Python으로 x86_64 명령어를 LLVM IR로 리프팅하는 기본 리프터의 구조, 시맨틱, 제어 흐름 복구, 그리고 브라이트닝 과정을 설명합니다.
eversinc33와 BinaryShield를 LLVM IR로 리프팅하는 문제를 논의하던 중, x86_64 명령어를 LLVM IR로 리프팅할 수 있는 기본적인 리프터를 Python으로 작성하면 유용하겠다고 생각하게 되었습니다. 그는 이후 블로그 글 Writing a Naive LLVM-based Devirtualizer를 공개했는데, 꼭 읽어보시길 권합니다! 이 글은 LLVM IR의 기초에 익숙하다고 가정합니다. 몇 가지 참고 자료는 글의 마지막에 정리해 두었습니다.
수년 동안 저는 많은 사람들이 리프터를 탐구하다가 중간에 막히는 것을 보았습니다. 기존 도구들을 컴파일하기가 너무 어렵기 때문입니다. 2025년 10월에는 약 한 달 동안 Remill의 빌드 시스템을 다시 작업했고(remill#723), 이달 초에는 Dna 프로젝트에 대해서도 같은 작업을 했습니다(Dna#9). 작년에는 Python bindings for LLVM 작업도 시작했는데, 이를 실제 프로젝트에 활용하고 싶었습니다. 리프터는 LLVMParty/striga에서 확인할 수 있습니다.
이 글의 목표는 진입 장벽을 낮추고 여러분이 LLVM IR로의 리프팅을 직접 실험해 볼 수 있게 하는 것입니다. 영감을 얻고 싶다면 Back Engineering Labs가 막 공개한 Static Devirtualization of Themida 글과, 3월에 ASU 연구진이 발표한 Pushan: Trace-Free Deobfuscation of Virtualization-Obfuscated Binaries 논문도 참고해 보세요.
이 글이 마음에 들고 더 배우고 싶다면, 오프라인 트레이닝 정보는 제 웹사이트를 참고하세요.
리프팅은 어셈블리 명령어를 어떤 종류의 중간 표현(IR)으로 번역하는 과정입니다. 보통의 동기는 (x86) 어셈블리 명령어를 직접 분석하고 조작하는 일이 복잡하고 오류가 발생하기 쉽기 때문입니다. 리프터는 기저에 있는 명령어의 시맨틱을 직접, 더 추론하기 쉬운 IR로 옮깁니다. 따라서 이후 조작도 더 쉬워집니다.
널리 쓰이는 IR 몇 가지는 다음과 같습니다.
이 프로젝트에서는 LLVM IR을 선택했습니다. 제가 가장 익숙하기도 하고, 잘 확립된 생태계를 갖추고 있기 때문입니다. LLVM에는 이미 일반적인 컴파일러 최적화들이 모두 들어 있으며, 대기업의 팀들이 사용하고 유지보수하고 있습니다.
리프터의 아키텍처는 remill에서 큰 영감을 받았지만, 따라가기 쉽게 몇 가지를 단순화했습니다. LLVM에서 레지스터 는 실제로 SSA 값입니다. 즉, 한 번만 대입할 수 있습니다. 반면 CPU 레지스터는 여러 번 대입될 수 있는 변수 입니다. 이를 모델링하기 위해 x86 CPU 상태를 나타내는 State 구조체를 메모리에 만듭니다.
struct State {
uint64_t rax;
uint64_t rbx;
uint64_t rcx;
uint64_t rdx;
// ... GPRs
uint8_t cf;
uint8_t zf;
uint8_t of;
// ... Flags
// ... XMM
};
RAX를 읽거나 쓰는 명령어는 State->rax에 대해 load/store를 수행합니다. 잘 설계하면 최적화기가 mem2reg 패스를 사용해 이를 SSA 형태로 자동 변환하고, 추가 최적화를 가능하게 해 줍니다.
실제 CPU와의 중요한 차이점 하나는 플래그를 독립적인 8비트 레지스터로 모델링한다는 점입니다. 비트필드로 압축하는 것보다 이렇게 하는 편이 추론하기 쉽습니다. 예를 들어 최적화기가 dead store elimination과 propagation을 수행하는 데 도움이 됩니다.
State 외에도 불투명한 memory 포인터가 필요합니다. 이것은 State 내부에 대한 load/store와 x86 CPU가 수행하는 메모리 접근을 구분하는 데 사용됩니다. 요약하면, State 포인터는 CPU를 모델링하는 데 쓰이고 memory 포인터는 RAM을 모델링하는 데 쓰입니다. 리프팅 중에는 리프팅된 함수의 프로토타입이 void lifted(State* state, void* memory)입니다. 이후에는 이를 다시 컴파일 가능한 형태로 바꾸기 위해 brightening 을 수행할 것입니다.
아래는 mov rax, rcx 명령어에 대한 LLVM IR이며, 주석은 의사 C입니다.
define internal void @lifted_0x140001000(ptr %state, ptr %memory) {
initialize:
; uint64_t* rcx = &state->rcx;
%rcx = getelementptr inbounds nuw %State, ptr %state, i32 0, i32 2
; uint64_t* rax = &state->rax;
%rax = getelementptr inbounds nuw %State, ptr %state, i32 0, i32 0
; Jump to the first instruction
br label %insn_0x140001000
insn_0x140001000: ; preds = %initialize
; uint64_t v0 = *rcx;
%0 = load i64, ptr %rcx, align 4
; *rax = v0;
store i64 %0, ptr %rax, align 4
; Jump to the next instruction
br label %insn_0x140001003
insn_0x140001003: ; preds = %insn_0x140001000
; Block terminator to keep the IR valid
ret void
}
우리는 initialize 블록에서 시작하는데, 이 블록은 관련 State 멤버들에 대한 포인터를 얻는 데 사용됩니다. 그 다음 각 명령어는 insn_<addr>라는 이름의 자체 basic block을 가집니다. 각 명령어는 자신의 후속 블록으로 무조건 분기하는 코드를 생성해야 합니다. 후속 블록의 basic block은 모듈 검증기가 불만을 가지지 않도록 ret terminator만 들어 있는 상태로 생성됩니다.
메모리 접근을 설명하기 위해 mov rax, qword [rbx+42]에 대한 LLVM IR을 보겠습니다.
define internal void @lifted_0x140001000(ptr %state, ptr %memory) {
initialize:
%rbx = getelementptr inbounds nuw %State, ptr %state, i32 0, i32 1
%rax = getelementptr inbounds nuw %State, ptr %state, i32 0, i32 0
br label %insn_0x140001000
insn_0x140001000: ; preds = %initialize
; uint64_t v0 = *rbx;
%0 = load i64, ptr %rbx, align 4
; uint64_t v1 = v0 + 42;
%1 = add i64 %0, 42
; uint8_t* v2 = &memory[v1];
%2 = getelementptr i8, ptr %memory, i64 %1
; uint64_t v3 = *(uint64_t*)v2;
%3 = load i64, ptr %2, align 1
; *rax = v3;
store i64 %3, ptr %rax, align 4
br label %insn_0x140001004
insn_0x140001004: ; preds = %insn_0x140001000
ret void
}
여기서 getelementptr i8, ptr %memory, i64 %1 명령어를 볼 수 있는데, memory를 베이스로 사용함으로써 이것이 x86 메모리에서의 읽기라는 점을 나타냅니다(이 부분은 나중에 정리할 것입니다).
리프터 자체는 약 500줄 정도의 Semantics 클래스에 담겨 있으며, 주요 함수는 다음과 같습니다(간결함을 위해 일부는 생략했습니다).
# src/striga/semantics.py
class Semantics:
def __init__(self, module: Module): ...
# Lifting
def begin(self, address: int) -> Function: ...
def get_or_create_block(self, address: int) -> BasicBlock: ...
def lift_bytes(self, address: int, code: bytes) -> list[Successor]: ...
# Semantic helpers
def reg_read(self, name: str) -> Value: ...
def reg_write(self, name: str, value: Value): ...
def mem_read(self, addr: Value, ty: Type) -> Value: ...
def mem_write(self, addr: Value, value: Value): ...
def op_mem(self, op: X86Op) -> Value: ...
def op_read(self, index: int) -> Value: ...
def op_write(self, index: int, value: Value): ...
def flag_read(self, name: str) -> Value: ...
def flag_write(self, name: str, value: Value): ...
# State (simplified)
module: Module
function: Function
ir: Builder
insn: CsInsn
begin(address) 함수는 LLVM IR 안에 lifted_<address> 함수를 만들고, 첫 번째 명령어로 분기하는 initialize 블록을 생성하는 데 사용됩니다.
def begin(self, address: int) -> Function:
name = f"lifted_{hex(address)}"
fn = self.module.get_function(name)
if fn is None:
fn = self.module.add_function(name, self.lifted_ty)
fn.param_attributes(0).add("noalias")
fn.param_attributes(1).add("noalias")
state, memory = fn.params
memory.name = "memory"
state.name = "state"
self.function = fn
self.reg_ptrs = {}
self.insn_blocks = {}
entry = fn.append_basic_block("initialize")
assert fn.last_basic_block == entry
with entry.create_builder() as ir:
ir.br(self.get_or_create_block(address))
else:
# Omitted for brevity
return self.function
명령어 블록을 만들기 위해서는 get_or_create_block이 사용됩니다.
def get_or_create_block(self, address: int) -> BasicBlock:
block = self.insn_blocks.get(address)
if block is None:
block = self.function.append_basic_block(f"insn_{hex(address)}")
with block.create_builder() as ir:
ir.ret_void()
self.insn_blocks[address] = block
assert block.function == self.function
return block
앞서 언급했듯이, 비어 있는 블록은 유효한 LLVM IR이 아니므로 ret 명령어를 넣어 둡니다. 실제로 그 basic block 안으로 리프팅할 때는 이 명령어가 리프팅된 코드로 대체됩니다.
단일 명령어를 리프팅하려면 주소와 바이트를 lift_bytes에 전달하고, 이 함수가 LLVM IR 생성을 담당합니다.
def lift_bytes(self, address: int, code: bytes) -> list[Successor]:
# Ensure we have a function to lift into
if not hasattr(self, "function"):
self.begin(address)
insn = self.cs_disasm(address, code)
if self.verbose:
print(";", hex(insn.address), insn.mnemonic, insn.op_str)
# Skip lifting if the block is already populated
block = self.get_or_create_block(address)
assert block.first_instruction
if block.first_instruction.opcode == Opcode.Ret:
block.first_instruction.erase_from_parent()
else:
return []
with block.create_builder() as ir:
# State used by semantic handlers
self.ir = ir
self.insn = insn
handler = _semantics.get(insn.mnemonic)
if handler is None and insn.mnemonic.startswith("lock "):
# LOCK preserves the single-threaded architectural result; the
# lifter does not model inter-thread atomicity separately.
handler = _semantics.get(insn.mnemonic.removeprefix("lock "))
if handler is None:
raise NotImplementedError(insn.mnemonic)
successors = handler(self)
if successors is None:
# Linear fallthrough - handler didn't emit a terminator.
fallthrough = address + insn.size
ir.br(self.get_or_create_block(fallthrough))
successors = [Successor(address, self.const64(fallthrough))]
# Make sure the handler produced valid IR
self.module.verify_or_raise()
return successors
이 함수는 먼저 임시 ret 명령어를 제거해 비어 있는 insn_<address> 블록을 보장합니다. 그런 다음 IR Builder를 생성하고, 현재 리프팅 중인 명령어에 대한 IR 생성을 담당하는 핸들러를 호출합니다(이 부분은 아래에서 더 설명합니다). 핸들러가 후속 블록 목록을 반환하지 않으면, lift_bytes는 다음 명령어에 대한 basic block을 만드는 방식으로 일반적인 fallthrough 경우를 처리합니다. Successor 튜플 목록을 처리하는 것은 호출자의 책임입니다.
class Successor(NamedTuple):
src: int
dst: Value
분기 목적지는 항상 구체적 이지는 않기 때문에(예: jmp reg) LLVM Value를 사용합니다.
시맨틱 핸들러는 전역으로 등록됩니다.
# src/striga/semantic.py
SemanticFn: TypeAlias = Callable[["Semantics"], list[Successor] | None]
_semantics: dict[str, SemanticFn] = {}
def semantic(fn: SemanticFn):
name = getattr(fn, "__name__")
_semantics[name.removesuffix("_")] = fn
return fn
# src/striga/x86/data.py
@semantic
def mov(sem: Semantics):
value = sem.op_read(1)
sem.op_write(0, value)
각 핸들러는 Semantics 인스턴스를 전달받는데, 이를 통해 오퍼랜드, 레지스터, 플래그, 메모리 같은 x86 구성 요소에 쉽게 접근할 수 있습니다. 예를 들어 op_read는 다음과 같이 구현됩니다.
def op_read(self, index: int) -> Value:
op: X86Op = self.insn.operands[index]
if op.type == CS_OP_REG:
name = self.reg_name(op.reg) # pyright: ignore[reportAssignmentType]
return self.reg_read(name)
if op.type == CS_OP_IMM:
return self.const_n(op.imm, op.size * 8)
if op.type == CS_OP_MEM:
addr = self.op_mem(op)
return self.mem_read(addr, self.types.int_n(op.size * 8))
assert False
예제 mov rax, rcx의 경우 이 함수는 reg_read로 전달됩니다.
def reg_read(self, name: str) -> Value:
if name in self.reg_types:
load = self.ir.load(self.reg_types[name], self.reg_ptr(name))
load.metadata["tbaa"] = self.tbaa_tags[name]
return load
full_name, size, bit_offset = self.subregs[name]
load = self.ir.load(self.reg_types[full_name], self.reg_ptr(full_name))
load.metadata["tbaa"] = self.tbaa_tags[full_name]
if bit_offset:
load = self.ir.lshr(load, self.const64(bit_offset))
return self.ir.trunc(load, self.types.int_n(size))
이 함수는 eax, ax, al, ah 같은 부분 레지스터 접근을 투명하게 처리하며, 로드된 레지스터 값을 담은 LLVM Value를 반환합니다. 마지막으로 남은 조각은 함수 엔트리에서 getelementptr를 만드는 역할을 하는 reg_ptr 함수입니다.
def reg_ptr(self, name: str) -> Value:
reg_ptr = self.reg_ptrs.get(name)
if reg_ptr is not None:
return reg_ptr
entry = self.function.entry_block
state = self.function.get_param(0)
with entry.create_builder() as ir:
ir.position_before(entry.terminator)
reg_ptr = ir.struct_gep(self.state_ty, state, self.reg_indices[name], name)
self.reg_ptrs[name] = reg_ptr
return reg_ptr
최적화기를 돕기 위해 레지스터 load/store 명령어에 TBAA Metadata를 추가합니다. 이 경우 우리는 레지스터들 간의 load/store가 서로 alias하지 않는다는 사실을 알고 있습니다. 이를 최적화기에 알려 주면, 리프팅된 명령어 시퀀스를 최적화할 때 더 공격적인 dead-store elimination을 수행할 수 있습니다.
지금까지 리프터의 아키텍처를 설명했지만, 실제로 다룬 명령어는 mov뿐이었습니다. 다른 거의 모든 명령어는 더 복잡한 동작을 가지며, 특히 플래그 처리 주변이 그렇습니다. 예를 들어 and/or/xor의 구현은 다음과 같습니다.
# src/striga/x86/bitwise.py
def write_logical_flags(sem: Semantics, result: Value):
false = sem.const_n(0, 1)
sem.flag_write("cf", false)
sem.flag_write("pf", sem.result_parity_even(result))
sem.flag_write_undef("af")
sem.flag_write("zf", sem.result_is_zero(result))
sem.flag_write("sf", sem.result_sign_bit(result))
sem.flag_write("of", false)
def logical_binop(sem: Semantics, opcode: Opcode):
dst = sem.op_read(0)
src = sem.resize_int(sem.op_read(1), dst.type)
result = sem.ir.binop(opcode, dst, src)
sem.op_write(0, result)
write_logical_flags(sem, result)
@semantic
def and_(sem: Semantics):
logical_binop(sem, Opcode.And)
@semantic
def or_(sem: Semantics):
logical_binop(sem, Opcode.Or)
@semantic
def xor(sem: Semantics):
logical_binop(sem, Opcode.Xor)
참고로 xor rax, rbx에 대해 리프팅된 LLVM IR과, 각 부분에 대응하는 Python 코드는 아래와 같습니다.
insn_0x140001000: ; preds = %initialize
; dst = sem.reg_read(0)
%0 = load i64, ptr %rax, align 4
; src = sem.resize_int(sem.op_read(1), dst.type)
%1 = load i64, ptr %rbx, align 4
; result = sem.ir.binop(Opcode.Xor, dst, src)
%2 = xor i64 %0, %1
; sem.op_write(0, result)
store i64 %2, ptr %rax, align 4
; sem.flag_write("cf", false)
store i8 0, ptr %cf, align 1
; sem.flag_write("pf", sem.result_parity_even(result))
%3 = trunc i64 %2 to i8
%4 = lshr i8 %3, 4
%5 = xor i8 %3, %4
%6 = lshr i8 %5, 2
%7 = xor i8 %5, %6
%8 = lshr i8 %7, 1
%9 = xor i8 %7, %8
%10 = and i8 %9, 1
%11 = icmp eq i8 %10, 0
%12 = zext i1 %11 to i8
store i8 %12, ptr %pf, align 1
; sem.flag_write_undef("af")
%13 = call i1 @__striga_undef_af(i64 5368713216)
%14 = zext i1 %13 to i8
store i8 %14, ptr %af, align 1
; sem.flag_write("zf", sem.result_is_zero(result))
%15 = icmp eq i64 %2, 0
%16 = zext i1 %15 to i8
store i8 %16, ptr %zf, align 1
; sem.flag_write("sf", sem.result_sign_bit(result))
%17 = lshr i64 %2, 63
%18 = trunc i64 %17 to i1
%19 = zext i1 %18 to i8
store i8 %19, ptr %sf, align 1
; sem.flag_write("of", false)
store i8 0, ptr %of, align 1
; Semantics.lift_bytes
br label %insn_0x140001003
자세히 보면 __striga_undef_af 호출이 보일 텐데, 이것은 LLVM IR 안에 명확한 대응물이 없는 것을 표현하기 위한 사용자 정의 intrinsic 입니다. 이 경우 xor 명령어 설명에는 다음과 같이 쓰여 있습니다.
OF와 CF 플래그는 클리어되고, SF, ZF, PF 플래그는 결과에 따라 설정된다. AF 플래그의 상태는 정의되지 않는다.
이는 Intel/AMD가 실리콘에서 AF 값이 정확히 어떻게 계산되는지를 문서화하고 싶어 하지 않는다는 뜻입니다. 실제로는 이것이 CPU 모델이나 세대에 따라 달라질 수 있으며, 안티 에뮬레이션 기법으로 악용될 수도 있지만 이 글에서는 자세히 다루지 않겠습니다. 우리는 사용자가 이를 원하는 방식으로 처리할 수 있도록 __striga_undef_af를 출력합니다. 관심이 있다면 이를 올바르게 모델링하는 방법에 대한 간단한 논의가 있는 remill#766를 참고하세요.
여기서 강조할 또 다른 명령어 종류는 다양한 분기 명령어입니다.
# src/striga/x86/control.py
def conditional_jump(sem: Semantics, cond: Value):
brtrue = sem.insn.operands[0].imm
brfalse = sem.insn.address + sem.insn.size
sem.ir.cond_br(
cond,
sem.get_or_create_block(brtrue),
sem.get_or_create_block(brfalse),
)
src = sem.insn.address
return [
Successor(src, sem.const64(brtrue)),
Successor(src, sem.const64(brfalse)),
]
def jcc(sem: Semantics, cc: str):
return conditional_jump(sem, cc_cond(sem, cc))
@semantic
def je(sem: Semantics):
return jcc(sem, "e")
@semantic
def jmp(sem: Semantics):
dst = sem.op_read(0)
if dst.is_constant:
sem.ir.br(sem.get_or_create_block(dst.const_zext_value))
else:
sem.ir.call(sem.jmp_handler, [dst])
sem.ir.ret_void()
return [Successor(sem.insn.address, dst)]
@semantic
def call(sem: Semantics):
dst = sem.op_read(0)
fallthrough = sem.insn.address + sem.insn.size
sem.push(sem.const64(fallthrough))
sem.ir.call(sem.call_handler, [dst])
sem.ir.br(sem.get_or_create_block(fallthrough))
return [Successor(sem.insn.address, sem.const64(fallthrough))]
@semantic
def ret(sem: Semantics):
dst = sem.pop(sem.i64)
if sem.insn.operands:
rsp = sem.reg_read("rsp")
sem.reg_write("rsp", sem.ir.add(rsp, sem.const64(sem.insn.operands[0].imm)))
sem.ir.call(sem.ret_handler, [dst])
sem.ir.ret_void()
return [Successor(sem.insn.address, dst)]
je imm에 대한 LLVM IR:
insn_0x140001000: ; preds = %initialize
%0 = load i8, ptr %zf, align 1
%1 = icmp ne i8 %0, 0
br i1 %1, label %insn_0x140001014, label %insn_0x140001002
insn_0x140001014: ; preds = %insn_0x140001000
ret void
insn_0x140001002: ; preds = %insn_0x140001000
ret void
}
jcc의 시맨틱 핸들러는 플래그에 기반한 적절한 조건과 함께, 목적지 블록 둘 다와 br 명령어를 직접 생성해야 한다는 점에 주목하세요.
jmp rbx에 대한 LLVM IR:
insn_0x140001000: ; preds = %initialize
%0 = load i64, ptr %rbx, align 4
call void @__striga_jmp(i64 %0)
ret void
call imm에 대한 LLVM IR:
insn_0x140001000: ; preds = %initialize
%0 = load i64, ptr %rsp, align 4
%1 = sub i64 %0, 8
store i64 %1, ptr %rsp, align 4
%2 = getelementptr i8, ptr %memory, i64 %1
store i64 5368713221, ptr %2, align 1
call void @__striga_call(i64 5369761797)
br label %insn_0x140001005
ret에 대한 LLVM IR:
insn_0x140001000: ; preds = %initialize
%0 = load i64, ptr %rsp, align 4
%1 = getelementptr i8, ptr %memory, i64 %0
%2 = load i64, ptr %1, align 1
%3 = add i64 %0, 8
store i64 %3, ptr %rsp, align 4
call void @__striga_ret(i64 %2)
ret void
}
보시다시피 다음 intrinsic들을 사용합니다.
__striga_jmp: 간접 점프__striga_call: call 명령어__striga_ret: ret 명령어이들도 사용자가 이러한 명령어를 어떻게 처리할지 유연하게 선택할 수 있도록 해 줍니다.
모든 명령어를 하나의 basic block으로 두는 설계 선택 덕분에, 단순한 함수의 제어 흐름을 복구하는 일은 꽤 직관적입니다.
def lift(module: Module, container: Container, start: int, *, verbose=True):
sem = Semantics(module, verbose=verbose)
lifted_fn = sem.begin(start)
queue: Queue[Successor] = Queue()
queue.put(Successor(0, sem.const64(start)))
# Keep destinations as LLVM Values instead of splitting constants into ints.
# This keeps the worklist uniform and matches later slicing/data-flow uses.
visited: set[Value] = set()
while not queue.empty():
src, dst = queue.get()
if not dst.is_constant:
if sem.verbose:
print(f"; non-constant branch destination: {hex(src)} -> {dst}")
continue
if dst in visited:
continue
visited.add(dst)
va = dst.const_zext_value
code = container.get_data(va, 15)
successors = sem.lift_bytes(va, code)
for successor in successors:
if successor.dst in visited:
continue
queue.put(successor)
sem.module.verify_or_raise()
return lifted_fn
이것은 제어 흐름 그래프 위에서의 단순한 너비 우선 탐색이며, 간접 분기가 없는 함수들을 복구할 수 있게 해 줍니다. 루프를 나타내는 back edge나 block splitting을 처리하기 위해 특별한 일을 할 필요가 없다는 점에 주목하세요. 리프팅된 코드는 명령어당 하나의 LLVM basic block으로 모델링되므로, 명령어들을 임의로 연결할 수 있습니다.
아래는 단순한 제어 흐름(if/else/loop)을 가진 함수입니다.
test_cfg:
cmp rax, 0
je .else_block
.if_true:
add rax, 1
jmp .merge
.else_block:
add rax, 2
.merge:
sub rax, 1
jne .merge
.exit:
ret
디스어셈블리의 그래프는 다음과 같습니다.
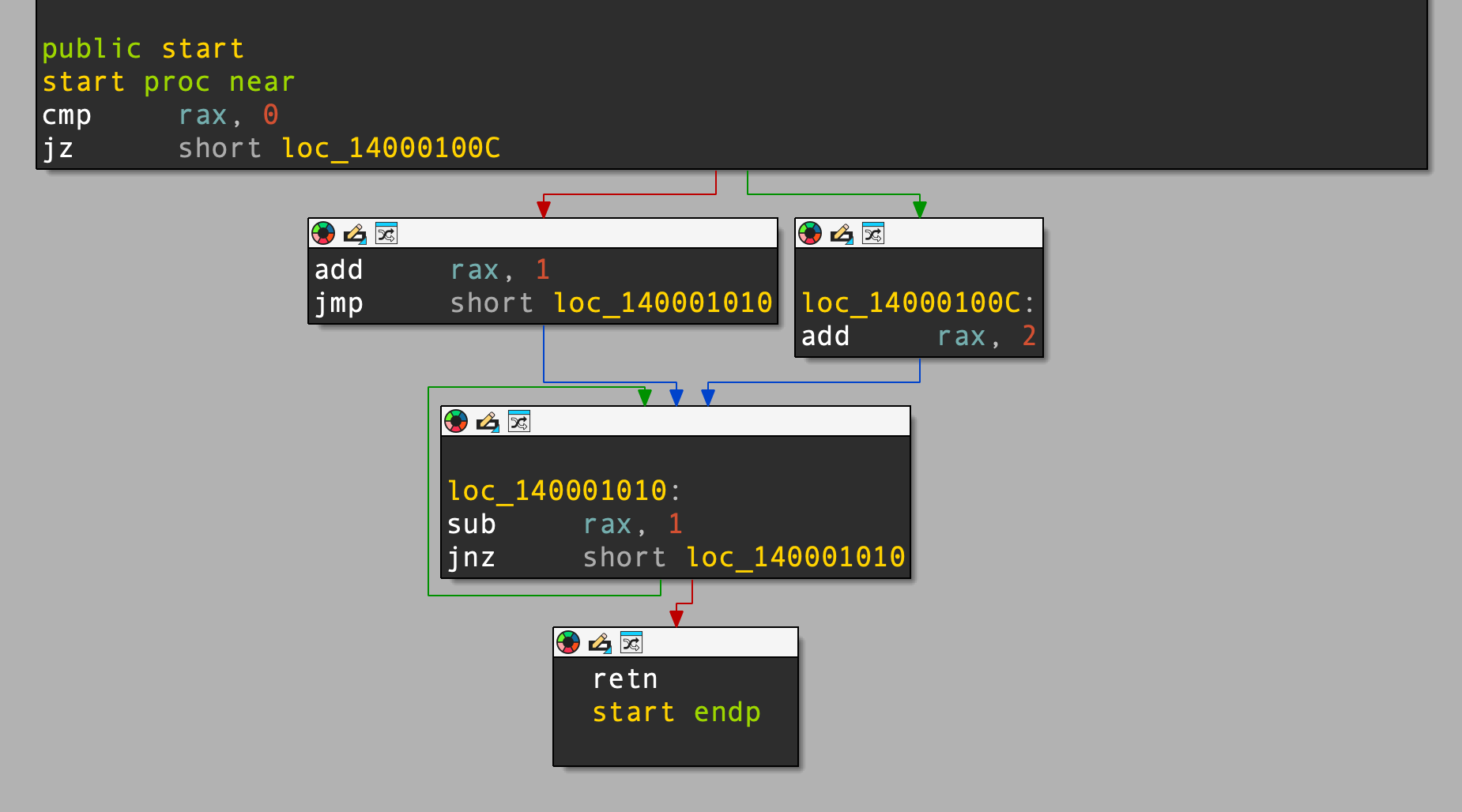
LLVM IR은 다음과 같습니다.
define internal void @lifted_0x140001000(ptr %state, ptr %memory) {
initialize:
%rax = getelementptr inbounds nuw %State, ptr %state, i32 0, i32 0
%zf = getelementptr inbounds nuw %State, ptr %state, i32 0, i32 51
%rsp = getelementptr inbounds nuw %State, ptr %state, i32 0, i32 6
br label %insn_0x140001000
insn_0x140001000: ; preds = %initialize
; cmp rax, 0
%0 = load i64, ptr %rax, align 4
%1 = sub i64 %0, 0
%19 = icmp eq i64 %1, 0
%20 = zext i1 %19 to i8
store i8 %20, ptr %zf, align 1
br label %insn_0x140001004
insn_0x140001004: ; preds = %insn_0x140001000
; je 0x14000100c
%30 = load i8, ptr %zf, align 1
%31 = icmp ne i8 %30, 0
br i1 %31, label %insn_0x14000100c, label %insn_0x140001006
insn_0x14000100c: ; preds = %insn_0x140001004
; add rax, 2
%32 = load i64, ptr %rax, align 4
%33 = add i64 %32, 2
store i64 %33, ptr %rax, align 4
br label %insn_0x140001010
insn_0x140001006: ; preds = %insn_0x140001004
; add rax, 1
%62 = load i64, ptr %rax, align 4
%63 = add i64 %62, 1
store i64 %63, ptr %rax, align 4
br label %insn_0x14000100a
insn_0x140001010: ; preds = %insn_0x140001014, %insn_0x14000100a, %insn_0x14000100c
; sub rax, 1
%92 = load i64, ptr %rax, align 4
%93 = sub i64 %92, 1
store i64 %93, ptr %rax, align 4
%111 = icmp eq i64 %93, 0
%112 = zext i1 %111 to i8
store i8 %112, ptr %zf, align 1
br label %insn_0x140001014
insn_0x14000100a: ; preds = %insn_0x140001006
; jmp 0x140001010
br label %insn_0x140001010
insn_0x140001014: ; preds = %insn_0x140001010
; jne 0x140001010
%122 = load i8, ptr %zf, align 1
%123 = icmp ne i8 %122, 0
%124 = xor i1 %123, true
br i1 %124, label %insn_0x140001010, label %insn_0x140001016
insn_0x140001016: ; preds = %insn_0x140001014
; ret
%125 = load i64, ptr %rsp, align 4
%126 = getelementptr i8, ptr %memory, i64 %125
%127 = load i64, ptr %126, align 1
%128 = add i64 %125, 8
store i64 %128, ptr %rsp, align 4
call void @__striga_ret(i64 %127)
ret void
}
명확성을 위해 일부 플래그 계산은 이 IR 덤프에서 생략했습니다.
브라이트닝은 2019년 Peter Garba와 Matteo Favaro가 SATURN 논문에서 만든 용어입니다.
Brightening [COMP.]verb – 코드를 사람이 더 읽기 쉽고 이해하기 쉬운 형태로 재구성하는 것
구체적으로는 LLVM IR을 리프팅된 형태의 코드(의사 C)에서:
/*
Lifted instructions:
add rdi, rsi
mov rax, rdi
ret
*/
void lifted(State* state, void* memory) {
state.rdi += state.rsi;
state.rax = state.rdi;
__striga_ret(...);
}
다음과 같이 리프팅된 플랫폼의 호출 규약을 따르는 일반 함수 형태로 되돌리는 것을 의미합니다.
// Linux calling convention: https://wiki.osdev.org/System_V_ABI#x86-64
uint64_t /* rax */ brightened(uint64_t /* rdi */ x, uint64_t /* rsi */ y) {
return x + y;
}
brightened 함수는 스택 위에 State를 설정하고, 대상 플랫폼 호출 규약에 맞는 레지스터에 인자를 배치합니다. 결과 레지스터는 함수의 반환값으로 되돌립니다. 개념 자체는 그렇게 어렵지 않지만, 이 트릭을 이해하려면 약간의 사고 전환이 필요합니다.
// Symbolic variable for memory
uint8_t RAM[0];
void lifted(State* state, void* memory) { ... }
uint64_t brightened(uint64_t x, uint64_t y) {
State state;
state.rdi = x;
state.rsi = y;
lifted(&state, RAM);
return state.rax;
}
인라이닝 패스를 거치면 대략 다음과 같이 보일 것입니다.
uint64_t brightened(uint64_t x, uint64_t y) {
State state;
state.rdi = x;
state.rsi = y;
state.rdi += state.rsi;
state.rax = state.rdi;
__striga_ret(...);
return state.rax;
}
이 경우 __striga_ret intrinsic을 제거할 수 있고, 그러면 최적화기가 함수를 원래의 형태로 축약할 수 있습니다.
uint64_t brightened(uint64_t x, uint64_t y) {
return x + y;
}
최적화 전 LLVM IR:
define i64 @brightened_0x1000(i64 %0, i64 %1) {
entry:
%state = alloca %State, align 8
%rdi = getelementptr inbounds nuw %State, ptr %state, i32 0, i32 5
store i64 %0, ptr %rdi, align 4
%rsi = getelementptr inbounds nuw %State, ptr %state, i32 0, i32 4
store i64 %1, ptr %rsi, align 4
%stack = alloca i8, i64 4096, align 1
%2 = getelementptr i8, ptr %stack, i64 4088
%3 = ptrtoint ptr %2 to i64
%rsp = getelementptr inbounds nuw %State, ptr %state, i32 0, i32 6
store i64 %3, ptr %rsp, align 4
store i64 3735928559, ptr %2, align 1
call void @lifted_0x1000(ptr %state, ptr @RAM)
%rax = getelementptr inbounds nuw %State, ptr %state, i32 0, i32 0
%4 = load i64, ptr %rax, align 4
ret i64 %4
}
default<O1>로 모듈을 최적화한 뒤:
define i64 @brightened_0x1000(i64 %0, i64 %1) {
entry:
%2 = add i64 %1, %0
ret i64 %2
}
메모리 접근을 처리하기 위해 전역 RAM 변수를 만들고 이를 memory 인자로 전달합니다. 앞선 예제에서는 이것이 사라졌지만, 일반적으로는 별도로 처리해야 합니다. 가장 단순한 형태는 포인터 매개변수에 대한 접근입니다.
uint64_t lift4_read(uint64_t *n) {
return *n ^ 1337;
}
현재 브라이트닝 전략으로는 최적화 후 리프팅된 코드가 다음과 같이 보입니다.
define i64 @brightened_0x1000(i64 %0) {
entry:
%1 = getelementptr i8, ptr @RAM, i64 %0
%2 = load i64, ptr %1, align 1, !alias.scope !19, !noalias !22
%3 = xor i64 %2, 1337
ret i64 %3
}
우리는 getelementptr i8, ptr @RAM, i64 %0 형태를 감지해서 이를 inttoptr 명령어로 바꿔야 합니다.
define i64 @brightened_0x1000(i64 %0) {
entry:
%1 = inttoptr i64 %0 to ptr
%2 = load i64, ptr %1, align 1, !alias.scope !19, !noalias !22
%3 = xor i64 %2, 1337
ret i64 %3
}
스택은 로컬 스택 변수를 할당하고 rsp가 그 버퍼의 끝을 가리키도록 하는 방식으로 모델링할 수 있습니다(x86에서는 스택이 낮은 주소 방향으로 자라기 때문입니다).
uint64_t brightened(uint64_t x, uint64_t y) {
uint8_t stack[4096];
State state;
state.rdi = x;
state.rsi = y;
state.rsp = (uint64_t)&stack[sizeof(stack) - 8];
lifted(&state, RAM);
return state.rax;
}
이 모든 것을 brighten.py에서 합치면 다음과 같습니다.
from llvm import Linkage, Module, Opcode, Value, global_context
from bfs import lift_bfs
from container import Container, RawContainer
OPT_PIPELINE = "default<O1>"
def rewrite_ram_geps(module: Module, ram: Value):
"""Replace GEPs rooted at @RAM with inttoptr(address)."""
types = module.context.types
for gep in ram.users:
if not gep.is_instruction or gep.opcode != Opcode.GetElementPtr:
raise ValueError(f"unexpected @RAM user: {gep}")
if gep.get_operand(0) != ram:
raise ValueError(f"unexpected @RAM GEP base: {gep}")
if gep.num_operands == 2:
if gep.gep_source_element_type != types.i8:
raise ValueError(f"expected i8 ptradd-style @RAM GEP: {gep}")
address = gep.get_operand(1)
elif gep.num_operands == 3:
zero = gep.get_operand(1)
if not zero.is_constant_int or zero.const_zext_value != 0:
raise ValueError(f"expected zero first @RAM GEP index: {gep}")
address = gep.get_operand(2)
else:
raise ValueError(f"unexpected @RAM GEP shape: {gep}")
with gep.create_builder() as ir:
ptr = ir.inttoptr(address, types.ptr)
gep.replace_all_uses_with(ptr)
gep.erase_from_parent()
if not ram.users:
ram.delete_global()
module.verify_or_raise()
def define_ret_stub(module: Module):
"""Make the modeled return hook removable for this demo wrapper."""
ret_handler = module.get_function("__striga_ret")
if ret_handler is not None and ret_handler.is_declaration:
ret_handler.linkage = Linkage.Internal
entry = ret_handler.append_basic_block("entry")
with entry.create_builder() as ir:
ir.ret_void()
def lift_brightened(container: Container, entry: int, args: list[str]):
with global_context().create_module("blog") as module:
sem = lift_bfs(module, container, entry, verbose=True)
# Convenience aliases
types = module.context.types
i8 = types.i8
i64 = types.i64
# Global RAM array
ram = module.add_global(types.array(i8, 0), "RAM")
# TODO: support different register sizes
brightened_ty = types.function(i64, [i64 for _ in args])
brightened = module.add_function(f"brightened_{hex(entry)}", brightened_ty)
with brightened.create_builder() as ir:
state = ir.alloca(sem.state_ty, "state")
def reg_ptr(name: str) -> Value:
return ir.struct_gep(sem.state_ty, state, sem.reg_indices[name], name)
# Assign arguments to register state
for i, name in enumerate(args):
ir.store(brightened.get_param(i), reg_ptr(name))
# Set up function stack
stack = ir.alloca(i8, i64.constant(4096), "stack")
stack_ptr = ir.gep(i8, stack, [i64.constant(4096 - 8)])
ir.store(ir.ptrtoint(stack_ptr, i64), reg_ptr("rsp"))
# Set up return address
retaddr_store = ir.store(i64.constant(0xDEADBEEF), stack_ptr)
retaddr_store.inst_alignment = 1
# Call lifted function
ir.call(sem.function, [state, ram])
# Load return value from rax and return it
ir.ret(ir.load(i64, reg_ptr("rax")))
module.verify_or_raise()
# 1. Inline/optimize with @RAM assigned to the lifted memory parameter.
module.optimize(OPT_PIPELINE)
# 2. Brighten lifted memory: @RAM + integer address -> inttoptr(address).
rewrite_ram_geps(module, ram)
# 3. Now that RAM accesses have been brightened, discard the modeled ret
# hook for this demo and let LLVM clean up the remaining wrapper noise.
# Undefined flag helpers are already declared memory(none) by Semantics,
# so their dead uses fold away without local stub definitions.
define_ret_stub(module)
module.verify_or_raise()
module.optimize(OPT_PIPELINE)
print(brightened)
이 코드는 다음과 같은 (최적화되지 않은) 함수를 깔끔하게 리프팅합니다.
; 0x1000 push rbp
; 0x1001 mov rbp, rsp
; 0x1004 mov qword ptr [rbp - 8], rdi
; 0x1008 mov rax, qword ptr [rbp - 8]
; 0x100c pop rbp
; 0x100d ret
define i64 @brightened_0x1000(i64 returned %0) {
entry:
ret i64 %0
}
이 글이 LLVM IR로의 리프팅에 대한 유익한 입문이 되었기를 바랍니다. LLVMParty/striga 저장소도 자유롭게 둘러보시고, 흥미로운 작업을 하게 되면 꼭 알려 주세요!
참고: Striga는 프로덕션 준비가 된 리프터를 목표로 하지 않습니다. 테스트가 없고, x86의 아주 제한적인 부분집합만 구현되어 있습니다.
리뷰어들에게 감사드립니다.
LLVM IR 참고 자료: