소프트웨어 시스템에서 백프레셔의 물리 법칙, 지연 시간의 죽음의 나선, 그리고 무한 큐가 왜 버그인지 설명합니다.
이 글은 소프트웨어 시스템에서의 백프레셔의 물리 법칙, 지연 시간의 죽음의 나선, 그리고 무한 큐가 왜 버그인지에 대한 이야기입니다.
대규모 트래픽 급증 상황에서 당직을 서 보았거나 운영 및 시스템 신뢰성을 책임져 본 적이 있다면, 그 느낌을 잘 알 것입니다. 경보가 울리고, CPU는 100%까지 치솟고, 메모리 사용량은 천정부지로 올라가며, 서버는 결국 크래시하거나 소프트웨어가 응답하지 않게 됩니다.
이때 팀의 즉각적인 반응은 거의 언제나 같습니다. 더 큰 버퍼가 필요하다는 것입니다. Go 채널 크기나 Redis 버퍼 한도를 늘립니다. 어쩌면 아직 시스템에 큐가 없어서 Kafka나 RabbitMQ를 추가하기로 결정할 수도 있습니다. 이제 문제 해결입니다! 이제는 이런 트래픽 급증도 크래시 없이 처리할 수 있습니다… 비즈니스가 더 큰 이정표에 도달해 다시 같은 상황으로 돌아오기 전까지는 말입니다.
이것은 오늘날 소프트웨어 엔지니어링에서 가장 직관적인 대응입니다. 큐는 임시방편으로만 쓰이는 것이 아니라 시스템을 분리하기 위한 수단으로 처음부터 추가되기도 합니다. 그런데도 한 시스템의 과부하는 다른 시스템들로 연쇄적으로 퍼져 나갑니다.
하지만 큐는 욕조나 싱크대와 다르지 않으며, 욕조와 마찬가지로 소프트웨어도 물리 법칙의 지배를 받습니다. 물이 배수구로 내려가는 속도보다 수도꼭지에서 더 빠르게 나온다면, 욕조를 더 크게 만든다고 해서 넘침을 막을 수는 없습니다. 그저 시점을 늦출 뿐입니다.
지연, 그것이 시스템에 미치는 영향, 그리고 신뢰할 수 있는 시스템을 위한 피드백 루프를 어떻게 설계할지에 대해서는 후속 글을 올릴 예정입니다. 지금은 큐의 물리와 그것이 왜 과부하를 해결하지 못하는지에 집중해 봅시다.
Fred Hebert가 유명하게 쓴 말처럼, “Queues don’t fix overload.” 큐는 작업 도착 속도가 작업 완료 속도보다 가끔, 그리고 일시적으로 높을 때만 유용합니다. 큐가 흡수하는 것은 지속적인 부하가 아니라 변동성입니다.
트래픽 급증을 처리하기 위해 무한 큐에 의존한다면, 문제를 해결하는 것이 아닙니다. 실패가 치명적이고 회복 불가능할 가능성이 높아지도록 보장하는 것입니다.
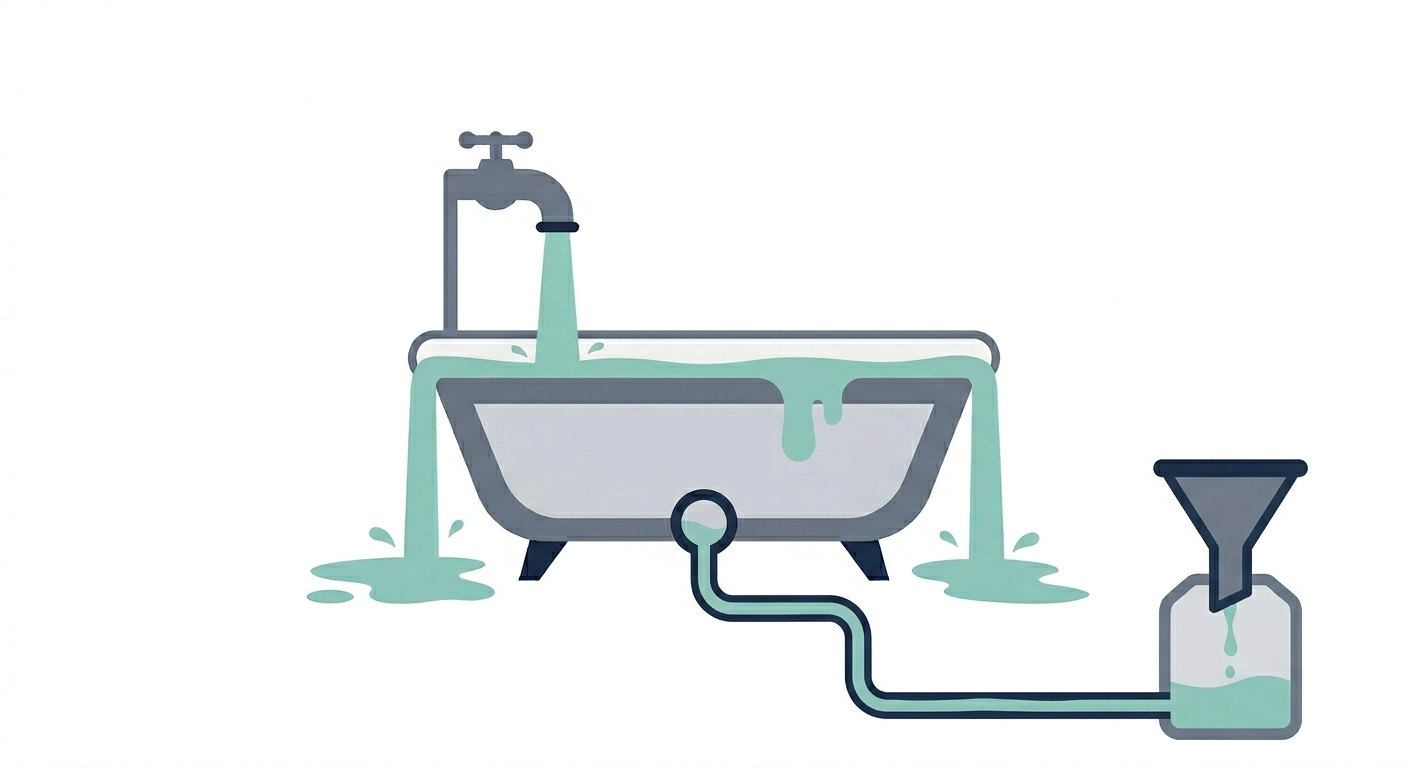
도착률(수도꼭지)이 처리율(좁은 배수관)을 초과하면 버퍼(욕조)는 결국 넘칩니다. 더 큰 욕조는 피할 수 없는 일을 늦출 뿐입니다.
큐의 물리를 살펴봅시다. 대기행렬 이론은 대기열, 즉 큐를 수학적으로 연구하는 분야이며, 이를 설명하는 수학적 증명이 있는데 그것이 바로 Little의 법칙입니다.
Little의 법칙은 시스템 안의 항목 수($L$)가 항목이 도착하는 비율($\lambda$)에 그것들을 처리하는 데 걸리는 평균 시간($W$)을 곱한 값과 같다고 말합니다.
L = λW
당신의 서비스가 초당 1,000개의 요청을 처리한다고 상상해 봅시다. 그런데 갑자기 초당 5,000개의 요청이 들어옵니다. 이제 초당 4,000개의 요청만큼 적자가 생긴 것입니다.
무한 메일박스나 큐를 사용하기 때문에 서비스는 즉시 크래시하지는 않습니다. 들어오는 모든 요청을 고분고분 받아들이고 메모리에 쌓아 둡니다. 도착률($\lambda$)이 처리 용량을 초과하는 동안, Little의 법칙에 따라 큐 안의 항목 수($L$)는 무한대로 증가할 수밖에 없습니다.
큐가 10,000, 50,000, 100,000에 도달하면, 그 거대한 큐 안에 있는 100,000번째 요청에는 무슨 일이 일어날까요?
워커 프로세스가 마침내 그 요청에 도달할 즈음이면, 그 요청을 보낸 클라이언트는 이미 타임아웃되었을 가능성이 큽니다. 또는 빙글빙글 도는 로딩 표시를 보다 답답해져서 페이지를 새로고침했을 수도 있습니다. 그 새로고침은 큐의 뒤쪽에 또 하나의 요청을 추가했고, 그 결과 도착률($\lambda$)은 더욱 높아집니다.
이제 서버는 이미 떠나버린 사용자의 죽은 요청을 처리하느라 값비싼 CPU 사이클을 소비하고 있습니다. 죽은 요청을 처리하고 있기 때문에 실질적인 처리 시간($W$)은 더 나빠집니다. 재시도 때문에 큐는 더 빠르게 커집니다. 메모리 압박은 가비지 컬렉션 중단을 유발하고, 이것은 처리율을 더욱 떨어뜨립니다.
배수구는 막혀 가는데 수도꼭지는 더 크게 열립니다.
이것이 바로 지연 시간의 죽음의 나선입니다. 응답 시간 증가가 요청 대기를 낳고, 그것이 추가 지연을 만들며, 결국 시스템 전체가 포화되는 연쇄적 시스템 장애입니다. 무한 큐에서는 바로 이런 일이 벌어집니다.
하드웨어가 허용하는 것보다 더 빠르게 데이터를 처리할 수는 없습니다. 네트워크의 데이터 전송률, CPU 처리 속도, 디스크 I/O 처리량이 이미 한계에 도달했다면, 소프트웨어만으로 그것을 마법처럼 더 빠르게 만들 수는 없습니다. 따라서 데이터를 버려야 합니다. 예를 들어 네트워킹 맥락에서는 패킷을 드롭합니다.
엔지니어링에서 여러분에게 남아 있는 유일한 선택은 그것을 어떻게, 그리고 어디서 버릴 것인가입니다.
대부분의 프레임워크는 데이터를 암묵적으로 버리도록 선택합니다. 큐는 서버 메모리가 바닥날 때까지 계속 커지고, 운영체제가 프로세스를 죽이며, 그 순간 모든 것이 함께 사라집니다. 그 결과 처리 중이던 모든 요청이 손실되고, 서비스는 재시작될 때까지 완전히 중단됩니다.
대안은 Load Shedding과 Backpressure를 통해 데이터를 명시적으로 버리는 것입니다.
시스템이 이미 용량 한계에 도달했다면 새 작업을 즉시 거부해야 합니다. 보내는 쪽을 똑바로 바라보며 “나는 가득 찼다. 물러가라.”고 말할 수 있어야 합니다. 보내는 쪽은 즉시 통보받아야 하며, 그래야 정책 결정을 내릴 수 있습니다. 이 요청을 버릴 것인가, 나중에 다시 시도할 것인가, 아니면 사용자에게 성능이 낮아진 경험을 보여 줄 것인가? 이것은 시스템의 실패가 아닙니다. 적절한 피드백 루프로 시스템이 스스로를 성공적으로 방어한 것입니다.
Tina에서 저는 프레임워크를 하나의 불변 법칙 위에 설계했습니다. 용량이 초과되면 초과분은 즉시 버린다는 것입니다.
Tina는 제가 Odin으로 만든, 코어당 스레드 방식의 고처리량 동시성 프레임워크입니다. 이 프레임워크는 과부하를 해결하기 위해 큐를 사용하지 않습니다. 시스템의 모든 자원, 즉 메일박스, 메시지 풀, 샤드 간 채널은 엄격히 제한되어 있으며 부팅 시점에 미리 할당됩니다. 운영 중에는 동적 할당(또는 malloc)이 없고, 메일박스에 “무한” 모드도 없습니다. 기본적인 Isolate 메일박스는 기본값으로 정확히 256개의 메시지를 담습니다(설정 가능한 값입니다).
Isolate는 Tina의 동시성 단위입니다. 메일박스에서 메시지를 순차적으로 처리하는 단일 스레드 메시지 전달 액터입니다.
Isolate가 가득 찬 메일박스로 메시지를 보내려고 할 때, 시스템은 숨겨진 버퍼를 할당하지 않습니다. 보내는 쪽을 멈추지도 않습니다. O(1) 시간 안에 메시지를 거부하고 그 실패를 즉시 보내는 쪽에 반환합니다.
[ Sender Isolate ] [ Target Isolate Mailbox ]
│ ┌───┬───┬───┬───┐
send(target, msg) ─────(Full!)───────X │msg│msg│...│msg│ (256/256)
│ └───┴───┴───┴───┘
▼
Returns .mailbox_full
(Zero allocation, O(1) fast rejection)
실패를 동기적으로 반환함으로써, 프레임워크는 시스템이 용량 한계에 도달한 바로 그 순간 애플리케이션이 정책 결정을 내리도록 강제합니다. 몇 분 뒤 다운스트림 타임아웃으로 실패를 미루는 것이 아닙니다.
코드에서는 다음과 같이 보입니다. Tina에서 메시지 전송은 Send_Result를 반환하는 동기 ctx_send 호출입니다.
result := tina.ctx_send(ctx, destination_handle, TAG_DATA, &payload)
#partial switch result {
case .ok:
// Message successfully enqueued.
return tina.Effect_Receive{}
case .mailbox_full:
// The destination is overwhelmed. We must shed load.
tina.ctx_log(ctx, .WARN, TAG_OVERLOAD, "Destination overloaded, dropping request.")
// We explicitly drop the work and wait for the next message.
return tina.Effect_Receive{}
case .pool_exhausted:
// The Shard's memory pool is fully saturated. Let it crash.
return tina.Effect_Crash{reason = .system_saturated}
}
만약 데이터를 버려도 괜찮은 텔레메트리나 메트릭 전송기를 만들고 있다면, 결과를 명시적으로 무시합니다. Tina에서는 밑줄이 백프레셔를 무시하기로 한 아키텍처적 결정을 문서화합니다.
// Fire-and-forget. If the metrics service is overloaded, drop the metric.
_ = tina.ctx_send(ctx, metrics_handle, TAG_METRIC, &payload)
ctx_send는 UDP처럼 동작합니다. 빠르고, 최선형이며, 즉각적인 피드백을 제공합니다. 하지만 결제 서비스를 작성하고 있고 보장된 응답이 반드시 필요하다면 어떻게 해야 할까요?
신뢰성이 필요하다면 .call 패턴을 사용합니다. 동기 함수 호출 대신 스케줄러에 Effect_Call을 반환합니다.
// Send a request and park the Isolate until a reply arrives.
return tina.Effect_Call{
to = billing_handle,
message = transform_request_to_message(request),
timeout = 5000, // Mandatory timeout in milliseconds
}
과부하 상태의 시스템에서는 결제 메일박스가 가득 차 .call 요청이 버려질 수 있습니다. 그렇게 되더라도 영원히 기다리지는 않습니다. 필수 타임아웃이 발생하고, 스케줄러는 TAG_CALL_TIMEOUT 메시지로 Isolate를 다시 깨우며, 여러분은 그 실패를 처리합니다.
“결제 서비스가 죽었다”, “메시지가 버려졌다”, “결제 서비스가 그저 느리다”를 구분할 수는 없습니다. 그리고 시스템 엔지니어링 관점에서 보면, 사실 그 차이는 중요하지 않습니다. 필요한 SLA 안에 시스템이 요청을 처리하지 못했다는 점에서 대응은 완전히 같기 때문입니다. 재시도하거나, 상위로 에스컬레이션하거나, 클라이언트 요청을 실패 처리해야 합니다.
메시지를 보낼 때마다 개발자에게 Send_Result 처리를 강제하는 것은, 무한 Erlang 메일박스나 무한 확장 가능한 Go 채널에 메시지를 던져 넣는 것보다 더 장황합니다.
저는 글자 수를 조금 덜 치는 것보다 예측 가능성과 크래시 안전성이 더 중요하다고 판단했기에 이 절충을 받아들였습니다.
큐를 엄격하게 제한하고 타임아웃을 강제함으로써, 우리는 지연 시간의 죽음의 나선을 구조적으로 제거합니다. 시스템은 점잖게 성능을 낮추며 버팁니다. 초과 부하를 즉시 덜어내고, 죽은 요청을 다음 20분 동안 처리하느라 시간을 쓰지 않기 때문에 트래픽이 정상화되는 즉시 회복할 수 있습니다.
코어당 스레드 방식의 고처리량 아키텍처, 무할당 상태 머신, 또는 결정적 시뮬레이션 테스트에 관심이 있다면, 제 프로젝트 Tina에 대한 아키텍처 비평을 꼭 듣고 싶습니다. 소스 코드, 문서, 예제는 GitHub 여기에서 확인할 수 있습니다.