Rust 매크로 확장에서 발생하는 모호성이 어떻게 `rustc`에서 세제곱급 성능 저하를 유발할 수 있는지, 그리고 packrat 기반 접근으로 이를 선형 시간에 처리할 수 있는 가능성을 살펴봅니다.
2026년 5월 3일 작성; 2026년 5월 4일 수정; 작성자 arya dradjica
지난주에 저는 우연히 rust-analyzer의 코드베이스를 훑어보게 되었습니다. 그러다 r-a와 Krabby(제가 만들고 있는 아주아주 WIP Rust 컴파일러)가 공통점이 많다는 걸 깨달았습니다. r-a는 rustc의 많은 부분을 다시 구현하고 있고, 이를 rustc와 비교하는 벤치마크와 테스트도 갖추고 있습니다. Krabby는 더 상위 수준의 목표는 다르지만, 정확히 같은 인프라가 필요합니다.
특히 제 눈에 띈 구성 요소 하나는 매크로 확장이었습니다. 예전부터 r-a가 매크로 확장에 많은 노력을 들인다는 이야기를 들은 적이 있는데, 일부는 흥미로운 LSP 기능(예를 들어 “이 매크로 확장하기”)을 제공하기 위해서이고, 일부는 매크로가 일반적인 LSP 기능(예를 들어 정의가 매크로로 생성된 경우의 “정의로 이동”)을 복잡하게 만들기 때문입니다. r-a는 때때로 rustc의 코드를 재사용하기도 하지만, 코드베이스를 빠르게 둘러본 결과 r-a의 매크로 처리 코드 대부분은 처음부터 새로 작성된 것으로 보였습니다. 그리고 훨씬 더 단순해 보이기도 했습니다. 이것이 더 간결하게 작성되었기 때문인지(rustc를 통해 얻은 사후적 통찰 덕분에), 진단에 덜 신경 쓰기 때문인지, 아니면 일부 경계 사례에서 rustc와 다르기 때문인지는 잘 모르겠습니다.
선언적 매크로 확장(예: foo!(a, b))에는 분명한 두 단계가 있습니다. 먼저 입력 (a, b)를 foo의 매치 팔들과 대조해야 합니다(“파싱”). 그런 다음 매치 팔 본문에서 메타변수를 채워 출력 결과를 계산해야 합니다(“전사”). 이 파싱 단계를 구현하는 r-a의 mbe/expander/matcher.rs에는 rustc의 mbe/macro_parser.rs를 가리키는 최상위 주석이 있습니다. 두 구현 모두 같은 알고리즘을 사용하는 것처럼 보이지만, 저는 아직 구현 세부를 완전히 이해하지는 못했습니다.
이 알고리즘에 대한 설명(mbe/macro_parser.rs에서 가져온 것)은 정말 흥미롭습니다:
파서가 동작하는 방식에 대한 짧은 소개:
“매처 위치”(또는 “position”, “mp”)란 매처 한가운데 있는 점으로, 보통
·로 표기합니다. 예를 들어· a $( a )* a b도 하나의 위치이고,a $( · a )* a b도 그렇습니다.파서는 입력을 토큰 하나씩 따라가며, 현재 입력 문자열 위치와 일치할 수 있는 스레드 목록
cur_mps를 유지합니다.이를 처리하는 동안, 매크로 호출이 지금 끝났다면 유효할 스레드는
eof_mps에,$e:expr같은 Rust 비단말을 기다리는 스레드는bb_mps에, 특정 토큰을 기다리는 스레드는next_mps에 채워 넣습니다. 로직의 대부분은 Kleene star로 표시된 반복을 통과하며·를 이동시키는 데 관련되어 있습니다. 입력을 소비하지 않고·를 이동시키는 규칙을 epsilon 전이라고 부릅니다.cur_mps스레드가 더 이상 남아 있지 않을 때에만 실제 Rust 파서를 호출하거나 다음 단계로 진행합니다.예시:
Start parsing a a a a b against [· a $( a )* a b].Remaining input: a a a a bnext: [· a $( a )* a b]- - - Advance over an a. - - -Remaining input: a a a bcur: [a · $( a )* a b]Descend/Skip (first position).next: [a $( · a )* a b] [a $( a )* · a b].- - - Advance over an a. - - -Remaining input: a a bcur: [a $( a · )* a b] [a $( a )* a · b]Follow epsilon transition: Finish/Repeat (first position)next: [a $( a )* · a b] [a $( · a )* a b] [a $( a )* a · b]- - - Advance over an a. - - - (this looks exactly like the last step)Remaining input: a bcur: [a $( a · )* a b] [a $( a )* a · b]Follow epsilon transition: Finish/Repeat (first position)next: [a $( a )* · a b] [a $( · a )* a b] [a $( a )* a · b]- - - Advance over an a. - - - (this looks exactly like the last step)Remaining input: bcur: [a $( a · )* a b] [a $( a )* a · b]Follow epsilon transition: Finish/Repeat (first position)next: [a $( a )* · a b] [a $( · a )* a b] [a $( a )* a · b]- - - Advance over a b. - - -Remaining input: ''eof: [a $( a )* a b ·]
제 눈에는 이것이 BFS처럼 보입니다. 가능한 모든 파스를 입력 토큰을 한 번만 훑으면서 동시에 평가하는 방식이니까요. 제 첫 생각은 여기서는 DFS가 더 낫지 않을까 하는 것이었습니다. 같은 영역을 탐색하면서도 메모리를 덜 쓰고, 아마 CPU와도 더 잘 맞을 것 같았기 때문입니다. 파싱 알고리즘에 대한 예전 경험(아마 packrat parsing에 대한 기억)이 떠오르면서, DFS에서는 메타변수를 캐시해야 할 수도 있겠다는 생각도 들었습니다. 매크로가 Rust 표현식을 파싱해야 한다면(예: $a:expr), DFS 탐색 중 나중을 위해 그 결과를 캐시할 수 있으니까요.
이 캐시는 구현이 비교적 단순해 보입니다. “위치 X에서 표현식/문장/기타를 파싱한다”를 그 결과에 대응시키는 해시 테이블을 두면 됩니다. 어떤 위치 Y에서 메타변수를 매치해야 할 때마다 먼저 해시 테이블을 확인하고, 없으면 처음부터 계산하면 됩니다. 테이블의 크기도 꽤 잘 제한됩니다. 하지만 저는 이 접근의 건전성이 걱정됐습니다. 혹시 입력의 길이 도 중요하면 어떨까요? 매크로의 한 팔이 ($e:expr)를 요구하고 다른 팔이 ($e:expr + 1)를 요구한다면(같은 위치에서), 첫 번째 파스의 캐시 결과는 두 번째에 사용할 수 없을 것입니다.
이 경우는 건전합니다. Rust는 메타변수 뒤에 그 메타변수가 소비할 수 있는 토큰이 오는 것을 금지하기 때문입니다. 하지만 모호성 은 문제입니다. rustc의 매처 코드에서는 알고리즘 설명 앞부분에서 Earley 파서가 언급되는데, 구체적으로는 “이 파서가 Earley 알고리즘을 사용한다고 말하지는 않는다. 그렇게 말하는 것은 불필요하게 부정확하기 때문이다.”라고 되어 있습니다. 하지만 이 알고리즘은 Earley 파서의 부분집합이고, 위키백과 문서가 언급하듯 Earley 파서는 비모호 문법에 대해서는 이차 시간에 동작합니다. 모호한 문법에 대해서는 Earley 파서가 세제곱 시간에 동작합니다. 그렇다면 어쩌면 rustc에서도 그런 동작을 끌어낼 수 있지 않을까요…
이쯤에서 저는 jyn과 이야기를 나누고 있었고, 그녀는 매크로 확장에서 이미 존재하는 퇴화 동작 사례를 알려주었습니다. 그러니까 퇴화 사례는 실제로 발생할 수 있습니다! 혹시 더 있는지 궁금해진 저는 모호성을 좀 더 들여다보기로 했습니다.
Rust 매크로는 반복을 포함한 메타변수를 매치할 수 있습니다. 예를 들어 $($e:expr),* 같은 형태입니다. 이 패턴은 쉼표로 구분된 표현식 시퀀스를 매치합니다. (대부분의?) 정규식과 달리, 매크로의 반복은 결정적이지 않습니다. 필요하다면 더 적은 횟수만 매치할 수도 있습니다. 다음 예시는 성공적으로 컴파일됩니다:
macro_rules! foo { ( $( @ )+ ) => {};}macro_rules! bar { ( $( @ )+ @ ) => {};}foo!(@ @ @ @); // parsed as '(@ @ @ @)'bar!(@ @ @ @); // parsed as '(@ @ @) @'
하지만 여기에는 모호성이 생기는 경우도 있습니다. 이런 반복 둘을 서로 옆에 두면 서로 겹칠 수 있습니다. 사실 반복 안에 반복을 둘 수도 있습니다! 한번 보시죠:
macro_rules! foo { ( $( @ )+ $( @ )+ ) => {};}macro_rules! bar { ( $( $( @ )+ )+ ) => {};}foo!(@ @ @ @); // error: ambiguity: multiple successful parsesbar!(@ @ @ @); // error: ambiguity: multiple successful parses
흠… 그렇다면 여기서 성공하는 파스는 정확히 무엇일까요? 한번 나열해 봅시다:
Valid parses for foo!(@ @ @ @):- (@ @ @) (@)- (@ @) (@ @)- (@ @) (@) (@)- (@) (@ @ @)Valid parses for bar!(@ @ @ @):- (@ @ @ @)- (@ @ @) (@)- (@ @) (@ @)- (@ @) (@) (@)- (@) (@ @ @)- (@) (@ @) (@)- (@) (@) (@ @)- (@) (@) (@) (@)
bar에서는 유효한 파스의 수가 입력 크기에 따라 이차적으로 증가합니다. 토큰이 하나만 더 있어도 매처 코드는 이 모든 유효한 파스를 확장하려고 시도할 것이고, 따라서 위키백과에서 언급된 세제곱 성장이 여기서 나타납니다. 하지만 어쩌면 괜찮을지도 모릅니다. 이런 모호성은 결국 오류를 발생시키니까요. 유효한 Rust 코드에서는 절대 일어날 수 없겠죠. 그렇죠? …그렇죠?
안타깝게도, 이 블로그 글은 아직 끝나지 않았습니다. rustc는 모든 유효한 파스를 추적하는 과정을 통해 최종 결과가 비모호한지 검사하기 때문에, 위 예시는 동작하지 않습니다. 하지만 이 검사는 각 매크로 호출에서만 수행됩니다. rustc는 그 자체로 모호한 매크로 정의에 대해서는 문제 삼지 않습니다. 이건 그럴 만도 합니다. 모호한 문법을 식별하는 것은 불가능하기 때문입니다. 이제 마지막 묘수를 써서, 특정 한 경우에서는 비모호한 모호 문법을 만들어 봅시다:
macro_rules! parse { // 'rustc' complains if I don't put an '@' in the outer // repetition, but it doesn't affect our analysis. ( $( $( @ )+ @ )+ @ @ ) => {}; // ^^^ n-2 tokens}parse!(@ @ @ @);// ^^^^^^^ n tokens
이 코드는 성공적으로 컴파일됩니다. 유일하게 유효한 파스는 반복이 한 번씩만 일어나는 최소 파스입니다. 하지만 여기서 rustc의 중간 처리 과정은 세제곱 성장을 포함합니다. 매치 팔 끝부분의 @ 토큰 개수(n-2)와 호출 쪽의 @ 토큰 개수(n)를 바꾸기만 하면 됩니다. 이제 그래프를 볼 시간일까요?
저는 주어진 @ 토큰 수에 맞춰 이런 Rust 코드를 생성하고, cargo -Zscript를 사용해 파일을 직접 실행하는 개념 증명을 작성했습니다. 실행 시간과 최대 메모리 사용량은 /usr/bin/time-f '%e %M'로 측정했고, 각 샘플을 5번씩 실행해(캐싱이 일어나지 않도록 하면서!) 평균을 냈습니다. 저는 n = 41까지만 갈 수 있었습니다. 이유는 보시면 압니다:
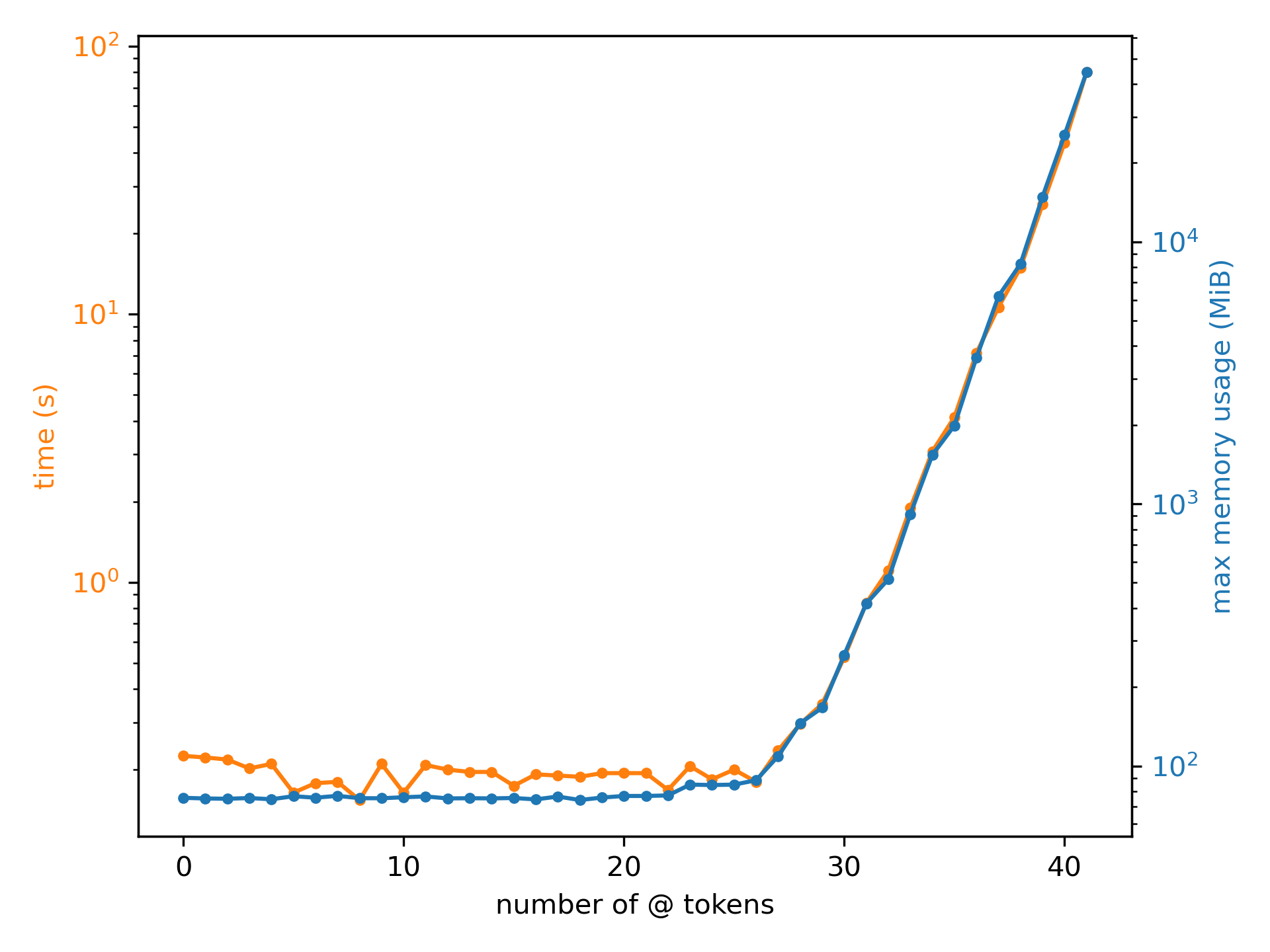 저는 세제곱 성장을 예상했지만, 이것은 걱정스러울 정도로 지수적으로 보입니다(시간과 메모리 사용량이 모두 로그 스케일로 그려졌다는 점에 주목하세요). 유효한 Rust 코드 중에서
저는 세제곱 성장을 예상했지만, 이것은 걱정스러울 정도로 지수적으로 보입니다(시간과 메모리 사용량이 모두 로그 스케일로 그려졌다는 점에 주목하세요). 유효한 Rust 코드 중에서 rustc를 가장 짧은 코드 조각으로 망가뜨리는 경쟁이 있다면, 이건 꽤 괜찮은 출품작이길 바랍니다. 여기서는 고정된 @ 토큰만 파싱하고 있다는 점도 참고하세요. $:expr 같은 복잡한 메타변수를 파싱하게 하면 상황은 더 악화될 수도 있습니다(아마 상수 배 정도로요?).
처음에는 여기서 DFS가 왜 도움이 되는지, 일반적으로도 그렇고 이 퇴화 사례에서도 그렇고, 또 여러 흥미로운 최적화를 가능하게 할 수 있다는 이야기를 몇 단락 써 두었습니다. 그러다 조금 더 생각해 보고, packrat parsing을 좀 더 자세히 들여다본 뒤, 재미있는 사실을 깨달았습니다.
Earley 스타일의 파싱은 여기서는 완전히 불필요하다는 사실입니다. 앞서 문법의 모호성 판정은 결정 불가능하다고 말했는데, 그건 구체적으로 문맥 자유 문법(CFG)에 대해서입니다. CFG(대개는 그 정렬된 변형인 PEG)가 프로그래밍 언어 문법을 정의하는 데 흔히 쓰이는 이유는 재귀를 허용하기 때문입니다. 하지만 매크로 매치 팔은 재귀적이지 않습니다. 물론 (순서 없는) 반복은 사용할 수 있지만, 그것은 진짜 재귀에 비하면 훨씬 더 제한적입니다. 이는 rustc 코드의 설명에서도 약간 드러납니다. 거기서는 매치 팔을 따라가는 진행 상태를 단일 정수 위치로 표현합니다. 일반적인 CFG/PEG의 진행은 그런 식으로 표현할 수 없습니다. 스택이 필요하기 때문입니다.
매크로 매치 팔의 모호성을 정적으로 검출하는 것이 결정 가능할지도 모르지만, rustc가 오늘날 이를 허용하고 있기 때문에 실제로는 그다지 의미가 없습니다. 실제 코드에는 약간 모호한 매크로가 분명 많이 있을 테고, 이를 금지하면 모두에게 짜증 나는 일이 될 것입니다. 하지만 우리는 매크로 호출의 파싱을 최적화할 수는 있습니다. 모호성 검출도, 부분적으로 모호한 문법 처리도 말입니다.
packrat 파서의 단순한 변형을 사용하면, 모호성을 감지하면서도 보장된 선형 시간에 매크로 매치 팔을 파싱할 수 있습니다. 파서의 단계를 “input[tpos..]를 arm[mpos..]로 파싱해 보라”라고 표현해 봅시다. 여기서 input은 매크로 호출의 입력이고 arm은 매치 팔이 지정한 패턴입니다. 한 단계는 성공할 수도 있고(메타변수 결과 포함), 실패할 수도 있고, 모호성을 감지할 수도 있습니다. $(<iter>)* <rest> 같은 반복은 현재 위치에서 두 가지 파스를 시도해 처리합니다. 즉 <iter> <rest>와 <rest>를 시도하는 것입니다. 둘 중 하나라도 성공하면 그 결과를 전달하고, 둘 다 성공하면 모호성을 감지합니다. 반복 때문에 동일한 단계에 여러 번 도달할 수 있으므로, 각 단계는 메모이즈합니다.
세상 대부분의 매크로가 모호하지 않다 하더라도, 반복을 사용하기 때문에 rustc의 현재 구현에서는 여전히 손해를 봅니다. 위키백과 문서는 Earley 파싱이 결정적 문법에 대해서는 선형 시간이라고 말하지만, 매크로 반복은 결정적이지 않습니다! 반복을 사용하는 모든 매크로는 오늘날 이차적 동작을 겪을 수 있습니다. 제가 위에서 설명한 packrat 기반 접근은 모든 입력에 대해 선형 시간 실행이 보장됩니다. 각 단계를 메모이즈하고, 가능한 단계 수는 input.len() * arm.len()뿐이기 때문입니다.
저는 rustc에 기여하는 일을 피하려고 해 왔습니다. 코드베이스에 빨려 들어갈까 걱정되기 때문입니다. 하지만 이 문제는 불안할 정도로 재미있습니다. 지금 꽤 바쁠지도 모르지만, 이것을 실제로 구현해 보고, 제 가설을 검증하고, 어쩌면 PR도 열어볼 생각입니다.
Copyright (c) 2026 arya dradjica. Licensed under CC BY-NC-SA 4.0. Using the Selenized color scheme by Jan Warchol.