유한 상태 기계를 데이터 구조로 사용해 정렬된 문자열 집합과 맵을 압축 표현하고, Rust의 fst 크레이트로 빠르게 검색하는 방법을 설명한다.
Andrew Gallant's Blog소개프로젝트GitHub후원하기
2015년 11월 11일
유한 상태 기계는 계산을 표현하는 것 외에도 쓸모가 있다는 사실이 드러납니다. 유한 상태 기계는 또한 매우 빠르게 검색할 수 있는 정렬된 문자열 집합이나 맵을 압축된 형태로 표현하는 데도 사용할 수 있습니다.
이 글에서는 정렬된 집합과 맵을 표현하는 데이터 구조 로서의 유한 상태 기계에 대해 설명하겠습니다. 여기에는 Rust로 작성된 구현인 fst crate 소개도 포함됩니다. 이 구현에는 완전한 API 문서가 함께 제공됩니다. 또한 간단한 명령줄 도구를 사용해 이를 빌드하는 방법도 보여드리겠습니다. 마지막으로 2015년 7월 Common Crawl Archive의 1,600,000,000개가 넘는 URL(134 GB)을 인덱싱하는 실험까지 다루겠습니다.
이 글에서 소개하는 기법은 Lucene이 역색인의 일부를 표현하는 방식이기도 합니다.
이 과정에서 메모리 맵, 정규 표현식과의 오토마톤 교집합, Levenshtein 거리 기반 퍼지 검색, 스트리밍 집합 연산에 대해서도 이야기하겠습니다.
대상 독자: 프로그래밍과 기본 자료구조에 대한 약간의 친숙함이 있는 분. 오토마타 이론이나 Rust 경험은 필요하지 않습니다.
어디로 가게 될지 보여주는 맛보기로, 예제를 아주 빠르게 살펴봅시다. 아직 1,600,000,000개의 문자열은 보지 않겠습니다. 대신 약 16,000,000개의 Wikipedia 문서 제목(384 MB)을 생각해 봅시다. 인덱싱은 다음과 같이 합니다:
$ time fst set --sorted wiki-titles wiki-titles.fst
real 0m18.310생성된 인덱스 wiki-titles.fst는 157 MB입니다. 비교하자면 gzip은 12초가 걸리고 91 MB까지 압축합니다. (일부 데이터 집합에서는 우리의 인덱싱 방식이 속도와 압축률 모두에서 gzip을 이길 수 있습니다.)
하지만 gzip이 할 수 없는 일이 있습니다. Homer the로 시작하는 모든 문서 제목을 빠르게 찾는 것입니다:
$ time fst grep wiki-titles.fst 'Homer the.*'
Homer the Clown
Homer the Father
Homer the Great
Homer the Happy Ghost
Homer the Heretic
Homer the Moe
Homer the Smithers
...
real 0m0.023s비교하자면 원본 비압축 데이터에서 grep은 0.3초가 걸립니다.
그리고 마지막으로, grep조차 할 수 없는 일도 있습니다. Homer Simpson과 특정 편집 거리 안에 있는 모든 문서 제목을 빠르게 찾는 것입니다:
$ time fst fuzzy wiki-titles.fst --distance 2 'Homer Simpson'
Home Simpson
Homer J Simpson
Homer Simpson
Homer Simpsons
Homer simpson
Homer simpsons
Hope Simpson
Roger Simpson
real 0m0.094s이 글은 꽤 길기 때문에, 만약 화려한 데모만 보러 오셨다면 1,600,000,000개 키를 인덱싱하는 섹션으로 바로 건너뛰셔도 됩니다.
이 글은 꽤 길기 때문에, 여기저기 건너뛰고 싶을 때를 대비해 목차를 준비했습니다.
첫 번째 섹션은 유한 상태 기계와 그것을 추상적인 데이터 구조로 사용하는 방법을 다룹니다. 이 섹션은 데이터 구조를 사고할 수 있는 정신 모델을 제공하는 데 목적이 있습니다. 이 섹션에는 코드는 없습니다.
두 번째 섹션은 첫 번째 섹션에서 만든 추상을 구현으로 보여줍니다. 이 섹션은 주로 제가 만든 fst 라이브러리 사용 개요를 위한 것입니다. 이 섹션에는 코드가 포함됩니다. 구현 세부도 일부 다루지만 너무 깊게 들어가지는 않겠습니다. 코드에는 관심 없고 실제 데이터 실험만 보고 싶다면 이 섹션은 건너뛰어도 괜찮습니다.
세 번째이자 마지막 섹션에서는 인덱스를 빌드하기 위한 간단한 명령줄 도구의 사용을 보여줍니다. 실제 데이터 집합 몇 가지를 살펴보며, 데이터 구조로서 유한 상태 기계의 성능을 이해해 보겠습니다.
유한 상태 기계(FSM)는 상태들의 집합과, 한 상태에서 다음 상태로 이동시키는 전이들의 집합입니다. 하나의 상태는 시작 상태로 표시되고, 0개 이상의 상태는 최종 상태로 표시됩니다. FSM은 언제나 정확히 하나의 상태에만 있습니다.
FSM은 꽤 일반적이어서 다양한 과정을 모델링하는 데 사용할 수 있습니다. 예를 들어, 제 고양이 Cauchy의 일상을 근사한 예를 보겠습니다:
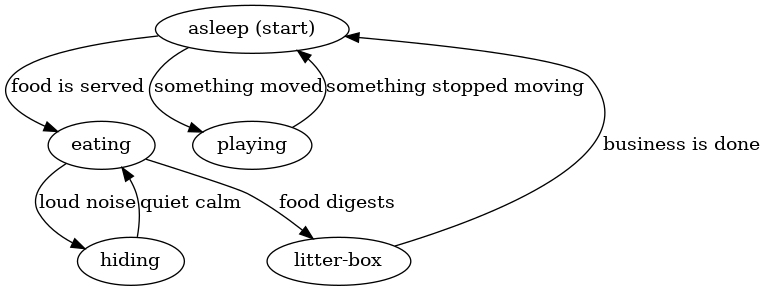
어떤 상태는 “잠자는 중” 또는 “먹는 중”이고, 어떤 전이는 “먹이가 나옴” 또는 “무언가 움직임”입니다. 여기에는 최종 상태가 없는데, 그건 괜히 지나치게 음산해지기 때문입니다!
FSM이 우리의 현실 인식을 근사한다는 점에 주목하세요. Cauchy는 동시에 놀면서 잠들 수는 없으므로, 기계가 한 번에 하나의 상태에만 있다는 조건을 만족합니다. 또한 한 상태에서 다음 상태로의 전이는 환경으로부터의 단 하나의 입력만 있으면 된다는 점도 주목하세요. 즉 “잠자는 중”이라는 상태에는 그것이 놀다가 피곤해져서 생겼는지, 식사 후 만족해서 생겼는지에 대한 기억이 없습니다. Cauchy가 어떻게 잠들었든 간에, 무언가 움직이는 소리를 듣거나 저녁 종소리가 나면 항상 깨어납니다.
Cauchy의 유한 상태 기계는 입력 시퀀스가 주어지면 계산을 수행할 수 있습니다. 예를 들어 다음 입력들을 생각해 봅시다:
이 입력들을 위 기계에 적용하면, Cauchy는 순서대로 “잠자는 중”, “먹는 중”, “숨는 중”, “먹는 중”, “화장실” 상태를 거치게 됩니다. 따라서 먹이가 나온 뒤 큰 소음이 있고, 그 다음 조용해졌고, 마지막으로 Cauchy가 소화했다는 것을 관찰했다면, 지금 Cauchy가 화장실에 있다고 결론 내릴 수 있습니다.
이 유난히 바보 같은 예시는 유한 상태 기계가 얼마나 일반적인지를 보여줍니다. 우리의 목적을 위해서는 정렬된 집합과 맵 데이터 구조를 구현하는 데 사용할 유한 상태 기계의 종류에 몇 가지 제약을 둘 필요가 있습니다.
정렬된 집합은 일반 집합과 비슷하지만, 집합 안의 키들에 순서가 있습니다. 즉 정렬된 집합은 키들에 대한 정렬 순회 기능을 제공합니다. 일반적으로 정렬된 집합은 이진 탐색 트리나 btree로 구현되고, 비정렬 집합은 해시 테이블로 구현됩니다. 여기서는 결정적 비순환 유한 상태 수용기 (약어 FSA)를 사용하는 구현을 살펴보겠습니다.
결정적 비순환 유한 상태 수용기는 다음 조건을 만족하는 유한 상태 기계입니다:
이 속성들을 사용해 어떻게 집합을 표현할 수 있을까요? 요령은 집합의 키를 기계의 전이에 저장하는 것입니다. 이렇게 하면 입력 시퀀스(즉 문자들)가 주어졌을 때, FSA의 평가가 최종 상태에서 끝나는지 여부를 바탕으로 키가 집합 안에 있는지 알 수 있습니다.
키가 하나뿐인 집합 “jul”을 생각해 봅시다. FSA는 다음과 같습니다:

FSA에게 키 “jul”이 있는지 물어보면 어떻게 될지 생각해 봅시다. 문자를 순서대로 처리해야 합니다:
j가 주어지면 FSA는 시작 상태 0에서 1로 이동합니다.u가 주어지면 FSA는 1에서 2로 이동합니다.l이 주어지면 FSA는 2에서 3으로 이동합니다.키의 모든 구성원이 FSA에 입력되었으므로 이제 이렇게 물을 수 있습니다. FSA는 최종 상태에 있는가? 그렇습니다(상태 3 주위의 이중 원을 보세요). 따라서 jul이 집합 안에 있다고 말할 수 있습니다.
집합에 없는 키를 검사하면 어떻게 되는지도 생각해 봅시다. 예를 들어 jun:
j가 주어지면 FSA는 시작 상태 0에서 1로 이동합니다.u가 주어지면 FSA는 1에서 2로 이동합니다.n이 주어지면 FSA는 이동할 수 없습니다. 처리가 중단됩니다.FSA가 이동할 수 없는 이유는 상태 2에서 나가는 유일한 전이가 l인데 현재 입력은 n이기 때문입니다. l != n이므로 FSA는 그 전이를 따를 수 없습니다. 입력이 주어졌을 때 FSA가 이동할 수 없는 순간, 그 키가 집합에 없다고 결론 내릴 수 있습니다. 입력을 더 처리할 필요가 없습니다.
다른 키 ju를 생각해 봅시다:
j가 주어지면 FSA는 시작 상태 0에서 1로 이동합니다.u가 주어지면 FSA는 1에서 2로 이동합니다.이 경우 전체 입력이 소진되고 FSA는 상태 2에 있습니다. ju가 집합 안에 있는지 결정하려면 2가 최종 상태인지 물어야 합니다. 최종 상태가 아니므로 ju 키는 집합에 없다고 보고할 수 있습니다.
여기서 짚고 넘어갈 가치가 있는 점은, 키가 집합 안에 있는지 확인하는 데 필요한 단계 수가 그 키의 문자 수에 의해 제한된다는 것입니다! 즉 키를 조회하는 데 걸리는 시간은 집합 크기와 전혀 관계가 없습니다.
집합에 다른 키를 하나 추가해서 모양을 보겠습니다. 다음 FSA는 키 “jul”과 “mar”를 가진 정렬된 집합을 나타냅니다:
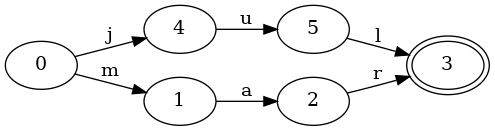
FSA가 조금 더 복잡해졌습니다. 시작 상태 0에는 이제 j와 m 두 전이가 있습니다. 따라서 키 mar가 주어지면 먼저 m 전이를 따르게 됩니다.
여기서 또 하나 중요한 점이 있습니다. 상태 3이 jul과 mar 키 사이에서 공유 됩니다. 즉 상태 3으로 들어오는 전이가 l과 r 두 개 있습니다. 키 사이에서 이런 상태 공유는 정말 중요합니다. 더 작은 공간에 더 많은 정보를 저장할 수 있게 해주기 때문입니다.
이제 jul과 공통 접두사를 공유하는 jun을 집합에 추가하면 어떻게 되는지 봅시다:
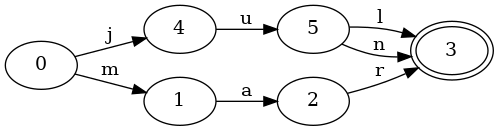
차이가 보이시나요? 작은 변화입니다. 이 FSA는 이전 것과 매우 비슷합니다. 차이는 하나뿐입니다. 상태 5에서 3으로 가는 새로운 전이 n이 추가되었습니다. 주목할 점은 FSA에 새로운 상태가 전혀 없다는 것입니다! jun과 jul이 둘 다 접두사 ju를 공유하므로 그 상태들을 두 키 모두에 재사용할 수 있습니다.
조금 바꿔서 october, november, december라는 키들을 가진 집합을 봅시다:

세 키가 모두 접미사 ber를 공유하기 때문에, 이는 FSA에 정확히 한 번만 인코딩됩니다. 두 키는 더 큰 접미사 ember도 공유하는데, 이것도 FSA에 정확히 한 번만 인코딩됩니다.
정렬된 맵으로 넘어가기 전에, 이것이 정말 정렬된 집합인지 잠깐 납득해 봅시다. 즉 FSA가 주어졌을 때 집합 안의 키들을 어떻게 순회할 수 있을까요?
이를 보여주기 위해 앞서 만든 jul, jun, mar 키를 가진 집합을 사용하겠습니다:
전이를 사전식 순서로 따라가며 전체 FSA를 순회하면 집합 안의 모든 키를 열거할 수 있습니다. 예를 들어:
0에서 초기화합니다. key는 비어 있습니다.4로 이동합니다. key에 j를 추가합니다.5로 이동합니다. key에 u를 추가합니다.3으로 이동합니다. key에 l을 추가합니다. 출력jul.5로 되돌아갑니다. key에서 l을 제거합니다.3으로 이동합니다. key에 n을 추가합니다. 출력jun.5로 되돌아갑니다. key에서 n을 제거합니다.4로 되돌아갑니다. key에서 u를 제거합니다.0으로 되돌아갑니다. key에서 j를 제거합니다.1로 이동합니다. key에 m을 추가합니다.2로 이동합니다. key에 a를 추가합니다.3으로 이동합니다. key에 r을 추가합니다. 출력mar.이 알고리즘은 방문할 상태 스택과 따라간 전이 스택으로 곧바로 구현할 수 있습니다. 집합 안의 키 개수를 n이라 할 때 시간 복잡도는 O(n)이고, 공간 복잡도는 집합에서 가장 큰 키의 크기를 k라 할 때 O(k)입니다.
정렬된 집합과 마찬가지로 정렬된 맵은 맵과 비슷하지만, 맵의 키에 순서가 정의되어 있습니다. 집합과 마찬가지로 정렬된 맵은 보통 이진 탐색 트리나 btree로 구현되고, 비정렬 맵은 보통 해시 테이블로 구현됩니다. 여기서는 결정적 비순환 유한 상태 트랜스듀서 (약어 FST)를 사용하는 구현을 살펴보겠습니다.
결정적 비순환 유한 상태 트랜스듀서는 다음 조건을 만족하는 유한 상태 기계입니다(처음 두 조건은 앞 섹션과 같습니다):
다시 말해 FST는 FSA와 같지만, 키가 주어졌을 때 “예/아니오”로 답하는 대신, “아니오” 또는 “예, 그리고 이 키에 연결된 값은 이것입니다”라고 답합니다.
이전 섹션에서는 집합을 표현하기 위해 기계의 전이에 키를 저장하기만 하면 충분했습니다. 입력 시퀀스가 집합의 키를 나타내는 경우에만 기계가 그것을 “수용”합니다. 여기서는 맵이 단순히 입력 시퀀스를 “수용”하는 것보다 더 많은 일을 해야 합니다. 즉 그 키에 연결된 값을 반환해야 합니다.
키에 값을 연결하는 한 가지 방법은 각 전이에 데이터를 붙이는 것입니다. 입력 시퀀스가 소비되면서 기계가 상태에서 상태로 이동하듯, 기계가 상태에서 상태로 이동할 때 출력 시퀀스 를 생성할 수 있습니다. 이 추가된 “능력” 때문에 기계는 트랜스듀서 가 됩니다.
예제로 값 7이 연결된 원소 하나짜리 맵 jul을 보겠습니다:

이 기계는 대응되는 집합과 같지만, 상태 0에서 1로 가는 첫 전이 j에 출력 7이 연관되어 있다는 점만 다릅니다. 다른 전이 u와 l에도 출력 0이 연결되어 있지만 그림에는 표시하지 않았습니다.
집합과 마찬가지로 맵에 키 “jul”이 있는지 물어볼 수 있습니다. 하지만 출력도 반환해야 합니다. 기계가 “jul”에 대한 조회를 처리하는 방법은 다음과 같습니다:
value를 0으로 초기화합니다.j가 주어지면 FST는 시작 상태 0에서 1로 이동합니다. value에 7을 더합니다.u가 주어지면 FST는 1에서 2로 이동합니다. value에 0을 더합니다.l이 주어지면 FST는 2에서 3으로 이동합니다. value에 0을 더합니다.모든 입력이 FST에 공급되었으므로 이제 이렇게 물을 수 있습니다. FST는 최종 상태에 있는가? 그렇습니다. 따라서 jul이 맵 안에 있다는 것을 압니다. 추가로 value를 키 jul에 연결된 값으로 보고할 수 있는데, 이는 7입니다.
그다지 놀랍지는 않죠? 예제가 너무 단순합니다. 키가 하나뿐인 맵은 많은 것을 보여주지 못합니다. 값 3에 연결된 mar를 맵에 추가하면 어떻게 되는지 봅시다:
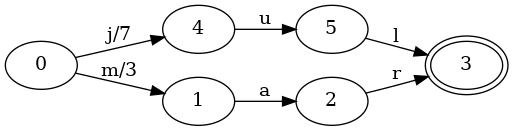
시작 상태에 출력 3을 가진 새 전이 m이 생겼습니다. 키 jul을 조회하면 과정은 이전 맵과 같습니다. 값 7을 얻습니다. 키 mar를 조회하면 과정은 다음과 같습니다:
value를 0으로 초기화합니다.m이 주어지면 FST는 시작 상태 0에서 1로 이동합니다. value에 3을 더합니다.a가 주어지면 FST는 1에서 2로 이동합니다. value에 0을 더합니다.r이 주어지면 FST는 2에서 3으로 이동합니다. value에 0을 더합니다.여기서 바뀐 것은, 다른 입력 전이를 따른다는 점 외에는 첫 이동에서 3이 value에 더해졌다는 것뿐입니다. 이후 모든 이동은 0을 더하므로, 기계는 mar에 연결된 값으로 3을 보고합니다.
계속 가봅시다. 공통 접두사를 공유하는 키가 있을 때는 어떻게 될까요? 위와 같은 맵에 값 6에 연결된 jun 키를 추가해 봅시다:
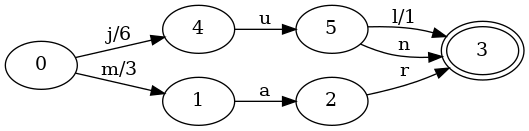
집합과 마찬가지로 상태 5와 3을 연결하는 추가 전이 n이 생겼습니다. 하지만 두 가지 추가 변화도 있었습니다!
j에 대한 0->4 전이의 출력이 7에서 6으로 바뀌었습니다.l에 대한 5->3 전이의 출력이 0에서 1로 바뀌었습니다.이 출력 변화는 매우 중요합니다. 왜냐하면 이제 키 jul에 연결된 값을 조회하는 세부 과정이 달라지기 때문입니다:
value를 0으로 초기화합니다.j가 주어지면 FST는 시작 상태 0에서 4로 이동합니다. value에 6을 더합니다.u가 주어지면 FST는 4에서 5로 이동합니다. value에 0을 더합니다.l이 주어지면 FST는 5에서 3으로 이동합니다. value에 1을 더합니다.최종 값은 여전히 7이지만, 다른 방식으로 그 값에 도달했습니다. 처음 j 전이에서 7을 더하는 대신 6만 더했고, 마지막 l 전이에서 1을 더해 부족한 값을 메웠습니다.
jun 키 조회도 올바른지 확인해 봐야 합니다:
value를 0으로 초기화합니다.j가 주어지면 FST는 시작 상태 0에서 4로 이동합니다. value에 6을 더합니다.u가 주어지면 FST는 4에서 5로 이동합니다. value에 0을 더합니다.n이 주어지면 FST는 5에서 3으로 이동합니다. value에 0을 더합니다.첫 전이에서 6이 value에 더해지지만, 그 이후 어떤 전이에서도 0보다 큰 값을 더하지 않습니다. 이는 jun 키가 jul이 지나는 마지막 l 전이를 지나지 않기 때문입니다. 이런 방식으로 두 키는 서로 다른 값을 가지면서도 공통 접두사를 가진 키들 사이에서 데이터 구조의 많은 부분을 공유할 수 있습니다.
실제로 이런 공유를 가능하게 하는 핵심 속성은, 맵의 각 키가 기계 안에서 고유한 경로 에 대응한다는 점입니다. 따라서 각 키마다 반드시 그 키만의 고유한 전이 조합이 존재합니다. 우리가 해야 할 일은 전이들 위에 출력을 어떻게 배치할지 알아내는 것뿐입니다. (다음 섹션에서 그 방법을 보게 됩니다.)
이 출력 공유는 공통 접두사뿐 아니라 공통 접미사를 가진 키에도 동작합니다. 예를 들어 요일 숫자와 연관된 키 tuesday와 thursday를 생각해 봅시다. 값은 각각 3과 5입니다.

두 키는 공통 접두사 t와 공통 접미사 sday를 가집니다. 또한 키에 연결된 값도 값에 대한 덧셈 관점에서 공통 접두사를 가집니다. 즉 3은 3 + 0으로, 5는 3 + 2로 쓸 수 있습니다. 이 아이디어가 기계에 반영됩니다. 공통 접두사 t에는 출력 3이 붙고, tuesday에는 없는 h 전이에는 출력 2가 붙습니다. 즉 tuesday를 조회할 때는 t의 첫 출력이 방출되지만 h 전이는 따르지 않으므로 그에 붙은 2 출력은 방출되지 않습니다. 나머지 전이의 출력은 0이며, 최종 value를 바꾸지 않습니다.
제가 출력을 설명한 방식이 조금 제한적으로 보일 수 있습니다. 정수가 아니면 어떡할까요? 실제로 FST에서 사용할 수 있는 출력 타입은 다음 연산이 정의된 것들로 제한됩니다:
출력은 또한 가법 항등원 I를 가져야 하며, 다음 법칙이 성립해야 합니다:
x + I = xx - I = xx와 y가 공통 접두사를 공유하지 않으면 prefix(x, y) = I정수는 이 대수를 아주 쉽게 만족합니다(prefix는 min으로 정의). 게다가 매우 작다는 이점도 있습니다. 다른 타입도 이 대수를 만족하도록 만들 수 있지만, 지금은 정수만 다루겠습니다.
위 예제에서는 덧셈만 필요했지만, FST를 구성 할 때는 나머지 두 연산도 필요합니다. 이제 그것을 다루겠습니다.
앞선 두 섹션에서는 정렬된 집합이나 맵을 표현하는 데 쓰이는 유한 상태 기계의 구성에 대해 일부러 말을 아꼈습니다. 구성은 단순 순회보다 조금 더 복잡하기 때문입니다.
단순하게 유지하기 위해 집합이나 맵의 원소들에 제약을 둡니다. 원소들은 사전식 순서로 추가되어야 합니다. 이는 꽤 부담스러운 제약이지만, 나중에 이를 완화하는 방법을 보게 될 것입니다.
유한 상태 기계의 구성을 설명하기 위해 트라이 에 대해 이야기해 봅시다.
트라이는 결정적 비순환 유한 상태 수용기로 생각할 수 있습니다. 따라서 이전 섹션에서 정렬된 집합에 대해 배운 모든 내용이 그대로 적용됩니다. 트라이와 이 글의 FSA 사이의 유일한 차이는, 트라이는 키들 사이의 접두사 공유만 허용하는 반면 FSA는 접두사와 접미사 모두의 공유를 허용한다는 것입니다.
키가 mon, tues, thurs인 집합을 생각해 봅시다. 접두사와 접미사 공유를 모두 활용하는 대응 FSA는 다음과 같습니다:
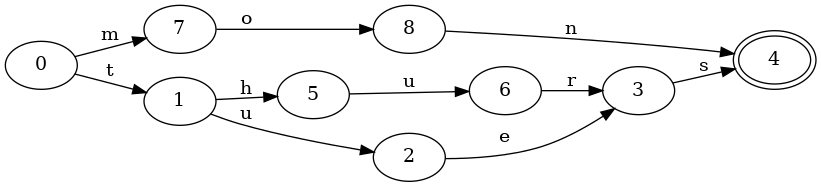
그리고 접두사만 공유하는 대응 트라이는 다음과 같습니다:
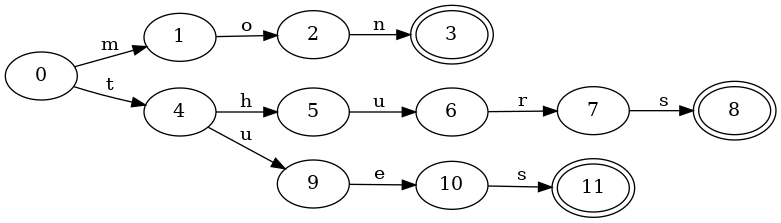
이제 서로 다른 최종 상태가 세 개 있고, 키 tues와 thurs는 최종 상태로 가는 s 전이를 중복해서 가져야 한다는 점에 주목하세요.
트라이 구성은 비교적 단순합니다. 삽입할 새 키가 주어지면, 일반적인 조회를 수행하면 됩니다. 입력이 모두 소진되면 현재 상태를 최종 상태로 표시해야 합니다. 유효한 전이가 없어 입력이 모두 소진되기 전에 기계가 멈추면, 남은 각 입력에 대해 새 전이와 새 노드를 만들기만 하면 됩니다. 마지막으로 만든 노드는 최종 상태로 표시해야 합니다.
트라이와 FSA의 차이는, FSA는 키들 사이의 접미사 공유를 허용한다는 점뿐이라는 것을 기억하세요. 트라이 자체도 FSA이므로, 트라이를 구성한 다음 일반적인 최소화 알고리즘을 적용해 접미사를 공유하도록 만들 수도 있습니다.
하지만 일반적인 최소화 알고리즘은 시간과 공간 모두에서 비용이 클 수 있습니다. 예를 들어, 키의 접미사 사이 구조를 공유하는 FSA에 비해 트라이는 종종 훨씬 더 클 수 있습니다. 대신 키가 사전식 순서로 추가된다고 가정할 수 있다면 더 잘할 수 있습니다. 핵심 요령은 새 키를 삽입할 때, 새 키와 접두사를 공유하지 않는 FSA의 어떤 부분은 얼려도 된다는 사실을 깨닫는 것입니다. 즉, 이후에 추가될 어떤 키도 그 부분을 더 작게 만들 수 없습니다.
그림 몇 개가 더 도움이 될 것입니다. 다시 mon, tues, thurs 키를 생각해 봅시다. 이 키들은 사전식 순서로 추가해야 하므로 mon, thurs, tues 순으로 추가하겠습니다. 첫 번째 키를 추가한 뒤 FSA는 다음과 같습니다:

그다지 흥미롭지 않죠. 이제 thurs를 삽입하면 어떻게 되는지 보겠습니다:

thurs를 삽입한 결과 첫 번째 키 mon이 얼어붙었습니다(그림에서는 파란색으로 표시). FSA의 어떤 특정 부분이 얼었다는 것은, 앞으로 그 부분이 절대로 수정될 필요가 없다는 뜻입니다. 즉 앞으로 추가될 모든 키는 >= thurs이므로, 미래의 어떤 키도 mon으로 시작할 수 없음을 압니다. 이것은 중요합니다. 왜냐하면 그 부분이 나중에 바뀔지 걱정하지 않고 오토마톤의 그 부분을 재사용할 수 있기 때문입니다. 달리 말하면, 파란색 상태들은 다른 키가 재사용할 후보입니다.
점선은 thurs가 아직 실제로 FSA에 추가된 것이 아님을 의미합니다. 실제로 추가하려면 재사용 가능한 상태가 있는지 검사해야 합니다. 안타깝게도 아직은 그럴 수 없습니다. 예를 들어 상태 3과 8은 지금 시점에서는 동등합니다. 둘 다 최종 상태이고 전이도 없습니다. 하지만 상태 8이 항상 상태 3과 같다고는 할 수 없습니다. 예를 들어 다음에 추가할 키가 thursday일 수 있기 때문입니다. 그러면 상태 8에는 d 전이가 생기고, 더 이상 상태 3과 같지 않게 됩니다. 따라서 아직은 키 thurs가 오토마톤에서 정확히 어떤 형태인지 결론 내릴 수 없습니다.
다음 키 tues를 삽입해 봅시다:
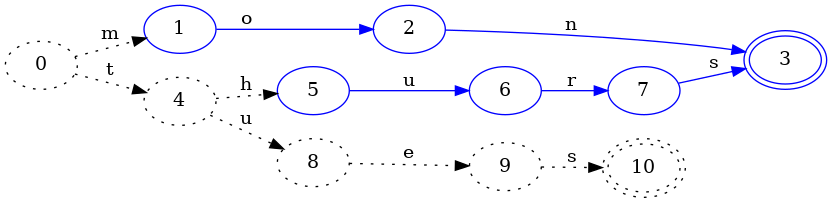
tues를 추가하는 과정에서 thurs 키의 hurs 부분도 얼릴 수 있다는 사실을 알아냈습니다. 왜일까요? 키가 사전식 순서로 삽입되기 때문에, 이후 삽입되는 어떤 키도 hurs가 따라가는 경로를 더 최소화할 수 없기 때문입니다. 예를 들어 이제 thursday라는 키가 절대로 집합에 포함될 수 없음을 알 수 있으므로, thurs의 최종 상태가 mon의 최종 상태와 동등하다고 결론 내릴 수 있습니다. 둘 다 최종 상태이고 전이도 없으며, 앞으로도 영원히 그렇습니다.
상태 4가 여전히 점선으로 남아 있는 점에 주목하세요. 이후 키 삽입에 따라 상태 4는 바뀔 수 있으므로, 아직은 다른 어떤 상태와 같다고 볼 수 없습니다.
핵심을 더 분명히 하기 위해 키를 하나 더 추가해 봅시다. zon을 삽입해 봅니다:

여기서 상태 4도 마침내 얼었다는 것을 볼 수 있습니다. zon 이후의 어떤 삽입도 상태 4를 바꿀 수 없기 때문입니다. 추가로 thurs와 tues가 공통 접미사를 공유한다는 점도 알 수 있고, 실제로 이전 그림의 상태 7과 9가 동등하다는 것도 알 수 있습니다. 둘 다 최종 상태가 아니고, 같은 상태를 가리키는 입력 s의 단일 전이를 갖기 때문입니다. 두 상태의 s 전이가 반드시 같은 상태를 가리켜야 한다는 점이 매우 중요합니다. 그렇지 않다면 같은 구조를 재사용할 수 없습니다.
마지막으로 키 삽입이 끝났음을 알려야 합니다. 이제 FSA의 마지막 부분 zon도 얼릴 수 있고, 중복 구조를 찾을 수 있습니다:
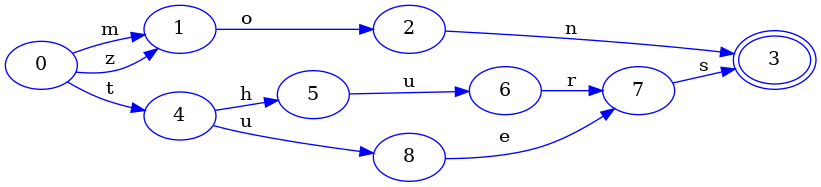
물론 mon과 zon은 공통 접미사를 공유하므로 실제로 중복 구조가 있습니다. 즉 이전 그림의 상태 9는 모든 면에서 상태 1과 동등합니다. 이것이 참인 이유는 상태 10과 11 또한 상태 2와 3에 각각 동등하기 때문입니다. 만약 그렇지 않다면 상태 9와 1을 같다고 볼 수 없습니다. 예를 들어 집합에 mom 키를 삽입했는데도 여전히 상태 9와 1이 같다고 가정하면, 결과 FSA는 대략 다음과 같이 될 것입니다:

그리고 이것은 틀립니다! 왜일까요? 이 FSA는 키 zom이 집합 안에 있다고 주장할 것이기 때문입니다. 하지만 우리는 실제로 그런 키를 추가한 적이 없습니다.
마지막으로, 여기서 설명한 구성 알고리즘은 키 개수를 n이라 할 때 O(n) 시간에 실행될 수 있다는 점도 언급할 가치가 있습니다. 중복 구조를 검사하지 않고 키를 처음 FST에 삽입하는 데는 각 키의 문자를 순회하는 것보다 오래 걸리지 않는다는 것은 자명합니다. 각 상태에서 전이를 조회하는 시간이 상수라고 가정하면 그렇습니다. 더 까다로운 부분은 중복 구조를 어떻게 상수 시간에 찾느냐입니다. 짧게 말하면 해시 테이블이지만, 실전에서의 구성 섹션에서 그 과제들을 설명하겠습니다.
결정적 비순환 유한 상태 트랜스듀서 의 구성은 결정적 비순환 유한 상태 수용기 의 구성과 거의 같은 방식으로 동작합니다. 핵심 차이는 전이 위에 출력을 배치하고 공유하는 방식입니다.
정신적 부담을 낮추기 위해 앞선 섹션의 mon, tues, thurs 예제를 그대로 재사용하겠습니다. FST는 맵을 표현하므로 각 키에 숫자 요일 2, 3, 5를 연결하겠습니다.
앞과 마찬가지로 첫 번째 키 mon 삽입부터 시작합시다:

(점선은 이후 키 삽입에서 바뀔 수 있는 FST 부분을 나타낸다는 점을 기억하세요.)
그다지 흥미롭지는 않지만, 적어도 출력 2가 첫 번째 전이에 배치된다는 점은 짚고 넘어갈 가치가 있습니다. 엄밀히 말하면 다음 트랜스듀서도 똑같이 올바릅니다:
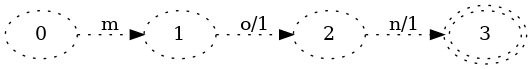
하지만 출력을 가능한 한 시작 상태에 가깝게 배치하면, 키들 사이에서 출력 전이를 공유하는 알고리즘을 훨씬 쉽게 작성할 수 있습니다.
이제 값 5에 매핑된 키 thurs를 삽입해 봅시다:

FSA 구성과 마찬가지로 thurs 키 삽입을 통해 mon 부분의 FST는 절대로 바뀌지 않을 것이라고 결론 내릴 수 있습니다. (그림에서는 파란색으로 표시됩니다.)
mon과 thurs 키는 공통 접두사를 공유하지 않고 맵 안의 유일한 두 키이므로, 각 출력 값 전체를 시작 상태에서 나가는 첫 전이에 둘 수 있습니다.
하지만 다음 키 tues를 추가하면 상황이 조금 더 흥미로워집니다:
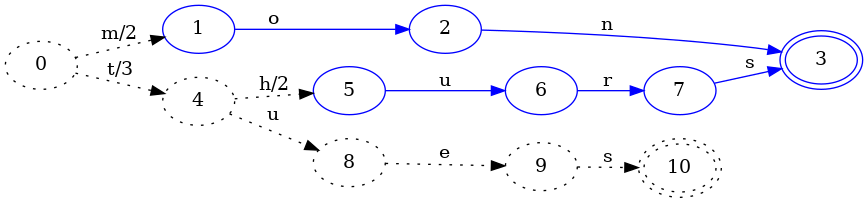
FSA 구성과 마찬가지로, 이 과정은 절대로 바뀌지 않을 FST의 다른 부분을 찾아내어 얼립니다. 여기서 차이는 상태 0에서 4로 가는 전이의 출력이 5에서 3으로 바뀌었다는 점입니다. 이는 tues 키의 값이 3이기 때문입니다. 초기 t 전이에서 5를 값에 더하면 값이 너무 커집니다. 가능한 한 많은 구조를 공유하고 싶으므로, 공통 접두사를 찾으면 출력 값에서도 공통 접두사를 찾습니다. 이 경우 5와 3의 접두사는 3입니다. 3은 tues 키에 연결된 값이므로, 나머지 전이의 출력은 모두 0이 될 수 있습니다.
하지만 0->4 전이의 출력을 5에서 3으로 바꾸면, thurs 키에 연결된 값은 이제 잘못됩니다. 그러면 5와 3의 접두사를 취하고 남은 값을 아래로 “밀어 넣어야” 합니다. 이 경우 5 - 3 = 2이므로, 상태 4 위의 각 전이에 2를 더합니다(새로 추가한 u 전이는 제외).
이런 식으로 이전 키들의 출력을 보존하고, 새 키의 새 출력을 추가하며, FST 안에서 가능한 한 많은 구조를 공유합니다.
전과 마찬가지로 키 하나를 더 추가해 봅시다. 이번에는 출력에 더 흥미로운 영향을 주는 키를 골라보겠습니다. 맵에 tye를 추가하고 값 99를 연결해 어떤 일이 일어나는지 봅시다.
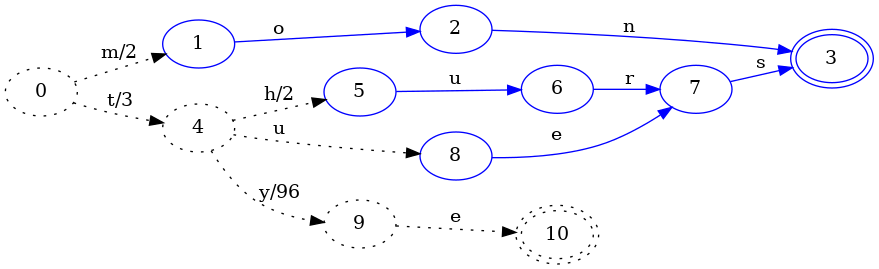
tye 키 삽입으로 tues 키의 es 부분을 얼릴 수 있게 되었습니다. 특히 FSA 구성과 마찬가지로, thurs와 tues가 FST 안에서 상태를 공유할 수 있도록 동등한 상태들을 식별했습니다.
여기서 FST 구성에서 다른 점은, tye 키를 위해 방금 추가된 4->9 전이에 연결된 출력이 96이라는 것입니다. 왜 96을 택했을까요? 그 이전 전이 0->4의 출력이 3이기 때문입니다. 99와 3의 공통 접두사는 3이므로, 0->4의 출력은 그대로 두고 4->9의 출력은 99 - 3 = 96으로 설정합니다.
완전성을 위해, 더 이상 키를 추가하지 않는다고 표시한 뒤의 최종 FST는 다음과 같습니다:
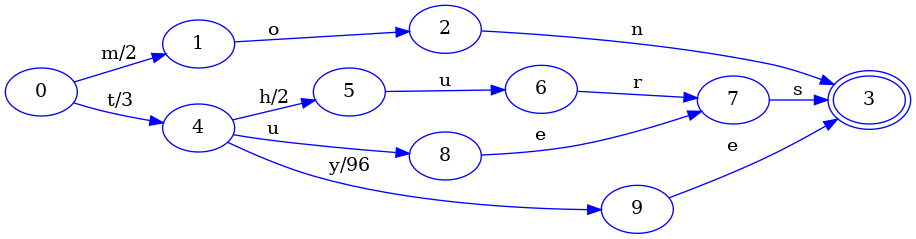
이전 단계와 비교한 유일한 실질적 변화는 tye 키의 마지막 전이가 다른 모든 키와 공유되는 최종 상태에 연결되었다는 점입니다.
위에서 그림으로 설명한 알고리즘을 실제 코드로 구현하는 것은 이 글의 범위를 조금 벗어납니다. (물론 빠른 구현은 제 fst 라이브러리에서 자유롭게 사용할 수 있습니다.) 하지만 논의할 가치가 있는 중요한 과제들이 있습니다.
FST 데이터 구조의 핵심 사용 사례 중 하나는 매우 많은 키를 저장하고 검색하는 능력입니다. 이 목표는 위 알고리즘과 어느 정도 상충합니다. 왜냐하면 그 알고리즘은 얼린 모든 상태를 메모리에 유지해야 하기 때문입니다. 즉 주어진 키에 대해 FST의 일부를 재사용할 수 있는지 감지하려면, 실제로 동등한 상태를 검색할 수 있어야 합니다.
이 알고리즘을 설명하는 문헌(다음 섹션에 링크됨)은 이를 위해 해시 테이블을 사용할 수 있다고 말합니다. 해시 함수가 좋다는 가정하에 이는 특정 상태에 대한 상수 시간 접근을 제공합니다. 문제는 해시 테이블은 대개 모든 상태를 메모리에 저장하는 비용 외에도 추가 오버헤드를 수반한다는 점입니다.
결과 FST의 최소성 보장을 희생하는 대신, 과도한 메모리 요구를 완화할 수 있습니다. 즉 크기가 제한된 해시 테이블을 유지하는 것입니다. 그러면 자주 재사용되는 상태는 해시 테이블에 남고, 덜 자주 재사용되는 상태는 축출됩니다. 실제로 약 10,000 슬롯의 해시 테이블은 괜찮은 절충을 제공하고, 제 비과학적인 실험에서는 최소성에 꽤 가깝게 근사했습니다. (실제 구현은 조금 더 잘합니다. 각 슬롯에 작은 LRU 캐시를 저장해서, 두 개의 흔하지만 서로 다른 노드가 같은 버킷에 매핑되더라도 여전히 재사용할 수 있게 합니다.)
일부 상태만 저장하는 크기 제한 해시 테이블을 사용하면 흥미로운 결과가 하나 생깁니다. 바로 FST 구성을 디스크 파일로 스트리밍 할 수 있다는 점입니다. 즉 앞선 두 섹션에서 설명한 대로 상태가 얼면, 그 전부를 메모리에 유지할 이유가 없습니다. 대신 즉시 디스크(또는 소켓 등 무엇이든)로 쓸 수 있습니다.
최종 결과는 사전 정렬된 키로부터 선형 시간과 상수 메모리에서 근사 최소 FST를 구성할 수 있다는 것입니다.
위에서 제시한 알고리즘은 제 것이 아닙니다. (제가 아는 한, LRU 캐시 아이디어는 제가 생각해 낸 것 같습니다. 하지만 그게 전부입니다!)
FSA 구성 알고리즘은 Incremental Construction of Minimal Acyclic Finite State Automata에서 얻었습니다. 특히 3절이 세부 사항을 꽤 잘 설명하지만, 논문 전체가 읽을 만합니다.
FST 구성 알고리즘은 Direct Construction of Minimal Acyclic Subsequential Transducers에서 얻었습니다. 논문 전체가 정말 좋지만, 모든 내용이 몸에 배기까지 일주일 동안 3~5번쯤 다시 읽어야 했습니다. 논문 끝부분에 알고리즘의 의사 코드가 있는데, 변수들의 의미에 뇌가 익숙해지고 나면 아주 읽기 쉽습니다.
이 두 논문이 지금까지 글에서 다룬 거의 모든 내용을 포괄합니다. 하지만 효율적인 구현을 실제로 작성하려면 더 읽을 만한 것이 있습니다. 특히 이 글에서는 FST 안에서 노드와 전이가 어떻게 표현되는지 자세히 다루지 않습니다. 짧게 말하면, FST의 표현은 메모리 안의 바이트 시퀀스이고, 대다수 상태는 정확히 1바이트 공간만 차지합니다. 실제로 유한 상태 기계의 표현은 활발한 연구 주제입니다. 저에게 가장 도움이 된 논문 두 편은 다음과 같습니다:
훌륭하지만 매우 길고 심층적인 개요를 원한다면 Jan Daciuk의 학위 논문 (gzipped PostScript 경고)이 좋습니다.
구성 알고리즘에 대한 짧고 간결하면서 실험 동기가 분명한 개요로는 Comparison of Construction Algorithms for Minimal, Acyclic, Deterministic, Finite-State Automata from Sets of Strings가 매우 좋습니다.
제가 만든 fst crate(Rust에서의 “컴파일 단위”라는 말)는 Rust로 작성되었고, 빠르며 메모리를 의식합니다. 정렬된 집합과 정렬된 맵에 대한 두 가지 편리한 추상을 제공하는 동시에, 기반 유한 상태 트랜스듀서에 대한 로우 접근도 제공합니다. 메모리 맵을 이용한 집합과 맵 로딩은 일급 기능이어서, 전체 데이터 구조를 메모리에 먼저 올리지 않고도 집합이나 맵을 질의할 수 있습니다.
정렬된 집합과 맵의 기능은 Rust 표준 라이브러리의 BTreeSet 및 BTreeMap와 유사합니다. 핵심 차이는 fst의 집합과 맵은 불변이며, 키는 바이트 시퀀스로 고정되고, 맵의 값은 항상 부호 없는 64비트 정수라는 점입니다.
이 섹션에서는 다음 주제를 둘러보겠습니다:
따라서 이 섹션은 Rust 코드가 매우 많습니다. Rust를 몰라도 무슨 일이 일어나는지 알 수 있도록 코드에 대한 고수준 설명을 최대한 붙이겠습니다. 다만 이 섹션을 최대한 잘 활용하려면 훌륭한 Rust Programming Language 책을 읽는 것을 권합니다.
추가로 이 섹션의 내용을 보완해 줄 수 있는 fst API 문서를 곁에 두는 것도 유용할 수 있습니다.
Rust의 대부분 데이터 구조는 가변적이어서 질의, 삽입, 삭제가 모두 하나의 API 안에 깔끔하게 묶여 있습니다. 하지만 이 블로그 글에서 설명한 FST 기반 데이터 구조는 일단 만들어지고 나면 더 이상 수정할 수 없기 때문에 사정이 다릅니다. 따라서 API는 FST를 구성 하는 것과 FST를 질의 하는 것 사이에 구분이 있습니다.
이 구분은 fst 라이브러리가 노출하는 타입들에 반영됩니다. 그중에는 Set과 SetBuilder가 있는데, 앞자는 질의를 위한 것이고 뒤는 삽입을 위한 것입니다. 맵도 Map과 MapBuilder로 비슷하게 나뉩니다.
이제 집합을 만들고 파일에 쓰는 간단한 예제로 가봅시다. 이 코드의 정말 중요한 성질은, 집합이 구성되는 동안 파일에 기록된다는 점입니다. 전체 집합이 메모리에 저장되는 순간은 전혀 없습니다!
(Rust가 익숙하지 않다면, 주석을 조금 자세히 달아두었습니다.)
build-set-file
// `File` 타입과 전체 `std::io` 모듈을 이 스코프로 가져온다.
use std::fs::File;
use std::io;
// `fst` 모듈에서 `SetBuilder` 타입을 가져온다.
use fst::SetBuilder;
// 현재 디렉터리의 "set.fst"에 쓸 파일 핸들을 만든다.
let file_handle = File::create("set.fst")?;
// 파일에 대한 쓰기가 버퍼링되도록 한다.
let buffered_writer = io::BufWriter::new(file_handle);
// 데이터 구조를 set.fst로 스트리밍하는 집합 빌더를 만든다.
// 여기에는 소켓이나 메모리 내 버퍼나, Rust에서 "writable"한 어떤 것이든
// 사용할 수 있다.
let mut set_builder = SetBuilder::new(buffered_writer)?;
// 역사상 가장 위대한 밴드의 키 몇 개를 삽입한다.
// 삽입은 두 가지 방식으로 실패할 수 있다. 키가 순서에 맞지 않게 삽입되었거나,
// 기반 파일에 쓰는 데 문제가 있었을 때다.
set_builder.insert("bruce")?;
set_builder.insert("clarence")?;
set_builder.insert("stevie")?;
// 집합 빌드를 끝내고 전체 데이터 구조가 디스크로 플러시되도록 한다.
// 이것이 호출된 뒤에는 더 이상 삽입할 수 없다. (실제로 Rust의 타입/소유권
// 시스템이 이를 막아준다!)
set_builder.finish()?;(Rust가 익숙하지 않다면 아마 이렇게 생각할지도 모르겠습니다. 저 ?는 대체 뭐지? 짧게 말하면, 이것은 조기 반환과 다형성을 사용해 에러 처리를 해주는 연산자입니다. 가장 좋은 이해 방법은 이렇습니다. ?를 볼 때마다 그 아래 연산이 실패할 수 있다는 뜻이고, 실패하면 에러 값을 반환하고 현재 함수를 즉시 종료합니다. 자세한 내용은 Rust의 에러 처리에 관한 제 다른 블로그 글을 보세요.
고수준에서 이 코드는 다음을 합니다:
SetBuilder를 만듭니다.SetBuilder::insert 메서드를 사용해 집합에 키를 삽입합니다.하지만 때로는 집합을 디스크 파일로 스트리밍할 필요도, 원하지도 않을 수 있습니다. 그냥 메모리에 만들고 사용하고 싶을 수도 있습니다. 그것도 가능합니다!
build-set-memory
use fst::{Set, SetBuilder};
// 데이터 구조를 메모리로 스트리밍하는 집합 빌더를 만든다.
let mut set_builder = SetBuilder::memory();
// 삽입은 이전과 같다.
// 순서에 맞지 않으면 여전히 실패할 수 있지만, 힙에 쓰는 것은 (대부분)
// 성공이 보장된다. 이 키들을 올바른 순서로 삽입하고 있다는 것을 알기 때문에
// 실패 시 패닉을 일으키거나 현재 실행 스레드를 중단하는 "unwrap"을 사용한다.
set_builder.insert("bruce").unwrap();
set_builder.insert("clarence").unwrap();
set_builder.insert("stevie").unwrap();
// 집합 빌드를 끝내고 FST로 읽을 수 있는 메모리 영역을 돌려받는다.
let fst_bytes = set_builder.into_inner()?;
// 그리고 그 바이트로 새 Set을 만든다.
// 질의에 관한 다음 섹션에서 더 자세히 다룬다.
let set = Set::from_bytes(fst_bytes).unwrap();이 코드는 핵심적인 두 차이점을 제외하면 대부분 앞선 것과 같습니다:
SetBuilder에게 메모리 영역을 할당해서 그것을 쓰라고 지시하기만 하면 됩니다.finish를 호출하는 대신 into_inner를 호출합니다. 이것은 finish와 같은 일을 하지만, SetBuilder가 데이터 구조를 쓰는 데 사용한 메모리 영역도 돌려줍니다. 그 메모리 영역으로 새 Set을 만들고, 그것을 질의에 사용할 수 있습니다.이제 같은 과정을 맵에 대해서도 보겠습니다. 거의 완전히 같고, 단지 이제 키와 함께 값을 삽입합니다:
build-map-memory
use fst::{Map, MapBuilder};
// 데이터 구조를 메모리로 스트리밍하는 맵 빌더를 만든다.
let mut map_builder = MapBuilder::memory();
// 삽입은 이전과 같지만, 이제 각 키에 값을 포함한다.
map_builder.insert("bruce", 1972).unwrap();
map_builder.insert("clarence", 1972).unwrap();
map_builder.insert("stevie", 1975).unwrap();
// 이 단계들은 이전과 정확히 같다.
let fst_bytes = map_builder.into_inner()?;
let map = Map::from_bytes(fst_bytes).unwrap();이것이 FST로 표현되는 정렬된 집합이나 맵을 만드는 거의 전부입니다. 집합과 맵 모두에 API 문서가 있습니다.
위 예제들에서는 빌더를 만들고, 키를 하나씩 삽입한 뒤, 마지막에 finish나 into_inner를 호출해야 비로소 집합이나 맵 빌드가 끝났다고 할 수 있었습니다. 이것은 실제로는 자주 편리합니다(예를 들어 파일의 줄들을 순회할 때). 하지만 블로그 글에서 간결한 예제를 보여주기에는 썩 편하지 않습니다. 그래서 작은 편의 기능을 사용하겠습니다.
다음 코드는 메모리에서 집합을 만듭니다:
build-set-shortcut
use fst::Set;
let set = Set::from_iter(vec!["bruce", "clarence", "stevie"])?;이것은 이전과 같은 결과를 냅니다. 차이는 집합을 구성하기 전에 동적으로 늘어나는 요소 벡터를 먼저 할당한다는 점뿐인데, 큰 데이터에서는 일반적으로 권장되지 않습니다.
같은 요령은 맵에도 적용됩니다. 다만 바이트 문자열의 시퀀스(키)가 아니라 튜플의 시퀀스(키와 값)를 받습니다:
build-map-shortcut
use fst::Map;
let map = Map::from_iter(vec![
("bruce", 1972),
("clarence", 1972),
("stevie", 1975),
])?;FST 기반 데이터 구조를 만드는 과정은 편의성의 전형이라고 하기는 어렵습니다. 특히 많은 연산이 실패할 수 있고, 데이터 구조를 파일에 직접 쓸 때는 더 그렇습니다. 따라서 FST 기반 데이터 구조의 구성에는 에러 처리가 필요합니다.
다행히 질의는 그렇지 않습니다. 집합이나 맵이 한 번 구성되고 나면, 마음 놓고 질의할 수 있습니다.
집합은 단순합니다. 핵심 연산은 “이 집합에 이 키가 있는가?”입니다.
query-set-contains
use fst::Set;
let set = Set::from_iter(vec!["bruce", "clarence", "stevie"])?;
assert!(set.contains("bruce")); // "bruce"는 집합에 있다
assert!(!set.contains("andrew")); // "andrew"는 없다
// 또 하나의 자명한 연산: 집합에 원소가 몇 개 있는가?
assert_eq!(set.len(), 3);맵도 다시 매우 비슷하지만, 키에 연결된 값에도 접근할 수 있습니다.
query-map-get
use fst::Map;
let map = Map::from_iter(vec![
("bruce", 1972),
("clarence", 1972),
("stevie", 1975),
])?;
// 맵에는 집합의 `contains`와 같은 `contains_key`가 있다:
assert!(map.contains_key("bruce")); // "bruce"는 맵에 있다
assert!(!map.contains_key("andrew")); // "andrew"는 없다
// 맵에는 `get`도 있는데, 값이 존재하면 그것을 가져온다.
// `get`은 `Option<u64>`를 반환하는데, 이는 값이 없거나(키가 존재하지 않을 때)
// 값이 있을 수 있는 무언가다.
assert_eq!(map.get("bruce"), Some(1972)); // bruce는 1972년에 밴드에 합류했다
assert_eq!(map.get("andrew"), None); // andrew는 밴드에 있었던 적이 없다간단한 멤버십 검사와 키 조회 외에도, 집합과 맵은 원소 순회를 제공합니다. 이들은 정렬된 집합과 맵이므로, 순회는 키의 사전식 순서로 원소를 산출합니다.
query-set-stream
use std::str::from_utf8; // UTF-8 바이트를 Rust 문자열로 변환한다
// 평소의 `Set` 외에도, 스트림에서 `next`를 호출할 수 있게 해주는
// 트레이트인 `Streamer`를 함께 가져온다.
use fst::{Streamer, Set};
// 얻은 값과 비교해 같은지 확인할 수 있도록 키를 어딘가에 저장한다.
let keys = vec!["bruce", "clarence", "danny", "garry", "max", "roy", "stevie"];
// `&keys`처럼 참조를 넘긴다. 그냥 `keys`를 썼다면 `Set::from_iter` 안으로
// *이동*해 버려서 아래에서 받은 키와 준 키가 같은지 확인할 때 쓸 수 없었을 것이다.
let set = Set::from_iter(&keys)?;
// 집합에 모든 키의 스트림을 요청한다.
let mut stream = set.stream();
// 원소를 순회하며 수집한다.
let mut got_keys = vec![];
while let Some(key) = stream.next() {
// 키는 바이트 시퀀스이지만, 우리가 삽입한 키는 문자열이다.
// Rust의 문자열은 UTF-8로 인코딩되므로 여기서 디코딩해야 한다.
let key = from_utf8(key)?.to_string();
got_keys.push(key);
}
assert_eq!(keys, got_keys);(Rust 사용자라면 왜 for 루프나 이터레이터 어댑터 대신 while let을 쓰는지 궁금할 수도 있습니다. 그 더러운 비밀을 말씀드리자면, fst crate는 이터레이터를 노출하지 않습니다. 대신 스트림 을 노출합니다. 기술적 정당화는 Streamer 트레이트 문서에 길게 설명되어 있습니다.)
이 예제에서는 집합에 스트림을 요청해서 집합의 모든 키를 순서대로 순회할 수 있게 했습니다. 스트림은 내부 버퍼에 대한 참조 를 산출합니다. Rust에서는 이것이 완전히 안전한데, 타입 시스템이 스트림 내부 버퍼에 대한 참조가 살아 있는 동안 next를 호출하지 못하게 막기 때문입니다(컴파일 시점에). 즉 소비자인 여러분이 모든 키를 메모리에 저장할지(이 예제처럼), 아니면 작업에 데이터 한 번 훑기만 필요하다면 각 키를 위한 공간을 할당하지 않을지를 제어할 수 있습니다. 이런 순회 방식을 스트리밍 이라고 부르는데, 원소의 소유권이 순회 자체에 묶여 있기 때문입니다.
이 과정이 BTreeSet 같은 다른 데이터 구조와는 명확히 다르다는 점을 주의해야 합니다. 트리 기반 데이터 구조는 보통 각 키마다 별도의 할당 위치를 가지므로, 그 할당에 대한 참조를 그대로 반환할 수 있습니다. 즉 순회로 산출되는 원소의 소유권이 데이터 구조 에 묶여 있습니다. FST 기반 데이터 구조에서는 각 순회마다 받아들일 수 없는 비용을 치르지 않고는 이런 스타일의 순회를 구현할 수 없습니다. FST는 각 키를 자체 위치에 저장하지 않기 때문입니다. 이 글의 앞부분을 떠올려보면, 키는 유한 상태 기계의 전이에 저장됩니다. 따라서 키는 순회 과정에서 구성 됩니다.
좋습니다. 다시 질의로 돌아갑시다. 모든 키를 순회하는 것 외에도, 범위 질의 를 통해 키의 부분집합만 효율적으로 순회할 수 있습니다. 앞선 예제를 확장한 예를 보겠습니다.
query-set-range
// 이제 범위 질의를 스트림으로 바꾸는 방법을 제공하는 IntoStreamer
// 트레이트가 필요하다.
use fst::{IntoStreamer, Streamer, Set};
// 이전 예제와 같다.
let keys = vec!["bruce", "clarence", "danny", "garry", "max", "roy", "stevie"];
let set = Set::from_iter(&keys)?;
// `c`보다 크거나 같고 `roy`보다 작거나 같은 모든 키를 포함하는
// 범위 질의를 만든다.
let range = set.range().ge("c").le("roy");
// 범위를 스트림으로 바꾼다.
let stream = range.into_stream();
// 스트림에 정의된 편의 메서드를 사용해 스트림의 원소를 문자열 시퀀스로
// 수집한다. 이는 이전 예제에서 직접 썼던 `while let` 루프의 짧은 형태다.
let got_keys = stream.into_strs()?;
// 올바른 키를 얻었는지 확인한다.
assert_eq!(got_keys, &keys[1..6]);위 예제의 핵심 줄은 이것입니다:
let range = set.range().ge("c").le("roy");range 메서드는 새 범위 질의를 반환하고, ge와 le 메서드는 각각 크거나 같음, 작거나 같음 경계를 설정합니다. gt와 lt 메서드도 있는데, 각각 초과 및 미만 경계를 설정합니다. 이 메서드들은 어떤 조합으로든 사용할 수 있으며(같은 메서드를 여러 번 쓰면 마지막 것이 이전 것을 덮어씁니다).
범위 질의가 만들어지면 이를 쉽게 스트림으로 바꿀 수 있습니다:
let stream = range.into_stream();스트림이 생기면, 이전 예제에서 봤듯 next 메서드와 while let 루프로 순회할 수 있습니다. 이 예제에서는 대신 into_strs 메서드를 호출했는데, 이것이 순회와 UTF-8 디코딩을 해주고 결과를 벡터로 반환합니다.
같은 메서드들은 맵에도 있지만, 순회가 키만이 아니라 키와 값의 튜플을 산출한다는 점만 다릅니다.
SetBuilder의 첫 번째 예제에서 데이터 구조를 파일에 곧바로 스트리밍 했던 것을 기억하시나요? 이것은 FST 기반 데이터 구조에서 특히 중요한 사용 사례입니다. 그 주력 분야가 거대한 키 모음이기 때문입니다. 전체 데이터 구조를 메모리에 저장하지 않고, 구성하면서 바로 디스크에 쓸 수 있다는 점은 아주 좋은 편의입니다.
디스크의 집합을 읽는 데도 비슷한 일을 할 수 있을까요? 물론 파일을 열고 내용을 읽어 Set을 만드는 것은 가능합니다:
read-set-mmap
use std::fs::File;
use std::io::Read;
use fst::Set;
// 파일 핸들을 열고 전체 내용을 메모리로 읽는다.
let mut file_handle = File::open("set.fst")?;
let mut bytes = vec![];
file_handle.read_to_end(&mut bytes)?;
// 집합을 구성한다.
let set = Set::from_bytes(bytes)?;
// 마지막으로 질의할 수 있다.
println!("number of elements: {}", set.len());이 코드에서 비싼 부분은 파일 전체를 메모리로 읽어야 한다는 점입니다. Set::from_bytes 호출 자체는 사실 꽤 빠릅니다. FST에 인코딩된 메타데이터를 조금 읽고 단순한 체크섬을 수행할 뿐입니다. 실제로 이 과정은 32바이트만 보면 됩니다!
이를 완화하는 한 가지 방법은 FST 데이터 구조에게 파일에서 직접 읽는 법을 가르치는 것입니다. 특히 유한 상태 기계를 순회하기 위해 파일 안을 이리저리 점프하는 seek 시스템 호출을 사용하게 만드는 것입니다. 하지만 seek 호출이 매우 자주 일어날 것이기 때문에 비용이 너무 클 수 있습니다. 모든 seek는 시스템 호출의 오버헤드를 수반하므로, FST 검색을 지나치게 느리게 만들 가능성이 큽니다.
또 다른 방법은 크기가 제한된 캐시를 유지하면서 파일의 청크를 메모리에 저장하되, 아마도 전부는 저장하지 않는 것입니다. 파일의 어떤 영역에 접근해야 하는데 그 영역이 캐시에 없다면, 그 영역을 포함하는 파일 청크를 읽어서 캐시에 추가합니다(오랫동안 접근하지 않은 청크를 축출할 수도 있습니다). 그 영역에 다시 접근했을 때 이미 캐시에 있으면 I/O는 필요 없습니다. 이 접근은 메모리에 무엇을 저장할지도 영리하게 제어할 수 있게 해줍니다. 예를 들어 기계의 시작 상태 근처의 청크는 이론상 가장 자주 접근될 테니 캐시에 항상 두도록 할 수 있습니다. 하지만 이 접근은 구현이 복잡하고 다른 문제들도 있습니다.
세 번째 방법은 메모리 맵 파일이라는 것입니다. 메모리 맵 파일이 만들어지면, 우리에게는 그것이 마치 메모리 안의 바이트 시퀀스인 것처럼 보입니다. 이 메모리 영역에 접근할 때, 실제로 파일의 데이터가 아직 읽혀 오지 않았을 수도 있습니다. 그러면 페이지 폴트 가 발생해 운영체제에게 파일에서 청크를 읽어 프로그램에 노출된 바이트 시퀀스에서 사용할 수 있게 하라고 알려줍니다. 그러면 파일의 어떤 부분이 실제로 메모리에 있을지는 운영체제가 관리합니다. 파일에서 데이터를 읽고 메모리에 저장하는 실제 과정은 프로그램에서 투명하게 처리됩니다. fst crate가 보는 것은 그냥 평범한 바이트 시퀀스뿐입니다.
이 세 번째 방법은 위에서 말한 캐시 아이디어와 실제로 매우 비슷합니다. 핵심 차이는 우리가 아니라 운영체제가 캐시를 관리한다는 점입니다. 구현이 극적으로 단순해집니다. 물론 비용도 있습니다. 운영체제가 캐시를 관리하므로 FST의 특정 부분이 항상 메모리에 있어야 한다는 사실은 알 수 없습니다. 따라서 때때로 질의 시간이 최적이 아닐 수 있습니다. 이런 단점은 mlock이나 madvise 같은 호출을 사용해 어느 정도 완화할 수 있습니다. 이런 호출을 통해 프로세스는 메모리 맵의 특정 영역을 메모리에 남기거나 빼라고 운영체제에 알릴 수 있습니다.
fst crate는 메모리 맵 사용을 지원합니다(하지만 아직 mlock이나 madvise는 사용하지 않습니다). 앞선 예제를 메모리 맵 사용으로 바꾼 버전은 다음과 같습니다:
read-set-file
use fst::Set;
// 파일 경로로부터 집합을 구성한다. fst crate는 이를 메모리 맵으로 구현하므로,
// 이 메서드는 unsafe하다. 호출자는 같은 프로그램 안에서 다른 가변 메모리 맵을
// 열지 않도록 보장해야 한다.
let set = unsafe { Set::from_path("set.fst")? };
// 마지막으로 질의할 수 있다. 전체 집합을 메모리에 읽지 않고도 즉시 가능하다.
println!("number of elements: {}", set.len());정말 이게 전부입니다. 질의 방식은 그대로입니다. 메모리 맵이 사용된다는 사실은 프로그램에 완전히 투명합니다.
여기서 한 가지 더 언급할 비용이 있습니다. 메모리 안에서 FST를 표현하는 형식은 데이터에 대한 랜덤 액세스를 지향합니다. 즉 키를 조회할 때 FST의 서로 멀리 떨어진 여러 영역으로 점프할 수 있습니다. 이는 메모리 맵을 통해 디스크에서 FST를 읽을 때 랜덤 액세스 I/O가 느리므로 비용이 클 수 있다는 뜻입니다. 특히 비SSD 디스크를 쓸 때는 랜덤 액세스마다 많은 물리적 탐색이 필요해 더 그렇습니다. 이런 상황에 있고 운영체제의 페이지 캐시가 이를 상쇄하지 못한다면, 선불 비용을 치르고 FST 전체를 메모리에 읽어야 할 수도 있습니다. 이것이 반드시 사형 선고는 아니라는 점을 기억하세요. FST의 목적은 매우 작아지는 것이기 때문입니다. 예를 들어 수백만 개 키를 가진 FST도 몇 메가바이트 메모리에 들어갈 수 있습니다. (예: Project Gutenberg 전체 말뭉치의 350만 개 고유 단어는 22 MB만 차지합니다.)
문자열 모음이 있을 때 아주 유용한 연산 중 하나가 퍼지 검색 입니다. 퍼지 검색에도 여러 종류가 있지만, 여기서는 그중 하나만 다루겠습니다. Levenshtein 또는 “편집” 거리 기반 퍼지 검색입니다.
Levenshtein 거리는 두 문자열을 비교하는 방법입니다. 즉 문자열 A와 B가 주어졌을 때, A를 B로 바꾸기 위해 수행해야 하는 문자 삽입, 삭제, 치환의 수가 A와 B의 Levenshtein 거리입니다. 간단한 예를 들면:
dist("foo", "foo") == 0 (변화 없음)dist("foo", "fo") == 1 (삭제 한 번)dist("foo", "foob") == 1 (삽입 한 번)dist("foo", "fob") == 1 (치환 한 번)dist("foo", "fobc") == 2 (치환 한 번, 삽입 한 번)두 문자열 사이의 Levenshtein 거리를 계산하는 알고리즘은 여러 가지가 있습니다. 대략적으로 보면 가장 좋은 경우 m과 n이 비교하는 문자열 길이일 때 O(mn) 시간이 최선입니다.
우리의 목적에서 답하고 싶은 질문은 이렇습니다. 이 키가 집합 안의 어떤 키와라도 Levenshtein 거리 n 이내로 일치하는가?
물론 두 문자열의 Levenshtein 거리를 계산하는 알고리즘을 구현하고, FST 기반 정렬 집합의 키들을 모두 순회하면서 각 키마다 알고리즘을 실행할 수도 있습니다. 질의와 키의 거리가 <= n이면 그것을 일치 항목으로 내보내고, 아니면 건너뛰고 다음 키로 갑니다.
문제는 이 접근이 엄청나게 느리다는 점입니다. 사실상 이차 시간 알고리즘을 집합의 모든 키에 대해 실행해야 합니다. 좋지 않습니다.
다행히 우리의 특정 사용 사례에서는 훨씬 더 잘할 수 있습니다. 우리의 경우, 하나의 검색 동안 모든 거리 계산에서 문자열 하나는 고정 입니다. 질의는 동일하게 유지됩니다. 이런 조건과 알려진 거리 임계값이 주어지면, 질의와 일치하는 모든 문자열을 인식하는 오토마톤을 만들 수 있습니다.
이게 왜 유용할까요? 우리의 FST 기반 정렬 집합 자체가 오토마톤이기 때문입니다! 따라서 정렬 집합으로 이 질문에 답하는 것은 두 오토마톤의 교집합을 취하는 것과 다르지 않습니다. 이것은 정말 빠릅니다.
정렬 집합에서 퍼지 검색을 수행하는 간단한 예를 보겠습니다.
levenshtein
// Levenshtein을 제외하면 모두 전에 본 import들이다.
// Levenshtein은 Levenshtein 오토마톤을 만드는 타입이다.
use fst::{IntoStreamer, Streamer, Set};
use fst_levenshtein::Levenshtein;
let keys = vec!["fa", "fo", "fob", "focus", "foo", "food", "foul"];
let set = Set::from_iter(keys)?;
// 퍼지 질의를 만든다. 이는 "foo"를 찾고, "foo"로부터 Levenshtein 거리
// 1 이하인 모든 키를 반환하라는 뜻이다.
let lev = Levenshtein::new("foo", 1)?;
// 만든 집합에 퍼지 질의를 적용하고 질의를 스트림으로 바꾼다.
let stream = set.search(lev).into_stream();
// 결과를 가져와 기대한 것과 같은지 확인한다.
let keys = stream.into_strs()?;
assert_eq!(keys, vec![
"fo", // 삭제 1번
"fob", // 치환 1번
"foo", // 삽입/삭제/치환 0번
"food", // 삽입 1번
]);오토마톤으로 집합을 검색하는 것의 정말 중요한 성질은, 검색할 집합의 전체 영역을 효율적으로 제외할 수 있다는 점입니다. 예를 들어 질의가 food이고 거리 임계값이 1이라면, 기반 FST에서 길이가 5보다 큰 키는 절대로 방문하지 않습니다. 그런 키는 결코 검색 조건을 만족할 수 없기 때문입니다. 다른 많은 키도 건너뛸 수 있습니다. 예를 들어 처음 두 글자가 f나 o가 아닌 키는 검색 조건을 만족할 수 없습니다. 이미 거리 임계값을 초과했기 때문입니다.
안타깝게도 Levenshtein 오토마타가 정확히 어떻게 구현되는지 이야기하는 것은 이 글의 범위를 벗어납니다. 구현은 부분적으로 Jules Jacobs의 통찰에 기반합니다. 하지만 구현에서 이야기할 가치가 있는 부분이 하나 있습니다. 바로 Unicode입니다.
앞선 섹션에서는 Levenshtein 오토마톤을 만드는 코드 예제를 보았습니다. 이것은 fst crate의 정렬 집합이나 맵에서 퍼지 검색에 사용할 수 있습니다.
우리가 대충 넘어간 아주 중요한 세부 사항은 Levenshtein 거리가 실제로 어떻게 정의되는가입니다. 제가 앞서 이렇게 말했죠. 강조는 제가 추가합니다:
Levenshtein 거리는 두 문자열을 비교하는 방법입니다. 즉 문자열
A와B가 주어졌을 때,A를B로 바꾸기 위해 수행해야 하는 문자 삽입, 삭제, 치환의 수가A와B의 Levenshtein 거리입니다.
정확히 “문자”가 무엇이며, 우리의 FST 기반 정렬 집합과 맵은 이것을 어떻게 다룰까요? 문자에 대한 유일한 정전적 정의는 없기 때문에, 기술적인 사람에게는 좋지 않은 표현이었습니다. 실제 구현을 반영하는 더 나은 표현은 Unicode 코드포인트 입니다. 즉 Levenshtein 거리는 한 키를 다른 키로 바꾸기 위해 필요한 Unicode 코드포인트의 삽입, 삭제, 치환 횟수입니다.
안타깝게도 여기서 Unicode 전체를 다룰 공간은 없지만, Introduction to Unicode는 중요한 용어를 간결하게 정의한 유익한 글입니다. David C. Zentgraf의 정리도 좋지만 훨씬 길고 자세합니다. 중요한 요점은 다음과 같습니다:
코드포인트를 사용하는 선택은 정확성, 구현 복잡도, 성능 사이의 자연스러운 절충입니다. 구현하기 가장 단순한 방법은 모든 문자가 단 하나의 바이트로 표현된다고 가정하는 것입니다. 하지만 키 안에 ☃(Unicode 눈사람, 단일 코드포인트)가 들어 있으면 어떻게 될까요? UTF-8에서는 3바이트로 인코딩됩니다. 사용자는 그것을 하나의 문자로 보지만, Levenshtein 오토마톤은 그것을 3개의 문자로 보게 됩니다. 좋지 않습니다.
우리의 FST는 실제로 바이트 기반 이므로(즉 트랜스듀서의 모든 전이는 정확히 하나의 바이트에 대응), Levenshtein 오토마톤에도 UTF-8 디코딩이 내장 되어 있어야 합니다. 제가 작성한 구현은 Russ Cox가 RE2에서 사용한 요령에 기반합니다(그리고 Russ Cox는 그것을 Ken Thompson의 grep에서 가져왔습니다). 자세한 내용은 utf8-ranges crate 문서를 보세요.
이 접근에서 나오는 아주 멋진 성질 하나는, 이 crate로 Levenshtein 질의를 실행하면 모든 키가 유효한 UTF-8임이 보장된다는 점입니다. 키가 유효한 UTF-8이 아니면 Levenshtein 오토마톤은 애초에 일치시키지 못합니다.
FST 기반 데이터 구조에 실행하고 싶은 또 다른 유형의 질의는 정규 표현식 입니다. 간단히 말해 정규 표현식은 정규 언어를 기술하는 단순한 패턴 문법입니다. 예를 들어 정규 표현식 [0-9]+(foo|bar)는 하나 이상의 숫자로 시작한 뒤 foo 또는 bar 중 하나가 오는 모든 텍스트에 일치합니다.
집합이나 맵을 정규 표현식으로 검색할 수 있다면 참 좋겠죠. 한 가지 방법은 모든 키를 순회하면서 각 키에 정규 표현식을 적용하는 것입니다. 일치하지 않으면 건너뜁니다. 안타깝게도 이것은 꽤 느립니다. Rust의 정규 표현식 엔진은 느린 편이 아니지만, 짧은 문자열에 대해 수백만 번 실행하면 느릴 수밖에 없습니다. 더 중요한 것은 이 접근에서는 집합의 모든 키를 반드시 방문해야 한다는 점입니다. 큰 집합에서는 정규 표현식 질의가 실현 불가능해질 수도 있습니다.
앞선 섹션의 Levenshtein 거리 계산과 마찬가지로, 여기서도 훨씬 더 잘할 수 있습니다. 우리의 정규 표현식은 검색 전체 동안 동일하게 유지되므로, 그 정규 표현식과 어떤 텍스트가 일치하는지 판단하는 오토마톤 을 미리 계산할 수 있습니다. 집합과 맵이 그 자체로 오토마톤이기 때문에, 두 오토마톤의 교집합을 취함으로써 데이터 구조를 매우 효율적으로 검색할 수 있습니다.
간단한 예를 보겠습니다:
regex
// Regex를 제외하면 모두 전에 본 import들이다.
// Regex는 정규 표현식 오토마톤을 만드는 타입이다.
use fst::{IntoStreamer, Streamer, Set};
use fst_regex::Regex;
let keys = vec!["123", "food", "xyz123", "τροφή", "еда", "מזון", "☃☃☃"];
let set = Set::from_iter(keys)?;
// 정규 표현식을 만든다. 문법이 틀렸거나 오토마톤이 너무 커지면 실패할 수 있다.
// 이 정규 표현식은 비어 있지 않고 문자만 포함하는 키에 일치한다.
// 여기서 `\pL`은 "문자로 간주되는 모든 Unicode 코드포인트"를 뜻한다.
let lev = Regex::new(r"\pL+")?;
// 만든 집합에 정규 표현식 질의를 적용하고 질의를 스트림으로 바꾼다.
let stream = set.search(lev).into_stream();
// 결과를 가져와 기대한 것과 같은지 확인한다.
let keys = stream.into_strs()?;
// "123", "xyz123", "☃☃☃"은 일치하지 않았다는 점에 주목하자.
assert_eq!(keys, vec![
"food",
"τροφή",
"еда",
"מזון",
]);이 예제에서는 정렬 집합에 대해 정규 표현식 질의를 실행하는 방법을 보여줍니다. 정규 표현식은 \pL+이며, UTF-8로 인코딩된 코드포인트 중 문자로 간주되는 것들만으로 이루어진 비어 있지 않은 키에만 일치합니다. 2 같은 숫자나 ☃ 같은 멋진 기호(Unicode 눈사람)는 문자가 아니므로, 그런 기호를 포함한 키는 정규 표현식과 일치하지 않습니다.
정규 표현식 질의는 Levenshtein 질의와 두 가지 중요한 공통점이 있습니다:
123처럼 문자로 시작하지 않는 키는 즉시 배제됩니다. xyz123 같은 키는 1이 보이는 순간 배제됩니다.Levenshtein 오토마타와 마찬가지로, 안타깝게도 오토마톤이 어떻게 구현되는지는 다루지 않겠습니다. 사실 이 주제는 꽤 크고, Russ Cox의 관련 글 시리즈가 권위 있는 자료입니다. 또한 regex-syntax crate 덕분에 이런 구현이 가능했다는 점도 언급할 가치가 있습니다. 이 덕분에 Rust의 regex crate와 정확히 같은 문법을 공유할 수 있습니다. (정규 표현식 파서는 구현에서 가장 어려운 부분 중 하나인 경우가 많습니다!)
마지막으로 한 가지 덧붙이면, 큰 집합에서 일치시키는 데 오랜 시간이 걸리는 정규 표현식을 쓰는 것은 아주 쉽습니다. 예를 들어 정규 표현식이 .*로 시작한다면(“0개 이상의 Unicode 코드포인트와 일치”를 뜻함), 오토마톤의 모든 키를 방문하게 될 가능성이 높습니다.
기본 질의를 마무리하기 위해 이야기해야 할 마지막 것이 하나 있습니다. 바로 집합 연산입니다. fst crate가 지원하는 일반적인 집합 연산으로는 합집합, 교집합, 차집합, 대칭 차집합이 있습니다. 이 연산들은 모두 임의 개수의 집합이나 맵 에 대해 효율적으로 동작할 수 있습니다.
이것은 디스크 위에 여러 집합이나 맵이 있고 그것들을 함께 검색하고 싶을 때 특히 유용합니다. fst crate는 그것들을 메모리 맵으로 다루는 것을 장려하므로, 여러 집합을 거의 즉시 검색할 수 있습니다.
여러 FST를 검색하고 그 결과를 하나의 스트림으로 합치는 예제를 봅시다.
setop
use std::str::from_utf8;
use fst::{Streamer, Set};
use fst::set;
// 5개의 집합을 만든다. 편의를 위해 메모리에 저장하지만,
// `Set::from_path`를 사용해 디스크에서 메모리 맵해도 된다.
let set1 = Set::from_iter(&["AC/DC", "Aerosmith"])?;
let set2 = Set::from_iter(&["Bob Seger", "Bruce Springsteen"])?;
let set3 = Set::from_iter(&["George Thorogood", "Golden Earring"])?;
let set4 = Set::from_iter(&["Kansas"])?;
let set5 = Set::from_iter(&["Metallica"])?;
// 집합 연산을 만든다. 각 집합에서 스트림을 추가하고 합집합을 요청하면 된다.
// (`intersection` 같은 다른 연산도 가능하다.)
let mut stream =
set::OpBuilder::new()
.add(&set1)
.add(&set2)
.add(&set3)
.add(&set4)
.add(&set5)
.union();
// 이제 모든 키를 수집한다. `stream`은 지금까지 본 다른 스트림과 같다.
let mut keys = vec![];
while let Some(key) = stream.next() {
let key = from_utf8(key)?.to_string();
keys.push(key);
}
assert_eq!(keys, vec![
"AC/DC", "Aerosmith", "Bob Seger", "Bruce Springsteen",
"George Thorogood", "Golden Earring", "Kansas", "Metallica",
]);이 예제는 메모리에서 5개의 서로 다른 집합을 만들고, 새 집합 연산을 만든 다음, 각 집합에서 스트림을 추가하고, 그 모든 스트림의 합집합을 요청합니다.
union 집합 연산은 다른 모든 집합 연산과 마찬가지로 스트리밍 방식으로 구현됩니다. 즉 각 집합의 키가 정렬되어 있기 때문에, 어떤 연산도 모든 키를 메모리에 저장할 필요가 없습니다. (실제 구현은 이진 힙이라는 데이터 구조를 사용합니다.)
스트림의 멋진 점은 조합 가능하다는 것입니다. 특히 전체 집합들의 합집합만 취할 수 있다면 아주 슬플 것입니다. 대신 실제로 집합들에 대해 어떤 종류의 질의든 실행한 뒤 그 결과들의 합집합을 취할 수 있습니다.
위와 같은 예제인데, 이번에는 공백을 하나 이상 포함하는 키만 일치시키는 정규 표현식을 사용해 보겠습니다:
setop-regex
use std::str::from_utf8;
use fst::{Streamer, Set};
use fst::set;
use fst_regex::Regex;
// 5개의 집합을 만든다. 편의를 위해 메모리에 저장하지만,
// `Set::from_path`를 사용해 디스크에서 메모리 맵해도 된다.
let set1 = Set::from_iter(&["AC/DC", "Aerosmith"])?;
let set2 = Set::from_iter(&["Bob Seger", "Bruce Springsteen"])?;
let set3 = Set::from_iter(&["George Thorogood", "Golden Earring"])?;
let set4 = Set::from_iter(&["Kansas"])?;
let set5 = Set::from_iter(&["Metallica"])?;
// 정규 표현식 질의를 만든다.
let spaces = Regex::new(r".*\s.*")?;
// 집합 연산을 만든다. 각 집합에서 스트림을 추가하고 합집합을 요청하면 된다.
// (`intersection` 같은 다른 연산도 가능하다.)
let mut stream =
set::OpBuilder::new()
.add(set1.search(&spaces))
.add(set2.search(&spaces))
.add(set3.search(&spaces))
.add(set4.search(&spaces))
.add(set5.search(&spaces))
.union();
// 이전 예제와 같지만, 검색이 결과를 조금 좁혀 주었다.
let mut keys = vec![];
while let Some(key) = stream.next() {
let key = from_utf8(key)?.to_string();
keys.push(key);
}
assert_eq!(keys, vec![
"Bob Seger", "Bruce Springsteen", "George Thorogood", "Golden Earring",
]);집합 연산을 구성하는 일은 어떤 종류의 스트림과도 함께 동작합니다. 어떤 스트림은 정규 표현식 질의일 수 있고, 어떤 것은 Levenshtein 질의일 수 있으며, 또 어떤 것은 범위 질의일 수 있습니다.
이 섹션은 집합을 다뤘지만 맵은 생략했습니다. 맵은 조금 더 복잡합니다. 맵의 키에 대한 집합 연산이 만들어내는 스트림은 각 키에 연결된 값도 포함해야 하기 때문입니다. 특히 합집합 연산에서는 스트림에서 방출되는 각 키가 여러 개의 맵에 등장했을 수도 있습니다. 이 부분은 예제가 포함된 fst의 맵 합집합 API 문서에 맡기겠습니다.
지금까지 본 모든 코드 예제는 fst crate의 Set 또는 Map 데이터 타입을 사용했습니다. 사실 Set이나 Map 구현 자체에는 흥미로운 것이 별로 없습니다. 둘 다 단지 Fst 타입을 감쌀 뿐이기 때문입니다. 실제 표현은 다음과 같습니다:
// Fst 타입은 `raw` 하위 모듈 안에 숨겨져 있다.
use fst::raw::Fst;
// 이 타입 선언은 집합과 맵이 단 하나의 멤버, 즉 Fst를 가진 구조체에
// 불과하다는 것을 정의한다.
pub struct Set(Fst);
pub struct Map(Fst);다시 말해 진짜 핵심은 Fst 타입에 있습니다. 대부분의 경우 Fst를 만들고 질의하는 패턴은 집합과 맵과 같습니다. 예를 보겠습니다:
fst-build
use fst::raw::{Builder, Fst, Output};
// Fst 타입도 집합과 맵처럼 별도의 빌더를 가진다.
let mut builder = Builder::memory();
builder.insert("bar", 1).unwrap();
builder.insert("baz", 2).unwrap();
builder.insert("foo", 3).unwrap();
// 구성을 끝내고 fst의 로우 바이트를 가져온다.
let fst_bytes = builder.into_inner()?;
// 질의 가능한 Fst를 만든다.
let fst = Fst::from_bytes(fst_bytes)?;
// 기본 질의.
assert!(fst.contains_key("foo"));
assert_eq!(fst.get("abc"), None);
// 값을 조회하면 `u64` 대신 `Output`을 돌려준다.
// 이것은 유한 상태 트랜스듀서에서 전이 위 출력의 내부 표현이다.
// 실제 u64 값은 `value` 메서드로 접근할 수 있다.
assert_eq!(fst.get("baz"), Some(Output::new(2)));
// `stream`, `range`, `search` 같은 메서드도 가능하며,
// 집합과 맵에서와 같은 방식으로 동작한다.여기까지 따라오셨다면, 이 코드는 이제 대부분 익숙해 보일 것입니다. 한 가지 핵심 차이는 get이 u64가 아니라 Output을 반환한다는 점입니다. Output이 노출되는 이유는 그것이 유한 상태 트랜스듀서의 전이에 있는 출력의 내부 표현이기 때문입니다. out의 타입이 Output이라면, out.value()를 호출해서 실제 숫자 값에 접근할 수 있습니다.
Fst 타입의 핵심 기능은 기반 유한 상태 기계에 대한 접근을 준다는 것입니다. 즉 Fst 타입에는 여러분이 사용할 수 있는 중요한 메서드 두 개가 있습니다:
root()는 기반 기계의 시작 상태, 즉 “노드”를 반환합니다.node(addr)는 주어진 주소의 상태, 즉 “노드”를 반환합니다.노드는 모든 전이를 순회할 수 있는 능력과 자신이 최종 상태인지 여부를 묻는 능력을 제공합니다. 예를 들어 기계에서 baz 키의 경로를 따라가기 시작한다고 생각해 봅시다:
fst-node
use fst::raw::{Builder, Fst};
let mut builder = Builder::memory();
builder.insert("bar", 1).unwrap();
builder.insert("baz", 2).unwrap();
builder.insert("foo", 3).unwrap();
let fst_bytes = builder.into_inner()?;
let fst = Fst::from_bytes(fst_bytes)?;
// 이 FST의 루트 노드를 가져온다.
let root = fst.root();
// 루트 노드에서 나가는 전이를 사전식 순서로 출력한다.
// "b" 다음 "f"가 출력된다.
for transition in root.transitions() {
println!("{}", transition.inp as char);
}
// 입력을 기준으로 전이의 위치를 찾는다.
let i = root.find_input(b'b').unwrap();
// 전이를 가져온다.
let trans = root.transition(i);
// 그 전이가 가리키는 노드를 가져온다.
let node = fst.node(trans.addr);
// 이하 생략...이 도구들로 실제로 contains_key 메서드를 구현하는 방법도 보여줄 수 있습니다!
fst-contains
use fst::raw::Fst;
// 이 함수는 Fst에 대한 참조와 키를 받아, 키가 Fst 안에 있을 때에만 true를 반환한다.
fn contains_key(fst: &Fst, key: &[u8]) -> bool {
// 검색을 루트 노드에서 시작한다.
let mut node = fst.root();
// 키의 모든 바이트를 순회한다.
for b in key {
// 이 바이트에 해당하는 전이를 현재 노드에서 찾는다.
match node.find_input(*b) {
// 찾을 수 없다면, 이 키가 이 FST 안에 없다고 결론 내리고 조기 종료할 수 있다.
None => return false,
// 그렇지 않다면, 현재 노드를 찾은 전이가 가리키는 노드로 설정한다.
// 즉 유한 상태 기계를 "한 단계 진행"한다.
Some(i) => {
node = fst.node(node.transition_addr(i));
}
}
}
// 조회할 키를 모두 소비한 뒤에는 최종 상태에서 끝났을 때에만 FST 안에 있다.
node.is_final()
}그리고 대체로 이게 전부입니다. Node 타입에는 문서화된 유용한 메서드가 더 몇 개 있으니 한 번 살펴보셔도 좋겠습니다.
저는 FST 명령줄 도구를 데이터를 쉽게 가지고 놀 수 있는 수단이자, 기반 라이브러리를 사용하는 방법을 보여주는 데모로 만들었습니다. 그 자체만으로 특별히 실용적인 도구가 되게 만들 생각은 꼭 없었지만, 이 블로그 글에서 실제 데이터로 실험을 진행하는 데는 충분히 좋습니다.
이 섹션에서는 먼저 명령어를 아주 간단히 개괄한 뒤, 곧바로 실제 데이터 실험으로 들어가겠습니다.
도구를 꼭 써보고 싶은 게 아니라면 굳이 다운로드할 필요는 없습니다. 이 섹션에서는 보통 제가 실행한 명령과 가능하면 그 출력을 함께 보여드릴 것이기 때문입니다.
현재 이 명령을 얻는 유일한 방법은 소스에서 컴파일하는 것입니다. 그러려면 먼저 Rust와 Cargo를 설치해야 합니다. (현재 안정판 Rust면 됩니다. 배포판에는 Rust와 Cargo가 모두 포함되어 있습니다.)
Rust 설치가 끝나면 fst 저장소를 clone하고 빌드합니다:
$ git clone git://github.com/BurntSushi/fst
$ cd fst
$ cargo build --release --manifest-path ./fst-bin/Cargo.toml제법 괜찮은 사양의 제 시스템에서는 컴파일에 1분이 조금 안 걸립니다.
컴파일이 끝나면 fst 바이너리는 ./fst-bin/target/release/fst에 위치합니다.
fst 명령줄 도구에는 여러 명령이 있습니다. 그중 일부는 순전히 진단용입니다(즉 “기반 트랜스듀서의 특정 상태를 보고 싶다”) 반면, 다른 일부는 더 실용적입니다. 이 글에서는 후자에 집중하겠습니다.
명령들은 다음과 같습니다:
dot - FST를 “dot” 형식으로 출력합니다. GraphViz가 이를 사용해 이미지를 시각적으로 렌더링할 수 있습니다. 이 블로그 글의 많은 이미지를 만들 때 이 유틸리티를 사용했습니다.fuzzy - Levenshtein 거리 기반 퍼지 질의를 FST에 대해 실행합니다.grep - 정규 표현식 질의를 FST에 대해 실행합니다.range - 범위 질의를 FST에 대해 실행합니다.set - FST로 표현되는 정렬 집합을 만듭니다. 입력은 단순한 줄 목록입니다. 기본적으로는 정렬되지 않은 데이터도 받지만, 데이터가 이미 정렬되어 있고 --sorted 플래그를 주면 더 빠르게 FST를 빌드할 수 있습니다.map - set과 같지만, 첫 번째 열이 키이고 두 번째 열이 정수 값인 CSV 파일을 입력으로 받습니다.set과 map 명령은 중요합니다. 평범한 데이터로부터 FST를 만들 수 있는 수단을 제공하기 때문입니다.
쉽게 시각화할 수 있는 간단한 예제로 시작해 봅시다. 월 약어에서 그레고리력상의 숫자 위치로 매핑하는 맵을 생각해 봅시다. 원시 데이터는 단순한 CSV 파일입니다:
jan,1
feb,2
mar,3
apr,4
may,5
jun,6
jul,7
aug,8
sep,9
oct,10
nov,11
dec,12이 데이터로부터 fst map 명령을 사용해 정렬된 맵을 만들 수 있습니다:
$ fst map months months.fst데이터가 이미 정렬되어 있었다면 --sorted 플래그를 줄 수 있습니다:
$ fst map --sorted months months.fst--sorted 플래그는 fst 명령에게 FST를 스트리밍 방식으로 빌드할 수 있다고 알려주며, 이것은 매우 빠릅니다. --sorted 플래그가 없으면 먼저 데이터를 정렬해야 합니다.
기반 트랜스듀서를 시각화하고 싶다면, graphviz가 설치되어 있다는 가정하에 쉽게 할 수 있습니다(아래에서 사용하는 dot 명령은 graphviz가 제공합니다):
$ fst dot months.fst | dot -Tpng > months.png
$ $IMAGE_VIEWER months.png그러면 다음과 비슷한 것을 보게 될 것입니다:
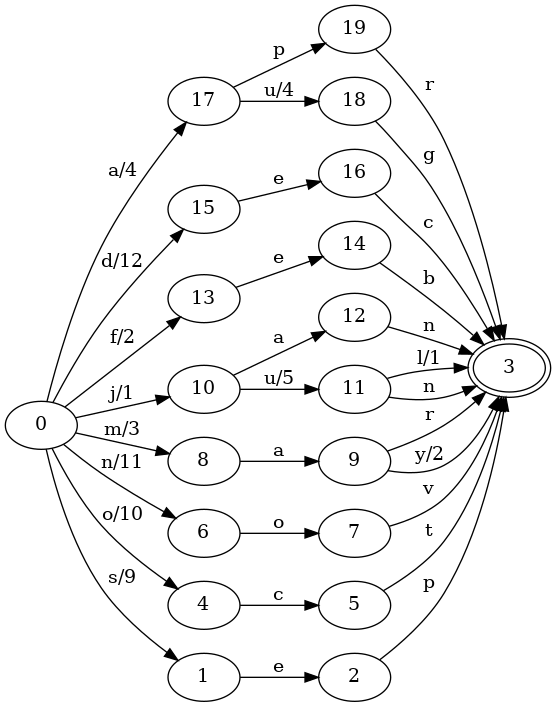
데이터 집합이 작기 때문에 검색은 그다지 흥미롭지 않지만, 그래도 몇 가지 질의를 해봅시다. 모두 나열하는 것은 fst range 명령으로 쉽습니다:
$ fst range months.fst
apr
aug
dec
feb
jan
jul
jun
mar
may
nov
oct
sep값도 보려면 --outputs 플래그를 넘기면 됩니다:
$ fst range months.fst
apr,4
aug,8
dec,12
...명령 이름이 암시하듯, 결과를 특정 범위로 제한할 수도 있습니다:
$ fst range months.fst -s j -e o
jan
jul
jun
mar
may
nov또는 jun과 Levenshtein 거리 1 이내의 모든 월을 fst fuzzy로 퍼지 검색할 수도 있습니다:
$ fst fuzzy months.fst jun
jan
jul
jun대부분의 명령은 몇 가지 추가 옵션을 갖습니다. fst CMD --help를 실행하면 확인할 수 있습니다.
이제 실제 데이터에서 유한 상태 기계를 데이터 구조로 쓰는 것이 어떤 느낌인지 드디어 간단히 살펴보겠습니다.
어디서부터 시작하겠습니까? Unix 기반 시스템 사용자 대부분은 이미 상당한 규모의 고유하고 정렬된 키 모음을 손쉽게 갖고 있습니다. 바로 사전입니다.
제 시스템에서는 /usr/share/dict/words에 있습니다(실제로는 /usr/share/dict/american-english로 가는 심볼릭 링크입니다). 119,095개의 고유 단어를 포함하고 있고 크기는 1.1 MB입니다.
이미 정렬되어 있으므로 --sorted 플래그를 사용해 집합을 빌드할 수 있습니다:
$ fst set --sorted /usr/share/dict/words words.fst
real 0m0.118s
user 0m0.090s
sys 0m0.007s
maximum resident set size: 9.4 MB결과물 words.fst는 324 KB이며, 원본 파일 크기의 29.4%입니다. 비교를 위해 같은 데이터를 gzip(LZ77)으로 압축하면 302 KB (27.4%), xz(LZMA)로 압축하면 232 KB (21.1%)입니다. 표준 명령줄 유틸리티 gzip과 xz의 기본 설정을 사용했습니다.
이제부터는 이런 결과를 더 편한 표 형식으로 제시하겠습니다. 데이터 집합이 커지면 xz는 너무 오래 걸리므로 더 이상 쓰지 않겠습니다.
시간은 주로 편의상 실제 경과 시간으로 제시합니다. 시간이 곧 충분히 커져서 작은 변동은 잡음 속에 묻힐 것이기 때문입니다.
119,095개 키를 가진 사전 데이터 집합에 대한 첫 번째 표는 다음과 같습니다:
| Format | Time | Max memory | Space |
|---|---|---|---|
| plain | - | - | 1100 KB |
| fst | 0.12s | 9.4 MB | 324 KB (29.4%) |
| gzip | 0.15s | 1.8 MB | 302 KB (27.4%) |
| xz | 0.35s | 30.1 MB | 232 KB (21.1%) |
FST 데이터 구조를 다른 압축 알고리즘과 비교하는 목적은 기준선을 제공하기 위해서입니다. 꼭 LZ77이나 LZMA보다 더 좋거나 더 빠른 것이 목표인 것은 아닙니다. 하지만 이들은 유용한 이정표입니다. 특히 FST는 압축된 상태에서도 실제로 데이터 구조라는 점을 기억하세요. LZ77이나 LZMA 같은 일반 압축 방식은 쉬운 랜덤 액세스나 검색에 적합하지 않습니다. 마찬가지로 LZ77이나 LZMA 알고리즘은 압축 전에 입력이 정렬되어 있을 필요가 없지만, FST는 그것이 필요합니다. 따라서 완전히 동일 선상 비교는 아닙니다.
FST 기반 데이터 구조의 한 가지 가능한 사용 사례는 전문 검색 엔진의 용어 인덱스입니다. 실제로 Lucene은 정확히 이 목적에 FST를 사용합니다. 따라서 단어 같은 키로 FST를 테스트하는 것은 의미가 있습니다.
이 테스트를 위해 Gutenberg 말뭉치를 골랐습니다. 구하기 쉬웠고, 자유롭게 접근 가능했으며, 전문 데이터베이스에 들어 있을 만한 것을 꽤 괜찮게 대표한다고 느껴졌기 때문입니다.
Gutenberg 전체를 하드디스크에 다운로드한 뒤, 모든 일반 텍스트를 이어 붙이고, 공백 기준으로 나누고, 그렇게 얻은 모든 토큰을 정렬하고, 중복을 제거했습니다. (각 토큰에서 문장부호도 제거하고 ASCII 소문자화도 적용했습니다. 더 이국적인 Unicode 문자를 포함한 토큰은 그대로 두었습니다.)
결과 데이터 집합에는 3,539,670개의 고유 용어가 있습니다. 다른 압축 형식과의 비교 표는 다음과 같습니다:
| Format | Time | Max memory | Space on disk |
|---|---|---|---|
| plain | - | - | 41 MB |
| fst | 2.04s | 21.8 MB | 22 MB (53.7%) |
| gzip | 2.50s | 1.8 MB | 13 MB (31.7%) |
| xz | 14.66s | 97.5 MB | 10 MB (24.0%) |
이 경우 gzip보다 빨랐다는 점은 꽤 좋습니다. 안타깝게도 FST는 원본 데이터 크기의 53.7%였고, 이전 예제의 사전 FST는 원본의 29.4%였습니다. gzip과 xz 모두 여전히 꽤 잘 작동하지만, 압축률 역시 나빠졌습니다. 이는 데이터 안에 활용할 수 있는 중복 구조가 더 적다는 것을 시사할 수 있습니다.
토큰이 미리 정렬되어 있지 않았다면 FST 생성 시간이 어떻게 보이는지도 다뤄야 합니다.
데이터 집합의 토큰이 미리 정렬되어 있지 않았다면(즉 fst set 명령에 --sorted 플래그를 줄 수 없다면), 걸리는 시간은 조금 더 길어집니다. Gutenberg 데이터 집합에서는 시간이 5.58s로 뛰고 메모리 129 MB를 사용합니다.
여기서 --sorted 플래그를 주지 않았을 때 실제로 어떤 일이 벌어지는지 잠깐 말할 가치가 있습니다. FST 데이터 구조는 키를 사전식 순서로 삽입해서 빌드해야 합니다. 이는 먼저 데이터를 정렬해야 함을 뜻합니다. 정렬의 문제는 가장 단순한 해법이 모든 키를 메모리에 올려 정렬하는 것이지만, 앞으로 볼 더 큰 데이터 집합들에서는 항상 가능하지 않다는 점입니다.
대신 fst 명령은 입력을 여러 청크로 나누고 각 청크를 개별적으로 정렬합니다. 청크가 정렬되면 /tmp에 각자의 FST로 기록합니다. 모든 청크가 정렬되어 FST로 바뀌면, 그 FST들을 모두 하나로 합집합합니다.
이 과정의 “배치 처리” 부분이 메모리 사용 129 MB에 기여했습니다. 구체적으로 기본 배치 크기는 100,000 키이고, fst 명령은 여러 배치를 병렬로 정렬합니다. 배치 크기를 줄이면 프로세스가 필요로 하는 메모리 양도 줄어듭니다.
하지만 그것만으로 전체 메모리 사용량이 설명되지는 않습니다! 실제로 time 명령이 보고하는 “resident set size”의 일부에는 메모리 맵으로 읽어들여 메모리에 상주하는 데이터도 포함됩니다. 각 배치에서 만든 중간 FST들은 병합하려면 전부 읽어야 하므로, 운영체제는 각 FST의 데이터를 모두 메모리로 읽어야 했습니다. 중요한 점은 이 데이터가 프로세스 힙 공간의 일부는 아니라는 것입니다. 즉 시스템이 필요로 하면 운영체제는 메모리 맵이 처음 차지했던 미사용 메모리를 스왑 아웃할 수 있고, 구성 성능에도 반드시 영향을 주지는 않습니다(일단 FST의 일부를 읽고 처리하고 나면 더 이상 필요 없기 때문입니다).
요컨대 FST와 메모리 맵을 사용할 때의 메모리 사용량은 분석하기 까다로울 수 있습니다.
거대한 문서 모음을 갖고 있고 각 문서의 제목에 대해 정말 빠른 자동 완성 서비스를 만들고 싶다고 해봅시다. 제목을 저장하는 데 FST를 사용하면 어떨까요? 조회는 아주 빠를 것입니다. (Elasticsearch는 자동 완성 제안기에 FST를 사용합니다.)
이 사용 사례에서는 Wikipedia보다 더 볼 필요가 없었습니다. 방대한 문서 모음을 갖고 있고, 실제 데이터가 어떤 모습일지 보여주는 꽤 좋은 대표 예이기 때문입니다.
사실 Wikipedia 전체를 다운로드하는 것은 꽤 쉽습니다. 모든 문서의 XML을 디스크에 저장한 뒤, 각 문서에서 제목만 뽑아 별도 파일로 만드는 간단한 프로그램을 작성했습니다. 그런 다음 제목들을 정렬했습니다. 총 15,777,626개의 문서 제목이 있고, 디스크에서 384 MB를 차지합니다.
이 데이터 집합의 비교 표를 봅시다.
| Format | Time | Max memory | Space on disk |
|---|---|---|---|
| plain | - | - | 384 MB |
| fst | 18.31s | 34.1 MB | 157 MB (40.9%) |
| gzip | 13.08s | 1.8 MB | 91 MB (23.7%) |
| xz | 140.53s | 97.6 MB | 68 MB (17.7%) |
Gutenberg 데이터 집합보다 압축률은 좋아졌지만, 그 대가로 gzip보다 약간 느려졌습니다.
이쯤 되자 크고 자유롭게 접근 가능한 실제 데이터 집합을 찾기가 점점 어려워졌습니다. 물론 임의의 키를 많이 생성하거나, 실제 데이터가 어떤 모습일지 근사해 볼 수도 있었겠지만, 그것은 너무 만족스럽지 않았습니다.
그러다 Internet Archive의 DOI 데이터셋을 발견했습니다. 학술 논문 URL이 거의 50,000,000개 들어 있습니다. (DOI는 Digital Object Identifier입니다.)
DOI 데이터 집합은 49,118,091개의 URL을 포함하고, 디스크에서 2800 MB를 차지합니다. 비교 표를 보겠습니다.
| Format | Time | Max memory | Space on disk |
|---|---|---|---|
| plain | - | - | 2800 MB |
| fst | 27.40s | 17.6 MB | 113 MB (4.0%) |
| gzip | 40.39s | 1.8 MB | 176 MB (6.3%) |
| xz | 716.60s | 97.6 MB | 66 MB (2.6%) |
이건 꽤 멋집니다. 이 데이터 집합에서는 FST 구성이 gzip보다 빠르면서 압축률도 더 좋습니다. 다만 이 데이터는 약간 특수한 경우이긴 합니다. 키 안에 말도 안 되게 많은 중복 구조가 있기 때문입니다. 이것들은 모두 학술 논문 URL이므로, 대부분 비슷하고 접미사만 약간 다른 긴 URL 시퀀스가 존재합니다. 이런 구조는 FST에 거의 완벽하게 이상적입니다. FST는 접두사를 압축하기 때문입니다. (공정하게 말하자면 트라이도 여기서는 잘할 것입니다.)
DOI 데이터 집합에서 멈출 수 없었습니다. 50,000,000개 키는 크고, 그것을 불과 27초에 압축하는 것도 좋은 결과지만, 저는 그것이 실제 작업 부하의 대표 예라고 보지는 않습니다. 그래서 제가 FST에 시도해 본 가장 큰 데이터 집합이 거의 최선의 경우 시나리오였다는 점은 아쉬웠습니다.
그래서 제 고민을 /r/rust에 올렸고, 짠, erickt가 제가 완전히 잊고 있던 Common Crawl을 다시 떠올리게 해주었습니다.
Common Crawl은 엄청나게 큽니다. 페타바이트 단위로 큽니다. 저는 야심은 있지만, 아직 그 정도로 야심차지는 않습니다. 다행히 Common Crawl 팀은 데이터셋을 월간 요약본으로 공개합니다. 저는 2015년 7월 크롤을 선택했는데, 145 TB가 넘습니다.
그래도 여전히 너무 큽니다. 저 모든 데이터를 다운로드하고 처리하는 데는 아주 오랜 시간이 걸릴 것입니다. 다행히 Common Crawl 팀은 다시 한 번 구원투수 역할을 합니다. 모든 “WAT” 파일의 인덱스를 제공합니다. “WAT” 파일은 크롤된 각 페이지의 메타데이터를 담고 있고 실제 원문 문서는 포함하지 않습니다. 그 메타데이터 안에는 제가 정확히 원하는 URL이 있습니다.
범위를 좁혔다 해도, 케이블 모뎀 2 MB/s 연결로 이 많은 데이터를 내려받는 것은 즐겁지 않을 것입니다. 그래서 c4.8xlarge EC2 인스턴스를 하나 띄우고, 다음 셸 스크립트로 2015년 7월 크롤 아카이브의 모든 URL 다운로드를 시작했습니다:
#!/bin/bash
set -e
url="https://aws-publicdatasets.s3.amazonaws.com/$1"
dir="$(dirname "$1")"
name="$(basename "$1")"
fpath="$dir/${name}.urls.gz"
mkdir -p "$dir"
if [ ! -r "$fpath" ]; then
curl -s --retry 5 "$url" \
| zcat \
| grep -i 'WARC-TARGET-URI:' \
| awk '{print $2}' \
| gzip > "$fpath"
fi이 파일을 dl-wat로 저장했다면, 다음처럼 실행할 수 있습니다:
$ zcat wat.paths.gz | xargs -P32 -n1 dl-wat그러면 32개의 동시 프로세스가 크롤 아카이브에서 모든 URL을 추출합니다. 이것이 끝나면, 결과 URL 파일들(각 wat 파일마다 하나씩 생성됩니다)을 cat으로 이어 붙이기만 하면 됩니다.
제가 얻은 URL 총 개수는 7,563,934,593개였고, 비압축 상태로 디스크에서 612 GB를 차지했습니다. 이를 정렬하고 중복 제거한 결과, 총 URL 수는 1,649,195,774개였고 디스크에서 134 GB를 차지했습니다.
이제 FST를 빌드할 수 있습니다. URL을 정렬하는 데는 아주 오랜 시간이 걸릴 것이므로, fst 명령이 대신 하도록 두겠습니다. 아래 비교 표는 정렬되지 않은 데이터에서 처음 구성하는 데 걸린 시간과, 정렬된 URL 목록으로 다시 같은 과정을 수행한 데 걸린 시간을 보여줍니다.
| Format | Time | Max memory | Space on disk |
|---|---|---|---|
| plain | - | - | 134 GB |
| fst (sorted) | 82 minutes | 56 MB | 27 GB (20.1%) |
| fst (unsorted) | 240 minutes | ? | same |
| gzip | 36 minutes | 1.8 MB | 15 GB (11.2%) |
| xz | - | - | - |
DOI URL이 “이상적인 경우”라는 제 직감은 이 결과로 어느 정도 맞았던 것으로 보입니다. 즉, 보다 현실적인 압축률 20.1%로 돌아왔고, gzip에게는 여전히 확실히 밀립니다.
xz 수치가 없는 이유는 실행하는 데 너무 오래 걸릴 것 같았기 때문입니다.
여기서 언급할 또 다른 점은 이 FST를 빌드하는 데 걸린 시간입니다. DOI 데이터 집합보다 키 수는 32배 많지만, 실행 시간은 182배나 걸렸습니다. 사실 저는 아직 완전한 답을 갖고 있지 않습니다. 한 가지 추정은 상태 재사용에 쓰이는 캐시가 가득 찼을 때 성능이 나빠질 수 있다는 것입니다. 다른 추정은 DOI 데이터 집합은 중복 구조가 너무 많았기 때문에 키들을 더 빨리 처리할 수 있었다는 것입니다. 즉 대부분의 키는 아주 적은 수의 상태만 컴파일되었을 가능성이 큽니다. 안타깝게도 Common Crawl 데이터 집합의 FST가 너무 커서 전통적인 도구로는 निरी하기 어려우므로, 이 문제는 쉽게 풀리지 않을 것입니다.
정렬되지 않은 입력으로 구성할 때의 최대 메모리 사용량은 측정하지 않았지만, htop을 보며 기억하는 바로는 프로세스의 공유 메모리 사용량이 꽤 높아졌습니다(수십 GB). 제 추정으로는 임시 FST들을 병합하는 동안 파일에서 메모리 맵으로 들어온 데이터를 반영한 것으로 보입니다. 실제로 다음 같은 명령을 실행하면 공유 메모리 사용량이 크게 내려가는 것을 볼 수 있었습니다:
$ cat lots of huge files > /dev/null즉 cat으로 큰 파일들을 많이 읽게 만들어, 운영체제가 fst 프로세스와 무관한 파일 I/O에 페이지 캐시 일부를 할당하게 강제했습니다. 이전까지 그 많은 부분이 fst 프로세스에 쓰이고 있었기 때문에, 운영체제는 fst 프로세스에서 일부를 가져가기 시작했고, fst 프로세스의 공유 메모리 사용량도 떨어졌습니다.
실제로 여러분이 큰 FST를 하나 만들고 다음 명령을 실행해 본다면:
$ fst range large.fst | wc -l이것이 실행되는 동안 htop을 보면 공유 메모리와 상주 메모리 사용량이 함께 올라가는 것을 볼 수 있을 것입니다. 예를 들어 DOI 데이터 집합에서는 상주 메모리 사용량이 일관되게 공유 메모리 사용량보다 3 MB 정도 큽니다. 하지만 दोनों 다 약 113 MB(DOI FST의 크기)까지 증가하고, 그 시점에서 모든 키가 열거되었습니다.
마지막으로, 이 거대한 FST를 질의하는 것이 어떤 느낌인지 잠깐 봅시다. 예를 들어 인덱싱된 Wikipedia URL을 모두 찾고 싶을 수도 있습니다. 정규 표현식 검색을 선택할 수 있습니다:
$ fst grep /data/common-crawl/201507/urls.fst 'http://en.wikipedia.org/.*' | wc -l
97054제가 이 명령을 처음 실행했을 때는 무려 2초가 걸렸습니다! 무슨 일일까요? 같은 명령을 다시 실행하면 약 0.1초에 끝납니다. 큰 차이죠. 실제로는 FST가 메모리에 없었고, 접근해야 하는 데이터를 운영체제가 메모리에 읽어들이는 데 시간이 걸렸기 때문입니다. (구체적으로 이것은 회전 디스크 위에서 실행된 것이므로, 실제 물리적 탐색 시간과 파일 I/O 비용을 지불하고 있는 셈입니다. 디스크 위 FST 형식은 랜덤 액세스를 지향한다는 점을 떠올리세요.)
실제로 time -v 출력은 운영체제가 파일 I/O를 통해 해결해야 했던 페이지 폴트가 164번 있었다고 알려줍니다. 이후 호출에서는 그 수가 0으로 떨어졌는데, 파일의 그 부분들이 여전히 메모리에 있었기 때문입니다.
빠른 비교를 위해 Common Crawl FST를 SSD로 복사하고, 페이지 캐시를 비운 뒤, 같은 grep 질의를 다시 실행했습니다. 페이지 폴트가 대략 164번 있었다는 것도 확인했습니다. 전체 실행 시간은 불과 0.16초였습니다(차가운 페이지 캐시를 가진 회전 디스크의 2초와 비교해 보세요). 다시 실행하면 다시 0.1초 수준으로 내려갑니다. 그러므로 SSD를 쓰면 빠른 질의에서는 페이지 캐시의 중요성이 거의 사라집니다.
인터넷이 판정자라면, 우리는 이제 세계 최대 FST를 만들었습니다(키 수 기준으로). 만세!
앞선 실험들에서 심각하게 빠진 것은 질의 성능을 측정하는 벤치마크입니다. 이 생략은 의도적입니다. 아직 좋은 벤치마크를 생각해 내지 못했기 때문입니다. 질의 성능 벤치마크의 핵심은 실제 질의를 부하 하에서 시뮬레이션하는 것입니다. 특히 여러 FST를 동시에 질의할 때, 그리고 운영체제 페이지 캐시에서 FST의 일부가 축출되었을 때 어떤 일이 일어나는지도 이상적으로 포함해야 합니다.
그렇다고 해도 질의 성능이 어떤 느낌인지 감을 잡는 것은 여전히 가치가 있습니다. 이를 위해, 두 가지 서로 다른 데이터 집합에서 집합 멤버십 연산을 fst::Set, std::collections::HashSet, std::collections::BTreeSet 사이에 비교하는 마이크로 벤치마크가 있습니다. fst::Set은 이 글에서 논의한 FST로 표현된 집합 자료구조입니다. HashSet은 해시 테이블로 구현된 집합이고, BTreeSet은 btree로 구현된 정렬 집합입니다.
첫 번째 데이터 집합은 Gutenberg 데이터 집합에서 무작위로 뽑은 100,000개 단어입니다. 이 벤치마크는 데이터 집합에서 임의의 단어를 조회합니다(따라서 집합 멤버십 결과가 항상 “예”인 경우만 측정합니다).
fst_contains 575 ns/iter
btree_contains 134 ns/iter
hash_fnv_contains 63 ns/iter
hash_sip_contains 84 ns/iter(시간은 연산당 나노초입니다. 즉 이 데이터 집합에서 FST 자료구조의 집합 멤버십은 약 575 나노초가 걸립니다.)
벤치마크 이름은 무엇을 테스트하는지 잘 보여줄 것입니다. (hash_fnv_contains와 hash_sip_contains의 차이는 사용하는 해시 함수의 종류입니다. 전자는 평범한 Fowler-Noll-Vo 해시이고, 후자는 암호학적으로 안전하지만 더 느린 SipHash입니다.)
이것은 FST 기반 데이터 구조가 고전적인 범용 데이터 구조보다 조회 성능이 확실히 나쁘다는 것을 보여줍니다. 하지만 이야기가 그렇게 나쁘기만 한 것은 아닙니다. 이 벤치마크에서 FST는 btree보다 겨우 5x 느릴 뿐입니다. FST가 느릴 수 있는 구체적 이유는 기반 기계 안의 상태와 전이를 디코딩하는 추가 작업이 필요하기 때문입니다. 이것은 알고리즘 복잡도만으로는 모든 것이 설명되지 않는 훌륭한 예입니다. 특히 FST의 조회 시간은 키 길이를 k라 할 때 O(k)인 반면, btree의 조회 시간은 집합 원소 수를 n이라 할 때 O(klogn)입니다. 차이는 btree가 더 많은 비교를 해야 하지만, 각 키에 훨씬 더 빨리 접근할 가능성이 높다는 데 있습니다.
다른 데이터 집합도 보겠습니다. Common Crawl 데이터 집합에서 뽑은 100,000개의 Wikipedia URL입니다.
fst_contains 1,169 ns/iter
btree_contains 415 ns/iter
hash_fnv_contains 101 ns/iter
hash_sip_contains 107 ns/iter이 데이터 집합의 키(URL)는 앞선 데이터 집합의 키(Gutenberg의 단어)보다 훨씬 길기 때문에, 모든 자료구조에서 시간이 늘어난 이유를 설명해 줍니다. 여기서 흥미로운 점은 FST 자료구조 조회가 이제 btree 조회보다 2.8x만 느리다는 것입니다. 사실 앞서 언급한 시간 복잡도 보장에 따르면 정확히 기대할 수 있는 결과입니다. btree는 logn번의 비교를 해야 하고, 각 비교는 k단계를 필요로 합니다. 반면 FST는 k단계만 한 번 하면 됩니다. 이 데이터 집합은 키가 훨씬 길기 때문에 각 k단계의 비용이 증가했고, 그 결과 btree 조회 성능이 FST에 비해 상대적으로 더 떨어졌습니다. 제 가설은 FST가 키 수와 키 길이 양쪽에서 모두 커질수록 btree보다 점점 더 빨라질 것이라는 것입니다.
해시맵을 이기는 것은 조금 더 까다로울 것입니다. 해시를 계산하는 시간도 O(k)이기 때문입니다. 그것만으로 해당 값을 얻는 데 충분합니다. 해시맵은 최악의 경우 조회에 이론상 O(n) 시간이 걸릴 수 있지만, 제 경험상 이것은 거의 걱정할 일이 아닙니다(물론 해시맵 구현자가 아니라면 말이죠!).
제 마음속에서 컴퓨터 과학은 언제나 계산적 절충의 연구 였습니다. 유한 상태 기계로 정렬된 집합과 맵을 표현하는 것은 그 연구의 빛나는 등대 같은 예입니다. 이 글의 대부분을 FST의 장점에 할애했으므로, 이제는 FST의 단점을 위한 작은 섹션을 따로 두겠습니다.
FST로 할 수 있는 멋진 일이 많음에도, 그것은 단순히 범용 데이터 구조로는 적합하지 않습니다. 코드를 쓸 때 비정렬 맵이나 정렬 맵이 필요하다면, 바로 HashMap이나 BTreeMap을 집어 들어야 합니다. FST 기반 데이터 구조가 유용해지기까지는 넘어야 할 장벽이 여러 개 있습니다.
무엇보다 먼저, 키가 얼마나 많을 것으로 예상하나요? 수십만 개를 넘길 가능성이 낮다면, 거의 확실하게 더 단순한 데이터 구조를 쓰는 편이 낫습니다. 퍼지 검색이나 정규 표현식 같은 질의를 지원해야 한다 해도, 키 수가 많지 않다면 그냥 키들 전체를 선형 탐색하는 것으로 충분할 가능성이 큽니다.
둘째, 키와 값은 어떤 모습인가요? 이 글에서 소개한 FST 기반 데이터 구조는 바이트 시퀀스인 키만 저장할 수 있고, 값도 부호 없는 64비트 정수만 저장할 수 있습니다. 키나 값을 그 형식으로 바꾸기 어렵다면, FST를 쓰는 것이 그럴 만한 가치가 없을 수 있습니다. (다만 약간의 작업을 하면 보통 가능하다는 점은 덧붙이고 싶습니다. 예를 들어 키가 32비트 정수라면, 모든 숫자가 4바이트를 차지하도록 big-endian 바이트 순서로 인코딩하면 FST와 아주 잘 맞습니다. big-endian은 정수의 자연스러운 순서를 사전식 순서에서도 보존하기 때문입니다. 주목할 점은 little-endian 인코딩은 동작하지 않는다는 것입니다! 소수 정수 집합을 저장하는 간단한 장난감 예제도 있습니다.)
셋째, 키에 대해 합리적인 순서를 정의할 수 있나요? 그것들을 정렬하는 것이 현실적으로 가능한가요? 특히 순서를 정의하는 것은 보통 가능하지만, 바이트로 변환한 뒤에도 그 순서가 사전식 순서로 보존되는지 확인해야 합니다(그렇지 않으면 범위 질의가 동작하지 않습니다). 키 정렬도 보통 치명적인 문제는 아닙니다. 키를 배치로 나누고, 정렬하고, 중간 FST를 만든 뒤, 나중에 그것들을 합집합하면 됩니다. 하지만 그것은 추가 비용이며, 여러분의 경우에 지불할 만한 가치가 있을 수도 있고 아닐 수도 있습니다.
넷째, 정기적인 변경이 필요한가요? HashMap과 BTreeMap 같은 표준 데이터 구조는 호출자가 마음껏 키와 값을 추가, 제거, 변경할 수 있게 해줍니다. 이 글에서 제시한 FST 기반 데이터 구조는 그런 능력이 없습니다. 한 번 만들어지고 나면 바꿀 수 없습니다. 다른 장벽들과 마찬가지로 이 문제도 극복할 수는 있지만, 변경마다 새 FST를 만들어야 합니다. 그것이 현실적인지는 변경을 배치할 수 있는지에 달려 있고, 그럴 수 있다면 변경마다 새 FST를 만드는 대신 주기적으로 새 FST를 만들 수 있습니다.
이 글에서 소개한 fst crate를 사용할 때의 또 다른 중요한 주의점은 64비트 시스템에서 더 견고하다는 점입니다. fst crate는 메모리 맵 사용을 강하게 선호하므로, 파일의 내용을 포인터로 주소 지정해야 합니다. 32비트 시스템에서는 포인터 타입이 최대 4 GB의 데이터만 가리킬 수 있으므로, FST의 크기도 그 정도로 제한됩니다(실제로는 시스템의 가상 메모리 가용량에 따라 더 적을 가능성이 큽니다). 예를 들어 이런 제약은 Common Crawl FST를 빌드하는 것과 검색하는 것 모두 불가능하게 만듭니다. (64비트 시스템에서 그것을 빌드한 뒤 32비트 시스템으로 옮겨 검색하려고 하면 fst crate는 panic할 것이고, 보통 프로그램이 중단됩니다.)
64비트 시스템에서 FST 크기는 사실상 사용 가능한 가상 메모리로 제한됩니다. 그리고 64비트 시스템에서는 가상 메모리가 매우 풍부합니다.
따라서 32비트 시스템에서 FST를 사용한다면, 생성하는 FST의 크기를 제한하도록 주의해야 합니다. 실제로 FST를 만들기 전에는 얼마나 커질지 알 수 없기 때문에 이것은 조금 까다롭습니다. 또한 FST를 검색하려는 어떤 프로세스든, 사용 가능한 가상 메모리를 다 써버리지 않는 방식으로 모든 구성 FST를 검색해야 함을 뜻합니다.
메모리와 디스크에서의 FST 형식은 특정 바이트에 빠르게 접근할 수 있다는 능력에 크게 의존합니다. 안타깝게도 참조 지역성은 거의 없습니다. (있을 수도 있지만, 확인하려면 더 많은 분석이 필요하고, 키의 중복 구조를 어떻게 활용하느냐에 크게 달려 있을 것입니다.) 이것은 FST가 기계식 디스크에 있고 아직 메모리에 올라오지 않았다면, 질의가 잠재적으로 꽤 느릴 수 있음을 뜻합니다. 이는 주로 SSD를 사용함으로써 완화됩니다. SSD는 탐색 지연이 0이어서, 랜덤 액세스 사용 사례를 당연히 잘 지원합니다.
FST가 정말 크다면 SSD는 비용이 너무 클 수도 있습니다. 하지만 위 실험들에서 보았듯, 10억 개가 넘는 키가 있어도 FST는 27 GB까지밖에 커지지 않았습니다. 그 정도라면 SSD 사용은 꽤 비용 효율적으로 보입니다. 사실 그 정도 메모리 사용량이라면 RAM을 쓰는 것조차 비용 효율적일 수 있습니다. 예를 들어 61 GB RAM을 가진 머신은 지금 Amazon EC2 스팟 인스턴스에서 (r3.2xlarge) 시간당 $0.0961입니다.
“FST를 RAM에 유지하기” 사용 사례는 fst crate가 잘 지원합니다. 제가 메모리 맵 사용을 강하게 밀었지만, 당연히 FST를 힙에 직접 저장하는 것도 가능합니다. 그러면 운영체제의 페이지 캐시에 좌우되지 않습니다. (물론 스와핑에는 여전히 영향을 받을 수 있겠지만, 제 이해로는 요즘은 대부분 그것을 비활성화합니다.)
여기까지 함께해 주셔서 감사합니다! 제 바람은 이 글이 유한 상태 기계를 데이터 구조로 사용하는 방법, 즉 많은 키를 작은 공간에 저장하면서도 쉽게 검색 가능하게 만드는 방법에 대해 조금이나마 알려드렸다는 것입니다.
또한 이 글의 아이디어를 효율적으로 구현하는 방법도 간단히 다뤘습니다. 이 구현은 Rust로 작성된 fst crate의 일부로 제공됩니다. 완전한 API 문서와 예제도 함께 제공됩니다.
마지막으로, 문자열과 관련해 제가 Rust에서 한 다른 작업에도 관심이 있을 수 있습니다:
regex - 대체로 빠른 정규 표현식.suffix - 선형 시간 접미사 배열 구성.aho-corasick - 매우 빠른 다중 부분 문자열 검색.