TigerBeetle 0.16.11~0.16.30을 대상으로 한 Jepsen 테스트 결과: 클라이언트/서버 크래시, 단일 노드 장애 시 지연 급증, 무기한 재시도 설계, 두 건의 안전성 이슈(다중 조건 쿼리 누락·디버그 타임스탬프 오류), 디스크 손상에 대한 뛰어난 복원력과 단일 노드 데이터 전손 복구 경로의 부재, 그리고 Strong Serializability 검증 및 이후 버전에서의 개선 사항을 다룬다.
TigerBeetle은 금융 트랜잭션을 지향하는 분산 OLTP 데이터베이스입니다. 우리는 TigerBeetle 0.16.11부터 0.16.30까지를 테스트했습니다. 그 결과 클라이언트와 서버에서 총 7건의 크래시를 발견했는데, 여기에는 클라이언트 종료 시 세그폴트 1건과 서버 업그레이드 중 발생한 여러 패닉이 포함됩니다. 단일 노드 장애만으로도 장애가 지속되는 동안 지연 시간이 크게 상승할 수 있었고, 요청을 의도적으로 무기한 재시도하도록 설계되어 있어 에러 핸들링을 복잡하게 만들었습니다. 안전성(safety) 이슈는 두 건뿐이었습니다. (1) 다중 조건(predicate)을 가진 쿼리에서 결과가 누락되는 문제, (2) 디버깅 API가 잘못된 타임스탬프를 반환하는 사소한 문제입니다. TigerBeetle은 모든 복제본의 파일이 손상되는 경우를 포함해 디스크 손상에 대해 탁월한 복원력을 보였습니다. 그러나 노드의 데이터가 완전히 유실된 경우를 안전하게 처리하는 방법이 부족했습니다. 0.16.30 기준으로 TigerBeetle은 Strong Serializability를 충족하는 것으로 보였습니다. 0.16.45 기준으로 TigerBeetle은 무기한 재시도 문제를 제외하고 우리가 발견한 모든 이슈를 해결했습니다. TigerBeetle은 이 작업과 짝을 이루는 동반 블로그 글도 작성했습니다. 본 보고서는 TigerBeetle, Inc.의 지원을 받아 작성되었으며 Jepsen 윤리 정책에 따라 수행되었습니다.
TigerBeetle은 온라인 트랜잭션 처리(OLTP) 데이터베이스로, 복식부기(double-entry accounting)를 위해 만들어졌고 안전성과 속도에 강한 초점을 둡니다. Viewstamped Replication(VR) 합의 프로토콜을 기반으로 Strong Serializable 일관성을 제공합니다. 범용 데이터베이스와 달리 TigerBeetle은 계정(accounts)과 그 사이의 이체(transfers)만 저장합니다. 이 데이터 모델은 금융 거래, 재고, 티켓팅, 유틸리티 계량(미터링)에 적합합니다. 다른 종류의 정보를 저장하려면 보통 TigerBeetle을 다른 데이터베이스와 함께 사용하고, 사용자 정의 식별자를 통해 연결합니다.
TigerBeetle은 중앙은행 스위치나 증권사 같은 고경합(high-contention)·고처리량(high-throughput) 워크로드에 최적화합니다. 중앙은행 교환 시스템은 파트너 은행당 하나씩 계정 레코드가 6개에서 수백 개 정도뿐일 수 있지만, 647개 은행 사이에서 하루에 수억 건의 거래를 처리할 수 있습니다. 대형 증권사는 거래일이 끝난 후 하루치 거래를 가능한 한 빨리 결제해야 할 수도 있습니다.1 이런 거래는 인기 종목 몇 개에 집중되는 경향도 있습니다. 고경합 상황에서는 객체별 동시성 제어가 처리량의 병목이 될 수 있습니다. TigerBeetle은 대신 모든 쓰기를 VR 프라이머리 노드의 단일 코어로 흘려보냅니다. 이는 처리량이 단일 노드가 실행할 수 있는 수준으로 제한됨을 의미합니다. TigerBeetle은 확장(scale-out)이 아니라 상향(scale-up)에 확고히 초점을 둡니다. 그 단일 노드를 가능한 한 빠르게 만들기 위해 TigerBeetle은 배칭, IO 병렬화, 고정 스키마, 하드웨어 친화 최적화(예: 고정 크기·캐시 정렬 데이터 구조) 등을 폭넓게 사용합니다.
인상적으로도 TigerBeetle은 마케팅과 문서에서 결함 허용(fault tolerance)을 강조합니다. 메모리, 프로세스, 클록, 스토리지, 네트워크 결함에 대한 명시적 모델을 제공합니다. ECC RAM은 올바르다고 가정합니다. 프로세스는 멈추거나 크래시할 수 있습니다. 클록은 앞으로/뒤로 점프할 수 있습니다. 디스크는 완전 실패뿐 아니라 개별 쓰기 찢김(write tear)이나 데이터 손상도 발생할 수 있다고 가정합니다. 네트워크는 메시지를 지연, 드롭, 중복, 오발송(misdirect), 손상시킬 수 있습니다. 이를 완화하기 위해 TigerBeetle은 Viewstamped Replication과 Protocol-Aware Recovery 기법을 결합하고, 데이터 블록과 분리해 저장되는 광범위한 체크섬을 사용하며, 중요 데이터는 여러 복사본을 쓰고 읽습니다. 또한 TigerBeetle은 런타임 정합성 어서션을 적극 활용해 결함과 버그로 인한 피해를 식별하고 제한합니다.
대부분의 분산 시스템과 달리 TigerBeetle은 어떤 레코드든 복제본 하나라도 사본을 보유하고 있으면 데이터 손실 없이 계속 동작한다고 주장합니다.
레코드는 클러스터의 모든 복제본에서 손상되어야만 유실될 수 있으며, 그 경우에도 시스템은 안전하게 정지(safely halt)합니다.
결함 하에서의 안전성을 테스트하기 위해 TigerBeetle은 결정적 시뮬레이션 테스트를 사용합니다. 이는 재현 가능한 의사난수 연산을 시스템에 수행하고 어떤 속성이 유지되는지 검증하는 테스트입니다.2 Viewstamped Operation Replicator(VOPR) 테스트는 클록, 디스크, 네트워크 인터페이스를 포함한 TigerBeetle 클러스터 전체를 시뮬레이션합니다. 클록 스큐를 시뮬레이션하고, 읽기/쓰기를 손상시키고, 네트워크 메시지를 유실·재정렬하는 등 다양한 상황을 모사합니다. 특정 서브시스템을 스트레스하는 다른 시뮬레이션 테스트들도 있으며, 다양한 전통적 통합/단위 테스트도 존재합니다.
TigerBeetle은 업그레이드에 대해서도 주목할 만한 접근을 제공합니다. 각 TigerBeetle 바이너리는 해당 버전 코드뿐 아니라 여러 이전 버전의 코드도 함께 포함합니다. 예컨대 0.16.21 바이너리는 0.16.17, 0.16.18 등부터 0.16.21까지 실행할 수 있습니다. 업그레이드하려면 디스크의 바이너리를 교체하기만 하면 됩니다. TigerBeetle은 새 바이너리를 로드하지만 현재 버전으로 계속 실행합니다. 그런 다음 클러스터 전체에서 조율하여 다음 버전들을 순차적으로 매끄럽게 롤아웃해, 모든 노드가 사용 가능한 최신 버전으로 실행되도록 합니다. 이 접근은 운영자가 업그레이드 순서를 신중히 맞출 필요를 줄입니다. 대신 업그레이드는 자동으로 수행되며, 복제 상태 머신에 결합됩니다. 또한 TigerBeetle은 버전 _x_에서 커밋된 연산이 다른 어떤 버전에서도 커밋되지 않도록 보장할 수 있어 상태 분기(state divergence)를 방지합니다.
TigerBeetle은 명시적인 시간 모델을 정의합니다. Viewstamped Replication은 상태 전이의 완전 순서(total order) 시퀀스를 만들며, view 번호와 op 번호는 완전 순서의 논리 시계로 사용할 수 있습니다. 금융 시스템은 보통 벽시계(wall clock)를 선호하므로, TigerBeetle 타임스탬프의 대부분은 “물리 시간(physical time)”입니다. 이는 Hybrid Logical Clocks처럼 POSIX 시간을 근사하되 더 강한 순서 보장을 제공합니다. 구체적으로 TigerBeetle 리더는 모든 복제본에서3 POSIX 타임스탬프를 수집하고, 노드 쿼럼에서 합리적인 오차 범위 내에 드는 시간을 찾으려 합니다.4 그 타임스탬프는 VR 복제 상태 머신에 포함되며, 엄격한 단조 증가(strictly monotonic)가 되도록 제한됩니다. 쿼럼의 클록이 20초 창 내에 들어오지 않는 상태가 60초 이상 지속되면, 클러스터는 클록이 다시 동기화될 때까지 요청을 거부합니다.
2024년 10월 기준으로 TigerBeetle 문서는 TigerBeetle 타임스탬프를 “UNIX epoch 이후 나노초”라고 설명했습니다. 이는 완전히 사실이 아닙니다. POSIX 시간은 현재 실제 epoch 이후 초 수보다 27초 적습니다. 윤초(leap second)나 다른 음의 시간 조정 동안 TigerBeetle의 클록은 CLOCK_REALTIME 값이 따라잡을 때까지 매우 느려집니다.
TigerBeetle의 데이터 모델은 복식부기를 위해 특별히 고안되었습니다. 임의의 행, 객체, 그래프, 블롭 등을 표현하는 방법은 없습니다.5 대신 TigerBeetle은 두 종류의 데이터를 저장합니다. _계정(accounts)_과 그 사이의 _이체(transfers)_입니다. 모든 필드는 고정 크기이며,6 숫자는 일반적으로 부호 없는 정수입니다. 제한된 예외를 제외하면 모든 값은 불변(immutable)입니다.
계정은 어떤 것을 보내고 받는 엔터티를 나타냅니다. 예를 들어 “총수익” 계정은 달러를 누적할 수 있고, “Meadow Lake 풍력 발전소”는 전력량(kWh)을 생성할 수 있으며, “Beyoncé”는 말할 것도 없이 계속 늘어나는 그래미 상을 보유할 것입니다. 계정은 사용자 정의 128비트 id로 고유 식별되며, 서로 상호작용할 수 있는 계정을 결정하는 ledger, 다양한 동작을 제어하는 flags 비트필드, 생성 timestamp, 사용자 정의 code, 그리고 다양한 크기의 커스텀 필드 user_data_32, user_data_64, user_data_128를 포함합니다. 또한 계정으로 들어온(credits) 및 나간(debits) 이체의 합계를 나타내는 4개의 파생 필드가 있습니다: debits_pending, debits_posted, credits_pending, credits_posted.
이체는 한 계정에서 다른 계정으로 이동하는 정수 수량을 나타내는 불변 레코드입니다. 계정처럼 이체도 사용자 지정 128비트 id, code, ledger, flags 비트필드, 커스텀 필드 user_data_32, user_data_64, user_data_128를 가집니다. 또한 관련된 두 계정의 debit_account_id와 credit_account_id, 그리고 이동한 정수 amount가 포함됩니다.
단일 단계(single-phase) 이체는 즉시 적용(게시, post)됩니다. 이체는 2단계로도 실행할 수 있으며, 이는 두 개의 이체 레코드로 표현됩니다. 1단계인 _pending_은 해당 금액만큼의 용량을 차변/대변 계정에 예약합니다. 2단계는 pending 이체를 게시하여, pending 금액 이하를 실제로 이체합니다. Pending 이체는 명시적으로 _void_하여 취소할 수 있고, timeout 필드로 제어되는 자동 _expire_도 가능합니다. 게시 및 void 이체는 플래그와 pending_id 필드를 사용해 어떤 pending 이체를 해소(resolve)하는지 나타냅니다. Pending 이체는 최대 한 번만 해소됩니다.
특수한 종류의 이체는 계정을 닫을(close) 수 있어 이후 이체에 참여하지 못하게 합니다. 닫기 이체는 항상 pending입니다. 계정 닫기는 닫기 이체를 void함으로써 “되돌릴” 수 있습니다.
계정은 다섯 가지 예외를 제외하면 불변입니다: 닫힘 여부를 나타내는 closed 플래그(닫기/재열기 이체에서 파생됨)와, pending/posted 이체 합계에서 파생되는 네 개의 잔액 필드입니다. 이체는 항상 불변입니다. 이체를 변경하거나 되돌리려면 새로운 상쇄(compensating) 이체를 생성합니다.
TigerBeetle 클라이언트는 데이터베이스 상태를 갱신하거나 조회하기 위해 요청(requests)을 보냅니다. 각 요청은 계정 생성이나 이체 조회 같은 단일 종류의 논리 연산을 나타냅니다. 요청과 응답은 보통 동일 타입의 이벤트(events) 배치를 포함하며, 최대 8190개까지 가능합니다. 예를 들어 create-transfers 요청은 생성할 이체들의 배치를 포함하고, 논리적으로7 이체당 하나씩 결과 배치를 반환합니다. 읽기 연산은 일반적으로 ID 목록 또는 쿼리 조건을 받아, 매칭되는 레코드 배치를 반환합니다.
데이터베이스 관점에서 각 TigerBeetle 요청은 하나의 트랜잭션입니다. 즉, 원자적으로 실행되는 마이크로 연산들의 순서 있는 그룹입니다. 요청 내 이벤트는 순서대로 실행됩니다. 각 이벤트는 고유하며 엄격히 증가하는 타임스탬프를 관측합니다.8 대화형 트랜잭션, 읽기-쓰기 혼합 트랜잭션, 다중 요청 트랜잭션은 없습니다.
TigerBeetle의 홈페이지는 Strong Serializability를 약속하며, 문서도 이 약속과 일치합니다. 요청은 최대 한 번 실행되며, 요청 내 이벤트는 “다른 요청의 이벤트와 인터리브되지 않습니다.” TigerBeetle은 또한 여러 세션 안전성 속성도 약속합니다. 세션은 “자신이 쓴 것을 읽고(reads its own writes)”, “클러스터에서 발생한 순서대로 쓰기를 관측(observes writes in order)”합니다. 이는 Strong Session Serializability로 보장되며, 이는 Strong Serializability가 성립하면 따라옵니다.
쓰기 요청은 두 종류입니다. create_accounts와 create_transfers는 계정이나 이체를 연속으로 추가합니다. 읽기 요청은 여섯 가지가 있습니다. 사용자는 lookup_accounts 및 lookup_transfers로 특정 ID를 조회합니다. 조건에 매칭되는 계정/이체를 쿼리하려면 query_accounts, query_transfers, get_account_transfers를 사용합니다. 마지막으로 get_account_balances는 과거 잔액 정보를 읽습니다.
요청은 “요청의 이벤트 전부 또는 전혀 실행되지 않는다”는 의미에서 원자적입니다. 그러나 커밋된 요청 안에서도 개별 이벤트는 논리적으로 실패하여 에러 코드를 반환할 수 있습니다. 예컨대 create_transfers 요청이 두 이체를 만들려 할 때 첫 번째는 잔액 제약으로 실패하고 두 번째는 성공할 수 있습니다. 이 경우 두 이체 중 하나만 DB에 추가되었더라도 요청은 커밋될 수 있습니다.
한 이벤트를 다른 이벤트의 성공에 종속시키기 위해 TigerBeetle은 요청 내부에서 일종의 논리적 서브 트랜잭션인 _체인(chain)_을 제공합니다. 체인의 각 이벤트는 다른 모든 이벤트가 성공할 때에만 성공합니다. 이를 통해 사용자는 복잡한 다단계 이체를 원자적으로 성공/실패하게 표현할 수 있습니다.
우리는 Jepsen 테스트 라이브러리를 사용해 TigerBeetle용 테스트 스위트를 만들었습니다. Jepsen은 프로퍼티 기반 테스트와 결함 주입을 결합합니다. 우리는 개발 빌드 일부를 포함해 TigerBeetle 0.16.11부터 0.16.30까지를 테스트했습니다. 테스트는 3~6개9 Debian 노드 클러스터에서, LXC 컨테이너 및 EC2 VM 환경 모두에서 실행했습니다.
TigerBeetle은 클러스터의 모든 노드에 연결하는 “스마트” 클라이언트만 제공합니다. 이 클라이언트는 모든 요청을 단일 서버로 라우팅함으로써 동시성 오류를 숨길 수 있습니다.10 이 스마트 클라이언트 동작을 테스트하는 것 외에도, 다른 노드 주소를 무효로 넘겨 각 클라이언트를 단일 노드에만 연결되도록 제한한 테스트도 수행했습니다. TigerBeetle의 팔로워는 register 요청을 리더로 프록시하지 않으므로, 대부분의 클라이언트는 끝없이 팔로워에 요청을 시도하느라 시간을 보냅니다. 리더 선출을 따라갈 만큼 충분히 빨리 타임아웃만 된다면 안전성 테스트에는 괜찮습니다.
TigerBeetle의 도메인 특화 데이터 모델은 검증에 도전 과제를 줍니다. Jepsen은 리스트, 셋, 레지스터의 Strict Serializability를 확인하기 위한 잘 확립된 기법이 있지만, TigerBeetle에는 그런 구조에 직접 대응되는 것이 없습니다.
2022년 Radix DLT 작업처럼, 각 계정을 이체 리스트로 해석하는 방식을 고려했습니다. 이체 생성은 차변/대변 계정에 대한 두 번의 append로 해석될 수 있습니다. 잔액 읽기는 제약 풀이기의 도움으로 종종 특정 이체 집합에 대한 읽기로 대응될 수 있습니다. 그러나 이 방식은 계정 생성과 대부분의 쿼리를 테스트하지 못합니다. 또한 TigerBeetle 이체의 풍부한 의미를 검증하기도 어렵습니다. 예컨대 TigerBeetle은 balancing 이체를 지원하는데, 이는 차변/대변 계정이 양/음 잔액 같은 불변식을 유지하도록 이체 금액을 조정합니다.
대신 우리는 TigerBeetle의 명시적인 트랜잭션 전체 순서를 활용하기로 했습니다. 큰 틀에서 우리의 체커는 문제를 서로 맞물린 두 부분으로 나눕니다. 첫째, 연산의 겉보기 타임스탬프가 Strong Serializable인지 확인합니다. 둘째, 타임스탬프 순서로 실행했을 때 그 연산들의 _의미(semantics)_가 타당한지 확인합니다.
타임스탬프 순서를 검증하는 것은 비교적 간단했습니다. TigerBeetle은 각 성공한 요청에 할당된 타임스탬프를 읽을 수 있는 새 클라이언트 API를 추가했습니다. 실패하거나 타임아웃된 연산은 그 효과의 타임스탬프에서 추론했습니다. 예컨대 계정 3 생성이 타임아웃되었지만 나중에 계정 3을 타임스탬프 72로 읽었다면, 우리는 그 쓰기가 타임스탬프 72에서 실행되었다고 가정했습니다. TigerBeetle이 요청 내부와 요청 간 모두에서 타임스탬프가 엄격히 정렬된다고 약속하기 때문에, 이 추론은 요청 타임스탬프와 양립 가능한 순서를 제공해야 합니다. 확정·비확정 실패 읽기는 모두 무시했습니다. 읽기는 의미적 부작용이 없으므로 안전합니다.
타임스탬프 추론은 시도된 모든 쓰기의 효과를 결국 관측해야 했습니다. 우리는 테스트를 두 단계로 나눴습니다. 쓰기와 읽기를 포함하는 _메인 단계_와, 미관측 쓰기를 TigerBeetle이 확실히 “예, 이 쓰기는 존재한다” 또는 “아니오, (아직) 존재하지 않는다”라고 응답할 때까지 읽어보는 _최종 읽기 단계_입니다. 목표는 메인 단계 동안 어떤 연산이 실행되었는지와 그 타임스탬프를 정확히 추론하는 것이었습니다.11
어떤 쓰기가 관측되었고, 추론된 타임스탬프가 마지막으로 성공적으로 확인(ack)된 쓰기의 타임스탬프12 이전이라면, 우리는 그것이 메인 단계 동안 실행되었다고 추론했습니다. 쓰기가 관측되지 않았다면 메인 단계 동안 실행되지 않았다고 가정했습니다. 가능한 시나리오는 둘입니다.
TigerBeetle이 Strong Serializable인 경우: 쓰기가 메인 단계에 실행되었다면 Strong Serializability 때문에 최종 읽기 단계에서 가시적이어야 합니다. 따라서 우리의 추론이 맞습니다.
TigerBeetle이 Strong Serializable이 아닌 경우: 쓰기가 메인 단계에 실행되지 않았다면 추론이 맞습니다. 실행되었는데도 관측되지 않았다면 추론이 틀립니다. 거짓 양성/거짓 음성이 생길 수 있지만, 어느 쪽이든 TigerBeetle은 약속한 불변식을 깨뜨린 것입니다.
TigerBeetle이 Strong Serializable이라면 우리 체커는 거짓 오류를 보고하지 않습니다. 만약 TigerBeetle이 (예:)오래된 읽기(stale read) 같은 Strong Serializability 위반을 보인다면, 우리는 이를 간접적으로 감지할 수 있습니다. 예컨대 훨씬 앞선 다른 연산에 대한 모델 체커 오류로 나타날 수 있습니다. 이런 비국소성은 이상적이지 않지만, 우리는 매우 좋은 커버리지와의 교환으로 받아들일 만하다고 판단했습니다.
메인 단계 동안 실행된 연산 집합과 각 타임스탬프를 추론한 뒤, 우리는 Elle로 연산 그래프를 구성했습니다. 연산 A가 끝난 뒤 연산 B가 시작되면 실시간 엣지(real-time edge)로 연결했습니다.13 또한 타임스탬프 오름차순으로도 연결했습니다. (타임스탬프 관점에서) Strong Serializability 위반은 이 그래프의 사이클로 나타납니다. Elle은 대략 선형 시간에 사이클을 검사하고, 일관성 위반의 간결한 예시(exemplar)를 구성합니다.
TigerBeetle 요청/응답의 의미가 올바른지 검증하기 위해 우리는 문서에 기반한 상세한 단일 스레드 모델의 TigerBeetle 상태 머신을 만들었습니다. 이 모델은 초기 상태 i n i t 와 전이 함수 s t e p(s t a t e, i n v o k e, c o m p l e t e) → s t a t e′로 볼 수 있으며, 상태·요청 호출·요청 완료를 받아 새 상태를 반환합니다. 불법 전이(예: 상태와 맞지 않는 읽기 완료 값)는 특별한 invalid 상태를 반환했습니다. 메인 단계에서 추론된 타임스탬프 정렬 연산 목록을 가지고, 각 연산을 순서대로 적용했습니다. invalid 상태가 나오면 오류로 보고했습니다.
우리는 상태를 (1) 현재 타임스탬프,14 (2) ID→계정/이체 맵, (3) 일시적 오류,15 (4) 효율적 쿼리를 위한 인덱스 집합, (5) 내부 통계 일부를 포함하는 불변 자료구조로 모델링했습니다. 클록 흐름을 모델링하기 위해, 테스트 중 수행된 읽기에서 도출한 ID→타임스탬프 사전 계산 맵을 각 상태에 제공했습니다. 그 ID가 생성될 때마다 해당 타임스탬프로 클록을 전진시켰습니다.
이 상태 머신은 놀랄 만큼 복잡합니다. 1,600줄이 넘는 Clojure 코드와 광범위한 테스트 스위트를 포함합니다. 중복 ID, 비단조 타임스탬프, 잔액 제약, 호환 불가 플래그 등 다양한 오류 조건을 처리해야 했습니다. 체인으로 연결된 이벤트는 상태의 가상 실행과 롤백이 필요했으며, 순수 함수형 접근 덕분에 단순해졌습니다. 우리는 Zach Tellman의 고성능 영속 자료구조 라이브러리 Bifurcan을 폭넓게 활용했습니다.
전체 상태 머신을 모델링하는 것은 시간이 들지만, 매우 상세한 정합성 검증을 가능하게 합니다. 체크를 계산적으로 가능하게 하기 위해, 일반적인 Jepsen 테스트는 소수의 엄선된 데이터 타입과 연산만을 사용합니다. 선택된 예시에서 DB의 동시성 제어 프로토콜이 제대로 동작하면 다른 워크로드에서도 대체로 맞을 것이라는 암묵적 가정이 있습니다. 상세 모델링 덕분에 우리는 TigerBeetle이 수행할 수 있는 거의16 모든17 연산을 검증할 수 있었습니다. 관측된 쿼리 결과가 특정 에러 코드까지 포함해 정확히 일치하는지 확인했습니다. 이 보고서에서 논의하듯, 이 접근은 다른 방식이라면 놓쳤을 버그들을 찾아냈습니다.
TigerBeetle 상태 머신의 많은 부분을 테스트하는 단점은 이를 _자극_하는 요청을 생성해야 한다는 점입니다. 문법적으로 유효한 요청을 만드는 것은 쉽지만, 자주 성공하는 요청이나 비어 있지 않은 결과를 반환하는 쿼리를 만드는 것은 놀랄 만큼 어렵습니다.
우리의 제너레이터는 각 테스트 동안 광범위한 인메모리 상태를 유지했습니다. 여기에는 존재할 가능성이 높은 계정/이체 ID에 대한 확률 모델, pending일 가능성이 높은 이체, 존재할 가능성이 높은 타임스탬프, 각 워커 프로세스의 현재 동작 등이 포함됩니다. 제너레이터는 각 연산의 호출/완료에 따라 이 상태를 갱신했습니다.
우리는 Zipf 분포의 ID, ledger, code 등을 선택해 매우 뜨거운(hot) 객체와 매우 차가운(cool) 객체가 섞이도록 했습니다. 요청 타입, 계정/이체 ID, 체인 길이, 플래그, 쿼리, 확률적 상태 갱신을 확률적으로 선택하도록 하는 다양한 파라미터를 사용했습니다. 이 파라미터들은 다양한 동시성, 요청률, 하드웨어 환경, 결함 조건에서 성공/실패의 균형, 비어 있지 않은 쿼리 결과, 불변식 위반 시도 등을 적절히 섞도록 세심하게 튜닝했습니다.
Jepsen은 여러 종류의 결함을 “기본 제공”합니다. 우리는 프로세스 크래시(SIGKILL), 일시정지(SIGSTOP), 다양한 전이/비전이 네트워크 파티션, 밀리초부터 수백 초에 이르는 클록 변경, 그리고 클록을 빠르게 앞뒤로 왕복시키는 스트로빙(strobing) 등으로 TigerBeetle에 스트레스를 주었습니다. 테스트 중에 노드를 여러 버전으로 업그레이드하기도 했습니다.
또한 새 파일 손상 네메시스를 통해 다양한 스토리지 결함을 주입했습니다. 우주선(cosmic ray) 간섭을 모사하기 위해 랜덤 비트를 뒤집었고, 오발송 쓰기(misdirected writes)를 모사하려고 파일의 일부 청크를 다른 청크로 바꾸기도 했습니다. 또한 파일 청크의 스냅샷을 저장해 두었다가 나중에 되돌려, 쓰기 유실(lost writes)을 모사했습니다.
각 TigerBeetle 노드는 단일 데이터 파일을 가지며, 이는 예측 가능한 오프셋에서 _존(zone)_으로 나뉩니다. 각 존은 단일 종류의 고정 크기 레코드를 저장합니다. 우리는 결함을 특정 존에만 적용하도록 범위를 제한했습니다. 예컨대 WAL 헤더만 손상시키거나, 슈퍼블록 존에 있는 네 개의 중복 사본 중 하나만 스냅샷으로 되돌리는 식입니다. 많은 테스트에서 우리는 여러 존 또는 전체 파일을 손상시켰습니다.
또한 파일 손상의 대상 노드도 다양하게 선택했습니다. 한 시나리오에서는 슈퍼블록 등 데이터를 광범위하게 손상시키되, 노드는 소수(minority)에만 적용했습니다. 다른 시나리오에서는 모든 노드의 데이터를 손상시키되, 노드마다 파일의 다른 청크를 선택했습니다. 예컨대 3노드 클러스터에서 한 노드는 1·4·7·10번째 청크를, 다른 노드는 2·5·8번째를 손상시키는 식입니다. 우리는 이를 나선형(helical) 디스크 결함이라고 불렀습니다. 클러스터 노드를 고리로 배열하고 파일 오프셋을 고리의 대칭축을 따라 그린다고 상상하면, 손상된 청크가 고리 주위를 “회전”하며 나선을 형성합니다. TigerBeetle의 파일 레이아웃은 (대체로) 최신 복제본 간 비트 단위로 동일하므로, 이 방식은 DB 내 어떤 단일 레코드도 복구 불능으로 손상시키지 않게 합니다.18
TigerBeetle의 첫 테스트는 자주 영원히 멈추곤 했습니다. 예컨대 이 테스트 실행에서는 첫 요청이 영원히 반환되지 않아 테스트가 끝나지 못했습니다. 이는 독특한 설계 결정의 결과였습니다. TigerBeetle은 요청이 절대 타임아웃되지 않는다고 실제로 보장했습니다.
요청은 타임아웃되지 않습니다. 클라이언트는 클러스터로부터 응답을 받을 때까지 지속적으로 요청을 재시도합니다. 네트워크 파티션의 경우, 클러스터로부터의 무응답은 요청이 처리되기 전에 드롭되었거나, 요청이 처리된 후 응답이 드롭되었음을 의미할 수 있기 때문입니다.
세션 문서도 같은 입장을 재확인했습니다. TigerBeetle 클라이언트는 “절대 타임아웃되지 않으며”, “네트워크 오류를 노출하지 않는다”고 말합니다. 이는 대부분의 시스템이 Strong Serializable 여부와 상관없이 네트워크 오류를 노출한다는 점에서 특히 놀랍습니다.
TigerBeetle의 엄격한 일관성 모델에서는, 이러한 오류를 클라이언트/애플리케이션 수준에서 노출하는 것이 오해를 부를 수 있습니다. 오류는 요청이 실행되지 않았음을 의미하는데, 그 사실은 알 수 없기 때문입니다[.]
분산 시스템의 오류는 크게 두 부류가 있습니다. 제약 위반 같은 확정(definite) 오류는 연산이 일어나지 않았고 앞으로도 일어나지 않음을 의미합니다. 타임아웃 같은 비확정(indefinite) 오류는 연산이 이미 일어났을 수도, 나중에 일어날 수도, 영원히 일어나지 않을 수도 있음을 의미합니다.19 문서와 일관되게 TigerBeetle은 무한 내부 재시도 루프로 두 종류의 오류를 모두 숨기려 합니다.
하지만 TigerBeetle 클라이언트는 실제로 타임아웃 오류를 만들 수 있습니다. 자바 클라이언트의 createTransfersAsync 같은 비동기 메서드는 CompletableFuture를 반환합니다. CompletableFuture는 네트워크 요청처럼 비확정 실패가 가능한 연산을 나타내며, 타입 자체에 타임아웃이 포함됩니다. .get(timeout, timeUnit)로 기다리거나, .orTimeout(seconds, timeUnit)로 자동 타임아웃 예외를 던지게 할 수 있습니다. .Net 클라이언트의 createTransferAsync 등도 Task 객체를 반환하며, 타임아웃 기반 Wait() 메서드를 제공합니다.
사용자가 동기 호출만 사용한다 하더라도, 애플리케이션은 보통 무한정 실행 시간을 가지지 않습니다. 애플리케이션이 TigerBeetle 호출을 자체 타임아웃으로 감쌀 가능성이 큽니다. 그렇지 않으면 애플리케이션이 결국 종료될 수 있는데, 이는 더 나쁜 비확정 실패입니다. 애플리케이션이 기다릴 수 있더라도, 클라이언트(혹은 작업을 기다리는 인간)는 언제든 포기할 수 있습니다. 비확정 오류의 문제는 비동기 네트워크에 내재되어 있으며 제거할 수 없습니다.
TigerBeetle 클라이언트는 모든 실패를 조용한 내부 재시도 메커니즘으로 처리함으로써, 불필요하게 확정 오류를 비확정 오류로 바꿉니다. 예컨대 흔한 결함을 상상해 봅시다: TigerBeetle 서버가 크래시했습니다. 애플리케이션이 createTransfer 요청을 만듭니다. 클라이언트는 TCP 연결을 열어 요청을 제출하려다가 ECONNREFUSED를 받습니다. 이때 클라이언트는 이 요청이 실행되었을 수 없음을 내부적으로 압니다. 확정 실패입니다. 하지만 호출자에게 알리기를 거부하고 계속 재시도합니다. 호출자가 볼 수 있는 유일한 신호는 클라이언트가 멈춘 것처럼 보인다는 점입니다. 호출자가 타임아웃하거나 종료하면, 확정 실패는 비확정 실패가 됩니다. 비확정 오류를 불가능하게 만드는 대신, TigerBeetle의 클라이언트 설계는 이를 _증식_시킵니다.
이는 TigerBeetle 내부에서도 계속 논의 중인 주제입니다(#206). Jepsen은 TigerBeetle이 확정/비확정 오류를 1급 표현(first-class representation)으로 개발하고, 문제가 발생할 때 이를 호출자에게 반환할 것을 권고했습니다. 자동 재시도(무한 재시도 포함)를 유지하는 것은 괜찮지만, 구성 가능해야 합니다. TigerBeetle 클라이언트는 연결 열기에 허용할 최대 시간과, 제출된 요청의 응답을 기다릴 최대 시간을 제어하는 옵션을 받아야 합니다. 사용자는 원하면 무한 타임아웃을 요청할 수 있습니다.
동기 클라이언트 연산은 타임아웃되지 않았기 때문에 초기 테스트는 대개 종료되지 못했습니다. 이를 피하기 위해 우리는 TigerBeetle 클라이언트 호출을 두 가지 방식의 타임아웃으로 감싸 보았습니다. 첫 번째는 새 스레드를 생성해 동기 호출을 수행하고, 몇 초 내에 완료되지 않으면 그 스레드를 인터럽트하는 방식입니다.20
(let [worker (future (.createAccounts
client accounts))
ret (deref worker 5000 ::timeout)]
(if (= ret ::timeout)
(do (future-cancel worker)
(throw {:type :timeout}))
retval))0.16.11에서는 이 방법이 즉시 JVM 전체를 세그폴트로 죽였습니다. TigerBeetle의 자바 클라이언트는 JNI로 Zig로 작성된 클라이언트 라이브러리에 바인딩되어 있고, Zig 패닉은 JVM도 함께 크래시시킵니다. 멀티스레딩이나 스레드 인터럽트가 문제일 수 있다고 우려하여, CompletableFuture를 반환하는 비동기 메서드를 사용하는 대체 접근을 시도했습니다. 퓨처가 몇 초 내 결과를 내지 않으면 클라이언트를 닫았습니다.
(let [future (.createAccountsAsync
c (account-batch accounts))
ret (deref future 5000 ::timeout)]
(if (= ret ::timeout)
(do (close! client)
(throw+ {:type :timeout}))
ret))—이것도 JVM 세그폴트를 일으켰습니다.
밀접히 관련된 이슈로, 0.16.11에서 새로 열린 클라이언트에 대해 client.close()를 호출하면 tb_client.zig:122에서 reached unreachable code 오류로 JVM이 패닉했습니다.
TigerBeetle은 이러한 문제를 클라이언트 요청 데이터 구조의 미설정 필드로 추적했습니다(#2435). 이 필드들은 보통 요청 제출 시 초기화됩니다. 그러나 요청 생성과 제출 사이에 클라이언트가 닫히면, 기본 0xaaa... 주소(Zig 언어 기본값)를 역참조하게 되었습니다. 이 이슈는 0.16.12에서 수정되었습니다.
공식 TigerBeetle 클라이언트는 서버가 세션이 퇴거되었다고 알리면 프로세스 전체를 크래시시켰습니다. TigerBeetle은 기본적으로 동시 세션 64개만 허용하므로 이 한도에 도달하기 쉽습니다.21 또한 서버보다 더 새로운 클라이언트 버전을 사용한 클라이언트도 퇴거시킵니다.
이 동작은 클라이언트가 퇴거에서 깔끔하게 복구하거나 부하 시 백오프하기 어렵게 만들었습니다. TigerBeetle은 #2484에서 이를 변경했습니다. 0.16.13부터 클라이언트는 퇴거 시 프로세스를 크래시하는 대신 호출자에게 오류를 반환합니다.
단일 노드가 실패하면, 클라이언트 지연 시간이 3~5자릿수로 증가하는 경우가 자주 있었습니다. 예를 들어 5노드 클러스터 테스트에서 클라이언트를 각자 단일 노드에만 연결하도록 제한한 상태에서 노드 하나를 죽이자 최소 지연 시간이 1밀리초 미만에서 10초로 상승했습니다. 1초까지 내려가는 변동도 있었지만, 전반적으로 높은 지연은 결함 지속 내내 유지되었습니다.
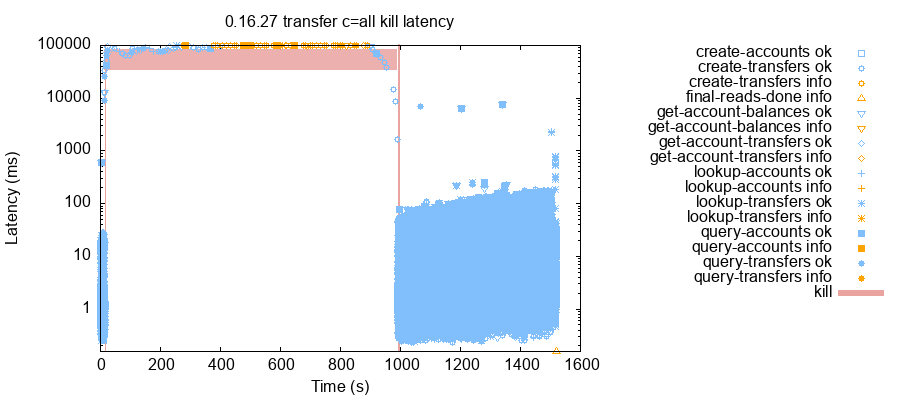
더 높은 부하에서는 상황이 훨씬 나빠질 수 있었습니다. 예를 들어 3노드 클러스터에서 각 클라이언트가 3노드 모두에 연결 가능했던 테스트를 봅시다. 테스트 시작 몇 초 후 n3를 죽였습니다. 그러자 모든 클라이언트의 지연이 1~50ms에서 요청당 약 100초로 상승했습니다. 이 상태는 n3를 재시작할 때까지 거의 1,000초 동안 지속되었습니다.
원래 Viewstamped Replication 및 Revisited에서는 프라이머리가 연산을 수행하려고 할 때 모든 세컨더리에 prepare 메시지를 보냅니다. 세컨더리는 프라이머리에 확인(ack)을 보내고, 프라이머리는 _f_개의 복제본으로부터 ack를 받으면 커밋할 수 있습니다. 단일 노드(빨간색)의 실패는 ack 하나를 잃게 하지만, 다른 노드나 그들의 ack에는 영향을 주지 않습니다. 시스템 전체는 단일 노드 실패에 비교적 둔감합니다.
TigerBeetle은 prepare를 다르게 처리합니다. 노드가 링으로 배치되고, 프라이머리는 링에서 다음 세컨더리에게 단 하나의 prepare 메시지를 보냅니다. 그 세컨더리는 그 다음 세컨더리에게 prepare를 보내는 식으로 모든 노드가 메시지를 받을 때까지 이어집니다. 확인(ack)은 프라이머리로 직접 전송됩니다. 이 접근은 단일 노드의 대역폭 요구를 줄이지만 약점이 있습니다. 프라이머리가 커밋하려면 _f_개의 ack를 받아야 한다면, 링에서 다음 _f_개 복제본 중 하나라도 실패하면 커밋이 아예 불가능해집니다. 단일 노드 실패의 영향이 링 전체로 전파됩니다. 우리는 이 이슈를 추적하기 위해 #2739을 열었습니다.
0.16.30은 이 문제를 완화하기 위한 새 전술을 포함합니다. prepare 메시지의 절반을 링의 _역방향_으로 보내면, 준비 메시지의 절반은 결함 노드를 우회할 수 있습니다. prepare는 순서대로 처리되어야 하므로, 역방향 prepare를 받은 복제본은 링 방향 prepare 메시지 중 놓친 것들을 복구해야 합니다. 복구에는 시간이 들지만 전체 효과는 큽니다. 단일 노드 결함에서 100초 지연 대신, 0.16.30은 우리의 테스트에서 1~30초 지연을 보였습니다.
협업 이후 TigerBeetle은 단일 노드 결함 허용을 계속 개선했고, 시뮬레이션 프레임워크에 결정적 성능 테스트를 추가했습니다. 0.16.43부터 TigerBeetle은 다양한 성능 개선을 포함합니다. 노드들은 링의 양방향으로 복제하여 지연과 단일 실패의 영향을 줄였습니다. 링 토폴로지는 이제 동적이며, 클러스터는 네트워크 상태와 결함에 기반해 지연을 최소화하도록 노드 순서를 지속적으로 조정합니다.
Jepsen 테스트를 지원하기 위해 TigerBeetle은 0.16.13에서 응답 메시지의 헤더에 포함된 실행 타임스탬프를 얻기 위한 새 실험적 API를 추가했습니다. 자바 클라이언트에서 이 API는 종종 잘못되고 중복된 타임스탬프를 반환했습니다. 예를 들어 아래 두 create-transfers 연산은 동일한 타임스탬프를 반환했습니다.
{:index 5827,
:type :ok,
:process 1,
:f :create-transfers,
:value [:ok],
:timestamp 1736185975365035812}
{:index 5829,
:type :ok,
:process 11,
:f :create-transfers,
:value [:ok :ok :ok :ok],
:timestamp 1736185975365035812}TigerBeetle은 이 버그를 자바 클라이언트의 가변 싱글턴 응답 객체인 Batch.EMPTY로 추적했습니다. 빈 응답은 모두 같은 인스턴스를 사용했고, 각 응답의 타임스탬프를 반영하도록 헤더를 갱신했습니다. 응답이 서로의 헤더를 덮어쓰면서 호출자는 잘못된 타임스탬프를 관측했습니다. TigerBeetle은 완전 성공 응답을 빈 배치로 표현하기 때문에 이 현상은 자주 발생했습니다.
이 버그(#2495)는 0.16.14에서 0.16.13 출시 7일 만에 수정되었습니다. 실제 데이터 정합성에는 영향이 없고, 자바 클라이언트 헤더 API의 요청 타임스탬프에만 영향을 주었습니다. 사용자 영향은 아마도 없었을 것입니다.
0.16.13에서는 query_accounts, query_transfers, get_account_transfers 응답이 일부 혹은 전체 결과를 자주 누락했습니다.22 누락은 항상 끝부분에서 발생했습니다. 즉, 응답은 정답 결과의 (비어 있을 수도 있는) 접두(prefix)였습니다. 이 동작은 정상 클러스터에서도 자주 나타났습니다. 예컨대 이 테스트 실행에서, 테스트 281초 지점에 클라이언트는 아래 필터로 query_transfers를 호출했습니다.
{:flags #{:reversed}
:limit 9
:ledger 3
:code 289}이 쿼리는 단 하나의 결과를 반환했습니다.
[{:amount 34N,
:ledger 3,
:debit-account-id 3137N,
:pending-id 0N,
:credit-account-id 1483N,
:user-data 9,
:id 327610N,
:code 289,
:timeout 0,
:timestamp 1733448783658756894,
:flags #{:linked}}]하지만 우리 모델은 TigerBeetle이 누락한 추가 8개의 이체를 기대했습니다. 예를 들어 이체 326112는 ledger 3, code 289였고, 이 쿼리가 시작되기 5초 전에 성공적으로 확인(ack)되었습니다. 결과에 포함되어야 했지만 그렇지 않았습니다.
{:amount 21,
:ledger 3,
:debit-account-id 123076N,
:pending-id 0N,
:credit-account-id 51358N,
:user-data 2,
:id 326112N,
:code 289,
:timeout 0,
:timestamp 1733448782536800935,
:flags #{}}이 쿼리는 ledger = 3과 code = 289 두 조건을 모두 만족하는 이체를 요청했다는 점에 주목하세요. 단일 필드만으로 필터링하는 쿼리에서는 이 문제가 나타나지 않았습니다. TigerBeetle은 원인을 다중 인덱스 간 지그재그(zig-zag) 머지 조인의 버그로 추적했습니다(#2544). 인덱스를 순회할 때 범위 검사(bounds check)가 같은 청크를 두 번 스캔하지 않도록 했습니다. 두 인덱스 조인 중에는 스캔들이 서로에게 어떤 레코드를 건너뛰어도 안전한지 알려줍니다. 이 과정이 최고(또는 최저) 키를 범위 검사 바깥으로 잘못된 방향으로 밀어, 스캔이 조기에 종료될 수 있었습니다. 이 이슈는 0.16.17에서 수정되었습니다.
이 버그는 인덱스 스캔을 수행하는 TigerBeetle의 네 가지 퍼저 모두에서 탐지되지 않았습니다. fuzz_lsm_tree와 fuzz_lsm_forest는 조인을 수행하지 않았고, 다른 두 퍼저 vopr와 fuzz_lsm_scan은 각 인덱스에서 우연히 연속으로 나타나는 객체를 생성해 머지 조인의 “지그재그” 부분이 실행되지 않았습니다. 스캔 퍼저를 재작성하여 예측 불가능한 객체를 생성하도록 하니 이 버그를 빠르게 재현할 수 있었습니다.
슈퍼블록, WAL, 그리드 존에서 단일 비트 파일 손상을 주입한 테스트는 때때로 TigerBeetle 0.16.20이 시작 시 크래시하게 만들었습니다. 프로세스는 panic: reached unreachable code를 출력한 후 종료했습니다.23
이 크래시는 섹터 패딩을 검사하는 거의 동일한 세 가지 버그 때문에 발생했습니다. 예컨대 TigerBeetle 데이터 파일의 각 슈퍼블록 헤더에는 일반적으로 0으로 채워진 미사용 패딩 영역이 있습니다. WAL과 그리드 블록의 엔트리에도 끝부분에 0 패딩 바이트가 있을 수 있습니다. TigerBeetle의 체크섬은 각 청크에 저장된 데이터를 커버하지만 패딩은 제외합니다. 패딩의 비트 하나가 0→1로 뒤집혀도 청크 체크섬은 통과합니다. 이후 TigerBeetle은 패딩 바이트가 여전히 0인지 확인했고, 뒤집힌 비트를 만나면 어서션 실패로 서버가 크래시했습니다. 이는 로그로 남길 만한 사건일 수는 있으나, 패딩 바이트 손상은 안전성을 해치지 않습니다. 손상된 패딩은 다시 0으로 만들거나 다른 복제본에서 복구할 수 있습니다.
VOPR은 전체 섹터를 손상시켰기 때문에 이 버그를 발견하지 못했습니다. 섹터가 손상되면 체크섬이 실패하여 복구가 트리거되고, 0 패딩 어서션까지 도달하지 않았습니다. TigerBeetle은 VOPR을 수정(#2681)하여 단일 바이트 오류를 도입했고, 이로써 버그를 재현했습니다. 0.16.26부터 TigerBeetle은 패딩이 손상된 섹터를 크래시 대신 복구합니다.
밀접히 관련된 버그로, 슈퍼블록의 패딩이 아닌 영역에서 비트를 뒤집었을 때도 TigerBeetle은 동일한 panic: reached unreachable code로 크래시할 수 있었습니다. 슈퍼블록의 네 사본 각각에는 디스크가 슈퍼블록을 오발송했는지 감지하기 위한 고유한 2바이트 copy 번호가 있습니다. 하지만 각 사본은 동일한 체크섬을 가져야 했기 때문에, 체크섬은 copy 번호를 건너뛰었습니다.
슈퍼블록을 디스크에 다시 쓸 때, TigerBeetle은 copy 번호가 0~3인지 확인(#2681)했습니다. 디스크에서 copy 번호가 손상되었고, 그 손상본이 메모리에 읽혀 들어오면, 쓰기 시점에 어서션이 실패해 패닉이 발생했습니다. TigerBeetle은 0.16.26에서 크래시 대신 copy 번호를 리셋하도록 수정했습니다.
0.16.25 이하에서 0.16.26 이상으로 업그레이드를 테스트할 때, panic: checkpoint diverged 같은 로그 메시지와 함께 TigerBeetle이 반복적으로 크래시하는 것을 관측했습니다. 예컨대 이 1분 테스트는 5노드 클러스터를 0.16.25에서 0.16.26으로 업그레이드했는데, 다른 결함은 없었습니다. n5는 21:48에 새 바이너리를 감지했고, 22:01에 0.16.26 실행으로 전환했습니다. 시작 직후 replica.zig:1766에서 패닉했습니다.
2025-02-13 21:22:06.159Z error(replica):
4: on_prepare: checkpoint diverged (op=23040
expect=3779fc8a6a13bf5cf9f995b8895c2609
received=05383d884c680d15e726071358854f67
from=2)
thread 227936 panic: checkpoint divergedTigerBeetle은 이 크래시를 0.16.26에서 CheckpointState 구조가 바뀐 것과 연결지었습니다. 체크포인트 사이에서 TigerBeetle은 파일에서 해제된 블록(released blocks) 집합을 추적합니다. 0.16.26에서 TigerBeetle은 그 집합을 비우는 시점을 변경했습니다. 이전 버전의 CheckpointState는 체크포인트 시점에 항상 빈 집합이었기 때문에 released blocks를 추적할 필요가 없었습니다. 새 버전은 released blocks를 포함합니다. 구버전 복제본이 신버전 복제본으로부터 상태를 동기화할 수 있게 하려면, 0.16.26 노드는 CheckpointState의 옛 버전과 새 버전을 모두 보낼 수 있어야 했습니다. 이는 0.16.26 노드가 0.16.25 노드에 released blocks가 빈 집합인 하위 호환 CheckpointState를 보낼 수 있게 했습니다. 그 노드가 이후 0.16.26으로 재시작하면, 다른 복제본들이 알고 있는 released blocks를 누락하게 됩니다. 다행히도 어서션이 이 분기를 감지해 노드를 크래시시켜, 클라이언트가 불일치 데이터를 관측하지 않도록 했습니다.
우리는 이미 더 최신 버전들이 여러 개 출시된 뒤 이 버그를 찾았습니다. 이 버그는 정상적인 복제 경로가 아니라 상태 동기화를 요구하기 때문에, 지연이 없고 정상인 클러스터에서는 일어나지 않을 것으로 봅니다. 영향도 소수 노드에 제한될 가능성이 큽니다. 이러한 점들과 업그레이드 전반에 대한 테스트 커버리지 부족을 고려해, TigerBeetle은 0.16.26 패치 릴리스 대신 변경 로그를 업데이트(#2745)하여 위험을 고객에게 알리기로 했습니다. 운영자는 0.16.26(또는 그 이후)로 업그레이드하기 전에 모든 클라이언트를 멈추고 복제본이 따라잡을 때까지 기다려야 합니다.
release_transition 패닉 (#2758)0.16.16에서 0.16.28로 업그레이드 테스트 중 TigerBeetle이 replica.zig의 release_transition 함수에서 어서션 실패로 크래시하는 것을 발견했습니다. 이는 ~20초 이내에 여러 번 업그레이드를 수행하거나 업그레이드 중 노드가 크래시/일시정지할 때 발생했습니다. 우리는 이 버그를 신뢰성 있게 재현할 수 있었습니다. 프로세스 일시정지를 포함하면 분당 몇 차례 나타났습니다.
TigerBeetle은 이 문제를 업그레이드 코드의 과도한 어서션으로 추적했습니다(#2758).
버전 _A_를 실행 중인 노드가 있고 운영자가 바이너리를 _B_로 교체한다고 합시다. 노드는 _B_를 감지하고, memfd로 새 바이너리를 열어 exec()로 실행 중인 프로세스를 새 코드로 교체합니다. 그 사이 운영자가 바이너리를 _C_로 또 교체합니다. 복제본은 _B_로 시작하지만, 안전 검사로 디스크의 바이너리( memfd가 아니라!)가 버전 헤더 _B_인지 어서션합니다. 그러나 디스크의 바이너리는 _C_이므로 어서션이 실패합니다.
TigerBeetle은 0.16.29에서 어서션을 경고 메시지로 바꿔 이 이슈를 해결했습니다. 디스크의 바이너리와 다른 버전을 실행하는 것은 실제로 안전성을 깨지 않습니다.
0.16.26에서 0.16.27 업그레이드 중 또 다른 간헐적 크래시를 만났습니다. 이 테스트 실행에서 두 노드는 업그레이드 직후 크래시했습니다. 둘 다 message_header.zig의 into_any 함수에서 panic: switch on corrupt value를 기록했습니다. 재시작 후 복구했습니다.
이 크래시는 메시지 타입에 따라 디스패치하는 switch 표현식에서 발생했습니다.https://github.com/tigerbeetle/tigerbeetle/pull/2763 0.16.28 이전에 TigerBeetle은 이 switch 표현식에서 폐기된 메시지 타입을 제거했습니다. 구버전 노드가 신버전 노드가 모르는 타입의 네트워크 메시지를 보낼 수 있었고, 신버전 노드는 해당 switch case가 없어 패닉했습니다. TigerBeetle은 0.16.29에서 switch 문에 폐기된 타입을 다시 추가하고 단순히 무시하도록 하여 해결했습니다.
TigerBeetle은 데이터 파일 손상에 대해 뛰어난 복원력을 제공합니다. 하지만 디스크 실패, 화재, EBS 볼륨 오류, 운영자 실수 등은 노드가 데이터 파일 전체를 잃거나 복구 불가능하게 손상시키게 할 수 있습니다. TigerBeetle은 결함 허용이므로 소수 노드가 오프라인이어도 안전하게 계속 실행할 수 있습니다. 그러나 실패 노드는 결국 교체해야 하며, 대부분의 분산 시스템에는 이를 위한 메커니즘이 있습니다. 멤버십 변경을 지원하는 시스템은 보통 새 교체 노드를 클러스터에 추가하고 실패 노드를 제거하는 것이 최선입니다. 다른 시스템은 전용 교체 절차가 있습니다.
놀랍게도 TigerBeetle은 실패 노드를 교체하는 이야기가 없었습니다. 문서는 이 문제에 대해 아무 말도 하지 않았습니다. 문서화되지 않은 복구 절차로는 tigerbeetle format을 실행해 노드를 빈 데이터 파일로 재초기화하고, TigerBeetle의 자동 복구 메커니즘이 다른 노드에서 데이터를 전송하도록 하는 방법이 있습니다. 테스트에서 데이터 파일을 종종 복구 불가능하게 손상시켰기 때문에, 우리는 이 리포맷 접근을 자주 사용했습니다.
리포맷은 대부분 잘 동작하지만, TigerBeetle이 Jepsen에 설명했듯 안전하지 않을 수 있습니다. 예컨대 3노드 중 2노드에 커밋된 연산 op가 있고, 그 2노드 중 하나를 리포맷하면, 이제 클러스터는 op를 관측하지 않은 상태로 view change를 실행할 수 있는 2/3 다수를 갖게 됩니다. 그 결과 op는 유실됩니다. 테스트에서 데이터 손실은 드물었고, 몇 개의 연산에 제한되었습니다. 예를 들어 이 실행에서는 두 개의 요청에서 생성된, 확인된(ack) 이체 5개가 유실되었습니다. 다른 문제로, 노드를 업그레이드하는 과정에서도 문제가 생길 수 있습니다. 노드를 더 새 바이너리로 포맷했지만 클러스터가 아직 그 버전으로 전환을 완료하지 않았다면, 노드는 replica.zig/open 중 시작 시 크래시할 수 있습니다.
TigerBeetle은 이 이슈 #2767을 오래전부터 알고 있었고, 노드 유실에 대한 안전한 복구 경로를 추가할 계획이었습니다. 그러나 설계·구현·문서화에 시간이 걸렸습니다. 협업 이후 TigerBeetle은 이 작업을 완료했습니다. 0.16.43부터는 치명적 데이터 유실을 겪은 노드를 복구하기 위한 새 tigerbeetle recover 명령이 포함됩니다.
| № | 요약 | 필요한 이벤트 | 수정 버전 |
|---|---|---|---|
| 206 | 요청이 절대 타임아웃되지 않음 | 없음 | 미해결 |
| 2435 | close 시 클라이언트 미초기화 메모리 접근 | 클라이언트 인터럽트 또는 close | 0.16.12 |
| 2484 | 퇴거 시 클라이언트 크래시 | 더 새 버전, 혹은 너무 많은 클라이언트 | 0.16.13 |
| 2739 | 단일 노드 결함 시 지연 급증 | 일시정지 또는 크래시 | 0.16.43 |
| 2495 | 자바 클라이언트의 잘못된 헤더 타임스탬프 | 없음 | 0.16.14 |
| 2544 | 쿼리 결과 누락 | 없음 | 0.16.17 |
| 2681a | 청크 패딩 비트플립에서 패닉 | 비트플립 후 재시작 | 0.16.26 |
| 2681b | 슈퍼블록 copy 번호 비트플립에서 패닉 | 비트플립 후 재시작 | 0.16.26 |
| 2745 | 체크포인트 분기 | 동기화 중 0.16.26 업그레이드 | 문서화됨 |
| 2758 | 업그레이드 중 release_transition 패닉 | 짧은 간격의 연속 업그레이드 | 0.16.29 |
| 2763 | 폐기된 메시지 타입에서 패닉 | 업그레이드 | 0.16.29 |
| 2767 | 단일 노드 디스크 실패 복구 경로 부재 | 단일 노드 디스크 실패 | 0.16.43 |
우리는 TigerBeetle에서 두 건의 안전성 이슈를 발견했습니다.2425 0.16.17 이전에는 정상 클러스터에서도 다중 필터를 가진 쿼리에서 결과가 자주 누락되었습니다. 또한 Jepsen 테스트를 위해 특별히 추가된 자바 클라이언트의 디버깅 API가 연산의 잘못되고 중복된 타임스탬프를 반환하는 매우 사소한 문제도 있었습니다. 0.16.26 이상에서는 우리의 관측이 TigerBeetle의 Strong Serializability 주장과 일치했습니다. 이는 동시 시스템에서 가장 강력한 일관성 모델 중 하나입니다. TigerBeetle은 프로세스 일시정지, 크래시, 네트워크 파티션, 클록 오류, 디스크 손상, 업그레이드의 다양한 조합에서도 이 속성을 보존했습니다.
우리는 TigerBeetle에서 7건의 크래시도 발견했습니다. 2건은 자바 클라이언트에 영향을 주었습니다. 공유 가변 자료구조로 인한 미초기화 메모리 접근, 그리고 서버가 클라이언트를 퇴거시키면 프로세스 전체를 크래시시키는 설계 선택입니다. 두 문제 모두 0.16.13까지 수정되었습니다. 5건은 서버에 관한 것으로, 디스크 손상에서의 패닉 2건과 업그레이드 관련 패닉 3건입니다. #2745를 제외하면 모든 크래시는 0.16.29까지 해결되었고, #2745는 현재 문서화되어 있습니다.
또한 TigerBeetle에서 놀라운 성능·가용성 문제도 발견했습니다. 단일 노드만 사용 불가능해도 서버 지연이 극적으로 상승했습니다. 이는 비정상적입니다. 대부분의 합의 시스템은 단일 노드 실패에 비교적 둔감하기 때문입니다. 원인은 프라이머리가 모든 백업으로 직접 브로드캐스트하는 대신 링으로 복제하는 설계 선택에 있었습니다. 0.16.30에서 다소 개선되었지만 여전히 눈에 띄었습니다. 협업 이후 TigerBeetle은 시뮬레이션 테스트를 확장해 다양한 결함 하에서 성능을 측정했고, 이를 바탕으로 0.16.43에서 광범위한 개선을 수행했습니다. 링 토폴로지는 관측된 지연에 맞춰 지속적으로 적응하며, 메시지는 링 양방향으로 브로드캐스트됩니다. 우리는 이 개선이 실패의 지연 영향을 크게 완화할 것으로 봅니다.
TigerBeetle은 또한 치명적인 디스크 실패로 데이터를 완전히 잃은 노드를 안전하게 복구하는 경로가 없었습니다. 협업 이후 TigerBeetle은 0.16.43부터 사용할 수 있는 새 복구 명령을 구축했습니다.
미해결 이슈는 하나만 남았습니다. 설계상 클라이언트 요청은 무기한 재시도되며, 이는 에러 핸들링을 복잡하게 합니다. TigerBeetle은 이를 해결할 계획이지만 시간이 필요합니다.
사용자는 본 보고서에서 언급한 이슈 중 하나를 제외하고 모두 해결한 0.16.43으로 업그레이드할 것을 권합니다. 0.16.26(또는 그 이후)로 업그레이드할 때는 특히 주의해야 하며, 릴리스 노트를 참조하세요. 또한 테스트 환경에서 단일 노드 실패를 시뮬레이션하고, 지연 상승에 애플리케이션이 어떻게 반응하는지 측정할 것을 권합니다.
TigerBeetle은 정합성에 대한 상쾌할 정도의 헌신을 보여줍니다. 아키텍처는 건전해 보입니다. Viewstamped Replication은 잘 확립된 합의 프로토콜이며, TigerBeetle의 유연 쿼럼과 프로토콜 인지 복구의 통합은 가용성 개선과 데이터 파일 손상에 대한 극한의 복원력을 가능하게 한 것으로 보입니다. 이러한 프로토콜 통합이 Strong Serializability의 핵심 불변식을 손상시킨 흔적은 보이지 않습니다. 우리의 발견 대부분은 안전성 오류라기보다는 크래시나 성능 저하였습니다. 더구나 그 크래시 중 일부는 과도하게 조심스러운 어서션 때문이었습니다.
우리는 이러한 견고함의 큰 부분을 TigerBeetle의 광범위한 시뮬레이션·통합·프로퍼티 기반 테스트에 기인한다고 봅니다. 이 테스트들은 참여 전과 참여 중에 광범위한 안전성 버그를 포착했습니다. 우리가 새로운 이슈를 TigerBeetle 팀에 가져가면, 그들은 이를 재현하기 위해 내부 테스트 스위트를 빠르게 확장했습니다. 신중한 엔지니어링과 엄격한 테스트에 대한 TigerBeetle의 투자는 계속해서 결실을 맺을 것이며, 이러한 기법이 더 많은 DB에서 채택되기를 기대합니다.
언제나 그렇듯 Jepsen은 안전성 검증에 실험적 접근을 취한다는 점을 강조합니다. 우리는 버그의 존재는 증명할 수 있지만, 부재는 증명할 수 없습니다. 문제를 찾기 위해 광범위한 노력을 기울이지만, 올바름을 증명할 수는 없습니다.
TigerBeetle은 디스크 결함에 대해 탁월한 복원력을 제공합니다. 우리의 테스트에서, 손상이 소수 노드에 제한되는 한, 노드 데이터 파일의 거의 모든 부분에서 비트플립과 다른 종류의 파일 손상으로부터 복구했습니다. 그리드 같은 일부 파일 존에서는 사본 하나만 남아도 나머지의 손상/유실을 견딜 수 있었습니다. 데이터 파일의 슈퍼블록, 클라이언트 응답, 그리드 존에서는, 모든 노드가 서로 겹치지 않는 파일 영역에서 손상되는 “나선형” 결함도 복구할 수 있었습니다.
앞서 언급했듯 슈퍼블록 copy 번호 비트플립이나 다양한 0 패딩 영역 비트플립은 TigerBeetle을 크래시시킬 수 있었지만, 이는 0.16.26에서 해결되었습니다.
노드의 슈퍼블록 4개 사본을 모두 이전 버전으로 롤백하면 TigerBeetle 노드는 영구적으로 비활성화될 수 있습니다. 슈퍼블록보다 새 WAL 엔트리를 감지하면 크래시하기 때문입니다. TigerBeetle은 이를 결함 모델 밖으로 봅니다. 우리도 동의합니다. TigerBeetle이 슈퍼블록을 4번 별도로 순차적으로 쓰고, 존재를 확인하기 위해 다시 읽는다는 점을 고려하면, 우연히 이런 일이 발생할 가능성은 매우 낮아 보입니다.
WAL에서의 나선형 결함은 TigerBeetle 클러스터를 영구적으로 비활성화할 수 있습니다. WAL의 가장 최근 “헤드(head)” 엔트리는 핵심이며, 일부 노드가 다른 노드보다 뒤처질 수 있으므로 헤드가 서로 다른 파일 오프셋에 있을 수 있습니다. 우리의 테스트에서 나선형 결함은 종종 과반수 노드의 WAL 헤드를 손상시켜 클러스터 전체를 사용할 수 없게 만들었습니다.
노드의 디스크 파일이 유실되거나 복구 불가능하게 손상되면, 당시 TigerBeetle에는 안전한 복구 경로가 없었습니다. 실패 노드를 리포맷할 때는 주의할 것을 권합니다. 노드가 다운된 동안 업그레이드를 피하고, 가능한 한 클러스터 나머지가 건강해 보일 때만 리포맷하십시오. 가능하다면 업그레이드 전에 클라이언트를 멈추고 노드 로그를 확인하세요. 어떤 노드도 sync 관련 메시지를 기록하고 있으면 안 됩니다.
사용자는 공식 TigerBeetle 클라이언트의 재시도 동작을 신중히 고려해야 합니다. 기본적으로 클라이언트는 연산을 영원히 재시도합니다. 동기 연산은 절대 타임아웃되지 않으므로, 자체 타임아웃을 구현해야 할 수 있습니다. 비동기 호출이 반환하는 future는 타임아웃 API를 제공하지만, 클라이언트는 그 연산을 여전히 영원히 재시도합니다. 장기간의 비가용성은 TigerBeetle 클라이언트가 계속 늘어나는 요청 집합을 버퍼링하고 재시도하려 하면서 무제한 메모리를 소비하게 할 수 있습니다.
이 재시도 동작은 확정/비확정 실패를 모두 비확정 실패로 평탄화합니다. 즉, 모든 것이 타임아웃이 됩니다. TigerBeetle 문서와 달리, 비확정 네트워크 오류는 매우 가능하며, 실제로는 별도의 네트워크 오류를 반환하는 시스템보다 TigerBeetle에서 더 가능성이 큽니다. 또한 TigerBeetle 사용자는 지수 백오프나 부하 차단(load-shedding) 회로 차단기(circuit breaker)를 구현하기 어려울 수 있습니다. 단일 요청을 포기하려면 전체 클라이언트를 내려야 하기 때문입니다.
Jepsen은 사용자가 결함 중 타임아웃 동작을 신중히 고려하고 테스트할 것을 권합니다. 또한 TigerBeetle이 최소 두 종류의 오류를 도입해 확정/비확정 결함을 구분할 수 있게 하길 제안합니다. 마지막으로, 클라이언트는 구성 가능한 타임아웃을 받아 사용자가 시간과 메모리 사용량을 제한할 수 있어야 합니다.
TigerBeetle은 안전성을 중시하며 이를 보장하기 위해 방어적 프로그래밍을 사용합니다. 신중한 알고리즘과 광범위한 테스트 외에도, 클라이언트와 서버 코드는 의도된 불변식이 유지되었는지 재확인하는 어서션으로 가득합니다. 어서션 실패는 안전성을 보존하기 위해 전체 프로그램을 크래시시킵니다. 이런 경우 클라이언트나 서버는 부분적 또는 전체적으로 가용하지 않을 수 있으며, 몇 분 동안이거나 영구적일 수도 있습니다. 우리가 발견한 문제 중 상당수는 “안전성 위험이 될 수 있었던 상황”을 “단순 크래시”로 바꾸는 어서션이었습니다. 안전이 중요한 시스템에서는 바람직한 트레이드오프입니다.
이는 합리적 접근입니다. 복잡한 시스템은 상호 맞물린 여러 가드를 통해 안전성을 보장하며, 각 가드는 다른 가드가 놓칠 수 있는 오류를 걸러냅니다. 잠재적으로 잘못된 실행을 중단하는 것은 Erlang/OTP의 “let it crash” 정신의 핵심이기도 합니다. 그러나 TigerBeetle의 접근도 단점이 있습니다.
첫째, 이 보고서에서 찾은 크래시 중 몇 건은 지나치게 보수적인 어서션 때문이었습니다. 예컨대 0.16.26 이전에 TigerBeetle은 디스크의 미사용 패딩 영역에서 0이 아닌 바이트를 만나면 크래시했습니다. 이런 오류는 안전성을 해치지 않지만, 가용성을 떨어뜨렸고, 사용자를 위험한 복구 경로(리포맷)로 몰아넣을 수 있었습니다.
둘째, 0.16.11에서 TigerBeetle 클라이언트 라이브러리는 클라이언트가 서버보다 새 버전을 사용하거나 서버 연결이 너무 많을 때 애플리케이션 프로세스 전체를 강제로 크래시시켰습니다. 이런 오류는 잘 설계된 애플리케이션이 지수 백오프/재시도 시스템을 통해, 또는 다른 클라이언트와 조율함으로써 복구할 수 있어야 합니다. 오류 코드나 예외를 반환하는 대신 프로세스를 크래시시키는 것은 애플리케이션이 이런 완화를 수행할 능력을 박탈합니다.
Erlang에서 “let it crash”는 단순히 계산을 일찍 포기하는 것 이상을 뜻합니다. 이는 Erlang의 액터 모델과 깊이 연결되어, 액터가 서로 독립적으로 크래시할 수 있습니다. 또한 Erlang의 _감독자 트리(supervisor trees)_에 의존합니다. 각 액터는 크래시를 통보받고 실패한 계산을 재시작할 수 있는 감독자를 가집니다. TigerBeetle에서 실패 도메인은 전체 POSIX 프로세스이며, 감독자는(존재한다면) init 시스템이나 Kubernetes 같은 것입니다. 이런 감독자는 대개 크래시 이유나 복구 방법에 대한 가시성이 없고, 변화하는 상황에 적응하도록 설계되지 않았습니다. 동일하게 계속 재시작하다가 매번 크래시할 수 있습니다. 반복 크래시가 계속되면, 프로세스를 영구히 포기할 수도 있습니다.
이런 한계에도 불구하고, 우리는 TigerBeetle이 합리적 절충을 했다고 봅니다. TigerBeetle은 무결성이 핵심인 금융 시스템의 장부(system of record)를 대상으로 하며, 지나치게 조심스러운 어서션은 문제가 드러나는 대로 쉽게 수정할 수 있습니다. 어서션은 또한 TigerBeetle 엔지니어들의 정신 모델을 실험적으로 검증하고 안내하는 데 도움이 됩니다. TigerBeetle의 클라이언트는 완전 크래시보다는 오류 코드를 반환하는 방향으로 더 이동했습니다.
보다 일반적으로, 우리는 엔지니어가 오류 경로를 설계할 때 실패 도메인을 생각할 것을 권합니다. “반드시 크래시해야 한다면 시스템의 일부라도 어떻게 계속 돌릴 수 있을까?” 그리고 크래시 후에는 “그 부분은 어떻게 복구할까?”를 묻는 것입니다. 이는 다른 시스템 안에서 ‘손님’인 클라이언트 라이브러리에서 특히 중요합니다.
TigerBeetle은 pending 이체에 대한 타임아웃 메커니즘을 포함합니다. 우리는 이 시스템을 견고하게 테스트하는 방법을 알지 못합니다. 설계상 타임아웃은 데드라인이 지난 뒤 한참 후에야 이체를 void할 수도 있기 때문입니다. 우리는 타임아웃 의미를 재검토해 정량적 경계를 설정할 수 있길 바랍니다.
이 연구 과정에서 Jepsen, TigerBeetle, 그리고 Antithesis는 Antithesis 환경에서 Jepsen의 TigerBeetle 테스트 스위트를 실행하기 위해 협업했습니다. Antithesis의 결정적 시뮬레이션, 결함 주입, 타임 트래블 디버깅 기능을 활용한 것입니다. 이 실험은 아직 초기 단계지만, 분산 시스템에 대한 강력하고 상보적인 분석을 위한 기반이 될 수 있습니다.
멀티버전 시스템은 구현이 지독하게 어렵습니다. TigerBeetle은 단일 버전에 대해서는 훌륭한 테스트 커버리지를 갖추고 있었지만, 교차 버전 업그레이드에 대한 퍼즈 테스트는 부족했습니다. 우리의 테스트는 업그레이드 과정의 여러 이슈를 발견했고, TigerBeetle은 향후 업그레이드 테스트를 확장할 계획입니다. 마찬가지로 분산 시스템에서 멤버십 변경은 악명 높게 어렵고, 현재 TigerBeetle에는 미구현입니다. TigerBeetle이 노드 추가/제거를 지원하게 되면, 추가 테스트를 위한 풍부한 기회가 있을 것으로 기대합니다.
마지막으로 TigerBeetle의 재시도 접근은 계속 논의 중이며, 이를 재설계하는 데는 시간이 걸릴 것입니다. 우리는 클라이언트 오류 표현을 견고하게 하기 위한 추가 작업이 이어지리라 예상합니다.
이 작업은 Fabio Arnold, Rafael Batiati, Chaitanya Bhandari, Lewis Daly, Joran Dirk Greef, djg, Alex Kladov, Federico Lorenzi, Tobias Ziegler를 포함한 TigerBeetle 팀의 귀중한 도움 없이는 불가능했을 것입니다. 본 연구에 사용된 새 파일 손상 네메시스 작성에 도움을 준 Ellen Marie Dash에게 감사를 전합니다. 편집 지원을 해 준 Irene Kannyo에게도 감사드립니다. 본 보고서는 TigerBeetle, Inc.의 지원을 받아 작성되었으며 Jepsen 윤리 정책에 따라 수행되었습니다.
인도의 Unified Payments Interface는 월 약 160억 건의 이체를 처리하는데, 이는 평균 초당 약 6,000건입니다. 뉴욕의 증권사 Clear Street는 장 마감 후 초당 30,000건 수준의 차변-대변 이체를 처리한다고 밝힌 바 있습니다.↩︎
결정적 시뮬레이션 테스트는 본질적으로 프로퍼티 기반 테스트에 비결정적 시스템을 결정적으로 바꾸는 기법을 결합한 것입니다. 클록, 디스크 상태, 스케줄러, 네트워크 전달, 외부 서비스 등을 제어해 재현성을 보장합니다. 더 알아보려면 PULSE, Simulant, FoundationDB, Antithesis를 참고하세요.↩︎
타임스탬프는 CLOCK_REALTIME에서 도출되며, 이는 NTP, PTP 등으로 동기화되었을 것으로 보입니다. 프라이머리는 클록 메시지의 네트워크 지연을 추정·보정하기 위해 CLOCK_BOOTTIME을 사용합니다.↩︎
많은 합의 시스템은 과반수 노드를 쿼럼으로 사용합니다. Heidi Howard가 2016년에 보였듯, Paxos는 리더 선출과 복제 단계에서 서로 다른 쿼럼을 사용할 수 있습니다. 이 두 쿼럼은 교차해야 하지만, 하나는 과반수보다 작을 수 있습니다. TigerBeetle은 이 “유연 쿼럼” 접근을 Viewstamped Replication에 적용합니다. 과반수가 아니라 절반의 클록만 동의해도 됩니다.↩︎
TigerBeetle의 코어는 임의의 상태 머신 복제를 위해 설계되어 있으므로, 향후 바뀔 수도 있습니다.↩︎
이 표현은 이례적입니다. 대부분의 DB는 사용자 정의 스키마, 다양한 타입, 가변 크기 데이터를 허용합니다. 그러나 TigerBeetle의 도메인은 잘 이해되어 있습니다. 금융 기록의 큰 형태는 수세기 동안 바뀌지 않았습니다. 또한 경직되고 고정 크기 스키마는 인코딩/디코딩 효율, 네트워크와 디스크 사이 구조체의 제로-카피 전송, 프리페처/분기 예측 친화성, 캐시 라인 정렬 등 큰 성능 이점을 제공합니다.↩︎
효율을 위해 TigerBeetle은 성공 결과를 실제 응답 메시지에서 생략하고, 오류가 있으면 오류만 반환합니다.↩︎
Datomic, FaunaDB, TigerBeetle은 모두 Strong Serializable한 시간(temporal) DB입니다. 하지만 트랜잭션 내부에서 시간과 효과가 흐르는 의미는 서로 다릅니다. Datomic은 트랜잭션의 부분을 동시에 평가하고 단일 타임스탬프를 부여합니다. Fauna는 순차적으로 실행하지만 모든 연산이 단일 타임스탬프를 관측합니다. TigerBeetle은 순차 실행하며 각 마이크로 연산에 서로 다른 타임스탬프를 부여합니다.↩︎
대부분의 합의 시스템이 과반수 쿼럼을 쓰고 홀수 노드에서 가장 잘 동작하는 것과 달리, TigerBeetle은 유연 쿼럼을 사용해 6노드 중 3노드만으로도 커밋되는 연산이 있을 수 있습니다.↩︎
쓰기 _w_가 노드 _a_에서 확인(ack)되었지만 _b_가 뒤처져 _b_로 보낸 읽기에서는 _w_가 보이지 않는 상황을 상상해 보세요. 이는 Strong Serializability 위반인 stale read입니다. 스마트 클라이언트는 요청을 a 또는 b 한쪽으로 몰아 보내는 경향이 있어, 두 노드 사이에서 로드를 분산하지 않습니다. 이런 클라이언트를 쓰는 테스트는 stale read를 놓칠 가능성이 큽니다.↩︎
이 기법은 imported 이벤트에는 동작하지 않습니다. 읽기가 실행 타임스탬프가 아니라 imported 타임스탬프를 알려주기 때문입니다. import를 테스트할 때는 매우 긴 타임아웃을 사용했고, 히스토리를 검사하려면 모든 연산이 성공해야 한다고 요구했습니다.↩︎
우리는 마지막 성공 쓰기의 타임스탬프를 메인 단계의 상한으로 사용했습니다. 쓰기가 최종 읽기 단계 동안 실행되었을 수도 있지만(예: 네트워크 지연 때문), 안전성 검증에서는 이를 무시했습니다.↩︎
효율을 위해 실시간 의존 그래프의 전이 축약(transitive reduction)을 실제로 계산했습니다.↩︎
TigerBeetle에는 클록 값을 제한하는 내부 타임스탬프가 세 가지 있습니다. “현재” 타임스탬프와, imported 계정/이체에 대한 두 개의 별도 클록입니다. 이 타임스탬프는 단조이지만 현재 시간보다 뒤처집니다.↩︎
TigerBeetle은 transient errors라 불리는 특정 종류의 오류가, 재제출하더라도 해당 이체가 항상 실패하도록 보장한다고 말합니다. 이는 DB 상태의 (잠재적으로) 단명 조건 때문에 발생한다는 의미에서 transient이지만, DB가 영원히 기억해야 한다는 의미에서 지속적이기도 합니다.↩︎
우리의 전략은 하나의 ID가 두 번 쓰이지 않는다는 요구가 있습니다. 우리는 동일 데이터를 중복으로 쓰려는 시도가 결코 성공하지 않고, 동일 ID에 대해 값이 분기되지도 않음을 검증하는 전용 idempotence 워크로드로 이를 보완했습니다.↩︎
TigerBeetle에는 pending 쓰기에 대한 자동 타임아웃 메커니즘이 있지만, 타임아웃은 완전히 결정적이지 않아 모델 체킹하기 어렵습니다.↩︎
이 규칙의 중요한 예외는 WAL입니다. WAL은 링 버퍼로 구성됩니다. WAL의 헤드는 핵심이며, 한 노드에서 WAL 헤드가 손상되면 그 노드는 자신의 데이터 파일을 신뢰할 수 없어 다른 노드에 복구를 요청해야 합니다. 노드가 서로 뒤처질 수 있어, WAL 헤드는 서로 다른 파일 오프셋에 있을 수 있습니다. 나선형 결함은 과반수 노드의 헤드를 손상시켜 클러스터가 복구하지 못하게 할 수 있습니다.↩︎
명확히 하자면 확정 실패도 재시도될 수 있고, 그 재시도 연산은 성공할 수도 있습니다. 우리가 “결코 일어나지 않는다”고 말할 때는 원래 연산에 대해 말하는 것이지, 재시도에 대해 말하는 것은 아닙니다.↩︎
이는 클라이언트 자체 타임아웃이 신뢰할 수 없을 때 쓰는 Jepsen의 표준 타임아웃 매크로입니다. 명확성을 위해 일부 에러 처리를 생략했습니다.↩︎
이 낮은 세션 한도는 의도적인 설계 선택입니다. TigerBeetle은 큰 배치의 요청에서 이점을 얻으며, 더 적은 클라이언트를 강제하면 사용자 설계가 클라이언트 측 배칭을 효율적으로 수행하도록 유도할 수 있습니다. PgBouncer 스타일 프록시가 유용할 수도 있습니다.↩︎
get_account_balances에서도 같은 현상이 있었지만, 당시 테스트 하네스는 아직 그 API를 커버하지 못했습니다.↩︎
모든 TigerBeetle 어서션 실패는 reached unreachable code를 출력하고 종료했기 때문에, 서로 구분할 메시지가 없었습니다. 디버그 빌드에서는 스택트레이스를 제공했습니다.↩︎
이슈 2745는 어떤 의미에서는 안전성과 라이브니스 둘 다입니다. 복제본이 어떤 블록이 자유(free)인지에 대해 불일치하여, TigerBeetle 설계의 핵심 안전 속성(복제본의 온디스크 상태가 동일해야 함)을 위반합니다. 그러나 방어적 어서션이 이 안전 위반을 크래시로 바꿔 사용자에게 분기가 관측되지 않게 막습니다. 이런 의미에서 라이브니스 이슈이며, 우리는 그렇게 보고합니다.↩︎
형식 검증 애호가를 위해 덧붙이자면: 네, 복구 가능한 크래시, 일시적 가용성 문제, 높은 지연은 모두 기술적으로 안전성 이슈입니다. 유한 반례를 포함하기 때문입니다.↩︎