std::Mutex와 parking_lot::Mutex의 내부 구현을 파고들고, 벤치마크로 핵심 차이를 비교해 언제 무엇을 써야 하는지 결정 가이드를 제공합니다.
얼마 전 우리 팀은 Rust 프로젝트를 진행하면서 곳곳에 std::sync::Mutex를 쓰고 있었습니다. 팀원 한 명이 대신 parking_lot::Mutex로 바꾸자고 제안했죠. 성능이 더 좋고, 메모리 사용이 더 작으며, 경합 시 동작이 더 예측 가능하다고 들었다는 겁니다.
저는 이 주장을 어떻게 평가해야 할지 전혀 감이 없었습니다. 검색을 해보니 대체로 parking_lot 쪽을 선호하는 결과가 많이 보였죠. 그런데 뭔가 석연치 않았습니다. 왜일까요? 제 머릿속에는 “std가 황금 표준이어야 한다”는 믿음이 있었거든요. 표준 라이브러리 팀은 뭘 하는지 잘 알고 있을 텐데요? 그리고 만약 parking_lot의 뮤텍스가 정말 성능에서 승자라면, 사람들이 말하지 않는 트레이드오프가 분명 있을 거라고 생각했습니다.
그 의문이 계속 맴돌았습니다. 믿음만으로는 도저히 넘어갈 수가 없었죠. 그래서 토끼굴로 뛰어들었습니다. 두 구현을 다 읽고, 벤치마크를 직접 작성했고, 그 결과를 가져왔습니다. 이 글에서 저는 다음을 다룹니다.
그 전에, 뮤텍스에 대한 기초를 다지고 갑시다(이미 익숙하다면 가볍게 훑어보세요).
뮤텍스가 해결하는 고전적인 문제 예시는 동시에 출금과 입금을 수행하는 상황입니다. 계좌에 $100이 있다고 가정해 봅시다. 스레드 A가 $80 출금을 시도하고, 스레드 B가 $50 입금을 시도하면, 적절한 동기화 없이 두 스레드는 동시에 잔액을 $100으로 읽어들인 뒤 각자 결과를 독립적으로 써버릴 수 있습니다:
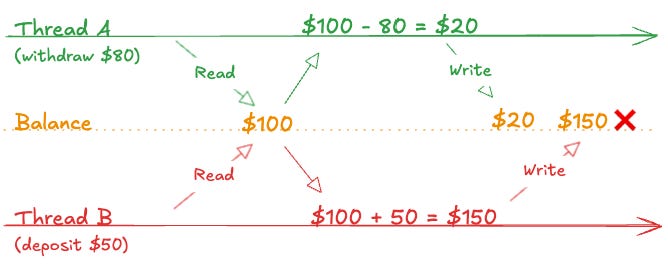
뮤텍스는 한 스레드가 다른 스레드의 업데이트가 끝날 때까지 기다리게 해서 이 문제를 깔끔하게 해결합니다:
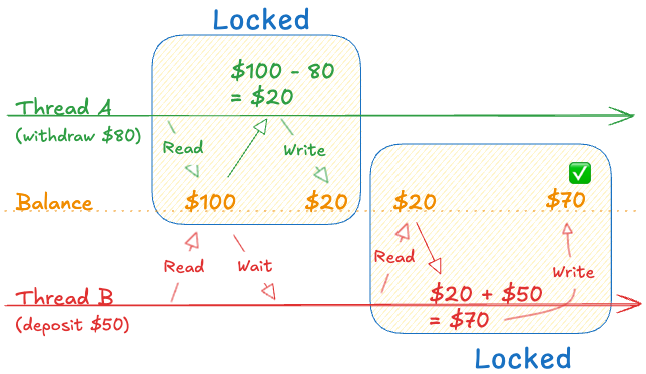
잔액을 읽고 쓰는 연산이 우리가 보호해야 할 부분입니다. 이를 **임계 구역(critical sections)**이라고 부르죠. 공유 데이터를 접근하는 모든 코드는 뮤텍스로 보호되는 임계 구역 안에 있어야 합니다.
간단하죠? 이제 뮤텍스 사용법을 보겠습니다(너무 기본이면 건너뛰세요).
Rust 이외의 언어에서는 보통 데이터와 별개로 뮤텍스를 선언하고, 임계 구역에 들어가기 전 수동으로 잠그고 끝난 뒤 해제합니다. C++에서는 대략 이렇게 보입니다:
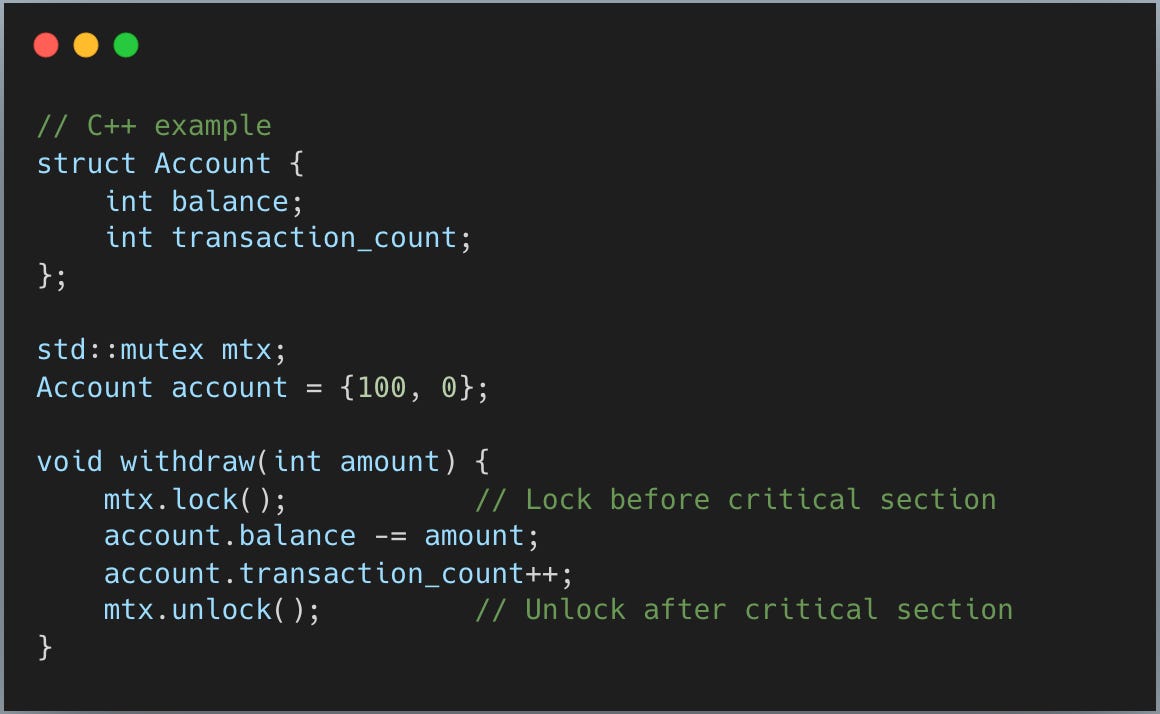
문제는? 컴파일러가 account를 잠그지 않고 접근하는 실수를 막아주지 못한다는 겁니다.
Rust는 완전히 다른 접근을 합니다. 뮤텍스가 데이터를 감싸고 소유하죠:
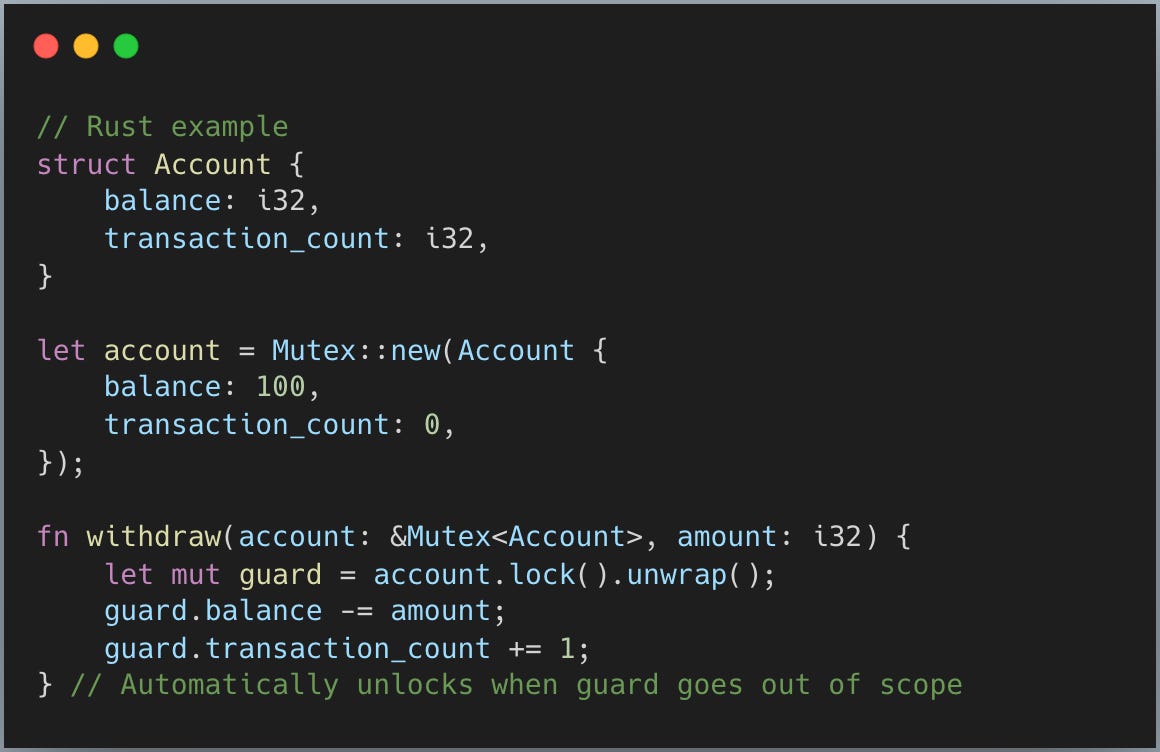
세 가지를 특히 주목하세요:
이제 기본은 충분합니다. 본격적으로 재미있는 부분으로 가보죠. Rust std의 뮤텍스 구현부터 시작합니다.
std::Mutex를 빠르게 들여다보면 이런 모양입니다
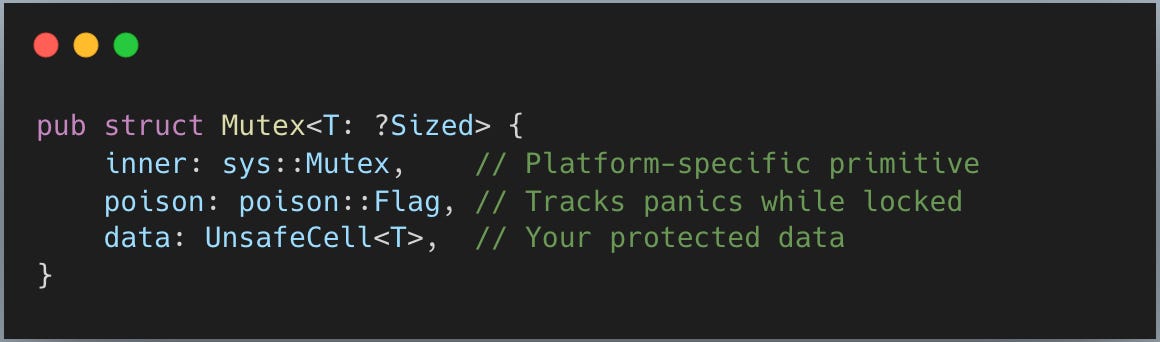
inner가 흥미로운 부분입니다. 코드가 꽤 길어서 단순화한 버전만 보겠습니다
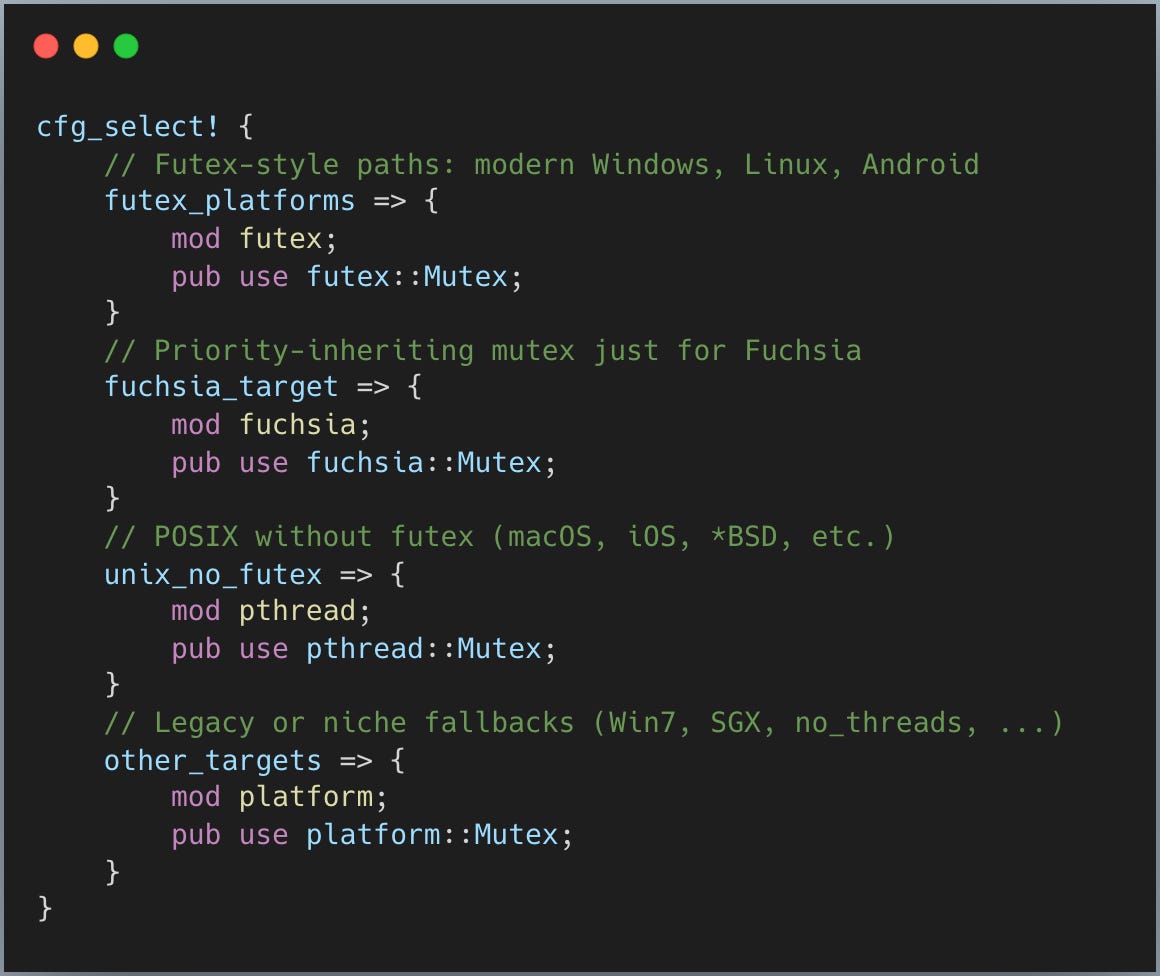
핵심 아이디어는 OS(그리고 OS 버전)에 따라 Rust가 다른 Mutex 구현을 사용한다는 점입니다. 하지만 크게 두 그룹으로 나눌 수 있습니다: Futex와 그 외 플랫폼 원시체(primitive).
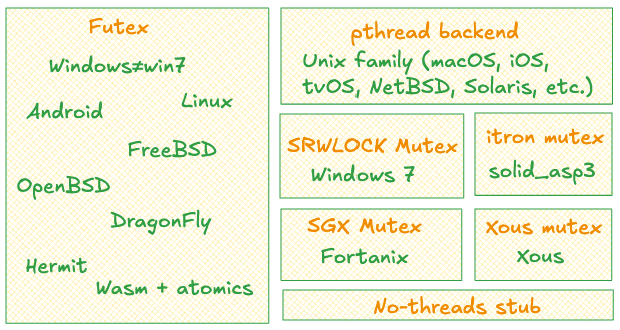
(와… 정말 많은 구현이 있네요. 이 모든 플랫폼별 코드를 작성하고 유지하는 건 정말 고된 일일 겁니다. 담당자분들께 큰 존경을 보냅니다.)
Futex가 가장 널리 쓰이고, 뮤텍스의 전형적인 구현이므로 안을 들여다보겠습니다.
futex의 중심에는 원자적 u32가 있습니다(단순화):

원자 타입에는 CPU가 원자적으로 실행하는 “Compare And Swap(CAS)”이라는 강력한 연산이 있습니다. 먼저 현재 값을 비교하고, 기대한 값과 같으면 새 값으로 설정합니다.
즉, 0을 Unlocked, 1을 Locked 상태로 삼으면, 스레드는 상태가 0인지 비교하고 1로 바꾸는 시도를 반복함으로써 간단한 뮤텍스를 만들 수 있습니다. 현재 상태가 1이면 성공할 때까지 계속 시도합니다.
따라서, 뮤텍스를 단순화하면 다음과 같습니다:
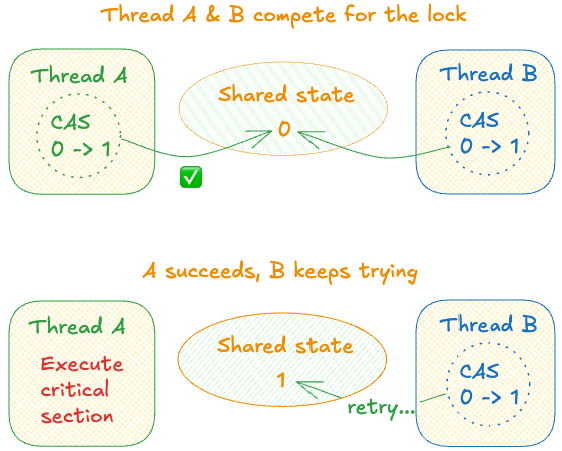
하지만 이런 의문이 생길 겁니다. 첫 번째 스레드가 오랫동안 락을 쥔다면, 두 번째 스레드는 계속 시도해야 하나요(무한 루프처럼)? 수백, 수천 개라면요? CPU가 타버릴지도 모릅니다.
물론 이에 대한 해법이 있습니다. 실제 구현에서 Rust의 futex는 3가지 상태를 가집니다:
Contended 상태에 주목하세요. 스레드는 최대한 락을 얻으려 시도합니다. 하지만 실패하면 락을 경합 중으로 표시하고 수면에 들어가며, 뮤텍스가 해제되면 프로세스가 깨워주길 기다립니다.
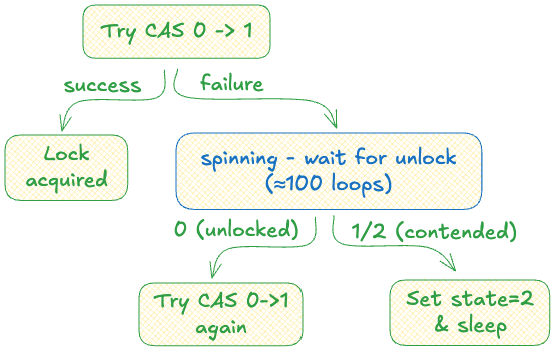
주의: 다이어그램의 스핀 부분 보이시나요? 스레드가 잠들기 전 약 100번 정도는 락 상태를 계속 확인합니다. 그 사이 언락되면 즉시 CAS를 시도하죠. 락이 금방 풀릴 때는 이렇게 해서 비싼 시스템 콜을 피합니다.
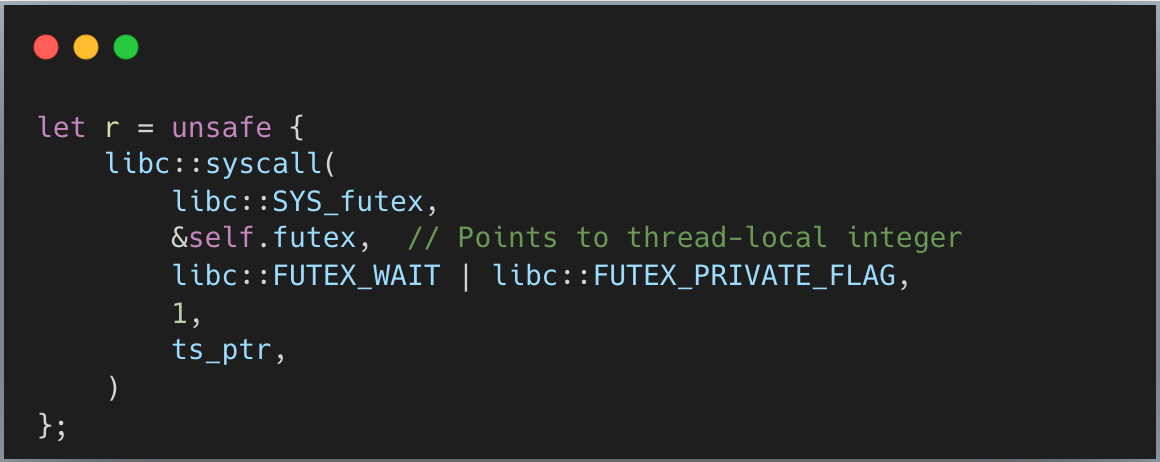
스레드가 잠들면 무슨 일이 벌어질까요? 커널이 이 잠든 스레드를 큐에 넣어 관리해 줍니다. 리눅스와 안드로이드에서 스레드를 수면 상태로 두는 시스템 콜(보통 “스레드를 주차(park)한다”고 합니다)을 보세요:
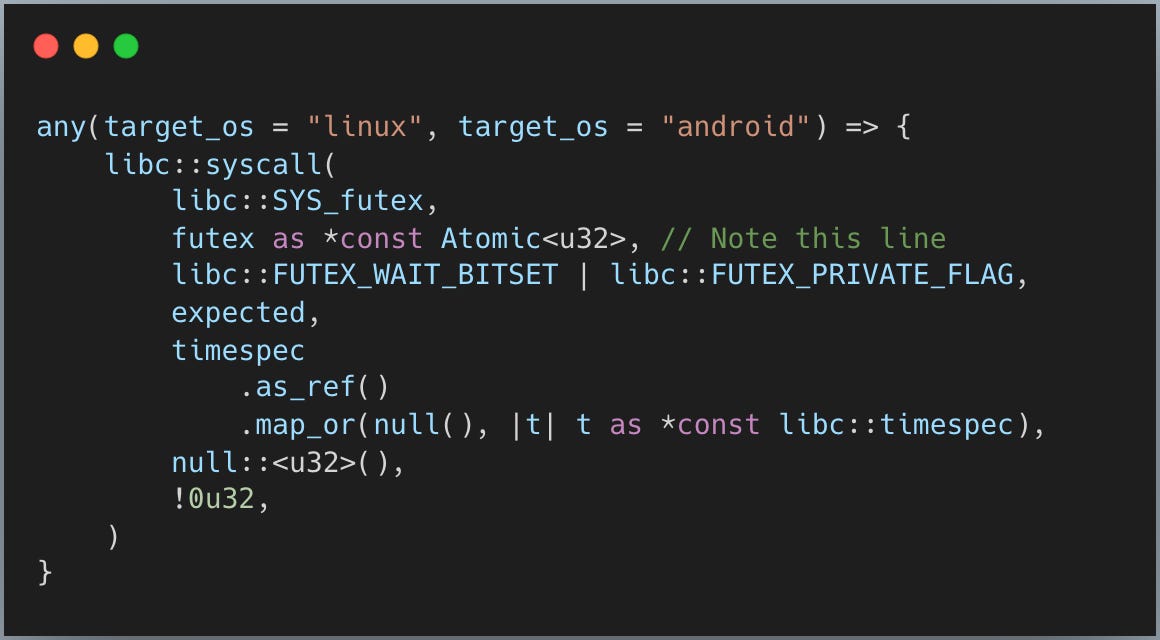
핵심은 **futex as *const Atomic<u32>**입니다. 커널에 메모리 주소를 주면 커널은 그 주소를 기준으로 스레드를 큐잉합니다. 나중에 스레드를 깨우고 싶으면 같은 주소를 주고, 커널은 그 큐에서 하나를 꺼내 깨웁니다.
스레드가 일을 마치면 상태를 unlocked로 바꿉니다. 상태가 contended였다면 시스템 콜로 대기 중인 스레드 하나를 깨웁니다. 큐가 빌 때까지 이 과정을 반복합니다.
std의 뮤텍스 마지막 퍼즐 조각은 포이즈닝(poisoning)입니다. 대부분의 다른 언어에는 없는 Rust만의 특징이죠.
Rust 표준 뮤텍스에는 포이즈닝이라는 독특한 기능이 있습니다. 스레드가 락을 쥔 채로 패닉하면 뮤텍스는 “독(poisoned)에 오염”됩니다. 이후 잠금 시도는 **Err(PoisonError)**를 반환하지만, 에러 안에 가드를 함께 제공합니다:
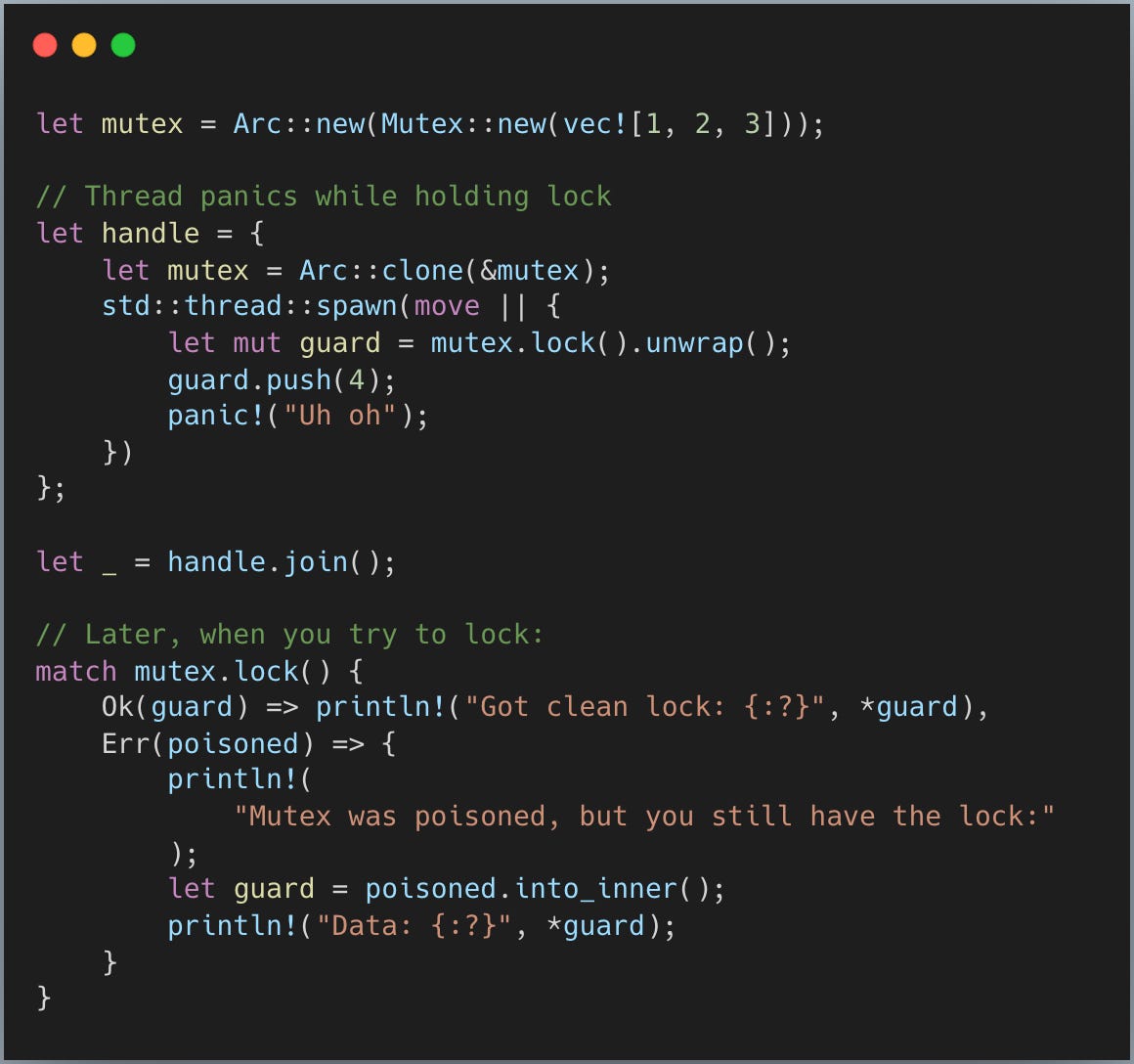
포이즈닝은 어떻게 동작할까요? 개념적으로는 MutexGuard::drop() 경로에서 벌어집니다(이해를 위해 단순화):
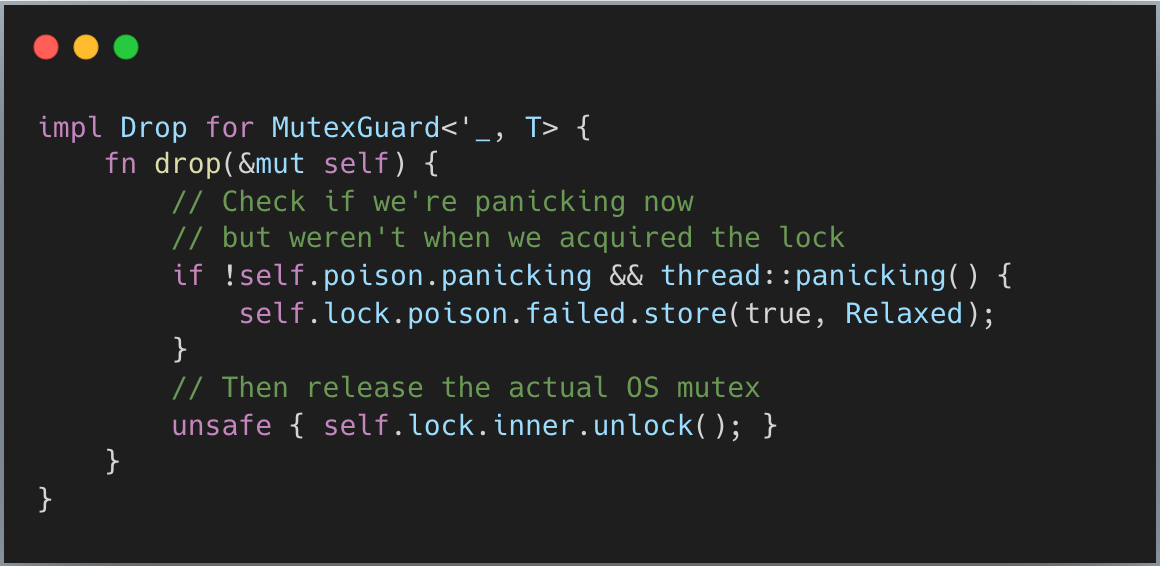
가드는 락을 획득했을 때 스레드가 패닉 상태였는지를 기록합니다. 그때는 패닉하지 않았는데 지금은 패닉 중이라면, 임계 구역에서 패닉이 발생한 것입니다. 이때 간단한 원자 저장으로 뮤텍스를 오염 상태로 표시합니다.
이는 “최선의 노력(best effort)” 메커니즘입니다. 이중 패닉이나 비-Rust 예외 같은 모든 경우를 잡아내지는 못하지만, 유용한 안전망을 제공합니다. 핵심은 뮤텍스가 오염되었더라도 데이터 접근 권한(가드)을 여전히 받기 때문에 손상된 상태를 검사하고 복구를 시도할 수 있다는 점입니다.
중요한 메모: 뮤텍스 포이즈닝은 사랑과 미움을 동시에 받습니다. 데이터 손상을 잡아내지만, 다른 언어에 익숙한 사람에게는 어색하게 느껴지죠(저도 그래요. 도움 되는 건 아는데 여전히 싫어요, ㅋㅋ). Rust 팀은 포이즈닝이 없는 변형을 추가 중입니다 - issue#134645 참고
parking_lot은 근본적으로 다른 접근을 취합니다. 두 가지 핵심 차이가 있습니다:
parking_lot의 뮤텍스는 놀랄 만큼 작습니다:
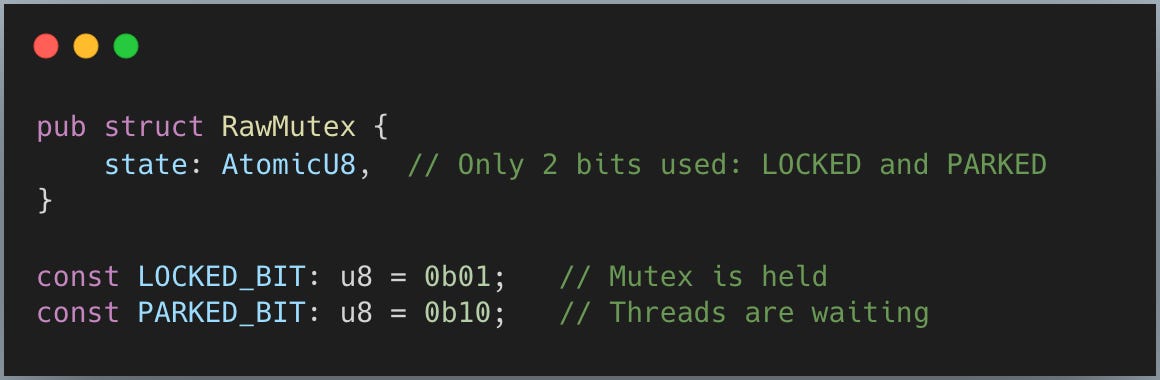
왜 std는 더 큰 크기를 쓰는데 parking_lot은 1바이트만으로 충분할까요? 이는 큐를 어떻게 다루느냐의 차이입니다.
std의 futex는 큐 관리를 커널에 맡깁니다. futex 시스템 콜을 호출할 때 원자 변수의 메모리 주소를 넘기면, 커널은 그 주소를 큐 ID로 사용합니다. 그런데 제약이 하나 있습니다. 커널은 이 주소가 32비트 경계에 정렬(aligned)되어 있기를 요구합니다. 그래서 std의 뮤텍스는 실제로 몇 비트만 필요하더라도 AtomicU32를 써야 합니다.
parking_lot은 사용자 공간에서 직접 큐를 관리합니다. 뮤텍스의 메모리 주소를 해시해 올바른 큐 버킷을 찾죠. 커널 정렬 요구사항을 만족할 필요가 없으니 단일 AtomicU8만으로 충분합니다.
더 많은 상태로 큐 관리하기
비트를 나눠 쓰면서 parking_lot은 네 가지 상태를 가집니다:
세 번째 상태(10)가 처음엔 이상해 보일 수 있습니다. 왜 뮤텍스가 언락인데 대기자가 남아있을까요? 이는 parking_lot의 언락 과정에서 발생하는 과도기 상태입니다. parking_lot은 자체 큐를 관리하기 때문에, 스레드가 큐에 남아있는지를 표시하기 위한 북키핑으로 PARKED_BIT를 사용합니다. 이는 스레드가 웨이크업 신호를 놓치는 “로스트 웨이크업”을 피하는 데 도움이 됩니다. std보다 유리해서가 아니라, 커널 대신 사용자 공간에서 큐를 관리할 때의 자연스러운 결과입니다.
스레드가 락을 얻지 못하면 어디서 기다릴까요? 여기서 parking_lot의 전역 해시 테이블이 등장합니다.
각 뮤텍스가 자체 큐를 가지는 대신(커널의 futex처럼), parking_lot은 프로그램 전체에서 공유하는 전역 해시 테이블 하나를 사용합니다. 스레드가 대기해야 하면:
스레드 큐를 직접 관리하는 능력은 parking_lot이 공정성을 강제하는 데 매우 중요합니다. 다음 섹션에서 바로 확인할 수 있습니다.
여기서 parking_lot은 std와 동작이 달라집니다. std의 futex는 큐에서 오래 기다린 스레드가 있더라도, 활성 상태의 어떤 스레드든 락이 풀리면 바로 가로채서(lock을) 획득할 수 있는 “바징(barging)” 전략을 씁니다. 이는 처리량을 최대화하지만 기아(starvation)를 유발할 수 있습니다.
스레드가 언락하면, 다시 락을 획득할 수 있는 후보는 두 부류입니다:
보시다시피 활성 스레드가 “누가 먼저 락을 잡느냐” 경쟁에서 유리합니다. 어떤 스레드가 락을 잡아 일을 끝내자마자 곧바로 다시 락을 시도하면, 다른 스레드들을 계속 굶길 수 있습니다.
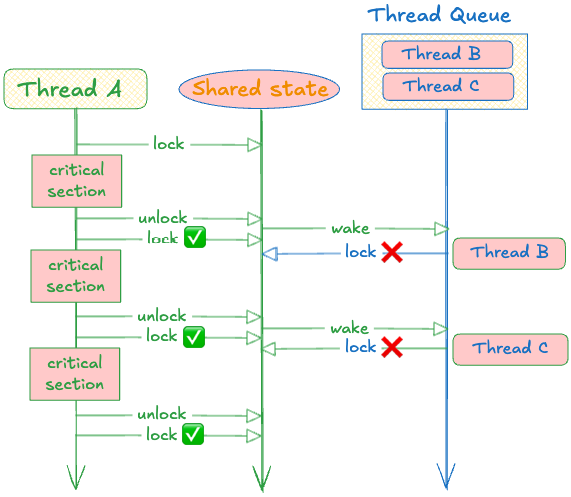
보시는 것처럼, 스레드 A는 풀자마자 곧바로 락을 다시 잡습니다. 스레드 B와 C도 시스템 콜에 의해 깨우긴 하지만, 락을 잡으려 할 즈음에는 스레드 A가 이미 선점해버렸습니다. 완전히 굶주린 상태죠.
parking_lot은 이를 막기 위해 “결국에는 공정해지는(eventual fairness)” 전략을 구현합니다.
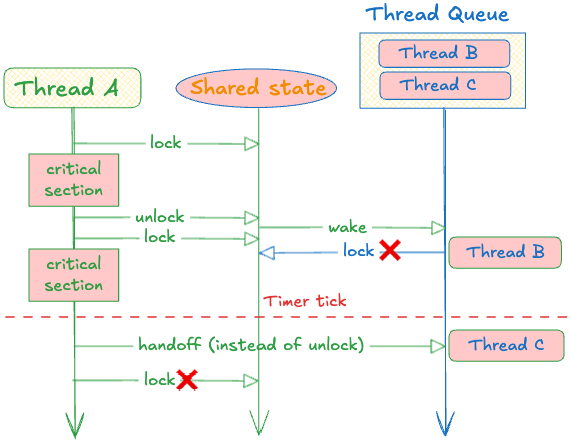
전역 해시 테이블의 각 버킷에는 약 0.5밀리초마다 발사되는 타이머가 있습니다. 타이머가 발사되면 다음 언락은 “공정 언락(fair unlock)”이 됩니다:
즉, 빠른 놈이 임의로 잡아가게 두는 대신, parking_lot은 큐의 다음 스레드에게 락을 직접 양도하도록 강제합니다(LOCKED_BIT를 유지한 채 핸드오프; 아예 언락하지 않습니다).
이 타이머 기반 접근 덕분에 parking_lot은 대부분의 시간에는 불공정(성능 우선)이지만, 약 0.5ms마다 공정을 보장해 어떤 스레드도 무기한으로 굶주리지 않게 합니다. 필요하다면 **unlock_fair()**로 명시적으로 공정 언락을 강제할 수도 있습니다.
parking_lot의 이 “결국 공정해지는” 기법, 꽤 영리하죠?
이쯤 되면 의문이 생길 수 있습니다. “그렇다면 parking_lot은 왜 각 뮤텍스 안에 32비트 futex 워드를 두지 않고도 스레드를 재우고 깨울 수 있지?” 정답은 스레드 로컬 저장소(TLS)입니다.
parking_lot도 std와 똑같이 futex 시스템 콜을 사용합니다. 다만 커널에 넘기는 주소가 뮤텍스 주소가 아닐 뿐입니다. 각 스레드는 재사용 가능한 i32를 담은 ThreadData 레코드를 TLS에 갖고 있습니다. 이 정수는 스레드 로컬에 살기 때문에 각 스레드는 시스템 콜에 사용할 고유한 주소를 갖습니다. 커널 입장에서는, 블록된 각 스레드가 자기만의 단일 엔트리 큐에 앉아 있는 셈이죠.
코드는 std의 futex 경로와 거의 동일합니다. 단 하나 다른 점은? parking_lot은 시스템 콜의 주소로 뮤텍스가 아니라 스레드 로컬 정수를 가리킨다는 겁니다:
언락할 때도 parking_lot은 같은 스레드 로컬 정수를 사용해 그 주소에 대해 FUTEX_WAKE를 호출합니다. 이렇게 하면 뮤텍스는 1바이트로 유지되면서, 잠재우고 깨우는 모든 보조 작업은 스레드 로컬 헬퍼가 처리합니다.
futex가 없는 플랫폼에서는, 파커(parker)가 동일한 스레드별 큐 설계를 유지한 채 로컬 블로킹 원시체로 대체합니다(macOS/BSD에서는 pthread_cond_t, Windows는 WaitOnAddress/keyed events, 혹은 단순 스핀 루프 등).
이제 실제로 두 구현이 어떻게 동작하는지 보겠습니다. 뮤텍스 동작의 서로 다른 측면을 드러내는 네 가지 시나리오로 벤치마크를 수행했습니다. 모두 리눅스에서 std는 futex 백엔드를 사용했습니다. 소스 코드와 전체 보고서는 https://github.com/cuongleqq/mutex-benches에서 볼 수 있습니다.
각 시나리오마다 다음을 제공합니다:
(숫자가 벅차다면, 시나리오 설정만 읽고 핵심 요약으로 바로 넘어가세요.)
설정: 스레드 4개, 10초, 임계 구역에서 최소 작업
시나리오: 스레드가 임계 구역에서 아주 작은 작업만 하고 빈번히 락을 잡았다가 푸는 일반적인 애플리케이션을 시뮬레이션합니다. 각 스레드는 카운터만 증가시키며, 작은 자료구조 보호나 빠른 상태 업데이트의 흔한 경우를 대표합니다.
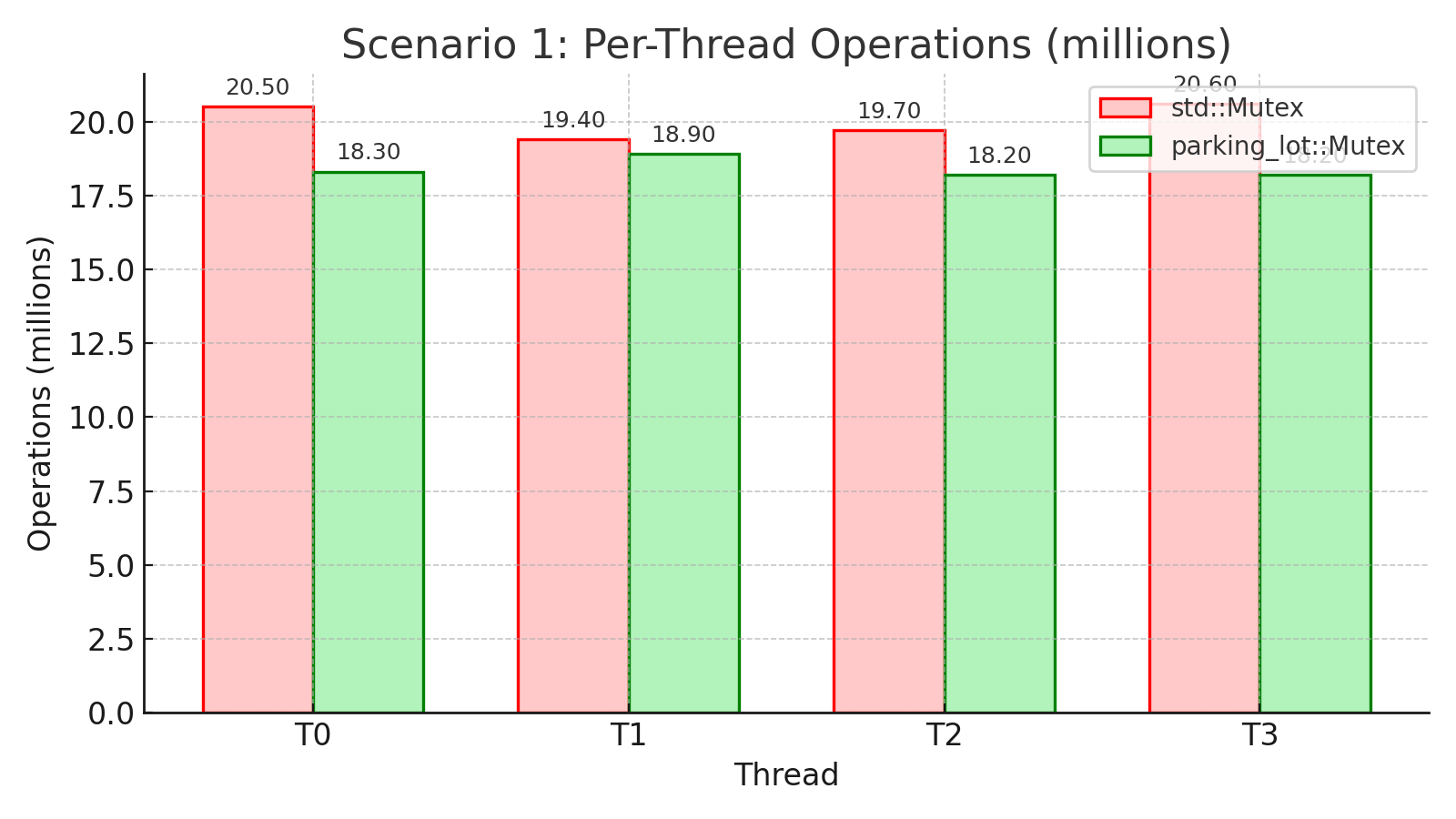
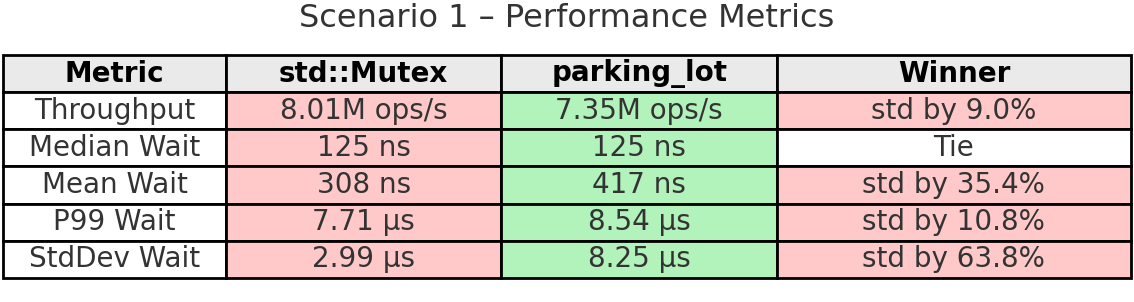
핵심 요약: 중간 정도의 경합과 짧은 임계 구역에서는 std의 futex가 빛납니다. 처리량이 9% 높고 평균 대기 시간이 낮습니다. 경합이 없을 때의 빠른 경로와 커널이 관리하는 효율적인 큐가 잘 작동한 덕분입니다. 다만 스레드별 연산 횟수를 보세요. std는 변동 폭이 5.6%(20.6M vs 19.4M)인데, parking_lot은 3.9%(18.9M vs 18.2M)입니다. std에 유리한 이 시나리오에서도 parking_lot의 공정성 메커니즘 덕에 스레드 간 작업 분배가 더 고르게 유지됩니다.
설정: 스레드 8개, 10초, 락을 쥔 채 500µs 수면
시나리오: 스레드가 락을 오랫동안 쥐는(500마이크로초) 강한 경합을 테스트합니다. I/O 작업, 느린 계산, 락을 쥔 채 원격 자원 접근 같은 상황을 시뮬레이션하죠. 8개 스레드가 매번 500µs 동안 락을 쥐고 경쟁하니 경합이 매우 심합니다.
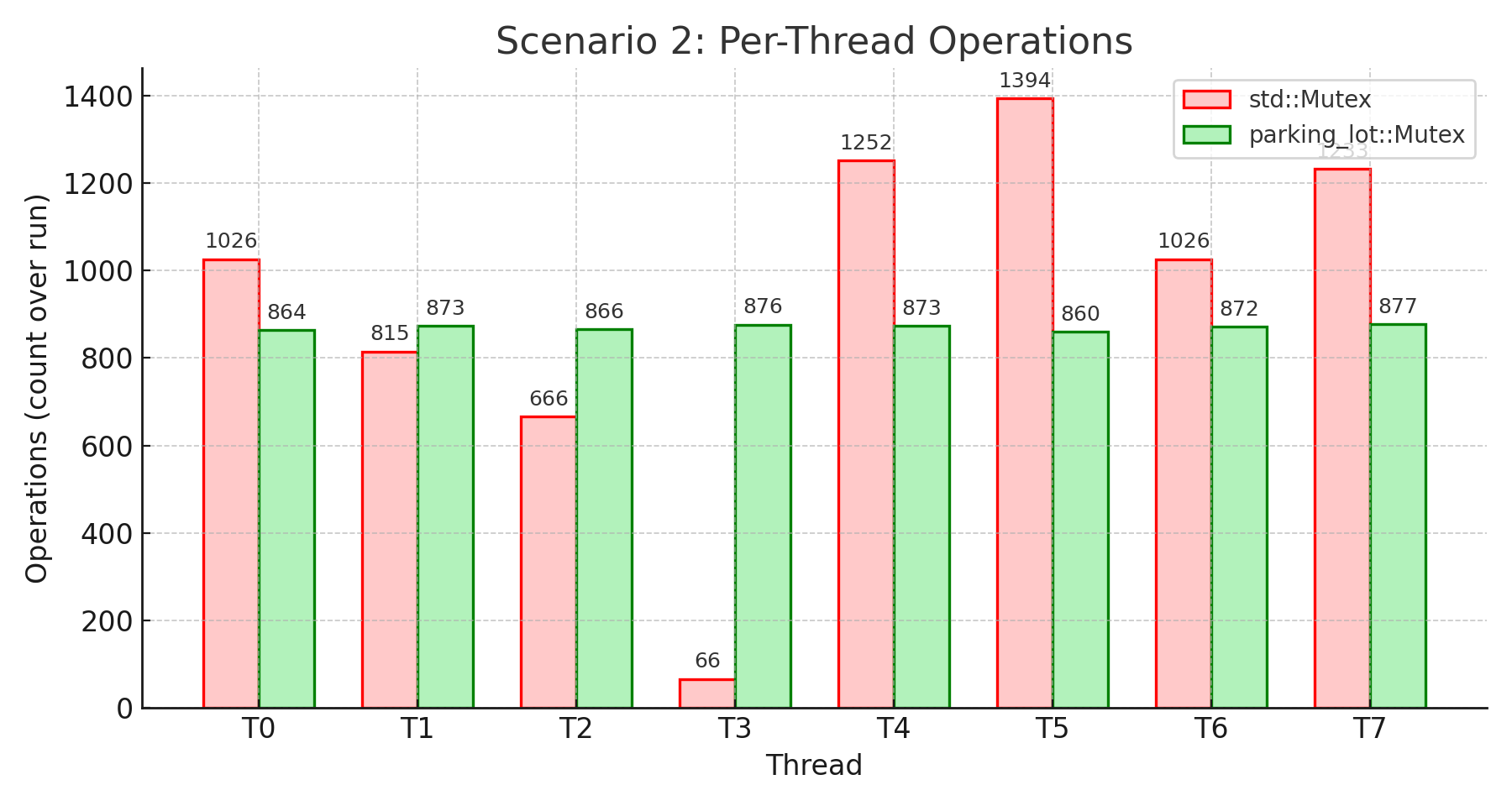
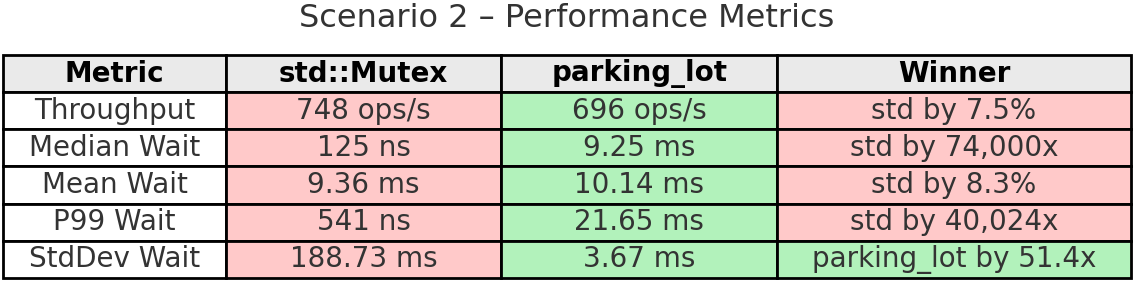
핵심 요약: 이 벤치마크는 강한 경합에서 std의 치명적인 약점을 드러냅니다. std에서 스레드 3은 66회만 완료했는데, 스레드 5는 1,394회를 완료했습니다. 변동 폭이 95.3%로 사실상 완전한 기아 상태입니다. 매우 낮은 중앙값(125ns)과 거대한 표준편차(188.73ms)가 동시에 나타난다는 건, 대부분의 락 시도는 빠르지만 일부 스레드는 극단적인 지연을 겪어 거의 락을 얻지 못한다는 뜻입니다.
parking_lot은 전혀 다른 그림을 보여줍니다. 모든 스레드가 860~877회(1.9% 변동) 완료했습니다. 공정성 메커니즘이 의도대로 정확히 작동한 겁니다. 처리량이 7.5% 낮고 중앙값 대기 시간이 더 높긴 하지만, 이는 모든 스레드가 진척을 내도록 보장하기 때문입니다. 대기 시간의 안정성은 51배 더 좋습니다(표준편차 3.67ms vs 188.73ms). 공정성이 중요할 때 parking_lot은 std가 보이는 병적인 기아를 방지합니다.
설정: 스레드 8개, 15초, 200ms 활성 / 800ms 유휴
시나리오: 스레드가 높은 활동 구간(200ms 동안 빠른 락 획득)과 유휴 구간(800ms 수면)을 번갈아가며 나타내는 버스티(workload burst)한 부하를 시뮬레이션합니다. 트래픽 급증을 처리하는 웹 서버, 배치 처리 시스템, 주기적인 활동 패턴을 갖는 애플리케이션 등을 떠올리면 됩니다. 경합 급증 후 한산해지는 전환을 뮤텍스가 어떻게 다루는지 테스트합니다.
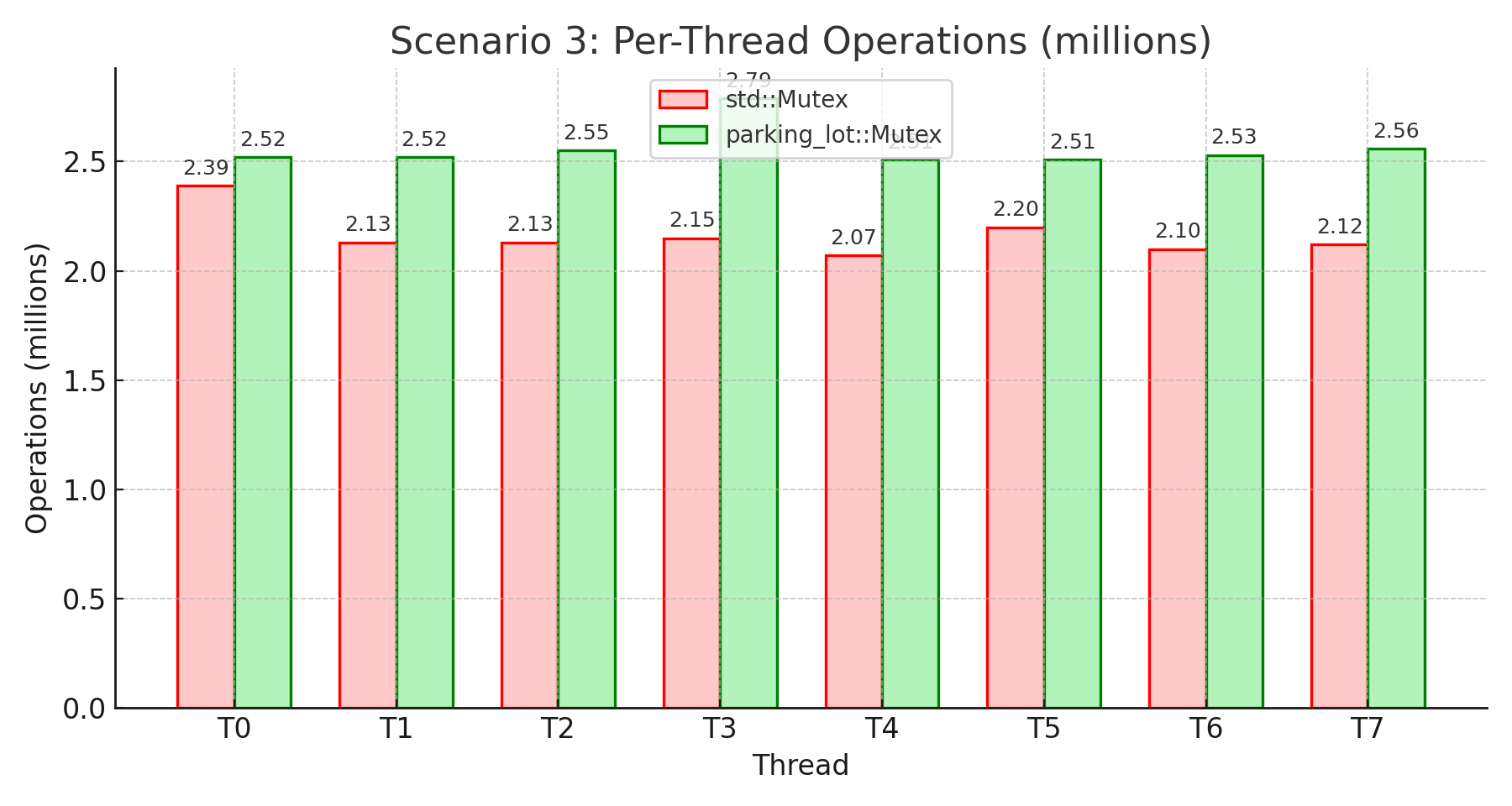
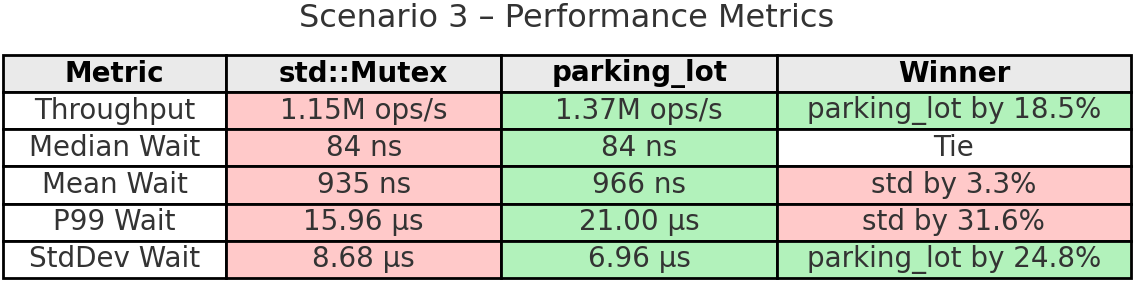
핵심 요약: parking_lot은 버스티한 워크로드에서 두각을 보이며 std보다 처리량이 18.5% 높습니다. 활성 구간 동안 8개 스레드가 치열하게 락을 두고 경쟁합니다. parking_lot의 적응형 스핀(spin)과 공정성 메커니즘이 이러한 주기적 경합 급증을 더 잘 처리해 더 고른 작업 분배(변동 9.9% vs 13.6%)를 보장합니다. 대기 시간 안정성도 24.8% 더 좋습니다. std가 꼬리 지연은 낮지만, parking_lot은 버스트 구간의 안정성과 공정성 덕에 전체 처리량이 더 높게 나옵니다.
설정: 스레드 6개, 15초, 한 스레드가 독점(락을 쥔 채 500µs 수면 반복)
시나리오: 최악의 경우를 테스트합니다. “hog(독식)” 스레드 하나가 반복적으로 락을 획득해 500µs 동안 쥐고 있고, 나머지 5개 스레드는 정상적으로 경쟁합니다. 우선순위 역전 등, 높은 우선순위나 바쁜 스레드가 풀자마자 곧바로 락을 다시 잡아 다른 스레드가 굶주릴 수 있는 현실적 상황을 시뮬레이션합니다. 뮤텍스가 독점을 막을 수 있을까요?
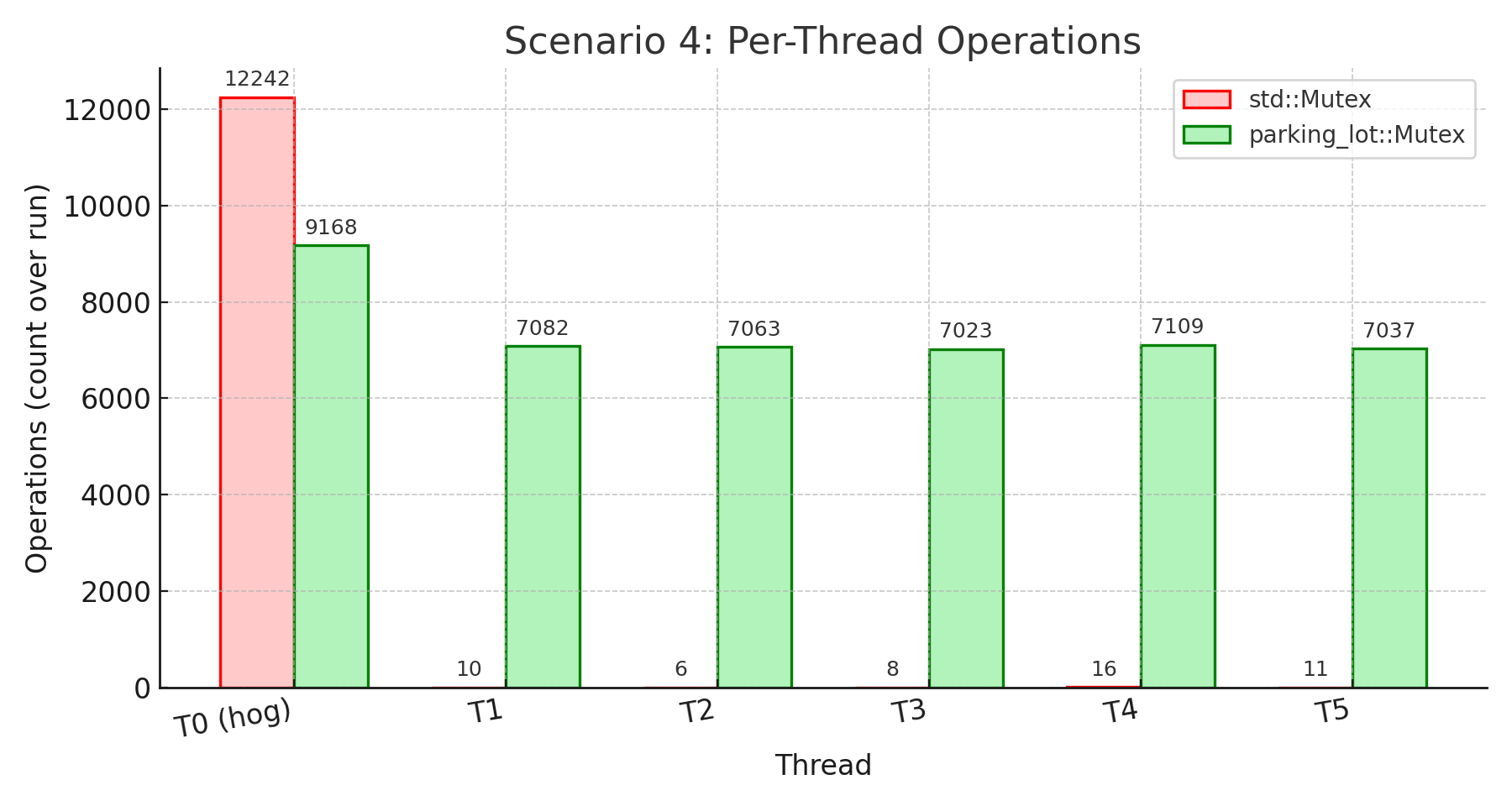
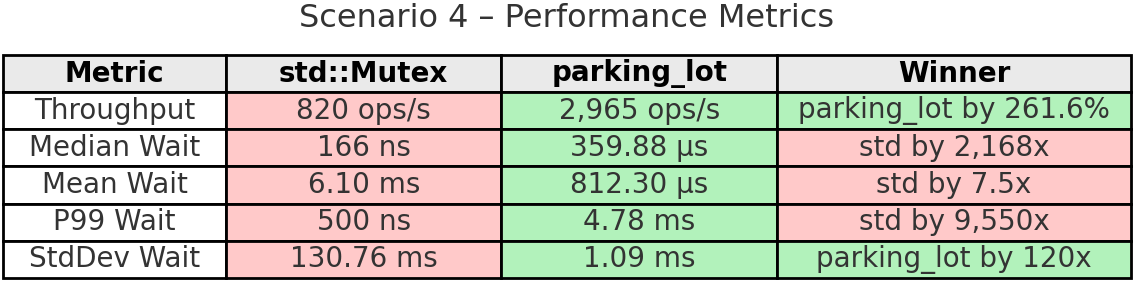
핵심 요약: 이는 std의 근본적인 비공정성을 보여주는 결정적 증거입니다. 독식 스레드는 12,242회를 완료했지만 다른 스레드들은 각자 6~16회에 그쳤습니다. 완전한 기아 상태죠. 변동 100%와 130ms 표준편차가 극도의 비예측성을 드러냅니다.
parking_lot의 공정성 타이머는 이런 참사를 막았습니다. 독식 스레드가 여전히 더 많은 연산(9,168회)을 수행했지만 독점과는 거리가 멉니다. 다른 모든 스레드도 의미 있는 진척(7,023~7,109회)을 보였습니다. 결과적으로 모든 6개 스레드가 일을 한 덕분에 전체 처리량이 261.6%나 높아졌습니다(5개 스레드가 사실상 놀지 않게 되었으니까요). 대기 시간 안정성도 120배 더 좋습니다(표준편차 1.09ms vs 130.76ms). 0.5ms 공정성 타이머가 약속한 그대로, 어떤 스레드도 무한정 락을 독점하지 못하게 합니다.
구현을 깊게 파고들고 포괄적인 벤치마크를 돌려본 뒤, 다음과 같이 정리할 수 있습니다.
의존성을 0으로 유지해야 할 때 - std에 있으니 항상 사용 가능
경합이 낮거나 중간이고 임계 구역이 짧을 때 - 이 경우 futex 구현이 뛰어납니다(짧게 보유하는 테스트에서 처리량 9% 빠름)
디버깅을 위해 포이즈닝이 필요할 때 - 패닉 관련 버그를 개발 중에 잡는 데 도움
플랫폼별 최적화가 중요할 때 - Fuchsia에서 우선순위 상속 등
공정성이 핵심일 때 - 스레드 기아를 방지합니다(강한 경합에서 공정성 49배 개선)
독점 위험이 있을 때 - 독식 시나리오에서 기아 방지로 처리량 261.6% 개선
버스티한 워크로드일 때 - 우리의 버스트 시나리오에서 18.5% 더 빠름
예측 가능한 동작이 필요할 때 - 높은 부하에서 지연이 51배 더 안정적
메모리 발자국이 중요할 때 - 플랫폼과 무관하게 항상 1바이트
타임아웃이나 공정성 제어가 필요할 때 - try_lock_for(), unlock_fair() 등
크로스플랫폼 일관성이 중요할 때 - 어디서나 동일한 동작
벤치마크는 근본적인 트레이드오프를 보여줍니다: std::Mutex는 평균적인 경우의 처리량을 최적화하고, parking_lot::Mutex는 최악의 경우의 공정성과 예측 가능성을 최적화합니다.
대부분의 애플리케이션에서는 경합이 가볍고 임계 구역이 짧기 때문에 std::Mutex가 훌륭한 성능을 냅니다. 하지만 다음과 같은 특성이 있다면:
이때는 parking_lot::Mutex의 “결국 공정해지는” 메커니즘이 큰 가치를 발휘합니다. 완전한 스레드 기아를 막기 위해 0.5ms짜리 공정성 타이머를 지불하는 비용은 매우 작습니다.
여기까지 읽으셨다면, 아마 저처럼 “사물이 정말 어떻게 동작하는지”에 집착하는 타입일 겁니다. 저는 Cuong이고, Rust와 프로그래밍에 관해 글을 씁니다. 같은 열정을 공유한다면 꼭 연결되었으면 합니다. X, LinkedIn에서 연락하시거나, 제 블로그(substack, medium)를 구독해 함께 한계를 밀어붙여 봅시다!