Zerocopy가 약속한 안전성과 효율성 사이의 긴장 속에서, 코드 생성 테스트와 문서화를 통해 ‘제로 비용’ 추상화가 실제로 어떤 코드젠을 내는지 검증하는 방법을 소개한다.
2026-03-09
Zerocopy는 저수준 메모리 조작과 캐스팅을 위해 안전하고 효율적인 추상화를 약속하는 툴킷입니다. 우리는 오랫동안 일반적인 방법(예: 테스트, 문서화, 추상화, miri)과 이례적인 방법(예: 증명, 정형 검증)을 모두 활용해, 스스로와 사용자에게 우리가 안전성 약속을 지켰음을 입증해 왔습니다. 하지만 효율성이라는 또 다른 약속은 #[inline(always)]와 LLVM에 대한 믿음이라는, 덜 설득력 있는 조합에 더 많이 의존해 지켜 왔습니다.
이 두 약속은 점점 더 서로 충돌해 왔습니다. zerocopy가 지원하는 타입과 변환이 더 복잡해질수록, 내부 추상화 또한 더 복잡해졌습니다. 문서를 따라 대부분의 메서드 소스 코드까지 들어가 보면, unsafe의 즉각적인 등장 사례는 거의 보지 못할 것입니다. 우리는 위험한 것들을 몇 번의 함수 호출 아래, 범위를 촘촘히 제한한 “제로 비용” 추상화 속에 격리해 둡니다. 하지만 이 추상화들이 정말로 제로 비용일까요?
음, zerocopy 0.8.42부터는 최적화기에 대한 신뢰가 조금 덜 맹목적이어도 됩니다. 우리는 zerocopy의 각 루틴에 대해, 대표적인 범위의 상황에서 기대할 수 있는 코드 생성(codegen)을 문서화하기 시작했습니다. 예를 들어 FromBytes::ref_from_prefix의 경우:
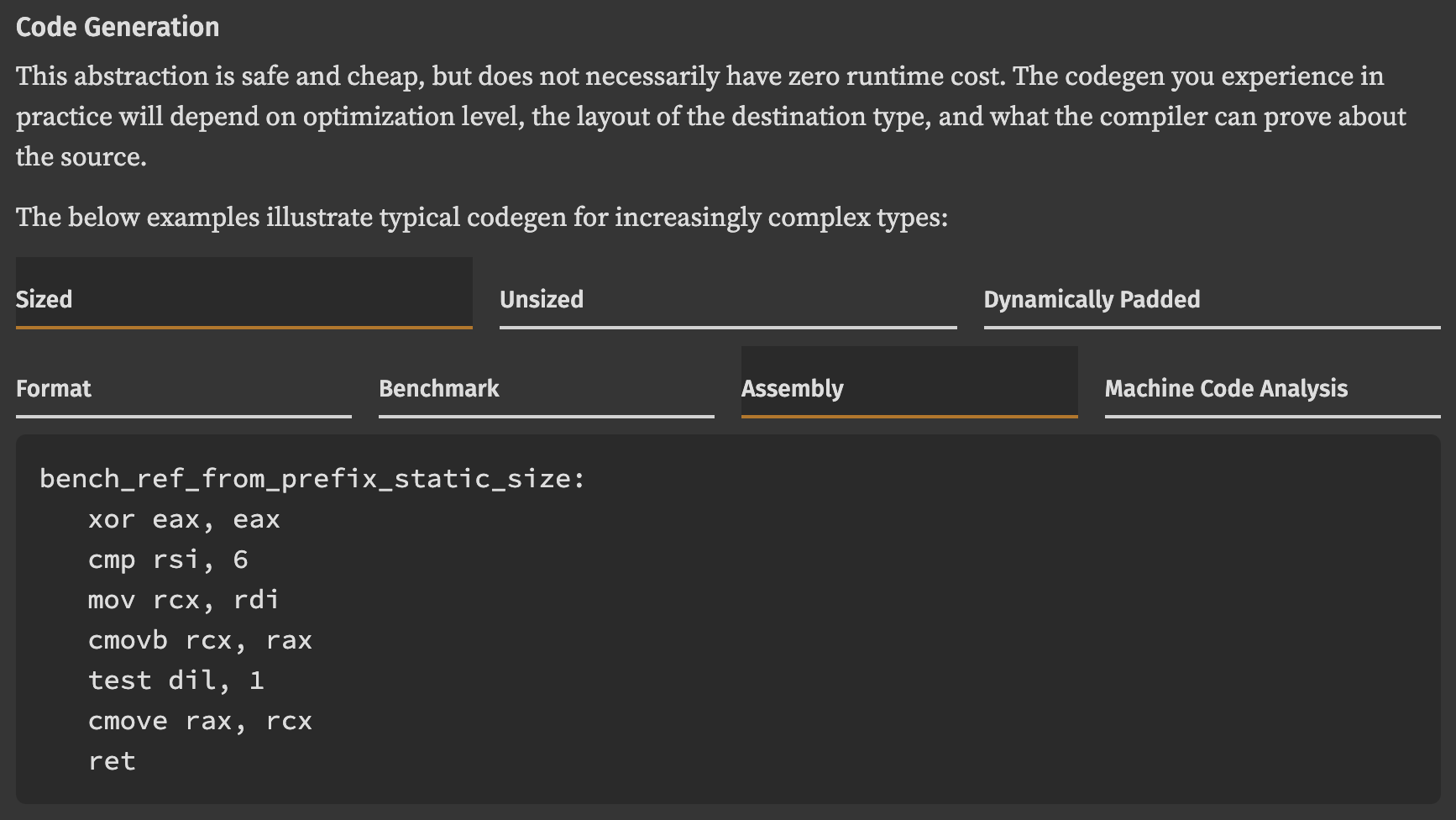
이 문서는 CI 파이프라인에 최근 추가된 요소, 즉 코드 생성 _테스트_를 드러냅니다. 우리는 저장소의 benches 디렉터리를 포괄적인 마이크로벤치마크 세트로 채웠습니다. 이 벤치마크를 실제로 하드웨어에서 실행하는 대신, cargo-show-asm을 사용해 생성된 머신 코드와 분석 결과가 저장소에 체크인된 모델 출력과 일치하는지 단언(assert)합니다. 그 결과, Rust와 LLVM이 우리의 추상화를 어떻게 최적화하는지에 대한 가정을 검증할 수 있고, 변경 사항이 코드젠에 어떤 영향을 주는지 쉽게 관찰할 수 있습니다.
댓글과 정정은 jack@wrenn.fyi로 이메일로 보내 주세요. Twitter에서 팔로우하세요!