기술 진보의 본질을 탐구하는 브라이언 아서의 논문을 바탕으로, 복잡한 기술이 어떻게 더 단순한 구성요소를 발판 삼아 거대한 탐색 공간을 헤쳐 나가며 만들어지는지, 그리고 새로운 기술을 찾는 일이 본질적으로 정보를 효율적으로 획득하는 문제임을 설명한다.
기술 진보의 본질에 관한 글을 읽는 데 나는 많은 시간을 쓴다. 그러면서 기술에 관한 문헌은 다소 불균등하다는 것을 알게 되었다. 어떤 특정 기술이 어떻게 생겨났는지를 알고 싶다면, 대체로 아주 좋은 자료를 구할 수 있다. 대부분의 주요 발명품, 그리고 그보다 덜 중요한 많은 발명품에도 괜찮은 책이 한 권쯤은 있다. 내가 특히 좋아하는 책으로는 Crystal Fire(트랜지스터의 발명에 관한 책), Copies in Seconds(Xerox 초기 역사에 관한 책), High-Speed Dreams(초음속 여객기를 만들기 위한 초기 노력에 관한 책)이 있다.
하지만 기술 진보의 본질을 좀 더 일반적으로 이해하려고 한다면, 괜찮은 선택지의 범위는 크게 좁아진다. 기술 진보 그 자체의 본질을 연구했고, 내가 읽을 가치가 있다고 생각하는 작업을 한 사람은 아마 열 명이나 스무 명을 넘지 않을 것이다.
그런 연구자 중 한 명이 Brian Arthur로, Santa Fe Institute의 경제학자다.1 Arthur는 기술의 본질에 관한 매우 훌륭한 책(적절하게도 제목이 “The Nature of Technology”이다)의 저자로, 나는 자주 이 책으로 돌아간다. 그는 또한 Wolfgang Polak과 함께 2006년 흥미로운 논문 “The Evolution of Technology within a Simple Computer Model”을 썼는데, 나는 이 논문이 특히 주목할 가치가 있다고 생각한다. 이 논문에서 Arthur는 간단한 구성 블록에서 출발해 점점 더 복잡한 기능들(예를 들어 두 개의 8비트 숫자를 더할 수 있는 회로)을 만들어 가는 방식으로 다양한 불 논리 회로를 진화시킨다. 불 논리 회로란 1과 0을 입력으로 받아 1과 0을 출력하는 회로를 뜻한다.
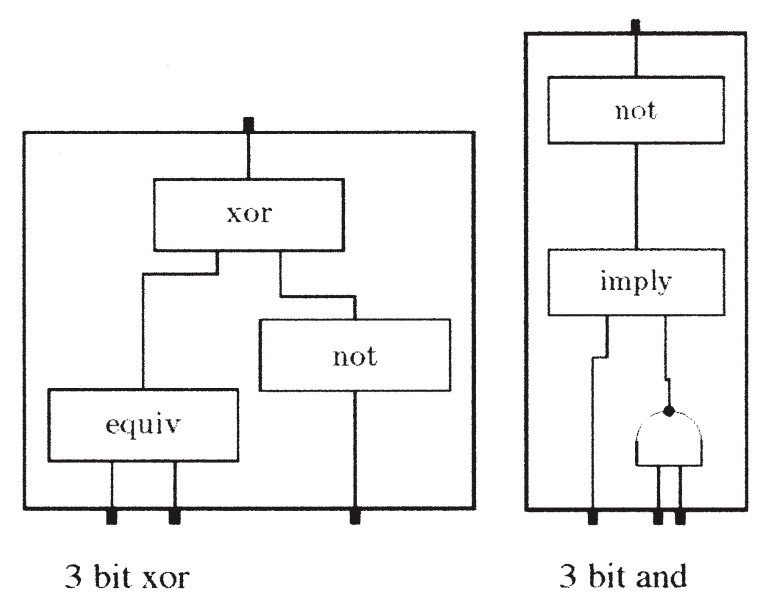
Arthur의 시뮬레이션이 발명한 논리 회로들.
나는 이 논문이 기술 진보의 본질에 대해 어느 정도 빛을 비춰 준다고 생각하기 때문에 이 논문을 강조하고 싶었다. 하지만 동시에, 이 논문은 가장 중요한 시사점을 다소 제대로 설명하지 못한다. 논문이 초점을 맞추는 내용 가운데 일부, 예를 들어 한 기술이 어떻게 더 우월한 기술로 대체되는가 같은 문제는 사실 내가 보기에는 그다지 큰 통찰을 주지 않는다. 반대로, 내가 보기에 이 논문에서 가장 중요한 측면, 즉 어떤 새로운 기술을 만들기 위해서는 거대한 탐색 공간을 성공적으로 항해해야 한다는 점은 모호하고 비껴 가는 식으로만 다뤄진다. 그러나 약간만 추가 작업을 하면 이런 아이디어를 더 풍부하게 만들고 강화할 수 있다. 그리고 조금 더 자세히 들여다보면, 이 논문이 वास्तव로 보여 주는 것은 어떤 새로운 기술을 찾는 일은 정보를 효율적으로 획득하는 문제 라는 점이다.
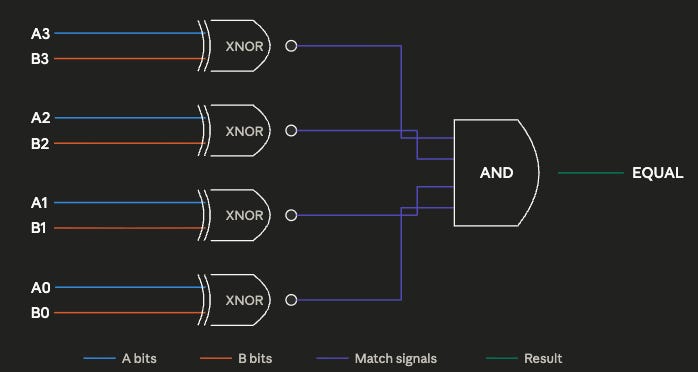
이 실험의 기본 설계는 단순하다. 무작위로 다양한 불 논리 회로를 생성하는 시뮬레이션을 실행하고, 그 시뮬레이션이 어떤 종류의 회로를 만들어 내는지 분석하는 것이다. 불 논리 회로는 다양한 함수(AND, OR, NOT, EQUAL 등)의 집합으로, 이 함수들은 이진수에 대해 특정 연산을 수행한다. 예를 들어 아래의 논리 회로는 4개의 exclusive nor(XNOR) 게이트를 이용해 두 개의 4비트 숫자가 같은지를 판단한다. XNOR 게이트는 두 입력이 같으면 1을 출력하고, 4입력 AND 게이트는 모든 입력이 1일 때 1을 출력한다. 불 논리 회로가 중요한 이유는 컴퓨터가 바로 이런 방식으로 만들어지기 때문이다. 현대 컴퓨터는 수십억, 수백억 개의 트랜지스터가 여러 논리 회로로 배열된 형태로 계산을 수행한다.
시뮬레이션은 무작위 생성 회로에 포함될 수 있는 세 가지 기본 회로 요소에서 시작한다. Not And(NAND) 게이트(두 입력이 모두 1일 때 0을 출력하고, 그렇지 않으면 1을 출력하는 게이트)와, 항상 1 또는 0을 출력하는 두 개의 CONST 요소다. NAND 게이트가 특히 중요한 이유는 NAND가 기능적으로 완전 하기 때문이다. 어떤 불 논리 회로든 NAND 게이트를 적절히 배열하면 만들 수 있다.
이 시작 요소들을 사용해 시뮬레이션은 더 높은 수준의 논리 함수를 만들어 내려고 한다. OR, AND, exclusive-or(XOR) 함수를 만드는 것 같은 목표는 단순해서 몇 개의 시작 요소만으로도 달성할 수 있다. 반면 다른 목표는 극도로 복잡해서 구현에 수십 개의 시작 요소가 필요하다. 예를 들어 8비트 가산기는 68개의 NAND 게이트를 올바르게 배열해야 한다.
이 목표를 달성하기 위해 시뮬레이션은 각 반복마다 몇 개의 회로 요소를 무작위로 결합한다. 처음에는 그 요소가 단지 NAND, 1, 0뿐이다. 시뮬레이션은 2개에서 12개 사이의 구성요소를 무작위로 선택해 임의로 연결한 뒤, 그 결과 회로의 출력이 목표 가운데 하나를 충족하는지 확인한다. 만약 우연히 이 무작위 조합이 AND 함수나 XOR 함수 또는 다른 목표 가운데 하나를 만들어 냈다면, 그 목표는 달성된 것으로 표시되고, 그것을 만족시키는 회로는 “캡슐화”되어 가능한 회로 요소 풀에 추가된다. 예를 들어 시뮬레이션이 NAND 구성요소의 배열을 통해 AND와 OR를 만들어 내면, 그 AND와 OR 배열은 NAND와 두 CONST와 함께 회로 요소 풀에 추가된다. 그러면 이후 반복에서는 AND, OR, NAND를 결합하다가 우연히 XOR를 찾아낼 수도 있다.
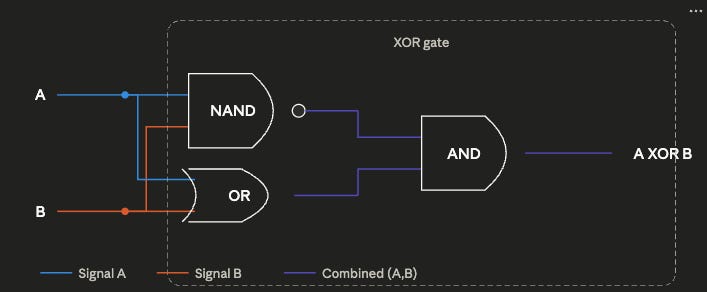
NAND, OR, AND 게이트로 만든 XOR 게이트.
주어진 목표에 정확히 일치하는 회로를 찾는 일이, 특히 목표가 더 복잡해질수록 어려울 수 있기 때문에, 시뮬레이션은 어떤 회로가 목표를 부분적으로 충족하더라도, 그것이 기존 회로보다 그 목표를 더 잘 만족시키면 사용 가능한 구성요소 풀에 추가한다. 어떤 목표를 부분적으로 충족하는 회로들(예를 들어 마지막 자리 하나만 틀리는 4비트 가산기)도 마찬가지로 다른 요소와 재조합할 수 있는 구성요소로 사용된다. 따라서 시뮬레이션은 부분적으로만 맞는 4비트 가산기를 다른 요소들(NAND, OR 등)과 연결해 보면서 어떤 결과가 나오는지 시험할 수 있다. 어쩌면 마지막 자리를 고쳐 줄 다른 미니 회로를 찾을 수도 있다.
시간이 지나면서 시뮬레이션이 무작위로 뽑아 쓰는 회로 요소 풀은 점점 더 커진다. 그 안에는 여러 목표를 완전히 만족시키는 회로들과, 일부는 부분적으로만 작동하는 회로들이 함께 들어간다. 어떤 회로는 기존의 같은 목표용 회로보다 비용이 더 적게 든다면, 즉 더 적은 구성요소를 사용한다면 역시 풀에 추가될 수 있다. 예를 들어 시뮬레이션에 10개 구성요소로 만든 2비트 가산기가 있는데, 우연히 8개 구성요소로 만든 2비트 가산기를 발견하면, 8개짜리 가산기가 10개짜리를 대체한다.
시뮬레이션을 실행하면, 처음에는 단지 NAND, 1, 0뿐인 구성요소들을 무작위로 결합하는 것부터 시작한다. 처음에는 OR, AND, NOT 같은 단순한 목표만 충족된다. 그런 뒤 이 목표를 만족하는 회로들이 더 복잡한 목표를 위한 구성 블록이 된다. 4입력 AND 게이트(모든 입력이 1일 때만 1을 출력하는 게이트)를 찾으면, 그것을 이용해 5입력 AND 게이트를 만들 수 있고, 다시 그것으로 6입력 AND 게이트를 만들 수 있다. 수십만 번의 반복을 거치면 놀랄 만큼 복잡한 회로를 생성할 수 있다. 두 개의 4비트 숫자가 같은지 비교하는 회로, 두 개의 8비트 숫자를 더하는 회로 등이 그런 예다.
하지만 더 단순한 목표가 먼저 충족되지 않으면, 시뮬레이션은 더 복잡한 목표의 해답을 찾지 못한다. 목표 목록에서 full-adder를 제거하면, 시뮬레이션은 더 복잡한 2비트 가산기를 결코 찾지 못한다. Arthur에 따르면, 이것은 더 단순한 기술이 더 복잡한 기술로 가는 “디딤돌” 역할을 한다는 점, 그리고 기술이 하위 기술들의 위계적 배열로 이루어진다는 점을 보여 준다(이것은 그의 책의 주요 주제이기도 하다).
우리는 우리의 인공 시스템이 복잡한 기술(회로)을 만들어 낼 수 있음을 발견한다. 하지만 그것은 먼저 더 단순한 것들을 구성 블록으로 만들어 낼 때만 가능하다. 우리의 결과는 Lenski et al.’s를 반영한다. 즉, 생물학적 진화에서 복잡한 특징은 더 단순한 기능이 먼저 선택되고 디딤돌 역할을 할 때만 만들어질 수 있다.
나는 Arthur가 실행한 원래 시뮬레이션에는 접근할 수 없지만, 현대의 AI 도구 덕분에 그것을 재현하고 이러한 결과 상당수를 복제하는 일은 비교적 쉬웠다. 백만 번 반복 실행한 결과, 나는 6-bit equal, full-adder(3개의 1비트 입력을 함께 더하는 장치), 7-bitwise-XOR, 심지어 15입력 AND 회로 같은 몇 가지 복잡한 목표까지 만들어 낼 수 있었다.

내 시뮬레이션이 실행 중인 화면.
하지만 나는 또한 원 논문의 시뮬레이션 설계 요소 가운데 모든 것이 반드시 핵심적인 것은 아니라는 점도 발견했다. 적어도 내가 재현한 버전에서는 그랬다. 특히 시뮬레이션의 많은 부분이 복잡한 “부분 충족” 메커니즘에 할애되어 있는데, 이 메커니즘은 목표를 부분적으로만 충족하는 회로를 추가하고, 더 잘 충족하는 회로가 발견되면 그것으로 점진적으로 교체한다. 내가 보기에 이 메커니즘의 의도는 부분적으로 작동하는 기술을 발판 삼아 점진적으로 목표에 수렴하게 만드는 것이고, 실제 세계의 기술도 이런 식으로 등장한다. 그러나 이 메커니즘을 꺼서 어떤 목표도 100% 충족하지 못하는 회로는 모두 버리도록 강제해도, 내가 찾은 목표 수에는 사실상 차이가 없었다. 부분 충족 메커니즘은 기본적으로 아무것도 더해 주지 않았다(물론 이것은 시뮬레이션 구현 방식의 차이 때문일 수도 있다).
내게 이 논문에서 가장 흥미로운 점은 새롭고 더 나은 기술이 이전 기술을 어떻게 대체하는가를 보여 주는 것이 아니라, 새로운 기술을 찾기 위한 탐색이 거대한 탐색 공간을 항해해야 한다는 점이다. 8비트 가산기나 6-bit equal 같은 복잡한 기능을 찾으려면, 작동하지 않는 함수들의 विशाल한 바다 한가운데서 작동하는 함수를 성공적으로 찾아내야 한다. 내가 무슨 뜻인지 보여 주겠다.
우리는 특정한 불 논리 함수를 진리표 로 정의할 수 있다. 이는 가능한 모든 입력과 출력 조합을 열거한 것이다. 예를 들어 두 입력이 모두 1일 때 1을 출력하고 그렇지 않으면 0을 출력하는 AND 함수의 진리표는 다음과 같다.
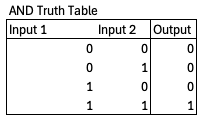
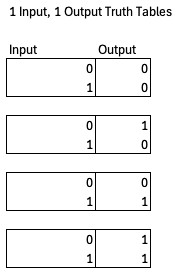
모든 논리 함수는 고유한 진리표를 가지며, 입력과 출력의 개수가 주어지면 가능한 논리 함수, 가능한 진리표의 수는 한정되어 있다. 예를 들어 입력 1개, 출력 1개인 함수는 단 4개뿐이다.
하지만 가능한 논리 함수의 공간은 아주 아주 빠르게, 아주 아주 거대해진다. 입력이 n개이고 출력이 m개인 함수에 대해 가능한 진리표의 수는 (2^m)^(2^n)이다. 따라서 입력 2개, 출력 1개라면 가능한 함수는 2^4 = 16개다(AND, NAND, OR, NOR, XOR, XNOR, 그리고 그 외 10개). 입력 3개, 출력 2개라면 이것은 4^8 = 65,536개의 가능한 논리 함수로 늘어난다. 8비트 가산기처럼 입력 16개, 출력 9개라면 가능한 논리 함수는 무려 10^177554개에 달한다. 비교를 위해 말하면, 우주의 원자 수는 대략 10^80 정도로 추정되고, 빅뱅 이후 지난 밀리초 수는 대략 4x10^20 정도다. 회로 공간에서 어떤 목표를 충족한다는 것은, 어마어마한 가능성의 바다 속에서 단 하나의 특정 함수를 찾아내는 것을 의미한다.
문제는 시뮬레이션이 이 거대한 탐색 공간을 어떻게 헤쳐 나가느냐는 것이다. Arthur는 그 답, 즉 더 단순한 목표를 거쳐 복잡한 목표로 나아간다는 점을 살짝 건드리지만, 논문에서는 조합론을 깊이 들여다보거나, 이 항해가 구체적으로 어떻게 이루어지는지까지는 분석하지 않는다.2
8비트 가산기 같은 회로의 출현은 그리 어렵지 않아 보인다. 하지만 조합론을 생각해 보라. 어떤 구성요소가 n개의 입력과 m개의 출력을 가진다면, 가능한 표현형은 (2^m)^(2^n)개이며, 각각은 실제로는 매우 많은 서로 다른 회로로 구현될 수 있다. 예를 들어 8비트 가산기는 16개의 입력과 9개의 출력을 가지는 10^177,554개가 넘는 표현형 가운데 하나일 뿐이다. 무작위 조합으로 250,000단계 안에 이런 회로가 발견될 가능성은 무시할 만하다. 우리의 실험, 혹은 알고리즘은 먼저 더 단순한 필요를 충족시키고, 그 결과를 구성 블록으로 사용해 더 복잡한 필요를 만족시키는 방향으로 스스로를 부트스트랩함으로써 복잡한 회로에 도달한다.
1962년 논문 “The Architecture of Complexity”에서 노벨상 수상 경제학자 Herbert Simon은 가상의 두 시계공, Hora와 Tempus를 설명한다. 두 사람 모두 1000개의 부품으로 된 시계를 만들고, 한 번에 한 부품씩 조립한다. Tempus의 시계는 시계공이 작업 도중 방해를 받으면, 예를 들어 전화를 받기 위해 시계를 내려놓으면 조립된 것이 모두 흩어져 버리고 처음부터 다시 시작해야 하는 방식으로 만들어져 있다. 반면 Hora의 시계는 안정적인 하위 조립체들로 구성된다. 부품 10개가 모여 1단계 조립체를 만들고, 1단계 조립체 10개가 모여 2단계 조립체를 만들며, 2단계 조립체 10개가 모여 최종 시계를 이룬다. Hora가 하위 조립체를 만드는 도중에 방해를 받으면 역시 그것은 Tempus의 시계처럼 흩어지지만, 하위 조립체가 한 번 완성되면 안정적이다. 그는 그것을 내려놓고 다음 조립으로 넘어갈 수 있다.
Tempus가 Hora보다 훨씬 적은 수의 시계를 만들 것이라는 점은 쉽게 알 수 있다. 둘 다 부품 하나를 넣을 때마다 1% 확률로 방해를 받는다면, Tempus는 완성된 시계를 조립할 확률이 0.99 ^ 1000 = 0.0043%에 불과하다. 대부분의 경우 그는 끝내기 전에 시계 전체가 흩어져 버린다. 하지만 Hora는 방해를 받아도 완전히 처음부터 다시 시작할 필요가 없고, 마지막으로 안정된 하위 조립체에서부터 다시 시작하면 된다. 그 결과 Hora는 Tempus보다 약 4,000배 빠르게 완성된 시계를 만든다.
Simon은 이 모델을 사용해 복잡한 생물학적 시스템이 어떻게 진화했을지를 설명한다. 생물학적 시스템이 어떤 화학물질들의 조합이라면, 그 화학물질들 가운데 작은 부분집합이 안정적인 하위 조립체를 형성할 수 있을 때, 우연히 그것들이 함께 모일 가능성이 훨씬 커진다는 것이다. 하지만 우리는 이 Tempus/Hora 모델을 Arthur의 논문에서 시뮬레이션되는 기술 진화를 설명하는 데에도 사용할 수 있다.
기술을 1,000개의 서로 다른 부품의 특정한 배열이라고 생각해 보자. Arthur의 논리 회로에서 기본 구성 블록이 되는 NAND 게이트들이 그런 예다. 올바른 부품 배열을 찾을 수 있다면, 작동하는 기술을 만들 수 있다. Tempus와 Hora가 시계를 조립하는 것처럼, 모든 1000개 부품이 추가될 때까지 한 번에 한 부품씩 더해 가며 기술을 만든다고 가정하자. 이 버전에서는 방해를 받아 다시 시작해야 하는 작은 확률 대신, 다음 구성요소를 올바르게 추측할 작은 확률(예를 들어 1%)이 있다고 하자. 이것은 어떤 목표를 달성하기 위해 구성요소를 올바르게 무작위 연결할 작은 확률이 있었던 Arthur의 시뮬레이션을 반영한다. 각 부품의 배열을 순서대로 정확히 추측해야만 작동하는 기술을 만들 수 있다.
Simon의 원래 모델에서 시계를 조립하는 일은 편향된 동전 1000개를 연속으로 던지는 것과 같았다. 각 동전은 99% 확률로 앞면이 나오고, 1000번 모두 앞면이 나와야만 시계가 성공적으로 조립되었다. 우리가 수정한 모델은 앞면이 나올 확률이 1%밖에 되지 않는 편향된 동전 1000개를 던지는 것과 같다. “Tempus” 방식으로 기술을 만드는 것은 동전 1000개를 연속으로 던지며 매번 앞면이 나오기를 바라는 것과 같다. 작동하는 기술이 나올 확률은 0.01^1000으로, 사실상 0이다. 하지만 “Hora” 방식처럼 안정적인 하위 조립체들로 기술을 만든다면, 조합론의 가혹함은 훨씬 줄어든다. 이제 우리는 1000번 연속 앞면 대신 단지 10번 연속 앞면만 필요하다. 10번의 성공적인 동전 던지기, 즉 10개 부품을 성공적으로 추가하면 안정적인 하위 조립체가 생기고, 사실상 “현재 위치를 저장”할 수 있게 된다. 뒷면이 나와도 완전히 0으로 돌아가는 것이 아니라 마지막 안정된 하위 조립체로만 돌아간다. 확률이 여전히 낮기는 하다. 각 하위 조립체마다 올바르게 맞출 확률은 0.01^10에 불과하다. 하지만 이는 Tempus 방식보다 엄청나게 높다. 기술이 더 단순하고 안정적인 구성요소들로 이루어져 있고, 개별 구성요소가 맞는지 판단할 수 있다면, 작동하는 기술을 우연히 찾아낼 가능성은 훨씬 커진다.
Arthur의 회로 시뮬레이션이 복잡한 기술을 찾아낼 수 있는 이유는 그것이 Tempus가 아니라 Hora처럼 작동하기 때문이다. 복잡한 회로는 더 단순한 기술들로부터 구축되며, 마치 Hora의 시계가 안정적인 하위 조립체들로부터 만들어지는 것과 같다. 아무것도 없는 상태에서 8비트 가산기로 곧장 가는 일은 Tempus가 매우 복잡한 시계 전체를 모든 단계를 완벽히 맞추어 만들려고 하는 것과 같다. Hora처럼 되는 편이 훨씬 쉽다. 즉, 다음 몇 단계만 올바르게 맞추어 안정적인 하위 조립체를 얻으면 되는 방식이다. 6비트 가산기에 몇 개의 구성요소를 더해 7비트 가산기를 만들고, 거기에 다시 몇 개를 더해 8비트 가산기를 만드는 식이다.
이 점은 Arthur의 회로 탐색을 변형한 버전으로 더 분명하게 설명할 수 있다. 이 버전에서는 방대한 목표 집합을 충족하려는 대신, 68개의 NAND 게이트로 이루어진 특정한 8비트 가산기의 설계를 찾으려 한다. 이를 더 단순한 하위 구성요소들(7비트 가산기, 6비트 가산기, full adder)로부터 쌓아 올리는 대신, 이 시뮬레이션에서는 그냥 NAND 게이트를 하나씩 추가해 나간다. 매 반복마다 NAND 게이트 하나를 더하고, 그것을 기존 NAND 게이트 집합에 무작위로 연결한다. 배선이 올바르면 그것을 유지하고 다음 게이트를 더한다. 틀리면 버리고 다시 시도한다.
이것은 일종의 모듈식 구성으로 생각할 수 있다. 더 단순한 회로들로부터 복잡한 회로를 만들어 올리는 것과 비슷하게, 각 단계에서는 기존 하위 조립체와 추가 NAND 게이트 하나, 이렇게 두 개의 구성요소를 결합할 뿐이다. 이렇게 하면 사실감은 다소 떨어진다. 각 하위 조립체가 더 이상 어떤 특정 기능을 구현하지 않기 때문이다(사실상 시뮬레이션이 올바른 게이트 배선에 우연히 도달했는지 알고 있다고 정해 버리는 셈이다). 하지만 우리가 잃는 것은 그렇게 많지 않다. 실제로 거의 모든 단계에서 단지 두 개의 구성요소만 필요로 하는 위계를 가진 8비트 가산기를 만드는 것이 가능하다(몇몇 단계는 세 개의 구성요소가 필요하다). 그리고 이 더 단순한 시뮬레이션은 각 단계의 조합론을 매우 쉽게 계산할 수 있다는 장점이 있다.
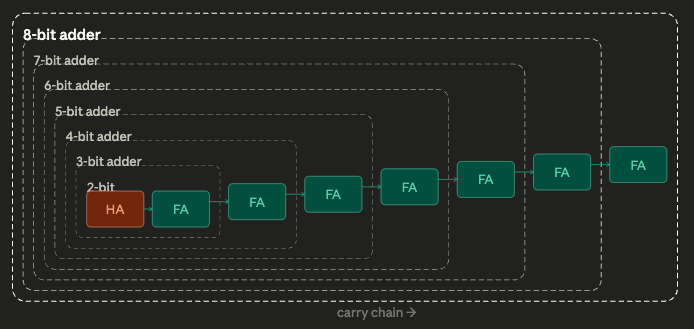
위계적인 8비트 가산기. FA는 full-adder(3개의 입력값을 함께 더하는 장치), HA는 half-adder(2개의 입력값을 더하는 장치)다. NAND 게이트까지의 완전한 분해는 표시하지 않았다.
68개의 NAND 게이트는 입력 16개, 출력 9개를 가진 약 2^852개의 가능한 배선 배열을 만들 수 있다. 이는 가능한 16입력 9출력 함수 10^177,554개보다는 훨씬 적지만, 그래도 터무니없이 거대한 수다. 만약 우리가 68개 게이트를 한꺼번에 모두 무작위로 추측해 올바른 배선 배열을 찾으려 한다면, 절대 성공하지 못할 것이다. 우주의 모든 원자가 컴퓨터이고, 각각이 초당 1조 번의 추측을 한다고 해도, 우리는 약 10,000,000,000,000…(0이 140개 더 이어지는) ..000년 동안 추측해야 한다.
하지만 게이트를 하나씩 진행하면, 평균적으로 453,000번의 반복 안에 올바른 배열을 찾을 수 있다. 게이트를 하나 추가할 때마다, 그것을 연결하는 가능한 방법은 겨우 수천 가지뿐이다. 따라서 수천 번 정도 반복하면 올바르게 맞추게 되고, 그 답을 고정한 뒤 다음 게이트로 넘어간다. 완전한 답을 한 번에 모두 맞히려는 대신, 각 단계가 맞는지 판정할 수 있게 되면 탐색은 현실적으로 가능해진다.
바로 이것이 Arthur의 원래 시뮬레이션이 더 단순한 필요를 먼저 충족하지 않고서는 복잡한 필요를 충족할 수 없었던 이유다. 한 번에 너무 많은 단계를 밟으려 하면 조합론의 대가가 너무 커져서, 무작위 추측으로 올바른 답을 찾는 것이 거의 불가능해지기 때문이다. 우리의 68 NAND 게이트 탐색에서는 한 번에 하나의 게이트씩 진행하면 8비트 가산기를 찾는 일이 비교적 쉽다. 하지만 이것을 한 번에 두 개의 게이트씩으로 바꾸면(게이트 하나를 무작위로 더하고, 또 하나를 더한 다음, 그 뒤에 맞는지 확인하는 방식), 기대 반복 횟수는 453,000에서 17억 5천만으로 뛰어오른다. 게이트 하나를 올바르게 맞출 확률이 1/1,000이라면, 게이트 두 개를 맞출 확률은 1/1,000,000이기 때문이다. 만약 한 번에 세 개의 게이트를 맞추려 한다면(맞출 확률이 10억분의 1), 68개 게이트를 모두 올바르게 맞추는 데 필요한 기대 반복 횟수는 약 9조 3천억으로 증가한다.
이 폭발적인 조합론은 Arthur의 시뮬레이션에서 나오는 몇몇 결과를 더 잘 이해하게 해 준다. 예를 들어 Arthur는 매 반복에서 시뮬레이션이 최대 12개의 구성요소를 결합한 뒤 작동하는 회로가 발견되었는지 확인한다고 말한다. 그런데 최대값을 바꾸어도 시뮬레이션 결과에는 큰 영향이 없다고도 지적한다. 여러 시뮬레이션 설정에 대해 그는 “[e]xtensive experiments with different settings have shown that our results are not particularly sensitive to the choice of these parameters.”라고 쓴다. 실제로 시뮬레이션을 다시 실행해 한 번에 최대 4개의 구성요소만 시도하게 해도, 12개일 때와 거의 비슷하게 잘 작동한다. 무작위 구성요소를 더 많이 한꺼번에 결합할수록 조합 가능한 경우의 수는 폭발하고, 유용한 것을 찾을 확률은 낮아진다. 구성요소 수가 커질수록 가능한 경우들 가운데 유용한 회로를 찾을 확률은 너무나 낮아져서, 애초에 그런 큰 조합을 시도하지 않아도 큰 손해가 없다. 마찬가지로 이것은 논문의 또 다른 결과도 설명해 준다. 즉, 관련된 더 단순한 목표들의 더 좁은 부분집합만 지정할수록 복잡한 목표를 찾기가 더 쉽다는 점이다. Arthur는 복잡한 8비트 가산기가, 가산기 구축과 관련된 몇 가지 목표만 시뮬레이션에 주었을 때 훨씬 더 빨리 발견된다고 말한다. 지정된 목표가 적을수록 가능한 기술 구성요소의 풀은 더 작게 유지되고, 가능한 무작위 조합 수도 줄어들며, 따라서 복잡한 목표를 찾기가 더 쉬워진다.
본질적으로, 더 단순한 구성요소를 더 복잡한 것의 디딤돌로 사용하는 것은 일종의 hill-climbing이다. 시뮬레이션은 여러 방향(구성 블록들의 가능한 조합)을 탐색하다가, 언덕에서 더 높은 지점에 해당하는 것(어떤 단순한 목표를 만족하는 회로)을 찾으면, 그 새롭고 더 높은 지점에서 다시 탐색을 시작한다. 이런 과정을 반복해 결국 꼭대기(복잡한 목표의 충족)에 도달한다. 시뮬레이션이 복잡한 목표를 충족할 수 있는 이유는, 복잡한 목표로 이어지는 길을 제공하는 더 단순한 목표들의 연속을 지정했기 때문이다. Arthur는 “[t]he algorithm works best in spaces where needs are ordered (achievable by repetitive pattern), so that complexity can bootstrap itself by exploiting regularities in constructing complicated objects from simpler ones.”라고 말한다.
그렇다면 복잡한 회로로 직접 가려는 시도는, 풍경 속의 무작위 위치들을 그저 찍어 보며 그것이 높은 지점인지 보는 것과 비슷하다. 높은 지점을 찾기 위해 풍경의 경사를 따라가는 것보다 이것이 훨씬 나쁘다는 것은 자명하다.
이 아이디어는 정보 이론의 몇몇 개념을 도입하면 더 날카롭게 다듬을 수 있다. 정보 이론은 1940년대 후반 Bell Labs의 Claude Shannon이 만들어 낸 것으로, 우리의 불확실성을 정량화하고 어떤 사건이 그 불확실성을 얼마나 줄이는지를 측정하는 틀을 제공한다.
내가 보기에 정보 이론을 이해하는 가장 쉬운 방법은 이진수다. 우리가 일상적으로 쓰는 보통의 수학은 10진수를 사용한다. 0부터 위로 세면 0에서 9까지 간 뒤, 첫째 자리를 0으로 되돌리고 다음 자리를 하나 올려 10이 된다. 이진수, 즉 2진수에서는 1에 도달한 다음 자리를 올린다. 따라서 10진수 1은 이진수 1이지만, 2는 10, 3은 11, 4는 100이 되는 식이다.
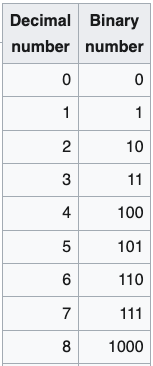
십진수(10진법)와 이진수(2진법).
이진수에서는 각 이진 자릿수, 즉 비트가 우리가 표현할 수 있는 수의 범위를 두 배로 늘린다. 따라서 두 자릿수로는 가능한 값 4개(10진수로 0, 1, 2, 3)를 표현할 수 있다. 3자릿수가 되면 이것이 두 배가 되어 가능한 값 8개(0부터 7까지)가 되고, 4자릿수면 다시 두 배가 되어 가능한 값 16개가 되는 식이다. 16비트 이진수는 2^16 = 65,536개의 가능한 값을 표현할 수 있기 때문에, 컴퓨터 프로그래밍에서 16비트 정수가 표현할 수 있는 최댓값이 65,535인 것이다.
이제 비트들의 문자열이 있는데, 그것이 1인지 0인지 모른다고 하자. 각 비트는 가능한 표현값의 수를 두 배로 늘리므로, 우리가 알지 못하던 비트를 하나 채울 때마다 가능한 값의 수는 절반으로 줄어든다. 3개의 이진 자릿수가 있다면 표현 가능한 수는 8개다. 비트 하나의 값을 알게 될 때마다 가능한 값의 수는 절반으로 줄어든다.
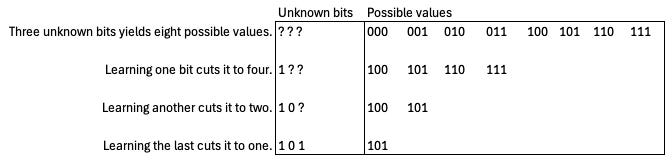
정보 이론에서는 이 개념을 조금 더 일반화한다. 정보 이론에서 1비트의 정보는 가능성의 공간을 50% 줄인다. 다시 말해, 각 비트는 우리의 불확실성을 절반으로 줄인다. 나처럼 휴대전화를 자주 재킷 주머니에서 잃어버리는 사람이라고 해 보자. 주머니가 2개 달린 코트를 입고 있고 휴대전화가 그중 하나에 있다는 것을 안다면, 휴대전화의 위치를 특정하는 것, 즉 2개의 가능성에서 1개로 좁히는 데는 1비트의 정보가 필요하다. 주머니가 4개 달린 코트를 입고 있다면 이제 2비트의 정보가 필요하다. 오른쪽인지 왼쪽인지 알려 주는 1비트, 그리고 위쪽 주머니인지 아래쪽 주머니인지 알려 주는 또 1비트다. 첫 번째 비트가 가능성을 절반으로 줄여 2개의 가능성만 남기고, 두 번째 비트가 그것을 다시 절반으로 줄인다. 재킷에 주머니가 8개 있다면 위치를 특정하는 데 3비트가 필요하고, 이런 식으로 계속된다. 어떤 것이 있을 수 있는 위치가 많을수록, 그 위치를 특정하는 데 더 많은 정보가 필요하다.
정보 이론은 어떤 특정 결과가 우리에게 얼마나 많은 정보를 주는지 정량화하는 데 특히 유용하다. 누군가 공정한 동전을 던졌다고 해 보자. 그가 앞면인지 뒷면인지를 알려 줄 때 나는 얼마나 많은 정보를 얻게 될까? 공개되기 전에는 그것이 앞면이나 뒷면, 두 가지 중 하나일 수 있다는 것만 알고 있었다. 공개는 가능한 경우의 수를 2개에서 1개로 줄인다. 가능성의 수를 절반으로 줄였으므로, 우리는 1비트의 정보를 얻었다. 더 일반적으로, 어떤 결과가 제공하는 정보량은 -log2(그 결과의 확률)과 같다. 따라서 공정한 동전의 결과를 밝히는 것은 -log2(0.5) = 1비트의 정보를 준다. 카드 한 장을 뒤집지 않은 채 받은 경우, 그 카드를 공개하면 가능한 카드의 수는 52장에서 1장으로 줄어들고, 우리는 -log2(1/52) = 5.7비트의 정보를 얻는다.
반복되는 과정에 대해서는 관련된 또 다른 양도 알고 싶다. 바로 엔트로피 다. 엔트로피는 가능한 각 결과에서 얻는 정보량을 계산하고, 그것에 그 결과의 확률을 곱한 뒤, 그 값을 모두 더해서 구한다. 어떤 특정 행동을 했을 때 기대할 수 있는 정보량인 셈이다.
내가 주머니 8개 달린 재킷에서 휴대전화를 잃어버렸고, 찾을 때까지 주머니를 무작위로 골라 확인한다고 해 보자. 무작위 추측은 휴대전화를 성공적으로 찾을 확률이 1/8이고, 빈손일 확률이 7/8이다. 올바르게 찾으면 예상대로 -log2(1/8) = 3비트의 정보를 얻게 된다. 한 번 맞추면 휴대전화의 위치를 알게 되기 때문이다. 하지만 틀린 추측은 겨우 0.19비트의 정보만 준다. 대부분의 주머니에 휴대전화가 없다는 것은 이미 알고 있었으므로, 어느 한 주머니에서 찾지 못했다고 해서 새로 알게 되는 것은 별로 없다. 한 번의 추측의 엔트로피는 (1/8) * log2(1/8) + (7/8) * log2(7/8) = 0.54비트다. 처음 주머니 하나를 확인할 때 나는 평균적으로 반 비트보다 조금 많은 정보를 얻을 것으로 기대할 수 있다. (이미 확인한 주머니를 제외해 나가면 기대 정보량은 매번 더 커지지만, 나 같은 사람이라면 휴대전화를 찾기 전에 같은 주머니를 몇 번이고 다시 확인할지도 모른다.)
우리가 얻는 정보의 각 비트는 남아 있는 가능성의 수를 50%씩 줄이기 때문에, 엄청나게 큰 탐색 공간을 좁히는 데 필요한 정보량은 생각보다 많지 않다. 68개의 NAND 게이트를 배선해 만들 수 있는 2^852개의 가능한 회로를 특정하는 데는 단지 852비트, 즉 가능성의 수를 절반으로 자르는 일을 852번 하는 것만 필요하다. (이는 대략 이 문장의 각 글자를 특정하는 데 필요한 비트 수와 비슷하다.)
엔트로피의 핵심적인 측면 하나는 각 결과가 똑같이 그럴듯할 때 우리가 얻는 정보량이 최대가 된다 는 점이다. 따라서 앞면이 나올 확률이 50%인 공정한 동전의 엔트로피는 1비트다. 하지만 앞면이 나올 확률이 90%라면 엔트로피는 0.46비트로 줄어든다. 앞면이 나올 확률이 99%라면 엔트로피는 0.08비트로 떨어진다. 어떤 결과 하나가 매우 가능성이 높을 때는, 매 시도마다 배우는 것이 훨씬 적다. 대부분 이미 그럴 것이라고 알고 있던 결과를 얻게 되기 때문이다. 이것이 “20 questions” 게임에서 가장 효율적인 전략이 답이 가능성의 수를 절반으로 나누는 질문을 하는 것인 이유다. “빵 상자보다 큰가요?”는 빵 상자보다 큰 물건과 작은 물건의 수가 대략 비슷할 가능성이 있으므로 좋은 시작 질문이다. “1997 Nissan Sentra인가요?”는 나쁜 시작 질문이다. 대부분의 가능성은 1997 Nissan Sentra가 아니기 때문에, 답이 “아니오”여도 우리는 거의 아무것도 배우지 못한다.
우리의 68 NAND 게이트 탐색은 매우 편향된 동전들을 연속으로 던지는 것과 같다고 생각할 수 있다. 각 동전이 앞면이 나올 확률은 대략 1/(수천 분의 1) 정도이며(여기서 “앞면”은 “그 특정 NAND 게이트에 맞는 올바른 배선 조합을 맞히는 것”이다). 이 과정의 엔트로피, 즉 우리가 얻게 되는 기대 정보량은 매우 낮아서 시도당 약 0.003비트 정도다. 매 시도마다 우리는 올바른 배선도에 대해 아주 조금만 배운다(“이 배열은 아니었고, 이것도 아니었고, 이것도 아니었다”). 그래서 8비트 가산기의 올바른 배선을 특정하는 데 필요한 852비트를 축적하려면 평균적으로 약 453,000번의 시도가 필요하다.3
한 번에 두 개의 게이트를 추측하려는 것은 동전을 더 심하게 편향시키는 것과 같다. 이제 각 동전이 앞면이 나올 확률은 대략 1/(수백만 분의 1)이다. 그러므로 우리는 시도당 훨씬 더 적은 정보를 얻는다. 평균적으로 시도당 0.000001비트보다도 적다. 따라서 필요한 정보를 축적하려면 훨씬 더 많은 시도가 필요하다.
이 68 NAND 게이트 탐색을 이해하는 유용한 방법은 그것을 거대한 분기 트리로 보는 것이다. 매 단계, 즉 게이트를 하나 추가할 때마다 수천 개의 가지가 있으며, 각각은 그 게이트를 배선하는 가능한 방법 하나를 나타낸다. 그런 다음 각 가지는 또 수천 개의 가지로 갈라지고(다음 게이트를 배선하는 모든 가능한 방법), 그것들이 또 수천 개로, 다시 수천 개로 갈라져, 결국 끝에는 2^852개의 가능한 “잎”이 생긴다. 각 잎은 68개 게이트 전체를 배선하는 하나의 고유한 방식을 나타낸다. 68개 게이트를 한꺼번에 모두 맞추고 그 다음에 맞았는지 확인하는 것은, 이 나무의 바닥에서 가지 끝까지 이어지는 하나의 단일 경로, 하나의 잎만을 살펴보는 것과 같다. 틀릴 가능성이 압도적으로 높을 뿐만 아니라, 가능성도 거의 전혀 좁혀지지 않는다. 우리가 아는 것은 단지 그 하나의 잎이 정답이 아니었다는 것뿐이며, 여전히 2^852개의 가능한 나머지 잎들을 뒤져야 한다.
반대로, 다음 게이트로 넘어가기 전에 우리가 추가한 각 게이트가 올바른지 확인하는 것은 가능성의 수를 대폭 줄여 준다. 어떤 게이트가 올바른 자리에 있지 않다고 판명될 때마다, 그 지점에서 갈라지는 모든 가능성이 제거된다. 각 게이트를 배선하는 가능한 방법이 1000개라면, 매번 우리가 올바르게 맞출 때마다 그 선택 지점 아래의 가능성은 99.9% 줄어든다. 각 올바른 추측마다 엄청난 범위의 가능성이 제거되므로, 우리는 정답으로 훨씬 더 빨리 수렴할 수 있다.
같은 기본 논리는 Arthur의 시뮬레이션에도 적용된다. (실제로 Arthur는 다른 출판물에서 매우 비슷한 은유를 사용해, 기술 탐색을 여러 장애물로 가득한 산을 오르는 작동 가능한 경로를 찾는 일에 비유한다.) 중간의 더 단순한 기능들의 도움 없이 복잡한 기능을 구축하는 것은 우주 크기의 나무에서 단 하나의 잎을 찾으려는 것과 같다. 더 단순한 구성요소를 구성 블록으로 사용해 복잡한 회로로 점진적으로 나아가면, 나무의 거대한 가지들을 한 번에 차단할 수 있다. 작동하는 2비트 가산기를 한 번 갖게 되면, 그 안에 작동하지 않는 2비트 가산기가 들어 있는 모든 가지는 차단된다. 각 반복은 훨씬 더 많은 정보를 산출하고, 탐색 문제는 다룰 수 있는 것이 된다.
Arthur의 시뮬레이션과 우리의 더 단순한 시뮬레이션의 논리는, 보다 일반적으로 새로운 기술을 만드는 일에도 적용된다. 논리 회로는 탐구하기에 유용한 모델이다. 그것은 실제 기술이면서 시뮬레이션에 매우 잘 맞기 때문이다(행동이 단순하고 명확하게 정의되어 있다). 하지만 일반적인 기술 역시, 더 단순한 구성요소나 요소들이 여러 방식으로 배열되어 더 복잡한 것을 만드는 조합으로 생각할 수 있다. Arthur가 말하듯이:
…1912년에 증폭기 회로는 이미 존재하던 삼극 진공관과 다른 기존 회로 구성요소들의 조합으로 만들어졌다. 증폭기는 다시 발진기(순수한 사인파를 생성할 수 있는 장치)를 가능하게 했고, 이것들은 다른 구성요소들과 함께 이종주파 혼합기(신호의 주파수를 바꿀 수 있는 장치)를 가능하게 했다. 이 두 구성요소는 다른 표준 구성요소들과 결합되어 연속파 무선 송신기와 수신기를 가능하게 했고, 이것들은 다시 다른 요소들과 결합되어 라디오 방송을 가능하게 했다. 집합적 의미에서 기술은 새로운 요소가 기존 요소들로부터 끊임없이 구성되는 요소들의 네트워크를 이룬다. 시간이 지나면서 이 집합은 단순한 요소를 결합해 더 복잡한 요소를 만들고, 소수의 구성 블록 요소로 다수를 만들어 내면서 스스로를 부트스트랩한다.
이 논문에서 얻을 수 있는 한 가지 교훈은, Arthur가 말하고 우리가 더 깊게 탐구했듯이, 복잡한 기술이 더 단순한 구성요소들로 이루어지고, 그 구성요소들이 다시 더 단순한 구성요소들로 이루어지는 위계적 배열이 어떤 새로운 기술을 훨씬 더 쉽게 만들게 한다는 점이다. 그러나 더 일반적인 교훈은 어떤 새로운 기술을 성공적으로 만든다는 것은 새로운 정보를 가능한 한 빨리 얻는 것을 뜻한다 는 점이다. 어떤 기술에 대해 각 요소가 수행해야 할 특정한 역할을 갖는 위계적이고 모듈적인 설계로부터 작업하거나, 혹은 그런 설계를 향해 작업하는 것은, 그 하위 부분들 가운데 하나를 만들려는 각 시도에서 배우는 것이 훨씬 많아지기 때문에 새로운 기술을 찾기 쉽게 만든다. 복잡한 기능 전체가 작동하는지 아닌지만 아는 것은, 어떤 개별 구성요소가 제대로 작동하는지, 그리고 문제를 고치려면 어떤 구체적 기능을 수정해야 하는지를 아는 것보다 훨씬 적은 정보를 준다.
실제로 수십 개의 NAND 게이트를 무작위로 결합해 보면, 거의 매번 무작위 진리표를 얻게 되며, 입력과 출력이 몇 개 되지 않는 중간 정도 복잡도의 함수조차 결코 풀지 못한다.
합산해 보면, 이 탐색은 실제로 852비트가 아니라 900비트가 넘는 정보를 산출한다는 것을 알 수 있다. 이는 순차 탐색의 정보 오버헤드 때문이다. 결국 실제로 필요하지 않은 “추가” 정보를 얻게 된다. 주머니가 8개인 재킷에서 휴대전화를 찾는 예에서, 우리가 무작위로 추측만 한다면 평균적으로 휴대전화를 찾기까지 8번 시도하게 된다. 8번의 시도 * 시도당 0.54비트는 4.32비트가 되는데, 이는 실제로 휴대전화의 위치를 특정하는 데 필요한 3비트보다 많다.