스코프 집합(scope sets)을 이용해 매크로 하이진과 이름 해석을 체계적으로 모델링하는 방법을 소개하고, 타깃 특화·조건부 컴파일·임포트 리네이밍·OO 스코핑 등으로의 확장 가능성과 라이브러리화 아이디어를 논한다.
최근에 스코프 집합(scope sets)에 관해 트윗을 몇 개 올렸다: (tweet 1, tweet 2)
스코프의 집합이라는 핵심 통찰은 그냥… 와. 이름 조회를 위한 피냐타 같다.
문자열/리네이밍/소스 범위/기타 등으로 생각하는 대신, 더 체계적인 방식으로 문제에 접근하면 쾅, 좋은 것들이 우르르 나온다.
이 아이디어로 ✨ 이름 해석 라이브러리 ✨ 를 만들 수 있을까(특히 화려한 매크로가 없는 호스트 언어를 위해)? 특정 API로 바인딩과 스코프를 만들면, (멀티스레드? 캐시된?) 이름 해석을 “공짜로” 얻고, 매크로가 있는 상황에서도 동작하게.
짧은 스레드에 약간의 관심이 생겼고, 그래서 “어, 트윗 몇 개로 담기엔 더 할 말이 많네.”라고 생각했다. 그래서 이 짧은 블로그 글을 쓴다.
옛날 옛적(읽기: 2016년)에 Matthew Flatt가 스코프 집합을 소개하는 논문을 썼다: Binding as Sets of Scopes. 이 논문은 스코프 집합을 사용해 매크로가 있는 프로그래밍 언어의 이름 해석을 이해하고 구현하는 일을 어떻게 단순화할 수 있는지 설명한다. 특히 그 매크로가 “화려한” 것일수록 더 그렇다.
나는 이 논문을 띄엄띄엄 읽고 또 읽어 왔고, 아직 모든 디테일을 완전히 흡수하진 못했지만 정말 마음에 든다. 그렇다고 이 글을 읽는 당신이 논문을 이미 읽었을 거라 기대하진 않는다. 필요한 기본은 진행하면서 다룰 것이다.
이 글의 대략적인 개요는 다음과 같다:
(면책 조항: 이 글은 기존 컴파일러를 다시 쓰자고 제안하려는 것이 아니다. 새 컴파일러를 어떻게 구현할 수 있을지 생각을 소리 내어 해보는 것이다.)
기본부터 시작하자.
탑레벨 let 정의, let in 표현식, 그리고 매크로가 있는 ML 계열 언어가 있다고 하자. 다음은 의사코드다:
let x = 1
macro get_x = x (* x is the value defined earlier *)
let y =
let x = x + 1 in
get_x (* y = 1 *)
이 코드를 순진하게 확장하면 다음이 된다:
(1) let x = 1
(2) macro get_x = x (* x is the value defined earlier *)
(3) let y =
(4) let x = x + 1 in
(5) x (* y = 2 *)
매크로 확장으로 도입된 x를 해석하려 하면, 5행의 x에 대한 참조(reference) 가 4행의 x 바인딩(binding) 에 묶여(bound) 버린다. 프로그램의 의미가 바뀌었다! 💩
문제는 하이진(hygiene) 이다. 순진한 치환은 하이진하지 않다. 이 경우 확장 지점(expansion site)에 무엇이 스코프에 있었는지 때문에 식별자를 우연히 캡처해 버렸다. 반대로, 확장 지점의 스코프 때문에 식별자를 우연히 섀도잉해 버리는 문제도 있다.
“그럼 컴파일러에서 변수를 x1, x2 같은 걸로 리네이밍하면 되지 않나?”라고 생각할 수도 있다. 맞다. 리네이밍으로 하이진 매크로 시스템을 구현할 수 있다. 하지만 리네이밍 기반 하이진 구현은 여러 이유로 그리 좋지 않다:
수년간 많은 똑똑한 사람들이 이 문제를 깊게 고민해 왔다. 이 글은 그 전체에 대한 것이 아니다. 관심 있다면 Flatt 논문의 참고문헌을 보라. 이 글이 다룰 것은, 이 분야에서 아주 멋진 혁신 하나: 스코프 집합이다. 핵심 아이디어는 이렇다:
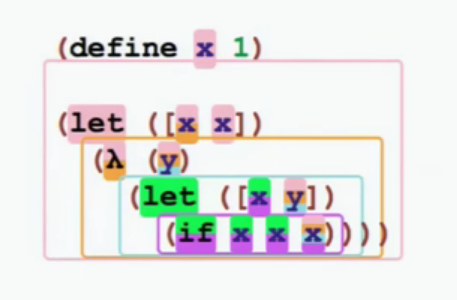
let 표현식, 람다 같은 바인딩 폼은 새로운 스코프를 도입한다.예제로 보는 게 가장 좋다. 아까 예제를 재사용하자:
(1) let x{a} = 1
(2) macro get_x{a,b} = x{a}
(3) let y{a,b} =
(4) let x{a,b,c} = x{a,b} + 1 in
(5) get_x{a,b,c}
a…c는 스코프에 붙인 임의의 이름이고, {...}는 스코프 집합을 뜻한다. 스코프는 어떻게 할당했을까?
Rule 1A: 비재귀(non-recursive) 바인딩 폼은, 바인딩과 정의의 끝 이후에 나타나는 모든 문법 조각에 적용되는 새로운 스코프를 도입한다.
여기서 Rule 1A가 어떻게 적용되는지 보자:
a는 1행의 x 정의가 도입한 새 스코프다. x의 스코프 집합뿐 아니라 이후의 모든 스코프 집합에 a가 들어 있는 점에 주목하라.b는 get_x 매크로 정의가 도입한 새 스코프다. get_x의 스코프 집합뿐 아니라 이후의 모든 스코프 집합에 b가 들어 있다. 2행의 x 참조는 get_x의 정의의 일부이지 “정의 끝 이후”가 아니므로, 그 스코프 집합에는 b가 없다.c는 let x = <..> in <..> 이 도입한 새 스코프다. 바인딩 x에는 c가 있고 매크로 호출에도 c가 있지만, 4행의 x 참조에는 스코프 집합에 c가 없다. (이게 동작하려면 let in 표현식에서 “정의의 끝”을 바디 시작 직전으로 해석해야 한다.)이제 구조를 이해했으니, 이름 해석을 보자.
Rule 2: 참조가 어떤 바인딩으로 해석되려면:
A와 그 부분집합들의 집합 {Ai | i ∈ I}가 주어졌을 때, 어떤 부분집합 Aj가 가장 큰 부분집합이라는 것은 모든 i ∈ I에 대해 Ai가 Aj의 부분집합이라는 뜻이다.)x 참조들을 Rule 2로 해석해 보자. (편의를 위해 코드 예제를 다시 적는다.)
(1) let x{a} = 1
(2) macro get_x{a,b} = x{a}
(3) let y{a,b} =
(4) let x{a,b,c} = x{a,b} + 1 in
(5) get_x{a,b,c}
x에 대한 후보 바인딩은 두 개다. 1행의 {a}와 4행의 {a,b,c}. Rule 2를 적용하면:
x 참조는 스코프 집합이 {a}다. {a}와 {a,b,c} 중 {a}만 {a}의 부분집합이므로, 2행의 x는 1행의 x에 바인딩된다.x 참조는 스코프 집합이 {a,b}다. {a}와 {a,b,c} 중 {a}만 {a,b}의 부분집합이므로, 4행의 x도 1행의 x에 바인딩된다.지금까지 좋다. 이제 매크로를 확장해도 여전히 동작하는지 보자.
(1) let x{a} = 1
(2) macro get_x{a,b} = x{a}
(3) let y{a,b} =
(4) let x{a,b,c} = x{a,b} in
(5) x{a,d}
Rule 1B: 매크로 확장은 새로운 스코프를 도입하고, 그 스코프는 매크로 바디의 모든 문법 조각에 적용된다.
Rule 1B에 의해, 매크로 확장이 새 스코프 d를 도입하고, 바디의 x 참조에 있던 스코프 집합 {a}에 d가 더해져 x{a,d}가 된다.
5행의 x 참조를 해석하려 하면, 4행의 x 바인딩은 {a,b,c}가 {a,d}의 부분집합이 아니므로 무시된다. 따라서 참조는 1행의 x{a}에 올바르게 해석된다. 만세, 스코프를 망치지 않았다! 🥳
더 복잡한 상황(재귀 바인딩과 재귀 매크로 등)은 이 글의 나머지에 필요하지 않으므로 생략하겠다. 자잘한 디테일은 논문을 보라. 지금은 “잘 된다”는 내 말을 믿어도 된다.
해피 케이스를 이야기했으니, 이제 에러 케이스를 훑어보자:
한 걸음 물러서서 이해를 정리해 보자:
S가 다른 스코프 집합 T에 대한 최선의 매치라는 것은, T의 모든 부분집합 U에 대해 U가 S의 부분집합이라는 뜻이다.마지막 제한은 지금까지 얘기하지 않았지만, ML 계열 언어 맥락에서는 그렇게 무리한 제약은 아니다.
Java, C++ 같은 타입 기반 오버로드 선택을 처리하고 싶다면, 이름을 “오버로드 집합”까지 먼저 해석하도록 모델링할 수 있다. 즉 같은 오버로드 집합의 여러 오버로드는 이름 해석기 단계에서 하나의 동치류로 뭉개지고, 나중에 타입 체커가 올바른 오버로드를 고르게 한다. (다만 C++에 대해서도 이게 될지는 완전히 확신하진 못하겠다. C++의 오버로드 해석 규칙은 좀… 지저분하니까.)
여기까지 오면 스코프 집합이 멋지다고 생각할 수도 있고, 혹은 시큰둥할 수도 있다. 시큰둥하다면 내가 왜 스코프 집합이 멋지다고 생각하는지 이유를 설명해 보겠다.⊕ SEC 공시 요건을 준수하기 위해, 나는 미래의 산업용 컴파일러에서 스코프 집합이 구현 기법으로 사용되기를 66% 정도 감정적으로 기대하고 있음을 공시한다.
스코핑과 관련된 가장 흔한 두 동작은 섀도잉(shadowing)과 모호성(ambiguity)이다. 스코프 집합 접근은 어떤 바인딩이 다른 바인딩을 섀도잉하게 만들려면(스코프 집합이 다른 쪽의 상위집합이 되도록) 어떻게 해야 하는지, 그리고 모호성을 만들려면(둘 중 어느 것도 더 크지 않게 겹치게) 어떻게 해야 하는지에 대한 명확한 레시피를 준다.
먼저 모호성부터 보자. 많은 언어에서 import는 순서와 무관하게 만들고 싶어 한다. import를 재배치해도 컴파일이 깨지면 곤란하니까. 이런 경우 보통의 동작은, 동일한 이름의 바인딩이 서로 다른 모듈에서 들어오면 그 바인딩을 사용하려 할 때 컴파일러가 모호성 에러를 내는 것이다. 예를 들어 Swift에서는 이렇게 보인다:
import A1 // exports a
import A2 // exports a
let x = a // error: ambiguous reference to 'a'
스코프 집합 관점에서 이 동작을 얻으려면, A1과 A2의 import에 대응하는 스코프 집합이 서로 부분집합 관계가 아니게 만들면 된다. 충분히 쉽다: A1과 A2가 내보내는 바인딩에 각각 다른 스코프(예: SA1, SA2)를 붙이고, 현재 모듈의 코드는 스코프 집합 {SA1, SA2}로 시작하게 하면 된다. a 참조를 해석하면 실패한다. 참조는 {SA1, SA2}인데 후보 바인딩은 {SA1}와 {SA2}이고, 둘 다 최선 후보가 아니기 때문이다.
이제 모호성에서 섀도잉으로 넘어가자. 섀도잉도 자연스러운 해법이 있다: 중간 스코프를 하나 도입하면 된다. 다시 Swift 예로, Swift에는 비수식(qualified가 아닌) 이름 조회에서 어떤 모듈의 import를 다른 것보다 우선하도록 표시하는 기능이 있다:
import A1 // exports a
import A2 // exports a
import var A2.a // A2's a should be preferred
let x = a // OK: a refers to A2.a
import var를 “중간 스코프를 추가하는 것”처럼 모델링할 수 있다. 이 경우 import var A2.a가 일반 import들과 모듈 코드 사이에 중간 스코프 SA2.a를 도입한다고 하자. 그러면:
a는 이제 스코프 집합이 각각 {SA1}, {SA2}, {SA1, SA2, SA2.a}인 3개의 바인딩을 가진다.a에 대한 참조는 스코프 집합 {SA1, SA2, SA2.a}를 가진다.이렇게 하면 스코핑이 기대대로 동작한다.1
스코프 집합의 정말 좋은 점 하나는, 스코프가 무엇인지 와 스코프가 프로그램에서 어떻게 생성되는지 를 분리한다는 것이다.
스코프 자체 는 프로그램 안의 어떤 추상적 영역이다.
그게 어떻게 드러났을까? 프로그래머가 { ... } 같은 무언가를 썼기 때문에 컴파일러가 스코프를 삽입했을 수도 있고, 매크로 확장 때문일 수도 있고(혹은 컴파일러가 암묵적으로 코드를 추가했을 수도 있다). AST의 특정 노드에 대응될 수도 있고 아닐 수도 있다. 소스 범위들의 집합에 대응될 수도 있고 아닐 수도 있다. 어떤 식별자들은 리네임됐을 수도 있다. Maybe it’s Maybelline.
스코프 생성과 이름 해석을 이렇게 분리하면, 이름 해석 입장에서는 스코프가 어떻게 생겨났는지는 사실 별로 중요하지 않다. 같은 스코프 구조로 귀결되기만 하면, 같은 방식으로 해석된다.
새 언어 기능을 설계할 때도 두 개의 질문을 분리해서 할 수 있다: “이게 스코프 생성 방식을 바꾸는가?”와 “이게 이름 해석에 영향을 주는가?”
복잡한 상황에서 스코핑을 이해할 때 흔한 골칫거리는, 머릿속에서 계속 컴파일러를 흉내 내야 한다는 점이다. 그런데 컴파일러는 이미 있는데?! 😂 그러면 왜 프로그래머가 컴파일러 역할극을 해야 하지? 왜 컴파일러가 어떤 바인딩을 골랐는지(또는 왜 모호한지) 이유 를 보여주면 안 되나?
문제의 일부는, 이름 해석을 애드혹하게 구현하면 이 정보를 이해 가능하면서도 과도하지 않게 보여주는 방식이 분명하지 않다는 점이다. 컴파일러가 “여길 봤는데 실패했고, 저길 봤는데 실패했고, 그래서 저쪽을 봤더니 네가 원한 게 있더라” 같은 로그를 제공해야 할까? 컴파일러 엔지니어에겐 괜찮을지 몰라도, IDE에서 도움이 되게 보여줄 수 있을까?
스코프의 집합을 쓰면 좋은 시각화 기회가 있다. 예를 들어 나는 앞에서 위첨자 같은 표기를 보여줬다. IDE는 그 위첨자를 클릭 가능하게 만들고 스코프가 어디서 왔는지 보여줄 수도 있다. Flatt의 발표에서는 스코프를 색으로 표현한다(아래 그림).
너무 단순화할 위험이 있지만, 스코프 집합이 잘 작동하는 이유는 두 가지다:
부분순서의 정의를 떠올려 보자. 집합 A 위의 부분순서란, 반사적(a ≤ a), 반대칭(a ≤ b 그리고 b ≤ a이면 a = b), 추이적(a ≤ b 그리고 b ≤ c이면 a ≤ c)인 이항 관계 ≤다. (용어가 낯설다면 Matt Might의 글 Order theory for computer scientists를 보라.)
부분순서의 성질이 스코프 사고방식과 어떻게 연결될까?
a ≤ b와 b ≤ a로 동치류를 만들어 부분순서로 사상할 수 있는데, 이는 내가 오버로드 집합에 관해 말한 점과 맞물린다.){ai | i ∈ I}를 뽑아 오면, 모든 다른 원소 ai, i ∈ I에 대해 크거나 같은 원소 aj, j ∈ I가 존재하지 않을 수도 있다.
어떤 의미에서는, 부분순서는 스코프를 생각하기에 완벽한 도구라고 주장할 수도 있겠다.
코드에서 대수적 구조로 생각하는 데 익숙하지 않다면, “왜 이게 유용하지? 그래, 대수네, 멋지네. 근데 결국 같은 말을 다른 방식으로 하는 거 아냐?”라고 생각할 수 있다. 하지만… 아니다! 대수적으로 생각하면 여러 이점이 있다:
그러면 이런 생각거리가 생긴다: 스코프와 비슷하거나 부분순서 구조를 가진 다른 언어 기능이 있을까? 그걸 스코프와 결합할 수 있을까? 찾아보자! 😉
앞서 말했듯이, Flatt는 _Binding as Sets of Scopes_에서 스코프 집합이 (표현력 있는) 매크로 시스템을 가진 언어 구현에 도움 된다고 말한다. 나는 이 아이디어를 더 확장할 수 있고, 매크로는 없지만 다른 종류의 복잡한 기능이 있는 언어(예: 다음)에서 이름 해석 구현을 단순화하는 데 스코프 집합(또는 그 확장)이 쓸모가 있다고 생각한다:
또한 스코프 집합이 툴링 구현에도 잠재적으로 도움 될 수 있는지 논한다.
일상적으로 소프트웨어를 만든다면, 특정 타깃에서만 쓰려고 만든 코드를 작성해 본 적이 있을 가능성이 크다. 예를 들어 다음에서만 동작하는 코드:
코드에 따라 휴대성을 위해 다른 타깃에 대한 폴백 구현이 있을 수도 있고, 의도적으로 타깃 전용이라 폴백이 없을 수도 있다.
타깃 체크는 동적으로 해야 할 수도 있다. 예를 들어 여러 OS에서 돌아가는 바이너리 하나를 제공하고, 오래된 OS 버전에는 워크어라운드가 필요할 수 있다. 혹은 빌드 시점에 타깃이 정확히 정해져 있을 수도 있다.
언어에 따라 이들은 서로 다른 방식으로 모델링된다. 예를 들어 Swift에서는:
@available 속성.#available.#if os(...), #if arch(...) 등.요컨대, 타깃 특화성은 컴파일러와 프로그래머 모두에게 복잡할 수 있다. 단순화할 수 있을까? 나는 가능하다고 생각한다.
타깃 특화성은 어떤 의미에서는 스코핑의 정확한 쌍대(dual)다! 스코핑이 “이 프로그램 조각은 어디에서 정의됐는가”라면, 타깃 특화성은 “이 프로그램 조각은 어디에서 사용될 수 있는가”다.
더 정확히 말하면, 타깃 특화성은 (지원하는 타깃을 원소로 갖는) 집합에 대해 상위집합(superset) 관계로 부분순서를 만들 수 있다:
여기서 핵심: 부분순서는 합성 가능하다는 점을 기억하나? 두 개념—스코프 집합과 타깃 특화성—을 하나로 합칠 수 있다: 도메인(domain) 이다. (더 좋은 이름 제안?) “스코프 집합”의 모든 사용을 “도메인”으로 바꾸고, 약간의 문구만 조정하면, 모든 것이 그냥 동작한다.
문법 조각은 식별자와 도메인의 쌍이다.
참조 해석은, 참조의 도메인에 가장 잘 맞는 바인딩의 도메인을 찾는 일이다.
한 도메인이 다른 도메인에 적용 가능(applicable)하려면:
도메인 D가 도메인 E에 대한 최선의 매치라는 것은, E에 적용 가능한 모든 도메인 F에 대해 F가 D에도 적용 가능하다는 뜻이다.
같은 도메인으로 동일 식별자가 중복 바인딩되지는 않는다.
이 점들을 염두에 두고, 아까의 타깃 특화성 예제를 가상의 Swift 유사 언어 문맥에서 다시 보자:
let x = 0 // Cross-platform by default
@target(arch: arm64)
let x = 1
@target(os: macOS)
let x = 2
@target(arch: arm64, os: macOS)
let x = 3
// No errors for multiple 'x' bindings in same scope as they have
// different target specificities (and hence different domains).
let y = x
// Say we are compiling for multiple platforms.
// The reference to 'x' will pick up the most specialized value.
// x86_64 Linux: y == 0
// arm64 Linux: y == 1
// x86_64 macOS: y == 2
// arm64 macOS: y == 3
예제는 다소 꾸며낸 것이지만, 이것이 실제로 어떻게 동작할 수 있는지 요점을 보여주길 바란다.3
왜 타깃 특화성을 스코프와 묶는 게 유용할까? 나는 이렇게 하면, 각 타깃의 조건부 컴파일 플래그가 동일할 때 여러 타깃에 대해 동시에 타입 체크를 올바르게 구현하기가 더 쉬워진다고 생각한다(조건부 컴파일은 다음 섹션에서 더 다룬다).
다만 타입 체크가 어떻게 바뀌는지 설명하기 전에, 현대 컴파일러에서 타깃 특화성이 오늘날 어떻게 처리되는지 이야기할 가치가 있다.
타깃 특화성을 지원하는 언어에서, 오늘날 컴파일러는 컴파일하는 각 타깃에 대해 전체 컴파일 파이프라인을 돈다. 반례가 있다면 기꺼이 틀렸음을 인정하겠다! 예를 들어 Intel 기반 Mac과 Apple Silicon 기반 Mac에서 모두 동작하는 macOS 앱의 universal binary를 만들면, Xcode는 컴파일러(Clang 또는 Swiftc)를 타깃별로 두 번 실행하고 결과 바이너리를 합친다. 이는 당신이 쓴 코드가 타깃 특화가 전혀 아니어도 타입 체크가 두 번 일어난다는 뜻이다! 😔
이런 동작의 이유는 (항상 그렇듯?) 역사 때문이라고 생각한다.
공정하게 말하면, 현대 언어 중 일부는 이를 어느 정도 개선했다. 앞에서 언급한 Swift의 OS 버전 처리용 @available을 떠올려 보라. macOS 9000은 없지만, 다음 코드는 타입 에러를 보고한다.
@available(macOS 9000, *)
public let x: () = 0 // error: cannot convert value of type 'Int' to specified type '()'
하지만 이는 OS 버전에 대해서만 그렇다. 타깃 아키텍처 체크는 일반 조건부 컴파일 구성인 #if를 타므로, 다음은 x86_64에서 컴파일된다:
#if arch(arm64)
let x: () = 0
#endif
그러나 미래의 언어에서 이런 상태가 계속될 필요는 없다. 식별자가 전체 타깃 특화성을 추적한다면, 다음 이점이 있다:
이전 섹션에서는 타깃 특화성을 스코프 집합과 결합해 여러 타깃을 동시에 타입 체크하는 방식을 잠재적으로 다뤘다.
Swift가 타깃 특화성을 부분적으로 조건부 컴파일로 모델링한다는 것도 상기하자. 내가 이해하기로 Rust도 그렇다. Rust에서 타깃 특화성은 조건부 컴파일에 많이 의존한다.
하지만 오늘날 언어의 조건부 컴파일 상태는 그리 좋지 않다:
조건부로 제외될 코드에 대해서도 타입 체크를 하는 것은 “파싱은 돼야 한다” 요구의 자연스러운 확장이다. 에러를 늦게보다 빨리 발견하는 게 더 낫다고 볼 수 있다. 특히 큰 프로젝트에서 설정 옵션 수가 조합적으로 폭발할수록 더 그렇다. 누군가 옵션을 뒤집으면 당신의 코드가 정말 컴파일되긴 하나?
예를 들어 컴파일 타임 기능 플래그 아래에서 무언가를 테스트하고 배포하려 한다고 하자. 작은 커밋에서 플래그를 켜고 복잡한 테스트를 돌린다. 동료가 와서 변경을 한다. 테스트에서 문제가 발견되어 플래그를 켠 변경을 되돌리려 한다. 그런데 놀랍게도 코드가 더 이상 컴파일되지 않는다! 💩
이 실패 모드를 피하는 대안이 몇 가지 있다: (1) 두 설정이 모두 컴파일되는지 확인하는 CI 봇을 만들거나, (2) 컴파일 타임 플래그 대신 런타임 플래그를 쓰는 것이다. 하지만 둘 다 컴파일 타임 플래그의 완벽한 대체는 아니다. 런타임 플래그는 플래그에 따라 타입이 바뀌어야 하면 잘 안 되고, 모든 기능 플래그 조합에 대해 CI 봇을 만드는 것은 확장성이 없다.
그렇다면 질문은 이거다: 조건부 컴파일을 “꿰뚫어 보는” 걸 근본적으로 막는 이유가 있을까? 모든 기능 플래그 조합에 대해 코드젠을 하고 싶지는 않다(우리는 모든 조합을 실행하지 않을 테니까). 하지만 왜 모든 조합에 대해 의미 분석(semantic analysis)은 못 할까?
이전 섹션을 힌트로 질문을 바꿔보자: 조건부 컴파일도 타깃 특화성처럼 모델링할 수 있을까? 더 정확히는, 조건부 컴파일 표현식 위에 직관적인 부분순서가 있을까?
단순화를 위해, 불리언 표현식과 불리언 값의 기능 플래그만 있는 조건부 컴파일 표현식 문법을 생각하자:
ccexpr := true
| false
| feature-flag
| not(ccexpr)
| and(ccexpr+)
| or(ccexpr+)
이런 표현식 위에 좋은 부분순서가 있을까? 있다! 만족 가능성(satisfiability)이다! 두 표현식 c1과 c2가 있을 때, c1 ≤ c2(읽기: c1이 c2보다 덜 특화됨)라 함은, 모든 기능 플래그 치환에 대해 c2가 참이면 c1도 참인 경우다(즉 c2가 c1을 함의).
위에서 정의한 ≤로 만족 가능성이 부분순서를 이룬다는 증명은 독자의 연습문제로 남긴다. 😛 (힌트: 반대칭성에는 conjunctive normal form을 써라.)
그래도 부호(polarity)가 맞는지 빠르게 점검해 보자: and(flag1, flag2)는 flag1을 함의하므로, flag1이 and(flag1, flag2)보다 덜 특화되어야 한다. 좋다.
물론 나는 컴파일러가 이름 해석 중간에 아무 생각 없이 SAT solver를 호출해야 한다고 말하는 게 아니다. 대부분의 애플리케이션 코드는 어느 정도 크로스플랫폼이고, 사람들이 컴파일 타임 기능 플래그를 아주 괴상하게 쓰진 않으니, 빠른 경로를 특수 처리하고 신중히 캐시하면 성능 좋게 만들 수 있을지도 모른다는 느낌이 든다. 아마도 그러면 안 된다. 하지만 조건부 컴파일 표현식 위에 부분순서가 생기는 귀여운 결과가 있으니, 도메인이 이제 스코프 집합, 타깃 특화성, 조건부 컴파일 표현식의 삼중쌍이라고 잠깐 가정해 보자.
실제로 어떤 이점이 있을까? 타깃 특화성과 비슷하다:
import 목록에서 이름을 바꾸는 기능은 꽤 흔하다. 내가 아는 언어 중 Rust, Python, Haskell은 모두 정도는 다르지만 import 시 리네이밍을 지원한다.
예로 Swift는 “cross-import overlays”라는 기능이 있다. 코드 예제로 보는 게 가장 좋다:
import SwiftUI
import MapKit
// Compiler looks at both imports (+ some files in the SDK) and
// implicitly inserts 'import _MapKit_SwiftUI', which is marked
// as a cross-import overlay for the (MapKit, SwiftUI) pair in
// the SDK.
import _MapKit_SwiftUI // (compiler-synthesized) exports MapView
typealias MV1 = MapView // OK, MapView comes from _MapKit_SwiftUI
typealias MV2 = MapKit.MapView
// OK, MapKit is marked as the "declarating module" for _MapKit_SwiftUI,
// so this behaves as if the user wrote _MapKit_SwiftUI.MapView
마찬가지로 진단과 문서화에서도 MapView는 _MapKit_SwiftUI 모듈에 정의되어 있음에도, 마치 MapKit에 정의된 것처럼 동작한다.
이 이름 변경은 스코프 집합으로 모델링할 수 있다. 어떤 import된 모듈이 cross-import overlay(여기서는 _MapKit_SwiftUI)라면, 새 스코프를 만들지 않고 선언 모듈(여기서는 MapKit)의 스코프를 재사용한다. 나는 여기서 Swift의 @_exported import가 섀도잉과 상호작용하는 방식 때문에 생기는 추가 복잡성을 일부러 뭉개고 있다. (cross-import overlay는 선언 모듈과 “옆에 서 있는” 모듈 모두에 대해 @_exported import를 사용할 것으로 기대된다.)
이 예제가 보여주듯, 리네이밍은 어떤 의미에서 스코프 조정 문제이며, 스코프 집합은 이를 잘 모델링한다.
언어의 객체지향 기능은 종종 고유의 스코핑 동작을 동반하는데, 근접성이 단지 어휘적(lexical)인 것뿐 아니라 타입 기반이기도 하다.
예를 들어 필드/프로퍼티와 메서드를 해석할 때는 슈퍼클래스를 따라 올라가야 한다. 트레이트와 프로토콜은 이름 해석 관점에서 슈퍼클래스와 비슷하다. 슈퍼클래스의 시퀀스나 DAG를 따라가는 대신, 트레이트/프로토콜의 숲(forest)을 뒤져야 한다. 많은 언어는 이미 정의된 타입에 메서드를 추가할 수 있는 “확장 메서드(extension methods)”도 지원한다.
나는 이런 구문들의 스코핑 동작도 타입에 기반한 중간 스코프를 추가하는 방식으로 구현할 수 있다고 생각한다. 예를 들어 클래스 Animal에 선언 스코프 SAnimal이 있다면, Animal을 상속하는 클래스 Cat 안에서 정의되는 모든 것의 스코프 집합에 SAnimal을 추가해야, 메서드 조회가 슈퍼클래스에 있는 것들도 찾을 수 있다. 다만 시스템이 복잡하면 이름 해석이 타입 체크와 부분적 혹은 완전하게 얽혀야 할 수도 있다.
언어가 성장할수록 사람들은 그 언어의 툴링 생태계에 더 큰 기대를 한다. 예를 들어 문서화 주석에서는 정의를 상호 참조해 빠른 탐색을 가능하게 하는 것이 중요하다.
스코프 집합이 여기서 유용할 수 있는 한 가지 이유는, 문서 컴파일러(소스에서 문서를 추출하고, 교차 참조를 해석해 HTML 같은 출력을 내는 도구)가 작업하기 좋은 추상화를 제공하기 때문이다.
예를 들어 한 파일에서 public 함수의 문서를 작성한다고 하자. 그런데 문서에서 public으로 표시하는 것을 잊어버린 함수를 참조한다. public 함수 구현에서 private 함수를 호출하는 것은 괜찮아야 하지만, 엄밀히 말하면 안정 ABI가 있고 public 함수의 구현이 노출된다면 거의 확실히 에러여야 한다… public 함수 문서에서 private 함수를 참조하는 것은 거의 확실히 실수다. 그러니 여기서는 문서용 스코핑 규칙이 해당 파일의 코드 스코핑 규칙과는 약간 달라야 한다. 문서 컴파일러를 순진한 접근(파일 스플라이싱, import로 주물럭 등)으로 구현하면 이런 디테일을 틀리기 쉽다. 또한 이름 해석을 두 번 구현하고 싶지 않다. 일반 컴파일러에 한 번, 문서 컴파일러에 프랑켄슈타인 버전으로 또 한 번.
이 경우 가능한 수정은 추가 스코프 Sprivate를 두는 것이다:
public 선언의 문서 주석 참조에는 이 스코프가 없으므로, private 함수를 참조하려 하면 스코핑 에러가 난다.
우연히도 이 수정은 public 선언이 private 선언을 참조할 수 없다는 제약(예: public 함수가 private 타입을 참조할 수 없음)도 모델링한다.
컴파일러의 호스트 언어가 정교한 매크로를 가진다면, 그 호스트 언어의 매크로 시스템을 “얹어서” 대상 언어의 스코핑을 구현할 수 있다. 내 믿음으로는 Hackett가 이렇게 한다. 확인해보진 않았으니 내 말만 믿진 말아 달라. DSL에서 이를 가능케 하는 최근 연구도 있다: Macros for Domain-Specific Languages. 이 논문을 알려준 Sam Elliott에게 감사!
하지만 대부분의 컴파일러는 Racket만큼 유연한 매크로 시스템을 가진 호스트 언어로 쓰이지 않는다. 그래서 나는 매크로가 없는 호스트 언어에서 새 컴파일러를 더 쉽게 쓰도록, 이름 해석을 라이브러리로 만들면 유용하다고 생각한다.
스코프 집합을 쓰면 스코프 생성 방식과 이름 해석 동작을 분리하므로, 다양한 대상 언어를 포괄할 만큼 유연한 이름 해석 라이브러리를 구현하는 것이 가능하리라 믿는다.
더 구체적으로, 그런 라이브러리의 핵심 API는 다음처럼 생길 수 있다:
스코프 타입.
스코프 집합 타입.
스코프 생성기.
이름 해석기 타입.
타입 파라미터:
API:
이런 라이브러리를 쓰는 모습은 다음과 같다:
라이브러리는 식별자와, 그 식별자에 대한 도메인 목록의 단조 증가 수정 시간(monotonic modification time)에 기반해 해석 질의를 캐싱할 수 있다.
자료구조 선택에 따라, 이 라이브러리가 안전한 멀티스레딩을 지원하도록 만들 수도 있다. 그러면 여러 스레드가 같은 이름 해석기에 접근할 수 있다. 스레드 간 스코프 정보의 상당 부분은 공유될 가능성이 크므로, 메모리 사용량을 줄이는 데도 도움이 될 수 있다. 또한 서로 다른 스레드에서 중복으로 하는 작업을 줄이는 데도 도움이 될 수 있다.
단순화를 위해 여기서는 핵심 API만 설명했다. 실제로는 더 좋은 효율을 위해 API가 더 복잡해야 할 것이다.6 다른 놓친 디테일도 있을지 모르지만, 대략적 아이디어는 전달됐길 바란다. 이게 정말 될지는 확신하지 못하지만, 나는 낙관적이다.
여기까지 왔다면, 다음 컴파일러를 구현하기 전에 스코프 집합을 더 배워보는 것을 최소한 고려해야 한다는 점에는 설득됐을 가능성이 크다.
그럼 어디서부터 시작해야 할까?
Flatt는 스코프 집합이 어떻게 동작하고, 기존 매크로 확장 모델보다 어떻게 개선되는지 설명하는 접근성 좋은 RacketCon 발표가 있다. Flatt는 Strange Loop 2016 발표도 있는데, 앞 발표와 겹치는 부분이 있지만 구현 쪽에 더 초점이 있다. 스코프 집합으로 하이진 매크로 확장기를 어떻게 만들 수 있는지 걸어간다. 물론 원 논문 자체도 있다: Binding as Sets of Scopes.
특정 매체를 선호하지 않는다면, 다음 순서로 보는 것을 권한다: RacketCon 발표 → StrangeLoop 발표 → 논문. (논문 HTML 버전은 문법 하이라이팅과 크로스 링크가 잘 되어 있다.) Racket에 익숙하지 않더라도 Strange Loop보다 RacketCon을 먼저 보기를 추천한다. Strange Loop 발표는 약간의 소용돌이 같다(아주 좋지만 흡수하는 데 시간이 걸린다). 반면 RacketCon 발표는 내 취향의 “적당한 속도”에 더 가까웠다.
구현 관점에서, 내가 알기로 오늘날 최소 3개의 컴파일러가 스코프 집합을 사용한다: Klister, Racket, Rust(컴파일러 크기 증가 순).
Klister 구현을 보고 싶다면, 좋은 출발점 두 개는 여기다: scope sets in Klister 그리고 resolution in Klister. 짧은 commentary on the implementation도 있다.
Racket 구현을 보고 싶다면, core resolve function 정의부터 시작해 보는 게 좋다.
Rust 구현은 나는 보지 않았지만, “macros 2.0” 기능이 스코프 집합으로 구현되었다는 얘기는 들었던 것 같다. Nick Cameron은 Rust의 매크로와 하이진에 관해 여러 블로그 글을 썼다. 예를 들어 blog post on scope sets를 보면 좋을 것이다.
마지막으로, Racket 문서는 아무리 추천해도 모자라다. 특히 스코핑 주제라면 다음을 보라:
private let a = A2.a를 더 추가하고 모듈 코드를 추가 스코프에 넣는 디슈가링이랑 같은 거 아냐?”라고 생각할 수도 있다. 글쎄, 언어에 따라 다르다. 모든 스코프가 충분히 균일하게 동작하지는 않으며, 탑레벨 스코프는 특별하다. 예를 들어 Swift에서 순진한 디슈가링은 접근 제어 레벨에 따라 실패할 수 있다.import A1
import A2
private let a = A2.a
do {
public let x = a
// error: attribute 'public' can only be used in a non-local scope
}
또한 이게 가능해진다 하더라도, 디슈가링은 동일한 수준의 진단 품질을 유지하려면 더 많은 작업이 필요하다. (디슈가링된 코드에 대한 진단을 개선하려는 시도를 하지 말라는 뜻은 아니다. Justin Pombrio와 Shriram Krishnamurthi의 resugaring 작업을 보라.)
나는 import 동작을 스코프 조작으로 모델링하는 것이 무슨 일이 일어나는지를 더 명확히 설명한다고 주장하겠다. 코드를 생성하는 게 아니라, 무엇이 스코프 안에 있고 밖에 있는지를 바꾸는 것뿐이다.↩︎
Swift 버그 트래커에서 자주 올라오고 “의도된 동작”으로 처리되는 버그 중 하나는, 사람들이 오버로드가 있는 상황에서 이름 해석에 어떤 부분순서를 쓰길 기대하는데 실제 구현은 다른 부분순서를 쓰기 때문에 발생하는 현상이다.
대충 말하자면, Swift 같은 오버로드가 있는 언어에서 이름 해석을 할 때는 두 부분순서가 있다: 스코프에 대한 것과 오버로드 특수성(specificity)에 대한 것이다.
Swift는 전략 1을 택한다. (어휘적으로) 가장 가까운 오버로드를 먼저 선호한다. 여러 개가 있으면 그들 사이에서 오버로드 해석을 하고, 더 바깥(멀리)에 있는 오버로드들은 무시한다(더 특수할 수도 있는데도).
버그를 올리는 사람들은 전략 2를 기대한다. 즉 “저 멀리 있는 오버로드가 이 더 가까운 오버로드보다 훨씬 더 특수한데 왜 그걸 안 골랐지?” 같은 반응이다.
불합리한 포인트는 아니다. 하지만… 내 느낌으로는, 문제의 본질(가능한 전략이 유일하지 않고 3개나 있음) 때문에 무엇을 선택하든 누군가 는 직관적이지 않다고 느낄 것이다.
나 개인적으로 새 언어를 만든다면, 이름 해석에서 부분순서를 결합하는 데 전략 3을 선호한다. 하지만 이것도 문제는 있다: (i) 타입 체크되는 코드가 엄밀히 더 줄어들고 (ii) 전략 1이나 2보다 느릴 텐데, 비교를 항상 2번 해야 하기 때문이다.↩︎
그다음은 진화(evolution) 문제다. 예를 들어 컴파일러가 RISC-V 아키텍처를 새 타깃으로 지원하게 된다면, 기존 코드는 자동으로 “RISC-V에서도 동작하는가?”에 대해 검사되기 시작해야 할까? 새로운 플랫폼이 새 에디션에서만 기본 집합에 추가되는, 에디션 같은 체크포인트 시스템이 있어야 할까?
또 컴파일러 설정이나 빌드 시스템 설정으로 강제 오버라이드를 할 수 있어야 한다는 문제도 있다. 앞 예제를 이어서, RISC-V 지원이 추가될 때 라이브러리 소스에 침습적인 변경 없이도 RISC-V에서 동작하지 않을 코드가 얼마나 되는지 보고 싶을 것이다.↩︎
typealias MyInt =
@target(pointer_width: 32) Int32
@target(pointer_width: 64) Int64
typealias YourInt =
@target(pointer_width: 32) Int32
@target(pointer_width: 64) Int64
@target(pointer_width: 32)
let x: Int32 = MyInt(0) // OK
@target(pointer_width: 64)
let y: Int64 = MyInt(0) // OK
let z: YourInt = MyInt(0) // OK
let w: Int32 = MyInt(0) // error: MyInt is Int32 only for 32-bit targets
이는(의미 분석에 한정해 말하면) 크로스 컴파일보다 나은데, 이유는 두 가지다:
크로스 컴파일을 써도(현대 컴파일러에서는) 대부분의 코드가 타깃 특화가 아닐 가능성이 높은데도 타입 체크를 두 번 해야 한다.
훌륭한 크로스 컴파일 툴체인 경험을 만드는 것은 어렵다. 가치가 없다는 뜻은 아니고, 절대적으로 가치 있다. 하지만 어떤 사람이 특정 타깃 디바이스가 없어서 코드를 실행하려는 게 아니라 의미 검증만 원한다면, 완전한 크로스 컴파일 툴체인을 세팅하라고 요구하는 건 큰 부담이다(말도 안 되게 쉽게 만들지 않는 한).
그렇다고 해도 Zig가 이 분야에서 멋진 일을 하고 있으니, 미래는 오늘날 사람들이 감당해야 하는 온갖 헛소리보다는 나아질지도 모른다.
효율을 위해서는 아마 좀 더 일반적인 API가 필요하다.
스코프 집합(또는 일반적으로 도메인 및/또는 도메인 리스트)을 인터닝(interning)해서 메모리 사용량을 줄이고 싶을 수도 있다.↩︎