Apache Iggy가 tokio 기반 아키텍처의 한계를 넘기 위해 io_uring을 활용한 thread-per-core(shared-nothing) 설계로 전환하며 겪은 선택과 시행착오, 그리고 성능 결과를 정리한다.
URL: https://iggy.apache.org/blogs/2026/02/27/thread-per-core-io_uring/
Apache Iggy에서 성능은 핵심 원칙 중 하나입니다. 우리는 “미친 듯이 빠른(blazingly fast)” 시스템을 자랑스럽게 여기며, 기반 하드웨어의 절대적인 한계까지 밀어붙여 왔습니다. 그리고 결국 기존 아키텍처로는 가능한 선택지를 모두 소진하게 되었고, 새로운 접근이 필요해졌습니다. Rust Reddit을 활발히 이용하는 분이라면 이미 이 논의를 보셨을지도 모릅니다. 이 글보다 앞서 진행된 논의이며, 이를 계기로 io_uring 기반의 thread-per-core shared-nothing 아키텍처를 더 깊이 탐구해 보기로 했습니다.
이 결정을 내린 “이유(why)”를 자세히 설명하려면, 먼저 현 상황에 대한 간단한 정리가 필요합니다. Apache Iggy는 비동기 런타임으로 tokio를 사용해 왔는데, tokio는 멀티 스레드 워크-스틸링(work-stealing) 실행기를 사용합니다. 이는 많은 애플리케이션에 매우 잘 맞습니다(워크 스틸링이 로드 밸런싱을 처리해 주기 때문입니다). 하지만 근본적으로 많은 “고수준” 라이브러리들이 겪는 문제, 즉 제어권 부족이라는 문제에 부딪힙니다.
tokio가 시작되면 N개의 워커 스레드(일반적으로 코어당 1개)를 띄우고, 이들이 지속적으로 Future를 실행하고 재스케줄링합니다. 스케줄러가 특정 Future를 어떤 워커에서 실행할지 결정하므로, 태스크가 워커 간 이동(task migration)할 수 있고, 이는 캐시 무효화(cache invalidation)와 예측하기 어려운 실행 경로를 유발합니다. Rust의 Send 및 Sync 바운드는 데이터 레이스로 인한 UB(정의되지 않은 동작)는 방지하지만, 데드락 같은 더 상위 수준의 동시성 버그까지 막아주지는 않습니다.
하지만 이런 도전 과제들이 마지막으로 우리를 결단하게 만든 것은 아니었습니다. 진짜 결정적 이유는 tokio가 블록 디바이스 I/O를 처리하는 방식이었습니다. tokio는 폴 기반(poll-based) Rust Futures 모델을 따르며, (플랫폼에 따라) 파일 디스크립터 I/O를 수행하기 위해 준비 상태(readiness) 기반의 알림 메커니즘을 사용합니다. 런타임은 특정 디스크립터의 readiness 알림을 구독하고, I/O 작업을 제출하기 위해 해당 readiness를 await합니다. 이 방식은 네트워크 소켓에서는 꽤 잘 동작하지만, 블록 디바이스에서는 완전히 호환되지 않습니다. Linux 커널은 일반 파일을 읽기/쓰기에서 항상 “ready”하다고 보기 때문에, epoll(또는 유사한 알림 메커니즘)은 즉시 반환하고, 그 다음 I/O 작업은 결국 실행 중인 스레드를 블로킹해 버립니다(페이지 캐시 락 경합 또는 기타 커널 작업 때문에). 이 문제를 해결하기 위해 tokio는 스레드 풀 접근을 사용합니다. 블록 디바이스 I/O 작업을 모두 공유 블로킹 스레드 풀로 아웃소싱하고, 스레드는 필요할 때마다 생성됩니다. 기본 설정에서 tokio는 이 블로킹 스레드 풀이 최대 512개 스레드까지 자랄 수 있게 허용합니다. 고성능 시스템은 이런 스레드 풀의 처리 능력을 빠르게 소진할 수 있고(512개 스레드를 서비스하는 오버헤드는 차치하더라도), 그래서 우리는 tokio가 우리의 요구에 맞게 스케일하지 않는다고 결론지었습니다.
확장성을 개선하기 위한 접근으로 우리가 도달한 결론이 바로 thread-per-core shared-nothing 아키텍처였습니다. 이 접근은 ScyllaDB와 Redpanda 같은 고성능 시스템에서 성공이 입증되었고, 두 프로젝트 모두 성능 목표 달성을 위해 Seastar 프레임워크를 사용합니다.
요약하면, 이 접근의 핵심 철학은 다음과 같습니다. CPU 코어마다 스레드 하나를 고정(pin)하고, 휴리스틱(보통 해싱)으로 리소스를 파티셔닝하며, 공유 상태를 제거하여 락 경합을 줄이고 캐시 지역성을 개선하고, 마지막으로 스레드(Seastar 용어로는 shards) 사이 통신은 메시지 패싱으로 수행합니다. 좋은 계획처럼 들리지만, 언제나 그렇듯 디테일에 악마가 숨어 있습니다.
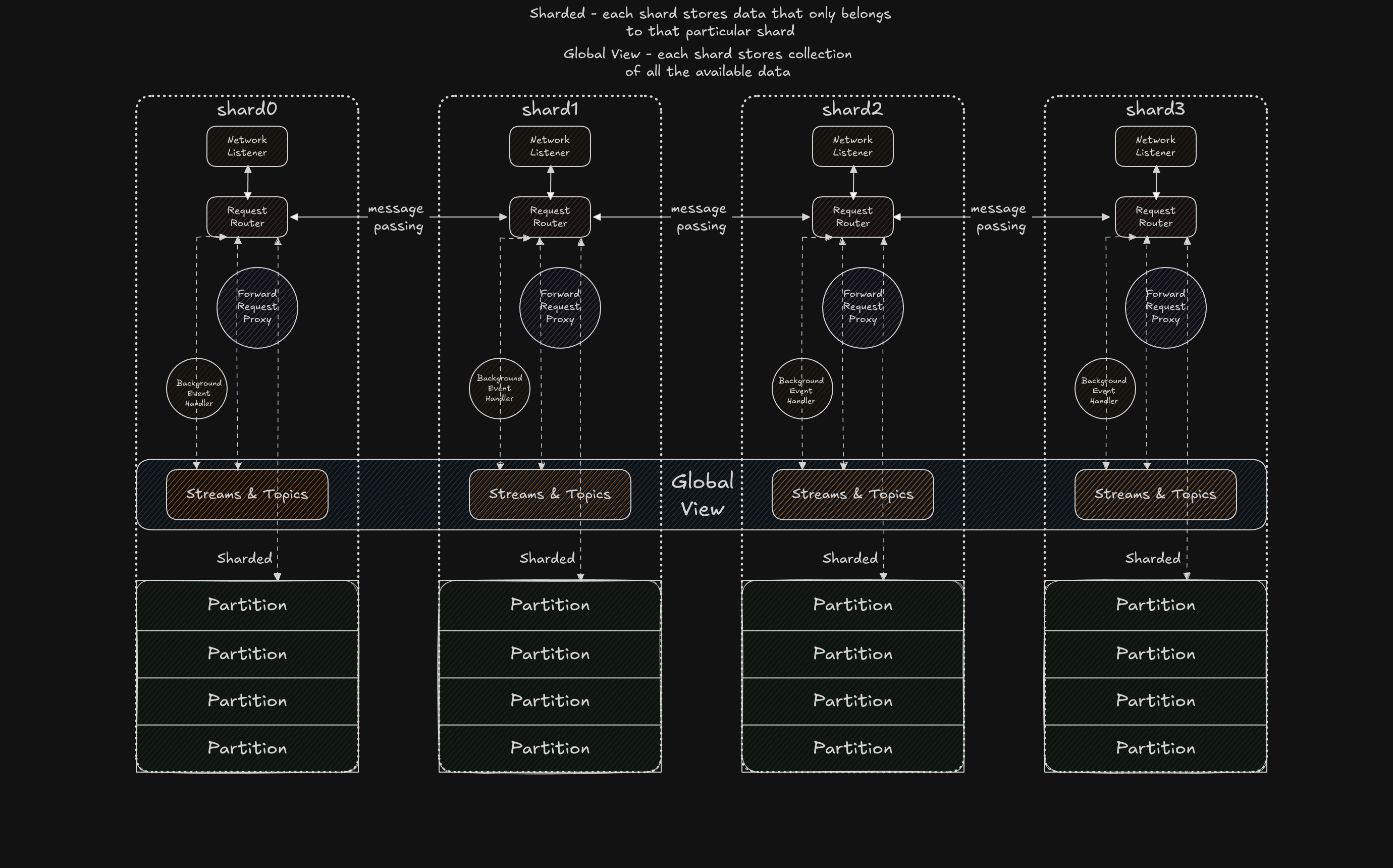
큰 그림에서 보면 이 아키텍처는 기존 접근의 핵심 문제를 해결합니다. work stealing에서 work steering으로 전환합니다. 큰 승리이지만, 블록 디바이스 I/O 문제는 여전히 남아 있었습니다. 파일 작업에 스레드 풀을 쓰면 코어 핀ning으로 얻는 성능 이득을 결국 상쇄하게 되므로, 진정한 비동기 I/O 인터페이스가 필요했고, 그렇게 io_uring을 발견했습니다.
io_uring은 요즘 핫한 주제라 자료가 아주 많습니다. 하지만 아주 간단히 말하면 인터페이스는 직관적입니다. io_uring은 준비 상태 기반(readiness-based) 알림 시스템이 아니라 완료 기반(completion-based)입니다. 작업을 제출하면 커널이 완료될 때까지 진행합니다. 핵심 메커니즘은 유저 공간과 커널이 공유하는 두 개의 락-프리 링 버퍼로 구성됩니다. 애플리케이션이 I/O 요청을 넣는 Submission Queue(SQ), 커널이 작업 완료 결과를 넣는 Completion Queue(CQ) 입니다.
이 모델은 Rust Future가 동작하는 방식(폴 기반)과 완전히 호환되지 않으므로, Future의 최초 poll이 요청 제출(submission) 용도로 사용됩니다. 완료 기반 I/O 패러다임에는 콜백 기반 continuation 모델이 더 잘 맞지만, 그 자체로도 단점이 있습니다. 그럼에도 임피던스 미스매치에서 오는 오버헤드는 무시할 만합니다. await는 간단히 CQ를 들여다보며, 현재 poll 중인 Future에 해당하는 완료 엔트리를 찾는 방식으로 구현됩니다(io_uring은 각 제출에 usize 타입 user_data 쿠키를 붙일 수 있는데, 이를 통해 해당 유저 공간 Future를 식별하고 깨웁니다). 나머지는—잠시만—마법이라고 가정합시다.
설계 조각들이 갖춰졌으니, 이제 async 런타임 시장을 둘러볼 차례였습니다. 우리는 3개의 후보를 평가했습니다.
monoioglommiocompio셋 모두 드라이버로 io_uring을 지원합니다(어떤 것은 거의 전용으로, 어떤 것은 여러 드라이버 중 하나로).
FIFO 순서대로, monoio가 최초 PoC에서의 선택이었습니다. 꽤 잘 동작했지만, io_uring의 방대한 API 표면을 탐색하면서 기능 동등성(feature parity) 측면에서 상당히 뒤처져 있고, 유지보수가 아주 활발해 보이지 않는다는 걸 깨달았습니다. 오해는 마세요. 런타임은 여전히 패치를 받고 있고, 특히 이런 사건 이후로는 더 그렇습니다. 하지만 빠르게 진화하는 io_uring 같은 인터페이스를 따라가기엔 전체 개발 속도가 부족했습니다.
다음은 glommio입니다. 특히 흥미로운 점은, 이 런타임이 원래 Seastar 프레임워크를 만든 ScyllaDB에서 일했던 Glauber Costa에 의해 개발되었다는 것입니다. glommio는 목록의 다른 두 런타임과 상당히 다릅니다. 여전히 thread-per-core 런타임이지만, proportional-share 스케줄러를 사용하고, 스레드당 io_uring 인스턴스를 3개(메인 링, 레이턴시 링, 폴링 링) 만들며, (Seastar처럼) 사용할 수 있는 고수준 API도 꽤 많이 제공합니다. 안타깝게도 monoio와 비슷한 운명을 겪었고, 현재로서는 사실상 유지보수가 중단된 상태입니다. 게다가 런타임이 꽤 “의견이 강한(opinionated)” 편인데, 우리는 그중 일부 의견에 동의하지 못했습니다(이는 뒤에서 더 다룹니다).
마지막으로 compio입니다. 최종적으로 우리가 선택한 것은 이것이었습니다. 아키텍처는 monoio와 매우 비슷하지만, io_uring 기능 커버리지가 넓고, 유지보수가 활발하며(우리 패치가 몇 시간 내로 머지되기도 했습니다), 코드베이스 구조가 좋았습니다. 특히 monoio와 달리 compio의 코드베이스는 driver가 executor와 분리(disaggregated)되어 있어, io_uring 드라이버를 재사용하면서도 자체 실행기를 만들 수 있습니다.
다만 compio는 SQ에 제출되는 I/O 요청을 박싱(boxing)하므로, 각 I/O 요청이 힙 할당을 유발합니다. 이는 monoio가 피하는 부분입니다. 우리 경우엔 크게 문제는 아니었습니다. 할당이 매우 작고, mimalloc이 작고 예측 가능한 할당에 대해 풀을 잘 유지해 주기 때문입니다. 우리는 Telegram 채널에서 monoio처럼 Slab 할당자를 쓰는 접근이 가능한지 질문했지만, 저자들은 반대했습니다. 실행기에 많은 복잡성이 추가되고, 실행기가 Windows IOCP 같은 다른 드라이버도 동일하게 지원하기 때문입니다.
디테일에 악마가 있다고 했죠? 이제 마이크를 그에게 넘겨봅시다.
처음 보기엔 thread-per-core shared-nothing 모델에서는 모든 상태가 각 shard에 로컬이고, 전역(global) 관점이 필요한 것은 메시지 패싱으로 샤드 간 복제해야 하므로, **내부 가변성(interior mutability)**에 완벽한 후보처럼 보입니다. Mutex를 RefCell로 바꾸고 빠른 승리를 챙길 수 있을 것처럼요. 그렇게 생각했다면, 안타까운 소식입니다. 단테의 지옥 9층에서 온 환영 인사처럼 이런 메시지를 맞게 될 겁니다.
thread 'shard-8' (496633) panicked at core/server/src/streaming/topics/helpers.rs:298:21: RefCell already borrowed
알고 보니 .await 지점을 가로질러 RefCell borrow를 잡고 있으면 런타임 borrow 패닉이 발생할 수 있습니다. 이건 clippy 린트로도 존재합니다: clippy::await_holding_refcell_ref.
Rust wg-async(async 워킹 그룹)도 이런 발목 잡는 함정(footgun)을 인지하고 있으며, 이 이야기에서 설명합니다. GhostCell 같은 프리미티브를 사용해 Futures에 대해 정적으로 검증되는 borrowing을 표현하는 것이 가능할 것처럼 느껴집니다. 실제로 그렇게 하는 PoC 런타임도 공유하고 있습니다. 하지만 일반 Rust와 구분되지 않는 수준의 인체공학적 API를 달성하려면, 아마 컴파일러와 Futures에 전달되는 Context에 상당한 변화가 필요할 것입니다.
우리는 내부 가변성을 (아직) 포기하지 않았습니다. 대신 근본 문제를 분석하고, 더 나은 API로 해결하려고 시도했습니다.
문제는 .await 지점에서 실행기가 실행 컨텍스트를 다른 Future로 양보(yield)할 수 있고, 그 다른 Future가 같은 RefCell을 borrow하려고 하면, 첫 번째 Future의 borrow가 여전히 활성화되어 있으므로 런타임 패닉이 발생한다는 점입니다. 우리는 데이터 구조가 도메인 모델과 맞춘 **컴파일 타임 계층(compile time hierarchy)**을 갖는 OOP 스타일을 따랐기 때문에 이를 자주 겪었습니다. 형태는 대략 이렇습니다.
struct Stream {
id: usize,
name: String,
storage: Storage
}
impl Stream {
async fn save(&mut self) {
// `name` 필드로 무언가를 하고...
self.storage.save().await; // <-- 비가변 borrow
}
}
// .....
struct Server {
streams: RefCell<Vec<Streams>>,
}
impl Server {
async fn save_stream(id: usize) {
// BorrowMut를 잡고 있는 상태
let streams = self.streams.borrow_mut();
let stream = streams.iter_mut().find(|s| s.id == id).unwrap();
// await 실수.
stream.save().await;
}
}save 절차는 두 부분으로 나눌 수 있습니다.
storage를 통한 I/O 작업이렇게 하면 RefCell을 더 세밀하게 사용할 수 있습니다. Stream의 인메모리 표현에만 RefCell을 쓰고, 스토리지는 범위 밖(out of bounds)에 두는 방식이죠. 하지만 이를 위해서는 더 큰 무기가 필요했습니다. **ECS(Entity Component System)**를 소개합니다.
ECS는 보통 게임 엔진에서 익숙하지, 메시지 스트리밍 플랫폼에서는 낯설 수 있습니다. 개인적으로 ECS의 핵심 아이디어인 **SOA(Struct of arrays)**는 전반적으로 저평가되어 있다고 생각합니다. 우리가 한 일은 Entities(Streams, Topics, Partitions 등)를 컴포넌트로 쪼개고, 각 컴포넌트를 자신만의 전용 컬렉션에 저장한 것입니다.
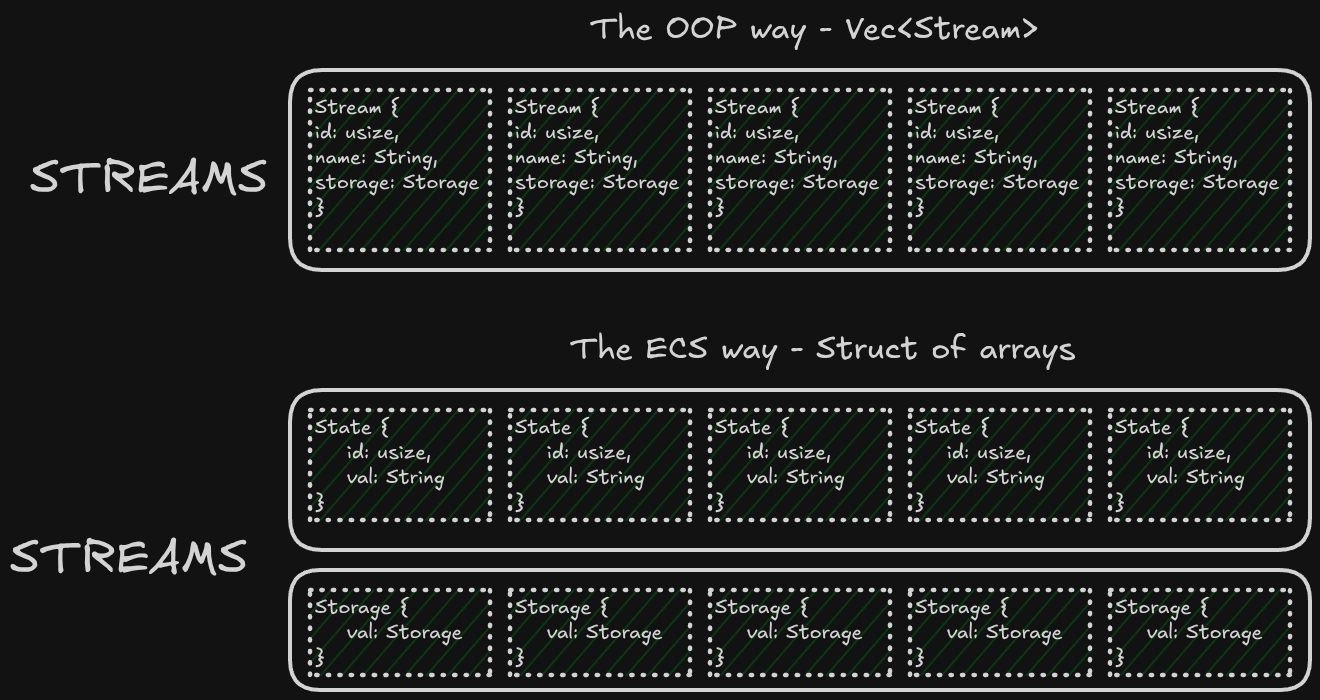
이 경우 컴포넌트는 State와 Storage입니다. 이를 통해 다음과 같이 작성할 수 있습니다.
struct Streams {
states: Vec<RefCell<State>>
storages: Vec<Storage>,
}
impl Streams {
async fn save_stream(id: usize) {
self.with_component_by_id_mut(id, |mut states| {
// 인메모리 표현 업데이트.
});
// AsyncFn 클로저가 우리가 작업하는 동안 막 안정화됨
// 우연이네요 :)
self.with_component_by_id_async(id, async |storage| {
storage.save().await;
}).await;
}
}Streams ECS에 컴포넌트 클로저를 붙여, 가변 borrow 안에서는 async 코드를 정적으로 금지하고 voilà.
하지만 이 접근도 순진한 시도만큼이나 비참하게 무너집니다...
thread-per-core shared-nothing 아키텍처는 한 샤드에서 상태가 바뀔 때마다 이벤트를 브로드캐스트해야 합니다. 예를 들어 shard-0이 CreateStream 요청을 받으면, 처리 완료 후 CreatedStream 이벤트를 채널을 통해 다른 모든 샤드에 브로드캐스트합니다. 수신 측에서는 각 샤드가 백그라운드 태스크로 이 채널을 폴링해 들어오는 이벤트를 처리합니다. 문제의 핵심은 바로 **백그라운드(background)**라는 단어에 있습니다.
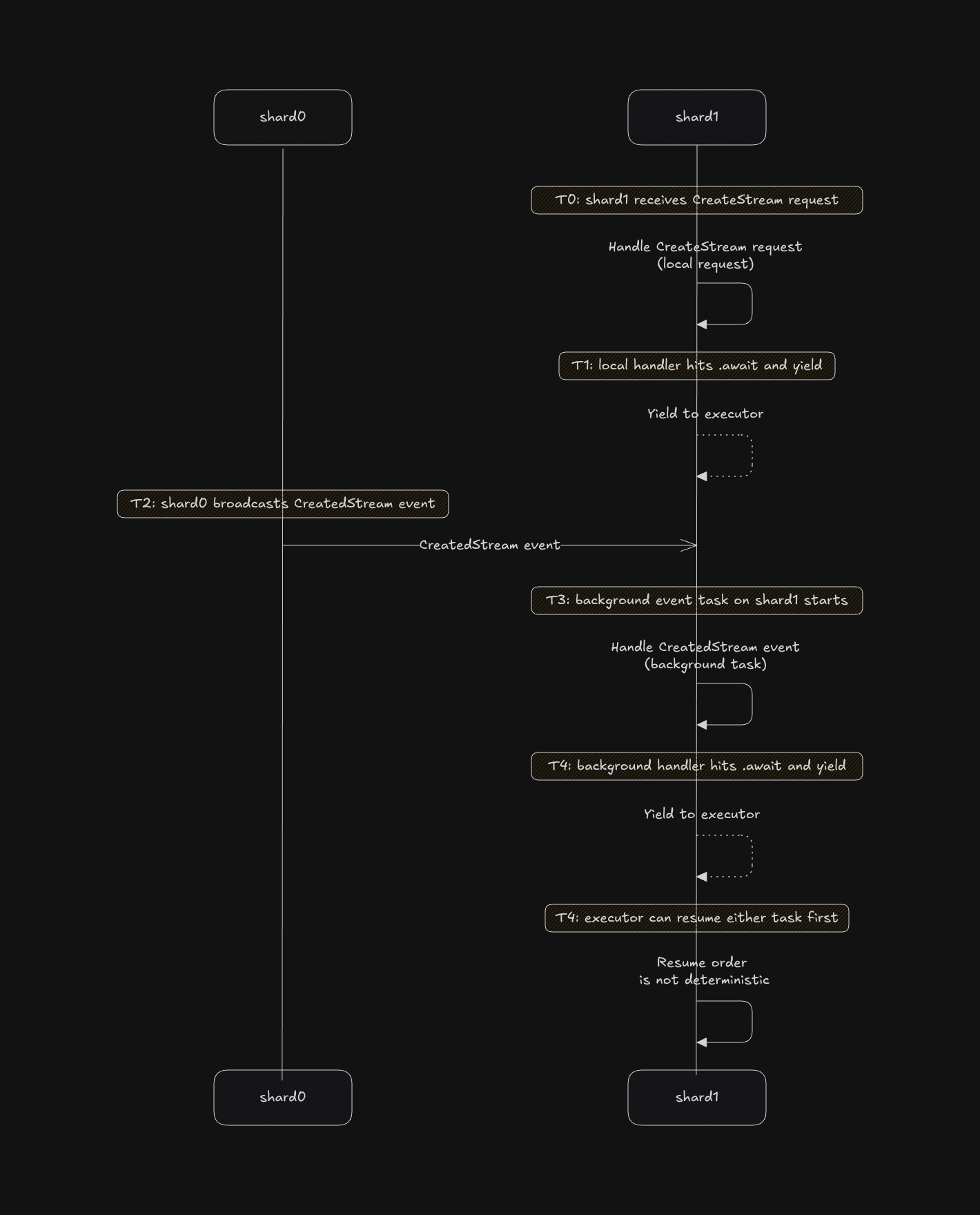
Streams 예제에서는 큰 문제처럼 보이지 않을 수 있지만, 실제로는 다른 Entities가 훨씬 복잡했고, thread-per-core shared-nothing 아키텍처에 필수적이지도 않은 다른 백그라운드 워커까지 포함하면 상황은 더 악화됩니다. 이 문제의 해결책으로 async 락을 쓰는 방법도 있겠지만, 이것들도 footgun이 될 수 있습니다.
놀랍게도, 단일 작성자(single-writer) 원칙을 강제한 시나리오에서도 이 문제는 계속되었습니다(모든 요청의 직렬화 지점을 담당하는 샤드를 하나 지정). 이것이 마지막 못이 되어 우리는 이 실험을 실패로 결론지었습니다. 공유되지 않지만 일관된 상태를 유지하는 것은 “그냥 메시지 패싱 쓰면 되지 bro”보다 훨씬 어렵습니다.
모든 길은 결국 _Mutex_로 통한다 — 다만 훨씬 더 정교한 Mutex로.
내부 가변성과 오랫동안 싸운 끝에, 우리는 억지로 성립시키려는 시도를 포기했습니다. 대신 이전 반복(iteration)에서 나온 산출물인 단일 작성자 원칙에 더 깊이 투자했습니다. 우리는 resources를 두 그룹으로 나눴습니다. 공유되고 강한 일관성을 요구하는 리소스와, 샤딩되며 최종적 일관성을 갖는 리소스입니다. 샤딩 리소스의 예로는 Partition이 있고, Streams와 Topics는 공유되며 강한 일관성을 유지합니다. 이 분리는 이후 (Control Plane/Data Plane)이라는 이름으로 불리게 되었습니다.
공유 리소스에 대해서는 left-right를 사용하기로 했습니다. 이는 단일 작성자와 다수 독자를 위해 설계된 동시성 데이터 구조입니다. 독자용 포인터와 작성자용 포인터 두 개를 유지하고, 작성자가 커밋할 때 이 포인터들을 원자적으로 스왑합니다(설명은 단순화했습니다). 단일 작성자는 첫 번째 샤드인 shard0이며, 나머지 샤드는 데이터에 대한 read 핸들을 가집니다. shard0이 아닌 샤드가 데이터를 변경하고 싶다면 flume 채널을 사용해 shard0에 요청을 보냅니다.
파티션에 대해서는 shards_table이라는 공유 테이블(DashMap)을 하나 유지합니다. 이는 생성/삭제 중인 Partition에 접근하려는 요청을 펜싱(fence)하는 배리어 역할을 합니다. 요청은 여전히 해당 Partition을 가진 샤드로 라우팅되지만, 라우팅 과정과 라우팅 이후에 shards_table을 조회함으로써 최종적 일관성이 우리를 물어뜯지 않도록 합니다.
이 설계는 (원한다면) “벌레가 든 깡통” 혹은 “바닥이 없는 구덩이”였습니다. 더 답해야 할 질문이 아주 많았습니다. 예를 들어 로드 밸런싱이 있습니다. tokio에서는 태스크-스틸링 실행기가 처리해주기 때문에 비교적 단순했습니다. 하지만 우리 경우, 접근 패턴이 예측 불가능하고 일부 샤드가 핫스팟이 되면 우리가 직접 처리해야 합니다. 진정한 양날의 검이죠. 향후 고려할 수 있는 이론적 최적화로는 withoutboats가 제안한 thread-per-core 블로그 포스트처럼 특정 파티션을 두 개 이상의 샤드에 걸쳐 샤딩하는 방법이 있습니다.
우리는 Partition이 segmented log를 사용한다는 사실을 활용할 수 있습니다. 따라서 세그먼트 범위와 어떤 세그먼트가 sealed 되었는지에 대한 지식을 바탕으로 파티션을 더 강하게 샤딩할 수 있습니다.
io_uring 자체에서 성능 이득을 끌어내는 것도 별도의 도전입니다(tokio를 io_uring 기반 런타임으로 바꾸기만 하면 끝이 아닙니다). io_uring 설계의 이점을 온전히 활용하려면 시스템 콜을 강하게 배치(batch)해야 합니다. 이것이 이 인터페이스의 핵심 장점이기 때문입니다(유저스페이스↔커널스페이스 컨텍스트 스위치 감소). Rust Futures는 이를 돕기 위해 잘 조합할 수 있지만, 조심해야 합니다.
아래 코드는 두 I/O 작업을 하나의 “배치”로 제출하지만, io_uring은 제출 순서 = 완료 순서를 보장하지 않습니다!
이 “체인”은 순서가 뒤바뀐 채로 실행될 수 있고, 서버가 중간에 크래시하면 블록 디바이스 상태가 깨질 수 있습니다.
let file = compio::fs::open("foo.bar").await.unwrap();
let content = "some".to_vec();
let content1 = "bytes".to_vec();
// 이제 이 두 write를 배치로 묶는다
let write1 = file.write_all(content)
let write2 = file.write_all(content1);
join!(write1, write2).await;작업 순서를 보존하면서 배치를 제출하려면, 제출된 SQE에 io_uring 체이닝 플래그 IOSQE_IO_LINK를 사용해야 합니다. 그리고 이는 다음 포인트로 이어집니다.
문제는 두 가지입니다. 첫째, 이 블로그 글 작성 시점에서 Seastar 프레임워크에 해당하는 Rust 동등물은 없습니다. 안타깝게도 glommio가 그 역할을 하려 했지만 상황이 바뀌었습니다. Glauber는 Turso 작업으로 옮겼고, Datadog 팀은 규모에서의 성능을 위한 Rust 실시간 시계열 스토리지 엔진을 만들면서도 런타임을 적극적으로 유지보수하는 것 같지 않습니다. 그 글에서도 sharding을 많이 언급하지만, 왜 그들은 완벽해 보이는 런타임을 “소유”하고 있으면서도 tokio를 선택했을까요?
둘째(“Secundo problemo”), 이런 런타임들은 std 라이브러리 API를 모방하는데, 이는 POSIX 호환을 따릅니다. 반면 io_uring의 가장 강력한 기능 중 다수는 POSIX 호환이 아니어서, 우리 같은 평범한 인간에게는 그 기능들이 닿지 않는 곳에 있습니다. 요청 체이닝은 빙산의 일각일 뿐입니다. 예를 들어 listen/recv에 대한 oneshot API, registered buffers 등이 있습니다. 결국 File, TcpListener, TcpStream은 올바른 추상화가 아닙니다. POSIX 호환성 관점에서는 그렇지만, 우리는 POSIX가 우리 모두를 인질로 잡도록 둘 수 없습니다.
이 문제를 인지한 건 우리뿐만 아닌 듯합니다. Microsoft가 최근 thread-per-core async 런타임을 발표했는데, 여기서는 추상화의 단위를 Operation으로 둡니다. 훨씬 더 좋은 아이디어입니다.
주목할 점은 우리가 compio를 선택한 주요 이유 중 하나가, 그들이 시대의 바람을 타며 점점 더 많은 io_uring API를 노출하려 한다는 점입니다. 코드베이스는 드라이버가 실행기와 분리되어 있는데, 나는 여기서 플러그 가능성을 더 밀고 싶습니다. 요즘 분산 시스템에서 매우 뜨거운 주제 중 하나가 DST(Deterministic Simulation Testing, 결정적 시뮬레이션 테스트)입니다. 이는 시스템의 모든 비결정적 원천(네트워크, 블록 디바이스, 시간 등)을 결정적인 것으로 치환하여, 단 하나의 seed 값으로 전체 실행을 재실행할 수 있게 하는 아이디어입니다. 현재 async Rust에서는 완전한 결정성을 달성하기가 매우 어렵고, 거의 불가능에 가깝습니다. 주요 요인은 예를 들어 실행기에서 타임아웃에 쓰는 타임 휠(time wheel)을 쉽게 교체할 수 없다는 점입니다. 라이브러리 저자들이 실행기 설계에서 타임 휠, 스케줄러, 네트워크/스토리지 드라이버 인터셉터를 플러그인처럼 교체할 수 있게 설계한다면, 우리는 기반 코드베이스를 전혀 바꾸지 않고도 시스템을 완전히 결정적으로 테스트할 수 있을 것입니다. Storage 뒤에 인터페이스를 둘 필요도 없고, 결정적인 것으로 바꿔야 하는 타임아웃 매니저도 필요 없습니다. Rust Futures 모델의 장점을 모두 활용하면서도 결정적 테스트 능력을 유지할 수 있게 됩니다.
스케일링은 thread-per-core 아키텍처가 진정으로 빛나는 지점입니다. 파티션과 프로듀서를 더 많이 던질수록 성능이 더 좋아집니다.
각 벤치마크는 인터랙티브이며, 이미지를 클릭하면 우리 사이트 benchmarks.iggy.apache.org에서 전체 리포트로 이동합니다.
v0.5.0 (tokio)
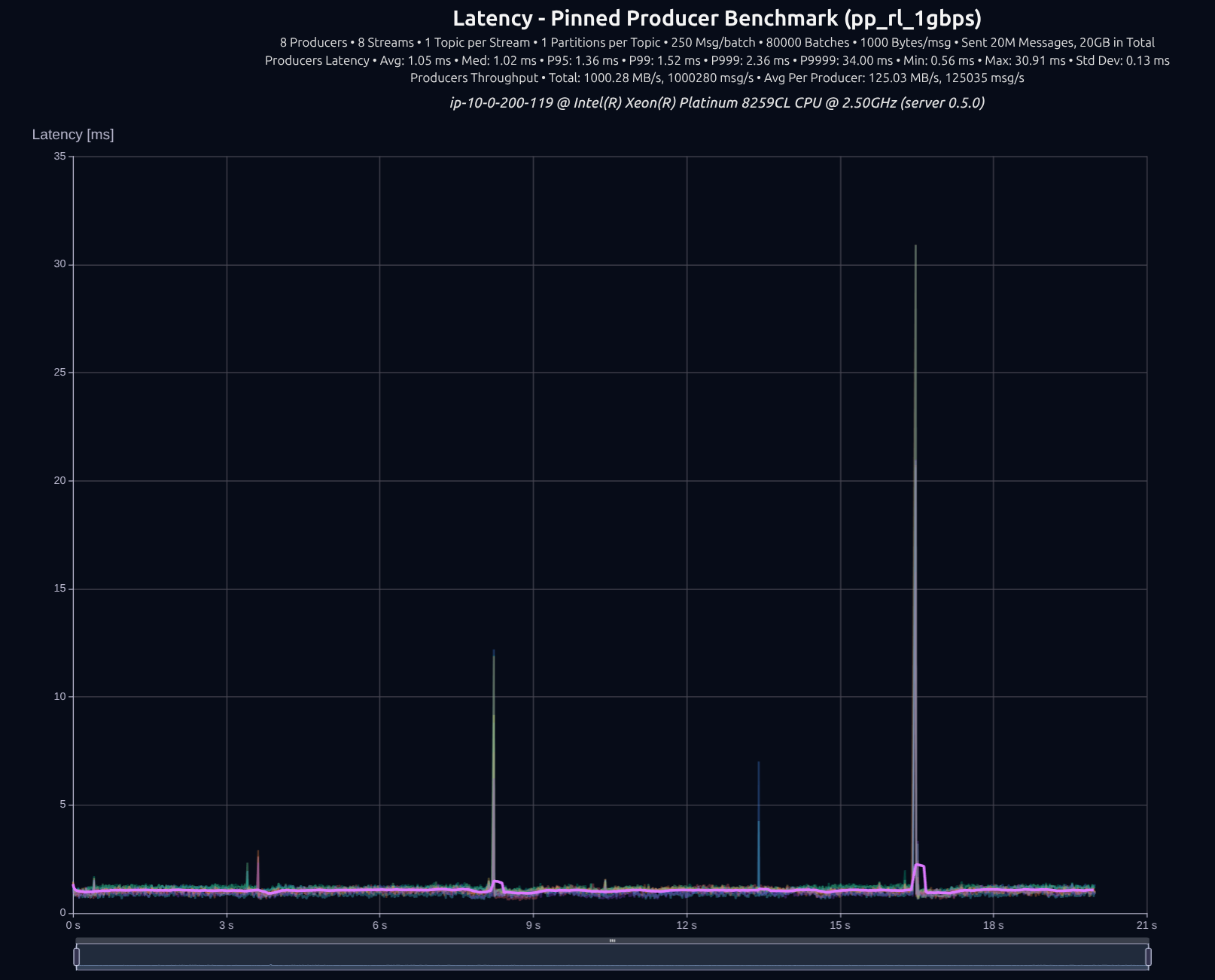
v0.6.1 (thread-per-core + io_uring)
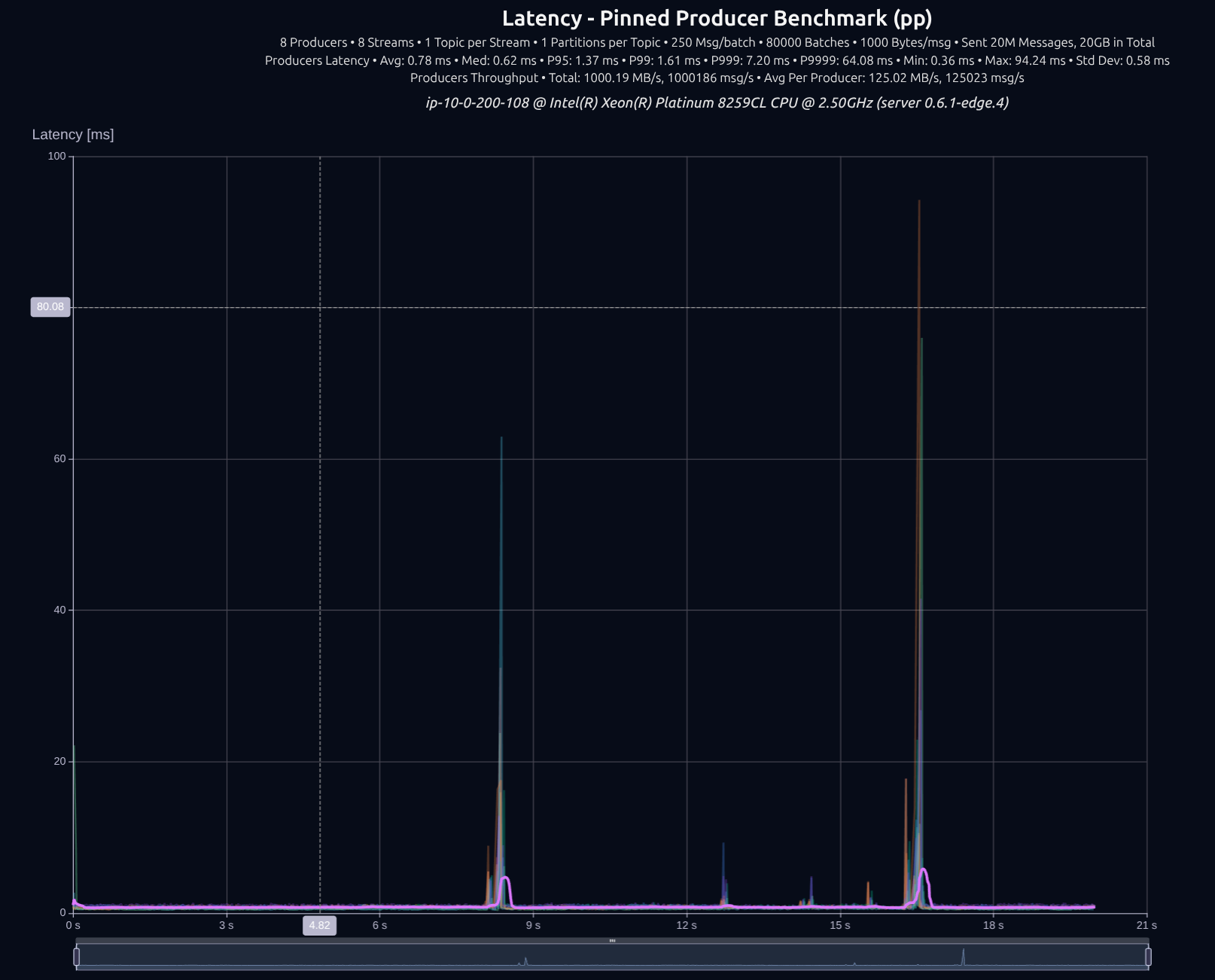
v0.7.0 (shared _something_)
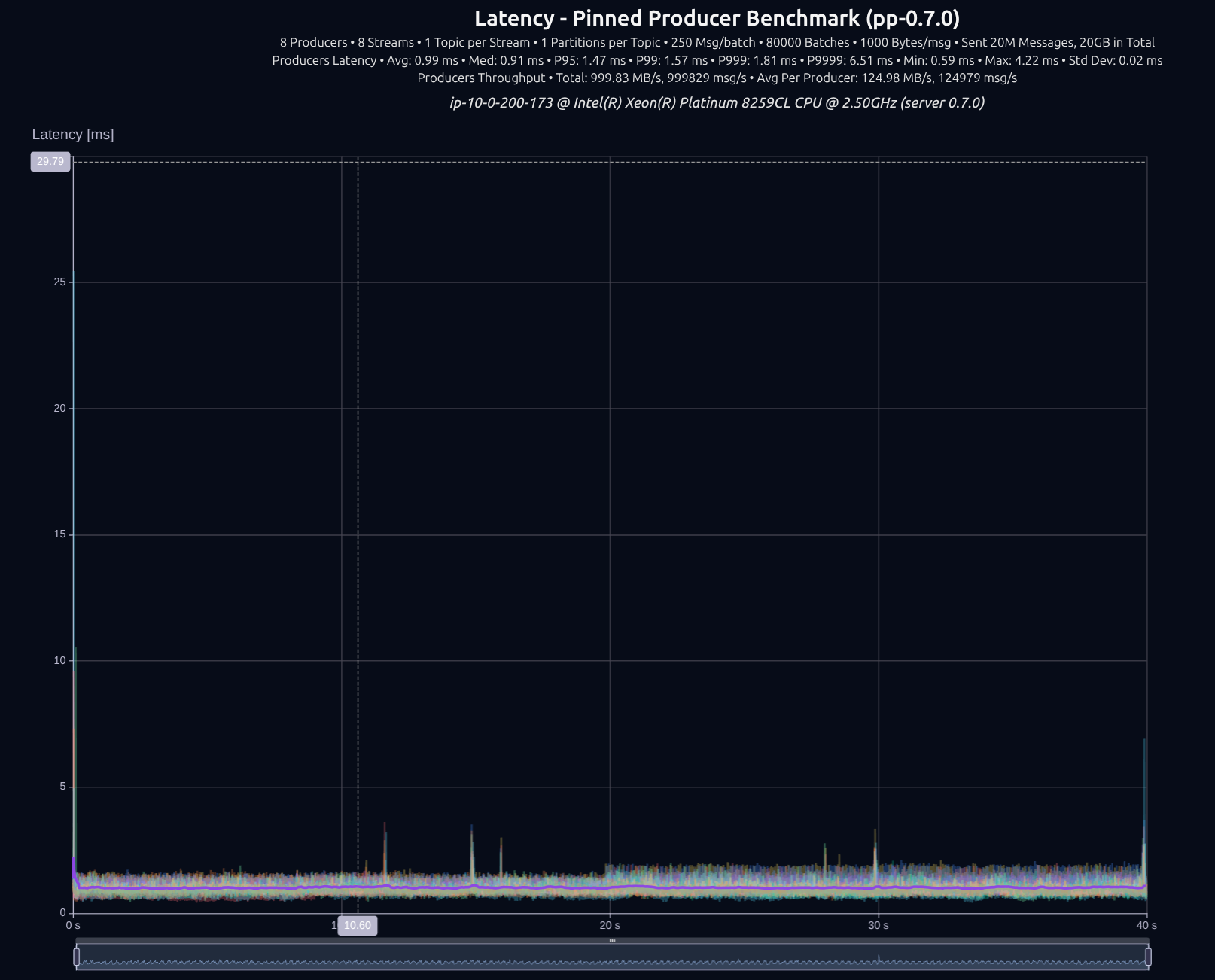
차이는 크지 않았습니다. 8 프로듀서에서는 tokio가 꽤 잘 따라왔습니다. 하지만 부하를 늘리면 격차가 크게 벌어집니다.
| Version | Throughput/node | P95 | P99 | P999 | P9999 |
|---|---|---|---|---|---|
| v0.5.0 | 1,000 MB/s | 1.36 ms | 1.52 ms | 2.36 ms | 34.00 ms |
| v0.7.0 | 1,000 MB/s | 1.47 ms | 1.57 ms | 1.81 ms | 6.51 ms |
| Improvement | — | +8% | +3% | -23% | -81% |
v0.5.0 (tokio)
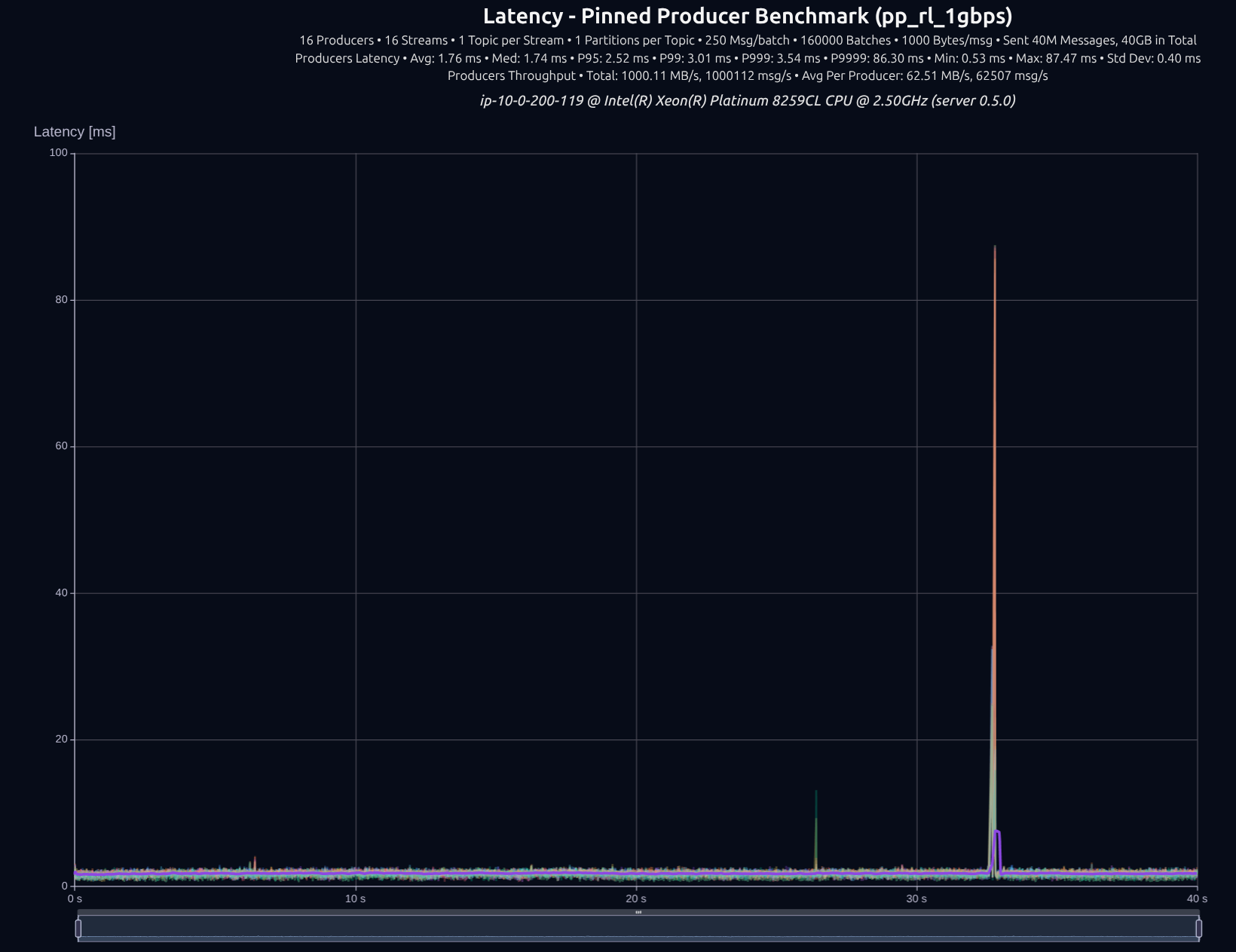
v0.6.1 (thread-per-core + io_uring)
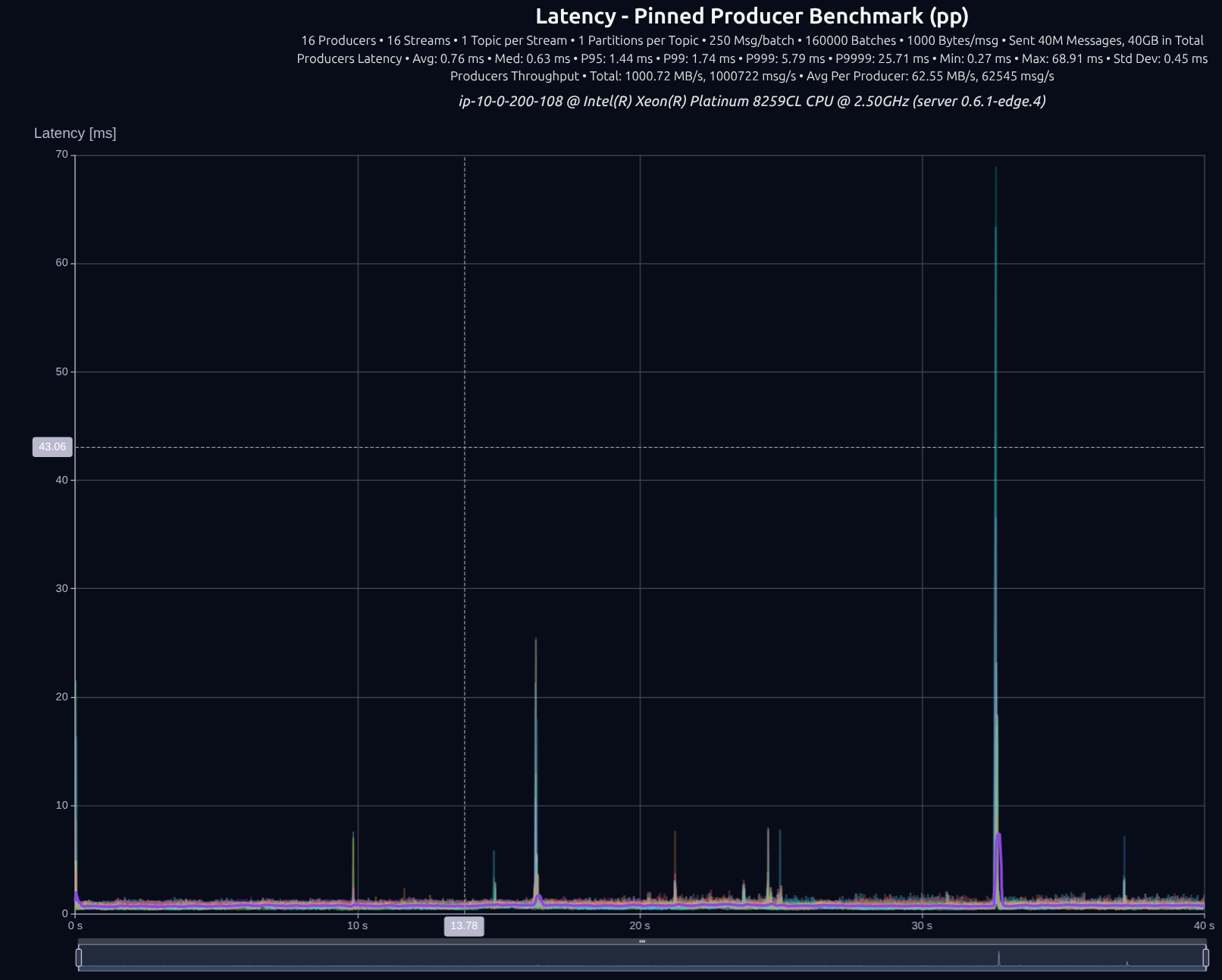
v0.7.0 (shared _something_)
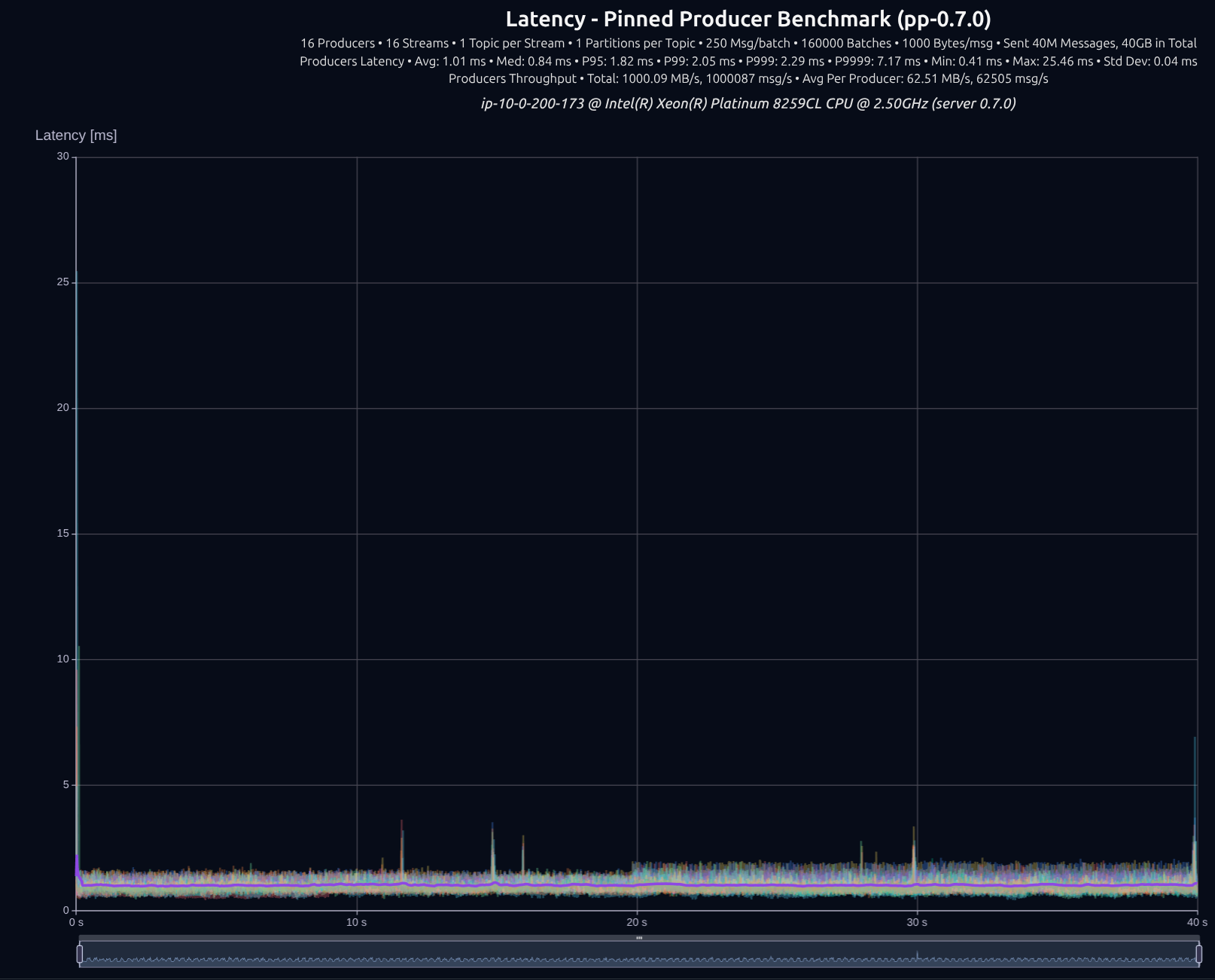
| Version | Throughput/node | P95 | P99 | P999 | P9999 |
|---|---|---|---|---|---|
| v0.5.0 | 1,000 MB/s | 2.52 ms | 3.01 ms | 3.54 ms | 86.30 ms |
| v0.7.0 | 1,000 MB/s | 1.82 ms | 2.05 ms | 2.29 ms | 7.17 ms |
| Improvement | — | -28% | -32% | -35% | -92% |
v0.5.0 (tokio)
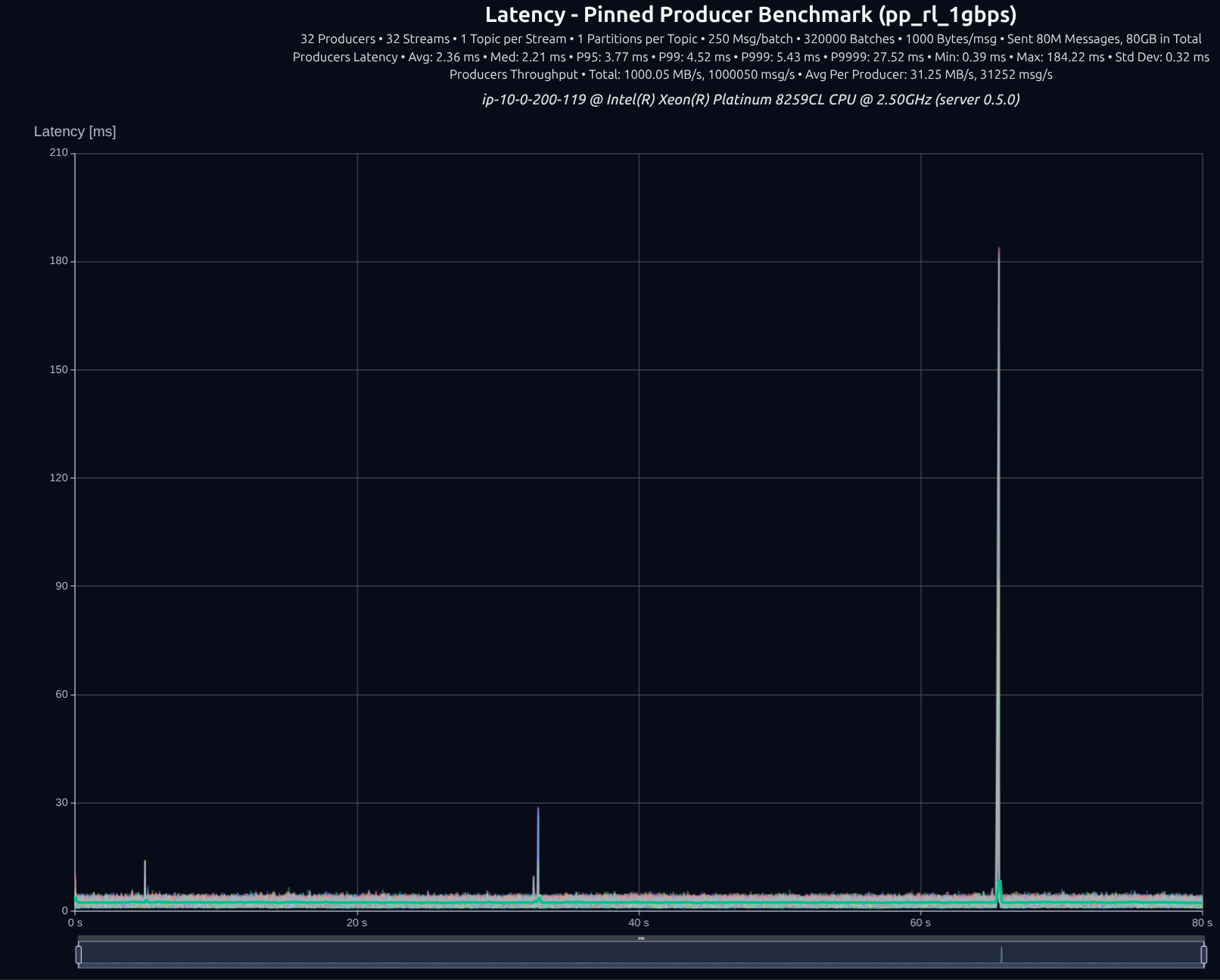
v0.6.1 (thread-per-core + io_uring)
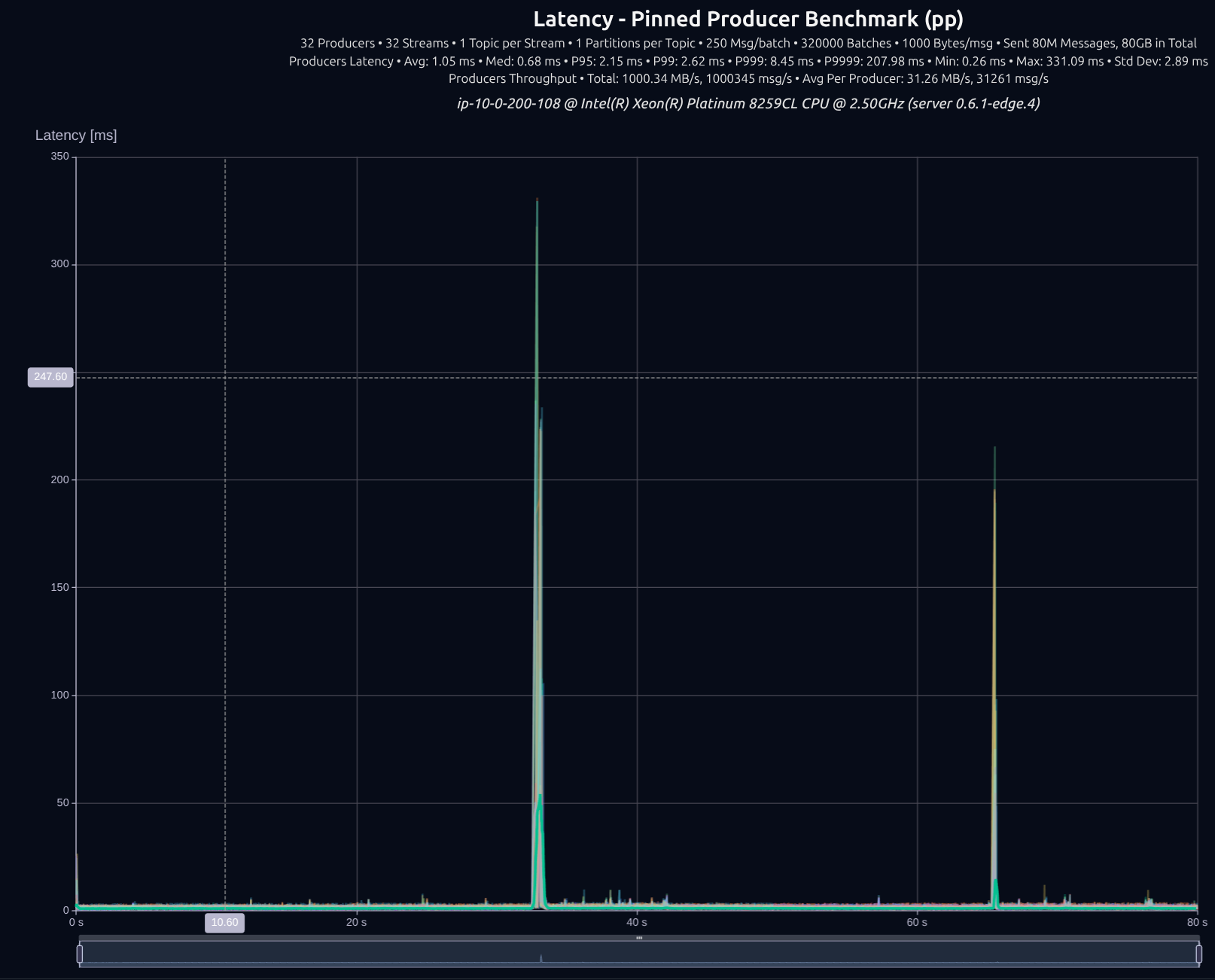
v0.7.0 (shared _something_)
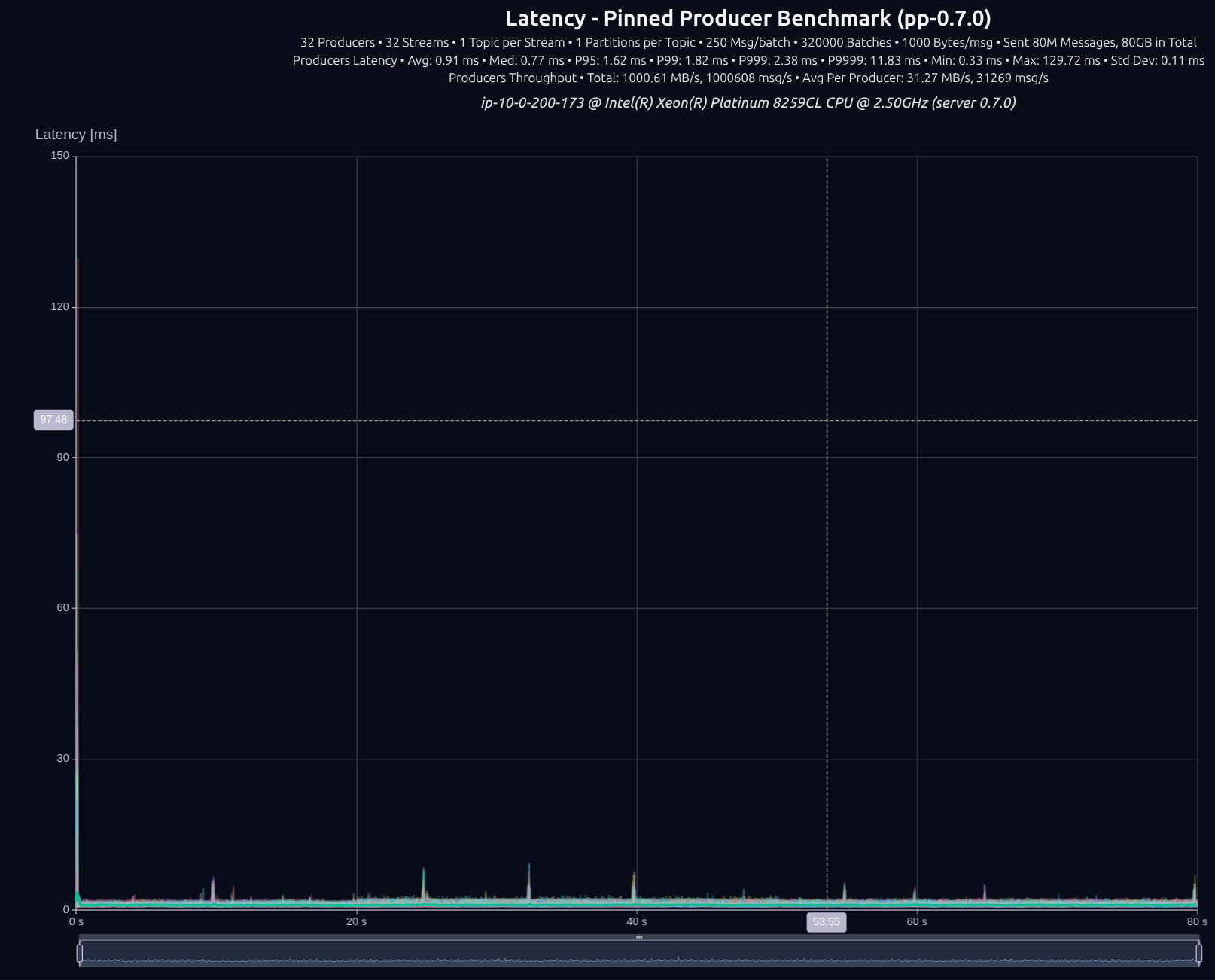
| Version | Throughput/node | P95 | P99 | P999 | P9999 |
|---|---|---|---|---|---|
| v0.5.0 | 1,000 MB/s | 3.77 ms | 4.52 ms | 5.43 ms | 27.52 ms |
| v0.7.0 | 1,001 MB/s | 1.62 ms | 1.82 ms | 2.38 ms | 11.83 ms |
| Improvement | — | -57% | -60% | -56% | -57% |
fsync)각 배치 write마다 데이터를 디스크로 플러시합니다.
v0.5.0 (tokio)
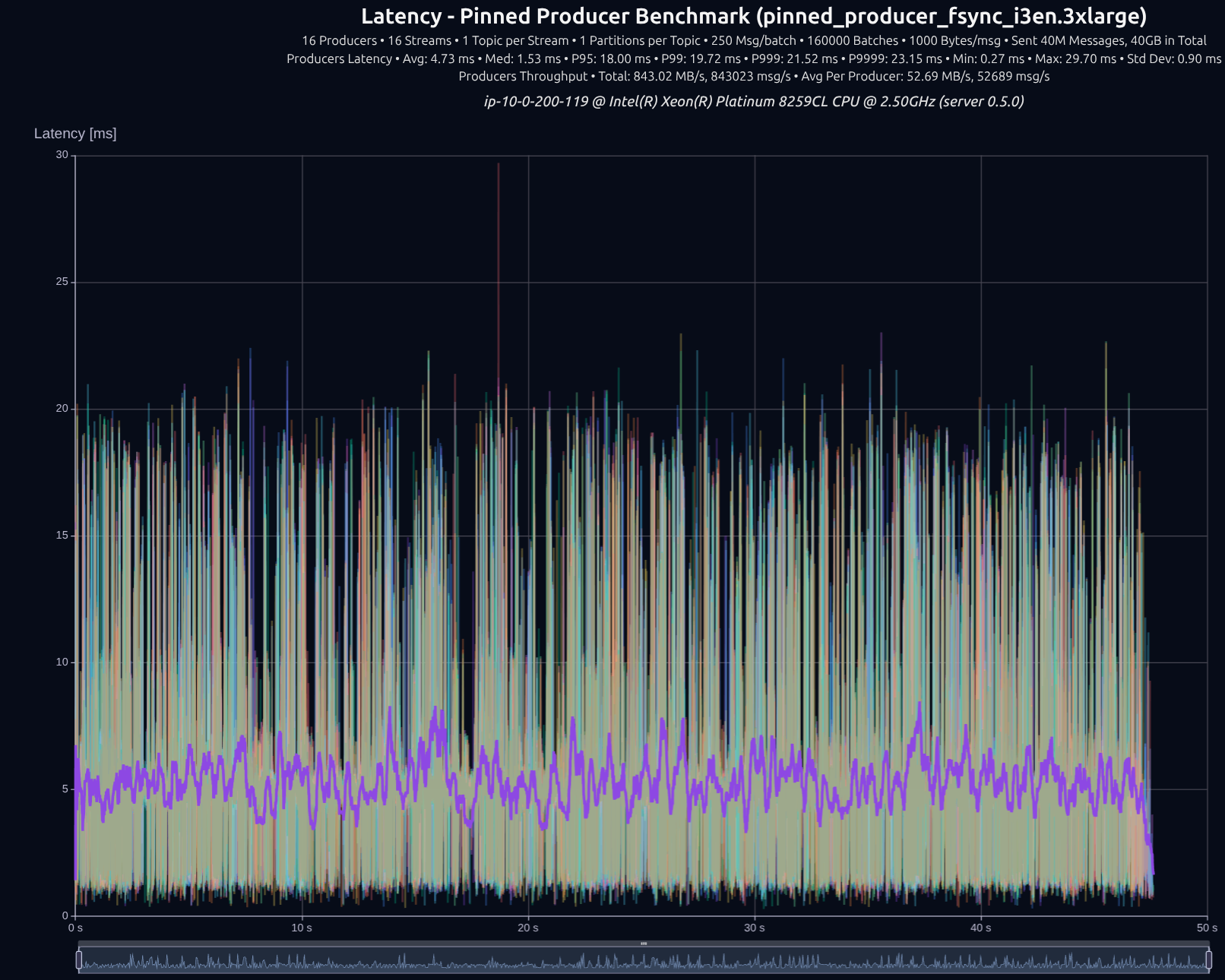
v0.7.0 (shared _something_)
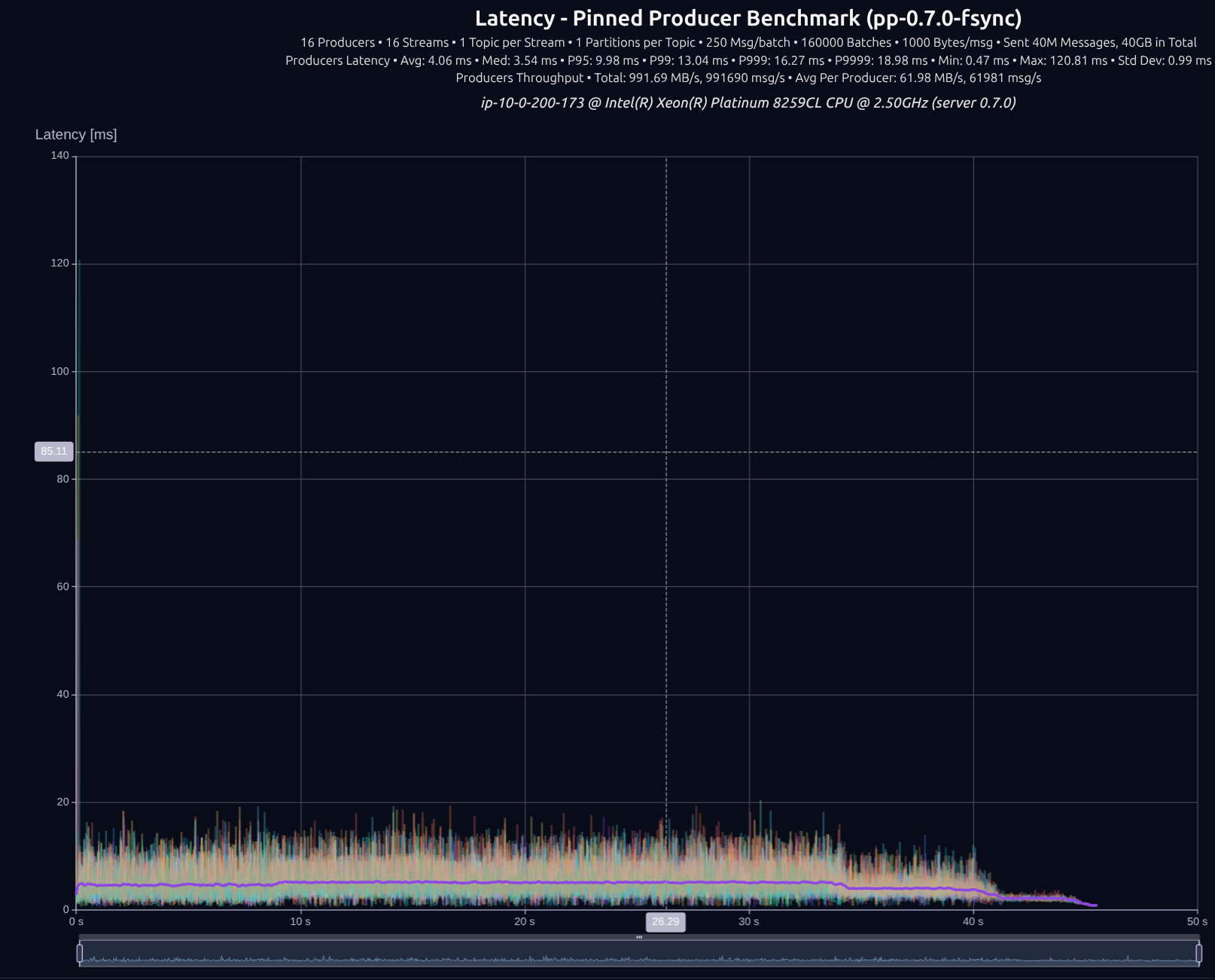
| Version | Throughput/node | P95 | P99 | P999 | P9999 |
|---|---|---|---|---|---|
| v0.5.0 | 843 MB/s | 18.00 ms | 19.72 ms | 21.52 ms | 23.15 ms |
| v0.7.0 | 992 MB/s | 9.98 ms | 13.04 ms | 16.27 ms | 18.98 ms |
| Improvement | +18% | -45% | -34% | -24% | -18% |
v0.5.0 (tokio)
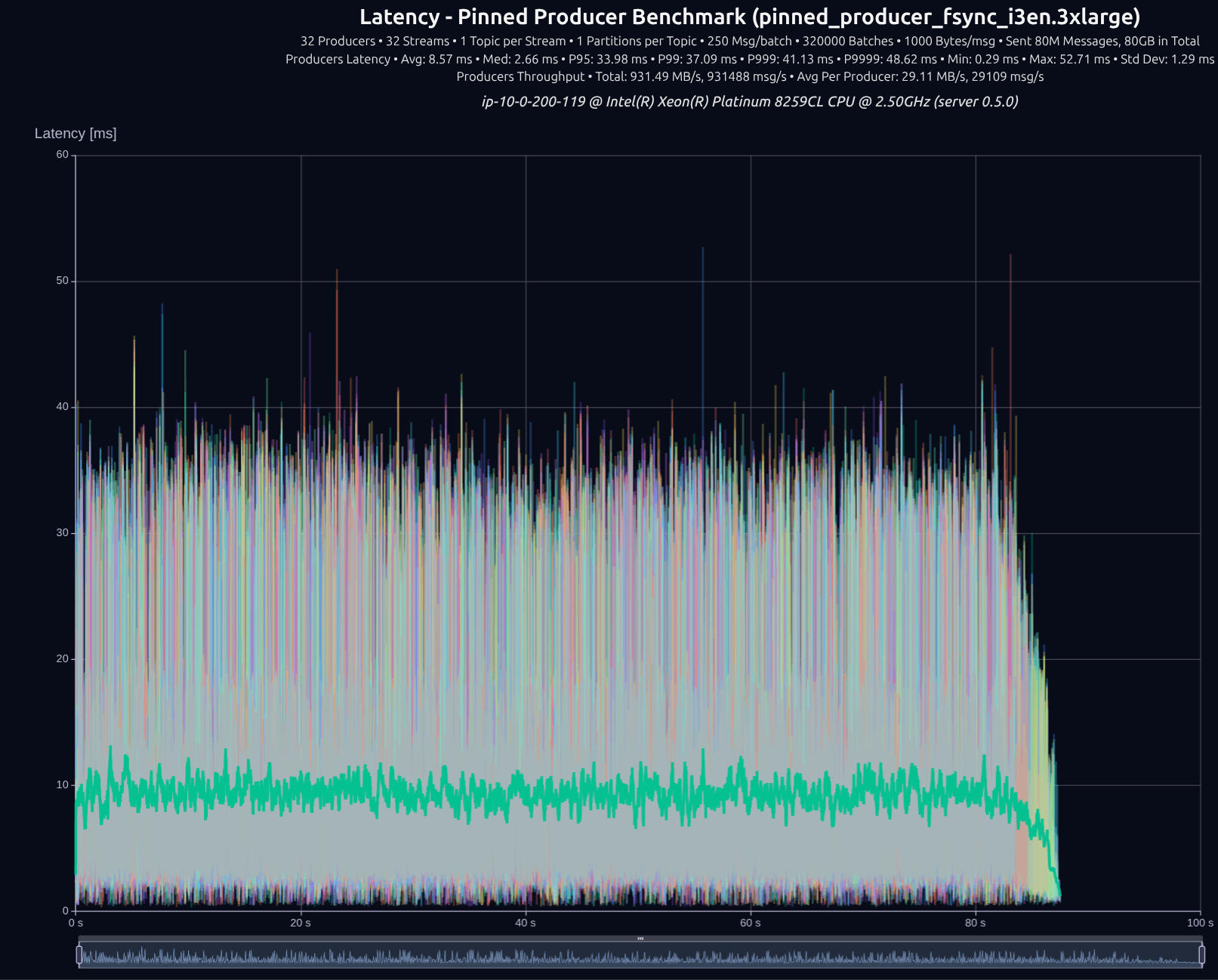
v0.7.0 (shared _something_)
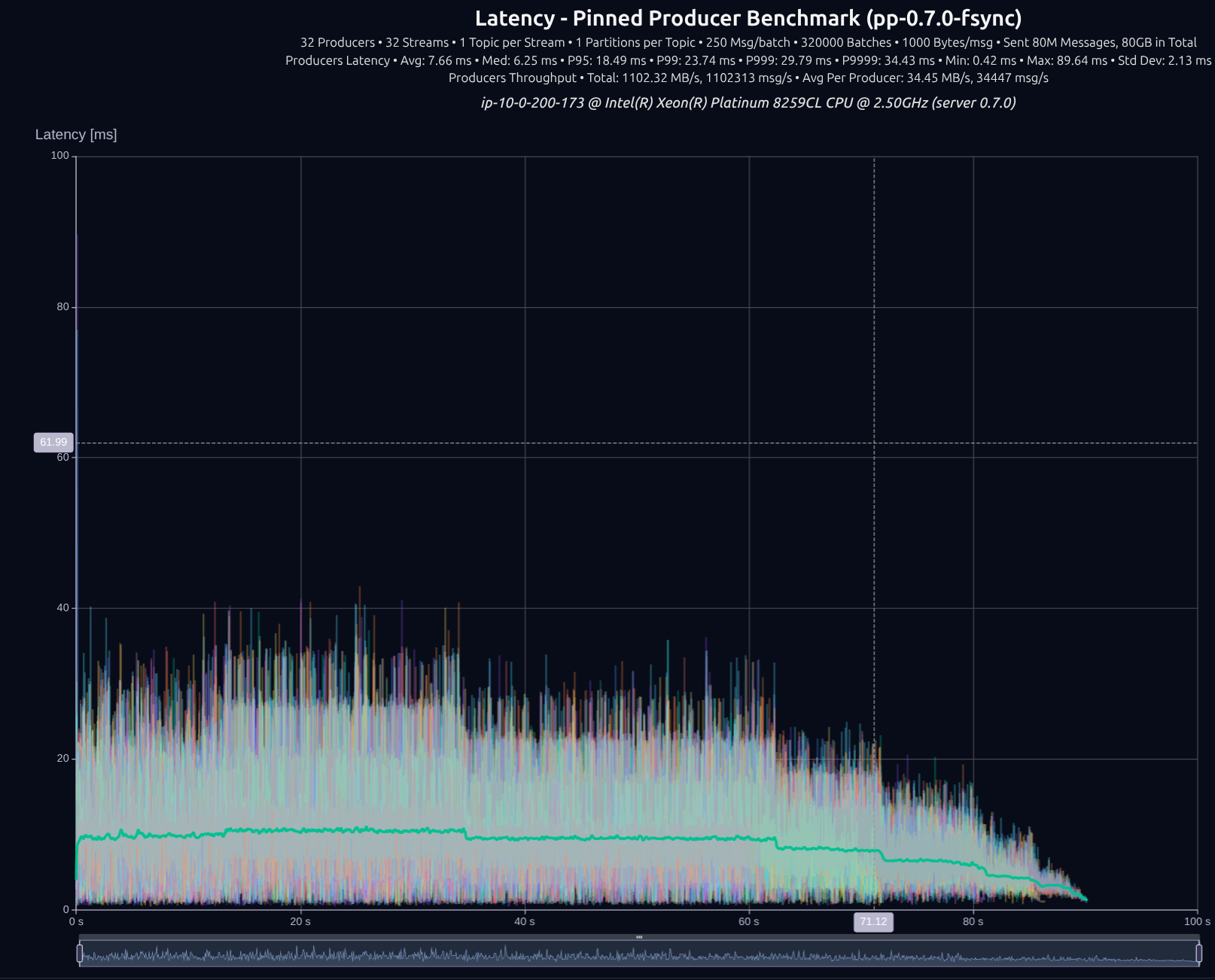
| Version | Throughput/node | P95 | P99 | P999 | P9999 |
|---|---|---|---|---|---|
| v0.5.0 | 931 MB/s | 33.98 ms | 37.09 ms | 41.13 ms | 48.62 ms |
| v0.7.0 | 1,102 MB/s | 18.49 ms | 23.74 ms | 29.79 ms | 34.43 ms |
| Improvement | +18% | -46% | -36% | -28% | -29% |
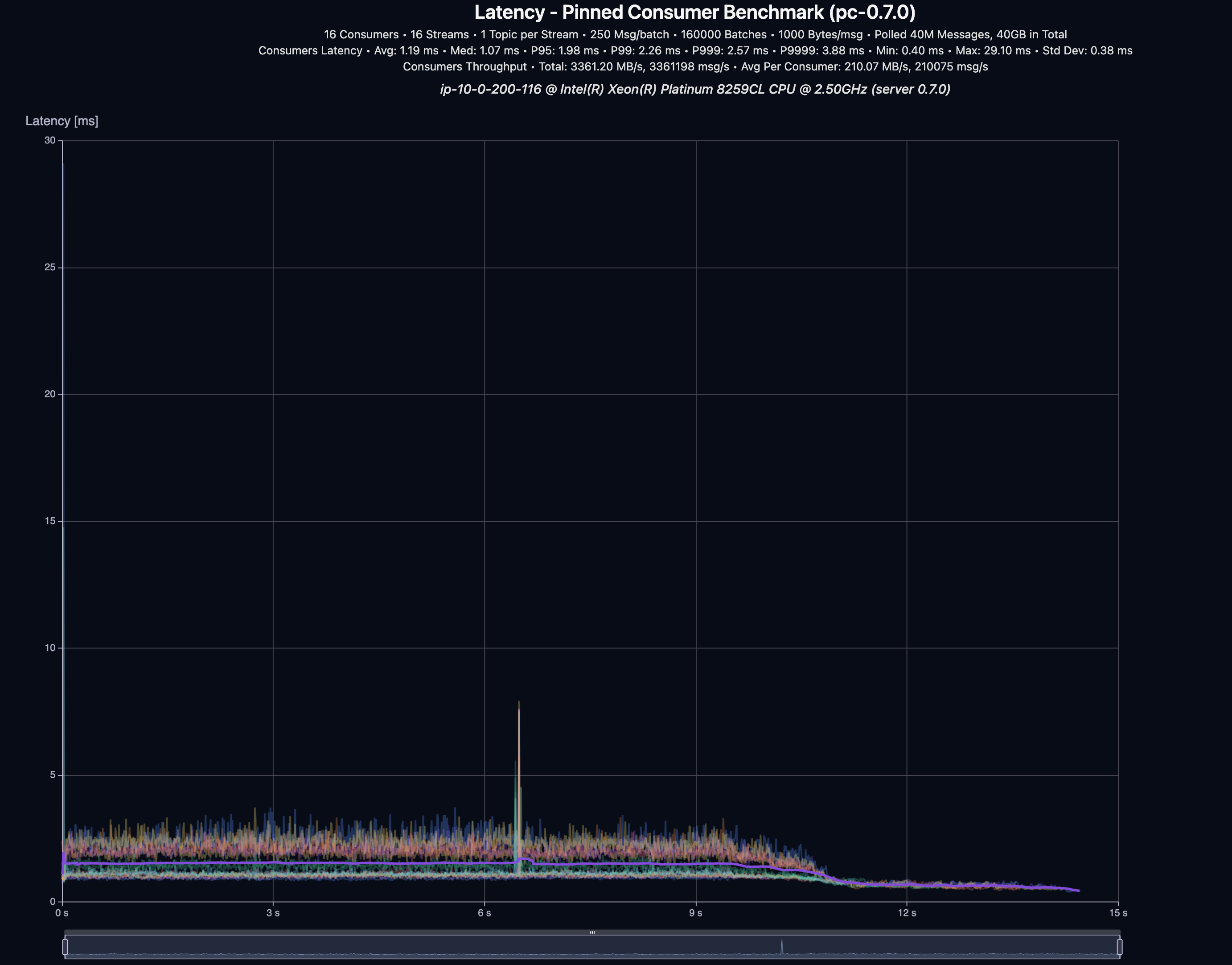
| Throughput | P95 | P99 | P999 | P9999 |
|---|---|---|---|---|
| 3,361 MB/s | 1.98 ms | 2.26 ms | 2.57 ms | 3.88 ms |
마지막으로, 이 블로그 글에서 상당히 많은 디테일을 다루긴 했지만, 사실 가능한 것들의 표면만 살짝 긁었을 뿐입니다. 여러 하위 섹션은 각각 하나의 블로그 글이 될 수도 있습니다. thread-per-core shared-nothing 설계에 대해 더 알아보고 싶다면 Seastar 프레임워크를 확인해 보세요. 이 분야의 SOTA입니다. 이제 우리는 클러스터링에 대한 진행 중인 작업으로 관심을 옮기며, Viewstamped Replication을 사용하고 있습니다.
이에 대한 딥다이브 블로그 글도 곧 나올 예정이니 기대해 주세요. 이제 시작입니다.