avatarl은 전통적 교차 엔트로피 대신 비평가(critic)와 현실(정답)을 혼합한 연속 보상 신호를 사용해 사전학습을 RL로 재구성한다. 학생과 비평가의 top-k, 정답을 통합한 능동 토큰 필터링·스무딩으로 밀집 보상 지형을 만들고, 동시 평가로 효율적인 정책경사 학습을 수행하는 방법과 초기 실험 결과를 소개한다.
avatarl: 순수 강화학습으로 언어 모델을 처음부터 학습하기
2025년 8월 9일
"if you know the way broadly you will see it in all things" — Miyamoto Musashi
표준 언어 모델 사전학습은 교차 엔트로피 목표에 의존한다. 이는 주어진 문맥에서 오직 하나의 토큰만이 정답인 것으로 모델을 엄격히 가르친다. 그러나 언어는 본질적으로 불완전하게 그렇게만 표현될 수 없으며, 여러 개의 다음 토큰이 그럴듯한 경우가 흔하다.
avatarl은 전통적 교차 엔트로피 목표를 정교한 강화학습(RL) 프레임워크로 대체한다. 사전학습 단계에서 플레이어(학생) 모델은 사전학습된 비평가(critic)와 현실(ground truth)로부터 도출된 연속 보상 신호를 학습한다. 이를 통해 플레이어는 단 하나의 '정답'만이 아니라 비평가가 판단했을 때 그럴듯한 대안들까지 보상받는, 풍부하고 분포적인 언어 이해를 습득한다. 이 접근은 보다 원칙적인 사전학습 목표로, 처음부터 더 깊고 섬세한 언어 이해를 갖춘 모델을 만들도록 설계되었다 [1].
한 아이(플레이어 모델)에게 피아노 치는 법을 가르친다고 상상해 보자.
전통적 사전학습: 피아노 학생은 틀릴 때마다 손을 때리는 엄격한 선생님과 앉아 있다. "안 돼! 여기서는 C#만! D는 절대 안 돼!" 학생은 수천 곡을 음표 하나하나 외우고 실수를 두려워한다. 그 결과 기술적으로 완벽하지만 외운 것만 재현하는 로봇 같은 연주자가 된다.
avatarl의 RL 접근: 학생은 재즈 클럽에서 연주하고 경험 많은 비평가가 지켜본다. 처벌 대신 박수를 받는다. 완벽한 음에는 큰 환호, 조화로운 대안에는 중간 정도의 박수, 창의적 시도에는 예의 있는 박수. 비평가(노련한 재즈 피아니스트)가 속삭인다: "여기서 B♭를 시도해봐, 긴장이 생겨" 학생은 무엇이 "정답"인지뿐 아니라 무엇이 음악적으로 의미 있는지도 배운다.
RL 용어로 보면:
가장 흥미로운 부분은 학생이 즉흥연주를 시작할 때다 — 자신의 아이디어(학생 top-k)를 연주하고, 비평가의 제안(비평가 top-k)을 고려하며, 원래의 선율(정답)을 염두에 둔다. 시간이 흐르며 음악 이론을 존중하면서도 자신만의 스타일을 발전시킨다. 이것이 강화학습이다. 즉, 엄격한 교정이 아닌 보상을 통해 학습하고, 암기보다 탐사를 통해 패턴을 발견한다.
볼 줄 아는 눈에는 어디에나 RL이 있다.
이것이 전통적 사전학습이지만, 동시에 이진 보상의 REINFORCE로도 볼 수 있다.
표준 교차 엔트로피 손실
문맥: "the cat..."
[sat] [jumped] [ran] [slept]
↓ ↓ ↓ ↓
WIN LOSE LOSE LOSE
당첨 규칙:
- 학습 데이터의 정확한 단어를 맞히면 = $1 당첨
- 그 외는 = 꽝
같은 문제를 누진 보상 복권으로 다시 상상해 보자.
avatarl의 연속 보상
문맥: "the cat..."
[sat] [jumped] [ran] [slept]
↓ ↓ ↓ ↓
HIGH MED LOW TINY
(전문가 합의에 따른) 지급 규칙:
- 정답( sat ) = $82
- 비평가의 선호 = $10-45
- 그럴듯한 대안 = $1-9
- 잡음 = 없음
그렇다면 RL에서 우리가 겪는 몇 가지 도전을 어떻게 설계로 풀어낼까?
전통적으로 모델을 어떻게 가르치는지 보자. 다음 토큰 예측을 위한 교차 엔트로피 손실로 하는 표준 사전학습. 이는 금 토큰만 보상 1.0, 나머지는 0을 받는 REINFORCE의 특수한 경우로 볼 수 있다 [3]. 최소한 금 토큰에 1, 나머지에 0인 이진 보상은 만들 수 있다. 사전학습을 RL 문제로 표상하는 것 자체는 어렵지 않지만, 몇 가지 우려점이 있다.
RL의 큰 흐름은 이렇다:
1단계: 행동 샘플링(각 행동의 확률 - 행동 공간 크기의 역수)
2단계: 롤아웃 실행(각 행동의 보상)
3단계: 정책 갱신(경사 하강)
첫 번째 문제는 언어 모델에서 토큰 수준 행동 공간이 너무 크다는 점이다. 어휘 크기가 약 5만이기 때문이다. 우리가 RL 전에 사전학습을 하는 가장 큰 이유 중 하나가, 가장 높은 확률의 행동이 올바를 가능성이 높도록 만들기 위해서다. 만약 올바른 토큰이 상위 64개 선택지에 있을 확률이 높다고 기대한다면, 64번 롤아웃해 각 행동의 보상을 얻으면 된다. 그러나 사전학습 없이라면 다음 토큰이 맞을 확률은 무작위 — 1/50,000, 즉 0.002%다. 그러면 롤아웃을 64번 해도 0.002% * 64 = 0.128% 확률로만 올바른 토큰을 밟는다. 단계당 막대한 롤아웃 수와 희소한 보상 신호 때문에 순수 RL만으로 모델을 학습하는 것은 계산 비용이 극도로 비싸진다.
두 번째 문제는 승리 조건이 절대적으로 명확하지 않다는 점이다. 전통적 게임 RL은 승패가 결정적이다. 각 행동에 대한 보상/처벌이 제한된 공간에서 올바른 행동을 학습하게 만든다. 그러나 언어 모델링에서는 승리 조건이 명확하지 않다. 같은 문맥에서도 올바른 다음 토큰은 크게 달라질 수 있다. 만약 명확한 승리 조건을 만들거나, 매끈한 확률적 부분 보상 범위를 만들고자 한다면, 거대 언어 모델에서는 극도로 어렵다. 모델은 게임에서 이기는 것이 아니라, 다음 토큰 예측의 손실을 최소화하려 한다. 문맥이 커질수록 올바른 다음 토큰의 변동성은 더 커진다.
핵심적으로 avatarl은 언어 모델 사전학습을 강화학습 문제로 재구성한다. 학생 모델은 환경(지금까지의 텍스트 시퀀스)에서 의사결정(다음 토큰 예측)을 배우는 RL 에이전트다. 이는 사전 계산을 재활용하는 재생성 RL(reincarnated RL) 패러다임 [8]과도 맞닿는다. (사전학습된 비평가를 재사용)
첫 번째 문제의 해법으로, 더 작은 행동 공간을 사용한다. 하지만 행동 공간을 임의로 줄이는 것만으로는 소용없다. **능동 토큰 필터링(active token filtering)**을 적용해 중요하지 않은 토큰을 제거한다. 비평가 모델로부터 세계 지식(비평가 top-k)을, 학생도 자신의 예측(학생 top-k)을 공유하게 하고, 여기에 정답을 결합해 올바를 가능성이 높은 행동의 부분집합(최대 2*k + 1)을 만든다. 학생은 가능성이 높은 행동들로부터 배운다. 언어 모델의 샘플링 맥락에 대해서는 top-k와 누클리어스(top-p) 샘플링 분석을 보라 [5].
두 번째 문제에서는, 행동에 적절히 보상을 줄 수 있는 매끈한 보상 범위를 제공하는 메커니즘이 필요하다. 정답 토큰에만 의존하면 보상 신호는 희소하고, 비평가 분포에만 의존하면 비평가가 더 큰 교사인 경우 단순 지식증류가 된다. 또한 보상 신호의 가치 상한이 생긴다. 학생은 비평가 수준에 도달하면 그 이후로는 보상에서 가치를 더 끌어내지 못한다. 비평가와 학생 양쪽의 보상 신호를 활용할 수 있어야 한다. 이상적으로는 원-핫 인코딩보다 더 풍부한 분포를 가르치면서도, 비평가 보상의 상한에 갇히지 않도록 해야 한다.
전체 과정은 다음과 같은 간단한 루프로 시각화할 수 있다:
+-------------------+ +-------------------+
| state s_t | ---> | student policy |
| (context tokens) | | π_θ(s_t) → logits |
+-------------------+ +-------------------+
| |
| +---------------+---------------+
| | |
v v v
+-----------+ +-----------+ +-------------+
| top-k_s | | top-k_c | | gold token |
| (student) | | (critic) | | a*_t |
+-----------+ +-----------+ +-------------+
\ | | /
\ | | /
\ v v /
+----------------------------------+
| filtered actions A_t |
| (≤ 2k + 1, deduped) |
+----------------------------------+
|
v
+----------------------------------+
| reward model (expert consensus):|
| reality + critic (blend); |
| active-token smoothing |
+----------------------------------+
|
v
+----------------------------------+
| r_i over A_t: renorm on A_t |
| reward only above-mean; clamp max|
+----------------------------------+
|
v
+----------------------------------+
| REINFORCE update |
| L = -Σ_i r_i · log π_θ(a_i|s_t) |
| + entropy bonus |
+----------------------------------+
|
v
+----------------------------------+
| update θ; pick a_t ∈ A_t |
| append to context → s_{t+1} |
+----------------------------------+
|
v
(loop)
위 표기: s_t = 시각 t의 문맥(지금까지 토큰); a*_t = 정답 다음 토큰; A_t = 학생 top-k ∪ 비평가 top-k ∪ {a*_t} (중복 제거, ≤ 2k+1); π_θ(a|s_t) = 학생의 토큰 정책; r_i = a_i ∈ A_t에 대한 보상.
avatarl 보상 메커니즘에서는, 올바른 토큰에 +1, 다른 모든 것에 0을 주는 희소 보상 대신, 각 단계에서 모든 가능한 행동에 대해 밀집하고 연속적인 보상 신호를 제공하는 "이상적" 보상 모델을 구성한다. 이 보상 모델은 **전문가 합의(expert consensus)**다.
주의하지 않으면 전문가 합의에는 미묘한 문제가 있다. 현실(expert)이
원-핫이면 보상이 초희소해져 학생은 탐색 신호를 거의 얻지 못한다.
비평가만 의존하면 학생은 비평가의 수준에 상한이 생기고 편향을 물려받는다.
전체 어휘에 스무딩하면 터무니없는 쓰레기에도 보상을 뿌려 그래디언트를 희석한다.
이유는 단순하다: 그럴듯한 대안에는 공정한 기회를 주되 잡음에는 보상하지 않는다.
대부분의 확률은 실제로 일어난 것(정답)에 남겨두되, 작은 ε만 이 문맥에서 가능성 있는 토큰들 사이에만 나눈다. 이렇게 하면 탐색이 집중되고, 비평가의 판단과도 잘 맞물리며, REINFORCE 업데이트가 안정화된다.
전문가 합의 내부 과정은 다음과 같다:
전문가 합의 내 능동 토큰 스무딩(현실 + 비평가)
문맥 s_t
|
학생 top-k_s 비평가 top-k_c 정답 a*
\ | | /
\ | | /
+--------------------------------------+
| A_t = dedup(top-k_s ∪ top-k_c ∪ {a*}) |
| (≤ 2k + 1 tokens) |
+--------------------------------------+
|
v
현실 분포(reality) over A_t:
- a*는 1 - ε
- A_t 내의 나머지는 ε / (|A_t| - 1)
- A_t 밖은 0
|
v
비평가 분포( A_t 로 제한 )
|
v
전문가 합의(현실 + 비평가 혼합)
- A_t 위에서만 재정규화
- 평균 초과(above-mean) 마스크 + 클램프
|
v
최종 보상 r_i over A_t → REINFORCE에서 사용
정답 토큰에 대한 보상 신호를 만들어야 한다. 전체 어휘에 대해 원-핫 인코딩을 사용할 수 있다. 하지만 이는 학습 신호로 좋지 않다. 보다 정보적인 보상 신호가 필요하며, 라벨 스무딩 기법을 사용할 수 있다.
이전: 전체 어휘에 대한 원-핫 이후: 능동 토큰 라벨 스무딩( A_t 한정 )
┌──────────────────────────────┐ ┌──────────────────────────────────────────────┐
│ 정답 a* = 100% │ │ A_t = dedup(top-k_s ∪ top-k_c ∪ {a*}) │
│ 나머지 = 0% │ → │ |A_t| ≤ 2k+1 (≈ 33 when k=16) │
└──────────────────────────────┘ │ │
│ p_reality(a*) = 1 - ε │
│ p_reality(a ≠ a*, a ∈ A_t) = ε/(|A_t|-1) │
│ p_reality(a ∉ A_t) = 0 │
│ │
│ 예: k=16, ε=0.10, |A_t|=33 │
│ a* = 90.000% │
│ A_t 내 각 토큰 ≈ 0.3125% │
└──────────────────────────────────────────────┘
"정답은 이미 있으니, 이 문맥에서 실제로 의미 있는 약 ~2*k + 1개 토큰에게만 작은 ε를 나눠 주겠다 — 나머지에는 0."
그럴듯한 대안을 만들기 위해 비평가 모델을 사용한다. 비평가 모델은 다음 토큰을 예측하도록 학습된 사전학습 모델이다. 이를 이용해 보상 신호를 구성할 수 있다.
┌─────────────────────┐
│ 모델 사전확률에 근거: │
│ "sat" = 60% │
│ "slept" = 30% │
│ "jumped" = 8% │
│ "flew" = 2% │
└─────────────────────┘
"여기서는 여러 가지가 가능하다; 우리는 그것들을 일관되게 점수화한다."
두 보상 신호는 가중 기하평균으로 결합한다:
현실(가중치 70%) 비평가(가중치 30%)
\ /
\ 기하평균 결합 /
\ p^0.7 × p^0.3 /
\ /
[결합된 지혜]
|
v
┌─────────────────┐
│ 최종 보상: │
│ "sat" = 82% │ <-- 정답은 여전히 가장 높음
│ "slept" = 15% │ <-- 비평가의 아이디어도 크레딧
│ "jumped" = 2% │ <-- 작은 아이디어도 의미 있음
│ "flew" = 0.1% │ <-- 미세하지만 0은 아님(탐색 촉진)
└─────────────────┘
공식의 시각화
현실 전문가: 비평가 전문가:
┌──────────────┐ ┌──────────────┐
│ "sat" = 0.9 │ │ "sat" = 0.6 │
│ others = 0.1 │ │ "slept" = 0.3│
└──────────────┘ │ "jumped"= 0.08│
↓ └──────────────┘
↓ 0.7제곱 ↓ 0.3제곱
↓ ↓
0.9^0.7 = 0.93 0.6^0.3 = 0.86
↓ ↓
└─────────────┬───────────────┘
│
곱하기
│
0.93 × 0.86
│
= 0.80
│
(전체 정규화)
│
↓
┌─────────────────┐
│ "sat" = 82% │ <-- 이상적 보상
│ "slept" = 15% │ <-- 준수한 보상
│ "jumped" = 2% │ <-- 다음 기회에
└─────────────────┘
↓
100 배 스케일
↓
이후 평균 초과만 보상(스파스화),
포지션별 비율 클램프(≤ 1.5)
직관: 높은 보상을 받으려면 두 전문가의 합의가 필요하다. 스무딩된 현실 전문가는 대안을 완전히 배제하지 않으면서도 정답을 강하게 선호하게 하고, 비평가 전문가는 모든 그럴듯한 토큰에 대해 매끈한 선호 구배를 제공한다. 결과 확률은 곧바로 양의 보상으로 사용된다.
avatarl의 핵심 통찰은, 학생이 택한 단일 행동에 대한 보상을 만들지 않는다는 것이다. 대신 먼저 능동 필터된 토큰들에 대한 밀집 보상 지형을 구성하고, 그 다음 학생의 정책을 이 지형에 대해 평가한다.
1. 전문가의 수학적 정의
a를 가능한 행동(토큰), a*를 데이터셋의 정답 토큰이라 하자.
p_reality(a | s): 정답 토큰 a*를 강하게 선호하지만 능동 토큰 라벨 스무딩을 사용해 연속 분포를 유지한다.
a = a*이면 p_reality(a | s) = 1 - ε (여기서 ε = 0.1)a ∈ active_tokens이고 a ≠ a*이면 p_reality(a | s) = ε / (num_active - 1)a ∉ active_tokens이면 p_reality(a | s) = 0 (즉, 능동 필터 토큰 집합 밖)여기서 active_tokens = 학생 top-k ∪ 비평가 top-k ∪ {정답} (중복 제거 후 일반적으로 ≤32 토큰)
이렇게 하면 정답에 90% 확률을 주고, 남은 10%는 전체 어휘가 아니라 능동 토큰에만 분배한다. 이는 5만+ 개의 무관한 토큰에 신호를 낭비하지 않고 관련 대안들에 탐색 신호를 집중시킨다.
p_critic(a | s): 비평가 모델의 어휘 분포.
p_critic(a | s) = softmax(critic_logits)2. 전문가 합의 정식화
이상적 분포 p_ideal은 두 전문가 분포의 가중 기하평균이다:
p_ref(a | s) ∝ [p_reality(a | s)]^w_r * [p_critic(a | s)]^w_m
여기서 w_r(reality_weight)와 w_m(mentor_weight)는 전문가 가중치이며, 기본값은 각각 0.7과 0.3이다. 행동 집합 A에서 정규화한 뒤 올바른 확률분포가 된다. 결과 p_ref는 우리의 양의 보상 신호로 사용된다 — A 위에서 보정된 "이상적" 확률(=보상) 벡터다.
3. 학생 정책의 평가
학생 정책 π_student(a | s)은 이 보상 지형에 대해 판정받는다. 정책경사 손실은 학생 분포를 이상 분포에 가깝게 옮기는 것을 목표로 한다. REINFORCE 규칙은 loss = -E_{a ~ π_student} [ r(a) ]이며, 여기서 보상 r(a) = p_ideal(a | s)이다 — 또한 탐색을 장려하기 위해 엔트로피 보너스 −β·H[π_θ(·|s)]를 추가한다(기본 β = entropy_coefficient = 0.01) [2, 4]. 실제로는 안정적 정책경사 업데이트를 위해 PPO 스타일의 클리핑과 GAE 같은 분산 감소 기법을 쓴다 [6, 7].
학생의 top-k 예측을 행동 공간에 포함함으로써 자기 강화 메커니즘을 만든다. 모델은 정답을 예측하는 법뿐 아니라 자신의 top-k를 통해 비평가의 예측을 보정(calibrate)하는 법도 배운다.
동시 top-k 평가
행동을 샘플링해 k회 순차 롤아웃하는 대신, avatarl은 학생 top-k, 비평가 top-k, 정답을 동시에 평가한다 — 안내된 탐색을 갖춘 효율적 2k+1 롤아웃 등가 방식. 구체적으로:
전형적 RL(순차 k 롤아웃): avatarl(2k+1 등가, 동시):
행동 샘플 → 롤아웃(×k) 학생 top-k + 비평가 top-k + 정답 수집
행동 샘플 → 롤아웃 ↓
행동 샘플 → 롤아웃 선택된 모든 행동에 대한 보상 계산
... n회 반복 ... ↓
↓ 모든 행동에 대해 정책 업데이트
보상 평균화 동시 1회 패스
↓
정책 업데이트 [빠르고 분산 낮음]
[느리고 분산 큼]
효율적 사전학습을 위해 몬테카를로 샘플링을 피하고, 축소된 행동 공간에 대한 전면 평가를 수행한다.
수학적 사실:
# avatarl이 하지 않는 것(토큰별 순차 롤아웃):
for rollout in range(num_rollouts): # 토큰당 순차 롤아웃 없음
action = sample_from_student() # 학습 시 확률적 롤아웃 샘플링 없음
reward = run_episode(action) # 토큰당 다단계 에피소드 없음
# avatarl이 실제로 하는 것(k 롤아웃 등가, 동시):
action_space = student_top_k ∪ critic_top_k ∪ ground_truth # ~32 actions
rewards = consensus_model(action_space) # 모든 행동에 대한 보상 사전계산
loss = -sum(log_prob(action) * reward for action in action_space) # 일괄 업데이트
예측당 통계:
avatarl은 1일 차부터 완전 공개 소스와 오픈 연구로 진행되었다.
따라서 여기 보이는 것은 작동을 확인한 직후의 초기 결과다.
30M–250M 파라미터 범위의 모델에 avatarl을 적용해 접근법을 검증했다. 각 경우 비평가 모델은 30M 파라미터였다. 약 20억 토큰으로 학습했고, 데이터셋은 openwebtext를 사용했다.
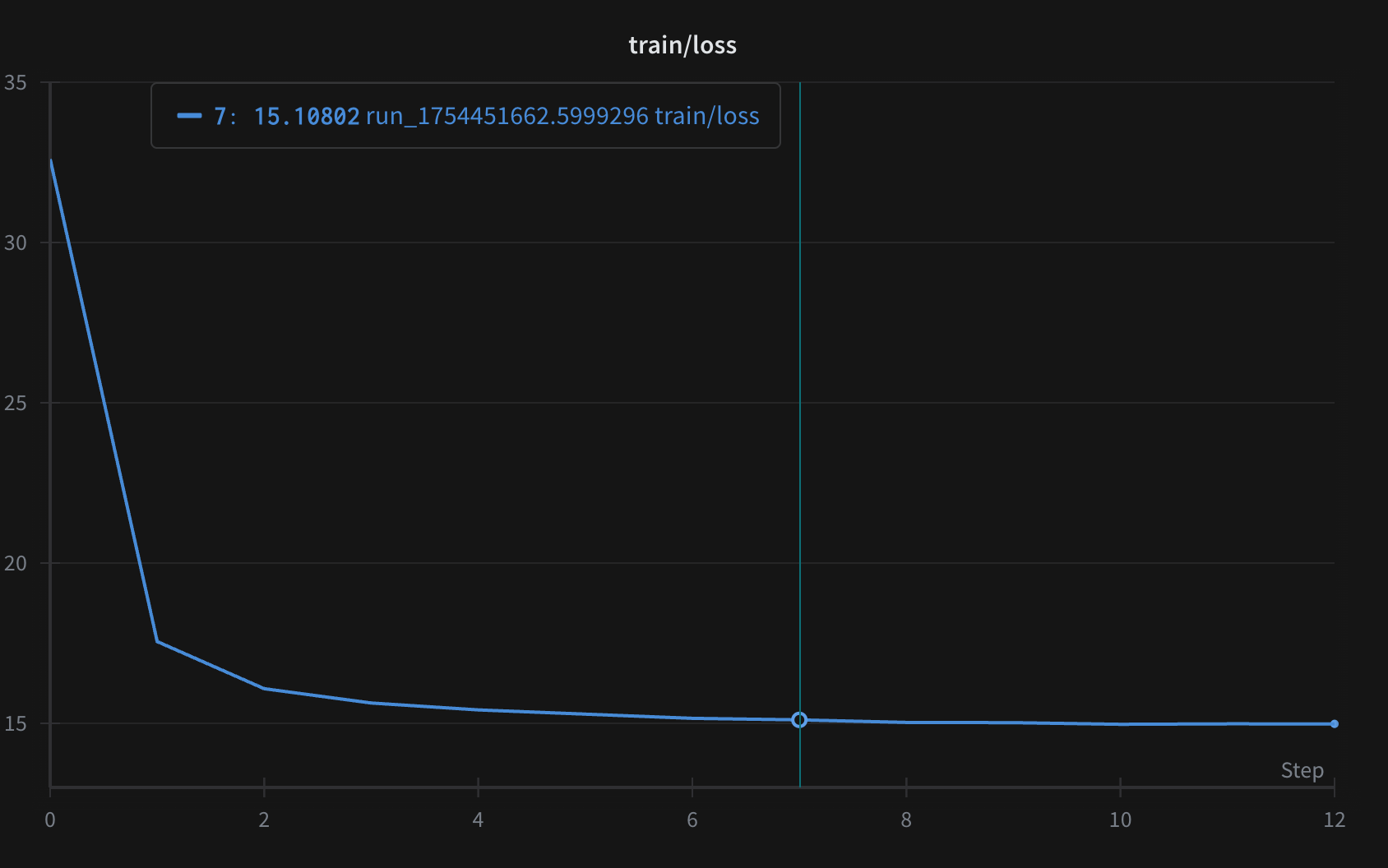
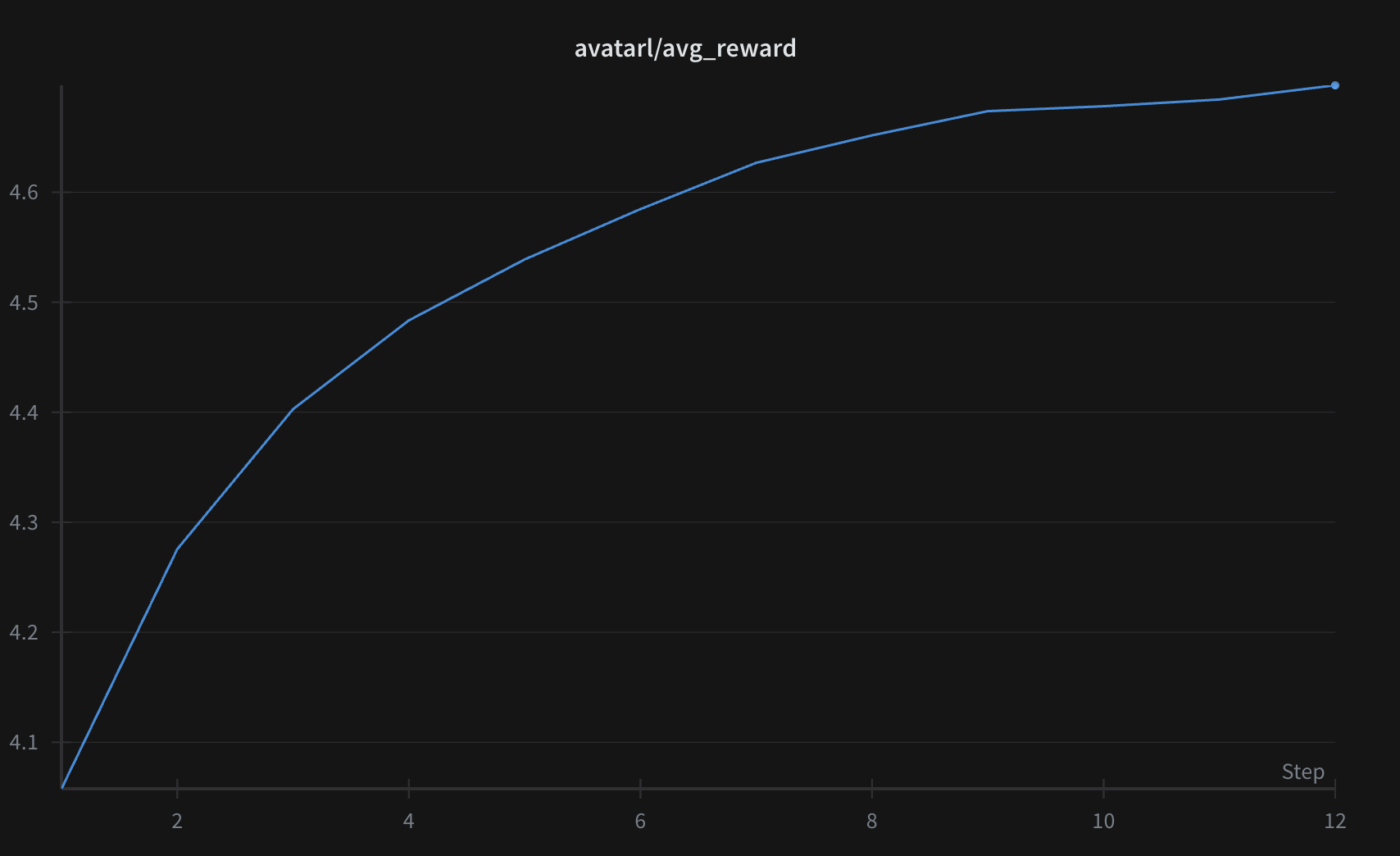
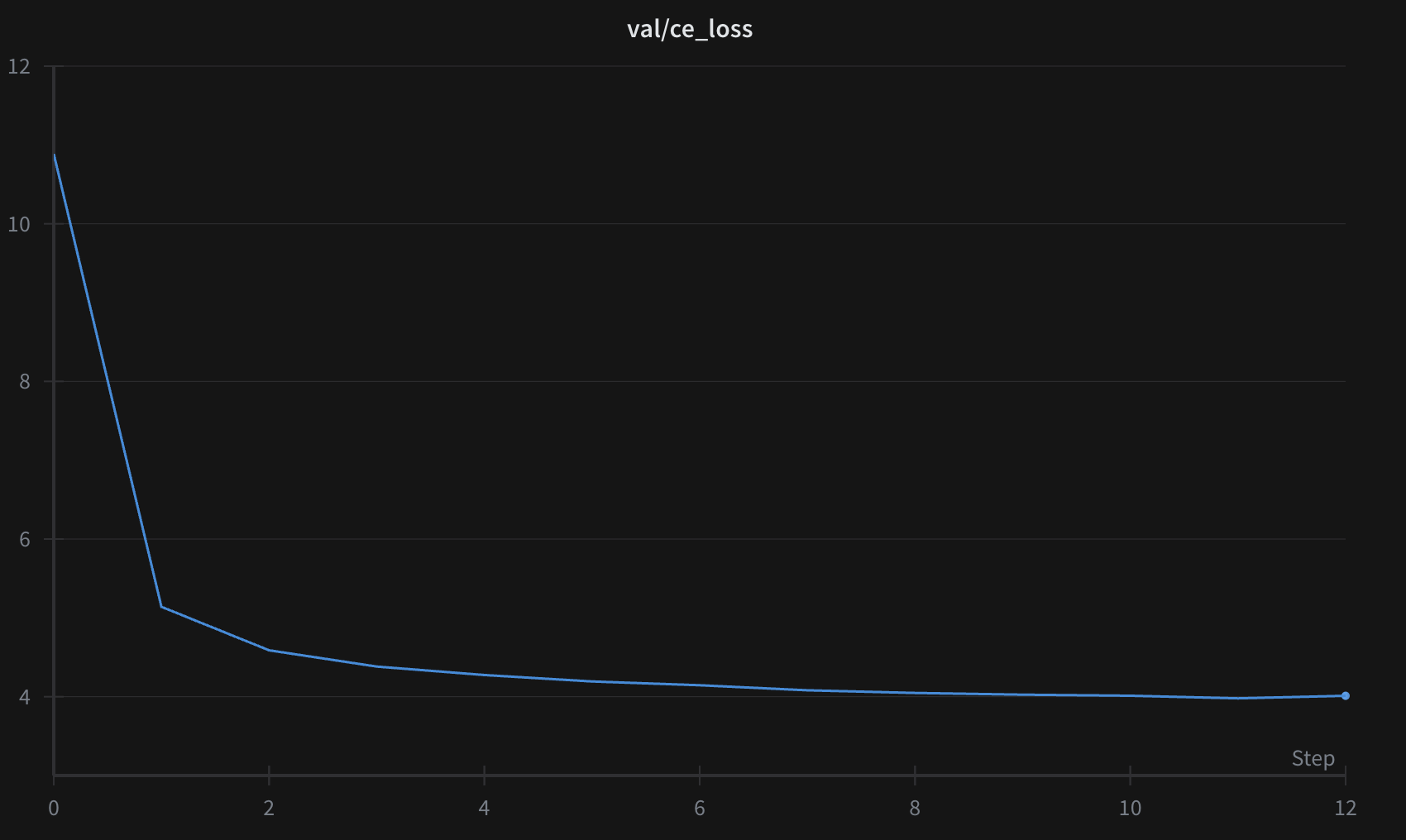
같은 파라미터 크기에서, avatarl로 학습한 모델은 표준 사전학습 모델과 유사한 교차 엔트로피 손실에 도달할 수 있다.
또한 밀집 보상 신호 덕분에, 20억 토큰의 데이터로 500–600억 토큰 상당의 학습 효과를 낼 수 있었다.
아래는 2.5억(250M) 파라미터 모델의 학습 및 검증 곡선으로, 매 500 스텝마다 검증했다.
프롬프트:"The true meaning of life is often"
The true meaning of life is often more complex than the actual cause, but we can think so much about each of them if we take into account the real and possible work that underlies an individual's character and personality.
When we do that, the very nature of our relations with other people takes us into their distinct forms and carries them far into their various circumstances. When a particular person is isolated from the "ideal" circle of people with whom we have worked – and others who are displaced from the
The true meaning of life is often an all-consuming exchange of goods — real commodities such as gold, services such as medicine, clothes and appliances — while also building up a certain personal meaning for all: this change helps us begin to transcend some material barrier to the search for meaning. Rather than content, though, we are simply noticing how the changes our material conditions are also creating.
Today, it's easy to underestimate how life can transition, if we didn't think so. Increasingly, health and education are more about
The true meaning of life is often put in terms of one's relationship with us. "There is life of this for us as well," Mr. Adams says. "For me, the meaning of life was precisely this."<|endoftext|>I was delighted to be offered the opportunity to see David Koretzner, one of my favorite television reporters who came into the world on such a busy note that I couldn't turn down this season's worth of tweets. Only four of them came
The true meaning of life is often malleable by the way they can change and change more naturally. If no matter how many lives they provide, life continues to be a process of change, and thus human life is often incomplete.
Is Life Any Better? If so, with all the information about human nature you would like to know about but have no knowledge about human nature, you might ask yourself why. It is not, in order to understand it, to practice and follow as best we can. The journey of your
The true meaning of life is often unknown: Death through illness has in fact brought death from one's own body into another.
Many now seem to see this in the light of a number of ways to die. But rather than focus on dying, we look to be on the look out for what death will bring to us. The notion of death is less cruel than life; death is more honest in each of its parts.
If the death of evil goes on all around us, our act of anger may well follow
The true meaning of life is often determined by circumstances and relationships. As such, personal freedom is a process unto itself and not something else.
This might seem like a completely false premise to be a "mystical situation." However, the fact that every species has at least some sort of a right to life outside of its senses and attitudes shows it, quite literally, to be a person.
In other words, what the individual doesn't have is a right to life of their own free
The true meaning of life is often one of 'making up your mind'.
It takes a lot of hard work and dedication every day for somebody to realize they are doing something amazing. After three years of planning and constant training it was almost clear that they had formed one of the best teams I've ever been given.
My team worked hard. I had a pretty amazing package coming out of the kit room after sending home a huge package. Doing the team thing took time because there were times when there was absolutely nothing I
The true meaning of life is often about a certain general understanding of our existence and how we cope with our suffering. This is how people of a certain age, or a particular religious persuasion, perceive our existence.
We are now reminded that our understanding is limited in comparison to the scope of relationships within us. The way that we may assess ourselves under the ideal of our being the sum of our self-interest, we may do it to others and to oneself in order to make our bodies and identities relevant, but it will be
교차 엔트로피 기반 다음 토큰 예측 사전학습은 (쓴 교훈의 알약 같은) 접근으로서 잘 작동한다. 이에 반대할 이유는 없다. 다만 세 가지 질문에 대한 탐구로 생각해 달라:
처음엔 이걸 cacklemaxxing 프로젝트(성공하면 그냥 웃음이 나올 아이디어)로 시작했다. 내 머릿속 질문을 만족시키기 위해 하고 있을 뿐이다.
아직 매우 초기 단계의 연구다.
숙련된 눈에는 미완처럼 보일 수 있음을 이해한다.
나 또한 주로 해커이고, 내 작업 전반에서 그런 냄새가 날 것이다.
AGI 랩은 인력이 부족하다(1명 — 나). 다음을 계획하고 있다:
이 아이디어를 가져가도 좋고, 협업하고 싶어도 좋다. 연락 바란다.
후원, 컴퓨트, 연구 협업 형태의 어떤 지원도 감사히 받겠다.
성공하지 못한 접근들에 대해서도 논의를 공유하겠다.
Chinmay Kak, 통화로 이 아이디어를 함께 논의했고, 곧장 GRPO로 해킹을 시작했다. 가장 초기 버전의 스켈레톤 코드는 그가 작성했다.
Telt — 지원과 컴퓨트에 감사.
Ravi Theja — 스스로 나서서 @except_raised와 연결해 주었다.
리포스트하고 공유해 초기 관심을 모아 준 모든 분들께 큰 감사. 여러분 모두 고맙다.
modal cloud는 최고다. 실험을 쉽게 만든다. 인스턴스 관리나 잊힌 리소스 걱정 없이 — 그냥 된다. 내 ADHD 해커 뇌에 아주 잘 맞는다.
인프라도 탄탄하다. 5–6초면 끝나는 콜드 스타트 덕분에 로컬에서 해킹하고 커맨드 한 번으로 잡을 트리거하기 좋다.
이 작업은 @except_raised, @twofifteenam, @modal_labs로부터 컴퓨트 크레딧 후원을 받았다.
모든 코드는 오픈소스로 github에 공개되어 있다.
[1] Dong, Q., Dong, L., Tang, Y., Ye, T., Sun, Y., Sui, Z., & Wei, F. (2025). Reinforcement Pre-Training. arXiv:2506.08007.
[2] Hong, J., Dragan, A., & Levine, S. (2024). Q-SFT: Q-Learning for Language Models via Supervised Fine-Tuning. arXiv:2411.05193.
[3] Norouzi, M., Bengio, S., Chen, Z., Jaitly, N., Schuster, M., Wu, Y., & Schuurmans, D. (2016). Reward Augmented Maximum Likelihood for Neural Structured Prediction. NeurIPS 2016.
[4] Shen, S., Cheng, Y., He, Z., He, W., Wu, H., Sun, M., & Liu, Y. (2016). Minimum Risk Training for Neural Machine Translation. Proceedings of ACL 2016.
[5] Ranzato, M. A., Chopra, M., Auli, M., & Zaremba, W. (2016). Sequence Level Training with Recurrent Neural Networks (MIXER). ICLR 2016.
[6] Bahdanau, D., Brakel, P., Xu, K., Goyal, A., Lowe, J., Pineau, J., Courville, A., & Bengio, Y. (2017). An Actor–Critic Algorithm for Sequence Prediction. ICLR 2017.
[7] Peters, J., & Schaal, S. (2007). Reinforcement Learning by Reward-Weighted Regression for Operational Space Control. ICML 2007.
[8] Agarwal, R., Schwarzer, M., Castro, P. S., Courville, A., & Bellemare, M. G. (2022). Reincarnating Reinforcement Learning: Reusing Prior Computation to Accelerate Progress. NeurIPS 2022. arXiv:2206.01626.
[9] Furlanello, T., Lipton, Z., Tschannen, M., Itti, L., & Anandkumar, A. (2018). Born Again Neural Networks. Proceedings of ICML 2018, PMLR 80:1607-1616. arXiv:1805.04770.