프로덕션에서 Rust로 작성된 서비스에서 발생한 메모리 문제와, 이를 해결하기 위해 사용한 도구 및 원인을 추적해 수정한 과정을 다룬 글.
그들은 컴퓨터 과학에는 어려운 문제가 2가지뿐이라고 말하는데, 나는 그 3가지를 다 맞닥뜨렸다.... 이 글은 Rust로 작성된 서비스에서 프로덕션 중 겪었던 메모리 문제와, 이를 해결하기 위해 사용한 도구들에 대한 블로그 포스트다.
S3든 다른 무엇이든 Object Storage는 로컬 디스크에 비해 지연 시간(latency) 성능이 그리 좋지 않다. 파일을 가져오는 데 오버헤드가 많이 들 수 있다. 게다가 같은 파일에 대한 반복 호출은 결국 같은 데이터에 대한 여러 요청을 의미한다. 한 가지 해결책은 파일을 사용하는 곳 가까이에 로컬 캐시를 두는 것이다. 그러면 자주 요청되는 파일에 대해 지연 시간을 줄이고, 백엔드 object store로 가는 요청 수를 감소시킬 수 있다.
가능한 해결책으로, 우리는 최근 foyer를 사용하도록 옮겼다. 이는 _하이브리드 캐시_로 홍보되는데, 메모리 캐시뿐 아니라 로컬 디스크 저장소와도 함께 사용할 수 있기 때문이다. 정말 뜨거운(hot) 파일은 메모리에서 제공된다. 더 차가운(colder) 파일은 로컬 ephemeral SSD에서 읽을 수 있어, 메모리에서 축출(evict)되더라도 어느 정도의 속도 향상을 제공한다. 이는 우리의 유스 케이스에 아주 잘 맞아 보였다.
하루 정도 캐시를 돌리기 전까지는 모든 것이 괜찮아 보였다. 그런데 우리가 설정한 메모리 제한이 지켜지지 않는 것을 발견했고, 이유가 OOMKilled로 표시된 pod 재시작을 보게 됐다. 캐시를 구성한 방식 어딘가가 잘못되어 있었다.
우리의 설정에서는 파일 전체를 캐시하고 싶지 않고, 요청된 바이트 범위(range)만 캐시하려고 한다. 우리의 요청 패턴상 range 간에 겹침이 전혀 없고, 정확히 동일한 range가 반복해서 요청된다.
그래서 Cache Key는 기본적으로 이렇게 생겼다:
struct CacheKey {
path: String,
start: usize,
end: usize,
}
그리고 Cache Value는 표준 Bytes로, 캐시는 대략 이런 형태가 된다:
struct ByteCacheAppState {
write_cache: HybridCache<CacheKey, Bytes>,
}
물론 캐시에서는 메모리 사용량이 _무제한_일 수는 없다. 그래서 메모리 내 바이트 길이를 사용(키의 memory_size 메서드로 경로 문자열 + usize 두 개까지 포함해 계산)하는 weighter를 설정했다. 비록 미미하더라도 가능한 정확하게 만들고 싶었다!
...
.with_weighter(|key, value| key.memory_size() + value.len())
...
Bytes 구조체는 여러 크레이트에서 널리 쓰이는 꽤 특별한 구조체다. 본질적으로는 Arc<[u8]>이지만, 다른 백킹 구현을 다루기 위한 약간의 마법이 있다. 값 복사가 매우 싸다: 실제 메모리는 복제되지 않고 참조 카운트만 갱신된다. 또한 부분 슬라이스(subslice)도 얻을 수 있어서, 재할당 없이 백킹 바이트의 일부 구간에 대한 뷰를 가질 수 있다.
바이트 범위 요청이 들어오면, 캐시(메모리 또는 디스크)에 있으면 해당 범위의 바이트를 반환하고, 없으면 object storage에서 읽어 캐시에 저장한 뒤 바이트를 반환하고 싶다.
foyer에서는 이를 위해 fetch 메서드를 사용할 수 있다:
let cache_entry = write_cache
.fetch(cache_key, || async move {
let mut req = read_from_store(&path, range, &store).await?;
let mut buffer = BytesMut::with_capacity(byte_len);
while let Some(bytes) = req.stream.try_next().await? {
buffer.extend_from_slice(&bytes);
}
Ok(bytes.freeze())
})
.await?;
그래서 우리의 캐시는 꽤 단순하다. 다시 요청될 확률이 있다고 예상되는 파일 슬라이스를 보관해 둔다.
메모리 제한 상황을 겪고 있었기 때문에, 무엇이 잘못됐을 수 있는지 트러블슈팅을 시작했다.
우리가 처음 시도한 것은, 캐시에 준 제한을 pod의 메모리 제한보다 훨씬 낮게 줄여서, 더 높은 한계에서라도 사용량이 평탄화(plateau)되는지 확인하는 것이었다. 이는 어느 정도 동작하는 것처럼 보였지만, 메모리 사용량이 여전히 다소 가변적이었다. 그리고 그 추가 메모리 사용이 어디서 오는지도 여전히 몰랐다. 힙에서 무슨 일이 벌어지는지 꼭 봐야 했다.
가비지 컬렉션 언어의 장점 중 하나는 힙을 아주 쉽게 들여다볼 수 있다는 점이다. Rust에서는 전통적으로 이것이 조금 더 어려웠다. 하지만 이제는 메모리 할당을 조사할 수 있는 훌륭한 도구들이 있다. 우리가 트러블슈팅에 사용한 도구 중 하나가 jemalloc_pprof 크레이트였다.
jemalloc_pprof로 프로파일링메모리 사용량을 프로파일링하는 한 방법은 jemalloc을 전역 할당자로 사용하고, 프로파일링을 켜는 몇 가지 설정을 한 뒤, jemalloc_pprof로 힙 프로파일을 덤프하는 것이다.
캐시는 단순한 axum 웹서버이므로, 캐시가 워밍업된 상태에서 할당 프로파일을 읽을 수 있는 요청 엔드포인트를 만들었다.
원한다면 따라 해볼 수 있도록, 당신의 프로젝트에 이를 추가하는 방법은 다음과 같다.
먼저, Cargo.toml에 tikv-jemallocator와 jemalloc_pprof 크레이트를 몇 가지 feature와 함께 추가한다:
tikv-jemallocator = { version = "0.6.0", features = ["profiling", "unprefixed_malloc_on_supported_platforms"] }
jemalloc_pprof = {version = "0.7.0", features = ["symbolize"]}
둘째, main.rs에서 이를 전역 할당자로 활성화하고, 몇 가지 설정을 export한다(설명은 jemalloc_pprof readme를 참고):
#[global_allocator]
static GLOBAL: tikv_jemallocator::Jemalloc = tikv_jemallocator::Jemalloc;
#[allow(non_upper_case_globals)]
#[export_name = "malloc_conf"]
pub static malloc_conf: &[u8] = b"prof:true,prof_active:true,lg_prof_sample:19\0";
셋째, 힙을 반환하는 간단한 axum 요청 핸들러를 만든다:
async fn get_heap() -> Result<Response<Body>, Error> {
let mut prof_ctl = jemalloc_pprof::PROF_CTL.as_ref().unwrap().lock().await;
let pprof = prof_ctl
.dump_pprof()?;
Ok(Response::builder().status(200).body(pprof.into())?)
}
마지막으로, 프로그램을 실행하고 어떤 할당이든 발생시키면 된다.
curl을 사용해 힙을 로컬에 저장할 수 있다:
curl http://127.0.0.1:8000/path_to_get_heap > heap.pprof
그리고 pprof를 사용해 결과를 웹페이지로 서빙할 수 있다:
pprof -http=:8080 heap.pprof
캐시 서비스에 계측을 넣은 뒤, 캐시에 10GB RAM 제한을 둔 인스턴스를 띄웠다. 그리고 그 제한을 초과하는 지점까지 캐시를 워밍업했다. 그런 다음 힙을 다운로드하여 조사했다.
플레임 그래프에서 문제를 찾을 수 있겠는가?
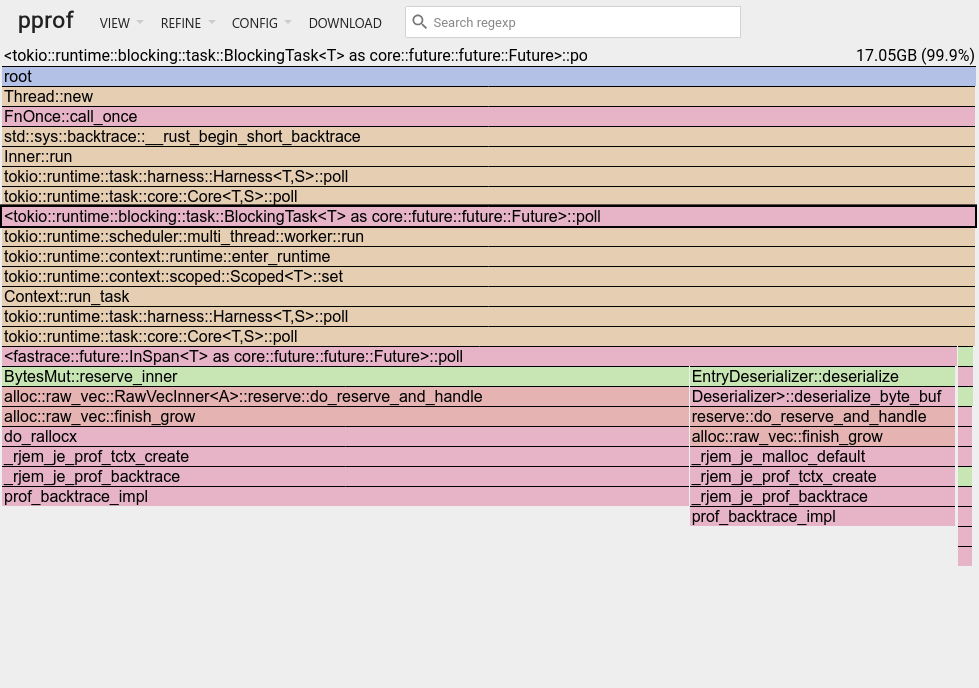
이 프로파일이 보여주는 것은 몇 가지가 있다. 약 2/3는 BytesMut을 사용하는 캐시 fetch 구현에서 오고, 나머지는 foyer 디스크 캐시에서 다시 하이드레이션(re-hydrate)된 값들에서 온다.
메모리 누수는 없는 듯하다. 하지만 힙이 전체적으로 보유하고 있는 바이트가 17GB로, 캐시에 설정한 메모리 양의 거의 _두 배_다.
BytesMut와 VecBytesMut::with_capacity를 사용하면, 이는 Vec를 백킹 저장소로 사용한다:
pub fn with_capacity(capacity: usize) -> BytesMut {
BytesMut::from_vec(Vec::with_capacity(capacity))
}
Vec 내부에는 길이가 두 개 있다. len()은 초기화된 값이 몇 개인지를 나타낸다. capacity()는 할당자에게 얼마나 요청했는지를 의미한다. 보통 capacity()는 값을 추가할 때 2의 거듭제곱 형태로 확장되며, 항상 엔트리 길이 이상이다. 이는 메모리 내 크기가 항상 기대한 대로가 아닐 수 있음을 의미한다.
따라서 고려해야 할 길이는 len()과 capacity()의 _두 가지_지만, 메모리 사용량을 더 정확히 반영하는 것은 capacity()다.
Bytes와 capacity()Bytes에는 백킹이 여러 구현 중 하나일 수 있기 때문에 capacity() 메서드가 없다. 이는 메모리 사용량을 더 정확하게 회계 처리하고 싶은 우리의 유스 케이스에는 그다지 좋지 않다.
Vec<u8>로 변경하기Bytes에서 capacity()를 사용할 수 없으므로, 한 가지 트러블슈팅 단계로 Vec을 직접 사용해 보았다. 이는 싸게 클론 가능한 바이트를 제공하지는 못하지만, 적어도 추가 메모리 사용이 여기서 비롯되는지 검증할 수는 있다.
그래서 캐시 구현은 이렇게 된다:
struct ByteCacheAppState {
write_cache: HybridCache<CacheKey, Vec<u8>>,
}
weighter는 이렇게:
...
.with_weighter(|key, value| key.memory_size() + value.capacity())
...
좋다. 10GB 제한으로 다시 실행해 새 플레임 그래프 프로파일을 보자:
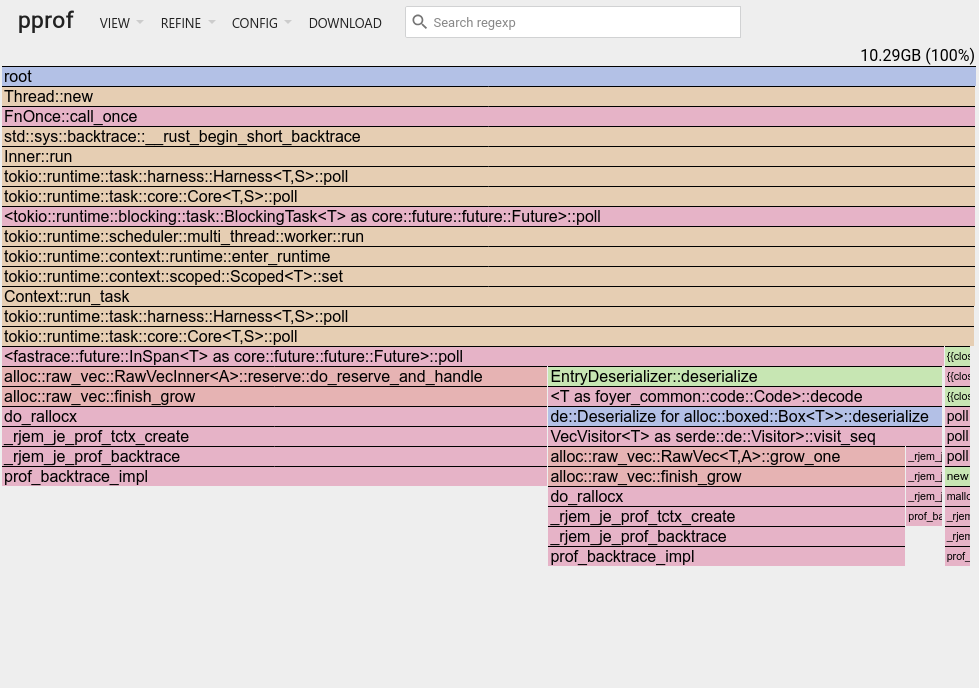
좋다. 훨씬 나아 보인다!
len()과 capacity()의 차이가 범인인 것처럼 보인다. 이 구현을 사용하거나, 실제 capacity를 읽을 수 있는 다른 구조체를 사용하면 된다.
문제 해결 아닌가? 하지만 이것은 _두 길이의 이야기_다!
Vec::with_capacityVec에서 할당이 동작하는 방식을 조금 더 파고들어 보면, 주어진 capacity로 Vec을 만들면 길이가 초기 capacity보다 커지기 전까지는 재할당하지 않아야 한다(2의 거듭제곱이 아니더라도). 우리의 fetch() 메서드에서 capacity를 명시적으로 설정하고 있으므로, 캐시 엔트리당 한 번만 할당하고 재할당은 하지 않아야 한다.
문서에는 with_capacity가 capacity()와 len()이 같음을 보장하지 않는다고 암묵적으로 적혀 있다. 즉, 예제에서도 이렇게 쓰여 있다:
let mut vec = Vec::with_capacity(10);
assert_eq!(vec.len(), 0);
assert!(vec.capacity() >= 10);
여기서 교묘한 >= 표시는 capacity가 with_capacity에 준 값과 같을 필요가 없음을 의미한다.
하지만 현재의 실사용 관점에서는, with_capacity를 쓰면 그 정확한 양을 할당자에게 요청하고, 초기 capacity보다 엔트리가 많아지기 전까지는 재할당하지 않는다:
let mut vec = Vec::with_capacity(10);
assert_eq!(vec.len(), 0);
assert_eq!(vec.capacity(), 10);
for i in 0..10 {
vec.push(i);
}
assert_eq!(vec.len(), 10);
assert_eq!(vec.capacity(), 10);
이제 다시 처음 구현으로 돌아가 보자:
let mut buffer = BytesMut::with_capacity(byte_len);
while let Some(bytes) = req.stream.try_next().await? {
buffer.extend_from_slice(&bytes);
}
with_capacity 호출 동안 한 번만 할당해야 한다. len()과 capacity()는 같아야 하고, 주어진 capacity byte_len과도 같아야 한다. 그런데 왜 같지 않은가? 그리고 힙 프로파일을 보면 재할당이 일어나는 것처럼 보이는 이유는 무엇인가?
바이트 범위를 요청하기 위해 표준 HTTP Range requests를 사용하고 있다. Rust 용어로는 이는 포함 범위(Inclusive Ranges)다. 즉,
start..=end
배제 범위(Exclusive)인 표준 Range
start..end
가 아니라는 뜻이다.
그리고 Rust에서는 거의 모든 것이 RangeInclusive가 아니라 Range를 기대한다. 하지만 HTTP range 요청을 만들 때는 반대로 변환해야 한다.
그래서 _배제_에서 _포함_으로 바꾸려면:
let start = range.start();
let end = range.end() - 1;
let inclusive = start..=end;
그리고 _포함_에서 _배제_로 바꾸려면:
let start = range.start();
let end = range.end() + 1;
let exclusive = start..end;
우리 CacheKey 구현에서는 start와 end를 배제 범위로 저장한다.
fn to_cache_key(path: &str, range: RangeInclusive<usize>) -> CacheKey {
CacheKey {
path: path.to_string(),
start: range.start(),
end: range.end() - 1,
}
}
그런 다음 이 캐시 키를 사용해 얼마나 할당해야 하는지 계산한다:
let byte_len = cache_key.end - cache_key.start;
그리고 object storage로 가는 백킹 요청에서는 이를 포함 범위로 다시 바꾸면서 이렇게 했다:
let range = RangeRequest {
start: cache_key.start,
end: cache_key.end + 1
};
위 코드에서 문제를 찾을 수 있겠는가?
여기서 구현이 무엇이 잘못됐는가?
다른 쪽으로 변환하는 방법을 다시 읽어 보면, 아마 잡아낼 수 있을 것이다.
그렇다. 위 코드의 변환은 _거꾸로_였다. 우리는 반대 방향으로 변환하고 있었다! byte_len은 항상 두 바이트가 부족했다. 즉 BytesMut은 항상 재할당을 하게 됐다.
더 나쁜 점은 byte_len이 올바른 길이가 아니었는데도, 두 오류가 서로 상쇄되었다는 것이다. 그 결과, 우리는 의도치 않게 object store에 올바른 요청을 보내고 있었고, 다운스트림 서비스는 원하는 바이트 범위를 받아 버그는 탐지되지 않았다. 할당된 메모리 제한에 도달하기 전까지는 말이다...
코드에 디버그 assertion을 몇 개 추가하니, 기존 테스트들이 실행될 때 실패하게 만드는 것은 쉬웠다:
let mut buffer = BytesMut::with_capacity(byte_len);
while let Some(bytes) = req.stream.try_next().await? {
buffer.extend_from_slice(&bytes);
}
debug_assert_eq!(bytes.len(), byte_len);
debug_assert_eq!(bytes.capacity(), byte_len);
결국 수정은 단순했다. 포함/배제 변환을 올바르게 수행해서 필요한 만큼만 할당하도록 하면 된다.
배제 범위 캐시 키로 변환:
fn to_cache_key(path: &str, range: RangeInclusive<usize>) -> CacheKey {
CacheKey {
path: path.to_string(),
start: range.start(),
end: range.end() + 1,
}
}
포함 범위 요청으로 다시 변환:
let range = RangeRequest {
start: cache_key.start,
end: cache_key.end - 1
};
이를 적용하니 Bytes 사용을 중단하지 않고도 모든 것이 잘 동작했고, 더 깊은 변경도 막을 수 있었다.
Rust는 메모리 관리를 잘 해주지만, 메모리 사용량을 면밀히 관찰해야 하는 상황도 있다. 캐시 서비스는 그 좋은 예다.
언어 초창기부터 있었으면 좋았을 것이고 지금은 바꾸기엔 확실히 너무 늦었겠지만, 표준 라이브러리 일부를 애초에 fallible allocation을 염두에 두고 설계했으면 어땠을까 싶다. 그런 형태의 API가 있었다면 이런 오류를 훨씬 쉽게 잡을 수 있었을 것이다. 물론 이제 Vec에는 try_reserve 같은 메서드가 있지만, BytesMut 같은 다운스트림 추상화에는 같은 메서드가 없다. 이렇게 생각해 보면, 명시적 동작을 자랑하는 언어치고는, 이 부분이 다소 덜 명시적인 영역처럼 느껴진다.
공정하게 말하자면, 이런 종류의 버그가 나타나지 않도록 캐시 구현에 더 많은 구조를 둘 수도 있다. 예컨대 범위를 표현하는 타입을 더 강하게 사용하는 식이다. 어쨌든, 때로는 버그가 놀라울 정도로 간단하게 고쳐질 수 있으며, 애플리케이션을 프로파일링할 수 있는 도구를 갖추는 것이 대단히 중요하다는 점을 보여준다.