Tokio 기반 Rust 프로그램에서 단 하나의 tokio::sync::Mutex만으로도 왜 직관에 반하는 멈춤 현상이 발생하는지, 그 원인과 실용적인 해결책을 설명합니다.
.svg)
리소스
회사 소개
엔지니어링
작성자
Samyak Sarnayak
&
Samyak Sarnayak
2026년 3월 23일
 “데드락”으로 이어지는 이벤트 순서
“데드락”으로 이어지는 이벤트 순서
%20(1).svg)
e6data가 실제로 어떻게 동작하는지 보고 싶으신가요?
데이터 팀이 어떻게 워크로드를 구동하는지 알아보세요.
데드락은 보통 매우 특정한 시나리오에서 발생합니다. 누군가가 하나의 락을 잡고, 다른 누군가가 쥐고 있는 또 다른 락을 얻으려 할 때입니다. 그런데 이 시나리오에는 락이 하나뿐이었습니다. Tokio 기반 Rust 프로그램에서 우리는 공유 상태를 단 하나의 tokio mutex로 보호했고, 일반적인 규칙이 그대로 적용될 것이라고 기대했습니다. 특정 워크로드에서 네 개의 future가 시작되고, 세 개는 완료되지만, 네 번째는 영원히 멈춰 있었습니다. 심지어 로그에는 mutex가 이미 해제되었다고 찍혀 있었는데도 말입니다. 이처럼 “락은 풀렸는데 여전히 멈춰 있는” 동작이야말로 이 Tokio mutex 데드락을 직관적으로 이해하기 어렵게 만드는 지점입니다.
처음 보면 이것은 전형적인 async 실수처럼 보입니다. std mutex를 .await를 가로질러 쥐고 있는 경우 말이죠. 하지만 우리는 그렇게 하지 않았습니다. 바로 그런 문제를 피하기 위해 tokio::sync::Mutex를 사용하고 있었습니다. 결국 설명은 tokio 내부 구현 안에 있었고, 이는 로깅만으로는 드러나지 않는 부분이었습니다.
재현 코드는 비교적 작습니다. 하나의 tokio mutex를 4개의 워커가 동시에 사용합니다. 특별한 PausableFuture가 있는데, 신호를 받으면 내부 future에 대한 polling을 멈춥니다. 또 하나 주목할 점은 tokio의 current_thread flavor를 사용하고 있다는 점인데, 이는 단일 스레드입니다. 유사한 동작은 워커 스레드 4개를 가진 multi_thread 런타임에서도 나타납니다.
//! Reproducer: tokio::sync::Mutex deadlock with a single, unlocked mutex.
//!
//! Cargo.toml:
//! [dependencies]
//! tokio = { version = "1", features = ["full"] }
use std::future::Future;
use std::pin::Pin;
use std::sync::Arc;
use std::sync::atomic::{AtomicBool, Ordering};
use std::task::{Context, Poll};
use std::time::Duration;
use tokio::sync::Mutex;
/// Future wrapper that stops forwarding polls when `stopped` is set.
struct PausableFuture<F> {
inner: Pin<Box<F>>,
stopped: Arc<AtomicBool>,
}
impl<F: Future> Future for PausableFuture<F> {
type Output = F::Output;
fn poll(mut self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<Self::Output> {
if self.stopped.load(Ordering::Acquire) {
return Poll::Pending;
}
self.inner.as_mut().poll(cx)
}
}
#[tokio::main(flavor = "current_thread")]
async fn main() {
let mutex = Arc::new(Mutex::new(()));
// Hold the lock so workers queue up.
let guard = mutex.lock().await;
println!("main acquired the lock");
// Spawn 4 workers, each wrapped in a PausableFuture.
// Each worker gets its own flag - whether to stop or not.
let stop_flags: Vec<_> = (0..4).map(|_| Arc::new(AtomicBool::new(false))).collect();
let mut handles = Vec::new();
for id in 0..4u32 {
let mutex = Arc::clone(&mutex);
let stopped = Arc::clone(&stop_flags[id as usize]);
handles.push(tokio::spawn(PausableFuture {
stopped,
inner: Box::pin(async move {
let guard = mutex.lock().await;
println!("worker {id}: acquired lock");
tokio::time::sleep(Duration::from_millis(100)).await;
drop(guard);
println!("worker {id}: released lock");
}),
}));
}
// Yield so all workers poll lock() and start waiting.
tokio::task::yield_now().await;
// Stop polling worker 1.
stop_flags[1].store(true, Ordering::Release);
// Release the lock. The mutex is now UNLOCKED.
drop(guard);
println!("main released the lock");
for (id, h) in handles.into_iter().enumerate() {
match tokio::time::timeout(std::time::Duration::from_secs(2), h).await {
Ok(Ok(())) => println!("worker {id}: done"),
Ok(Err(e)) => println!("worker {id}: error: {e}"),
Err(_) => println!("worker {id}: DEADLOCKED"),
}
}
}실행하면 다음과 같은 로그가 나옵니다.
main acquired the lock
main released the lock
worker 0: acquired lock
worker 0: released lock
worker 0: done
worker 1: DEADLOCKED
worker 2: DEADLOCKED
worker 3: DEADLOCKEDmain과 worker 0이 모두 락을 해제한 것을 볼 수 있습니다. 아무도 락을 쥐고 있지 않은데도, 다른 스레드들은 데드락에 빠집니다!
실제 프로덕션 코드에서 이 현상을 보았을 때는 이렇게 단순하지 않았습니다. 해당 코드는 내부적으로 tokio를 사용하는 DataFusion 기반의 쿼리 엔진입니다. 우리는 일부 스트림을 잠시 멈췄다가 나중에 재개하고 있었습니다. tokio mutex는 특정 워크로드에서만 나타났기 때문에 대부분의 경우 스트림은 문제없이 실행됐습니다. 항상 Pending을 반환하는 PausableFuture 대신, 우리에게는 스스로 정상 종료되는 스트림이 있었습니다.
이제 이 데드락을 디버그해 봅시다.
주어진 코드 조각이 데드락을 일으킬 수 있는지 판단하는 방법 중 하나는 그것이 Coffman 조건을 모두 만족하는지 확인하는 것입니다.
이 분석에 따르면 우리는 데드락을 만나지 않아야 합니다. 실제로 무슨 일이 일어나는지 이해하려면 Rust future와 tokio mutex가 내부적으로 어떻게 작동하는지 살펴봐야 합니다.
Rust의 async에 대한 심층 설명은 tokio의 이 튜토리얼을 참고하세요. 하지만 여기서는 몇 가지 핵심만 알면 됩니다. 이미 async Rust에 익숙하다면 이 섹션은 건너뛰어도 됩니다.
다른 몇몇 언어의 async 프리미티브와 달리, Rust의 future는 lazy합니다. poll 되지 않으면 어떠한 계산이나 동작도 수행하지 않습니다. Future trait의 정의를 보면 poll이라는 메서드 하나만 있으며, 이는 어떤 반환값과 함께 Poll::Ready(_)를 반환하거나 아직 완료되지 않았음을 뜻하는 Poll::Pending을 반환할 수 있습니다. future는 이 poll 메서드가 호출될 때만 진행됩니다. 네트워크 호출이나 mutex가 풀리기를 기다리는 것 같은 async 작업에서, Ready를 반환할 때까지 반복문에서 poll 메서드를 계속 호출하는 바쁜 폴링은 비효율적입니다. 바쁜 폴링을 피하기 위해 Rust에는 waker라는 개념이 있습니다. future가 Poll::Pending을 반환할 때마다, 자신이 기다리는 조건이 충족되면 깨워질 waker를 등록해야 합니다.
이것의 흥미로운 부수 효과는 cancellation이 매우 쉬워진다는 점입니다. future를 poll하지 않고 그냥 drop하면 취소됩니다.
Rust에서는 일반적으로 다음 두 가지 mutex 구현 중 하나를 사용하게 됩니다.
std::sync::Mutex(std mutex): 표준 라이브러리의 블로킹 mutex입니다. 경합이 발생하면 현재 OS 스레드를 블로킹합니다. 동기 코드에 가장 적합하며, async 코드에서는 guard가 .await를 가로질러 유지되지 않는다고 보장할 수 있을 때만 안전합니다.
tokio::sync::Mutex (tokio mutex): async를 인지하는 mutex입니다. 획득은 lock().await로 이루어지므로, 경합이 있는 락은 executor 스레드를 블로킹하는 대신 양보합니다. 핵심 기능은 guard를 .await 지점 너머로도 유지할 수 있다는 것입니다.
우리는 락을 쥔 상태에서 async 함수를 호출해야 했기 때문에 Tokio Mutex를 선택했습니다. 또한 cancellation에도 주의를 기울였습니다. 비행 중인 async 작업을 중간에 drop하면 상태가 이상해질 수 있고, Tokio mutex는 기본적으로 ‘cancellation safe’하지 않기 때문에 이를 고려한 설계가 필요합니다. 그렇게 조심했는데도 여전히 멈춤 현상을 겪었습니다.
“데드락”으로 이어지는 이벤트 순서
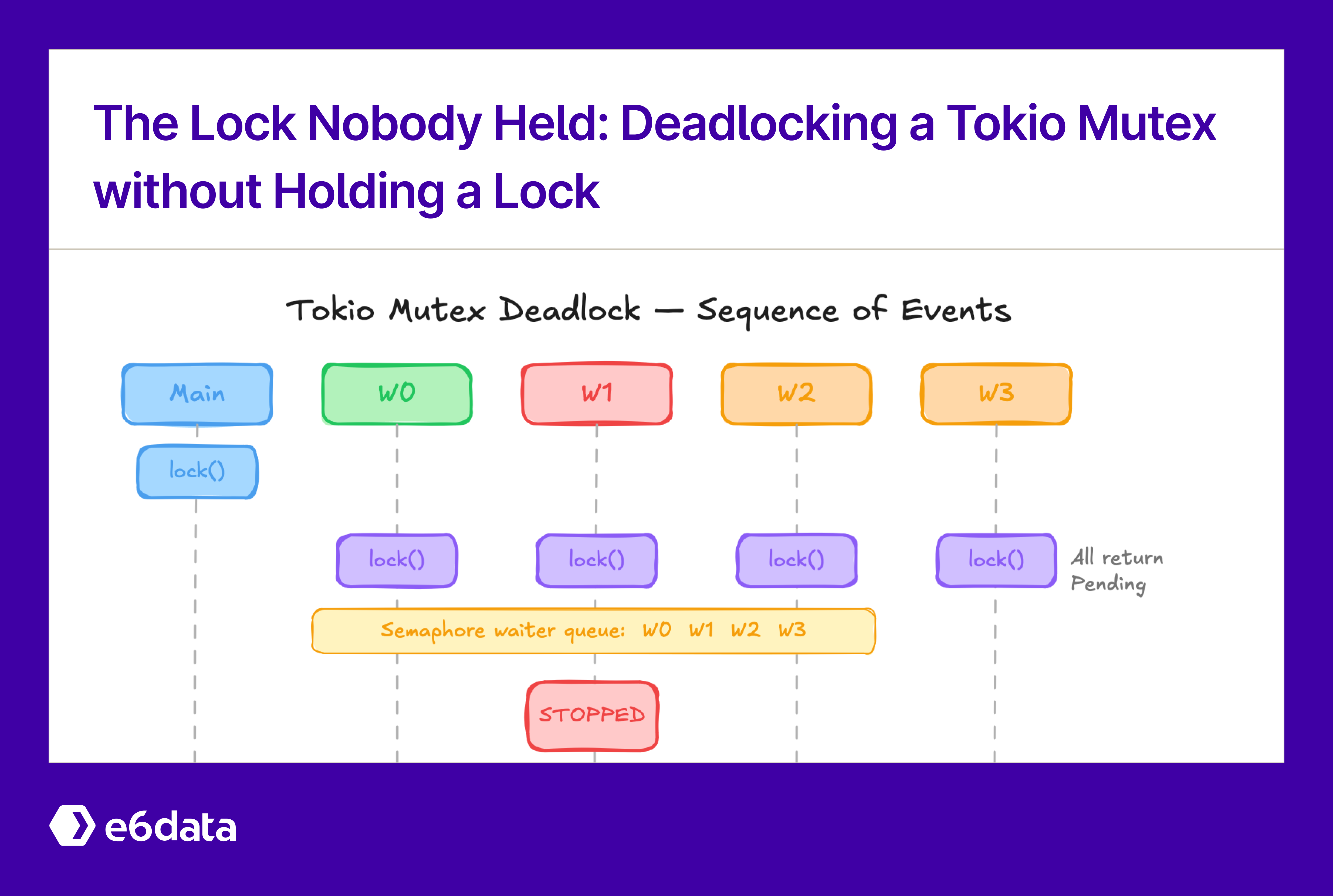
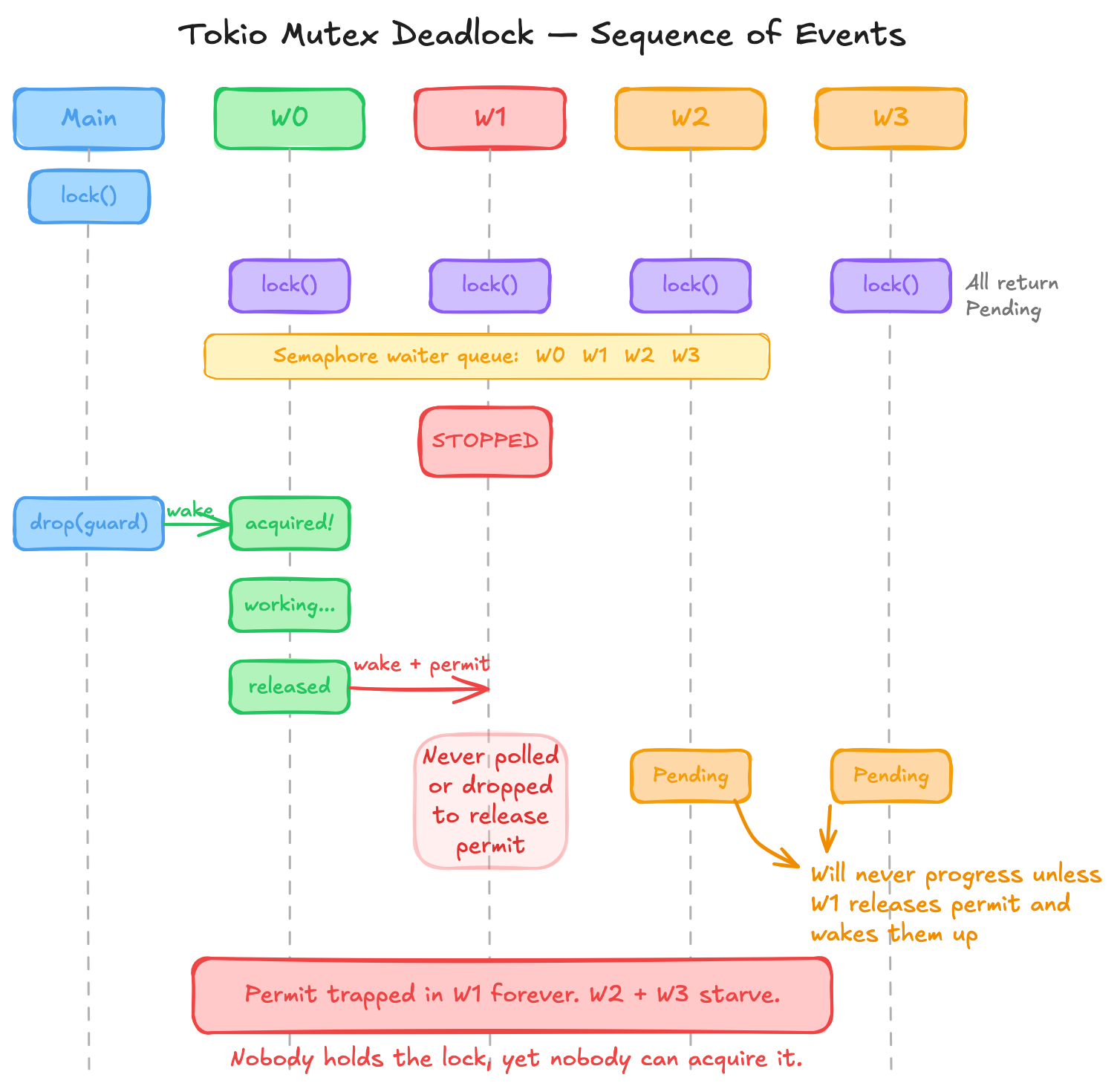
설명은 Tokio 내부 구현에 있지만, 버그는 PausableFuture에 있었습니다. 내부적으로 tokio mutex는 커스텀 semaphore를 사용하고, 이 semaphore는 대기자(waiter) 큐를 저장합니다. mutex의 경우 semaphore에는 permit이 1개 저장됩니다. future가 사용 가능한 permit이 없음을 발견하면, 그 future의 waker와 함께 큐에 추가됩니다. 이후 어떤 future가 permit을 해제하면, 큐를 확인하고 기다리던 future 중 하나를 즉시 깨웁니다.
작업 순서는 다음과 같습니다.
push_front를 통해 연결 리스트의 앞쪽으로 들어갑니다). 각 future의 waker는 semaphore waiter 내부에 등록됩니다.stopped flag는 true로 설정되어 있습니다. 일반적인 future라면 내부 future를 poll하겠지만, PausableFuture는 깨어난 뒤 Poll::Pending을 반환합니다. 그래서 semaphore permit을 이미 받은 내부 future는 결코 poll되지 않습니다.문제는 tokio semaphore가 future가 다시 poll되지 않더라도 첫 번째 waiter에게 permit을 즉시 할당한다는 점입니다. 하지만 그것이 핵심 문제는 아닙니다. 여기에는 계약 위반이 있습니다. PausableFuture는 내부 future의 waker에 의해 깨워졌지만, 그 내부 future를 전혀 poll하지 않았습니다. waker의 계약은 wake() 호출이 해당 waker를 등록한 future에 대해 적어도 한 번의 poll 로 이어져야 한다는 것입니다. Tokio의 semaphore는 이것이 참이라고 가정하지만, PausableFuture는 그 가정을 깨뜨립니다.
이 경우 future를 “일시정지”하는 것은 cancellation과 비슷하지만, 내부 future가 결코 drop되지 않는다는 차이가 있습니다. 따라서 정리 작업을 수행할 기회가 없습니다. 구체적으로 semaphore permit을 포함한 future가 drop되면 permit이 해제됩니다. PausableFuture가 self.stopped가 true가 되었을 때 내부 future를 drop했다면, 문제없이 동작했을 것입니다.
permit 획득을 곧 락 획득으로 볼 수 있습니다. future가 로그를 남길 기회는 없었지만, 기술적으로는 permit을 가지고 있었고, 따라서 락도 가지고 있었습니다. 로그가 오해를 불러일으킨 것입니다.
이 정보를 바탕으로 보면, 이것은 실제로는 데드락이 전혀 아닙니다! 단지 어떤 프로세스 하나가 락을 해제하지 않고 영원히 붙잡고 있는 상황일 뿐입니다.
future가 tokio::sync::Mutex를 건드릴 가능성이 있다면, 임의의 지점에서 일시정지하지 마세요.
대신 다음과 같이 하세요.
future가 끝까지 실행되도록 둡니다.
스트림이라면 다음 아이템/결과를 산출할 때까지 실행한 뒤에만 일시정지하거나 취소합니다.
일시정지하는 대신 future를 drop해서 취소합니다. 물론 이것은 해당 future가 cancel safe하다는 가정하에서입니다.
우리 코드베이스에서는 일시정지되고 있던 것이 스트림이었기 때문에, 일시정지하기 전에 더 많이 poll하도록(즉, 아이템을 하나 내놓거나 끝날 때까지) 수정하여 문제를 해결했습니다.
재현 코드에서는 PausableFuture가 문제입니다. poll하지 않을 future를 그냥 보관해 두면 안 됩니다. 항상 poll하게 하거나(PausableFuture를 없애거나), 일시정지되면 내부 future를 drop해야 합니다. 여기 내부 future를 drop하도록 수정한 재현 코드가 있습니다: 수정된 재현 코드.
std::sync::Mutex를 선호하라핵심 질문은 이것입니다. 정말로 .await를 가로질러 락을 쥐고 있어야 하는가?
std::sync::Mutex에는 mutex 락은 제공되었지만 스레드가 그것을 받지 못하거나 받을 수 없는 중간 상태가 없기 때문에 이 문제를 피할 수 있습니다. 스레드는 블로킹되거나, 아니면 락을 가지고 있습니다. 락을 쥔 채 await하지 않도록 임계 구역을 재구성할 수 있다면, 이런 문제 부류 전체를 피할 수 있습니다. 이는 tokio mutex를 std::sync::Mutex와 tokio::sync::Notify 같은 시그널링 프리미티브의 조합으로 대체함으로써 가능합니다. Notify::notify_waiters는 가장 오래된 waiter 하나만 깨우는 대신, 기다리는 모든 future를 깨웁니다. 이는 사용되지 않은 permit 하나가 나머지를 막아버리는 상황을 방지하는 데 도움이 됩니다.
예를 들어 다음을 비교해 볼 수 있습니다: 이전 (tokio mutex 사용) 과 이후 (std mutex + Notify 사용). 이 예제는 tokio::sync::OnceCell<T>와 비슷하지만 cancellation 시 재시도 대신 에러를 반환하는 OnceCompute<T>라는 동기화 추상화를 구현한 것입니다. 우리는 이것을 내부적으로 공통 테이블 식(CTE)을 구현하는 데 사용합니다.
핵심 정리
tokio mutex는 std mutex의 async 버전을 그대로 대체하는 드롭인 도구가 아닙니다. waiter 큐는 정확성 이야기의 일부이며, poll되지 않는 future를 겉보기에 데드락처럼 보이는 상태로 만들 수 있습니다. tokio::sync::Mutex가 필요하다면 의도적으로 사용하세요. 경합 빈도를 최소화하고, cancellation/일시정지가 안전한 경계에서만 작업을 멈추도록 설계해야 합니다.
래퍼 future나 래퍼 스트림을 작성할 때는 항상 waker 계약을 기억하세요. future가 waker를 등록하고 그 waker가 발화하면, 런타임은 가장 바깥 future를 poll하고, 그 결과 결국 래퍼도 poll됩니다. 그런데 여러분의 future가 그 poll을 삼켜버리고 내부 future로 전달하지 않으면, 똑같은 문제 부류에 부딪히게 됩니다. 따라서 모든 poll을 내부 future로 전달하거나, 아니면 내부 future를 drop해서 정리 작업이 일어나게 해야 합니다. 안전한 중간 지대는 없습니다.
공유하기
 Engineering 대규모 메타데이터: 수천만 개 파일을 가진 Apache Iceberg 테이블 다루기 By Arnav Borkar & October 16, 2025
Engineering 대규모 메타데이터: 수천만 개 파일을 가진 Apache Iceberg 테이블 다루기 By Arnav Borkar & October 16, 2025
 Engineering SQL에서 더 빠른 JSON: Variant 데이터 타입 심층 분석 By Samyak Sarnayak & October 10, 2025
Engineering SQL에서 더 빠른 JSON: Variant 데이터 타입 심층 분석 By Samyak Sarnayak & October 10, 2025
무거운 워크로드를 위해 e6data를 사용해 보세요!
기존 데이터 인프라에 e6data를 어떻게 통합하나요?
우리는 보편적으로 상호운용 가능하며 오픈소스 친화적입니다. 어떤 오브젝트 스토어, 테이블 포맷, 데이터 카탈로그, 거버넌스 도구, BI 도구, 기타 데이터 애플리케이션과도 통합할 수 있습니다.
과금은 어떻게 이루어지나요?
우리는 vCPU 사용량 기반 가격 모델을 사용합니다. 사용한 vCPU 수에 따라 과금되므로 실제로 소비한 컴퓨트 파워에 대해서만 비용을 지불합니다.
e6data는 어떤 파일 포맷을 지원하나요?
Parquet, ORC, JSON, CSV, AVRO 등 모든 유형의 파일 포맷을 지원합니다.
e6data로 어떤 성능 향상을 기대할 수 있나요?
e6data는 시장의 어떤 컴퓨트 엔진과 비교해도, 어떤 동시성 환경에서도 5배에서 10배 더 빠른 쿼리 속도와 50% 이상 낮은 총소유비용을 약속합니다.
e6data에서는 어떤 배포 모델을 제공하나요?
서버리스와 in-VPC 배포 모델을 지원합니다.
e6data는 데이터 거버넌스 규칙을 어떻게 처리하나요?
기존 거버넌스 도구와 통합할 수 있으며, 데이터 거버넌스, 접근 제어, 보안을 위한 자체 제공 기능도 갖추고 있습니다.
![]()
.svg)
.svg)
.svg)
제공 위치
.png)

© 2025 e6data Inc. All rights reserved.
.svg)
우리 웹사이트는 사용자 경험을 향상하고 사이트 트래픽을 측정하기 위해 쿠키를 사용합니다.
.svg)
제품
.svg)
제품
Hybrid Data LakehouseReal-time Streaming IngestLakehouse Query EngineLakehouse Compute EngineData Lakehouse Engine
제품 출시
.svg)
e6data의 Hybrid Data Lakehouse: 10배 더 빠른 쿼리, 거의 0에 가까운 Egress, 1초 미만 지연 시간
호환성
호환성
SnowflakeDatabricksAmazon SageMakerMicrosoft Fabric
비용 계산기
.svg)
다른 엔진과 비교한 e6data의 월간 컴퓨트 비용 확인하기
고객사
고객사
사례 연구
.png)
e6data는 세계 유수 기업들을 위한 데이터 엔지니어링을 한 단계 끌어올립니다
개발자
개발자
블로그 최신 글
Snowflake에서 현대적인 데이터 파이프라인 구축하기: Snowpipe에서 Managed Iceb...
목차:
.svg)
전체 팟캐스트 듣기
e6data 팀이 읽고 있는 대규모 데이터 엔지니어링 관련 주간 이야기 3개를 받아보세요.
감사합니다! 제출이 접수되었습니다!
앗! 양식 제출 중 문제가 발생했습니다.
이 글 공유하기
.svg)
.svg)
2026년 3월 23일
/
Samyak Sarnayak
엔지니어링
데드락은 보통 매우 특정한 시나리오에서 발생합니다. 누군가가 하나의 락을 잡고, 다른 누군가가 쥐고 있는 또 다른 락을 얻으려 할 때입니다. 그런데 이 시나리오에는 락이 하나뿐이었습니다. Tokio 기반 Rust 프로그램에서 우리는 공유 상태를 단 하나의 tokio mutex로 보호했고, 일반적인 규칙이 그대로 적용될 것이라고 기대했습니다. 특정 워크로드에서 네 개의 future가 시작되고, 세 개는 완료되지만, 네 번째는 영원히 멈춰 있었습니다. 심지어 로그에는 mutex가 이미 해제되었다고 찍혀 있었는데도 말입니다. 이처럼 “락은 풀렸는데 여전히 멈춰 있는” 동작이야말로 이 Tokio mutex 데드락을 직관적으로 이해하기 어렵게 만드는 지점입니다.
처음 보면 이것은 전형적인 async 실수처럼 보입니다. std mutex를 .await를 가로질러 쥐고 있는 경우 말이죠. 하지만 우리는 그렇게 하지 않았습니다. 바로 그런 문제를 피하기 위해 tokio::sync::Mutex를 사용하고 있었습니다. 결국 설명은 tokio 내부 구현 안에 있었고, 이는 로깅만으로는 드러나지 않는 부분이었습니다.
재현 코드는 비교적 작습니다. 하나의 tokio mutex를 4개의 워커가 동시에 사용합니다. 특별한 PausableFuture가 있는데, 신호를 받으면 내부 future에 대한 polling을 멈춥니다. 또 하나 주목할 점은 tokio의 current_thread flavor를 사용하고 있다는 점인데, 이는 단일 스레드입니다. 유사한 동작은 워커 스레드 4개를 가진 multi_thread 런타임에서도 나타납니다.
//! Reproducer: tokio::sync::Mutex deadlock with a single, unlocked mutex.
//!
//! Cargo.toml:
//! [dependencies]
//! tokio = { version = "1", features = ["full"] }
use std::future::Future;
use std::pin::Pin;
use std::sync::Arc;
use std::sync::atomic::{AtomicBool, Ordering};
use std::task::{Context, Poll};
use std::time::Duration;
use tokio::sync::Mutex;
/// Future wrapper that stops forwarding polls when `stopped` is set.
struct PausableFuture<F> {
inner: Pin<Box<F>>,
stopped: Arc<AtomicBool>,
}
impl<F: Future> Future for PausableFuture<F> {
type Output = F::Output;
fn poll(mut self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<Self::Output> {
if self.stopped.load(Ordering::Acquire) {
return Poll::Pending;
}
self.inner.as_mut().poll(cx)
}
}
#[tokio::main(flavor = "current_thread")]
async fn main() {
let mutex = Arc::new(Mutex::new(()));
// Hold the lock so workers queue up.
let guard = mutex.lock().await;
println!("main acquired the lock");
// Spawn 4 workers, each wrapped in a PausableFuture.
// Each worker gets its own flag - whether to stop or not.
let stop_flags: Vec<_> = (0..4).map(|_| Arc::new(AtomicBool::new(false))).collect();
let mut handles = Vec::new();
for id in 0..4u32 {
let mutex = Arc::clone(&mutex);
let stopped = Arc::clone(&stop_flags[id as usize]);
handles.push(tokio::spawn(PausableFuture {
stopped,
inner: Box::pin(async move {
let guard = mutex.lock().await;
println!("worker {id}: acquired lock");
tokio::time::sleep(Duration::from_millis(100)).await;
drop(guard);
println!("worker {id}: released lock");
}),
}));
}
// Yield so all workers poll lock() and start waiting.
tokio::task::yield_now().await;
// Stop polling worker 1.
stop_flags[1].store(true, Ordering::Release);
// Release the lock. The mutex is now UNLOCKED.
drop(guard);
println!("main released the lock");
for (id, h) in handles.into_iter().enumerate() {
match tokio::time::timeout(std::time::Duration::from_secs(2), h).await {
Ok(Ok(())) => println!("worker {id}: done"),
Ok(Err(e)) => println!("worker {id}: error: {e}"),
Err(_) => println!("worker {id}: DEADLOCKED"),
}
}
}실행하면 다음과 같은 로그가 나옵니다.
main acquired the lock
main released the lock
worker 0: acquired lock
worker 0: released lock
worker 0: done
worker 1: DEADLOCKED
worker 2: DEADLOCKED
worker 3: DEADLOCKEDmain과 worker 0이 모두 락을 해제한 것을 볼 수 있습니다. 아무도 락을 쥐고 있지 않은데도, 다른 스레드들은 데드락에 빠집니다!
실제 프로덕션 코드에서 이 현상을 보았을 때는 이렇게 단순하지 않았습니다. 해당 코드는 내부적으로 tokio를 사용하는 DataFusion 기반의 쿼리 엔진입니다. 우리는 일부 스트림을 잠시 멈췄다가 나중에 재개하고 있었습니다. tokio mutex는 특정 워크로드에서만 나타났기 때문에 대부분의 경우 스트림은 문제없이 실행됐습니다. 항상 Pending을 반환하는 PausableFuture 대신, 우리에게는 스스로 정상 종료되는 스트림이 있었습니다.
이제 이 데드락을 디버그해 봅시다.
주어진 코드 조각이 데드락을 일으킬 수 있는지 판단하는 방법 중 하나는 그것이 Coffman 조건을 모두 만족하는지 확인하는 것입니다.
이 분석에 따르면 우리는 데드락을 만나지 않아야 합니다. 실제로 무슨 일이 일어나는지 이해하려면 Rust future와 tokio mutex가 내부적으로 어떻게 작동하는지 살펴봐야 합니다.
Rust의 async에 대한 심층 설명은 tokio의 이 튜토리얼을 참고하세요. 하지만 여기서는 몇 가지 핵심만 알면 됩니다. 이미 async Rust에 익숙하다면 이 섹션은 건너뛰어도 됩니다.
다른 몇몇 언어의 async 프리미티브와 달리, Rust의 future는 lazy합니다. poll 되지 않으면 어떠한 계산이나 동작도 수행하지 않습니다. Future trait의 정의를 보면 poll이라는 메서드 하나만 있으며, 이는 어떤 반환값과 함께 Poll::Ready(_)를 반환하거나 아직 완료되지 않았음을 뜻하는 Poll::Pending을 반환할 수 있습니다. future는 이 poll 메서드가 호출될 때만 진행됩니다. 네트워크 호출이나 mutex가 풀리기를 기다리는 것 같은 async 작업에서, Ready를 반환할 때까지 반복문에서 poll 메서드를 계속 호출하는 바쁜 폴링은 비효율적입니다. 바쁜 폴링을 피하기 위해 Rust에는 waker라는 개념이 있습니다. future가 Poll::Pending을 반환할 때마다, 자신이 기다리는 조건이 충족되면 깨워질 waker를 등록해야 합니다.
이것의 흥미로운 부수 효과는 cancellation이 매우 쉬워진다는 점입니다. future를 poll하지 않고 그냥 drop하면 취소됩니다.
Rust에서는 일반적으로 다음 두 가지 mutex 구현 중 하나를 사용하게 됩니다.
std::sync::Mutex(std mutex): 표준 라이브러리의 블로킹 mutex입니다. 경합이 발생하면 현재 OS 스레드를 블로킹합니다. 동기 코드에 가장 적합하며, async 코드에서는 guard가 .await를 가로질러 유지되지 않는다고 보장할 수 있을 때만 안전합니다.
tokio::sync::Mutex (tokio mutex): async를 인지하는 mutex입니다. 획득은 lock().await로 이루어지므로, 경합이 있는 락은 executor 스레드를 블로킹하는 대신 양보합니다. 핵심 기능은 guard를 .await 지점 너머로도 유지할 수 있다는 것입니다.
우리는 락을 쥔 상태에서 async 함수를 호출해야 했기 때문에 Tokio Mutex를 선택했습니다. 또한 cancellation에도 주의를 기울였습니다. 비행 중인 async 작업을 중간에 drop하면 상태가 이상해질 수 있고, Tokio mutex는 기본적으로 ‘cancellation safe’하지 않기 때문에 이를 고려한 설계가 필요합니다. 그렇게 조심했는데도 여전히 멈춤 현상을 겪었습니다.
“데드락”으로 이어지는 이벤트 순서
설명은 Tokio 내부 구현에 있지만, 버그는 PausableFuture에 있었습니다. 내부적으로 tokio mutex는 커스텀 semaphore를 사용하고, 이 semaphore는 대기자(waiter) 큐를 저장합니다. mutex의 경우 semaphore에는 permit이 1개 저장됩니다. future가 사용 가능한 permit이 없음을 발견하면, 그 future의 waker와 함께 큐에 추가됩니다. 이후 어떤 future가 permit을 해제하면, 큐를 확인하고 기다리던 future 중 하나를 즉시 깨웁니다.
작업 순서는 다음과 같습니다.
push_front를 통해 연결 리스트의 앞쪽으로 들어갑니다). 각 future의 waker는 semaphore waiter 내부에 등록됩니다.stopped flag는 true로 설정되어 있습니다. 일반적인 future라면 내부 future를 poll하겠지만, PausableFuture는 깨어난 뒤 Poll::Pending을 반환합니다. 그래서 semaphore permit을 이미 받은 내부 future는 결코 poll되지 않습니다.문제는 tokio semaphore가 future가 다시 poll되지 않더라도 첫 번째 waiter에게 permit을 즉시 할당한다는 점입니다. 하지만 그것이 핵심 문제는 아닙니다. 여기에는 계약 위반이 있습니다. PausableFuture는 내부 future의 waker에 의해 깨워졌지만, 그 내부 future를 전혀 poll하지 않았습니다. waker의 계약은 wake() 호출이 해당 waker를 등록한 future에 대해 적어도 한 번의 poll 로 이어져야 한다는 것입니다. Tokio의 semaphore는 이것이 참이라고 가정하지만, PausableFuture는 그 가정을 깨뜨립니다.
이 경우 future를 “일시정지”하는 것은 cancellation과 비슷하지만, 내부 future가 결코 drop되지 않는다는 차이가 있습니다. 따라서 정리 작업을 수행할 기회가 없습니다. 구체적으로 semaphore permit을 포함한 future가 drop되면 permit이 해제됩니다. PausableFuture가 self.stopped가 true가 되었을 때 내부 future를 drop했다면, 문제없이 동작했을 것입니다.
permit 획득을 곧 락 획득으로 볼 수 있습니다. future가 로그를 남길 기회는 없었지만, 기술적으로는 permit을 가지고 있었고, 따라서 락도 가지고 있었습니다. 로그가 오해를 불러일으킨 것입니다.
이 정보를 바탕으로 보면, 이것은 실제로는 데드락이 전혀 아닙니다! 단지 어떤 프로세스 하나가 락을 해제하지 않고 영원히 붙잡고 있는 상황일 뿐입니다.
future가 tokio::sync::Mutex를 건드릴 가능성이 있다면, 임의의 지점에서 일시정지하지 마세요.
대신 다음과 같이 하세요.
future가 끝까지 실행되도록 둡니다.
스트림이라면 다음 아이템/결과를 산출할 때까지 실행한 뒤에만 일시정지하거나 취소합니다.
일시정지하는 대신 future를 drop해서 취소합니다. 물론 이것은 해당 future가 cancel safe하다는 가정하에서입니다.
우리 코드베이스에서는 일시정지되고 있던 것이 스트림이었기 때문에, 일시정지하기 전에 더 많이 poll하도록(즉, 아이템을 하나 내놓거나 끝날 때까지) 수정하여 문제를 해결했습니다.
재현 코드에서는 PausableFuture가 문제입니다. poll하지 않을 future를 그냥 보관해 두면 안 됩니다. 항상 poll하게 하거나(PausableFuture를 없애거나), 일시정지되면 내부 future를 drop해야 합니다. 여기 내부 future를 drop하도록 수정한 재현 코드가 있습니다: 수정된 재현 코드.
std::sync::Mutex를 선호하라핵심 질문은 이것입니다. 정말로 .await를 가로질러 락을 쥐고 있어야 하는가?
std::sync::Mutex에는 mutex 락은 제공되었지만 스레드가 그것을 받지 못하거나 받을 수 없는 중간 상태가 없기 때문에 이 문제를 피할 수 있습니다. 스레드는 블로킹되거나, 아니면 락을 가지고 있습니다. 락을 쥔 채 await하지 않도록 임계 구역을 재구성할 수 있다면, 이런 문제 부류 전체를 피할 수 있습니다. 이는 tokio mutex를 std::sync::Mutex와 tokio::sync::Notify 같은 시그널링 프리미티브의 조합으로 대체함으로써 가능합니다. Notify::notify_waiters는 가장 오래된 waiter 하나만 깨우는 대신, 기다리는 모든 future를 깨웁니다. 이는 사용되지 않은 permit 하나가 나머지를 막아버리는 상황을 방지하는 데 도움이 됩니다.
예를 들어 다음을 비교해 볼 수 있습니다: 이전 (tokio mutex 사용) 과 이후 (std mutex + Notify 사용). 이 예제는 tokio::sync::OnceCell<T>와 비슷하지만 cancellation 시 재시도 대신 에러를 반환하는 OnceCompute<T>라는 동기화 추상화를 구현한 것입니다. 우리는 이것을 내부적으로 공통 테이블 식(CTE)을 구현하는 데 사용합니다.
핵심 정리
tokio mutex는 std mutex의 async 버전을 그대로 대체하는 드롭인 도구가 아닙니다. waiter 큐는 정확성 이야기의 일부이며, poll되지 않는 future를 겉보기에 데드락처럼 보이는 상태로 만들 수 있습니다. tokio::sync::Mutex가 필요하다면 의도적으로 사용하세요. 경합 빈도를 최소화하고, cancellation/일시정지가 안전한 경계에서만 작업을 멈추도록 설계해야 합니다.
래퍼 future나 래퍼 스트림을 작성할 때는 항상 waker 계약을 기억하세요. future가 waker를 등록하고 그 waker가 발화하면, 런타임은 가장 바깥 future를 poll하고, 그 결과 결국 래퍼도 poll됩니다. 그런데 여러분의 future가 그 poll을 삼켜버리고 내부 future로 전달하지 않으면, 똑같은 문제 부류에 부딪히게 됩니다. 따라서 모든 poll을 내부 future로 전달하거나, 아니면 내부 future를 drop해서 정리 작업이 일어나게 해야 합니다. 안전한 중간 지대는 없습니다.
전체 팟캐스트 듣기
이 글 공유하기
e6data는 쿼리 속도를 늦추지 않으면서 Snowflake 컴퓨트 비용을 어떻게 줄이나요?
e6data는 업계 유일의 atomic architecture로 구동됩니다. 단계적으로 점프하며 확장하는 대신(L x 1 -> L x 2), e6data는 1 vCPU 단위처럼 아주 작게도 원자적으로 확장합니다. 프로덕션에서 부하가 크게 변하는 환경에서는 이것이 60%를 넘는 TCO 절감으로 이어집니다.
Snowflake에서 벗어나야 하나요?
아니요. 우리는 클라우드, 온프레미스, 카탈로그, 거버넌스, 테이블 포맷, BI 도구 등 기존 데이터 아키텍처에 그대로 들어맞습니다.
e6data는 Snowflake 위의 Iceberg를 더 빠르게 만들 수 있나요?
네. 워크로드에 따라, 네이티브 및 고급 Iceberg 지원을 통해 최대 10배까지 더 빠른 속도를 볼 수 있습니다.
Snowflake는 Iceberg를 지원합니다. 그런데 데이터를 실시간으로 어떻게 거기에 넣나요?
우리의 실시간 스트리밍 적재는 Kafka 또는 SDK 데이터를 Flink 없이 곧바로 Iceberg로 스트리밍합니다. 60초 이내에 적재되고 각 스냅샷이 자동 등록되어 즉시 쿼리할 수 있습니다.
Snowflake와 함께 e6data를 배포하는 데 얼마나 걸리나요?
양식을 작성하고 인스턴스를 시작하면 됩니다. Snowflake에서 데이터를 복사하거나 마이그레이션하지 않고도 어떤 클라우드, 리전, 배포 모델에도 배포할 수 있습니다.
락을 들고 있지 않은데도 Tokio Mutex 데드락이 발생하는 원인은 무엇인가요?
custom wrapper(PausableFuture 같은 것) 때문에 tokio::sync::Mutex를 사용하는 future들이 mutex가 풀린 뒤에도 poll되지 않게 되면 멈춤이 발생할 수 있습니다. mutex 자체가 잡혀 있는 것은 아니지만, future들은 다시 poll되기를 무기한 기다리게 됩니다.
Rust future는 이 데드락에 어떻게 기여하나요?
Rust future는 lazy하며 진행하려면 polling이 필요합니다. future가 잘못 일시정지되거나 부적절하게 drop되면, executor가 그 future를 다시 poll하지 않기 때문에 다른 태스크들이 리소스를 획득하지 못할 수 있습니다.
이 데드락은 단일 스레드와 다중 스레드 Tokio 런타임 모두에서 발생하나요?
네. 여러 future가 같은 mutex를 두고 경쟁하고 그중 일부가 더 이상 poll되지 않을 때, current_thread(단일 스레드)와 multi_thread Tokio 런타임 모두에서 이 문제가 관찰되었습니다.
왜 Coffman 데드락 분석은 이 문제를 예측하지 못하나요?
전통적인 Coffman 조건은 리소스를 점유하고 있는 상황을 가정합니다. 하지만 이 Tokio 시나리오에서는 데드락이 발생할 때 어떤 스레드도 mutex를 들고 있지 않은 것처럼 보입니다. future가 polling을 멈추는 현상은 표준 데드락 분석에 포착되지 않기 때문에 이해하기 어렵습니다.
std mutex와 tokio mutex의 차이는 무엇인가요?
std::sync::Mutex는 블로킹 방식이며 .await 지점을 가로질러 들고 있으면 안 됩니다. tokio::sync::Mutex는 async를 인지하며, 경합 시 제어를 양보하므로 .await를 가로질러 안전하게 유지할 수 있고 비동기 Rust 코드에서 사용됩니다.
Rust future의 cancellation은 mutex 동작에 어떤 영향을 주나요?
future를 drop하면 즉시 취소됩니다. mutex 락을 들고 있는 future가 drop되면 mutex도 unlock됩니다. 이로 인해 데이터가 일관되지 않은 상태로 남을 수 있습니다.
이런 종류의 데드락을 피하려면 어떤 실질적인 조치를 취해야 하나요?
mutex를 기다리는 future를 일시정지하거나 drop하지 마세요. 모든 future가 계속 polling되도록 하거나, future들이 진행을 위해 다른 future의 재개에 의존하지 않도록 async 흐름을 재설계하세요.
왜 어떤 워커는 정상 완료되고 다른 워커는 데드락에 빠지나요?
mutex를 계속 polling하는 워커는 정상적으로 진행되지만, PausableFuture에 의해 멈춘 워커는 더 이상 poll되지 않습니다. 이 선택적 일시정지가 mutex가 비어 있음에도 일부 워커를 무기한 멈추게 만듭니다.
왜 std Mutex 대신 tokio Mutex를 사용하나요?
Tokio mutex는 async를 인지하므로 경합 시 스레드를 블로킹하는 대신 태스크가 양보할 수 있습니다. .await 지점을 가로질러도 안전하게 유지할 수 있다는 점이 std mutex와 다릅니다.
Tokio에서 이런 멈춤 현상은 어떻게 디버그하나요?
디버깅하려면 future의 polling, mutex 내부 구현, executor 동작을 이해해야 합니다. 로깅만으로는 멈춰 있는 태스크를 드러내지 못할 수 있습니다. 어떤 future가 poll되고 어떤 future가 Pending 상태로 남아 있는지 관찰하는 것이 핵심입니다.
모두 보기
엔지니어링
이것은 div 블록 안의 텍스트입니다.
2025년 10월 16일
/
Arnav Borkar
.svg)
대규모 메타데이터: 수천만 개 파일을 가진 Apache Iceberg 테이블 다루기
Arnav Borkar
2025년 10월 16일
모두 보기
엔지니어링
이것은 div 블록 안의 텍스트입니다.
2025년 10월 10일
/
Samyak Sarnayak
SQL에서 더 빠른 JSON: Variant 데이터 타입 심층 분석
Samyak Sarnayak
2025년 10월 10일
모두 보기
엔지니어링
이것은 div 블록 안의 텍스트입니다.
2025년 9월 19일
/
Yash Bhisikar
German Strings: 더 빠른 분석을 위한 16바이트의 비밀
Yash Bhisikar
2025년 9월 19일
![]()
제공 위치
© 2025 e6data Inc. All rights reserved.
 Engineering German Strings: 더 빠른 분석을 위한 16바이트의 비밀 By Yash Bhisikar & Samyak Sarnayak September 19, 2025
Engineering German Strings: 더 빠른 분석을 위한 16바이트의 비밀 By Yash Bhisikar & Samyak Sarnayak September 19, 2025.svg) 뒤로
뒤로.svg)