설치 과정에서 패키지 매니저가 수행하는 수많은 semver 비교와, npm/yarn/pnpm이 사용하는 semver 라이브러리를 최대 33배까지 더 빠르게 만들 수 있는 방법을 살펴본다.
📖 tl;dr: 설치 과정에서 패키지 매니저는 엄청나게 많은 semver 비교를 수행합니다. npm, yarn, pnpm에서 사용하는 semver 라이브러리는 대략 33배 더 빠르게 만들 수 있습니다.
Preact 저장소를 만지작거리다가 npm install을 실행하는 데 3초가 넘게 걸린다는 걸 발견했습니다. 너무 길어 보였고 흥미가 생겼죠. 마침 cpupro를 써볼 만한 좋은 사례를 기다리고 있었는데, 딱 알맞아 보였습니다.
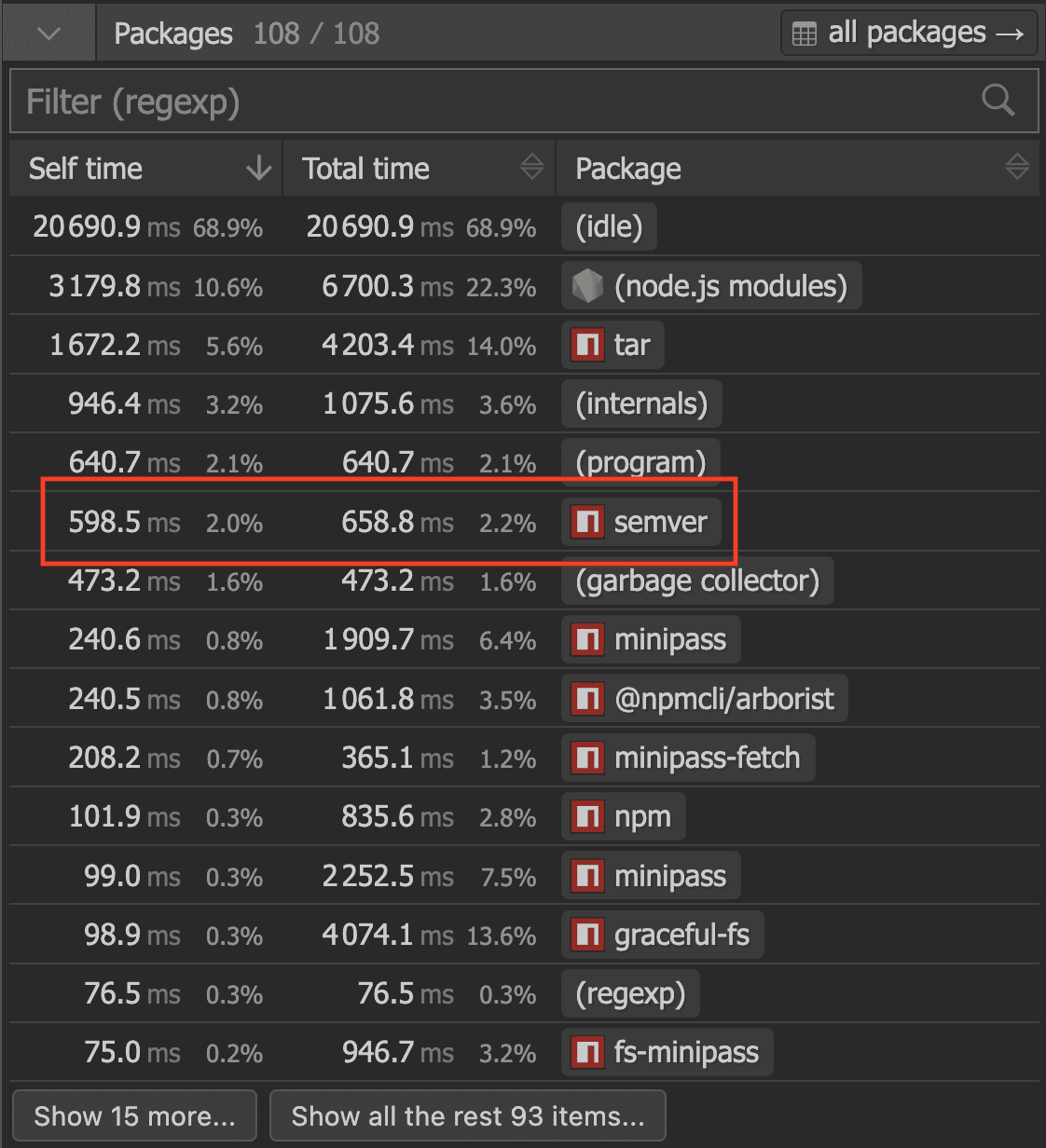
tar 라이브러리가 상위에 있는 건 어느 정도 예상할 수 있습니다. tarball을 푸는 데 시간이 꽤 쓰이니까요. 하지만 제 시선을 사로잡은 건 semver 패키지였습니다. 이 패키지는 프로젝트의 모든 의존성에 대해 모든 버전 범위를 비교해, 어떤 버전을 설치할지 결정합니다. 버전 표기는 semver 표준을 기반으로 하며, major, minor, patch, 그리고 선택적인 prerelease 구성 요소를 정의합니다:
1.2.3 # major.minor.patch2.0.0-alpha.3 # major.minor.patch-prerelease
패키지 매니저는 여기서 더 나아가 범위(range)나 제약(constraint)을 지정할 수 있게 해줍니다. 정확한 버전만 허용하는 대신 ^1.0.0 같은 값을 넘길 수 있는데, 이는 “이 버전보다 큰 minor 또는 patch 버전을 허용하라”는 뜻입니다. 범위는 조합도 가능합니다. peerDepdendencies를 선언할 때 1.x || 2.x 같은 형식을 종종 보게 될 겁니다. npm은 의존성에 대해 원하는 버전 범위를 표현하는 매우 다양한 방법을 지원합니다.
1.2.3 # =1.2.34.0.0-alpha.4 # =4.0.0-alpha.44.0.0-2 # =4.0.0-2# 부분 버전도 가능1 # =1.0.01.2 # =1.2.0# 범위^2.0.0 # >= 2.0.0 && <3.0.0~2.0.0 # >= 2.0.0 && <2.1.01.x || 2.x # >=1.0.0 || >=2.0.01.2.3 - 1.4.0 # >=1.2.3 && <=1.4.01.x # >=1.0.0# ...그 외에도 많음
npm 바이너리가 semver를 얼마나 자주 호출하는지 감을 잡기 위해, npm 저장소를 클론하고 npm install을 실행한 뒤, semver 라이브러리의 모든 export를 래핑해서 어떤 함수가 어떤 인자로 호출되는지 로그를 남기게 했습니다.
preact 저장소에서 설치를 수행하면 semver 호출이 총 약 21.2k회 발생합니다. 예상보다 훨씬 많았습니다. 호출된 함수 통계는 다음과 같습니다:
| 함수 | 호출 수 |
|---|---|
satisfies | 11151 |
valid | 4878 |
validRange | 4911 |
sort | 156 |
rcompare | 79 |
simplifyRange | 24 |
표를 보면 호출 수의 대부분이 버전 제약이 만족되는지 확인하고, 유효성을 검사하는 데 집중되어 있음을 알 수 있습니다. 의존성 설치 중 패키지 매니저가 해야 하는 일이 바로 그것이니 당연하죠. 원본 함수 호출 로그를 보면 흔한 패턴이 보입니다:
valid [ '^6.0.0', true ]validRange [ '^6.0.0', true ]satisfies [ '6.0.0', '^6.0.0', true ]valid [ '^0.5.0', true ]validRange [ '^0.5.0', true ]satisfies [ '0.5.0', '^0.5.0', true ]valid [ '^7.26.0', true ]validRange [ '^7.26.0', true ]satisfies [ '7.26.0', '^7.26.0', true ]valid [ '^7.25.9', true ]validRange [ '^7.25.9', true ]satisfies [ '7.25.9', '^7.25.9', true ]valid [ '^7.25.9', true ]validRange [ '^7.25.9', true ]satisfies [ '7.25.9', '^7.25.9', true ]valid [ '^7.26.0', true ]validRange [ '^7.26.0', true ]satisfies [ '7.26.0', '^7.26.0', true ]
s atisfies 호출의 상당 부분이 그 직전에 valid와 validRange를 둘 다 호출합니다. 이는 satisfies에 전달되는 인자를 검증하기 위해 이 두 함수를 사용하고 있다는 신호입니다. npm cli 소스는 공개되어 있으니, 이 함수들이 뭘 하는지 코드를 확인해볼 수 있습니다.
const valid = (version, options) => {\tconst v = parse(version, options);\treturn v ? v.version : null;};const validRange = (range, options) => {\ttry {\t\t// truthiness가 동작하도록 '' 대신 '*'를 반환\t\t// 어차피 유효하지 않으면 throw 됨\t\treturn new Range(range, options).range || "*";\t} catch (er) {\t\treturn null;\t}};const satisfies = (version, range, options) => {\ttry {\t\trange = new Range(range, options);\t} catch (er) {\t\treturn false;\t}\treturn range.test(version);};
입력의 올바름을 검증하기 위해 두 검증 함수는 입력을 파싱하고, 결과 데이터 구조를 할당한 다음, 검증을 통과하면 원래 입력 문자열을 다시 반환합니다. 그런데 satisfies를 호출하면, 방금 버렸다시피 한 그 일을 다시 똑같이 합니다. 이는 "검증하지 말고 파싱하라" 규칙을 따르지 않아 필요 이상의 일을 두 번 하게 되는 전형적인 사례입니다.
파서가 있는 상황에서 파싱 전에 입력을 검증하고 있다면, 불필요하게 CPU 사이클을 태우고 있는 겁니다. 파싱 자체가 그 자체로 검증입니다. 무의미하죠. 중복 검증을 제거하면 약 9.8k번의 함수 호출을 줄일 수 있습니다.
앞서 함수 호출을 로그로 남겨두었기 때문에, 이상적인 벤치마크 케이스가 있습니다. 중복 검증이 있는 경우와 없는 경우를 비교해 시간을 측정할 수 있죠. 여기서는 deno bench 도구를 사용했습니다.
| benchmark | time/iter (avg) | iter/s | (min … max) | p75 | p99 | p995 |
|---|---|---|---|---|---|---|
| validate + parse | 99.9 ms | 10.0 | ( 85.5 ms … 177.3 ms) | 91.1 ms | 177.3 ms | 177.3 ms |
| parse | 28.0 ms | 35.7 | ( 22.8 ms … 73.3 ms) | 26.4 ms | 73.3 ms | 73.3 ms |
중복 검증을 없애는 것만으로도 이미 꽤 좋은 속도 향상이 있습니다. 코드가 ~70% 더 빨라집니다.
시간이 지나면서 semver 라이브러리 개발자들도 이 문제를 깨닫고 LRU 캐시를 추가했습니다. 자바스크립트 관점에서 보면 제한된 개수의 엔트리를 갖는 일종의 Map 특별 변형이라고 할 수 있습니다. Map이 무한정 커지는 걸 방지하려는 목적이죠. 그리고 실제로 어느 정도는 속도 향상에 효과가 있습니다. 캐시 히트/미스를 로그로 찍어보니 26k번 호출 중 523번만 캐시되지 않은 결과를 반환했습니다. 꽤 좋네요!
캐싱을 제거하면 얼마나 시간을 절약했는지 감을 잡을 수 있습니다.
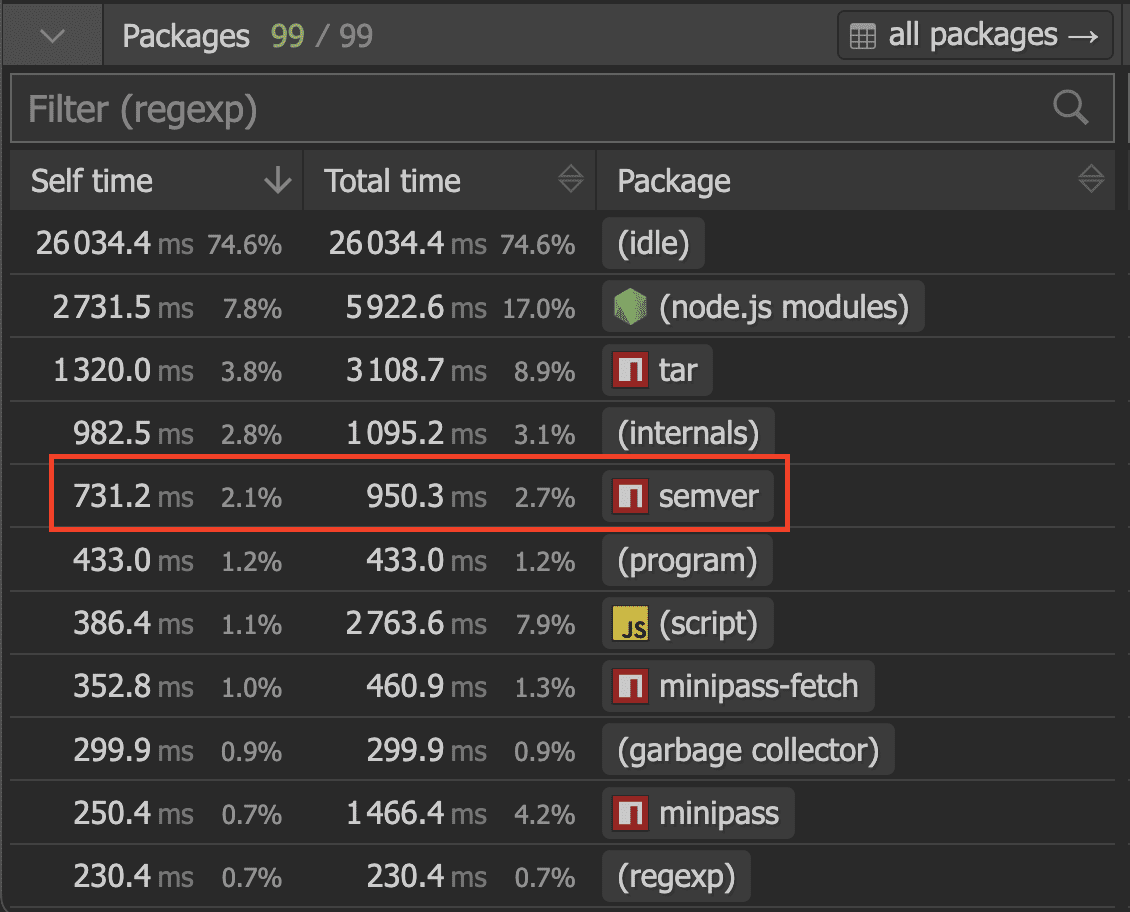
총합으로 캐시 덕분에 약 133ms를 절약했습니다. 없는 것보단 낫지만, 캐시 히트가 많다는 것에 비하면 큰 그림에서는 그다지 효과적이지 않습니다.
| 시나리오 | 시간 |
|---|---|
| 캐시 없음 | 731ms |
| 캐시 있음 | 598ms |
캐시는 개인적으로 약간의 불만(?)이 있는 주제입니다. 적절한 지점에 절제해서 사용하면 매우 유용할 수 있지만, 자바스크립트 생태계 전반에서 악명 높을 정도로 남용되는 경우가 많습니다. 코드를 빠르게 만들기보다는 결과를 캐시해두고 “잘 되겠지” 하는, 성능을 올리는 게으른 방법처럼 느껴질 때가 많습니다. 하지만 많은 경우 코드 자체를 빠르게 만드는 편이 훨씬 더 좋은 결과를 냅니다.
캐시는 다른 모든 옵션을 다 써본 뒤 마지막 수단으로 고려해야 합니다.
semver의 파싱 문법이 작다 보니, 직접 한 번 해보고 싶다는 욕심이 생겼습니다. 하루 정도에 걸쳐 semver 파서를 작성했고, npm이 허용하는 모든 semver 제약 표현을 지원하도록 했습니다. 코드는 특별한 일을 하지 않습니다. 입력 문자열을 순회하면서 관련 토큰을 감지하고 최종 데이터 구조를 만들어냅니다. 파서에 익숙한 사람이라면 누구나 비슷하게 작성했을 겁니다. 특별한 자바스크립트 성능 트릭이나 그런 건 없습니다.
function parseSemver(input: string): Semver {\tlet ctx = { input, i: 0 };\tlet major = 0;\tlet ch = ctx.input.charCodeAt(ctx.i);\tif (ch >= Char.n0 || ch <= Char.n9) {\t\tmajor = parseNumber(ctx);\t} else {\t\tthrow invalidErr(ctx);\t}\tch = expectDot(ctx);\tlet minor = 0;\tif (ch >= Char.n0 || ch <= Char.n9) {\t\tminor = parseNumber(ctx);\t} else {\t\tthrow invalidErr(ctx);\t}\t// ...이어서 계속}
그리고 버전이 semver 제약을 만족하는지 검사하는 코드도 필요하며, 구조는 비슷합니다.
앞서 모든 함수 호출을 로그로 남겨두었기 때문에, 벤치마크에 이상적인 데이터셋이 있습니다. 첫 번째는 validate + parse 단계를 유지한 채로 비교했습니다.
| benchmark | time/iter (avg) | iter/s | (min … max) | p75 | p99 | p995 |
|---|---|---|---|---|---|---|
| node-semver | 99.9 ms | 10.0 | ( 85.5 ms … 177.3 ms) | 91.1 ms | 177.3 ms | 177.3 ms |
| custom | 3.9 ms | 255.3 | ( 3.7 ms … 6.1 ms) | 4.0 ms | 4.7 ms | 6.1 ms |
불필요한 validate 단계를 포함하고도, 커스텀 파서는 25x 더 빠릅니다. CPU 프로파일로 작업량을 보면 차이는 더 극명합니다.
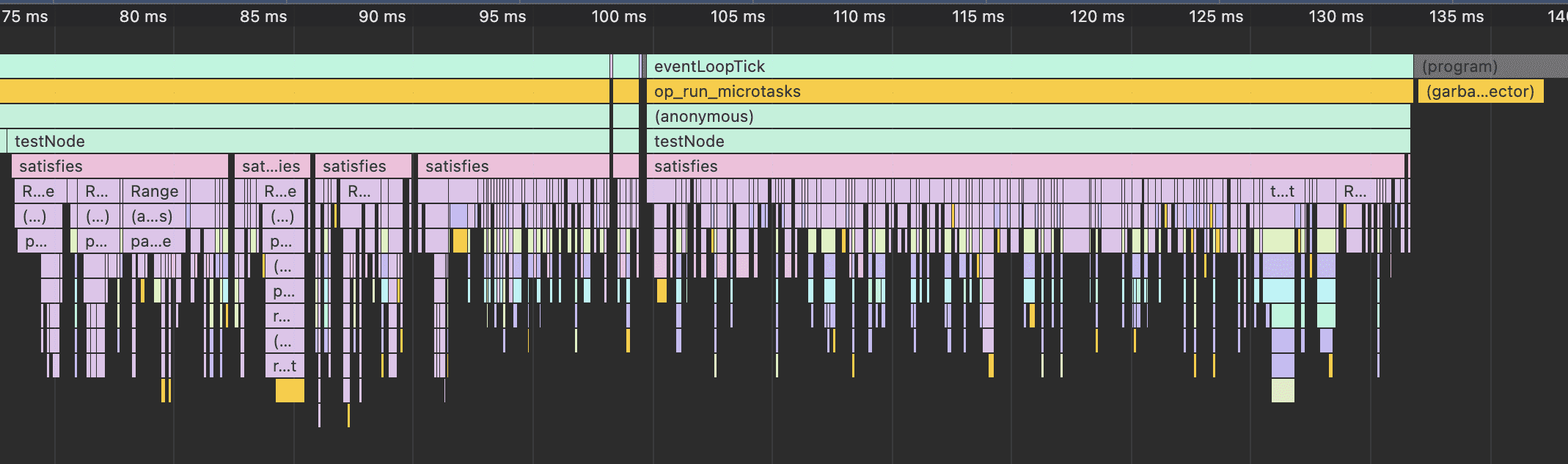
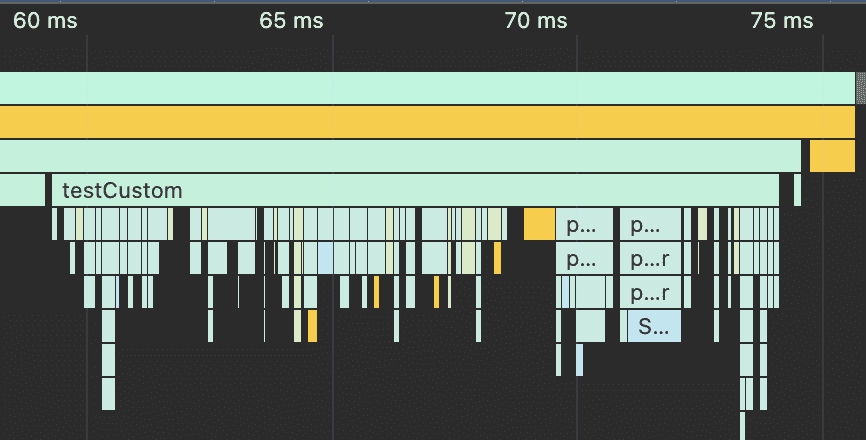
다음 벤치마크에서는 둘 다 불필요한 검증 단계를 제거해, 공정하게 비교해봅시다.
| benchmark | time/iter (avg) | iter/s | (min … max) | p75 | p99 | p995 |
|---|---|---|---|---|---|---|
| node-semver | 28.0 ms | 35.7 | ( 22.8 ms … 73.3 ms) | 26.4 ms | 73.3 ms | 73.3 ms |
| custom | 2.9 ms | 347.2 | ( 2.7 ms … 6.4 ms) | 2.9 ms | 3.4 ms | 6.4 ms |
불필요한 검증을 하지 않는다는 동일한 조건에서는 차이가 훨씬 줄어들지만, 그래도 여전히 10x 정도 더 빠릅니다. 정리하자면, semver 체크는 현재보다 33x 더 빠르게 만들 수 있습니다.
늘 그렇듯 자바스크립트 생태계의 도구들이 느린 건 언어 탓이 아니라 코드가 느리기 때문입니다. 이 글을 쓰는 시점 기준으로 semver 라이브러리는 모든 주요 패키지 매니저에서 사용됩니다. npm, yarn, pnpm 모두에서요. 이것을 더 빠르게 만들거나 더 빠른 대안으로 교체한다면, 이들 모두의 설치 과정이 상당히 빨라질 것입니다.