웹 스트림(WHATWG Streams) API의 사용성·성능 문제를 짚고, 현대 자바스크립트의 언어 기능(특히 async iterable)을 기반으로 한 대안적 스트리밍 API 설계를 제안한다.
URL: https://blog.cloudflare.com/a-better-web-streams-api/
Title: 자바스크립트를 위한 더 나은 스트림 API가 필요하다
2026-02-27
24 min read

스트림에서 데이터를 다루는 일은 애플리케이션을 구축하는 방식의 근간이다. 스트리밍이 어디서나 동작하도록, WHATWG Streams Standard (비공식적으로 "웹 스트림(Web streams)"이라 불림)은 브라우저와 서버 전반에서 공통으로 사용할 수 있는 API를 확립하기 위해 설계되었다. 이 표준은 브라우저에 탑재되었고, Cloudflare Workers, Node.js, Deno, Bun에 채택되었으며, fetch() 같은 API의 기반이 되었다. 이는 대단히 큰 과업이며, 이를 설계한 사람들은 당시의 제약과 도구 속에서 어려운 문제를 풀고 있었다.
하지만 웹 스트림 위에서 수년간 구축해 오면서(Node.js와 Cloudflare Workers 모두에서 구현해 보고, 고객 및 런타임의 프로덕션 이슈를 디버깅하고, 개발자들이 너무도 많은 흔한 함정을 헤쳐 나가도록 도왔던 경험을 통해) 나는 표준 API에 근본적인 사용성과 성능 문제가 있으며, 이것은 점진적 개선만으로는 쉽게 고칠 수 없다고 믿게 되었다. 문제는 버그가 아니다. 10년 전에는 타당했을지 모르지만, 오늘날 자바스크립트 개발자들이 코드를 작성하는 방식과는 맞지 않는 설계 결정의 결과다.
이 글은 웹 스트림에서 내가 보는 몇 가지 근본 문제를 살펴보고, 현대 자바스크립트 언어 프리미티브를 중심으로 구성된 대안적 접근을 제시하며, 더 나은 것이 가능하다는 점을 보여준다.
벤치마크에서 이 대안은 내가 테스트한 모든 런타임(Cloudflare Workers, Node.js, Deno, Bun, 그리고 모든 주요 브라우저 포함)에서 웹 스트림 대비 2배에서 _120배_까지 빠를 수 있다. 개선은 영리한 최적화 때문이 아니라, 현대 자바스크립트 언어 기능을 더 효과적으로 활용하는 근본적으로 다른 설계 선택에서 비롯된다. 이전 작업을 폄하하려는 것이 아니라, 다음에 무엇이 올 수 있을지에 대한 대화를 시작하려 한다.
Streams Standard는 2014년에서 2016년 사이에 "저수준 I/O 프리미티브에 효율적으로 매핑되는 데이터 스트림을 생성, 조합, 소비하기 위한 API"를 제공한다는 야심 찬 목표로 개발되었다. 웹 스트림 이전에는 웹 플랫폼에 스트리밍 데이터를 다룰 표준 방법이 없었다.
당시 Node.js에는 브라우저에서도 동작하도록 이식된 자체 스트리밍 API가 이미 있었지만, WHATWG는 웹 브라우저의 요구만을 고려하도록 헌장(차터)화되어 있었기 때문에 이를 출발점으로 삼지 않기로 선택했다. 서버 사이드 런타임은 Cloudflare Workers와 Deno가 일급 웹 스트림 지원과 런타임 간 호환성을 우선순위로 내세우며 등장한 이후에야 웹 스트림을 채택했다.
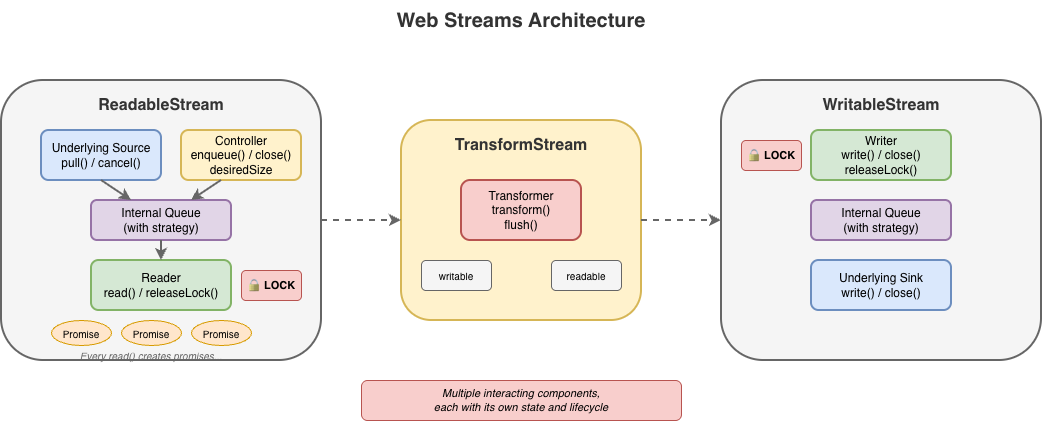
웹 스트림의 설계는 자바스크립트의 async iteration보다 앞선다. for await...of 문법은 Streams Standard가 처음 마무리된 뒤 2년이 지난 ES2018에서야 들어왔다. 이 시점 차이 때문에, API는 결국 비동기 시퀀스를 소비하는 관용적 방식이 될 기능을 처음에는 활용할 수 없었다. 대신 스펙은 자체적인 reader/writer 획득 모델을 도입했고, 그 결정은 API의 모든 측면에 파급되었다.
스트림으로 가장 흔히 하는 작업은 끝까지 읽는 것이다. 웹 스트림에서는 이렇게 한다:
// 먼저 스트림에 대한 배타적 락을 제공하는
// reader를 획득한다...
const reader = stream.getReader();
const chunks = [];
try {
// 둘째, read를 반복 호출하고 반환된 promise를 await하여
// 데이터 청크를 받거나 완료됨을 표시한다.
while (true) {
const { value, done } = await reader.read();
if (done) break;
chunks.push(value);
}
} finally {
// 마지막으로 스트림에 대한 락을 해제한다
reader.releaseLock();
}
이 패턴이 스트리밍에 본질적이라고 생각할 수도 있다. 하지만 그렇지 않다. reader 획득, 락 관리, { value, done } 프로토콜은 모두 필수 요건이 아니라 설계 선택일 뿐이다. 이것들은 웹 스트림 스펙이 작성된 방식과 시점의 산물이다. async iteration은 시간이 지나 도착하는 시퀀스를 처리하기 위해 존재하지만, 스트림 스펙이 쓰일 당시에는 async iteration이 존재하지 않았다. 여기의 복잡성은 근본적 필요가 아니라 순수한 API 오버헤드다.
이제 웹 스트림이 for await...of를 지원하니 대안을 생각해 보자:
const chunks = [];
for await (const chunk of stream) {
chunks.push(chunk);
}
보일러플레이트가 훨씬 적어져서 더 낫다. 하지만 모든 것이 해결되지는 않는다. async iteration은 이를 염두에 두고 설계되지 않은 API에 나중에 덧붙여진 것이고, 그 흔적이 드러난다. 예를 들어 BYOB(bring your own buffer) 읽기 같은 기능은 iteration을 통해 접근할 수 없다. reader, 락, controller의 근본 복잡성은 여전히 존재하고, 단지 숨겨져 있을 뿐이다. 뭔가 잘못되거나 API의 추가 기능이 필요해지면, 개발자들은 다시 원래 API의 수렁으로 돌아가 스트림이 왜 "locked"인지, releaseLock()이 왜 기대대로 동작하지 않았는지 이해하려 하거나, 제어할 수 없는 코드의 병목을 찾아 헤맨다.
웹 스트림은 여러 소비자가 읽기를 서로 섞어(interleave) 실행하는 것을 방지하기 위해 락 모델을 사용한다. getReader()를 호출하면 스트림은 락된다. 락된 동안에는 다른 어떤 것도 스트림에서 직접 읽을 수 없고, pipe할 수도 없고, 심지어 cancel도 할 수 없다. 실제로 reader를 쥐고 있는 코드만 가능하다.
그럴듯하게 들리지만, 얼마나 쉽게 망가지는지 보면 생각이 달라진다:
async function peekFirstChunk(stream) {
const reader = stream.getReader();
const { value } = await reader.read();
// 이런 — reader.releaseLock() 호출을 잊었다
// 그리고 반환할 때 reader는 더 이상 사용할 수 없다
return value;
}
const first = await peekFirstChunk(stream);
// TypeError: Cannot obtain lock — stream is permanently locked
for await (const chunk of stream) { /* 절대 실행되지 않음 */ }
releaseLock()을 잊어버리면 스트림이 영구적으로 깨진다. locked 속성은 스트림이 락되어 있음을 알려주지만, 왜 락됐는지, 누구에 의해 락됐는지, 락이 여전히 유효한지조차 알려주지 않는다. 파이핑(piping)은 내부적으로 락을 획득하므로, pipe 작업 중 스트림이 사용 불가능해지는 방식이 명확하지 않다.
대기 중인 read가 있을 때 락을 해제하는 의미도 수년간 불명확했다. read()를 호출해 놓고 await하지 않은 뒤 releaseLock()을 호출하면 무슨 일이 일어나는가? 최근 스펙이 락 해제 시 대기 중인 read를 취소하도록 명확히 했지만, 구현마다 달랐고, 이전의 미정 동작에 의존하던 코드는 깨질 수 있다.
그렇다고 락 자체가 나쁘다는 뜻은 아니다. 락은 애플리케이션이 데이터를 올바르고 질서 있게 소비/생산하도록 하는 중요한 목적을 실제로 수행한다. 핵심 문제는 getReader()와 releaseLock() 같은 API로 락을 사용자가 수동으로 구현해야 했던 원래 방식이다. async iterable을 통해 자동 락/reader 관리가 가능해지면서, 사용자 관점에서 락을 다루는 일은 훨씬 쉬워졌다.
구현자 입장에서는 락 모델이 만만치 않은 내부 장부 정리(bookkeeping)를 추가한다. 모든 연산이 락 상태를 확인해야 하고, reader를 추적해야 하며, 락/취소/에러 상태의 상호작용이 만들어내는 엣지 케이스 매트릭스를 모두 올바르게 처리해야 한다.
BYOB(bring your own buffer) 읽기는 스트림에서 읽을 때 메모리 버퍼를 재사용할 수 있게 해 주도록 설계되었다. 이는 고처리량 시나리오에서 중요한 최적화로 의도되었다. 발상은 건전하다. 매 청크마다 새 버퍼를 할당하는 대신, 사용자가 버퍼를 제공하면 스트림이 이를 채운다.
하지만 실제로는(물론 항상 예외는 있다) BYOB는 측정 가능한 이점이 거의 없을 만큼 드물게 사용된다. API는 기본 읽기보다 훨씬 복잡하다. 별도의 reader 타입(ReadableStreamBYOBReader)과 다른 특수 클래스(예: ReadableStreamBYOBRequest), 신중한 버퍼 생명주기 관리, ArrayBuffer 분리(detachment) 의미론을 이해해야 한다. BYOB read에 버퍼를 넘기면 버퍼는 스트림으로 전송되어 detached되고, 대신 잠재적으로 다른 메모리 위의 다른 뷰가 반환된다. 이 전송 기반 모델은 오류가 나기 쉽고 혼란스럽다:
const reader = stream.getReader({ mode: 'byob' });
const buffer = new ArrayBuffer(1024);
let view = new Uint8Array(buffer);
const result = await reader.read(view);
// 'view'는 이제 detached되어 사용 불가해야 한다
// (모든 구현에서 항상 그런 것은 아님)
// result.value는 잠재적으로 다른 메모리 위의 새로운 뷰다
view = result.value; // 재할당해야 한다
BYOB는 async iteration이나 TransformStream과 함께 사용할 수도 없어서, 제로-카피 읽기를 원하면 개발자는 다시 수동 reader 루프로 돌아가야 한다.
구현자에게 BYOB는 상당한 복잡성을 더한다. 스트림은 대기 중인 BYOB 요청을 추적해야 하고, 부분 채우기를 처리해야 하며, 버퍼 detachment를 올바르게 관리해야 하고, BYOB reader와 underlying source 사이를 조율해야 한다. readable byte streams에 대한 Web Platform Tests에는 detached 버퍼, 잘못된 뷰, enqueue 이후 응답 순서 같은 BYOB 엣지 케이스만을 위한 테스트 파일이 따로 있다.
결국 BYOB는 사용자와 구현자 모두에게 복잡하지만 실제 채택은 적다. 대부분의 개발자는 기본 읽기를 사용하고 할당 오버헤드를 감수한다.
사용자 공간(userland)에서 커스텀 ReadableStream을 구현할 때도, 단일 스트림에서 기본 읽기와 BYOB 읽기를 모두 올바르게 지원하기 위해 필요한 각종 의식을 대개 감당하지 않는다. 그럴 만하다. 제대로 구현하기 어렵고, 소비 코드는 대부분 기본 읽기 경로로 폴백하기 때문이다. 아래는 "올바른" 구현이 해야 할 일의 예시다. 크고, 복잡하고, 오류가 나기 쉽다. 보통 개발자가 감당하고 싶어 하는 수준의 복잡성이 아니다:
new ReadableStream({
type: 'bytes',
async pull(controller: ReadableByteStreamController) {
if (offset >= totalBytes) {
controller.close();
return;
}
// BYOB 요청을 먼저 확인
const byobRequest = controller.byobRequest;
if (byobRequest) {
// === BYOB 경로 ===
// 소비자가 버퍼를 제공했으므로 이를 (부분적으로라도) 채워야 한다
const view = byobRequest.view!;
const bytesAvailable = totalBytes - offset;
const bytesToWrite = Math.min(view.byteLength, bytesAvailable);
// 소비자 버퍼에 대한 뷰를 만들고 채운다
// bytesToWrite != view.byteLength일 때 더 안전
const dest = new Uint8Array(
view.buffer,
view.byteOffset,
bytesToWrite
);
// 순차 바이트로 채우기(우리의 "데이터 소스")
// 여기서는 view에 쓰는 어떤 것이든 가능
for (let i = 0; i < bytesToWrite; i++) {
dest[i] = (offset + i) & 0xFF;
}
offset += bytesToWrite;
// 몇 바이트를 썼는지 알림
byobRequest.respond(bytesToWrite);
} else {
// === 기본 reader 경로 ===
// BYOB 요청이 없으면 할당 후 청크를 enqueue
const bytesAvailable = totalBytes - offset;
const chunkSize = Math.min(1024, bytesAvailable);
const chunk = new Uint8Array(chunkSize);
for (let i = 0; i < chunkSize; i++) {
chunk[i] = (offset + i) & 0xFF;
}
offset += chunkSize;
controller.enqueue(chunk);
}
},
cancel(reason) {
console.log('Stream canceled:', reason);
}
});
호스트 런타임이 런타임 자체에서 바이트 지향 ReadableStream을 제공하는 경우(예: fetch Response의 body), 런타임이 BYOB 읽기에 대해 최적화된 구현을 제공하는 것이 훨씬 쉬운 경우가 많다. 그러나 그 구현도 기본 읽기와 BYOB 읽기 패턴을 모두 처리할 수 있어야 하며, 그 요구사항은 상당한 복잡성을 동반한다.
백프레셔(느린 소비자가 빠른 생산자에게 속도를 줄이라고 신호를 보내는 능력)는 웹 스트림의 일급 개념이다. 이론적으로는. 실제로는 모델에 심각한 결함이 있다.
주요 신호는 컨트롤러의 desiredSize다. 양수(데이터를 원함), 0(용량 한계), 음수(초과), null(닫힘)일 수 있다. 생산자는 이 값을 확인하고 양수가 아닐 때 enqueue를 멈추라고 되어 있다. 그러나 이를 강제하는 것은 없다. controller.enqueue()는 desiredSize가 크게 음수여도 항상 성공한다.
new ReadableStream({
start(controller) {
// 아무것도 이걸 막지 않는다
while (true) {
controller.enqueue(generateData()); // desiredSize: -999999
}
}
});
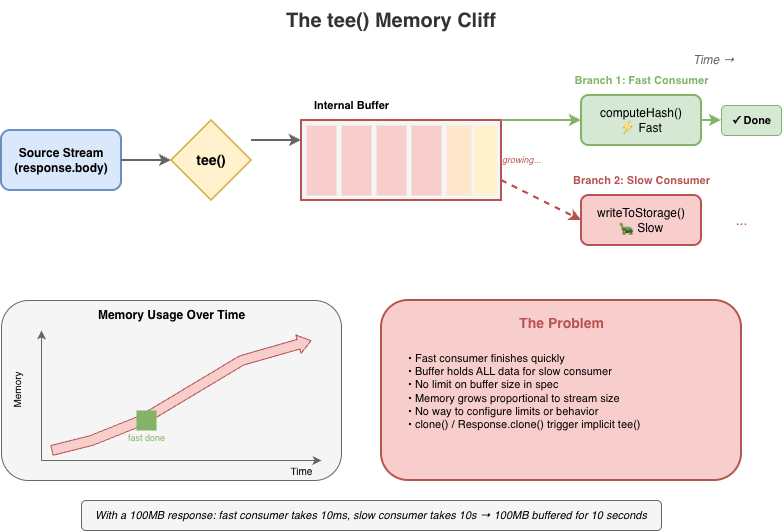
스트림 구현은 백프레셔를 무시할 수 있고, 실제로 무시하기도 한다. 또한 스펙에 정의된 기능 중 일부는 명시적으로 백프레셔를 깨뜨린다. 예컨대 tee()는 하나의 스트림에서 두 갈래를 만든다. 한 갈래가 다른 갈래보다 빨리 읽으면 내부 버퍼에 제한 없이 데이터가 쌓인다. 빠른 소비자가 느린 소비자를 기다리게 하며 메모리가 무한정 증가할 수 있고, 느린 갈래를 cancel하는 것 외에는 설정하거나 회피할 방법이 없다.
웹 스트림은 highWaterMark 옵션과 커스텀 size 계산을 통해 백프레셔 동작을 조정하는 명확한 메커니즘을 제공하지만, 이 역시 desiredSize처럼 무시하기 쉽고, 많은 애플리케이션이 이를 신경 쓰지 않는다.
동일한 문제는 WritableStream 측에도 존재한다. WritableStream은 highWaterMark와 desiredSize를 가지며, 데이터 생산자는 writer.ready 프라미스를 주의 깊게 봐야 하지만 종종 그렇지 않다.
const writable = getWritableStreamSomehow();
const writer = writable.getWriter();
// 생산자는 writer.ready를 기다려야 한다
// 이것은 promise이며, resolve되면
// writable 내부 백프레셔가 해소되어
// 더 많은 데이터를 써도 된다는 뜻이다
await writer.ready;
await writer.write(...);
구현자에게 백프레셔는 보장 없이 복잡성만 더한다. 큐 크기를 추적하고, desiredSize를 계산하고, 올바른 시점에 pull()을 호출하는 기계장치를 정확히 구현해야 한다. 하지만 이 신호들이 권고(advisory) 수준이므로, 그 모든 작업이 백프레셔가 해결하려는 문제를 실제로 막지는 못한다.
웹 스트림 스펙은 수많은 지점에서 프라미스 생성을 요구한다. 종종 핫 패스에서, 그리고 사용자에게 보이지 않는 곳에서 말이다. 각 read() 호출은 단지 프라미스를 반환하는 것에 그치지 않고, 내부적으로 큐 관리, pull() 조율, 백프레셔 신호를 위해 추가 프라미스를 생성한다.
이 오버헤드는 스펙이 버퍼 관리, 완료, 백프레셔 신호를 위해 프라미스에 의존하기 때문에 강제된다. 일부는 구현 세부이지만, 스펙대로 따르려면 피할 수 없는 부분이 많다. 고빈도 스트리밍(비디오 프레임, 네트워크 패킷, 실시간 데이터)에서는 이 오버헤드가 상당하다.
파이프라인에서는 문제가 더 커진다. 각 TransformStream은 소스와 싱크 사이에 또 하나의 프라미스 기계장치 층을 추가한다. 스펙은 동기적 fast path를 정의하지 않으므로 데이터가 즉시 उपलब्ध해도 프라미스 기계장치는 여전히 돌아간다.
구현자에게 이런 프라미스 중심 설계는 최적화 기회를 제한한다. 스펙은 특정 프라미스 해소 순서를 강제하므로, 미묘한 준수(compliance) 실패 위험 없이 작업을 배치하거나 불필요한 async 경계를 건너뛰기 어렵다. 구현자들이 실제로 많은 숨은 내부 최적화를 하기도 하지만, 이는 복잡하고 올바르게 구현하기 어렵다.
이 글을 쓰는 동안, Vercel의 Malte Ubl이 Node.js의 웹 스트림 구현 성능 개선 연구를 다룬 블로그 글을 공개했다. 그 글에서 그는 모든 웹 스트림 구현이 직면하는 근본 성능 최적화 문제를 논한다:
"또는 pipeTo()를 생각해 보자. 각 청크는 완전한 Promise 체인을 통과한다: read, write, 백프레셔 확인, 반복. read마다 {value, done} 결과 객체가 할당된다. 에러 전파는 추가 Promise 분기를 만든다.
이 중 어느 것도 틀린 것은 아니다. 이 보장들은 브라우저에서 중요하다. 스트림이 보안 경계를 넘고, 취소 의미론이 빈틈없어야 하며, 파이프 양 끝을 모두 제어할 수 없기 때문이다. 하지만 서버에서, 1KB 청크의 React Server Components를 세 개의 transform을 거쳐 파이핑할 때, 비용은 누적된다.
우리는 네이티브 WebStream pipeThrough를 1KB 청크에서 630 MB/s로 벤치마크했다. 동일한 passthrough transform으로 Node.js pipeline()은 ~7,900 MB/s였다. 이는 12배 격차이며, 차이는 거의 전적으로 Promise와 객체 할당 오버헤드다." - Malte Ubl, https://vercel.com/blog/we-ralph-wiggumed-webstreams-to-make-them-10x-faster
그들의 연구의 일환으로, Node.js 웹 스트림 구현에서 특정 코드 경로의 프라미스를 제거해 최대 10배 성능 향상을 얻을 수 있는 개선안을 마련했다. 이는 프라미스가 유용하지만 상당한 오버헤드를 추가한다는 점을 입증한다. Node.js의 핵심 메인테이너 중 한 사람으로서, Malte와 Vercel 팀이 제안한 개선이 반영되도록 돕게 되기를 기대한다!
최근 Cloudflare Workers 업데이트에서도, 내부 데이터 파이프라인에서 특정 애플리케이션 시나리오에서 생성되는 자바스크립트 프라미스 수를 최대 200배까지 줄이는 유사한 수정을 했다. 그 결과 해당 애플리케이션 성능이 몇 자릿수(orders of magnitude) 향상되었다.
fetch()가 response를 반환할 때, body는 ReadableStream이다. 상태만 확인하고 body를 소비하거나 cancel하지 않으면 어떻게 될까? 구현마다 다르지만, 흔한 결과는 리소스 누수다.
async function checkEndpoint(url) {
const response = await fetch(url);
return response.ok; // Body를 소비하거나 cancel하지 않음
}
// 루프에서 실행하면 커넥션 풀을 고갈시킬 수 있다
for (const url of urls) {
await checkEndpoint(url);
}
이 패턴은 Node.js 애플리케이션에서 undici(Node.js 내장 fetch() 구현) 사용 시 커넥션 풀 고갈을 유발해 왔고, 다른 런타임에서도 유사한 문제가 나타났다. 스트림이 기반 커넥션에 대한 참조를 유지하고, 명시적 소비나 cancel이 없으면, 커넥션은 가비지 컬렉션까지 남아 있을 수 있는데, 부하 상황에서는 GC가 충분히 빨리 돌지 않을 수 있다.
문제는 스트림 가지를 암묵적으로 만드는 API로 인해 더 악화된다. Request.clone()과 Response.clone()은 body 스트림에 대해 암묵적으로 tee()를 수행하는데, 이는 놓치기 쉬운 세부다. 로깅이나 재시도 로직을 위해 요청을 clone하는 코드는 자신도 모르게 각각 독립적으로 소비해야 하는 분기 스트림을 만들어 리소스 관리 부담을 늘린다.
물론 이런 유형의 문제는 _구현 버그_다. 커넥션 누수는 undici가 자체 구현에서 고쳐야 할 일이었다. 하지만 스펙의 복잡성은 이런 문제를 다루기 쉽게 만들지 않는다.
"Node.js의 fetch() 구현에서 스트림을 클론하는 건 보기보다 어렵다. request나 response body를 clone하면 tee()를 호출하는데, 이는 하나의 스트림을 두 갈래로 나눠 둘 다 소비되어야 한다. 한 소비자가 다른 쪽보다 빨리 읽으면, 느린 분기를 기다리며 데이터가 메모리에 무한정 버퍼링된다. 두 분기를 제대로 소비하지 않으면 기반 커넥션이 누수된다. 하나의 소스를 공유하는 두 reader를 조율하는 것은 원래 요청을 망가뜨리거나 커넥션 풀을 고갈시키기 쉬워진다. 단순한 API 호출이지만, 내부 메커니즘은 복잡하고 제대로 맞추기 어렵다." - Matteo Collina, Ph.D. - Platformatic 공동 창업자 & CTO, Node.js TSC 의장
tee()는 스트림을 두 분기로 나눈다. 단순해 보이지만, 구현에는 버퍼링이 필요하다. 한 분기가 다른 분기보다 빨리 읽으면, 느린 분기가 따라잡을 때까지 데이터를 어딘가에 보관해야 한다.
const [forHash, forStorage] = response.body.tee();
// 해시 계산은 빠르다
const hash = await computeHash(forHash);
// 저장소 쓰기는 느리다 — 그 사이 전체 스트림이
// 이 분기를 기다리며 메모리에 버퍼링될 수 있다
await writeToStorage(forStorage);
스펙은 tee()에 대한 버퍼 한도를 의무화하지 않는다. 공정하게 말하자면 스펙은 tee()와 다른 API의 내부 메커니즘을, 관측 가능한 규범적 요구사항만 충족한다면 구현이 어떤 방식으로든 구현할 수 있게 허용한다. 하지만 구현이 스트림 스펙에 서술된 특정 방식대로 tee()를 구현하기로 선택하면, tee()는 우회하기 어려운 내장 메모리 관리 문제를 동반하게 된다.
구현들은 이를 처리하기 위해 각자의 전략을 개발해 왔다. Firefox는 초기에 연결 리스트 접근을 사용해 소비 속도 차이에 비례하는 O(n) 메모리 증가를 유발했다. Cloudflare Workers에서는 가장 빠른 소비자가 아니라 가장 느린 소비자에 의해 백프레셔가 신호되도록 공유 버퍼 모델을 구현했다.
TransformStream은 중간에 처리 로직을 둔 readable/writable 쌍을 만든다. transform() 함수는 read가 아니라 write 시점에 실행된다. 즉, 소비자가 준비됐는지와 무관하게 데이터가 도착하는 즉시 변환 처리가 eager하게 수행된다. 이는 소비자가 느릴 때 불필요한 작업을 만들며, 양쪽 사이의 백프레셔 신호에 틈이 있어 부하 시 무한 버퍼링을 초래할 수 있다. 스펙의 기대는 변환될 데이터를 생산하는 쪽이 transform의 writable 측 writer.ready 신호에 주의를 기울인다는 것이지만, 실제로는 생산자들이 이를 무시하는 경우가 많다.
변환의 transform()이 동기이고 항상 즉시 출력을 enqueue한다면, downstream 소비자가 느려도 writable 측으로 백프레셔를 전혀 신호하지 않는다. 이는 많은 개발자가 간과하는 스펙 설계의 결과다. 브라우저에서는 보통 단일 사용자이고 동시에 활성화된 스트림 파이프라인 수가 적어 이런 발목잡이가 문제가 되지 않을 수 있지만, 수천 개 동시 요청을 처리하는 서버/엣지 런타임에서는 큰 영향을 미친다.
const fastTransform = new TransformStream({
transform(chunk, controller) {
// 동기적으로 enqueue — 백프레셔를 적용하지 않는다
// readable 측 버퍼가 가득 차도 이 호출은 성공한다
controller.enqueue(processChunk(chunk));
}
});
// 빠른 소스를 변환을 거쳐 느린 싱크로 파이핑
fastSource
.pipeThrough(fastTransform)
.pipeTo(slowSink); // 버퍼가 제한 없이 증가
TransformStream이 해야 하는 일은 컨트롤러에서 백프레셔를 확인하고 프라미스로 그것을 writer에 전달하는 것이다:
const fastTransform = new TransformStream({
async transform(chunk, controller) {
if (controller.desiredSize <= 0) {
// 백프레셔가 해소될 때까지 어떻게든 기다린다
}
controller.enqueue(processChunk(chunk));
}
});
하지만 여기에는 어려움이 있다. TransformStreamDefaultController는 Writer처럼 ready promise 메커니즘이 없으므로, TransformStream 구현은 controller.desiredSize가 다시 양수가 되는 시점을 주기적으로 확인하는 폴링 메커니즘을 구현해야 한다.
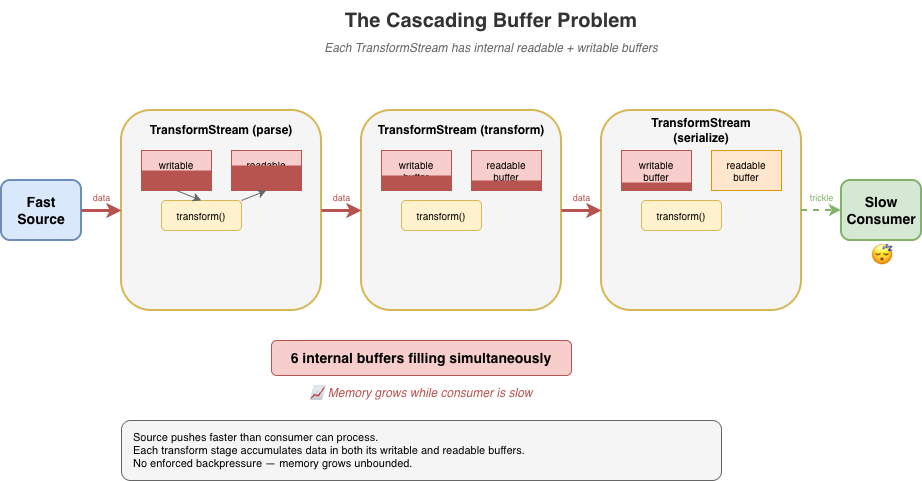
파이프라인에서는 더 악화된다. parse, transform, serialize처럼 여러 변환을 연결하면 각 TransformStream은 자체 내부 readable/writable 버퍼를 가진다. 구현이 스펙을 엄격히 따르면, 데이터는 push 지향 방식으로 버퍼를 폭포처럼 흘러간다: 소스가 transform A로 push하고, A가 B로 push하고, B가 C로 push하며, 최종 소비자가 pull을 시작하기도 전에 중간 버퍼들에 데이터가 축적된다. 변환이 3개면 내부 버퍼가 6개가 동시에 차오를 수 있다.
개발자들은 소스/변환/목적지 생성 시 highWaterMark 같은 옵션을 기억해 사용해야 하지만, 종종 잊거나 무시한다.
source
.pipeThrough(parse) // 버퍼가 차오름...
.pipeThrough(transform) // 더 많은 버퍼...
.pipeThrough(serialize) // 더더 많은 버퍼...
.pipeTo(destination); // 소비자는 아직 pull하지도 않음
구현들은 identity transform을 접거나, 관측 불가능한 경로를 단축시키거나, 버퍼 할당을 지연시키거나, 자바스크립트를 전혀 실행하지 않는 네이티브 코드로 폴백하는 방식으로 변환 파이프라인을 최적화해 왔다. Deno, Bun, Cloudflare Workers는 "네이티브 경로(native path)" 최적화를 성공적으로 구현해 오버헤드 상당 부분을 제거했고, Vercel의 최근 fast-webstreams 연구도 Node.js에 유사한 최적화를 적용 중이다. 하지만 최적화 자체가 큰 복잡성을 더하며, TransformStream의 본질적으로 push 지향인 모델에서 완전히 벗어날 수는 없다.
스트리밍 서버 사이드 렌더링(SSR)은 특히 고통스러운 사례다. 전형적인 SSR 스트림은 수천 개의 작은 HTML 조각을 렌더링하고, 각 조각이 스트림 기계장치를 통과한다:
// 각 컴포넌트가 작은 청크를 enqueue
function renderComponent(controller) {
controller.enqueue(encoder.encode(`<div>${content}</div>`));
}
// 수백 개 컴포넌트 = 수백 번 enqueue
// 각 호출은 내부적으로 promise 기계장치를 트리거
for (const component of components) {
renderComponent(controller); // 프라미스 생성, 객체 할당
}
각 조각마다 read() 호출을 위한 프라미스, 백프레셔 조율 프라미스, 중간 버퍼 할당, { value, done } 결과 객체가 만들어지며, 대부분은 거의 즉시 가비지가 된다.
부하 시 이는 GC 압력을 만들어 처리량을 망가뜨릴 수 있다. 자바스크립트 엔진은 유용한 일을 하기보다 단명 객체를 수집하느라 상당한 시간을 쓴다. GC 일시정지로 요청 처리가 끊기면서 지연 시간이 예측 불가능해진다. 나는 SSR 워크로드에서 GC가 요청당 총 CPU 시간의 상당 부분(50% 이상)에 이르는 경우도 보았다. 이는 실제로 콘텐츠를 렌더링하는 데 쓰일 수 있는 시간이다.
아이러니하게도 스트리밍 SSR은 콘텐츠를 점진적으로 보내 성능을 개선하려는 것이다. 그러나 스트림 기계장치의 오버헤드가 특히 많은 작은 컴포넌트를 가진 페이지에서는 그 이득을 상쇄할 수 있다. 개발자들은 웹 스트림으로 스트리밍하는 것보다 전체 응답을 버퍼링하는 것이 더 빠르다는 사실을 발견하기도 하는데, 이는 목적을 완전히 무너뜨린다.
쓸만한 성능을 얻기 위해 모든 주요 런타임은 웹 스트림을 위해 비표준 내부 최적화에 의존해 왔다. Node.js, Deno, Bun, Cloudflare Workers는 각자 우회책을 개발했다. 특히 시스템 레벨 I/O와 연결된 스트림은 관측 불가능한 기계장치가 많아 단축할 수 있는 경우가 많다.
이런 최적화 기회를 찾는 것 자체가 큰 과업이 될 수 있다. 관측 가능한 동작과 생략 가능한 동작을 구분하기 위해 스펙 전반을 끝에서 끝까지 이해해야 한다. 그럼에도 어떤 최적화가 스펙 준수인지가 종종 불명확하다. 구현자는 호환성을 깨지 않고 완화할 수 있는 의미론이 무엇인지 판단해야 한다. 이는 런타임 팀에, 받아들일 만한 성능을 얻기 위해서라도 스펙 전문가가 되어야 하는 엄청난 부담을 준다.
이 최적화들은 구현하기 어렵고 오류가 잦으며 런타임 간 동작 불일치를 낳는다. Bun의 "Direct Streams" 최적화는 스펙의 많은 기계장치를 통째로 우회하는, 의도적으로 관측 가능하게 비표준적인 접근을 취한다. Cloudflare Workers의 IdentityTransformStream은 패스스루 변환에 대한 fast-path를 제공하지만 Workers 전용이며 표준 TransformStream과 다른 동작을 구현한다. 각 런타임은 자기만의 트릭을 갖게 되고, 자연스러운 경향은 비표준 솔루션으로 향한다. 빠르게 만들려면 종종 그것이 유일한 방법이기 때문이다.
이 파편화는 이식성을 해친다. "표준" API를 쓰는데도 한 런타임에서 빠른 코드가 다른 런타임에서는 다르게 동작하거나 느릴 수 있다. 구현자 부담은 크고, 미묘한 동작 차이는 특히 여러 런타임에서 효율적으로 돌아가야 하는 프레임워크 개발자에게 마찰을 만든다.
또한 많은 최적화는 사용자 코드에 관측되지 않는 스펙 영역에서만 가능하다는 점을 강조할 필요가 있다. 대안(예: Bun Direct Streams)은 스펙이 정의한 관측 가능한 동작에서 의도적으로 벗어나는 것이다. 그래서 최적화는 종종 "불완전"해 보인다. 어떤 시나리오에서는 동작하고 다른 시나리오에서는 안 되며, 어떤 런타임에서는 되고 다른 런타임에서는 안 된다. 이런 경우가 늘수록 웹 스트림 접근의 지속 불가능한 복잡성은 커진다. 그 결과 대부분의 런타임 구현자는 일단 적합성 테스트가 통과하면 스트림 구현을 더 개선하는 데 큰 노력을 기울이지 않게 된다.
구현자가 이런 장애물 코스를 뛰어넘을 필요는 없다. 합리적 성능을 얻기 위해 스펙 의미론을 완화하거나 우회해야 한다면, 스펙 자체에 문제가 있다는 신호다. 잘 설계된 스트리밍 API는 기본적으로 효율적이어야지, 런타임마다 탈출 해치(escape hatch)를 발명하게 만들면 안 된다.
복잡한 스펙은 복잡한 엣지 케이스를 만든다. streams에 대한 Web Platform Tests는 70개가 넘는 테스트 파일에 걸쳐 있으며, 포괄적 테스트는 좋은 일이지만, 무엇을 테스트해야 하는지가 시사하는 바가 크다.
구현이 통과해야 하는 더 난해한 테스트 몇 가지를 보자:
프로토타입 오염(prototype pollution) 방어: 한 테스트는 Object.prototype.then을 패치해 프라미스 해소를 가로챈 다음, pipeTo()와 tee()가 프로토타입 체인을 통해 내부 값을 누출하지 않는지 검증한다. 이는 스펙의 프라미스 중심 내부 구현이 공격면을 만들기 때문에 존재하는 보안 성질을 테스트한다.
WebAssembly 메모리 거부: BYOB 읽기는 WebAssembly 메모리에 의해 백업되는 ArrayBuffer를 명시적으로 거부해야 한다. 일반 버퍼처럼 보이지만 전송할 수 없기 때문이다. 이 엣지 케이스는 스펙의 버퍼 detachment 모델 때문에 존재한다. 더 단순한 API라면 이런 경우를 처리할 필요가 없다.
상태 머신 충돌 크래시 회귀: 한 테스트는 enqueue() 이후 byobRequest.respond()를 호출해도 런타임이 크래시하지 않는지 확인한다. 이 시퀀스는 내부 상태 머신에서 충돌을 만든다. enqueue()가 대기 중인 read를 충족해야 하므로 byobRequest는 무효화되어야 하지만, 구현은 메모리 손상 없이 이후 respond()를 우아하게 처리해야 한다. 이는 개발자가 복잡한 API를 올바르게 쓰지 않을 가능성이 매우 높기 때문이다.
이것들은 테스트 작성자가 진공 속에서 꾸며낸 시나리오가 아니다. 스펙 설계의 결과이며 현실의 버그를 반영한다.
런타임 구현자에게 WPT 통과는 대부분의 애플리케이션 코드가 결코 마주치지 않을 정교한 코너 케이스를 처리한다는 의미다. 테스트는 단지 happy path뿐 아니라 reader, writer, controller, queue, strategy, 그리고 이를 모두 잇는 프라미스 기계장치 간 상호작용 전체 매트릭스를 인코딩한다.
더 단순한 API는 더 적은 개념, 개념 간 상호작용의 감소, 올바르게 처리해야 할 엣지 케이스 감소를 의미하며, 구현이 실제로 일관되게 동작한다는 신뢰를 높인다.
웹 스트림은 사용자와 구현자 모두에게 복잡하다. 스펙의 문제는 버그가 아니다. 설계된 대로 API를 사용했을 때 자연스럽게 나타나는 문제들이다. 점진적 개선만으로 고칠 수 있는 종류의 이슈가 아니다. 근본 설계 선택의 결과이기 때문이다. 개선하려면 다른 기반이 필요하다.
여러 런타임에서 웹 스트림 스펙을 여러 번 구현하고, 그 고통 지점을 직접 보면서, 오늘날의 관점에서 처음 원리부터 더 나은 대안적 스트리밍 API가 어떤 모습일 수 있는지 탐구할 때라고 생각했다.
아래는 개념 증명(proof of concept)이다. 완성된 표준도, 프로덕션 준비 라이브러리도, 새로운 무언가에 대한 구체적 제안도 아닐 수 있다. 하지만 웹 스트림의 문제는 스트리밍 자체에 내재한 것이 아니라 특정 설계 선택의 결과이며, 다르게 선택할 수 있음을 보여주는 논의의 출발점이다. 이 정확한 API가 정답인지보다, 스트리밍 프리미티브에 실제로 무엇이 필요한지에 대한 생산적 대화를 촉발하는지가 더 중요하다.
API 설계로 들어가기 전에, 스트림이 무엇인지 묻는 것이 가치 있다.
핵심에서 스트림은 시간이 지나면서 도착하는 데이터의 시퀀스다. 한 번에 전부 갖고 있지 않다. उपलब्ध해지는 대로 점진적으로 처리한다.
유닉스 파이프는 아마도 이 아이디어의 가장 순수한 표현일 것이다:
cat access.log | grep "error" | sort | uniq -c
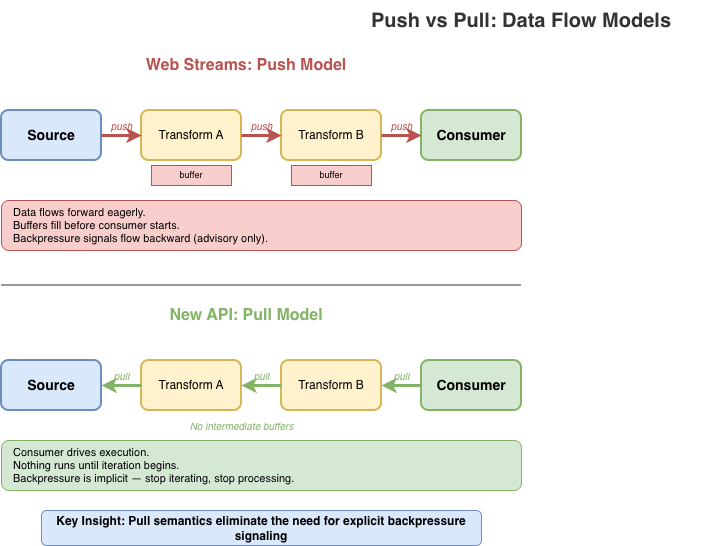
데이터는 왼쪽에서 오른쪽으로 흐른다. 각 단계는 입력을 읽고, 일을 하고, 출력을 쓴다. 획득해야 할 pipe reader도 없고, 관리할 controller 락도 없다. downstream 단계가 느리면 upstream도 자연스럽게 느려진다. 백프레셔는 별도의 메커니즘이 아니라 모델에 내재한다.
자바스크립트에서 "시간에 따라 도착하는 것들의 시퀀스"에 대한 자연스러운 프리미티브는 이미 언어에 존재한다: async iterable이다. for await...of로 소비한다. 반복을 멈추면 소비도 멈춘다.
새 API가 보존하려는 직관은 이것이다: 스트림은 반복처럼 느껴져야 한다. 왜냐하면 그것이 본질이기 때문이다. 웹 스트림의 복잡성(reader, writer, controller, lock, queuing strategy 등)은 이 근본 단순성을 가린다. 더 나은 API는 단순한 경우를 단순하게 만들고, 정말 필요한 곳에서만 복잡성을 추가해야 한다.
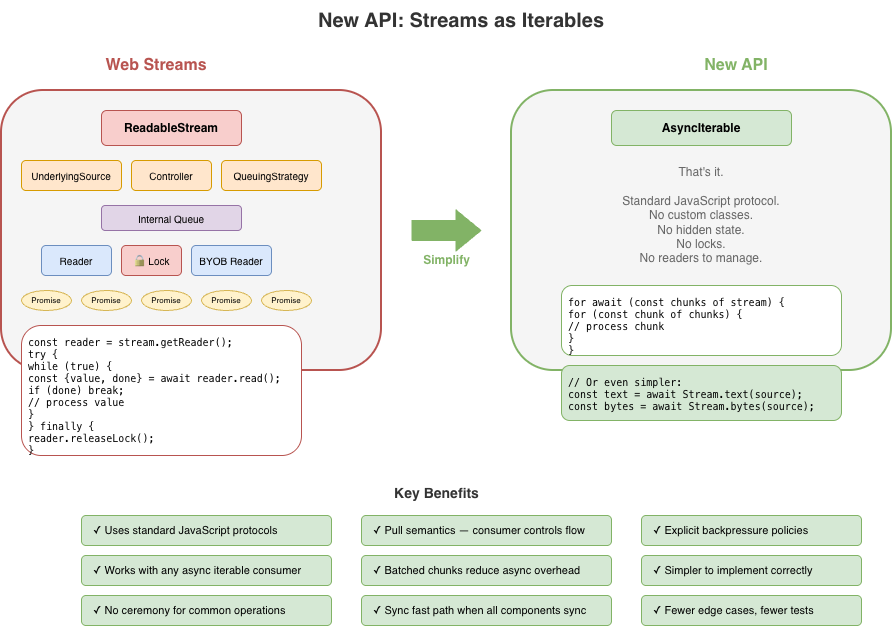
이 개념 증명 대안은 다른 원칙 집합을 중심으로 만들었다.
숨겨진 내부 상태를 가진 커스텀 ReadableStream 클래스가 아니다. 읽기 가능한 스트림은 그냥 AsyncIterable<Uint8Array[]>이다. for await...of로 소비한다. 획득할 reader도, 관리할 락도 없다.
소비자가 pull하기 전까지 변환은 실행되지 않는다. eager 평가도 없고 숨은 버퍼링도 없다. 데이터는 소스에서 변환을 거쳐 소비자에게 온디맨드로 흐른다. 반복을 멈추면 처리도 멈춘다.
기본값으로 백프레셔는 엄격하다. 버퍼가 가득 차면 쓰기는 조용히 누적되는 대신 거부(reject)된다. 공간이 생길 때까지 블록, 가장 오래된 것 드롭, 가장 최신 것 드롭 같은 대체 정책을 설정할 수 있지만, 명시적으로 선택해야 한다. 더 이상 조용한 메모리 증가가 없다.
반복마다 청크 하나를 yield하는 대신, 스트림은 Uint8Array[](청크 배열)을 yield한다. 이는 여러 청크에 걸쳐 async 오버헤드를 상각해 프라미스 생성과 핫 패스의 마이크로태스크 지연을 줄인다.
API는 바이트(Uint8Array)만 다룬다. 문자열은 UTF-8로 자동 인코딩된다. "값 스트림"과 "바이트 스트림"의 이분법이 없다. 임의의 자바스크립트 값을 스트리밍하고 싶다면 async iterable을 직접 사용하면 된다. 이 API는 Uint8Array를 사용하지만 청크를 불투명(opaque)하게 취급한다. 부분 소비도 없고, BYOB 패턴도 없고, 스트리밍 기계장치 내부에서 바이트 단위 연산도 없다. 청크는 들어가면 나오는 것이며, 변환이 명시적으로 수정하지 않는 한 그대로다.
API는 동기 데이터 소스가 필요하면서도 흔하다는 점을 인정한다. 애플리케이션은 가능한 선택지가 비동기 스케줄링뿐이라는 이유로 항상 성능 비용을 떠안아서는 안 된다. 동시에 동기/비동기 처리 혼용은 위험할 수 있으므로, 동기 경로는 항상 옵션이어야 하며, 항상 명시적이어야 한다.
웹 스트림에서 간단한 생산자/소비자 쌍을 만들려면 TransformStream, 수동 인코딩, 신중한 락 관리가 필요하다:
const { readable, writable } = new TransformStream();
const enc = new TextEncoder();
const writer = writable.getWriter();
await writer.write(enc.encode("Hello, World!"));
await writer.close();
writer.releaseLock();
const dec = new TextDecoder();
let text = '';
for await (const chunk of readable) {
text += dec.decode(chunk, { stream: true });
}
text += dec.decode();
이 비교적 깔끔한 버전조차도 TransformStream, 수동 TextEncoder/TextDecoder, 명시적 락 해제가 필요하다.
새 API에서는 동등한 코드는 다음과 같다:
import { Stream } from 'new-streams';
// 푸시 스트림 생성
const { writer, readable } = Stream.push();
// 데이터 쓰기 — 백프레셔 강제
await writer.write("Hello, World!");
await writer.end();
// 텍스트로 소비
const text = await Stream.text(readable);
readable은 그냥 async iterable이다. 이를 기대하는 어떤 함수에도 넘길 수 있으며, Stream.text()처럼 전체 스트림을 수집해 디코드하는 함수에도 넘길 수 있다.
writer는 단순한 인터페이스를 가진다: write(), 배치 쓰기를 위한 writev(), 완료를 알리는 end(), 에러를 위한 abort(). 사실상 이것이 전부다.
Writer는 구체 클래스가 아니다. write(), end(), abort()를 구현하는 어떤 객체든 writer가 될 수 있어, 상속 없이 기존 API를 어댑트하거나 특화 구현을 만들기 쉽다. start(), write(), close(), abort() 콜백이 컨트롤러를 통해 조율되어야 하는 복잡한 UnderlyingSink 프로토콜도 없다. 그 컨트롤러는 결합된 WritableStream과 독립된 생명주기/상태를 가지며, 그 자체가 복잡성을 만든다.
아래는 작성된 모든 데이터를 모으는 간단한 인메모리 writer다:
// 최소 writer 구현 — 메서드가 있는 객체일 뿐
function createBufferWriter() {
const chunks = [];
let totalBytes = 0;
let closed = false;
const addChunk = (chunk) => {
chunks.push(chunk);
totalBytes += chunk.byteLength;
};
return {
get desiredSize() { return closed ? null : 1; },
// 비동기 변형
write(chunk) { addChunk(chunk); },
writev(batch) { for (const c of batch) addChunk(c); },
end() { closed = true; return totalBytes; },
abort(reason) { closed = true; chunks.length = 0; },
// 동기 변형은 boolean 반환(true = 수락됨)
writeSync(chunk) { addChunk(chunk); return true; },
writevSync(batch) { for (const c of batch) addChunk(c); return true; },
endSync() { closed = true; return totalBytes; },
abortSync(reason) { closed = true; chunks.length = 0; return true; },
getChunks() { return chunks; }
};
}
// 사용
const writer = createBufferWriter();
await Stream.pipeTo(source, writer);
const allData = writer.getChunks();
확장할 베이스 클래스도, 구현할 추상 메서드도, 조율할 컨트롤러도 없다. 올바른 모양(shape)의 객체이면 된다.
새 API 설계에서는 데이터가 소비되기 전까지 변환은 어떤 일도 해서는 안 된다. 이것이 근본 원칙이다.
// 반복이 시작될 때까지 아무것도 실행되지 않는다
const output = Stream.pull(source, compress, encrypt);
// 반복하면서 변환이 실행된다
for await (const chunks of output) {
for (const chunk of chunks) {
process(chunk);
}
}
Stream.pull()은 지연(lazy) 파이프라인을 만든다. compress와 encrypt 변환은 output을 반복하기 시작할 때까지 실행되지 않는다. 각 반복은 필요할 때 파이프라인을 통해 데이터를 pull한다.
이는 파이프를 설정하자마자 소스에서 변환으로 데이터를 능동적으로 펌핑하기 시작하는 웹 스트림의 pipeThrough()와 근본적으로 다르다. pull 의미론은 처리 시점을 사용자가 통제하게 해 주며, 반복을 멈추면 처리도 멈춘다.
변환은 무상태일 수도, 상태를 가질 수도 있다. 무상태 변환은 청크를 받아 변환된 청크를 반환하는 함수일 뿐이다:
// 무상태 변환 — 순수 함수
// chunks 또는 null(플러시 신호)을 받는다
const toUpperCase = (chunks) => {
if (chunks === null) return null; // 스트림 종료
return chunks.map(chunk => {
const str = new TextDecoder().decode(chunk);
return new TextEncoder().encode(str.toUpperCase());
});
};
// 직접 사용
const output = Stream.pull(source, toUpperCase);
상태ful 변환은 호출 간 상태를 유지하는 멤버 함수를 가진 간단한 객체다:
// 상태ful 변환 — 소스를 감싸는 제너레이터
function createLineParser() {
// Uint8Array를 이어 붙이는 헬퍼
const concat = (...arrays) => {
const result = new Uint8Array(arrays.reduce((n, a) => n + a.length, 0));
let offset = 0;
for (const arr of arrays) { result.set(arr, offset); offset += arr.length; }
return result;
};
return {
async *transform(source) {
let pending = new Uint8Array(0);
for await (const chunks of source) {
if (chunks === null) {
// 플러시: 남은 데이터가 있으면 yield
if (pending.length > 0) yield [pending];
continue;
}
// pending 데이터와 새 청크를 연결
const combined = concat(pending, ...chunks);
const lines = [];
let start = 0;
for (let i = 0; i < combined.length; i++) {
if (combined[i] === 0x0a) { // newline
lines.push(combined.slice(start, i));
start = i + 1;
}
}
pending = combined.slice(start);
if (lines.length > 0) yield lines;
}
}
};
}
const output = Stream.pull(source, createLineParser());
에러/취소 시 정리가 필요한 변환은 abort 핸들러를 추가한다:
// 리소스 정리를 포함한 상태ful 변환
function createGzipCompressor() {
// 가상의 압축 API...
const deflate = new Deflater({ gzip: true });
return {
async *transform(source) {
for await (const chunks of source) {
if (chunks === null) {
// 플러시: 압축 마무리
deflate.push(new Uint8Array(0), true);
if (deflate.result) yield [deflate.result];
} else {
for (const chunk of chunks) {
deflate.push(chunk, false);
if (deflate.result) yield [deflate.result];
}
}
}
},
abort(reason) {
// 에러/취소 시 압축기 리소스 정리
}
};
}
구현자 입장에서는 start(), transform(), flush() 메서드와 컨트롤러 조율이 결합된 Transformer 프로토콜이 없다. 숨은 상태 머신과 버퍼링 메커니즘을 가진 TransformStream 클래스도 없다. 변환은 함수 또는 단순 객체일 뿐이다. 구현/테스트가 훨씬 쉽다.
유한 버퍼가 가득 찼는데 생산자가 더 쓰려 할 때 할 수 있는 일은 몇 가지뿐이다:
쓰기 거부: 더 이상 데이터를 받지 않는다
대기: 공간이 생길 때까지 블록한다
오래된 데이터 폐기: 자리를 만들기 위해 이미 버퍼링된 것을 제거한다
새 데이터 폐기: 들어오는 것을 드롭한다
그게 전부다. 다른 반응은 이들의 변형(예: "버퍼를 늘린다"는 사실상 선택을 미루는 것) 또는 일반 스트리밍 프리미티브에 넣을 일이 아닌 도메인 특화 로직이다. 웹 스트림은 현재 기본값으로 항상 2번(대기)을 선택한다.
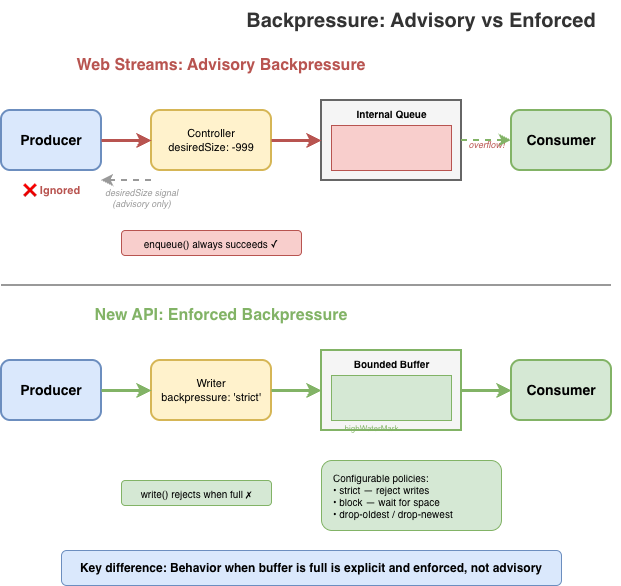
새 API는 이 네 가지 중 하나를 명시적으로 선택하게 한다:
strict(기본값): 버퍼가 가득 차고 대기 중 쓰기가 너무 많으면 쓰기를 거부한다. 생산자가 백프레셔를 무시하는 "fire-and-forget" 패턴을 잡아낸다.
block: 버퍼 공간이 생길 때까지 쓰기가 대기한다. 생산자가 쓰기를 올바르게 await한다고 신뢰할 수 있을 때 사용.
drop-oldest: 가장 오래된 버퍼 데이터를 드롭해 공간을 만든다. 오래된 데이터의 가치가 떨어지는 라이브 피드에 유용.
drop-newest: 가득 찼을 때 들어오는 데이터를 버린다. 과부하를 피하며 가진 데이터를 처리하고 싶을 때 유용.
const { writer, readable } = Stream.push({
highWaterMark: 10,
backpressure: 'strict' // 또는 'block', 'drop-oldest', 'drop-newest'
});
생산자가 협조하기만을 바라지 않아도 된다. 선택한 정책이 버퍼가 찰 때의 동작을 결정한다.
각 정책이 소비자보다 생산자가 더 빠르게 쓰는 경우 어떻게 동작하는지 보자:
// strict: 백프레셔를 무시하는 fire-and-forget 쓰기를 잡아낸다
const strict = Stream.push({ highWaterMark: 2, backpressure: 'strict' });
strict.writer.write(chunk1); // ok (await하지 않음)
strict.writer.write(chunk2); // ok (슬롯 버퍼를 채움)
strict.writer.write(chunk3); // ok (pending에 큐)
strict.writer.write(chunk4); // ok (pending 버퍼도 채움)
strict.writer.write(chunk5); // throw! 대기 중 쓰기가 너무 많음
// block: 공간이 생길 때까지 대기(대기 큐는 무한)
const blocking = Stream.push({ highWaterMark: 2, backpressure: 'block' });
await blocking.writer.write(chunk1); // ok
await blocking.writer.write(chunk2); // ok
await blocking.writer.write(chunk3); // 소비자가 읽을 때까지 대기
await blocking.writer.write(chunk4); // 소비자가 읽을 때까지 대기
await blocking.writer.write(chunk5); // 소비자가 읽을 때까지 대기
// drop-oldest: 오래된 데이터를 버려 공간 확보
const dropOld = Stream.push({ highWaterMark: 2, backpressure: 'drop-oldest' });
await dropOld.writer.write(chunk1); // ok
await dropOld.writer.write(chunk2); // ok
await dropOld.writer.write(chunk3); // ok, chunk1이 버려짐
// drop-newest: 가득 찼을 때 들어오는 데이터를 버림
const dropNew = Stream.push({ highWaterMark: 2, backpressure: 'drop-newest' });
await dropNew.writer.write(chunk1); // ok
await dropNew.writer.write(chunk2); // ok
await dropNew.writer.write(chunk3); // 조용히 드롭됨
// 명시적 버퍼 관리와 함께 공유
const shared = Stream.share(source, {
highWaterMark: 100,
backpressure: 'strict'
});
const consumer1 = shared.pull();
const consumer2 = shared.pull(decompress);
무제한 버퍼를 숨기는 tee() 대신, 명시적인 멀티 소비자 프리미티브를 제공한다. Stream.share()는 pull 기반이다. 소비자들이 공유 소스에서 pull하고, 버퍼 한도와 백프레셔 정책을 사전에 구성한다.
푸시 기반 멀티 소비자 시나리오를 위한 Stream.broadcast()도 있다. 둘 다 소비자들의 속도가 다를 때 무슨 일이 일어나는지 생각하도록 요구하는데, 이는 숨겨서는 안 되는 현실적 우려다.
모든 스트리밍 워크로드가 I/O를 포함하는 것은 아니다. 소스가 인메모리이고 변환이 순수 함수라면, async 기계장치는 이점 없이 오버헤드만 더한다. 아무도 기다리지 않는데 "기다림"을 조율하는 비용을 지불하는 셈이다.
새 API는 완전한 동기 버전들을 병렬로 제공한다: Stream.pullSync(), Stream.bytesSync(), Stream.textSync() 등. 소스와 변환이 모두 동기라면 프라미스 하나 없이 전체 파이프라인을 처리할 수 있다.
// 비동기 — 소스나 변환이 비동기일 수 있을 때
const textAsync = await Stream.text(source);
// 동기 — 모든 구성요소가 동기일 때
const textSync = Stream.textSync(source);
프라미스가 전혀 없는 완전 동기 파이프라인(압축, 변환, 소비) 예시는 다음과 같다:
// 인메모리 데이터로부터의 동기 소스
const source = Stream.fromSync([inputBuffer]);
// 동기 변환
const compressed = Stream.pullSync(source, zlibCompressSync);
const encrypted = Stream.pullSync(compressed, aesEncryptSync);
// 동기 소비 — 프라미스 없음, 이벤트 루프 왕복 없음
const result = Stream.bytesSync(encrypted);
전체 파이프라인이 단일 호출 스택에서 실행된다. 프라미스가 생성되지 않고, 마이크로태스크 큐 스케줄링이 없으며, 단명 async 기계장치로 인한 GC 압력도 없다. 인메모리 데이터의 파싱, 압축, 변환 같은 CPU 바운드 워크로드에서는, 모든 구성요소가 동기임에도 async 경계를 강제하는 웹 스트림 코드보다 훨씬 빠를 수 있다.
웹 스트림에는 동기 경로가 없다. 소스가 즉시 데이터가 있고 변환이 순수 함수여도 매 연산마다 프라미스 생성과 마이크로태스크 스케줄링 비용을 지불한다. 프라미스는 실제로 기다림이 필요한 경우에 훌륭하지만, 항상 필요한 것은 아니다. 새 API는 필요할 때 동기 세계에 머물 수 있게 해 준다.
async iterator 기반 접근은 이 대안과 웹 스트림 사이의 자연스러운 브리지를 제공한다. 바이트를 yield하도록 설정된 ReadableStream에서 이 새 방식으로 넘어올 때는 readable을 입력으로 넘기기만 하면 기대대로 동작한다:
const readable = getWebReadableStreamSomehow();
const input = Stream.pull(readable, transform1, transform2);
for await (const chunks of input) {
// chunks 처리
}
ReadableStream으로 어댑트할 때는, 대안이 청크 배치를 yield한다는 점 때문에 약간의 작업이 필요하지만, 어댑터 레이어도 쉽게 직관적으로 만들 수 있다:
async function* adapt(input) {
for await (const chunks of input) {
for (const chunk of chunks) {
yield chunk;
}
}
}
const input = Stream.pull(source, transform1, transform2);
const readable = ReadableStream.from(adapt(input));
소비되지 않은 body: pull 의미론에서는 반복하기 전까지 아무 일도 일어나지 않는다. 숨은 리소스 유지가 없다. 스트림을 소비하지 않으면 커넥션을 붙잡는 백그라운드 기계장치도 없다.
tee() 메모리 절벽: Stream.share()는 명시적 버퍼 구성을 요구한다. highWaterMark와 백프레셔 정책을 미리 선택한다. 소비자 속도가 다를 때 조용한 무제한 성장은 없다.
Transform 백프레셔 틈: pull-through 변환은 온디맨드로 실행된다. 데이터가 중간 버퍼를 폭포처럼 채우지 않는다. 소비자가 pull할 때만 흐른다. 반복을 멈추면 처리도 멈춘다.
SSR에서의 GC 난타: 배치 청크(Uint8Array[])가 async 오버헤드를 상각한다. Stream.pullSync() 동기 파이프라인은 CPU 바운드 워크로드에서 프라미스 할당을 완전히 제거한다.
설계 선택은 성능에 영향을 준다. 다음은 가능한 대안의 레퍼런스 구현과 웹 스트림을 비교한 벤치마크( Node.js v24.x, Apple M1 Pro, 10회 평균)이다:
시나리오 대안 웹 스트림 차이
Small chunks (1KB × 5000) ~13 GB/s ~4 GB/s ~3× faster
Tiny chunks (100B × 10000) ~4 GB/s ~450 MB/s ~8× faster
Async iteration (8KB × 1000) ~530 GB/s ~35 GB/s ~15× faster
Chained 3× transforms (8KB × 500) ~275 GB/s ~3 GB/s ~80–90× faster
High-frequency (64B × 20000) ~7.5 GB/s ~280 MB/s ~25× faster
특히 변환 체인 결과가 눈에 띈다. pull-through 의미론은 웹 스트림 파이프라인을 괴롭히는 중간 버퍼링을 제거한다. 각 TransformStream이 내부 버퍼를 eager하게 채우는 대신, 데이터는 소비자에서 소스로 온디맨드로 흐른다.
물론 공정하게 말하면 Node.js는 아직 웹 스트림 구현 성능 최적화에 큰 노력을 기울이지 않았다. 핫 패스를 최적화하면 Node.js의 결과는 크게 개선될 여지가 있다. 그럼에도 Deno와 Bun에서도 이 대안적 iterator 기반 접근이 웹 스트림 구현보다 유의미한 성능 향상을 보인다.
브라우저 벤치마크(Chrome/Blink, 3회 평균)도 일관된 이득을 보여준다:
시나리오 대안 웹 스트림 차이
Push 3KB chunks ~135k ops/s ~24k ops/s ~5–6× faster
Push 100KB chunks ~24k ops/s ~3k ops/s ~7–8× faster
3 transform chain ~4.6k ops/s ~880 ops/s ~5× faster
5 transform chain ~2.4k ops/s ~550 ops/s ~4× faster
bytes() consumption ~73k ops/s ~11k ops/s ~6–7× faster
Async iteration ~1.1M ops/s ~10k ops/s ~40–100× faster
이 벤치마크는 통제된 시나리오에서 처리량을 측정하며, 현실 성능은 구체적 사용 사례에 따라 달라진다. Node.js와 브라우저에서의 이득 차이는 각 환경이 웹 스트림을 최적화하는 경로가 다르기 때문이다.
주목할 점은, 이 벤치마크가 새 API의 순수 TypeScript/JavaScript 구현을 각 런타임의 네이티브(JavaScript/C++/Rust) 웹 스트림 구현과 비교한다는 것이다. 새 API의 레퍼런스 구현은 성능 최적화 작업을 전혀 하지 않았고, 이득은 전적으로 설계에서 나온다. 네이티브 구현이라면 더 큰 개선이 있을 가능성이 높다.
이 이득은 근본 설계 선택이 누적(compound)되는 모습을 보여준다. 배치가 async 오버헤드를 상각하고, pull 의미론이 중간 버퍼링을 제거하며, 데이터가 즉시 उपलब्ध할 때 동기 fast path를 사용할 자유가 모두 기여한다.
"우리는 Node streams에서 성능과 일관성을 개선하기 위해 많은 일을 해 왔지만, 처음부터 다시 시작하는 것에는 독특한 힘이 있다. New streams 접근은 레거시 짐 없이 현대 런타임 현실을 받아들이며, 이는 더 단순하고 성능 좋고 더 일관된 스트림 모델로 가는 문을 연다." - Robert Nagy, Node.js TSC 멤버 및 Node.js streams 기여자
이 글은 대화를 시작하기 위해 공개한다. 무엇을 제대로 했고 무엇을 놓쳤는가? 이 모델에 맞지 않는 사용 사례는 있는가? 마이그레이션 경로는 어떤 모습이어야 하는가? 목표는 웹 스트림의 고통을 느껴본 개발자들로부터, 더 나은 API가 무엇이어야 하는지에 대한 피드백을 모으는 것이다.
이 대안적 접근의 레퍼런스 구현은 지금 이용 가능하며, https://github.com/jasnell/new-streams에서 찾을 수 있다.
API 레퍼런스: 전체 문서는 API.md 참고
예제: samples 디렉터리에 흔한 패턴의 동작 코드가 있다
이슈, 토론, PR을 환영한다. 내가 다루지 못한 웹 스트림 문제를 겪었거나 이 접근에 빈틈이 보인다면 알려 달라. 하지만 다시 말하지만, 여기서의 아이디어는 "반짝이는 새 물건을 다 같이 쓰자"가 아니다. 웹 스트림의 현재 상태를 넘어, 다시 처음 원리로 돌아가 어떤 스트리밍 프리미티브가 필요한지 논의하자는 것이다.
웹 스트림은 아무것도 없던 웹 플랫폼에 스트리밍을 도입한 야심 찬 프로젝트였다. 설계자들은 2014년의 제약 속에서 합리적 선택을 했다. async iteration도 없었고, 프로덕션 경험이 엣지 케이스를 드러내기 전이었다.
하지만 그 이후로 우리는 많은 것을 배웠다. 자바스크립트는 진화했다. 오늘 설계된 스트리밍 API는 더 단순하고, 언어와 더 잘 맞으며, 백프레셔와 멀티 소비자 동작 같은 중요한 것들에 더 명시적일 수 있다.
우리는 더 나은 스트림 API를 누릴 자격이 있다. 그러니 그것이 어떤 모습일지 이야기해 보자.
Cloudflare의 connectivity cloud는 기업 네트워크 전체를 보호하고, 고객이 인터넷 규모 애플리케이션을 효율적으로 구축하도록 돕고, 어떤 웹사이트나 인터넷 애플리케이션도 가속하며, DDoS 공격을 방어하고, 해커를 차단하며, Zero Trust 여정을 지원한다.
어떤 기기에서든 1.1.1.1을 방문해 인터넷을 더 빠르고 안전하게 만드는 무료 앱을 시작해 보자.
더 나은 인터넷을 만들겠다는 우리의 미션에 대해 더 알고 싶다면 여기에서 시작하라. 새로운 커리어 방향을 찾는다면 채용 공고를 확인하라.
StandardsJavaScriptTypeScriptOpen SourceCloudflare WorkersNode.jsPerformanceAPI