생물학적 진화가 성적 재조합과 유전자 공유를 통해 탐색 과정을 어떻게 모듈화하고 정보를 더 빠르게 획득하는지 살펴본다.
몇 주 전 우리는 경제학자 Brian Arthur의 기술 진화 시뮬레이션을 살펴보았다. 그 시뮬레이션에서 그는 단순한 구성 요소들(예를 들어 NAND gate)로 시작해, 점점 더 유용한 기존 구성 요소들을 무작위로 결합함으로써 놀랄 만큼 복잡한 회로들(예를 들어 12-way AND gate나 4-bit adder)을 진화시킬 수 있었다. 우리는 이것을 탐색 문제를 단순화하는 한 방법으로 분석했다. 즉, 이미 작동하는 기존 구성 요소를 몇 개씩 결합해 더 복잡한 모듈을 만들고, 다시 그것들 을 더 복잡한 모듈로 결합하는 방식은 탐색 트리에서 전망이 없고 시간이 많이 드는 많은 가지를 미리 걸러낸다. 그 결과 시뮬레이션은 엄청나게 많은 분기 가능성 속에서도 유용한 기술을 찾아낼 수 있다.
물론 실제 인간의 기술은 구성 요소를 무작위로 결합해 보고 쓸모가 있는지 확인하는 방식으로 생성되지 않는다. 이런 시뮬레이션에서의 무작위성은 단지 서로 다른 조건에서 새로운 기술을 만들어내는 일이 얼마나 쉽거나 어려운지를 보기 위한 수단일 뿐이다. 하지만 생물학적 기술 — 미세한 단세포 생물에서부터 737 크기의 고래에 이르기까지, 지구에 존재하는 방대한 생명체의 총체 — 역시 무작위성에 의해 생성된다. 진화는 유전적 변이의 결실을 활용해 생물학적 기술을 조금씩 구축하며, 이 변이는 흔히 무작위 돌연변이에 의해 발생한다. 그리고 더 적합한 개체가 자신의 유전자를 미래로 더 잘 전파하도록 우선적으로 선택된다. 수십억 년에 걸쳐 이 과정은 놀라울 정도로 복잡한 생물학적 시스템을 만들어낼 수 있다.
흥미로운 점은 생물학적 진화가 Arthur의 회로 시뮬레이션과 매우 비슷한 요령을 사용한다는 것이다. 유전적 수준의 모듈성을 활용함으로써, 개체군은 유용한 유전 변이가 집단 전체로 퍼지는 속도를 높일 수 있고, 그 결과 사실상 정보 획득 속도를 높일 수 있다. 성적 생식은 수평적 유전자 전달 같은 다른 유전 물질 공유 방식들과 함께, 본질적으로 이를 수행하는 메커니즘이다. 몇 가지 간단한 시뮬레이션으로 이를 보여줄 수 있다.
생물이 번식하는 가장 단순한 방식은 무성생식이다. 이 경우 부모는 자기 자신의 유전적 복사본인 자식을 만든다. 예를 들어 단순한 단세포 생물은 세포 분열을 통해 번식하며, 둘 혹은 그 이상의 “자식”으로 나뉘고, 각 자식은 원래 부모와 동일한 유전자를 가진다.
하지만 자식이 반드시 부모와 완전히 동일한 복사본인 것은 아니다. 유전적 돌연변이 때문에, 분열 과정 중 일부 유전자가 무작위로 바뀔 수 있으며, 그 결과 자식은 약간 다른 유전자를 갖게 된다. 어떤 경우에는 이런 돌연변이가 유용할 수 있으며, 항생제 내성 같은 추가 기능을 부여해 생존과 번식의 확률을 높여줄 수 있다. 생물의 적합도에 기여하기 때문에, 시간이 지나면 유용한 돌연변이는 개체군에서 점점 더 흔해진다.
이것은 간단한 시뮬레이션으로 보여줄 수 있다. 우리의 시뮬레이션은 100마리의 생물 개체군으로 시작하며, 각 개체는 200개의 개별 유전자로 이루어진 유전체를 가진다. 유전자는 1(유전자의 “좋은” 버전) 또는 0(“나쁜” 버전)일 수 있다. 초기 개체군은 무작위이며, 각 개체는 대략 좋은 유전자와 나쁜 유전자가 반반 섞여 있다. 시뮬레이션의 각 반복에서 각 개체는 두 자식을 만든다. 자식은 부모의 유전자를 복사하지만, 돌연변이 때문에 각 유전자는 0.2% 확률로 뒤집혀 1에서 0으로 또는 그 반대로 바뀐다. 가장 적합한 100명의 자식들(여기서 적합도는 단순화된 모델에서 1이 “좋은” 유전자이므로 각 유전자 값의 합이다)이 다음 세대로 선택되고, 이 사이클이 반복된다. 이는 실제 진화 작동 방식에 비해 단순화된 것이다. 예를 들어 각 유전자가 적합도에 독립적으로 기여한다고 가정하며, 실제로는 한 유전자의 적합도 값이 다른 유전자들에 의존하는 경우가 많다는 사실을 무시한다. 하지만 작동하는 역학을 보여주기에는 충분하다.
이 시뮬레이션을 실행하면, 적합도가 더 높은 자손이 적합도가 낮은 자손을 경쟁에서 이기면서 개체군 내 “좋은” 유전자의 비율이 시간이 지남에 따라 꾸준히 상승한다. 돌연변이율에 따라 개체군은 결국 가능한 최대 적합도 200에 도달할 수도 있고, 그보다 낮은 어떤 수준에서 정체될 수도 있다.
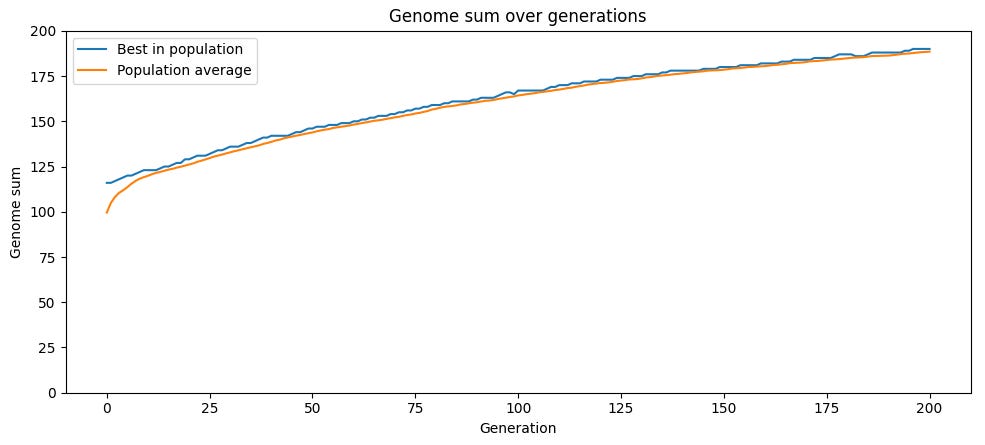
이 전략의 문제점 — 하나의 부모에 대한 잡음이 섞인 복사본인 자식을 만들고, 유전적 변이의 원천으로 순전히 무작위 돌연변이에만 의존하는 방식 — 은 평균보다 높은 적합도에 도달하면 돌연변이가 평균적으로 해로울 가능성이 높다는 것이다. 어떤 유전체가 0보다 1을 더 많이 가지고 있다면, 무작위 변화는 0을 1로 바꾸는 것보다 1을 0으로 바꿀 가능성이 더 크다. 따라서 평균 이상의 적합도를 가진 부모의 경우, 자식은 평균적으로 부모보다 적합도가 낮다.
그럼에도 돌연변이는 무작위이기 때문에 변이는 여전히 존재하며, 어떤 자식들은 부모보다 더 높은 적합도를 갖게 된다. 그리고 매 반복마다 선택이 가장 적합도가 낮은 개체들을 제거하기 때문에, 선택된 자식 집단은 부모보다 더 높은 평균 적합도를 갖게 되어 평균 적합도는 시간이 지남에 따라 증가할 수 있다. 하지만 돌연변이가 평균 적합도를 감소시키기 때문에 이 과정은 발목이 잡힌다.
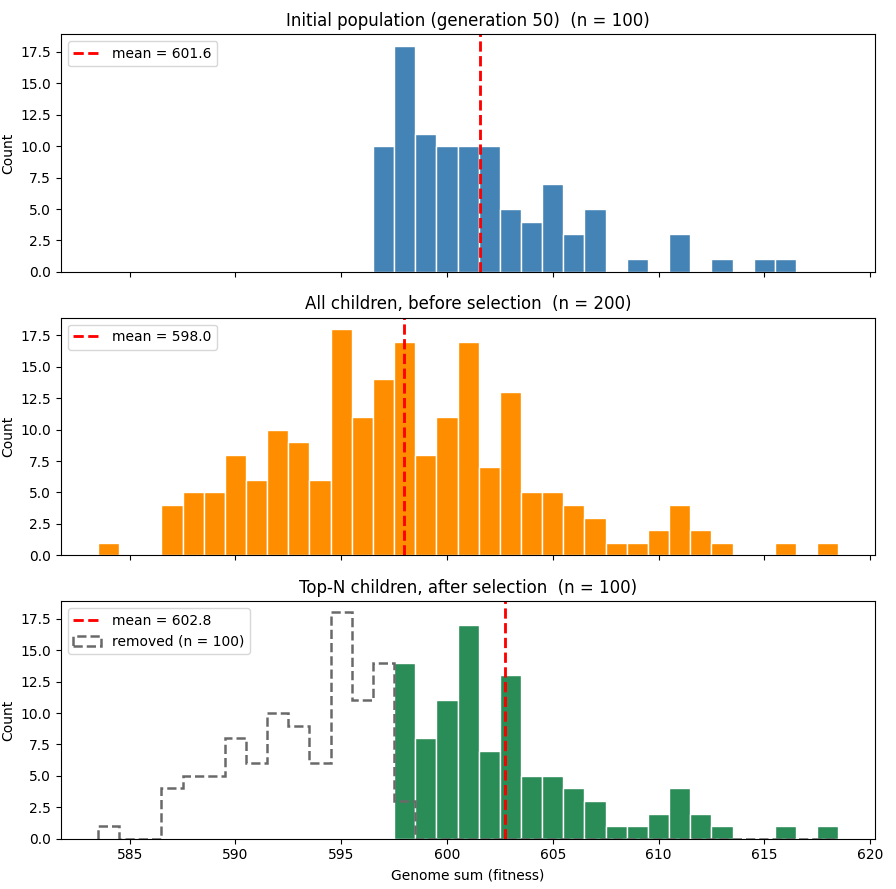
이 점은 아래 그래프에서 볼 수 있다. 더 쉽게 경향을 보기 위해 약간 다른 매개변수(유전체 길이 1000, 돌연변이율 2%)를 사용한 시뮬레이션이다. 맨 위 그래프는 50세대 시점의 개체군 적합도 분포를 보여주고, 두 번째 그래프는 선택 이전 개체군 자식들의 분포를 보여준다. 돌연변이 덕분에 평균 적합도가 떨어졌지만, 무작위성 때문에 일부 자식들은 운 좋게 더 높은 적합도를 얻게 되었음을 볼 수 있다. 마지막 그래프는 분포의 상위 절반이 선택된 뒤의 자식들을 보여준다. 평균 적합도는 상승하며 이제 초기 개체군보다 높지만, 그 차이는 겨우 미미하다.
이제 다른 번식 전략의 시뮬레이션을 보자. 바로 성적 생식이다. 이 경우 자식은 한 부모가 아니라 두 부모로부터 유전자를 받는다. 이 시뮬레이션에서도 우리는 여전히 200개 유전자를 가진 100마리 생물의 개체군을 사용하며, 각 유전자는 0 또는 1일 수 있다. 하지만 이제 자식에게는 두 부모가 있고, 각 반복에서 개체군 구성원들은 무작위로 짝지어지며 각 쌍은 네 자식을 만든다. 자식은 두 부모 모두에게서 유전자를 받는데, 각 유전자는 특정 부모에게서 올 확률이 50%다. 그런 다음 가장 적합한 상위 100명의 자식이 다음 세대로 선택되고, 반복이 계속된다. 이 시뮬레이션에는 돌연변이가 없으므로 유전적 변이는 전적으로 부모 유전자의 재배열에서 나온다.
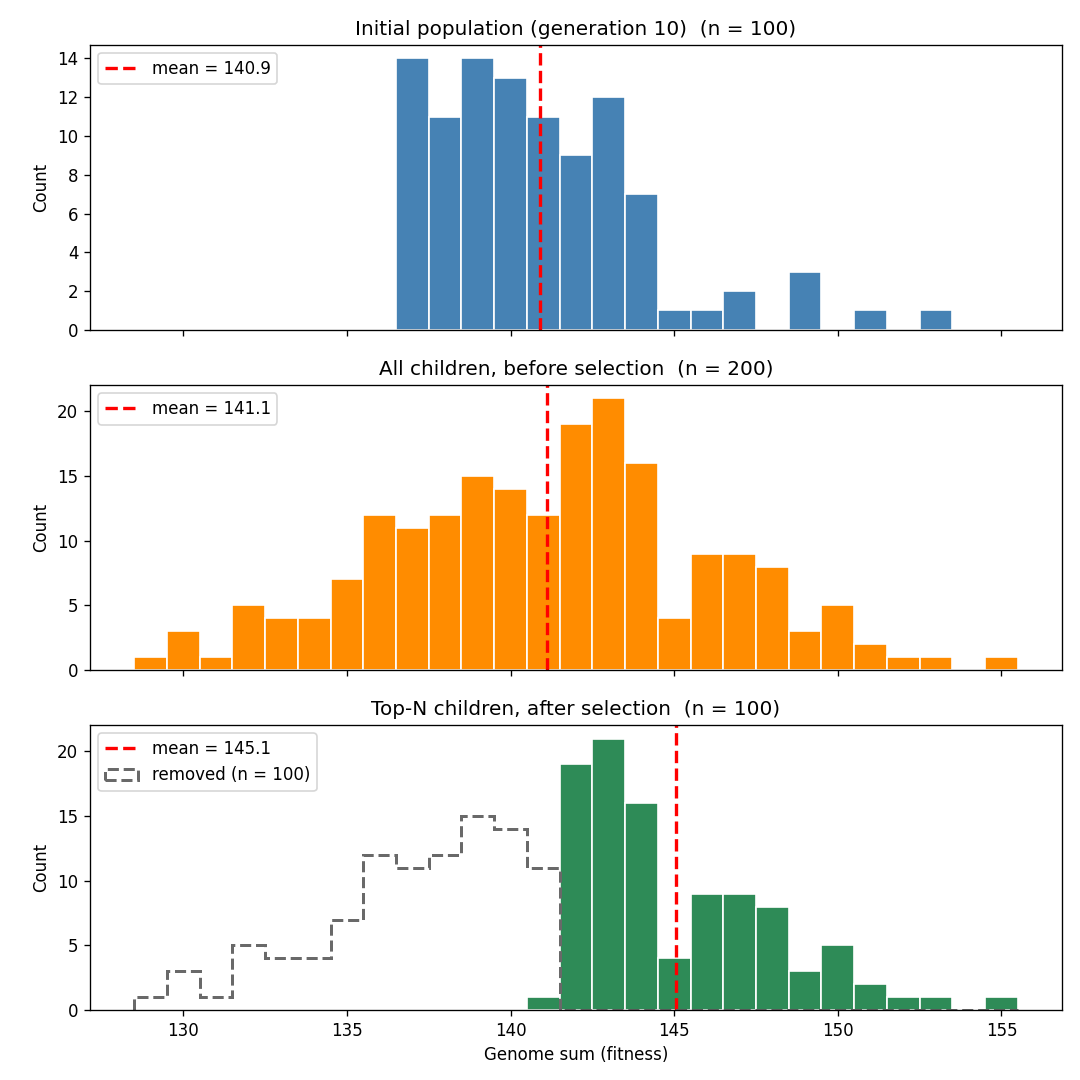
앞선 시뮬레이션과 마찬가지로 개체군은 점차 최대 적합도에 도달한다. 하지만 성적 생식은 훨씬 더 빠르게 거기에 이른다. 무성생식에서는 200세대 후 개체군 평균 적합도가 약 187이었다. 성적 생식에서는 개체군 평균이 단 33세대 만에 적합도 최대치 200에 도달했다.
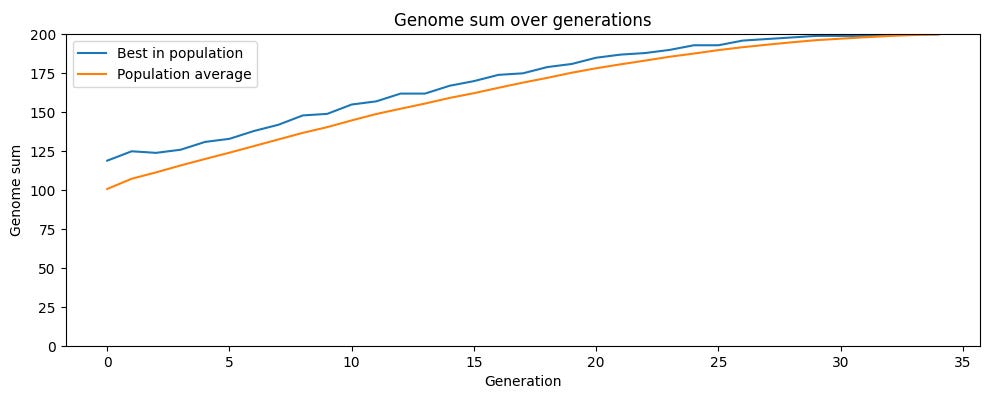
핵심은 성적 생식이 평균 적합도를 낮추지 않으면서 유전적 변이를 도입한다는 점이다. 자식은 부모 유전자의 무작위 조합이므로, 평균적으로는 부모와 같은 적합도를 가진다(일부는 무작위로 더 높은 적합도를 갖고, 다른 일부는 무작위로 더 낮은 적합도를 갖는다). 다음 세대를 위해 가장 적합한 자식들을 선택하는 것은 무성생식 시뮬레이션의 자식 분포보다 평균이 훨씬 높은 분포에서 상위 절반을 취하는 셈이다. 따라서 평균 적합도는 훨씬 더 빠르게 상승한다.
수학을 직접 전개해 보거나(혹은 나처럼 단순히 누군가 이미 전개해 둔 수학을 읽어 보면), 무성 개체군에서 적합도 증가율은 1/(8*f)이며, 여기서 f는 차등 정규화 적합도 다. (개체군의 정규화 적합도는 그 개체군에서 좋은 유전자가 차지하는 평균 비율이다. 따라서 유전체 200개 중 평균적으로 한 구성원이 좋은 유전자 150개를 가진다면 정규화 적합도는 0.75가 된다. 차등 정규화 적합도는 개체군의 정규화 적합도에서 무작위로 생성된 개체군의 정규화 적합도인 0.5를 뺀 값이다.) 초기에는 개체군의 적합도가 빠르게 증가할 수 있지만, 증가율은 곧 세대당 적합도 1단위 증가 아래로 떨어진다(즉 평균적으로 한 유전자가 0에서 1로 뒤집히는 정도). 개체군이 가능한 최대 적합도에 가까워질수록, 적합도 증가율은 0.25에 수렴한다(평균적으로 네 세대마다 한 번 한 유전자가 0에서 1로 뒤집힘).
반면 성적 생식에서는 적합도 증가율이 훨씬 더 높으며, 유전체 길이의 제곱근에 비례한다.
성적 생식이 왜 그렇게 강력한지 생각하는 한 가지 방법은 계통을 보는 것이다. 무성생식하는 개체군의 구성원 하나가 새로운 유용한 돌연변이를 우연히 얻었다고 하자. 유전자는 한 부모에서 한 자식에게 전달되므로, 이 유전자가 개체군 전체로 퍼지는 유일한 방법은(개체군의 다른 구성원도 우연히 같은 돌연변이를 얻지 않는 한) 그것을 가진 개체의 자식들이 다른 모든 개체의 자식들보다 경쟁에서 이기는 것이다. 이 시나리오에서는 결국 개체군 전체가 특정 한 구성원의 후손으로만 이루어지게 된다. 이 확산의 필수 조건으로서, 다른 모든 유전 계통은(그리고 그들이 우연히 얻었을지 모를 유용한 돌연변이들과 함께) 사라진다.
이 점은 시뮬레이션 결과에서도 확인할 수 있다. 아래 차트는 초기 개체군의 각 구성원과 그 자식들에게 고유한 색을 부여한다. 시뮬레이션은 100가지 다른 색(개체군의 각 구성원당 하나)으로 시작하지만, 이는 곧 훨씬 더 적은 수로 줄어든다. 몇 세대 후에는 개체군이 한 가지 균일한 색이 되는데, 모두 초기 개체군의 특정 한 구성원의 후손이다. (이 차트는 특정 한 번의 시뮬레이션 실행 결과지만, 반복 실행해도 같은 행동이 나타난다.)
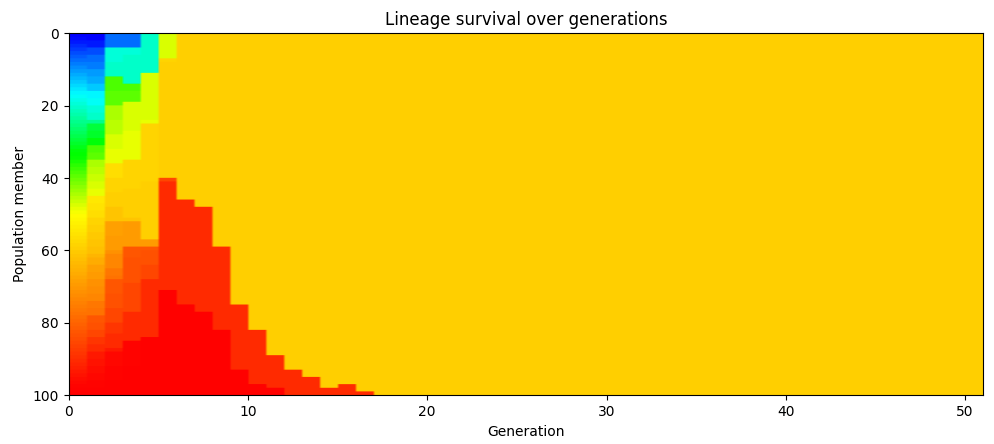
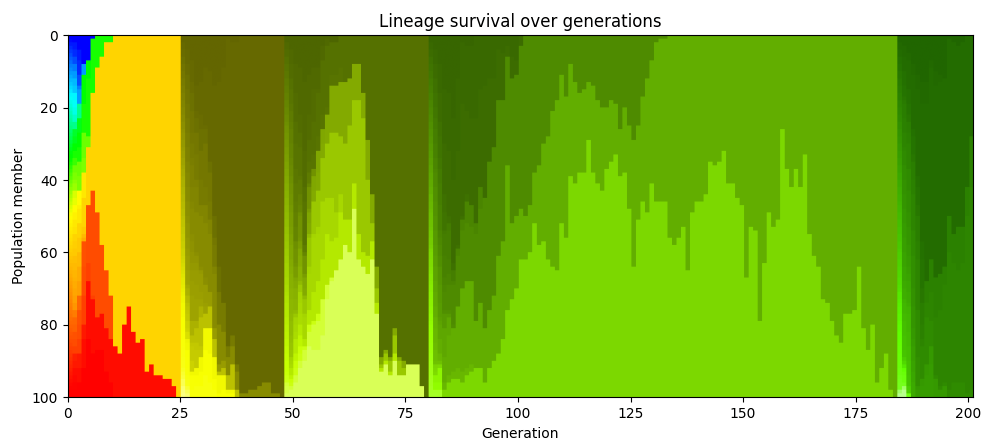
개체군 전체가 단일 조상의 후손이 되는 지점에 도달할 때마다 색상 코딩을 다시 하면, 이런 일이 반복적으로 일어남을 볼 수 있다. 아래 차트에서 48세대의 개체군은 25세대에 살았던 특정 한 구성원의 후손들로만 이루어져 있다. 80세대에서는 48세대에 살아 있던 특정 한 구성원의 후손들로만 이루어진다.
진화생물학에서 이 현상은 “클론 간섭”으로 알려져 있다. 같은 세대의 개체군 구성원들 중 서로 다른 개체에서 두 개의 유익한 돌연변이가 발생하면 그것들을 공유할 수 없기 때문에 서로 경쟁하게 되고, 결국 하나의 유익한 돌연변이는 사라지게 된다.
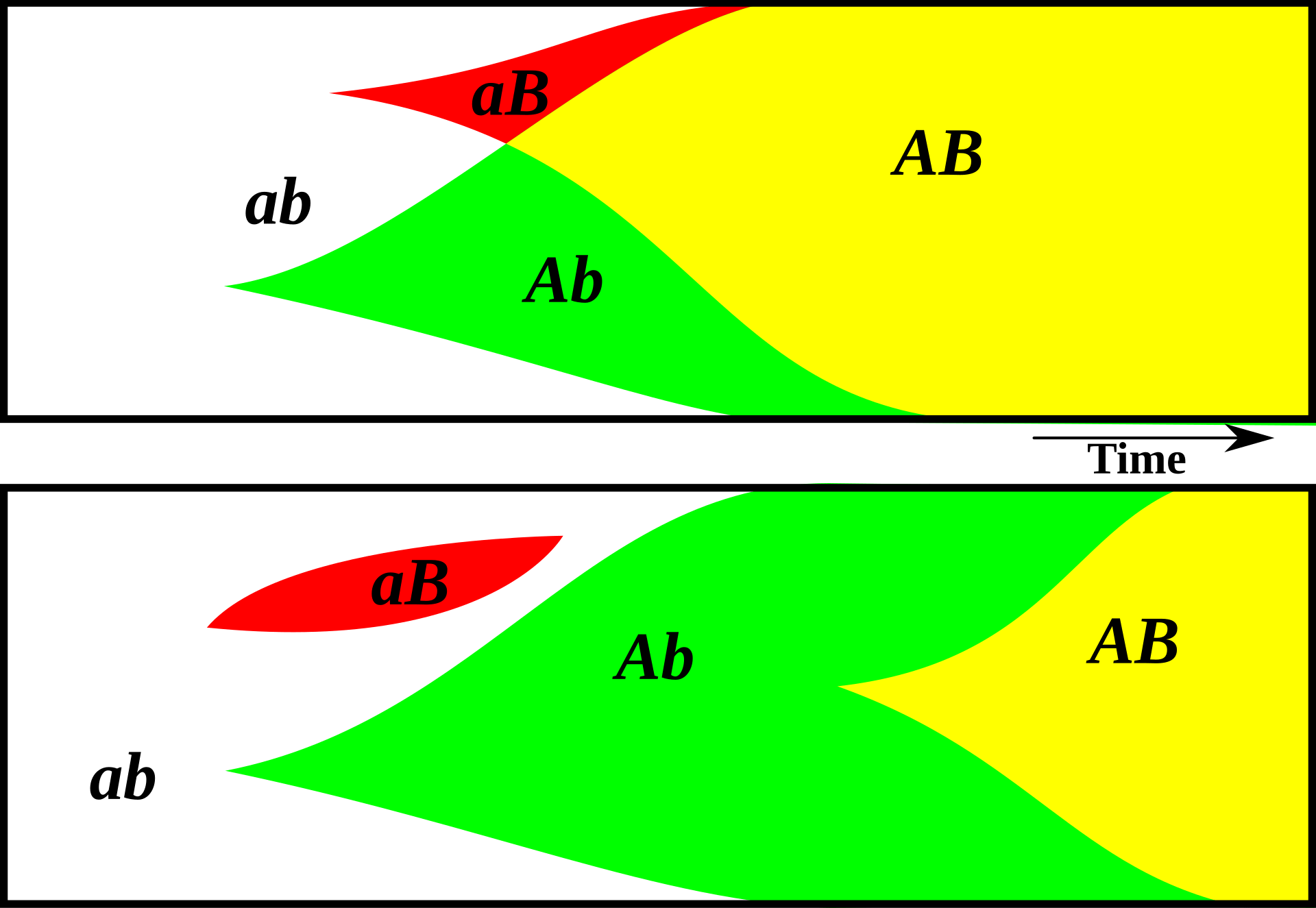
Wikipedia를 통한 클론 간섭 이미지. 아래쪽의 무성생식 개체군 그림에서는 유익한 돌연변이 “B”와 “A”가 서로 다른 계통에서 나타나지만, 이후 “B”는 사라지고, 나중에 돌연변이를 통해 다시 나타난 뒤 개체군 전체로 퍼진다. 위쪽의 성적 생식 개체군 표현에서는 B와 A가 독립적으로 나타나지만 빠르게 공유될 수 있어 개체군 전체로 훨씬 더 빨리 퍼진다.
반면 성적 생식을 하는 개체군에서는 유용한 돌연변이가 훨씬 더 쉽게 공유될 수 있다. 무성 개체군에서 한 구성원은 부모 하나, 조부모 하나, 증조부모 하나를 갖고, 이런 식으로 이어진다. 하지만 성적 개체군에서 한 구성원은 부모 둘, 조부모 넷, 증조부모 여덟을 가진다. 이전 세대의 유익한 변이는 훨씬 더 쉽게 퍼질 수 있다.
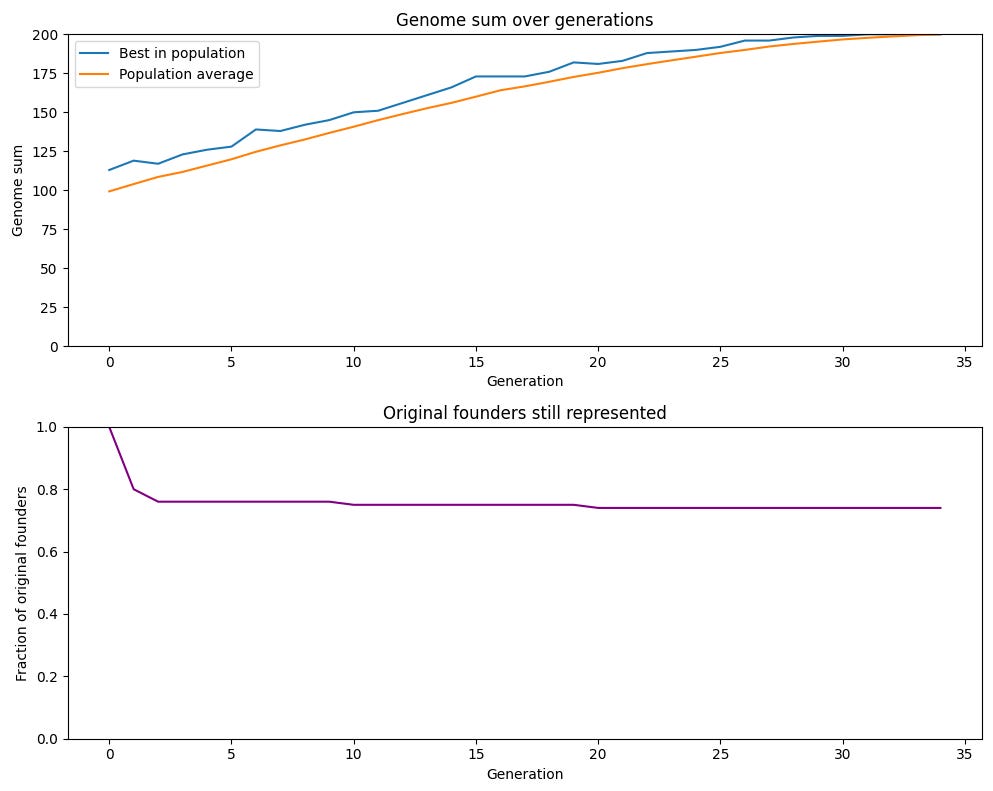
이 점은 아래 그래프에서 볼 수 있는데, 이 그래프는 성적 생식을 하는 개체군의 원래 구성원들의 유전자가 어느 시점에서든 유전자 풀에 얼마나 반영되어 있는지를 보여준다. 이 비율이 매우 높게 유지됨을 볼 수 있다. 34세대 후에도 거의 75%의 원래 개체군에서 온 유전자가 개체군에서 발견된다. 무성 개체군에서는 이 값이 1%였고(개체군이 더 크면 더 낮아질 텐데, 단순히 1/초기 총개체수이기 때문이다).
우리는 앞서 Brian Arthur의 회로 시뮬레이션이 모듈성을 활용한다고 지적했다. 유용한 하위 구성 요소를 찾고, 그 설계를 고정한 뒤, 그것들을 사용해 더 복잡한 기술을 구축하는 것이다. 시뮬레이션이 3-way AND gate를 찾으면 그것으로 4-way AND gate를 만들 수 있고, 그것으로 다시 5-way AND gate를 만들 수 있다. 또한 NAND gate를 무작위로 결합해 8-bit adder를 만들려고 할 때, 한 번에 NAND gate 하나씩 추가하면서 올바른지 검증할 수 있다면, 68개의 gate를 한꺼번에 모두 맞혀야 하는 경우보다 훨씬 쉽다고도 지적했다.
이것은 누군가가 번호 조합 자물쇠를 푸는 것과 비슷하게 생각할 수 있다. 각 자리마다 가능한 값이 100개인 다섯 자리 조합 자물쇠는 100^5 = 10 billion개의 가능한 조합을 가진다. 조합을 하나씩 시도하는 방식은 영원히 걸릴 것이다.
기술적 모듈성은 각 자리 숫자를 시도할 때 그것이 맞는지 확인할 수 있는 숙련된 자물쇠 따개와 같다(아마도 아주 주의 깊게 들으면 다이얼이 올바른 위치에 왔을 때 특징적인 “딸깍” 소리를 들을 수 있을 것이다). 이제는 10 billion개의 가능한 조합 전체를 탐색하는 대신, 각각 100개의 가능한 값이 있는 다섯 번의 탐색, 즉 총 500개의 가능성만 다루면 된다. 고려해야 하는 가능한 선택지의 공간이 엄청나게 줄어든다.
내가 이해하기로 성적 생식도 비슷한 일을 한다. 두 부모의 유전자가 결합되어 자식을 형성되도록 함으로써, 사실상 각 유전자의 적합도를 독립적으로 시험할 수 있게 해 주며, 탐색을 “가장 좋은 200-유전자 유전체를 찾기” 같은 문제에서 200개의 병렬적인 “이 위치에서 가장 좋은 유전자를 찾기” 탐색에 더 가까운 것으로 바꾼다. 조합 자물쇠 비유로 말하자면, 모듈식 회로 시뮬레이션은 다이얼을 돌리다가 “딸깍” 소리를 듣는 것과 비슷하다. 그 소리는 주어진 숫자가 맞다는 것을 뜻한다. 성적 생식은 오히려 여러 무작위 조합을 시도한 뒤 “이 조합이 얼마나 풀림에 가까운가”에 대한 점수를 받고, 그 점수를 바탕으로 어떤 “다이얼”이 맞는지 추론하는 것과 더 비슷하다. 그에 따라 탐색 공간은 크게 좁아지고, 탐색은 훨씬 더 빠르게 진행된다.
Arthur의 기술 탐색에 대해 우리는 이런 축소를 정보이론의 관점에서 설명했고, 반복당 획득되는 정보의 비트를 계산했다. (다시 말해, “bit”는 단지 “고려해야 할 가능성의 수를 절반으로 줄이는 무언가”다.) 우리의 8-bit adder, 68 NAND gate 탐색에서 작동하는 배열을 찾으려면 2^853개의 가능성을 좁혀야 했고, 즉 853 bits가 필요했다. 68개의 gate를 한꺼번에 모두 맞히려는 방식은 시도당 0.000001 bits도 채 안 되는 정보를 주어, 길고 고통스러운 탐색이 필요했다. 하지만 모듈성을 사용하면 — gate를 하나씩 진행하고 각 gate가 올바른 위치에 있는지 알 수 있다면 — 우리는 훨씬 더 빨리 정보를 축적하게 되며, 시도당 약 0.003 bits를 얻는다(비모듈식 탐색보다 3,000x 빠름).
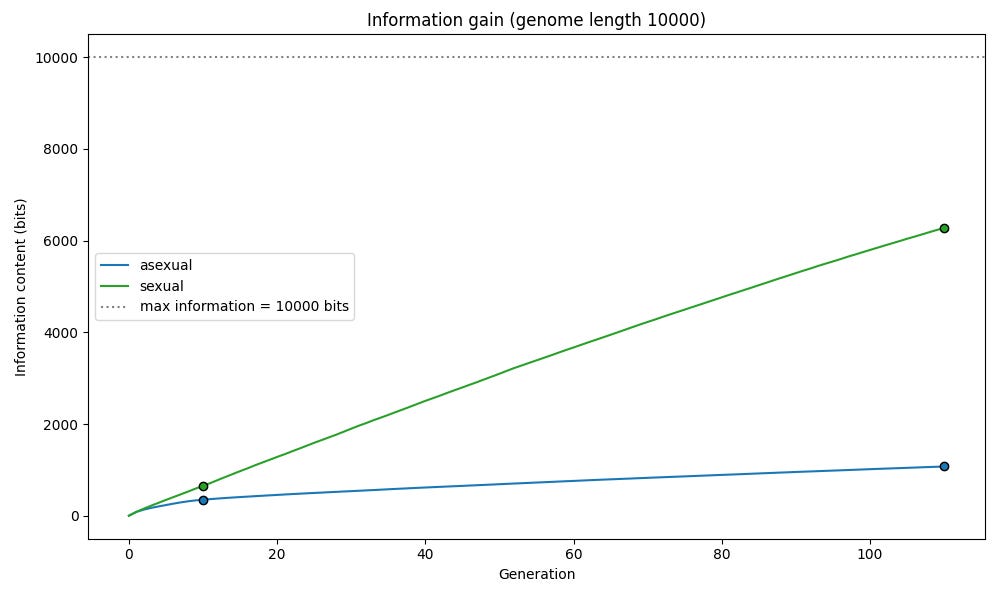
마찬가지로 우리는 생물학적 진화와 유용한 유전 변이의 확산을 정보 획득의 관점에서 볼 수 있다. 우리의 시뮬레이션에서 어떤 시점에 우리가 가진 정보는 개체군이 각 유전자의 값에 대해 얼마나 “확신”하고 있는지의 함수다. 초기의 무작위화된 개체군에서는 각 유전자에 대해 대략 50%의 개체가 1을 가지고 50%가 0을 가지므로, 우리는 최대한 불확실하며 각 유전자당 0 bits의 정보를 가진다. 개체군이 최대 적합도에 도달하면(모든 구성원이 모든 유전자에 대해 1을 가질 때) 우리는 최대한 확실해지며 각 유전자당 1 bit의 정보를 갖는다. 따라서 총 정보량은 대략 2 * (F - G/2)와 같으며, 여기서 F는 적합도이고 G는 유전체 길이다.
우리의 성적 생식 시뮬레이션에서는 무성생식 시뮬레이션보다 정보가 훨씬 더 빠르게 획득됨을 볼 수 있다.
위 분석 전체에는 중요한 단서가 있다. 유전자가 적합도에 독립적으로 기여한다고 가정한다는 점이다. 즉, 유전자 27의 유용성이 유전자 145의 함수가 아니라는 뜻이다. 유전자가 이런 식으로 결합되어 있고, 한 유전 변이의 유용성이 다른 어떤 유전 변이를 가지고 있는가에 따라 달라질 때(실제로는 종종 그렇다), 진화적 탐색 과정은 분석하기 훨씬 더 복잡해진다. (Stuart Kauffman은 NK landscape 개념으로 이 분야에서 많은 작업을 했으며, 이에 대해서는 여기와 여기에서 읽을 수 있다.) 하지만 단순한 가산적 적합도 사례도 이런 진화 메커니즘을 이해하는 데 여전히 유용하다.
또한 실제 세계에서는 박테리아처럼 무성생식하는 생물들도 성적 생식의 이점 일부를 얻을 수 있게 해 주는 유전자 공유 방법을 가지고 있다는 점을 아는 것이 중요하다. 박테리아는 수평적 유전자 전달로 알려진 것을 널리 수행하는데, 이는 말 그대로 기존 개체군 구성원들 사이에서 유전자가 전달되는 것이다. 항생제 내성 유전자는 주로 이런 방식으로 퍼지는 것으로 보이며, 일부 분석은 박테리아 유전체의 20-80%가 이런 종류의 유전자 전달의 결과라고 시사한다.
기술적 탐색 과정은 모듈성으로부터 큰 이점을 얻는다. 즉, 기술을 특정 기능을 지닌 하위 구성 요소들로 분해할 수 있고, 그 하위 구성 요소들이 제대로 작동하는지 판단할 수 있는 능력이다. 정보이론적 용어로 말하면, 이것은 탐색 과정에서 고려해야 하는 가능성을 크게 좁힌다. 흥미로운 점은 전혀 별개의 영역에서 생성되고 작동하는 생물학적 진화 역시 비슷한 종류의 요령을 사용한다는 것이다. 즉, 유전적 재조합(성적 생식과 수평적 유전자 전달의 형태로)을 이용해 탐색 과정을 더 모듈식으로 만들고 정보를 더 빠르게 획득한다.
(진화와 정보 획득에 관한 이런 아이디어를 더 알고 싶다면, 훨씬 더 엄밀한 수학적 처리를 포함해 David Mackay의 책 “Information Theory, Inference, and Learning Algorithms” 19장을 보라.)