C, C++, Rust가 저수준에서 메모리를 어떻게 관리하는지 탐구하는 n부작 시리즈의 첫 글. 하드웨어가 바라보는 바이트에서 출발해 객체, 저장 기간, 수명, 별칭(aliased) 개념으로 나아가며 소유권을 이해하기 위한 어휘를 쌓는다.
URL: https://lukefleed.xyz/posts/who-owns-the-memory-pt1/
C, C++, Rust가 저수준에서 메모리를 어떻게 관리하는지 탐구하는 n부작 시리즈의 첫 글이다. 우리는 하드웨어가 그러하듯 바이트에서 시작한다. 그리고 객체, 저장 기간(storage duration), 수명(lifetime), 별칭(aliasing)으로 확장해 나가며, 소유권(ownership)을 이해하는 데 필요한 어휘를 구축한다.
이 글은 Hacker News, Reddit, Lobsters에서 토론할 수 있다.
64비트 프로세서는 메모리를 2^64(2^{64})개의 주소 지정 가능한 바이트로 이루어진 평평한 배열로 본다. CPU는 struct가 무엇인지 모른다. int가 무엇인지도 모른다. 우리가 mov rax, [rbx]를 실행하면 CPU는 rbx에 들어 있는 주소부터 시작하는 8바이트를 가져와 rax에 넣고 다음으로 진행한다. 그 바이트들이 포인터를 나타내는지, 부동소수점 수를 나타내는지, UTF-8 문자열의 일부인지 같은 의미론적 해석은 오직 우리의 소스 코드와 우리가 생성한 명령어 안에만 존재한다.
이 기반 위에 우리가 구축한 기계장치—C의 유효 타입(effective type), C++의 객체 수명(object lifetime), Rust의 유효성 불변식(validity invariants)—은 하드웨어가 볼 수 없는 것을 컴파일러가 추론할 수 있도록 돕기 위해 존재한다. 이런 추상화는 최적화를 가능하게 한다. 컴파일러가 두 포인터가 별칭(alias)될 수 없음을 알면 메모리에서 다시 읽는 대신 레지스터에 값을 유지한다. 레퍼런스가 절대 null이 아님을 알면 null 체크를 제거한다. 객체의 수명이 끝났음을 알면 그 저장 공간을 재사용한다.
현대 운영체제는 프로세스에게 물리 RAM에 대한 직접 접근을 주지 않는다. 대신 각 프로세스는 MMU(Memory Management Unit)가 유지하는 허구인 “자기만의 가상 주소 공간” 안에서 동작하며, MMU는 가상 주소를 물리 프레임으로 매핑한다. C 표준은 이 추상화를 명시적으로 담고 있다. C의 포인터는 가상 메모리를 가리키며, 언어는 물리적 배치에 대해 어떤 보장도 하지 않는다.
이 추상화로 우리는 두 가지 성질을 얻는다. 첫째, 격리(isolation): 프로세스 A의 포인터는 프로세스 B의 메모리를 참조할 수 없다. 매핑되지 않은 주소를 역참조하면 페이지 폴트가 발생하며, 보통 프로세스는 종료된다. 이는 프로세스 수준 보안에 핵심인데, 침해되거나 버그가 있는 프로세스가 브라우저의 자격 증명을 읽거나 커널의 자료구조를 손상시키지 못하게 하기 때문이다. 둘째, 이식성(portability): 코드가 실행되는 머신의 물리 메모리 토폴로지를 알 필요가 없다.
우리 관점에서 가상 메모리란, 우리가 다루는 주소가 DRAM에 도달하기 전에 하드웨어에 의해 변환된다는 뜻이다. 이 변환은 성능에 영향을 준다. TLB 미스는 비싸지만, 추상화는 유지된다. 우리는 OS가 관리해주는 연속적인 주소 공간 위에서 작업한다.
모든 바이트 주소가 동등한 것은 아니다. x86-64에서는 8로 나누어 떨어지지 않는 주소에서 x86-64에서는 uint64_t를 로드하면 페널티가 발생한다. 정렬되지 않은 접근을 지원하지 않는 ARM 같은 더 엄격한 아키텍처나 오래된 SPARC에서는 하드웨어 트랩이 발생한다.uint64_t에 대한 비정렬 접근이 CPU에 의해 투명하게 처리되며, 대부분의 워크로드에서 오버헤드는 무시할 수준이다. Intel은 Sandy Bridge(2011) 이후 이 경로를 최적화해왔다. 페널티가 의미 있게 커지는 경우는 로드가 캐시 라인 경계(64바이트)를 가로지르거나, 더 나쁘게는 페이지 경계를 가로지를 때뿐이다. 정렬되지 않은 접근을 지원하지 않는 ARM 같은 더 엄격한 아키텍처나 오래된 SPARC에서는 하드웨어 트랩이 발생한다.
이유는 기계적이다. DRAM은 정렬된 덩어리로 접근한다. CPU가 0x1003 주소의 데이터를 요청했지만 메모리 버스가 8바이트 정렬 블록을 가져온다면, 메모리 컨트롤러는 두 블록(0x1000-0x1007, 0x1008-0x100F)을 모두 가져온 뒤 필요한 바이트를 추출하고 재조립해야 한다. 이는 사이클을 소모한다.
C 표준은 정렬 개념을 다음과 같이 형식화한다.
#include <stdalign.h>
#include <stdio.h>
int main(void) {
printf("alignof(int) = %zu\n", alignof(int)); // 보통 4
printf("alignof(double) = %zu\n", alignof(double)); // 보통 8
printf("alignof(max_align_t) = %zu\n", alignof(max_align_t)); // 보통 16
}alignof 연산자(C11/C23)는 타입이 요구하는 정렬을 반환한다. 정렬 요구사항을 위반한 주소에서 객체에 접근하는 것은 미정의 동작(undefined behavior)이다. 표준이 까다로워서가 아니라 하드웨어가 이를 신뢰성 있게 실행할 수 없기 때문이다. 이는 컴파일러가 정렬된 접근을 가정하고, 비정렬 주소에서 트랩을 일으키거나 잘못된 결과를 내는 명령을 생성할 수 있게 한다. x86-64에서는 비정렬 스칼라 로드가 동작하지만 캐시 라인을 넘을 수 있으며, ARM 같은 더 엄격한 아키텍처에서는 트랩이 난다.
Modern C에서 가져온 다음의 구체적 실패 사례를 보자.
union {
unsigned char bytes[32];
complex double val[2];
} overlay;
// complex double은 보통 16바이트 정렬이 필요함 (sizeof는 16)
complex double *p = (complex double *)&overlay.bytes[4]; // 비정렬
*p = 1.0 + 2.0*I; // 미정의 동작x86-64에서 정렬 검사를 활성화한 경우나 ARM에서는 버스 에러로 크래시가 난다. 포인터 산술은 C에서 합법이지만, 결과 주소가 complex double의 정렬 요구사항을 위반한다. 하드웨어가 거부하는 것이다.
정렬은 또 다른 하드웨어 현실인 캐시 라인과 상호작용한다. 현대 x86-64 프로세서에서 L1 캐시는 64바이트 라인 단위로 동작한다. 우리가 1바이트만 읽어도 CPU는 실제로 64바이트를 가져온다. 데이터 구조의 배치가 나쁘면 사용하지도 않을 바이트들을 가져오느라 대역폭을 낭비하게 된다.
더 나쁘게는, 하나의 논리적 데이터가 두 캐시 라인에 걸쳐 있으면 매 접근마다 캐시에서 두 번 가져와야 한다. 64바이트 경계를 가로지르는 struct라면 메모리 트래픽이 두 배가 된다.
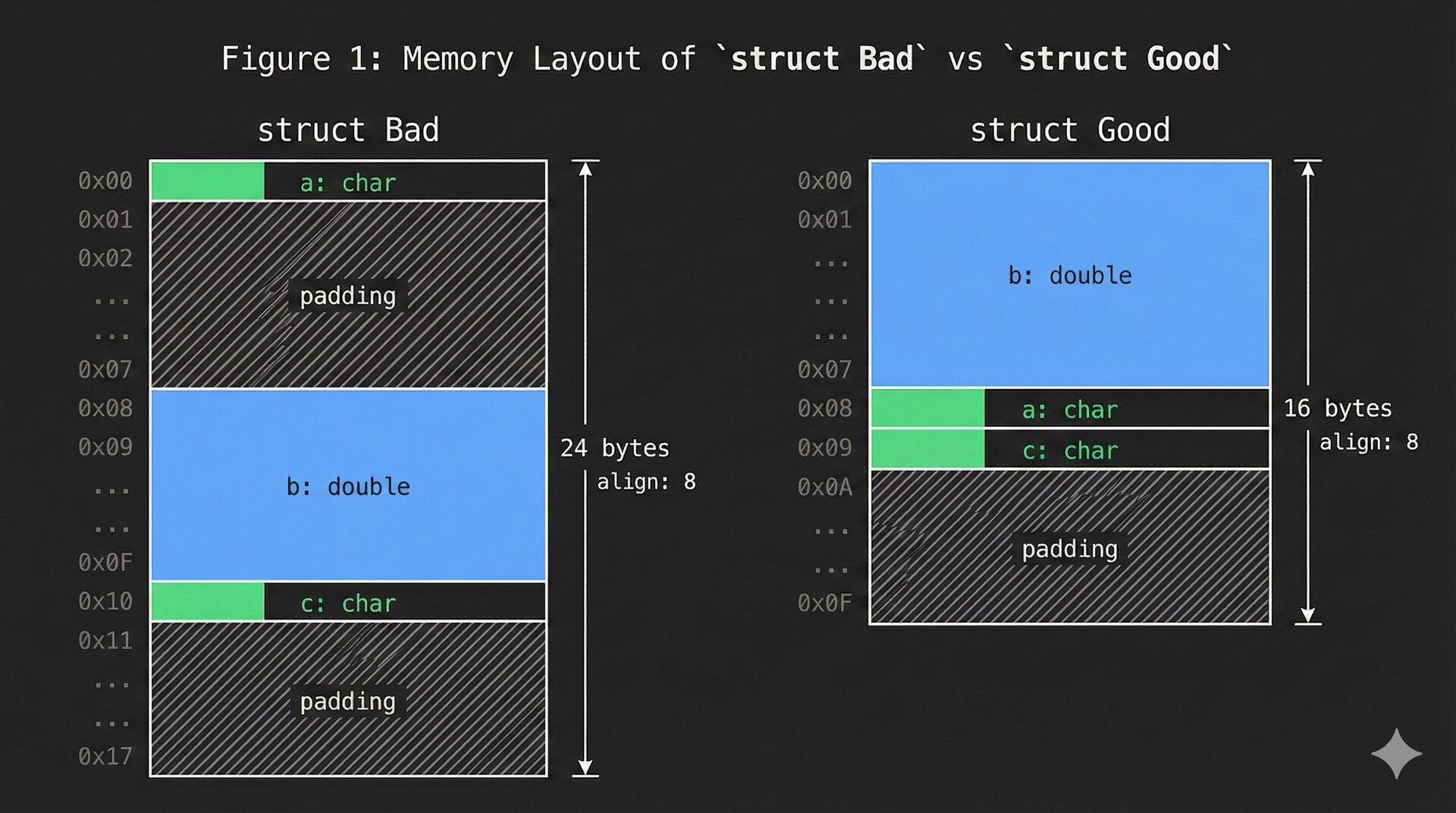
이 때문에 컴파일러는 구조체 필드 사이에 패딩을 삽입한다. 예를 들어:
struct Bad {
char a; // 1바이트
// 7바이트 패딩
double b; // 8바이트
char c; // 1바이트
// 7바이트 패딩(구조체 전체 정렬을 맞추기 위해)
};
struct Good {
double b; // 8바이트
char a; // 1바이트
char c; // 1바이트
// 6바이트 패딩
};sizeof(struct Bad)는 24바이트다. sizeof(struct Good)는 16바이트다. C에서 컴파일러는 필드 순서를 재배치할 수 없다(표준은 필드가 선언 순서대로, 증가하는 주소에 나타남을 보장한다). 따라서 우리가 직접 레이아웃을 고려해야 한다.
네, Gemini로 만들었다. Figma는 잘 못 한다.
malloc(n)을 호출해도 정확히 n바이트의 “사용 가능한” 메모리를 받는 것은 아니다. 할당자는 청크 헤더, 크기 필드, 프리 리스트 포인터 같은 메타데이터를 유지하는데, 이들은 우리가 받은 할당 영역 인접한 곳에 놓인다. glibc의 ptmalloc2에서 할당된 청크는 대략 이렇게 생겼다.
+------------------+
| prev_size | (8바이트, 이전 청크가 free일 때만 사용)
+------------------+
| size |N|M|P| (8바이트, 하위 3비트에 플래그 포함)
+------------------+
| user data... | <- malloc이 반환하는 포인터
| |
+------------------+size 필드는 청크 크기와 함께 3개의 플래그 비트를 저장한다. P(이전 청크 사용 중), M(mmap으로 얻은 청크), A(메인 아레나가 아닌 아레나). 실제 사용 가능한 크기는 size & ~0x7이다.
이는 몇 가지 함의를 가진다. 모든 할당에는 오버헤드가 있고, 작은 할당일수록 상대적으로 더 불리하다. 예컨대 16바이트를 요청해도(할당자에 따라 다르지만) 실제로는 최소 32바이트(데이터 16 + 메타데이터 16)를 사용할 수 있다. 또한 할당자는 자체 정렬을 강제한다. malloc은 어떤 기본 타입(max_align_t)에도 충분한 정렬을 보장하는데, 대부분의 64비트 플랫폼에서 이는 16바이트다. 마지막으로 free() 이후에도 메모리가 진정으로 “자유”로워지는 것은 아니다. 할당자는 영역을 추적하며, free()는 OS에 즉시 돌려주지 않을 수 있다. 보통은 재사용을 위해 프리 리스트로 돌려준다.
뒤에서 소유권과 자원 관리에 대해 논의할 때 이것을 기억하자. 언어 수준에서 “메모리 해제”란 바이트를 할당자에 반환하는 것을 의미한다. OS에 페이지를 (언제, 혹은 정말로) 돌려줄지는 할당자가 결정한다.
C 표준은 이를 명시한다. 모든 객체는 unsigned char 배열로 볼 수 있다.
int x = 42;
unsigned char *bytes = (unsigned char *)&x;
for (size_t i = 0; i < sizeof(int); i++) {
printf("%02x ", bytes[i]);
}
// 리틀 엔디언 x86-64에서의 출력: 2a 00 00 00이것이 객체 표현(object representation), 즉 메모리 안의 실제 바이트들이다. 이 바이트들이 정수 42를 나타낸다는 의미론적 해석은 타입 시스템이 위에 얹는 층이다.
Rust와 C++도 이 모델을 상속한다. Rust의 i32가 정렬 4로 4바이트를 차지한다고 말할 때, 이는 C에서와 똑같은 뜻이다. 4로 나누어 떨어지는 주소에 연속된 4바이트가 있다는 것. 타입 시스템이 그 바이트들에 대해 허용하는 연산은 크게 다르지만 물리적 표현은 동일하다.
여기가 출발점이다. 가상 주소 공간 안에 있는 바이트들, 하드웨어 접근을 위한 정렬, 할당자가 관리하는 바이트들. 이후에 나오는 모든 것(유효 타입, 소유권, 수명)은 이 물리적 현실 위에 얹는 추상화 층이다.
메모리의 한 구역은 우리가 그 위에 타입 해석을 부여할 때 **객체(object)**가 된다. 타입은 몇 바이트가 참여하는지, 정렬 요구사항이 무엇인지, 어떤 연산이 유효한지 등을 규정한다. 하지만 세 언어는 이 부여가 언제/어떻게 일어나는지, 그리고 타입이 어떤 불변식을 담는지에서 근본적으로 다르다.
C에서 메모리와 타입의 관계는 **유효 타입(effective type)**이라는 개념으로 설정된다. 객체의 유효 타입은 그 객체에 어떻게 접근할 수 있는지를 결정한다.
선언된 변수의 경우 유효 타입은 선언 타입과 같다.
int x = 42; // x의 유효 타입은 int
변수 x는 어떤 주소에 sizeof(int) 바이트를 차지하며, 그 바이트들은 int 또는 unsigned char로 접근해야 한다. float*로 접근하면 미정의 동작이다.
int x = 42;
float *fp = (float *)&x;
float f = *fp; // 미정의 동작: 호환되지 않는 타입으로 접근이는 런타임 체크가 아니다. 컴파일러는 접근을 검증하는 코드를 삽입하지 않는다. 대신 이 규칙은 최적화를 위해 존재한다. 컴파일러가 int*를 통한 쓰기와 float*를 통한 읽기를 보면, strict aliasing 규칙 덕분에 이 포인터들이 서로 다른 객체를 가리킨다고 가정할 수 있다. 그 결과 로드/스토어 재배치, 레지스터 유지, 중복 접근 제거 같은 최적화가 가능해진다.
이 규칙에는 중요한 비대칭이 있다. 어떤 객체든 unsigned char 배열로 볼 수 있다.
int x = 42;
unsigned char *bytes = (unsigned char *)&x;
for (size_t i = 0; i < sizeof(int); i++) {
printf("%02x ", bytes[i]); // 유효: char 접근은 항상 허용
}하지만 그 역은 미정의다.
unsigned char buffer[sizeof(int)] = {0};
int *p = (int *)buffer;
int val = *p; // 미정의 동작이 버퍼의 유효 타입은 unsigned char[4]다. int*로 접근하면 유효 타입 규칙을 위반한다. 바이트들이 우연히 int의 유효한 표현을 이룬다는 사실은 중요하지 않다. 컴파일러는 이런 접근이 일어나지 않는다고 가정해도 되고, 그 결과 쓰레기 값을 내거나 크래시하는 코드를 생성할 수 있다.
동적 할당 메모리에서는 상황이 다르다. malloc이 반환한 메모리는 우리가 거기에 쓰기 전까지 유효 타입이 없다.
void *p = malloc(sizeof(double));
double *dp = p;
*dp = 3.14; // 이 쓰기가 유효 타입을 double로 설정이후 할당 영역의 유효 타입은 double이 된다. 이후 double*를 통한 읽기는 유효하다. int*로 읽으면 다시 미정의다.
유효 타입 장치는 순수하게 최적화를 위한 것이다. 컴파일러가 별칭을 추론할 때 사용한다. 런타임 안전성을 제공하지 않는다.
C++은 C의 유효 타입 규칙을 상속하지만, 별도의 개념인 **객체 수명(object lifetime)**을 추가한다. 객체 수명은 그 객체에 접근하는 것이 잘 정의되는 기간이다.
C++ 표준은 경계를 정확히 규정한다. 타입 T의 객체는 적절한 정렬과 크기의 저장 공간을 얻고 초기화(있다면)가 완료되면 수명이 시작된다. 수명은 (클래스 타입의 경우) 소멸자 호출이 시작될 때, (비클래스 타입의 경우) 객체가 파괴될 때, 또는 저장 공간이 해제/재사용될 때 끝난다.
placement new를 보자.
struct Widget {
int value;
Widget(int v) : value(v) { }
~Widget() { std::cout << "destroyed\n"; }
};
alignas(Widget) unsigned char buffer[sizeof(Widget)];
Widget* w = new (buffer) Widget(42); // 여기서 수명 시작
w->~Widget(); // 여기서 수명 종료
// buffer에는 여전히 바이트가 남아 있지만, Widget 객체는 존재하지 않음placement new와 소멸자 호출 사이에는 그 주소에 Widget 객체가 존재한다. placement new 전과 소멸자 이후에는 바이트는 존재하지만 Widget은 없다. w->~Widget() 이후에 w->value에 접근하면, 바이트가 그대로 남아 있어도 미정의 동작이다.
소멸자 호출은 메모리를 해제하지 않는다. 저장 공간은 그대로 두고 객체의 수명만 끝낸다. placement new와 명시적 소멸자 호출이 의존하는 것이 바로 이것이다. 기존 저장 공간에 객체를 구성하고, 사용하고, 파괴한 다음, 같은 저장 공간에 다른 객체를 다시 구성할 수 있는 능력.
trivial 타입(생성자/소멸자/가상 함수가 없는 타입)에서는 C++ 객체는 사실상 C 객체처럼 동작한다. 비trivial 특수 멤버 함수를 가진 클래스 타입에서는 수명 경계가 중요해진다. 파괴된 std::string을 접근하면 소멸자가 내부 버퍼를 해제했을 수 있으므로, 해제된 메모리나 손상된 포인터를 읽게 된다.
C++20은 **암묵적 객체 생성(implicit object creation)**도 도입했다. 예를 들어 std::malloc 같은 특정 연산은, 프로그램을 정의된 동작으로 만들 수 있다면 **암묵적 수명 타입(implicit-lifetime types)**의 객체를 암묵적으로 생성한다.
struct Point { int x, y; }; // 암묵적 수명 타입(트리비얼)
Point* p = (Point*)std::malloc(sizeof(Point));
p->x = 1; // C++20에서는 잘 정의됨
p->y = 2; // malloc이 Point 객체를 암묵적으로 생성이는 오래전부터 흔했지만 기술적으로는 미정의였던 코드 패턴을 사후적으로 잘 정의하기 위해 추가되었다.
Rust는 더 강한 요구사항을 부과한다. 모든 타입에는 **유효성 불변식(validity invariants)**이 있으며, 타입의 불변식을 위반하는 값을 만들어내는 순간 즉시 미정의 동작(UB)이다. 컴파일러의 최적화기는 이러한 불변식이 무조건 성립한다고 가정한다.
Rust Reference는 타입별 유효성을 정의한다.
// bool은 0x00(false) 또는 0x01(true)이어야 함
let b: bool = unsafe { std::mem::transmute(2u8) }; // UB: 유효하지 않은 bool
// 레퍼런스는 null이 아니고, 정렬되어 있으며, 유효한 값을 가리켜야 함
let r: &i32 = unsafe { std::mem::transmute(0usize) }; // UB: null 레퍼런스
// char는 유효한 유니코드 스칼라 값이어야 함(서로게이트 제외)
let c: char = unsafe { std::mem::transmute(0xD800u32) }; // UB: 서로게이트
// enum은 유효한 판별자(discriminant)를 가져야 함
enum Status { Active = 0, Inactive = 1 }
let s: Status = unsafe { std::mem::transmute(2u8) }; // UB: 유효하지 않은 판별자
// never 타입은 존재해서는 안 됨
let n: ! = unsafe { std::mem::zeroed() }; // UB유효하지 않은 값이 생성되는 순간 미정의 동작이 발생한다. Rust 컴파일러는 프로그램 실행 중 생성되는 모든 값이 유효하다고 가정한다. 따라서 유효하지 않은 값을 만들어내는 것은 즉시 UB다.
C에서는 int 변수가 어떤 32비트 패턴이든 담을 수 있고, 특정 방식으로 읽지만 않으면 UB가 아닐 수도 있다. Rust에서는 bool에 0x02가 들어 있는 순간, 이후에 그 값을 읽든 말든 상관없이 생성 지점에서 이미 UB다.
레퍼런스를 보자. C/C++에서는 포인터가 null일 수 있고, 이를 역참조하는 것이 UB다. 하지만 포인터 자체는 존재할 수 있고 전달될 수도 있다. Rust에서는:
let ptr: *const i32 = std::ptr::null(); // 유효: raw pointer는 null 가능
let r: &i32 = unsafe { &*ptr }; // UB는 여기(레퍼런스 생성 시점)에 발생UB는 레퍼런스를 통해 읽을 때가 아니라 레퍼런스를 만들 때 발생한다. &T는 불변식을 가진다. null이 아니고, 올바르게 정렬되어 있고, 유효한 T를 가리켜야 한다. 이 불변식을 어느 시점이든 위반하면 이후에 무엇을 하든 UB다.
이 엄격함은 더 공격적인 최적화를 가능하게 한다. 컴파일러는 &T를 보면 LLVM에 dereferenceable, nonnull 같은 애트리뷰트를 붙인다. bool에 대한 match는 2~255 같은 값에 대한 기본 분기를 만들 필요가 없다. 유효하지 않은 값이 존재할 수 있다면 이런 최적화는 건전할 수 없다.
대신 더 많은 연산이 unsafe를 필요로 한다. 잠깐이라도 잠재적으로 유효하지 않은 메모리에 대한 레퍼런스를 만들 수 없다. raw pointer를 사용하고, 유효성이 보장될 때만 레퍼런스로 변환해야 한다.
let ptr: *const i32 = some_ffi_function();
if !ptr.is_null() && ptr.is_aligned() {
let r: &i32 = unsafe { &*ptr }; // 건전함: 유효성을 확인
println!("{}", *r);
}세 언어 모두 객체의 표현(representation)(메모리 안의 바이트)과 값(value)(그 바이트의 의미론적 해석)을 구분한다. 하지만 경계선을 어디에 긋는지는 다르며, 각 언어가 어디에 선을 긋는지 이해하는 것이 어떤 저수준 조작이 건전한지 결정한다.
모든 객체는 연속된 바이트 열을 차지한다. 타입의 **크기(size)**는 바이트 수이고, **정렬(alignment)**은 그 바이트들이 시작할 수 있는 주소를 제한한다. 정렬이 8인 타입은 8로 나누어 떨어지는 주소에 저장되어야 한다. 이는 앞서 본 것처럼 메모리 버스가 데이터를 가져오는 방식과 연결된다.
C에서는 어떤 객체든 unsigned char[]로 자유롭게 살펴볼 수 있다.
double d = 3.14159;
unsigned char *bytes = (unsigned char *)&d;
// bytes[0..7]에는 IEEE 754 표현이 들어 있음바이트는 표현이고, 값은 IEEE 754에 따라 그 바이트가 의미하는 것이다. C는 의미론을 신경 쓰지 않고 바이트를 관찰하는 것을 허용한다. C++은 이를 상속하지만 객체 수명에 대한 제약을 추가한다. 살아 있는 객체의 바이트는 볼 수 있지만, 소멸자가 실행된 뒤에는 저장 공간이 재사용되지 않았더라도 접근이 미정의다.
Rust는 raw pointer와 transmute를 통해 바이트 수준 관찰을 허용하지만, C/C++에는 없는 유효성 제약을 부과한다.
let x: i32 = 42;
let bytes: [u8; 4] = unsafe { std::mem::transmute(x) };
// bytes는 리틀 엔디언 표현: [42, 0, 0, 0]
// 반대 방향은 주의가 필요:
let bytes: [u8; 1] = [2];
let b: bool = unsafe { std::mem::transmute(bytes) }; // UB: 2는 유효한 bool이 아님이 비대칭은 C의 유효 타입 규칙을 닮았다. 타입 있는 값을 바이트로 바꾸는 것은 대체로 안전하다. 바이트를 타입 있는 값으로 바꾸려면, 그 바이트가 대상 타입의 유효한 값을 구성해야 하며, Rust의 유효성 불변식은 C보다 더 엄격하다.
이 구분은 구조체 레이아웃을 고려할 때 중요하다. C는 필드가 선언 순서대로 나타남을 보장하며, 컴파일러는 패딩을 삽입하지만 재배치는 못 한다. C++도 표준 레이아웃 타입에는 이 보장을 상속한다. Rust는 기본적으로 최소한의 보장만 한다. repr(Rust) 레이아웃은 패딩을 최소화하기 위해 컴파일러가 필드를 재배치할 수 있다. 예:
struct A {
a: u8,
b: u32,
c: u16,
}Rust는 (b, c, a, padding)처럼 배치하여 12바이트 대신 8바이트를 만들 수도 있다. 같은 구조체의 서로 다른 제네릭 인스턴스는 서로 다른 레이아웃을 가질 수도 있다. C와의 상호운용을 위해 Rust는 #[repr(C)]를 제공하며, 이는 C 호환 레이아웃(선언 순서, 표준 알고리즘에 따른 패딩)을 보장한다.
repr(C)의 레이아웃 알고리즘은 결정적이다. 오프셋 0에서 시작하고, 각 필드를 선언 순서대로 처리한다. 오프셋이 해당 필드 정렬의 배수가 될 때까지 패딩을 추가하고, 필드 오프셋을 기록한 뒤, 필드 크기만큼 오프셋을 증가시킨다. 마지막으로 구조체 전체 크기를 구조체 정렬의 배수로 올림한다. 이것이 struct Bad가 24바이트가 되고 struct Good가 16바이트가 된 이유다. 알고리즘은 기계적이지만 필드 순서는 우리의 책임이다.
그렇다면 mem::transmute는 언제 건전한가? 크기는 같아야 하며(컴파일러가 강제), 정렬은 호환되어야 한다. 예를 들어 &u8를 &u64로 transmute하는 것은 크기가 맞더라도 u8이 8바이트 정렬이 아닐 수 있으므로 건전하지 않다. 그리고 유효성도 보존해야 한다. 바이트가 대상 타입의 유효한 값을 구성해야 한다. 이 마지막 제약이 Rust가 C에 더해 추가하는 것이다. repr(transparent)는 0이 아닌 크기의 필드가 하나뿐인 타입에 대해 동일 레이아웃을 보장하여, 둘 사이의 transmute를 건전하게 만들고 비용 없는 newtype을 가능하게 한다.
모든 객체는 메모리 어딘가에 존재한다. 객체의 **저장 기간(storage duration)**은 그 메모리가 언제 할당되고 언제 무효가 되는지를 결정한다. 세 언어 모두 같은 근본 범주를 인식하지만, 용어와 해제 보장 방식은 다르다.
C는 네 가지 저장 기간을 정의하며 C++도 이를 상속한다. Rust는 동일한 모델에 대응하지만 명세에서 동일 용어를 쓰지는 않는다.
정적 저장 기간(static storage duration): 객체가 프로그램 실행 전체 동안 존재한다. C/C++에서 전역 변수, static으로 선언된 변수, 문자열 리터럴이 포함된다. Rust에서는 static 아이템과 문자열 리터럴(타입 &'static str)이 포함된다. 이들의 메모리는 보통 실행 파일의 .data 또는 .rodata 세그먼트에 놓이며 런타임 할당이 필요 없다.
스레드 저장 기간(thread storage duration): 객체가 스레드 수명 동안 존재한다. C11은 _Thread_local(C23부터 thread_local 표기), C++11은 thread_local, Rust는 thread_local! 매크로를 제공한다. 각 스레드는 변수의 인스턴스를 하나씩 가지며, 스레드 시작 시 할당되고 종료 시 해제된다.
자동 저장 기간(automatic storage duration): 객체가 어휘적 스코프(보통 함수 본문이나 블록) 안에서 존재한다. 스코프에 진입하면 공간이 예약되고, 벗어나면 해제된다. C/C++에서 static이나 thread_local이 없는 지역 변수는 자동 저장이다. Rust에서는 모든 지역 바인딩이 자동 저장이다. 이는 보통 스택으로 구현된다.
할당(동적) 저장 기간(allocated/dynamic storage duration): 객체의 수명이 프로그램에 의해 명시적으로 제어된다. C에서는 malloc/free, C++에서는 new/delete 또는 할당자 인지 컨테이너, Rust에서는 Box, Vec, String 같은 힙 할당 타입이 이에 해당한다.
자동 저장은 거의 항상 호출 스택으로 구현된다. 함수가 호출되면 컴파일러는 스택 포인터를 조정해 지역 변수 공간을 확보한다. System V ABI를 따르는 x86-64에서 이는 대략 이렇게 보인다.
my_function:
push rbp
mov rbp, rsp
sub rsp, 48 ; 로컬을 위해 48바이트 예약
; ... 함수 본문 ...
mov rsp, rbp
pop rbp
retsub rsp, 48 한 번으로 모든 지역 변수의 공간이 할당된다. 컴파일러는 (정렬을 고려해) 지역 변수 크기를 합산하여 필요한 크기를 컴파일 타임에 계산한다. 해제도 똑같이 싸다. mov rsp, rbp는 그 공간을 즉시 전부 반환한다.
이는 두 가지 결과를 낳는다. 첫째, 자동 저장의 할당/해제는 객체 수와 무관하게 O(1)이다. 지역 변수가 100개인 함수도 2개인 함수와 동일한 비용을 치른다. 둘째, 공간은 초기화되지 않는다. sub rsp, 48 이후 48바이트에는 이전에 스택에 있던 값이 남아 있다. C에서는 초기화되지 않은 자동 변수를 읽으면 미정의 동작이다(값이 불확정(indeterminate)). C++도 같은 규칙이 적용된다. Rust에서는 컴파일러가 “반드시 초기화(definite initialization)”를 강제해서, 대입 전에는 변수를 읽을 수 없다.
C에서 초기화되지 않은 자동 변수를 읽는 것은 미정의 동작(값이 불확정)이다. C++은 C++26 이전에는 동일하다. C++26은 새로운 범주인 erroneous behavior를 도입한다. 값은 여전히 불확정이지만 읽는 것이 UB는 아니며, 구현이 진단하거나 0으로 초기화할 수 있다. Clang의
-ftrivial-auto-var-init=zero는 수년 전부터 이 동작을 제공해왔다.
fn example() {
let x: i32;
println!("{}", x); // 오류: 초기화되지 않았을 가능성이 있는 변수 차용
}Rust 컴파일러는 제어 흐름을 통해 초기화 상태를 추적하고, 미초기화 메모리를 읽을 수 있는 프로그램을 거부한다. 이는 런타임 비용 없는 컴파일 타임 체크다.
동적 할당은 근본적으로 다르다. malloc(n)을 호출하면 할당자는 사용 중이 아닌 연속된 n바이트 이상 영역을 찾아 “할당됨”으로 표시하고 포인터를 반환해야 한다. free(p)를 호출하면 할당자는(사용자 데이터 옆 메타데이터에 저장된) 할당 크기를 알아내고, 그 영역을 향후 할당을 위해 사용 가능으로 표시하며, 단편화를 줄이기 위해 인접 free 영역을 병합할 수도 있다.
이는 자료구조 조작, (OS에서 더 많은 메모리가 필요하면) 시스템 호출 가능성 등을 포함하며, 힙 상태에 따라 지연 시간이 변할 수 있다. 비용은 O(1)이 아니다.
C에서는 힙 할당이 명시적이다.
int* p = malloc(sizeof(int) * 100);
if (p == NULL) {
// 할당 실패
}
// ... p 사용 ...
free(p);할당 실패 체크, free를 정확히 한 번 호출, free 이후 사용 금지, 이중 해제 금지—모두 우리의 책임이다. 이를 위반하면 UB 또는 메모리 누수다. 언어는 아무 도움도 주지 않는다.
C++에서는 동적 할당이 명시적(new/delete)일 수도 있고, RAII로 관리될 수도 있다.
// 명시적(위험)
int* p = new int[100];
delete[] p;
// RAII(더 안전)
auto v = std::make_unique<int[]>(100);
// v는 스코프를 벗어나면 자동으로 delete됨std::unique_ptr는 raw pointer를 감싸 소멸자에서 delete를 호출한다. v가 스코프를 벗어나면 소멸자가 실행되어 메모리가 해제된다. 우리는 delete를 수동으로 호출하지 않는다.
하지만 이는 선택 사항이다. 여전히 raw new/delete를 쓸 수 있고, 댕글링 포인터도 만들 수 있다. 컴파일러는 정합성을 검증하지 않는다.
Rust에서는 힙 할당이 소유 타입을 통해 처리된다.
let v: Vec<i32> = Vec::with_capacity(100);
// v는 스코프를 벗어나면 자동으로 해제됨Vec<T>는 힙에 할당된 메모리를 소유한다. v가 스코프를 벗어나면 Vec의 Drop 구현이 실행되어 할당자에 버퍼를 반환한다. 해제를 잊을 방법이 없고, 이중 해제할 방법이 없고, use-after-free도(컴파일러가 그런 프로그램을 거부하므로) 불가능하다.
C++과의 차이는 Rust의 소유권이 선택이 아니라는 점이다. 모든 힙 할당은 정확히 하나의 바인딩이 소유한다. 소유권 이전은 move다. move 이후 원래 바인딩은 사용할 수 없다.
let v1 = vec![1, 2, 3];
let v2 = v1; // v1이 v2로 move됨
println!("{:?}", v1); // 오류: move된 값을 차용동적 저장을 다루는 방식에서 C, C++, Rust의 핵심 차이는 “해제 책임”이다.
C에서는 우리가 언제 free를 호출할지 결정한다. 언어는 소유권을 추적하지 않는다. 포인터를 함수에 넘기면 그 함수가 free할 수도, 안 할 수도 있다. 알 방법은 문서나 관례뿐이다.
void process(int* data) {
// 이 함수가 data를 free하나? 문서를 읽어야만 안다.
}C++에서는 RAII가 소멸자로 책임을 옮긴다. unique_ptr를 쓰면 소멸자가 free한다. shared_ptr를 쓰면 소멸자가 참조 카운트를 감소시키고 0이 되면 free한다. 하지만 여전히 raw pointer를 쓸 수 있고, 컴파일러는 코드베이스의 관례를 알 수 없다.
void process(int* data) {
// Raw pointer: 누가 소유? 여전히 모호.
}
void process(std::unique_ptr<int[]> data) {
// 소유권 이전: 이 함수는 끝나면 free할 것.
}Rust에서는 타입 시스템이 소유권을 인코딩한다.
fn process(data: Vec<i32>) {
// 이 함수가 data를 소유한다. process가 리턴하면 해제된다.
}
fn process_ref(data: &Vec<i32>) {
// 이 함수는 data를 빌린다. 호출자가 소유권을 유지한다.
}
fn process_mut(data: &mut Vec<i32>) {
// 가변 대여. 호출자가 소유권 유지.
// 이 호출 동안 다른 접근은 허용되지 않는다.
}시그니처가 모든 것을 말해준다. Vec<i32>는 소유권 이전, &Vec<i32>는 불변 대여, &mut Vec<i32>는 가변 대여. 컴파일러가 이를 강제한다. Vec을 넘긴 뒤 계속 사용하려 하면 move가 되어 거부된다.
Rust는 데이터가 스택에 있을지 힙에 있을지에 대해 세밀한 제어를 제공한다. 기본적으로 지역 바인딩은 스택에 할당된다.
let x: [i32; 1000] = [0; 1000]; // 스택에 4000바이트
하지만 배열이 스택에 너무 크면(플랫폼에 따라 보통 1~8MB) 문제가 된다. 큰 할당에는 Box를 사용한다.
let x: Box<[i32; 1000000]> = Box::new([0; 1000000]); // 힙
Box<T>는 힙 할당을 가리키는 포인터다. 크기는 raw pointer와 같고(64비트에서 8바이트), Deref를 구현해서 레퍼런스처럼 사용할 수 있으며, Drop에서 할당을 해제한다.
Box<T>의 메모리 레이아웃은 포인터 하나다.
use std::mem::size_of;
assert_eq!(size_of::<Box<[i32; 1000]>>(), 8); // 포인터 하나deleter를 담을 수도 있는 C++의 unique_ptr와 달리, Box<T>는 항상 전역 할당자를 쓰며 공간 오버헤드가 없다. 해제 함수는 정적으로 알려져 있다.
저장 기간은 메모리가 언제 할당/해제되는지 결정한다. 객체 수명은 그 메모리에 접근하는 것이 언제 잘 정의되는지 결정한다. C에서는 둘이 동일하다. C++에서는 다를 수 있다. Rust에서는 수명이 제어 흐름 그래프 위에서 제약 전파를 통해 추적되는 컴파일 타임 속성이 된다.
C는 “저장 공간이 존재한다”와 “객체가 살아 있다”를 구분하지 않는다. 자동 저장 기간 객체는 정의된 블록에 진입할 때부터 나갈 때까지 살아 있다. 정적 저장 기간 객체는 프로그램 전체 동안 살아 있다. 할당 저장 기간 객체는 malloc부터 free까지 살아 있다.
그 결과 C에는 “저장 공간은 있지만 객체가 아직 구성되지 않았다”는 개념이 없다. 스택 프레임이 생성되면 모든 자동 변수는 존재한다. 초기화 여부는 별개의 문제다.
int* dangling(void) {
int x = 42;
return &x;
}
int main(void) {
int* p = dangling();
printf("%d\n", *p); // 미정의 동작
}이 프로그램은 컴파일된다. dangling이 x의 주소를 반환하지만 x는 자동 저장 기간이다. dangling이 리턴하면 스택 프레임이 해제되고, 포인터 p는 더 이상 어떤 살아 있는 객체에도 속하지 않는 메모리를 가리킨다. 역참조는 미정의 동작이다.
C 표준은 컴파일러가 이를 거부하도록 요구하지 않는다. 구현이 경고를 낼 수는 있지만 프로그램은 문법적으로 유효하다. 부담은 전적으로 우리에게 있다.
C++은 구분을 도입한다. 저장 기간은 메모리 할당/해제를 결정하고, 객체 수명은 그 객체에 접근할 수 있는지를 결정한다. 클래스 타입에서 수명은 생성자가 완료되면 시작되고 소멸자가 시작되면 끝난다.
placement new를 다시 보자.
struct Widget {
std::string name;
Widget(const char* n) : name(n) { }
~Widget() { std::cout << "destroyed\n"; }
};
alignas(Widget) unsigned char buffer[sizeof(Widget)];
// 저장 공간은 존재하지만 Widget 객체는 없음.
Widget* w = new (buffer) Widget("test");
// 생성자가 실행되어 Widget 객체가 생김.
w->~Widget();
// 소멸자가 실행되어 Widget 객체는 더 이상 없음.
// 저장 공간은 여전히 존재.소멸자 호출 이후 w->name에 접근하면 미정의 동작이다. 바이트는 있다. 객체는 없다.
C++은 이를 형식화한다. 타입 T의 객체 수명은 적절한 저장 공간을 얻고 초기화가 완료되면 시작되고, (클래스 타입이면) 소멸자 호출이 시작되거나 (비클래스 타입이면) 객체가 파괴되거나 저장 공간이 해제/재사용되면 끝난다.
trivial 타입은 C처럼 동작하지만, 비trivial 생성자/소멸자를 가진 클래스에는 이 구분이 중요하다.
댕글링 레퍼런스 문제는 여전히 존재한다.
int& dangling() {
int x = 42;
return x;
}컴파일된다. 좋은 컴파일러는 경고한다. 표준은 거부를 요구하지 않는다.
Rust는 컴파일 타임 분석으로 댕글링 레퍼런스를 막는다. 동등한 코드는 컴파일되지 않는다.
fn dangling() -> &i32 {
let x = 42;
&x
}컴파일러는 이렇게 거부한다.
error[E0106]: missing lifetime specifier
--> src/lib.rs:1:18
|
1 | fn dangling() -> &i32 {
| ^ expected named lifetime parameter레퍼런스를 반환하려면 수명을 명시해야 한다. 추가해도:
fn dangling<'a>() -> &'a i32 {
let x = 42;
&x
}error[E0515]: cannot return reference to local variable `x`
--> src/lib.rs:3:5
|
3 | &x
| ^^ returns a reference to data owned by the current function컴파일러는 x가 수명 'a를 만족할 만큼 오래 살지 못함을 알아낸다. 어떻게 알까? 답은 **영역 추론(region inference)**에 있다.
Rust에서 수명은 **영역(region)**이다. 레퍼런스가 유효해야 하는 제어 흐름 그래프(CFG)상의 지점들의 집합이다. 대여 검사기는 제약 전파를 통해 이 영역을 계산한다.
다음 코드를 보자.
let x = 0;
let y = &x;
let z = &y;각 let 바인딩은 암묵적 스코프를 도입한다. 대여 검사기는 각 레퍼런스에 필요한 최소 영역을 추론한다. (유효한 Rust 문법은 아니지만 구조를 설명하기 위한) 디슈가 예:
'a: {
let x: i32 = 0;
'b: {
let y: &'b i32 = &'b x;
'c: {
let z: &'c &'b i32 = &'c y;
}
}
}y는 사용을 덮는 가장 작은 영역이 'b이므로 수명 'b를 가진다. z는 'c다. 대여 검사기는 필요에 따라 수명을 최소화한다.
레퍼런스가 바깥 스코프로 전달되면 더 큰 수명이 추론된다.
let x = 0;
let z;
let y = &x;
z = y;디슈가:
'a: {
let x: i32 = 0;
'b: {
let z: &'b i32;
'c: {
let y: &'b i32 = &'b x; // 'c가 아니라 'b여야 함
z = y;
}
}
}y가 z에 대입되고 z가 'b 스코프에 살아 있으므로, 레퍼런스는 'b 동안 유효해야 한다. 대여 검사기는 이 요구를 전파한다.
대여 검사기는 MIR(Mid-level Intermediate Representation) 위에서 동작한다. 과정은 두 단계다.
1단계: replace_regions_in_mir
컴파일러는 함수 시그니처에 등장하는 보편 영역(universal regions)(예: fn foo<'a>(x: &'a u32)의 'a)을 식별하고, 그 외 모든 영역을 새로운 추론 변수로 치환한다. 보편 영역은 함수 본문에서 “자유”이며 호출자로부터 오는 제약을 나타낸다.
2단계: compute_regions
컴파일러는 MIR에 대해 타입 체커를 실행하여 영역 사이의 제약을 수집하고, 제약 전파를 통해 각 추론 변수의 값을 계산한다.
영역 값은 집합이다. 이 집합에는 다음이 들어간다.
'a: 'b(영역 'a가 'b보다 오래 산다)이면, end('b)가 'a의 집합에 들어간다. end('b)는 현재 함수가 리턴한 이후 호출자의 CFG에서의 구간을 나타낸다.end('static): 함수가 리턴한 이후부터 프로그램 종료까지를 나타낸다.주요 제약은 두 가지다.
'a: 'b이면 'b의 모든 원소와 end('b)를 'a에 추가해야 한다.다음 함수를 보자.
fn bad<'a, 'b>(x: &'a usize) -> &'b usize {
x
}이는 컴파일되면 안 된다. 'a가 'b보다 오래 산다는 보장이 없기 때문이다. 'a가 더 짧으면 반환값은 댕글링 레퍼런스가 된다.
컴파일러는 추론 변수를 도입한다. '#1이 'a, '#3가 'b, '#2가 표현식 x에 대응한다고 하자. L1은 x의 위치다.
liveness 제약에서 나온 초기 상태:
| 영역 | 내용 |
|---|---|
| '#1 | (비어 있음) |
| '#2 | L1 |
| '#3 | L1 |
return 문이 outlives 제약 '#2: '#3을 만든다(반환되는 레퍼런스가 반환 타입 영역보다 오래 살아야 함). 전파하면:
| 영역 | 내용 |
|---|---|
| '#1 | L1 |
| '#2 | L1, end('#3) |
| '#3 | L1 |
매개변수가 outlives 제약 '#1: '#2를 만든다(입력이 표현식으로 흐름). 전파하면:
| 영역 | 내용 |
|---|---|
| '#1 | L1, end('#2), end('#3) |
| '#2 | L1, end('#3) |
| '#3 | L1 |
이제 컴파일러가 검사한다. '#1에 정당화할 수 없는 end('x)가 있는가? 있다. '#1에는 end('#3)가 있지만 'a: 'b를 말해주는 where 절이나 암묵적 경계가 없다. 따라서 오류다.
rustc의 RegionInferenceContext는 다음을 저장한다.
constraints: 모든 outlives 제약liveness_constraints: 모든 liveness 제약universal_regions: 함수 시그니처에서 온 영역 집합universal_region_relations: 보편 영역 사이의 알려진 관계(where 절 등)solve 메서드는 전파를 수행하고, check_universal_regions가 보편 영역이 정당화할 수 없는 end 마커를 포함하게 되었는지 확인한다.
Rust 2018 이전에는 수명이 어휘적(lexical)이었다. 레퍼런스는 어휘적 스코프 끝까지 살아 있다고 간주되어, 유효한 프로그램이 거부되기도 했다.
let mut data = vec![1, 2, 3];
let x = &data[0];
println!("{}", x);
data.push(4); // 예전 Rust에서는 오류: x가 아직 스코프 안에 있음어휘적 수명에서는 x가 닫는 중괄호까지 살아 있다고 판단되어 push의 가변 대여와 충돌한다.
비-어휘적 수명(NLL)은 CFG에서의 마지막 사용을 기준으로 liveness를 계산한다. 레퍼런스는 생성부터 마지막 사용까지 살아 있고 스코프 끝까지가 아니다.
let mut data = vec![1, 2, 3];
let x = &data[0];
println!("{}", x); // x의 마지막 사용
data.push(4); // ok: x는 더 이상 live가 아님x를 위한 data의 대여는 println! 호출까지 확장되며, 이후 대여는 끝난다. 따라서 push를 위한 가변 대여와 충돌하지 않는다.
미묘한 점도 있다. 타입에 소멸자가 있으면, 소멸자도 “사용”으로 간주된다. 소멸자는 스코프 끝에서 실행되므로 수명이 늘어난다.
struct Wrapper<'a>(&'a i32);
impl Drop for Wrapper<'_> {
fn drop(&mut self) { }
}
let mut data = vec![1, 2, 3];
let x = Wrapper(&data[0]);
println!("{:?}", x);
data.push(4); // 오류: x의 소멸자가 스코프 끝에서 실행됨Drop 구현 때문에 x는 스코프 끝에서 사용된다. 대여가 그 시점까지 확장되어 push와 충돌한다. 해결하려면 push 전에 drop(x)를 명시적으로 호출하면 된다.
수명에는 구멍이 생길 수 있다. 변수를 재대여(reborrow)할 수 있다.
let mut data = vec![1, 2, 3];
let mut x = &data[0];
println!("{}", x); // 첫 대여의 마지막 사용
data.push(4); // ok: 첫 대여 종료
x = &data[3]; // 새 대여 시작
println!("{}", x);대여 검사기는 같은 변수에 묶여 있어도 두 개의 서로 다른 대여로 본다. 첫 번째는 첫 println! 이후 끝나고, 두 번째는 재대입에서 시작한다.
제어 흐름도 중요하다. 분기마다 마지막 사용이 다를 수 있다.
fn condition() -> bool { true }
let mut data = vec![1, 2, 3];
let x = &data[0];
if condition() {
println!("{}", x); // 이 분기에서 마지막 사용
data.push(4); // ok
} else {
data.push(5); // ok: 이 분기에서는 x를 사용하지 않음
}if 분기에서는 push 전에 x를 사용한다. else 분기에서는 x를 전혀 사용하지 않으므로 대여는 사실상 x 생성 지점에서 끝난 것으로 취급된다.
함수 내부에서는 대여 검사기가 모든 정보를 가진다. 모든 레퍼런스의 모든 사용을 안다. 함수 경계를 넘으면 이 정보가 사라진다. 함수 시그니처는 입력과 출력 수명 사이의 관계를 선언해야 한다.
fn first_word(s: &str) -> &str {
// 입력의 슬라이스를 반환
}시그니처는 출력 수명이 입력 수명과 같다고 말한다. 반환 슬라이스는 s에서 빌려온다. 호출자는 s가 무효가 된 뒤 반환값을 사용할 수 없다.
시그니처가 모호하면 컴파일러는 명시적 주석을 요구한다.
fn longest(x: &str, y: &str) -> &str {
if x.len() > y.len() { x } else { y }
}이는 컴파일되지 않는다. 반환이 x에서 올 수도 y에서 올 수도 있어 컴파일러가 관계를 알 수 없다. 따라서:
fn longest<'a>(x: &'a str, y: &'a str) -> &'a str {
if x.len() > y.len() { x } else { y }
}이 시그니처는 두 입력이 최소 'a 동안 유효해야 하며, 출력도 'a 동안 유효하다고 말한다. 호출자는 결과가 두 입력보다 오래 살지 않도록 보장해야 한다.
흔한 패턴은 명시적 주석이 필요 없다. 생략 규칙이 수명을 추론한다.
규칙 1: 각 입력 레퍼런스는 서로 다른 수명을 가진다.
fn f(x: &i32, y: &i32)
// 는
fn f<'a, 'b>(x: &'a i32, y: &'b i32)규칙 2: 입력 수명이 정확히 하나라면, 그 수명이 모든 출력에 할당된다.
fn f(x: &i32) -> &i32
// 는
fn f<'a>(x: &'a i32) -> &'a i32규칙 3: 입력 중 하나가 &self 또는 &mut self이면, 그 수명이 모든 출력에 할당된다.
impl Foo {
fn method(&self, x: &i32) -> &i32
// 는
fn method<'a, 'b>(&'a self, x: &'b i32) -> &'a i32
}생략 규칙만으로 모든 수명이 결정되지 않으면 명시가 필요하다.
'static'static 수명은 프로그램 실행의 전체 기간 남은 기간 동안 유효함을 의미한다. 문자열 리터럴은 바이너리의 읽기 전용 데이터 세그먼트에 저장되므로 &'static str 타입을 가진다.
let s: &'static str = "hello";
T: 'static 바운드는 T가 non-static 레퍼런스를 포함하지 않는다는 뜻이다. 스레드를 스폰할 때 필요하다. 스폰된 스레드가 현재 스택 프레임보다 오래 살 수 있기 때문이다.
fn spawn<F>(f: F) where F: FnOnce() + Send + 'static
지역 변수 x에 대한 &x를 캡처하는 클로저는 'static을 만족하지 못한다. 스폰하는 함수가 리턴하면 레퍼런스가 댕글링이 되기 때문이다.
모든 런타임 할당 메모리는 처음엔 미초기화 상태로 시작한다. 바이트는 존재하지만 이전 사용에서 남아 있던 값들을 담고 있다. 문제는 “쓰기 전에 읽으면 어떻게 되는가?”다.
C는 값을 **불확정(indeterminate)**이라고 한다. C++은 **공허한 초기화(vacuous initialization)**를 추가한다. Rust는 “미초기화 메모리를 읽는 것은 미정의 동작”이라고 단호하게 말하며, 이를 제어해서 다루기 위한 메커니즘으로 MaybeUninit<T>를 제공한다.
C에서 초기화되지 않은 자동 변수를 읽으면 **불확정 값(indeterminate value)**이 나온다. C23 표준은 이를 비값 표현(non-value representation)(이전의 트랩 표현, trap representation)과 구분하는데, 이는 해당 타입의 어떤 유효 값에도 대응하지 않는 비트 패턴이다.
void example(void) {
int x;
printf("%d\n", x); // 불확정 값
}여기서 무슨 일이 일어나는가? 표준은 프로그램이 크래시한다고 말하지도 않고, 임의의 값으로 계속 진행한다고 말하지도 않는다. 단지 “미정의 동작”이라고 말한다. 컴파일러는 이 코드가 실행되지 않는다고 가정할 수 있다.
불확정 값과 비값 표현의 구분은 모든 비트 패턴이 유효하지 않은 타입에서 중요하다. bool은 0(false)과 1(true)만 유효하다. 하지만 bool은 최소 8비트를 차지한다. 다른 비트 조합은 비값 표현을 만든다.
bool b;
memset(&b, 0xFF, sizeof(b)); // 모든 비트를 1로
if (b) { /* ... */ } // 미정의 동작컴파일러는 0인지 테스트할 수도 있고, 최하위 비트만 테스트할 수도 있다. 최적화 레벨에 따라 결과가 달라질 수 있다. 이는 단지 “미정(specified되지 않음)”이 아니라 “미정의”다.
비값 표현이 없는 타입(현대 하드웨어에서 대부분의 정수 타입)에서도 불확정 값을 읽는 것은 여전히 UB다. 컴파일러가 어떤 값을 보게 될지 추론할 수 없기 때문이다. 최적화기는 프로그램 전체에 모순되는 가정을 전파할 수 있다.
C++은 스칼라 타입에 대해서는 C의 규칙을 상속하지만, 클래스 타입에서는 복잡성이 추가된다. 변수가 기본 초기화(default-initialized)되었고 그 클래스 타입이 trivial 기본 생성자를 가지면 그 변수는 **공허한 초기화(vacuous initialization)**를 가진다.
struct Trivial {
int x;
int y;
};
void example() {
Trivial t; // 공허한 초기화: x와 y는 불확정
}객체 t는 존재하고 수명도 시작됐다. 하지만 멤버 x, y는 불확정 값을 가진다. 이를 읽으면 C처럼 UB다.
비trivial 생성자를 가진 클래스는 기본 초기화가 생성자를 실행한다.
struct Nontrivial {
int x;
Nontrivial() : x(0) { }
};
void example() {
Nontrivial n; // 생성자 실행, x는 0
}C++20은 암묵적 객체 생성을 도입했다. 특정 연산(할당 함수, memmove, memcpy, unsigned char 또는 std::byte 배열 생성)은 저장 영역 안에 암묵적 수명 타입의 객체를 암묵적으로 생성한다. 이로 인해 과거에 UB였던 패턴 일부가 잘 정의가 되었다.
struct X { int a, b; };
X* make_x() {
X* p = (X*)std::malloc(sizeof(struct X));
p->a = 1; // C++20 이전: UB (X 객체가 존재하지 않음)
p->b = 2; // C++20: ok (X가 암묵적으로 생성됨)
return p;
}표준은, 정의된 동작을 주는 데 필요하다면 malloc이 암묵적 수명 타입의 객체를 암묵적으로 생성한다고 규정한다. 이는 수십 년간 “malloc + 대입 = 객체 생성”이라고 가정해 온 코드를 위한 실용적 수정이다.
Rust는 가장 엄격한 입장이다. 미초기화 메모리를 읽는 것은 타입과 무관하게 “읽는 지점에서” 미정의 동작이다. Rust Reference는 정수, 부동소수점 값, raw pointer가 반드시 초기화되어야 하며, 미초기화 메모리에서 얻어서는 안 된다고 말한다.
이는 u8(유효하지 않은 비트 패턴이 없음)에도 적용된다. 컴파일러가 모든 값이 초기화되어 있다고 가정할 수 있어야 하기 때문이다. 이 보장이 없다면 최적화기는 값 전파, 죽은 저장 제거, 메모리 내용에 대한 어떤 가정도 할 수 없다.
Rust는 안전 코드에서 “반드시 초기화” 분석으로 이를 컴파일 타임에 강제한다.
fn example() {
let x: i32;
println!("{}", x); // 오류: 초기화되지 않았을 가능성이 있는 x 사용
}분석은 제어 흐름을 따라 초기화 상태를 추적한다.
fn example(condition: bool) {
let x: i32;
if condition {
x = 1;
}
println!("{}", x); // 오류: x가 미초기화일 수 있음
}if의 한 분기만 x를 초기화하므로 프로그램은 거부된다.
분석은 제어 흐름은 이해하지만 값 자체를 평가하진 않는다.
fn example() {
let x: i32;
if true {
x = 1;
}
println!("{}", x); // 오류: 컴파일러는 true를 평가하지 않음
}루프는 주의가 필요하다.
fn example() {
let x: i32;
loop {
if true {
x = 0;
break;
}
}
println!("{}", x); // ok: break에 도달함을 알고, 그 전에 초기화됨
}컴파일러는 println!에 도달하려면 break를 거쳐야 하고, 그 break 전에 초기화가 있음을 안다.
Rust에서 값을 변수에서 move해가면, 그 변수는 논리적으로 미초기화 상태가 된다.
fn example() {
let x = Box::new(42);
let y = x; // x가 move되어 논리적으로 미초기화
println!("{}", x); // 오류: move된 값 사용
}Copy 타입에는 적용되지 않는다. 값이 복사되고 양쪽 모두 초기화 상태로 남는다.
fn example() {
let x: i32 = 42;
let y = x; // copy, move 아님
println!("{}", x); // ok
}move된 변수는 다시 초기화할 수 있다.
fn example() {
let mut x = Box::new(42);
let y = x; // x가 move됨
x = Box::new(43); // x 재초기화
println!("{}", x); // ok
}재초기화는 “변경”으로 간주되므로 mut가 필요하다.
MaybeUninit<T>: 탈출구성능상 미초기화 메모리를 다뤄야 한다면 Rust는 MaybeUninit<T>를 제공한다. 이는 초기화된 T 또는 미초기화 바이트를 담을 수 있는 union 타입이다.
use std::mem::MaybeUninit;
let x: MaybeUninit<i32> = MaybeUninit::uninit();핵심 성질: MaybeUninit<T>를 drop해도 아무 일도 일어나지 않는다. T의 소멸자를 실행하지 않는다. 값이 초기화되지 않았을 수 있으므로, 미초기화 값을 drop하는 것은 UB가 되기 때문이다.
초기화하려면 MaybeUninit에 쓴다.
let mut x: MaybeUninit<i32> = MaybeUninit::uninit();
x.write(42); // 이제 초기화됨초기화된 값을 꺼내려면 assume_init를 호출한다.
let mut x: MaybeUninit<i32> = MaybeUninit::uninit();
x.write(42);
let value: i32 = unsafe { x.assume_init() };assume_init는 컴파일러가 “정말로 초기화했는지” 검증할 수 없으므로 unsafe다. 우리는 컴파일러에게 “믿어라, 초기화돼 있다”고 단언한다. 거짓이면 UB다.
안전한 Rust는 배열의 부분 초기화를 허용하지 않는다. 모든 요소를 한 번에 초기화해야 한다.
let arr: [i32; 4] = [1, 2, 3, 4]; // ok
let arr: [i32; 1000] = [0; 1000]; // ok, 모두 0동적 초기화를 위해 MaybeUninit가 경로를 제공한다.
use std::mem::{self, MaybeUninit};
const SIZE: usize = 10;
let arr: [Box<u32>; SIZE] = {
// 미초기화 MaybeUninit 배열 생성
let mut arr: [MaybeUninit<Box<u32>>; SIZE] =
[const { MaybeUninit::uninit() }; SIZE];
// 각 원소 초기화
for i in 0..SIZE {
arr[i] = MaybeUninit::new(Box::new(i as u32));
}
// 초기화된 타입으로 transmute
unsafe { mem::transmute::<_, [Box<u32>; SIZE]>(arr) }
};MaybeUninit<T>는 T와 같은 레이아웃을 가지므로 transmute는 건전하다. 모든 원소를 초기화했으니 배열은 유효한 Box<u32>를 담는다.
중요한 디테일: arr[i] = MaybeUninit::new(...)는 이전 값을 drop하지 않는다. MaybeUninit<T>는 Drop이 없다. 만약 일반 Box<u32> 배열에 대입했다면, 대입은 이전 값을 drop하려고 할 텐데, 미초기화 메모리의 drop은 UB다.
MaybeUninit::new가 적합하지 않으면 raw pointer 연산을 쓴다. ptr 모듈은 다음을 제공한다.
ptr::write(ptr, val): 기존 값을 읽거나 drop하지 않고 val을 ptr에 기록ptr::copy(src, dest, count): count개 원소를 src에서 dest로 복사(memmove)ptr::copy_nonoverlapping(src, dest, count): 겹치지 않는다고 가정하고 복사(memcpy)이 함수들은 목적지의 drop을 수행하지 않고 바이트를 덮어쓴다. 미초기화 메모리에는 올바르지만, 소멸자가 있는 값이 들어 있는 초기화된 메모리에는 위험하다. std::mem::needs_drop::<T>()로 타입이 drop glue가 필요한지 컴파일 타임에 확인할 수 있다.
미묘한 점: 목적지 포인터는 대상 할당에 대한 **프로비넌스(provenance)**를 가져야 한다. Rust의 메모리 모델은 단지 주소뿐 아니라, 어떤 할당에 접근할 수 있는 포인터인지도 추적한다. 정수로부터 만든 포인터(ptr::from_exposed_addr)는 레퍼런스에서 파생된 포인터보다 프로비넌스 보장이 약하다.
use std::ptr;
let mut x: MaybeUninit<String> = MaybeUninit::uninit();
unsafe {
ptr::write(x.as_mut_ptr(), String::from("hello"));
}
let s = unsafe { x.assume_init() };미초기화 String에 대해 &mut 레퍼런스를 만들 수는 없다. 유효하지 않은 값에 대한 레퍼런스를 만드는 것 자체가 UB이기 때문이다. as_mut_ptr는 레퍼런스를 만들지 않고 raw pointer를 반환한다.
구조체 필드에는 중간 레퍼런스를 만들지 않기 위해 raw reference 문법을 사용한다.
use std::{ptr, mem::MaybeUninit};
struct Demo {
field: bool,
}
let mut uninit = MaybeUninit::<Demo>::uninit();
let field_ptr = unsafe { &raw mut (*uninit.as_mut_ptr()).field };
unsafe { field_ptr.write(true); }
let demo = unsafe { uninit.assume_init() };&raw mut 문법은 레퍼런스를 만들지 않고 raw pointer를 만든다. &mut (*uninit.as_mut_ptr()).field는 미초기화 bool에 대한 레퍼런스를 만들어 UB가 되므로 이것이 중요하다.
Rust에서 미초기화 메모리의 가장 흔한 사용은 컬렉션을 만드는 것이다. Vec<T>는 내부적으로(RawVec를 통해) MaybeUninit를 사용해 버퍼를 관리한다. vec.reserve(n)을 호출하면, 벡터는 n개의 추가 원소를 위한 공간을 할당하지만 초기화하지 않는다.
외부 소스에서 벡터를 채우는 성능 패턴:
fn read_into_vec(src: &[u8], count: usize) -> Vec<u8> {
let mut v: Vec<u8> = Vec::with_capacity(count);
unsafe {
// 미초기화 버퍼의 raw pointer
let ptr = v.as_mut_ptr();
// 소스에서 복사(src.len() >= count 가정)
std::ptr::copy_nonoverlapping(src.as_ptr(), ptr, count);
// Vec에 이제 원소들이 초기화되었음을 알림
v.set_len(count);
}
v
}set_len은 우리가 처음 count개 원소가 초기화되었다고 단언하는 것이므로 unsafe다. 벡터는 이를 믿는다. 거짓이면 벡터 drop 시 미초기화 값을 drop하려 하며(소멸자가 있는 타입에 대해) UB다.
u8에는 소멸자가 없으므로 즉각적인 위험은 쓰레기 읽기다. 하지만 컴파일러는 여전히 “모든 값은 초기화되어 있다”는 가정에 기반해 최적화할 수 있다.
안전한 대안은 resize나 extend다.
fn read_into_vec_safe(src: &[u8], count: usize) -> Vec<u8> {
let mut v: Vec<u8> = Vec::with_capacity(count);
v.extend_from_slice(&src[..count]);
v
}이 방식은 원소를 추가할 때마다 초기화한다. 큰 버퍼에서는 unsafe 버전이 중복 초기화를 피하므로 눈에 띄게 더 빠를 수 있다. 성능 이득이 의미 있는지는 워크로드에 달렸다.
mem::uninitialized오래된 Rust 코드는 mem::uninitialized::<T>()로 미초기화 값을 만들었다. 이 함수는 폐기(deprecated)되었고 새 코드에서 사용하면 안 된다. 문제는 T를 반환한다는 점이다. 호출자는 “초기화된 T 값”을 받는데 실제로는 쓰레기다.
// 이렇게 하지 말 것
let x: bool = unsafe { std::mem::uninitialized() };
// x는 쓰레기 비트를 가진 "초기화된" bool
// x를 어떤 방식으로든 사용하면 미정의 동작컴파일러는 x가 초기화되었다고 믿는다. 이 “값”을 프로그램 전체로 전파할 수 있다. 결과는 예측 불가다.
MaybeUninit는 미초기화 상태를 컴파일러가 이해하는 타입으로 감싸 해결한다. 내부 값은 assume_init를 호출하기 전에는 접근할 수 없다. 그래서 컴파일러가 초기화 상태에 대해 잘못된 가정을 하지 못한다.
두 포인터가 같은(또는 겹치는) 메모리 영역을 가리키면 그들은 **별칭(alias)**한다고 한다. 이는 별칭이 컴파일러 최적화를 제약하기 때문에 중요하다. 컴파일러가 두 포인터가 서로 다른 메모리를 가리킨다고 증명하지 못하면, 한쪽을 통한 쓰기가 다른 쪽을 통한 읽기에 영향을 줄 수 있다고 가정해야 한다. 그러면 보수적인 코드 생성이 필요해진다. 값을 레지스터에 두지 못하고 메모리에서 다시 로드해야 하고, store 재배치도 못 하고, 최적화의 많은 부분이 불가능해진다.
별칭 규칙은 안전을 위한 것이 아니라 최적화를 위한 것이다. C/C++에는 별칭 규칙이 있고, 이를 위반하면 UB다. 컴파일러가 우리를 보호하려고 검사하는 게 아니다. 우리가 규칙을 따른다고 가정하고 최적화한다. 그 가정을 깨면 최적화기가 잘못된 코드를 생성한다.
Rust는 별칭 규칙을 명시적이고 컴파일러가 검사하도록 만든다. &T/&mut T 구분이 단순한 불변식을 인코딩한다. 동시에 여러 공유 레퍼런스는 가능하지만, 가변 레퍼런스는 하나만 가능하며 둘을 동시에 가질 수 없다. 대여 검사기가 이를 컴파일 타임에 강제한다.
다음 함수를 보자.
fn compute(input: &u32, output: &mut u32) {
if *input > 10 {
*output = 1;
}
if *input > 5 {
*output *= 2;
}
}우리는 컴파일러가 이를 다음처럼 최적화하길 원한다.
fn compute(input: &u32, output: &mut u32) {
let cached_input = *input;
if cached_input > 10 {
*output = 2;
} else if cached_input > 5 {
*output *= 2;
}
}이 최적화는 *input을 레지스터에 캐시하고, 두 번째 조건에서 중복 읽기를 제거한다. 또한 *input > 10이면 최종 값이 항상 2임을 알아차리고 2를 바로 쓴다.
이 최적화는 input과 output이 별칭되지 않을 때만 유효하다. 같은 메모리를 가리키면 *output = 1이 *input이 읽는 값을 바꾼다.
let mut x: u32 = 20;
compute(&x, &mut x); // input과 output이 모두 x를 가리킴별칭이 있으면 원래 함수는 1을 만든다.
*input은 20이므로 *output = 1(이제 x는 1)*input은 1이므로 두 번째 조건은 false최적화된 함수는 2를 만든다.
cached_input은 20이므로 *output = 2Rust에서는 compute(&x, &mut x) 호출이 컴파일 타임에 거부된다. 대여 검사기는 x에 대해 공유 레퍼런스와 가변 레퍼런스를 동시에 만들려는 시도를 발견하고 프로그램을 컴파일하지 않는다.
C에서는 같은 코드가 컴파일되며 최적화기가 잘못된 결과를 낼 수 있다.
C 표준은 유효 타입 규칙을 규정한다. 객체는 유효 타입 또는 문자 타입을 통해서만 접근해야 한다. 호환되지 않는 타입의 포인터로 접근하면 미정의 동작이다.
int x = 42;
float* fp = (float*)&x;
float f = *fp; // 미정의 동작: int를 float*로 접근이를 흔히 strict aliasing이라고 부른다. 컴파일러는 서로 다른 타입의 포인터가 별칭되지 않는다고 가정한다. int*와 float*는 같은 객체를 가리킬 수 없다(문자 타입과 union 관련 일부 예외는 있다). 이 가정은 **타입 기반 별칭 분석(TBAA)**을 가능하게 한다. 컴파일러는 포인터 타입을 추적해, 호환되지 않는 타입은 서로 겹치지 않는 메모리를 가리킨다고 가정한다.
예:
void update(int* pi, float* pf) {
*pi = 1;
*pf = 2.0f;
printf("%d\n", *pi);
}strict aliasing 하에서 컴파일러는 pi와 pf가 별칭되지 않는다고 가정할 수 있다. *pf에 대한 쓰기는 *pi에 영향을 줄 수 없으므로, 메모리에서 다시 로드하지 않고 1을 출력할 수 있다. store를 재배치하거나 *pi를 레지스터에 둘 수도 있다.
실제로 별칭되는 포인터를 넘기면:
union { int i; float f; } u;
update(&u.i, &u.f); // 미정의 동작최적화기의 가정이 깨진다. 생성된 코드는 메모리에 이제 2.0f의 비트 패턴이 들어 있어도 1을 출력할 수 있다. 혹은 완전히 다른 값을 출력할 수도 있다. 동작은 미정의다.
고전적인 strict aliasing 위반은 union 없이 타입 펀닝(type punning) 하는 것이다.
uint32_t float_bits(float f) {
return *(uint32_t*)&f; // 미정의 동작
}float의 비트 표현을 보기 위해 주소를 uint32_t*로 캐스팅해 읽는다. 객체의 유효 타입은 float인데 uint32_t*로 접근하므로 유효 타입 규칙 위반이다.
올바른 방법은 union을 쓰거나:
uint32_t float_bits(float f) {
union { float f; uint32_t u; } converter = { .f = f };
return converter.u;
}memcpy를 쓰는 것이다.
uint32_t float_bits(float f) {
uint32_t result;
memcpy(&result, &f, sizeof(result));
return result;
}현대 컴파일러는 작은 크기의 memcpy를 레지스터 이동으로 최적화한다. 결과 어셈블리는 미정의 타입 펀닝 버전과 동일하지만 의미론은 잘 정의된다.
restrict 한정자타입 기반 별칭 분석은 포인터 타입이 다를 때만 도움이 된다. 두 int*는 별칭될 수 있으므로, 컴파일러는 별도의 정보가 없으면 별칭 가능성을 가정해야 한다.
C99는 restrict 한정자를 도입했다. restrict가 붙은 포인터는 우리가 하는 약속이다. 이 포인터의 수명 동안, 다른 어떤 포인터도 같은 메모리에 접근하는 데 사용되지 않을 것이라는 약속.
void add_arrays(int* restrict dest, const int* restrict src, size_t n) {
for (size_t i = 0; i < n; i++) {
dest[i] += src[i];
}
}restrict는 dest와 src가 겹치지 않음을 컴파일러에 알려준다. 그러면 컴파일러는 루프를 벡터화하고, src를 한 번에 여러 개 로드하고, dest를 한 번에 여러 개 저장할 수 있다. dest[i]의 store가 이후 src[j]의 load에 영향을 줄 걱정을 하지 않아도 된다.
restrict가 없으면:
void add_arrays(int* dest, const int* src, size_t n) {
for (size_t i = 0; i < n; i++) {
dest[i] += src[i];
}
}컴파일러는 dest와 src가 겹칠 수도 있다고 가정해야 한다. 예를 들어 dest == src + 1이면, 각 dest[i] store가 다음 src[i+1] load에 영향을 준다. 루프는 벡터화될 수 없다. 각 반복은 순차적으로 완료되어야 한다.
restrict는 제약이 아니라 약속이다. 컴파일러는 이를 검사하지 않는다. 우리가 거짓말하고 겹치는 포인터를 넘기면, 최적화된 코드는 틀린 결과를 낸다.
표준 라이브러리 함수들은 restrict를 광범위하게 사용한다.
void* memcpy(void* restrict dest, const void* restrict src, size_t n);
void* memmove(void* dest, const void* src, size_t n);memcpy는 겹치지 않는 영역을 약속한다. memmove는 겹침을 올바르게 처리하지만 그만큼 공격적으로 최적화할 수 없다.
Rust의 별칭 모델은 더 단순하고 컴파일러가 강제한다. 규칙은 “어떤 시점이든 메모리의 한 조각은 여러 공유 레퍼런스(&T)를 가지거나 하나의 가변 레퍼런스(&mut T)를 가지거나 둘 중 하나지만, 동시에 둘 다는 안 된다”이다.
이를 흔히 shared XOR mutable 또는 aliasing XOR mutation이라고 쓴다. 핵심 통찰은 별칭이 위험한 것은 “변경(mutation)”과 결합될 때뿐이라는 것이다. 여러 독자는 같은 메모리를 안전하게 읽을 수 있다. 독자가 없다면 단일 작성자는 안전하게 수정할 수 있다. 문제는 읽기와 쓰기가 예측 불가능하게 교차할 수 있을 때다.
let mut x = 5;
let r1 = &x; // 공유 레퍼런스
let r2 = &x; // 또 다른 공유 레퍼런스, ok
println!("{} {}", r1, r2);
let r3 = &mut x; // 가변 레퍼런스
*r3 += 1;
println!("{}", r3);이 코드는 컴파일된다. 공유 레퍼런스 r1, r2는 println! 이후 더 이상 사용되지 않으므로, 가변 레퍼런스 r3가 만들어지기 전에 수명이 끝난다.
let mut x = 5;
let r1 = &x;
let r3 = &mut x; // 오류: `x`를 가변으로 빌릴 수 없음
println!("{}", r1);이 코드는 컴파일되지 않는다. 공유 레퍼런스 r1이 아직 live인 상태에서 가변 레퍼런스 r3를 만들려고 하기 때문이다. 대여 검사기가 거부한다.
Rust 컴파일러는 이 불변식에 기반해 LLVM에 애트리뷰트를 붙인다. &T는 읽기 연산에 대해 noalias를 받고, &mut T는 무조건 noalias를 받아 이 레퍼런스의 수명 동안 다른 어떤 포인터도 이 메모리에 접근하지 않는다고 LLVM에 알려준다. 이는 C의 restrict가 제공하는 것과 같은 최적화를 가능하게 하지만, Rust에서는 프로그래머의 약속이 아니라 컴파일러가 검증한 보장이다.
대여 검사기는 연산의 의미론을 이해하지 못한다. &data[0]과 &data[1]이 서로 다른 요소를 가리킨다는 것도 모른다. 단지 대여를 보고 수명을 추적한다.
예를 들어 대여 검사기가 거부하는 코드:
let mut v = vec![1, 2, 3];
let x = &v[0]; // v의 불변 대여
v.push(4); // push를 위해 v의 가변 대여
println!("{}", x);대여 검사기는 &v[0]가 어떤 수명의 레퍼런스를 만들고, x가 println!까지 살아야 하며, v.push(4)가 &mut v를 요구하고, push 시점에 x가 아직 live이므로 충돌이 있다고 본다. &mut v와 &v는 동시에 존재할 수 없다.
대여 검사기는 push가 벡터를 재할당하여 x를 무효화할 수 있다는 사실을 “이해해서” 막는 게 아니다. 단지 별칭 규칙을 강제한다. 그 결과로 iterator invalidation 버그를 예방한다.
또한 대여 검사기는 &mut v[0]과 &mut v[1]이 서로 분리된다는 것도 모른다.
let mut arr = [1, 2, 3];
let a = &mut arr[0];
let b = &mut arr[1]; // 오류: `arr[_]`를 두 번 이상 가변으로 빌릴 수 없음인덱싱 arr[i]는 전체 배열을 빌리는 메서드 호출로 디슈가된다. 대여 검사기는 배열 요소 두 개에 대한 대여가 아니라, arr에 대한 두 개의 가변 대여로 본다.
대여 검사기는 구조체 필드를 서로 분리된 것으로 이해한다.
struct Point { x: i32, y: i32 }
let mut p = Point { x: 0, y: 0 };
let px = &mut p.x;
let py = &mut p.y; // ok: 서로 다른 필드
*px = 1;
*py = 2;p.x와 p.y가 서로 다른 메모리를 차지한다는 것을 컴파일러가 알기 때문이다. 따라서 동시에 가변 대여가 가능하다.
슬라이스/배열의 경우 표준 라이브러리가 split_at_mut를 제공한다.
let mut arr = [1, 2, 3, 4];
let (left, right) = arr.split_at_mut(2);
// left는 &mut [1, 2], right는 &mut [3, 4]
left[0] = 10;
right[0] = 30;split_at_mut의 구현은 unsafe를 사용한다.
pub fn split_at_mut(&mut self, mid: usize) -> (&mut [T], &mut [T]) {
let len = self.len();
let ptr = self.as_mut_ptr();
assert!(mid <= len);
unsafe {
(std::slice::from_raw_parts_mut(ptr, mid),
std::slice::from_raw_parts_mut(ptr.add(mid), len - mid))
}
}unsafe 블록은 raw pointer로부터 두 개의 가변 슬라이스를 만든다. 우리는 두 슬라이스가 겹치지 않음을 단언한다. 안전한 API는 이를 “구성적으로” 보장한다. 슬라이스는 [0, mid)와 [mid, len)를 덮으므로 겹치지 않는다. 이는 “unsafe 원시 위에 safe 추상화를 쌓는” 매우 Rust다운 패턴이다. split_at_mut 사용자는 별칭 규칙을 위반할 수 없다. 대여 검사기는 반환된 두 슬라이스가 올바르게 사용되는지 검증한다.
별칭 정보는 컴파일러가 값을 레지스터에 유지하고 메모리에서 재로드하지 않게 해준다. 하지만 효과는 중복 로드 제거를 넘어선다. 예를 들어 컴파일러가 루프를 벡터화하려 할 때를 생각해보자.
void scale(float* dest, const float* src, float factor, size_t n) {
for (size_t i = 0; i < n; i++) {
dest[i] = src[i] * factor;
}
}dest와 src가 겹칠 수 있으면 각 반복이 이전 반복에 의존한다. dest[i]에 쓰면 src[i+1]이 바뀔 수도 있다. 컴파일러는 반복을 순차적으로 실행해야 한다.
.loop:
movss xmm1, [rsi] ; src에서 float 하나 로드
mulss xmm1, xmm0 ; factor 곱
movss [rdi], xmm1 ; dest에 float 하나 저장
add rsi, 4
add rdi, 4
dec rcx
jnz .loop한 번에 한 원소. 현대 x86-64 CPU는 256비트 AVX 레지스터로 8개의 float를 담을 수 있는데, 여기서는 그중 32비트만 쓰고 나머지 224비트는 놀고 있다.
restrict를 추가해 겹치지 않음을 약속하자.
void scale(float* restrict dest, const float* restrict src, float factor, size_t n) {
for (size_t i = 0; i < n; i++) {
dest[i] = src[i] * factor;
}
}이제 컴파일러는 반복들이 독립임을 안다.
vbroadcastss ymm0, xmm0 ; factor를 8개 레인으로 브로드캐스트
.loop:
vmovups ymm1, [rsi] ; src에서 float 8개 로드
vmulps ymm1, ymm1, ymm0 ; 8개 모두 곱
vmovups [rdi], ymm1 ; dest에 8개 저장
add rsi, 32
add rdi, 32
sub rcx, 8
jnz .loop한 반복에 8원소. 큰 배열에서는 워크로드에 따라 거의 8배까지도 속도가 날 수 있다.
Rust에서 동등한 함수:
fn scale(dest: &mut [f32], src: &[f32], factor: f32) {
for (d, s) in dest.iter_mut().zip(src.iter()) {
*d = *s * factor;
}
}시그니처가 비별칭 제약을 인코딩한다. 대여 검사기는 호출 지점에서 dest와 src가 겹치지 않음을 검증한다. 컴파일러는 LLVM에 noalias를 전달하고, LLVM은 동일한 벡터화 루프를 생성한다.
C에서 restrict는 우리가 어길 수 있는 약속이다. Rust에서는 대여 검사기가 이를 강제한다. 생성된 코드는 동일하다. 안전성 보장은 동일하지 않다.
이것이 별칭 규칙이 존재하는 이유다. 최적화기가 하드웨어를 효과적으로 사용하기 위해 필요한 정보다. C는 타입 규칙과 프로그래머 주석으로 이를 제공한다. Rust는 정적 분석으로 제공한다. CPU는 우리가 어떤 언어를 썼는지 신경 쓰지 않는다. 실제 메모리 접근 패턴과 명령어가 일치하는지만 신경 쓴다.
2부에서는 객체가 해제되어야 하는 자원을 소유할 때 무슨 일이 일어나는지—즉, “누가 free를 호출하는가”라는 질문을 탐구할 것이다.