SemiAnalysis의 분해 분석은 Huawei Kirin 9030과 SMIC N+3 공정을 통해, 중국의 최첨단 로직 밀도 달성과 그에 따른 복잡성·효율·공정 제어의 대가를 보여준다.
거의 4년 전, 우리는 SMIC가 7 nm (N+1) 칩 출하를 시작했다고 공개했다. 이제 SMIC는 Huawei의 Kirin 9030에 3세대 7 nm (N+3) 공정을 출하하고 있으며, 최소 금속 피치 32.5 nm를 달성했다. 이는 Intel의 최신 Panther Lake CPU가 18A에서 출하하는 36 nm 최소 금속 피치보다 약 10% 더 촘촘하다.
제목은 사실이지만, 불완전하게 선택된 지표다. N+3는 공격적인 DUV 멀티패터닝과 설계-기술 공동 최적화(DTCO)를 통해 TSMC N6 수준의 밀도에 도달하지만, 그 대가로 복잡성, 효율, 공정 제어 측면에서 비용을 치른다.
우리는 SMIC의 N+3 공정 기술, Huawei의 패키징, 메모리, 아키텍처 등을 다루는 리버스 엔지니어링 및 분해 분석에서 이것과 그 이상을 확인했다. SemiAnalysis는 지난 1년 반 동안 세계에서 가장 앞선 중요 칩들을 분석할 수 있는 최첨단 분해 분석 연구소를 Oregon에 구축해 왔다. 우리는 이미 최근의 주요 TSMC 고객 COUPE CPO optical engine + EIC 3D stack 리버스 엔지니어링을 포함해 고급 데이터센터 칩 분해 분석으로 매출을 창출했다.
이번 보고서는 SemiAnalysis Teardown Engineering & Evaluation Lab, 줄여서 STEEL의 첫 공개 보고서다. 이 연구소는 공격적으로 규모를 확장하고 있으며, 우리는 이를 공개적으로 발표하게 되어 기쁘다. 이는 수십 년 동안 사실상 신뢰할 만한 경쟁이 없었던 가운데 private equity 소유 하에 현재 매각 중인 TechInsights에는 다소 불편한 시점이다. 그 결과 TechInsights는 CAPEX 투자를 소홀히 해왔다.
SemiAnalysis는 venture나 private equity 소유 없이도, 그리고 창업 6년밖에 되지 않았음에도 매출 면에서 TechInsights를 앞선다. 우리는 외부 투자자가 없고 창업자가 직접 이끄는 회사이기 때문에 더 빠르게 움직이고, 더 빠르게 구축하며, 주요 고객에 대해서는 데이터센터에 집중하면서도 고객용 칩 분해 분석을 정기적으로 무료 공개할 수 있다.
다음은 우리 연구소의 첫 공개 이미지인 HiSilicon Kirin 9030 Pro SoC다:
HiSilicon Kirin 9030 다이 주석. 출처: SemiAnalysis
이 보고서는 Kirin 9030 분해 분석과 중국에서 가장 앞선 SMIC의 N+3 공정에 대한 우리의 발견을 자세히 다룬다. 비교를 위해 TSMC N6에서 제작된 MediaTek Helio G99의 분해 분석도 함께 제시한다. 이 비교를 통해 수출 통제의 효과를 볼 수 있다. SMIC N+3와 TSMC N6는 비슷한 노드지만, 하나는 강력한 수출 통제 대상이고 다른 하나는 서방의 가장 앞선 장비를 자유롭게 사용할 수 있다.
여기서 우리는 중국의 진전과 제약을 동시에 본다. SMIC N+3는 TSMC N6 수준의 로직 밀도에 도달하지만, 훨씬 더 공격적인 DUV 멀티패터닝이 필요하므로 공정 성숙도나 비용 면에서는 N6와 같지 않다. Kirin 9030 Pro는 3년 전 Android 플래그십과 비슷한 성능을 내지만, Apple, Qualcomm, MediaTek, Samsung의 현재 플래그십 SoC보다는 크게 뒤처진다. 효율 격차는 더 크다.
수출 통제는 Huawei와 SMIC의 첨단 실리콘 출하를 막지 못했지만, 다른 경로를 강제했다. EUV 없이 SMIC는 DUV 멀티패터닝, DTCO, 점점 더 복잡한 통합에 더 크게 의존하고 있다. 로드맵은 더 엄격한 설계 규칙과 backside power를 통해 계속 전진하지만, 단계마다 비용과 공정 리스크가 늘어난다. Huawei의 τ scaling과 LogicFolding은 또 다른 길을 보여준다. 즉, active logic을 적층하고 고급 패키징과 system-technology co-optimization (STCO)을 통해 밀도를 회복하는 것이다.
Kirin 9030을 이해하려면 먼저 Huawei의 SoC 역사를 이해해야 한다. HiSilicon은 Huawei의 칩 설계 부문으로, Kirin 스마트폰 SoC, Kunpeng 서버 CPU, Ascend AI accelerator, 그리고 switch/router 네트워킹 실리콘을 담당한다.
수출 통제 이전에 Huawei는 TSMC의 최대 고객 중 하나였다. TSMC의 첫 EUV 노드 N7+의 유일한 고객이었고, Apple과 함께 N5의 초기 고객 중 하나이기도 했다. 이는 2020년 말에 끝났다. Huawei는 플래그십 스마트폰에서 Qualcomm SoC로 전환했지만, 수출 통제로 인해 4G 전용 변형만 사용할 수 있었다.
2023년 말, Huawei는 TSMC N5가 아닌 SMIC N+2에서 제조된 Kirin 9000의 후속작 Kirin 9000s로 자체 실리콘에 복귀했다. 이후 몇 년간 동일한 N+2 공정으로 Kirin 9010과 9020을 출시했다. 이 칩들은 Huawei의 자체 TaiShan CPU 코어와 Maleoon GPU를 사용했다.
우리는 Kirin 9020을 직접 분해하지는 않았으므로, 이전 세대의 다이 샷은 Kurnal에서 가져왔다. 다이 샷은 Huawei가 실리콘 예산을 어디에 투입했는지, 어떤 기능 블록이 어디에 배치되었는지, 그리고 그 면적이 이전 세대와 어떻게 비교되는지를 보여준다.
HiSilicon Kirin 9020(왼쪽)와 Kirin 9030(오른쪽) 다이 주석. 출처: Kurnal, SemiAnalysis
먼저 다이 위 주요 블록에 대한 간단한 안내부터 보자.
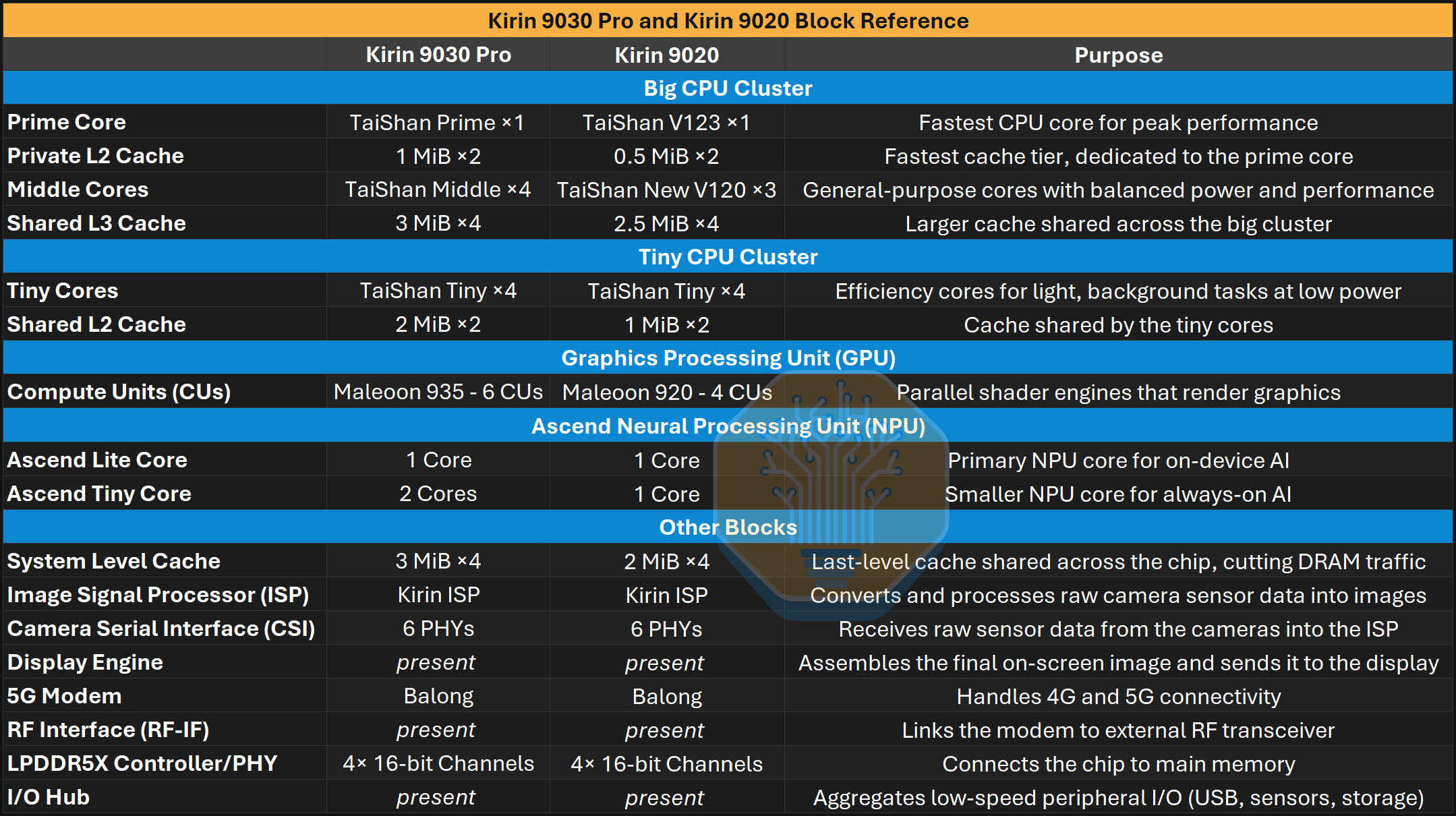
Kirin 9030 Pro와 Kirin 9020 블록 참조. 출처: SemiAnalysis
총 다이 면적은 거의 동일하지만, 9030은 그 면적을 더 공격적으로 활용한다. 더 높은 밀도의 공정 덕분에 Huawei는 같은 면적 안에 중간 CPU 코어 하나를 더 넣고, GPU 및 NPU 코어를 늘리며, 더 큰 캐시를 넣을 수 있었다.
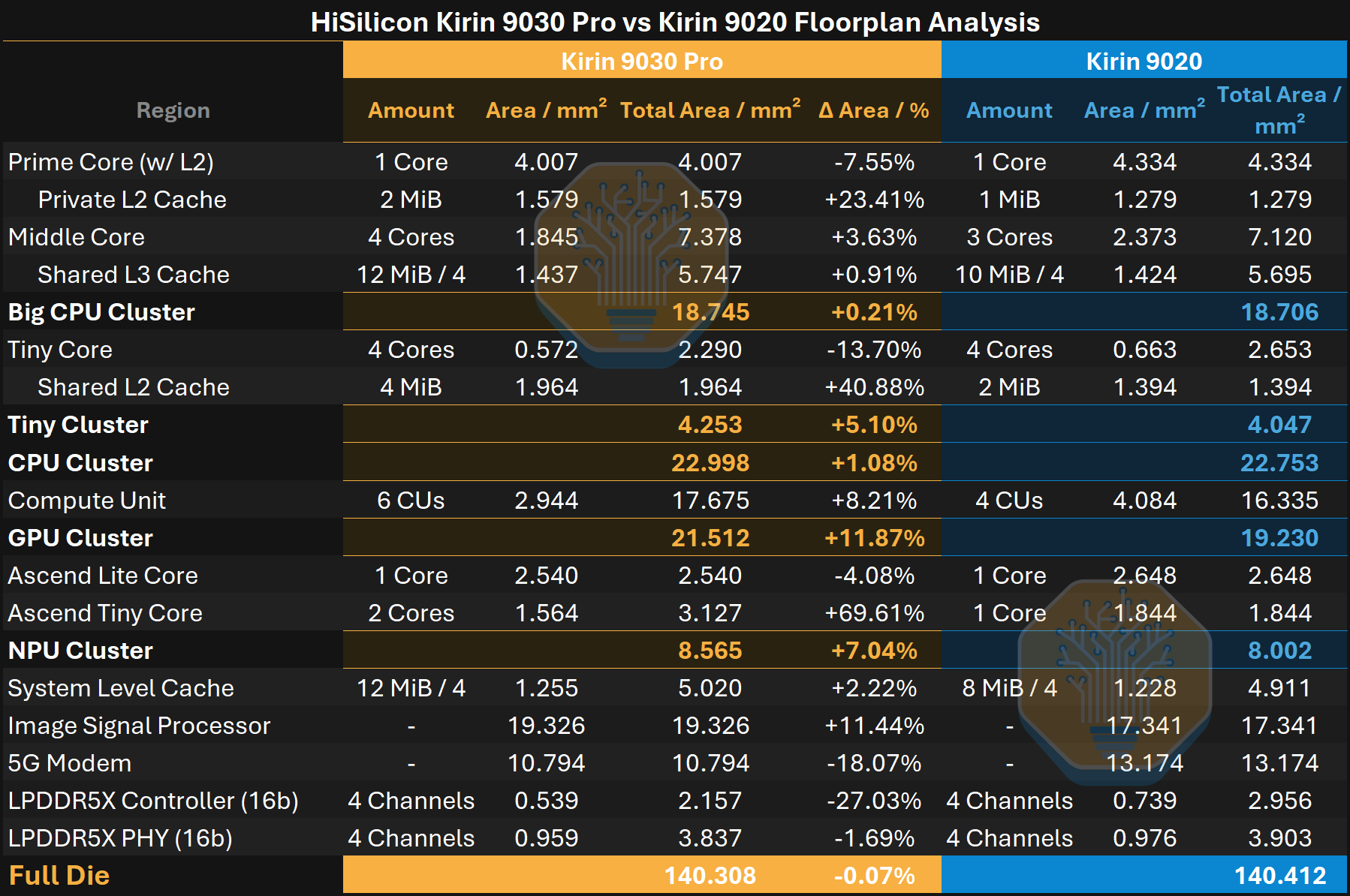
Kirin 9030 Pro 대 Kirin 9020 플로어플랜 분석. 출처: Kurnal, SemiAnalysis
반대로 Helio G99는 훨씬 더 작은 저비용 SoC로, 플래그십 기기보다는 보급형 스마트폰용으로 설계됐다. Kirin 9030이 약 140 mm²인 반면, G99는 약 29 mm²에 불과해 면적이 대략 5분의 1 수준이다. 그러나 기반이 되는 TSMC 공정 기술은 SMIC를 분석하기 위한 기준선으로 직접 비교 가능하다.

MediaTek Helio G99 다이 주석. 출처: SemiAnalysis
Kirin 9030은 완전히 새로 설계한 제품이 아니라 점진적 리프레시다. CPU, GPU, NPU 코어는 9020의 계열을 이어받았고, 개선은 세 가지 레버에서 나온다. 즉 SMIC N+2에서 N+3로의 공정 전환, DTCO와 플로어플랜 작업, 그리고 점진적 마이크로아키텍처 개선이다. 면적은 앞의 두 요소가 가장 잘 드러나는 부분이며, 9030은 여기서 좋은 스케일링을 보여준다. 성능과 효율은 더 까다로운 시험대다. Huawei의 설계는 그 노드 수준이 암시하는 것보다는 더 잘 버티지만, 칩은 여전히 뒤처진다. 이는 N+3가 선단 노드보다 뒤에 있기 때문이기도 하고, 코어 자체도 유능하긴 하지만 최신 설계보다 몇 세대 뒤처져 있기 때문이다.
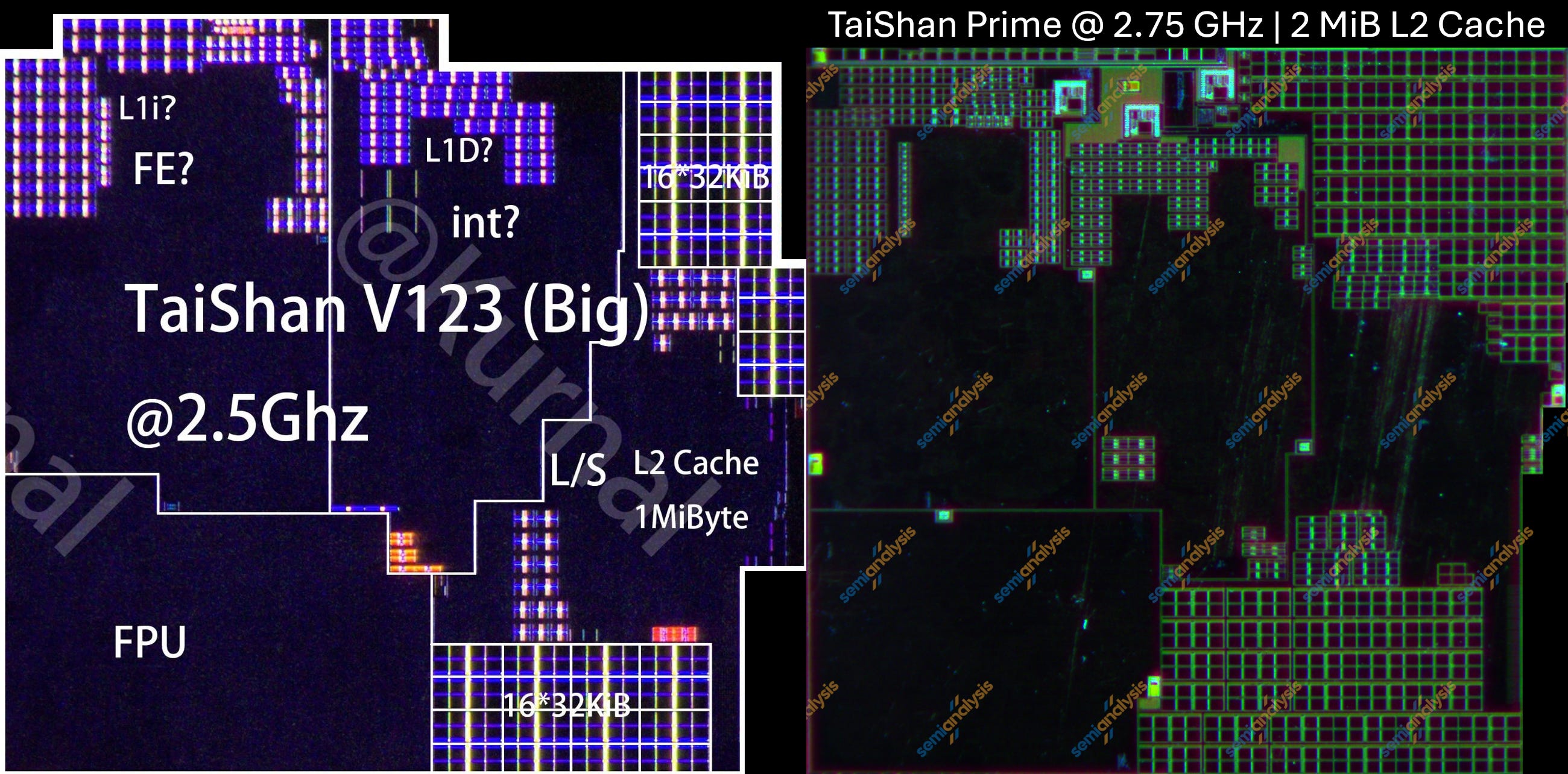
Kirin 9020 TaiShan V123(왼쪽)와 Kirin 9030 TaiShan Prime(오른쪽) 코어. 출처: Kurnal, SemiAnalysis
새로운 prime 코어는 점진적 업데이트다. 주요 변화는 주파수가 2.5 GHz에서 2.75 GHz로 10% 증가했고, L2 캐시가 1 MiB에서 2 MiB로 두 배가 되었다는 점이다. 캐시가 커졌음에도 코어 크기는 7.6% 감소했다. private L2 캐시를 제외하면 코어 크기는 21% 감소했다. 이는 점진적 노드 전환치고는 큰 감소다.

Kirin 9020 TaiShan New V120(왼쪽)와 Kirin 9030 TaiShan Middle(오른쪽) 코어. 출처: Kurnal, SemiAnalysis
Kirin 9020의 TaiShan New V120 코어와 비교하면, Kirin 9030의 middle 코어는 아키텍처적으로 거의 변하지 않았지만 각 코어는 약 22% 축소됐다. 그 대부분은 N+2에서 N+3로의 이동에서 나오며, 나머지는 레이아웃 최적화 덕분일 가능성이 높다.
시각적으로 가장 눈에 띄는 변화는 middle 코어 수가 3개에서 4개로 늘었다는 점이다. 또한 big cluster의 공유 L3 캐시가 20% 증가했다. 이는 면적 손실을 크게 감수하지 않으면서 멀티코어 성능을 개선하는 데 도움을 준다.
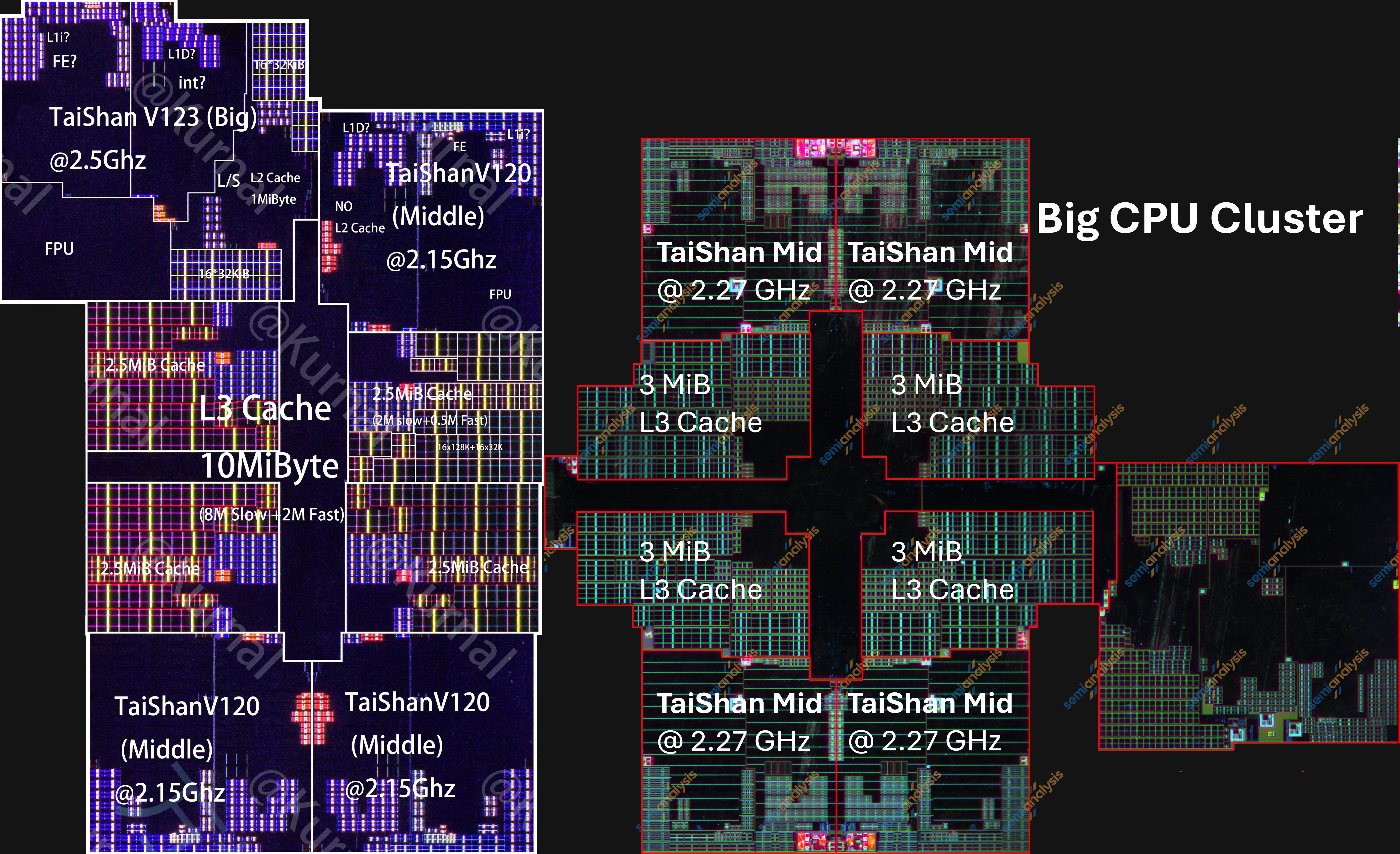
Kirin 9020(왼쪽)과 Kirin 9030(오른쪽) Big CPU cluster. 출처: Kurnal, SemiAnalysis
각 코어가 축소되었음에도 big CPU cluster의 총 면적은 사실상 변하지 않았다. 코어당 절감된 면적은 추가 middle 코어와 더 큰 캐시에 다시 투입됐다.

Kirin 9020(왼쪽)과 Kirin 9030(오른쪽) TaiShan Tiny 코어. 출처: Kurnal, SemiAnalysis
tiny 코어는 prime 코어(L2 캐시 제외)나 middle 코어보다 덜 축소됐다. 이는 작은 코어에서는 고정 오버헤드 비중이 더 크기 때문일 가능성이 높다. 다이 샷만으로는 아키텍처 변화를 판별할 수 없지만, 아래에 제시된 클록당 성능 및 효율 개선은 순수한 공정 및 레이아웃 스케일링 이상의 변화가 있음을 시사한다. 면적 감소는 공유 L2 캐시가 2 MiB에서 4 MiB로 두 배가 되면서 상쇄되어, tiny CPU cluster의 총 면적은 약간 더 커졌다.
면적은 다이 샷에서 가장 쉽게 확인되는 개선점이지만, PPA(power, performance, area)의 일부에 불과하다. 현대 로직에서는 전력과 성능이 그만큼 중요하며, 종종 더 중요하다. 2000년대 중반 Dennard scaling이 무너진 이후 전압과 주파수는 트랜지스터 크기 축소와 함께 스케일되지 않았기 때문에, 각 노드는 성능과 효율 개선을 위해 훨씬 더 치열하게 싸워야 했다.
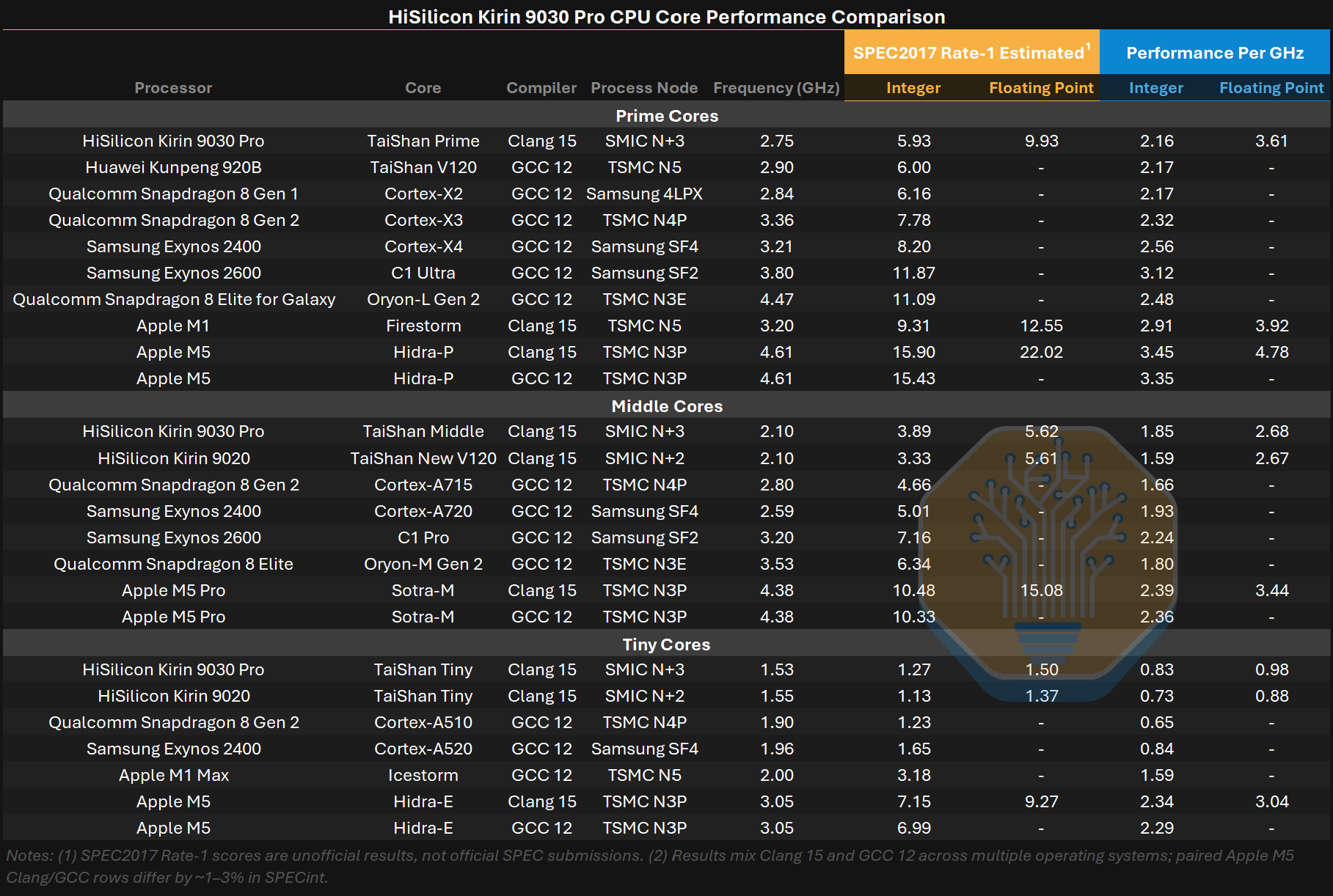
Kirin 9030 Pro CPU 코어 성능 비교. 출처: Littertree66, SimpleTech, David Huang, SemiAnalysis
가장 극적인 비교는 Kirin 9020 대 Kirin 9030 Pro가 아니다. Apple의 efficiency 코어는 Huawei의 prime 코어를 압도한다. Apple의 저전력 코어는 20% 더 높은 정수 성능을 제공하면서도 전력 소모는 1 W에 불과한 반면, Huawei의 prime 코어는 4.5 W를 소모한다. N+3는 TSMC N6와 맞먹지만, N6는 이미 여러 세대 지난 노드다. Apple과 Qualcomm은 N4와 N3P를 사용하며, 이들은 더 높은 밀도와 더 나은 전압-주파수 곡선을 제공해 더 큰 트랜지스터 예산과 더 높은 와트당 성능을 가능하게 한다.
9030 자체의 코어는 개선됐다. middle 코어와 tiny 코어는 9020 대비 클록당 정수 성능이 각각 17%, 14% 향상되었고, 부동소수점은 middle 코어는 정체, tiny 코어는 11% 상승했다. tiny 코어는 성능이 오르면서 전력은 낮아지고, 정수 효율은 45%, 부동소수점 효율은 24% 증가하는 깔끔한 개선을 보였다. middle 코어는 혼합된 결과다. 정수 성능은 상승했지만 전력 상승폭이 더 커 정수 효율은 7% 감소했고, 반면 더 낮은 전력 덕분에 부동소수점 효율은 16% 향상됐다.
같거나 더 낮은 주파수에서의 클록당 성능 향상은 마이크로아키텍처적 개선을 의미하므로, 이 코어들은 단순히 축소된 것이 아니라 튜닝되었다. 두 코어 모두 명시된 최대 주파수를 유지하지 못했는데, 이는 열, 전력, 또는 안정성 한계를 가리킨다. 클록당 기준으로 middle 코어는 Arm Cortex-A720 수준, tiny 코어는 Cortex-A520에 가깝지만, 절대 성능은 Huawei가 훨씬 더 낮은 클록으로 동작시키기 때문에 뒤처진다.
prime 코어는 클록당 기준으로 대략 Cortex-X2급이며, 이는 2021년 설계다. Apple의 2020년 M1 Firestorm 코어는 여전히 클록당 35% 더 높고, 비슷한 4.5 W에서 절대 정수 성능은 57% 더 빠르다. 현재 선단은 다시 한 번 더 앞서 있다. Apple M5 P-core는 클록당 60% 더 높고 2.7배 더 빠르며, Arm C1 Ultra는 클록당 45% 더 높고 2배 더 빠르다.
구형 하이엔드 코어와 클록당 성능을 맞추는 것은 분명한 설계 성과다. Huawei가 맞출 수 없는 것은 선단 노드의 전압-주파수 곡선과 트랜지스터 예산이다. 이 덕분에 Apple, Qualcomm 등은 같은 면적에서 더 넓은 코어, 더 큰 캐시, 더 깊은 버퍼에 더 많은 트랜지스터를 투입하면서도 더 낮은 전압으로 동작할 수 있다.
Huawei의 LogicFolding 로드맵은 이에 대한 하나의 해답으로, active logic을 적층해 밀도를 회복하고 신호 경로를 단축한다. 이에 대해서는 뒤에서 다시 다룬다.
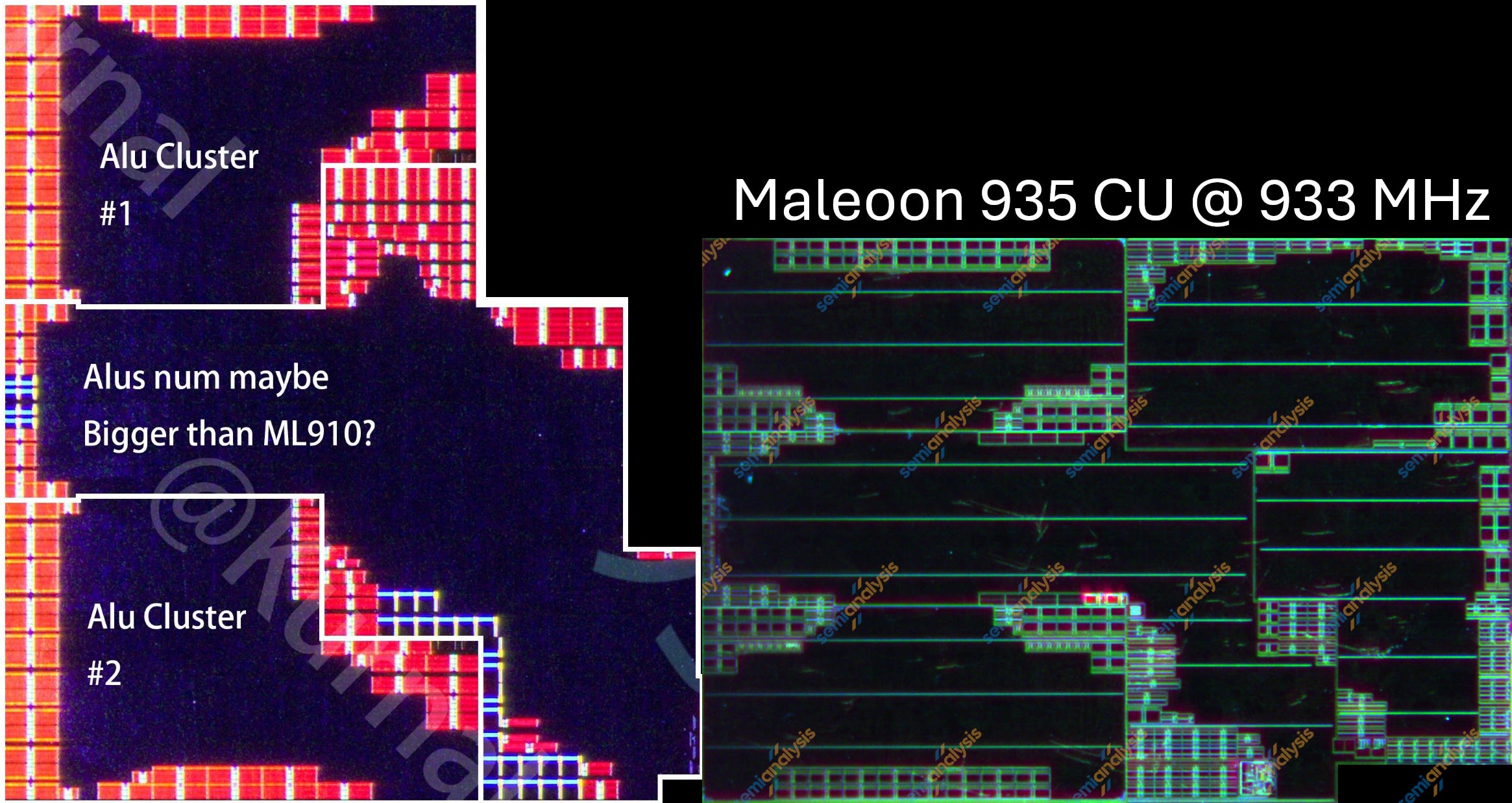
Kirin 9020(왼쪽)과 Kirin 9030(오른쪽) Maleoon GPU compute units. 출처: Kurnal, SemiAnalysis
GPU compute unit(CU)는 CPU 코어보다 더 눈에 띄게 바뀌었으며, arithmetic logic unit (ALU) cluster와 CU 전체 모두가 더 직사각형에 가까운 레이아웃으로 이동했다. ray-tracing 지원이 추가되었음에도 CU 하나는 약 28% 축소됐다.

Kirin 9020 Maleoon 920(왼쪽)와 Kirin 9030 Maleoon 935(오른쪽) GPU cluster. 출처: Kurnal, SemiAnalysis
하지만 이러한 축소는 CU 수가 4개에서 6개로 증가하고, CU 외부 면적이 33% 커진 것으로 상쇄된다. 전체적으로 GPU cluster는 약 10% 더 커졌다.
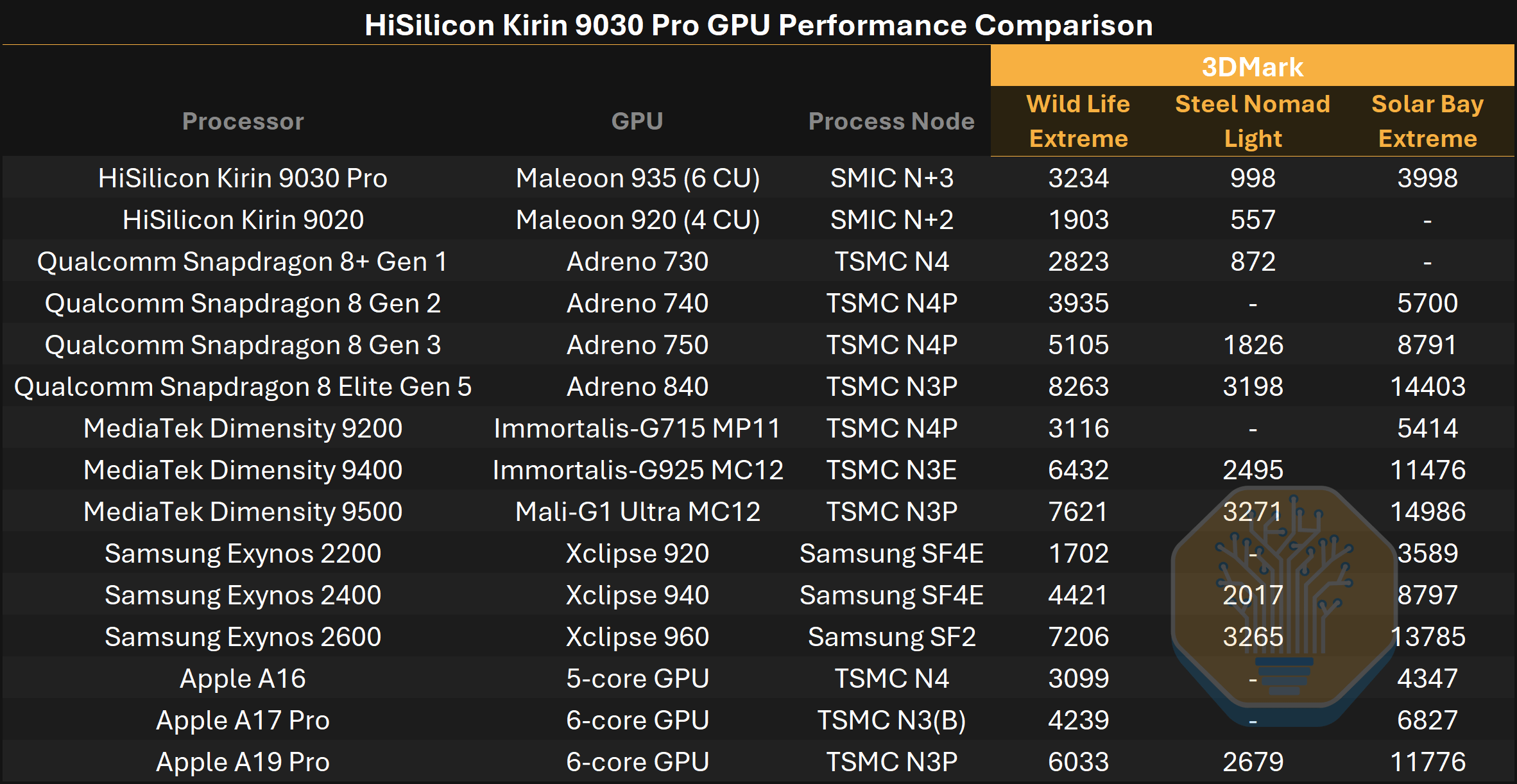
Kirin 9030 Pro GPU 성능 비교. 출처: Notebookcheck, SemiAnalysis
GPU는 Huawei가 가장 큰 향상을 보이는 부분이다. Maleoon 935는 현재 플래그십과 경쟁할 수준은 아니지만, 920 대비 큰 도약이며 구형 플래그십 수준에는 도달한다. 3DMark에서 Wild Life Extreme (WLE)은 70%, Steel Nomad Light (SNL)는 79% 더 빠르다. 클록 11% 증가와 CU 50% 증가를 감안하면 약 67%의 이론적 향상이 대략 WLE와 맞아떨어지고 SNL에서는 이를 넘어선다.
WLE와 SNL에서 Snapdragon 8+ Gen 1을 소폭 앞서고, WLE에서는 Dimensity 9200과 Apple A16도 앞서지만, 최신 제품들과는 큰 차이를 보인다. Snapdragon 8 Elite Gen 5와 Dimensity 9500은 WLE에서 약 2.4–2.6배, SNL에서는 약 3.2배 더 빠르다.
Maleoon 935는 Huawei 최초의 hardware-accelerated ray tracing GPU다. 이 영역에서는 Exynos 2200을 약간 앞서고 Apple A16과 비슷한 수준이며, 현재 플래그십은 최대 3.7배 더 빠르다.
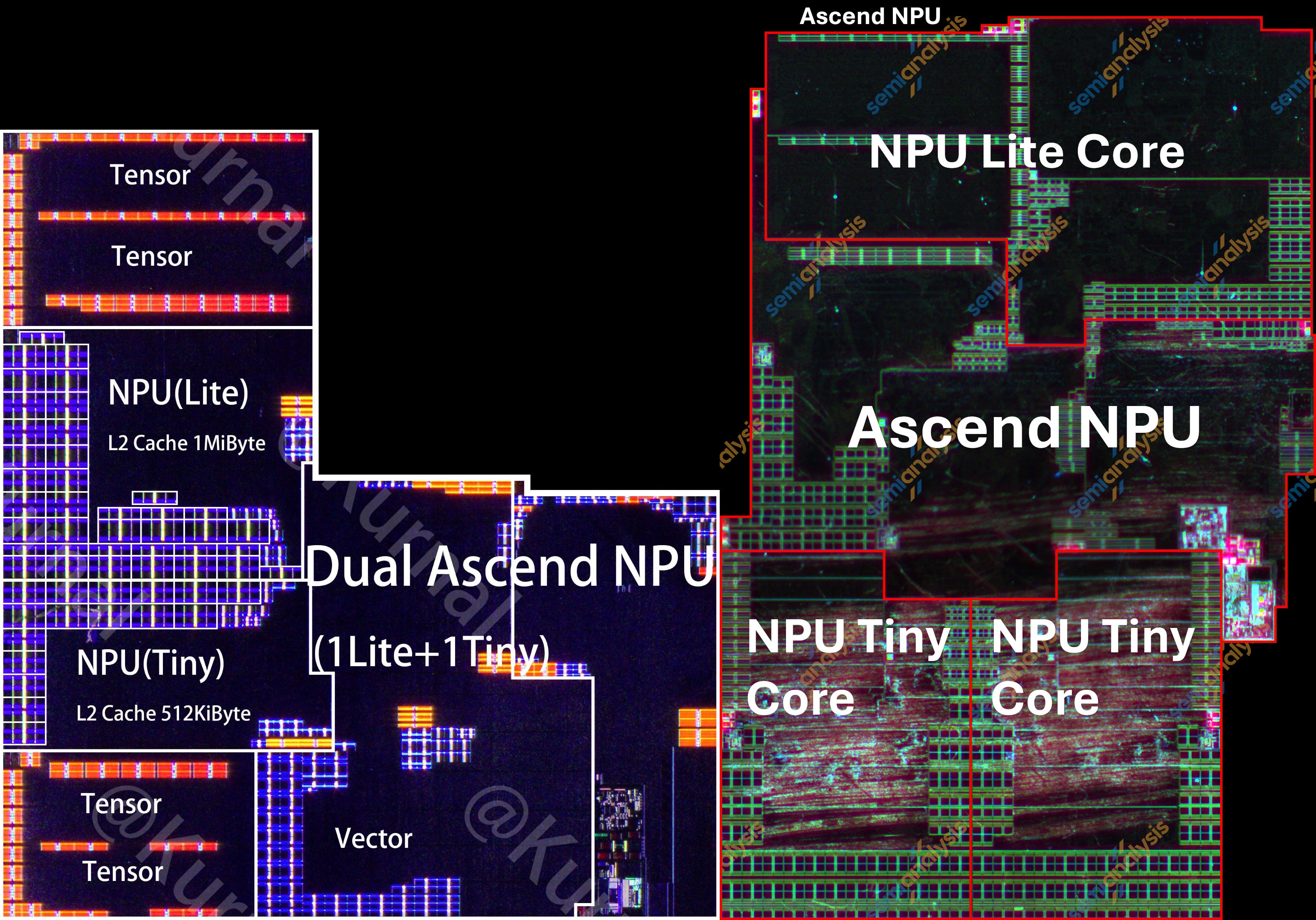
Kirin 9020(왼쪽)과 Kirin 9030(오른쪽) Ascend NPU. 출처: Kurnal, SemiAnalysis
Neural Processing Unit (NPU)는 모든 블록 중 구조 변화가 가장 컸다. Kirin 9020의 Lite 코어 1개와 Tiny 코어 1개 구성에서, Kirin 9030은 Lite 코어 1개와 Tiny 코어 2개로 바뀌었다. 두 코어 유형 모두 레이아웃상 상당한 변화를 보인다.
이는 Huawei의 NPU 설계에서의 반전이다. TSMC N5에서 제작된 마지막 플래그십 칩 Kirin 9000 5G는 Lite 코어 2개와 Tiny 코어 1개를 사용했다. SMIC N+2 기반 SoC 시리즈에서는 면적 절감을 위해 Lite 코어 1개와 Tiny 코어 1개로 이동한 것으로 보인다. Kirin 9030에서 Huawei는 더 큰 멀티코어 NPU cluster 쪽으로 다시 방향을 틀었지만, 추가 면적은 Lite 코어가 아니라 Tiny 코어에 할당됐다.
우리는 시장에 나오는 가장 앞선 데이터센터 및 AI 하드웨어를 깊이 있게 분석하고 있다. 파이프라인에 무엇이 있는지 더 알고 싶거나 맞춤형 분해 분석을 의뢰하고 싶다면 sales@semianalysis.com으로 문의해 달라. 이 여정에 함께하고 싶고 변화를 만들 수 있다고 생각한다면 Careers 페이지를 확인해 달라.
공정 스택으로 들어가기 전에, 패키지와 메모리는 SoC 자체와 분리해서 볼 가치가 있다.
Kirin 9030의 Pro 변형은 Samsung DRAM 12 GB를 탑재하며, 각각 4개 다이로 이루어진 두 개의 스택을 사용한다. 이 다이는 K4L2E165YD로 식별되었으며, Samsung의 1a 노드에서 제조된 12 Gb LPDDR5X-9600 장치다. 이는 1x, 1y, 1z에 이은 Samsung의 10 nm급 DRAM 4세대다. 1a는 2022년부터 대량 출하되어 왔으므로, 이는 구형 노드 재고가 아니라 최신 메모리다.
우리가 확보한 16 GB Pro Max 변형은 CXMT와 Samsung 패키지 모두에서 발견됐다. CXMT 패키지는 CXDD7JEDM으로 표시되어 있으며, 4개 다이 2개 스택으로 구성되고 2025년 45주차에 패키징됐다. X-ray computed tomography (CT)로부터 추론한 다이 크기는 CXMT G4 공정의 알려진 약 0.3 Gib/mm² 밀도와 일치하며, 이는 다른 제조사의 1z 공정과 대략 동등하다.

Kirin 9030 Pro의 Samsung K4L2E165YD DRAM. 위: 부분 다이(SEC 표기)와 4단 스택. 아래: 두 4단 스택의 단면. 출처: SemiAnalysis
Kirin 9030은 일반적인 integrated package-on-package (iPoP) 스택을 사용한다. 여러 DRAM 다이가 메모리 패키지 안에서 organic redistribution layer (RDL) interposer 위에 놓이고, 그 아래에 SoC와 package substrate가 있다. 전체 패키지는 다시 ball-grid array (BGA) solder bump를 통해 printed circuit board (PCB)에 실장된다.
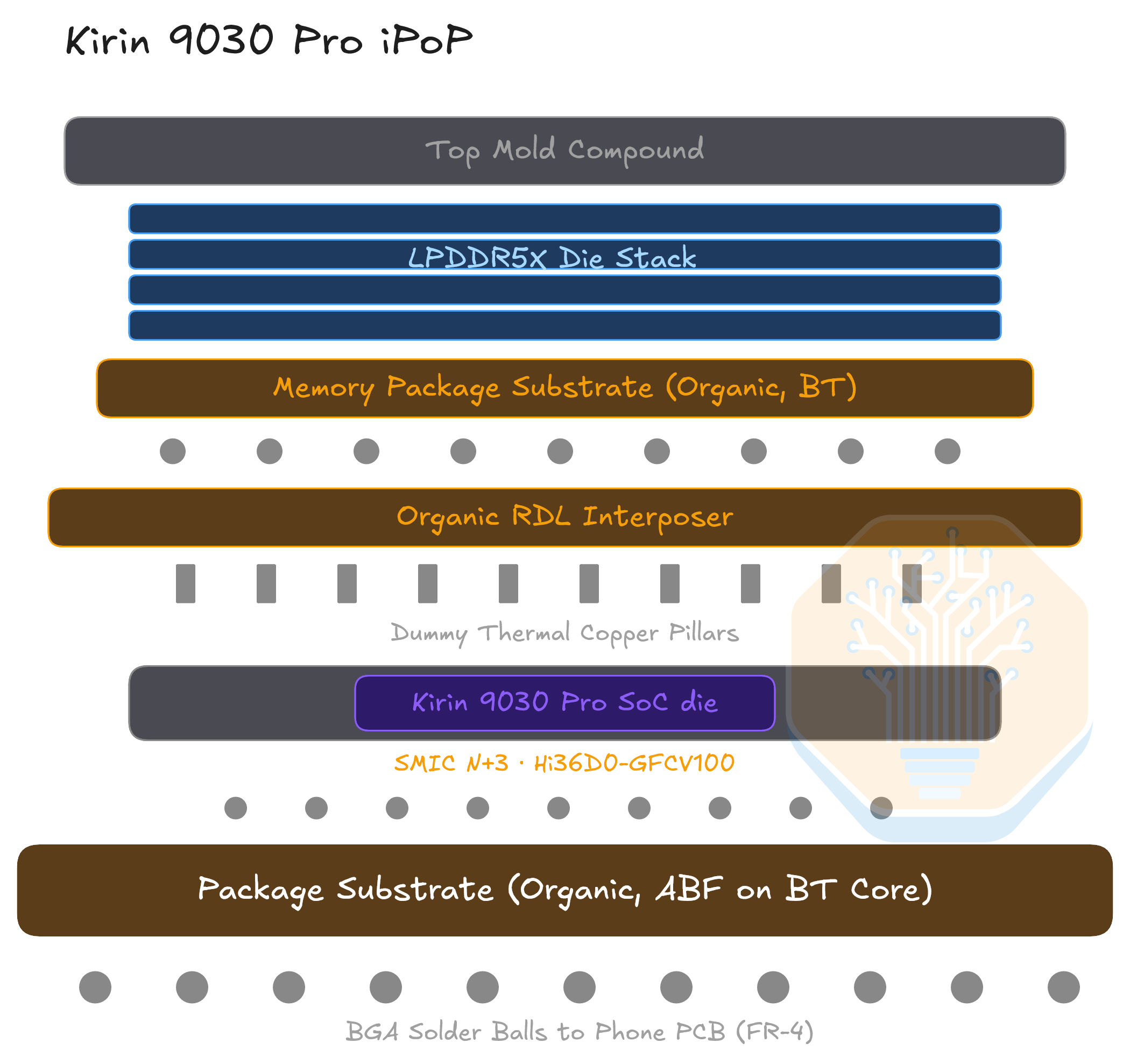
Kirin 9030 iPoP 스택. 출처: SemiAnalysis
메모리 package substrate는 LPDDR5X 스택을 지지하는 얇은 bismaleimide-triazine (BT) laminate다. SoC 위의 organic RDL interposer는 PoP 신호를 다이 주변으로 라우팅하고, 가능한 dummy thermal copper pillar를 지닌다. package substrate는 더 두꺼운 Ajinomoto Build-up Film (ABF) build-up을 BT 코어 위에 형성한 구조로, flip-chip bump를 BGA 피치로 팬아웃하고 전력 plane을 내장한다.
전체 스택은 유기물 기반이다. 실리콘은 SoC와 LPDDR5X 다이뿐이며, silicon interposer는 없다. 모든 것을 유기물로 유지하면 패키지의 coefficient of thermal expansion (CTE)이 PCB에 가까워져 보드 수준 뒤틀림이 줄어들고, SoC 대역폭에 필요하지 않은 silicon interposer 비용도 피할 수 있다.

Mate 80 Pro(왼쪽)와 Pro Max(오른쪽)의 Kirin 9030 Pro 패키지. 출처: SemiAnalysis
iPoP 스택에서 메모리 패키지는 solder bump 배열을 통해 organic RDL interposer에 연결된다. underfill은 그 bump 주변의 틈을 메워 강성을 더하고 접합부를 기계적 응력으로부터 보호한다. Pro와 Pro Max 변형은 이 부분에서 차이가 있으며, 이는 유료 구독 뒤에서 다룬다.

DRAM 제거 후 Mate 80 Pro 패키지의 측면 프로파일, BGA와 underfill 표시. 출처: SemiAnalysis
다이 샷과 아키텍처는 Huawei가 실리콘 예산을 어떻게 배분했는지 보여준다. 공정은 SMIC가 무엇을 제조할 수 있는지 보여준다. 우리는 TSMC N6의 공정 기준으로 Helio G99를 사용한다. SMIC N+3와 TSMC N6는 모두 이전 7 nm급 노드의 진화형이다.
우리는 로직과 메모리 영역을 통과하는 목표 TEM 단면을 사용했고, fin-cut 방향과 gate-cut 방향 모두에서 이미징했다. 각 단면 캡션에는 HFW(horizontal field width), 즉 촬영 영역의 실제 가로 폭이 제시된다. 우리는 트랜지스터 fin에서 시작해 standard cell, local interconnect, SRAM으로 위로 올라간다.
SMIC가 Intel이나 TSMC를 추월한 것은 아니다. SMIC는 공격적인 DUV 스케일링과 DTCO를 사용해 N6급 밀도에 도달하지만, 그 밀도가 비슷한 성능과 효율로 이어지지는 않는다. 이유는 두 가지다. 선단 노드와의 노드 격차, 그리고 Huawei의 코어 설계다.
FinFET 공정에서 가장 중요한 조절 변수 중 하나는 fin profile이다. 즉, 개별 fin의 형상과 전류가 source에서 drain으로 흐르는 channel의 형상이다. 이상적인 fin은 높고, 좁고, 거의 수직이다. 더 높은 fin은 유효 channel 폭을 늘리고, 더 좁은 fin은 gate가 제어해야 하는 body를 얇게 만들어 electrostatic control을 개선한다. 어느 한쪽이든 지나치게 밀어붙이면 공정이 대가를 치르게 된다. drive current 약화, 취약한 fin, taper, footing, line-edge variation이 수율과 소자 변동성을 악화시킨다.

Intel의 FinFET 아키텍처 진화. 출처: Intel
Intel의 22 nm, 14 nm, 10 nm fin 단면은 FinFET 노드가 시간이 지나며 어떻게 개선되었는지를 보여준다. 22 nm fin은 1세대 구조로 상대적으로 낮고 넓으며 강하게 테이퍼져 있다. 이 형상은 전류 밀도를 제한하고 fin 높이 전반에 걸친 gate 제어의 균일성을 떨어뜨린다. 14 nm와 10 nm에서 Intel은 fin을 더 높고 더 좁게 만들면서 측벽도 더 수직에 가깝게 만들었다. 이는 단순한 소자 축소가 아니라 fin당 유효 channel 폭을 증가시키고 electrostatic control을 개선하는 변화다. 대가로 더 촘촘한 피치에서 더 높은 fin을 제조하기가 훨씬 어려워진다.

Kirin 9030 TaiShan Prime(왼쪽)와 Helio G99 Cortex-A55(오른쪽), fin profile, fin-cut, HFW 321.4 nm. 출처: SemiAnalysis
이제 TSMC N6의 Helio G99와 SMIC N+3의 Kirin 9030을 비교해 보자. 두 공정은 같은 급에 속하며, N+3의 fin pitch는 30-32 nm, 우리가 본 N6 단면에서는 34 nm다. N6의 피치는 특히 흥미로운데, N7의 HD library는 일반적으로 33 nm fin pitch로 알려져 있고 N6는 직접 피치를 줄이지 않았기 때문이다. N6의 밀도 향상은 더 촘촘한 피치가 아니라 DTCO에서 나왔다. 34 nm 피치는 우리가 샘플링한 영역에서 안정적으로 관찰되었고, 더 깊게 조사하지 않은 SMIC N+3와의 비교 기준으로 기능한다.
N+3의 fin 패터닝 방식을 정확히 파악하려면 코어 유닛 하나만으로는 부족하다. CPU 코어는 약 32 nm의 조밀한 피치를 보여주며, N-P fin 쌍 사이 피치는 78 nm와 88 nm가 번갈아 나타난다. 로직만 놓고 보면 120 nm와 110 nm의 dual-pitch mandrel과 일치할 수도 있지만, 이는 복잡하고 이례적인 접근이다. 더 복잡한 반복 단위를 갖는 8T SRAM의 피치와 CPU 코어의 시퀀스를 결합하면 패터닝 단계를 더 높은 신뢰도로 리버스 엔지니어링할 수 있다.
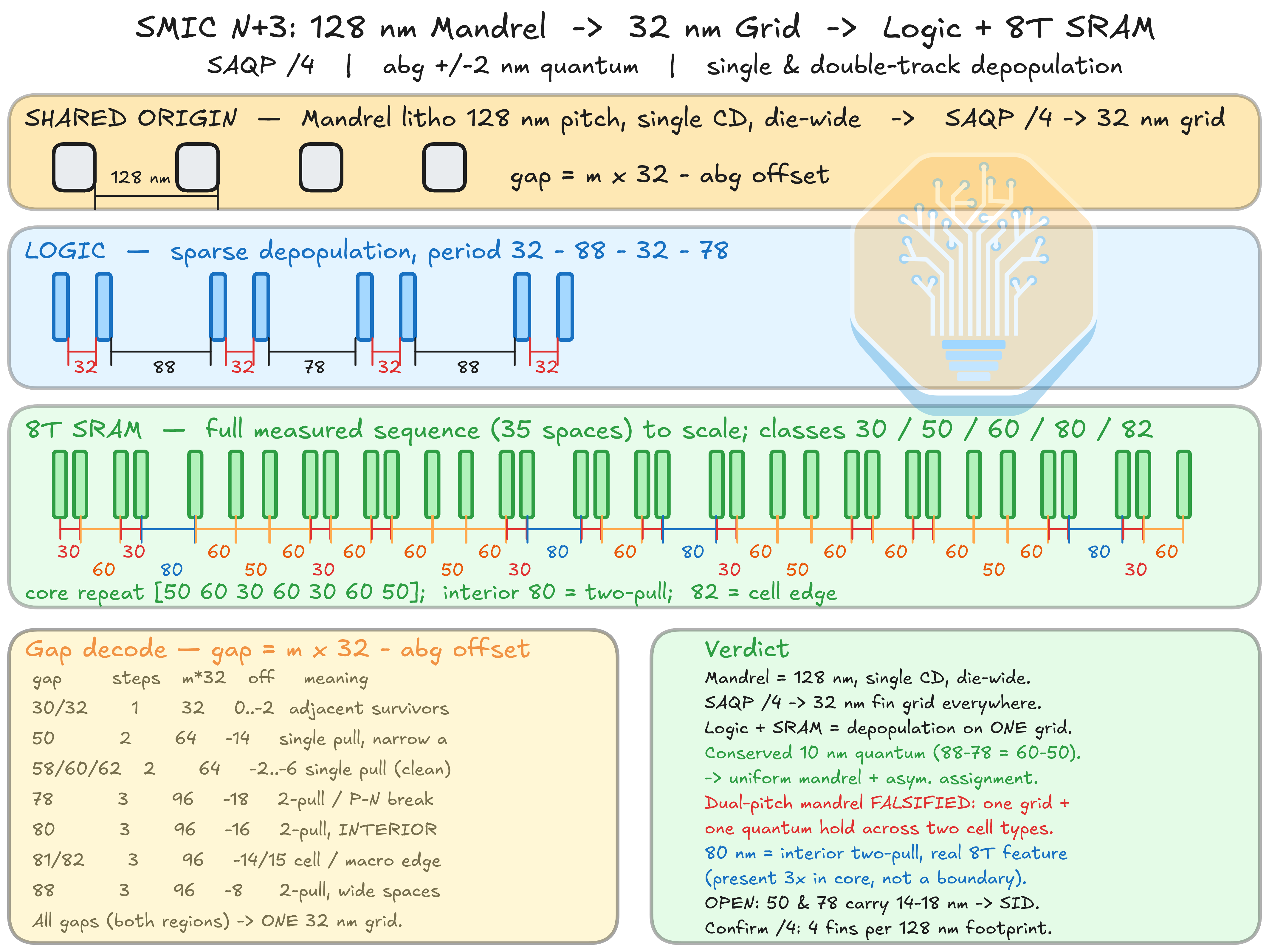
CPU 코어와 8T SRAM fin 패턴 기반 SMIC N+3 fin 패터닝 통합. 출처: SemiAnalysis
로직과 SRAM은 동일한 기본 grid를 공유해야 하므로, 128 nm 피치의 단일 CD mandrel lithography 패턴이 SAQP를 거치면 다이 전체에 걸쳐 약 32 nm grid(128 nm/4)를 형성하고, 이는 로직과 SRAM 셀 양쪽에서 관찰되는 피치 시퀀싱을 설명해 준다.
샘플링한 단면에서 N+3는 N6보다 더 높고, 더 좁고, 더 높은 종횡비의 fin을 보여준다. 측정된 fin aspect ratio는 N+3가 약 9.5:1, N6가 7.8:1이다. N+3는 top rounding도 더 적으며, 추정 반경은 약 2 nm인 반면 N6는 2.8 nm다. fin 폭이 다르더라도 top rounding 대 fin 폭의 비율 역시 같은 이야기를 한다. N+3는 0.37, N6는 0.44다. 기하학적으로는 낮을수록 좋으며, 완전히 직사각형인 fin은 top-rounding penalty가 없다.
이는 소수의 단면에서 측정한 한 자릿수 나노미터 특징이므로 절대 수치는 근사치로 봐야 한다. 중요한 결과는 상대적인 격차다. N+3의 fin은 일관되게 더 높고, 더 좁고, 덜 둥글다.
우리는 시장에 나오는 가장 앞선 데이터센터 및 AI 하드웨어를 깊이 있게 분석하고 있다. 파이프라인에 무엇이 있는지 더 알고 싶거나 맞춤형 분해 분석을 의뢰하고 싶다면 sales@semianalysis.com으로 문의해 달라. 이 여정에 함께하고 싶고 변화를 만들 수 있다고 생각한다면 Careers 페이지를 확인해 달라.
standard cell은 칩 레이아웃의 기본 구성 요소다. 동일 높이의 행 안에서 하나의 NMOS와 하나의 PMOS 트랜지스터가 gate를 공유하며 짝을 이루고, 이들이 grid 형태로 반복되어 로직 블록을 만든다. 핵심 치수는 contacted gate pitch (CGP), cell height (CH), fin 수, 그리고 하부 금속 라우팅 grid다.
밀도를 측정하기 위해 우리는 Bohr metric을 사용한다. 이는 NAND2 gate 면적(60%)과 scan flip-flop 면적(40%)의 가중 평균이다. 이는 조합 논리와 순차 논리가 현실적으로 섞인 구성을 나타낸다. 이 지표는 특히 TSMC의 FinFLEX처럼 fin 수가 다른 셀을 교대로 사용하는 복잡한 셀 레이아웃에서는 한계가 있다. 그럼에도 순수한 공정 수준 비교를 위한 최선의 지표다.
또 다른 중요한 측정치는 fin pitch다. 이는 동일한 트랜지스터의 두 fin 사이 거리를 뜻한다. FinFET 공정에서는 drive current, 즉 성능을 높이기 위해 하나의 트랜지스터 안에 여러 fin을 사용한다.
TSMC N6는 셀당 PMOS 2개와 NMOS 2개 fin을 사용하는 high-density (HD) library와, 각각 3개를 사용하는 high-performance (HP) library를 모두 출하한다. 공유 gate 아래 fin이 많을수록 유효 channel 폭이 커진다. HP 셀은 면적을 희생하는 대신 더 강하게 스위칭한다. 설계자들은 주로 타이밍이 중요한 경로에 HP 셀을 투입하면서 두 라이브러리를 다이 내에서 혼합해 PPA 목표를 맞춘다.

Helio G99 Cortex-A55 standard cell, fin-cut (TSMC N6 HD), HFW 562.5 nm. 출처: SemiAnalysis
Helio G99의 Cortex-A55 코어에서 우리는 HD 셀의 cell height가 240 nm임을 확인했다. MediaTek은 G99에서 다이 크기, 즉 비용을 최소화하기 위해 HD 셀을 사용했다. 약 $100 가격대의 보급형 스마트폰용 SoC라는 점을 고려하면 이는 필수적이다.
반면 Kirin 9030에서는 2 NMOS와 2 PMOS fin을 사용하는 하나의 library만 확인됐다. 이는 HD와 HP library가 모두 널리 쓰이는 TSMC N6보다 더 좁은 library 전략을 시사한다. 이는 더 적은 고객 기반과 더 제약된 국내 설계 및 electronic design automation (EDA) 생태계를 반영할 가능성이 크다.
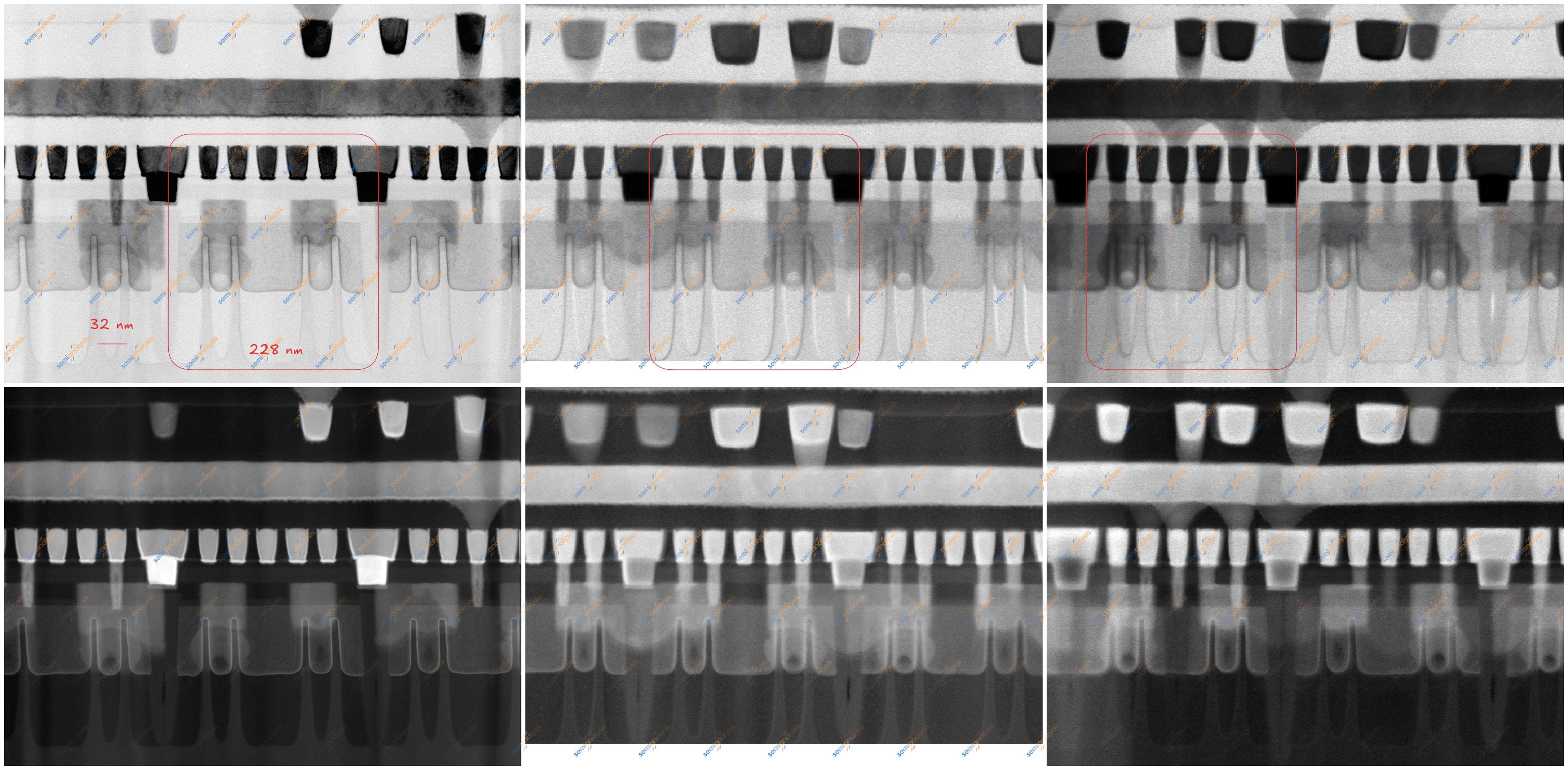
Kirin 9030 TaiShan Prime(왼쪽), Middle(가운데), Tiny(오른쪽) standard cell, fin-cut (SMIC N+3), HFW 562.5 nm. 출처: SemiAnalysis
Kirin 9030의 세 CPU 코어 모두에서 우리는 228 nm의 cell height를 확인했으며, 이는 N6보다 5% 작다. 또한 SMIC N+2의 252 nm cell height보다 9.5% 감소한 수치이기도 하다.

Kirin 9030 TaiShan Prime(왼쪽)와 Helio G99 Cortex-A55(오른쪽) gate profile, gate-cut, HFW 321.4 nm. 출처: SemiAnalysis
SMIC N+3와 TSMC N6의 HD library는 모두 57 nm의 CGP를 갖는다. SMIC 기준으로 이는 N+2 대비 9.5% 축소다.
과거에는 CGP와 cell height만으로도 트랜지스터 밀도를 비교하기에 충분했을 수 있다. 그러나 이제는 scaling booster와 DTCO도 고려해야 한다. SMIC의 밀도 향상은 EUV에서 오지 않는다. 가능한 모든 DTCO booster를 공격적으로 활용한 결과다.
첫 번째는 fin depopulation이다. 즉, 각 셀에서 NMOS와 PMOS fin 수를 줄이는 것이다. 최초의 FinFET 노드는 각 트랜지스터에 보통 3개 또는 4개의 fin을 사용했다. SMIC N+3와 TSMC N6 HD는 모두 트랜지스터당 2개의 fin만 사용해, drive strength를 희생하는 대신 밀도를 얻는다.
다음은 contact over active gate (COAG)다. gate contact를 isolation region 위가 아니라 active gate 바로 위에 배치하면 cell height를 줄일 수 있다. N+3는 COAG를 통합하지만 N6는 그렇지 않다. 우리의 N+3 gate-cut 단면은 gate contact가 active region 위에 위치함을 보여 COAG를 시사하지만, N6는 off-gate contact를 보여준다.
마지막은 single diffusion break (SDB)다. diffusion break는 같은 행의 셀 사이에 삽입되어 전기적 절연을 제공하지만, 동시에 local layout effects (LLE), 즉 전기적 특성의 layout-dependent shift를 유발한다. 과거에는 두 개의 CGP 공간을 차지하는 double diffusion break가 사용됐다. 대신 SMIC N+3와 TSMC N6는 SDB를 사용해 면적을 절약하지만, LLE 민감도는 커진다. 이는 공정 수준에서 제어되어야 하고, process design kit (PDK)에서 정확히 모델링되어 EDA 도구가 이를 반영할 수 있어야 한다.
전체적으로 SMIC N+3의 트랜지스터 밀도는 113.4 MTr/mm²로, TSMC N6의 107.7 MTr/mm²보다 약간 높다. EUV 없이도 SMIC는 EUV를 활용하는 TSMC의 성숙한 N6 노드를 넘어서는 밀도를 달성했다.
이번 분해 분석에서 가장 작은 임계 치수는 M0다. SMIC N+3는 32.5 nm의 local metal pitch를 사용한다. 이는 Panther Lake의 Intel 18A에서 사용된 36 nm M0 pitch보다 더 작다. 그러나 이것이 SMIC가 Intel 18A나 TSMC N3P보다 더 나은 공정을 가졌다는 뜻은 아니다. M0는 셀 내부의 local intra-cell routing layer다. 그 유용성은 전체 interconnect stack, 즉 M1과 M2 피치, track 수, via 및 line 저항, 설계 규칙, mask 수, overlay 제어, 라우팅 유연성에 달려 있다.
32.5 nm M0는 self-aligned quadruple patterning (SAQP)와 일치하며, 우리는 그 네 개 집단 line-width loading을 거칠게 21.5~24 nm 폭이 번갈아 나타나는 형태로 읽었다. 38 nm와 40 nm인 M1과 M2는 self-aligned double patterning (SADP), 즉 단일 A/B 분할과 일치한다. TSMC N6에서는 M0, M2, M3가 완화된 약 40 nm에 위치하며 quadruple patterning이 필요 없는 SADP급 double patterning과 일치한다. 다만 예를 들어 M2는 희소 라우팅 때문에 부풀려졌을 가능성이 있는 약 43 nm로 측정된다. 우리는 단면만으로 특정 층을 EUV라고 단정하지 않는다. 우리가 구분할 수 있는 것은 lithography 파장이 아니라 double patterning과 quadruple patterning의 차이다.
front-end-of-line (FEOL)에서의 트랜지스터 수준 밀도는 상한선을 정하지만, 설계는 결국 interconnect stack이 얼마나 라우팅할 수 있는가에 의해 제한된다. 최하위 금속층은 standard-cell 밀도에 가장 중요하지만, semi-global 및 global 층은 그 밀도가 블록 및 칩 수준에서 얼마나 실제로 활용 가능한지를 결정한다.

Kirin 9030 TaiShan Prime(왼쪽)와 Helio G99 Cortex-A55(오른쪽) 하부 금속, fin-cut, HFW 562.5 nm. 출처: SemiAnalysis
칩 단면에는 일반적으로 두 가지 축이 사용된다. fin-cut과 gate-cut이다. 위 마이크로그래프는 fin-cut이며 metal 0부터 3까지를 보여준다. 이 축에서는 짝수 번호 금속층을 볼 수 있고, M0는 fin 바로 위에 위치한다.
M0 라인에는 두 종류가 있다. 첫 번째는 전원 레일이다. 이는 각 standard cell의 위아래 가장자리를 따라 수평으로 달리는 VDD와 VSS용 넓은 배선이다. 이 넓은 배선은 폭이 55 nm로, 다른 M0 라인의 두 배가 넘는다. 폭이 넓어야 저항을 최소화하고 IR drop을 줄일 수 있다. 두 번째는 intra-cell wire로, 셀 내부에서 단자를 M1에 연결하는 짧은 세그먼트다. 이들은 21.5 nm와 24 nm 사이에서 폭이 번갈아 나타난다.
M0 피치는 32.5 nm이며, N+2와 N6 대비 19% 감소했다. 이 피치에서는 DUV 패터닝에 더 공격적인 멀티패터닝이 필요해 mask 수, overlay 민감도, 공정 복잡성, 비용이 증가한다.
M0는 단일 DUV-defined spacer(SADP)로는 해결할 수 있는 수준 아래에 있으므로, SMIC는 두 번째 spacer 단계(SAQP)를 연쇄 적용한다. 단면은 그 비용을 반영한다. M0 trench는 같은 칩의 M1이나 M2보다 더 뚜렷하게 re-entrant 형태를 보이며(아래가 위보다 좁음), trench가 etch-stop layer와 만나는 지점에는 밝은 barrier-rich foot가 있다. 이 형상은 부분적으로는 약간 좁은 바닥이 void-free copper fill에 도움을 주는 의도된 damascene profile이지만, M0에서 그 정도가 큰 이유는 촘촘한 피치와 더 높은 trench 종횡비 때문이다.
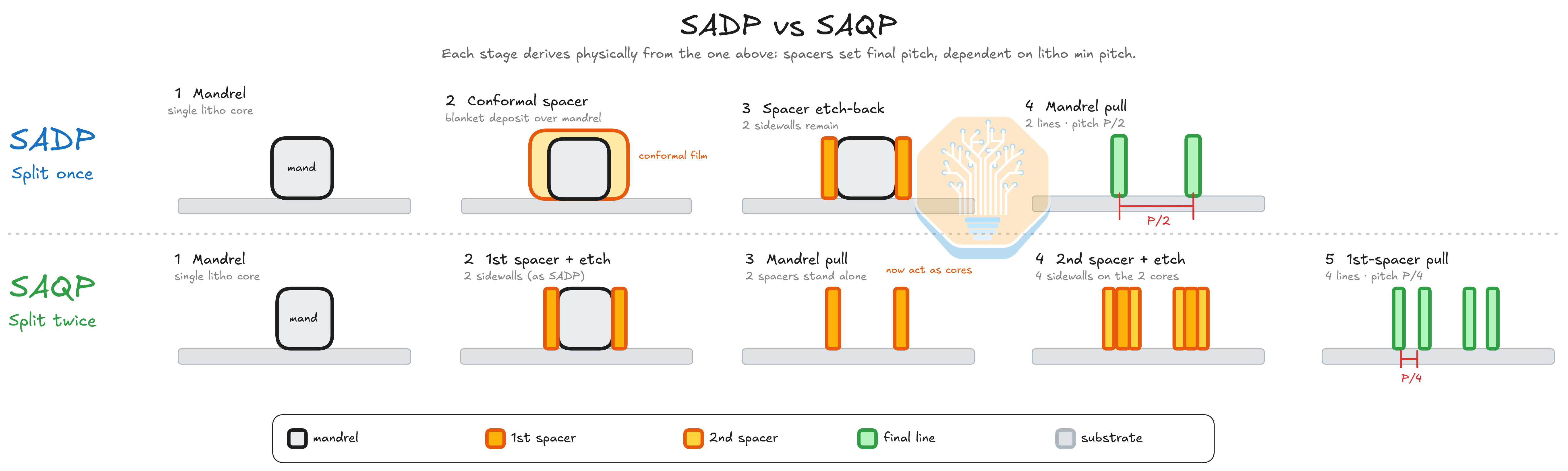
self-aligned double (SADP)와 quadruple (SAQP) patterning의 단순화 비교. 출처: SemiAnalysis
Intel 18A는 32 nm의 M0 pitch를 지원하지만, Panther Lake는 더 느슨한 36 nm pitch로만 출하되었다. 이는 Intel이 HP library를 많이 사용하기 때문이다. 선단 노드 중 18A는 PowerVia 덕분에 가장 느슨한 M0 피치를 가진다. 전력 라우팅이 backside로 이동하면서 혼잡이 줄어들고, front-side 전체 금속 스택을 신호 라우팅에 사용할 수 있다.
M2는 첫 번째 진정한 inter-cell routing layer다. M0처럼 수평으로 달리지만 여러 셀을 가로질러 블록 수준 신호를 운반한다. M2 pitch는 cell의 track height, 즉 VDD와 VSS 레일 사이에 들어가는 M2 track 수를 결정하며, 이것이 library에서 말하는 6-track 또는 7.5-track cell을 정의한다. 이 층은 전체 블록의 라우팅을 제한하는 가장 중요한 층이다.
SMIC N+3는 5.7-track cell을 특징으로 한다. M2 pitch는 40 nm로, N+2보다 5% 감소했고 N6와는 같다. 이 축소는 피치를 double patterning이 가능한 한계선에 머물게 한다. 미래 노드는 라우팅 한계 때문에 track 수를 줄이는 것이 훨씬 더 어려워지므로, M2에 필요한 mask 수를 늘려야 할 것이다.
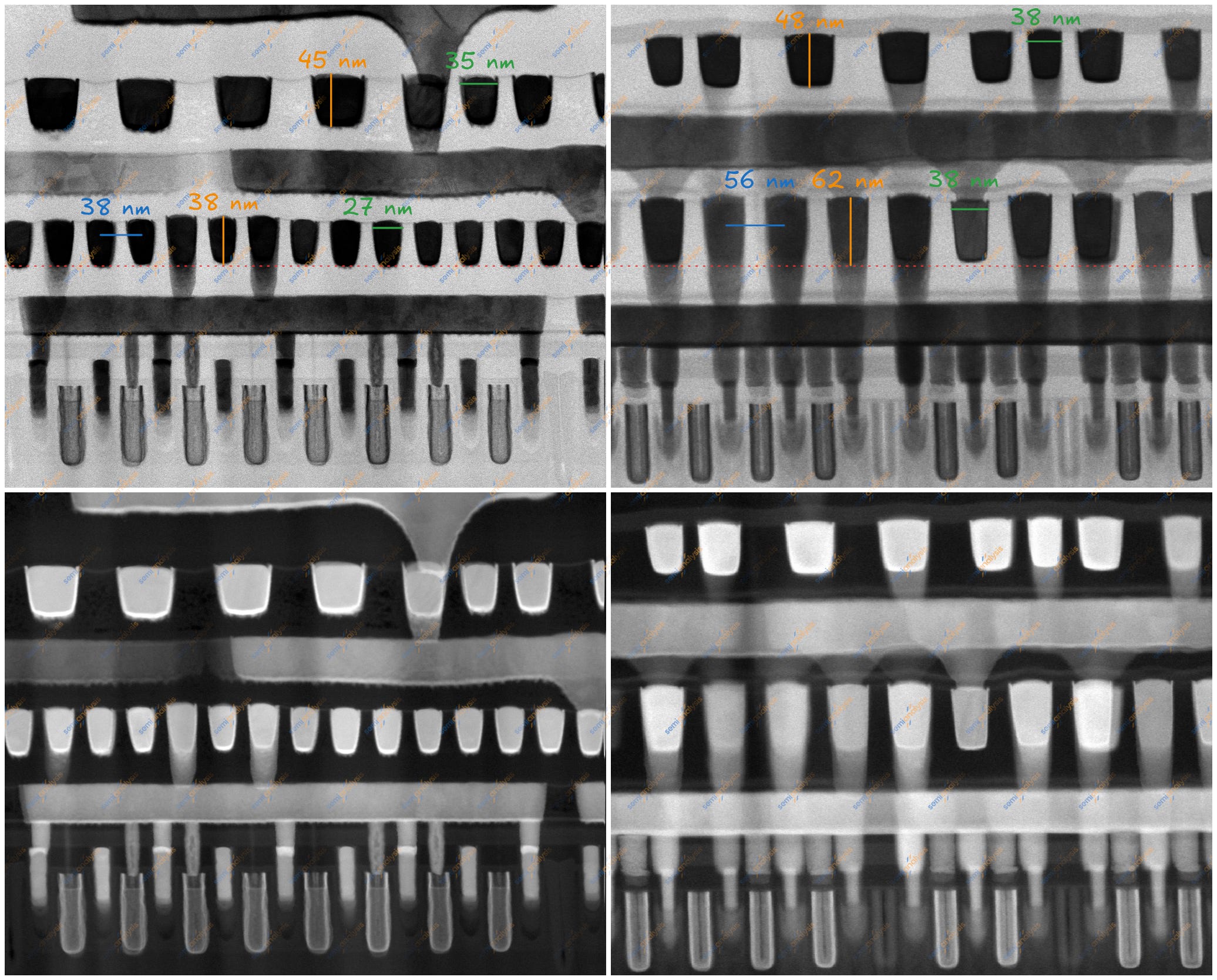
Kirin 9030 TaiShan Prime(왼쪽)와 Helio G99 Cortex-A55(오른쪽) 하부 금속, gate-cut, HFW 562.5 nm. 출처: SemiAnalysis
위 마이크로그래프는 수직 방향인 gate-cut이며, metal 0부터 4까지를 보여준다. 이를 통해 홀수 번호의 수직 금속층을 보고 측정할 수 있다.
M1 pitch는 38 nm로, N+2보다 9.5% 작고 N6보다 33% 작다. M1 대 gate 비율은 셀 내부의 local routing flexibility를 결정하기 때문에 중요하다. N+2와 N+3는 3:2 비율을 사용하고, N6는 1:1 비율을 사용하기 때문에 M1 pitch 차이가 크게 난다. gate에 비해 M1 라인이 많을수록 셀 내부에서 전원 및 신호 교차를 처리할 유연성이 커진다. 라우팅 유연성은 더 복잡하고 더 나은 셀을 가능하게 한다. grid는 주기성을 가지므로 깔끔한 분수 비율이 레이아웃에 유리하다. 3:2 비율은 엄격한 1:1 grid보다 SMIC에 더 높은 local routing flexibility를 주지만, 동시에 레이아웃과 패터닝을 더 복잡하게 만든다. 이는 DTCO 선택으로, SMIC는 EUV 없이 밀도와 라우팅 가능성을 회복하기 위해 공정 복잡성을 높이고 있다.
이 3:2 비율은 선단 노드에서 그리 인기가 높지 않다. TSMC는 N7+, N5 계열, 그리고 단명한 N3(B)에서만 사용했다. N3E에서는 다시 1:1 비율로 돌아갔다. Intel은 10 nm/Intel 7 계열에서만 사용했으며, Intel 4, 3, 18A는 모두 1:1 비율을 사용한다. Samsung만이 여전히 선단에서 3:2 비율을 사용하고 있으며, SF4와 SF3 계열에 이를 적용한다. SMIC가 앞으로도 3:2 비율을 유지할지, 아니면 미래 노드에서 1:1 비율로 이동할지는 지켜봐야 한다.
업계는 여전히 이러한 local-routing 비율을 적극적으로 탐색하고 있다. VLSI 2026에서 imec은 최대 14% 면적 절감을 가능하게 하는 2:1 방식을 포함해 더 높은 비율에 대한 연구를 발표할 예정이다. 우리는 향후 뉴스레터 기사에서 이 컨퍼런스를 다룰 것이다.
우리는 시장에 나오는 가장 앞선 데이터센터 및 AI 하드웨어를 깊이 있게 분석하고 있다. 파이프라인에 무엇이 있는지 더 알고 싶거나 맞춤형 분해 분석을 의뢰하고 싶다면 sales@semianalysis.com으로 문의해 달라. 이 여정에 함께하고 싶고 변화를 만들 수 있다고 생각한다면 Careers 페이지를 확인해 달라.
N+3의 마지막 local interconnect layer는 M3이며, pitch는 44 nm다. M3 pitch는 N+2와 같고 N6보다 10% 더 크다.

Kirin 9030 Middle(왼쪽)와 Helio G99 Cortex-A55(오른쪽) metal stack, fin-cut, HFW 4.59 µm (Kirin 9030) 및 3.91 µm (Helio G99). 출처: SemiAnalysis
semi-global layer는 블록 수준 신호 라우팅의 대부분을 담당한다. 이들은 하위 local layer보다 더 굵은 pitch를 가진다. 선단 노드에서는 DUV single patterning 한계선에 맞춰 설계된다.
M4부터 M11까지의 pitch는 80–82 nm(M4–M6), 128 nm(M7–M10), 148 nm(M11)로 나뉘어 있음을 확인했다. 샘플 수가 제한적이므로, 조밀한 라우팅 영역에서는 더 세분화되어 있을 가능성도 있다. 최상단에는 두 개의 거대한 금속층 M12와 M13이 있다. 이들은 각각 1920 nm와 4600 nm로 N+2와 동일한 pitch를 유지했다.
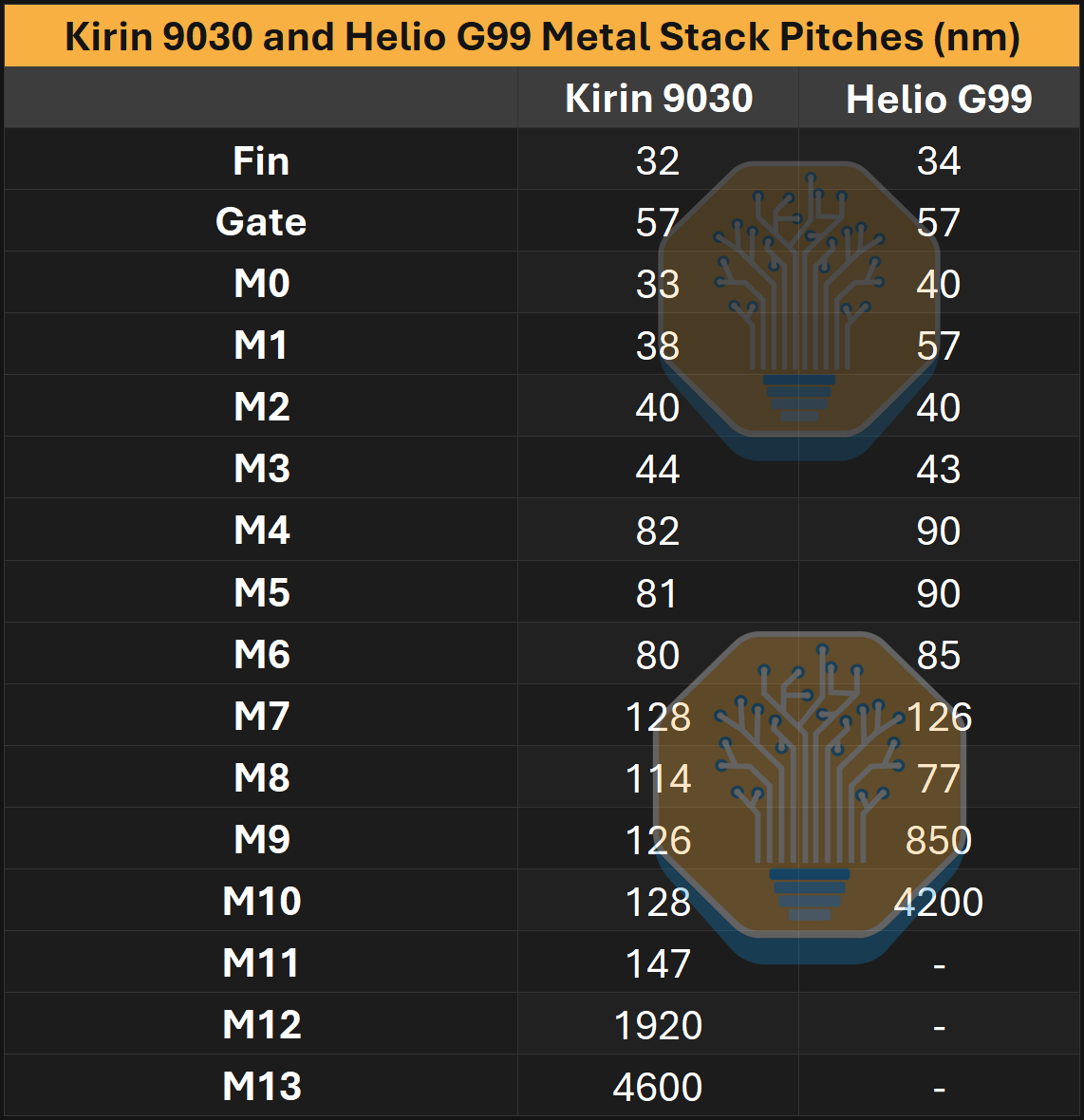
Kirin 9030과 Helio G99 metal stack pitch 요약. 출처: SemiAnalysis
하부 층 피치는 일반적으로 공정과 library에 의해 고정되지만, 상부 층은 설계에 따라 pitch와 층 수가 훨씬 크게 달라진다. 같은 공정의 스마트폰 SoC 두 개라도 metal stack이 크게 다를 수 있다. Helio G99는 더 적은 라우팅 층을 사용하며 M9에서 이미 850 nm의 거친 금속 피치에 도달하는 반면, 더 크고 더 높은 성능의 Kirin 9030은 M11까지 미세한 피치를 유지한다.
선단에서 SRAM은 로직보다 스케일링이 훨씬 더 어렵다. TSMC의 최신 노드는 bitcell 스케일링이 거의 없거나 전혀 없는 반면, 로직은 여전히 더 많은 DTCO 레버를 활용할 수 있다.
GPU compute unit에서 다른 로직 library를 찾다가 우연히 SRAM을 발견했다. 가장 일반적인 SRAM은 6개 트랜지스터(6T)를 사용하지만, 이 셀은 대신 8개 트랜지스터(8T)를 사용했다.
8T SRAM은 전용 read port를 형성하기 위해 트랜지스터 두 개를 추가한다. 6T 셀처럼 읽기가 저장 상태를 교란하는 구조와 달리, 분리된 read port는 read-disturb를 제거해 읽기 안정성을 높이고 더 공격적인 성능 최적화를 가능하게 한다.
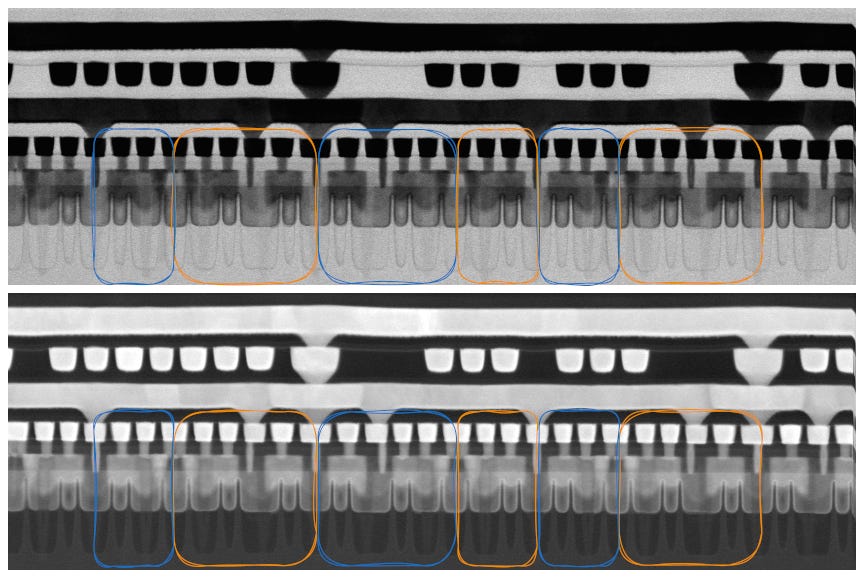
Kirin 9030 8T SRAM, fin-cut, HFW 1.55 µm. 출처: SemiAnalysis
처음 봤을 때 이 단면은 특이한 로직 library처럼 보였는데, 각 셀 행에 한 극성 fin 3개와 다른 극성 fin 5개가 있는 형태였다. 행의 방향도 번갈아 나타났다.
Energy-dispersive X-ray spectroscopy (EDS)가 우리의 혼란을 풀어줬다. 이 단면은 GPU 로직이 아니라 그 옆의 SRAM macro를 관통한 것이었다. 특이한 fin 패턴은 SRAM library 때문이었다. EDS에 대해서는 유료 구독 뒤의 공정 흐름 분석에서 다시 다룬다.
SRAM library는 전통적인 로직 library와 다르다. PMOS와 NMOS 트랜지스터 수가 불균등하기 때문에 특수한 규칙과 레이아웃 library가 필요하다. 로직 library처럼 유연성이 필요하지 않으므로, 하나의 목적, 즉 조밀하고 신뢰할 수 있는 메모리를 위해 극단적으로 최적화된다.
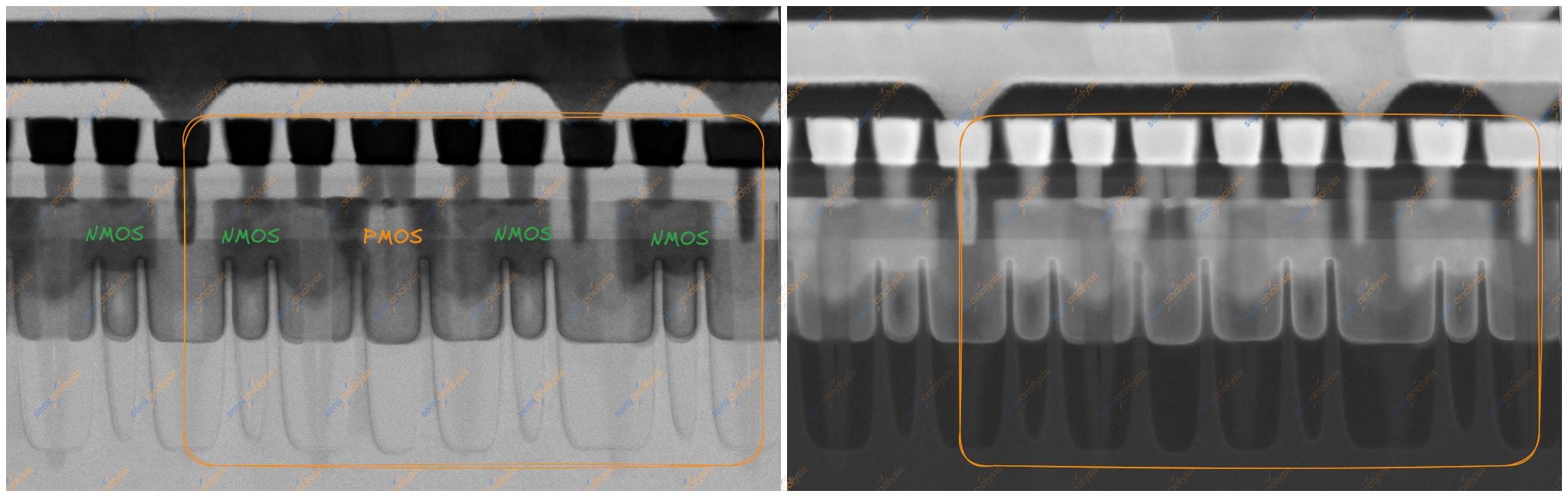
Kirin 9030 8T SRAM, fin-cut, HFW 562.5 nm. 출처: SemiAnalysis
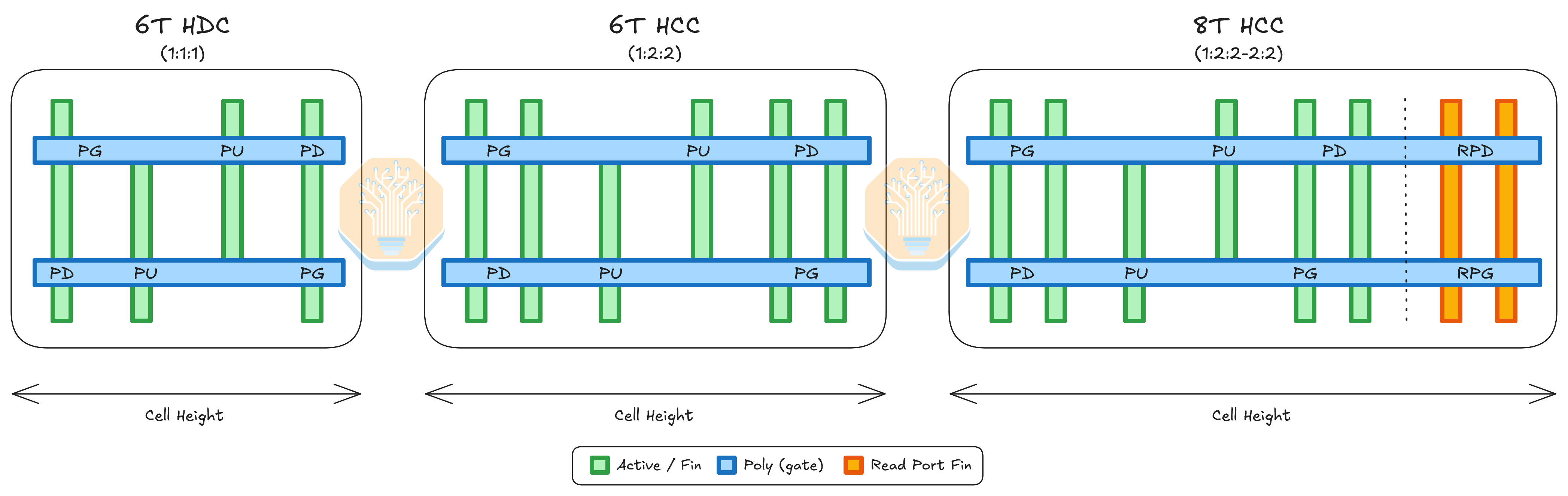
6T HDC (1:1:1), 6T HCC (1:2:2), 그리고 8T HCC (1:2:2-2:2) bitcell schematic, 왼쪽부터 오른쪽 순. 출처: SemiAnalysis
우리가 발견한 SRAM 셀은 1:2:2-2:2 셀이다. 이는 pull-up (PU) PMOS 트랜지스터당 fin 1개, pull-down (PD) 및 pass-gate (PG) NMOS 트랜지스터당 fin 2개를 의미한다. 보통 이 2 PU, 2 PD, 2 PG 트랜지스터는 단일 6T high-current cell (HCC)을 형성한다. 8T HCC는 여기에 각각 2개의 fin을 가진 read-pull-down (RPD)과 read-pass-gate (RPG) NMOS 트랜지스터를 추가한다.
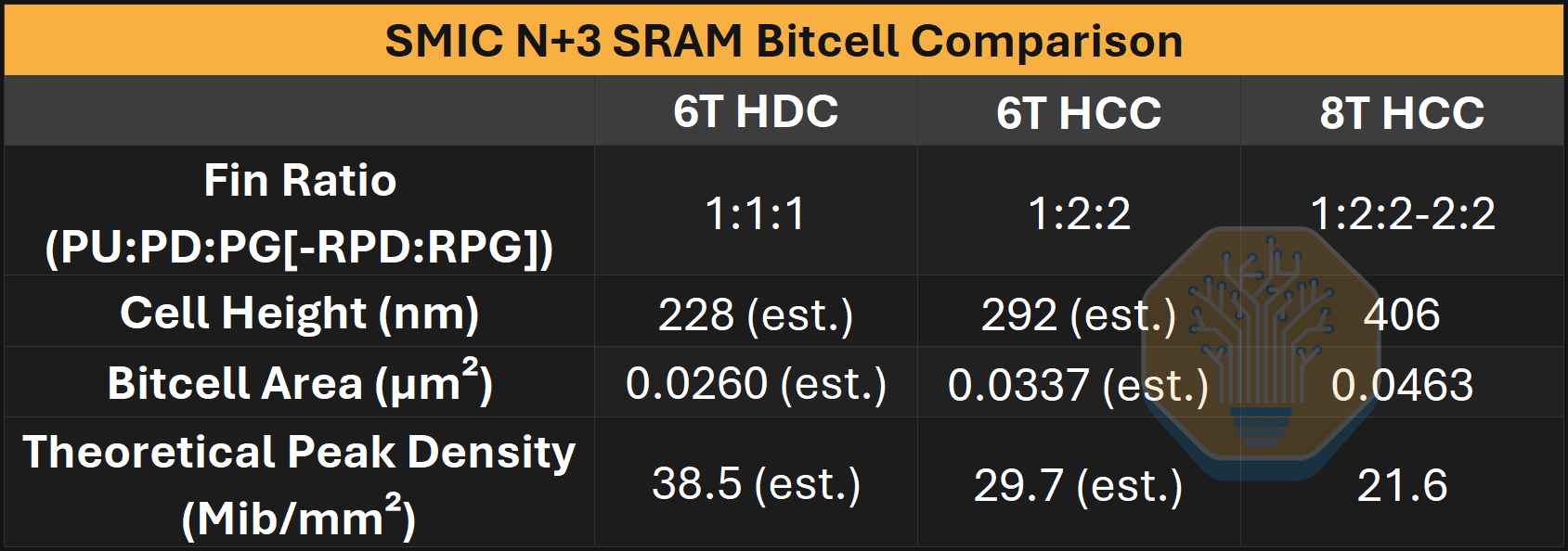
SMIC N+3 SRAM bitcell 비교. 출처: SemiAnalysis
우리는 cell height를 406 nm로 측정했으며, 이로부터 bitcell 크기는 0.0463 µm²가 된다. 이는 이론상 최대 21.6 Mib/mm² 밀도다. 우리는 6T HCC의 경우 cell height가 292 nm, 크기가 0.0337 µm²가 될 것으로 추정한다. 이는 Intel 3 및 4의 6T HCC보다 약 12% 더 크다.
또한 6T high-density cell (HDC)은 cell height가 228 nm이고 크기가 0.0260 µm²일 것으로 추정한다. 이는 우연히도 앞서 측정한 로직 standard-cell height와 동일하다. 이 추정은 이 셀을 Samsung 7LPP/5LPP에 가깝고 TSMC N7/N6보다 약간 낮은 수준에 위치시킨다. 이는 이론상 최대 38.5 Mib/mm² 밀도다. 6T HDC는 칩에서 가장 큰 캐시인 L3 캐시와 system-level cache (SLC)에 사용되기 때문에 arguably 가장 중요한 셀이다.
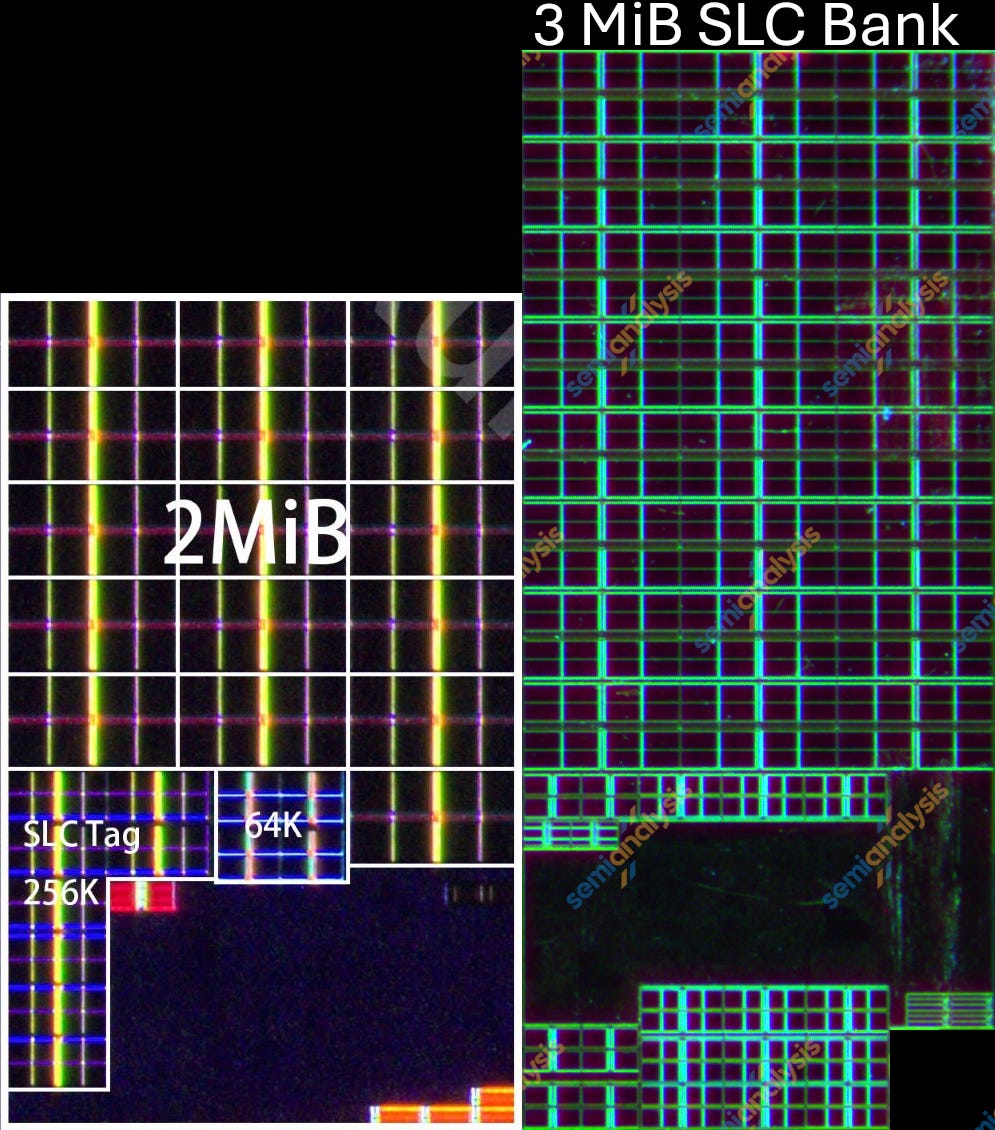
Kirin 9020(왼쪽)와 Kirin 9030(오른쪽) SLC bank. 출처: Kurnal, SemiAnalysis
Kirin 9020과 9030은 모두 전체 SLC 대역폭을 높이기 위해 SLC를 4개 bank로 분할했다. Kirin 9030에서는 bank당 SLC가 2 MiB에서 3 MiB로 증가했다. 이에 따라 bank 내 array 수도 16개에서 24개로 50% 늘었다. 각 array는 128 KiB를 저장할 수 있으며 다이 샷에서 질서정연한 패턴을 이룬다.
Kirin 9020에서 Kirin 9030으로 가며 128 KiB SLC array의 면적은 0.0477 mm²에서 0.0392 mm²로 줄어들어 18% 축소됐다. 달성된 밀도는 25.5 Mib/mm²로, 이론 최대의 66%다.
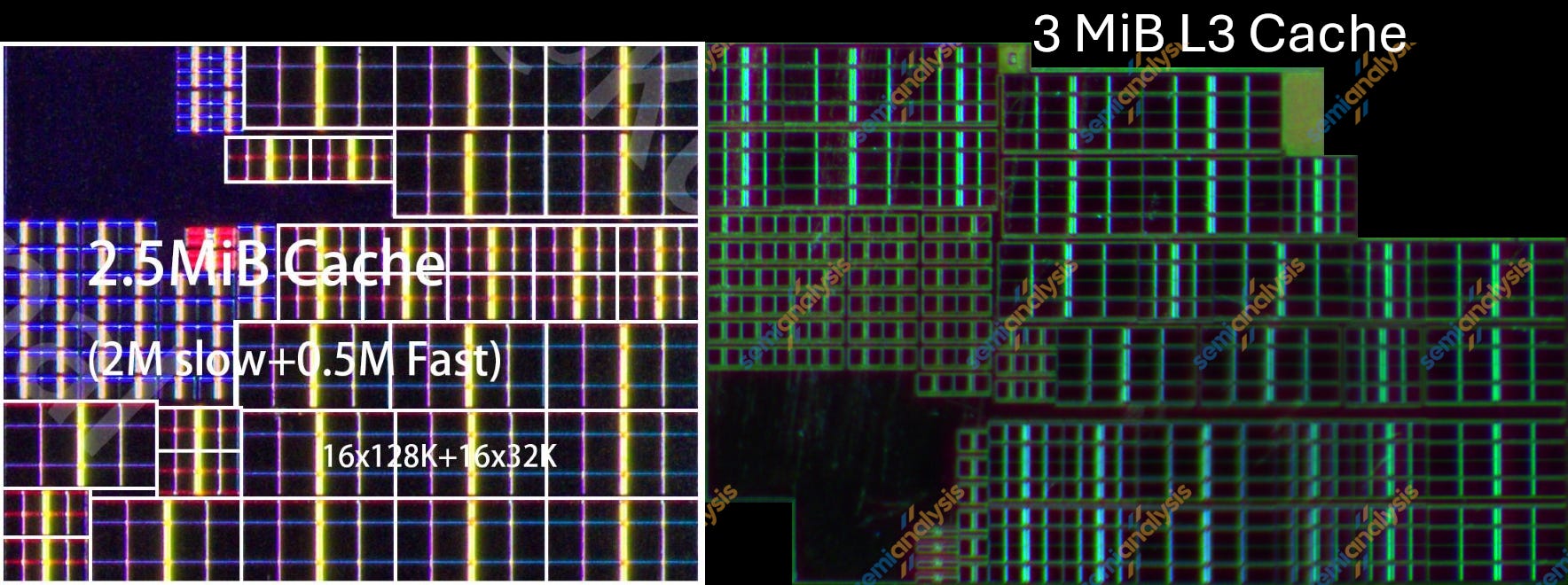
Kirin 9020(왼쪽)와 Kirin 9030(오른쪽) big CPU cluster L3 캐시 bank. 출처: Kurnal, SemiAnalysis
SLC는 두 칩에서 꽤 비슷했지만, L3는 특히 레이아웃 측면에서 큰 변화를 겪었다. 총 용량도 10 MiB에서 12 MiB로 증가했다. SLC와 마찬가지로 L3도 4개 bank로 나뉜다.
Kirin 9020에서 L3 bank는 16개의 128 KiB array와 16개의 32 KiB array로 구성됐다. 반면 Kirin 9030의 L3 bank는 48개의 64 KiB array로 구성된다.
Kirin 9020 L3에서 128 KiB array는 0.0513 mm²였고 32 KiB array는 0.0154 mm²였다. 128 KiB array의 크기가 L3와 SLC에서 다른 이유는 두 array의 목적에 따라 assist circuitry가 다르기 때문이다.
Kirin 9030 L3에서 64 KiB array는 0.0210 mm²다. 완전히 같은 조건의 비교는 아니지만, 용량 기준으로 정규화하면 9020의 128 KiB L3 array보다 18% 작고, 32 KiB L3 array보다 31% 작다. 달성된 밀도는 SLC보다 약간 낮은 23.8 Mib/mm²로, 이론 최대의 62%다.
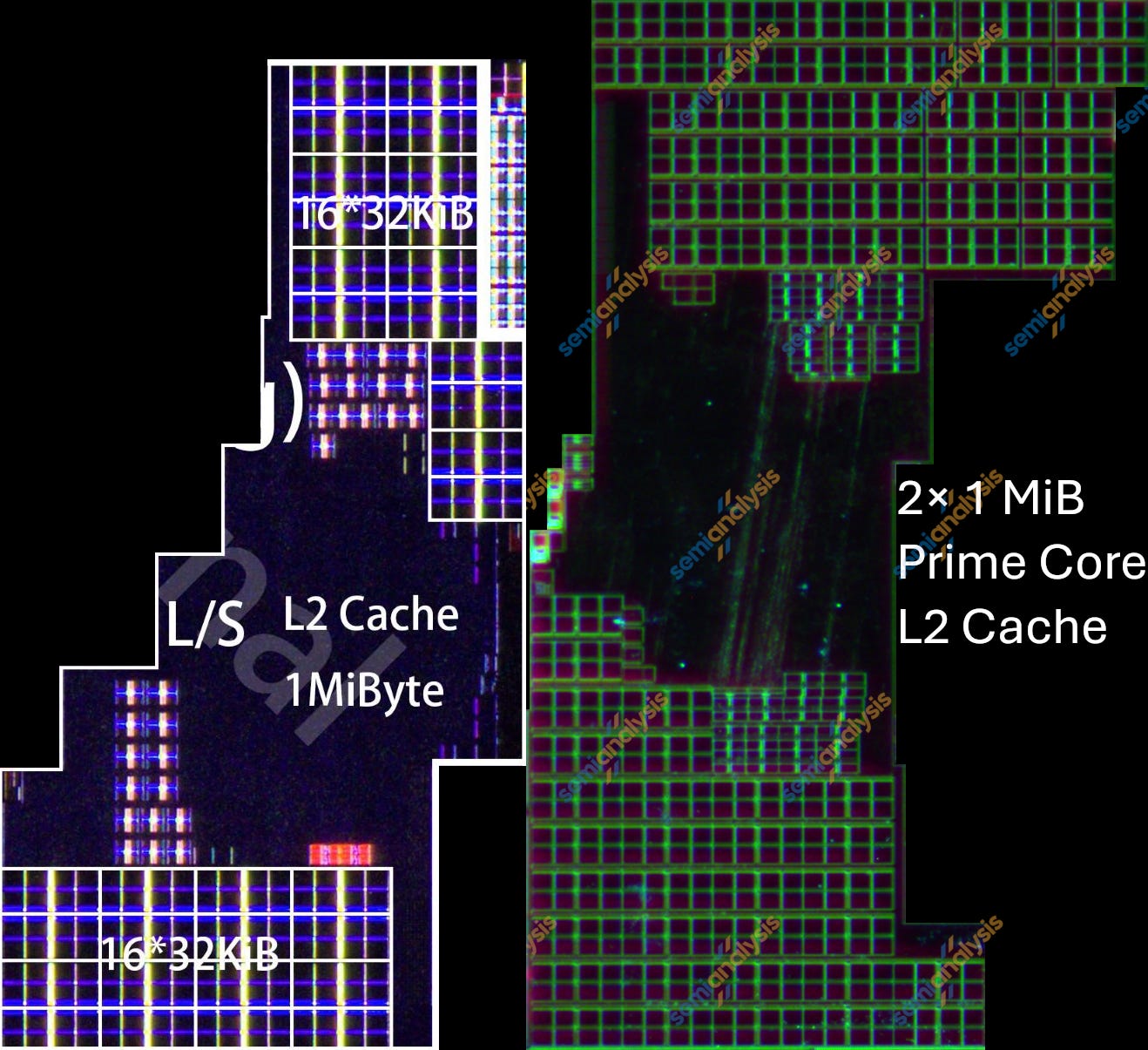
Kirin 9020(왼쪽)와 Kirin 9030(오른쪽) prime 코어 private L2 캐시. 출처: Kurnal, SemiAnalysis
L3와 SLC와 달리 prime 코어의 private L2 캐시는 2-bank 설계를 사용한다. prime 코어의 L2는 지연 시간에 민감하므로 6T HDC 대신 6T HCC를 사용할 가능성이 높다. 9020은 각 bank에 16개 array를, 9030은 32개를 가진다. 각 array 용량은 32 KiB다.
L2의 32 KiB array는 0.0171 mm²에서 0.0142 mm²로 줄어 약 17% 축소됐다. 밀도는 17.6 Mib/mm²로, 6T HCC 이론 최대의 약 59%다.
SRAM은 N+2에서 N+3로 약 19% 축소되어, 이론적 로직 축소율에 가깝게 잘 스케일링되었다. 다만 N+2의 bitcell이 비정상적으로 커서 비슷한 7 nm급 노드보다 더 컸다는 점이 단서다. 따라서 이 향상의 일부는 진정한 스케일링이라기보다 따라잡기 성격이다.
STEEL의 분해 분석 인사이트를 바탕으로, 우리는 향후 뉴스레터 기사에서 SRAM을 깊이 있게 다룰 예정이다.
위의 모든 내용은 STEEL 분해 분석 하나에서 나왔다. 다이 주석, 블록 수준 면적 분석, 그리고 로직과 SRAM을 관통하는 TEM 단면이다. 우리는 시장에 나오는 가장 앞선 데이터센터 및 AI 하드웨어를 깊이 있게 분석하고 있다. 파이프라인에 무엇이 있는지 더 알고 싶거나 맞춤형 분해 분석을 의뢰하고 싶다면 sales@semianalysis.com으로 문의해 달라.
N+3를 규명한 동일한 단면은 또한 SMIC가 다음에 어디로 갈 수 있는지도 보여준다. N+3는 이미 여러 층에서 DUV 멀티패터닝의 실질적 한계에 가까워졌지만, SMIC에는 아직 몇 가지 스케일링 레버가 남아 있다.
가상의 N+4는 아마 cell height부터 시작할 것이다. N+3는 전원 레일 사이에 5개의 M0 track을 사용한다. 이를 SMIC N+2와 TSMC N6처럼 4개 M0 track으로 줄이면 cell height를 대략 15% 줄일 수 있다. 라우팅 grid는 축소의 한쪽 측면일 뿐이며, front end도 더 작은 셀 안에 들어가야 한다.
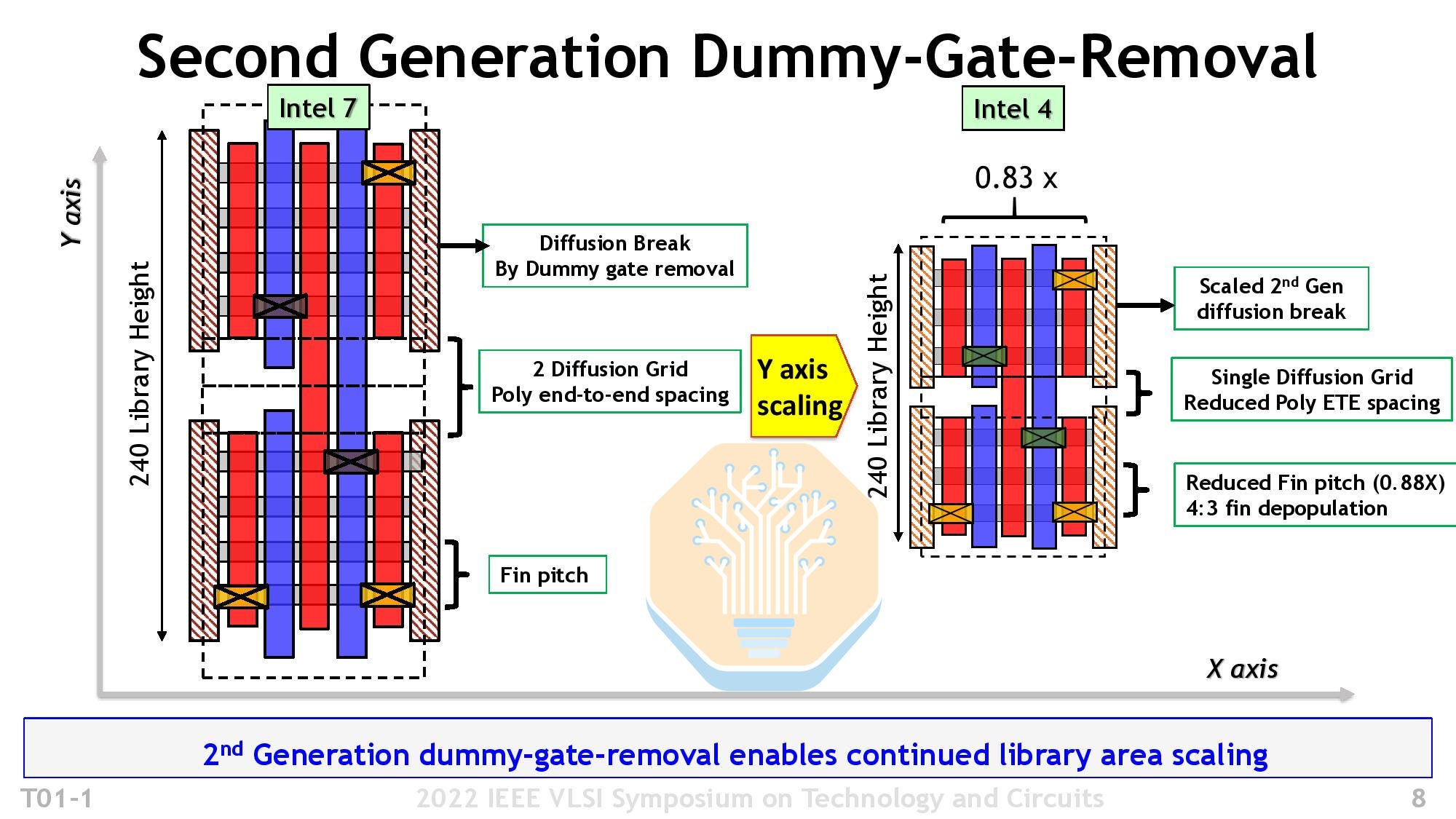
감소된 poly end-to-end spacing을 가진 Intel 4 Single Diffusion Grid. 출처: Intel, VLSI 2022
가능한 FEOL 레버 중 하나는 p-to-n isolation spacing을 두 개 diffusion grid unit에서 하나로 줄이는 것이다. Intel은 Intel 4에서 이 scaling booster를 사용했고, TSMC도 N3 계열에서 그렇게 했다. 이 경로는 레이아웃 유연성을 밀도와 교환한다. M0 track 수가 줄어들면 local routing resource가 감소하고, 더 촘촘한 p-to-n spacing은 통합과 설계 규칙의 난도를 높인다.
M2도 cell height 축소에 의해 제약을 받는다. SMIC가 약 5.7-track cell을 유지하려면 M2는 약 35 nm 쪽으로 이동해야 한다. 그러면 또 다른 층이 SAQP 영역으로 들어가게 된다.
SMIC는 CGP를 57 nm에서 54 nm로 줄일 수도 있다. Intel은 EUV 없이 Intel 10 nm/Intel 7에서 비슷한 CGP에 도달했다. local interconnect는 더 어렵다. SMIC가 3:2 M1 대 gate 비율을 유지한다면 M1은 36 nm로 줄어야 하고, 이 경우 역시 SAQP가 필요할 가능성이 높다. SMIC가 1:1 비율로 이동하면 M1은 54 nm로 완화될 수 있지만, 라우팅 유연성을 포기해야 한다.
이 가상의 경로에서 우리는 SMIC N+4가 cell height 198 nm, CGP 54 nm에 도달할 수 있다고 추정하며, 이는 137.8 MTr/mm²의 Bohr 밀도를 의미한다. 이는 TSMC N5 또는 Samsung SF4와 비슷한 수준이다. 그러나 어려움은 누적된다. 각 단계는 개별적으로는 가능성이 있지만, 모두 합치면 N+4는 N+2에서 N+3로의 전환보다 더 어렵다. 더 오래 걸리고, 비용이 더 들며, 공정 여유는 더 적을 가능성이 높다.
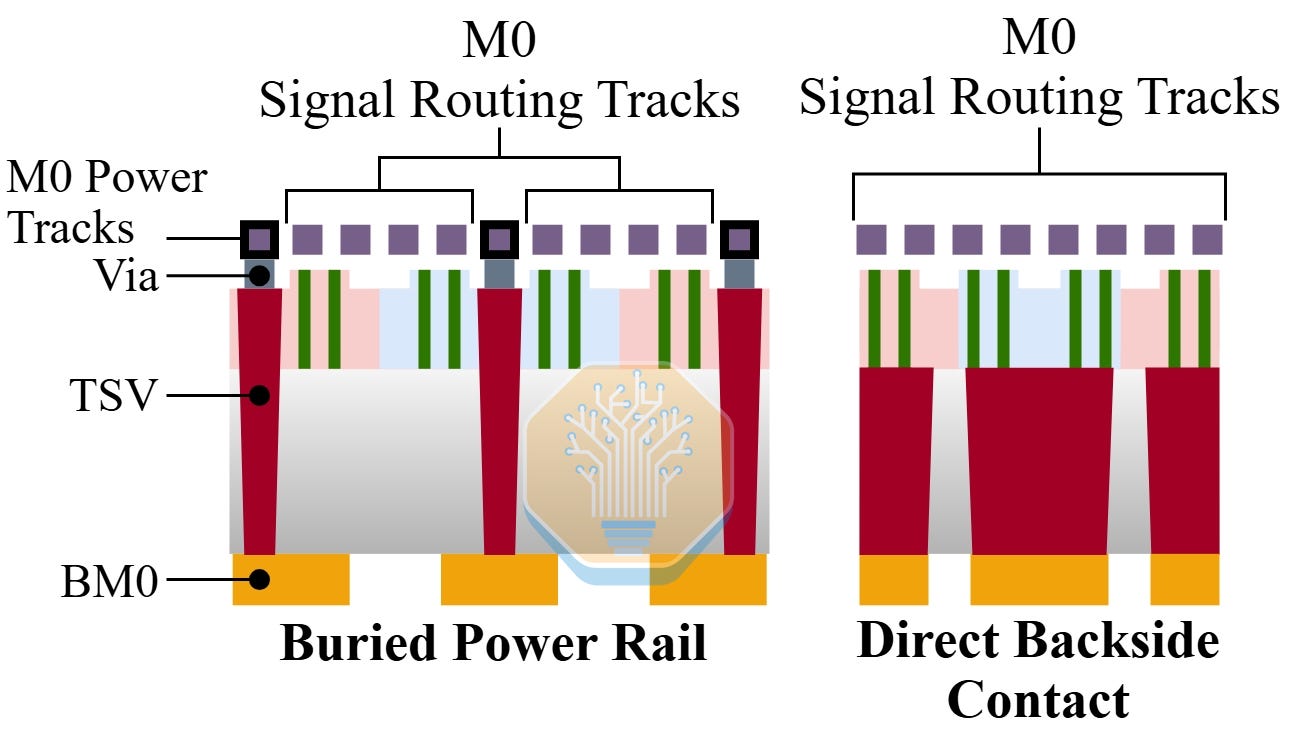
backside power delivery를 위한 buried power rail과 backside contact 접근법. 출처: UC San Diego, ISPD 2026
가상의 N+5는 더 큰 통합 변화가 필요하다. 한 가지 가능한 경로는 backside contacts (BSCon)로, 전력 라우팅과 source/drain contact를 backside로 이동시켜 front-side 라우팅 압력을 줄이고 cell height를 한 번 더 낮출 수 있다.
front-side 금속 피치는 공정 복잡성을 줄이기 위해 완화될 수 있다. M0는 약 34 nm로 약간 완화될 가능성이 높고, M2와 M4 피치는 더 완화될 수 있다. CGP는 더 이상 크게 줄어들 가능성이 낮다. EUV가 있더라도 48 nm는 수율과 공정 제어 측면에서 사실상 한계였다.
이 접근은 N+5의 cell height를 170 nm, CGP를 53 nm로 낮출 수 있게 한다. 이는 163.6 MTr/mm²의 Bohr 밀도를 의미하며 Intel 18A의 HP library와 맞먹는 수준이다. 그러나 그렇다고 해서 N+5가 선단과 비용 경쟁력을 갖게 되는 것은 아니다. 훨씬 더 비싼 경로를 통해 비슷한 밀도에 도달하게 될 것이다. 통합 난도는 backside alignment, wafer thinning, contact reveal, backside metallization을 위한 새로운 공정 흐름 때문에 급격히 상승한다.
이 지점을 지나면 standard density와 interconnect scaling은 점점 매력적이지 않게 된다. 바로 이 지점에서 Huawei의 로드맵은 일반적인 파운드리 로드맵이 아니라 패키징 로드맵처럼 보이기 시작한다.
ISCAS 2026에서 Huawei는 τ scaling law를 공개하며 공정 스케일링을 시간 영역에서 재정의했다. τ는 데이터 이동과 처리의 시간 비용이다. 즉, 트랜지스터의 스위칭 지연, 회로의 RC 신호 전파 지연, 연산, 메모리, 네트워킹 지연을 포함한다. Huawei의 용어를 벗어나면 이는 system-technology co-optimization이라고 부른다.
이것이 EUV lithography 부재에 대한 Huawei의 해답이다. EUV 없이 평면 밀도는 TSMC, Intel, Samsung을 따라갈 수 없다. 트랜지스터 밀도를 더 줄일 수 없다면, Huawei의 대안은 배선을 짧게 하고, 버퍼를 줄이고, 로직을 수직으로 적층하는 것이다.
Huawei가 이 새로운 스케일링 아이디어를 구현한 “LogicFolding”은 실제로는 공격적인 3D 적층 접근법이다. AMD V-Cache는 CPU 다이 위나 아래에 SRAM을 배치한다. AMD의 MI350X는 active interposer die (AID)를 accelerator 및 compute die (XCD) 아래에 배치하며, AID가 cache, IO interface, network-on-chip (NoC), embedded metal-insulator-metal (MIM) capacitor를 처리한다. LogicFolding에서는 같은 로직 블록의 일부를 ultra-fine pitch로 face-to-face 결합된 여러 active die에 나누어 배치한다. 이를 통해 Huawei는 단순히 캐시 용량을 늘리거나 IO 및 interconnect를 오프로딩하는 것을 넘어, 일부 임계 경로를 단축하고 버퍼 오버헤드를 줄일 수 있다.
배선을 짧게 하는 것이 더 높은 클록의 원천이다. 현대 코어의 지연과 에너지 예산의 상당 부분은 긴 interconnect와 그 위의 repeater buffer를 구동하는 데 쓰인다. LogicFolding은 매우 미세한 pitch로 결합된 여러 적층 tier에 블록의 critical-path gate를 분산시키므로, bond interface가 추가 금속층처럼 작동하고 가장 긴 경로가 짧아진다. Huawei가 공정 자체만으로는 얻을 수 없는 주파수와 효율을 회복할 수 있다고 기대하는 이유가 여기에 있다.
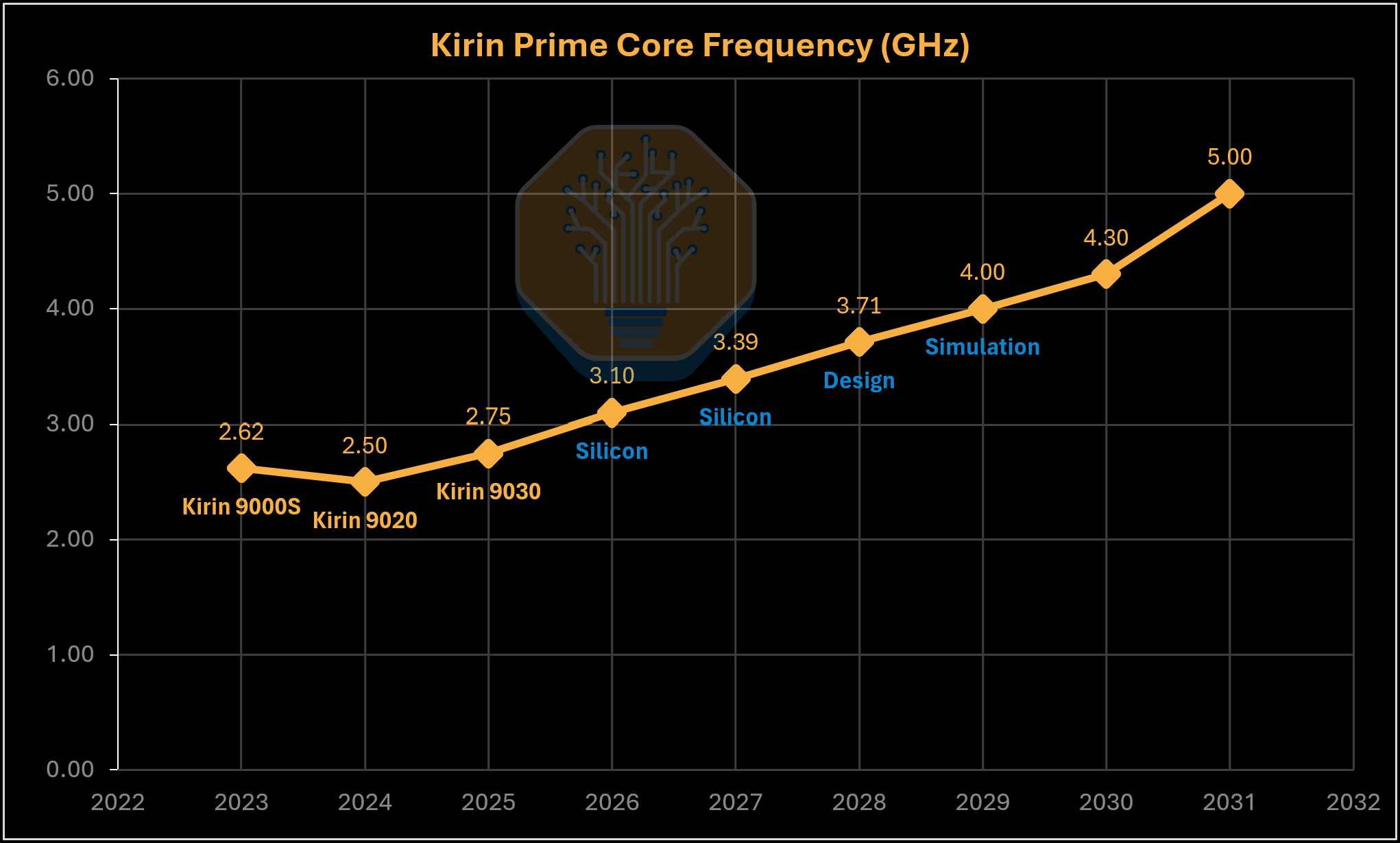
Huawei Prime Core 주파수 로드맵. 출처: Huawei, SemiAnalysis
Huawei의 로드맵은 그 의도를 보여준다. Prime 코어 주파수는 Kirin 9030의 2.75 GHz에서 2031년경 약 5 GHz로 상승하는 것을 목표로 하고 있으며, 이는 평면 스케일링만으로는 도달할 수 없는 수준이다. 3.1 GHz와 3.39 GHz 클록의 prime 코어가 이미 연구소에서 테스트되고 있지만, 전력 소모는 알려지지 않았다. 그 이후의 칩들은 설계, 시뮬레이션 또는 pathfinding 단계에 있어 이 주파수는 목표치다. 그러나 더 중요한 것은 방향성이다. LogicFolding은 밀도뿐 아니라 성능에도 도움이 된다.
문제는 Huawei의 밀도 주장과 파운드리 밀도를 직접 비교할 수 없다는 점이다. 적층 설계는 active layer를 추가함으로써 패키지 footprint당 더 많은 트랜지스터를 보고할 수 있으며, 각 패턴화된 다이의 front-end 밀도는 여전히 TSMC나 Intel에 한참 뒤처질 수 있다. Huawei가 2031년까지 foundry 14A급 밀도에 도달한다고 주장할 수 있는 이유가 여기에 있다.
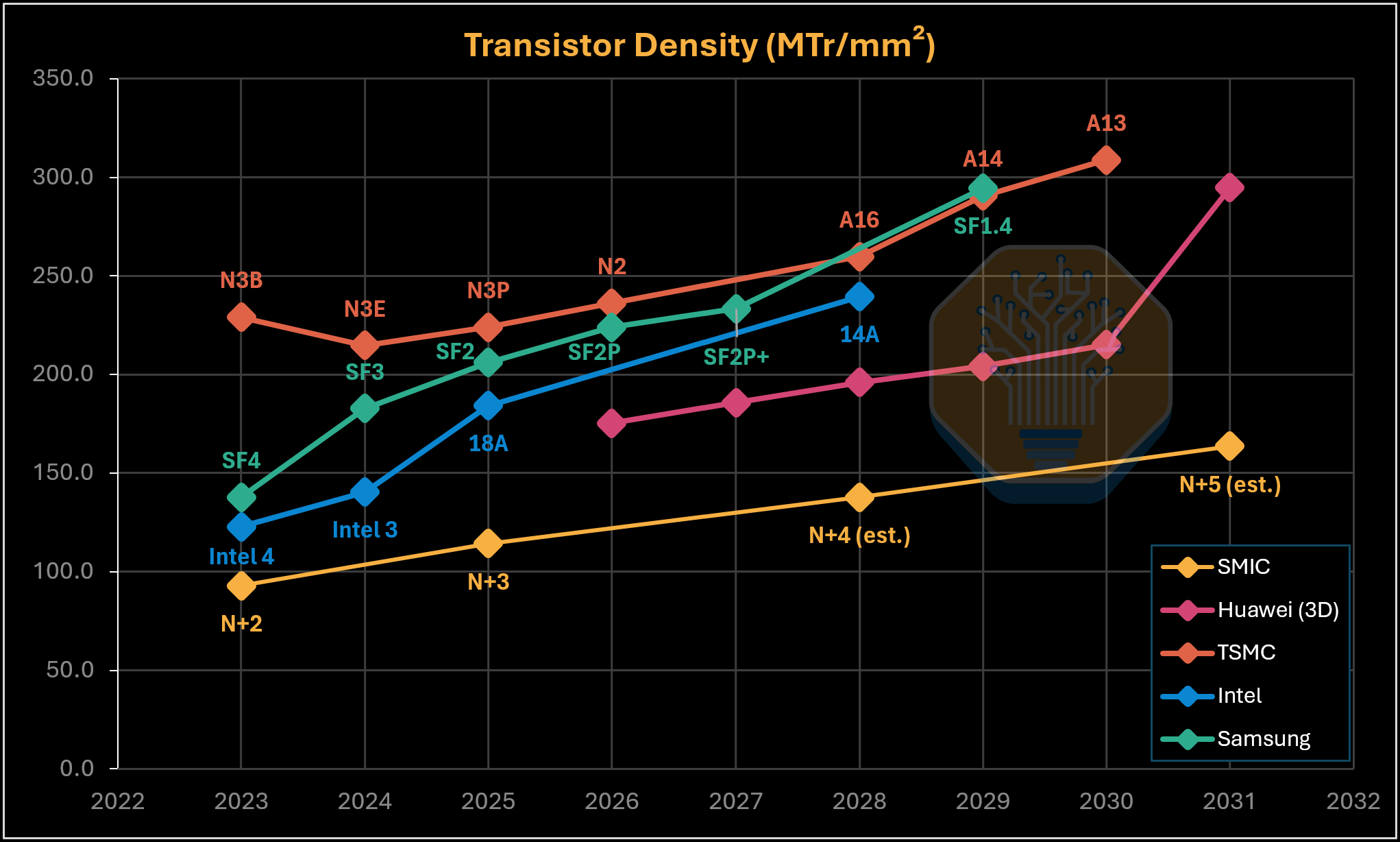
SMIC, Huawei (3D), TSMC, Intel, Samsung의 밀도 로드맵. 출처: Huawei, SemiAnalysis
이는 Huawei가 적층 로직을 사용하고 패키지 footprint당 밀도를 측정하기 때문에 동일 조건의 파운드리 비교가 아니다. 정규화된 Bohr 밀도 기준으로 SMIC N+3는 약 114 MTr/mm²로, Intel 18A HD library보다 38% 낮다. Huawei의 3D 로드맵은 active logic 적층으로 이 격차를 좁혀 2030년 215 MTr/mm²에 도달한다. 2031년에는 로드맵 밀도가 295 MTr/mm²로 뛰는데, 이는 세 번째 active layer, 부분적 EUV 도입, 또는 공격적인 평면 DUV 스케일링 중 하나를 시사한다.
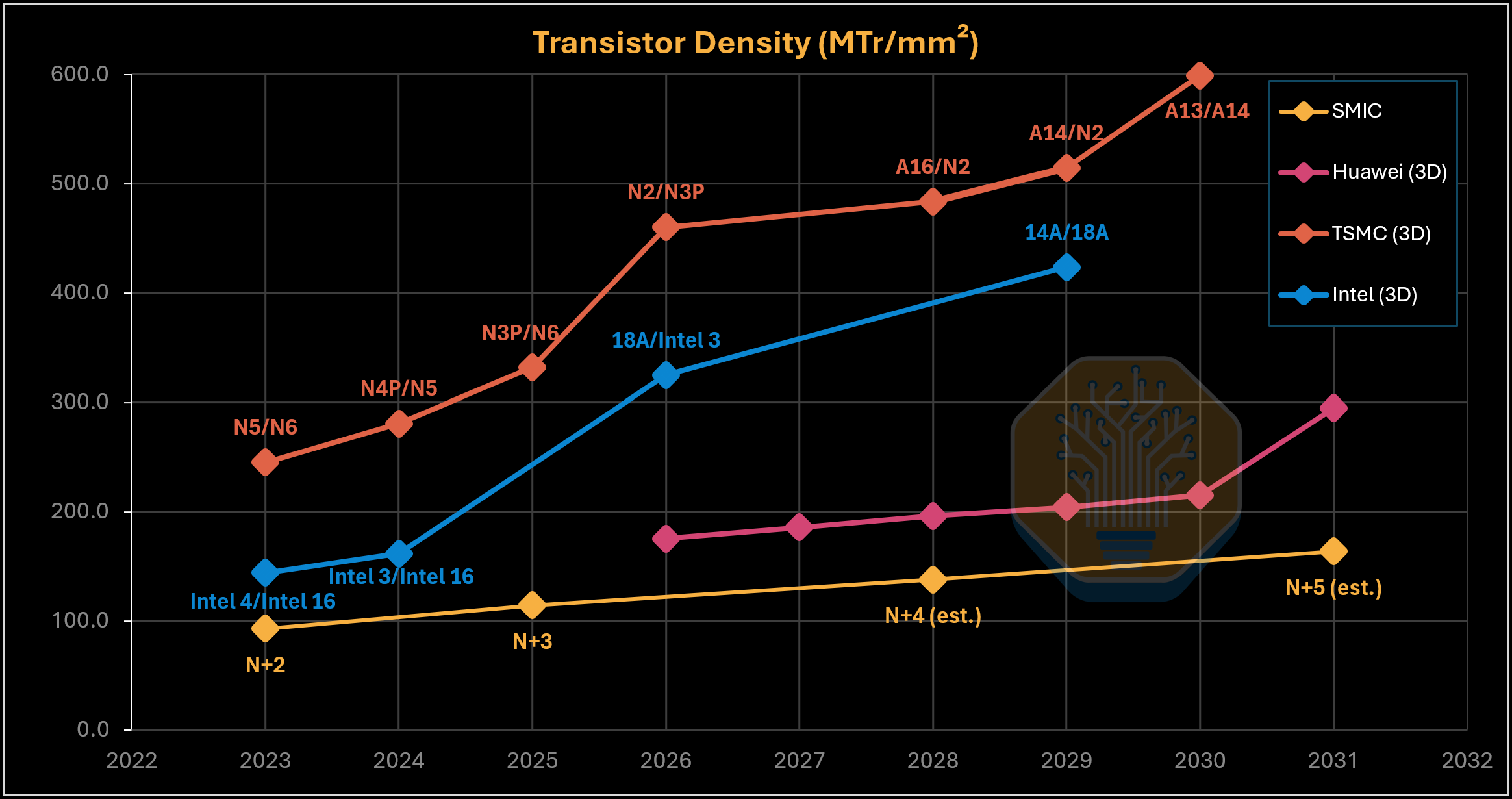
TSMC 및 Intel 적층 로직과 비교한 Huawei LogicFolding 밀도 로드맵. 출처: Huawei, SemiAnalysis
Huawei의 방법론을 적용하면 다른 파운드리도 훨씬 더 조밀해 보인다. 이를 N3P base die 위에 N2 top die를 올린 AMD의 MI450X에 적용하면, 2026년에 이론상 460.2 MTr/mm²가 되며, 이는 Huawei의 2031년 295 MTr/mm²와 비교된다.
이번 Kirin 9030은 LogicFolding을 사용하지 않으며, 여전히 전통적인 모바일 SoC 패키지에 머문다. 대신 이는 Huawei와 SMIC가 평면 스케일링을 얼마나 밀어붙일 수 있는지에 대한 기준선 역할을 한다. 앞으로의 Kirin과 Ascend 칩 분해 분석은 평면 로직 밀도와 Huawei의 hybrid bonding 해법을 모두 보여줄 것이다.
수출 통제는 중국의 최적화 문제를 끝낸 것이 아니라 바꾸어 놓았다. EUV 제한은 선단 제조의 비용과 복잡성을 높였지만, 그것을 동결시키지는 못했다. SMIC는 DUV immersion, SAQP, DTCO를 통해 N6급 로직 밀도에 도달하고, Huawei는 그 부담을 더 많이 아키텍처, 패키징, 시스템 수준 통합으로 이동시킨다.
미래 노드는 더 어려울 것이다. N+3는 여전히 local metal을 더 조이고 cell height와 CGP를 줄일 여지가 있었다. EUV 없이 추가 스케일링을 하려면 남은 레버가 더 적다. 더 공격적인 멀티패터닝은 mask와 overlay error를 늘린다. SMIC는 계속 DUV를 밀어붙일 수 있지만, 단계마다 비용은 더 올라가고 공정은 덜 관대해질 것이다.
설계 측면도 그만큼 중요하다. Huawei는 Kirin 9030 이전부터 국내 EDA 도구와 흐름을 갖추고 있었으며, Kirin 9000s, 9010, 9020이 이를 분명히 보여준다. Huawei는 서방 EDA 스택에서 차단된 상태에서도 SMIC N+2와 N+3에서 여러 소비자용 SoC를 출하할 수 있었다.
미국의 수출 통제는 2022년에 첨단 칩용 EDA 도구를 제한했지만, 더 성숙한 칩용 도구는 겨냥하지 않았다. 2025년 미국 정부는 한때 Synopsys, Cadence 등에서 제공하는 EDA 소프트웨어에 대해 훨씬 더 광범위한 제한을 걸었지만, 희토류와 연계된 무역 합의의 일환으로 두 달도 되지 않아 해제했다. 그러나 Huawei는 미국의 무역 블랙리스트에 계속 올라 있기 때문에 그 도구들에 접근할 수 없었다.
그 결과 Huawei, SMIC, 그리고 중국 학계는 자체 도구와 흐름을 구축해야 했다. 최근 Peking University 연구진은 Huawei의 LogicFolding 아키텍처용 프로토타입 EDA 도구를 발표했는데, 이는 다층 레이아웃과 플로어플랜을 처리하기 위한 새로운 흐름이 필요하다. 이것이 Synopsys나 Cadence 전체 스택을 대체하는 것과 같지는 않지만, 국내 EDA가 어디로 향하는지는 보여준다. 즉, 아키텍처, 공정, 패키징 사이의 더 긴밀한 공동 최적화 쪽이다.
이러한 진전은 중국 생태계 전반으로도 확산되고 있다. SMIC는 정부 지시에 따라 자발적 선택이 아니라 HLMC/Hua Hong에 N+2와 N+3 공정을 라이선스하고 있다. 동일한 공정 학습이 AI 학습 및 추론용 Ascend accelerator에 투입된다면, 병목은 특정 파운드리 한 곳에서 생태계 전체로 이동한다. Alibaba의 T-Head 실리콘 부문과, ByteDance 공급이 예상되는 중국 AI 칩 설계사 Cambricon도 주요 수혜자가 될 수 있다. 제조 지식이 다른 팹과 설계 하우스로 확산된 이후에는 SMIC만 겨냥한 제재의 효과가 약해진다.
중국이 Intel, Samsung, TSMC와의 격차를 닫고 있는 것은 아니다. 이번 분해 분석은 여러 곳에서 그 반대를 보여준다. EUV 부재, backside power 부재, 더 높은 공정 복잡성, 그리고 눈에 보이는 절충이다.
그러나 중국은 여전히 전진하고 있다. 국내 칩이 스마트폰, 추론, 네트워킹, 보안 민감 워크로드에 대해 충분히 좋은 수준에 도달한다면, 선단에서 TSMC와 맞먹지 않더라도 전략적으로 중요할 수 있다.
유료 구독 뒤에서는 SMIC N+3의 소재 및 공정 흐름 분석, 그리고 Kirin 9030 패키지 분석을 통해 STEEL이 또 무엇을 할 수 있는지 보여준다.
우리는 시장에 나오는 가장 앞선 데이터센터 및 AI 하드웨어를 깊이 있게 분석하고 있다. 파이프라인에 무엇이 있는지, Kirin 9030 및 SMIC N+3 전체 분석에 접근하는 방법, 또는 맞춤형 분해 분석 의뢰에 대해 더 알고 싶다면 sales@semianalysis.com으로 문의해 달라.

우리 분해 분석 파이프라인에 있는 다른 칩들의 일부 모습. 출처: SemiAnalysis