PostgreSQL 확장과 사이드카 생태계에서 Rust가 어떻게 핵심 도구가 되었는지, pgrx, Wrappers, ParadeDB, pgdog, Neon을 중심으로 살펴본다.
대부분의 사람들은 PostgreSQL을 MariaDB나 CLickHouse 같은 단순한 데이터베이스로 보지만, 실제로는 Linux가 프로세스와 리소스를 관리하는 “컴퓨팅 커널”인 것과 같은 방식으로, 데이터가 저장되고 질의되는 방식을 관리하는 “데이터 커널”로 진화해 왔다. 리더 선출, 하이브리드(전체 텍스트 + 벡터) 검색, OLAP(시계열) 등 더 많은 기능을 포함해, Postgres는 확장과 사이드카로 이루어진 건강한 생태계의 혜택을 받아 대부분—아니, 어쩌면 모든—워크로드에 잘 맞는 선택지가 된다.
지난주 _Using Rust and Postgres for everything: patterns learned over the years_에서 보았듯이, Postgres와 Rust는 환상의 조합이지만 거기서 끝나지 않는다. Rust는 Postgres를 확장하는 데에도 완벽한 도구다. 이 데이터 플랫폼의 코어인 PostgreSQL 자체는 C로 작성되어 있지만, 이제 대부분의 확장은 Rust로 작성되고 있다.
Postgres 생태계는 일반적으로 3가지 종류의 확장으로 구성된다:
왜? 어떻게? 무엇을? 알아보자!
pgrx는 비교적 덜 알려져 있지만, 개발자가 C 대신 안전하고 인체공학적인 Rust로 Postgres 확장을 만들 수 있게 해주는, 아마도 생태계에서 가장 중요한 프로젝트 중 하나다.
pgrx는 Postgres 타입을 Rust 타입으로 매핑하는 일을 처리하고, 확장을 Postgres 내부와 통합하는 데 필요한 모든 것을 제공한다.
나는 C로 진지한 코드를 쓸 자신이 절대 없다. 발목을 잡는 함정이 너무 많다. 하지만 pgrx와 함께라면 Postgres 확장을 작성할 수 있고, 컴파일러와 타입 시스템이 정확성을 보장하도록 맡길 수 있다.
Wrappers는 개발 프레임워크이자 Postgres Foreign Data Wrappers 모음이다. 이를 통해 개발자는 외부 데이터 소스를 PostgreSQL에서 직접 질의할 수 있다. 데이터의 진정한 소스(source of true)는 외부 데이터 소스에 남아 있지만, 익숙한 SQL 인터페이스로 데이터를 질의하고 조인할 수 있다.
예를 들어, Stripe 데이터를 질의해 자신의 데이터와 바로 조인할 수 있다:
SELECT invoices.* FROM stripe.invoices
INNER JOIN users
ON stripe.invoices.customer = users.stripe_customer_id
WHERE users.id = 123;
개인적으로는 프로덕션에서 외부 시스템을 통합하는 최선의 방법인지 확신하진 않지만, 프로토타입을 만든다면 일부 wrapper는 확실히 쓸 것 같다.
공식 웹사이트에서 더 읽을 수 있다: https://fdw.dev
ParadeDB는 Postgres 내부에서 바로 고품질(Elasticsearch 유사) 검색을 제공하는 것을 목표로 하는 Postgres 확장 pg_search를 개발한다. 내부적으로는 Tantivy 전체 텍스트 검색 엔진을 사용한다.
v0.14.0부터 pg_search는 Postgres의 블록 스토리지와 네이티브로 통합되는데, 이는 (무엇보다도) 다음을 가능하게 한다는 점에서 매우 큰 의미가 있다:
ParadeDB와 pg_search 확장은 Timescale의 발자취를 따르고 있다. Timescale 역시 Postgres의 스토리지 API와 통합함으로써 Postgres의 강점을 유지하면서도 OLAP 가능한 데이터베이스로 만들었는데, 시계열 대신 검색을 대상으로 같은 일을 하고 있는 셈이다.
pgdog는 Postgers를 위한 로드 밸런서이자 “리버스 프록시”로, 백엔드 서비스가 아니라 데이터베이스를 대상으로 하는 Pingoo 같은 존재다.
pgdog는 C 프로젝트(PgBouncer)를 Rust로 다시 작성하면 정확히 어떤 일이 벌어지는지 보여준다. 사용하기 더 쉽고, 샤딩과 관측 가능성 같은 기능을 훨씬 빠르게 출시할 수 있으며, 그와 동시에 더 빠르고 더 안전하다.
PostgreSQL(또는 어떤 데이터베이스든)을 운영할 때 가장 큰 고통 지점 중 하나는 디스크와 머신이 고장 나더라도 데이터의 고가용성과 내구성을 보장하는 것이다. 보통 중복 구성된 네트워크 디스크(예: AWS의 EBS)로 달성하는데, 이는 큰 성능 페널티를 유발한다.
Neon은 Postgres 컴퓨트 인스턴스가 로컬 디스크 대신 S3 호환 스토리지를 사용하도록 함으로써 데이터베이스 세계를 재정의하고 있다. 분산된 safekeepers 레이어를 추가하면서 Postgres의 모놀리식 아키텍처를 복잡하게 만들지만, 동시에 많은 문제를 해결한다. 읽기 복제본(read-replicas)은 (오류가 나기 쉬운) 복제 대신 단일한 진실의 소스를 사용하게 되었고, 고가용성과 내구성을 위해 느리고 비싼 네트워크 스토리지(예: AWS의 EBS)를 더 이상 쓸 필요가 없어졌으며, 데이터베이스 스케일 업/다운은 이제 새 컨테이너/마이크로VM을 스폰하는 문제로 바뀌었다. 어떤 복제도 필요 없다.
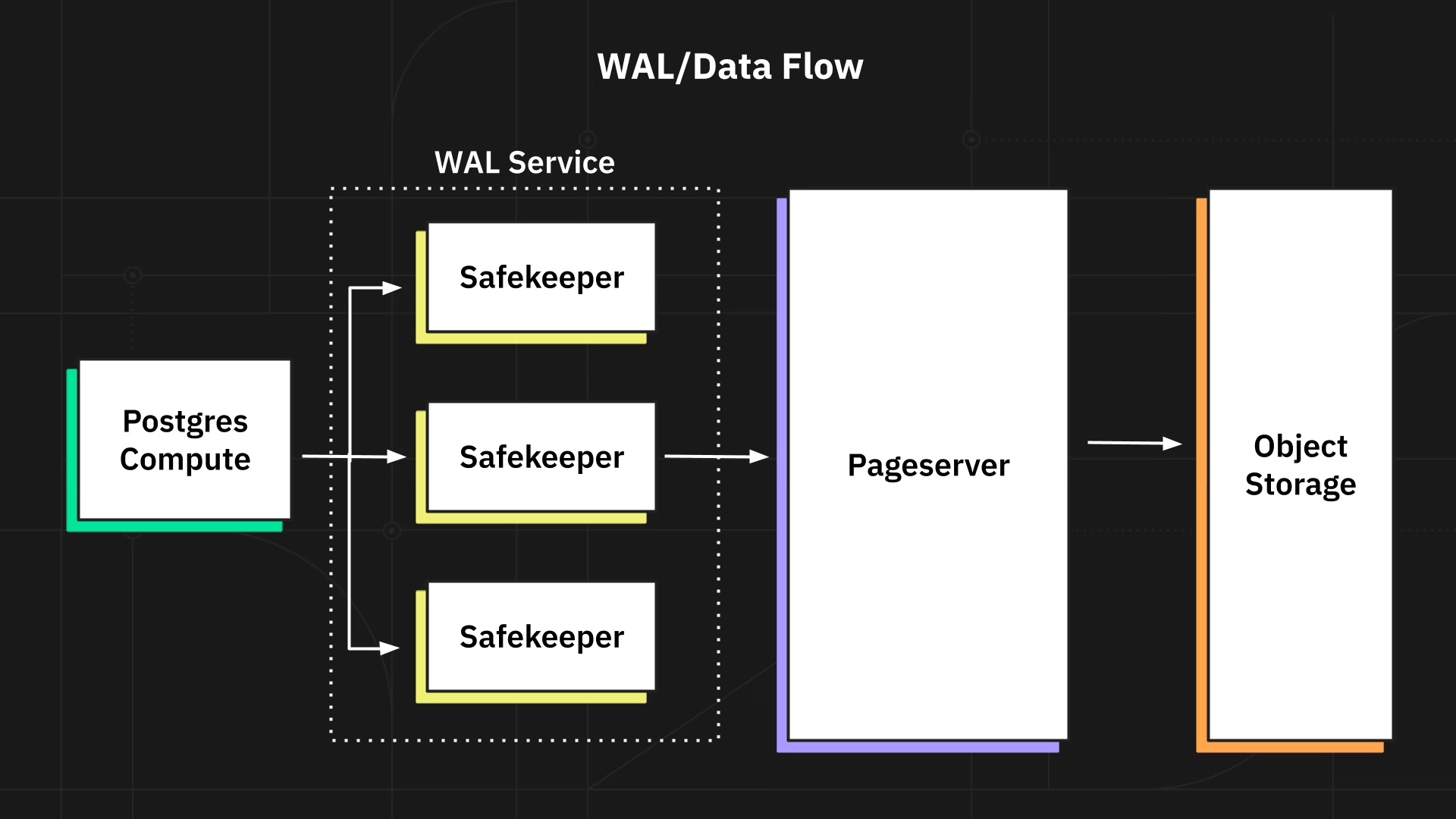
회사 전체를 위해 Neon 클러스터를 운영하는 Ops 팀이 있고, 모든 개발 팀에 셀프 서비스 형태로 Postgres 인스턴스를 제공하는 모습을 상상해 볼 수 있다.
Neon에서 특히 훌륭한 점은 스토리지 레이어만 교체했다는 것이다. 그래서 Postgres 생태계와의 완전한 호환성을 유지한다.
그들이 몇 년 전—AI 열풍이 오기 전—프로젝트를 시작할 때 예상했을 수도, 예상하지 못했을 수도 있는 점은 Neon이 에이전트에 완벽히 들어맞는다는 것이다. 데이터베이스를 띄우고 파괴하는 일이 수백 밀리초면 되기 때문에, 임시적이고 병렬적인 개발 환경에 이상적이다.
솔직히, Rust가 확장 개발자의 생산성을 끌어올리는 모습을 보는 건 좋지만, 나는 Turso가 SQLite에 대해 하고 있는 것처럼 누군가 미친 듯이 Postgres를 Rust로 재작성하는 일을 맡아주길 기다리고 있다. 언젠가 Postgres에 기여하고 싶지만, C로 작성되어 있는 한 불가능하다. 나는 내 자신을 믿지 못한다.
그렇다고 해도, Postgres를 확장하고 실제로 당신의 요구에 맞는 데이터 플랫폼으로 만들어주는 흥미로운 Rust 프로젝트는 더 많이 있다. 몇 가지는 여기에서 찾을 수 있다.
SIMD 프로그래밍을 배우고 싶다면 SIMD programming in pure Rust를 살펴보라.
Rust로 백엔드 개발을 배우고 싶다면 내 글 Architecting and building medium-sized web services in Rust with Axum, SQLx and PostgreSQL을 살펴보라.
임베디드 개발을 배우고 싶다면 Introduction to embedded development with Rust: Overview of the ecosystem를 살펴보라.
응용 암호학, 보안 엔지니어링, 안전하고 프로덕션 준비가 된 Rust 코드를 작성하는 방법 같은 흑마술을 배우고 싶다면, 내 책 **Black Hat Rust**를 살펴보라. 그 안에서(무엇보다도) 종단 간 암호화된 Remote Access Tool, 익스플로잇, 셸코드, 그리고 Rust로 된 웹 서버를 만들게 될 것이다.