XGrammar-2는 에이전트 애플리케이션을 위해 설계된 XGrammar의 대규모 업그레이드로, Structural Tag를 통해 도구 호출·추론 채널·맞춤 출력 구조를 통합하고, 대규모 구조에서도 낮은 오버헤드와 높은 정확도를 제공한다.
![]()
2026년 5월 4일 • MLC Community
요약. XGrammar-2는 에이전트 애플리케이션을 위해 구축된 XGrammar의 대규모 업그레이드입니다. 이는 Structural Tag를 도입해 OpenAI harmony 형식, 도구 호출, 추론 채널, 그리고 모든 맞춤 출력 구조를 통일적으로 표현하는 조합 가능한 JSON 프로토콜을 제공하며, 서빙 엔진의 API를 통해 직접 노출됩니다. 교차 문법 캐싱, 반복 상태 압축, 배치 처리 및 speculative decoding 지원과 같은 여러 효율성 최적화를 통해, 매우 큰 구조에서도 빠른 처리와 최소한의 오버헤드를 보장합니다. XGrammar-2는 선도적인 프런티어 AI 연구소와****선도적인 AI 기업들의 제품에 채택되었습니다. SGLang, vLLM, TensorRT-LLM, 그리고 MLC-LLM은 이를 통합하여 엄격한 도구 호출을 지원하고 API를 통한 맞춤화를 제공합니다.
지난 1년 동안 Claude Code부터 OpenClaw에 이르기까지 에이전트 애플리케이션은 복잡성이 빠르게 증가했습니다. 이러한 시스템은 LLM이 도구 호출이나 구조화된 JSON과 같은 특정 출력 구조를 생성하며 상호작용해야 하는 정교한 하네스 를 정의합니다. 이러한 구조가 더 복잡해질수록, LLM이 이를 안정적으로 따르기는 더욱 어려워집니다.
1년여 전, 우리는 XGrammar를 공개했습니다. XGrammar는 constrained decoding을 사용해 거의 0에 가까운 오버헤드로 100%의 구조적 정확성을 보장합니다. 그 이후 많은 조직과 오픈소스 프로젝트가 XGrammar를 채택했으며, 커뮤니티에서는 활발한 논의와 기여가 이어졌습니다. XGrammar는 이미 JSON 및 기타 일반적인 구조를 효율적으로 처리하지만, 새롭게 등장하는 에이전트 애플리케이션은 훨씬 더 복잡한 구조를 요구하며, 이는 유연성과 효율성 양쪽에서 새로운 과제를 제기합니다.
이러한 과제에 대응하기 위해, 우리는 에이전트 애플리케이션을 위해 특별히 설계된 대규모 업그레이드인 XGrammar-2를 소개하게 되어 매우 기쁩니다. XGrammar-2는 에이전트를 위한 복잡한 구조를 쉽게 표현할 수 있게 해주고, 매우 큰 문법에서도 높은 성능을 제공하며, 크로스플랫폼 네이티브 API를 제공하고, 완전한 하위 호환성도 유지합니다. 이 글에서는 먼저 XGrammar를 간단히 되짚어본 뒤, XGrammar-2의 핵심 기능을 살펴보겠습니다.
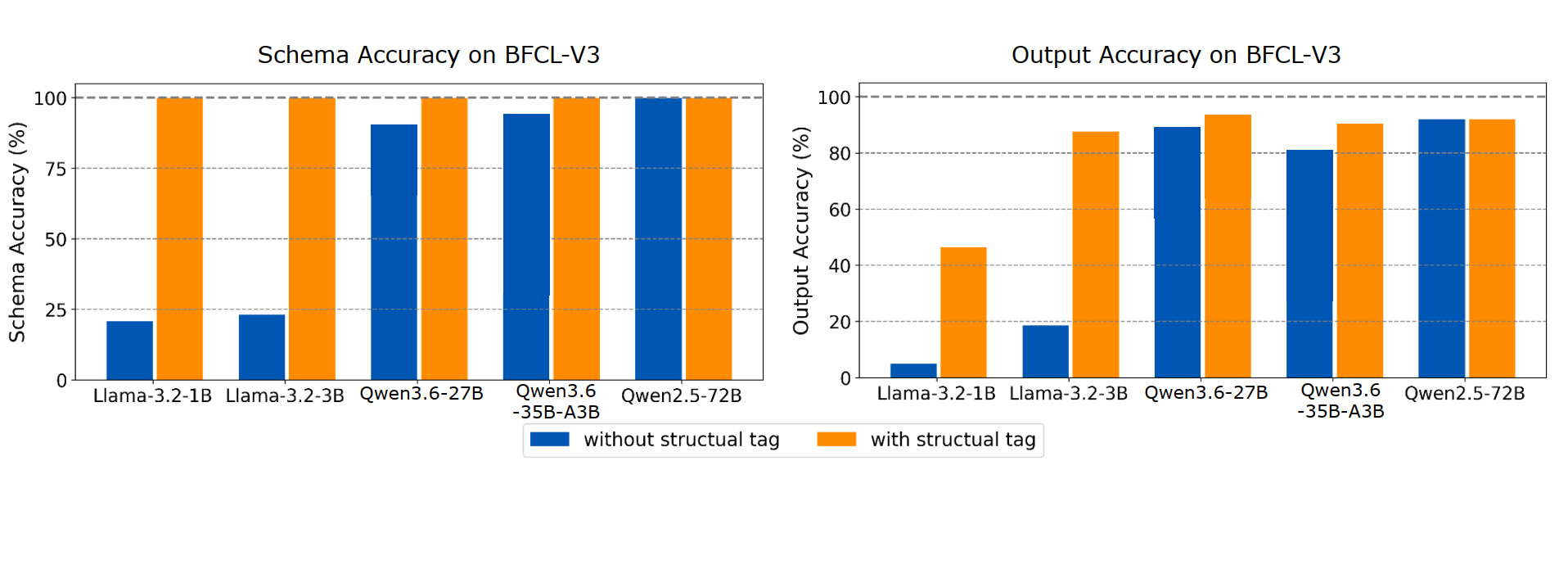
그림 1: XGrammar-2는 100% 스키마 정확도를 달성하며 도구 호출 작업에서 더 높은 엔드투엔드 정확도를 제공합니다.
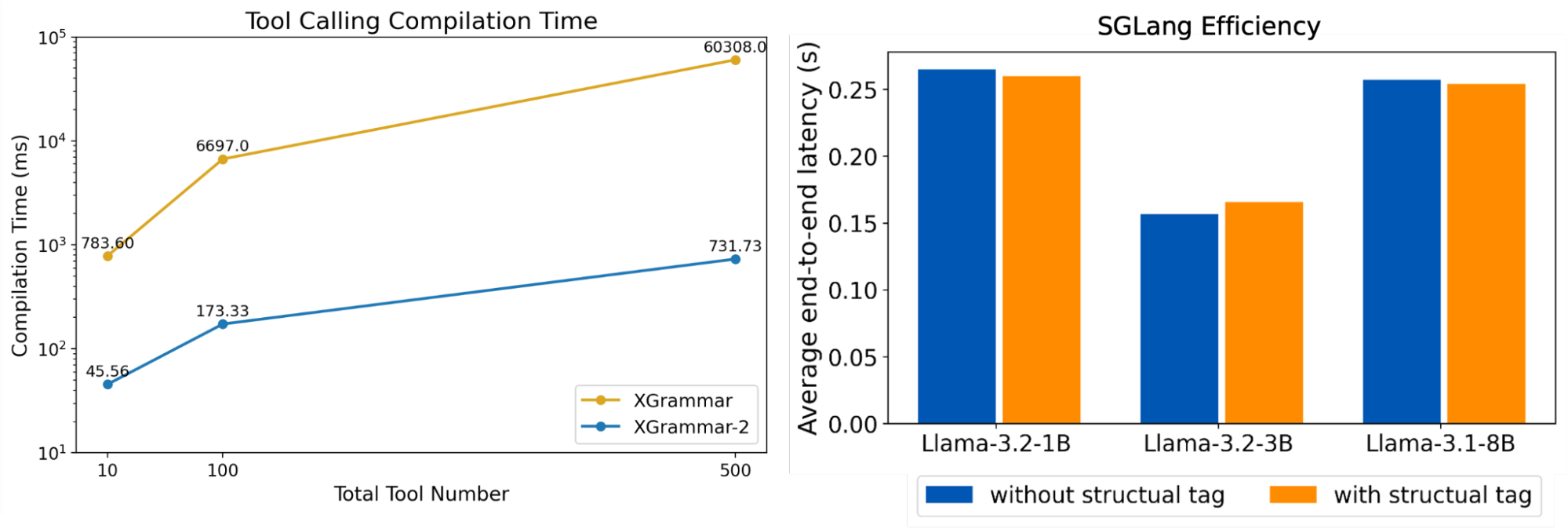
그림 2: XGrammar-2는 XGrammar 대비 최대 80배의 효율 향상을 제공하며, LLM 서빙 시나리오에서 거의 0에 가까운 오버헤드를 달성합니다.
XGrammar는 constrained decoding을 사용하여 LLM 출력이 주어진 구조를 100% 따르도록 보장합니다. 각 디코딩 단계에서 constrained decoding은 구조에 따라 유효하지 않은 토큰을 차단하는 마스크를 생성합니다. 샘플링 중에는 유효하지 않은 토큰에 0의 확률이 할당되므로, 유효한 토큰만 생성됩니다. XGrammar의 핵심 통찰은 컴파일 시점에 효율적인 토큰 마스크 캐시를 사전 계산하는 것이며, 이를 통해 마스크 생성 시간을 크게 줄이고 생성 중 거의 0에 가까운 오버헤드를 달성합니다.
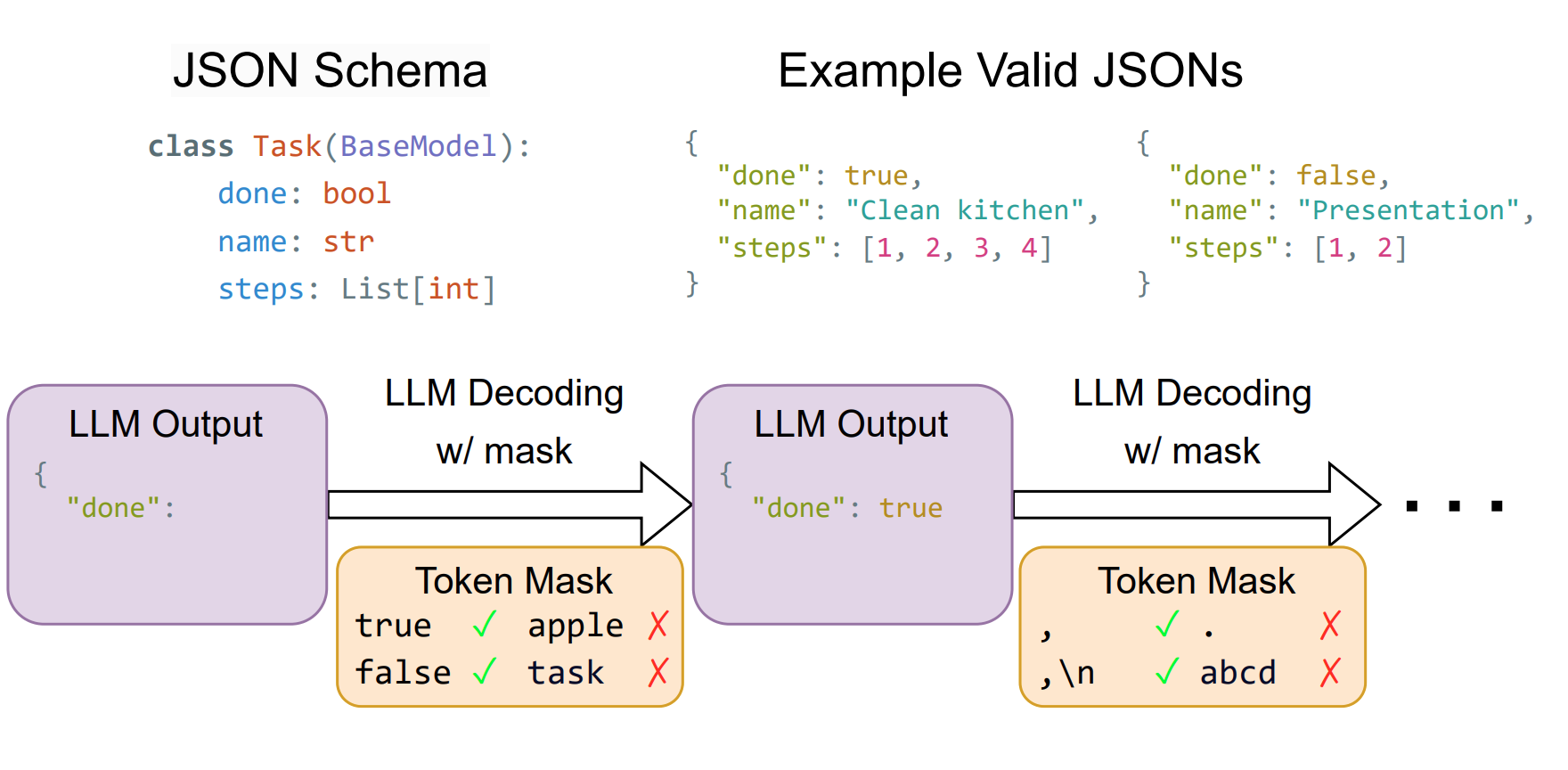
그림 3: Constrained Decoding: JSON Schema로부터 출력 생성
XGrammar는 LLM 응답의 의미를 바꾸기 위한 것이 아니라, 형식 제약을 강제하는 데 가장 적합합니다. 이는 잘못된 형식의 출력으로 인해 후속 프로그램이 치명적으로 실패하는 일을 방지하면서도, 모델 정확도에 미치는 영향을 최소화합니다. 우리의 실험에서 XGrammar는 100% 유효한 도구 호출 형식을 보장했으며, 많은 경우 형식 관련 실패를 제거함으로써 도구 호출 정확도도 향상시켰습니다.
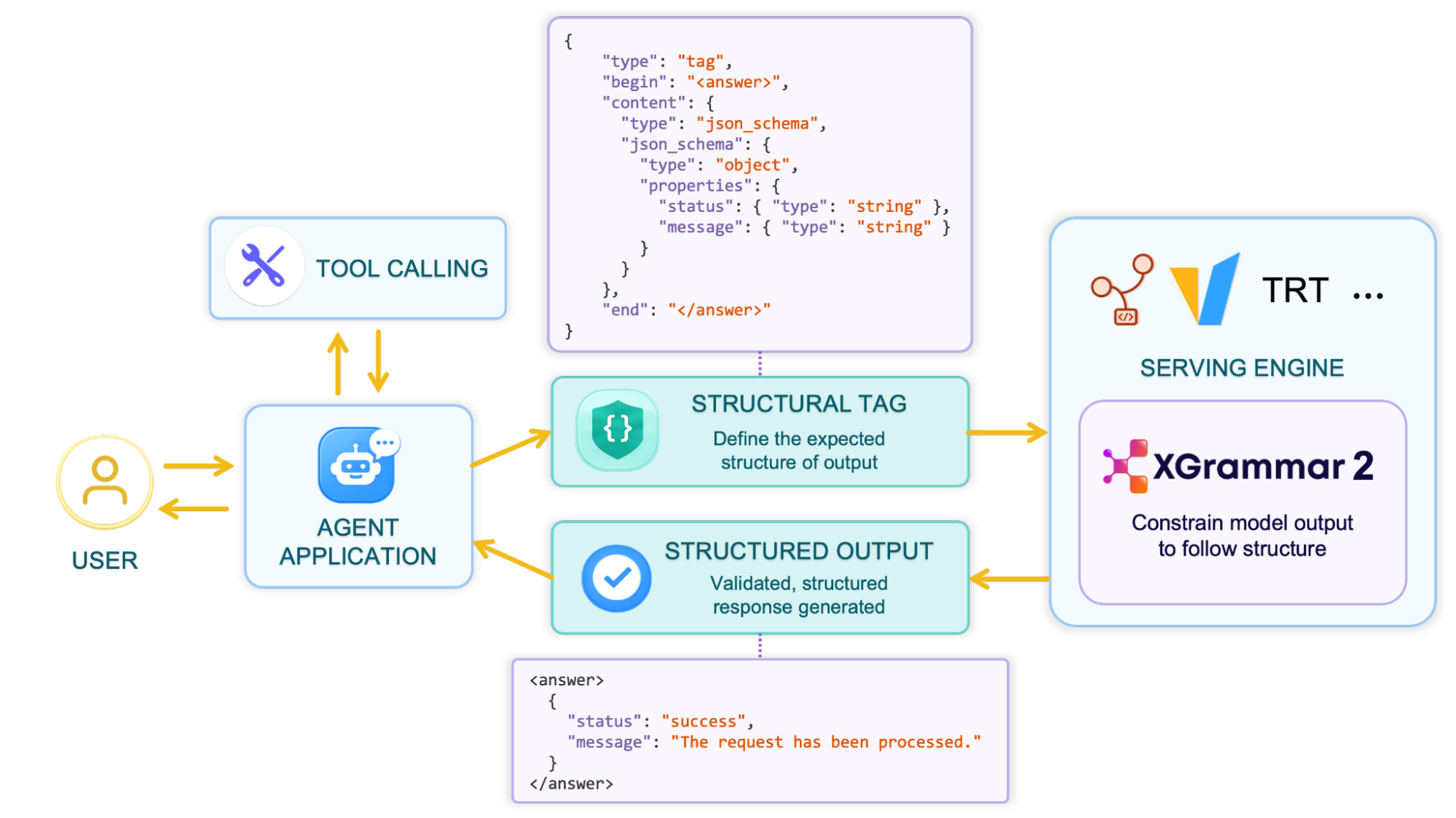
그림 4: Structural Tag의 워크플로우
에이전트 애플리케이션은 LLM이 점점 더 복잡한 형식을 따르도록 요구하고 있습니다. 대표적인 예로 OpenAI Harmony Format이 있는데, 이 형식은 출력을 추론, 도구 호출, 최종 응답 등 여러 채널로 나누며, 각 채널은 고유한 형식을 가집니다. 또한 각 오픈소스 모델도 자체적인 도구 호출 형식을 정의합니다. 이 모든 것을 지원하려면 서빙 엔진과 다운스트림 애플리케이션에 상당한 노력이 필요하며, 그럼에도 공식 사양과 정확히 일치하지 않을 수 있습니다.
XGrammar-2는 Structural Tag를 도입합니다. 이는 JSON 기반 DSL로서, OpenAI Harmony 형식부터 오픈소스 모델의 도구 호출 프로토콜, 그리고 그 외 수많은 맞춤 형식에 이르기까지, 에이전트가 필요로 하는 다양한 구조를 통합적이고 가볍고 확장 가능한 방식으로 기술할 수 있게 해줍니다.
예를 들어, 추론과 도구 호출이 포함된 DeepSeek V4 출력은 다음과 같습니다:
Let me check the weather in Beijing.</think>
I'll look that up for you.
<|DSML|tool_calls>
<|DSML|invoke name="get_weather">
<|DSML|parameter name="city" string="true">Beijing</|DSML|parameter>
</|DSML|invoke>
</|DSML|tool_calls>
여기에는 두 개의 뚜렷한 부분이 있습니다. 첫 번째 부분은
</think>토큰이 나올 때까지 이어지는 자유 형식의 추론입니다. 두 번째 부분은 추가 자유 텍스트이거나 구조화된 도구 호출이며, 모델이
<|DSML|tool_calls>마커를 출력하면 시작됩니다. 이에 대응하는 Structural Tag는 이 두 부분 구조를 직접 포착합니다:
{
"type": "structural_tag",
"format": {
"type": "sequence",
"elements": [
/* Reasoning Part */
{ "type": "tag", "begin": "", "content": { "type": "any_text" }, "end": "</think>" },
/* Output & Tool Calling Part */
{
"type": "triggered_tags",
"triggers": ["<|DSML|tool_calls>"],
"tags": [
{
/* DeepSeek Tool Calling Format */
"type": "tag",
"begin": "<|DSML|tool_calls>\n",
"content": {
"type": "tag",
"begin": "<|DSML|invoke name=\"get_weather\">\n",
"content": {
"type": "json_schema", "json_schema": {...}, "style": "deepseek_xml"
},
"end": "</|DSML|invoke>\n"
},
"end": "</|DSML|tool_calls>\n"
}
],
"excludes": ["<think>", "</think>"]
}
]
}
}
이 예제는 다섯 가지 Structural Tag 타입으로 구성되며, 각각은 명확한 역할을 가집니다:
begin마커, 일부 제약된 콘텐츠, 그리고
end마커에 일치합니다. 여기서 추론 태그는 비어 있는
begin을 가지는데, 이는 채팅 템플릿이 이미 프롬프트에 내용을 덧붙이기 때문입니다. 3. AnyText는 이를 감싸는 태그의
end마커가 나올 때까지 임의의 텍스트에 일치하며, 이는 자유 형식의 추론 콘텐츠에 정확히 필요한 동작입니다. 4. TriggeredTags는 기본적으로 모델이 자유 텍스트를 생성하게 두지만, 일단 트리거 문자열을 출력하면 그 이후 출력은 대응하는 구조화 태그를 따라야 합니다.
excludes필드는
<think>및
</think>가 최종 출력 섹션에 나타나는 것을 막습니다. 5. JSONSchema는 도구의 인자를 주어진 스키마로 제한합니다.
style="deepseek_xml"옵션은 XGrammar에 인자를 원시 JSON이 아니라 DeepSeek의 XML 파라미터 형식으로 기대하라고 알려줍니다.
Structural Tag의 핵심 아이디어는 이러한 타입들이 조합 가능하다는 점입니다. JSON Schema, regex, 리터럴 문자열, 토큰 ID는 모두 이 언어 안에서 일급 원자 타입입니다. 이를 중첩하고 결합함으로써, 단순한 JSON 응답부터 위와 같은 다중 파트의 추론+도구 호출 형식까지, 임의로 복잡한 출력 구조를 기술할 수 있습니다.
XGrammar는 DeepSeek V4, Qwen 3.6, GPT-OSS 등 일반적인 모델을 위한 내장 Structural Tag를 함께 제공합니다. Structural Tag는 이미 SGLang, vLLM, TensorRT-LLM 및 다른 서빙 엔진에 통합되어 있어, 즉시 사용할 수 있는 엄격한 도구 호출 및 추론 지원을 제공합니다.
Structural Tag는 서빙 엔진을 통해 OpenAI 호환 response format으로도 노출되므로, 에이전트 애플리케이션을 위한 자체 출력 구조를 맞춤 설정할 수 있습니다:
# 클라이언트가 호스팅된 vLLM, SGLang, 또는 TensorRT-LLM 서버에 연결되어 있다고 가정합니다.
response = client.chat.completions.create(
model="deepseek-ai/DeepSeek-V4",
messages=[...],
extra_body={
"response_format": {
"type": "structural_tag",
"format": {
"type": "tag",
"begin": "<answer>",
"content": {
"type": "json_schema",
"json_schema": {
"type": "object",
"properties": {
"status": { "type": "string" },
"message": { "type": "string" }
}
}
},
"end": "</answer>",
}
}
}
)예를 들어, 우리는 Molmo-2 모델로 비디오 내 객체를 감지하고 주석이 달린 출력을 렌더링하는 멀티모달 비디오 에이전트를 구축했습니다. 각 객체의 시간 범위, 위치, 이름을 포함한 원하는 형식을 structural tags로 지정함으로써, 다운스트림 처리에서 비디오에 직접 매핑할 수 있는 정밀한 모델 출력을 얻을 수 있습니다.
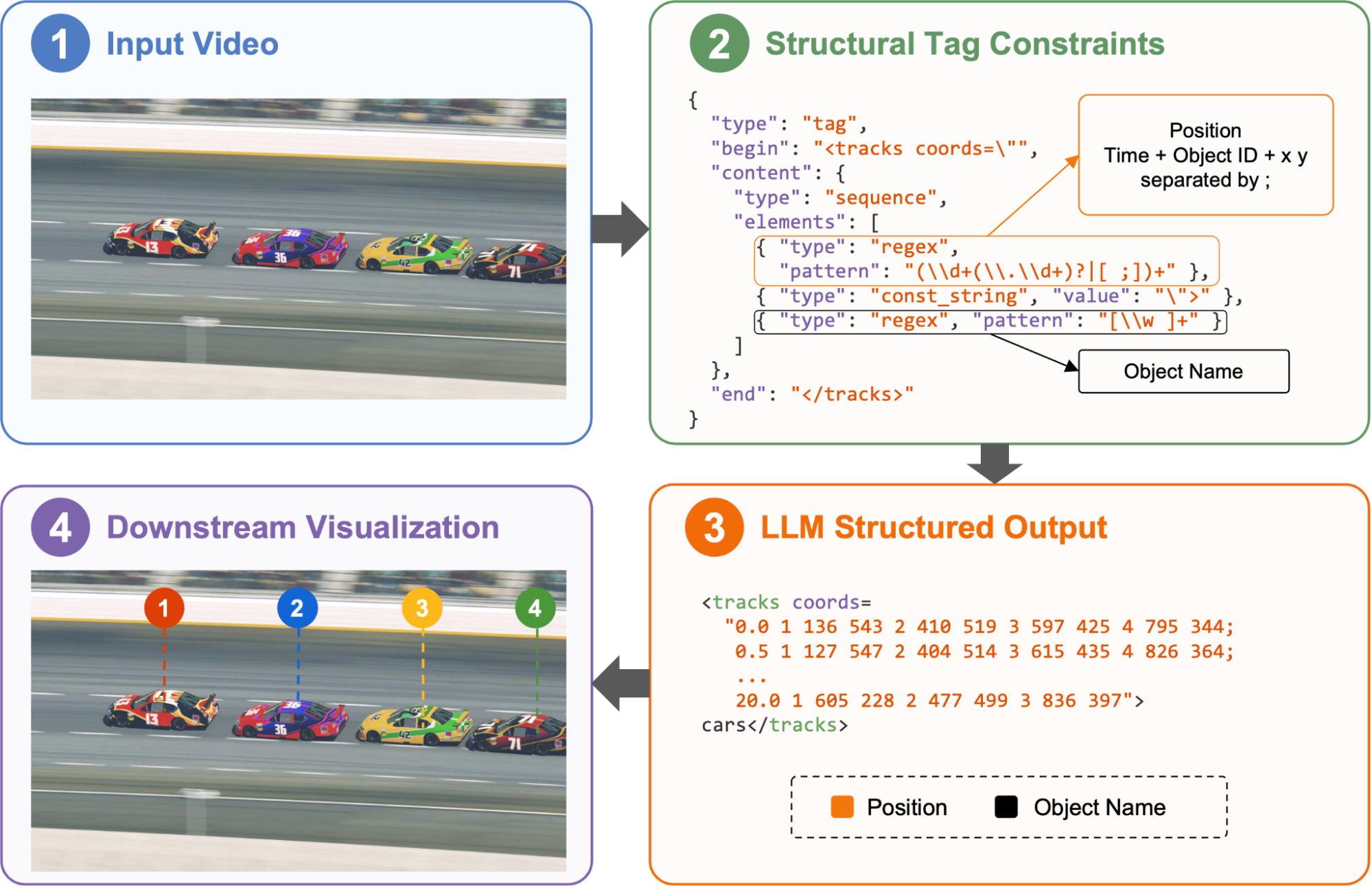
그림 5: 정밀한 출력을 위해 Structural Tags로 구동되는 멀티모달 에이전트
에이전트가 의존하는 구조 역시 점점 더 커지고 있습니다. 특히 도구 호출은 한 세션에서 수십 개, 심지어 수백 개의 도구를 포함할 수 있습니다. 이는 구조화 생성에 막대한 부담을 줍니다. 문법 전처리와 마스크 생성 모두 상당한 오버헤드를 유발해 전체 요청을 느리게 만들기 때문입니다. XGrammar-2는 복잡한 구조를 다루고, 매우 큰 문법에서도 오직 최소한의 오버헤드만 발생하도록 보장하기 위해 일련의 최적화를 도입합니다.
서로 다른 문법 구조와 동일 문법의 서로 다른 부분은 종종 많은 공통 하위 구조를 공유합니다. 예를 들어, 서로 다른 JSON 스키마는 모두
{"type": "string"}으로 기술되는 동일한 문자열 필드를 공유합니다. 이러한 반복 구조는 전처리 중 완전히 재사용될 수 있습니다. XGrammar-2는 오토마톤 기반의 계층적 해싱 알고리즘을 구현하여, 문법 내부와 문법 간의 공유 부분을 자동으로 찾아내고 문법 전처리의 재사용을 극대화합니다. 50개 도구에 대한 JSON Schema 컴파일 실험에서, 거의 50%의 구조가 재사용되는 것으로 나타났습니다.
반복은 많은 구조에서 흔합니다. 예를 들어,
{"type": "array", "maxItems": 1000000}으로 기술되는 최대 1M개 항목의 배열에는 큰 반복 구성 요소가 포함됩니다. 이를 순진하게 처리하면, 이런 문법의 전처리에는
O(repetition_count)시간이 필요합니다. XGrammar-2는 허용되는 반복 횟수와 무관하게 크기가 일정하게 유지되는 새로운 문법 원시 타입 repetition을 도입하여 이를
O(1)로 압축합니다. 또한 이 새로운 원시 타입이 다른 문법 구성 요소만큼 쉽게 처리되도록 특화된 파싱 및 토큰 마스크 캐시 알고리즘도 설계했습니다. 복잡한 JSON schema 구조에서, 우리의 실험은 repetition compression이 압축 시간을 534 ms에서 5.37 ms로 줄여 100배의 시간 절감을 보여주었습니다.
XGrammar-2는 현대적인 서빙 시스템의 핵심 기능인 배치 처리와 speculative decoding도 지원합니다. 배치 처리를 위해, XGrammar-2는 C++ 측에서 여러 문법 상태를 한 번에 유연하게 결합하고 처리할 수 있는 batch APIs를 제공하여, Python 측 루프를 피하고 배치 오버헤드를 줄입니다.
speculative decoding을 위해, XGrammar-2는 draft tree를 한 번 순회하고 모든 노드에 대한 마스크를 생성하는 plaintext traverse_draft_tree 를 제공합니다. 더 세밀한 제어를 위해, 문법 상태를 포크하고 롤백하면서 수동으로 트리를 탐색할 수도 있습니다.
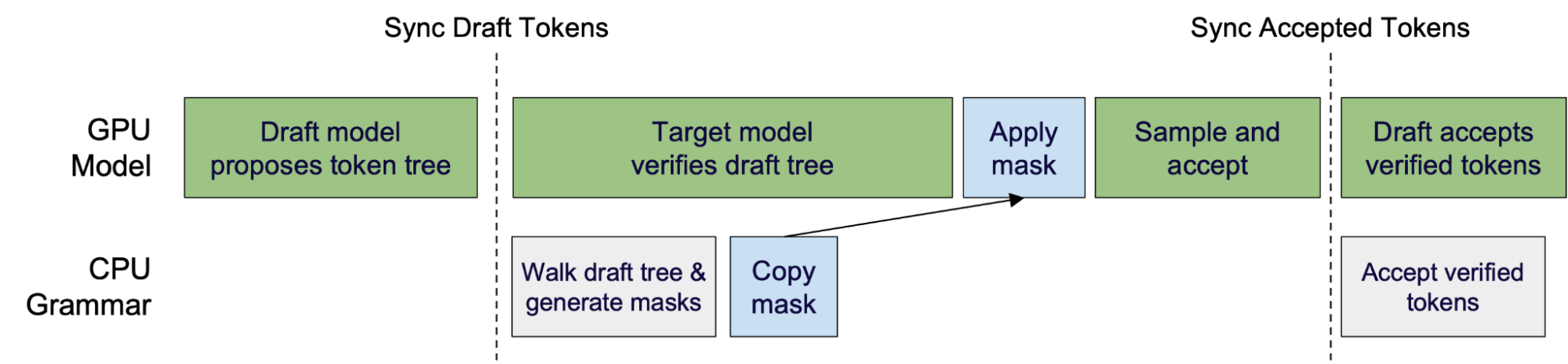
그림 6: Constrained Decoding과 Speculative Decoding을 위한 중첩 패턴
이는 constrained decoding이 speculative decoding과 겹쳐 실행되도록도 해줍니다. 타깃 모델이 GPU에서 draft tree를 검증하는 동안, XGrammar는 CPU에서 동일한 트리를 순회하며 병렬로 마스크를 생성해 오버헤드를 더 줄입니다. 우리는 이 패턴을 speculative decoding 파이프라인에 통합하기 위해 서빙 엔진 팀들과 협업했습니다. 더 자세한 내용은 TensorRT-LLM 팀과 함께한 블로그를 확인해 주세요.
다른 시스템 수준 최적화와 결합하여, XGrammar-2의 성능은 매우 큰 구조에서도 확장 가능하게 유지됩니다.
에이전트는 고성능 서버에서만 배포되지 않습니다. 에지 디바이스, 개인 기기, 그리고 매우 다양한 시스템에서도 실행됩니다. 따라서 우리는 XGrammar-2가 예를 들어 다음과 같은 폭넓은 AI 시스템을 지원하기를 원합니다:
XGrammar-2는 ML 시스템을 위한 개방형 ABI 및 FFI 라이브러리인 TVM-FFI를 활용하여, 이러한 플랫폼 전반에 걸친 통합 지원과 일관된 크로스언어 인터페이스를 제공합니다. 이제 XGrammar-2는 다음을 제공합니다:
우리는 정확도와 효율성 양쪽 측면에서 XGrammar-2를 평가합니다. 정확도 측정을 위해, 규모가 서로 다른 네 가지 대표 모델에 대해 BFCL-V3의 simple 및 parallel 하위 집합을 사용하고, 멀티도구 설정에서 스키마 정확도와 출력 정확도를 모두 측정합니다. Structural Tag는 스키마 정확도를 100%로 향상시켜, 모든 도구 호출이 대상 JSON 스키마를 따르도록 보장합니다. 또한 그림 1에서 보이듯, 특히 소형 모델에서 출력 정확도도 크게 향상됩니다.
효율성 측정을 위해, 도구 수가 10개에서 500개로 증가할 때의 문법 컴파일 시간을 측정합니다. XGrammar-2는 XGrammar 대비 최대 80배의 컴파일 속도 향상을 달성합니다. 또한 XGrammar-2를 SGLang에 통합하고, 동일한 데이터셋과 모델에서 엔드투엔드 요청 지연 시간을 측정합니다. 워밍업이 적용되고 출력 길이가 유사한 단일 배치 설정에서, Structural Tag는 그림 2와 같이 최소한의 지연 시간 오버헤드만 추가합니다.
전반적으로 XGrammar-2는 오버헤드를 최소로 유지하면서 스키마 신뢰성과 도구 호출 정확도를 모두 향상시키며, 신뢰할 수 있는 도구 사용에 의존하는 에이전트 애플리케이션에 매우 적합합니다. 평가 스크립트는 블로그 말미에서 확인할 수 있습니다.
우리는 에이전트 애플리케이션에 대한 포괄적인 지원을 제공하도록 설계된 일련의 새로운 추상화와 최적화를 담은 릴리스, XGrammar-2를 소개했습니다.
XGrammar-2는 최신 모델에 선도적인 프런티어 AI 연구소들이 채택했으며, 제품에는 선도적인 AI 기업들이 도입했습니다. 협업 파트너 목록은 collaborator list를 확인해 주세요.
XGrammar-2는 SGLang, vLLM, TensorRT-LLM, 그리고 MLC-LLM을 포함한 주류 LLM 서빙 엔진에 통합되었습니다. XGrammar는 이러한 엔진이 DeepSeek V4 및 Qwen 3.6과 같은 인기 모델에 대해 strict mode 도구 호출을 지원하도록 해주며, 이는 API 호출을 통해 직접 사용할 수 있습니다. 이러한 모델은 또한 요청의
response_format필드에서 Structural Tag를 사용해 맞춤 형식의 출력을 생성하는 요청도 지원합니다.
앞으로 우리는 파트너들과 협력하여 XGrammar를 더욱 많은 환경으로 확장해 나갈 계획입니다. 우리는 에이전트 하네스를 위한 견고한 기반을 제공하고, 다양한 에이전트 애플리케이션 생태계를 위한 토대를 마련하는 데 전념하고 있습니다. 시작하거나 더 알아보려면 다음 자료를 확인해 주세요:
우리는 xAI, Databricks, DeepSeek Infra, Google Vertex AI, RadixArk, SGLang, TensorRT-LLM, vLLM 팀과 기타 협업자들의 지원과 협력에 깊이 감사드립니다. 또한 Ke Bao, Ben Browning, Russell Bryant, Bingqing Chen, Jeffrey Chen, Lequn Chen, Cade Daniel, Flora Feng, Michael Goin, Hanchen Li, Jialin Ouyang, Aaron Pham, Alex Trotta, Xinyuan Tong, Lion Ushiromiya, Qingyuan Wang, Xingbo Wang, Yi Wang, Ying Wang, Kan Wu, Liangsheng Yin, Chenyang Yu, Lianmin Zheng, Qi Zheng, Enwei Zhu, Ligeng Zhu께도 엔지니어링 지원, 통합 작업, 논의, 검토, 그리고 피드백에 대해 감사드립니다. 마지막으로 CUDA graph를 활용한 speculative decoding 지원에서 협력해 준 TensorRT-LLM 팀에도 감사드립니다.