Postgres를 큐 백엔드로 선택할 때의 배경, 장단점, 의사결정 기준과 ‘지루한 기술(Choose Boring Technology)’ 철학을 바탕으로 Redis/Kafka/RabbitMQ/SQS 등과 비교하며, NOTIFY/LISTEN과 SKIP LOCKED를 활용한 큐 처리 방법을 설명한다.
Postgres 큐 기술은 아름답지만, 주류와는 거리가 있다. 비교적 알려지지 않은 이유의 일부는 “스케일”에 대한 카고 컬트 때문이다. 스케일러빌리티 컬트는 Postgres보다 더 뛰어난 “스케일러빌리티”를 갖춘 큐 기술이 여럿 있다고 단정하고, 그 이유만으로 Postgres는 누구의 큐잉 요구에도 충분히 확장되지 않는다고 여긴다. 이 스케일의 컬트는 구체적인 고객과 비즈니스 요구를 충족하는 애플리케이션보다 우리의 상상을 초월해 확장되는 애플리케이션을 만들기를 원한다. Postgres의 운영 단순성 따위는 잊고, 먼저 스케일이고 운영은 나중이라는 식이다.
그럼에도 webapp.io와 같은 몇몇 진취적인 기술자들은 파문을 무릅쓰고 그들의 제품 핵심 기능을 Postgres 큐에 의존한다. webapp.io 같은 회사들은 “스케일러빌리티”보다 더 중요한 원칙들이 있음을 인정한다는 점에서 예외적이다. 스케일의 컬트가 균열을 일으키면 그 균열은 대개 작지만, 운영 단순성, 유지보수성, 이해 용이성, 친숙함 같은 새로운 원칙들로 응고된다. 때로는 오래된 기술을 새로운 방식으로 재활용하거나, 큐 용도로 Postgres를 사용하는 등의 새로운 아이디어로 응고되기도 한다. 당신도 스케일 컬트에서 파문당할 위험을 감수해 보길 권한다.
Postgres 큐 기술은 두 부분으로 구성된다. 새 작업을 알리고 구독하는 것(pub/sub)과 상호 배제(행 잠금)다. 둘 다 2016년에 릴리스된 Postgres 9.5부터 기본 제공된다.
NOTIFY와 LISTEN을 결합하면 Postgres는 어떤 애플리케이션에도 pub/sub을 손쉽게 추가할 수 있게 해준다. pub/sub에 더해, Postgres는 FOR UPDATE SKIP LOCKED를 통해 “워커당 한 작업” 의미론도 제공한다. 이 접미사가 붙은 쿼리는 조건에 맞는 레코드에 행 잠금을 획득하고, 이미 잠금이 걸린 레코드는 건너뛴다. 이를 job 레코드에 적용하면 간단한 큐 처리 쿼리를 구현할 수 있다. 예: SELECT * FROM jobs ORDER BY created_at FOR UPDATE SKIP LOCKED LIMIT 1.
이 두 기능을 결합하면 자원 효율적인 큐 처리를 위한 기반이 된다. 중요한 점은 SKIP LOCKED가 데이터의 “비일관적” 뷰를 제공한다는 것이다. 그 비일관성은 큐에서 정확히 필요한 특성이다. 이미 처리 중인 작업(즉, 행 잠금이 걸린 작업)은 다른 워커에게 보이지 않으므로 분산 상호 배제를 제공한다. 이러한 잠금은 주기적인 배치 처리와, 새 작업에 대해 LISTEN 중인 워커들에게 NOTIFY하여 실시간으로 작업을 처리하는 길을 모두 열어준다.
이러한 Postgres 기능의 사용자는 많지만, 이를 큐 백엔드로 결합해 쓰자고 공개적으로 옹호하는 목소리는 상대적으로 적다. 예를 들어, 이 Hacker News 댓글은 Postgres를 이런 방식으로 쓰는 것이 “hacky”하다고 했고, 아무도 반박하지 않았다. 나는 그 댓글이 완전히 헛소리이며 허수아비 논법이라고 생각했다. 업계의 “지배적 지혜”는 대략 이렇다. 큐 기술을 공개적으로 이야기하려면 그것이 관계형 데이터베이스여서는 안 된다는 식이다. 카고 컬트가 만연한 이 업계는 어떤 것이 “지배적”인 지혜이든 간에 그것에 반박하려는 의지가 별로 없다. 나는 Postgres가 열등한 큐 기술이라는 생각을 버리도록 돕고 싶다.
논의의 명분으로 “백그라운드 작업”을 사용하자. 애플리케이션에 백그라운드 작업 처리를 추가하는 것은 개발자들이 흔히 내리는 결정이며, 시스템 유지보수 부담에 지대한 영향을 미칠 수 있다. “백그라운드 작업”은 “보고서를 생성해 고객에게 이메일로 보내기”나 “이미지를 처리해 여러 형식으로 변환하기”처럼 잠재적으로 오래 걸릴 수 있는 모든 작업을 포함한다. 이런 용례는 일반적으로 큐를 필요로 한다.
모든 기술 선택이 그렇듯, 장기 실행 작업을 처리하는 방법을 고르는 일에는 많은 트레이드오프가 따른다. 지난 10년 동안, 업계는 장기 실행 작업을 큐잉해 처리하기 위한 좋은 도구 몇 가지에 암묵적으로 합의해 온 듯하다.
좋아하는 도구가 빠졌다면 사과한다. 이 목록은 포괄적이지 않다.
^ “메시지 브로커”란 큐 위에 다른 화려한 기능을 얹는 시스템을 의미하지만, 여기서는 메시지 브로커를 큐로 간주하자. 나는 “큐”와 “큐 처리”와 사실상 동의어로 여겨도 되는 여러 단어와 구문이 있다고 본다. “메시지 브로킹/브로커”, “스트림 처리”, “스트리밍 데이터” 등. 물론 이 용어들이 정확히 “큐”나 “큐 처리”와 동일한 의미는 아니라는 것을 안다.
여기서 잠시 멈춰 “백그라운드 작업” 세계에서 Redis의 중요성을 짚고 넘어가는 것이 중요하다고 생각한다. background jobs GitHub 주제를 살펴보면, 상위 다섯 개 인기 라이브러리는 모두 Redis를 백엔드로 사용한다.
그럴 만한 이유가 있다. Redis는 데이터를 메모리에 저장하므로 쓰기와 읽기 속도가 모두 탁월하다. 게다가 pub/sub API가 내장돼 있고, 네이티브 list와 set 자료구조가 있어 이를 결합하면 훌륭한 큐를 만들 수 있다. Redis는 scales. 많은 개발자에게 그 확장성은 Redis를 기본 선택지로 만들었고, 기본값은 엄청난 힘을 갖는다.
그러나 단지 Redis가 스케일이 잘 된다는 이유로 선택하기 전에, Ben Johnson의 I’m All-In on Server-Side SQLite에서 한 이 인용문을 떠올려 보자. 데이터베이스 스케일러빌리티에 관한 이야기지만, 큐 같은 다양한 인프라를 스케일링하는 문제에도 그대로 적용된다.
새로운 데이터베이스 아키텍처를 생각할 때 우리는 스케일 한계에 최면이 걸린다. 페타바이트, 최소한 테라바이트를 다루지 못하면 대화의 대상조차 되지 못한다. 하지만 대부분의 애플리케이션은 성공하더라도 테라바이트에 이르지 못한다. 우리는 다듬질 못 하나 박으려고 공기 해머를 쓰고 있다.
업계는 “스케일”에 완전히 집착하게 되었다. 단순성, 유지보수 용이성, 개발자 인지 부하 감소 같은 모든 것을 희생하면서까지 말이다. 우리는 모두 우리가 Google, Facebook, Uber급의 스케일을 요구하는 다음 거물을 만들고 있다고 믿고 싶어 하지만, 사실은 거의 항상 — 그렇지 않다. 우리의 기술 선택은 그 사실을 반영해야 한다. 우리는 상대적으로 작은 스케일을 위해 만드는 경우가 더 많고, 기술적 우월성보다는 팀 구성과 더 관련된 전혀 다른 요인들에 맞춰 의사결정을 최적화해야 한다.
프로젝트와 비즈니스를 시작할 때, 처음에는 스케일 말고 모든 것을 최적화해야 한다. 물론 기술 선택으로 코너에 몰리고 싶지는 않지만, 또한 확장성 부족 외의 모든 이유로 실패할 가능성이 높은 마케팅 사이트를 위해 Kubernetes 클러스터를 짓고 싶지도 않다. 우리가 잘 아는 기술, 충분히 괜찮은 기술, 사용자 요구와 팀의 역량에 부합하는 가장 고된 일이 적은 해결책을 고민해야 한다. “최고”보다 “충분히 좋음”을 선택한 것에 자부심을 가져라. 때로 “최고”는 불가피한 실패로 가는 더 어려운 길일 뿐이다. 스케일하지 못해서 실패한 제품들을 머릿속에 떠올려 보라. 그보다 훨씬 긴 목록이, 스케일을 필요로 하기도 전에 실패한 제품들로 채워져 있을 것이다.
아직 말하지 않았지만, Postgres는 실제로 스케일도 잘 된다. 다만 Postgres는 범용 소프트웨어이므로 큐 용례에서 스케일링 “최고”는 아닐 것이다. Postgres는 수행하는 모든 일에서 그렇듯, 큐 용례에서도 꽤 잘 작동할 것이다.
여기까지 읽고 내가 할 말은 충분히 본 것 같다면, 이 페이지를 떠나 Dan McKinley의 슬라이드 데크 choose boring technology를 훑어봐도 좋다. 이 글을 끝까지 읽든, Dan의 슬라이드를 보든, 다음번 큐 기술 선택에서 비슷한 결정을 내리리라 확신한다. 어쨌든 Dan의 “Choose Boring Technology” 강연이 이 글 제목의 영감이 되었으니까.
기술을 선택할 때 가장 중요한 질문은 다음과 같다. 지금 내가 사용하고 잘 이해하는 기술은 무엇인가?
이 질문에 대한 답은 소프트웨어 스택에 기술을 선택하는 “비용”을 가늠하게 해 준다. 이미 사용 중인 기술은, 아마도, 저렴하다. 잘 이해하고 있다는 전제하에서 말이다.
당신은 이미 관계형 데이터베이스를 사용 중일 확률이 높다. 그 관계형 데이터베이스가 Postgres라면, 다른 소프트웨어보다 먼저 큐 용도로 고려해 보자. 만약 Postgres가 아니라면, 다른 무엇보다 먼저 당신에게 가장 지루한(boring) 기술을 고려하라.
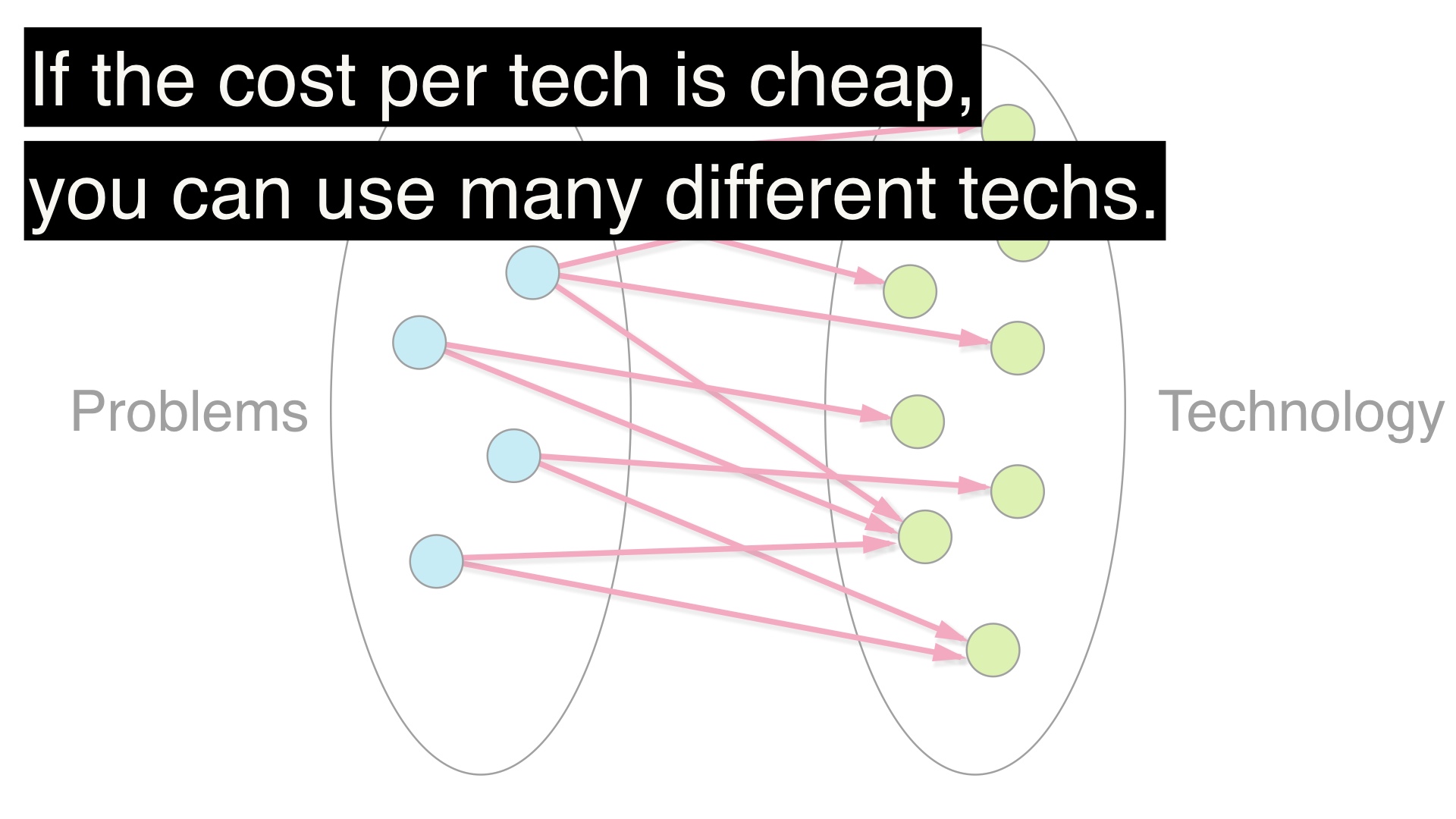
비용이 낮으면, 아무거나 골라도 된다. 출처: https://boringtechnology.club
기존에 (아직) 사용하지 않는 기술은 더 비싸다.
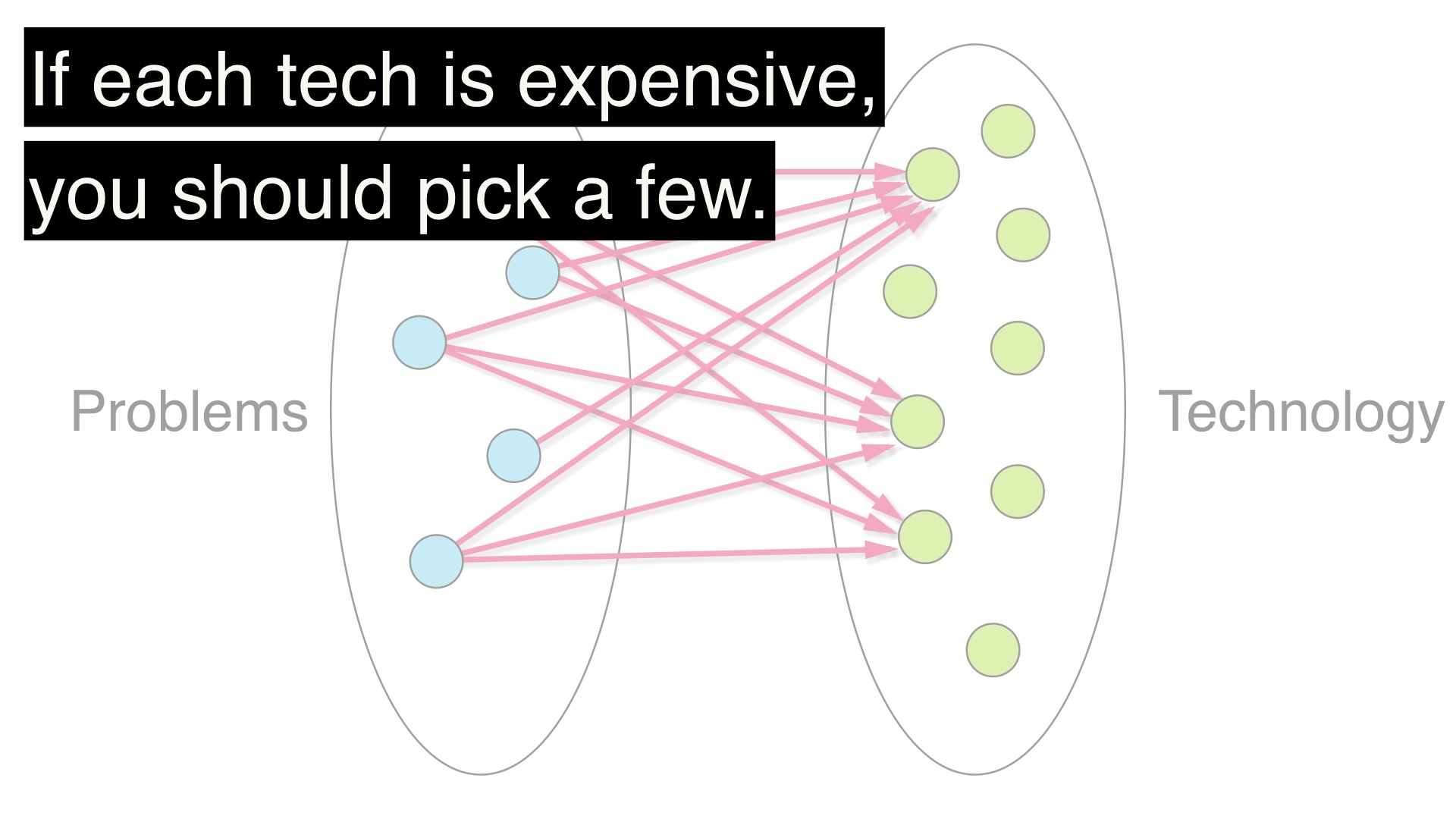
비용이 높으면, 소수만 골라라. 출처: https://boringtechnology.club
다시 말해, 지루한 기술이란 이미 사용 중인 것과의 상대 개념이다. 알림 시스템처럼 메시지 전달에 초점을 둔 애플리케이션은 RabbitMQ를 지루한 기술이라 여길 수 있다. 캐시 중심 애플리케이션은 Redis를 지루한 기술로 여길 수 있다. 대량의 관계형 데이터를 다루는 애플리케이션은 Postgres를 지루한 기술로 여길 수 있다. 가장 지루한 선택이 아마도 당신과 팀에게 옳은 선택일 가능성이 높다.
이미 Redis, Kafka, RabbitMQ, SQS를 사용하지 않는다면, 오직 백그라운드 작업을 위해 그중 하나를 도입하는 것은 비싸다. 애플리케이션 수명 동안 개발, 테스트, 프로덕션 모든 환경에 새로운 시스템 의존성을 추가하는 셈이다. 앞으로 합류할 모든 개발자, DBA, SRE 역할에 새로운 기술 역량이 요구된다. 이제 이들은 새로운 시스템의 복잡한 장애 양상과 설정 노브를 알아야 한다. 지원자는 이 새로운 기술을 학습할 가치가 있다고 설득되어야 한다. DBA/SRE는 운영 장애에서 복구하는 법, 문제를 진단하는 법, 성능을 모니터링하는 법을 알아야 한다. 알아야 할 것이 많고, 팀 누구도 알아야 한다는 사실조차 모르는 것들이 많다. 이들 시스템의 알려지지 않은 미지의 요소(unknown unknowns)는 리스크다. 특히 이것들이 당신의 기본 선택지이고, 왜 기본 선택인지에 대해 깊이 생각해 보지 않았다면 더더욱 그렇다.
이는 가장 지루한 기술이 — Postgres를 포함해 — 만병통치약이라는 뜻은 결코 아니다. 친숙함, 알려진 장애 양상, 누적된 “비용” 절감을 택하는 대가로, 성능 또는 다른 중요한 원칙을 포기해야 할 수도 있다. 결국 Postgres 큐에서의 push/pop은 Redis보다 상당히 느리다. 큐 용도로 Postgres를 쓰면, 단일 서버의 단일 관계형 데이터베이스 대신 애플리케이션이 “애플리케이션” 데이터베이스와 “큐” 데이터베이스를 필요로 할 수 있다. 심지어 백그라운드 작업을 독립적으로 확장하기 위해 완전히 별도의 데이터베이스 서버가 필요할 수도 있다. 데이터베이스를 더 자주 VACUUM해야 할 수도 있고, 그 과정에서 성능 저하가 발생할 수도 있다. 큐 용도로 Postgres를 채택하기 전에 고려해야 할 많은 함의가 있으며, 팀과 애플리케이션의 요구에 비추어 저울질하여 정보에 입각한 결정을 내려야 한다. Postgres가 기본 선택이어서는 안 된다. 마찬가지로 Redis, Kafka, RabbitMQ, SQS, 그 밖의 어떤 분산 큐도 기본 선택이어서는 안 된다. 지루한 기술을 선택하는 것이 기본이어야 한다.
기술 선택은 끝까지 내려가도 트레이드오프다. 나는 Dagster가 취한 실용적 접근법이 인상적이었다. 확신이 서지 않는다면 다음 공리를 떠올려라.
지루한 기술이 요구를 충족할 수 없다는 것이 증명될 때, 그리고 그럴 때에만 대안을 고려하라.
앞서 “코너에 몰리지 말자”고 했다. 백그라운드 작업과 관련해 이는 작업 처리용 애플리케이션 코드가 큐에 독립적이어야 한다는 뜻이다.
어느 날의 최첨단 기술은 다른 날의 지루한 기술이 된다. 애플리케이션이 성장하고 성공을 거두면, 필요에 의해 새로운 기술이 애플리케이션에 덧붙여지는 경향이 있다. memcached나 Redis를 캐시 계층으로 추가하는 것이 흔하다(하지만 먼저 Postgres의 unlogged 테이블도 고려하라!). 그렇게 되면 이 기술들은 시간이 지남에 따라 “지루한” 기술이 되고, 비용이 낮아지며, 이를 큐로 사용하는 계산법도 달라진다.
탈출구(escape hatch)를 마련해 설계한다는 것은 결국 추상화에 관한 일이다. 앞서 GitHub에서 가장 인기 있는 다섯 개의 백그라운드 작업 라이브러리를 나열했다. Hangfire를 제외하면 그 어떤 라이브러리도 Redis 이외의 큐 기술로 탈출구를 제공하지 않는다. 즉, 튼튼한 추상화 레이어가 없기 때문에 큐를 바꾸려면 애플리케이션 코드를 다시 써야 한다.
그렇게 되어서는 안 된다. 큐 기술은 추상화되어야 하며, 사용자가 작업에 맞는 큐를 선택할 수 있어야 한다. 나는 Hangfire(또는 C#) 사용자도 아니지만, Hangfire는 추상화를 제대로 해낸 것으로 보인다.
이러한 지루한 기술을 선택하고 탈출구를 마련한다는 철학으로 나는 Neoq를 만들었다 https://github.com/acaloiaro/neoq. Neoq의 큐는 인메모리, Postgres, Redis일 수 있다(당신이 선호하는 지루한 기술에 대한 기여를 환영한다!). 사용자는 애플리케이션 코드를 전혀 바꾸지 않고도 큐를 전환할 수 있다 — 단지 다른 큐 백엔드로 초기화하면 된다. Neoq는 구체 구현이라기보다 추상화에 더 가깝다. 인메모리와 Postgres 구현은 퍼스트파티이고, Redis 구현은 asynq다. 특정 큐 기술에 개발자를 가두기보다 탈출구를 제공하는 데 초점을 맞춘 것이다.
Go 이외의 언어에도 neoq 같은 라이브러리가 더 많아지길 바란다. 탈출구가 있는 소프트웨어 라이브러리가 부족해서 많은 개발자가 코너에 몰리고, Redis가 필요해지기 훨씬 전부터 Redis 의존성을 안고 간단한 프로젝트를 시작하게 되는 일이 벌어진다고 생각한다. Redis는 훌륭하지만, 항상 그 작업에 맞는 큐이거나 적절한 복잡도는 아니다. Kafka, RabbitMQ, SQS도 마찬가지다.
이 글이 다음번 큐 기술을 선택할 때 스케일 컬트에서 파문당할 용기를 내도록 누군가를 격려하길 바란다. 기술을 선택할 때 고려해야 할 “스케일” 외의 중요한 원칙은 아주 많다. 지루한 기술을 기본 선택으로 삼고, 그것이 당신을 지루하게 만든다면 Postgres를 선택하라.
건승을 빕니다!