OpenAI가 o3 pro와 함께 AI 모델의 새로운 시대를 열며 맥락과 환경에 대한 이해, 도구 사용능력, 그리고 업무 통합에서의 진전을 보여준다. 본 글은 o3 pro를 조기 체험한 후 쓴 깊이 있는 소감이다.
소문대로 오늘 OpenAI는 o3 가격을 80% 인하했으며 (출처), 이는 o3-pro ($20/$80) 출시를 위한 전초전이다. o3-pro는 커뮤니티에서 제기된 이론(논문 및 팟캐스트에서도 언급됨)처럼 -pro 버전이 기본 모델보다 10배 많은 호출과 다수결 투표를 사용한다는 설을 뒷받침한다. o3-pro는 인간 평가자 대상에서 64%의 승률을 보였고, 주요 신뢰성 벤치마크 4개에서 약간 더 우수한 결과를 기록했다. 하지만 sama가 지적했듯, 이 모델의 진면목은 다른 방식으로 테스트할 때 드러난다…
지난 일주일간 o3 pro를 조기 체험했습니다. 아래는 (아직 초기이지만) 제 생각들입니다:

우리는 과업 특화 모델의 시대에 살고 있습니다. 한편으로는 3.5 소네트, 4o 등 "일반적인" 모델이 있어 친구처럼 대화하거나 일상적인 질문에 답하며 글쓰기를 돕습니다. 다른 한편에는 느리고 비싸며 지능지수가 극대화된 초거대 추론 모델들이 있어 깊은 분석, 복잡한 문제의 원샷 해결, 순수 지능의 한계를 밀어붙입니다.
제가 트위터에서 말했듯, o-reasoning 계열 모델과는 우여곡절이 있었습니다. 처음 o1/o1-pro를 접했을 때 상당히 별로라는 인상이었죠. 그러나 다른 사람들의 극찬에 힘입어 인내하며 써 보니, 실은 제가 이 모델을 잘못 쓰고 있다는 걸 깨달았습니다. 그 과정을 모두 글로 정리했고 @sama와 @gdb의 반응도 받았죠.
핵심은, _대화형_이 아니라, 리포트 생성기 처럼 다루라는 것이었습니다1. 맥락을 주고, 목표를 설정해주고, 그 뒤엔 결과물을 기다리는 겁니다. 오늘날 o3를 쓸 때도 꼭 그렇게 합니다.
하지만 이 접근법이 o3 pro 평가에 고민을 낳는 부분입니다.
이 모델은 더 똑똑합니다. 훨씬 똑똑해요.
하지만 그 실력을 보려면 훨씬 더 많은 ‘맥락’을 줘야 합니다. 그런데 전 맥락이 다 떨어져가고 있습니다.
무엇인가 질문을 던져 바로 놀랄만한 답이 인간처럼 튀어나오는 단순 테스트는 불가능했어요.
그래서 방향을 달리했습니다. 공동창업자 알렉시스와 함께 **Raindrop**에서 가진 역대 모든 기획 회의록, 목표, 음성 메모까지 총집합시켜서 o3-pro에게 계획을 짜보라고 했죠.
결과는 놀라웠습니다. LLM에 기대하던 바로 그 구체적이고 실용적인 계획과 분석—핵심 지표, 일정, 우선순위, 절대 제외해야 할 것까지 철저하게 짚어서 제시해줬거든요.
기본 o3의 결과물도 그럴듯했지만, o3 Pro가 주는 해법은 훨씬 구체적이고, 현실감이 있어 진짜로 우리의 사고방식이 바뀌게 만들었습니다.
이건 단순한 평가로 잡아내기 어렵죠.
o3 Pro를 경험하며 느낀 것은, 오늘날 모델들이 "혼자서는 너무 잘"해서 이젠 단순 테스트가 소용없는 수준이 됐다는 점입니다. 진짜 과제는 이 AI들을 사회에 통합하는 일이죠. 거의 IQ 160짜리 12살이 대학 들어간 상황과 흡사해요. 머리는 뛰어나지만, 사회에 적응하지 못하면 쓸모 없는 직원일 수도 있다는 거죠.
오늘날 이런 통합은 주로 도구 활용에 달려 있습니다. 즉, 모델이 인간, 외부 데이터, 기타 AI들과 얼마나 협력하는지—생각은 훌륭하지만 ‘일꾼’으로 성장하려면 더 필요한 셈이죠. o3 Pro는 이 지점에서 확실히 진전을 보입니다. 자기 ‘환경’을 더 잘 파악하고, 어떤 도구에 접근 가능한지, 외부 정보를 언제 질문할지, 어떤 도구가 현재 일을 가장 잘 수행할지를 실제로 더 정확하게 판단합니다.
o3 pro(좌) vs o3(우):
o3 pro(좌)는 환경의 경계를 훨씬 더 잘 이해하고 있음을 알 수 있습니다.
초기 접속에서 느낀 한 가지: 정보를 충분히 주지 않으면 오버씽킹(너무 깊게 파고듦) 경향이 있습니다. 분석은 뛰어나고, 도구를 써서 ‘행동’하는 건 훌륭하지만 직접 뭔가를 만들어내는 일은 다소 약점이 있어요. 오케스트레이터(조율자)로는 최고일 듯싶습니다. 예를 들어 ClickHouse SQL 질문에서는 o3 일반 버전이 더 나을 때도 있었습니다. 경험마다 다를 수 있겠죠!
예시로:
o3 Pro는 Opus나 Gemini 2.5 Pro와는 완전히 다른 느낌입니다. Claude Opus가 ‘크다’는 느낌은 주지만 실제로 그 ‘거대함’의 증거를 보여준 적은 드물었는데, o3 Pro의 해석은 한 수 위입니다. 완전히 다른 리그에 들어온 기분.
OpenAI는 수직 RL(강화학습) 경로(Deep Research, Codex)를 뚜렷이 타고 있죠. 단순히 도구 사용법만이 아니라 ‘언제’ 써야 할지도 추론하게 교육하는 방향입니다.
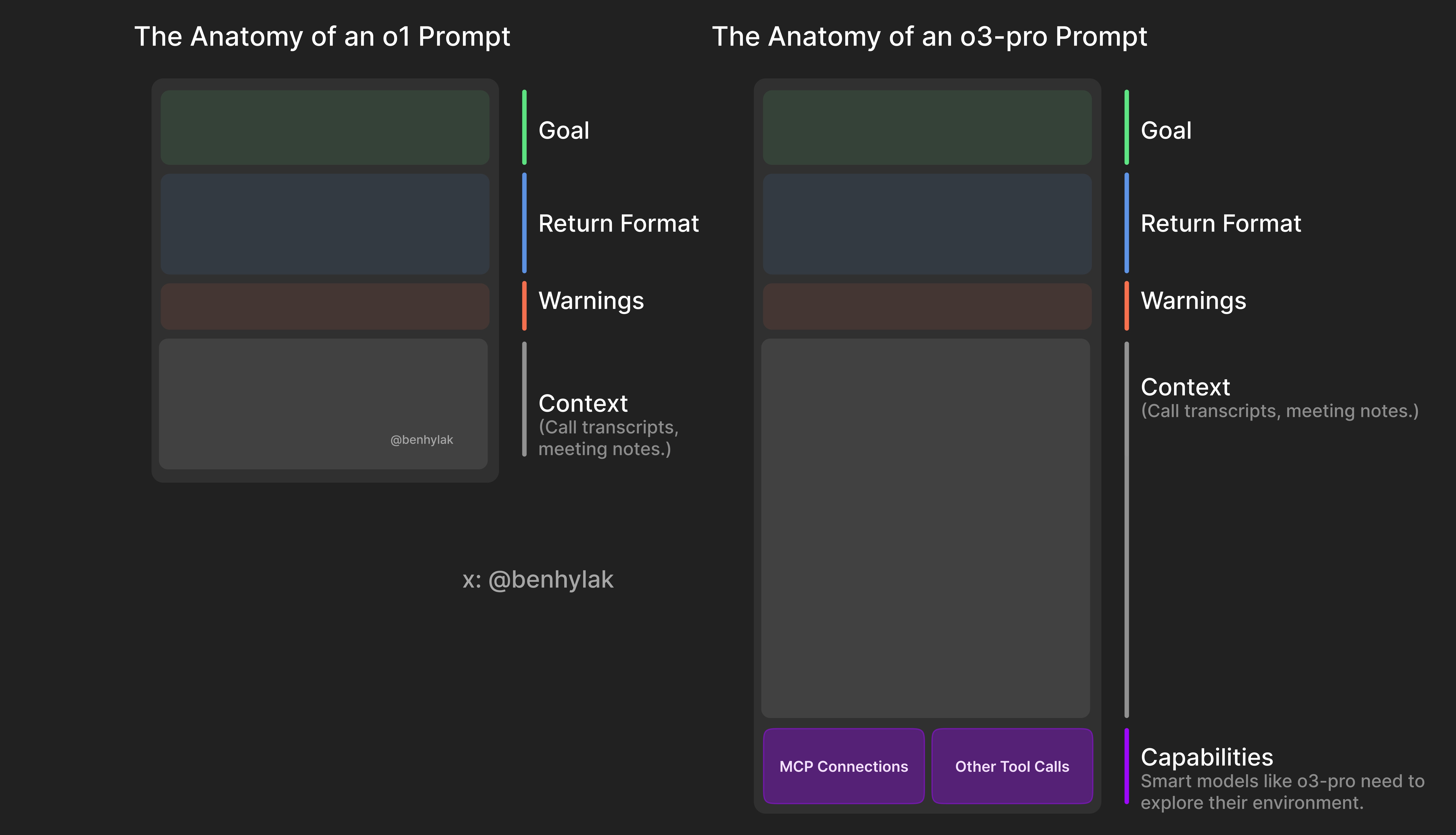
추론형 모델을 프롬프트하는 최고의 방법은 변하지 않았습니다. o1 프롬프트 가이드는 여전히 유효합니다. 맥락은 모든 것이며, 쿠키몬스터(쿠키를 집어먹는 괴물)에게 쿠키를 던져주는 것과 같습니다. LLM의 메모리를 부트스트랩(확장)하는 방법인데, 제대로 타겟팅하면 상당히 잘 먹힙니다. 그리고 시스템 프롬프트(시스템 지침)는 정말 중요합니다. 최신 모델들은 유연성이 매우 높아졌기에 환경과 목표로 모델을 ‘조련’하는 LLM 하네스(틀)의 효과가 엄청 크죠. 이 하네스—모델, 도구, 메모리, 기타 기법이 결합된 구조—가 AI 제품의 실 사용성을 결정짓는 핵심입니다(그래서 커서(Cursor) 같은 서비스가 거의 항상 잘 작동하죠).
기타 자잘한 테스트 소감: