단순한 호기심에서 출발해 TigerBeetle로 티켓팅을 복식부기로 모델링하고, 핫/콜드 경로와 Redis·PostgreSQL·오토 배칭을 통해 파이썬만으로 초당 977건 예약을 달성한 설계, 최적화, 벤치마킹 여정을 소개합니다.
단순한 호기심에서 초당 977장 예약까지의 여정
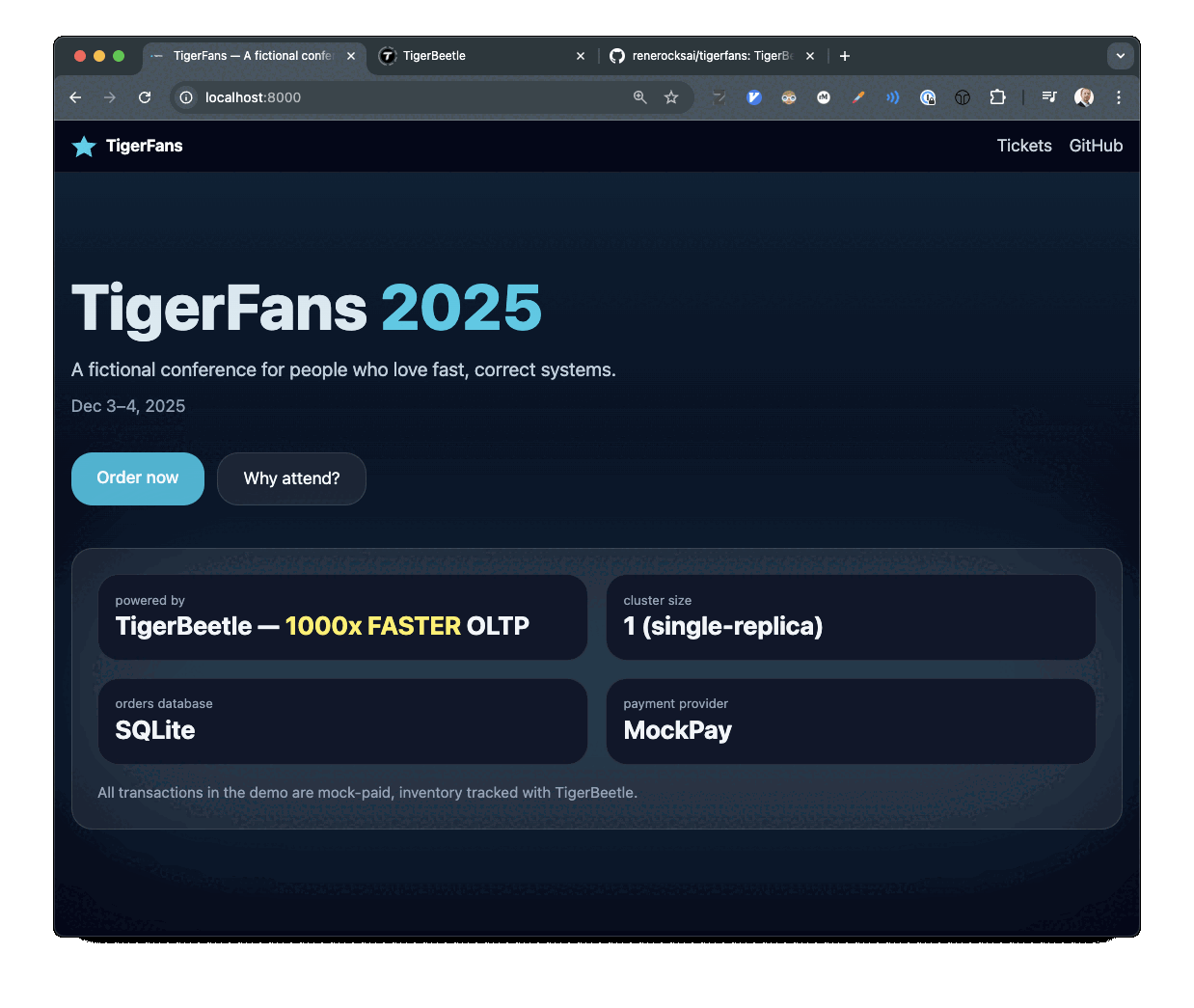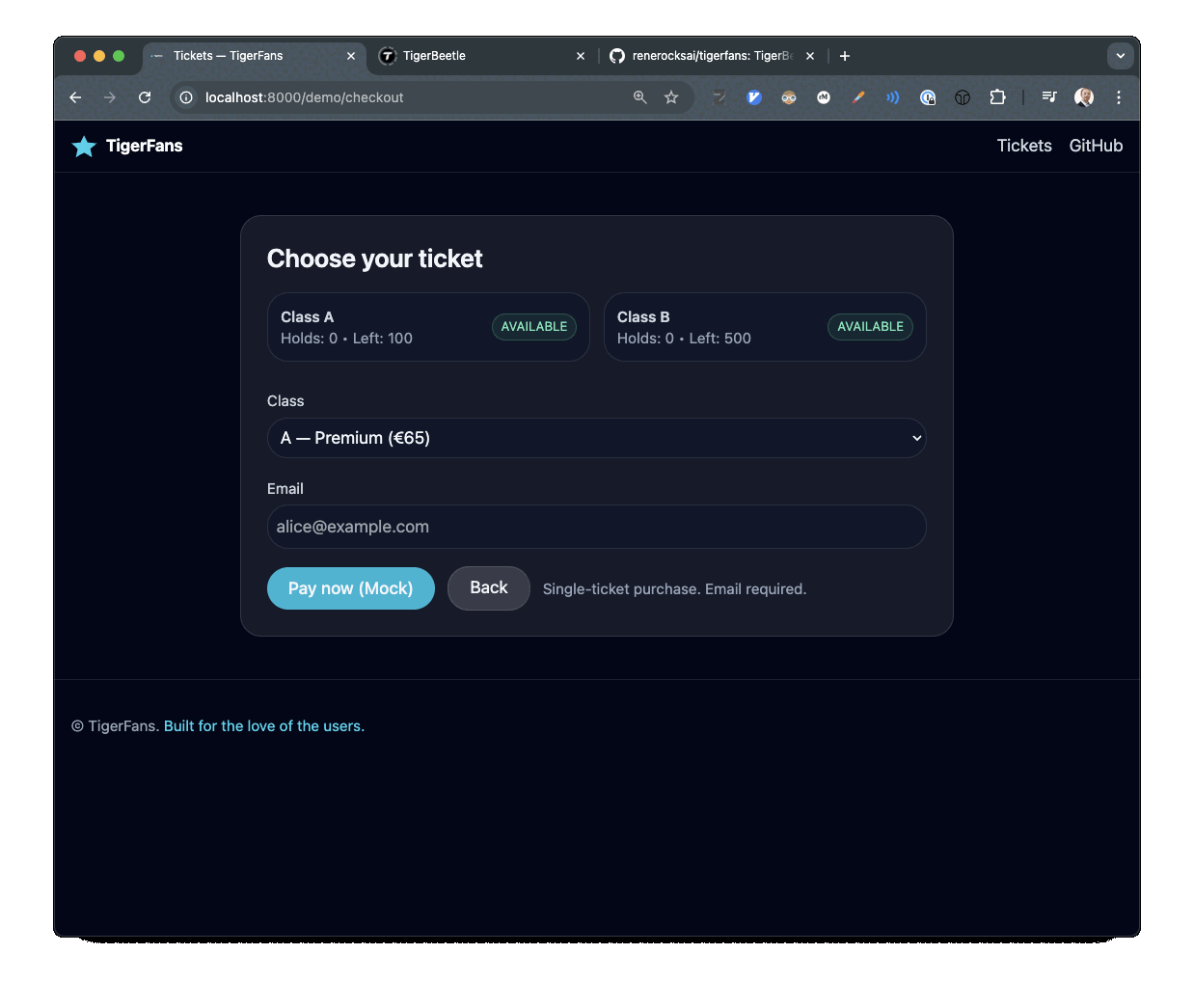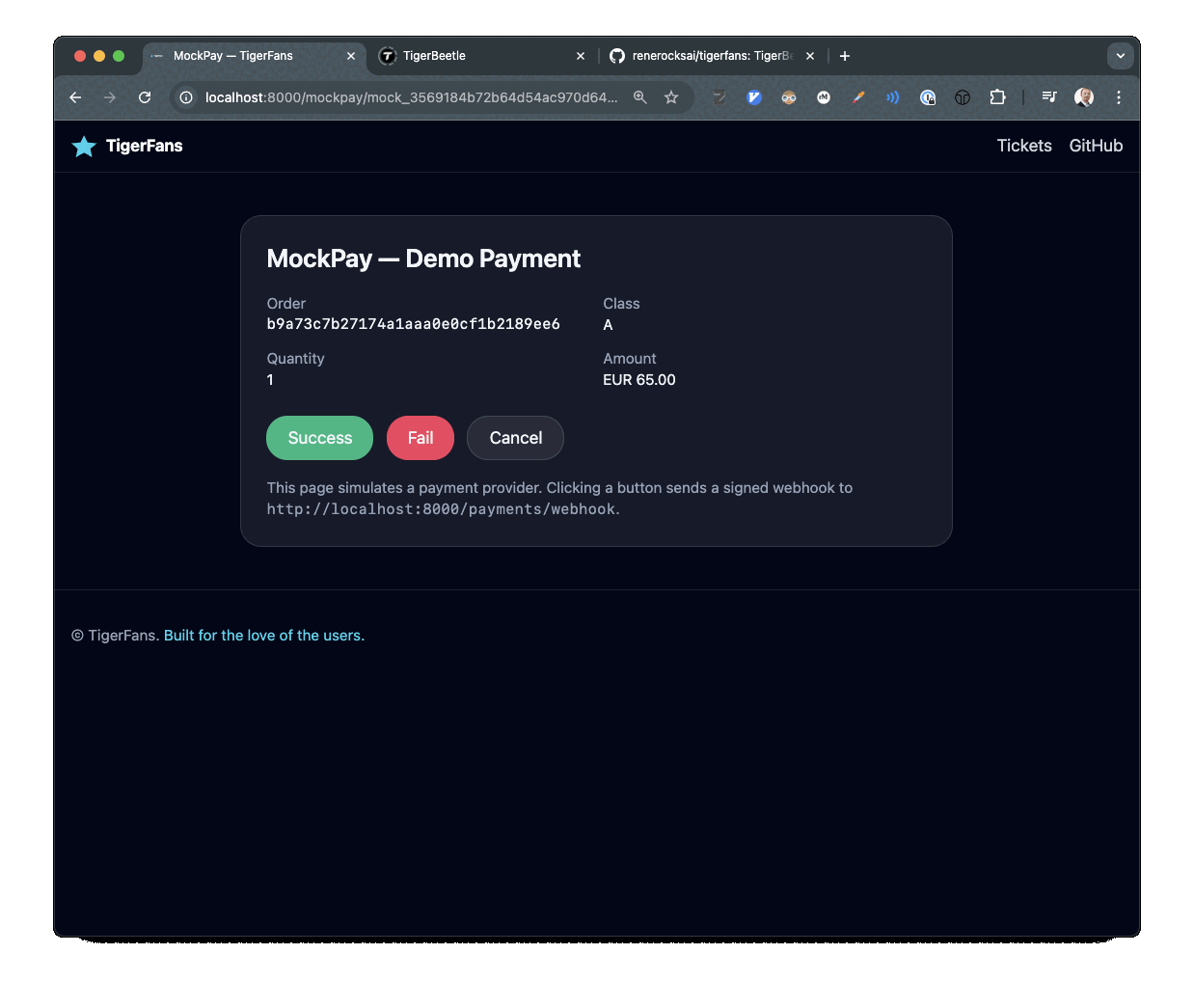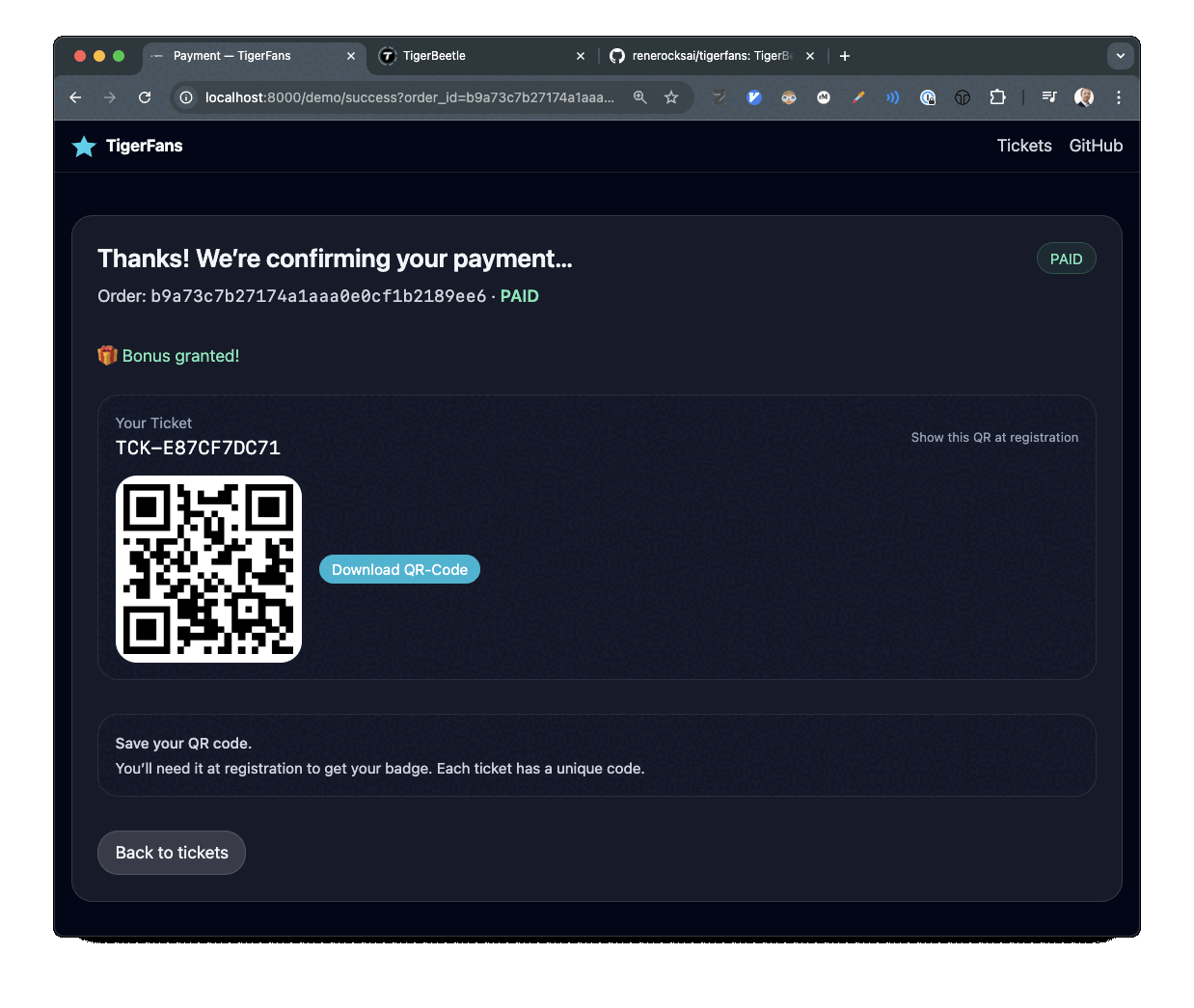
티켓 체크아웃과 결제 흐름을 보여주는 TigerFans 데모
오아시스(Oasis)급 콘서트를 위한 티켓팅 솔루션을 어떻게 만들 거냐는 트위터 질문—순간 수십만 명이 동시에 웹사이트로 몰려드는 상황에서, 중복 판매는 절대 없어야 하고 결제한 모든 사람에게 티켓이 정확히 발급되어야 하는 문제—에 대한 Joran Dirk Greef의 답변이었다. Joran은 TigerBeetle의 창업자이자 CEO다.
그는 옳았다. TigerBeetle을 아는 사람이라면 누구나 같은 조언을 할 것이다. TigerBeetle은 바로 이런 문제—극한 부하 아래에서도 자원을 절대적으로 정확하게 세는 문제—를 위해 설계된 금융 트랜잭션 데이터베이스다.
하지만 나는 구체적인 구현을 이해하고 싶었다. 개념이 아니라 실제 코드가 필요했다.
티켓 트랜잭션을 금융 트랜잭션으로 어떻게 모델링할까? 계정 구조는 어떻게 생겼을까? 결제 제공자까지 포함한 현실적인 예약 시스템에서 이체는 어떻게 흐를까? 타임아웃되는 보류 예약은? 웹훅 재시도로 인한 멱등성은?
배우는 가장 좋은 방법: 직접 만들어 보기.
그래서 만들었다. 사흘 뒤, 작동하는 데모가 나왔다. 교육용으로 시작한 프로젝트가 19일간의 최적화 여정으로 확장되며 초당 977건의 티켓 예약—Oasis 기준선보다 15배 빠른1—까지 밀어붙였다. 그것도 파이썬만으로.
목표는 명확했다. HOW에 답하는, 실제로 동작하는 데모를 만드는 것. 장난감 예제가 아니라, 현실의 결제 시스템이 가진 지저분한 복잡성까지 담아낸 예약 흐름.
첫 번째 난관: TigerBeetle은 범용 데이터베이스가 아니다. 금융 트랜잭션 데이터베이스다. 즉, 계정(accounts), 이체(transfers), 차변(debits), 대변(credits) 같은 복식부기(dual-entry) 원시 개념으로 사고하도록 강제한다는 뜻이다.
그래서 질문은 이렇게 바뀌었다. 티켓을 금융 트랜잭션으로 어떻게 모델링할 것인가?
은행이 돈을 다루는 방식을 떠올려 보자. 수백 년 동안 사용된 복식부기는 내장된 오류 탐지와 완벽한 감사 추적을 제공한다. 모든 거래는 최소 두 개의 계정에 영향을 준다. 하나는 차변, 다른 하나는 대변. 차변의 합은 항상 대변의 합과 같아서 시스템은 항상 균형을 이루고, 오류는 즉시 드러난다.
TigerBeetle은 티켓에도 같은 접근을 요구한다.
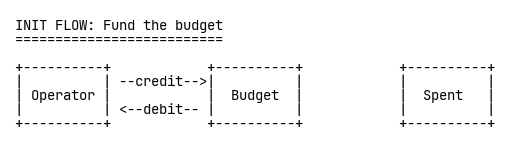
각 리소스—A석 티켓, B석 티켓, 한정판 티셔츠—마다 세 개의 TigerBeetle 계정을 만든다: 모든 가용 재고를 보유하는 운영자(Operator) 계정, 판매 가능한 양을 나타내는 예산(Budget) 계정, 소진된 재고를 기록하는 Spent(소진) 계정.
먼저 초기화 단계에서 운영자 계정에서 예산 계정으로 자금을 이전한다:
누군가 체크아웃을 시작하면, 예산에서 Spent로 5분 타임아웃이 걸린 보류(pending) 이체를 만든다. 핵심은 TigerBeetle의 DEBITS_MUST_NOT_EXCEED_CREDITS 제약 플래그다. 이는 과판매를 아키텍처적으로 불가능하게 만든다—꼼꼼한 프로그래밍으로 막는 게 아니라, 설계상 불가능하다. 데이터베이스가 정확성을 강제한다.
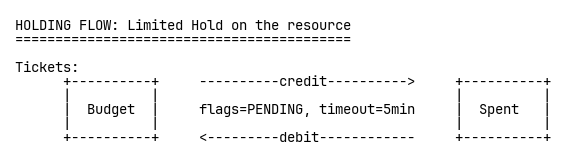
결제가 성공하면, 보류 이체를 게시(post)해 영구화한다:
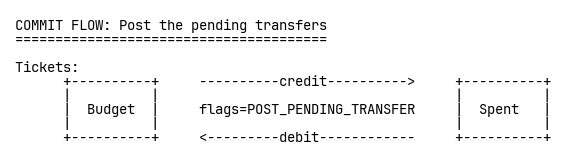
결제가 실패하거나 타임아웃되면, 해당 이체를 무효화(void)한다. 그냥 사라진다. 클린업 잡도, 경쟁 조건도 없다. 감사 추적은 완벽하다.
데모 스택은 의도적으로 단순하게 구성했다. 빠르게 만들고 이해하기 쉬운 파이썬 비동기 웹 프레임워크 FastAPI. 관리해야 할 프로세스를 하나라도 줄이기 위해 SQLite. 개발 모드의 TigerBeetle. 그리고 Stripe 같은 실제 웹훅 흐름을 흉내 낸 시뮬레이티드 결제 제공자 MockPay.
코드를 쓰고, UI를 만들고, 계정 모델을 문서화했다. 모든 것이 작동했다. 웹훅이 포함된 2단계 체크아웃 흐름, 자동 만료되는 보류 예약—all good.
라이브 데모는 지금도 tigerfans.io에서 직접 체험할 수 있다—MockPay 시뮬레이터 포함.
목표 달성. HOW를 이해했다.
세상에 공유하기 전에, 먼저 Joran과 TigerBeetle 팀에 보여주고 싶었다. 내가 보낸 메일은 조심스러웠다:
“세상에 공유(포스팅)하기 전에 먼저 보여드리고 싶습니다. ‘안티 패턴’을 퍼뜨리고 싶지 않아요.”
결국 모든 모델링을 내가 임의로 설계한 것이다. 아마 티켓을 TigerBeetle로 모델링하는 더 나은, 더 회계적인 방법이 있을지도 모른다. 교육용 프로젝트가 나쁜 예시가 되는 건 원치 않았다.
Joran은 여행 중이라 어딘가에서 비행기 지연을 겪고 있었지만, 시간을 내어 답장을 보냈다. 따뜻하고 격려하는 내용이었다. TigerBeetle의 핵심 개발자 중 한 명인 Rafael Batiati도 조언을 보탰다. 공개되면 사람들은 필연적으로 벤치마크를 돌리기 시작할 거라고. 아. 맞다. 생각해보니 그럴 만했다.
그리고 Joran은 이를 친근한 도전으로 바꾸었다. 그가 언급한 건 Oasis 티켓 판매1—약 6시간 동안 140만 장, 대략 초당 65장. 그리고 결정타: “6시간보다 더 잘해내면 정말 멋질 것 같네요.”
그 숫자—초당 65장—이 새로운 기준선이 되었다.
교육용 데모로 시작했지만 완전히 다른 무언가로 변했다. 패턴은 검증됐다. 구현은 올바르다. 그러나 이제 다른 질문이 떠올랐다: 숨은 비효율을 얼마나 없앨 수 있을까?
근본적인 한계 말고—파이썬은 파이썬이고, 인터프리터 언어가 낼 수 있는 속도에는 한계가 있다. 하지만 우리가 실제로 고칠 수 있는 병목, 아키텍처 비효율은 무엇일까? TigerBeetle을 얼마나 잘 활용할 수 있을까?

티켓 예약 성능이 초당 115건에서 977건으로 향상된 추이
성능 테스트에 앞서 데이터베이스 병목을 제거할 필요가 있었다. SQLite의 블로킹 I/O는 FastAPI 이벤트 루프에서 요청 처리를 직렬화하지만, PostgreSQL의 비동기 드라이버는 진정한 동시 처리를 가능하게 한다. 그래서 SQLite에서 PostgreSQL로 전환했다.
이는 인프라 업그레이드를 의미했다—작은 2 vCPU 스팟 인스턴스에서 4 vCPU, 8GB RAM의 c7g.xlarge EC2 머신으로. PostgreSQL은 별도 프로세스로 동작하므로, OS에 1 vCPU, HTTP 워커에 1 vCPU, 데이터베이스에 1 vCPU를 할당하고, 나중에 여러 워커를 실험할 여유도 확보하고 싶었다.
또 SQL 쿼리를 최적화하고, 트랜잭션 처리 방식을 다듬고, 더 빠른 이벤트 루프인 uvloop를 적용해 성능 테스트를 위한 탄탄한 기준선을 만들었다.
결과: 초당 115장. Oasis 기준선보다는 낫다.
나는 수치를 Joran에게 약간의 농담과 함께 보냈다: “이미 TPS를 tickets per second(초당 티켓 수)로 재정의했죠. 그럼 빅 O 표기도 big Oasis 표기로 재정의해볼까요? O(1) = 65 TPS. 우리는 지금 ~O(1.7)쯤입니다.”
Joran의 답장은 늘 그렇듯 격려로 가득했지만 현실 점검도 포함하고 있었다: “TPS가 너무 낮아 보여서 놀랐어요. 최소 대략 1만은 되어야 합니다.”
만. 우리는 115였다.
TigerBeetle은 1000배가 넘는 성능으로 유명하다. 바로 이런 용도다. 그런데 왜 전체 시스템은 이렇게 굼뜰까?
전체 시퀀스 다이어그램을 그려보았다. 모든 API 요청, 모든 데이터베이스 왕복, 모든 연산. 연습은 많은 걸 드러냈다:
체크아웃 흐름:
웹훅 흐름(결제 확인):
모든 API 요청이 PostgreSQL을 2~4번씩 두드리고 있었다. PostgreSQL이 항상 크리티컬 패스에 있었다.
병목을 더 잘 이해하기 위해 측정을 두 단계로 나눴다:
결과는 문제를 확인시켜줬다:
PostgreSQL은 두 단계 모두에서 느렸다. 병목은 어디서나 PostgreSQL이었다.
두 단계 모두에서 PostgreSQL이 병목인 걸 확인하고 아키텍처 자체를 의심하기 시작했다. 실제로 관계형 기능을 거의 쓰지 않는데, 관계형 데이터베이스가 필요한가? 우리가 하는 일은 사실상 주문과 멱등성 키 저장뿐이다.
Redis를 DATABASE_URL의 완전한 대체로 구현했다. 시스템은 이제 세 가지 백엔드를 교체 가능하게 지원했다: SQLite, PostgreSQL, 혹은 Redis. 인터페이스는 동일하고 저장소만 다르다. 세션만이 아니라 PostgreSQL 전부를 Redis로 바꿨다.
fsync를 everysec 모드로 설정한 Redis에서 벤치마크를 돌렸다—내구성과 성능의 균형점.
결과는 인상적이었다:
숫자는 짜릿했다. 하지만 문제가 있었다. everysec 모드의 Redis는 크래시 시 최대 1초치 주문을 잃을 수 있다. Redis가 빨라질수록 이 문제는 더 커진다. 나는 주문 같은 영구 데이터까지 포함해 PostgreSQL 전부를 Redis로 대체했는데, 데모라 해도 이는 용납하기 어렵다.
그래서 인상적인 벤치마크 결과(그리고 내구성 우려)를 Rafael에게 보냈다.
Rafael의 답장은 시스템을 바꿀 아키텍처 통찰을 담고 있었다. 상세한 벤치마크를 반겨주면서도, 데모라 해도 내구성을 도박에 맡기지 말라고 경고했다. 핵심 인사이트: 휘발성 세션 데이터와 영구 주문 레코드를 분리하자.
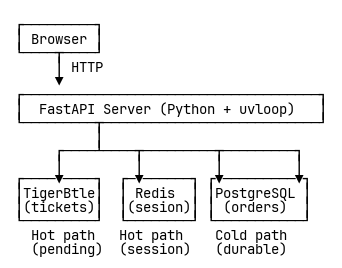
이게 바로 핫/콜드 경로 인사이트—내 속도 실험과 올바른 내구성 사이의 절충. PostgreSQL을 전부 Redis로 대체(내구성 희생)하는 대신, Redis는 결제 세션(핫 경로)에만 쓰고, 주문(콜드 경로)에는 쓰지 않는다.
결제 세션은 휘발성이다. 사용자가 결제하는 몇 분 동안만 중요하다. 결제가 성공하거나 실패하면 세션은 더 이상 필요 없다. 멱등성 키도 마찬가지—웹훅 재시도에서 중복 청구를 막기 위한 일시적 중복 제거 데이터다.
하지만 주문은? 영구적으로 안전해야 한다. 이를 위해서는 PostgreSQL이 필요하다.
인사이트는 명료했다: 모든 데이터가 즉시 내구성을 필요로 하는 건 아니다!
정말 멋진 아이디어였다!
어떤 크래시나 포기된 장바구니도 결국 TigerBeetle의 타임아웃 메커니즘에 의해 되돌려진다. 실제 서비스라면, Redis에서 웹훅 콜백을 찾지 못한다거나 TigerBeetle에서 이미 만료됐다면, 결제 게이트웨이에서 결제를 역전시킬 것이다.
아키텍처가 제자리를 찾았다:
결제 세션은 Redis, 회계(어카운팅)는 TigerBeetle, 영구 주문은 PostgreSQL로 분리해 시스템을 재구축했다.
핫 경로는 진짜로 ‘핫’해졌다—모든 요청을 Redis와 TigerBeetle이 처리. PostgreSQL은 결제가 실제로 성공할 때만 쓰기 작업을 받는다. 실패한 체크아웃은 아예 데이터베이스를 건드리지 않는다.
효과는 즉각적이었다. 처리량이 초당 865장으로 도약. 크리티컬 패스에서 PostgreSQL을 빼자 성능이 크게 열렸다.
이게 작동하는 핫/콜드 아키텍처—빠를 곳은 빠르게, 지속해야 할 곳은 내구성 있게.
핫/콜드 아키텍처가 자리 잡자, Joran이 흥미로운 제안을 했다. “비포/애프터”를 보여줄 수 있을까? 모든 것을 PostgreSQL로 돌리면? 거기에 Redis만 영리하게 더하면? 사람들이 TigerBeetle이 실제로 무엇을 가능케 하는지 보고 싶어할 거라고.
맞는 말이었다. 진행 과정 자체가 이야기였다—정확히 어디에서 성능 개선이 나왔는지 보여주고, 무엇이 실제로 느렸는지에 대한 우리의 가정을 검증한다. 마크 트웨인이 말했다: “당신을 곤경에 빠뜨리는 건 모르는 것이 아니다. 사실이 아닌데도 확실히 안다고 믿는 것이다.” 검증되지 않은 가정은 조용한 살인자다.
이를 위해 백엔드를 교체할 수 있도록 코드를 재구성해, 구성 간 공정한 비교가 가능하게 했다.
세 가지 구성을 만들었다:
리팩터링 과정에서 일부 비효율도 정리되며—레벨 3은 강력한 성능을 유지했다.
결과는 분명했다:
TigerBeetle은 모든 것을 가속한다.
3단계 비교 구조를 갖춘 뒤, 시간을 어디에 쓰는지 정확히 파악하기 위한 종합 테스트 인프라를 구축했다.
이미 앞서(병목 조사 당시) 측정을 두 단계로 분리했다:
여기에 TigerBeetle 핵심 연산만 측정하는 격리 엔드포인트를 추가했다: 순수 체크아웃(예약 회계만), 순수 웹훅(확정 회계만). 나머지는 모두 걷어내고 TigerBeetle 그 자체의 성능을 보려 했다.
하지만 더 원했다. HTTP 요청 타이밍은 현실적으로 중요하지만, ‘잠재력’을 보여주진 못한다. 가령 가정적으로, PostgreSQL이 4ms, Redis가 2ms, TigerBeetle이 1ms 걸리고, 요청당 연산이 2개라면, PostgreSQL+Redis에서 TigerBeetle+Redis로 바꿔도 2배 향상만 보일 것이다—실제로 TigerBeetle은 4배 빠른데도 말이다. 이 가정에서 Redis의 오프셋이 진짜 속도를 가린다.
해법: 서버 내부에 트랜잭션 시간을 계측하고, 테스트 후 질의해 비교하자. 요청-응답 지연뿐 아니라, 실제 연산 시간 자체를 비교한다.
그리고 TigerBench를 만들었다—세 가지 구성 전체 진행을 보여주는 인터랙티브 시각화:
페이지에는 두 단계 모두, 두 개의 격리 연산 모두, 그리고 컴포넌트별로 쪼갠 모든 타이밍이 표시된다. 각 구성에서 시간이 정확히 어디로 가는지 볼 수 있다.
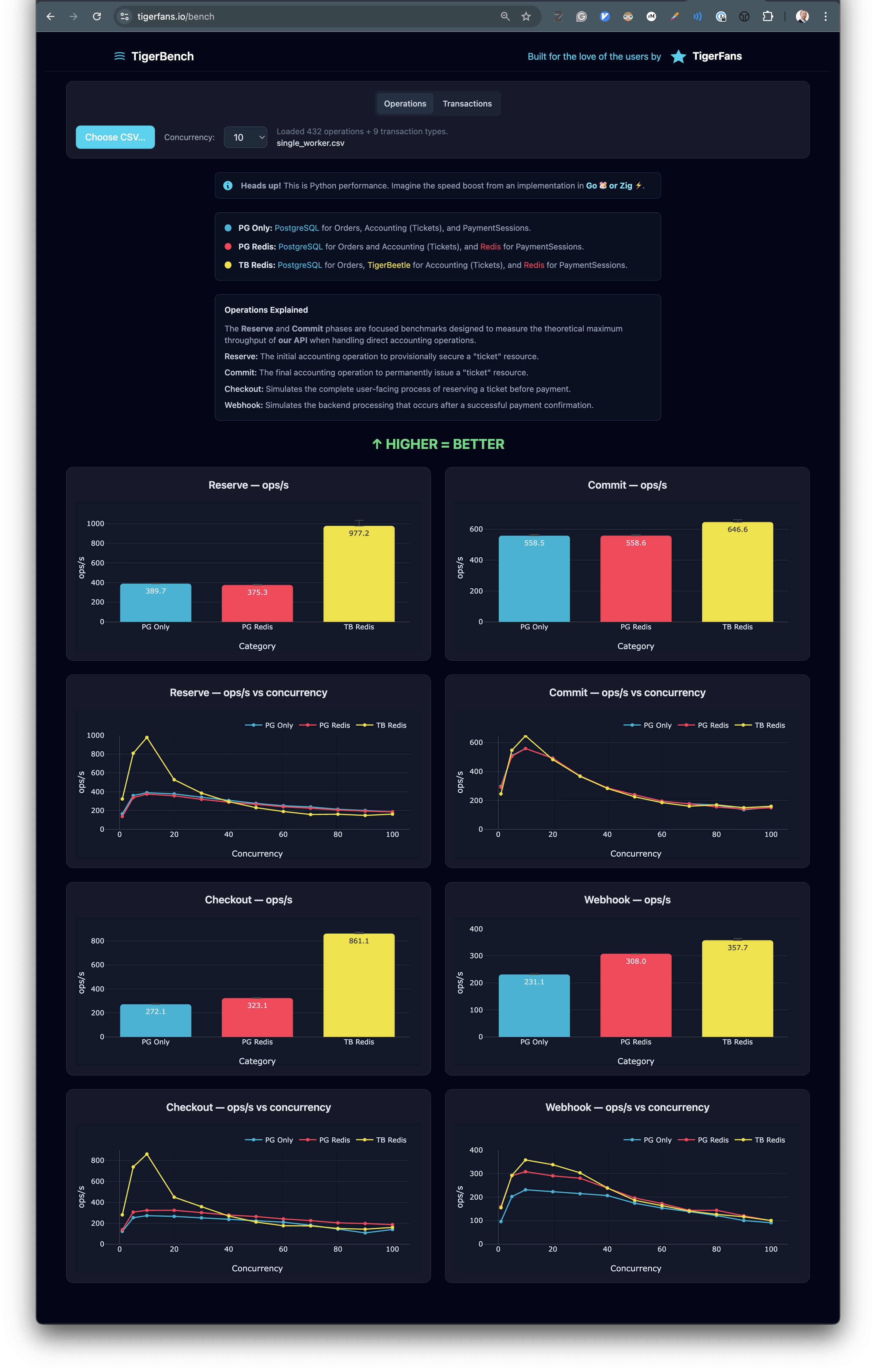
세 가지 구성 간 성능 비교를 보여주는 TigerBench 시각화
직접 살펴보세요: tigerfans.io/bench
그다음 TigerBeetle 호출 내부에서 실제로 무슨 일이 일어나는지 보려고 계측을 더했다. 숫자가 이상한 이야기를 들려줬다: 우리는 TigerBeetle에 배치 크기 1을 보내고 있었다.
요청마다 이체 1개. 매번.
TigerBeetle은 배칭을 위해 설계된 인터페이스를 제공한다. 그런데 나는 동시 요청이 많은 환경에서, 각각 배치 크기 1을 만들고 있었던 것이다.
하지만 TigerBeetle은 요청당 최대 8190개의 연산을 처리한다. 그럴 때 진가가 발휘된다. 그러나 FastAPI의 요청 지향 설계는 모든 await가 즉시 발사되는 특성이 있어, 인터페이스 임피던스 미스매치를 만든다. 승객 한 명 나르려고 747을 띄우는 꼴이다.
해결책은 커스텀 배칭 레이어—LiveBatcher였다. 애플리케이션과 TigerBeetle 사이에 앉아, 도착하는 동시 요청을 수집해 효율적인 배치로 꾸린다. 한 배치를 처리하는 동안 새 요청은 큐에 쌓인다. 처리가 끝나면 큐에 쌓인 요청을 즉시 묶어 보내고, 파이프라인이 계속 가득 차도록 연쇄적으로 이어간다.
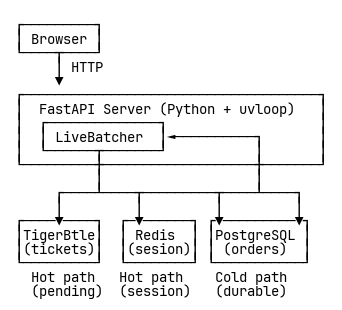
결과: 평균 배치 크기 5~6 이체. 처리량은 초당 977건 예약으로 도약—Oasis 기준선의 15배.
배칭 지표도 TigerBench에 추가했다—동시성 수준에 따른 배치 크기 분포, 배칭 효율이 성능 곡선을 어떻게 바꾸는지 확인할 수 있다.
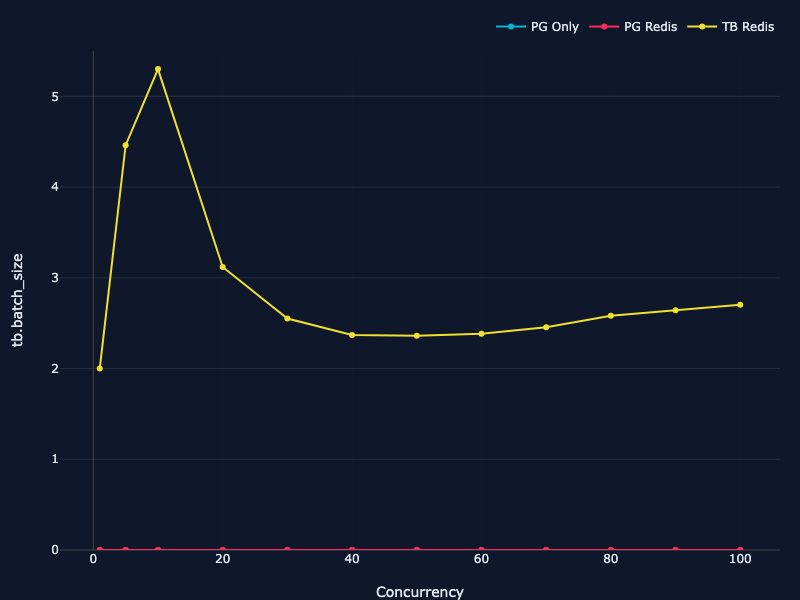
동시성 수준별 TigerBeetle 배치 크기 분포 선 그래프
그리고 프로젝트 전체에서 가장 직관에 반하는 발견이 찾아왔다.
이 테스트를 위해 인스턴스를 c7g.2xlarge(8 vCPU, 16 GB RAM)로 올렸다.
멀티 워커로 돌려봤다. 상식적인 관행 아닌가? CPU 8개면 워커도 여러 개. 모든 코어를 활용한다.
가설: 워커가 많을수록 처리량도 늘어난다?
결과: 아니다.
1000건 예약 테스트:
측정값은 명확했다. 처음엔 말이 안 되는 듯 보였지만, 곧 이유를 이해했다.
멀티 워커는 배치를 이벤트 루프들 사이로 쪼갠다. 로드 밸런서는 요청 1을 워커 1에, 요청 2를 워커 2에, 요청 3을 워커 3에 보낸다. 각 워커의 배처는 전체 동시 부하의 일부만 본다. 배치가 작아진다. 그리고 TigerBeetle은 어차피 그 배치들을 순차 처리하므로, 이 쪼개짐은 병렬성을 주지 못하고 오버헤드만 만든다.
배칭 효율이 핵심일 때는, 분산보다 통합이 이긴다. 암달의 법칙 그대로다.

단일 워커와 멀티 워커의 배치 분절 비교
수 주간의 반복과 측정 끝에 시스템은 초당 977건의 티켓 예약을 달성했다. Oasis 기준선의 열다섯 배. 그것도 전부 파이썬으로.
지연시간 중앙값: 11ms. 99퍼센타일에서도 요청은 26ms에 완료됐다. 평균 배치 크기는 5~6 이체—TigerBeetle의 이론적 최적에는 못 미치지만, 실제 성능을 끌어내기엔 충분했다.
제한 요인은 분명했다: 요청당 약 5ms의 파이썬 이벤트 루프 오버헤드. 전체 시간의 45%다. 설령 TigerBeetle이 무한히 빠르다 해도, 파이썬을 벗어나지 않는 한 더 크게 빨라지긴 어렵다.
하지만 그게 요점이었다. 파이썬의 오버헤드가 있음에도 이 정도로 잘 된다면, 아키텍처는 건전하다는 뜻이다.
레시피는 검증됐다. 이 구현—파이썬, 모든 오버헤드 포함—으로 초당 977건 예약을 달성한다. 아키텍처는 문서화했고, 패턴은 설명했고, 교훈은 기록했다.
같은 아키텍처를 Go로 구현한다고 상상해 보자. 파이썬의 5ms 오버헤드를 걷어내면 10~30배 더 높은 처리량을 기대할 수 있다. 혹은 Zig에서는 수동 최적화로 50~100배까지도 밀어붙일 수 있을지 모른다.
TTC 챌린지는 단순하다: 언어와 스택은 무엇이든 좋다. 당신의 버전을 만들고, 결과를 공유해 달라. TigerBeetle의 배치 지향 설계가 시스템 프로그래밍 언어와 만날 때 티켓팅이 얼마나 빨라질 수 있는지 보자.
참고 자료:
TigerBeetle를 만든 Joran Dirk Greef에게 감사드립니다. 최적화 여정을 시작하게 만든 “벤치마크도 있으면 좋겠다”는 도전, 그리고 내내 큰 격려가 되어 주셨습니다.
핫/콜드 경로 절충안을 제시해 속도와 내구성의 완벽한 균형을 잡아주고, 깊이 있는 코드 리뷰와 TigerBeetle 파이썬 배칭 동작 분석으로 마지막 성능 단계를 여는 데 큰 도움을 주신 Rafael Batiati께 감사드립니다.
지식과 시간을 아낌없이 나눠주며 훌륭한 데이터베이스를 만들어 주신 TigerBeetle 팀 전체에도 감사드립니다.
마지막 커밋 메시지에는 이렇게 썼다:
“이 작업을 하며 인생 최고의 시간을 보냈습니다 😊!”
가장 멋진 프로젝트는 종종 계획한 것이 아니다. 스스로 당신을 붙잡고, 도전하고, 가르치고, 모든 구석을 탐험하고, 모든 질문에 답하고, 문제에서 마지막 한 방울의 인사이트를 짜낼 때까지 놓아주지 않는 그것들이다.
기술 상세:
리소스: