오픈 소스 모델이 로컬 워크스테이션에서 실행되며 AI를 지배할 가능성과 그 이유를 살펴본다.
AI의 미래는 로컬인가?
데이터센터 구축의 폭발적 증가가 가치 있는 투자인지에 대한 논쟁은 두 가지 시나리오를 중심으로 전개된다:
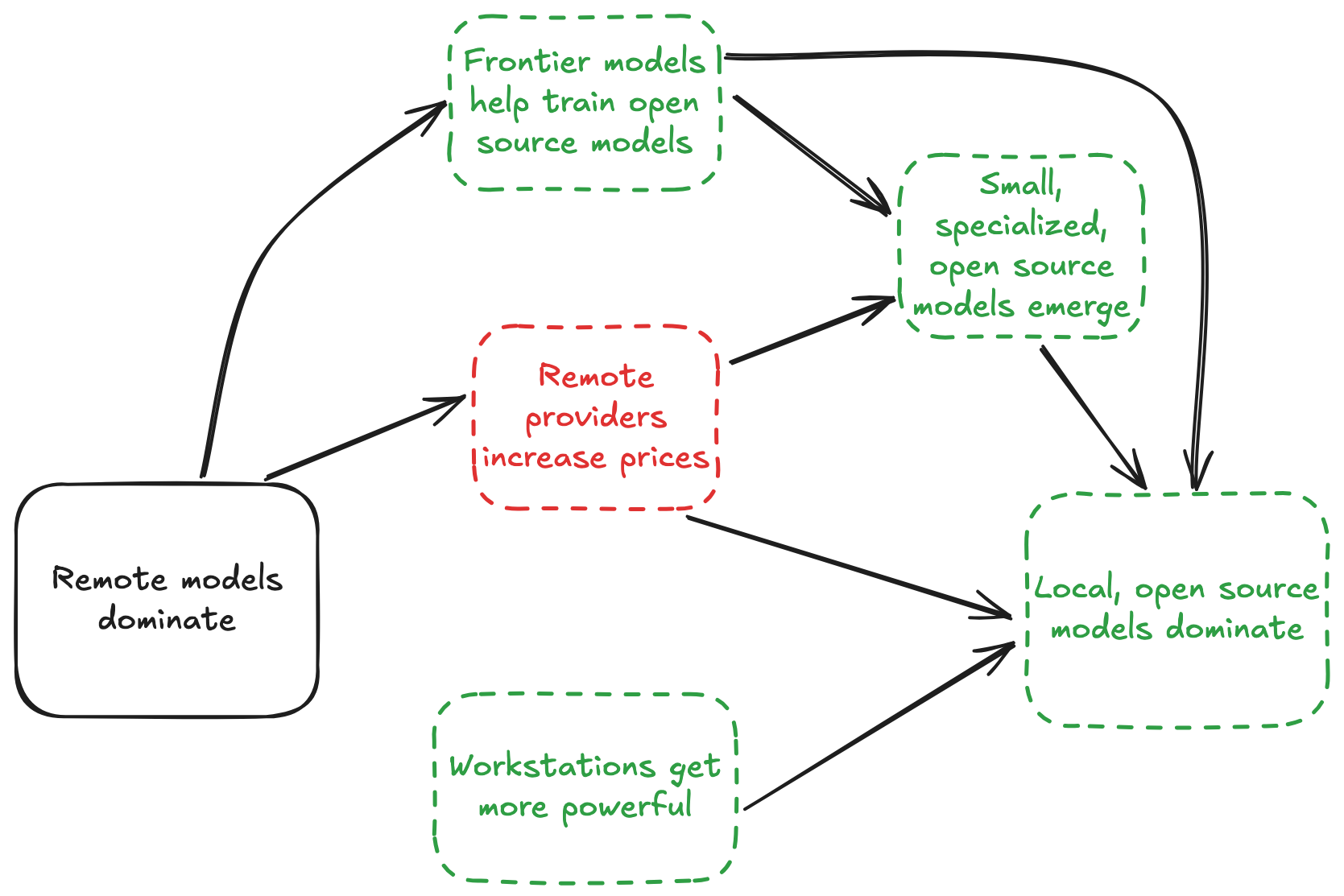
하지만 세 번째 시나리오도 매우 그럴듯하다:
로컬 워크스테이션에서 실행되는 오픈 소스 모델이 AI를 지배한다
이 일이 일어날 수 있는 이유는 몇 가지가 있다:
gpt-4를 제외하면, 오픈 소스 모델은 프런티어 모델 출시 후 6개월 이내에 프런티어 모델의 성능에 도달해 왔다(data):
프런티어 모델과의 오픈 소스 동등성까지 걸린 개월 수
OpenAI Anthropic
물론 오픈 소스 모델이 평가를 교묘히 맞춘다는 비난도 있었지만, 프런티어 모델도 똑같이 한다.
이 추세는 계속될 것으로 예상할 수 있다. 스타트업은 보통 해자를 만들려 하지만, 모델 제공업체들은 워터슬라이드를 만든다: 프런티어 모델이 오픈 소스 경쟁자를 훈련시키는 데 도움을 준다.
무단 증류는 대응하기 어려운 위협이다. 제공업체는 경쟁사가 자사 모델을 이용해 경쟁 모델을 훈련한다고 불평할 수 있고(이미 그렇게 한 바도 있다). 그러나 실질적으로는, 이러한 "절도"1를 막는 것이 불가능할 수도 있다.
프런티어 모델의 단위 경제성은 Uber의 "저렴한 승차 시대"를 떠올리게 한다. 예를 들어, $13 billion의 매출에도 불구하고 OpenAI는 2026년에 $14 billion의 손실을 전망하고 있다. 이 청구서에는 $8 billion의 컴퓨트 비용이 포함된다.
Anthropic의 경우, Cursor는 최근 월 $200의 Claude Max 구독이 최대 $5,000의 컴퓨트를 소모할 수 있다고 추정했다. 이 보도가 나오기 전에도, Anthropic은 해당 구독에 속도 제한을 도입했다.
새로 출시된 Claude Code Review 기능의 가격은 매우 비싼 $15-$25 per PR이다. 이 기능 발표에는 왜 이것이 기존 PR 리뷰 워크플로를 대체해야 하는지에 대한 설명이 거의 없었다. 이는 기업이 어느 정도의 가격까지 감내할 의향이 있는지 보기 위한 가격 실험처럼 보인다.
OpenAI의 경우에는 곁가지 베팅을 정리하고 엔터프라이즈에 집중하고 있다는 공개 보도2가 있다.
오늘날의 낮은 가격을 고려하면, 토큰 사용량에는 상대적으로 하방 경제 압력이 거의 없다. 사람들은 당면한 작업과 무관하게 가장 강력한 모델을 선택한다.
가격이 상승하면 이것은 바뀔 것이고, 서브에이전트 주도 워크플로라는 지배적 패턴은 자연스러운 전환 경로를 제공한다. 내 Python PR의 스타일 문제를 고치는 데 프런티어 모델이 꼭 필요하지는 않을 것이다. 작고 특화된 모델이면 충분히 처리할 수 있다. 만약 프런티어 모델이 극적으로 더 비싸진다면(즉, PR 리뷰당 $25), 이런 모델에 대한 수요는 증가할 것이고, 오픈 소스 커뮤니티는 그 수요를 충분히 충족할 수 있을 것이다.
이 일은 이미 작은 규모로 일어나고 있다. 한 백서는 파인튜닝된 GPT-4o-mini 모델로 GPT-4o와 동등한 성능을 비용의 2%로 달성했다고 주장했다.
Apple은 기술 대기업들 가운데 유일한 역발상주의자다. 데이터센터에 막대한 자본을 쏟아붓고 있지 않기 때문이다:
Apple은 AI에서 "뒤처졌다"는 비판을 받아왔지만, 그들의 베팅은 다음과 같은 것으로 보인다: 경쟁사들이 모델 훈련에 현금을 태우게 두고, 그 진보가 오픈 소스 모델로 전파되게 한 뒤, 기기가 그것들을 실행할 만큼 충분히 좋아지게 만든다.
현재로서는 프런티어급 오픈 소스 모델을 실행하려면 사용자가 특수한 하드웨어를 구매해야 한다. 그러나 가장 최근의 Macbook 4 pro Max는 로컬에서 실용적인 모델 크기에서 도약을 이룬 것으로 보인다(data):
기기별 최대 실사용 가능 모델
MacBook Pro 추정치 / 추측치
오늘날에도 로컬 워크스테이션에서 프런티어 모델을 실행하는 것은 여전히 손이 닿지 않는 일이다. 하지만 그 격차는 좁혀지고 있다.
호스팅된 대안과 동등한 수준에 도달할 수 있다면, 로컬 오픈 소스 모델은 강력한 가치 제안을 갖는다: 빠르고, 비공개이며, 무료다. 이 가능성은 그다지 많은 주목을 받지 못했다. 여기서 초대형 부자가 탄생할 가능성은 없기 때문이다. 하지만 현재의 선두 주자들에게는 강력한 위협이다.
| 프런티어 모델 | 제공업체 | 출시 | 벤치마크 | 점수 | 오픈 소스 일치 시점 | OS 모델 | 동등성까지 개월 수 | 출처 |
|---|---|---|---|---|---|---|---|---|
| GPT-3.5 / ChatGPT | OpenAI | Nov 2022 | MMLU | ~70% | Aug 2023 | Llama 2 70B (70B) | ~9 | Stanford HAI AI Index 2025 |
| GPT-4 | OpenAI | Mar 2023 | MMLU | 86.4% | Jul 2024 | Llama 3.1 405B (405B) | ~16 | Epoch AI |
| Claude 3 Opus | Anthropic | Mar 2024 | MMLU | 86.8% | Jul 2024 | Llama 3.1 405B (405B) | ~4 | Epoch AI |
| GPT-4o | OpenAI | May 2024 | MMLU-Pro | 71.6% | Dec 2024 | DeepSeek-V3 (671B total / 37B active) | ~7 | DeepSeek V3 Technical Report |
| Claude 3.5 Sonnet | Anthropic | Jun 2024 | MMLU-Pro | 73.3% | Dec 2024 | DeepSeek-V3 (671B total / 37B active) | ~6 | DeepSeek V3 Technical Report |
| o1 | OpenAI | Sep 2024 | AIME 2024 | 79.2% | Jan 2025 | DeepSeek-R1 (671B total / 37B active) | ~4 | DeepSeek R1 via TechCrunch |
정의: "최대 실사용 가능 모델"은 기기 RAM에 들어가고 또한 8k 컨텍스트 윈도우에서 초당 ≥8 토큰으로 실행되는 가장 큰 Q4 양자화 모델이다. 이는 반응성 있는 대화형 경험을 위한 기준이다. 이는 min(RAM-fit, speed-fit)이며, 각 항목은 다음과 같다:
RAM × 0.8 / 0.75 — 사용 가능한 RAM(전체의 80%)을 Q4에서 파라미터당 바이트 수(~0.75 bytes/param, 오버헤드 포함 후)로 나눈 값(memory_bandwidth / 51.2 GB/s) × (baseline_speed / bits_per_weight) × target_t/s_factor — 51.2 GB/s 기기에서 초당 8 t/s로 약 11B 파라미터를 처리하는 기준값으로부터 스케일링MoE 모델의 경우, RAM-fit은 전체 파라미터에 적용된다(모든 가중치가 로드되어야 함). speed-fit은 활성 파라미터에만 적용된다.
MacBook Pro
| 기기 | 연도 | 칩 | RAM | 최대 모델 | RAM-fit | Speed-fit | 출처 |
|---|---|---|---|---|---|---|---|
| MacBook Pro M1 | 2020 | M1 | 16 GB | 15.0B | 17.1B | 15.0B | Wikipedia |
| MacBook Pro M1 Pro | 2021 | M1 Pro | 16 GB | 17.1B | 17.1B | 43.9B | Wikipedia |
| MacBook Pro (M1 Pro) | 2022 | M1 Pro | 16 GB | 17.1B | 17.1B | 43.9B | Wikipedia |
| MacBook Pro M3 Pro | 2023 | M3 Pro | 18 GB | 19.2B | 19.2B | 32.9B | Apple |
| MacBook Pro M4 Pro | 2024 | M4 Pro | 24 GB | 25.6B | 25.6B | 59.9B | Apple |
| MacBook Pro M5 | 2025 | M5 | 32 GB | 33.6B | 34.1B | 33.6B | Apple Support, Apple Newsroom |
| MacBook Pro M5 Max | 2026 | M5 Max | 128 GB | 134.9B | 136.5B | 134.9B | @JoshKale |
이러한 불만은, 제공업체들 자신이 취해 온 지식재산에 대한 허락보다 용서를 구하는 접근 방식을 고려하면 아이러니하다. ↩
물론, 이것의 일부는 Sora 비디오 생성 앱처럼 일부 곁가지 베팅이 채택을 얻지 못했기 때문인 것으로 보인다. ↩