Postgres를 pub/sub 메시징과 큐 용도로 벤치마크해 실제로 어느 정도 스케일까지 커버되는지 보여주고, 언제 Postgres만으로 충분한지에 대한 실용적 관점을 제시합니다. 저사양 단일 노드, 3노드 복제, 고사양 단일 노드에서의 결과를 정리하고, 기술 선택에서 단순함과 조직적 비용을 강조합니다.
나는 테크 업계가 두 진영으로 나뉜다고 느낀다.
이 진영은 그게 알맞은지 충분히 고민하지 않은 채 인기 있는 것을 채택하는 경향이 있다. 그리고 세일즈 피치가 내세우는 장점—실시간, 무한 확장, 최첨단, 클라우드 네이티브, 서버리스, 제로 트러스트, AI 기반 등—을 곧이곧대로 믿는 경향이 있다.
Kafka 세계에서 이런 현상을 어디서나 본다: Streaming Lakehouse™️, Kappa™️ Architecture, Streaming AI Agents1.
이 현상은 때때로 이력서 주도 설계(resume-driven design)라고 알려져 있다. 현대 실무는 이를 적극 장려한다. 컨설턴트들은 벤더 기술로 잔뜩 채운 “통찰” 보고서를 통해 “혁신적 아키텍처”를 밀어붙인다2. 시스템 설계 면접은 당신이 면접 보는 회사가 실제로 필요로 하는 규모보다 100배 큰 구글 스케일의 아키텍처를 설계하길 기대한다. 커리어 성장도 자원 절약보다는 핫한 신상 스택™️으로 재플랫폼하는 것을 보상한다.
이 진영은 훨씬 더 실용적이다. 불필요한 복잡성을 벗겨내고 과도하게 설계된 해법을 피한다. 기술 선택 전에 제1원리로 사고한다. 마케팅 과장을 경계하고 벤더의 주장에 건강한 회의를 유지한다.
역사적으로는 1번 진영이 숫자와 소음에서 확실히 우위를 점했다고 느껴졌다. 오늘은 최소한 조금이라도 진자(추)가 반대로 흔들리기 시작한 듯하다. 최근 두 가지 트렌드가 2번 진영 편에 서 있다:
Trend 1 - “Small Data” 운동[https://topicpartition.io/Small-Data]. 사람들은 두 가지를 깨닫고 있다—자신들의 데이터는 그렇게 크지 않고, 컴퓨터는 커지고 있다는 것. AWS에서 128코어, RAM 4TB 인스턴스를 임대할 수 있다. AMD는 올여름 192코어 CPU를 발표했다. 웬만해선 그걸로 충분하다3.
Trend 2 - Postgres 르네상스. 이 영역은 놀라운 성장과 투자를 받고 있다4. 지난 2년 동안 “그냥 Postgres 쓰자(모든 것에)”라는 문구가 크게 유행했다. 기본 전제는 필요하지 않은데 새 기술로 복잡하게 만들지 말고, Postgres만으로도 대부분의 문제를 꽤 잘 해결한다는 것. Postgres는 다음과 같은 특화 솔루션들과 경쟁한다:
tsvector/tsquery로 기능 지원)jsonb)CREATE UNLOGGED TABLE)pgvector, pgai)pg_mooncake, pg_duckdb)그리고… Kafka(이 블로그의 주제).
여기서의 주장은 Postgres가 이런 전문 시스템과 기능적으로 동일하다는 게 아니다. Postgres가 그들의 사용 사례 80%+를 개발 노력의 20%로 처리한다는 주장이다. (파레토 법칙)
두 트렌드를 결합하면 매력이 명확해진다. Postgres는 검증되고 널리 알려진 시스템이며 단순하고 확장 가능하며 신뢰할 수 있다. 오늘날의 강력한 하드웨어와 조합하면, 대개 조직의 스케일을 처리하는 데 최첨단의 고도 최적화된 복잡한 분산 시스템이 필요하지 않다는 사실을 빠르게 깨닫게 된다.
Kafka에 편향된 사람임에도 나는 대체로 동의한다. Kafka도 Postgres처럼 안정적이고 성숙했으며 전장(프로덕션)에서 검증되었고 강한 커뮤니티를 갖고 있다. 또한 훨씬 더 멀리 확장된다. 그럼에도 많은 경우에 적합하지 않다고 생각한다. 종종 말이 안 되는 곳에 도입되는 것을 본다.
500 KB/s 워크로드에 Kafka를 쓰면 안 된다. 문제에 대해 항상 “최고의” 기술을 고르는 스케일리티 카고 컬트가 있는데, 이는 숲을 보지 못하고 나무만 보는 격이다. “최고의” 해결책은 종종 기술적인 질문이 아니라 실용적인 질문이다. Adriano는 PG as Queue 블로그 (2023)에서 왜 “단순한 기술”을 선택해야 하는지 빈틈없는 논리를 펼친다. 이 글에 영감을 준 글이다.
배경은 이쯤 하자. 이 글에서는 세 가지 단순한 일을 한다:
나는 철저한 심층 평가를 목표로 하지 않는다. 벤치마크는 엉망진창이다. 대신, 논의를 시작할 수 있는 합리적인 데이터 포인트를 공개하는 것이 목표다.
(이 글은 Postgres를 대상으로 하지만, 마음껏 여러분이 선호하는 데이터베이스로 바꿔 생각해도 된다)
바로 결과만 보고 싶다면, 여기 있다:
🔥 The Benchmark Results
| Setup | ✍️ Write | 📖 Read | 🔭 e2e Latency5 (p99) | Notes |
|---|---|---|---|---|
| 1× c7i.xlarge | 4.8 MiB/s 5036 msg/s | 24.6 MiB/s 25 183 msg/s (5x fanout) | 60 ms | ~60 % CPU; 4 partitions |
| 3× c7i.xlarge (replicated) | 4.9 MiB/s 5015 msg/s | 24.5 MiB/s 25 073 msg/s (5x fanout) | 186 ms | ~65 % CPU; cross-AZ RF≈2.5; 4 partitions |
| 1× c7i.24xlarge | 238 MiB/s 243,000 msg/s | 1.16 GiB/s 1,200,000 msg/s (5x fanout) | 853 ms | ~10 % CPU (idle); 30 partitions |
| Setup | 📬 Throughput (read + write) | 🔭 e2e Latency5 (p99) | Notes |
|---|---|---|---|
| 1× c7i.xlarge | 2.81 MiB/s 2885 msg/s | 17.7 ms | ~60 % CPU; read-client bottleneck |
| 3× c7i.xlarge (replicated) | 2.34 MiB/s 2397 msg/s | 920 ms ⚠️6 | replication lag inflated E2E latency |
| 1× c7i.24xlarge | 19.7 MiB/s 20,144 msg/s | 930 ms ⚠️6 | ~50 % CPU; single-table bottleneck |
최소한 글의 마지막 섹션—철학하는—은 읽어보라: # Should You Use Postgres?
Postgres를 큐로 쓰는 블로그는 수십 개가 있지만, 흥미롭게도 pub-sub 메시징 시스템으로 쓰는 글은 보지 못했다.
둘이 자주 혼동되기에 간단히 구분부터 하자:
큐(Queue)는 점대점(point-to-point) 통신을 위한 것이다. 비동기 백그라운드 작업에 널리 쓰인다: 워커 앱(클라이언트)이 이메일 보내기나 알림 푸시 같은 큐의 작업을 처리한다. 이벤트는 한 번 소비되면 끝이다. 메시지는 소비되면 즉시 큐에서 삭제(팝)된다. 큐는 엄격한 순서를 보장하지 않는다7.
Pub-sub 메시징은 하나-대-다수 통신을 위한 점에서 큐와 다르다. 본질적으로 큰 읽기 팬아웃이 있다—여러 읽기 클라이언트가 동일 메시지에 관심을 가진다. 좋은 pub-sub 시스템은 데이터를 디스크에 저장해 리더와 라이터를 분리한다. 이를 통해 인메모리 큐가 OOM을 막으려 큐 깊이 최대치를 강제해야 하는 것과 달리, 최대 큐 깊이 제한을 두지 않는다.
또한 일반적으로 엄격한 순서가 기대된다—이벤트는 시스템에 들어온 순서대로 읽혀야 한다.
여기서 Postgres의 주요 경쟁자는 오늘날의 표준인 Kafka다. 다양한(대체로 상용) 대안도 있다8.
Kafka는 로그(Log) 데이터 구조를 사용해 메시지를 보관한다. 내 벤치마크는 사실상 Postgres 프리미티브로부터 로그를 재구성한다.
Postgres에는 pub-sub9 용도로 널리 쓰이는 라이브러리가 없어 직접 작성해야 했다. 내가 선택한 Kafka 영감의 워크플로는 다음과 같다:
INSERT INTO)를 생성한다. 각 트랜잭션은 하나의 배치 인서트를 담고 단일 topicpartition 테이블11을 대상으로 한다.log_counter 테이블의 특정 행이 주어진 topicpartition 테이블의 최신 오프셋을 나타낸다.topicpartition 데이터와 log_counter 행을 원자적으로 업데이트한다. 이를 통해 동시 라이터 간에 일관된 오프셋 추적을 보장한다.topicpartition 테이블(들)을 낮은 오프셋부터 순차적으로 소비하며 점진적으로 읽어 올라간다.topicpartition 테이블들에서 진도를 낸다.topicpartition 테이블당 1개의 리더를 가진다.consumer_offsets 테이블에 저장하며, 각 topicpartition,group 쌍에 대해 한 행을 가진다.이로써 Kafka와 유사한 시맨틱스를 보장한다—갭 없는 단조 증가 오프셋과 적어도 한 번/최대 한 번 처리. 이 테스트는 특히 적어도 한 번(at-least-once)을 사용하지만, 둘 중 어느 선택도 벤치마크 결과에 영향을 주지 않는다.
CREATE TABLE log_counter (
id INT PRIMARY KEY, -- topicpartition table name id
next_offset BIGINT NOT NULL -- next offset to assign
);
for i in NUM_PARTITIONS:
CREATE TABLE topicpartition%d (
id BIGSERIAL PRIMARY KEY,
-- strictly increasing offset (indexed by UNIQUE)
c_offset BIGINT UNIQUE NOT NULL,
payload BYTEA NOT NULL,
created_at TIMESTAMPTZ NOT NULL DEFAULT now()
);
INSERT INTO log_counter(id, next_offset) VALUES (%d, 1);
CREATE TABLE consumer_offsets (
group_id TEXT NOT NULL, -- consumer group identifier
-- topic-partition id (matches log_counter.id / topicpartitionN)
topic_id INT NOT NULL,
-- next offset the consumer group should claim
next_offset BIGINT NOT NULL DEFAULT 1,
PRIMARY KEY (group_id, topic_id)
);
벤치마크는 N개의 writer 고루틴을 실행한다. 이들은 라이터 클라이언트를 나타낸다. 각 라이터는 루프를 돌며 최신 오프셋을 업데이트하면서 $BATCH_SIZE 레코드를 원자적으로 삽입한다:
WITH reserve AS (
UPDATE log_counter
SET next_offset = next_offset + $1
WHERE id = $3::int
RETURNING (next_offset - $1) AS first_off
)
INSERT INTO topicpartition%d(c_offset, payload)
SELECT r.first_off + p.ord - 1, p.payload
FROM reserve r,
unnest($2::bytea[]) WITH ORDINALITY AS p(payload, ord);
벤치마크는 또한 N개의 reader 고루틴을 실행한다. 각 리더는 특정 컨슈머 그룹과 파티션에 할당된다. 그룹 전체로는 모든 파티션을 읽되, 그룹의 각 리더는 한 번에 오직 하나의 파티션만 읽는다.
리더는 루프를 돌며 트랜잭션을 열고, 낙관적으로 $BATCH_SIZE 레코드를 클레임(그들 앞까지 오프셋 마크를 전진)하고, 그것들을 선택하여 처리한다. 성공하면 트랜잭션을 커밋하고 이를 통해 그룹의 오프셋을 전진시킨다.
Kafka처럼 푸시가 아닌 풀 기반 읽기다. 리더가 폴링할 레코드가 없으면 잠시 잔다.
먼저 트랜잭션을 연다:
BEGIN TRANSACTION
그런 다음 오프셋을 클레임한다:
WITH counter_tip AS (
SELECT (next_offset - 1) AS highest_committed_offset
FROM log_counter
WHERE id = $3::int -- partition id
),
-- select & lock the particular group<->topic_partition<->offset pair
to_claim AS (
SELECT
c.group_id,
c.next_offset AS n0, -- old start offset pointer before update
-- takes the min of the batch size
-- or the current offset delta w.r.t the tip of the log
LEAST(
$2::bigint, -- BATCH_SIZE
GREATEST(0,
(SELECT highest_committed_offset FROM counter_tip) - c.next_offset + 1)
) AS delta
FROM consumer_offsets c
WHERE c.group_id = $1::text AND c.topic_id = $3::int
FOR UPDATE
),
-- atomically select + update the offset
upd AS (
UPDATE consumer_offsets c
SET next_offset = c.next_offset + t.delta
FROM to_claim t
WHERE c.group_id = t.group_id AND c.topic_id = $3::int
RETURNING
t.n0 AS claimed_start_offset, -- start = the old next_offset
(c.next_offset - 1) AS claimed_end_offset -- end = new pointer - 1
)
SELECT claimed_start_offset, claimed_end_offset
FROM upd;
그 다음, 클레임한 레코드를 선택한다:
SELECT c_offset, payload, created_at
FROM topicpartition%d
WHERE c_offset BETWEEN $1 AND $2
ORDER BY c_offset
마지막으로 데이터는 비즈니스 로직에서 처리(우리 벤치마크에서는 no-op)되고 트랜잭션을 닫는다:
COMMIT;
만약 “왜 NOTIFY/LISTEN을 안 쓰지?”라고 궁금하다면—그 기능은 최적화일 뿐 완전히 신뢰할 수 없다고 이해했다. 결국 폴링이 필요하다12. 그래서 그냥 Kafka의 비교적 단순한 설계를 복사했다.
전체 코드와 상세 결과는 GitHub의 stanislavkozlovski/pg-queue-pubsub-benchmark에 공개했다. 세 가지 설정—단일 노드 4 vCPU, 3노드 복제 4 vCPU, 단일 노드 96 vCPU—를 실행했다. 각 설정의 요약 결과는 다음과 같다:
결과는 2분 테스트 3회의 평균이다. [full results link]
Setup:
c7i.xlarge Postgres 서버, 25GB gp3 9000 IOPS EBS 볼륨
대부분 기본 Postgres 설정(synchronous commit, fsync);
autovacuum_analyze_scale_factor = 0.05 설정(효과 있는지는 불명)각 행 payload는 1 KiB (1024 bytes)
topicpartition 테이블 4개
라이터 10개(평균 파티션당 2개)
5x read fanout (컨슈머 그룹 5개)
리더 총 20개(그룹당 4개)
쓰기 배치 크기: 100 레코드
읽기 배치 크기: 200 레코드
Results:
쓰기 메시지 레이트: 5036 msg/s
쓰기 처리량: 4.8 MiB/s
쓰기 레이턴시: p99 38.7ms / p95 6.2ms
읽기 메시지 레이트: 25,183 msg/s
읽기 처리량: 24.6 MiB/s
읽기 레이턴시: p99 27.3ms (실행 간 8.9ms~47ms 변동); p95 4.67ms
엔드투엔드 레이턴시5: p99 60ms / p95 10.6ms
서버 CPU 약 ~60%
디스크는 초당 ~1200 writes, iostat 기준 46 MiB/s
꽤 좋은 결과다. 비슷한 워크로드에 복잡한 분산 시스템인 Kafka를 운영하는 사람들이 대다수라는 걸 생각하면 아이러니하다13.
이제, Kafka의 내구성과 가용성 보장을 좀 더 정확히 흉내 내기 위해 복제 구성으로 가보자.
5분 테스트 2회의 평균. [full results link]
Setup:
3× c7i.xlarge Postgres 서버, 25GB gp3 9000 IOPS EBS 볼륨
sync 레플리카, 하나는 potential14 레플리카wal_compression, max_worker_processes, max_parallel_workers, max_parallel_workers_per_gather, 그리고 물론 hot_standby 등 몇 가지 커스텀 설정
autovacuum_analyze_scale_factor = 0.05 설정(효과 있는지는 불명)각 행 payload는 1 KiB (1024 bytes)
topicpartition 테이블 4개
라이터 10개(평균 파티션당 2개)
5x read fanout (컨슈머 그룹 5개)
리더는 오직 프라이머리 DB에만 접근15; 리더는 프라이머리와 같은 AZ에 존재
리더 총 20개(그룹당 4개)
쓰기 배치 크기: 100 레코드
읽기 배치 크기: 200 레코드
Results:
쓰기 메시지 레이트: 5015 msg/s
쓰기 처리량: 4.9 MiB/s
쓰기 레이턴시: p99 153.45ms / p95 6.8ms
읽기 메시지 레이트: 25,073 msg/s
읽기 처리량: 24.5 MiB/s
읽기 레이턴시: p99 57ms; p95 4.91ms
엔드투엔드 레이턴시5: p99 186ms / p95 12ms
서버 CPU 약 ~65%
디스크는 초당 ~1200 writes, iostat 기준 46 MiB/s
이건 정말 놀라운 결과다! 처리량은 전혀 영향 받지 않았다. 레이턴시는 늘었지만 극적이지 않았다. p99 e2e 레이턴시는 3배(60ms → 185ms) 증가했지만 p95는 10.6ms에서 12ms로 거의 변하지 않았다.
이는 단순한 3노드 Postgres 클러스터가 매우 흔한 Kafka 워크로드—5 MB/s 인제스트와 25 MB/s 이그레스트—를 꽤 쉽게 버틴다는 걸 보여준다. 게다가 비용도 저렴하다. 1년에 고작 $11,51416.
일반적으로, 이 사용 사례에 효율적이도록 설계되지 않았기 때문에 특정 스케일에서는 Postgres가 Kafka보다 더 비쌀 것으로 예상한다. 하지만 여기선 아니다. Kafka를 직접 운영해도 비용은 비슷하다. 같은 워크로드를 Kafka 벤더로 돌리면 연 $50,000 이상 든다. 🤯
참고로 Kafka에서는 클라이언트 측 압축을 적용하는 게 관례다. 메시지가 5 KB이고 클라이언트가 꽤 일반적인 4배17 압축률을 적용한다고 가정하면—Postgres는 실제로 20 MB/s 인그레스와 100 MB/s 이그레스를 처리하고 있는 셈이다.
좋다, Postgres가 어디까지 가는지 보자.
결과는 2분 테스트 3회의 평균이다. [full results link]
Setup:
c7i.24xlarge (96 vCPU, 192 GiB RAM) Postgres 서버, 250GB io2 12,000 IOPS EBS 볼륨
수정된 Postgres 설정(huge_pages on, 기타 설정은 머신에 맞춰 스케일)
autovacuum_analyze_scale_factor = 0.05 설정(효과 있는지는 불명)각 행 payload는 1 KiB (1024 bytes)
topicpartition 테이블 30개
라이터 100개(평균 파티션당 ~3.33개)
5x read fanout (컨슈머 그룹 5개)
리더 150개(그룹당 5개)
쓰기 배치 크기: 200 레코드
읽기 배치 크기: 200 레코드
Results:
쓰기 메시지 레이트: 243,000 msg/s
쓰기 처리량: 238 MiB/s
쓰기 레이턴시: p99 138ms / p95 47ms
읽기 메시지 레이트: 1,200,000 msg/s
읽기 처리량: 1.16 GiB/s
읽기 레이턴시: p99 24.6ms
엔드투엔드 레이턴시5: p99 853ms / p95 242ms / p50 23.4ms
서버 CPU ~10%(사실상 아이들)
병목: 병목은 파티션당 쓰기 속도였다. 이 설계에서 테이블당 8 MiB/s(초당 8000 메시지) 이상으로 쓰기가 오르지 않는 듯했다. 더 밀어붙이지는 않았지만, 지금 와서 드는 생각은—쓰기가 어디까지 스케일했을까?
인그레스 240 MiB/s, 이그레스 1.16 GiB/s면 꽤 좋다! 96 vCPU 머신은 이 테스트엔 과했는데—더 많은 걸 해낼 수 있었거나 더 작은 머신을 써도 됐다. 참고로 이 스케일에서는 별도 Kafka 클러스터를 배포할 가치가 있다고 본다. Kafka는 Diskless Kafka 같은 기능으로 AZ 간 네트워크 트래픽을 더 효율적으로 처리해 많은 비용을 절약할 수 있다.
세 테스트 결과의 요약 표는 여기 → 👉 stanislavkozlovski/pg-queue-pubsub-benchmark
이 테스트들은 낮은 스케일에선 Postgres가 Kafka와 꽤 경쟁력이 있음을 보여준다.
눈치챘겠지만 어떤 테스트도 유난히 장시간 돌리진 않았다. 오래 돌리는 테스트의 가치는 Postgres에서 테이블 진공(VACUUM)을 검증하는 데 있다. 이는 성능에 부정적 영향을 줄 수 있다. Pub-sub 섹션에서는 테이블이 append-only이므로 VACUUM이 해당되지 않는다. 더 짧게 돌린 또 다른 이유는 비용을 통제하고 시간을 너무 많이 쓰지 않기 위해서였다18.
어쨌든, 완벽한 벤치마크란 없다. 내 목표는 “$MY_CLAIM”을 반박 불가로 증명하는 게 아니다. 오히려 가능한 것이 대부분이 생각하는 것보다 크다는 걸 보여 논의를 시작하려는 것이다. 특히 pub-sub 부분에서 이렇게 좋은 숫자가 나올 줄은 나도 예상치 못했다.
Postgres에서 큐는 SELECT FOR UPDATE SKIP LOCKED로 구현할 수 있다. 이 명령은 잠기지 않은 행을 선택해서 잠근다. 이미 잠긴 행은 건너뛴다. 이 방식으로 상호 배제가 달성된다—워커는 다른 워커의 작업을 가져갈 수 없다.
Postgres에는 매끈한 큐 API를 제공하는 매우 인기 있는 pgmq 라이브러리가 있다. 단순함을 유지하고 end-to-end 플로를 더 잘 이해하기 위해 내 큐를 직접 구현했다. 기본 버전은 매우 쉽다. 내 워크플로는 다음과 같다:
INSERT)SELECT FOR UPDATE SKIP LOCKED){여러분의 비즈니스 로직})UPDATE 또는 별도 테이블로 DELETE & INSERT)여기서 Postgres는 RabbitMQ, AWS SQS, NATS, Redis19, 그리고 어느 정도는 Kafka20와 경쟁한다.
간단한 queue 테이블을 사용한다. 큐에서 처리된 요소는 archive 테이블로 이동한다.
CREATE TABLE queue (
id BIGSERIAL PRIMARY KEY,
payload BYTEA NOT NULL,
created_at TIMESTAMP NOT NULL DEFAULT NOW()
)
CREATE TABLE queue_archive (
id BIGINT,
payload BYTEA NOT NULL,
created_at TIMESTAMP NOT NULL, -- ts the event was originally created at
processed_at TIMESTAMP NOT NULL DEFAULT NOW() -- ts the event was processed at
)
다시 N개의 라이터 클라이언트 고루틴을 실행한다. 각 라이터는 루프를 돌며 테이블에 무작위 아이템 하나를 순차적으로 삽입한다:
INSERT INTO queue (payload) VALUES ($1)
스테이트먼트당 메시지 하나만 넣기에, 스케일에서는 비효율적이다.
다시 M개의 리더 클라이언트 고루틴을 실행한다. 각 리더는 루프를 돌며 메시지 하나를 처리한다. 처리는 데이터베이스 트랜잭션 안에서 수행된다.
BEGIN;
SELECT id, payload, created_at
FROM queue
ORDER BY id
FOR UPDATE SKIP LOCKED
LIMIT 1;
-- Your business code "processes" the message. In the benchmark, it's a no-op.
DELETE FROM queue WHERE id = $1;
INSERT INTO queue_archive (id, payload, created_at, processed_at)
VALUES ($1,$2,$3,NOW());
COMMIT;
각 리더는 트랜잭션당 한 번에 오직 하나의 메시지만 처리한다.
여기서도 동일한 세 가지 설정—단일 노드 4 vCPU, 3노드 복제 4 vCPU, 단일 노드 96 vCPU—을 실행했다. 각 설정의 요약 결과는 다음과 같다:
결과는 15분 테스트 2회의 평균. 2분 테스트 3회도 실행했으며, 성능은 비슷했다. [full results link]
Setup:
Results:
내가 발견한 Postgres의 약점은 클라이언트 수 처리였다. 이 설정의 병목은 리드 클라이언트였다. 각 클라이언트는 중앙값 읽기 레이턴시와 순차적 읽기 특성 때문에 초당 ~192 메시지 이상 읽지 못했다.
클라이언트 수를 늘리면 처리량은 올라가지만 내 목표였던 ~60% CPU를 초과했다. 라이터 50, 리더 50으로 실행하면 큐 깊이를 늘리지 않고도 4000 msg/s까지 올라갔지만 서버 CPU가 100%에 달했다. 머신이 낼 수 있는 최대치를 찍기보다는 프로덕션에서 돌릴 법한 현실적인 벤치마크로 유지하고 싶었다. 이는 커넥션 풀러(모든 프로덕션 PG 배포에서 표준)나 더 큰 머신으로 쉽게 완화할 수 있다.
또 하나 언급할 점은 이 워크로드는 읽기보다 쓰기를 훨씬 더 버틸 수 있었다는 것이다. 벤치마크를 스로틀링하지 않으면 쓰기는 12,000 msg/s, 읽기는 2,800 msg/s로 나왔다. 단순함의 정신으로 더 디버그하지 않고, 쓰기를 스로틀링해 쓰기:읽기가 1:1로 안정적인 지점을 찾았다.
10분 테스트 1회. [full results link]
Setup:
3× c7i.xlarge Postgres 서버, 25GB gp3 9000 IOPS EBS 볼륨
sync 레플리카, 하나는 potential14 레플리카wal_compression, max_worker_processes, max_parallel_workers, max_parallel_workers_per_gather, 그리고 hot_standby 등 몇 가지 커스텀 설정
각 행 payload는 1 KiB (1024 bytes)
라이터 10개, 리더 15개
리더는 오직 프라이머리 DB에만 접근15; 리더는 프라이머리와 같은 AZ에 존재
Results:
예상대로 처리량과 레이턴시는 다소 영향 받았다. 하지만 크게는 아니다. 여전히 초당 2000건이 넘는다. HA 큐로서는 꽤 좋다!
2분 테스트 3회의 평균. [full results link]
Setup:
c7i.24xlarge Postgres 서버, 250GB io2 12,000 IOPS EBS 볼륨
수정된 Postgres 설정(huge_pages on, 기타 설정은 머신에 맞춰 스케일)
각 행 payload는 1 KiB (1024 bytes)
라이터 100개, 리더 200개
Results:
이 실행은 그리 인상적이지 않았다. 이 스케일의 단일 테이블 큐 접근에는 어떤 병목이 있었는데, 굳이 더 알아보지 않았다. 현실적인 시나리오라면 여러 큐가 있고 단일 큐에서 20,000 msg/s에 도달할 일은 없기 때문이다. 여러 개의 개별 큐 테이블을 병렬로 돌렸다면 96 vCPU 인스턴스는 훨씬 더 멀리 스케일했을 것이다.
세 테스트 결과의 요약 표는 여기 → 👉 stanislavkozlovski/pg-queue-pubsub-benchmark
조촐한 Postgres 노드조차도 초당 수천 건의 큐 작업을 내구성 있게 밀어낼 수 있다. 이는 단일 큐로 99% 회사가 도달하는 스케일을 이미 커버한다. 앞서 말했듯 지난 2년 사이 “그냥 Postgres 쓰자”라는 구호는 주류가 되었다. pgmq라이브러리의 스타 히스토리는 이 트렌드를 완벽히 보여준다: 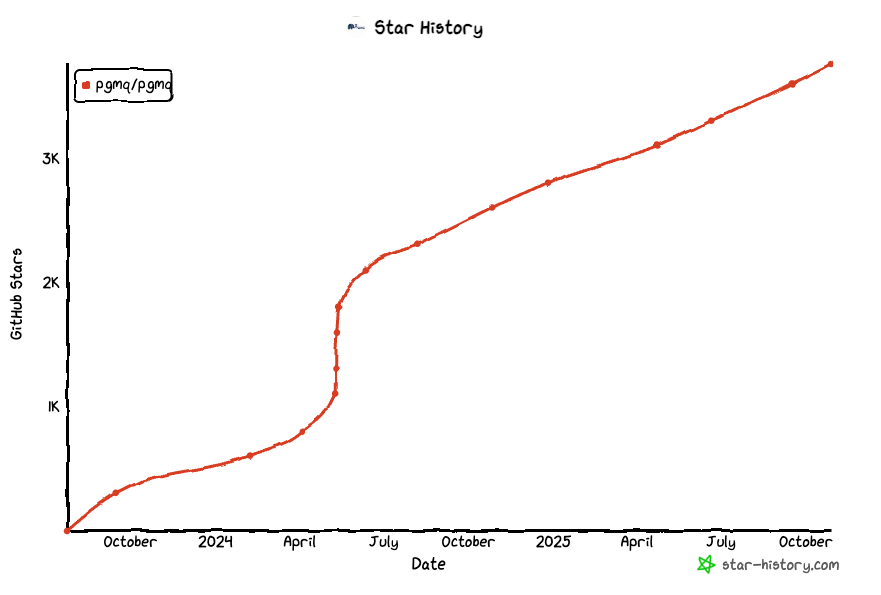
대부분의 경우—그렇다. 제약이 틀렸음을 입증할 때까지는 항상 Postgres를 기본값으로 삼아라.
Kafka는 당연히 pub-sub 워크로드에 더 최적화되어 있다. 큐 시스템은 큐 워크로드에 더 최적화되어 있다. 요지는, 기술적 최적화만으로 기술을 고르는 건 잘못된 접근이라는 것이다. 비유하자면:
포뮬러 원(F1) 차는 더 빠르게 달리도록 최적화되어 있지만, 난 출퇴근에 세단을 쓴다. 나는 F1 차보다 내 세단을 운전할 때 훨씬 더 편하다.
(진심으로, 이들의 스티어링 휠을 보라)
Postgres 세단은 F1 Kafka가 갖지 못한 많은 삶의 질 향상을 제공한다:
ID=54, name="John", cost>1000)이런 편의는 F1 차가 시속 378km(235mph)로 달리기 위해서라면 기꺼이 포기할 만하지만, 시속 25km(15mph)로 달릴 계획이라면 마조히즘이다.
Donald Knuth는 1974년에 경고했다—프리메이처 최적화는 모든 악의 근원이다. 작은 스케일에서 Kafka를 배포하는 건 프리메이처 최적화다. 이 글의 요지는 사람들이 기억하는 것보다 이 “작은 스케일” 숫자가 더 커졌다는 걸 보여주는 것이다—여러 MB/s도 편하게 의미할 수 있다.
우리는 이유가 있어 Postgres 르네상스에 있다: Postgres는 자주 충분히 좋다. 최신 NVMe와 저렴한 RAM은 그것이 터무니없이 높게 스케일하도록 해준다.
대안은 무엇인가?
순진한 엔지니어는 필요의 기미만 보여도 특화 기술을 채택하는 경향이 있다:
좋은 엔지니어는 더 큰 그림을 생각한다.
작은 스케일에서는 이런 시스템이 이익보다 해가 더 크다. 분산 시스템—노드 수와 시스템 가짓수 모두—은 존중하고, 두려워하고, 피하고, 특히 악성 문제에 대한 최후의 수단으로만 써야 한다. 분산 시스템이 되면 모든 것이 더 도전적이고 시간이 든다.
문제는 조직적 오버헤드다. 새로운 시스템을 도입하고, 그 미묘함과 설정을 배우고, 모니터링을 구축하고, 배포·업그레이드 프로세스를 수립하고, 운영 전문성을 쌓고, 런북을 만들고, 테스트하고, 디버그하고, 클라이언트와 API를 채택하고, UI를 익히고, 생태계를 따라잡는 등등의 조직적 오버헤드.
이 모든 것은 시스템이 어렵지 않더라도(많은 경우 어렵다) 제대로 갖추는 데 몇 달이 걸릴 수 있는 실제 조직적 비용이다. 매니지드 SaaS는 일부 조직적 오버헤드를 더 큰 금전적 비용과 맞바꾸지만, 그래도 모두 제거하진 못한다. 그리고 그 기술이 필요할 스케일에 도달하기 전까지는, 여러분은 추가적인 {금전적, 조직적} 비용을 의미 있는 이득 없이 지불하는 셈이다.
이미 조직적 비용을 지불한 기술(예: Postgres)로 동일한 일을 할 수 있다면, 너무 이른 시점에 다른 것을 채택하는 건 확실한 안티 패턴이다. 웹 스케일 문제가 없을 때 웹 스케일 기술은 필요 없다.
내가 더 낫다고 생각하는 접근은 최소 실행 가능한 인프라(MVI, minimum viable infrastructure)를 추구하는 것이다: 가치를 제공하면서도 가능한 가장 작은 시스템을 구축하라.
조직이 이미 익숙한 충분히-좋은(good-enough) 기술을 선택하라 * 충분히-좋은 == 너무 느리거나/비싸거나/불안하지 않으면서 사용자 요구를 충족 * 익숙한 == 조직에 선경험, 런북/운영 셋업, 모니터링, UI 등이 갖춰져 있음
그것으로 실제 문제를 해결하라
최소한의 기능만 사용하라 * 적은 기능을 쓸수록 미래에 해당 인프라에서 이탈할 유연성이 커진다(예: 벤더 락인 완화)
보너스 포인트—그 기술이:
MVI 접근은 인프라의 표면적을 줄인다. 움직이는 부품이 적을수록 걱정할 실패 모드가 줄고 유지할 글루 코드도 적다.
안타깝게도, 인간의 본성은 이와 반대로 흐른다. 스타트업이 MVP 비대화에 고통받듯 (기능 하나만 더!), 인프라 팀도 MVI 비대화에 고통받는다 (시스템 하나만 더!)
정확한 경로 의존적 결과를 매핑할 수 있다고는 못하지만, 내 추측은 이렇다:
이 트렌드는 반대 관점을 충분히 밀 만한 강력한 경쟁력이 없기에 계속 커진다. 단순함을 유지하려 동기 부여가 되어 있어야 할 회사 내부의 엔지니어조차 추가 복잡성을 추구할 강한 유인을 갖는다. 다음 승진을 위한 프로젝트 탄약을 주고 다음 이직을 위한 이력서(멋진 기술/스토리)를 개선해주기 때문이다. 게다가 그냥 더 재미있다.
그래서 업계로서 우리는 항상 가장 단순한 해결책을 쓰지 않는다고 생각한다.
대부분의 경우, Postgres가 그 단순한 해결책이다.
이제 글을 마무리하고 싶지만, “그건 스케일 안 된다”라는 반론은 꼭 다루고 싶다.
그 주장은 대략 이렇다: “오늘날 우리는 한순간에 바이럴 될 수 있다; 이런 바이럴 순간은 비즈니스에 매우 가치 있으므로, 트래픽 급증에서도 앱이 안정적으로 버티도록 공격적으로 설계/테스트해야 한다”
이에 대한 내 반박은 세 가지다:
2025년 현재, OpenAI는 여전히사용한다 샤딩되지 않은 Postgres 아키텍처를—쓰기용 단 하나의 프라이머리 인스턴스만으로22. OpenAI는 급격한 바이럴 성장의 전형적 사례다. 그들은 가장 빠르게 1억 사용자에 도달한 스타트업 기록을 보유한다.
OpenAI 인프라 팀의 일원이고 OtterTune 공동 창업자인 Bohan Zhang은 다음과 같이 말한다23:
“OpenAI에서는 하나의 writer와 여러 reader를 둔 비샤딩 아키텍처를 사용하며, PostgreSQL이 거대한 읽기 부하에서도 우아하게 스케일할 수 있음을 보여준다.”
“내 발표의 핵심 메시지는, 쓰기 부하가 너무 크지 않다면 단 하나의 마스터만으로도 리드 레플리카를 통해 매우 높은 읽기 처리량까지 Postgres를 스케일할 수 있다는 것이다! 이는 앱의 ‘대다수’를 포괄하는 메시지다.”
“Postgres는 아마 지금 개발자들의 기본 선택일 것이다. 매우 오랫동안 Postgres를 쓸 수 있다. 읽기 중심 워크로드의 스타트업을 만든다면, 그냥 Postgres로 시작하라. 스케일 문제에 부딪히면 인스턴스 크기를 키워라. 매우 큰 스케일까지 스케일할 수 있다. 미래에 데이터베이스가 병목이 된다면 축하한다. 당신은 성공적인 스타트업을 만들었다. 좋은 문제다.”
(명확성과 문법을 위해 약간 편집함)
그들의 폭발적 성장 속에도 8억 이상의 사용자 기반에서 OpenAI는 여전히 웹 스케일 분산 데이터베이스를 선택하지 않았다. 그들이 안 했다면… 검증되지 않은 당신의 프로젝트가 왜 필요한가?
현재 스케일의 약 10배를 설계/테스트하는 게 좋은 원칙이라고 해보자. 현재 스케일의 10배에 도달하는 데 필요한 연간 ‘지속적’ 성장률과 연수는 다음과 같다:
| annual growth | years to hit 10× scale |
|---|---|
| 10 % | 24.16 y |
| 25 % | 10.32 y |
| 50 % | 5.68 y |
| 75 % | 4.11 y |
| 100 % | 3.32 y |
| 150 % | 2.51 y |
| 200 % | 2.10 y |
극단적 성장률에서도 다른 솔루션로 마이그레이션할 시간이 ‘여전히 몇 년’은 있음을 보여준다. 하지만 개발자의 다수는 연간 0-50% 성장률의 회사에서 일한다. 그들은 솔루션을 바꿀 때가 오기 전에 더 일찍 다른 직장으로 옮겨갈 가능성이 크다(있다면).
이상적인 세상에서는, 당신은 스케일과 앞으로 10년간 마주할 모든 문제까지 대비해 구축할 것이다.
현실 세계에서는, 당신의 대역폭은 유한하고, 가장 즉각적이고 ROI가 가장 높은 문제를 위해 구축해야 한다.
lobste.rs의 댓글러 snej가 이를 잘 포착했다:
당신의 인프라를 그런 상황(극단 트래픽)을 처리할 수 있게 계획하는 것은, 마치 당신의 차고 밴드가 콜드플레이 오프닝 무대에 초대받을지도 모른다고 해서 첫 기타 앰프로 거대한 마샬 스택을 사는 것과 같다.
그냥 Postgres를 쓰다가—부러질 때까지.
제목 영감은 최근의 훌륭한 글—“Redis is fast - I’ll cache in Postgres”—에서 가져왔다.
나는 완전한 Postgres 초보다. 여기서 멍청한 실수를 많이 볼 수도 있다. 기꺼이 지적해주길 바란다—배우길 원한다. 일부 PG 도구 사용에는 AI의 도움을 많이 받았다. 이는 내가 문맥에 미숙하다는 점과 동시에 시작하기가 얼마나 쉬운지를 보여준다. 단기적으로 AI의 약속에 대해 대체로 회의적이지만, 틈새/저수준 지식의 민주화에 큰 흔적을 남겼다는 건 부정할 수 없다.
연락하고 싶다면 LinkedIn이나 X (Twitter)에서 나를 찾을 수 있다.
이 용어들을 완전히 이해하지 못해도 걱정하지 마라. 나는 이런 걸 뿜어내는 업계에서 풀타임으로 일하지만 나도 잘 모른다. 마케팅 찌꺼기다. ↩
Gartner 등은 기술 주도가 아닌 민망한 권고를 내놓는다. 종종 정반대—이익 주도다. Gartner는 오직 보고서 접근권을 위해 조직당 ‘좌석당’ $50k를 청구하는 컨설팅 서비스만으로 $6.72B를 번다. 이런 찌꺼기 아키텍처를 추천한다. pay-to-win 바가지 모델이라는 생각이 모이는 것도 이상하지 않다. ↩
솔직히, 하드웨어의 발전을 대부분의 시니어 엔지니어가 제대로 체감하지 못했다고 본다. 최신 세대 AMD CPU는 192코어를 자랑한다. 최신 SSD는 초당 무작위 읽기 550만 건, 또는 순차 읽기 약 28GB/s가 가능하다. 둘 다 지난 10년 대비 10-20배 향상이다. 단일 노드는 그 어느 때보다 강력하다. ↩
최근 6개월만 봐도—Snowflake가 Crunchy Data를 약 $2.5억에 인수, Databricks가 Neon을 10억 달러에 인수; 최근 12개월 동안 Supabase는 밸류에이션을 5배 이상(9억 → 50억) 올렸고, 단일 해에 세 번의 시리즈로 $3.8억을 조달했다(!!!). ↩
여기서의 엔드투엔드 레이턴시는 now() - event_create_time으로 정의된다; 본질적으로, 새로 영속화된 이벤트가 소비되기까지 얼마나 걸리는지를 추적한다. 이는 컨슈머가 일시적으로 라이트 레이트를 따라잡지 못할 때처럼 큐 지연이 튀는 경우를 보여주는 데 도움된다. ↩↩2↩3↩4↩5↩6↩7
일부 큐 테스트는 더 높은 E2E 레이턴시를 보였는데, 버그 때문이라고 본다. Pub-sub 테스트에서는 1000ms 슬립을 통해 리더가 라이터보다 먼저 시작하도록 보장했다. 그러나 큐 테스트에서는 그렇게 하지 않았다. 그 결과 테스트 시작 시 라이터가 먼저 앞서 나가 큐 깊이가 즉시 튄다. 이 결함 때문에 E2E 레이턴시가 인위적으로 높아졌다고 본다. ↩↩2↩3↩4
사실, 해피 패스에서는 순서가 지켜진다. 재시도 중에만 순서가 어긋날 수 있다. 예: t=0에 클라이언트 A가 작업 N을 읽는다; t=1에 클라이언트 B가 작업 N+1을 읽어 성공적으로 처리한다; t=2에 A가 실패해 N을 처리하지 못한다; t=3에 클라이언트 B는 다음 사용 가능한 작업—N—을 가져간다. 따라서 B는 [N+1, N] 순서로 실행하며, 올바른 순서는 [N, N+1]이었다. ↩
오픈소스 프로젝트로는 Apache Pulsar (오픈소스), RedPanda (소스-어베일러블), AutoMQ (Kafka 포크)가 있고, 상용도 많다—AWS Kinesis, Google Pub/Sub, Azure Event Hubs, Confluent Kora, Confluent WarpStream, Bufstream 등. 이들 프로젝트의 90%에서 공통적인 점은 모두 Apache Kafka API를 ‘구현’한다는 점으로, Kafka가 이 영역의 프로토콜 표준임을 의심의 여지없이 만든다. 또한 플러그형 Postgres나 S3 백엔드 위에 Kafka API를 노출하는 오픈소스 프로젝트 Tansu도 있다(Rust, btw :] ). ↩
내가 찾은 가장 인기 있는 라이브러리는 pg-pubsub로, 작성 시점(2025년 10월) 106 스타다. 마지막 커밋은 3개월 전. ↩
클라이언트별 메시지 배칭은 여기서 스케일에 매우 중요하다. 이는 Kafka의 잘 알려지지 않은 성능 “트릭” 중 하나다. ↩
이 테이블들은 서로 다른 로그 데이터 구조로 동작한다. 별도의 ‘토픽’이거나 하나의 토픽의 ‘파티션’(샤드)으로 볼 수 있다. ↩
Postgres는 모든 NOTIFY 이벤트를 단일 전역 큐에 저장한다. 이 큐가 가득 차면 NOTIFY를 호출하는 트랜잭션은 커밋 시 실패한다. (src) ↩
RedPanda의 보고서에 따르면 응답자의 약 55%가 1 MB/s 미만의 Kafka를 사용한다. Kafka 벤더 Aiven도 유사하게 공유했듯, 그들의 Kafka 배포의 50%가 10 MB/s 미만의 인제스트 레이트를 가진다. ↩
이 복제는 Kafka의 RF=2와 동등하며, 비동기 레플리카 하나가 추가된 형태다. RF=2.5라고 부르자. 클라이언트는 하나의 sync 레플리카가 변경을 확인하면 응답을 받는다. 다른 potential 레플리카는 쓰기 경로를 막지 않고 비동기로 복제한다. 만약 다른 레플리카가 죽으면 sync로 승격된다. ↩↩2
테스트는 스탠바이로 읽기 트래픽을 전송하지 않았다. 이는 프라이머리에 추가 부하를 유발했다—대부분의 프로덕션 워크로드는 스탠바이에서 읽는다. 그럼에도 결과는 여전히 좋았다! 내 테스트에서 추가 읽기 워크로드는 DB에 부정적 영향을 주지 않는 듯했다—이런 꼬리 읽기는 캐시에서만 제공된 듯하다. ↩↩2
노드와 디스크 비용은 연 $1826이다. 이를 3대 운영하므로 연 $5478. AWS에서 네트워킹은 GB당 $0.02이며, 우리의 설정은 4.9MB/s를 두 인스턴스에 걸쳐 복제한다—이는 연 294.74TB의 AZ 간 네트워킹에 해당. 즉, 복제 네트워킹 비용은 연 $6036. 클라이언트가 쓰기/읽기하는 DB와 동일 AZ에 있다면 그 네트워킹은 무료다. 연 비용은 $11,514가 된다. ↩
로그처럼 압축 가능한 데이터에서 10배+ 압축률을 현실적으로 달성할 수 있다(이는 Kafka의 흔한 사용처). 단 하나의 주의점은 더 큰 배치—예: 25KB+—를 압축해야 한다는 점으로, pub-sub 데이터 모델에서 약간의 재설계가 필요하다. ↩
이미 이 벤치마크에 충분한 근무일을 썼고, 벤치마크와 방법론을 반복하면서 수없이 테스트를 재실행했다. 대형 인스턴스에서는 비용이 빠르게 누적되고, 높은 MB/s 레이트로 오랜 시간 테스트하려면 누적 데이터를 저장하기 위해 훨씬 더 크고 비싼 디스크를 배포해야 한다. 들인 노력은 이 글의 목표와 부합한다. 더 철저한 조사를 후원할 Postgres 벤더가 있다면—연락 바란다! ↩
놀랍게도(나에겐), Redis는 백그라운드 작업을 위한 큐 유사 백엔드로 매우 인기 있다. 가장 인기 있는 오픈소스 라이브러리 대다수가 이를 사용한다. PG도 충분히 잘 할 수 있다고 확신하지만, 많은 개발자는 바닥부터 만들거나 덜 잘 관리되는 것을 쓰기보다, 확립된 라이브러리를 선호할 것이다. PG 기반 라이브러리도 개발되어야 한다고 본다! ↩
역사적으로 Kafka는 큐가 아니었다. 큐로 쓰려면 어려운 우회로를 개발해야 했다. 하지만 오늘날 Kafka는 일급 큐 유사 인터페이스를 구현 중이다(현재 프리뷰). ↩
가장 중요하게, synchronous commit과 fsync가 모두 켜져 있다. 이는 모든 쓰기가 디스크에 내구성 있게 영속화됨을 의미한다. ↩
이 스케일을 지원하기 위해 그들이 한 최적화는 멋지지만, 새롭진 않다. 두 발표를 보라: a) PGConf.dev 2025 (내 트랜스크립트)와 b) POSETTE (내 트랜스크립트) ↩
발표 출처: PGConf.dev 2025 (내 트랜스크립트)와 POSETTE (내 트랜스크립트) ↩