대규모 언어 모델의 데이터 한계와 AI의 다음 도약을 위한 탐험 및 경험 축적의 중요성을 고찰합니다.
대규모 언어 모델(LLM)은 30여 년에 걸쳐 온라인에 자유롭게 축적된 인간 텍스트의 우연한 부산물입니다. Ilya Sutskever는 이러한 정보의 보고를 화석 연료에 비유했습니다. 풍부하지만 결국 유한하다는 뜻입니다. 일부 연구에 따르면 현재의 토큰 소비 속도라면, 선두 AI 연구소들은 이 10년이 끝나기 전 고품질 영어 웹 텍스트를 고갈시킬 수 있다고 합니다. 이런 예측이 지나치게 비관적이라 하더라도 한 가지는 분명합니다. 오늘날의 모델들이 데이터를 소비하는 속도는 인간이 데이터를 생산하는 속도를 훨씬 앞지릅니다.
David Silver와 Richard Sutton은 이 다음 국면을 '경험의 시대'라고 부릅니다. 의미 있는 진보는 학습 에이전트가 스스로 만들어내는 데이터에 의존하게 될 것이라는 뜻입니다. 저는 이들 주장에 한 걸음 더 나아가 말하고 싶습니다. 병목은 아무 경험이 아니라 학습에 유익한, 올바른 종류의 경험을 모으는 것입니다. AI의 다음 혁신 물결은 파라미터(모델 크기) 쌓기가 아니라, **새롭고 유익한 경험을 얻는 과정인 탐험(Exploration)**에 달려 있습니다.

경험을 수집한다는 말을 하려면, 그 경험을 모으는 데 드는 비용이 무엇인지도 물어야 합니다. 스케일링이란 결국 자원의 문제입니다. — 컴퓨팅 사이클, 합성 데이터 생성, 데이터 큐레이션 파이프라인, 인간 감독 등 학습 신호를 생성하는 모든 지출. 간단히 설명하기 위해 이러한 비용을 모두 _flops_라는 단일 회계 단위로 묶겠습니다. 엄밀히 말하면 flop은 한 번의 부동소수점 연산이지만, 요즘은 "이 시스템이 얼마만큼의 노력을 들였는가?"라는 공통 언어로 쓰입니다. 엔지니어링적 정밀성보다는, 추상적인 공통 화폐를 제공한다는 점에서 쓰는 용어임을 밝힙니다. 제 논의는 구체적인 실리콘, 데이터, 인간 시간의 비율이 아니라 상대적 투입량에만 의존합니다. flop을 "확장성을 제한하는 희소 자원"의 대명사로 생각하십시오.
아래에서는 몇 가지 관찰과, 서로 다른 맥락에서 나오는 아이디어들을 엮어 설명합니다. 탐험(exploration)은 강화학습(RL)에서 자주 쓰이지만, 저는 여기서 훨씬 더 넓은 의미로 — RL에서의 좁은 탐험을 넘어 — 모든 데이터 기반 시스템이 학습에 앞서 어떤 경험을 모을지 먼저 결정해야 한다는 뜻에서 쓰려 합니다. 이 용법은 제 친구 Minqi의 훌륭한 글인 '일반 지능은 탐험에 대한 재고를 요구한다'에서도 영감을 받았습니다.
남은 글의 구조는 다음과 같습니다. 먼저, 사전학습이 어떻게 탐험 문제의 일부를 우연히 해결했는지, 둘째, 왜 더 나은 탐험이 더 나은 일반화로 이어지는지, 마지막으로 우리가 향후 GPU 10만 년어치의 자원을 어디에 써야 할지 논합니다.
표준 LLM 파이프라인은 (1) 대규모 텍스트로 다음 토큰 예측을 하는 큰 모델을 사전학습(pretraining)한 뒤, (2) RL로 파인튜닝해 목표를 달성하는 방식입니다. 대규모 사전학습이 없다면 RL 단계는 거의 진전을 내지 못합니다. 이 차이는 사전학습이 스크래치(tabula rasa) RL로는 어렵거나 불가능한 무언가를 해결해줬다는 점을 보여줍니다.
최근 연구에서 자주 보이는 모순적이면서도 흥미로운 경향이 하나 더 있습니다. 소형 모델이 대형 모델이 생성한 chain-of-thought(사고의 연쇄)를 증류(distillation)하여, 추론 능력이 대폭 향상되는 경우입니다. 이를 두고 "대규모 모델이 추론에 필수는 아니다"라고 해석하기도 합니다. 하지만 저는 그런 결론이 잘못 되었다고 봅니다. 만약 모델 용량(capacity)이 추론의 병목이 아니라면, 왜 소형 모델이 대형 모델에서 증류를 받아야만 하는 걸까요?
양쪽 현상을 동시에 설명하는 설득력 있는 답은, 바로 사전학습의 막대한 비용이 선불 '탐험세(exploration tax)'를 치르는 것이라는 점입니다. 사전학습이 없거나 소규모 모델은, 스스로 해답의 공간을 탐험하고 훌륭한 솔루션을 찾아내는 데 훨씬 큰 어려움을 겪습니다[1]. 사전학습은 거대한 연산량을 다양하고 방대한 데이터에 쏟아부음으로써, 정답이 실제로 나올 확률이 높은 sampling 분포를 먼저 학습합니다. 증류는 이 탐험세를 대형 모델 대신 소형 모델이 상속받게 해주는 메커니즘입니다.
사전 지불된 탐험이 왜 중요한 걸까요? 일반적인 RL 루프는 다음처럼 요약할 수 있습니다.
이 학습 루프가 효과를 내려면, 에이전트가 탐험 단계에서 최소한 일정 비율의 "좋은" 경로를 만들 수 있어야 합니다. RL에서는 이를 **커버리지(coverage)**라 부르기도 합니다. LLM의 경우, 보통 모델의 autoregressive 분포에서 샘플링하는 방식으로 탐험합니다. 이런 상황에서 정답이 이미 그 분포 상에서 꽤 나올 만해야 RL이 유의미한 학습을 할 수 있습니다. 만약 소형 모델이 우연히라도 정답에 거의 도달하지 못한다면 강화할 신호 자체가 전무하겠죠.
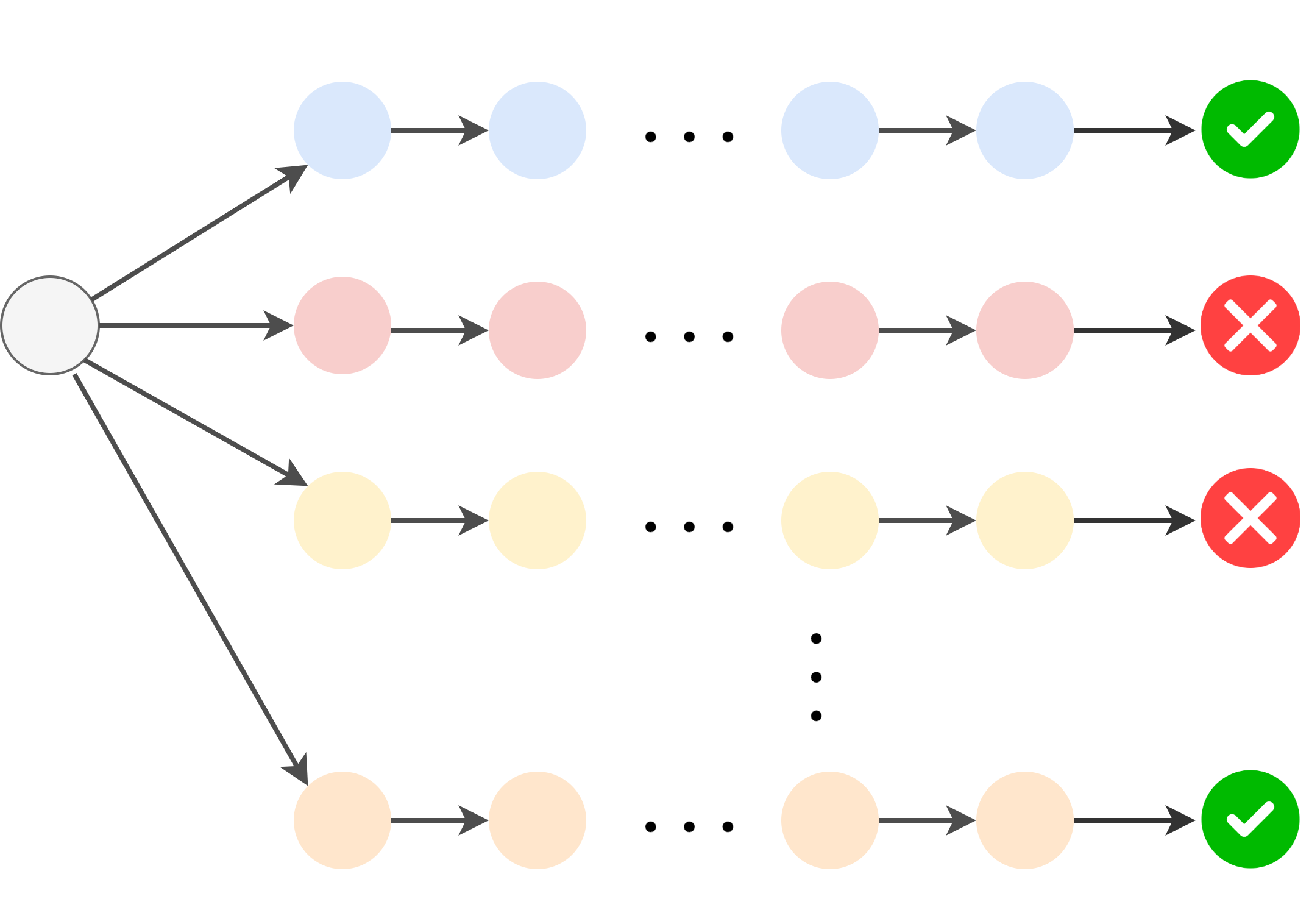
사전 정보 없이 하는 탐험은 아주 어려운 과정입니다. 가장 단순한 테이블형(tabular) RL 조차도, 이론적으로 충분한 학습을 하려면 엄청나게 많은 시행착오가 필요합니다. 표(상태 공간, 행동 공간)가 작은 환경에서 조차 샘플 복잡도 하한(Dann & Brunskill, 2015)에 따르면, 상태 개수, 행동 개수, 에피소드 길이(수평선), 최적 해까지의 거리 등과 모두 비례합니다. 즉, 가능한 상태-행동 쌍이 많아질수록, 시간이 길어질수록 학습에 필요한 시행 횟수는 기하급수적으로 늘어납니다. LLM의 경우, 상태 공간은 모든 가능한 텍스트 접두사이고, 행동 공간은 그 다음 가능한 토큰 전부입니다. 이 둘은 상상 이상으로 큽니다. 사전 정보 없이 여기서 RL을 하라는 건 사실상 불가능에 가깝습니다.
지금까지는 사전학습에서 미리 더 나은 사전확률(prior)을 배우는 것이 탐험의 고생을 덜어주는 주된 방법이었습니다. 하지만 이렇게 되면 모델이 샘플링하는 경로의 종류가 그 사전확률에 강하게 제한됩니다. 앞으로 나아가려면 어떻게 이 한계를 넘어설지 고민해야 합니다.
역사적으로 RL 연구는 한 번에 하나의 환경에 집중해(예를 들면 Atari, MuJoCo), 학습과 테스트에 같은 환경을 쓰는 방식이었습니다. 이는 결국 한 데이터셋에 overfit하는 셈이죠. 하지만 우리가 진정 원하는 것은 완전히 새로운 상황에서도 잘 해내는 일반화 능력입니다. 머신러닝은 결국 일반화를 위한 것입니다. 이미 아는 문제라면 맞춤형 솔루션을 짤 수 있으나, 전혀 예상하지 못한 문제에서 성공하는 것이 진짜 가치입니다.
이런 RL의 일반화 성능은 LLM에도 매우 중요합니다. LLM은 학습 중에 유한한 프롬프트만 봅니다. 그러나 실제 서비스에서는 사용자들이 전혀 훈련 때 등장하지 않은 문제를 수없이 던져줍니다. 현행 LLM이 잘하는 영역(예: 코딩 퍼즐, 논리 증명)도 보상이 명확한 문제에 한정됩니다. 보다 모호하고 피드백이 희박한 영역(예: 논문 작성, 소설 창작)에서는 큰 어려움을 겪으며, 이 방면은 대규모 학습과 데이터 수집 자체가 어렵습니다.
일반화 가능한 모델을 만들기 위한 전략은 무엇일까요? 딥러닝에서는 반복해서 "데이터 다양성이 일반화 성능을 높인다"는 교훈이 등장합니다. 탐험(Exploration)은 데이터의 다양성을 직접적으로 조절하는 메커니즘입니다. 지도학습은 라벨이 달린 데이터 한 건을 단 한 번의 forward pass로 모두 활용합니다[2]. (다만, 모델 역량이 제한적일 뿐 정보 자체는 완전히 노출됩니다.) 데이터를 더 다양하게 하려면 데이터를 더 모으는 방법밖에 없습니다. 반면, RL에서는 한 번의 상호작용으로 환경의 아주 좁은 단면만 관찰합니다. 때문에 대표성 있는 정책을 만들려면 충분히 다양한 경로를 누적해야 합니다. 수집된 경로가 다양하지 않을 경우(예: 단순 무작위 샘플링), 정책이 특정 경로에 과적합되어 심지어 같은 환경 안에서도 쉽게 실패할 수 있습니다.
이 문제는 여러 환경이 존재할 때 더욱 심각해집니다. RL의 대표적인 일반화 벤치마크로는 Procgen이 있습니다. 이는 각 게임이 무작위로 생성되는 Atari류 게임들 묶음입니다. 즉, 사실상 '무한히 많은' 환경이 존재합니다. 목표는 일정 개수의 환경에 한정해 학습시키고, 완전히 보지 않은 환경에서 일반화 성능을 시험하는 것입니다[3].

이런 벤치마크에 대응하는 대부분의 기존 방법들은 표현 학습(representation learning) 문제로 보고, 드롭아웃, 데이터 증강과 같은 지도학습의 정규화 기법을 적용합니다. 물론 도움이 되긴 하지만, '탐험'이라는 RL의 본질적인 구조를 간과합니다. RL에서는 에이전트가 자기 데이터를 스스로 모으기 때문에 탐험 방식만 바꿔도 일반화가 향상될 수 있습니다. 저는 이전 연구에서, 기존 RL 알고리즘에 더 강한 탐험 전략을 결합하는 것만으로 Procgen에서 명시적인 정규화 없이도 일반화 성능을 2배 높였다는 것을 보였습니다. 더 최근 연구에서는, 더 나은 탐험이 더 표현력이 높은 모델 구조와 연산 자원을 더욱 효율적으로 활용할 수 있게 하며, Procgen에서 더 탁월하게 일반화한다는 사실을 밝혔습니다[4].
물론 Procgen은 오늘날 LLM들이 다루는 문제만큼 어렵거나 복잡하지는 않습니다. 그러나 본질은 같다—강화학습 에이전트가 유한개 문제(훈련 환경)에만 노출된 뒤, 추가학습 없이 완전히 새로운 환경(테스트 환경)에서 실력을 시험하는 구조입니다. 현재 LLM에서의 탐험은 매우 단순합니다: 대개 autoregressive 분포 샘플에 온도나 엔트로피 보너스를 살짝 바꿔주는 수준입니다. 즉, 더 효과적인 탐험 설계 공간이 상당히 넓게 남아 있습니다. 물론 아직까지는 뚜렷한 성공사례가 많지 않습니다. 어쩌면 너무 어려운 과제인지, flop 효율성이 떨어져 실용적이지 못해서인지, 아니면 그저 충분히 시도해보지 않아서일 수 있습니다. 하지만 Procgen에서의 탐험 개선 효과가 LLM에도 연결된다면, 엄청난 효율성—혹은 전혀 새로운 능력까지—놓치고 있는지도 모릅니다. 다음은 어디에 집중해볼 만한지 제안합니다.
여기서 넓은 의미로 탐험이란, 학습자가 어떤 데이터를 볼지 선택하는 결정 과정입니다. 이 결정은 두 개의 뚜렷한 축을 가집니다.
지도/비지도 사전학습에서는 두 번째 축(경로 샘플링)의 비용이 사실상 상수입니다. 한 번의 forward/backward pass가 각 데이터의 정보를 모두 노출하기 때문입니다(예: 크로스 엔트로피 손실). 한 데이터 내에서 "더 깊이 파고들거나" 하는 추가적 방법이 없습니다(모델을 키우는 것 외에는). 그래서 탐험 비용은 거의 전적으로 첫 번째 축(월드 샘플링)에 집중됩니다. flop 자원을 새 데이터 포인트 획득 또는 기존 데이터 큐레이션/합성에 사용할 수 있습니다.
반대로, RL은 두 축 모두에서 훨씬 더 다양한 선택이 가능합니다. 무작위 탐험 경로는 거의 쓸모없는 정보만 주기에, 여기서 정보 밀도(플롭당 유용한 비트)는 지도학습보다 훨씬 낮습니다. 단순히 무작위 경로 샘플만 반복한다면, flop을 노이즈에 다 낭비할 위험이 있습니다. 그래서 flop 투입 방식을 매우 신중히 선택해야 합니다[5]. 한 환경 안에서 탐험에 flop을 사용하는 다양한 방식이 있습니다. 예컨대, 한 환경에서 경로를 더 많이 샘플링하거나, 경로 샘플링 방식을 더 똑똑하게 고안(즉 최적 상태/행동을 효율적으로 발견)할 수 있습니다.
대부분(혹은 모든) 머신러닝 과제의 상위 목표는 "플롭당 정보량 최대화"로 이해할 수 있습니다. 이런 관점에서, 두 축은 trade-off 곡선을 형성합니다. 월드 샘플링에만 너무 많은 자원을 쓰면 각 환경에서 아무 유익한 경험도 못 얻을 수 있습니다. 경로 샘플링에만 너무 몰두하면, 훈련 환경에 과적합 되어 대체 환경에서는 전혀 일반화하지 못합니다. 이상적인 경우는, 두 단계에 자원을 적절히 배분, 새 환경도 적당히 추가하면서, 각 환경에서도 무작위보다 나은 알고리즘을 써서 경험을 최대한 뽑아내는 케이스입니다.
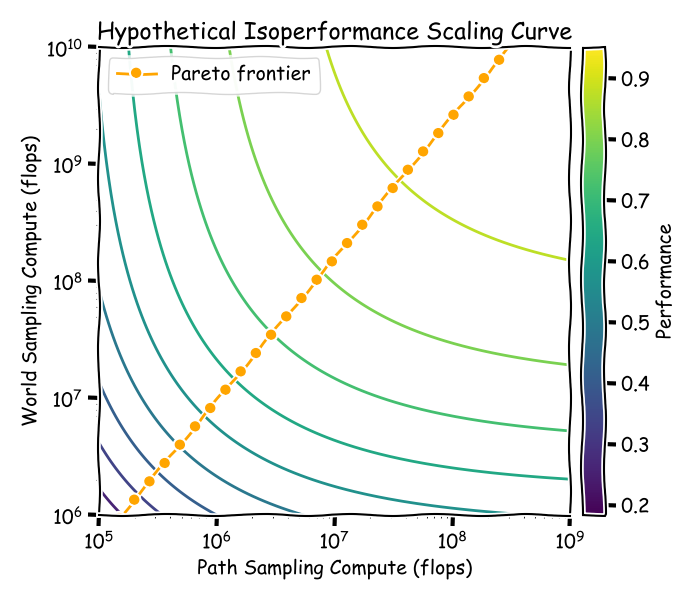
스케일링 법칙에 익숙하다면, 위 설명이 Chinchilla scaling law와 닮았음을 알 것입니다. 다만, 두 축이 파라미터와 데이터가 아니라 "각종 샘플링에 투입된 연산량"이라는 차이만 있습니다. 각 성능 레벨에서는, x축–y축에 각각 환경 상호작용과 환경 자체 생성/실행에 할당된 연산량을 두고 등성능 곡선을 그릴 수 있습니다.
두 축 중 경로 샘플링은 비교적 잘 정의된 과제입니다. 환경 내 탐험의 원칙은 모델의 불확실성을 줄이는 방식입니다[6]. 기존 탐험 알고리즘들은 샘플 복잡도 면에서는 훌륭하지만, 대형 LLM 규모로 쓰기엔 대부분 비용이 너무 큽니다. 그래도 분명 직관적 목적이 있으니, 계산 효율적 근사치를 찾으면 진전이 기대됩니다. 반대로 월드 샘플링의 객관적 목적함수는 훨씬 불분명합니다. "Open-ended learning"(열린 결말식 학습)도 등장하지만, 역시 우주 전체(혹은 모든 환경) 명세나, 관찰자가 흥미로운 목표/성과를 판단하는 기준 등, 정의가 필요합니다.
월드 샘플링은 어떤 목표함수를 가져야 할까요? 냉혹(혹은 다행)하게도, 환경 공간은 무한하지만 우리의 자원은 유한합니다. 의미 있는 가치를 내려면, 환경 간에 일종의 선호(preference)를 표현해야만 합니다. 제 생각엔, 앞으로 환경 설계도 사전학습 데이터 선정과 비슷해질 것 같습니다. 어떤 환경이 왜 도움이 되고 얼마나 다른 환경에 도움을 주는지, 딱 떨어지는 답이 어렵고, 따라서 많고 다양한 환경들이 필요해질 겁니다. 즉, "깔끔한 목적함수" 따위는 존재하지 않을 수도 있습니다.
더 현실적인(이미 진행 중인) 시나리오는, 각자가 자신이 잘 아는 영역의 환경 스펙부터 설계하기 시작한다는 것입니다. 충분히 많은 "인간이 승인한" 또는 "유용한" 스펙이 쌓이면, 공통 원리를 뽑고, 그조차도 자동화하는(즉, 데이터를 통해 학습하는) 방향을 모색하게 될 겁니다. 물론, 사전학습 데이터만큼이나 많은 환경이 필요하다면 매우 번거롭겠지만, 예비 연구에 따르면 꼭 그럴 필요는 없을 수 있습니다. 최근 연구에서 우리는 꽤 적은 수의 환경만으로도 일반적 탐험, 의사결정 능력을 길러, OOD(분포 외) 환경에도 적응 가능한 에이전트를 학습할 수 있음을 보였습니다. 또, 기존 LLM도 환경 설계에 크게 도움이 될 것입니다.
물론 여기까지는 매우 상위 레벨의 사색에 가까우며, 두 축을 실제로 어떻게 확장할지는 사전학습 스케일링만큼 명확하지 않습니다. 그러나 월드 샘플링의 확장성 있는 방법과 더 지능적인 경로 샘플링 방식을 확립할 수 있다면, 등성능 곡선을 좀 더 원점에 가깝게(아마도 부드럽진 않아도) 만드는데 성공할 수도 있습니다. 이런 스케일링 법칙은, 에이전트와 환경 쌍방에 연산 자원을 최적 배분하는 법을 알려줄 겁니다.
더 많은 곁가지를 펼쳐볼 수도 있겠습니다. — 보다 나은 호기심 목표, open-endedness, meta-exploration처럼 탐험 자체를 학습하는 메타화까지 — 하지만 저는 상위 메시지를 분명히 전달하는 것이 더 중요하다고 생각합니다.
기존 스케일링 패러다임은 아주 효과적이었습니다. 그러나 그 어떤 패러다임도 언젠가는 포화에 도달합니다. 그렇다면 다음 수십~수백 배의 컴퓨팅은 어디에 부어야 할까요? 저는 탐험(월드/경로 샘플링 모두)이 매우 유망한 투자처라고 생각합니다. 올바른 스케일링 법칙, 환경 생성기, 탐험 목표가 아직 명확히 정립된 것은 아니지만, 분명 가능하다고 직감합니다. 앞으로 수년간 우리는, 기존 방식 위에서 탐험이 우리의 flop 효율을 한 단계 더 밀어줄 수 있는지 시험하게 될 것입니다. 저는 그건 충분히 시도해볼 가치가 있다고 봅니다.
감사의 글
Allan Zhou, Sam Sokota, Minqi Jiang, Ellie Haber, Alex Robey, Swaminathan Gurumurthy, Kevin Li, Calvin Luo, Abitha Thankaraj, Zico Kolter에게 초안의 피드백과 토론에 깊이 감사드립니다.