(
expressions=[
Sum(
this=Column(
this=Identifier(this=l_quantity, quoted=False)))],
from_=From(
this=Table(
this=Identifier(this=lineitem, quoted=False))),
where=Where(
this=GT(
this=Column(
this=Identifier(this=l_shipdate, quoted=False)),
expression=Literal(this='2024-01-01', is_string=True))))
SQLGlot 라이브러리의 AST.
트리 구조가 있기에 엔진의 나머지 부분이 제 역할을 할 수 있습니다. 바인더는 노드를 순회하며 l_quantity를 특정 테이블의 특정 컬럼으로 해석합니다. 옵티마이저는 서브트리를 패턴 매칭하여 WHERE 조건을 스캔 쪽으로 푸시다운할 수 있음을 인식합니다. 물리 계획기는 함수 호출 노드를 실행 가능한 연산자로 매핑합니다. 이 어떤 단계도 원시 SQL에 직접 작동할 수 없습니다. 모두 타입이 있는 구조를 순회하고, 패턴 매칭하고, 재작성해야 합니다.
다음 단계는 바인딩으로, AST의 모든 이름을 카탈로그에 대해 해석합니다. lineitem은 알려진 스키마를 가진 특정 테이블이 됩니다. l_quantity는 알려진 타입을 가진 특정 컬럼이 됩니다. sum은 그 컬럼의 입력 타입과 맞는 특정 집계 함수가 됩니다. 타입 검사도 여기서 일어납니다. l_shipdate를 문자열 '2024-01-01'와 비교할 수 있는 이유는 바인더가 그 리터럴을 날짜로 강제 변환하기 때문입니다.
그 결과물은 각 노드가 자신이 무엇을 가리키는지, 어떤 타입을 산출하는지 아는 바운드 트리입니다. 해석되지 않은 컬럼, 모호한 참조, 타입 불일치 같은 오류는 이 단계에서 드러납니다.
이 시점에서 DuckDB는 원시 SQL 텍스트를 타입이 있는 트리로 바꾸었습니다. 엔진은 더 이상 l_quantity를 쿼리 안의 단순한 문자열로 보지 않습니다. 특정 테이블의 특정 타입을 가진 특정 컬럼으로 봅니다.
DuckDB의 옵티마이저는 실제로 개별적으로 살펴보고 비활성화할 수도 있는, 작고 집중된 변환들의 순서로 이루어져 있습니다.
D SELECT * FROM duckdb_optimizers();
┌────────────────────────────┐
│ name │
│ varchar │
├────────────────────────────┤
│ expression_rewriter │
│ filter_pullup │
│ filter_pushdown │
│ empty_result_pullup │
│ cte_filter_pusher │
│ regex_range │
│ in_clause │
│ join_order │
│ deliminator │
│ unnest_rewriter │
│ unused_columns │
│ statistics_propagation │
│ common_subexpressions │
│ common_aggregate │
│ column_lifetime │
│ limit_pushdown │
│ row_group_pruner │
│ top_n │
│ top_n_window_elimination │
│ build_side_probe_side │
│ compressed_materialization │
│ duplicate_groups │
│ reorder_filter │
│ sampling_pushdown │
│ join_filter_pushdown │
│ extension │
│ materialized_cte │
│ sum_rewriter │
│ late_materialization │
│ cte_inlining │
│ common_subplan │
│ join_elimination │
│ window_self_join │
└────────────────────────────┘
33 rows
SET disabled_optimizers = 'filter_pullup, join_order'를 실행하면 특정 패스를 끌 수 있어서 그것들이 무엇을 하고 있었는지 볼 수 있습니다.
흥미로운 옵티마이저 몇 가지를 보겠습니다.
이것은 고전적인 데이터베이스 최적화입니다. WHERE 조건을 가능한 한 스캔에 가깝게 이동시켜 데이터를 가능한 한 이른 시점에 잘라내는 것입니다. DuckDB는 먼저 필터를 계획의 위쪽으로 끌어올려 결합하고 재구성할 수 있게 한 뒤, 다시 가능한 한 아래로 밀어 넣습니다.
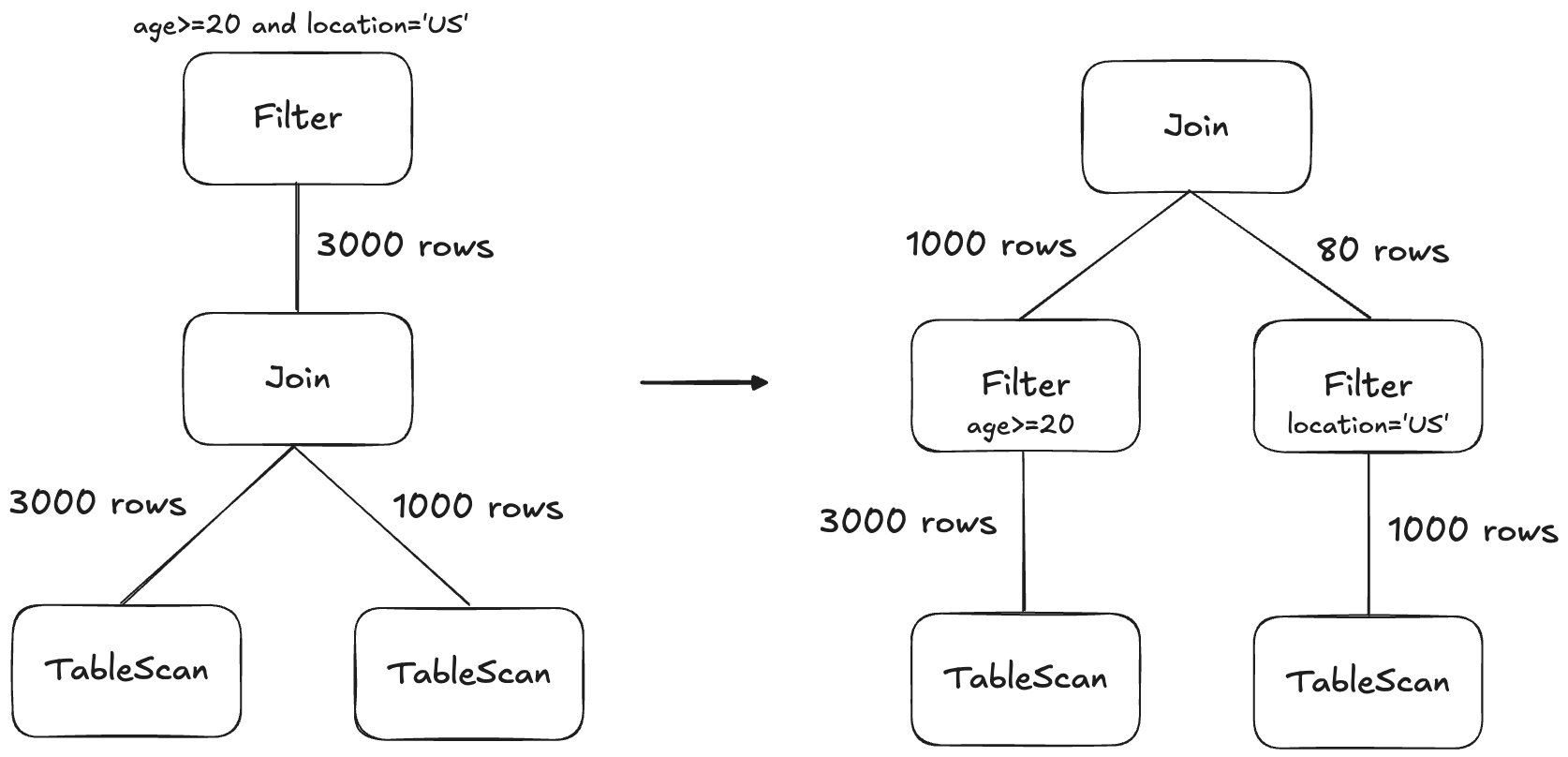
아래에서 위로 읽으세요. 필터 푸시다운은 가능할 때 트리에서 필터를 더 이른 위치로 이동시킵니다.
상관 서브쿼리는 전통적으로 외부 행마다 내부 쿼리를 한 번씩 실행하게 만들어 느립니다. DuckDB는 Unnesting Arbitrary Queries 논문의 기법을 구현하여 이를 조인으로 재작성하며, 이 방식은 훨씬 빠릅니다.
해시 조인 중에는(해시 조인에 대한 자세한 설명은 여기), probe side가 시작되기 전에 build side를 완전히 읽어야 합니다. DuckDB는 이 순서를 활용합니다. build side가 메모리에 올라오면, 실제로 포함된 조인 키 값의 최소와 최대를 계산한 뒤, 그 경계를 런타임 필터로 probe side 스캔에 다시 푸시합니다. build side에 100에서 200 사이 값만 있는 것으로 드러났다면, probe 스캔은 테이블의 zonemap을 사용해 그 범위 밖의 row group을 읽기 전에 건너뛸 수 있습니다.
build side에 서로 다른 조인 키 값이 50개보다 적으면, 필터는 min-max 범위 대신 IN 목록이 되며, 더 정확하고 더 많은 행을 건너뛸 수 있습니다.
조인 순서는 옵티마이저가 내리는 가장 중요한 결정입니다. 조인이 실행되는 순서는 각 중간 결과가 얼마나 커지는지를 결정합니다. 여섯 개 테이블을 조인하는 쿼리에는 30,240개의 가능한 트리 형태가 있으며, 최선과 최악의 차이는 실행 시간 기준으로 자릿수 차이가 날 수 있습니다. 잘 고르려면 각 후보 조인이 몇 개의 행을 만들어낼지 추정해야 하며, 이는 테이블 크기, 조건 선택도, 그리고 그 이전에 수행된 조인의 순서에 달려 있습니다.
DuckDB는 쿼리를 그래프로 모델링합니다. 각 테이블은 노드이고, 각 조인 조건은 자신이 참조하는 테이블들을 연결하는 간선입니다. 옵티마이저의 일은 노드들을 하나의 트리로 결합하는 순서를 고르는 것이며, 각 결합은 하나의 조인입니다. 예를 들어 a와 b, b와 c, c와 d를 조인하는 쿼리가 있다면, 그래프는 다음과 같을 수 있습니다.
a ── b ── c ── d
최적의 트리를 찾기 위해 DuckDB는 DPhyp나 DPccp 같은 동적 계획법을 사용합니다. 동적 계획법은 어려운 말처럼 들리지만 아이디어는 단순합니다. {a, b, c}를 조인하는 최선의 방법을 이미 알아냈다면, {a, b, c, d}를 조인하는 최선의 방법을 찾을 때 그 답을 재사용할 수 있다는 것입니다. {a, b, c} 내부의 모든 순서를 다시 탐색할 필요가 없습니다. DuckDB는 이것을 연결된 모든 쌍, 세 쌍, 네 쌍 등에 대해 수행합니다.
탐색할 최적화는 이 밖에도 수십 가지가 더 있으며, 전체 최적화 단계는 보통 약 1밀리초 안에 끝납니다. 최적화가 끝나면 DuckDB는 논리 계획을 갖게 됩니다. 다음 단계는 그 계획을 엔진이 실제로 실행할 수 있는 형태로 번역하는 것입니다.
여기까지 재미있게 읽으셨다면 구독을 고려해 주세요. DuckDB와 다른 여러 쿼리 엔진의 복잡한 내부에 대해 계속 더 많이 공유하겠습니다.
옵티마이저가 엔진에 다음과 같은 계획을 넘긴다고 상상해 봅시다. 평이한 영어로 쓰면 이렇습니다.
디스크에서
events를 읽는다.event_date가 2026-01-01 이하인 행은 버린다. 남은 것을customer_id로 그룹화하고amount를 합산한다. 결과를 총합 내림차순으로 정렬한다. 상위 10개를 반환한다.
이제 엔진은 이 단계들을 CPU를 잘 활용하고 코어 간 병렬화도 되는 방식으로 실제 어떻게 실행할지 결정해야 합니다.
옵티마이저의 출력은 아직 논리 계획입니다. 각 단계가 무엇을 계산해야 하는지는 말하지만, 어떤 알고리즘이 그 계산을 수행해야 하는지는 말하지 않습니다. 대부분의 논리 단계에는 여러 물리적 구현이 있습니다.
조인을 예로 들면, 같은 논리 조인도 해시 조인, 인덱스 조인, piecewise merge join, cartesian join 중 어느 것으로든 바뀔 수 있습니다.
DuckDB는 논리 계획을 순회하며 각 노드에 대해 입력과 조건의 형태를 바탕으로 물리 연산자를 선택합니다. 그 결과는 물리 계획, 즉 실행기가 실행하는 방법을 아는 물리 연산자 트리입니다.
벡터화 실행의 자세한 내용은 2부로 미루겠지만, 지금 유용한 실행 개념 하나가 있습니다. 물리 계획은 하나의 거대한 트리 순회로 실행되지 않습니다. DuckDB는 이를 파이프라인으로 나눕니다.
파이프라인을 조립 라인이라고 생각해 보세요. 데이터가 한쪽 끝으로 들어와 여러 작업대 사슬을 통과합니다. 각 작업대는 한 가지 일만 합니다. 행을 버리거나, 컬럼을 변환하거나, 해시 테이블에서 값을 조회한 뒤 결과를 다음 작업대로 넘깁니다. 각 작업대가 한 행만 보고도 무엇을 할지 결정할 수 있다면, 라인은 계속 움직일 수 있습니다. 파이프라인의 예시는 다음과 같습니다.
DuckDB에서는 이렇게 연결된 스트리밍 작업대 사슬을 파이프라인이라고 부릅니다. 파이프라인은 깔끔하게 병렬화됩니다. 각 CPU 코어가 입력의 자기 몫 조각에 대해 조립 라인의 자기 복사본을 실행할 수 있기 때문입니다.
어떤 연산자들은 이런 방식으로 동작할 수 없습니다. 출력을 만들기 전에 전체 입력을 모두 봐야 합니다.
ORDER BY는 모든 행을 보기 전까지 정렬된 행 하나도 내보낼 수 없습니다. 어떤 행이 먼저 와야 하는지 모르기 때문입니다.GROUP BY는 한 그룹의 모든 행을 반영하기 전까지 최종 합계를 내보낼 수 없습니다.이런 연산자들을 파이프라인 브레이커 또는 sink라고 부릅니다. 이들은 하나의 파이프라인 끝과 다음 파이프라인 시작을 표시합니다. 물리 계획은 사실상 sink로 이어 붙여진 파이프라인들의 연속입니다.
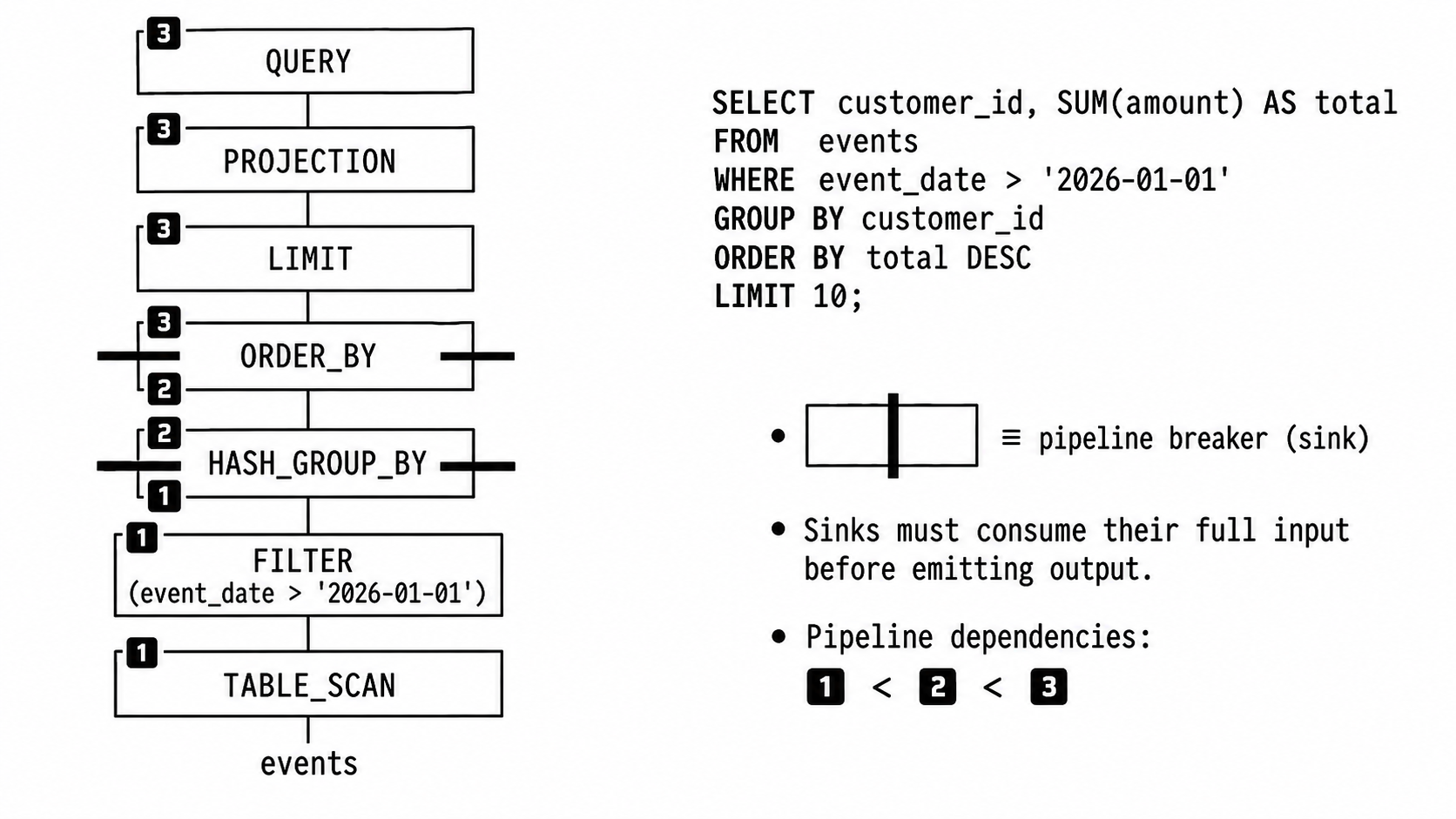 원래 쿼리로 돌아가 보면, 물리 계획은 대략 다음과 같을 수 있습니다.
원래 쿼리로 돌아가 보면, 물리 계획은 대략 다음과 같을 수 있습니다.
GROUP BY sink에서 끝납니다.scan events → filter event_date > '2026-01-01' → GROUP BY의 해시 테이블에 기록
ORDER BY sink에서 끝납니다.해시 테이블에서 그룹을 읽음 → 정렬 런에 기록
정렬 런을 읽음 → 처음 10개 행을 취함 → 결과 반환
각 파이프라인은 내부적으로 병렬 실행됩니다. 여러 스레드가 전체 조립 라인을 동시에 실행하되, 각각 입력의 자기 morsel을 담당합니다. 서로 의존하는 파이프라인은 순차적으로 실행됩니다. 파이프라인 2는 파이프라인 1의 GROUP BY가 기록을 끝내기 전에는 읽기를 시작할 수 없기 때문입니다.
sink는 sink, combine, finalize의 세 단계로 실행됩니다.
모든 스레드는 청크(DuckDB의 2048행 배치)를 받아 각자의 로컬 상태에 기록합니다. 예를 들어 HASH_GROUP_BY라면 자기 해시 테이블, ORDER_BY라면 자기 정렬 런, UNGROUPED_AGGREGATE라면 자기 부분 집계, HASH_JOIN의 build side라면 자기 해시 테이블에 기록합니다. 스레드들은 상태를 공유하지 않습니다. 모든 스레드가 하나의 공유 해시 테이블에 기록한다면, 삽입할 때마다 잠금을 두고 싸워야 할 것입니다. 로컬 상태는 각 스레드가 조정 없이 최대 속도로 sink할 수 있게 해 줍니다.
모든 스레드가 자기 로컬 공간에 기록을 끝내면, 결과를 하나의 전역 상태로 합쳐야 합니다. GROUP BY의 경우, 이는 모든 스레드 로컬 해시 테이블에 흩어진 각 그룹의 부분 합계와 개수를 합치는 것을 뜻합니다. DuckDB는 combine 단계 자체도 마지막에 단일 스레드로 병합하는 대신 모든 코어에서 실행되도록 sink를 설계했습니다(3부에서 다룹니다).
병합된 전역 상태는 다음 파이프라인의 입력으로 읽혀 나옵니다. 우리 GROUP BY 예시라면, customer_id, total) 행의 스트림이 됩니다.
파이프라인은 각 스레드에 자기 입력 morsel을 줌으로써 모든 코어에서 실행됩니다. sink는 각 스레드에 자기 로컬 상태를 주고 병렬로 병합함으로써 모든 코어에서 실행됩니다. DuckDB는 전체 쿼리에 대한 전역 병렬성을 계획하려 하지 않고, 한 번에 하나의 파이프라인만 병렬화합니다. 이것이 morsel 기반 병렬화(3부에서 다룸)와 벡터화 실행(2부에서 다룸)이 작동하게 만드는 요소의 일부입니다.
DuckDB의 놀라운 점은 대부분의 파일을 SQL 데이터베이스로 바꿀 수 있다는 것이며, 실제로 Parquet, CSV, JSON, XLSX 등과 같은 파일 형식을 직접 질의하는 데 자주 사용된다는 점입니다.
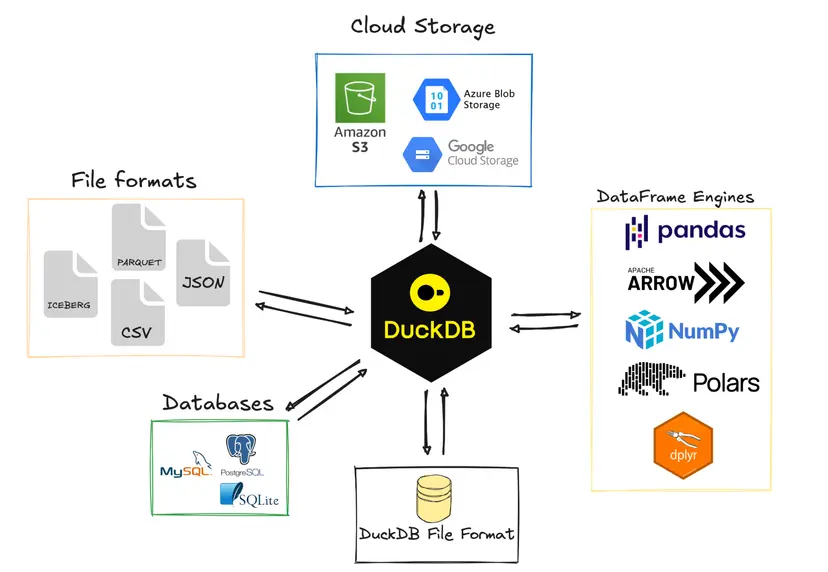
DuckDB는 많은 소스에 연결하고 질의할 수 있습니다. (source)
DuckDB 데이터베이스는 관례적으로 .duckdb 또는 .db 확장자를 쓰는 단일 파일입니다. 이는 SQLite에서 영감을 받았습니다. 파일 하나는 이동, 백업, 공유가 쉽습니다.
파일 내부에서 데이터는 고정 크기 블록으로 나뉩니다. 기본 블록 크기는 256 KB이지만, 더 작은 블록 크기(최소 16 KB까지)도 설정할 수 있습니다. 헤더에는 magic bytes, 스토리지 형식 버전, 데이터베이스 헤더 같은 메타데이터가 들어 있습니다.
모든 블록에는 _checksum_도 함께 저장됩니다. checksum은 블록 내용에서 계산된 작은 값입니다. DuckDB가 블록을 읽을 때 checksum을 다시 계산해 비교합니다. 값이 일치하지 않으면, 데이터가 어떤 식으로든 손상된 것이므로 DuckDB는 오류를 발생시킵니다. checksum이 중요한 이유는 메모리나 디스크에서 비트가 가끔 뒤집히기 때문입니다. 우주선이 셀을 때리거나, 펌웨어 버그가 바이트를 떨어뜨리거나, 불안정한 케이블이 쓰기를 망가뜨리는 식입니다. 클라우드 데이터 웨어하우스는 메모리 내장 오류 정정과 디스크 간 중복성으로 이를 완화할 수 있습니다. 노트북이나 edge device 같은 소비자 하드웨어는 일반적으로 보호가 더 약하므로, checksum은 유용한 최후 방어선입니다.
블록 내부에서는 컬럼들이 서로 분리되어 저장됩니다. row store는 전체 레코드를 디스크에 연속되게 저장합니다. 예를 들면 다음과 같습니다.
[id_1, name_1, age_1]
[id_2, name_2, age_2]
[id_3, name_3, age_3]
이 방식은 SELECT * FROM users WHERE id = 42 같은 쿼리에 빠릅니다. 레코드의 바이트가 메모리에서 물리적으로 서로 가깝게 놓여 있기 때문입니다.
column store는 컬럼들을 디스크에 연속되게 저장합니다.
[id_1, id_2, id_3]
[name_1, name_2, name_3]
[age_1, age_2, age_3]
300개 컬럼을 가진 테이블에서 4개 컬럼만 읽는 쿼리는 그 4개 컬럼만 읽으면 됩니다. row store라면 300개 컬럼을 모두 읽고, 그중 296개는 버려야 합니다. 그래서 조직들이 분석용으로 column store(Snowflake, BigQuery, ClickHouse 등)를 사용하는 것입니다. 분석 쿼리는 소수의 컬럼을 선택적으로 읽고, 그 컬럼들로 그룹화하고, 집계하는 경향이 있기 때문입니다.

각 컬럼은 최대 122,880행의 row group으로 나뉘고, row group 내부에서는 보통 하나의 256 KB 블록에 매핑되는 column segment로 나뉩니다. row group은 병렬성의 단위입니다. 8개 스레드로 실행되는 쿼리라면 모든 스레드를 바쁘게 유지하려면 범위 안에 최소 8개의 row group이 있어야 합니다.
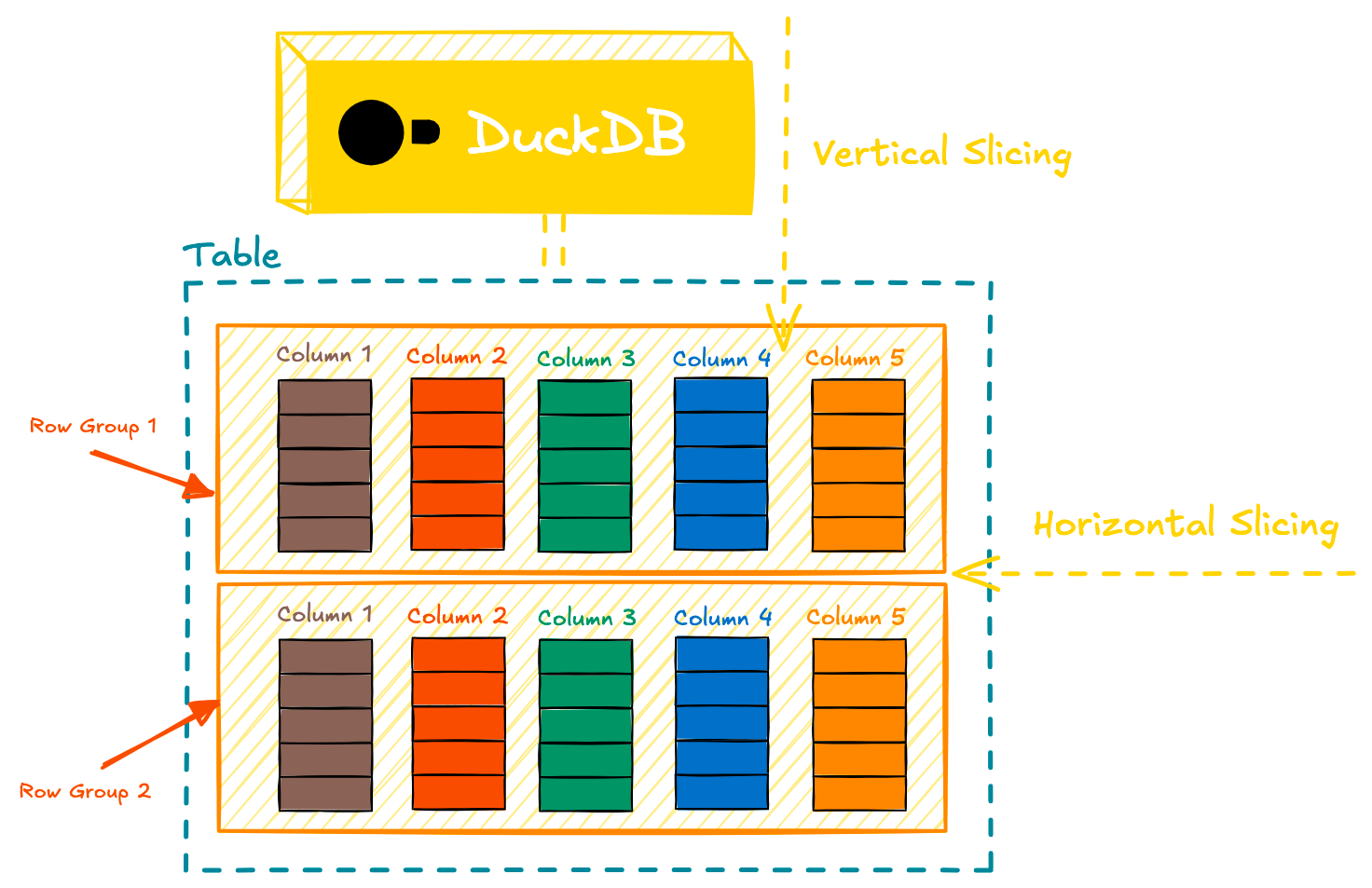
(source)
각 row group에는 _zone map_도 함께 있습니다. zone map은 row group 내 최소값과 최대값, 그리고 null 개수를 담고 있습니다. WHERE event_date > '2026-01-01' 같은 조건으로 스캔이 실행되면, DuckDB는 데이터를 읽기 전에 각 row group의 최대값을 확인합니다. 최대 event_date가 '2026-01-01' 이하인 row group은 통째로 건너뜁니다.
이것은 주요 클라우드 데이터 웨어하우스들이 다른 이름으로 사용하는 유사한 기법입니다. Snowflake는 이를 micro-partition pruning이라 부르고, BigQuery는 block pruning이라 부르며, ClickHouse는
minmaxdata skipping indexes를 사용합니다.
zone map의 효과는 컬럼 정렬 순서에 크게 좌우됩니다. 정렬되어 있거나 삽입 시각 기준으로 자연스럽게 정렬되는 컬럼은 row group마다 min-max 범위가 좁습니다. 반대로 값이 테이블 전체에 무작위로 흩어진 컬럼은 범위가 매우 넓어지고, zonemap의 효과는 훨씬 약해집니다.
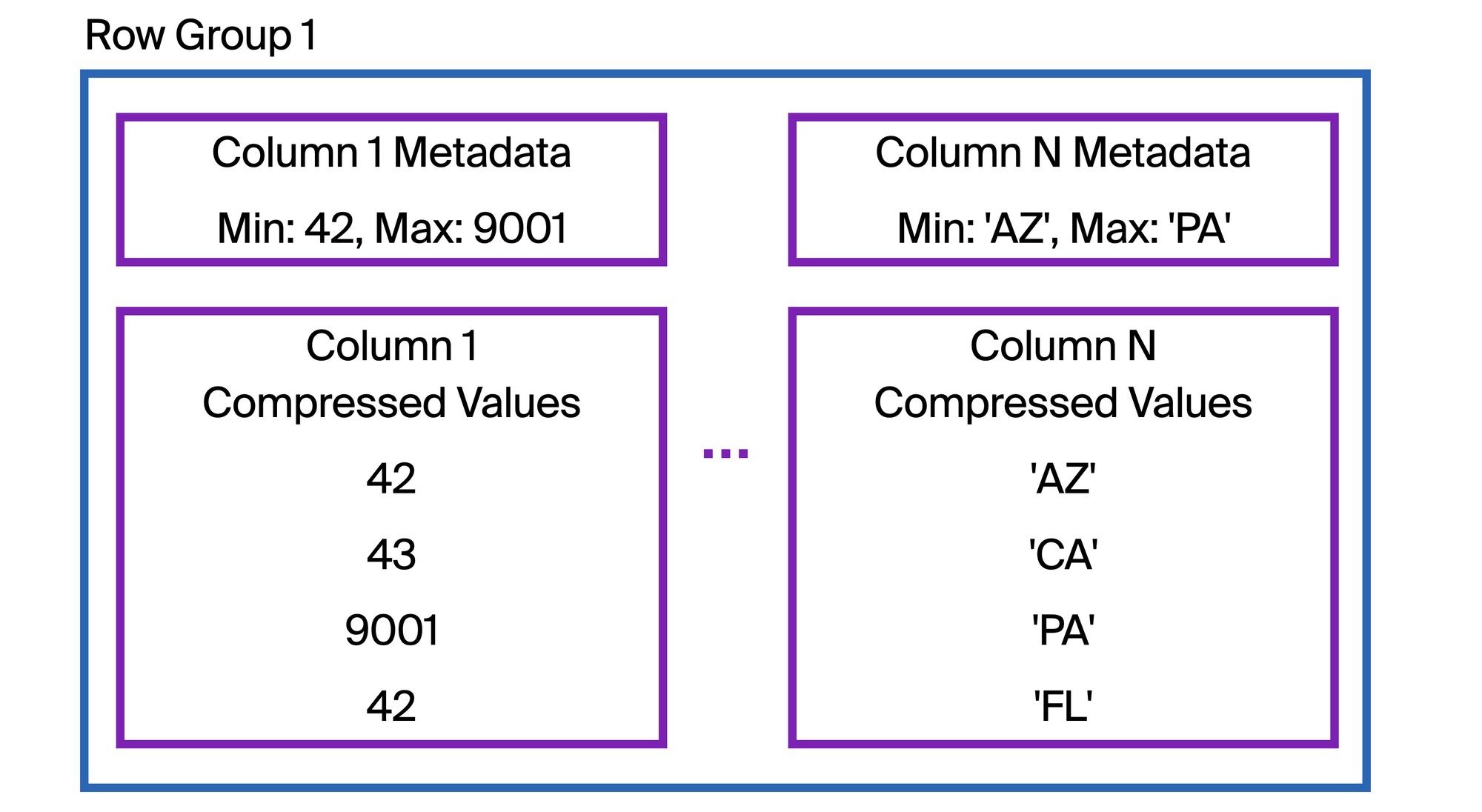
Zone map (source)
대부분의 경우 실무자들은 DuckDB 테이블을 질의하지 않습니다. DuckDB를 Parquet 파일에 직접 연결합니다. 일반적인 패턴은 두 가지입니다.
-- Query a parquet file directly
SELECT
customer_id
, SUM(amount) as total_amount
FROM read_parquet('/my/nice/files/*.parquet', union_by_name=TRUE)
WHERE
event_date > '2026-01-01'
GROUP BY ALL;
-- Or load it into a DuckDB table first
CREATE TABLE events AS
SELECT * FROM read_parquet('s3://bucket/events/*.parquet');
Parquet 파일 질의가 왜 이렇게 빠를까요? DuckDB가 데이터를 자기 형식으로 변환한 것도 아닙니다. DuckDB가 만든 zone map도 없고, DuckDB 쪽 압축도 없고, .duckdb 파일도 없습니다. 그런데도 어떤 쿼리는 네이티브 DuckDB 테이블만큼 빠르게 실행됩니다.
Parquet는 DuckDB의 네이티브 형식과 유사한 설계 원칙을 갖고 있습니다.
Parquet를 질의할 때 DuckDB는 footer를 읽어 파일의 스키마와 row group 통계를 알아냅니다. 이 통계를 사용해 어떤 row group이 쿼리 조건을 만족할 수 있는지 판단합니다. 살아남은 각 row group에 대해서는 쿼리에 필요한 column chunk만 읽고, 압축을 풀어, 앞서 설명한 pipeline-and-sink로 흘려보냅니다.
파일이 원격에 저장되어 있다면 DuckDB는 파일 전체를 내려받지 않습니다. 필요한 footer만 가져오기 위해 HTTP 요청을 보내고, 어떤 row group과 column chunk가 필요한지 결정한 다음, 그 바이트들만 가져오기 위한 요청을 다시 보냅니다. 제대로 가지치기되는 WHERE 절은 네트워크를 통한 성능을 극적으로 높일 수 있습니다.
CSV는 Parquet와 정반대입니다. 자기 기술적 형식이 아닙니다. Parquet는 사실상 스키마, 통계, 압축된 데이터가 들어 있는 chunked column을 DuckDB에 넘겨줍니다. CSV는 그렇지 않습니다. 그냥 텍스트일 뿐입니다. DuckDB는 어떤 문자가 컬럼 구분자인지, 값에 따옴표가 있는지, 따옴표 이스케이프는 어떻게 되는지, 첫 행이 컬럼 이름인지, 각 컬럼의 타입은 무엇이어야 하는지를 알아내야 합니다. DuckDB는 이를 CSV sniffer로 수행합니다.
SELECT *
FROM 'events.csv';
-- Alternatively
SELECT *
FROM read_csv('events.csv');
DuckDB가 CSV를 읽을 때는 자동으로 세 가지를 감지하려고 시도합니다. dialect, 컬럼 타입, 그리고 파일에 헤더 행이 있는지 여부입니다.
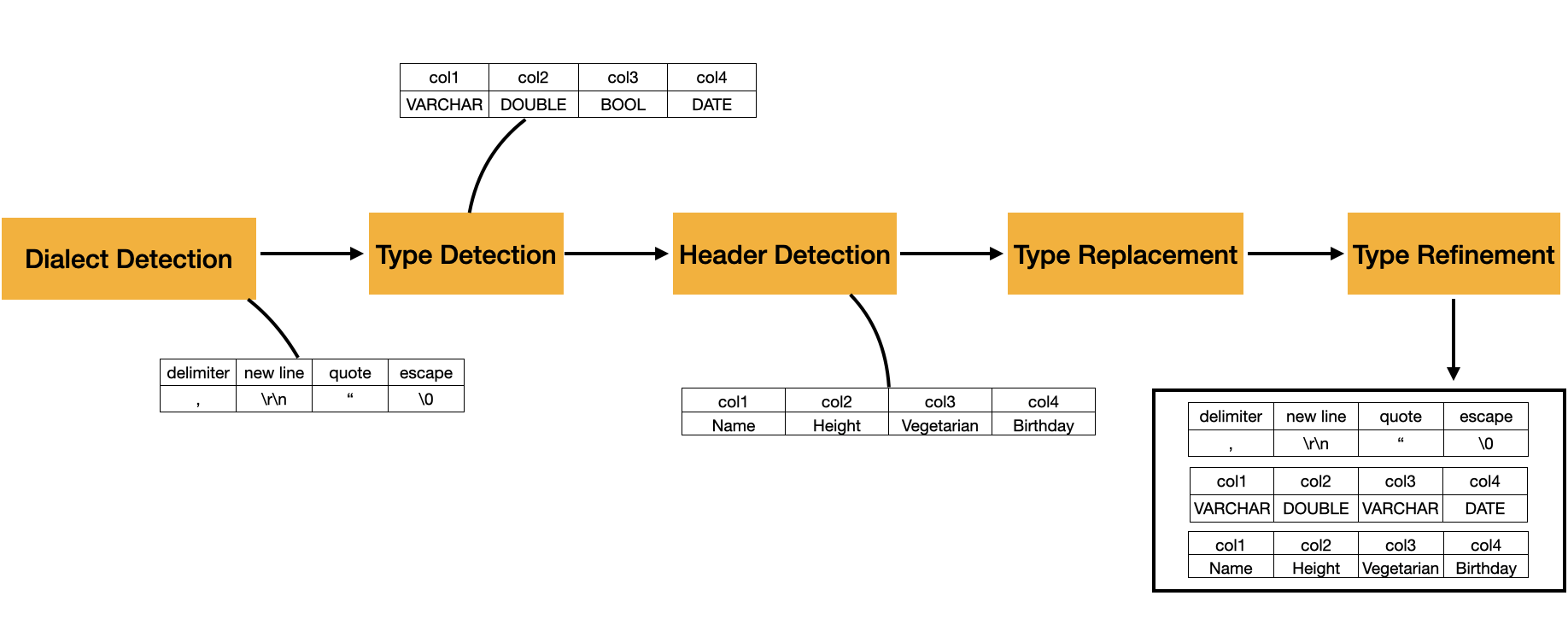
DuckDB CSV sniffer의 단계들. (source)
Dialect는 파일의 파싱 문법입니다. 구분자, 따옴표 문자, 이스케이프 문자, 줄바꿈 스타일을 뜻합니다. DuckDB는 후보 dialect를 시험하고, 가장 일관된 행과 가장 많은 컬럼 수를 만들어내는 것을 고릅니다. 예를 들어 다음과 같은 파일은
Company|Category|City|IsSuperCool
DuckDB|OLAP database|Amsterdam, Netherlands|True
Snowflake|data warehouse|Bozeman, MT|True
BigQuery|data warehouse|Mountain View, CA|N/A
Greybeam|multi-engine router|San Francisco, CA|True
도시 이름에 쉼표가 들어 있어도 ,가 아니라 |를 기준으로 분할되어야 합니다. sniffer는 |가 일관된 4컬럼 테이블을 만들어내기 때문에 이를 알아낼 수 있습니다.
dialect가 선택되면, DuckDB는 각 컬럼의 샘플 값들을 후보 타입으로 변환해 보며 컬럼 타입을 감지합니다. 어떤 값이 특정 후보 타입으로 변환될 수 없으면, 그 타입은 해당 컬럼의 후보 집합에서 제거됩니다. 샘플 처리가 끝나면, DuckDB는 남은 후보 타입 중 우선순위가 가장 높은 타입을 선택합니다. 문서화된 기본 후보 타입의 우선순위는 NULL, BOOLEAN, TIME, DATE, TIMESTAMP, TIMESTAMPTZ, BIGINT, DOUBLE, VARCHAR 순입니다. 모든 값은 VARCHAR로 표현 가능하므로, 이것이 최종 fallback 타입입니다.
그다음은 헤더 감지입니다. 첫 행이 그 아래 행들과 다르게 보이면, 예를 들어 Company, Category 같은 문자열이라면 컬럼 이름으로 처리합니다. 그렇지 않으면 column0, column1 같은 기본 이름을 생성합니다.
sniffer는 전체 파일을 스캔하는 대신 샘플로 동작합니다. 기본 샘플 크기는 20,480행입니다. 이 값을 늘리거나, sample_size = -1로 설정해 전체 파일을 검사할 수 있습니다.
분명히 쿼리가 실제로 실행되기 전에도 엄청난 작업이 일어납니다. AST로 파싱되고, 스키마에 바인딩되며, 약 30개의 패스를 거쳐 최적화되고, 물리 계획으로 컴파일됩니다. 심지어 스토리지 레이어도 미리 엄청난 일을 해 둡니다.
2부는 실행 단계부터 이어집니다. 기대해 주세요!
Greybeam에서 우리는 이것이 데이터의 미래를 위해 멀티 엔진 라우터를 만드는 일이 매우 흥미로운 이유 중 하나라고 봅니다. DuckDB가 빠르다는 것은 분명합니다. DuckDB의 강점은 현실적입니다. Snowflake의 강점도 그렇고, BigQuery의 강점도 그렇습니다.
우리는 데이터 팀이 각 쿼리를 가장 빠르게 실행하도록 만들어진 쿼리 엔진을 사용할 수 있는 미래를 믿습니다. 함께 가시죠.