2013년 시작된 자바스크립트용 스트림 API 설계의 배경과 Streams Standard의 의의, 그리고 최근 제기된 비판에 대한 반박과 개선점에 대한 고찰.
URL: https://domenic.me/streams-standard/
Title: On the Streams Standard
2013년, 나는 자바스크립트를 위한 새로운 스트림 API를 설계하는 프로젝트를 시작했다. 목적은 Node.js의 스트림에서 얻은 교훈(“streams2로의 전환” 포함)을 배우고, 개발 중인 여러 웹 API를 뒷받침할 수 있는 무언가를 만드는 것이었다. 이 사이트에는 내가 API의 발전을 되돌아보며 쓴 몇 편의 에세이가 있다. 특히 파일 vs. 소켓처럼 서로 다른 기반 자원들이 어떻게 하나의 원시(primitive) 뒤로 추상화될 수 있는지 고민하며 작업하던 시기의 기록이다.
그 결과물이 Streams Standard였다. 이 기초 클래스들은 이제 fetch()부터 번역까지, 매우 다양한 웹 API를 구동한다. Streams Standard API는 URL, EventTarget, AbortController, fetch(), Worker, 등 다른 웹 표준과 비슷한 방식으로, 여러 다른 자바스크립트 생태계에도 편입되었다.
최근 James Snell이 Streams Standard API를 비판하고, 자바스크립트 생태계에 더 적합하다고 믿는 대안을 제안하는 글 “We deserve a better streams API for JavaScript”을 발표했다. 나는 이 문제 영역에서의 James의 작업과 통찰을 높이 평가한다. 그 글에는 여러 타당한 지점이 있다—James는 실제 약점들을 짚어냈고, 그 부분은 곧 다루겠다—하지만 높은 수준에서의 프레이밍에는 의문스러운 점이 많고, 몇몇은 그저 혼동되어 있거나 틀렸다.
그러니 이 기회에 James의 주장들을 파고들어 보자. 그러면서 플랫폼 원시를 설계할 때 내가 어떻게 생각했는지에 대한 약간의 통찰과, 앞으로 플랫폼을 전진시킬 사람들을 위한 조언도 함께 전할 수 있기를 바란다.
James의 글에서 가장 답답한 부분 중 하나는, 그가 자신의 구현에서 나타난 성능 문제가 근본적이며 표준의 설계 결정에서 비롯된다고 믿는 점이다. 이는 구현자가 명세 텍스트의 단계를 자바스크립트 코드로 옮겨 적기만 하면, 아무 추가 노력 없이 바로 좋은 성능이 나올 수 있다고 여기는 순진한 태도를 드러낸다.
잠깐 한 발 물러나 표준이 어떻게 작동하는지 바라보면, 이것이 터무니없다는 걸 금방 알 수 있다. 만약 어떤 자바스크립트 엔진이 문자열을 16비트 코드 유닛 벡터로 구현해 놓고는, 문자열 연결이나 === 비교에서 좋은 성능을 내기 어렵게 만든 “근본적 설계 결정”을 탓하며 징징댄다면, 아무도 그들을 진지하게 받아들이지 않을 것이다. 표준은 따르기 쉽게 쓰이고, _관측 가능한 결과_를 못 박아 서로 다른 구현들이 같은 결과를 내게 하는 것이 목적이다. 표준은 구현 로드맵이 아니며, 성능을 내는 것은 플랫폼 엔지니어의 업무 중 큰 부분이다.
Streams Standard는 가능한 한 많은 것을 관측 불가능하게(unobservable) 만들기 위해 큰 노력을 기울인다. 최적화된 fast path를 구현할 수 있도록 하기 위해서다. 이는 여러 층위에서 설계에 녹아 있다. 예컨대 잠금(locking) 시스템 덕분에 stream1.pipeTo(stream2)는 sendfile(2) 호출로 최적화될 수 있다. async iteration 같은 고수준 API 덕분에, 일반적인 경우에는 promise 객체나 { value, done } 컨테이너를 할당할 필요조차 없다. James는 “The hidden cost of promises”라는 섹션 전체를 할애해 다음과 같이 말하며 시작한다.
Each
read()call doesn’t just return a promise; internally, the implementation creates additional promises for queue management,pull()coordination, and backpressure signaling.
하지만 “구현(the implementation)”은 그가 통제한다! 그 promise들 중 어떤 것도 개발자의 자바스크립트로 명시적으로 노출되지 않는 한, 굳이 만들 필요가 없다. James의 “GC thrashing in server-side rendering” 섹션도 비슷한 오해를 드러낸다. 명세가 객체를 만들라고 하면, 실제로 가비지 컬렉션되는 객체를 매번 할당해야 한다고 가정하기 때문이다.
“The optimization treadmill”이라는 섹션에서 James는 잘 작성된 런타임이라면 이런 문제를 겪지 않아도 된다는 점을 어느 정도 인식하는 듯하다. 하지만 그 방식이 이상하다. 그는 이런 기초적인 성능 작업을 다음과 같이 깎아내린다.
every major runtime has resorted to non-standard internal optimizations
그리고 이렇게 불평한다.
Finding these optimization opportunities can itself be a significant undertaking. It requires end-to-end understanding of the spec to identify which behaviors are observable and which can safely be elided.
이에 대해 나는 뭐라고 답해야 할지 잘 모르겠다. 다만 그게 일이다. V8이 자바스크립트 표준을 구현하든, ICU가 유니코드 표준을 구현하든, Chromium이 URL 표준을 구현하든, Cloudflare Workers가 Streams Standard를 구현하든, 목표는 좋은 성능의 구현을 만드는 것이다. 만약 그 부분이 싫다면, Vercel이 했듯이 AI 에이전트에게 시켜도 된다. 하지만 그걸 “지속 불가능한 복잡성”이라고 불평하는 건, 프로덕션 런타임을 만드는 사람에게서 나올 태도로는 놀랍다.
이런 식으로 구현 품질 문제를 표준 탓으로 돌리는 패턴은 James의 글 다른 곳에서도 계속된다. 예를 들어 “Exhausting resources with unconsumed bodies” 섹션에서는 Node.js 버그를 불평하고, “Falling headlong off the tee() memory cliff”에서는 “구현들이 자기들만의 전략을 개발해야 했다”고 다시 불평하며, 올바른 접근으로 손을 잡고 이끌어 주지 않았다고 탓한다.
요약하자면: 표준 기반 API를 순진한 구현만 보고 평가하는 것은 부당하다. 그렇게 하면, 당연히 표준을 맞출 필요가 없는 당신의 처음부터 만든 라이브러리가 더 빠를 것이다. 또한 원래 표준 API 구현에서 다양한 버그를 고친 뒤에 작성했으니 버그도 더 적을 것이다.
James의 글에서 마찬가지로 혼란스러운 부분은 “The compliance burden” 섹션이다. 그는 … API가 너무 잘 테스트된다고 불평한다?
표준 API에 대한 포괄적 테스트 스위트의 부상은 2010년대의 가장 큰 승리 중 하나다. 웹 플랫폼 테스트 프로젝트와 그 안의 Interop 202X 스프린트 같은 노력은, 우리가 2000년대의 지옥도를 벗어나는 데 아마도 가장 큰 요인이었다. 오늘날에도 상호운용성은 완벽하진 않지만, 지금 마주치는 엣지 케이스는 Internet Explorer, Netscape/Firefox, Safari가 EventTarget를 서로 다르게 구현해 jQuery 같은 정규화 레이어가 필요했던 시절과는 비교도 되지 않는다.
현시대의 문화는 명확하다. 관측 가능한 모든 것에는 테스트가 필요하다. 일반적인 경우만이 아니라, 오류 시나리오, 무효화(invalidation), 다른 기능과의 통합: 두 구현이 갈라질 수 있는 어떤 것이든. 커버리지 공백을 발견해서 구현들이 서로 다르게 동작한다면, 테스트를 추가하라.
James는 이렇게 불평한다.
For runtime implementers, passing the WPT suite means handling intricate corner cases that most application code will never encounter. The tests encode not just the happy path but the full matrix of interactions between readers, writers, controllers, queues, strategies, and the promise machinery that connects them all.
대부분의 애플리케이션 코드가 엣지 케이스를 만나지 않는 것은 사실이다. 하지만 인터넷 규모에서는 “대부분”을 제외하고도 소수 쪽에 속한 좌절한 개발자들이 여전히 매우 많다! 표준의 강점 중 하나는 흔한 경우만이 아니라 모든 개발자 시나리오를 상호운용적으로 지원하겠다는 약속이다. 이는 다중 구현 표준과, 누군가 npm에 올리거나 nodejs/node의 main 브랜치에 넣는 라이브러리를 가르는 중요한 구분점 중 하나다.
James의 큰 틀의 입장은 혼란스럽다고 생각하지만, 더 미시적인 수준에서는 그가 Streams Standard API의 여러 약점을 찾아낸 데 동의한다. 이들 중 다수는 선행자인 Node.js 스트림을 지나치게 가깝게 따르면서 생겼고, 13년의 후견지명 속에서 공동체가 개선 가능성을 찾아낸 것은 자연스럽다.
나는 James의 “BYOB: complexity without payoff” 섹션에 대체로 동의한다. 돌이켜 보면 BYOB 스트림은 이론에 너무 많은 비중을 두고, 실제 성능과 사용성에는 충분히 맞추지 못한 채 설계되었다. 초기 논의에서 Node.js 코어 팀원들은 Node.js 스트림이 항상 버퍼 복사를 요구한다는 점을 후회한다고 했고, 그래서 Takeshi Yoshino와 나는 이 문제를 풀어보려 달려갔다.
현실에서는 memcpy()가 그렇게 느리지 않다. 그리고 보안이나 아키텍처적 이유로 어차피 종종 필요하다. 데이터는 커널 공간/사용자 공간 경계, 프로세스 경계, 혹은 네트워크 스택과 자바스크립트 힙 사이를 넘어 이동해야 하기 때문이다. transferral 메커니즘으로 데이터 레이스를 피하기 위해 기울였던 주의는, 2017년에 SharedArrayBuffer가 출시되면서 어느 정도 퇴색했다. 또한 0-copy writable 또는 transform 스트림에 대한 설계를 끝내 내놓지 못했다는 사실도 분명 부정적 신호다.
복사 횟수를 줄여 유의미한 속도 향상을 얻는 시나리오를 상상할 수는 있지만, 현재 내 생각으로는 이를 범용 스트림 원시에 baked-in 시켜서 자바스크립트 스트림 생성자, 소비자, 라이브러리 개발자가 모두 깊게 관여해야 할 필요는 없다. 대신 구현이 백그라운드에서 수행할 수 있는, 관측 불가능한 최적화들 중 하나로 남겨도 된다.
James의 “Backpressure: good in theory, broken in practice” 섹션은 실제 문제를 건드린다. Streams Standard의 백프레셔 개념은 Node.js streams1/streams2 설계에서 쓰던 소박한 접근에서 왔다. (이를 약간 현대화하고, "readable" 리스너를 추가하면 백프레셔 모드가 전환되는 것 같은 까다로운 디테일은 제거했다.) 자발적인 desiredSize + ready promise 접근보다 더 나은 모델이 있을 수 있다는 점은 충분히 그럴듯하다.
James의 새 라이브러리에는 명시적인 네 가지 백프레셔 모드가 포함되어 있다. 이 네 가지 모두가 실제 애플리케이션에서 유용한지, 또는 Node.js/Streams Standard 설계만큼 전장에서 검증되었는지는 나는 모른다. 기본값으로 “strict” 백프레셔를 택한 것은 맞지 않을 가능성이 커 보인다. 빠른 인터넷에서는 잘 동작하다가도 사용자의 휴대폰 신호가 한 칸으로 떨어지면 예외를 던지는 코드를, 서버 사이드 개발자들이 많이 원할 것 같지 않기 때문이다. 하지만 전반적으로 개발자에게 더 많은 제어권을 주는 것은 좋은 아이디어일 가능성이 높다는 데 동의한다.
비슷하게, 그는 teeing 시 백프레셔를 처리하는 두 가지 별도 모드를 제안하며 개발자가 둘 중 하나를 선택하게 한다. 이는 좋은 아이디어이고, Streams Standard에도 제안된 바 있다.
Transform 스트림 역시 Streams Standard가 Node.js 선행자에게 너무 영향을 받은 영역이다. James가 “Transform backpressure gaps”에서 하는 불평은 주로 transform이 느긋하게(read 시 실행) 동작하지 않고, write 시점에 eager하게 실행된다는 점이다. 우리는 Streams Standard에서 이 문제를 확실히 인지하고 있지만, 원인은 James가 설명하는 것과는 조금 다르다.
핵심 문제는 WritableStream이 내부 큐잉은 원하지 않지만 단일 write 하나는 받아들일 의향이 있다는 신호를 보낼 방법이 없다는 것이다. 대표 이슈는 whatwg/streams#1158이고, 이 표현력 공백을 메우기 위한 드래프트 PR도 있다. 그 일환으로, 기본값을 lazy transform으로 만들고, transform 내부의 큐잉은 명시적인 highWaterMark 옵션이 전달된 경우에만 생기게 할 것이다.
하지만 그 해결책이 작동하는 방식이 복잡하다는 점은 다음 포인트로 이어진다…
Streams Standard에서 우리가 내린 가장 큰 초기 결정은 스트림 생태계의 각 절반을 자체 완결적으로(self-contained) 만드는 것이었다. 즉, underlying sources에 의해 뒷받침되는 ReadableStream과, underlying sinks에 의해 뒷받침되는 WritableStream이다. 다시 말해, 이것도 Node.js 스트림 API에서 영감을 받았는데, Node.js도 같은 패턴을 사용했다(다만 단일 클래스로 뭉개져 있었지만).
주요 대안으로 제안된 것은 두 절반을 합쳐 단일 “채널(channel)” 원시를 두는 것이었다. 예를 들면 다음과 같다.
const { readable, writable } = new Channel();
여기서 소비자 코드에는 readable을 넘겨주고, writable에 써서 채울 수 있다. 혹은 생산자 코드에 writable을 넘겨주고, 자신은 readable을 유지해 그들이 무엇을 썼는지 볼 수도 있다.
지금까지도 어떤 설계가 더 나은지 나는 확신하지 못한다. 당시에는 채널 설계가 우리의 목표 중 일부를 달성하기엔 충분히 강력하지 않다고 스스로를 설득했다. 하지만 뒤돌아보면, Node.js 스트림에 가깝게 유지하려는 욕구에 너무 영향을 받았고, 대안을 공정하게 평가하지 못했던 것 같다. James의 새 라이브러리는 실제로 채널 접근을 택하고 있다. 그리고 그의 라이브러리가 보여주듯, 채널 설계는 transform도 크게 단순화한다.
채널 설계는 너무 단순할 수도 있다. 특히 상태 관리와 큐잉을 둘러싼 몇몇 패턴은 Streams Standard API가 대신 관리해 줄 때 훨씬 쉽다. 채널 타입 API에서는 개별 스트림 생성자가 그 패턴들을 직접 구현해야 하고, 사람마다 조금씩 다르게 구현할 수도 있다. 하지만 내 직감으로는, 그런 패턴들이 2013년에 우리가 예상한 것보다 결국 더 드물었던 것 같다. 그래서 나는 이 대체 진화 경로에 대한 탐색에 조심스러운 낙관을 가지고 있다.
James의 라이브러리에서 특정 설계 선택에 대한 짧은 코멘트 몇 가지:
오류 처리: James의 글과 라이브러리에서 가장 큰 공백은 오류 처리에 대한 논의가 전혀 없다는 점이다. 이는 무섭다! 스트림의 오류 처리는 제대로 만들기 가장 어려운 것 중 하나이었고, Node.js에 비해 Streams Standard에서 개선한 점들 중 내가 가장 자랑스러워하는 영역 중 하나다. 읽기 스트림의 무과실(no-fault) cancelation, 쓰기 스트림의 오류에 가까운 aborting, underlying sink/source에서 오는 오류, 그리고 스트림들이 서로 연결되었을 때 이것들이 어떻게 전파되는지는 꽤 복잡하며, 프로그램의 정합성을 보장하는 데 결정적이다. 나는 Streams Standard의 이 설계가 완벽하다고 주장하지 않는다—특히 AbortSignal 이전에 설계되어 그들과 잘 통합되지 않는다—하지만 이 영역이 반드시 주목받아야 한다는 점을 강조하고 싶다.
바이트 전용: 이것이 생태계의 요구를 충족할지 회의적이다. 텍스트나 JSON에서 파싱한 객체처럼, 데이터를 비바이트 형식으로 변환하는 것이 너무 편리하기 때문이다. 하지만 만약 충족한다면, 분명 엄청난 단순화가 된다. 여기서의 우려는 생태계가 바이트 스트림(제임스의 라이브러리로 처리)과 객체 스트림(여러 다른 유틸리티로 처리)으로 양분될 수 있다는 점이다.
동기/비동기 분리: 나는 이것이 나쁜 아이디어라고 생각한다. 소비자가 데이터가 동기 소스에서 오는지 비동기 소스에서 오는지 신경 쓰게 만들고, 각각에 대해 별도의 소비 메서드를 제공하는 것은 고생길이다. 대신 동기 소비 훅은 구현 내부에 숨겨져 존재해야 하며, James가 그렇게 구현하길 꺼리는 fast-path 최적화의 일부가 되어야 한다. 소비자는 체인의 끝에서 단 하나의 promise 비용만 지불하면 되고, 그로써 애플리케이션 코드 한가운데에서 Zalgo를 풀어놓는 일을 피할 수 있다.
스트림은 iterable이다: 이는 메서드를 가진 객체 vs. 독립 함수라는 오래된 논쟁일 뿐이다. 나는(적어도 자바스크립트에서는) 메서드를 가진 객체가 API 설계 전쟁에서 결정적으로 이겼다고 생각한다. 그래서 이 점에서 James의 라이브러리는 개발자 경험 측면에서 후퇴라고 본다. 관련해서 James는 스트림의 내부 상태 머신을 많이 불평하지만, (그가 async iterable을 만들기 위해 쓰는) async generator도 그에 못지않게 복잡한 상태 머신을 갖고 있다는 점은 무시하는 듯하다.
잠금 없음: James는 Streams Standard의 잠금 API를 좋아하지 않고, 나도 개선될 여지가 있다고 본다. 하지만 “그냥 async iterator를 써라”라는 그의 설계는 잠긴 스트림이 제공하는 많은 최적화 기회를 무력화한다. 자바스크립트 코드가 언제든 iterable.next()를 호출할 수 있는데, 어떻게 async iterable 파이프라인 체인을 sendfile(2)로 바꿀 수 있겠는가? 어쩌면 이건 “대부분의 애플리케이션 코드는 결코 마주치지 않을, 복잡한 코너 케이스”일지도 모르고, 누가 테스트를 작성하지 않는 한 우리는 괜찮을지도…
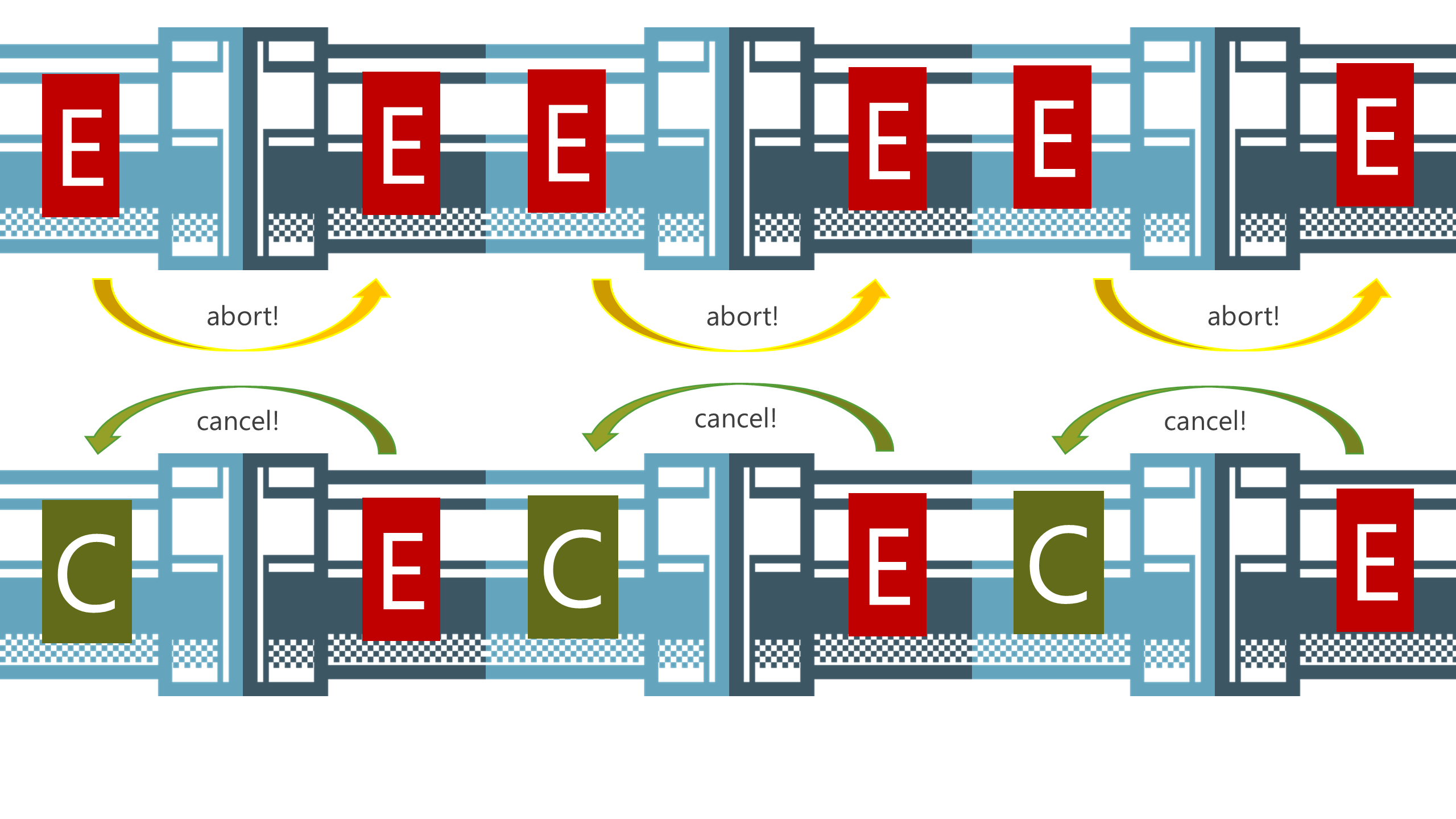
내 2014년 발표 Streams for the Web에서 가져온 슬라이드로, 파이프 체인을 따라 abort와 cancelation이 어떻게 흐르는지 보여준다.
이 대화를 시작해 준 James에게 감사한다. 덕분에 나 자신과 다른 많은 사람들이 수년에 걸쳐 Streams Standard에 쏟아부은 작업을 되돌아볼 기회를 얻었다. 물론 완벽하진 않다. 하지만 핵심 아이디어 중 상당수는 견고하다고 생각한다. 그리고 버그가 있거나 순진한 구현을 근거로 판단할 것이 아니라, 잘 구현할 수도 못 구현할 수도 있는 표준으로서 평가하는 것이 중요하다.
좋든 싫든, 웹 API는 영원하다. 웹이 두 번째 스트림 API를 갖게 되지는 않을 것이다. 따라서 브라우저 코드와 같은 원시를 사용하고 싶은 자바스크립트 생태계의 영역들에겐, 처음부터 다시 시작하기보다는 Streams Standard를 진화시키고 개선하는 편이 아마 더 생산적일 것이다. Streams Standard 스트림이나 Node.js 스트림이라는 고릴라들 옆에서 돌아가는 2차 스트림 생태계를 만들려는 수많은 | 이전 | 시도들이 있었고, 그들 나름의 제한적인 성공을 거두었다. 나는 James의 라이브러리가 그 전통 안에서 가능한 한 큰 성공을 거두길 바란다.
불행히도 Streams Standard를 진화시키는 것은 어렵다. 2010년대의 ZIRP 전성기에는 나와 협업자들이 promise, 스트림, 모듈, 웹 컴포넌트 같은 원시들을 만들 수 있었다. 웹 플랫폼의 기초를 정비하는 일에는 비즈니스적 지원이 컸다. 요즘은 상황이 다르다. 지금 있는 것이 ‘충분히 좋기’ 때문에, 브라우저 회사의 디렉터들이 점진적 개선에 예산을 쓰도록 설득하기가 훨씬 어렵다. 그래서 사소한 개선조차도 수년간 멈춰 서 있곤 한다. 영웅들이 명세 텍스트, 웹 플랫폼 테스트, 브라우저 구현 한두 개까지 혼자 기여해 새 기능을 밀어붙일 수는 있다. 하지만 새 자바스크립트 라이브러리를 하나 쓰는 것보다 확실히 어렵다.