신경망이 영상과 제어입력을 바탕으로 생성하는 새로운 방식의 가상 세계 구현 사례와 그 의미에 대한 탐구를 다룹니다. 본문에서는 실제 숲길 데이터를 활용한 신경 세계 구축 사례를 소개하며, 전통적 게임 제작 방식과 신경망 기반 세계의 차이점도 논의합니다.
아파트 근처 숲길을 플레이 가능한 신경망 세계로 변환해봤습니다. 웹 브라우저에서 그 세계를 여기에서 바로 체험할 수 있습니다.
"신경 세계"란, 이전 영상과 조작 데이터를 입력으로 받아 신경망이 새로운 영상을 생성하는 구조입니다. 레벨 지오메트리도, 조명이나 그림자 계산 코드도, 스크립트 애니메이션도 없습니다. 오로지 루프 속의 신경망뿐입니다.
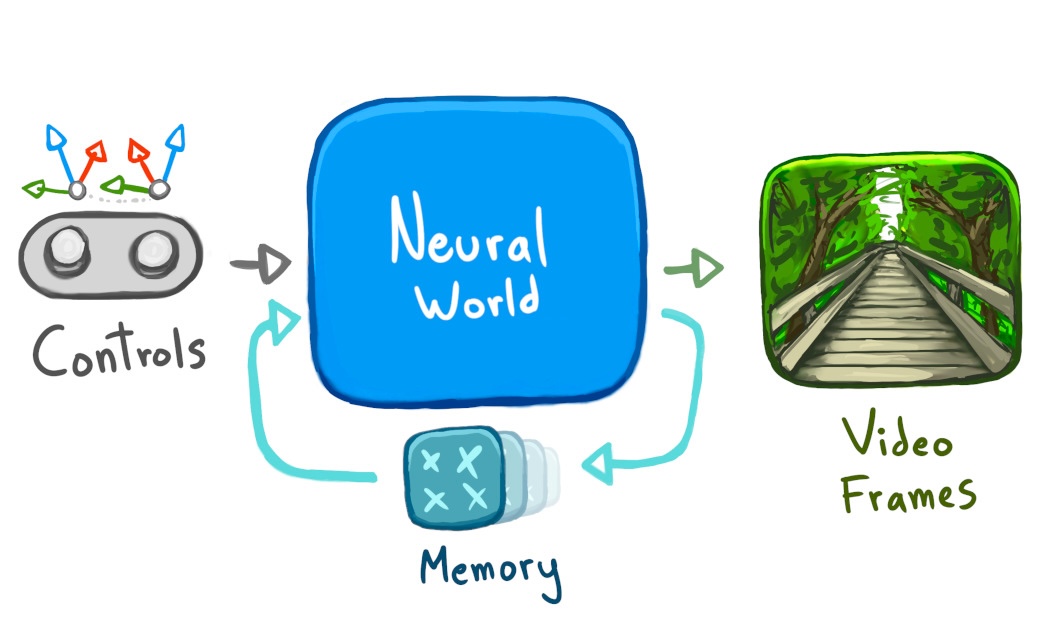
또 “웹 브라우저에서”란 의미는, 이 세계가 _여러분 기기 내_에서 돌아간다는 의미입니다. 한 번 로드만 하면 비행기 모드에서도 탐험을 계속할 수 있습니다.
개념적으로 흥미로운 이유들이 있습니다만(나중에 설명), 결국 제 목적은 전보다 더 멋진 결과를 내고 싶은 욕심이었습니다.
3년 전쯤, 이전 글에서 유튜브 게임플레이 영상을 학습시켜 2D 게임 세계를 브라우저에서 신경망으로 구현해봤습니다.
2D 게임 세계 모방은 귀엽지만 쓸모는 떨어졌습니다. 이미 그 게임은 원본이 있고, 에뮬레이션도 잘 됩니다.
신경망 기반 세계의 멋지고 독특한 점은 아무 영상 파일 이면 무엇이든 세계로 만들 수 있다는 겁니다. 오래된 게임 화면 영상만이 아니라 말이죠. 전 글에선 이 부분이 잘 드러나지 못했습니다.
그래서 이번엔, 신경망의 특별함을 보여주고자, 실제 세계(현실)의 플레이 영상을 학습 데이터로 삼았습니다.
먼저, 숲길을 걸으며 휴대폰으로 영상을 녹화했고, 전용 카메라 앱을 써서 기기의 움직임 정보도 함께 저장했습니다.
15분 정도의 영상과 움직임을 모았습니다. 왼쪽엔 ‘걷기’ 조이스틱, 오른쪽엔 ‘보기’ 조이스틱처럼 모션 데이터를 시각화했습니다.
녹화를 노트북에 옮긴 뒤, (이전 프레임, 조작 → 다음 프레임) 쌍 목록으로 섞었습니다. 게임 에뮬레이션 때와 똑같은 포맷입니다.
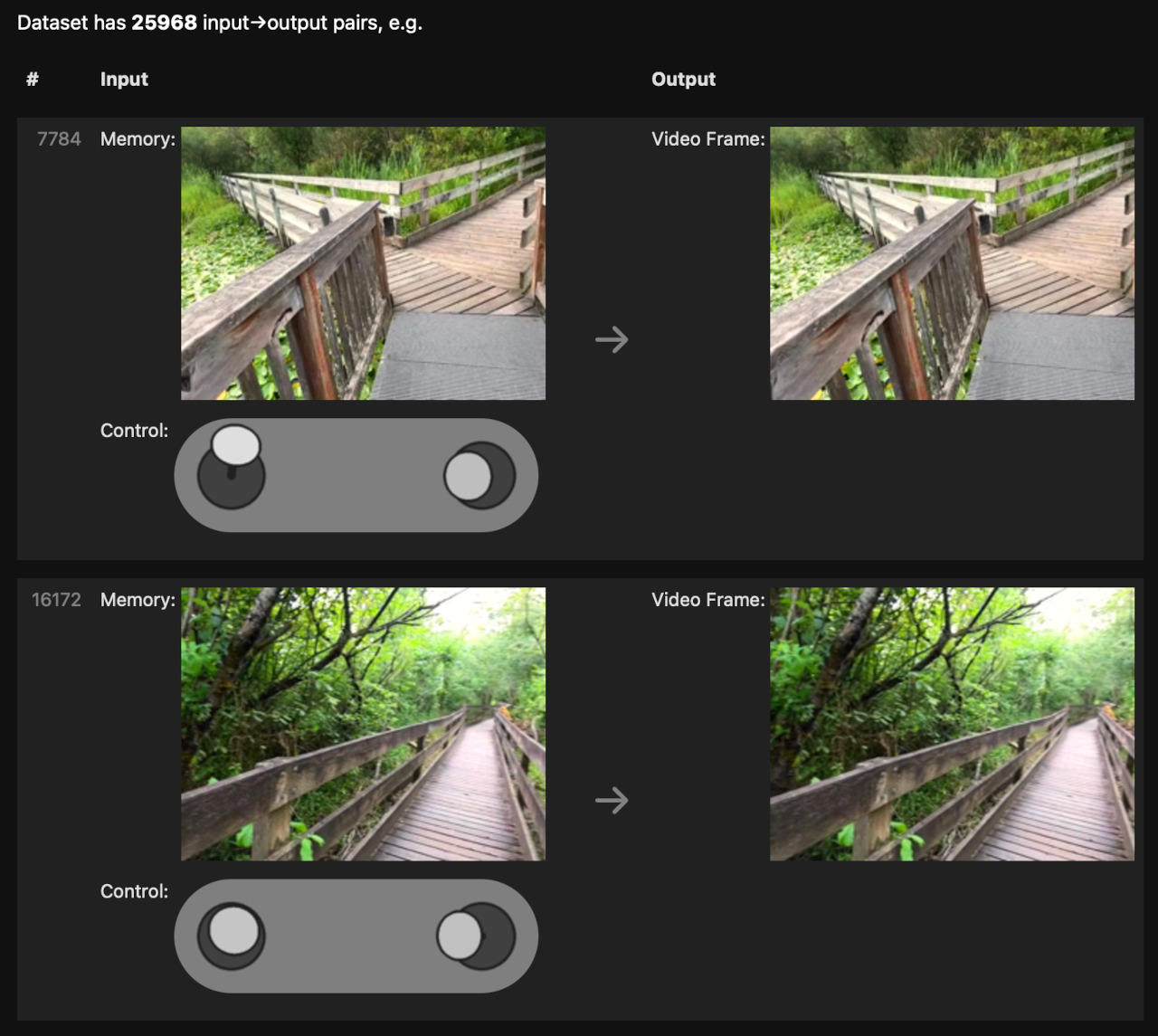
이제 남은 일은 신경망에게 이 입력→출력 쌍 행동을 학습시키는 것뿐. 이미 전작에서 잘 돌아가는 코드를 갖고 있었기에, 우선 그 코드를 그대로 실행해봤습니다.
게임 영상을 흉내 내던 기존 신경망 레시피를 이 데이터셋에 적용하자, 아쉽게도 ‘상호작용 가능한 숲맛 수프’만 만들어졌습니다.
신경망이 실제 다음 프레임 예측도 못 하고, 새로운 세부 묘사 생성도 느려서, 실행하면 세계가 금방 붕괴했습니다(초기 프레임을 진짜 영상을 써서 시작해도 마찬가지).
좌절하지 않고, 신경세계 훈련용 새로운 코드 작업에 들어갔습니다.
실세계 영상을 더 잘 이해시키기 위해 아래와 같이 개선했습니다:
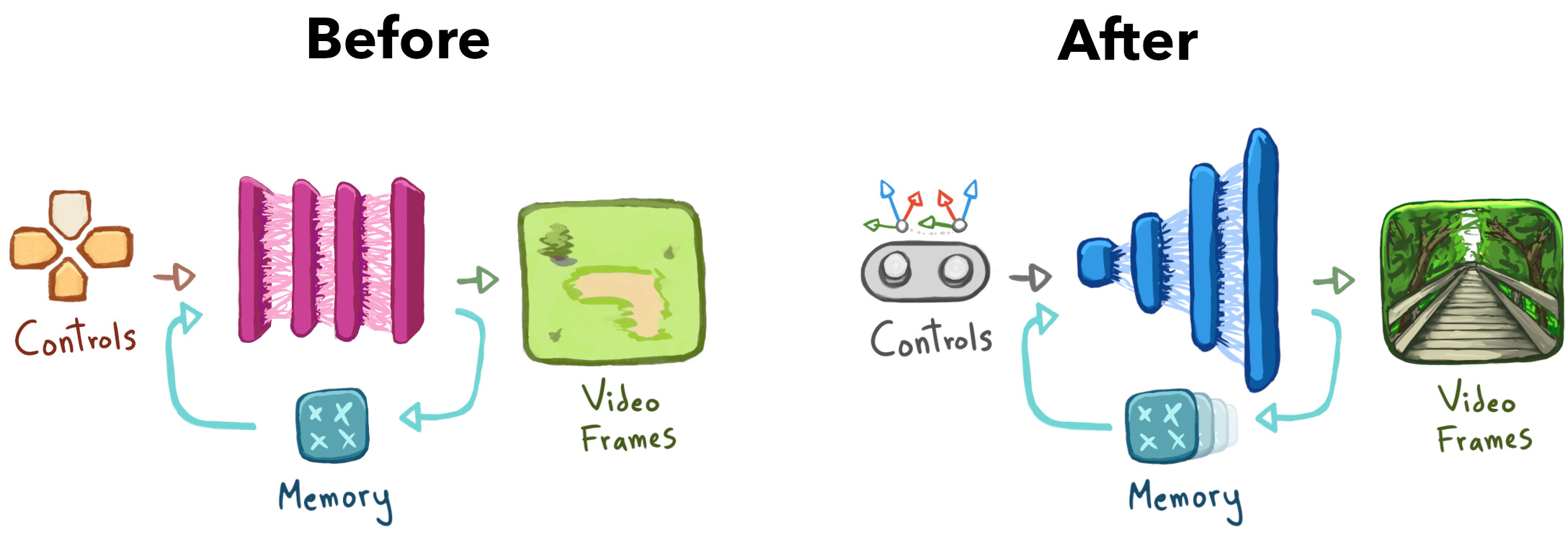
이 업그레이드 덕분에 붕괴는 막았고, 반쯤 완성된 데모를 얻었습니다.
이건 큰 진전이었지만, 여전히 세계가 덜 녹은 상태라 2차 개선 작업을 시작했습니다(이번엔 살짝 좌절...).
이번엔 입출력 구조는 유지하고, 학습 방식에 소소한 개선을 시도했습니다. 여기서 가장 영향이 컸던 것은:
최종 숲세계 레시피는 다음과 같습니다:

낮은 해상도의 신경 세계에 수십 시간을 투자한 이유는 뭘까요? 좀 더 전통적이고 선명한 결과물을 만들려는 시도가 더 효율적이지 않을까요?
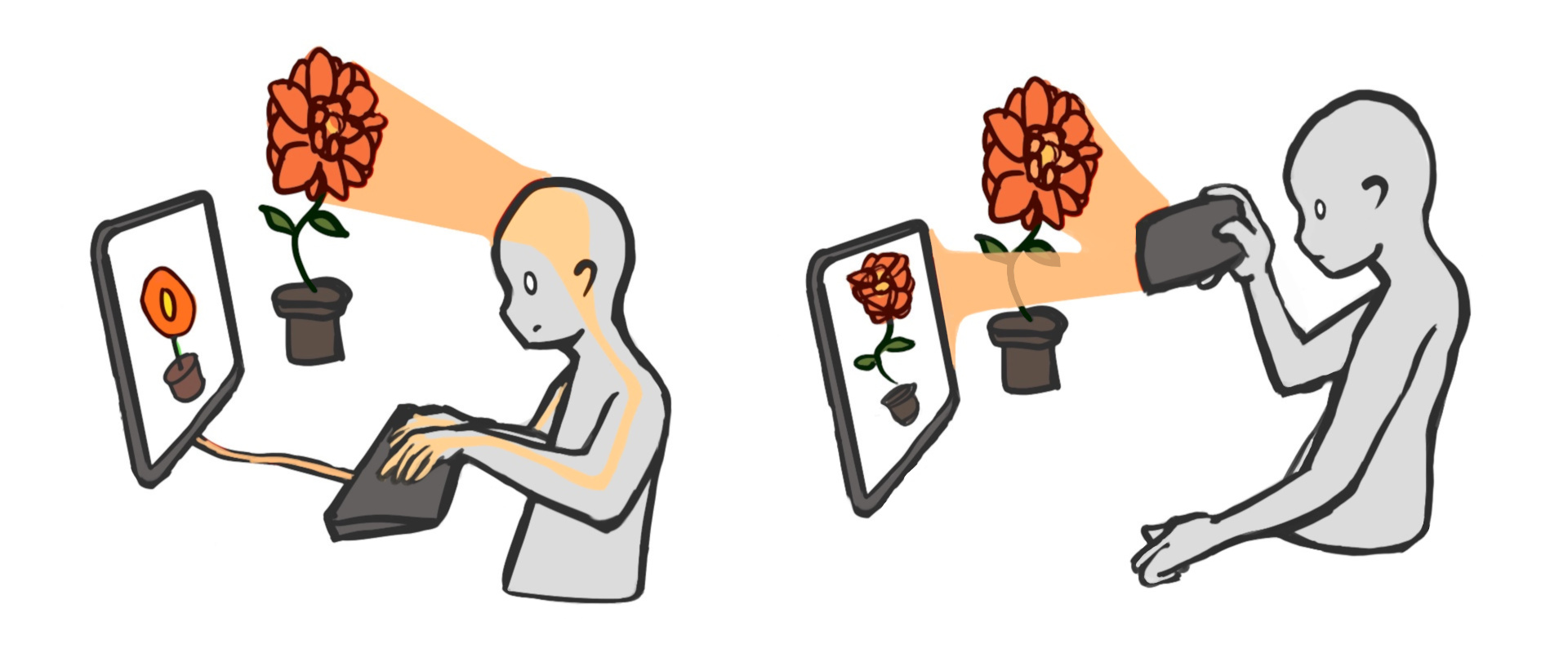
전통적 게임 세계는 그림 그리듯 만듭니다. 빈 캔버스에 키스트로크를 쌓아 생동감 있는 모습을 얻습니다. 모든 디테일은 아티스트가 직접 그려서 존재합니다.
신경 세계는 완전히 다릅니다. 숲 세계를 만들려면 실제 숲에 들어가 단지 ‘녹화’ 버튼만 누르면 됩니다. 모든 디테일은 단지 스마트폰이 녹화하여 들어온 것입니다.
즉, 전통적 세계가 ‘그림’이라면 신경 세계는 ‘사진’과 같습니다. 정보가 센서→화면으로 사람 손을 거치지 않고 흐릅니다.
물론 지금 시점의 신경 세계는 아주 초기 사진과 닮았습니다. 초기 카메라는 제대로 작동하는지조차 불확실했고, 사진도 거의 실물과 달랐습니다.

하지만 중요한 것은, 카메라는 예술가의 문제였던 ‘현실 감각’ 재현 문제를 기술적 문제로 전환시켰다는 점입니다. 기술이 발전하며 사진도 점점 더 현실적이 되었으나, 그림은 그렇지 않았죠.

저는 신경 세계도 언젠가 사진처럼 화질이 발전할 것이라 믿습니다. 결국은 바람에 나뭇가지가 흔들리고, 빗방울에 연잎이 출렁이며, 새들이 서로 지저귀는 세계도 그려낼 수 있겠지요. 그건 예술가가 그려서가 아니라, 실제 세계를 ‘기록’하므로 가능한 일입니다.
그리고 언젠가 신경 세계 저작 도구가 카메라만큼이나 간편해질 수도 있다고 생각합니다. 버튼 한 번이면 영상이나 이미지를 얻듯, ‘세계 만들기’ 도구가 생길 수도 있겠죠.
신경 세계가 사진만큼 생생하고 저렴하며 조합 가능해진다면, 그 자체로 서사적 연출의 매체가 될지도 모릅니다. 어쩌면 사진이 그림과 달랐듯, 신경 세계는 오늘날의 비디오게임과도 다른 새로운 창작 방식이 될 수 있습니다.
그 미래가 정말 기대됩니다!
세계 자체를 모델링하는 신경망은 대개 "world model"(세계 모델)이라 부르며, 많은 연구자들이 이 분야에 도전해 왔습니다. 대표적인 예시로 Comma의 "Learning a Driving Simulator", 최근엔 OpenDriveLabs의 Vista, Wayve의 GAIA-2 등이 있습니다. 직접 세계모델을 학습해보고 싶다면 DIAMOND나 Diffusion Forcing 프로젝트를 참고해볼 만합니다.
본 글에서 소개한 GAN 기반 세계 모델은 수십억 파라미터의 “Foundation World Model”에 비하면 토이 수준(그것도 꽤 불안정)입니다. 그래도 레시피를 더 개선하고 새로운 세계 여러 개를 만드는 것도 즐거운 일일 겁니다. 혹시 시애틀 근교에서 신경 세계로 남기고픈 장소가 있다면, 연락 주세요!