수학 분야에서 Qwen 2.5 기반 언어 모델에 무작위, 오류 등 다양한 보상 신호로 강화학습을 적용해도 유의미한 성능 향상이 발생하는 최신 연구를 소개합니다.
수학 영역에서 오픈 언어모델을 훈련할 때 검증 가능한 보상을 이용하는 강화학습(RLVR)이 실제로 무엇을 해주는지 애매하게 만드는 논문들이 쏟아져 나오고 있습니다. RLVR이 정말로 모델의 능력 향상에 기여하는지 의문을 제기하고, 단 한 개의 예시로만 훈련해도, 검증기 없이 훈련해도, 또는 기존 모델에서 표본 추출만 더 많이 해도 RLVR의 많은 이점을 얻을 수 있음을 보여주는 실험이 계속되고 있습니다(해당 논문 소개).
이런 결과를 보며 소규모 공개된 RLVR 연구 상당수가 결국 포맷팅(정답 표현 방식 등)에 관한 것이라는 점을 받아들이며 넘어간 적이 많았습니다. 뭔가 미묘하게 이상하긴 했지만, 과학적 절차 자체를 부정할 정도는 아니었습니다.
RLVR의 효과를 검증한 논문들은 대부분 Qwen 2.5 계열 베이스 모델(혹은 수학 특화 Math 버전)에서 실험이 이뤄졌습니다. RLVR의 효과가 수학(MATH) 같은 태스크에서 가장 두드러지게 나타나는 모델군입니다! 최근 저도 참여한 워싱턴 대학 대학원생 그룹 논문에서, Qwen 2.5 (특히 Math 버전) 모델은 무작위(random) 혹은 오류(buggy) 보상으로 RLVR을 해도 MATH 점수가 15~20점 이상 향상 된다는 점이 밝혀졌습니다. 블로그 게시글 및 논문 PDF에서 자세히 볼 수 있습니다 (arXiv 등록 예정).
저는 이 중 "무작위 보상도 왜 효과가 나는가"를 파악하는 데에 주로 참여했습니다.
이 논문에 따르면 Qwen 2.5 Math 7B는 다음과 같은 각종 보상으로도 MATH-500 기준 15점 이상 점수가 상승합니다:
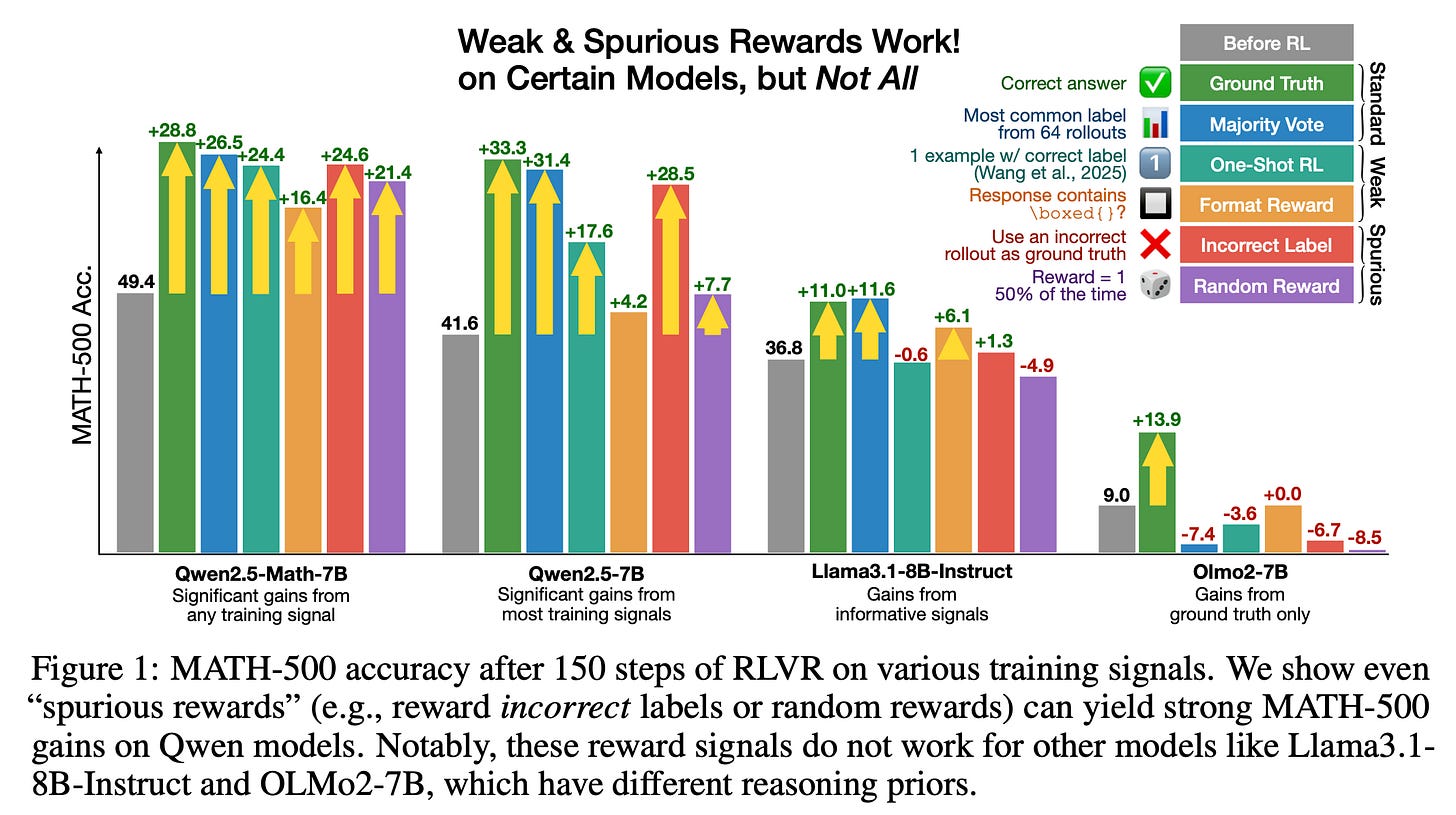
이 결과는 Llama 3.2 3B Instruct, OLMo 2 7B 등 다른 인기 오픈모델에선 나타나지 않습니다(그래프 참조). 이런 결과가 사실이라면, Qwen 베이스 모델 특정에 뭔가 특수한 요인이 있다는 가설이 어느 정도 맞는 셈입니다1. 다만 다수결은 Llama 계열 모델 등에선 유효할 수도 있고, 이 역시 베이스 모델의 신뢰성 등 추가 연구가 요구됩니다.
이 모든 것이 Qwen이 테스트셋으로 학습시켰다는 의심으로 보일 수 있지만, 개인적으로 Qwen 모델(소개 글)을 좋아하고 이것으로 과학 연구가 복잡해졌다는 점만 받아들일 뿐입니다. 이런 현상들은 완전히 확정짓기 어렵기 때문이죠. 중요한 것은 오픈모델 여러 곳에서 재현연구를 시도하는 것이지, 특정 모델의 이상한 행동에 집착하지 않는 것입니다.
이 논문의 핵심 전개를 논문 본문에서 인용하면:
우리는 RLVR의 훈련 성과 차이가 각 모델이 사전학습(pretraining)에서 습득한 특정 추론 전략의 차이에서 비롯된다고 가정한다. 즉, 어떤 전략은 RLVR로 쉽게 유도되지만, 어떤 전략은 아예 없거나 드러내기 어렵다.
아래에서는 Qwen-Math가 효과적으로 활용하는 사전내재적 전략(수학적 추론을 위해 코드 생성하기)을 확인하고, 다른 모델군들은 이를 덜 사용하는 것을 보여준다.
RLVR 훈련 과정에서 코드 추론 전략의 빈도를 추적한 결과, 가설을 뒷받침하는 강한 근거를 찾았다.
Qwen 2.5 Math는 특히 도구 기반 수학 데이터로 (SFT 기반 가공) 사전학습 되었을 가능성이 있습니다. 구체적으로, MATH 같은 경우 Qwen은 동일한 문제 기술/본문에 정답만 바꾼 질문들로 학습했을 수 있습니다:
Qwen2.5-Math-7B는 주요 수학 벤치마크의 질문에서 숫자를 다르게 변형해도 문제의 정답을 맞춘다.
또한, 코드 출력 예측 시 높은 정밀도로 복잡한 수치 답도 자주 만들어낸다.
예를 들면, MATH 테스트셋 문제에 툴 없이 답변을 생성해도 다음과 같이 추정 답안을 냅니다:

즉 Qwen은 테스트셋을 정확히 학습한 것은 아니지만, 문제 설명이나 배경 텍스트는 같되 정수만 다르게 한 데이터로 사실상 시험문제를 학습한 셈입니다.
평가 데이터: $(4+5x^3+100+2\pi x^4+\sqrt{10}x^4+9)$의 차수는?
학습 데이터: $(2+8x^4+44+\pi x^3+\sqrt{20}x^2+1)$의 차수는?
MATH 분야에서 더 깊은 분석은 MATH-Perturb 벤치마크를 참고하세요(해당 논문의 많은 분석은 Instruct 모델 기준, 본 논문은 베이스모델 기준).
O3 모델을 코드 사용 없이 테스트할 때 소수점 8자리까지 답을 산출합니다. OLMo 32B는 소수점 4자리서 실패합니다.
결론적으로, 논문의 중요한 관찰점은 "RLVR은 MATH-500 성능을 높일 뿐 아니라, 코드 기반 추론의 빈도를 함께 올린다"는 것으로, "코드 추론 비율과 MATH-500 정확도가 RLVR 훈련 과정에서 같이 증가"합니다. 즉 Qwen 모델에선 RLVR의 주요 역할이 이미 내재된 코드 추론 습관을 더 적극적으로 끌어내 점수 상승을 유도한다는 것. 예를 들어 무작위 보상에서도 코드추론 전략 비중이 베이스 모델의 65%에서 RLVR 후 90% 이상으로 올라갑니다.
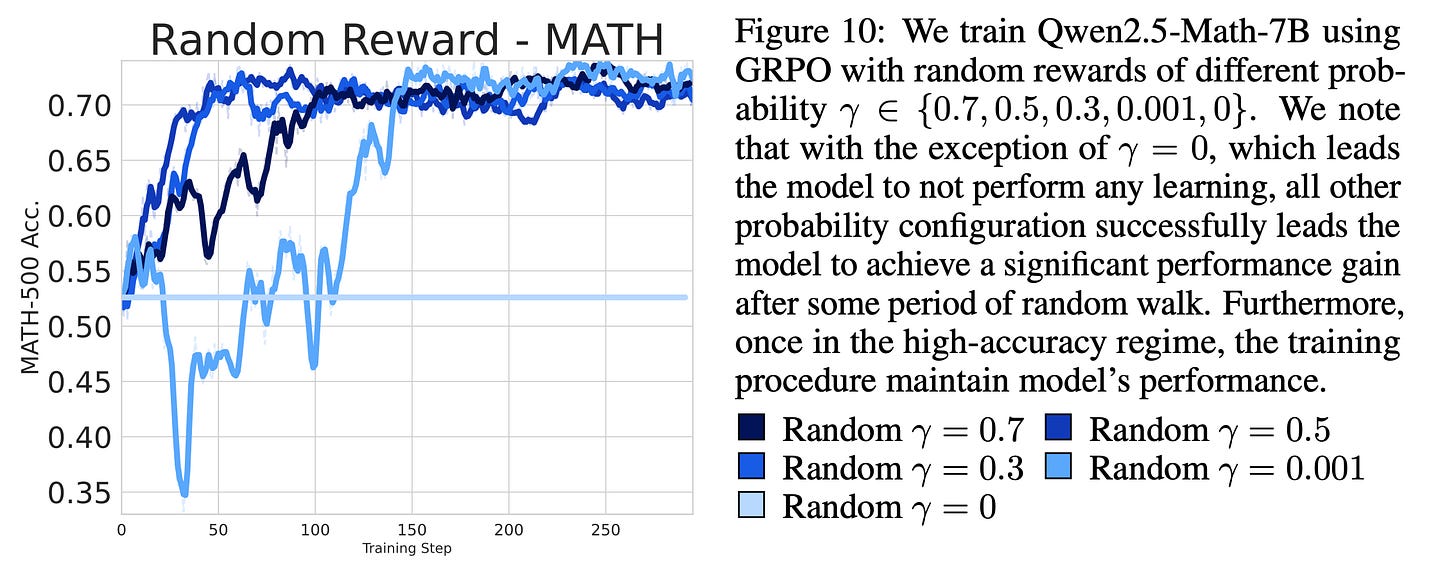
본 논문에서 무작위 보상 실험이 흥미로운 부분은, 언어모델이 생성한 내용과 무관하게 프롬프트별로 독립된 이득을 주는 유일한 보상 함수라는 점입니다.
예를 들어, 프롬프트에 보상을 할당하는 확률이 다르면 훈련 동향도 달라집니다. 여기서, 보상이 전혀 주어지지 않는 가로선이 중요한데, 이 경우 policy gradient는 항상 0입니다. 반면 보상이 무작위로 주어지면 정책그래디언트가 양의 값을 가질 수 있습니다.
정책 그래디언트 알고리즘의 핵심 요소는 advantage 외에도 확률비(probability ratio)입니다. 이 값이 학습 동역학을 결정짓는 유일한 항입니다.
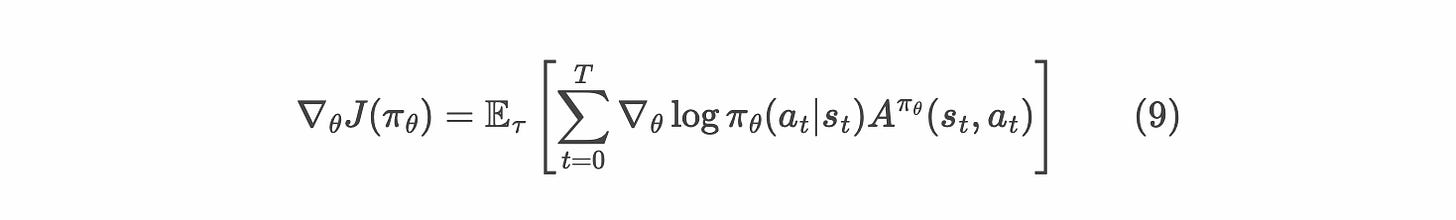
출처: rlhfbook.com
그리고 GRPO 방정식:
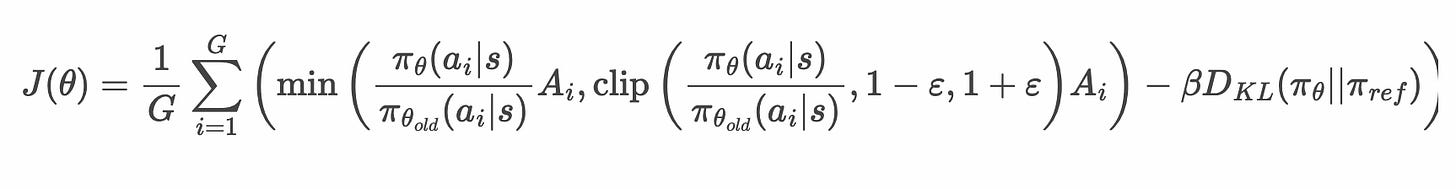
이런 맥락을 이해하기 위해, DAPO 논문의 GRPO clipping 논의(강조 부분 포함)를 다시 봅니다(인터커넥츠의 DAPO 소개):
기본 PPO[21] 또는 GRPO[38]를 써서 실험하면 순차적으로 정책의 엔트로피가 급격히 감소하는 현상(엔트로피 붕괴)이 관찰된다(그림 2b). 특정 그룹의 샘플 응답은 거의 동일해진다. 이는 탐색 감소와 조기 결정적 정책을 의미하며, 스케일업 과정에 방해가 된다.
이를 해결하기 위해 Clip-Higher 전략을 제안. Clipping은 PPO-Clip[21] 등에서 학습 안정성을 위해 도입됐으나, 상위 클립은 탐색 제한 효과가 있어 확률이 낮은 행동의 탐색 가능성을 심하게 억제하게 된다.
즉 clipping이 모델의 탐색을 저해합니다. 다시 말해, 확률이 낮은 행동은 상대적으로 더 빨리 감소합니다. GRPO에서 여러 번 그라디언트를 적용할 때, 정책비 항이 더 낮은 확률 토큰에서 더욱 크게 변하지요. clipping이 이를 더욱 왜곡시킬 가능성이 있습니다.
저자들은 무작위 보상 baseline이 clipping 없이도 효과가 있는지 실험했습니다(즉, GRPO 방식의 vanilla policy gradient에 가까움). 만약 clipping이 코드 추론 전략을 활성화시키는 효과라면, clipping 해제시 결과가 달라져야 하고 실제로 아래와 같이 관측되었습니다:
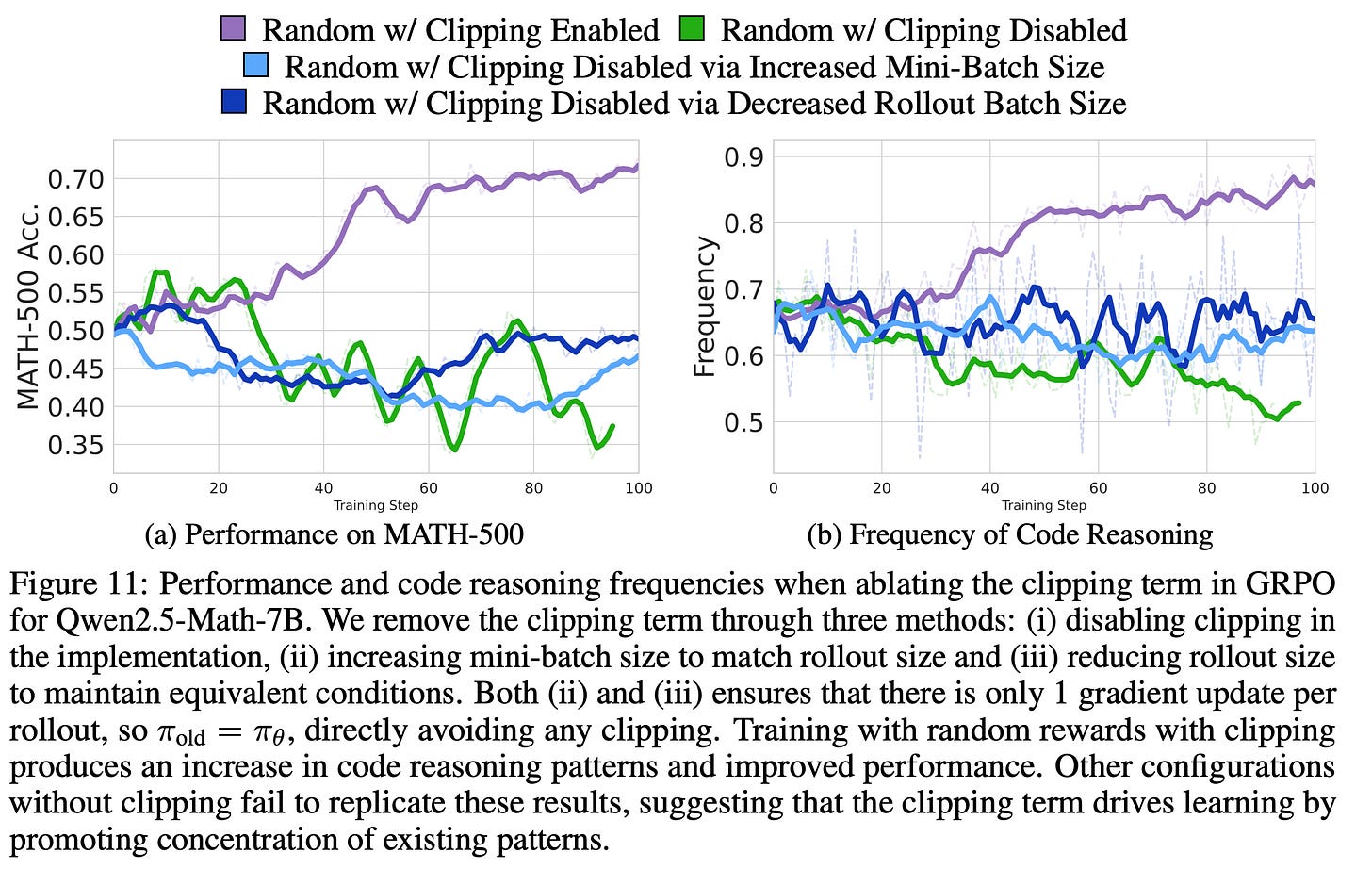
이 현상은 위에서 말한 코드/수학 행동이 베이스 모델에 내재화돼 있을 때만 성능향상이 일어납니다. 베이스 모델이 애초에 랜덤하다면, 대부분의 모델에서처럼 이 방법은 효과가 없습니다.
위 내용은 Qwen의 의도적 특성을 단정짓진 않으나, RL 알고리즘이 모델의 미묘한 설계 선택과 어떻게 상호작용할 수 있는지 강력하게 보여줍니다.
시사점은 다음과 같습니다. RLVR용 reward verifier가 너무 까다로우면 gradient가 0에 수렴합니다. 반대로 buggy verifier(=GRPO에서 신용 할당이 비정상적 동작하는 경우)를 쓰면, 정책에 어떤 방식으로든 비정상적 편향 또는 특정 방향 성향(예: 답 길이 편향)으로 이끌 수 있습니다.
이러한 이상 현상과 앞서 언급한 사례들은 Elicitation Theory(사후학습은 사전학습 모델의 유용 행동을 나타내기 위한 것)를 강하게 지지합니다. 정말 Qwen에게 코드만 잘 쓰게 하면 RLVR이 특별할까요?
o3까지는 이 견해가 맞았습니다. 즉, RL 전체가 아닌 '이끌어내기'(elicitation)만으로도 대부분을 설명할 수 있었습니다. 사후학습은 모델 최종 능력에서나 컴퓨트 비용 측면에서 소소한 일이었지만, 지금은 크게 달라지고 있습니다. 이제 o3와 같은 모델이 보이는 검색질문 응답 능력을 수작업으로 생성하는 건 불가능에 가깝습니다. 사후학습 단계는 더 커졌고, RL은 처음 기획된 대로 완전히 새로운 행동을 가르칠 단계로 가고 있습니다.
이러한 변화 속에서, 학계 RLVR 연구는 여전히 소규모 컴퓨트 환경에 갇혀 있지만, 주요 AI 연구소들은 사후학습 컴퓨트를 10-30% 수준까지(추정) 대폭 확대 중입니다. (o1은 1~3%, o3는 10~30%로 추정)
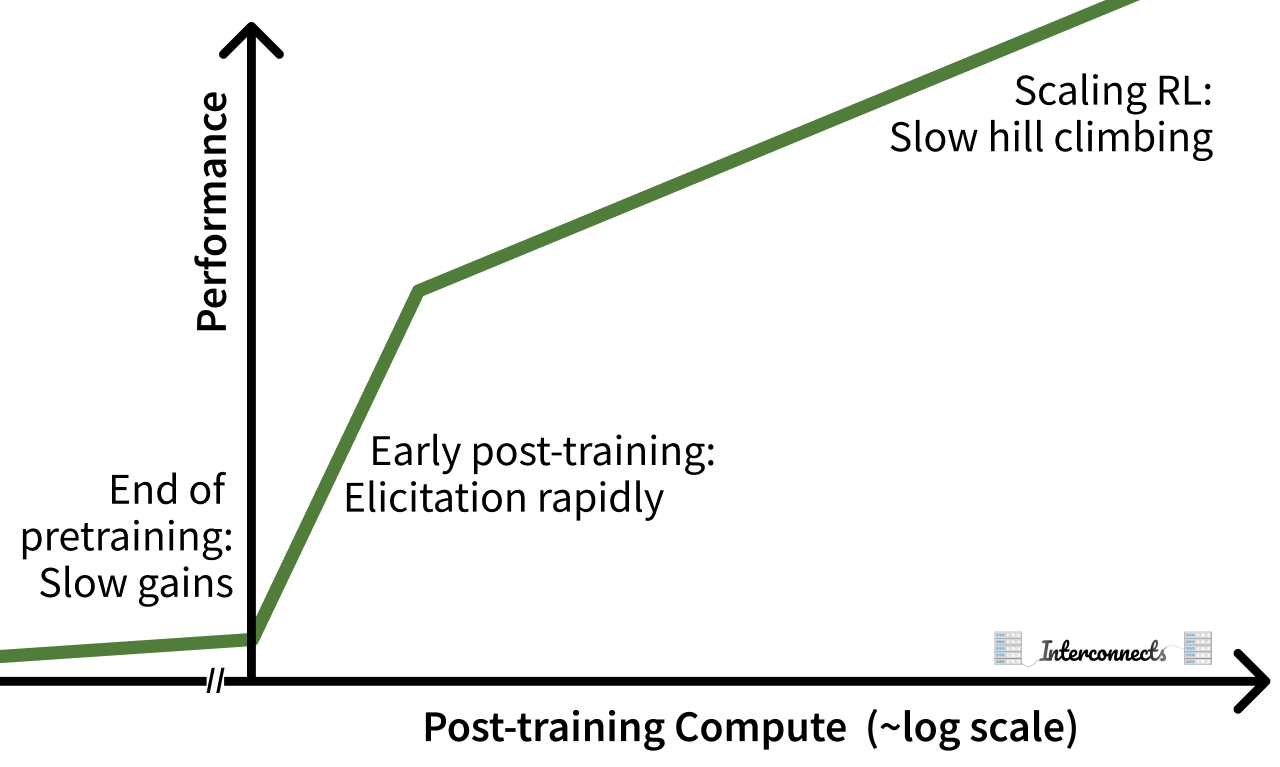
이제 우리가 가야 할 새로운 영역은 아래 그림과 같습니다:
RL 확장의 이슈는 여러 연구자들도 주목합니다. Dwarkesh Claude 4 팟캐스트에서 Sholto Douglas는 이렇게 말합니다:
실제로 RL에 얼마나 컴퓨트를 썻는지 잘 모르겠지만, 베이스모델때와 비교하면 상대적으로 적었을 것으로 봅니다. 모델이 새로운 지식이나 능력을 실제로 획득하는 데 쓰인 컴퓨트가 전체 훈련 컴퓨트 중 어느 정도인지가 실제로 중요합니다.
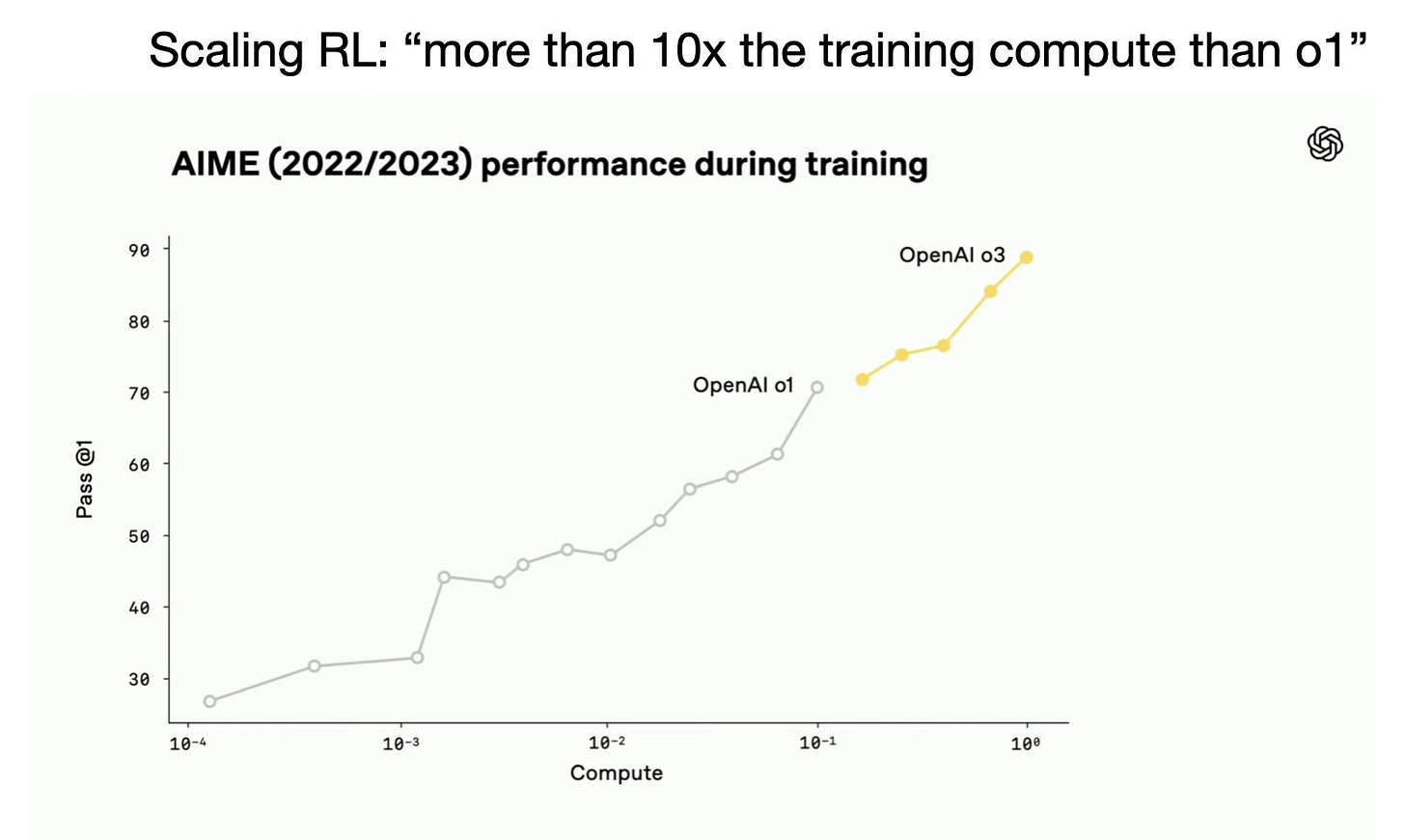
OpenAI o3는 그 예시였습니다. o1에 비해 10배 컴퓨트를 쓴 것이죠:
장기적으로는, 베이스 모델 내재 행위만 발굴하는 수준을 넘어, 새 행동을 실제로 학습하는 단계로 넘어가게 될 것입니다. RL의 본래 목적이 바로 새로운 행동 습득이라는 점을 상기하면, 오늘날처럼 단순 포맷 학습만 하고 있는 현상은 다소 역설적인 셈입니다.
Douglas의 말처럼, RL은 튼튼한 보상 신호만 있으면 완전히 새로운 행동(예: AlphaZero의 바둑, 체스 초월적 실력)을 실제로 학습할 수 있습니다.
학계 RLVR 연구가 pre-scaling(스케일링 이전) 영역에 머무는 한, 이런 '조리된 베이스모델'에서 비롯된 이상 결과에 머물 수밖에 없습니다. 이 판을 깨야 합니다. 쉽진 않겠지만, 각종 대학의 컴퓨트 인프라가 갖춰지고 있으니 이제 곧도전이 가능해집니다.
Douglas는 RL 스케일업 전략에 관한 비유를 덧붙입니다:
우주선을 쏘아 올릴 때, 기술트리를 더 올려놓고 나중에 쏘면 우주선이 훨씬 빨리 간다는 우화가 있듯, RL도 마찬가지입니다. 알고리즘적으로 제대로 된 것을 갖춘 다음 본격 컴퓨트 투자를 해야 진짜 성과가 날 수 있습니다.
우리에겐 데이터와 RL의 성질에 대한 이해는 있으나, 확장된 RL이 어떻게 동작하는지는 아직 본격 성과가 없습니다. 이제 거의 준비됐습니다.
정확한 진상은 학습 데이터를 몰라선 알기 어렵습니다.