현대 CPU의 레지스터 리네이밍이 어떻게 거짓 의존성을 제거하고 비순차 실행과 0-사이클 명령 최적화를 가능하게 하는지 살펴본다.
게시일 2026-04-24 · 태그 #compilers, #cs 그리고 #llvm
질문 하나로 시작해 보자. 여러분의 CPU에는 레지스터가 몇 개나 있을까?
전형적인 AArch64 머신을 쓰고 있다면, 일반 목적 레지스터(x0-x31), SIMD 레지스터(Q0-Q31), 제로 레지스터(xzr), 스택 포인터(SP), 프로그램 카운터(PC) 등을 먼저 떠올릴 것이다. 이렇게 더하면 총 66개의 레지스터가 된다. 하지만 CPU의 다이 샷을 확대해서 본다면 x0, x1 같은 레지스터는 보이지 않을 것이다. 대신 수백 개의 레지스터를 가진 거대한 레지스터 파일을 발견하게 된다. 이런 것들은 흔히 “물리 레지스터”라고 부르며, “아키텍처 레지스터”(x0, x1 …)와 구분된다.
이 글은 이 회로를 알고리즘 관점에서 살펴보고, 이것이 가능하게 하는 컴파일러 최적화를 다룬다.
현대의 고성능 CPU는 비순차 실행 방식으로 명령을 수행하여 명령어 수준 병렬성을 활용한다. 그 결과 실행 파이프라인은 병렬 실행을 지원하기 위해 다중 포트를 가지며, 깊고 복잡해지는 경향이 있다.
예를 들어, 다음은 ARM Neoverse V2 마이크로아키텍처 (PDF)의 실행 파이프라인이다:
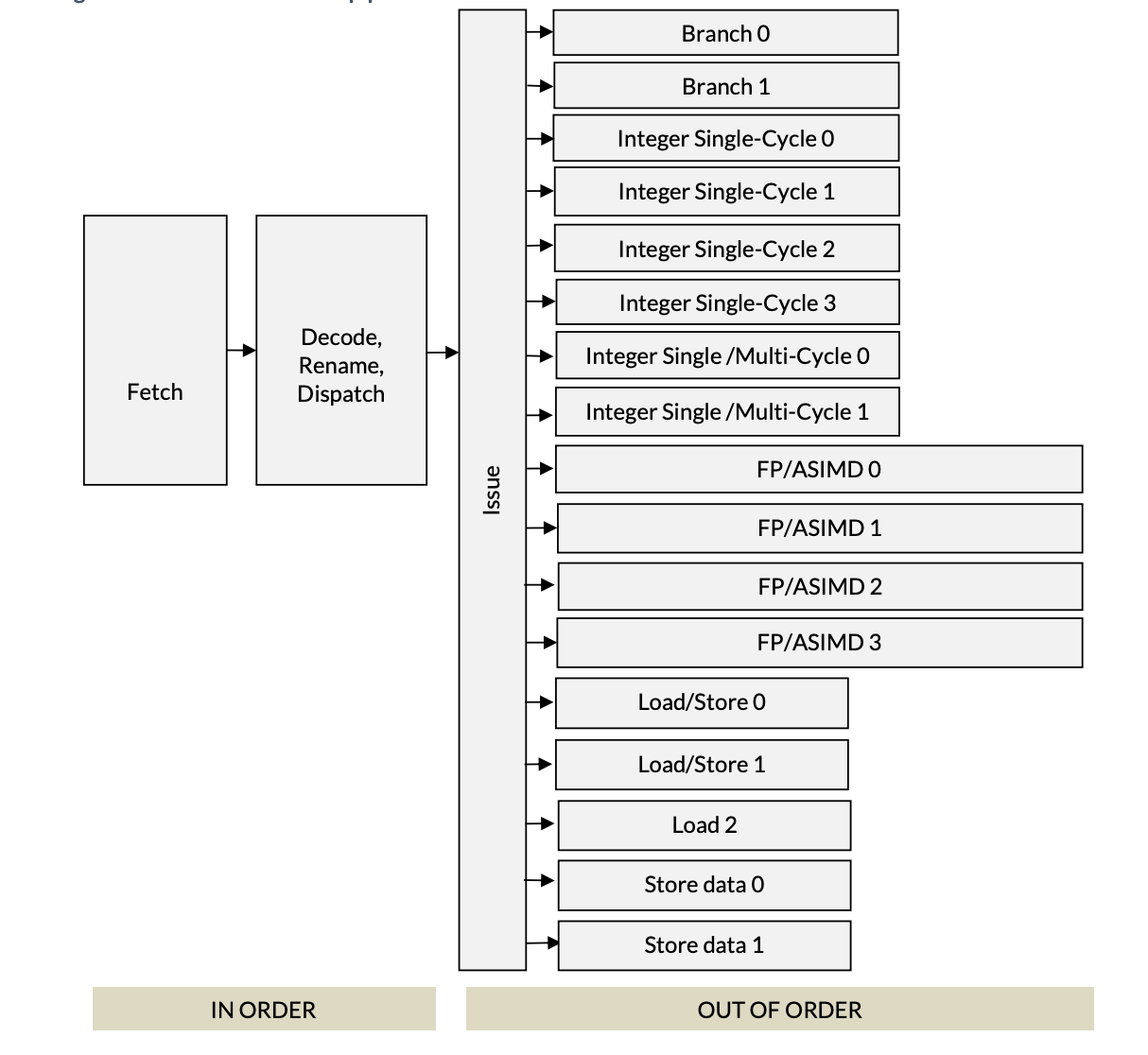
ARM Neoverse V2 파이프라인
파이프라인의 처음 두 단계는 순차적이다. 즉, fetch 유닛은 프로그램 순서대로 DRAM에서 명령을 가져오고, decode 유닛도 이 명령들을 역시 순서대로 처리한다. 흥미로운 일들은 모두 decode 유닛에서 벌어지며, 이 글의 주제도 바로 그것이다. decode 유닛 이후에는 병렬 실행 유닛들에 의해 비순차적으로 실행이 이루어진다.
위 그림의 Neoverse에는 서로 병렬로 동작하는 17개의 서로 다른 실행 유닛이 있다. 이름만 봐도 알 수 있듯이, 분기 유닛은 분기 명령을 처리하고, 정수 유닛은 단일/다중 사이클 연산으로 나뉘어 add, div, mul 같은 명령을 처리한다.
먼저 decode 유닛부터 보자. 디코더는 어떤 명령이 얼마나 많은 자원(예를 들어 Re-Order Buffer의 슬롯)을 필요로 하는지, 어느 실행 유닛에 속하는지 판단하고, 하나의 명령을 여러 micro-ops로 분해한다. 예를 들어 AArch64의 STP 명령은 두 개의 마이크로옵, 즉 store-address와 store-data로 나뉜다. 마이크로아키텍처는 일반적으로 “x-wide” 분류로 설명된다. 예를 들어 Neoverse V2는 4-wide이고 Apple M1은 8-wide이다. 이 너비 는 decode 유닛에서 비롯된다. 4-wide라는 것은 디코더가 사이클당 4개의 마이크로옵을 디스패치할 수 있음을 뜻한다.
디코더 다음에는 rename/map 유닛이 온다. 리네임 유닛은 각 아키텍처 레지스터마다 물리 레지스터를 매핑하고 할당한다. 이 유닛은 명령 집합에서 거짓 의존성을 제거하여 비순차 실행이 가능하도록 만드는 역할을 한다. 다음 AArch64 어셈블리 코드를 보자:
1 add x3, x2, x1
2 sub x4, x3, x1
3 add x3, x5, x1
4 mul x6, x8, x7
명령 2는 분명히 명령 1의 결과(레지스터 x3에 기록된 값)에 의존한다. 그리고 명령 4는 명령 3에 의존한다. 얼핏 보면 I3도 I1에 의존하는 것처럼 보일 수 있지만, 이것은 Write-After-Write (WAW)의 경우이며, I3가 I1이 쓴 값을 전혀 사용하지 않기 때문에 보통 “거짓 의존성”이라고 부른다. I3가 x3가 아닌 다른 레지스터를 사용했다면 이런 문제는 없었을 것이다.
우리는 코드를 바꿀 수도 있고, CPU가 이것을 자동으로 하게 둘 수도 있다. 위 코드 조각에서 사용된 레지스터는 “아키텍처 레지스터”다. 어떤 의미에서 아키텍처 레지스터는 가상의 존재다. CPU의 다이 샷을 확대해서 본다고 해도 x3 라고 명시된 레지스터는 찾을 수 없다. 대신 수백 개의 레지스터를 가진 큰 레지스터 파일을 보게 된다. 이것들이 “물리” 레지스터, 즉 실제 레지스터다. 이를 P1, P2 같은 식으로 부르자.
리네이머는 x1, x2 … 를 물리 레지스터 P1, P2…에 매핑한다. 또한 명령이 언제 retire 되는지를 추적하여, 그 명령에 할당되었던 물리 레지스터를 다시 회수할 수 있게 한다.
이 매핑을 저장하는 하드웨어를 Register Alias Table(RAT)이라고 한다. 대략 말하면, 키가 아키텍처 레지스터이고 값이 Physical Register File(PRF) 안의 물리 레지스터를 가리키는 포인터인 단순한 키-값 맵이다.
위 명령들에 대해, 디코더를 빠져나오면서 명령은 다음과 같이 리네임된다.
Step Arch Instruction Source Lookups Dest Map Physical Instr Relevant RAT 0(Initial State)---x1:P1, x2:P2 1 add x3 x2 x1 x2:P2, x1:P1 x3=P10 add P10, P2, P1 x3:P10 2 sub x4 x3 x1 x3:P10, x1:P1 x4=P11 sub P11, P10, P1 x4:P11 3 add x3 x5 x1 x5:P5, x1:P1 x3=P12 add P12, P5, P1 x3:P12 4 mul x6 x8 x7 x8:P8, x7:P7 x6=P13 mul P13, P8, P7 x6:P13
초기 상태에서 I1은 x2와 x1을 각각 P1, P2에 매핑하고, x3(목적지 레지스터)는 P10에 매핑되게 만든다. I1에 명확히 의존하는 I2는 x3를 통해 P10에 대한 의존성을 올바르게 인식한다. x3에 대해 거짓 의존성(Write-After-Write)을 갖고 있던 I3는 목적지 레지스터가 P12로 리네임되므로 문제가 해결된다. 마지막으로, 앞의 세 명령과 독립적이었던 I4에는 새로운 물리 레지스터가 할당된다.
변환된 명령은 위 표의 ‘Physical Inst’ 열에서 볼 수 있다. 새 명령들을 보면 이제 거짓 의존성이 더는 존재하지 않는다는 점이 분명하다.
앞 절에서는 리네이밍이 CPU가 명령을 비순차적으로 스케줄링할 수 있게 해 주는 방식을 보았다. OoO 실행은 ILP를 가능하게 하고, 이는 처리량에 직접 영향을 주므로, 이것이야말로 리네이머가 가능하게 하는 가장 큰 최적화다.
리네이머는 0-사이클 또는 issue-less 명령이라는 매우 중요한 최적화도 제공한다. 다음 코드를 보자:
orr x1, xzr, x2
이것은 x1 = 0 | x2이며, 본질적으로 x2를 x1에 대입하는 것이다. x1과 x2는 각각 어떤 물리 레지스터에 매핑되어 있으므로, 이 명령은 리네임 단계에서 x2의 물리 레지스터를 x1에 할당하는 방식으로 처리할 수 있다. 그러면 이것은 issue-less 명령, 즉 0-사이클 명령이 된다. llvm-mca로 이를 확인할 수 있다:
$ echo "orr x1, xzr, x2" | llvm-mca -mcpu=neoverse-v2
Resource pressure by instruction:
[0.0] [0.1] [1.0] [1.1] [2.0] [2.1] [2.2] [3] [4.0] [4.1] [5] [6] [7] [8] [9] [10] [11] [12] [13] [14] Instructions:
- - - - - - - - - - - - - - - - - - - - mov x1, x2
위 표는 이 명령이 실행 유닛의 자원을 전혀 소비하지 않음을 보여 준다. 전적으로 리네임 단계에서 처리된다.
다음 예도 보자:
mov x1, #4
이것은 상수 대입 이다. 일부 아키텍처는 이것도 리네임 단계에서 처리할 수 있지만, 항상 그런 것은 아니다. Neoverse V2에서는 상수 대입도 여전히 실행 유닛이 필요하다:
$ echo "mov x1, #4" | llvm-mca -mcpu=neoverse-v2
Resource pressure by instruction:
... [4.0] [4.1] [5] [6] [7] [8] [9] [10] [14] Instructions:
... - - 0.16 0.16 0.17 0.17 0.17 0.17 - mov x1, #4
잠깐, 왜 0.16과 0.17로 표시될까? 이 명령은 6개의 정수 유닛([5]부터 [10]) 중 어느 곳에서나 처리될 수 있고, llvm-mca는 그들 사이에 걸리는 평균 압력을 보여 주기 때문이다.
0-사이클 명령은 흥미롭게 들리지만, 이것들도 파이프라인의 fetch와 decode 부분에서는 공간을 차지한다는 점을 기억하는 것이 중요하다. 완전히 공짜 는 아니다. 이들이 실제로 도움이 되는 지점은 실행 파이프라인을 비워 두어, 레지스터 클리어/레지스터 이동 같은 사소한 명령 때문에 계산이 방해받지 않게 하는 데 있다.
다음은 레지스터 리네이밍과 그 밖의 관련 개념을 이해하는 데 내가 참고한 문서들이다:
이 웹사이트는 blag로 만들어졌다.
atom feed를 구독하라.
© 2025, Shreeyash Pandey