에이전트를 ‘도구를 실행하는’ 존재로 재정의하며, MCP를 공통 프로토콜로 보는 관점 전환을 통해 왜 LLM이 반드시 입력 데이터를 가공할 필요는 없는지, 그리고 스트리밍 에이전트·SaaS 통합에서 어떤 실용적 이점과 트레이드오프가 있는지 탐구한다.
감자로 못을 박아본 적 있나요?
저도 없습니다만, 에이전트를 제대로 이해하고, 만들 예시 에이전트를 구상해 보려 할 때 제가 하려던 게 딱 그런 짓처럼 느껴졌습니다.
제가 이전에 Simon Willison을 인용하며 썼듯이, LLM 에이전트는 목표를 달성하기 위해 도구를 루프에서 실행한다. ETL/ELT 파이프라인을 만드는 것과 달리, 이건 현실 세계의 그럴듯한 예로 끼워 맞추기 힘들었던 새로운 개념들이라 애를 먹었습니다.
그건 제가 완전히 잘못 생각하고 있었기 때문입니다.
지난 콜록20 콜록 년 동안 저는 실제로든, 혹은 이전 경험을 바탕으로 예제로든 데이터 처리 파이프라인을 만들어 왔습니다. 항상 같은 패턴입니다:
데이터가 들어오고
데이터가 처리되고
데이터가 나간다
ELT 대 ETL처럼 순서를 조금 바꿀 수도 있고, 특정 예제는 파이프라인의 어느 한 지점에 더 초점을 둘 수도 있지만—개념들은 익숙하게 그대로입니다. 상자에 무엇을 넣을지만 정하면 됩니다:

저는 이것을 확장해서 급조하여 이야기해 오기도 했습니다—애플리케이션과 마이크로서비스(같은 것들)에 대해요. 입력을 받고, 다른 무언가가 일어나게 합니다.

솔직히 제 경험을 약간은 벗어나긴 하지만, 그래도 원리는 같습니다. 이 일이 일어나면, 컴퓨터가 저 일을 하게 만든다.
제가 너무 글자 그대로 받아들이는 건지, 수년간 벤더의 과대선전에 지쳐서 그런 건지, 아니면 그냥 제 뇌 구조가 그런 건지 모르겠습니다만—저는 구체적이고 손에 잡히는 실전 예시를 좋아합니다.
그래서 에이전트 얘기가 나오면, 특히 지금처럼 하이프 사이클이 한창일 때, 이해를 쌓을 수 있는 실제 예시가 정말로 필요했습니다. 게다가 직접 몇 개 만들어 보고도 싶었고요. 하지만 어디서 시작해야 할까요?
이게 제 멘탈 모델이었습니다. 각 상자에 들어갈 현실 세계의 예시를 생각해 보려고 종이에 진짜로 끄적여 본 스케치였죠:
하지만 여기서 막혔습니다. 며칠 동안 공회전만 했죠. 생각나는 예제마다 결국 이렇게 중얼거렸습니다. …근데 왜 굳이 그렇게 해.
첫 번째 실수는 LLM 파트를 입력 데이터에 뭔가를 해야 하는 것으로 생각했다는 겁니다.

저에겐 (예를 들어 riverlevels 같은) 흥미로운 데이터 소스가 잔뜩 있었지만, 머릿속에선 "그건 숫자인데, LLM으로 그걸 대체 뭘 할 수 있지?!"라는 생각이 막혀 있었습니다. 에이전트의 LLM 부분은, 제가 착각하길, 의미 있으려면 비정형 입력 데이터가 필요하다고 여겼죠. 어차피 정형이라면, 그냥 기존 프로세스로 처리하면 되지—여기에 요정 가루가 필요할 이유가 없잖아요.
도구 부분도 마찬가지로 저를 혼란스럽게 했습니다. 돌이켜보면, 정확한 문제가 곧 해결책이었습니다. 설명해 볼게요…
다른 옵션도 있지만, 많은 경우 에이전트가 도구를 호출할 때 MCP를 사용합니다. 그래서, 꼬리로 개를 흔들듯 순서를 거꾸로 잡고, MCP 서버를 찾아 나섰습니다.
어리둥절해진 채, 비정형 데이터 소스를 쓰는 실제 활용 사례를 찾아 헤맸습니다. 오 이런…설마 또 '트윗 스트림을 읽고 주가/크립토 토큰을 조회' 그거를 하자는 건가요?
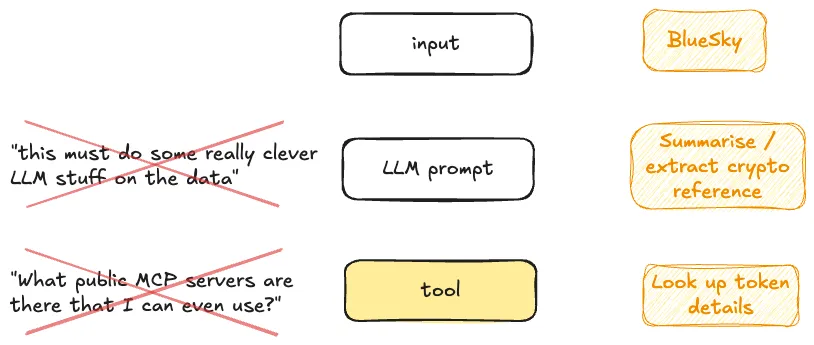
그림 1. 2021년이 전화해서 데모 돌려달래요
제가 저지른 실수는 이겁니다. 에이전트 정의에서 LLM 부분에 초점을 맞췄다는 것:
LLM 에이전트가 목표를 달성하기 위해 도구를 루프에서 실행한다
사실, 에이전트의 핵심은 이겁니다:
[…] 도구를 실행한다
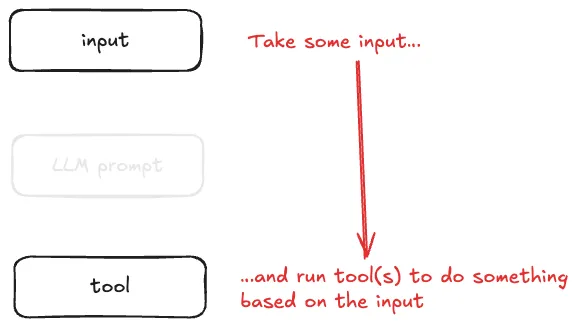
LLM 부분은 _멋진 LLM 기능_을 할 수도 있지만—그건 도구를 호출하고, 도구가 해야 할 일을 했는지 판단하는 역할을 위해서도 존재합니다.
도구는 흔히 API에 대한 래퍼일 뿐입니다. 그러니 MCP를 통해 우리는 API에 대한 공통 인터페이스를 갖게 됩니다. 그게…전부예요.
우리는 시스템과 상호작용하는 에이전트를 정의하고, 그 상호작용 방식은 MCP라는 공통 프로토콜을 통해 이뤄집니다. 우리가 웹 페이지를 로드할 때, 크롬이 내부에서 무엇을 하는지 신경 쓰지 않고, TCP와 HTTP가 쓰인다는 것도 굳이 생각하지 않죠. 그냥 서로가 대화하는 공통 방식일 뿐입니다.
MCP도, 그리고 에이전트의 도구 호출도 그런 아이디어입니다. (네, 에이전트가 도구를 호출하는 다른 방식도 있지만, 현재로선 MCP가 가장 큽니다).
이렇게 관점을 바꾸고 나니, 공개 MCP 서버가 왜 이렇게 적은지 이해가 갔습니다. MCP 서버가 API 접근을 제공한다면, 누가 자기 API를 아무나 쓰게 열어두겠어요? CoinGecko나 AlphaVantage처럼 읽기 전용 데이터를 제공하는 곳이면 모를까.
일반적으로 도구로 진짜 유용하게 할 수 있는 건 _시스템의 상태를 바꾸는 일_입니다. 그래서 쓸만한 SaaS 플랫폼이라면 앞다투어 MCP 서버를 제공하려는 겁니다. 단지 AI 밴드왜건에 올라타려는 게 아니라, 만약 이게 에이전트를 통한 자동화의 공통 프로토콜이 된다면, 모두가 VHS를 쓰는데 혼자 베타맥스를 내놓고 싶진 않으니까요.
SaaS 플랫폼은 여전히 직접 통합을 위한 API를 제공하겠지만, 추가로 MCP 서버도 제공할 겁니다. 이론적으로, 조직 내에서 개발한 애플리케이션도 MCP를 제공하지 못할 이유가 없습니다.
아니요, 꼭 그렇진 않습니다. 제게는 꽤 합리적으로 보입니다. 개인적으로도 SQL 우선, 진짜 코더는 아닌 관점에서 이 접근이 마음에 듭니다.
설명해 볼게요.
어떤 일이 발생했을 때 외부 시스템과 상호작용하도록 시스템을 만들고 싶다면, 지금 선택지는 두 가지입니다:
다른 시스템과 상호작용하고 싶다면, 그 API를 새로 이해하고, 호출 방법을 설계하고, 코드를 다시 써야 합니다.
다른 시스템을 호출하고 싶다면, 에이전트는 거의 그대로 둡니다. 바뀌는 것은 호출하는 MCP 서버와 도구뿐입니다.
물론 커스텀 코드를 작성할 수도 있고—앞으로도 계속 그렇게 해야 하는 좋은 사례들이 있습니다. 하지만 더 이상 반드시 그럴 필요는 없습니다.
카프카를 쓰는 분들께는, 여기서 카프카 커넥트를 통한 데이터 통합을 비유로 들 수 있겠습니다. 카프카 커넥트는 데이터 통합의 끈적하고 지저분한 것들(확장성, 오류 처리, 타입, 연결성, 재시작, 모니터링, 스키마, 등등등)을 처리해 줍니다. 우리는 적절한 커넥터를 골라 설정만 하면 됩니다. 다른 시스템인가요? 커넥터만 바꾸면 됩니다. 바퀴를 다시 발명하고, 이미 해결된 문제를 다시 풀고 _싶으면_요? 얼마든지 하세요; 어쩌면 당신은 특별하니까요. 아니면 NIH(Not Invented Here) 증후군이 진짜일지도 ;P
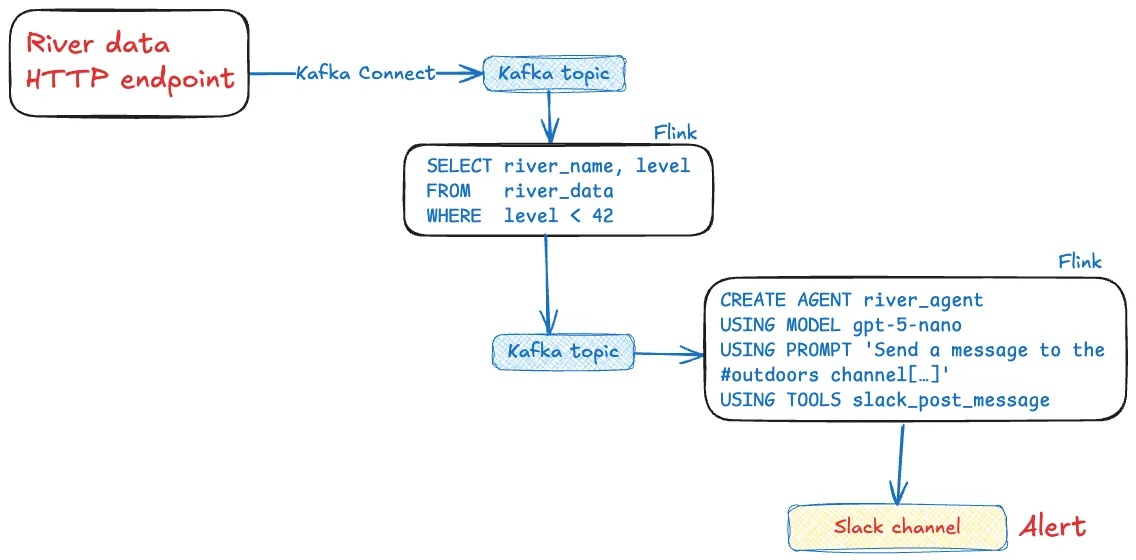
그렇다면…이런 관점으로 보면 실제 에이전트는 어떤 모습일까요? 이렇게요:

물론, LLM이 입력에 대해 똑똑한 일을 할 수도 있습니다. 하지만 우리가 원하는 바를 자연어로 표현하면, 그걸 그대로 실행하게 만들 수도 있습니다.
에이전트는 여러 MCP 서버의 여러 도구를 사용할 수 있습니다.
Confluent는 올해 초 Streaming Agents를 출시했습니다. 완전관리형 Confluent Cloud 플랫폼의 일부로, 위에서 설명한 것 같은 에이전트를 카프카 토픽의 이벤트로 구동하여 실행하는 방법을 제공합니다.
위의 에이전트를 스트리밍 에이전트로 바꾸면 이런 모습입니다:
이거 과설계 아닌가요? 에이전트가 정말 필요한가요? 그냥 이렇게 하면 안 되나요?
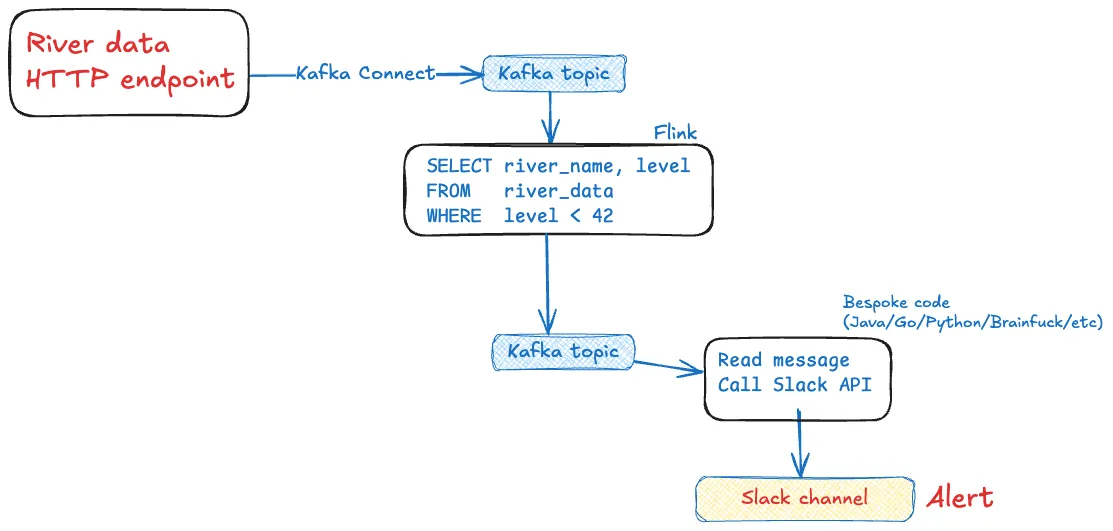
아니면 이렇게?
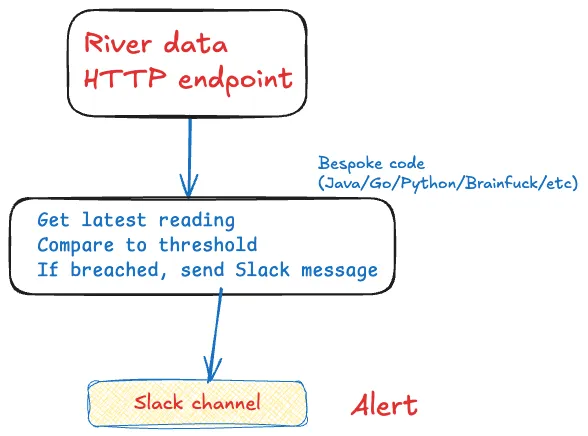
그렇게 해도 됩니다. 어쩌면 그래야 할지도요. 하지만…장애 상황을 잊지 마세요. 그리고 재시작. 테스트. 스케일링.
이런 것들은 전부 Flink가 처리해 줍니다.
현실 점검
런타임 고려사항을 대신 처리해 주는 건 좋지만, LLM이 새롭게 끼워 넣는 또 다른 실패 벡터를 잊으면 안 됩니다: 헛소리 환각. 되는지 안 되는지로 갈리는 파이썬 코드 한 덩어리와 달리, LLM은 때로는 자신만만하게 틀린 일을 저지르며 우리를 긴장하게 만듭니다. 그런데 그게 틀렸다는 걸 우리는 어떻게 알죠? 파이썬 프로그램은 크래시가 나거나, 보기 좋게 처리된 에러를 던질 수 있지만, 방치해 두면 AI 에이전트는 존재하지 않는 파라미터를 지어내 도구를 호출하고도 모든 게 잘됐다고 기쁘게 보고할 수 있습니다.
완화할 수 있는 조치들이 있긴 하지만, 접근법들 간의 트레이드오프를 인식하는 게 중요합니다.
이 논리를 스틸매닝(steel-manning) 방식으로 좀 더 밀어붙이는 걸 허락해 주세요. 꽤 설득력 있는 주장일지도 모르니까요.
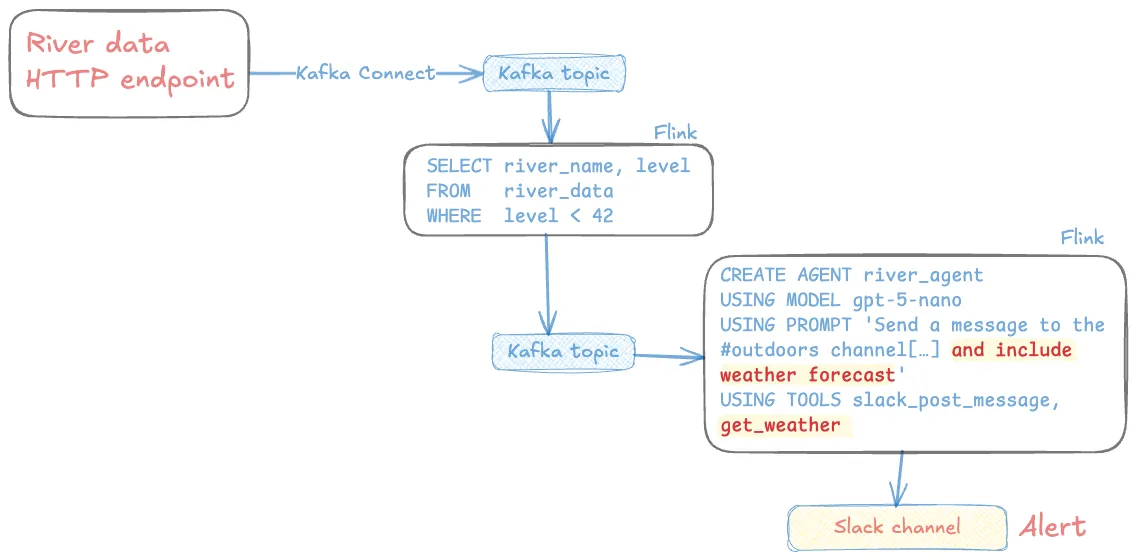
위의 단순한 에이전트—데이터 포인트를 받으면 슬랙으로 메시지를 보내는—를 만들었다고 해 봅시다. 이제 여기에 날씨 예보 정보도 포함하도록 확장하고 싶습니다.
에이전트는 개념적으로 대략 이런 모습일 겁니다:

위의 스트리밍 에이전트는 프롬프트를 수정하고 새 도구를 추가하는 정도로 바뀝니다(MCP 서버와 그 도구를 정의하는 DDL 문 몇 개만 추가):
맞춤형 애플리케이션은 겉보기에는 사소한 변경이 들어갈 수도 있겠죠:
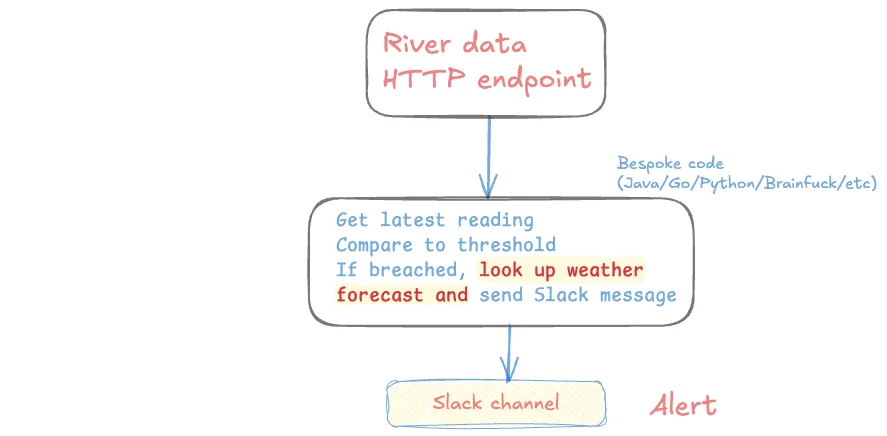
하지만 실제로는 어떤 모습일지 생각해 보세요. API를 파악하고, 호출을 처리할 새 코드 줄들을 추가하고, 장애 처리 등등을 다뤄야 합니다. 아, 그 와중에—맞춤 코드에 버그는 절대 넣지 말아야겠죠. 변경 사항 문서화도 잊지 말고요. 물론 대단히 어려운 일은 아니고, 그런 걸 좋아하는 사람에겐 좋은 도전일 겁니다. 하지만 MCP 덕분에, 에이전트에서 프롬프트를 바꾸고 도구 하나를 추가해서 나머지는 에이전트가 알아서 하게 만드는 것만큼 그렇게 간단할까요?
현실 점검
현실을 너무 미화하진 맙시다. 에이전트에 새 도구 호출을 추가하는 게 확실히 더 쉽고 코드 오류를 덜 유발하긴 하지만, LLM은 본질적으로 비결정적입니다—즉, 프롬프트와 도구 호출을 주의 깊게 설계해 에이전트가 여전히 설계 의도대로 동작하는지 확인해야 합니다. 최소한 비(非) 에이전트 경로(애플리케이션에 API 호출을 직접 코딩하는 방식)는 실제로 테스트하고 제대로 동작함을 증명할 수 있다는 주장은 틀리지 않습니다.
AI 에이전트에는 여러 유형이 있는데—제가 설명한 것은 도구 기반 유형입니다. 위에서 언급했듯, 그 일은 도구를 실행하는 것입니다.
LLM은 도구를 호출하기 위한 자연어 인터페이스를 제공합니다. 또한 선택적으로 다음과 같은 마법을 좀 더 부릴 수도 있습니다:
[비정형] 입력을 처리하기—예를 들어 요약하거나 핵심 값을 추출하기
목표 달성에 필요한 도구(들)를 결정하기
하지만 본질은, 호출되는 도구에 있습니다. 제가 이걸 잘못 생각하고 있던 지점이 바로 여기였습니다. 다르게 생각해야 했던 부분이었죠 :)

Robin Moffatt는 Confluent의 DevRel 팀에서 일한다. 3인칭으로 자기 자신에 대해 글 쓰는 것, 맛있는 아침 식사, 그리고 맛있는 맥주를 좋아한다.