CockroachDB의 쿼리 옵티마이저가 왜 자체 구현되었는지, 비용 기반 최적화에서 대안 계획을 생성·탐색·선택하는 과정, 통계 수집과 지역성 인지 최적화까지의 개요를 정리한다.
CockroachDB: Postgres 호환 Geo-Distributed SQL 데이터베이스
아키텍처
이 발표는 SQL 계층에 초점을 맞춘다.
왜 Postgres(또는 다른 OSS) 옵티마이저를 쓰지 않았나?
CDB의 첫 번째 옵티마이저
사실상 옵티마이저가 아니었다. 휴리스틱(규칙)으로 실행 계획을 선택했다.
시간이 지나면서 규칙이 이런 형태가 되기 시작했다:
관리가 어려워졌다.
이런 종류의 옵티마이저는 OLTP에는 동작하지만, 고객들이 CDB를 OLAP 쿼리에도 사용하고 있었다.
비용 기반(cost-based) 옵티마이저
Q/A
Postgres처럼 초기 비용은 저렴한 근사치로 계산하고, 나머지를 끝까지 하기로 결정하면 최종 비용을 계산하는 식의 작업을 하거나, 아니면 단일 비용 모델이 단일 값을 내는 방식인가?
비용 모델 추정을 논리 노드(logical node)에서 할 수 있나, 아니면 항상 물리 노드(physical node)여야 하나?
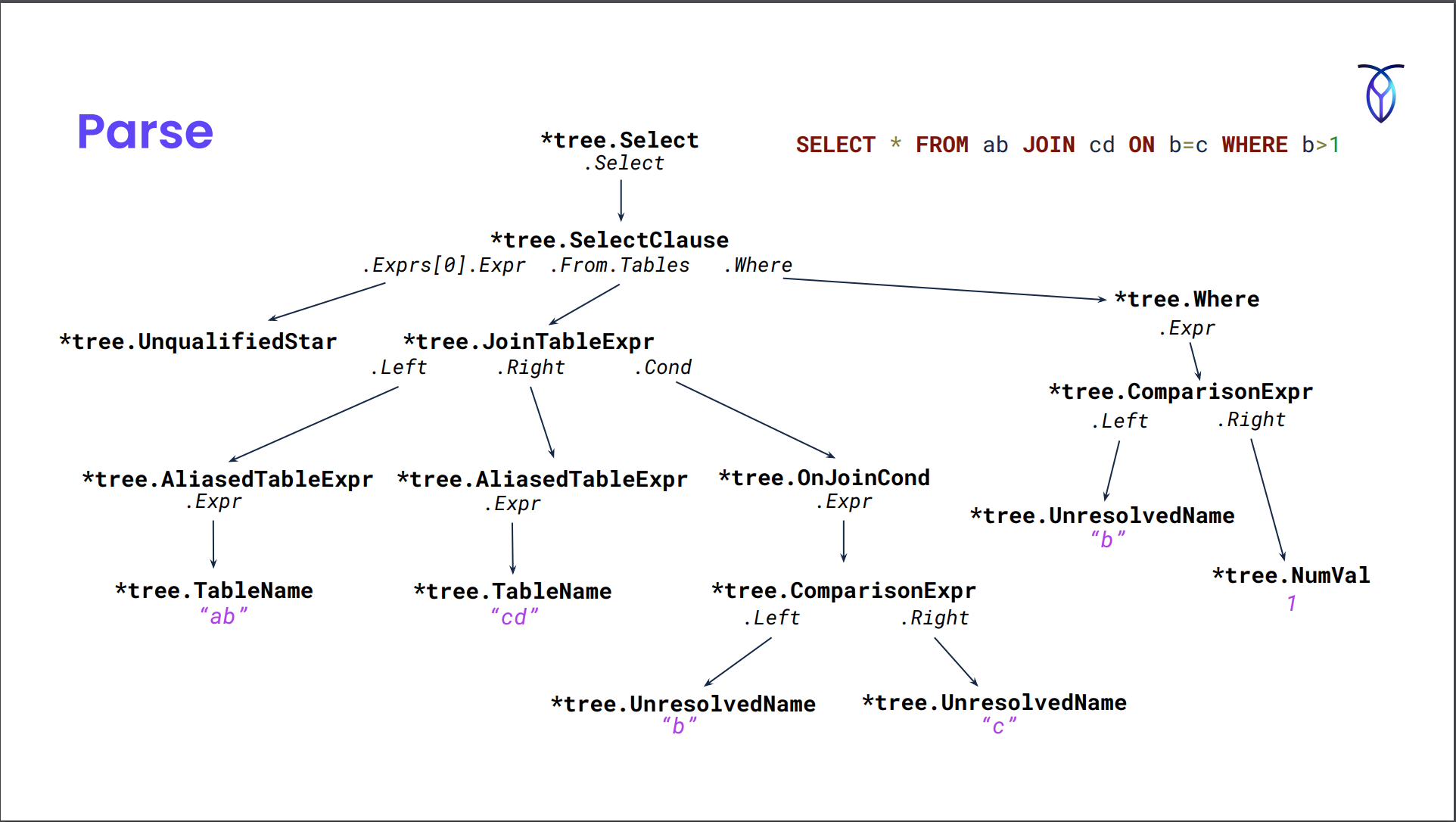
계획 생성 단계
예시 쿼리
CREATE TABLE ab (a INT PRIMARY KEY, b INT, INDEX(b));
CREATE TABLE cd (c INT PRIMARY KEY, d INT);
SELECT * FROM ab JOIN cd ON b=c WHERE b>1;
ConstructSelect(
ConstructInnerJoin(
ConstructScan(),
ConstructScan(),
ConstructFiltersItem(
ConstructEq(
ConstructVariable(),
ConstructVariable(),
),
),
),
ConstructFiltersItem(
ConstructGt(
ConstructVariable(),
ConstructConst(),
),
),
)
의미(semantic) 분석도 수행한다. 예:
*가 어떤 컬럼들을 선택하는가?Q/A:
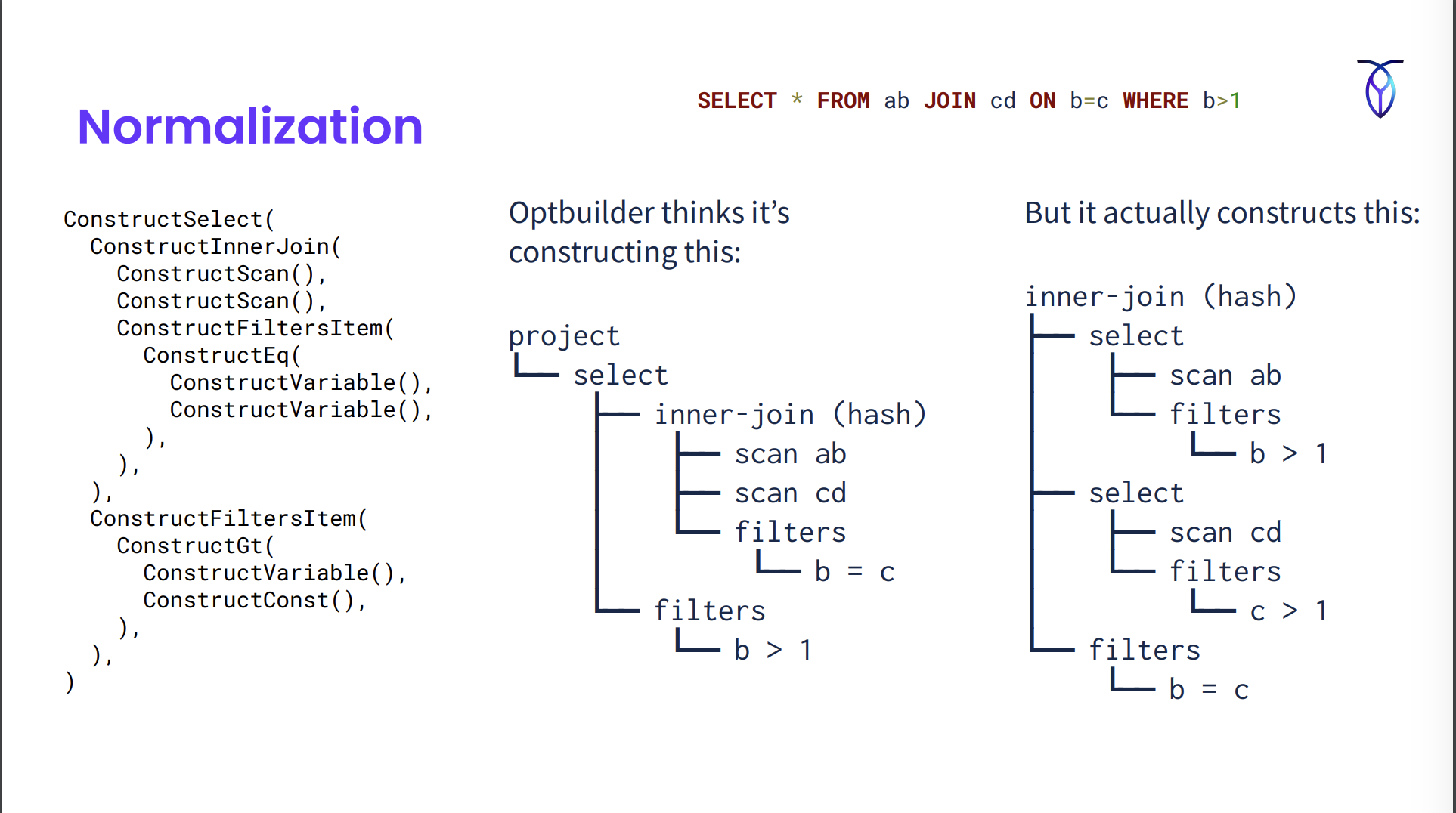
b=c라는 사실을 이용해, b>1이면 c>1임을 추론하고 필터를 조인 아래로 푸시다운했다.NOT (NOT) x -> x5 = x -> x = 5length('abc') -> 3# EliminateNot discards a doubled Not operator // 규칙을 설명하는 코멘트
[EliminateNot, Normalize] // rulename, tag가 있는 헤더
(Not (Not $input:*)) // 규칙 매칭
=>
$input // 표현식 치환
// ConstructNot constructs an expression for the Not operator.
func (_f *Factory) ConstructNot(input opt.ScalarExpr) opt.ScalarExpr {
// [EliminateNot]
{
_not, _ := input.(*memo.NotExpr)
if _not != nil {
input := _not.Input
if _f.matchedRule == nil || _f.matchedRule(opt.EliminateNot) {
_expr := input
return _expr
}
}
}
// ... other rules ...
e := _f.mem.MemoizeNot(input)
return _f.onConstructScalar(e)
}
# MergeSelects combines two nested Select operators into a single Select that
# ANDs the filter conditions of the two Selects.
[MergeSelects, Normalize]
(Select (Select $input:* $innerFilters:*) $filters:*)
=>
(Select $input (ConcatFilters $innerFilters $filters))
// [MergeSelects]
{
_select, _ := input.(*memo.SelectExpr)
if _select != nil {
input := _select.Input
innerFilters := _select.Filters
if _f.matchedRule == nil || _f.matchedRule(opt.MergeSelects) {
_expr := _f.ConstructSelect(
input,
// DSL은 (ConcatFilters 같은) 임의의 Go 함수를 호출할 수 있게 해주며
// 이런 함수들은 그들이 정의한다.
_f.funcs.ConcatFilters(innerFilters, filters),
)
return _expr
}
}
}
Q/A
Memo after normalization
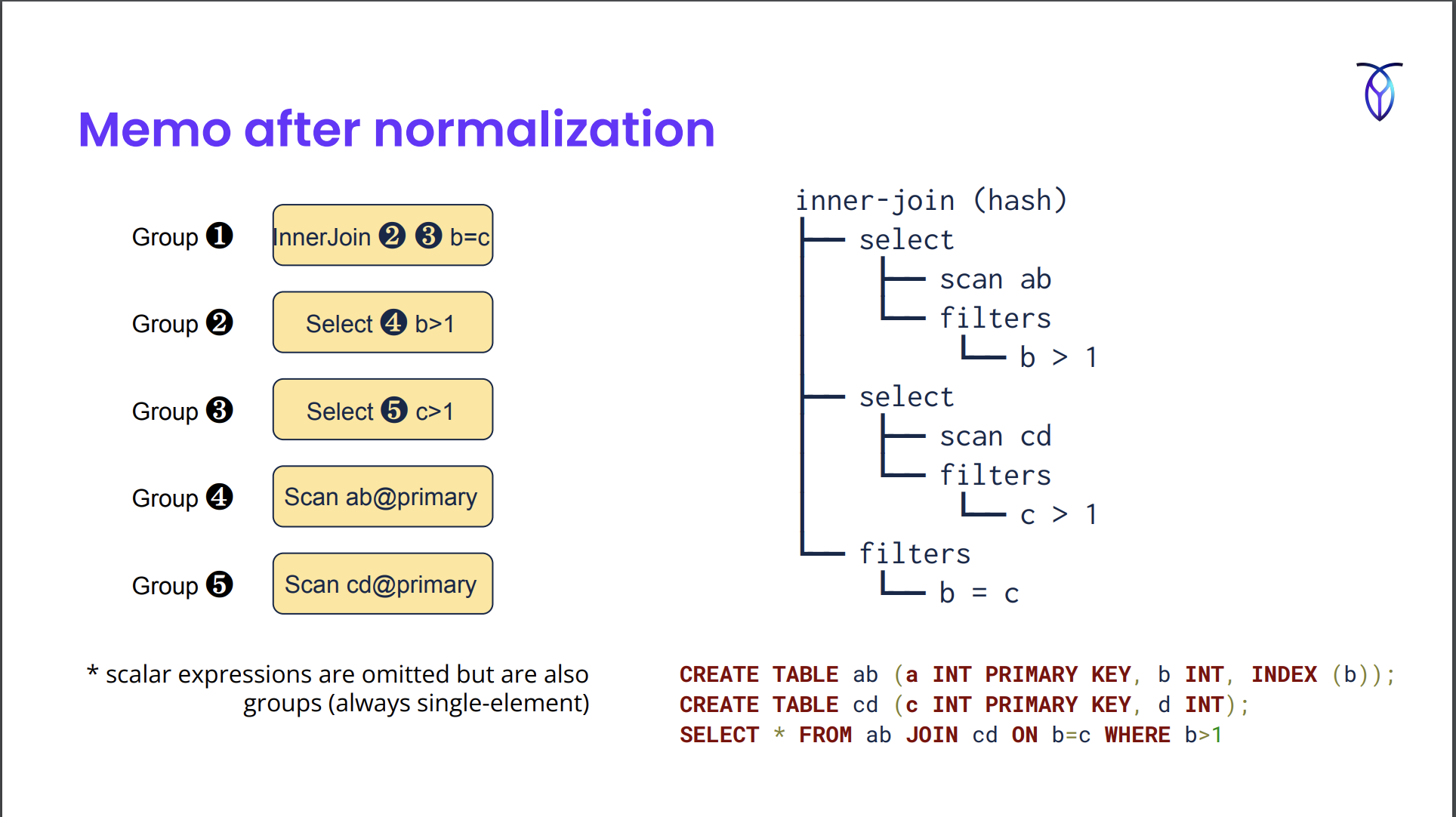
탐색에서는 그룹들을 순회하며 어떤 탐색 규칙이 매칭되는지 확인한다.
GenerateIndexScans는 기본 키 인덱스가 아니라 보조 인덱스를 스캔하는 대체 스캔을 생성했다.
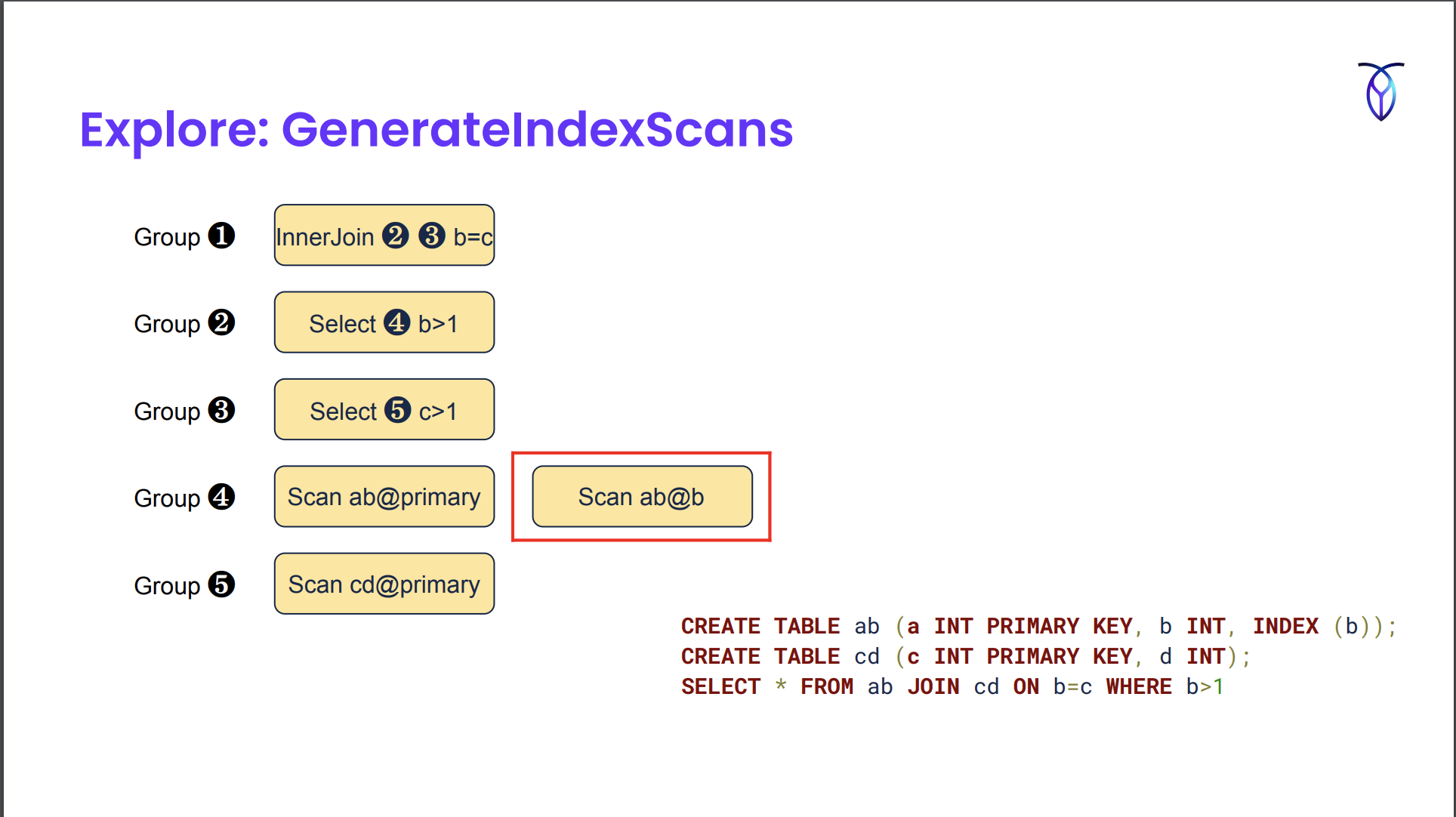
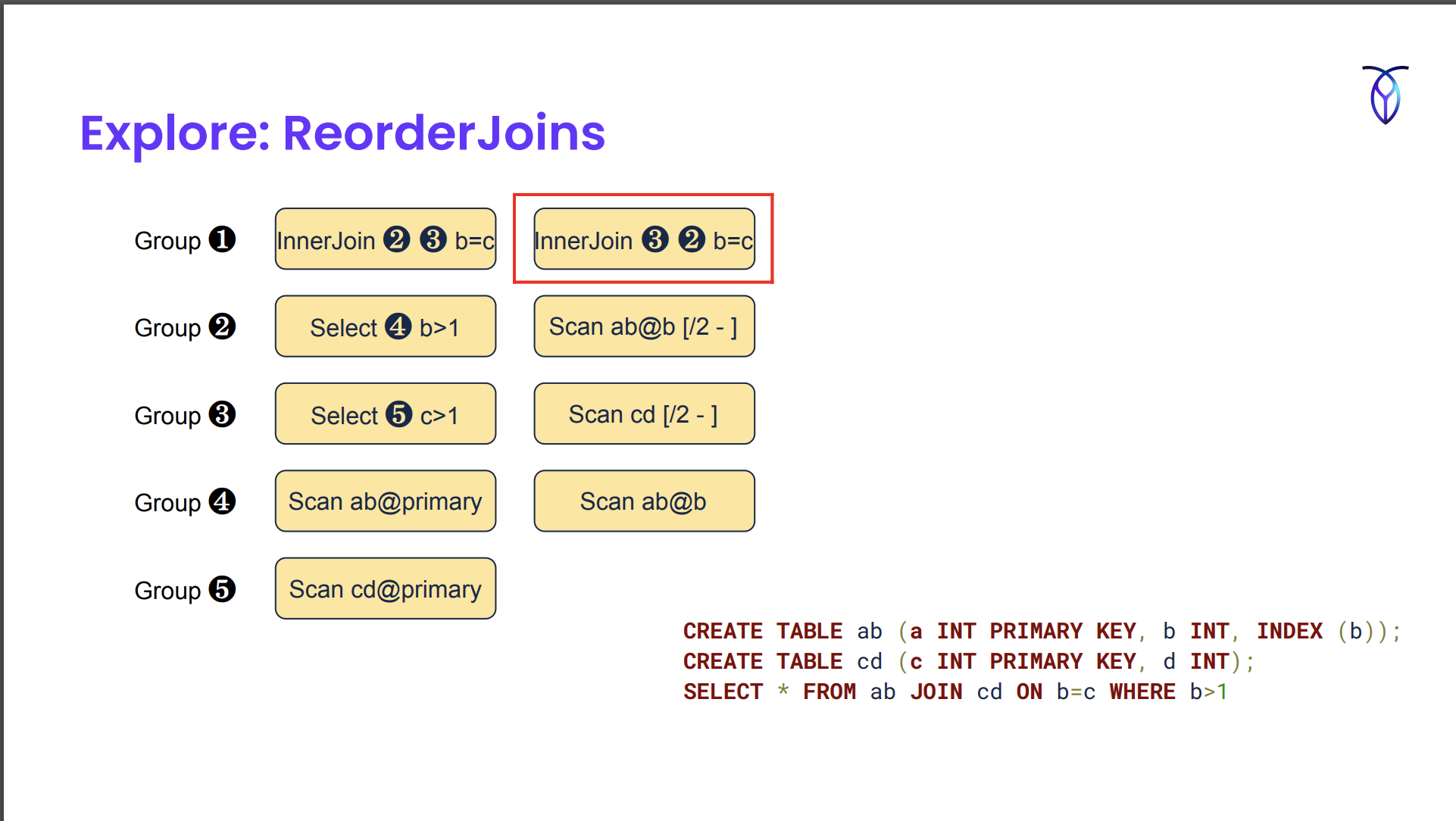
https://www.querifylabs.com/blog/memoization-in-cost-based-optimizers 의 예시
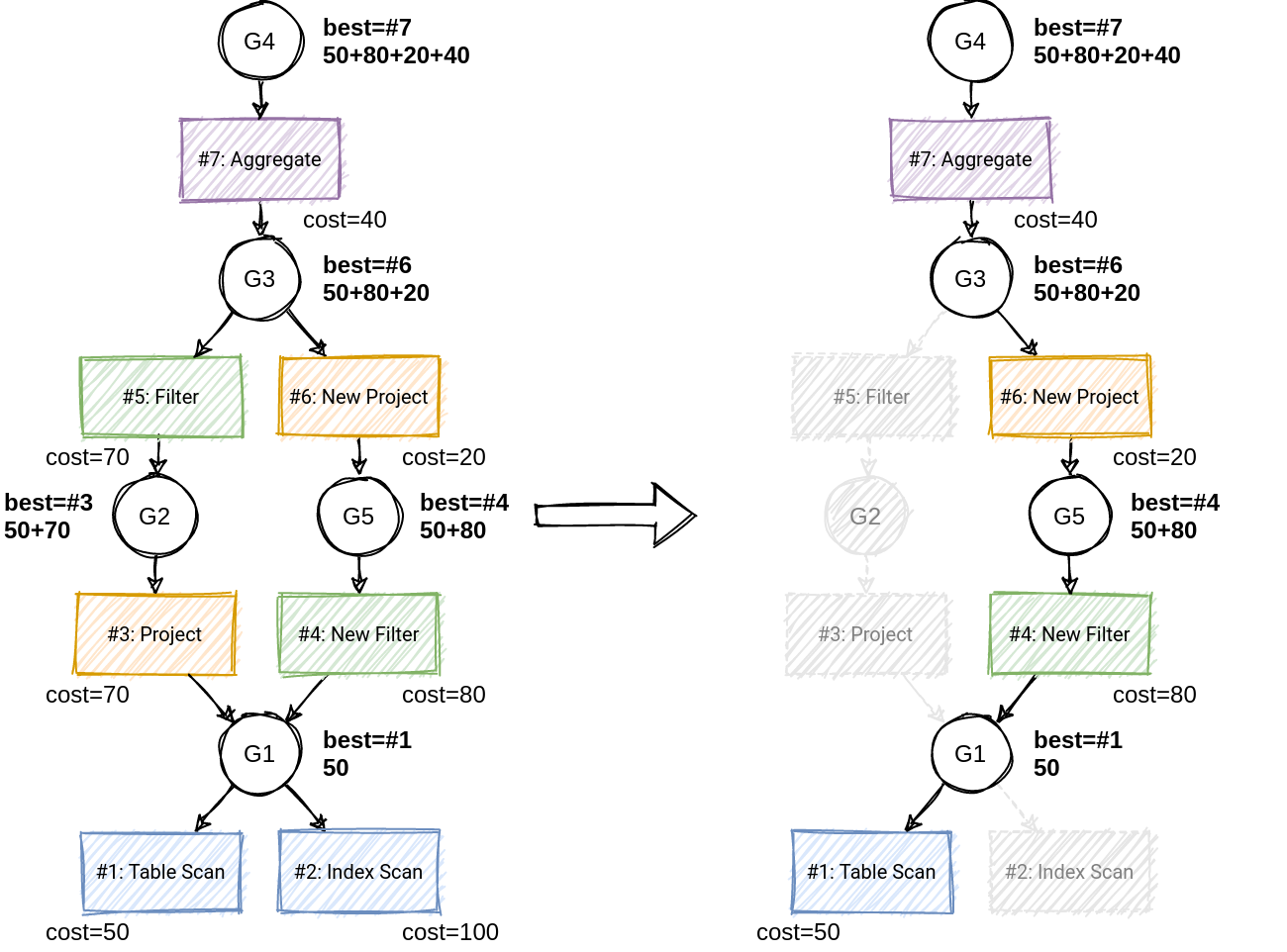
최적의 계획은 비용 결정 이후 다음 단계로 전달된다.
옵티마이저로부터 계획을 받아, 클러스터 토폴로지에 맞게 확장한다.
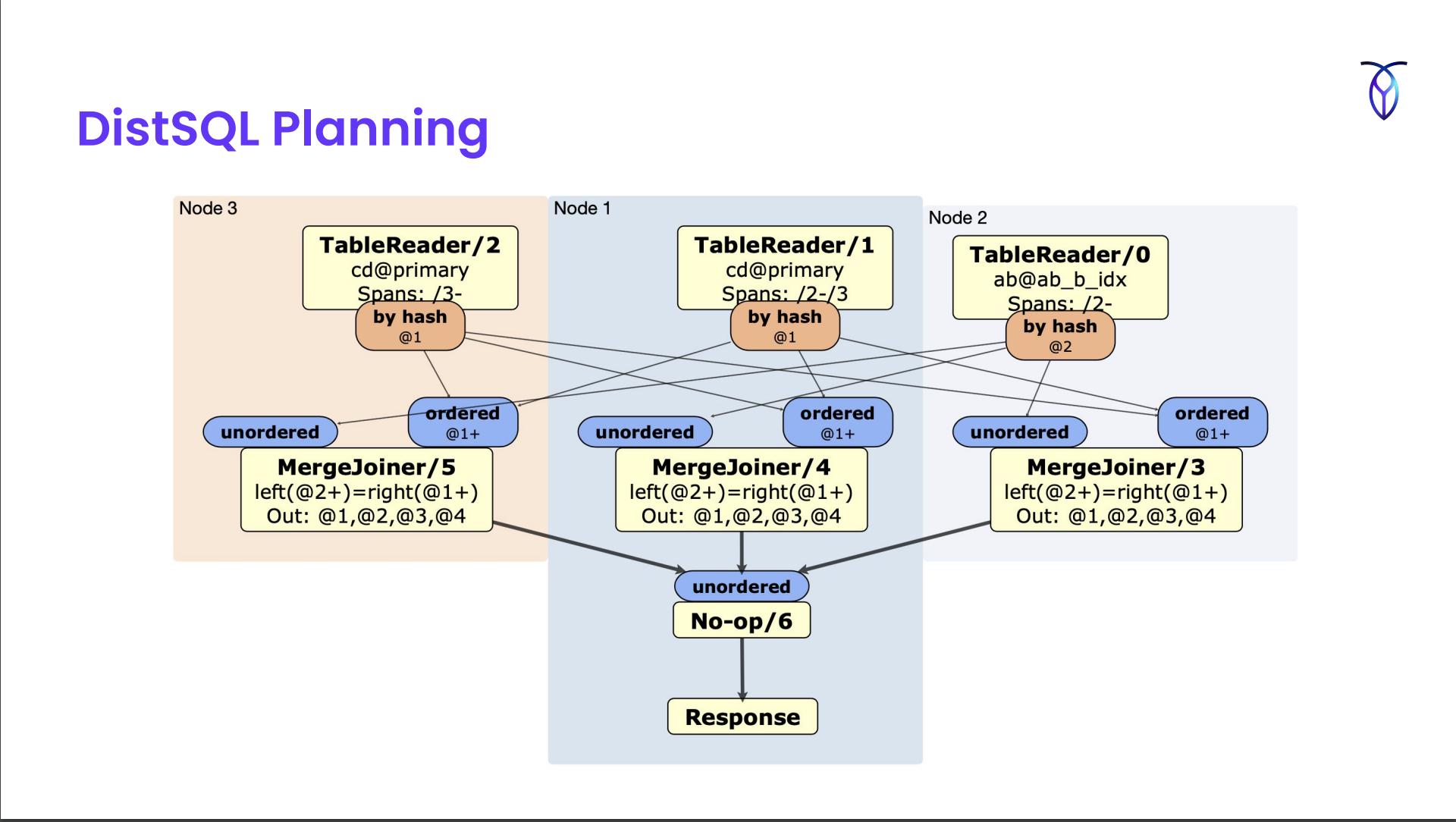
현재는 테이블이 디스크에 어떻게 배치되어 있는지, 조인을 위해 더 작은 테이블의 데이터를 다른 쪽으로 브로드캐스트하는 최적화 등은 활용하지 않지만, 가까운 미래에 계획되어 있다.
하드웨어 구성
데이터 분포
연산자 타입
각 연산자가 처리하는 행 수
각 연산자가 처리하는 행 수
통계 수집: 행 수(Row count), 고유 개수(Distinct count), Null 개수(Null count), 히스토그램
단일 컬럼 통계뿐 아니라 다중 컬럼 통계도 수집한다.
통계 수집(CREATE STATISTICS): 전체 테이블 스캔 -> 샘플링 수행(크기: 10K rows) -> 각 행을 HyperLogLog 스케치에 넣어 각 컬럼의 distinct count를 계산 -> 샘플 집계
CREATE STATISTICS는 다음 경우 자동으로 실행된다:
데이터의 20%가 변경되었다는 것은 어떻게 판단하나?
P(refresh) = no. of rows updated / (no. of rows in table * 0.20)아직 통계가 없거나, 마지막 리프레시 이후 시간이 꽤 지났으면 항상 리프레시한다.
각 통계 생성 실행은 몇 분이 걸린다. 전체 테이블 스캔은 성능에 영향을 줄 수 있다. 동시에 많은 테이블 스캔이 발생하면 클러스터가 다운될 수 있다.
성능 영향을 최소화하기 위해
CREATE STATISTICS를 job으로 실행한다.
스로틀링을 사용해 통계 job의 CPU 사용량을 제한한다.
복제 제약(replication constraints)을 사용해 복제본을 서로 다른 지리적 리전에 고정(pinning)한다(예: US-East, US-West, EU).
옵티마이저는 비용 모델에 locality를 포함하고, 같은 locality의 인덱스를 자동으로 선택한다: primary, idx_eu 또는 idx_usw
CREATE TABLE postal_code (
id INT PRIMARY KEY,
code STRING,
INDEX idx_eu (id) STORING (code),
INDEX idx_usw (id) STORING (code),
)
중복 인덱스를 “global tables”로 대체
geo-partitioned unique index 지원
DistSQL planning을 옵티마이저로 이동
비용 모델에 지연시간(latency) 반영
OLTP 최적화
단순 휴리스틱 플래너에서 비용 기반 옵티마이저로 전환했을 때, 단순한 OLTP 쿼리(예: 기본 키 조회)에 대한 오버헤드를 최소화하는 데 많은 집중이 필요했다. 휴리스틱 플래너는 문제가 있었지만 매우 빨랐기 때문이다.
정규화 규칙은 매우 중요하다. 이 발표 시점 기준으로 정규화 규칙 242개, 탐색 규칙 29개가 있다.
외래 키 검사 및 cascade를 “post queries”로 최적화
조인 순서(Join Ordering)
v1은 조인 순서 최적화 없이 출시되었다.
처음에는 2개의 규칙으로 구현했다: CommuteJoin, AssociateJoin
한 인턴이 “Guido Moerkotte, Pit Fender, and Marius Eich. 2013. On the correct and complete enumeration of the core search space.”의 DP SUBE를 구현하여 더 효율적으로 만들었다.
Query Cache
Other features
옵티마이저 힌트
디버깅 도구 EXPLAIN ANALYZE (DEBUG) ...
옵티마이저는 어떻게 테스트하나? 비용 모델이 제대로 동작하는지 어떻게 테스트하나?
입력 파라미터만으로 필요한 모든 것을 디버깅할 수 있나?
어떤 종류의 SQL fuzzer를 돌리나?
일반적으로 어떤 복잡도의 쿼리를 보나? Cockroach는 Snowflake 같은 시스템이 아니라서 복잡한 쿼리는 그쪽으로 밀릴 수 있는데, TPC-H, TPC-DS 정도로 제한되나?
재작성 규칙이 처리할 수 있는 복잡도에 제한이 있나? 임의의(그들이 프로그래밍한) Go 함수를 호출할 수 있다고 했는데.