스레드가 CPU 밖에서(블록된 상태로) 대기하는 시간을 스택 트레이스 등 컨텍스트와 함께 측정·분석해, I/O·락·타이머·페이징 등으로 인한 지연 원인을 찾는 방법을 소개한다.
URL: https://www.brendangregg.com/offcpuanalysis.html
Title: Off-CPU Analysis
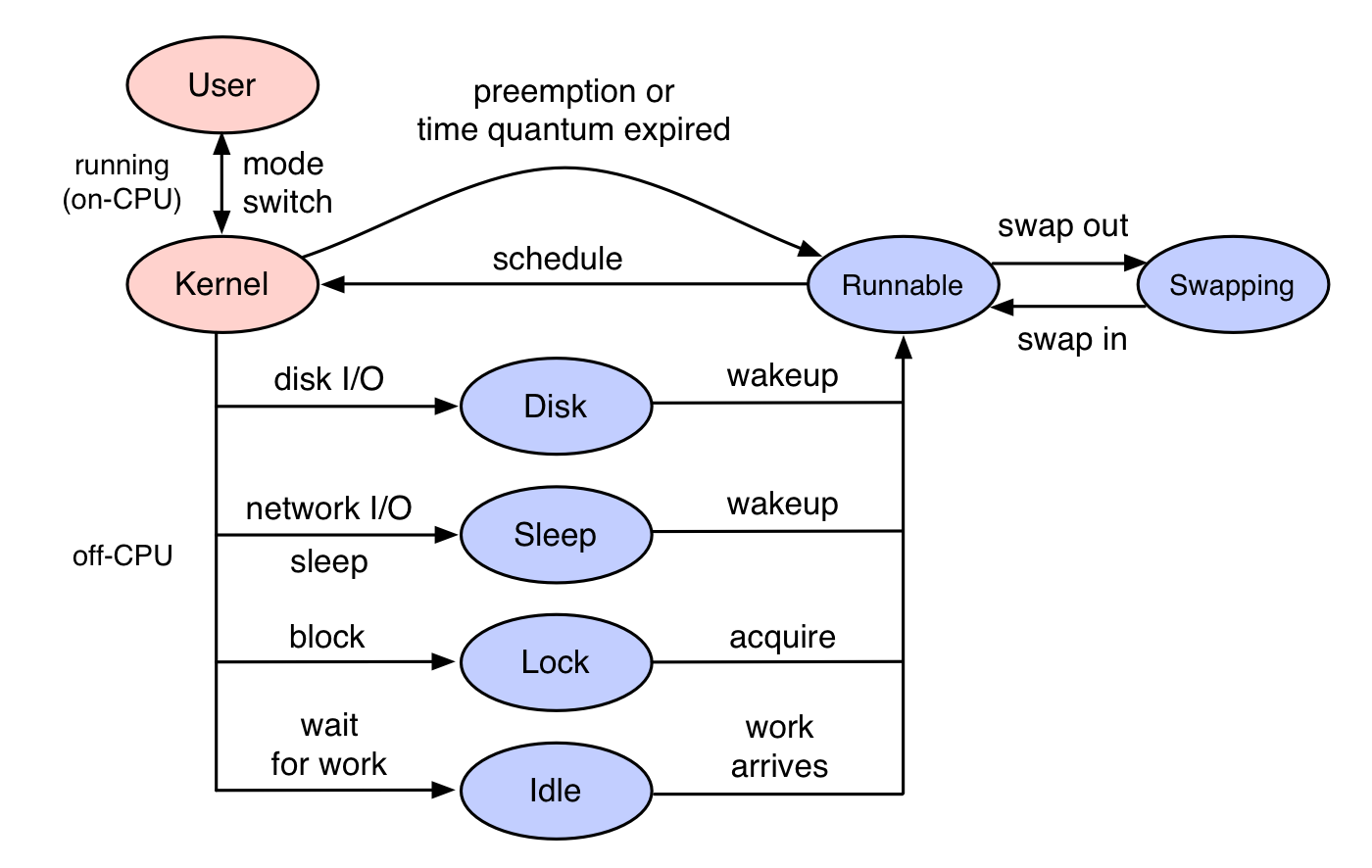
일반적인 스레드 상태
성능 문제는 다음 두 가지 유형 중 하나로 분류할 수 있습니다:
오프-CPU 분석(off-CPU analysis)은 오프-CPU 시간을 측정하고(스택 트레이스 같은 컨텍스트와 함께) 이를 연구하는 성능 방법론입니다. 이는 CPU 프로파일링과 다른데, CPU 프로파일링은 스레드가 on-CPU에서 실행 중일 때만 스레드를 조사합니다. 여기서의 대상은 오른쪽 다이어그램에서 파란색으로 표시된 것처럼 블록되어 off-CPU 상태인 스레드 상태입니다.
오프-CPU 분석은 CPU 분석과 상호 보완적이며, 스레드 시간의 100%를 이해할 수 있게 해줍니다. 또한 이 방법은 흔히 블록되는 애플리케이션 함수에 계측(instrumentation)을 넣는 트레이싱 기법과도 다른데, 이 방법은 커널 스케줄러의 “블로킹” 개념을 대상으로 하며, 이는 편리한 만능(catch-all) 기준이 됩니다.
스레드는 I/O와 락 등 여러 이유로 CPU를 떠날 수 있지만, 현재 스레드의 실행과는 무관한 이유(예: CPU 자원 수요가 높아져 발생하는 비자발적 컨텍스트 스위칭, 인터럽트)로도 CPU를 떠날 수 있습니다. 어떤 이유이든, 이것이 워크로드 요청(동기 코드 경로) 중에 발생한다면 지연(latency)을 유발합니다.
이 페이지에서는 지표로서의 오프-CPU 시간을 소개하고 오프-CPU 분석 기법을 요약합니다. 예시 구현으로 Linux에 오프-CPU 분석을 적용한 다음, 뒤 섹션에서 다른 OS들을 요약하겠습니다.
목차:
오프-CPU 분석은 트레이서가 스택 트레이스를 사용할 수 있어야 하는데, 이 부분을 먼저 고쳐야 할 수도 있습니다. 많은 애플리케이션이 gcc 옵션 -fomit-frame-pointer로 컴파일되어 프레임 포인터 기반 스택 워킹이 깨집니다. Java 같은 VM 런타임은 메서드를 즉석에서 컴파일하며, 트레이서가 추가 도움 없이 심볼 정보를 찾지 못하면 스택 트레이스가 16진수로만 보일 수 있습니다. 그 외에도 여러 함정이 있습니다. perf 기준으로 스택 트레이스를 고치는 방법은 이전 글 Stack Traces 및 JIT Symbols을 참고하세요.
오프-CPU 분석의 역할을 설명하기 위해, 비교 대상으로 먼저 CPU 샘플링과 트레이싱을 요약하겠습니다. 그 다음 오프-CPU 분석의 두 가지 접근(트레이싱, 샘플링)을 요약합니다. 저는 10년 넘게 오프-CPU 분석을 홍보해왔지만, 생산 환경의 Linux에서 이를 측정할 도구가 부족했던 탓에 아직 널리 쓰이는 방법론은 아닙니다. 그러나 eBPF와 최신 Linux 커널(4.8+)로 인해 상황이 바뀌고 있습니다.
전통적인 프로파일링 도구 다수는 모든 CPU 전반에 걸쳐 일정 시간 간격/속도(예: 99Hz)로 활동을 타임드 샘플링하여, 현재 명령어 주소(프로그램 카운터) 또는 전체 스택 백트레이스의 스냅샷을 수집합니다. 그러면 실행 중인 함수 또는 스택 트레이스의 카운트를 얻을 수 있고, CPU 사이클이 어디에 쓰이는지에 대한 합리적인 추정을 계산할 수 있습니다. Linux에서는 perf 도구를 샘플링 모드(예: -F 99)로 사용하면 타임드 CPU 샘플링을 수행합니다.
애플리케이션 함수 A()가 함수 B()를 호출하고, B()가 블로킹 시스템 콜을 호출한다고 합시다:
CPU Sampling ----------------------------------------------->
| | | | | | | | | | | |
A A A A B B B B A A A A
A(---------. .----------)
| |
B(--------. .--)
| | user-land
이는 핫 코드 경로와 적응형 뮤텍스 스핀 같은 on-CPU 문제를 연구하는 데 매우 효과적일 수 있지만, 애플리케이션이 블록되어 off-CPU에서 대기하는 동안에는 데이터를 수집하지 못합니다.
App Tracing ------------------------------------------------>
| | | |
A( B( B) A)
A(---------. .----------)
| |
B(--------. .--)
| | user-land
여기서는 함수 시작 "(" 및 종료 ")" 시점에 타임스탬프를 수집하도록 함수를 계측하여 함수에 소요된 시간을 계산합니다. 타임스탬프가 경과 시간과 CPU 시간(예: times(2) 또는 getrusage(2) 사용)을 포함한다면, 어떤 함수가 on-CPU에서 느렸는지 vs 블록되어 off-CPU에서 느렸는지도 계산할 수 있습니다. 샘플링과 달리, 이러한 타임스탬프는 매우 높은 해상도(나노초)를 가질 수 있습니다.
이 방식은 동작하지만 단점이 있습니다. 모든 애플리케이션 함수를 트레이싱하면 성능 영향이 상당할 수 있고(측정하려는 성능 자체에 영향을 줌), 아니면 블록될 가능성이 큰 함수만 골라 트레이싱해야 하는데, 그 경우 놓치는 지점이 있을 수 있습니다.
여기서는 개요만 요약하고, 다음 섹션에서 더 자세히 설명하겠습니다.
Off-CPU Tracing -------------------------------------------->
| |
B B
A A
A(---------. .----------)
| |
B(--------. .--)
| | user-land
이 접근에서는 스레드를 off-CPU로 전환시키는 커널 함수만(타임스탬프 및 유저랜드 스택 트레이스와 함께) 트레이싱합니다. 이렇게 하면 애플리케이션 함수를 전부 트레이싱할 필요도 없고, 애플리케이션이 무엇인지 알 필요도 없이 off-CPU 이벤트에 집중할 수 있습니다. MySQL, Apache, Java 등 어떤 애플리케이션의 어떤 블로킹 이벤트에도 동작합니다.
오프-CPU 트레이싱은 어떤 애플리케이션에 대해서도 모든 대기 이벤트를 포착합니다.
이 페이지의 뒤쪽에서는 커널 오프-CPU 이벤트를 트레이싱하고, 비동기 대기 시간(예: 일을 기다리는 스레드)을 걸러내기 위해 애플리케이션 수준 계측을 일부 추가하겠습니다. 애플리케이션 계측과 달리, off-CPU로 블록될 수 있는 모든 지점을 찾아다닐 필요가 없습니다. 애플리케이션이 시간 민감한 코드 경로(예: MySQL 쿼리 수행 중)에 있는지만 식별하면, 그 지연이 워크로드에 동기적임을 알 수 있습니다.
오프-CPU 트레이싱은 제가 오프-CPU 분석에 가장 많이 사용해온 주된 접근입니다. 하지만 샘플링도 있습니다.
Off-CPU Sampling ------------------------------------------->
| | | | | | |
O O O O O O O
A(---------. .----------)
| |
B(--------. .--)
| | user-land
이 접근은 타임드 샘플링으로 on-CPU에서 실행 중이 아닌(블록된) 스레드들의 스택 트레이스를 캡처합니다. 이는 월타임(wall-time) 프로파일러로도 달성할 수 있는데, 월타임 프로파일러는 스레드가 on-CPU인지 off-CPU인지와 무관하게 항상 모든 스레드를 샘플링합니다. 그 후 월타임 프로파일 출력에서 off-CPU 스택만 필터링할 수 있습니다.
오프-CPU 샘플링은 시스템 프로파일러에서 드물게 사용됩니다. 샘플링은 보통 CPU별 타이머 인터럽트로 구현되며, 인터럽트된 “현재 실행 중” 프로세스를 조사하여 on-CPU 프로파일을 만듭니다. 오프-CPU 샘플러는 다른 방식으로 동작해야 합니다. 즉 각 애플리케이션 스레드에 타이머를 설정해 깨어나게 하여 스택을 캡처하거나, 커널이 일정 간격으로 모든 스레드를 워킹하며 스택을 캡처해야 합니다.
경고: 오프-CPU 트레이싱을 할 때 스케줄러 이벤트가 매우 빈번할 수 있다는 점(극단적으로는 초당 수백만 이벤트)을 인지해야 합니다. 트레이서가 이벤트당 오버헤드를 아주 조금만 추가하더라도, 이벤트율 때문에 누적 오버헤드가 커져 유의미해질 수 있습니다. 오프-CPU 샘플링 역시 오버헤드 문제가 있는데, 시스템에 수만 개 스레드가 있을 수 있으며 이를 계속 샘플링해야 하므로 CPU 개수만 샘플링하는 CPU 샘플링보다 몇 자릿수 더 큰 오버헤드가 될 수 있습니다.
오프-CPU 분석을 사용하려면 매 단계에서 오버헤드에 주의를 기울여야 합니다. 모든 이벤트를 유저 공간으로 덤프해 사후 처리하는 트레이서는 분당 수 GB의 트레이스 데이터를 만들 수 있어 쉽게 감당 불가능해집니다. 이 데이터는 파일시스템/스토리지에 기록되고, 또 후처리되어야 하므로 CPU를 더 소모합니다. 그래서 Linux eBPF처럼 커널 내에서 요약(in-kernel summary)을 할 수 있는 트레이서가 오버헤드를 줄이고 오프-CPU 분석을 실용화하는 데 매우 중요합니다. 또한 피드백 루프(트레이서가 자기 자신이 만든 이벤트를 트레이싱하는 경우)도 조심하세요.
새 스케줄러 트레이서를 전혀 모르는 상태로 시작할 때, 저는 보통 0.1초(1/10초)만 트레이싱해 보고, 시스템 CPU 사용률, 애플리케이션 요청률, 애플리케이션 지연에 미치는 영향을 면밀히 측정하면서 점진적으로 시간을 늘립니다. 또한 컨텍스트 스위치율(예: vmstat의 "cs" 컬럼)을 고려하고, 더 높은 스위치율을 가진 서버에서는 더 조심합니다.
오버헤드 감을 드리기 위해, Linux 4.15를 실행하는 8 CPU 시스템에서 강한 MySQL 부하로 초당 102k 컨텍스트 스위치가 발생하는 상황을 테스트했습니다. 서버는 일부러 CPU 포화(유휴 0%) 상태로 두어, 트레이서 오버헤드가 애플리케이션 성능 저하로 눈에 띄게 나타나도록 했습니다. 그런 다음 Linux perf와 eBPF로 스케줄러 트레이싱 기반 오프-CPU 분석을 비교했습니다. perf는 이벤트 덤핑, eBPF는 커널 내 요약이라는 서로 다른 접근을 보여줍니다:
트레이스 지속 시간을 늘리면 어떻게 될까요? eBPF는 유일한(unique) 스택만 캡처하고 변환하므로 지속 시간에 선형으로 스케일하지 않습니다. 10초에서 60초로 늘려 테스트했더니 eBPF 사후 처리는 6초에서 7초로만 증가했습니다. 반면 perf는 35초에서 212초로 증가했는데, 6배의 데이터 양을 처리해야 했기 때문입니다. 완전히 이해하려면, 사후 처리가 사용자 레벨 활동이며 스케줄러 우선순위 등을 조정해 운영 워크로드에 덜 간섭하도록 튜닝할 수 있다는 점도 유념해야 합니다. 예를 들어 이 활동의 CPU를 10%(CPU 1개 기준)로 제한하면 성능 손실은 무시할 만해질 수 있고, eBPF 사후 처리 단계는 70초가 될 수 있습니다(나쁘지 않음). 하지만 perf script는 2120초(35분)가 되어 조사 과정이 멈출 수 있습니다. perf의 오버헤드는 CPU뿐 아니라 디스크 I/O도 포함합니다.
이 MySQL 예제는 운영 워크로드와 비교하면 어떨까요? 초당 102k 컨텍스트 스위치는 비교적 높은 편입니다. 제가 요즘 보는 많은 운영 시스템은 20~50k/s 범위입니다. 그렇다면 여기서 설명한 오버헤드는 그런 운영 시스템에서는 대략 2배 낮을 가능성이 있습니다. 하지만 MySQL의 스택 깊이는 상대적으로 얕아 보통 20~40 프레임인데, 운영 애플리케이션은 100 프레임을 넘기도 합니다. 이는 중요하며, 제 MySQL 스택 워킹 오버헤드가 운영에서 보는 것의 절반 정도일 수 있다는 뜻이기도 합니다. 따라서 운영 시스템에서는 대략 상쇄될 수도 있습니다.
오프-CPU 분석은 어떤 운영체제에서도 동작해야 하는 일반적 접근입니다. 여기서는 Linux에서 오프-CPU 트레이싱으로 이를 시연하고, 뒤 섹션에서 다른 OS를 요약합니다.
Linux에는 오프-CPU 분석을 위한 많은 트레이서가 있습니다. 여기서는 eBPF를 사용하겠습니다. eBPF는 스택 트레이스와 시간을 커널 내에서 쉽게 요약할 수 있기 때문입니다. eBPF는 Linux 커널의 일부이며, bcc 프런트엔드 도구로 사용하겠습니다. 스택 트레이스 지원을 위해 최소 Linux 4.8이 필요합니다.
eBPF 이전에는 어떻게 오프-CPU 분석을 했을까요? 매우 다양한 방법이 있었고, 블로킹 유형마다 완전히 다른 접근을 쓰기도 했습니다(예: 스토리지 I/O는 스토리지 트레이싱, 스케줄러 지연은 커널 통계 등). 실제로 오프-CPU 분석을 위해 SystemTap을 사용했고, perf 이벤트 로깅도 사용했습니다(오버헤드는 더 큼: perf_events Off-CPU Time Flame Graph 참고). 한때는 특정 PID에 대해 /proc/PID/stack을 샘플링하는 간단한 월타임 커널 스택 프로파일러 proc-profiler.pl을 만들기도 했습니다. 충분히 쓸 만했습니다. 이런 월타임 프로파일러를 처음 만든 것은 저만이 아닙니다. poormansprofiler와 Tanel Poder의 quick'n'dirty 문제 해결 글도 참고하세요.
이는 스레드가 off-CPU(블록된 시간)로 대기하며 보낸 시간이며, on-CPU에서 실행 중인 시간은 아닙니다. 기간 동안의 총합으로 측정할 수도 있고(/proc 통계로 이미 제공), 각 블로킹 이벤트마다 측정할 수도 있습니다(보통 트레이서 필요).
먼저, 이미 익숙할 수 있는 도구로 총 오프-CPU 시간을 보여주겠습니다. time(1) 명령입니다. 예: tar(1) 측정:
$ time tar cf archive.tar linux-4.15-rc2
real 0m50.798s user 0m1.048s sys 0m11.627s
tar는 약 1분이 걸렸지만, time 출력은 총 50.8초의 경과 시간 중 사용자 모드 CPU 시간 1.0초, 커널 모드 CPU 시간 11.6초만 사용했다고 보여줍니다. 38.2초가 빠져 있습니다! 이것이 tar 명령이 off-CPU로 블록되어 대기한 시간이며, 아카이브 생성 중 스토리지 I/O를 했기 때문일 것입니다.
오프-CPU 시간을 더 자세히 보기 위해서는 커널 스케줄러 함수의 동적 트레이싱 또는 sched 트레이스포인트를 이용한 정적 트레이싱을 사용할 수 있습니다. bcc/eBPF 프로젝트에는 Sasha Goldshtein이 개발한 cpudist가 포함되어 있으며, -O 모드에서 오프-CPU 시간을 측정합니다. 이는 Linux 4.4 이상이 필요합니다. tar의 오프-CPU 시간 측정:
pgrep -nx tarTracing off-CPU time... Hit Ctrl-C to end. ^C usecs : count distribution 0 -> 1 : 3 | | 2 -> 3 : 50 | | 4 -> 7 : 289 | | 8 -> 15 : 342 | | 16 -> 31 : 517 | | 32 -> 63 : 5862 |*** | 64 -> 127 : 30135 |**************** | 128 -> 255 : 71618 |**************************************| 256 -> 511 : 37862 |******************* | 512 -> 1023 : 2351 |* | 1024 -> 2047 : 167 | | 2048 -> 4095 : 134 | | 4096 -> 8191 : 178 | | 8192 -> 16383 : 214 | | 16384 -> 32767 : 33 | | 32768 -> 65535 : 8 | | 65536 -> 131071 : 9 | |
이는 대부분의 블로킹 이벤트가 64~511마이크로초 사이였음을 보여주며, 플래시 스토리지 I/O 지연(이 시스템은 플래시 기반)과 일치합니다. 트레이싱 중 가장 느린 블로킹 이벤트는 65~131밀리초 범위(히스토그램 마지막 버킷)에 도달했습니다.
이 오프-CPU 시간은 무엇으로 구성될까요? 스레드가 블록된 순간부터 다시 실행을 시작할 때까지의 모든 시간이며, 스케줄러 지연도 포함됩니다.
이 글을 쓰는 시점에서 cpudist는 kprobe(커널 동적 트레이싱)로 finish_task_switch() 커널 함수를 계측합니다. (API 안정성을 위해서는 sched 트레이스포인트를 사용해야 하지만, 첫 시도는 성공적이지 않아 현재는 리버트된 상태입니다.)
finish_task_switch()의 프로토타입은 다음과 같습니다:
static struct rq *finish_task_switch(struct task_struct *prev)
이 도구가 어떻게 동작하는지 감을 드리면: finish_task_switch()는 다음에 실행될 스레드의 컨텍스트에서 호출됩니다. eBPF 프로그램은 kprobe로 이 함수와 인자를 계측하고, 현재 PID(bpf_get_current_pid_tgid())와 고해상도 타임스탬프(bpf_ktime_get_ns())를 가져올 수 있습니다. 위 요약에 필요한 정보는 이것뿐이며, 요약은 eBPF 맵을 사용해 커널 컨텍스트에서 히스토그램 버킷을 효율적으로 저장합니다. 전체 소스는 cpudist에 있습니다.
eBPF만이 Linux에서 오프-CPU 시간을 측정하는 유일한 도구는 아닙니다. perf 도구는 perf sched timehist 출력에 "wait time" 컬럼을 제공하는데, 인접 컬럼에서 스케줄러 시간이 따로 표시되므로 wait time은 스케줄러 시간을 제외합니다. 이 출력은 스케줄러 이벤트마다 대기 시간을 보여주며, eBPF 히스토그램 요약보다 측정 오버헤드가 더 큽니다.
오프-CPU 시간을 히스토그램으로 측정하는 것은 약간 유용하지만 그리 많지는 않습니다. 우리가 정말로 원하는 것은 컨텍스트, 즉 왜 스레드가 블록되어 off-CPU로 가는지입니다. 이것이 오프-CPU 분석의 핵심입니다.
오프-CPU 분석은 off-CPU 시간과 스택 트레이스를 함께 분석하여, 스레드가 블록된 이유를 식별하는 방법론입니다. 오프-CPU 트레이싱 분석 기법은 다음 원리 덕분에 구현이 쉬울 수 있습니다:
애플리케이션 스택 트레이스는 off-CPU 동안 변하지 않는다.
즉 off-CPU 구간의 시작 또는 끝 중 한 번만 스택 트레이스를 측정하면 됩니다. 보통 끝에서 측정하는 것이 더 쉬운데, 어차피 그때 시간 구간을 기록하기 때문입니다. 다음은 스택 트레이스와 함께 오프-CPU 시간을 측정하는 트레이싱 의사코드입니다:
on context switch finish: sleeptime[prev_thread_id] = timestamp if !sleeptime[thread_id] return delta = timestamp - sleeptime[thread_id] totaltime[pid, execname, user stack, kernel stack] += delta sleeptime[thread_id] = 0
on tracer exit: for each key in totaltime: print key print totaltime[key]
몇 가지 메모: 모든 측정은 하나의 계측 지점, 즉 컨텍스트 스위치 루틴의 끝에서 일어납니다. 이 지점은 다음 스레드의 컨텍스트에 있으며(예: Linux finish_task_switch() 함수), 이렇게 하면 현재 컨텍스트(pid, execname, 유저 스택, 커널 스택)를 가져오는 것만으로 오프-CPU 지속 시간 계산과 그 구간의 컨텍스트 획득을 동시에 할 수 있습니다. 트레이서는 이를 쉽게 해줍니다.
이것이 바로 bcc/eBPF의 offcputime 프로그램이 하는 일이며, 동작하려면 최소 Linux 4.8이 필요합니다. tar 프로그램의 블로킹 스택을 측정하기 위해 bcc/eBPF offcputime 사용을 시연하겠습니다. 시작은 커널 스택만으로 제한하겠습니다(-K):
pgrep -nx tarTracing off-CPU time (us) of PID 15342 by kernel stack... Hit Ctrl-C to end. ^C [...]
finish_task_switch
__schedule
schedule
schedule_timeout
__down
down
xfs_buf_lock
_xfs_buf_find
xfs_buf_get_map
xfs_buf_read_map
xfs_trans_read_buf_map
xfs_da_read_buf
xfs_dir3_block_read
xfs_dir2_block_getdents
xfs_readdir
iterate_dir
SyS_getdents
entry_SYSCALL_64_fastpath
- tar (18235)
203075
finish_task_switch
__schedule
schedule
schedule_timeout
wait_for_completion
xfs_buf_submit_wait
xfs_buf_read_map
xfs_trans_read_buf_map
xfs_imap_to_bp
xfs_iread
xfs_iget
xfs_lookup
xfs_vn_lookup
lookup_slow
walk_component
path_lookupat
filename_lookup
vfs_statx
SYSC_newfstatat
entry_SYSCALL_64_fastpath
- tar (18235)
661626
finish_task_switch
__schedule
schedule
io_schedule
generic_file_read_iter
xfs_file_buffered_aio_read
xfs_file_read_iter
__vfs_read
vfs_read
SyS_read
entry_SYSCALL_64_fastpath
- tar (18235)
18413238
출력은 마지막 세 스택만 남기도록 일부 잘랐습니다. 마지막 스택은 총 18.4초의 off-CPU 시간이며, read 시스템 콜 경로에서 io_schedule()로 끝납니다. 이는 tar가 파일 내용을 읽고 디스크 I/O로 블록되는 상황입니다. 그 위 스택은 stat 시스템 콜에서 662ms이며, xfs_buf_submit_wait()를 통해 스토리지 I/O를 기다립니다. 맨 위 스택은 총 203ms로, getdents 시스템 콜(디렉터리 나열) 수행 중 락에서 블록된 것으로 보입니다.
이 스택 트레이스를 해석하려면 소스 코드에 대한 어느 정도의 친숙함이 필요하며, 애플리케이션의 복잡도와 언어에 따라 달라집니다. 많이 해볼수록 같은 함수와 스택을 알아보게 되어 더 빨라질 것입니다.
이제 유저 레벨 스택을 포함해 보겠습니다:
pgrep -nx tarTracing off-CPU time (us) of PID 18311 by user + kernel stack... Hit Ctrl-C to end. [...]
finish_task_switch
__schedule
schedule
io_schedule
generic_file_read_iter
xfs_file_buffered_aio_read
xfs_file_read_iter
__vfs_read
vfs_read
SyS_read
entry_SYSCALL_64_fastpath
**[unknown]**
- tar.orig (30899)
9125783
이건 동작하지 않았습니다. 유저 레벨 스택이 모두 "[unknown]"입니다. 이유는 기본 tar가 프레임 포인터 없이 컴파일되어 있고, 이 버전의 bcc/eBPF는 스택 트레이스를 워킹하기 위해 프레임 포인터가 필요하기 때문입니다. 여러분도 이런 함정에 걸릴 수 있어 어떤 모습인지 보여드리고자 했습니다.
저는 (앞의 Prerequisites 참고) tar 스택을 고쳐서 어떤 모습인지 확인해 봤습니다:
pgrep -nx tarTracing off-CPU time (us) of PID 18375 by user + kernel stack... Hit Ctrl-C to end. [...]
finish_task_switch
__schedule
schedule
io_schedule
generic_file_read_iter
xfs_file_buffered_aio_read
xfs_file_read_iter
__vfs_read
vfs_read
SyS_read
entry_SYSCALL_64_fastpath
__read_nocancel
dump_file0
dump_file
dump_dir0
dump_dir
dump_file0
dump_file
dump_dir0
dump_dir
dump_file0
dump_file
dump_dir0
dump_dir
dump_file0
dump_file
create_archive
main
__libc_start_main
[unknown]
- tar (15113)
426525
[...]
좋습니다. tar는 파일시스템 트리를 재귀적으로 순회하는 알고리즘을 쓰는 것처럼 보입니다.
이 스택 트레이스는 훌륭합니다. 애플리케이션이 왜 off-CPU로 블록되어 대기했는지, 그리고 얼마나 오래였는지를 보여줍니다. 이것이 제가 보통 찾는 정보입니다. 하지만 블로킹 스택 트레이스가 항상 흥미로운 것은 아니며, 때로는 요청-동기(request-synchronous) 컨텍스트를 찾아야 합니다.
소켓에서 스레드 풀을 두고 일을 기다리는 웹 서버처럼, “일을 기다리는” 애플리케이션은 오프-CPU 분석에 도전 과제를 던집니다. 종종 블로킹 시간 대부분이 일(work)을 하는 동안이 아니라 일을 기다리는 스택에 들어가며, 이는 출력에 흥미롭지 않은 스택을 잔뜩 쏟아냅니다.
이 현상의 예로, 아무 일도 하지 않는 MySQL 서버 프로세스(초당 요청 0)의 off-CPU 스택을 보겠습니다:
pgrep -nx mysqldTracing off-CPU time (us) of PID 29887 by user + kernel stack... Hit Ctrl-C to end. ^C [...]
finish_task_switch __schedule schedule do_nanosleep hrtimer_nanosleep sys_nanosleep entry_SYSCALL_64_fastpath __GI___nanosleep srv_master_thread start_thread - mysqld (29908) 3000333
finish_task_switch
__schedule
schedule
futex_wait_queue_me
futex_wait
do_futex
sys_futex
entry_SYSCALL_64_fastpath
pthread_cond_timedwait@@GLIBC_2.3.2
os_event::wait_time_low(unsigned long, long)
srv_error_monitor_thread
start_thread
- mysqld (29906)
3000342
finish_task_switch
__schedule
schedule
read_events
do_io_getevents
SyS_io_getevents
entry_SYSCALL_64_fastpath
[unknown]
LinuxAIOHandler::poll(fil_node_t**, void**, IORequest*)
os_aio_handler(unsigned long, fil_node_t**, void**, IORequest*)
fil_aio_wait(unsigned long)
io_handler_thread
start_thread
- mysqld (29896)
3500863
[...]
여러 스레드가 작업을 폴링하거나 다른 백그라운드 작업을 수행하고 있습니다. 이런 백그라운드 스택은 바쁜 MySQL 서버에서도 출력의 대부분을 차지할 수 있습니다. 제가 보통 찾는 것은 데이터베이스 쿼리/명령 동안의 off-CPU 시간입니다. 그 시간이 고객을 괴롭히는 시간입니다. 출력에서 그것을 찾으려면 쿼리 컨텍스트의 스택을 찾아다녀야 합니다.
예를 들어, 이번에는 바쁜 MySQL 서버에서:
pgrep -nx mysqldTracing off-CPU time (us) of PID 29887 by user + kernel stack... Hit Ctrl-C to end. ^C [...]
finish_task_switch __schedule schedule io_schedule wait_on_page_bit_common __filemap_fdatawait_range file_write_and_wait_range ext4_sync_file do_fsync SyS_fsync entry_SYSCALL_64_fastpath fsync log_write_up_to(unsigned long, bool) trx_commit_complete_for_mysql(trx_t*) [unknown] ha_commit_low(THD*, bool, bool) TC_LOG_DUMMY::commit(THD*, bool) ha_commit_trans(THD*, bool, bool) trans_commit_stmt(THD*) mysql_execute_command(THD*, bool) mysql_parse(THD*, Parser_state*) dispatch_command(THD*, COM_DATA const*, enum_server_command) do_command(THD*) handle_connection pfs_spawn_thread start_thread - mysqld (13735) 1086119
[...]
이 스택은 쿼리 동안의 일부 시간(지연)을 식별합니다. do_command() -> mysql_execute_command() 코드 경로가 힌트입니다. 저는 이 스택의 여러 부분(MySQL과 커널 내부)의 코드에 익숙하기 때문에 이를 알 수 있습니다.
애플리케이션별 패턴 매칭으로 관심 있는 스택만 뽑아내는 간단한 텍스트 후처리기를 상상할 수 있습니다. 잘 동작할 수도 있습니다. 다른 방법도 있는데, 조금 더 효율적이지만 애플리케이션 특화가 필요합니다. 트레이싱 프로그램을 확장해 애플리케이션 요청(이 MySQL 예시에서는 do_command() 함수)을 함께 계측하고, 애플리케이션 요청 중에 발생한 off-CPU 시간만 기록하도록 하는 것입니다. 저는 예전에 해본 적이 있고 도움이 될 수 있습니다.
가장 큰 주의점은 앞의 오버헤드 섹션에서 설명한 오프-CPU 분석의 오버헤드이며, 그 다음은 앞의 Prerequisites 섹션에서 요약한 스택 트레이스 동작 문제입니다. 또한 스케줄러 지연과 비자발적 컨텍스트 스위치에 유의해야 하며, 여기서 이를 요약합니다. 웨이크업 스택은 뒤 섹션에서 다룹니다.
이 스택에서 빠져 있는 것 중 하나는 오프-CPU 시간이 CPU 런큐에서 대기한 시간을 포함하는지 여부입니다. 이 시간은 스케줄러 지연(scheduler latency), 런큐 지연(run queue latency), 디스패처 큐 지연(dispatcher queue latency)이라고 합니다. CPU가 포화 상태라면, 스레드가 블록할 때마다 깨어난 뒤 CPU에서 자기 차례를 기다리는 추가 시간을 겪을 수 있습니다. 이 시간은 off-CPU 시간에 포함됩니다.
추가 트레이스 이벤트를 사용하면 off-CPU 시간을 “블록 시간”과 “스케줄러 지연”으로 분리해낼 수 있지만, 실무에서는 CPU 포화는 꽤 쉽게 발견되므로, CPU 포화 문제가 명백한 상황에서 off-CPU 시간을 오래 연구할 가능성은 낮습니다.
유저 레벨 스택 트레이스가 말이 안 되게 보이고, 블록되어 off-CPU로 가는 이유가 전혀 보이지 않는다면, 비자발적 컨텍스트 스위칭 때문일 수 있습니다. 이는 CPU가 포화 상태일 때 흔히 발생하며, 커널 CPU 스케줄러가 스레드에 CPU를 번갈아 주다가 타임슬라이스에 도달하면 스레드를 밀어냅니다. 스레드는 CPU 사용량이 큰 코드 경로 중간에서도 언제든지 밀려날 수 있고, 그 결과 off-CPU 스택 트레이스는 말이 안 되게 됩니다.
offcputime에서 비자발적 컨텍스트 스위치로 보이는 예시 스택은 다음과 같습니다:
pgrep -nx mysqldTracing off-CPU time (us) of PID 29887 by user + kernel stack... Hit Ctrl-C to end. [...]
finish_task_switch
__schedule
schedule
exit_to_usermode_loop
prepare_exit_to_usermode
swapgs_restore_regs_and_return_to_usermode
Item_func::type() const
JOIN::make_join_plan()
JOIN::optimize()
st_select_lex::optimize(THD*)
handle_query(THD*, LEX*, Query_result*, unsigned long long, unsigned long long)
[unknown]
mysql_execute_command(THD*, bool)
Prepared_statement::execute(String*, bool)
Prepared_statement::execute_loop(String*, bool, unsigned char*, unsigned char*)
mysqld_stmt_execute(THD*, unsigned long, unsigned long, unsigned char*, unsigned long)
dispatch_command(THD*, COM_DATA const*, enum_server_command)
do_command(THD*)
handle_connection
pfs_spawn_thread
start_thread
- mysqld (30022)
13
[...]
함수명만 보면 이 스레드가 Item_func::type()에서 왜 블록됐는지 명확하지 않습니다. 서버가 CPU 포화였으므로 비자발적 컨텍스트 스위치로 추측합니다.
offcputime에서의 해결책으로는 TASK_UNINTERRUPTIBLE 상태(2)로 필터링하는 방법이 있습니다:
pgrep -nx mysqld --state 2Linux에서 비자발적 컨텍스트 스위치는 TASK_RUNNING(0) 상태에서 발생하는 반면, 우리가 보통 관심 있는 블로킹 이벤트는 TASK_INTERRUPTIBLE(1) 또는 TASK_UNINTERRUPTIBLE(2) 상태이며, offcputime은 --state로 이를 매칭해 필터링할 수 있습니다. 저는 이 기능을 Linux Load Averages: Solving the Mystery 글에서 사용했습니다.
Flame Graphs는 프로파일링된 스택 트레이스를 시각화한 것으로, 오프-CPU 분석이 만들어낼 수 있는 수백 페이지의 스택 트레이스 출력을 빠르게 이해하는 데 매우 유용합니다. Yichun Zhang이 SystemTap으로 오프-CPU 타임 플레임 그래프를 처음 만들었습니다.
offcputime 도구는 -f 옵션으로 스택 트레이스를 “폴디드(folded) 포맷”으로 출력할 수 있습니다. 이는 세미콜론으로 구분된 한 줄이며, 뒤에 지표가 붙습니다. 이 포맷은 제 FlameGraph 소프트웨어가 입력으로 받는 포맷입니다.
예를 들어 mysqld에 대해 오프-CPU 플레임 그래프를 만드는 방법:
pgrep -nx mysqld 30 > out.stacks[...원하면 out.stacks를 로컬 시스템으로 복사...]
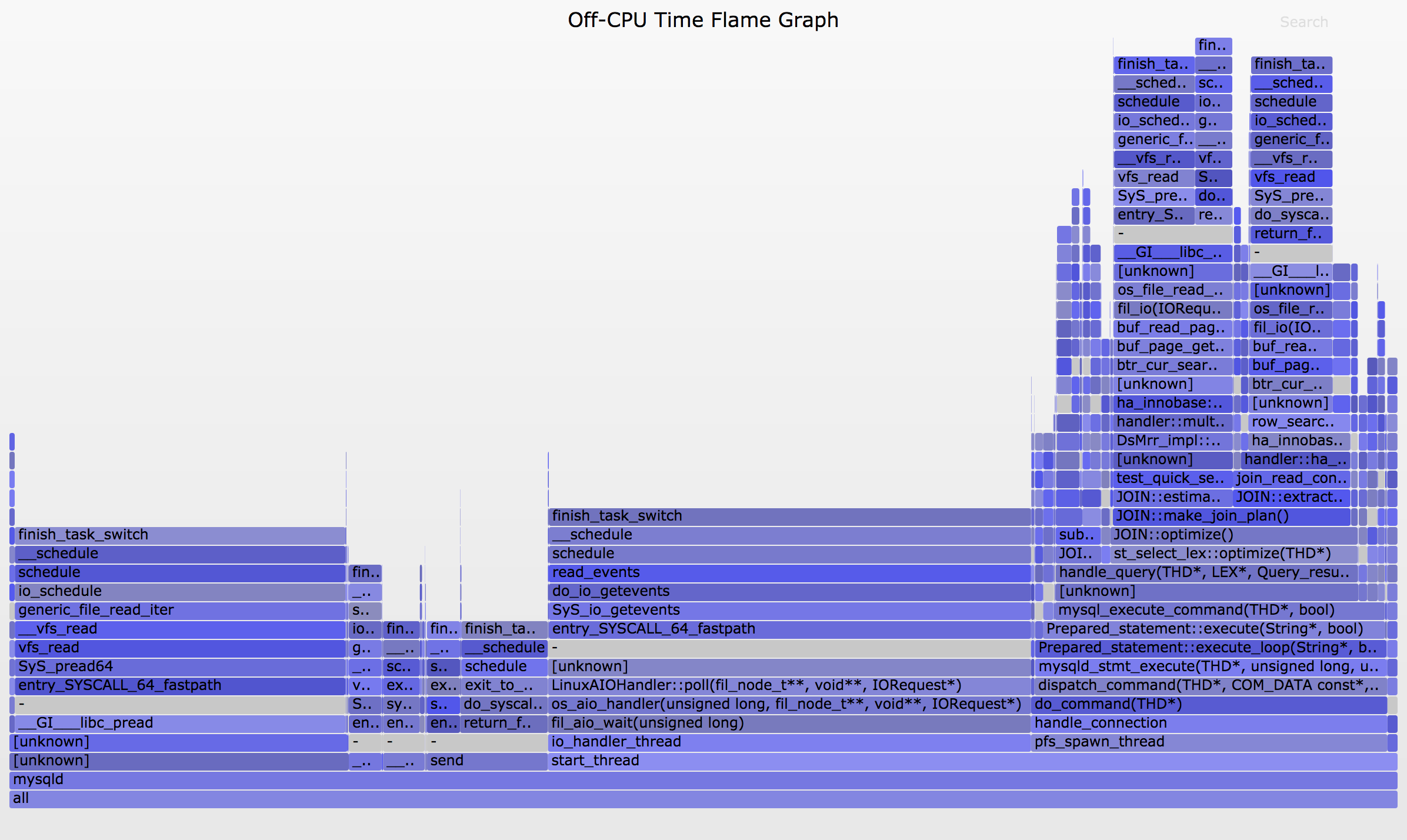
그 다음 out.svg를 웹 브라우저로 여세요. 이렇게 보입니다(SVG, PNG):
훨씬 낫습니다. 이는 모든 off-CPU 스택 트레이스를 보여주며, y축은 스택 깊이, 폭은 각 스택의 총 시간에 해당합니다. 좌우 순서는 의미가 없습니다. -d 옵션으로 offcputime이 커널 스택과 유저 스택 사이에 구분 프레임 "-"를 삽입합니다.
클릭해서 줌인할 수 있습니다. 예를 들어 오른쪽 아래의 "do_command(THD*)" 프레임을 클릭하면, 쿼리 동안 발생한 블로킹 경로를 확대할 수 있습니다. 이 경로만 보이도록 플레임 그래프를 만들고 싶을 수도 있는데, 폴디드 포맷은 스택당 한 줄이므로 grep만으로도 간단합니다:
아주 좋습니다.
오프-CPU 플레임 그래프에 대한 더 많은 내용은 제 Off-CPU Flame Graphs 페이지를 참고하세요.
이제 오프-CPU 트레이싱을 수행하고 플레임 그래프를 생성할 수 있게 되었으니, 플레임 그래프를 더 자세히 보고 해석하기 시작할 것입니다. 많은 off-CPU 스택이 블로킹 경로를 보여주지만, 왜 블록되었는지에 대한 “완전한” 이유는 보여주지 못한다는 점을 발견할 수 있습니다. 그 이유와 코드 경로는 다른 스레드, 즉 블록된 스레드를 깨운(wakeup) 스레드에 있습니다. 이런 일은 늘 발생합니다.
이 주제는 Off-CPU Flame Graphs 페이지에서 다루고 있으며, wakeuptime과 offwaketime이라는 두 도구를 소개합니다. 이 도구들은 웨이크업 스택을 측정하고, 오프-CPU 스택과 연관시키는 데도 사용됩니다.
저는 2005년 즈음 DTrace sched 프로바이더와 그 sched:::off-cpu 프로브의 용도를 탐색한 후 이 방법론을 사용하기 시작했습니다. DTrace 프로브 이름을 따서 이를 off-CPU 분석, 지표를 off-CPU time이라 불렀습니다(완벽한 이름은 아닙니다. 2005년 애들레이드에서 DTrace 수업을 가르칠 때 한 Sun 엔지니어가 CPU가 “꺼진(off)” 것이 아니라며 off-CPU라고 부르면 안 된다고 말했습니다). Solaris Dynamic Tracing Guide에는 특정 케이스/프로세스 상태에 대해 sched:::off-cpu에서 sched:::on-cpu까지의 시간을 측정하는 예시가 있었습니다. 저는 프로세스 상태로 필터링하지 않고 모든 off-CPU 이벤트를 캡처했으며, 왜 그런 일이 생겼는지 설명하기 위해 스택 트레이스를 포함했습니다. 이 접근은 자명해 보이므로 제가 최초는 아닐 것이라 생각하지만, 한동안 이 방법론을 적극적으로 홍보한 사람은 저뿐이었던 것 같습니다. 2007년에 DTracing Off-CPU Time 글로 이를 썼고, 이후 여러 글과 발표에서 다뤘습니다.
오프-CPU 분석은 스레드가 블록되어 다른 이벤트를 기다리면서 발생하는 지연 유형을 찾는 데 효과적인 방법이 될 수 있습니다. 커널 스케줄러 함수에서 스레드를 컨텍스트 스위치하는 지점을 트레이싱함으로써, 여러 소스를 따로 트레이싱할 필요 없이 모든 off-CPU 지연 유형을 같은 방식으로 분석할 수 있습니다. off-CPU 이벤트가 왜 발생했는지 이해하기 위한 컨텍스트를 보려면 유저 및 커널 스택 백트레이스를 함께 살펴볼 수 있습니다.
CPU 프로파일링과 오프-CPU 분석을 함께 사용하면 스레드가 어디에 시간을 쓰는지 전체 그림을 얻을 수 있습니다. 두 기법은 상호 보완적입니다.
오프-CPU 분석에 대한 더 많은 내용은 Off-CPU Flame Graphs 및 Hot/Cold Flame Graphs의 시각화를 참고하세요.
오프-CPU 분석에 대한 제 첫 글은 2007년의 DTracing Off-CPU Time입니다.
2012년 업데이트:
2013년 업데이트:
2015년 업데이트:
2016년 업데이트:
2017년 업데이트:
{kind=link}
{kind=link}
{kind=link}
{kind=link}