이 글은 vLLM의 코어 구성 요소와 고급 기능(스케줄링, PagedAttention, 연속 배칭, 청크 프리필, 프리픽스 캐싱, 가이드·추측 디코딩, 프리필/디코드 분리), 단일 GPU에서 다중 GPU·멀티 노드 분산 서빙까지 확장하는 방법, 그리고 벤치마크·오토튜닝으로 지연시간과 처리량을 측정·최적화하는 과정을 체계적으로 설명합니다.
이 글에서는 현대의 초고처리량 LLM 추론 시스템을 구성하는 핵심 시스템 컴포넌트와 고급 기능을 점진적으로 소개합니다. 특히 vLLM [1]이 어떻게 작동하는지 분해해 설명합니다.
이 글은 연재의 첫 번째 글입니다. 먼저 큰 그림을 제시하고(역피라미드 접근) 점차 세부를 쌓아 올리며, 자질구레한 부분에 빠지지 않고도 전체 시스템의 정확한 고수준 멘탈 모델을 형성할 수 있도록 합니다.
후속 글에서는 특정 서브시스템을 더 깊게 파고들 예정입니다.
이 글은 다섯 부분으로 구성되어 있습니다:
📝메모
LLM 엔진은 vLLM의 근본 빌딩 블록입니다. 이 자체만으로도 오프라인 환경에서는 고처리량 추론이 가능합니다. 다만 아직 웹으로 고객에게 서빙할 수는 없습니다.
다음 오프라인 추론 스니펫을 러닝 예제로 사용합니다(basic.py에서 변형).
from vllm import LLM, SamplingParams
prompts = [
"Hello, my name is",
"The president of the United States is",
]
sampling_params = SamplingParams(temperature=0.8, top_p=0.95)
def main():
llm = LLM(model="TinyLlama/TinyLlama-1.1B-Chat-v1.0")
outputs = llm.generate(prompts, sampling_params)
if __name__ == "__main__":
main()
📝환경 변수:
이 구성은 다음과 같습니다:
여기서부터 표준 트랜스포머를 서빙하되, 온라인·비동기·다중 GPU·멀티 노드 추론 시스템으로 점차 확장해 나가겠습니다.
이 예제에서 하는 일은 두 가지입니다:
generate를 호출해 주어진 프롬프트에서 샘플링생성자를 분석하는 것부터 시작합니다.
엔진의 주요 구성 요소는 다음과 같습니다:
EngineCoreRequests로 변환)InprocClient를 사용하며 사실상 EngineCore와 동일합니다. 점차 확장해 대규모 서빙이 가능한 DPLBAsyncMPClient로 나아가겠습니다.)EngineCoreOutputs → 사용자에게 보이는 RequestOutput으로 변환)📝메모:
V0 엔진이 deprecated됨에 따라 클래스 이름과 세부가 변할 수 있습니다. 여기서는 정확한 시그니처보다는 핵심 아이디어를 강조합니다. 일부 세부는 추상화하지만 전부는 아닙니다.
엔진 코어는 다음 서브 컴포넌트로 구성됩니다:
Worker 프로세스를 가진 UniProcExecutor를 다룹니다.) 이후 여러 GPU를 지원하는 MultiProcExecutor까지 확장합니다.waiting 및 running 큐KV-캐시 매니저는 free_block_queue를 유지합니다 — 사용 가능한 KV-캐시 블록 풀(보통 VRAM 크기와 블록 크기에 따라 수십만 개 규모). PagedAttention 동안 블록은 토큰을 해당 계산된 KV 캐시 블록에 매핑하는 인덱싱 구조로 쓰입니다.
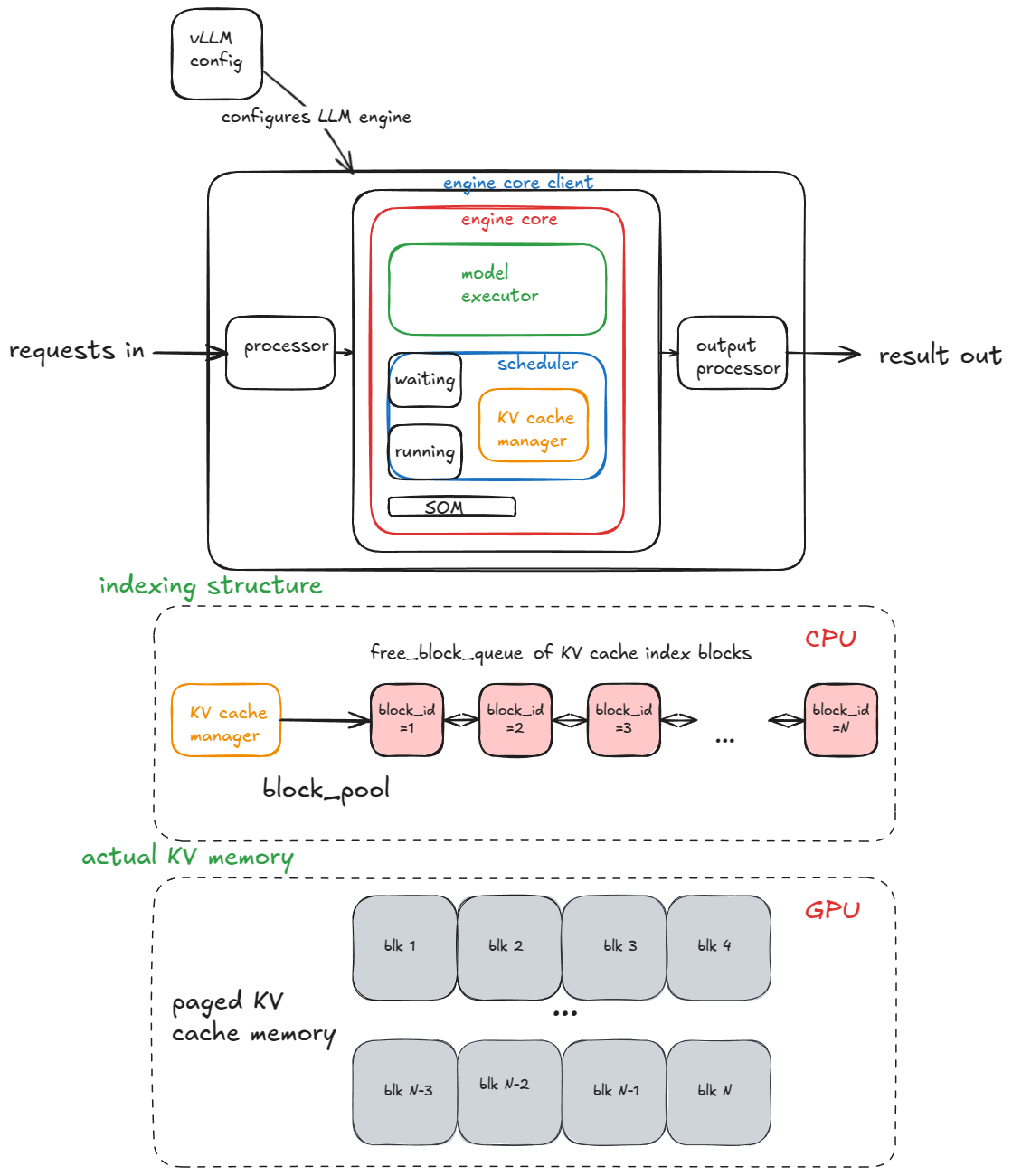
이 섹션에서 설명한 코어 컴포넌트와 그 관계
표준 트랜스포머 레이어(MLA 아님 [4])의 블록 크기는 다음과 같이 계산됩니다:
2 * block_size(기본=16) * num_kv_heads * head_size * dtype_num_bytes(bf16이면 2)
모델 실행기 구성 시 Worker 객체가 생성되고 세 가지 핵심 절차가 실행됩니다. (나중에 MultiProcExecutor에서는 동일한 절차가 서로 다른 GPU의 각 워커 프로세스에서 독립적으로 실행됩니다.)
디바이스 초기화:
* 워커에 CUDA 디바이스 할당(예: "cuda:0"), 모델 dtype 지원 여부 확인(예: bf16)
* 요청된 gpu_memory_utilization(예: 0.8 → 총 VRAM의 80%)을 고려해 충분한 VRAM이 있는지 검증
* 분산 설정 구성(DP / TP / PP / EP 등)
* model_runner 인스턴스화(샘플러, KV 캐시, input_ids, positions 등 forward 버퍼 보유)
* InputBatch 객체 인스턴스화(CPU 측 forward 버퍼, KV-캐시 인덱싱용 블록 테이블, 샘플링 메타데이터 등 보유)
모델 로드: * 모델 아키텍처 인스턴스화 * 모델 가중치 로드 * model.eval() 호출(PyTorch 추론 모드) * 선택: torch.compile() 호출
KV 캐시 초기화:
* 레이어별 KV-캐시 스펙을 가져옵니다. 과거에는 항상 FullAttentionSpec(동질 트랜스포머)이었지만, 하이브리드 모델(슬라이딩 윈도, Transformer/SSM 혼합인 Jamba 등)로 복잡해졌습니다(Jenga 참고 [5]).
* 더미/프로파일링 forward를 실행하고 GPU 메모리 스냅샷을 통해 사용 가능한 VRAM에 몇 개의 KV 캐시 블록이 들어가는지 계산
* KV 캐시 텐서를 할당·리쉐이프하고 어텐션 레이어에 바인딩
* 어텐션 메타데이터 준비(예: 백엔드를 FlashAttention으로 설정) — forward 중 커널이 소비
* --enforce-eager가 없으면, 여러 워밍업 배치 크기에 대해 더미 실행을 하고 CUDA 그래프를 캡처합니다. CUDA 그래프는 GPU 작업 전체 시퀀스를 DAG로 기록합니다. 이후 forward에서 미리 구운 그래프를 재생·런치함으로써 커널 런치 오버헤드를 줄여 지연시간을 개선합니다.
여기서 많은 로우레벨 세부는 생략했지만, 이후 섹션에서 반복 참조할 핵심 조각들을 먼저 소개했습니다.
이제 엔진 초기화가 끝났으니 generate 함수로 넘어가겠습니다.
첫 단계는 요청을 검증하고 엔진에 주입하는 것입니다. 각 프롬프트에 대해 다음을 수행합니다:
prompt, prompt_token_ids, type(text, tokens, embeds 등)을 담은 딕셔너리를 반환EngineCoreRequest로 패킹Request 객체로 감싸고 상태를 WAITING으로 설정. 그런 뒤 해당 요청을 스케줄러의 waiting 큐에 추가(FCFS면 append, priority면 힙 push)이 시점에서 엔진은 피드되었고 실행을 시작할 수 있습니다. 동기 엔진 예제에서는 이러한 초기 프롬프트만 처리합니다 — 실행 도중 새로운 요청을 주입하는 메커니즘이 없습니다. 반대로 비동기 엔진은 이를 지원합니다(즉, 연속 배칭[6]): 각 스텝 후에 새 요청과 기존 요청을 모두 고려합니다.
forward 패스가 배치를 하나의 시퀀스로 납작하게(flatten) 만들고 커스텀 커널이 이를 효율적으로 다루기 때문에, 연속 배칭은 동기 엔진에서도 근본적으로 지원됩니다.
다음으로, 처리할 요청이 있는 동안 엔진은 반복적으로 step() 함수를 호출합니다. 각 스텝은 세 단계로 구성됩니다:
Request에 추가, 디토크나이즈, 종료 조건 확인. 요청이 완료되면 정리(예: 해당 KV-캐시 블록을 free_block_queue로 반환)하고 출력을 조기 반환📝종료(중지) 조건:
max_model_length 또는 자체 max_tokens)ignore_eos가 활성화되면 예외 → 특정 개수의 출력 토큰 생성을 강제하고 싶은 벤치마크에 유용)stop_token_ids 중 하나와 일치stop_token_ids는 출력에 남지만 스톱 문자열은 남지 않음)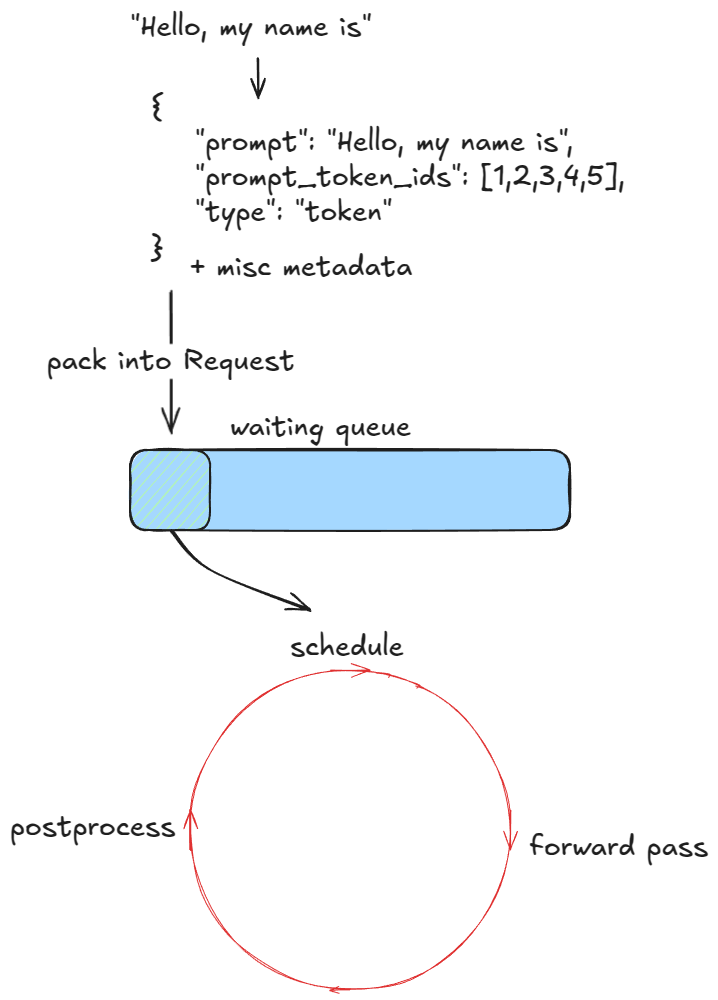
엔진 루프
스트리밍 모드에서는 생성되는 즉시 중간 토큰을 전송하지만, 여기서는 무시하겠습니다.
다음으로 스케줄링을 자세히 봅니다.
추론 엔진이 처리하는 워크로드 유형은 두 가지입니다:
벤치마크 섹션에서 GPU 성능의 so-called roofline 모델을 분석합니다. 프리필/디코드 성능 프로파일의 배경을 더 자세히 설명합니다.
V1 스케줄러는 더 영리한 설계 덕분에 같은 스텝 안에서 두 유형의 요청을 혼합 처리할 수 있습니다. 반면 V0 엔진은 프리필 또는 디코드 중 하나만 동시에 처리할 수 있었습니다.
스케줄러는 디코드 요청 — 즉 running 큐에 이미 들어 있는 요청 — 을 우선합니다. 각 요청에 대해:
allocate_slots 함수 호출(아래에 자세히).이후 waiting 큐의 프리필 요청을 처리할 때는:
allocate_slots 호출.RUNNING으로 설정.이제 allocate_slots가 무엇을 하는지 봅시다:
n) 개수를 결정. 각 블록은 기본적으로 16 토큰 저장. 예를 들어 프리필 요청의 신규 토큰이 17개면 ceil(17/16) = 2 블록이 필요.kv_cache_manager.free 호출로 블록을 블록 풀에 반환), 또는 스케줄링을 건너뛰고 실행을 이어갈 수 있음.free_block_queue 양방향 연결 리스트)에서 처음 n개 블록을 가져옴. 이를 req_to_blocks(각 request_id를 해당 KV-캐시 블록 리스트에 매핑하는 딕셔너리)에 저장.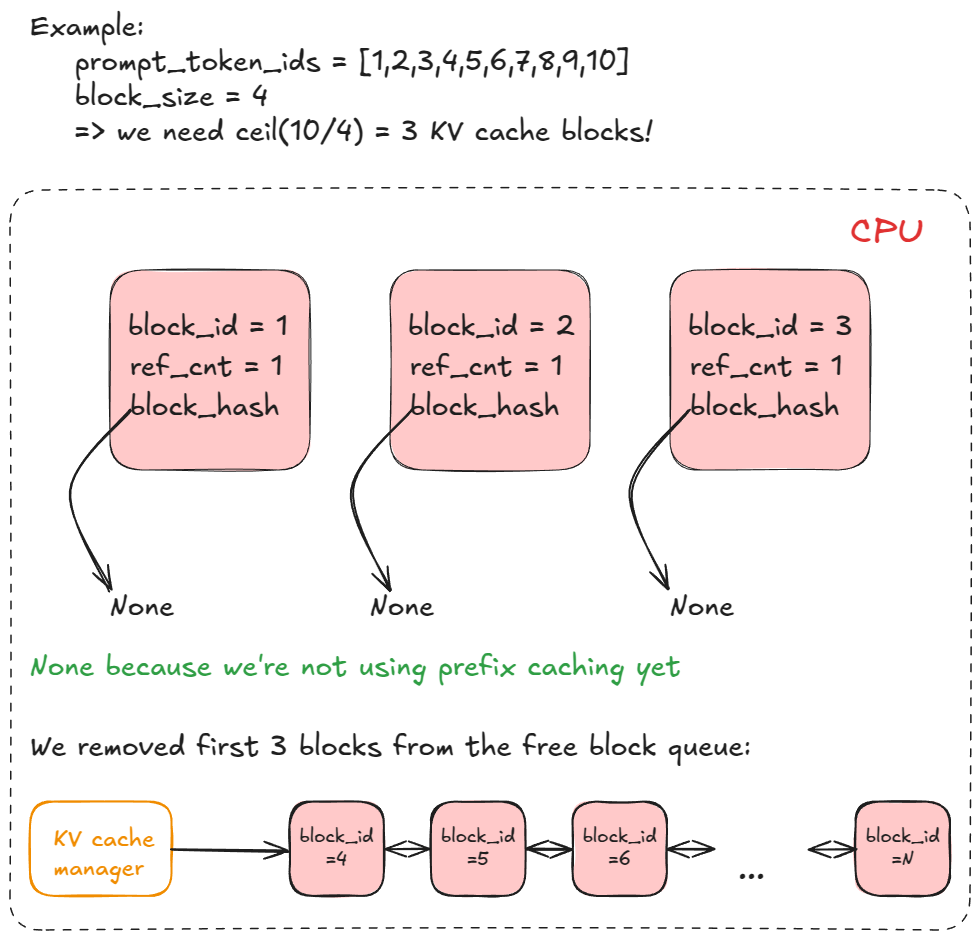
KV 캐시 블록의 리스트
드디어 forward 패스를 실행할 준비가 되었습니다!
모델 실행기의 execute_model을 호출하면, 이는 Worker로 위임되고, 다시 model runner로 위임됩니다.
주요 단계는 다음과 같습니다:
input_batch에서 제거; forward 관련 메타데이터 갱신(예: 이후 페이징된 KV 캐시 메모리 인덱싱에 사용할 요청별 KV 캐시 블록 수 등).slot_mapping 구축(예제에서 추가 설명); 어텐션 메타데이터 구성.forward 단계에는 두 가지 실행 모드가 있습니다:
아래 구체 예시는 연속 배칭과 PagedAttention을 명확히 이해하는 데 도움이 됩니다:
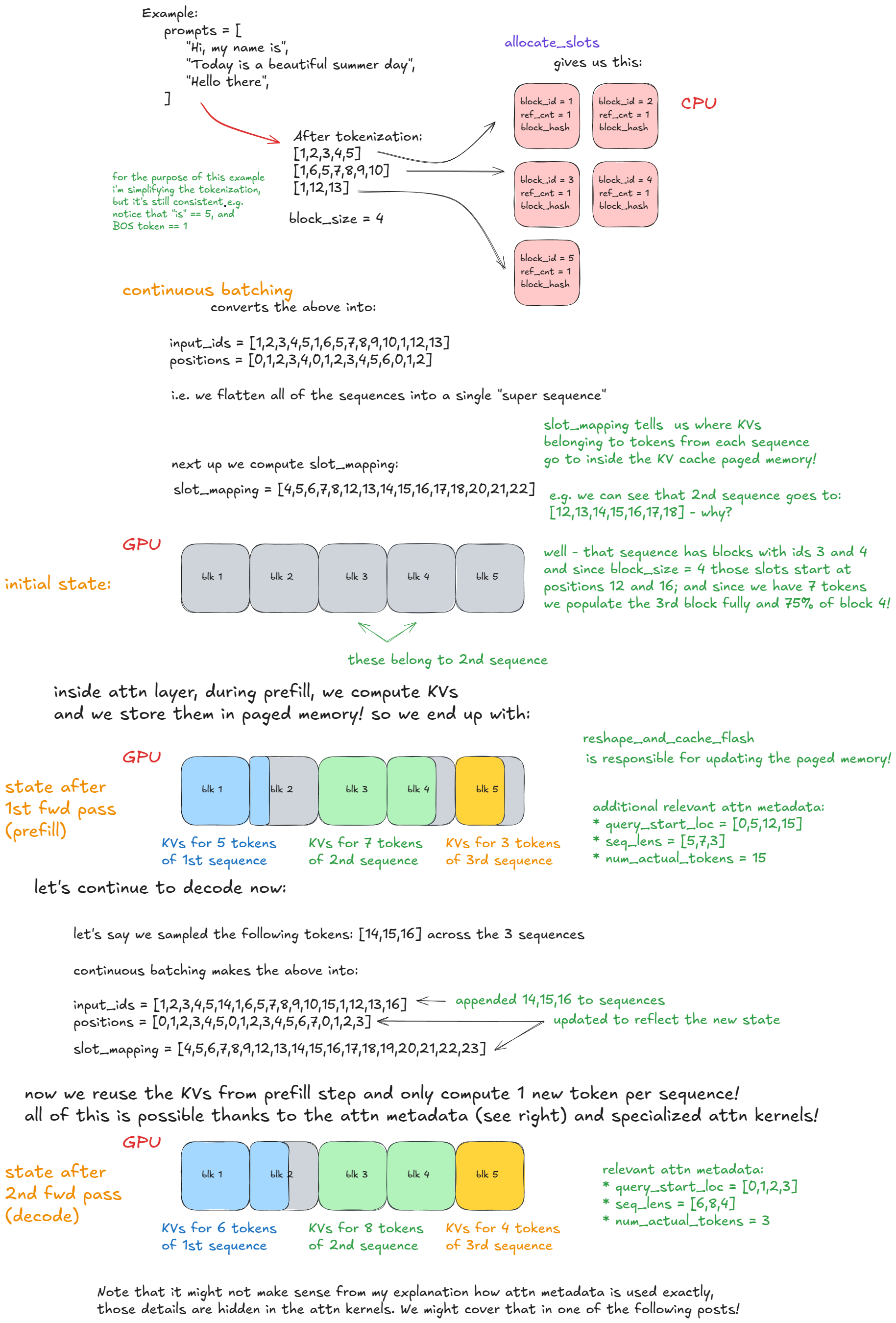
Forward 패스: 연속 배칭과 PagedAttention
기본 엔진 플로우를 이해했으니, 이제 고급 기능으로 넘어갑니다.
이미 선점(preemption), PagedAttention, 연속 배칭을 논의했습니다.
다음 항목을 다룹니다:
청크 프리필은 긴 프롬프트의 프리필 단계를 더 작은 청크로 나누어 처리하는 기법입니다. 이 기능이 없으면 매우 긴 단일 요청이 한 엔진 스텝을 독점해 다른 프리필 요청이 실행되지 못할 수 있습니다. 그러면 다른 모든 요청이 지연되어 지연시간이 늘어납니다.
예를 들어, 각 청크에 n(=8)개의 토큰이 있고, 하이픈("-")으로 구분된 소문자 라벨을 붙인다고 해봅시다. 긴 프롬프트 P가 x-y-z처럼 보이고, z는 불완전 청크(예: 2 토큰)입니다. P의 전체 프리필을 실행하려면 ≥ 3 엔진 스텝이 필요하고(중간 스텝에 스케줄되지 않으면 더 늘 수 있음), 마지막 청크 프리필 스텝에서만 새 토큰을 하나 샘플링합니다.
시각 예시는 다음과 같습니다:
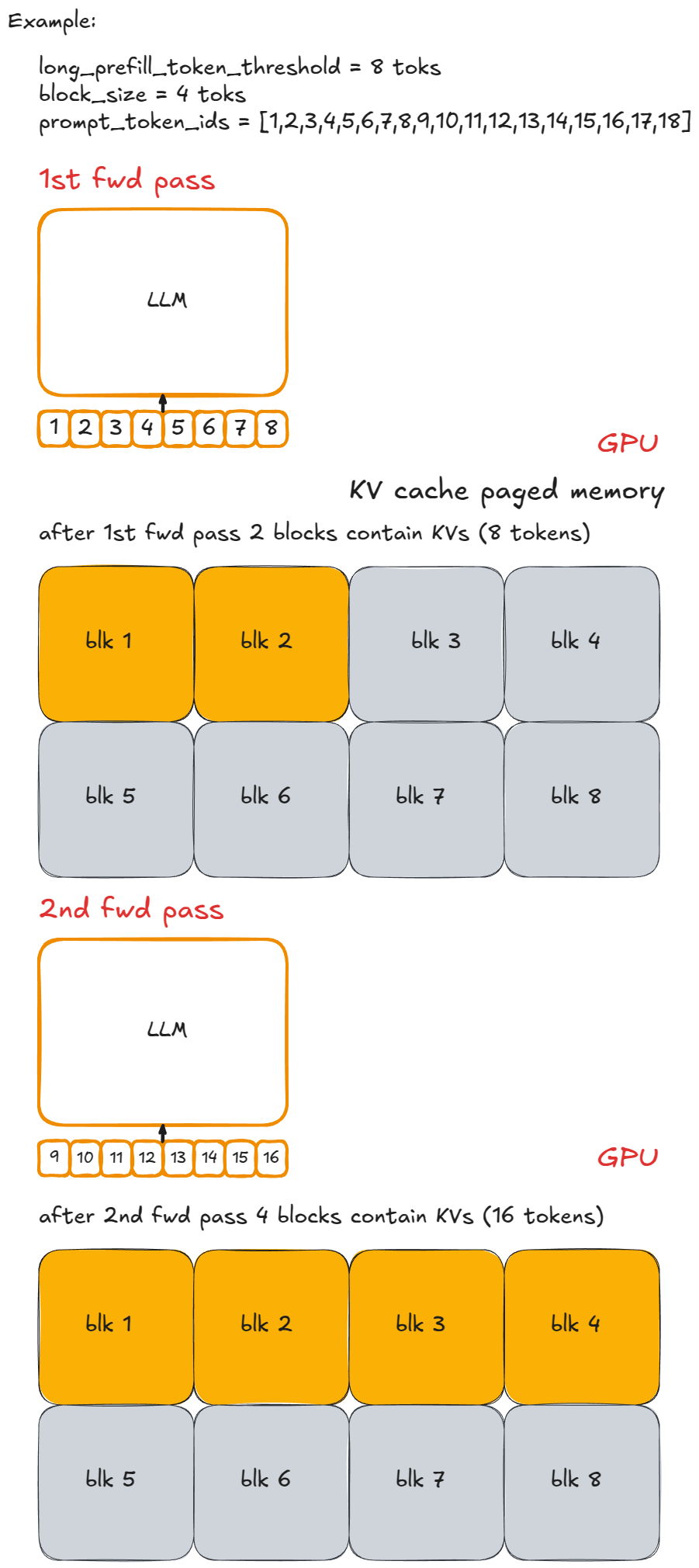
구현은 간단합니다: 스텝당 신규 토큰 수를 상한으로 제한합니다. 요청된 수가 long_prefill_token_threshold를 초과하면 정확히 그 값으로 재설정합니다. 그 외의 인덱싱 로직(앞서 설명)이 나머지를 처리합니다.
vLLM V1에서는 long_prefill_token_threshold를 양수로 설정해 청크 프리필을 활성화합니다. (기술적으로는, 프롬프트 길이가 토큰 예산을 초과하면 잘라서 청크 프리필로 실행하기 때문에 이 값과 무관하게 발생할 수도 있습니다.)
프리픽스 캐싱이 어떻게 동작하는지 설명하기 위해 원래 코드 예제를 약간 수정해 보겠습니다:
from vllm import LLM, SamplingParams
long_prefix = "<a piece of text that is encoded into more than block_size tokens>"
prompts = [
"Hello, my name is",
"The president of the United States is",
]
sampling_params = SamplingParams(temperature=0.8, top_p=0.95)
def main():
llm = LLM(model="TinyLlama/TinyLlama-1.1B-Chat-v1.0")
outputs = llm.generate(long_prefix + prompts[0], sampling_params)
outputs = llm.generate(long_prefix + prompts[1], sampling_params)
if __name__ == "__main__":
main()
프리픽스 캐싱은 여러 프롬프트가 시작 부분에서 공유하는 토큰의 재계산을 피합니다 — 그래서 **prefix(접두사)**입니다.
핵심은 long_prefix입니다: 이는 KV-캐시 블록(기본 16 토큰)보다 긴 모든 접두사를 의미합니다. 예시를 단순화하기 위해 long_prefix의 길이가 정확히 n x block_size(여기서 n ≥ 1)라고 가정합시다.
즉, 블록 경계에 완벽히 정렬됩니다 — 그렇지 않으면 불완전 블록은 캐시할 수 없으므로 long_prefix_len % block_size 토큰을 재계산해야 합니다.
프리픽스 캐싱이 없으면 동일한 long_prefix를 가진 새 요청을 처리할 때마다 n x block_size 토큰을 매번 재계산합니다.
프리픽스 캐싱이 있으면 해당 토큰은 한 번만 계산(해당 K/V가 페이징된 KV 캐시 메모리에 저장)되고 이후 재사용되므로, 새 프롬프트 토큰만 처리하면 됩니다. 이는 프리필 요청을 가속하지만 디코드에는 도움이 되지 않습니다.
vLLM에서는 어떻게 동작할까요?
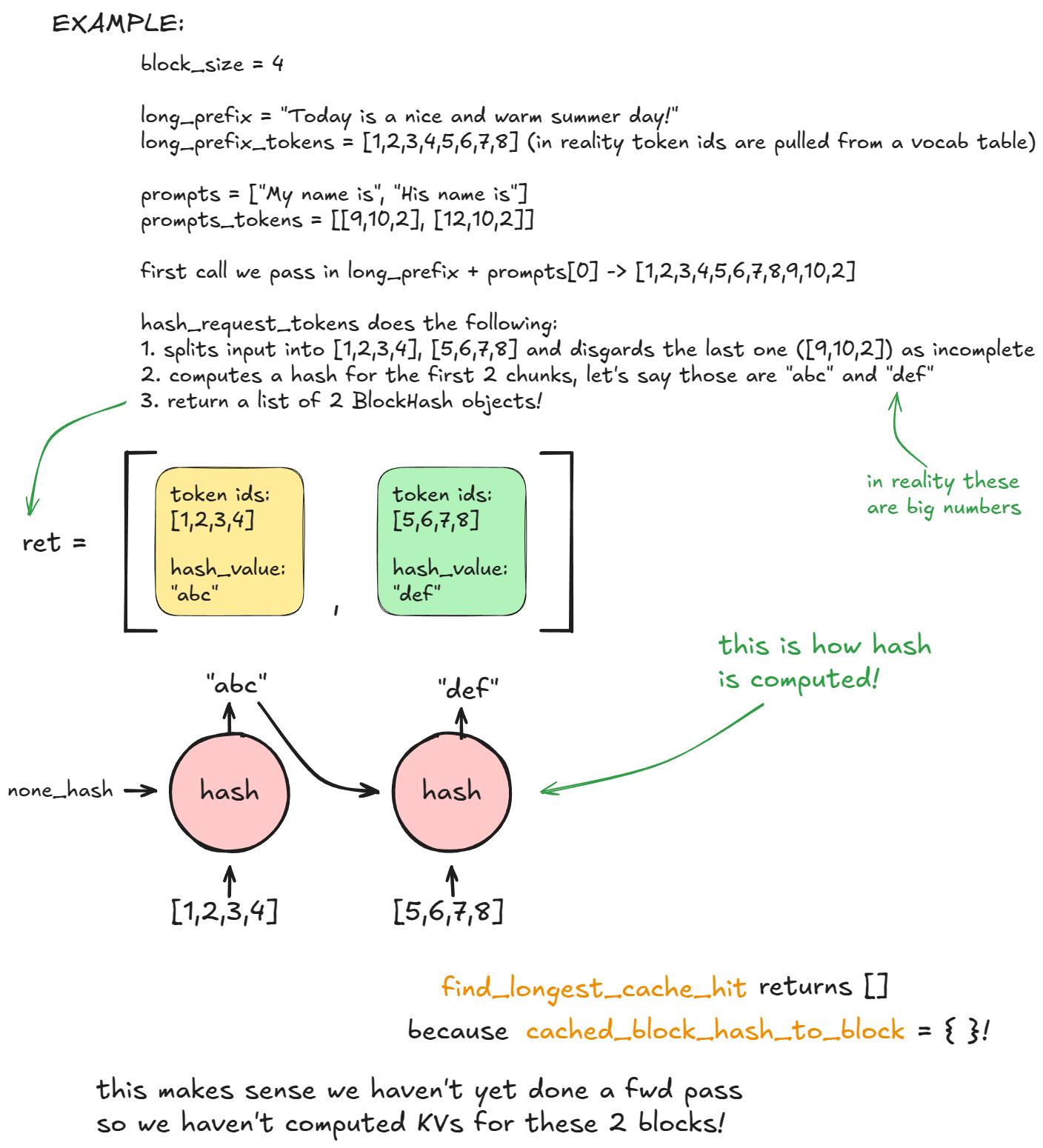
첫 번째 generate 호출의 스케줄링 단계에서, kv_cache_manager.get_computed_blocks 내부에서 엔진이 hash_request_tokens를 호출합니다:
long_prefix + prompts[0]를 16토큰 청크로 분할합니다.선택적 메타데이터에는 MM 해시, LoRA ID, 캐시 솔트(첫 블록의 해시에 주입되어 동일 솔트를 가진 요청만 블록 재사용 가능)가 포함됩니다.
BlockHash 객체로 저장됩니다. 블록 해시 리스트를 반환합니다.이 리스트는 self.req_to_block_hashes[request_id]에 저장됩니다.
다음으로 엔진은 find_longest_cache_hit을 호출해 이들 해시가 cached_block_hash_to_block에 이미 존재하는지 확인합니다. 첫 요청에서는 일치가 없습니다.
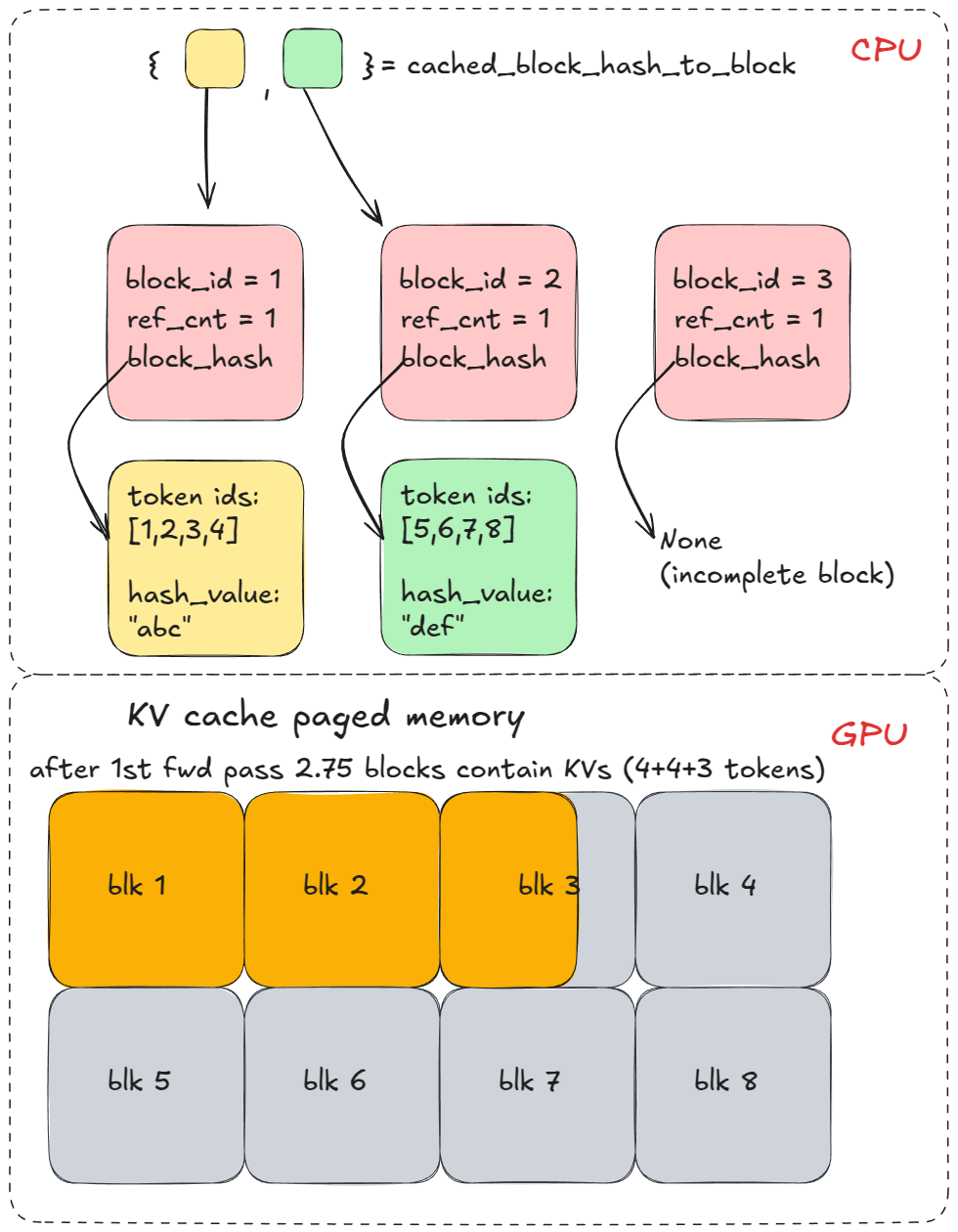
그다음 allocate_slots를 호출하는데, 여기서 coordinator.cache_blocks가 호출되어 새로운 BlockHash 항목을 할당된 KV 블록에 연결하고 이를 cached_block_hash_to_block에 기록합니다.
이후 forward 패스가 위에서 할당한 KV 캐시 블록에 해당하는 페이징된 KV 캐시 메모리에 K/V를 채웁니다.
여러 엔진 스텝 후 더 많은 KV 캐시 블록을 할당하겠지만, 우리의 예시에서는 long_prefix 직후 접두사가 곧바로 갈라지므로 상관없습니다.
같은 접두사로 두 번째 generate 호출을 하면, 1~3단계를 반복하지만 이번엔 find_longest_cache_hit이 모든 n 블록에서 일치(선형 탐색)를 찾습니다. 엔진은 해당 KV 블록을 바로 재사용할 수 있습니다.
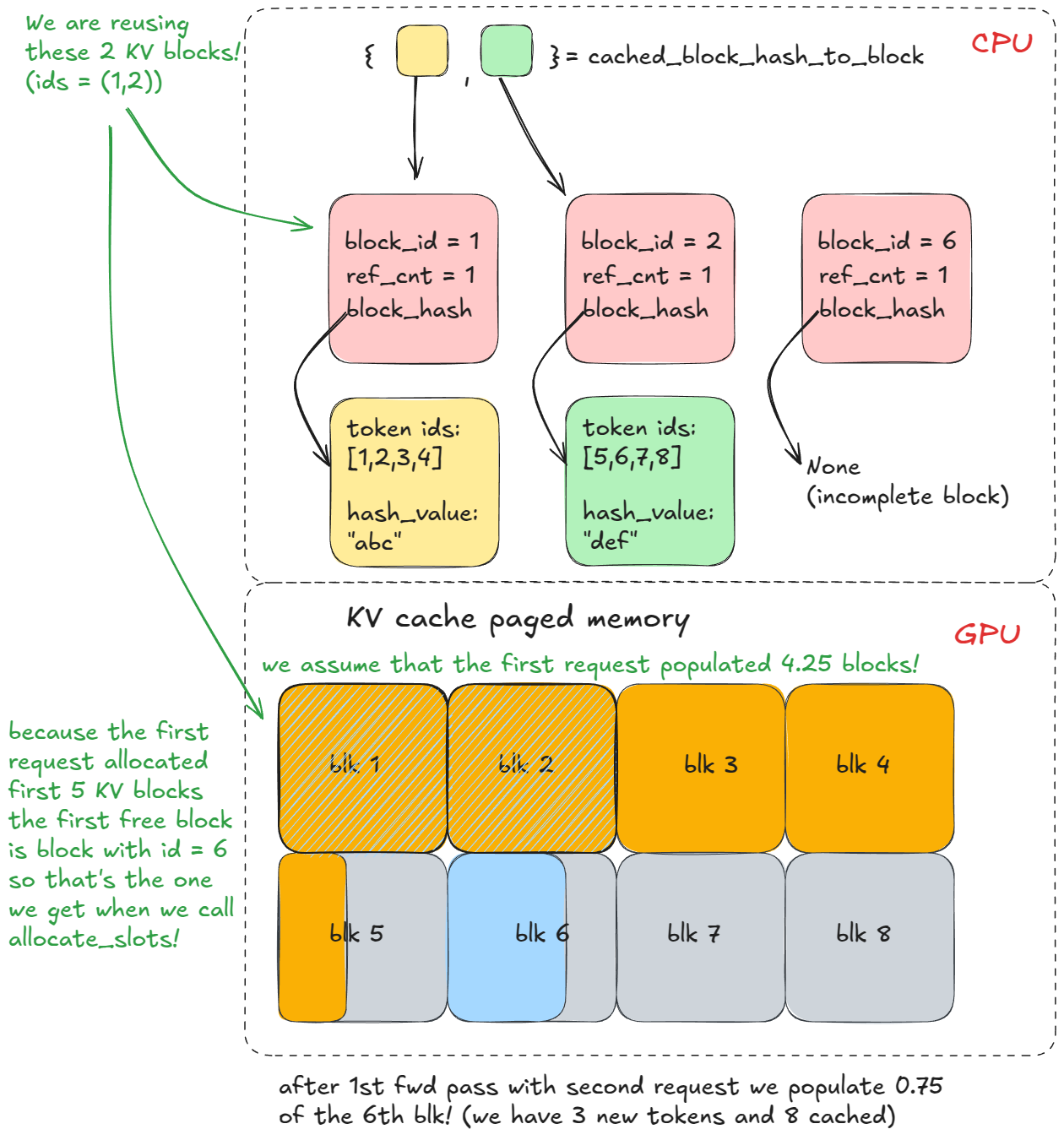
원래 요청이 아직 살아 있었다면, 그 블록의 참조 카운트가 증가했을 것입니다(예: 2). 이 예시에서는 첫 요청이 이미 완료되어 블록이 풀로 반환되고 참조 카운트가 0으로 돌아갔습니다. 하지만 cached_block_hash_to_block에서 이를 다시 찾을 수 있었기 때문에(해당 방식으로 KV 캐시 매니저 로직이 구성됨) 단지 free_block_queue에서 다시 꺼내 재사용하면 됩니다.
📝고급 메모:
KV-캐시 블록은 free_block_queue(왼쪽에서 pop)에서 재할당 직전에, 해당 블록에 해시가 남아 있고 cached_block_hash_to_block에 존재한다는 사실이 발견될 때만 무효화됩니다. 그 순간 블록의 해시를 지우고 cached_block_hash_to_block에서 해당 항목을 제거해, 더 이상 프리픽스 캐싱을 통해(최소한 그 오래된 프리픽스에 대해서는) 재사용할 수 없도록 보장합니다.
요약하자면 프리픽스 캐싱은 이미 본 접두사를 재계산하지 않고 해당 KV 캐시를 재사용하는 것입니다!
이 예시를 이해했다면 PagedAttention의 동작도 이해한 것입니다.
프리픽스 캐싱은 기본 활성화입니다. 비활성화하려면: enable_prefix_caching = False.
가이드 디코딩은 각 디코딩 스텝에서 문법 기반 유한상태기계(FSM)로 로짓을 제한하는 기법입니다. 이를 통해 문법이 허용하는 토큰만 샘플링됩니다.
이는 강력한 설정으로, 정규 문법(촘스키 유형-3, 예: 임의 정규식 패턴)부터 컨텍스트 자유 문법(유형-2, 대부분의 프로그래밍 언어 포함)까지 강제할 수 있습니다.
덜 추상적으로 만들기 위해, 앞선 코드에 기반한 가장 단순한 예시로 시작해 봅시다:
from vllm import LLM, SamplingParams
from vllm.sampling_params import GuidedDecodingParams
prompts = [
"This sucks",
"The weather is beautiful",
]
guided_decoding_params = GuidedDecodingParams(choice=["Positive", "Negative"])
sampling_params = SamplingParams(guided_decoding=guided_decoding_params)
def main():
llm = LLM(model="TinyLlama/TinyLlama-1.1B-Chat-v1.0")
outputs = llm.generate(prompts, sampling_params)
if __name__ == "__main__":
main()
장난감 예시(문자 단위 토크나이즈 가정)에서는: 프리필 단계에서 FSM이 로짓을 마스킹해 "P" 또는 "N"만 가능하도록 합니다. "P"가 샘플링되면 FSM은 "Positive" 분기로 이동하고, 다음 스텝에서는 "o"만 허용되는 식입니다.
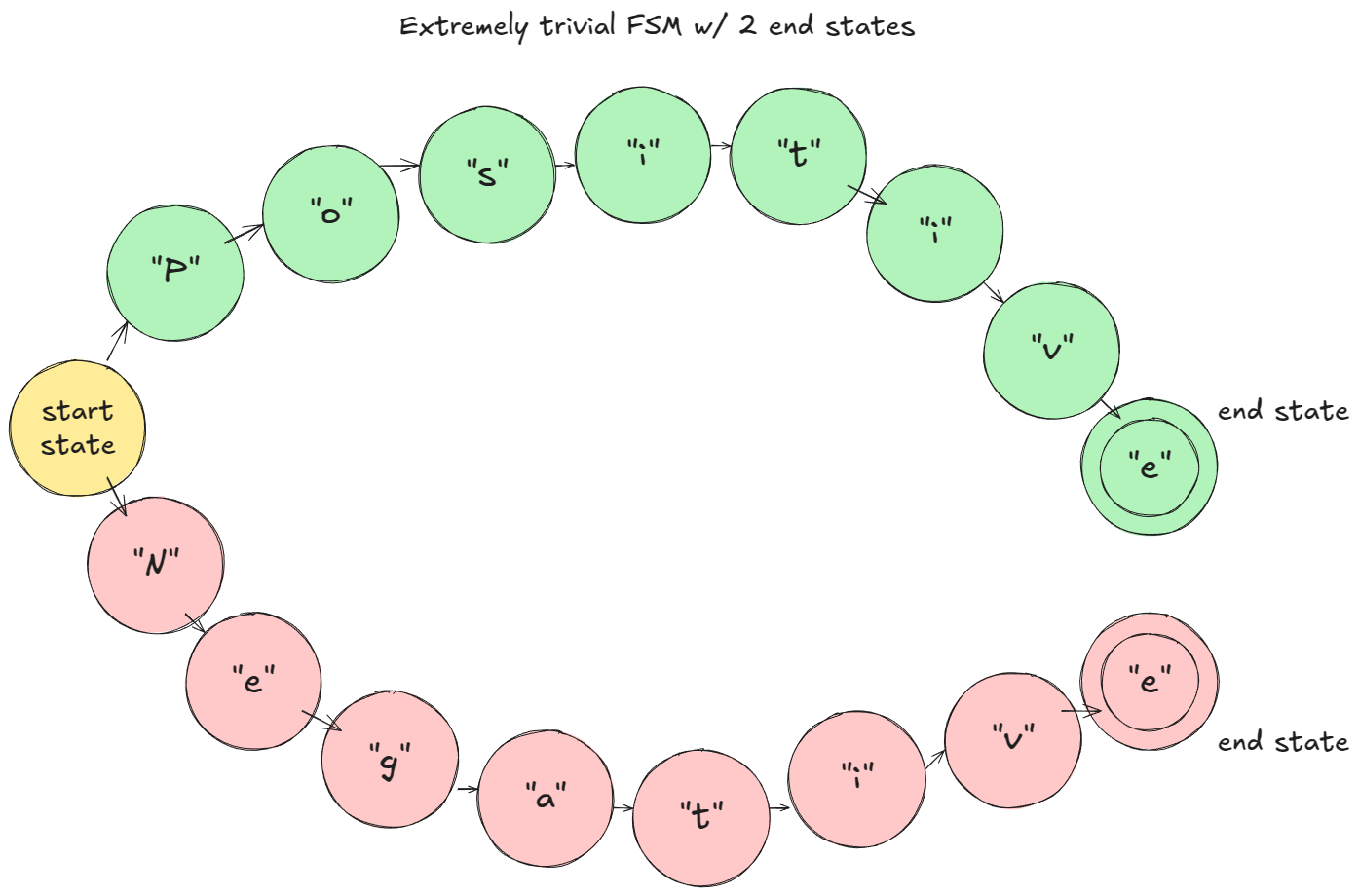
장난감 예시 FSM
vLLM에서의 동작 방식:
StructuredOutputManager가 생성됩니다. 이는 토크나이저에 접근할 수 있고 _grammar_bitmask 텐서를 유지합니다.WAITING_FOR_FSM으로 설정하고 grammar_init이 백엔드 컴파일러(예: xgrammar[7]; 백엔드는 3rd party 코드)를 선택합니다.WAITING으로 바꾸고 request_id를 structured_output_request_ids에 추가합니다. 아니면 skipped_waiting_requests에 넣고 다음 엔진 스텝에서 재시도합니다.StructuredOutputManager가 백엔드에 _grammar_bitmask 준비/업데이트를 요청합니다.accept_tokens로 요청의 FSM을 전개합니다. 시각적으로 FSM 다이어그램에서 다음 상태로 이동합니다.6단계는 추가 설명이 필요합니다.
vocab_size = 32라면 _grammar_bitmask는 단일 정수입니다. 그 이진 표현이 허용("1")/비허용("0") 토큰을 인코딩합니다. 예를 들어 "101…001"은 길이 32 배열 [1, 0, 1, …, 0, 0, 1]로 확장되고, 0 위치의 로짓은 –∞로 설정됩니다. 더 큰 어휘에서는 여러 개의 32비트 단어를 사용하고 이를 확장/연결합니다. 백엔드(예: xgrammar)가 현재 FSM 상태를 사용해 이러한 비트 패턴을 생성합니다.
📝메모:
대부분의 복잡성은 xgrammar 같은 3rd party 라이브러리에 숨겨져 있습니다.
더 단순한 예시로 vocab_size = 8과 8비트 정수를 쓰면 다음과 같습니다(시각 자료를 좋아하는 분들을 위해):
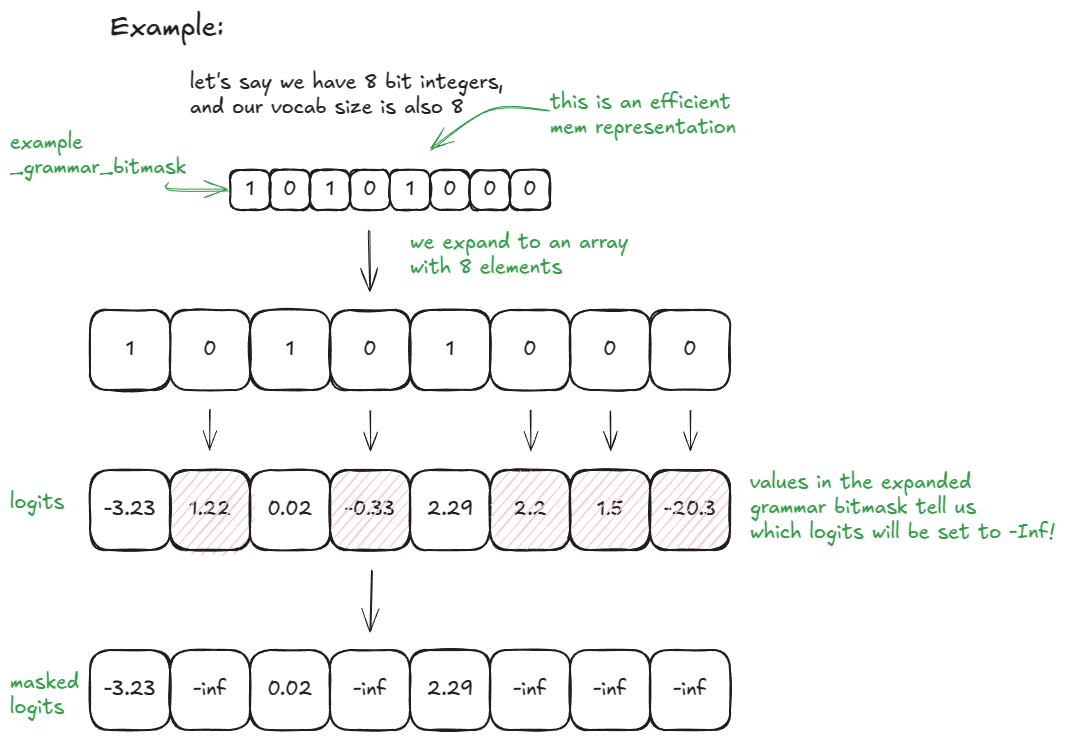
장난감 예시
vLLM에서는 원하는 guided_decoding 구성으로 이를 활성화할 수 있습니다.
오토리그레시브 생성에서 새 토큰마다 대형 LM의 forward 패스가 필요합니다. 이는 비용이 큽니다 — 매 스텝마다 모든 모델 가중치를 다시 로드·적용해 단 하나의 토큰만 계산하니까요! (배치 크기 B 일반화시 B개)
스페큘레이티브 디코딩 [8]은 더 작은 드래프트 LM을 도입해 속도를 높입니다. 드래프트가 k개의 토큰을 저렴하게 제안합니다. 하지만 최종적으로 작은 모델에서 샘플하고 싶지는 않습니다 — 이는 후보 연속을 추측하는 용도일 뿐입니다. 큰 모델이 무엇이 유효한지 최종 결정합니다.
절차는 다음과 같습니다:
Draft: 작은 모델을 현재 컨텍스트에 실행해 k 토큰을 제안
Verify: 큰 모델을 컨텍스트 + 드래프트의 k 토큰에 한 번 실행. 그러면 그 k 위치 + 하나 추가(총 k+1 후보)의 확률이 생성됨
Accept/reject: 왼쪽에서 오른쪽으로 k 드래프트 토큰을 검사:
* 큰 모델의 해당 토큰 확률 ≥ 드래프트의 확률이면 수락
* 아니면 p_large(token)/p_draft(token)의 확률로 수락
* 첫 거절에서 중단하거나 k 전부 수락
k 모두 수락되면, 큰 모델에서 추가로 계산된 (k+1)번째 토큰을 "공짜로" 샘플p_large - p_draft, 하한 0, 합 1로 정규화)를 만들고 마지막 토큰을 그 분포에서 샘플이 기법이 작동하는 이유: 작은 모델로 후보를 제안하지만, 수락/거절 규칙이 기대값 수준에서 시퀀스가 마치 큰 모델에서 한 토큰씩 샘플링한 것과 정확히 동일한 분포가 되도록 보장합니다. 즉, 스페큘레이티브 디코딩은 통계적으로 표준 오토리그레시브 디코딩과 동등하지만, 큰 모델의 단일 패스로 최대 k+1 토큰을 얻을 수 있어 잠재적으로 훨씬 빠릅니다.
📝메모:
간단한 구현은 gpt-fast와 원 논문의 수학적 상세·동등성 증명을 참고하세요.
vLLM V1은 LLM 드래프트 모델 방식을 지원하지 않으며, 대신 더 빠르지만 정확도는 낮은 제안 스킴들을 구현합니다: n-gram, EAGLE [9], Medusa [10].
각 방법 한 줄 요약:
prompt_lookup_max 토큰을 가져와 시퀀스에서 과거 일치를 찾고, 찾으면 그 일치 뒤를 이은 k 토큰을 제안. 못 찾으면 윈도우를 줄여 prompt_lookup_min까지 재시도현재 구현은 첫 번째 일치에서 k 토큰을 반환합니다. 자연스럽게는 최근성 바이어스를 넣어 검색 방향을 반대로 하는 게 더 낫지 않을까요? (즉, 마지막 일치를 채택)
k 토큰을 병렬 예측; 별도 소형 LM 실행보다 효율적으로 제안vLLM에서 ngram을 드래프트로 쓰는 스페큘레이티브 디코딩 호출 예시:
from vllm import LLM, SamplingParams
prompts = [
"Hello, my name is",
"The president of the United States is",
]
sampling_params = SamplingParams(temperature=0.8, top_p=0.95)
speculative_config={
"method": "ngram",
"prompt_lookup_max": 5,
"prompt_lookup_min": 3,
"num_speculative_tokens": 3,
}
def main():
llm = LLM(model="TinyLlama/TinyLlama-1.1B-Chat-v1.0", speculative_config=speculative_config)
outputs = llm.generate(prompts, sampling_params)
if __name__ == "__main__":
main()
vLLM에서의 동작 방식은 다음과 같습니다.
설정(엔진 구성 중):
drafter(드래프트 모델, 예: NgramProposer)와 rejection_sampler 생성(일부는 Triton으로 작성).그 후 generate 함수 안에서(새 요청이 들어왔다고 가정):
propose_draft_token_ids(k)를 호출해 드래프트 모델에서 k 토큰을 제안.request.spec_token_ids에 저장(요청 메타데이터 갱신).len(request.spec_token_ids)를 더해 allocate_slots가 forward용 KV 블록을 충분히 예약하도록 함.spec_token_ids를 input_batch.token_ids_cpu에 복사._calc_spec_decode_metadata로 메타데이터 계산(input_batch.token_ids_cpu에서 토큰 복사, 로짓 준비 등), 그다음 큰 모델로 드래프트 토큰에 대한 forward 실행.rejection_sampler로 좌→우 수락/거절을 수행해 output_token_ids를 생성.가장 좋은 이해 방법은 디버거로 코드베이스를 따라가는 것이지만, 이 섹션이 감을 잡는 데 도움이 되길 바랍니다. 아래 시각 자료도 참고하세요:
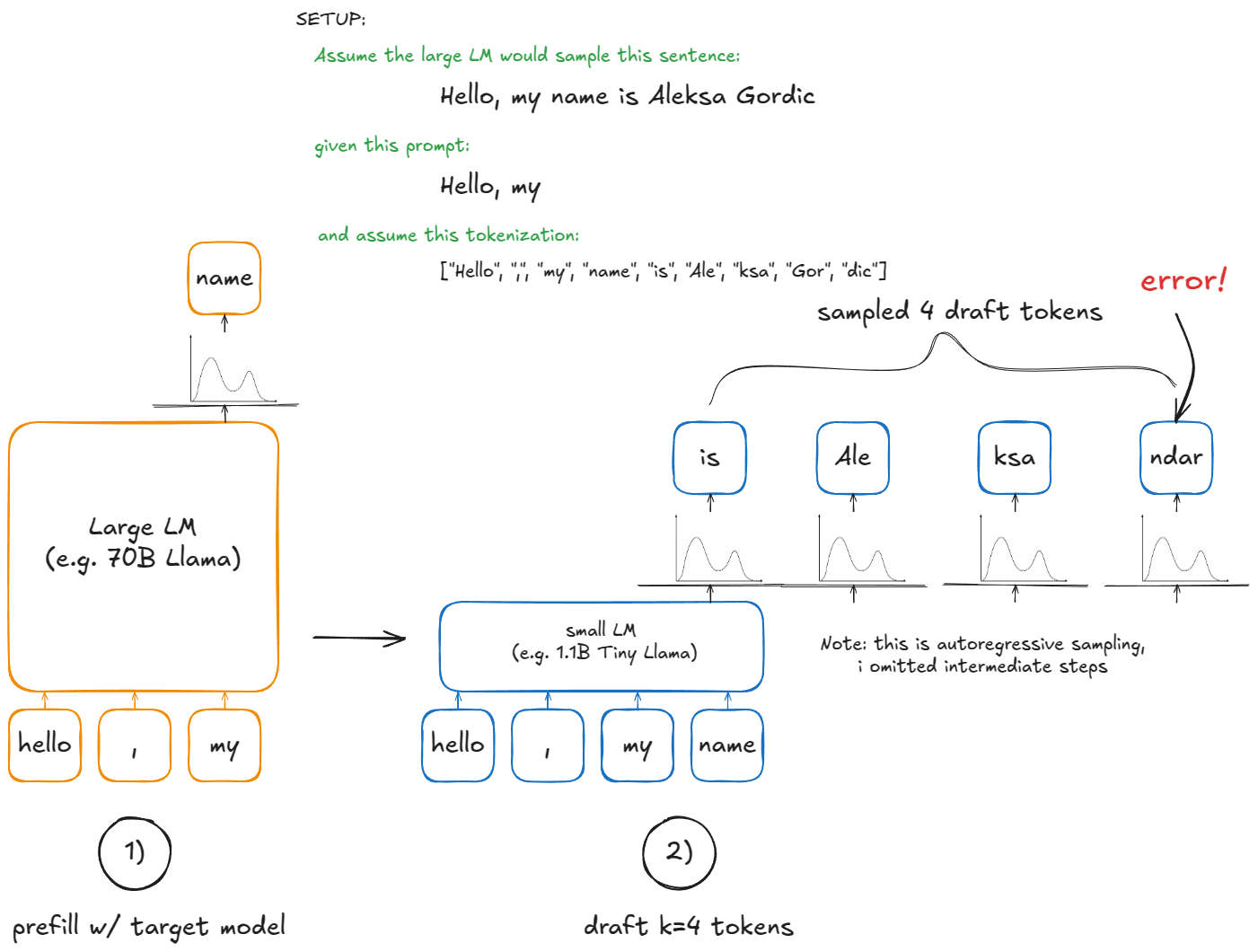
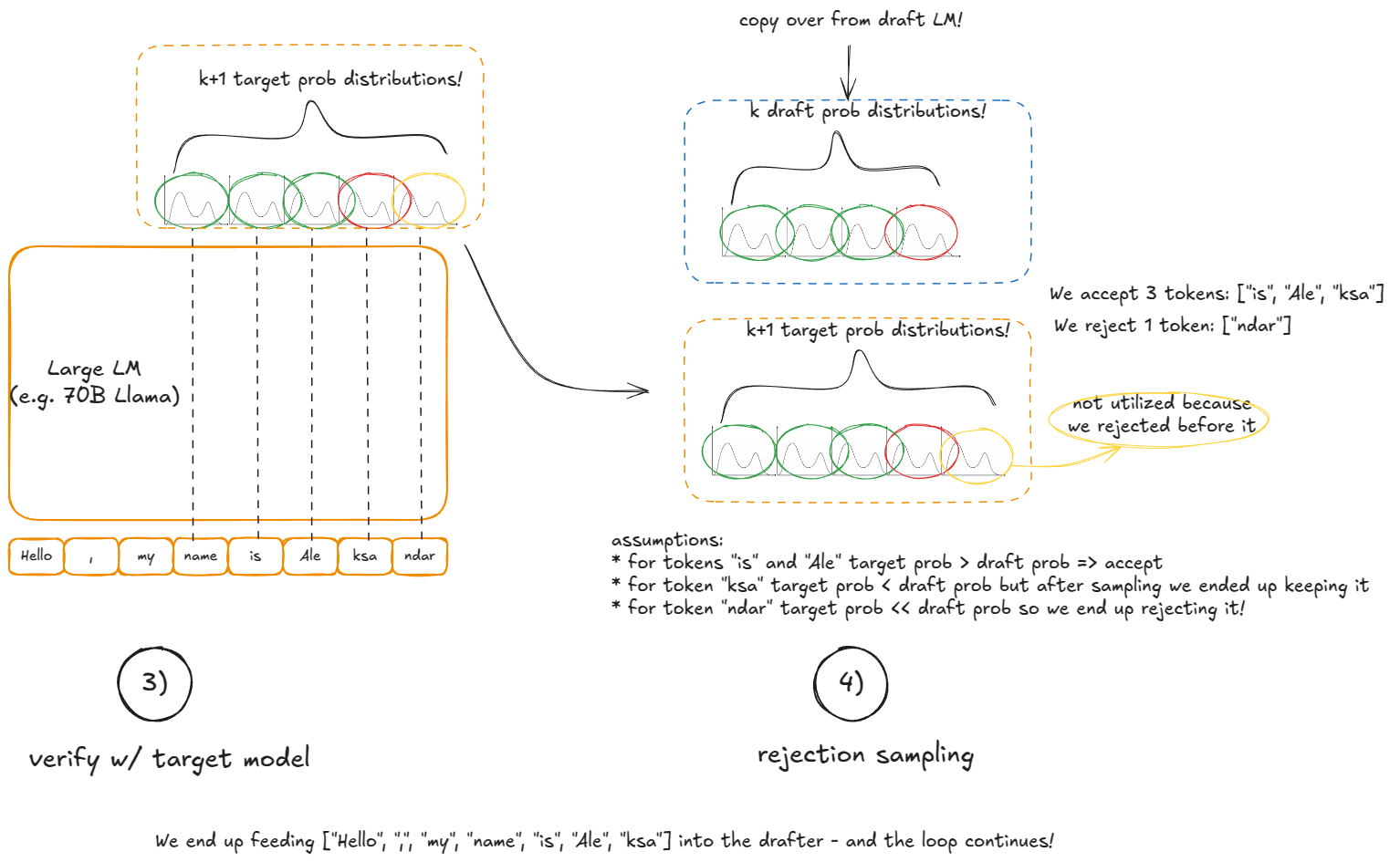
앞서 프리필/디코드 분리의 동기를 암시적으로 언급했습니다.
프리필과 디코드는 매우 다른 성능 프로파일(컴퓨트 바운드 vs 메모리 대역폭 바운드)을 가지므로, 실행을 분리하는 것이 합리적입니다. 이는 지연시간 — TFTT(time-to-first-token)와 ITL(inter-token latency) — 을 더 촘촘히 제어하게 합니다. 자세한 내용은 벤치마크 섹션에서 다룹니다.
실무에서는 N개의 vLLM 프리필 인스턴스와 M개의 vLLM 디코드 인스턴스를 실행하고, 라이브 요청 믹스에 따라 오토스케일링합니다. 프리필 워커는 KV를 전용 KV-캐시 서비스에 쓰고, 디코드 워커는 거기서 읽습니다. 이렇게 하면 길고 돌발적인 프리필이 안정적이고 지연 민감한 디코드와 분리됩니다.
vLLM에서는 어떻게 동작할까요?
명확성을 위해 아래 예시는 디버깅용 커넥터 구현인 SharedStorageConnector에 의존합니다. 메커니즘을 설명하는 데 적합합니다.
커넥터는 인스턴스 간 KV 교환을 처리하는 vLLM의 추상화입니다. 커넥터 인터페이스는 아직 안정화되지 않았으며, 단기간 내 개선이 예정되어 있어 일부(잠재적으로 깨지는) 변경이 있을 수 있습니다.
2개의 vLLM 인스턴스를 실행합니다(GPU 0은 프리필, GPU 1은 디코드). 그리고 KV 캐시를 그 사이에 전송합니다:
import os
import time
from multiprocessing import Event, Process
import multiprocessing as mp
from vllm import LLM, SamplingParams
from vllm.config import KVTransferConfig
prompts = [
"Hello, my name is",
"The president of the United States is",
]
def run_prefill(prefill_done):
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
sampling_params = SamplingParams(temperature=0, top_p=0.95, max_tokens=1)
ktc=KVTransferConfig(
kv_connector="SharedStorageConnector",
kv_role="kv_both",
kv_connector_extra_config={"shared_storage_path": "local_storage"},
)
llm = LLM(model="TinyLlama/TinyLlama-1.1B-Chat-v1.0", kv_transfer_config=ktc)
llm.generate(prompts, sampling_params)
prefill_done.set() # 디코드 인스턴스에 KV 캐시 준비됨을 알림
# 디코드 노드가 끝나지 않은 경우 프리필 노드를 계속 실행시킵니다.
# 그렇지 않으면 스크립트가 너무 일찍 종료되어 디코딩이 불완전할 수 있습니다.
try:
while True:
time.sleep(1)
except KeyboardInterrupt:
print("Script stopped by user.")
def run_decode(prefill_done):
os.environ["CUDA_VISIBLE_DEVICES"] = "1"
sampling_params = SamplingParams(temperature=0, top_p=0.95)
ktc=KVTransferConfig(
kv_connector="SharedStorageConnector",
kv_role="kv_both",
kv_connector_extra_config={"shared_storage_path": "local_storage"},
)
llm = LLM(model="TinyLlama/TinyLlama-1.1B-Chat-v1.0", kv_transfer_config=ktc)
prefill_done.wait() # 프리필 인스턴스에서의 KV 캐시를 기다리며 블록
# 내부적으로 디코딩 루프를 시작하기 전에 KV 캐시를 먼저 가져옵니다
outputs = llm.generate(prompts, sampling_params)
if __name__ == "__main__":
prefill_done = Event()
prefill_process = Process(target=run_prefill, args=(prefill_done,))
decode_process = Process(target=run_decode, args=(prefill_done,))
prefill_process.start()
decode_process.start()
decode_process.join()
prefill_process.terminate()
📝메모:
가장 빠른 프로덕션 준비 커넥터인 LMCache[11](NVIDIA NIXL을 백엔드로 사용)도 실험했지만, 아직 최신 경계선에 있어 약간의 버그를 만났습니다. 복잡성이 외부 저장소에 많이 있으므로, 설명에는 SharedStorageConnector가 더 적합합니다.
vLLM에서의 단계:
인스턴스화 — 엔진 구성 중 커넥터는 두 곳에서 생성됩니다: * 워커의 디바이스 초기화 절차 내부(워커 분산 환경 초기화 함수 아래)에서, 역할은 "worker". * 스케줄러 생성자 내부에서, 역할은 "scheduler".
캐시 조회 — 스케줄러가 waiting 큐의 프리필 요청을 처리할 때(로컬 프리픽스 캐시 점검 후), 커넥터의 get_num_new_matched_tokens를 호출합니다. 이는 외부 KV-캐시 서버에서 캐시된 토큰을 확인합니다. 프리필은 항상 0, 디코드는 히트가 있을 수 있습니다. 결과는 allocate_slots 호출 전 로컬 카운트에 더해집니다.
상태 업데이트 — 스케줄러는 connector.update_state_after_alloc을 호출해 캐시가 있었던 요청을 기록합니다(프리필은 no-op).
메타 빌드 — 스케줄링 끝에서 스케줄러는 meta = connector.build_connector_meta를 호출:
* 프리필은 is_store=True인 모든 요청을 추가(KV 업로드용).
* 디코드는 is_store=False인 요청을 추가(KV 다운로드용).
컨텍스트 매니저 — forward 전에 엔진은 KV-커넥터 컨텍스트 매니저에 진입:
* enter 시: kv_connector.start_load_kv 호출. 디코드는 외부 서버에서 KV를 로드해 페이징 메모리에 주입. 프리필은 no-op.
* exit 시: kv_connector.wait_for_save 호출. 프리필은 KV 업로드가 끝날 때까지 블록. 디코드는 no-op.
시각 예시는 다음과 같습니다:
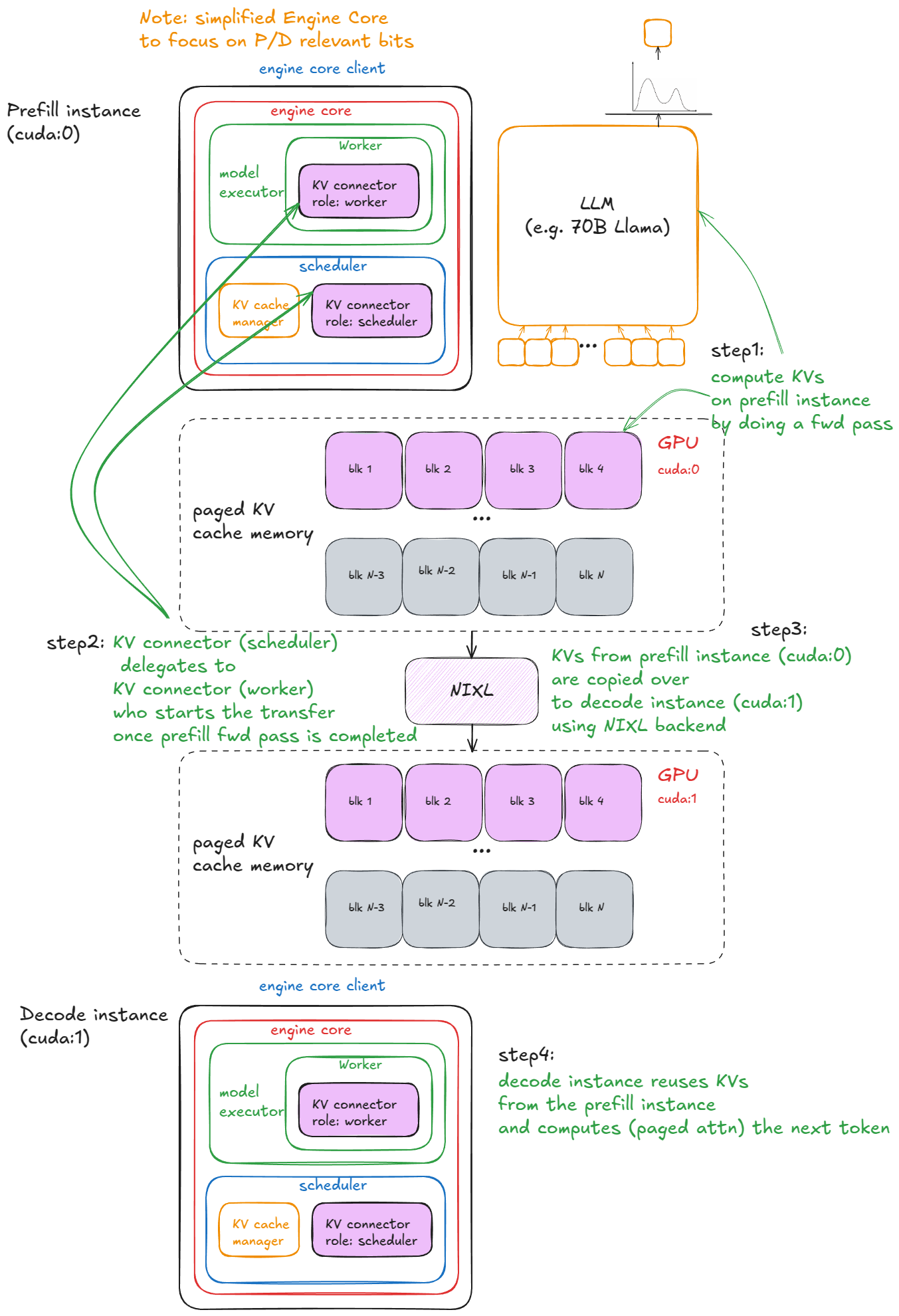
disaggregated P/D
📝추가 메모:
SharedStorageConnector의 "외부 서버"는 단지 로컬 파일 시스템입니다.핵심 기법들을 갖추었으니, 이제 스케일 업을 이야기합시다.
모델 가중치가 더 이상 단일 GPU VRAM에 들어가지 않는다고 가정합니다.
첫 옵션은 동일 노드의 여러 GPU에 텐서 병렬로 모델을 샤딩하는 것입니다(예: TP=8). 그래도 모델이 맞지 않으면 다음은 노드 간 파이프라인 병렬입니다.
📝메모:
이 단계에서는 여러 GPU 프로세스(워커)와 그들을 조정할 오케스트레이션 레이어가 필요합니다. 이것이 바로 MultiProcExecutor가 제공하는 것입니다.
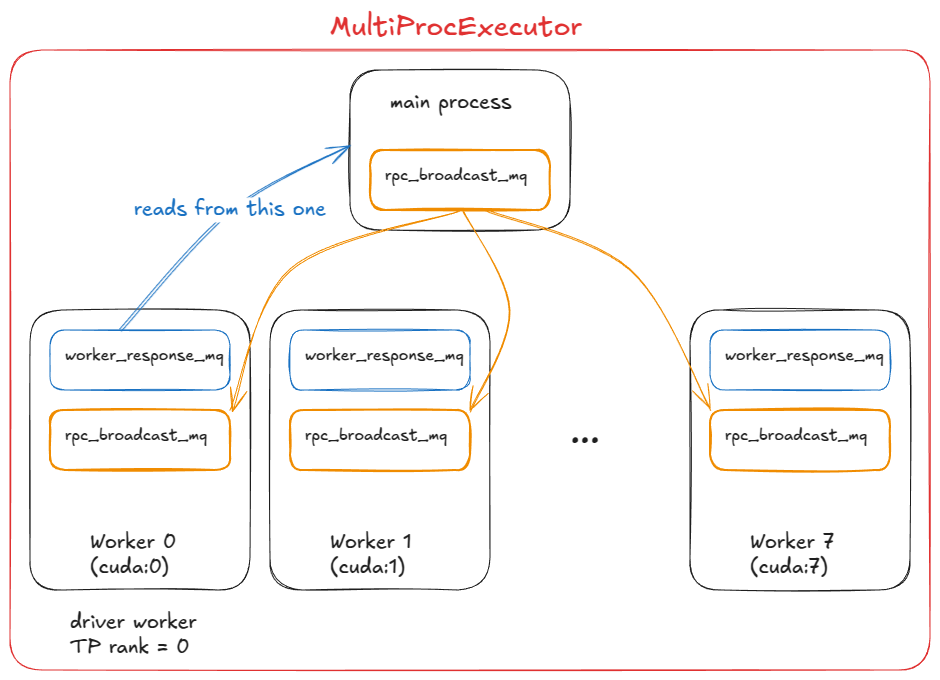
TP=8 설정에서의 MultiProcExecutor(드라이버 워커는 rank 0)
vLLM에서의 동작 방식:
MultiProcExecutor는 rpc_broadcast_mq 메시지 큐를 초기화합니다(내부적으로 공유 메모리로 구현).
생성자는 world_size(예: TP=8 ⇒ world_size=8)만큼 루프를 돌며 WorkerProc.make_worker_process로 각 랭크에 대한 데몬 프로세스를 생성합니다.
각 워커에 대해 부모는 먼저 리더/라이터 파이프를 만듭니다.
새로운 프로세스는 WorkerProc.worker_main을 실행하며, 워커를 인스턴스화합니다(앞서 UniProcExecutor에서와 동일한 "디바이스 초기화", "모델 로드" 등 수행).
각 워커는 자신이 드라이버인지(TP 그룹의 rank 0) 또는 일반 워커인지 판별합니다. 모든 워커는 두 큐를 설정합니다:
* 작업 수신용 rpc_broadcast_mq(부모와 공유)
* 결과 회신용 worker_response_mq
초기화 도중 각 자식은 자신의 worker_response_mq 핸들을 파이프를 통해 부모에게 보냅니다. 모두 수신되면 부모가 언블록 — 조정이 완료됩니다.
워커들은 바쁜 루프에 들어가 rpc_broadcast_mq.dequeue에서 블록. 작업이 도착하면 이를 실행(UniProcExecutor와 같지만 이제 TP/PP 분할 작업)하고 결과를 worker_response_mq.enqueue로 회신합니다.
런타임에 요청이 도착하면, MultiProcExecutor는 모든 자식 워커를 위해 해당 요청을 rpc_broadcast_mq에 논블로킹으로 큐잉합니다. 이후 지정된 출력 랭크의 worker_response_mq.dequeue에서 최종 결과를 수집합니다.
엔진 관점에서는 아무것도 변하지 않습니다 — 이 모든 멀티프로세싱 복잡성은 모델 실행기의 execute_model 호출로 추상화됩니다.
UniProcExecutor의 경우: execute_model이 직접 워커의 execute_model 호출로 이어짐MultiProcExecutor의 경우: execute_model이 rpc_broadcast_mq를 통해 각 워커의 execute_model 호출로 간접 이어짐이제 같은 엔진 인터페이스로 리소스가 허락하는 한 큰 모델을 실행할 수 있습니다.
다음 단계는 스케일 아웃입니다: 데이터 병렬(DP > 1)을 활성화해 모델을 노드 간 복제하고, 경량 DP 조정 레이어를 추가하며, 레플리카 간 로드밸런싱을 도입하고, 앞단에 하나 이상의 API 서버를 두어 들어오는 트래픽을 처리합니다.
서빙 인프라를 구성하는 방법은 다양하지만, 구체적으로 두 개의 H100 노드로 네 개의 vLLM 엔진을 실행하려는 예를 봅시다.
모델이 TP=4를 요구한다면 노드를 다음과 같이 구성할 수 있습니다.
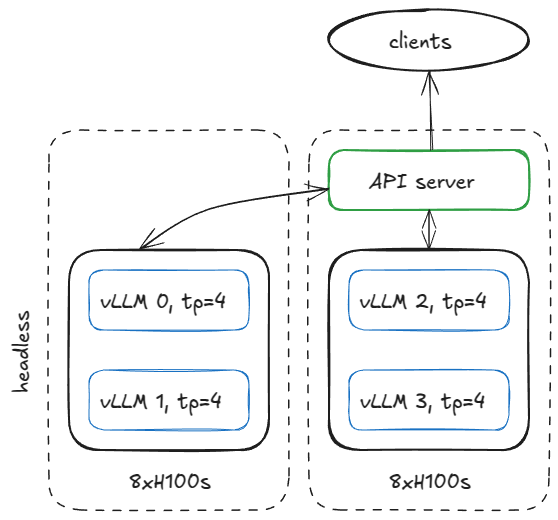
2×8xH100 노드 서버 구성(1대는 headless, 1대는 API 서버)
첫 번째 노드에서 다음 인자로 엔진을 헤드리스 모드(API 서버 없음)로 실행합니다:
vllm serve <model-name>
--tensor-parallel-size 4
--data-parallel-size 4
--data-parallel-size-local 2
--data-parallel-start-rank 0
--data-parallel-address <master-ip>
--data-parallel-rpc-port 13345
--headless
그리고 다른 노드에서 약간 수정해 동일 명령을 실행합니다:
--headless 제거vllm serve <model-name>
--tensor-parallel-size 4
--data-parallel-size 4
--data-parallel-size-local 2
--data-parallel-start-rank 2
--data-parallel-address <master-ip>
--data-parallel-rpc-port 13345
📝메모:
이는 모든 노드가 지정된 IP와 포트에 접근할 수 있도록 네트워킹이 구성되어 있다고 가정합니다.
VLLM에서는 어떻게 동작할까요?
헤드리스 노드에서는 CoreEngineProcManager가 2개의 프로세스를 실행합니다(--data-parallel-size-local당 하나). 각 프로세스는 EngineCoreProc.run_engine_core를 실행합니다. 이 함수는 DPEngineCoreProc(엔진 코어)를 생성하고 바쁜 루프에 들어갑니다.
DPEngineCoreProc는 부모 EngineCoreProc(엔진 코어의 자식)을 초기화합니다. 이는 다음을 수행합니다:
input_queue와 output_queue 생성(queue.Queue).DEALER ZMQ 소켓(비동기 메시징 라이브러리)으로 초기 핸드셰이크를 수행하고, 조정 주소 정보를 수신.MultiProcExecutor를 사용해 EngineCore 초기화(앞서 설명한 대로 4개의 GPU에서 TP=4).ready_event 생성(threading.Event).threading.Thread) 시작 — process_input_sockets(…, ready_event) 실행. 출력 스레드도 동일하게 시작.ready_event 대기, 완료 시 ready_event.set() 실행.num_gpu_blocks 등의 메타데이터와 함께 프런트엔드에 "ready" 메시지 전송.요약: 최종적으로 DP 레플리카 4개(프로세스 4개)가 각각 메인·입력·출력 스레드를 실행합니다. 이들은 DP 코디네이터와 프런트엔드와의 조정 핸드셰이크를 완료한 뒤, 프로세스당 3개 스레드 모두 정상 상태의 바쁜 루프를 수행합니다.
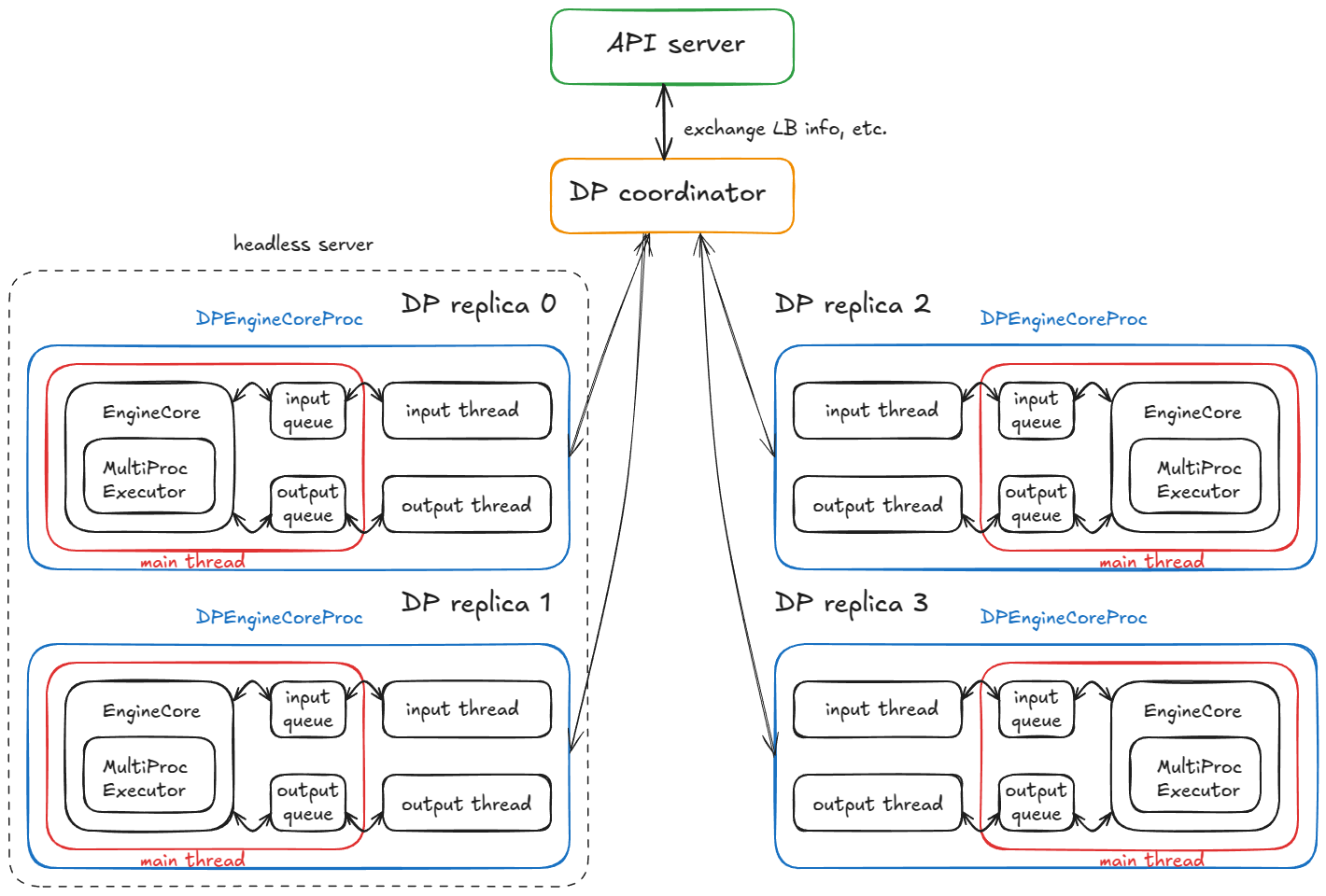
4개의 DP 레플리카가 4개의 DPEngineCoreProc를 실행하는 분산 시스템
정상 상태:
input_queue.put_nowait(...)로 작업 항목을 큐에 넣은 뒤, 다시 소켓에서 블록.input_queue.get(...)으로 깨어나 엔진에 요청을 공급; MultiProcExecutor가 forward를 실행하고 결과를 output_queue에 큐잉.output_queue.get(...)으로 깨어나 결과를 API 서버로 송신한 뒤 다시 블록.추가 메커니즘:
락스텝 보충 설명: 이는 실제로 MoE 모델에서만 필요합니다. 전문가 레이어가 EP 또는 TP 그룹을 이루는 동안 어텐션 레이어는 여전히 DP이기 때문입니다. 현재는 DP에서도 항상 수행되지만, 이는 내장 비-MoE DP의 유즈케이스가 제한적이기 때문이며, 일반적으로는 독립 vLLM 여러 개를 실행하고 통상의 방식으로 로드밸런싱하면 됩니다.
이제 두 번째 부분, API 서버 노드에서는 무엇이 일어날까요?
AsyncLLM 객체(LLM 엔진의 asyncio 래퍼)를 인스턴스화합니다. 내부적으로 DPLBAsyncMPClient(데이터 병렬, 로드밸런싱, 비동기, 멀티프로세싱 클라이언트)를 생성합니다.
부모 클래스 MPClient 내부에서 launch_core_engines 함수가 실행되어:
DPCoordinator 프로세스를 스폰.CoreEngineProcManager를 생성(헤드리스 노드와 동일).AsyncMPClient(MPClient의 자식) 내부에서는:
outputs_queue(asyncio.Queue)를 생성.process_outputs_socket을 생성 — 이는 모든 4개 DPEngineCoreProc의 출력 스레드와 출력 소켓을 통해 통신하고 outputs_queue에 기록.AsyncLLM의 또 다른 asyncio 태스크 output_handler가 이 큐에서 읽어 최종적으로 create_completion 함수에 정보를 전달.DPAsyncMPClient 내부에서는 run_engine_stats_update_task라는 asyncio 태스크를 생성해 DP 코디네이터와 통신합니다.
DP 코디네이터는 프런트엔드(API 서버)와 백엔드(엔진 코어) 사이에서 중재합니다:
run_engine_stats_update_task로 전송.SCALE_ELASTIC_EP 명령을 받아 엔진 수를 동적으로 변경(레이 백엔드에서만 동작).START_DP_WAVE 이벤트를 보내고, 웨이브 상태 업데이트를 다시 보고.요약하면, 프런트엔드(AsyncLLM)는 여러 asyncio 태스크를 실행합니다(동시성, 병렬 아님):
generate 경로로 처리하는 태스크(클라이언트 요청마다 새 asyncio 태스크 생성).process_outputs_socket, output_handler)는 하위 엔진에서의 출력 메시지를 처리.run_engine_stats_update_task)는 DP 코디네이터와의 통신을 유지: 웨이브 트리거 송신, LB 상태 폴링, 동적 스케일링 처리.마지막으로 메인 서버 프로세스는 FastAPI 앱을 만들고 OpenAIServingCompletion, OpenAIServingChat 같은 엔드포인트를 마운트합니다. /completion, /chat/completion 등을 노출하고, Uvicorn으로 스택을 서빙합니다.
모든 것을 합치면, 전체 요청 라이프사이클은 다음과 같습니다!
터미널에서 다음을 전송합니다:
curl -X POST http://localhost:8000/v1/completions -H "Content-Type: application/json" -d '{
"model": "TinyLlama/TinyLlama-1.1B-Chat-v1.0",
"prompt": "The capital of France is",
"max_tokens": 50,
"temperature": 0.7
}'
그 다음 일어나는 일:
OpenAIServingCompletion의 create_completion 라우트에 도착.AsyncLLM.generate를 호출 — 이는 동기 엔진과 동일한 플로우를 따르며, 최종적으로 DPAsyncMPClient.add_request_async를 호출.get_core_engine_for_request를 호출 — DP 코디네이터 상태에 기반한 엔진 간 로드밸런싱 실행(최소 점수/최저 부하 선택: score = len(waiting) * 4 + len(running)).input_socket으로 ADD 요청을 전송.input_queue에 넣은 뒤 다시 블록.
* 메인 스레드 — input_queue에서 언블록되어 요청을 엔진에 추가하고, 종료 조건을 만족할 때까지 반복적으로 engine_core.step()을 호출, 중간 결과를 output_queue에 큐잉.상기 리마인더: step()은 스케줄러와 모델 실행기(필요 시 MultiProcExecutor!) 등을 호출합니다. 이미 살펴본 내용이죠!
* 출력 스레드 — `output_queue`에서 언블록되어 결과를 출력 소켓으로 전송.
7. 이 결과는 AsyncLLM의 출력 asyncio 태스크들(process_outputs_socket, output_handler)을 트리거하고, FastAPI의 create_completion 라우트로 토큰을 전파.
8. FastAPI가 메타데이터(종료 사유, logprobs, usage info 등)를 첨부하고 Uvicorn을 통해 터미널로 JSONResponse를 반환!
이렇게 간단한 curl 명령 뒤에 전체 분산 기계가 숨겨져 있습니다! :) 정말 재미있죠!!!
📝추가 메모:
/scale_elastic_ep)를 노출할 수 있습니다.지금까지는 엔진/시스템 내부에서 요청이 흐르는 방식을 분석했습니다. 이제 시스템 전체를 조망하며 묻습니다: 추론 시스템의 성능은 어떻게 측정할까요?
최상위에는 서로 경쟁하는 두 메트릭이 있습니다:
지연시간은 응답을 기다리는 인터랙티브 애플리케이션에서 가장 중요합니다.
처리량은 사전/사후 학습용 합성 데이터 생성, 데이터 정제/처리 등 오프라인 배치 추론 작업에서 중요합니다.
지연시간과 처리량이 왜 경쟁하는지 설명하기 전에, 몇 가지 일반적인 추론 메트릭을 정의합시다:
| 메트릭 | 정의 |
|---|---|
TTFT (time to first token) | 요청 제출 시점부터 첫 출력 토큰을 받을 때까지의 시간 |
ITL (inter-token latency) | 두 연속 토큰(예: 토큰 i-1 → i) 사이의 시간 |
TPOT (time per output token) | 한 요청의 평균 ITL |
Latency / E2E (end-to-end latency) | 요청 처리 총 시간, 즉 TTFT + 모든 ITL의 합, 혹은 요청 제출 ↔ 마지막 출력 토큰 수신 사이의 시간 |
Throughput | 초당 처리된 총 토큰 수(입력/출력/합계) 또는 초당 요청 수 |
Goodput | SLO(예: 최대 TTFT, TPOT, e2e 지연시간)를 만족하는 처리량. 예를 들어, 해당 SLO를 만족한 요청의 토큰만 집계 |
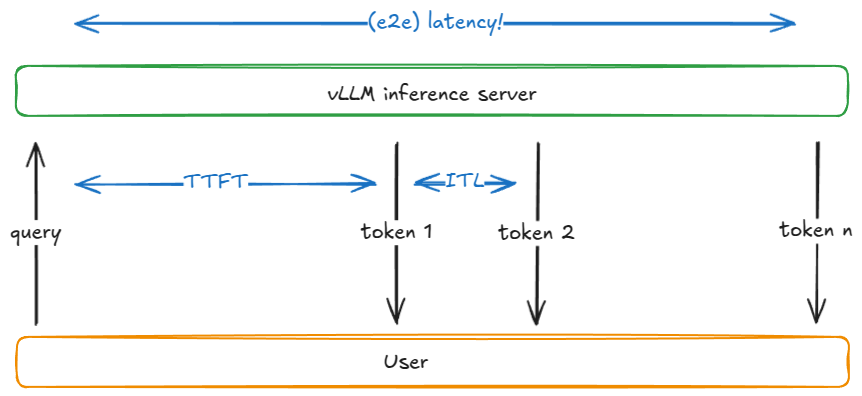
ttft, itl, e2e 지연시간
아래는 이 두 메트릭의 경쟁적 본질을 설명하는 단순화 모델입니다.
가정: weight I/O가 지배적이고 KV 캐시 I/O는 아님; 즉, 짧은 시퀀스를 다룸.
배치 크기 B가 단일 디코드 스텝에 미치는 영향을 보면 트레이드오프가 명확해집니다. B가 1에 가까워질수록 ITL은 떨어집니다: 스텝당 작업이 줄고 토큰이 다른 토큰과 "경쟁"하지 않기 때문입니다. B가 무한대로 증가하면, 스텝당 FLOPs가 늘어 ITL은 증가하지만(커널이 컴퓨트 바운드가 되기 전까지), 가중치 I/O가 더 많은 토큰에 분배되어 처리량은 향상됩니다(피크 성능에 도달할 때까지).
루프라인(roofline) 모델이 이해에 도움이 됩니다: 포화 배치 B_sat 아래에서는 스텝 시간이 HBM 대역폭(레이어마다 온칩 메모리로 가중치를 스트리밍) 지배를 받아 거의 평평 — 1개 vs 10개 토큰 계산 시간이 유사할 수 있습니다. B_sat를 넘으면 커널이 컴퓨트 바운드가 되어 스텝 시간이 대략 B에 비례해 증가; 각 추가 토큰이 ITL을 늘립니다.
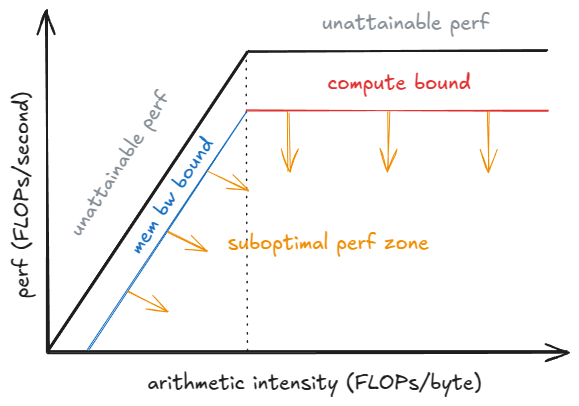
roofline 성능 모델
📝메모:
보다 엄밀하게는 커널 오토튜닝을 고려해야 합니다: B가 커질수록 런타임은 해당 셰이프에 더 효율적인 커널로 전환해 달성 성능 P_kernel이 변합니다. 스텝 지연시간은 t = FLOPs_step / P_kernel이며, FLOPs_step은 스텝의 작업량입니다. P_kernel이 P_peak에 도달하면 스텝당 연산이 늘어나는 만큼 지연시간이 직접 증가합니다.
vLLM은 vllm / benchmarks / {server,latency,throughput}.py를 래핑한 vllm bench {serve,latency,throughput} CLI를 제공합니다.
스크립트는 다음을 수행합니다:
QPS=Inf 모드)하고, 런 전체의 입력/출력/총 토큰 수와 초당 요청 수를 보고합니다.latency 스크립트 실행 예시:
vllm bench latency
--model <model-name>
--input-tokens 32
--output-tokens 128
--batch-size 8
}'
CI에 사용되는 벤치마크 구성은 .buildkite/nightly-benchmarks/tests 아래에 있습니다.
또한 serve 벤치마크를 구동해 목표 SLO(예: "p99 e2e < 500 ms를 유지하면서 처리량 최대화")를 만족하는 인자 설정을 찾는 오토튜닝 스크립트도 있으며, 제안 구성안을 반환합니다.
기본 엔진 코어(UniprocExecutor)에서 시작해, 스페큘레이티브 디코딩과 프리픽스 캐싱 같은 고급 기능을 더하고, MultiProcExecutor(with TP/PP > 1)로 스케일 업한 뒤, 비동기 엔진과 분산 서빙 스택으로 스케일 아웃까지 확장 — 마지막으로 시스템 성능을 측정하는 법을 정리했습니다.
vLLM에는 여기서 생략한 특수 처리도 포함됩니다. 예:
MLA, MoE, 인코더-디코더(예: Whisper), 풀링/임베딩 모델, EPLB, m-RoPE, LoRA, ALiBi, attention-free 변형, 슬라이딩 윈도 어텐션, 멀티모달 LM, 상태공간 모델(예: Mamba/Mamba-2, Jamba)좋은 점은, 대부분이 위에서 설명한 메인 플로우에 대해 직교한다는 것입니다 — 거의 "플러그인"같이 다룰 수 있습니다(실제로는 어느 정도 결합이 있긴 합니다).
저는 시스템을 이해하는 것을 좋아합니다. 그렇지만 이 고도에서는 해상도가 다소 떨어진 것도 사실입니다. 다음 글에서는 특정 서브시스템을 확대해 미시적 디테일까지 파고들겠습니다.
💡연락하기:
글에서 오류를 발견하셨다면 DM 주세요 — X, LinkedIn 또는 익명 피드백으로 메시지를 남겨 주세요.
지난 1년간 실험을 위해 H100을 제공해 주신 Hyperstack에 큰 감사를 드립니다!
사전 공개 버전을 읽고 피드백을 주신 Nick Hill(vLLM 핵심 기여자, RedHat), Mark Seraphim(PyTorch), Kyle Krannen(NVIDIA, Dynamo), Ashish Vaswani께도 감사합니다!