구문적 타입 건전성의 한계를 짚고, 데이터 추상화와 안전하지 않은 기능의 안전한 캡슐화를 다룰 수 있는 의미적 타이핑과 의미적 타입 건전성의 구조(적합성, 의미적 타이핑 규칙)를 Rust 예제와 함께 설명한다. 이어서 고차 프로그램 논리를 통한 기계 검증 가능성도 개관한다.
타입 시스템은 현대 프로그래밍 언어에서 어디에나 존재하며 필수적이다. 타입 시스템은 독립적으로 개발된 프로그램 조각들이 서로 “제대로 맞물리게” 도와주고, 실행 시점 오류의 큰 부류를 정적으로 방지한다.
그렇다면 타입 시스템이 제 역할을 하는지 보장하기 위해 실제로 무엇을 증명할 수 있을까? 가장 흔한 답은 타입 건전성(또는 타입 안전성)이다. 40여 년 전 Robin Milner가 처음 도입한 바에 따르면, 프로그래밍 언어 L의 타입 건전성 정리는 L로 작성된 프로그램 P가 L의 타입 검사를 통과한다면, P를 실행했을 때 잘 정의된 행동을 보장받는다는 것을 말한다. 흔히 Milner의 구호—“well-typed programs can’t go wrong(잘 형식화된 프로그램은 잘못되지 않는다)”—로 요약되는 타입 건전성은 “안전한” 프로그래밍 언어들의 타입 시스템이 만족해야 할 대표적 속성이 되었다.
그러나 이 글에서 논하듯, 가장 일반적인 구문적 접근법은 타입이 유용한 이유 중 중요한 측면을 빠뜨린다. 특히 John Reynolds가 1983년에 유명하게 말했듯이, “타입 구조는 추상화 수준을 강제하는 구문적 규율”인데, 여기서 “추상화”란 프로그램 구성 요소가 다른 구성 요소로부터 정보를 숨기는 능력을 가리킨다. 하지만 구문적 타입 건전성은 추상화에 대해 말해주는 바가 거의 없다. 이 글에서는 의미적 형태의 타입 건전성을 통해, 타입 시스템의 장점을 보다 만족스럽고 포괄적으로 설명할 수 있음을 보인다.
Wright와 Felleisen이 개척하고 이후 Harper가 단순화한 구문적 접근은 “진행(progress)”과 “보존(preservation)”으로 알려진 두 정리를 증명하는 것이다. 작은 단계 연산적 의미론 하에서 프로그램이 실행 도중 더 이상 진행할 수 없는 비종결 상태—즉 다음 실행 단계가 존재하지 않아 막히는(stuck) 일이 결코 일어나지 않으면, 그 프로그램은 잘 정의된 동작을 가진다고 본다. 보존 정리는 프로그램이 실행되는 동안 타입이 유지됨을 말하고, 진행 정리는 잘 형식화된 프로그램이 종결 상태에 있거나 다음 실행 단계가 잘 정의되어 있음을 말한다. 이 둘을 합치면, 잘 형식화된 프로그램의 실행은 잘 정의되어 있으며—즉 결코 막히지 않음을 뜻한다.
이 구문적 접근—그리고 진행과 보존에 의한 증명법—은 지난 25년간 프로그래밍 언어 연구의 대표적 업적 중 하나다. 개념적으로 단순하고, 다양한 언어 기능으로 쉽게 확장되며, 인기 있는 교재들(예: Pierce, Harper)에서 중심적 구성 역할을 한다. 그 결과, 프로그래밍 언어 기초 전반에서 가장 널리 알려지고, 널리 가르쳐지며, 널리 적용되는 형식적 방법 중 하나가 되었다.
안타깝게도 구문적 타입 건전성에는 널리 인식되지 않은(적어도 우리의 경험상) 두 가지 중요한 한계가 있다.
첫째 한계는 데이터 추상화에 관한 것이다. 많은 언어의 타입 시스템의 주요 기능은 데이터 추상화 경계를 강제하는 방법을 제공하는 데 있다. 즉, 모듈/클래스의 비공개 데이터 표현에 대한 불변식을 설정하고, 클라이언트 코드가 그 불변식을 침해하지 않도록 보장하는 것이다. 하지만 구문적 타입 건전성은 어떤 언어의 데이터 추상화 기제가 실제로 잘 작동하는지에 대해 아무런 보장을 제공하지 않는다—데이터 추상화 메커니즘이 완전히 망가진 타입 시스템의 구문적 건전성을 증명하는 것은 극히 쉽다. 예를 들어, 비교적 최근까지 Java의 리플렉션 메커니즘은 클래스의 클라이언트가 그 클래스의 private 필드에 대한 내부 구현 불변식을 깨뜨릴 수 있게 했다. 그러나 구문적 타입 건전성 관점에서는, 무제한 리플렉션은 전혀 문제가 되지 않는다.
둘째 한계는 안전하지 않은 기능(unsafe features)에 관한 것이다. 실제로 대부분의 “안전한” 언어는 안전하지 않은 탈출구—예: OCaml의 Obj.magic, Haskell의 unsafePerformIO, Rust의 unsafe 블록, 또는 FFI(다른 언어로 작성된 코드 호출)—를 제공한다. 이는 체크되지 않은 캐스트나 배열 접근처럼, 언어의 안전한 부분이 금지하는 잠재적으로 위험한 연산을 수행할 수 있게 해준다. 이러한 탈출구는 기능성 측면—언어의 안전한 타입 시스템이 필요 이상으로 제한적인 경우—과 효율성 측면—성능상 더 저수준의 비안전 추상을 써야 하는 경우—에서 모두 필수적임이 입증되었다. 그러나 구문적 타입 건전성은 안전하지 않은 기능을 사용하는 프로그램에 대해 아무 말도 하지 못한다. 그냥 범위 밖으로 선언해 버릴 뿐이다.
이 두 한계는 사실 밀접하게 연결되어 있다. 안전하지 않은 기능의 “안전한” 사용을 데이터 추상화에 호소함으로써 정당화하는 일이 흔하기 때문이다. 구체적으로, 프로그래머들은 안전하지 않은 연산을 “안전한 API” 뒤에 캡슐화 했기 때문에 해가 없다고 흔히(비형식적으로) 주장한다. 즉, API의 추상화 경계 덕분에, API 구현이 자신의 비공개 데이터 표현에 불변식을 부과하고 이를 통해 안전하지 않은 기능의 사용이 정의되지 않은 동작으로 이어지지 않게 할 수 있다고 주장하는 것이다. 하지만 이러한 추론을 형식적으로 하려면, 해당 언어가 데이터 추상화를 제대로 강제하고 있는지를 알아야 하며, 바로 그 지점이 구문적 건전성이 침묵하는 부분이다.
우리는 구문적 타입 건전성만으로는 타입 시스템이 정말 제 역할을 하는지 판단하기에 충분치 않음을 주장했다. 그렇다면 더 나은 방법이 있을까?
있다! 지난 15년 동안, 우리는 여러 동료 및 협력자들과 함께 구문적 타입 건전성에 대한 실행 가능한 대안을 개발·정제해 왔다. 이 대안은 데이터 추상화는 물론 안전하지 않은 기능의 안전한 사용에 대한 추론을 뒷받침하는 유연한 토대를 제공한다. 우리의 접근법은 다양한 프로그래밍 언어 안전성 증명에 적용되어 왔고(그중 여럿은 기계 검증됨), 특히 프린스턴의 Foundational Proof-Carrying Code 프로젝트와, 더 최근에는 Rust 프로그래밍 언어의 안전성을 검증하는 RustBelt 프로젝트에서 두드러진 성과를 보였다.
우리의 접근은 Milner의 원 논문에 나타난 바와 같은 _의미적 타입 건전성_의 고전적 아이디어 위에 세워져 있다. 의미적 건전성은 구문적 건전성의 핵심 문제—“안전함”을 “구문적으로 잘 형식화됨”과 동일시하여, 잠재적으로 안전하지 않은 기능을 잘 캡슐화하여 사용하는 코드의 안전성을 설명하지 못하는 문제—를 해결한다.
이 문제를 극복하기 위해, 의미적 타입 건전성은 안전성을 보다 자유로운 관점의 잘 형식화됨으로 모델링하는데, 이를 _의미적 타이핑(semantic typing)_이라 부른다. 구문적 타이핑—기호로 
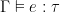
간단하지만 시사적인 예로, 다음 Rust 모듈을 보자:
mod example { // Rust 모듈 = 추상화 경계
// 불변식: 이 벡터의 길이는 최소 1.
pub struct NonEmptyVec { v: Vec<i32> }
impl NonEmptyVec {
pub fn new(v: Vec<i32>) -> NonEmptyVec {
// v가 비어 있으면 실행 중단.
if v.len() == 0 { panic!("v should be nonempty"); }
NonEmptyVec { v }
}
pub fn get(&self) -> i32 {
unsafe { *self.v.get_unchecked(0) }
}
}
}
여기서 우리는 추상 데이터 타입 NonEmptyVec를 정의한다. 내부적으로는 정수 벡터로 구현되지만, 이는 모듈의 클라이언트에게 노출되지 않으므로, NonEmptyVec 내부의 벡터는 항상 비어 있지 않다(즉, 길이가 최소 1)라는 불변식을 비공개적으로 강제할 수 있다. NonEmptyVec의 생성자는 NonEmptyVec가 만들어질 때 이 불변식이 유지되도록 보장한다. 그 결과, get 메서드가 호출되면, 벡터의 첫 번째 원소에 대한 체크되지 않은 접근을 안전하게 수행할 수 있는데, 벡터가 비어 있을 수 없음을 알고 있기 때문이다.
일반적으로 체크되지 않은 벡터 접근은 안전하지 않은 연산이므로, Rust는 get에서 그러한 연산의 사용을 unsafe 블록으로 감쌀 것을 요구한다. 그러나 위에서 주장했듯이, Rust의 데이터 추상화 덕분에 이 체크되지 않은 접근은 성공이 보장된다. 즉, 안전하지 않은 연산의 사용이 NonEmptyVec의 API에 의해 _안전하게 캡슐화_되었다. 따라서 get은 Rust의 안전한 부분언어 안에서는 _구문적으로는 잘못 형식화_되어 있지만, _의미적으로는 잘 형식화_되어 있다.
의미적 타이핑이 “안전한 캡슐화”가 무엇을 뜻하는지 설명하는 데 적합하다고 믿기 시작했다면, 다음과 같은 의문이 들 수 있다: “의미적 타입 건전성”을 증명한다는 것은 무엇을 의미할까? 의미적 타입 건전성 증명의 상위 구조는 매우 단순하다.
적합성(Adequacy). 먼저 적합성(adequacy) 정리를 증명한다. 이는 닫힌(자유 변수 없는) 의미적으로 잘 형식화된 항—즉 
의미적 타이핑 규칙. 다음으로, 더 흥미로운 단계로 언어의 구문적 타이핑 규칙들의 의미적 버전을 증명한다. 예를 들어, 여러분의 언어에 다음과 같은 함수 적용에 대한 타이핑 규칙이 있다고 하자:
그러면 이에 대응하는 _의미적 타이핑 규칙_을 증명해야 한다:
구문적 타이핑 규칙이 구문적 타이핑의 _정의_의 일부인 것과 달리, 의미적 타이핑 규칙은 의미적 타이핑이 만족해야 하는 _성질_이다. 즉, 우리가 의미적 타이핑 관계를 어떻게 형식화하든, 이 규칙의 전제가 결론을 함의해야 한다. 의미적 타이핑 규칙은 의미적 타이핑이 구문적 타이핑과 같은 방식으로 합성 가능함을 보여준다.
의미적 타이핑 규칙의 즉각적 귀결 중 하나는, 구문적 타이핑이 의미적 타이핑을 함의한다는 것—즉 
하지만 우리가 의미적 타입 건전성을 중요하게 여기는 주된 이유는, 이것이 구문적 타입 건전성보다 엄밀히 더 강한 결과이기 때문이다. 의미적 건전성은 프로그램의 구문적으로 잘 형식화된 조각들을, 다른 한편으로 구문적으로 잘못 형식화된(예: 안전하지 않은 기능 사용) 조각들과도, 그 다른 조각들이 _의미적으로 잘 형식화_되어 있는 한 안전하게 합성할 수 있음을 보여준다. 예컨대, 위의 example Rust 모듈이 의미적으로 잘 형식화되었음을 증명하고 나면, example이 구문적으로(또는 의미적으로) 잘 형식화된 어떤 클라이언트 프로그램에 의해 사용되더라도, 그 결합된 전체 프로그램이 실행해도 안전함을 도출할 수 있다.
문제는 일반적으로 example과 같은 모듈이 의미적으로 잘 형식화되었음을 증명하는 데 임의로 흥미로운 검증 노력이 필요할 수 있다는 점이다. 모듈의 내부 불변식을 형식화하고 그것이 유지됨을 보장해야 하기 때문이다. 그러나 이는 당연한 일이다. 의미적 건전성의 목표는 바로 모듈이 내부 불변식을 올바르게 유지함을 확립하는 데 도움을 주는 것이며, 이는 종종 코드의 완전한 기능적 정확성을 증명하는 일에 해당한다.
물론, 아직 남은 큰 질문은 이것이다: 의미적 타이핑을 실제로 어떻게 _정의_하며, 그에 필요한 성질을 증명하는 데 무엇이 수반되는가?
이 시리즈의 다음 글에서는 이 질문을 자세히 살펴보고, 왜 과거의 의미적 타이핑 정의 접근법들이 더 널리 채택되지 못했는지 탐구한다. 이어서 고차 프로그램 논리의 최근 발전이 어떻게 의미적 타이핑을 정의하고 비교적 수월하게 기계 검증된 의미적 건전성 증명을 수행할 수 있게 했는지 보여줄 것이다. 기대해 달라!
그동안 이 주제 전반을 폭넓게 개관하고, 의미적 타이핑을 어떻게 정의할 수 있을지에 대한 몇 가지 세부사항을 담은 Derek Dreyer의 POPL’18 기조연설을 참고할 수 있다.
Derek Dreyer는 독일 자를브뤼켄의 Max Planck Institute for Software Systems(MPI-SWS)와 Saarland Informatics Campus의 컴퓨터 과학 교수로, Foundations of Programming 그룹과 RustBelt 프로젝트를 이끌고 있다.
Amin Timany는 플란데런 연구재단(FWO)의 박사후 펠로로, KU Leuven 컴퓨터 과학과 DistriNet 연구 그룹에서 일하고 있다.
Robbert Krebbers는 Delft 공과대학교의 프로그래밍 언어 분야 조교수다.
Lars Birkedal은 Aarhus 대학교의 교수이자 Villum Investigator로, Logic and Semantics 그룹과 Center for Basic Research in Program Verification을 이끌고 있다.
Ralf Jung은 독일 자를브뤼켄의 Max Planck Institute for Software Systems(MPI-SWS)와 Saarland Informatics Campus의 박사과정 학생이다.
면책 조항: 이 글들은 커뮤니티의 이익을 위해 SIGPLAN 블로그에서 생각을 공유하려는 개인 필자들이 작성한 것이다. 블로그에 표현된 모든 견해나 의견은 개인적이며, 글쓴이 본인에게만 속하며 ACM SIGPLAN이나 그 상위 기관인 ACM의 견해를 대변하지 않는다.

