스킵리스트와 이를 일반화한 스킵트리가 대규모 분석 데이터베이스에서 트리 질의를 효율적으로 처리하는 데 어떻게 쓰였는지 설명합니다.
← 블로그 얼마 전, 나는 Phil Eaton의 The Art of Multiprocessor Programming 북클럽에 참여했는데, 그 자리에서 스킵리스트 이야기가 나왔다.
내 경력의 대부분 동안 스킵리스트는 늘 틈새 자료구조처럼 보였다. 열성적인 추종자는 많지만 내 삶에 실제로 적용할 일은 그리 많지 않은 것 같았다. 그런데 6년쯤 전, Antithesis에서 도저히 풀기 어려워 보이던 문제가 하나 있었고, 알고 보니 우리가 정확히 필요로 했던 것은 스킵리스트의 일반화된 형태였다.
하지만 그 이야기를 하기 전에, 먼저 스킵리스트가 무엇인지 설명하겠다(이미 잘 안다면 앞부분은 건너뛰어도 좋다).
스킵리스트는 무작위화된 자료구조로, 기본적으로는 이진 탐색 트리를 그대로 대체할 수 있다. 인터페이스도 같고 각 연산의 점근적 복잡도도 같다. 어떤 사람들은 비교적 단순하고 이해하기 쉬운 락 프리 동시성 구현을 만들 수 있어서 이를 좋아하고, 또 어떤 사람들은 그냥 취향의 문제로 좋아한다. 혹은 당신이 절대로 들어본 적 없는 밴드 음악 듣기를 좋아해서일 수도 있다.
구현 관점에서 보면, 대략 연결 리스트에 “급행 차선”을 더한 것으로 생각할 수 있다.
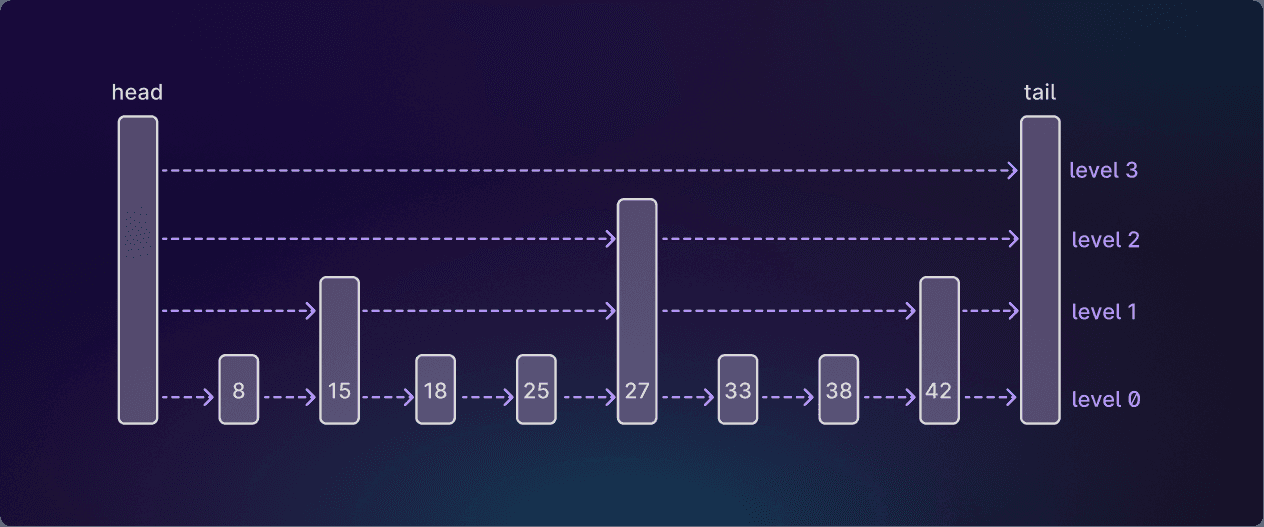
기본 연결 리스트에서 시작한 다음, 점점 더 적은 수의 노드를 담는 연결 리스트 계층을 그 위에 추가한다. 위 예시에서는 상위 리스트의 노드들이 확률적으로 선택되며, 각 노드는 다음 레벨로 승격될 확률이 50%다.1
이 구조는 탐색에 도움이 된다. 상위 레벨 리스트를 이용하면 원하는 노드까지 더 빠르게 건너뛸 수 있기 때문이다.
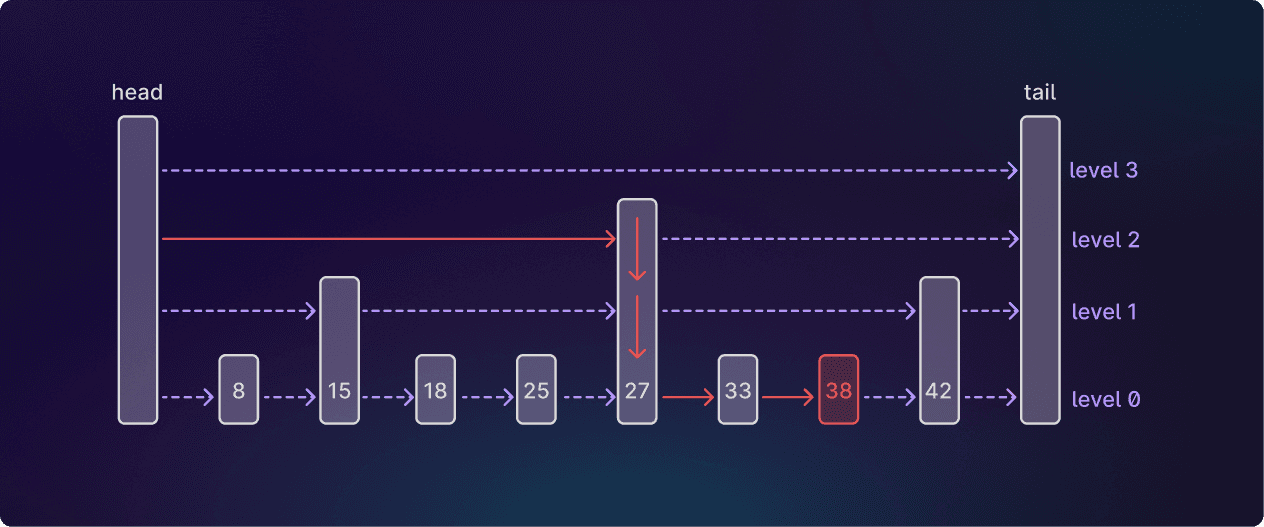
여기서는 최상위 레벨에서 시작해 아래로 내려가면서 ID가 38인 노드를 찾았다. 각 레벨에서 다음 노드의 ID가 너무 커지기 전까지 전진한 뒤, 한 레벨 아래로 내려간다.
노드가 n개인 일반 연결 리스트에서는 노드를 찾는 데 O(n) 시간이 든다. 노드를 하나씩 따라가며 지나가야 하기 때문이다. 스킵리스트에서는 레벨을 건너뛸 수 있고, 각 레벨마다 확인해야 할 노드 수가 절반으로 줄어드므로 결국 O(log n) 시간에 노드를 찾게 된다.
전부 아주 훌륭한 이야기이긴 하지만, 나는 이 자료구조를 읽고 나서 문자 그대로 다시는 떠올리지 않았다. 그러다가 어느 날 Antithesis에서 다음과 같은 문제를 마주치기 전까지는 말이다…
Antithesis는 버그를 찾기 위해 고객의 소프트웨어를 여러 번 실행한다. 실행할 때마다 우리 퍼저는 서로 다른 결함을 주입하고, 테스트 코드가 서로 다른 무작위 결정을 내리도록 만든다. 많은 실행을 거치면 이러한 선택들이 타임라인의 분기 트리를 만든다. 루트에서 리프까지의 각 경로는 퍼저가 내린 하나의 선택 시퀀스와 그 결과로 일어난 일을 나타낸다.
우리가 하고 싶었던 질의 중 상당수는 본질적으로 이 트리를 위아래로 접어 올리거나 내려가는 fold 연산에 해당했다. 예를 들어, 특정 로그 메시지가 주어졌을 때 거기에 이르게 한 사건들의 유일한 이력은 무엇인가? (그 노드에서 부모 포인터를 따라 루트까지 올라간다.)
문제는 테스트 중인 소프트웨어가 출력하는 데이터 양이 너무 방대해서, 이 모든 것을 분석용 데이터베이스에 넣어야 했고 당시에는 Google BigQuery를 사용하고 있었다는 점이다. 분석용 데이터베이스는 방대한 양의 데이터를 병렬로 스캔해 집계 결과를 계산하는 데 최적화되어 있다. 그 대가로, ID로 특정 행 하나를 가져오는 식의 포인트 조회는 느리다.
이 점이 중요한 이유는, 데이터베이스에서 트리를 표현하는 자연스러운 방식이 부모 포인터이기 때문이다. 각 노드는 테이블의 한 행이고, parent_id 열이 부모를 가리킨다. “이 로그 메시지에 이르게 한 이력을 보여줘” 같은 질문에 답하려면 트리를 한 번에 한 노드씩 거슬러 올라가야 한다. 노드를 조회하고, 부모 ID를 얻고, 부모 노드를 조회하고, 이런 식으로 계속한다. 각 단계가 포인트 조회다. 포인트 조회용으로 설계된 OLTP 데이터베이스라면 괜찮다.2 하지만 BigQuery에서는 사실상 모든 연산이 전체 테이블 스캔으로 이어지므로, 가장 기본적인 질의조차도 전체 데이터셋에 대해 O(depth)번 읽기를 하게 된다. 끔찍하다!
대안으로는 데이터를 분리할 수도 있었다. 트리 구조 자체(부모 포인터)만 포인트 조회에 강한 데이터베이스에 저장하고, 대용량 데이터는 BigQuery에 두는 방식이다. 하지만 이 접근은 다른 문제를 만들어냈을 것이다. 삽입할 때마다 두 시스템 모두에 써야 하고, 우리는 새 쓰기가 스트리밍으로 들어오는 동안에도 데이터를 온라인으로 분석하고 싶었기 때문에 두 데이터베이스를 일관되게 유지하려면 2단계 커밋(2PC) 같은 것이 필요했을 것이다. 나는 필요하지도 않은 곳에 새로운 2PC 문제를 발명하고 싶지 않다. 게다가 당시 BigQuery는 일관성 의미론도 아주 느슨해서, 두 시스템을 실제로 동기화하는 것이 가능했을지조차 불분명했다.
이때 스킵리스트가 구원투수로 등장했다! 아니, 더 정확히는 우리가 발명한 이상한 물건인 “스킵트리”가 등장했다…
음, 스킵리스트 같은데 트리다.
좀 더 도움이 되게 설명하자면, 예시는 다음과 같다.
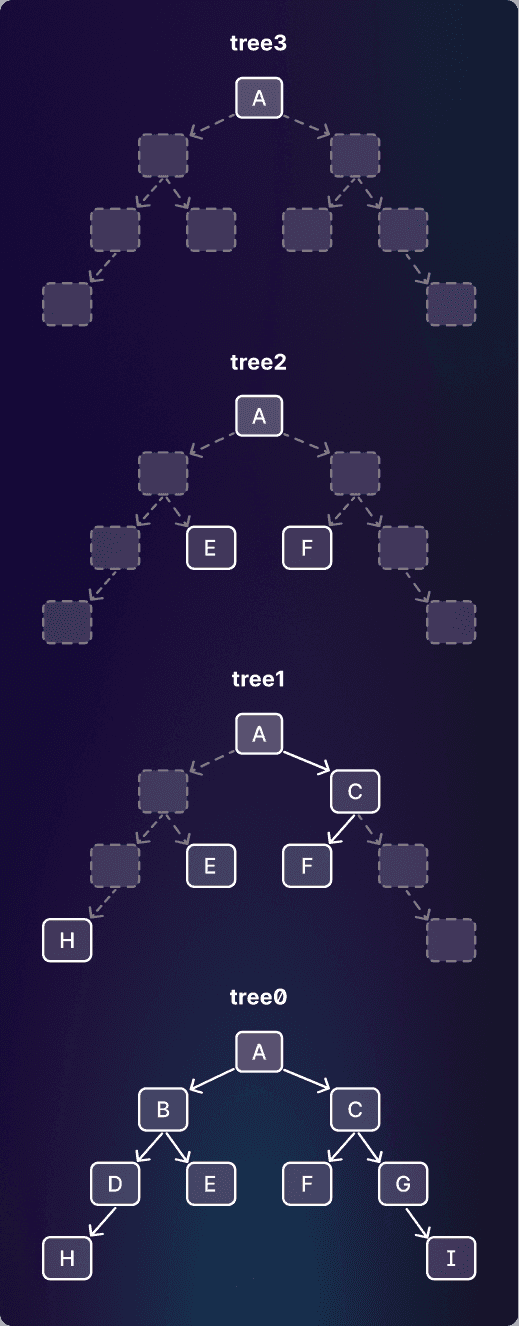
레벨 0 트리가 하나 있고, 그 위에 트리 계층이 놓인다. 각 트리는 바로 아래 레벨 노드의 대략 50%를 가진다(제거된 노드들은 그림에서 회색 점선으로 표시되어 있다).
루트에서 리프까지의 임의의 경로 하나를 잡아 보면, 그 경로 위의 노드들과 상위 레벨 트리에서의 대응 노드들이 함께 하나의 스킵리스트를 이룬다. 따라서 스킵트리는 사실상 구조를 공유하는 여러 스킵리스트의 묶음이며, 트리의 각 루트-리프 경로마다 하나씩 존재한다고 볼 수 있다.
스킵트리를 저장하려면 레벨마다 SQL 테이블을 하나씩 만든다. tree0, tree1 같은 식이다. 각 테이블에는 해당 트리의 모든 노드에 대한 행이 있다. 단일 parent_id 열 대신, 바로 위 트리에서 가장 가까운 조상 노드를 가리키는 열 하나(이를 next_level_ancestor라고 하자)와 현재 노드와 그 다음 레벨 조상 사이에 있는 모든 노드 목록을 담는 또 다른 열 하나(ancestors_between라고 하자)를 둔다.
위 그림에서 tree0는 다음과 같다.
id | next_level_ancestor | ancestors_between |
|---|---|---|
A | null | [] |
B | A | [] |
C | A | [] |
D | A | [B] |
E | A | [B] |
F | C | [] |
G | C | [] |
H | A | [B, D] |
I | C | [G] |
예를 들어 노드 H의 행을 보자. 노드 H의 부모는 D인데, D는 tree1에 없다. D의 부모 B도 tree1에 없지만, B의 부모 A는 있으므로 next_level_ancestor는 A가 된다. 그리고 ancestors_between에는 B와 D를 저장한다.
상위 레벨 테이블도 같은 방식으로 동작한다.
tree1:
id | next_level_ancestor | ancestors_between |
|---|---|---|
A | null | [] |
C | A | [] |
E | A | [B] |
F | C | [] |
H | A | [B, D] |
tree2:
id | next_level_ancestor | ancestors_between |
|---|---|---|
A | null | [] |
E | A | [B] |
F | A | [C] |
tree3:
id | next_level_ancestor | ancestors_between |
|---|---|---|
A | null | [] |
이 테이블들을 사용하면 JOIN을 연쇄적으로 이어 붙여 테이블을 따라 위로 올라가면서 어떤 노드의 조상들을 찾을 수 있다.
예를 들어 노드 I의 모든 조상을 찾으려면 table0에서 시작한다. next_level_ancestor 열은 table1의 노드 C에 JOIN하라고 알려 주고, 가는 길에 ancestors_between 열에서 노드 G를 수집한다. 그러고 나서 table1에서는 next_level_ancestor가 노드 A임을 알 수 있고, 그 사이에 수집할 다른 노드는 없다. 노드 A는 트리의 루트이므로 이제 끝이다. 전체 조상 목록은 [G, C, A]다. 더 깊은 트리라면 tree2, tree3 등을 계속 살펴보면 된다.
이제 됐다! 고정된 개수의 JOIN만으로, 재귀 없는 단일 SQL 질의로 조상을 찾을 수 있다. 우리가 해야 했던 일은 그저… 40개 안팎의 JOIN을 쓰는 것뿐이었다.3
무엇보다도 당시 BigQuery의 과금은 계산량이 아니라 스캔한 데이터 양 기준이었고, 테이블 크기의 기하급수적 분포 덕분에 이런 질의 하나의 비용은 일반적인 테이블 전체 스캔의 두 배 정도에 불과했다.4
물론 단점도 있었다. 예를 들면 SQL 자체 말이다. 이 질의들의 텍스트 크기는 종종 킬로바이트 단위로 측정되었다. 하지만 내가 무슨 원시인처럼 보이나? 우리는 SQL을 직접 쓰지 않았다. 대신 그것을 생성하는 JavaScript 컴파일러를 썼다. 그리고 그것이 바로 Antithesis의 대부분의 테스트 속성이 회사의 첫 6년 동안 평가되던 방식이었다. 마침내 효율적인 트리 형태 질의를 수행할 수 있는 우리만의 분석 데이터베이스를 만들기 전까지는 말이다.5
나중에 나는 스킵트리가 스킵 그래프라는 실제 자료구조와 밀접한 관련이 있다는 사실을 알게 되었다. 스킵 그래프는 스킵리스트를 기반으로 한 분산 자료구조다. 이것이 보여 주는 것은 결국 세상에 완전히 새로운 것은 없다는 점이다. 당신이 떠올린 어떤 기상천외한 아이디어든, 이미 다른 어떤 괴짜가 먼저 해 봤을 가능성이 높다. 이 이야기의 교훈은 이렇다. 이국적인 자료구조가 언제 당신의 시간과 돈을 크게 절약해 줄지 아무도 모른다.
또한, Andy Pavlo의 이 말도 맞다. 잘 작성된 트리는 언제나 스킵리스트를 압도한다. 하지만 스킵리스트의 훌륭한 점은 _완전히 순진한 구현_조차도 성능이 충분하다는 데 있다. 이를테면 SQL로 구현할 때, 그런 점이 아주 유용하다.
Phil Eaton이 이 글을 써 보자고 제안해 준 것에 감사한다.