Val Town이 Supabase에서 Render의 더 단순한 Postgres 구성으로 이전한 이유, 배운 점, 그리고 실제 마이그레이션 과정을 공유합니다.
 on 2023년 5월 19일
on 2023년 5월 19일
지난 몇 주 동안 저희는 Val Town을 Supabase에서 Render의 더 단순한 데이터베이스 구성으로 이전했습니다. 이에 대해 몇 가지 질문을 받았기 때문에, 왜 이런 결정을 내렸는지, 무엇을 배웠는지, 그리고 어떻게 해냈는지를 공유하고자 합니다. Supabase는 매우 많은 만족스러운 사용자를 보유한 대단히 성공적인 제품이지만, 저희 팀의 요구사항에 맞게 확장하는 과정에서 많은 문제를 겪게 되었습니다. 여러분의 경험은 다를 수 있겠지만, 저희의 경험이 유용한 참고 사례가 되길 바랍니다.
Val Town은 2022년 7월 Steve Krouse가 서버 측 JavaScript 스니펫을 작성하고, 실행하고, 배포하고, 공유할 수 있는 사이트로 시작했습니다. 사용자들은 저희를 “백엔드를 위한 Codepen”이라고 부릅니다. 사람들은 저희 서비스를 이용해 작은 API를 만들고, cron 작업을 예약하고, 서비스 간 작은 통합을 만듭니다. 예를 들어 다운타임감지기, 가격추적기, 프로그래밍 방식의알림서비스 등이 있습니다.
Steve는 Supabase 위에서 Val Town의 초기 버전을 만들었습니다. 저(Tom MacWright)는 2023년 1월에 합류했습니다.
Supabase는 백엔드 서버를 직접 작성하지 않고도 애플리케이션 전체 백엔드를 구축할 수 있는 방법이 될 수 있습니다. Supabase는 데이터베이스이지만, row security policies를 통해 접근을 제어하는 방법도 제공합니다. 그리고 PostgREST를 사용해 프론트엔드에서 바로 데이터베이스를 질의할 수 있게 해줍니다. 인증 계층으로 gotrue를 통합하여 사용자가 서비스에 가입할 수 있게 하고, 마지막으로 코드 한 줄 작성하거나 CLI를 사용하지 않아도 데이터베이스와 관련 서비스 전반을 관리할 수 있는 완전한 UI도 제공합니다.
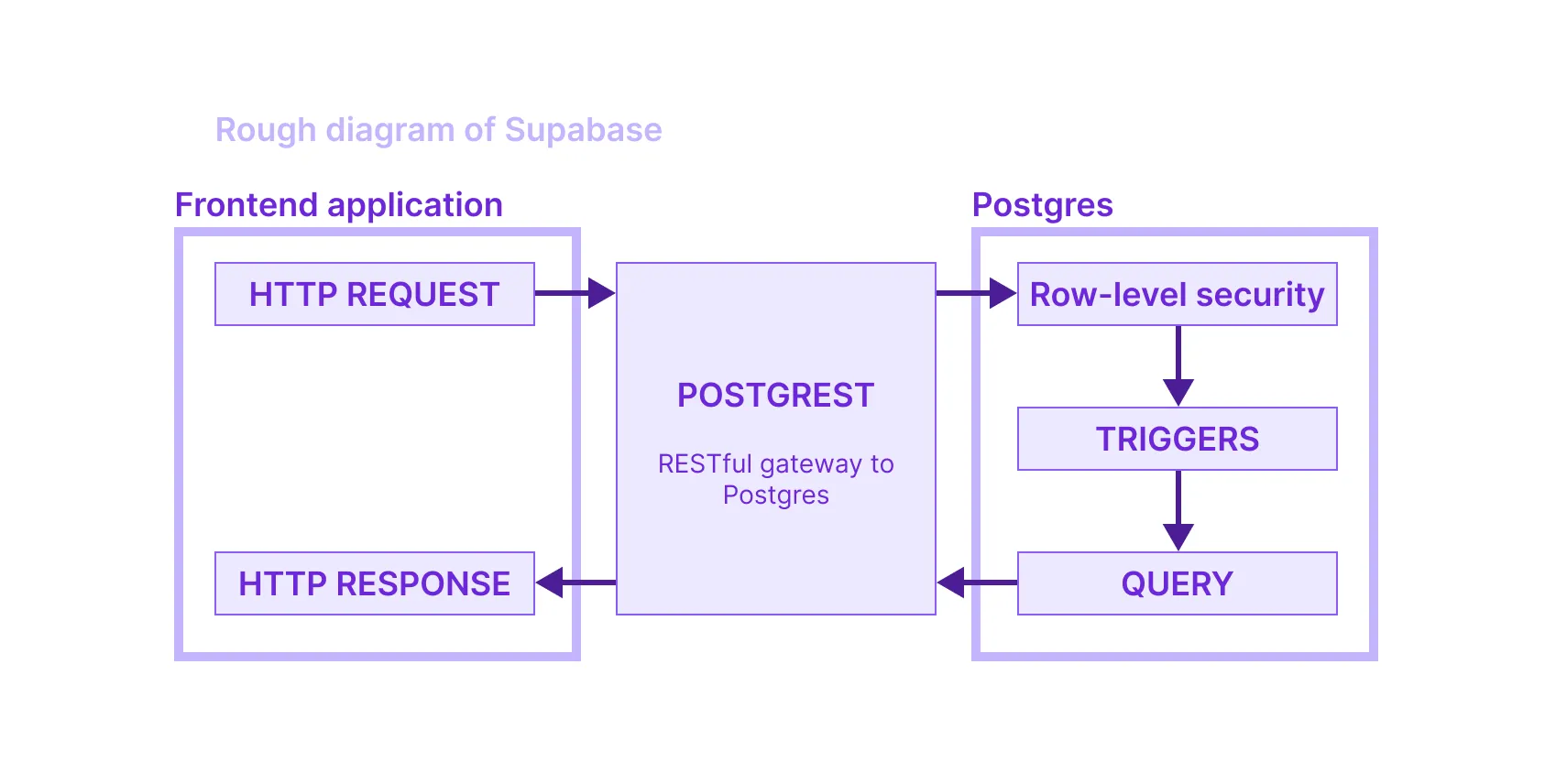
사실상 Supabase는 데이터베이스를 하나의 완전한 백엔드 애플리케이션으로 바꿉니다. 이를 위해 Postgres의 온갖 기법을 활용합니다. row-level security뿐 아니라, 저희는 트리거, materialized view, database role, 그리고 여러 스키마까지 사용하고 있었습니다. Postgres는 엄청나게 강력한 플랫폼입니다. 데이터베이스 안에서 로직을 작성하기 위해 SQL에 내장된 JavaScript를 작성하는 수준까지 갈 수도 있습니다.
잘 작동할 때는 정말 놀라웠습니다. 여러 번 듣기만 했던 Firebase를 사용하는 듯한 속도를, 빠르게 움직이는 오픈 소스 스택과 함께 누릴 수 있었습니다.
Supabase를 사용하면서 저희가 마주한 가장 큰 문제는 로컬 개발이었습니다. 제가 합류했을 때, 모든 개발은 프로덕션에서 이뤄지고 있었습니다. 모두가 프로덕션 데이터베이스에 연결했고, 모든 “마이그레이션”은 라이브 데이터베이스 스키마를 직접 수정하는 방식으로 수행됐습니다. 실제 적용 전에 프로덕션에서 테이블을 복제하고 그 복제본을 먼저 마이그레이션해 테스트하곤 했습니다. 때로는 웹 인터페이스를 사용해 컬럼 타입이나 인덱스 같은 것을 변경하기도 했는데, 이게 가장 무서운 방식이었습니다. 어떤 SQL을 실행하려는지 미리 보여주지도 않고, 때로는 실제 동작이 예상과 다르기 때문입니다.
제게 이건 꽤 무서운 일이었습니다. 일반적으로 엔지니어링 팀은 로컬 개발 환경과 스테이징 환경에서 작업하고, 프로덕션 데이터베이스는 아주 신중하고 잠깐만 건드립니다.
다행히 Supabase는 로컬 개발을 위한 도구 체인을 개발해 왔습니다. 바로 Supabase CLI입니다. 이 CLI는 로컬에서 Supabase 스택을 관리합니다. Postgres, gotrue, realtime 서버, storage API, API gateway, image resizing proxy, Postgres 관리를 위한 restful API, Studio 웹 인터페이스, edge runtime, logging system 등, 총 11개의 Docker 컨테이너가 서로 연결되어 있습니다.
하지만 안타깝게도 저희는 이걸 제대로 작동시키지 못했습니다. 저는 깨진 Docker 컨테이너부터, 사용자 정의 role을 처리하지못하는 데이터베이스 마이그레이션 시스템, 그리고 부족한 CLI 도움말까지 온갖 문제를 겪었습니다. 로컬 개발 환경을 하루 이상 안정적으로 유지할 수 없었습니다. CLI가 깨지거나, 마이그레이션이 잘못 생성되어 적용할 수 없었습니다.
CLI 사용이 어려웠던 이유 중 하나는 문서가 아직 완전히 작성되지 않았기 때문입니다. supabase db remote commit 명령은 “Commit Remote Changes As A New Migration”이라고 문서화되어 있습니다. supabase functions new 명령은 “Create A New Function Locally.”라고 되어 있습니다. 문서 페이지는 아름답지만, 그 안의 문구는 아직 완성되지 않았습니다. 이런 명령들은 문서화가 매우 중요합니다. db remote commit은 실제로 로컬 데이터베이스에 영향을 주고 마이그레이션도 손봅니다. 실행하기 전에 정확히 무엇을 하는지 아는 것이 정말 중요합니다.
안타깝게도 다른 부분의 문서도 크게 낫지는 않습니다. 예를 들어 Supabase의 Remix integration은 괜찮은 튜토리얼은 있지만, 개념 설명이나 API 레퍼런스 문서는 빠져 있습니다. 저는 Remix 통합을 구현하는 데 하루 이틀을 쓴 뒤에야, 이것을 사용하려면 localStorage 기반 인증에서 cookie 기반 인증으로 전환해야 하고, 그 결과 모든 사용자 세션을 초기화해야 한다는 사실을 깨달았습니다.
그리고 다운타임 문제가 찾아왔습니다. Val Town은 예약된 코드 조각을 실행하는 책임을 집니다. 빠른 TypeScript 함수를 작성하고 시계 아이콘을 클릭하면, 그 시점부터 매시간 실행되도록 예약할 수 있습니다. 그런데 매일 밤 자정 무렵이 되면 vals가 작동을 멈추는 것을 발견했습니다. 조금 추적해 본 결과, Supabase가 매일 자정에 데이터베이스 백업을 수행하면서 데이터베이스를 완전히 오프라인으로 만들고 있었습니다. 어느 정도 이해할 수는 있는 일입니다. 하지만 덜 반가운 점은, 그 백업을 중단하고 저희를 오프라인 상태에서 벗어나게 하는 데 꼬박 일주일이 걸렸다는 것입니다.
공정하게 말하자면, 현재 Val Town은 데이터베이스를 정말 거칠게 사용합니다. 쓰기 비중이 높은 애플리케이션이고, json 컬럼을 많이 사용하며, 모든 과거 평가 결과를 저장하는 매우 큰 테이블도 있습니다. 그리고 Supabase는 지원 과정에서 정말 많은 도움을 주었고, 데이터베이스 스키마 일부를 재설계하는 데까지 도와주었습니다. 저희가 운영하는 애플리케이션은 어떤 의미에서는 데이터베이스 구성에 대한 스트레스 테스트입니다.
Supabase는 데이터베이스 크기에 대해 다소 특이한 방식을 사용합니다. 큰 데이터베이스를 미리 할당해 두고 시간이 지나며 채우는 대신, 데이터베이스는 작게 시작해 커지면서 자동으로 크기가 조정됩니다. 데이터베이스는 8GB로 시작하고, 90%에 도달하면 50% 더 큰 데이터베이스로 업그레이드됩니다. 그런데 안타깝게도 이 시스템에 우연한 문제가 있었습니다. 어느 일요일, 그들의 시스템이 저희 데이터베이스 크기를 조정하지 못했고, 대신 디스크가 95% 찬 상태에서 읽기 전용 모드로 전환됐습니다. 이런 시스템을 다뤄본 적이 있다면, 그 다음에 무슨 일이 일어나는지 짐작하실 수 있을 겁니다.
디스크 최대 용량에 이렇게 가까워지면 일종의 진퇴양난에 빠집니다. 디스크 사용량을 줄이기 위해 하고 싶은 모든 작업은 약간의 임시 공간을 추가로 필요로 하는데, 그 공간이 없습니다. 예를 들어 크기를 줄이기 위해 테이블에 VACUUM을 실행하고 싶다고 해도, VACUUM 작업 자체가 약간의 추가 저장 공간을 필요로 합니다. 그 정도만으로도 디스크 사용률이 100%를 넘어 재시작이 발생할 수 있습니다. 컬럼 타입을 바꿔 몇 바이트라도 절약해보려 해도, 사용률 100%에 도달해 다시 재시작됩니다.
상황을 더 나쁘게 만든 것은 Supabase 웹 사용자 인터페이스가 데이터베이스 자체에 크게 의존한다는 점이었습니다. 그래서 데이터베이스가 죽으면 관리 인터페이스도 같이 죽었습니다. 관리 인터페이스를 실행하는 시스템과, 그 관리 대상이 되는 시스템은 분리되어 있는 편이 더 좋고 바람직합니다.
어쨌든, 공황 상태의 일요일 오후 대형 장애를 겪은 뒤, 더 이상 사용하지 않던 테이블 하나를 찾아냈고, 그 덕분에 저장 공간 5GB를 확보해 읽기 전용 모드에서 벗어날 수 있었습니다. 몇 시간 뒤 지원 팀이 업데이트를 보내왔습니다.
이 이야기의 교훈 중 일부는 데이터베이스가 어렵다는 것입니다. 데이터베이스를 안정적으로 운영하는 일만으로도, 신뢰성과 확장성을 갖출 수 있다면 성공적인 회사를 만들 수 있습니다. 실제로 CrunchyData 같은 그런 회사들이 있습니다. 데이터베이스 관리는 어렵고 냉정한 일입니다. 하지만 바로 그렇기 때문에 저희는 shared_buffers를 조정하는 법을 알고, 서비스를 중단시키지 않고 백업을 수행할 줄 아는 현명한 전문가들인 관리형 제공업체에 비용을 지불합니다. 훌륭한 사용자 인터페이스와 추가 기능이 있는 것도 좋지만, 무엇보다도 반석처럼 견고한 데이터베이스가 기반이 되어야 합니다.
내부적으로 Supabase는 그저 Postgres입니다. 그들의 서비스에 가입하고, 웹 사용자 인터페이스는 전혀 사용하지 않으며, Supabase를 단순한 Postgres 데이터베이스인 것처럼 애플리케이션을 구축하고 싶다면 그렇게 할 수 있습니다. 실제로 그렇게 하는 사람도 많습니다. 무료 티어를 제공하는 몇 안 되는 제공업체 중 하나이기 때문입니다.
하지만 어려운 부분은 Supabase를 “Firebase 대안”처럼 사용할 때입니다. 즉, 트리거, stored procedure, row-level security 등을 사용해 애플리케이션 계층의 많은 부분을 데이터베이스 안에 넣으려 하면, 일반적인 Postgres 도구들은 Supabase를 이해하지 못하고, 반대로 Supabase도 그 도구들을 잘 이해하지 못하는 지점들을 만나게 됩니다.
예를 들어 마이그레이션을 관리하는 훌륭한 시스템은 많이 있습니다. TypeScript 생태계에서는 Prisma와 drizzle-orm이 저희 목록의 최상단에 있었습니다. 하지만 그런 마이그레이션 도구들은 트리거나 row level security를 지원하지 않기 때문에, Supabase 전략을 따르면서도 구조적인 방식으로 데이터베이스를 발전시키기가 어려웠을 것입니다. 그래서 마이그레이션이 어려워집니다. 질의도 어렵습니다. row-level-security를 유지하면서 질의하는 문제는 Prisma에서 논의되고 있는 주제이지만, Kysely나 drizzle-orm에서 어떻게 할 수 있을지는 분명하지 않습니다.
저희가 데이터베이스를 Postgres처럼 사용하다가 가끔 Supabase로 관리하려고 했을 때도 비슷한 단절이 계속 발생했습니다. 예를 들어 저희는 jsonb가 아닌 json 컬럼을 가지고 있었는데, Studio 인터페이스가 특정한 가정을 하고 있어서 컬럼 타입을 올바르게 표시하지 못했습니다. 또는 테이블 안에 JSON 값이 있어도, 웹 인터페이스의 깨진 CSV 내보내기 때문에 이를 내보낼 수 없었습니다. 복합 외래 키가 잘못 표시되는 문제도 보였고, UI를 통해 스키마를 수정할 때 예상치 못하고 파괴적인 쿼리가 실행되는 문제를 우려해야 했습니다. 이런 문제들 중 많은 것은 수정되었습니다. 이제 Studio는 빈 선택 상자 대신 varchar와 json 타입을 보여주고, CSV도 올바르게 내보내야 합니다.
양쪽 방향 모두에서, 두 시스템이 서로의 짝을 100% 포착하지 못하는 단절이 있다는 느낌이 들었습니다. 일반적인 데이터베이스 마이그레이션 질의 도구들이 이해하지 못하는 것이 너무 많았고, 반대로 데이터베이스에서 직접 할 수 있는 일들 중 Supabase 웹 인터페이스가 제대로 처리하지 못하는 것도 있었습니다.
안타깝게도 Supabase 전략의 몇 가지 한계는 저희 애플리케이션 설계에도 스며들었습니다. 예를 들어 저희는 데이터 접근 제어를 Row-Level Security 중심으로 구축하고 있었는데, 이름 그대로 이것은 행 단위입니다. RLS에서는 컬럼 단위 접근을 제한하는 명확한 방법이 없습니다. 그래서 모두가 접근하면 안 되는 “email” 같은 민감한 컬럼이 있는 “users” 테이블이 있다면, 꽤 어려운 해결책들만 남습니다.
어쩌면 그 테이블의 데이터베이스 뷰를 만들 수 있겠지만, 실수로 그것을 공개 읽기 가능하게 만들어버리기 쉽습니다. 결국 저희는 사용자 테이블을 세 개 갖게 되었습니다. 프론트엔드에서 접근할 수 없는 Supabase 내부 테이블 auth.users, 백엔드에서 접근 가능한 private_users 테이블, 그리고 프론트엔드에서 질의 가능한 users 테이블입니다.
또한 기본 Supabase 질의 클라이언트를 사용해서는 효율적인 질의를 작성할 수 없었기 때문에, 비정규화된 데이터베이스 테이블도 많이 설계했습니다. 물론 질의 시점 성능과 삽입 시점 성능 사이에는 언제나 절충이 있습니다. 하지만 저희는 매우 기본적인 수준에서 막혀 있었고, 질의 최적화를 거의 할 수 없었기 때문에, 많은 작은 질의를 작성하거나 질의를 빠르게 하기 위해 비정규화된 컬럼에 중복 데이터를 저장하는 방향으로 밀려났습니다.
제 생각에는 이걸 잘 작동하게 만드는 방법이 있긴 할 겁니다. 많은 SQL을 작성하고 데이터베이스에 크게 의존하는 방식 말입니다. Postgres에서는 무엇이든 할 수 있습니다. pgTAP으로 테스트를 작성하고, plv8로 Postgres 함수 안에서 JavaScript를 작성할 수도 있습니다. 하지만 그렇게 하면 데이터베이스 안에 애플리케이션을 넣는다는 발상에 저희가 더 깊이 묶이게 되고, 저희에게는 그것이 디버깅과 개선을 더 어렵게 만들었습니다.
결국 저희는 Render의 “바닐라” Postgres 서비스를 사용하기로 전환했습니다.
저희는 Supabase를 자체 호스팅하고 싶지 않았습니다. devops 문제가 문제의 일부일 뿐이었기 때문입니다. 저희는 그냥 데이터베이스가 필요했습니다. Render는 이미 몇 달 동안 Val Town의 나머지 부분을 호스팅해 왔고, 상당히 훌륭했습니다. Render Preview Environments는 정말 대단합니다. 모든 pull request마다 프론트엔드 remix 서버, node api 서버, deno 평가 서버, 그리고 이제 postgres 데이터베이스까지 포함한 전체 스택의 완전한 복제본을 띄워줍니다. Blueprint Specification 시스템은 수동으로 구성한 인프라와 Kubernetes 같은 것을 설정하기 위해 필요한 엄청난 양의 YAML 사이에서 좋은 중간 지점을 제공합니다.
저희는 CrunchyData, neon, RDS 등 다른 Postgres 호스트도 몇 군데 고려했지만, Render의 응집력 있고 포괄적인 기능 세트를 이기기는 어렵습니다. 게다가 그들은 매우 유능하고 전문적인 엔지니어들입니다. 저는 수년간 Render에 애플리케이션을 호스팅해 왔고, 불만이 거의 없습니다.
목표는 데이터베이스를 로컬에서 실행하고, 프로덕션에 적용하기 전에 마이그레이션을 테스트할 수 있게 만드는 것이었습니다. 저희는 데이터 계층을 재작성해, 데이터베이스를 애플리케이션이 아니라 단순한 영속성 계층으로 다루도록 했습니다. 모든 트리거, stored procedure, row-level security 규칙을 제거했습니다. 그 로직은 이제 애플리케이션에 있습니다.
저희는 데이터베이스 사용 방식을 대폭 단순화했고, SQL 질의를 만들기 위해 drizzle-orm을 사용하기 시작했습니다. 정말 꿈처럼 잘 작동합니다. 이제 데이터베이스 스키마가 코드에 담기고, 제안된 데이터베이스 마이그레이션이 포함된 pull request를 만들 수 있으며, 누구도 로컬 컴퓨터에서 프로덕션 데이터베이스에 연결하지 않습니다. 더 효율적으로 데이터를 질의하고 더 정확한 접근 제어를 정의할 수 있게 되면서, 몇몇 테이블은 아예 제거할 수도 있었습니다.
데이터를 마이그레이션하는 데는 일주일이 걸렸습니다. 첫 번째 문제는 데이터베이스 크기가 40gb라는 점이었습니다.
저희는 몇 시간 동안 서비스를 중단하고 마이그레이션을 수행하는 방안도 고려했습니다. 하지만 저희는 클라우드 서비스 제공업체이고, 그 책임을 गंभीर하게 받아들입니다. 저희가 다운되면 사용자들의 API 엔드포인트와 cron 작업이 멈춘다는 뜻이기 때문입니다. 다운타임은 최후의 수단이었습니다.
핵심적인 통찰은 데이터의 80%가 tracing 테이블에 있다는 점이었습니다. 이 테이블은 모든 Val Town 함수 실행의 과거 평가 이력을 저장합니다. 이것은 이력성 데이터였고 운영에 필수적이지 않았기 때문에, 먼저 핵심 데이터를 마이그레이션한 뒤 이 로그성 테이블은 점진적으로 옮기기로 했습니다.
다음 문제는 다운로드와 업로드 속도를 개선하는 것이었습니다. 다운로드를 위해 us-east-1의 Supabase 근처에 ec2 서버를 띄웠고, 각각 다운로드와 업로드에 최대한 가깝게 하기 위해 Ohio Render 리전에도 서버를 띄웠습니다. pg_dump를 몇 차례 더 최적화한 뒤, tracing 테이블을 제외한 모든 데이터 다운로드는 15분이 걸렸습니다. 그 파일을 Render 서버로 scp한 뒤, 거기서 pg_restore를 실행했는데 추가로 10분이 걸렸습니다. 그리고 나서 프로덕션 서버들이 새 Render Postgres 데이터베이스를 사용하도록 전환했습니다.
저희는 고객들에게 마이그레이션 사실과, tracing 데이터는 곧 백그라운드에서 복구될 것이라고 알렸습니다. 그 사이 약 30분 동안 생성된 새 데이터가 소량 있었습니다. 저희는 그 차이 데이터를 수동으로 가져와 새 데이터베이스에 업로드했습니다. evaluations 테이블 덤프는 밤새 걸렸습니다. 그리고 scp 자체에도 몇 시간이 걸렸고 AWS egress 비용으로 6달러가 들었습니다. 과거 tracing 데이터 업로드를 마치는 데는 또 하룻밤이 더 걸렸습니다.
조언 하나를 드리자면, 데이터베이스 안팎으로 데이터를 옮길 때는 데이터베이스 서버와 같은 네트워크 안에서 작업하는 것이 훨씬 유리합니다.
이제 Val Town은 Render의 단순한 Postgres 구성 위에서 안정적으로 돌아가고 있고, 저희는 전통적이고 고전적인 마이그레이션으로 데이터베이스를 발전시키며 로컬에서 애플리케이션을 개발할 수 있게 되었습니다. 마이그레이션이 로컬에서, preview 브랜치에서, 그리고 main에 병합될 때 실행된다는 점은 이상할 만큼 미래적이면서도 다시 과거로 돌아간 느낌을 줍니다. 저는 몇 시간 만에 likes 기능(즉, val에 ❤️를 누를 수 있는 기능)을 배포했고, 무엇보다도 불안감 없이 해낼 수 있었습니다. Supabase를 쓰던 시절에는 데이터베이스 스키마를 건드리는 것이 무서워서 그런 기능들을 미루곤 했습니다.
가끔은 Supabase 인터페이스의 친근한 테이블 뷰가 그립기도 합니다. 그들의 멋진 launch week를 보며 감탄합니다. Supabase를 사용한다는 것은 애플리케이션을 구축하는 또 다른, 어쩌면 미래적인 방식을 엿보는 것과 같았습니다. 하지만 이제 저희는 innovation tokens를 다른 곳에 쓰고 있고, 덕분에 더 빠르게 기능을 출시할 수 있게 되었습니다.