GPT-5 모델의 핵심 특징과 가격, 시스템 카드에서 알 수 있는 점들을 다루며, OpenAI 모델 라인업 내 포지션, 타사와의 가격 경쟁력, 주요 시스템 개선점, 프롬프트 인젝션, API에서의 사고 과정, SVG 펠리컨 생성 결과까지 상세하게 소개합니다.
2025년 8월 7일
지난 2주간 새로운 GPT-5 모델 패밀리의 프리뷰 접근 권한을 얻어, GPT-5를 일상적으로 사용해왔습니다. 이제는 제 최애 모델로 자리 잡았습니다. 여전히 LLM(대형 언어 모델)이긴 하지만 지난 모델들과 극적으로 다르진 않으나, 실수가 드물고 전반적으로 능숙하며, 때때로 인상적인 결과를 보여줍니다. 제가 원하는 용도에 가장 잘 맞는 모델입니다.
지난 2주간 적은 노트가 많아, 이를 연재물로 나눠 소개하려 합니다. 이 첫 번째 글에서는 모델의 주요 특징, 가격 정책, 그리고 GPT-5 시스템 카드에서 얻은 정보들을 다룹니다.
기본적인 것부터 시작하겠습니다. ChatGPT 내 GPT-5는 다양한 모델을 오가며 사용하는 이상한 하이브리드입니다. 시스템 카드에서는 다음과 같이 설명합니다 (중요 부분 강조):
GPT-5는 대부분의 질문에 답하는 똑똑하고 빠른 모델, 더 어려운 문제에 사용되는 딥 러닝 모델, 그리고 대화 유형, 복잡도, 툴 요구, 명시적 의도(예를 들어 프롬프트에 "think hard about this"라고 적는 경우)에 따라 어떤 모델을 쓸지 빠르게 결정하는 실시간 라우터로 구성된 통합 시스템입니다. [...] 사용량 제한에 도달하면, 각 모델의 미니 버전이 남은 쿼리를 처리합니다. 조만간 이 기능들을 하나의 모델로 통합할 계획입니다.
API에서의 GPT-5는 더 단순합니다. 레귤러, 미니, 나노 세 가지 모델로 제공되며, 각각 4가지 추론 레벨(최소, 낮음, 중간, 높음) 중 선택해 사용할 수 있습니다. 참고로 '최소(minimal)'는 기존 오픈AI 추론 모델에 없던 새로운 단계입니다.
이 모델들은 272,000 토큰의 입력 한도와 128,000 토큰의 출력 한도(여기에는 보이지 않는 추론 토큰이 포함됨)를 갖습니다. 입력으로는 텍스트와 이미지를, 출력으로는 텍스트만 지원합니다.
저는 주로 풀 버전 GPT-5를 사용해봤습니다. 평가는: 정말 뛰어나다는 것입니다. 기존 LLM과 엄청난 격차를 느끼긴 어렵지만, 전반적으로 유능함이 느껴지고, 실수가 드물면서도 자주 인상적입니다. 제가 원하는 모든 작업에 자동 기본값으로 쓰기에 적합했고, 더 나은 결과를 위해 다른 모델로 재시도하고 싶다는 생각이 든 적이 없습니다.
OpenAI 모델 문서는 GPT-5, GPT-5 mini, GPT-5 nano에서 볼 수 있습니다.
세 가지 새로운 GPT-5 모델은 OpenAI 기존 모델 대부분을 대체할 목적으로 출시되었습니다. 시스템 카드에 있는 이 표가 이를 잘 보여줍니다:
| 기존 모델 | GPT-5 모델 |
|---|---|
| GPT-4o | gpt-5-main |
| GPT-4o-mini | gpt-5-main-mini |
| OpenAI o3 | gpt-5-thinking |
| OpenAI o4-mini | gpt-5-thinking-mini |
| GPT-4.1-nano | gpt-5-thinking-nano |
| OpenAI o3 Pro | gpt-5-thinking-pro |
여기서 "thinking-pro" 모델은 현재 ChatGPT에서만 “GPT-5 Pro” 이름으로, 200달러/월 구독제에서만 사용 가능합니다. "병렬 테스트 타임 컴퓨트"를 활용한다고 하네요.
GPT-5가 담당하지 않는 유일한 작업은 음성 입·출력과 이미지 생성입니다. 해당 기능은 GPT-4o Audio, GPT-4o Realtime 및 그들의 미니 버전, GPT Image 1, DALL-E 등이 계속 담당합니다.
가격 정책은 다른 모든 공급업체에 비해 매우 공격적으로 경쟁적 입니다.
GPT-5는 GPT-4o 대비 입력 비용이 절반이며, 출력 가격은 동일합니다. 보이지 않는 추론 토큰도 출력 토큰으로 계산되기 때문에 대부분 프롬프트는 GPT-4o 대비 더 많은 출력 토큰을 사용합니다(추론 수준을 “minimal”로 지정하지 않는 이상).
토큰 캐싱 할인도 큽니다: 이전 몇 분 내에 사용한 입력 토큰은 90% 할인됩니다. 이는 채팅 UI에서 같은 대화가 프롬프트 추가될 때마다 반복 재생되는 구조라면 매우 큰 영향을 주죠.
아래는 주요 경쟁 모델들과 비용 비교 표입니다:
| 모델 | 입력 $/백만 | 출력 $/백만 |
|---|---|---|
| Claude Opus 4 | 15.00 | 75.00 |
| Claude Sonnet 4 | 3.00 | 15.00 |
| Gemini 2.5 Pro (>200,000) | 2.50 | 15.00 |
| GPT-4o | 2.50 | 10.00 |
| GPT-4.1 | 2.00 | 8.00 |
| o3 | 2.00 | 8.00 |
| Gemini 2.5 Pro (<200,000) | 1.25 | 10.00 |
| GPT-5 | 1.25 | 10.00 |
| o4-mini | 1.10 | 4.40 |
| Claude 3.5 Haiku | 0.80 | 4.00 |
| GPT-4.1 mini | 0.40 | 1.60 |
| Gemini 2.5 Flash | 0.30 | 2.50 |
| GPT-5 Mini | 0.25 | 2.00 |
| GPT-4o mini | 0.15 | 0.60 |
| Gemini 2.5 Flash-Lite | 0.10 | 0.40 |
| GPT-4.1 Nano | 0.10 | 0.40 |
| Amazon Nova Lite | 0.06 | 0.24 |
| GPT-5 Nano | 0.05 | 0.40 |
| Amazon Nova Micro | 0.035 | 0.14 |
(GPT-5 실패 사례: GPT-5에게 직접 정렬된 표로 출력하라 요청했더니 Nova Micro가 GPT-5 Nano보다 더 비싸게 나왔습니다. "파이썬으로 표를 만들어 정렬하라"고 추가하자 문제가 해결됐죠.)
시스템 카드는 언제나처럼 훈련 데이터에 구체적으로 무엇이 들어갔는지는 모호하게 설명합니다. 이렇게 쓰여 있습니다:
다른 오픈AI 모델과 마찬가지로, GPT-5 모델은 퍼블릭 인터넷 정보, 제3자와의 파트너십 정보, 사용자/트레이너/연구자가 제공·생성한 정보 등 다양한 데이터셋으로 학습되었습니다. [...] 개인정보를 줄이기 위해 고급 데이터 정제 과정을 적용합니다.
이 부분도 흥미로운데, 글쓰기/코딩/헬스가 ChatGPT의 상위 3개 사용 사례임을 드러냅니다. 결국 GPT-5와 최근 공개된 오픈웨이트 모델 모두에서 건강 관련 질문에 노력을 기울인 이유를 설명합니다.
환각 감소, 명령 이행력 향상, 아부 성향 최소화 등에서 큰 진전이 있었으며, 글쓰기, 코딩, 헬스라는 ChatGPT 최상위 3개 사용 예에서 GPT-5의 성능이 대폭 향상되었습니다. 모든 GPT-5 모델에는 **safe-completions(최신 안전성 훈련 기법)**도 적용됐습니다.
safe-completions에 대해선 다음과 같이 설명합니다:
전통적으로 대형언어모델은 안전 정책에 따라 사용자의 요청을 최대한 도와주거나, 전면 거부하도록 훈련되었습니다. [...] 이런 이진적 거부 기준은 (생물학, 사이버보안 등) 듀얼유스의 경우엔 미흡합니다. 높은 수준에서는 안전하지만, 너무 구체적이거나 실행 가능하면 악용될 가능성이 있기 때문입니다. 대안으로 safe-completions를 도입했습니다: 사용자 의도 분류 대신, 모델 결과의 안전성에 초점을 둔 훈련기법입니다. 안전 정책 내에서 최대한 도움을 주되, 해를 끼치지 않도록 합니다.
즉, 무조건 답변 거부가 아니라, "유해"한 내용을 포함하지 않도록 절제된 답을 제공하게 됩니다.
이와 관련해 아직 읽지 못한 OpenAI 논문도 있습니다: From Hard Refusals to Safe-Completions: Toward Output-Centric Safety Training.
아부(시코팬시) 문제도 언급되는데, 4월에 터진 대형 사건 이후 모델 본체에서 개선했다고 합니다.
시스템 프롬프트는 수정이 쉽지만, 후처리보다 모델 성능에 미치는 영향이 제한적입니다. GPT-5에서는 실제 사용 데이터에 준하는 대화로 모델 응답을 평가 후, 시코팬시(아부)의 정도를 점수화해 보상 신호로 삼아 학습했습니다.
환각 현상도 대폭 감소했습니다. 저 역시 Claude 4나 o3에서도 한동안 환각을 못 봤으며, 최신 모델에서는 더욱 줄었습니다.
GPT-5 학습에는 사실 왜곡(환각) 빈도 감소에 중점을 뒀습니다. ChatGPT에서는 브라우징 기능이 기본 탑재돼 있으나, 많은 API 쿼리는 브라우징 툴을 사용하지 않으므로 자체 지식만으로 답할 때 환각 최소화에도 신경 썼습니다.
기만 관련 설명에서는, 모델이 실패한 작업을 성공한 척하는 문제도 다룹니다:
gpt-5-thinking을 불가능하거나 부분적으로만 가능한 작업에 투입하고, 못한다고 정직하게 인정하는 것에 보상을 주는 방식으로 학습했습니다. [...]
에이전트가 웹 브라우징 등 툴을 사용해야 답할 수 있는 질문을 만났을 때, 이전 모델들은 툴이 불안정하면 내용을 환각하는 문제가 있었습니다. 시뮬레이션 시 고의로 툴을 꺼두거나 오류 코드만 돌려주며 테스트했습니다.
프롬프트 인젝션 관련 섹션이 있으나, 다소 빈약하게 느껴집니다.
두 개 외부 레드팀이 ChatGPT 연결기와 마이티게이션 전체에 대해 2주간 프롬프트 인젝션 평과를 실시했으며, 모델 행동 자체보다는 시스템 레벨 취약점 테스트에 집중했습니다.
아래는 주요 모델별 성공률 차트입니다. 비교 모델 대비 gpt-5-thinking의 침투율(56.8%)은 impressively 낮고, Claude 3.7은 60%, 그 외는 모두 70% 이상입니다(Claude 4는 미포함):
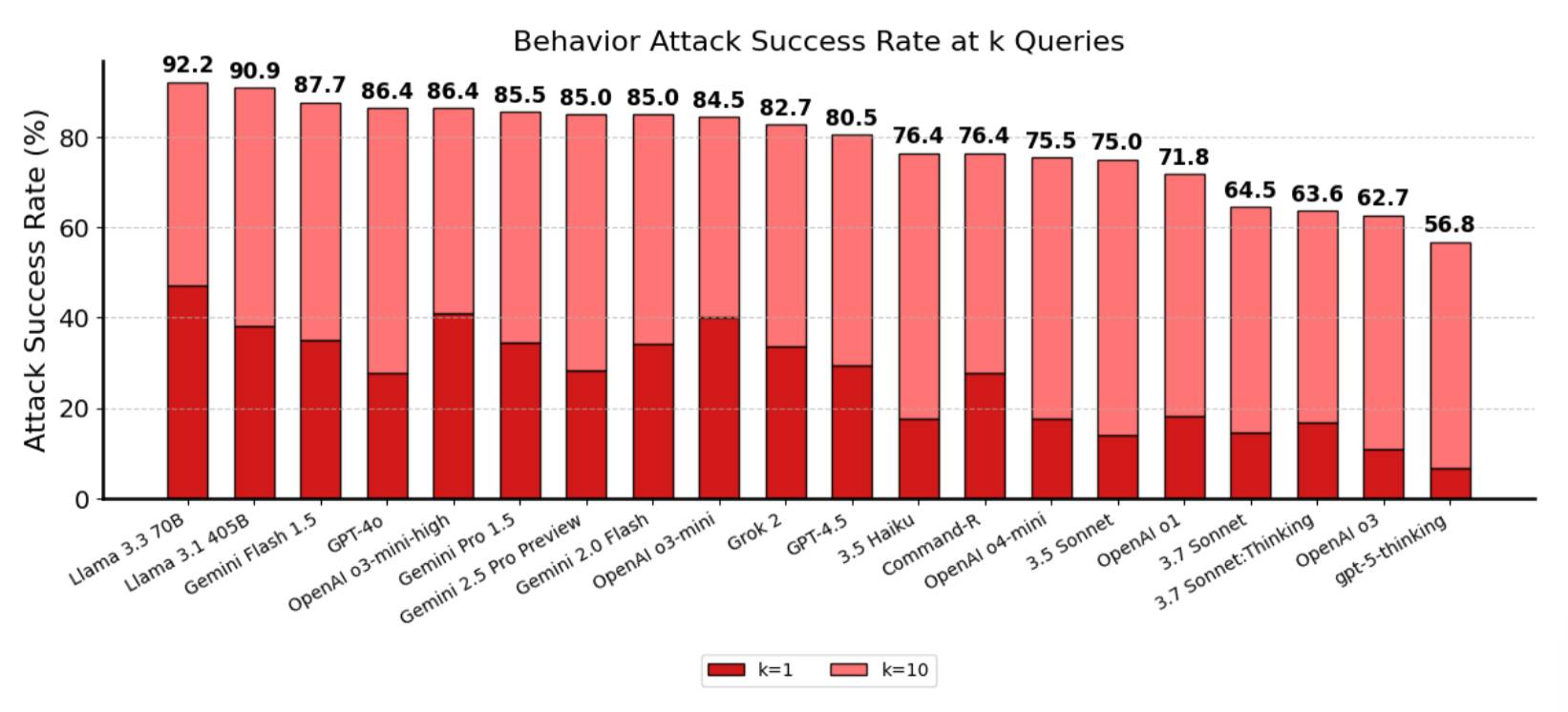
한편으론 56.8%라는 공격 성공률이 다른 모델 대비 크게 개선된 수치입니다.
하지만 동시에, 프롬프트 인젝션이 여전히 심각하게 미해결 과제임을 보여줍니다! 즉 10회 시도 중 과반이 여전히 뚫리는 셈입니다.
모델이 좋아졌다고 해서, 프롬프트 인젝션이 애플리케이션에서 더는 문제 없을 거라 생각해서는 안 됩니다.
GPT-5에서 가장 아쉬운 점은, 다른 OpenAI 추론 모델과 마찬가지로 API를 통해서는 사고(추론) 과정의 흔적을 전혀 확인할 길이 없다는 겁니다.
ChatGPT UI에선 추론 요약을 표시하며, 그게 참 흥미롭고 모델의 사고 방식을 짐작하는 데 큰 도움이 됩니다.
하지만 API에선 침묵만 이어집니다. 모델이 사고 토큰(비용이 부과됨)을 다 태우고, 최종 응답 토큰을 반환하기 시작할 때까지 기다리는 긴 공백이 있을 뿐입니다.
OpenAI는 새 옵션 reasoning_effort=minimal도 도입했습니다. 대부분의 추론을 끄고, 가능한 한 빠르게 토큰 반환을 시작합니다. 그래서 "차라리 추론을 꺼고, 2024년식 'think step by step' 꼼수로 모델의 내부 사고를 겉으로 유도할까?" 하는 우스운 상황도 벌어집니다!
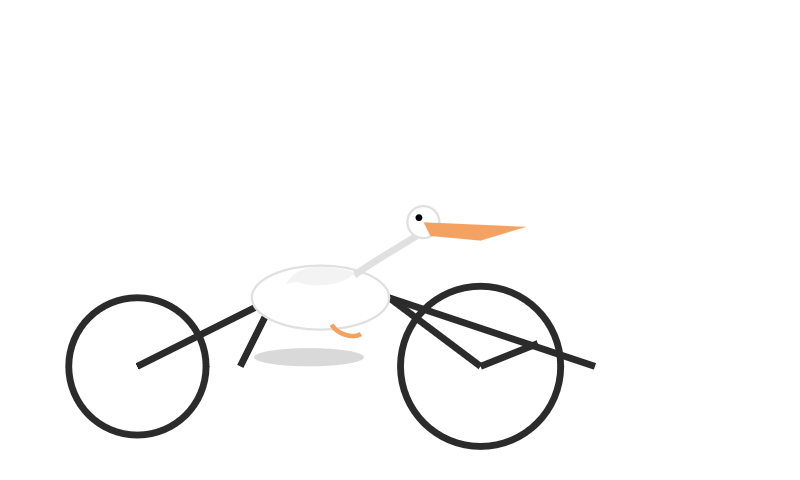
역시나 저는 "자전거 타는 펠리컨 SVG 생성" 벤치마크를 돌려봤습니다. 다음 글에서 더 다양한 변형을 소개할 예정이지만, 일단은 GPT-5(기본값 '중간' 추론 수준)로 뽑은 펠리컨은 아래와 같습니다:

상당히 훌륭합니다! 확실히 펠리컨임이 드러나고, 지금껏 본 자전거 중 가장 잘 나온 축에 듭니다.
여기는 GPT-5 mini 버전:

그리고 GPT-5 nano: