클라우드 네이티브 분리형(컴퓨트/스토리지 분리) OLTP RDBMS 설계들을 벤더별로 정리하고, 주요 설계 선택을 대표하는 논문들을 요약·비교한다. ★ 표시는 빠른 개요를 위한 추천 논문이다.
URL: https://transactional.blog/notes-on/disaggregated-oltp
Title: Notes On: Disaggregated OLTP Systems
이 노트들은 다양한 클라우드 네이티브 분리형(disaggregated) OLTP RDBMS 설계가 최근 논문으로 발표되면서, 이를 비공식 발표에서 소개하기 위해 처음 준비되었다. 그리고 눈에 띄는 설계 선택마다 대표 논문 1편씩을 골라 정리했다. 당시 다룬 논문들에 대해서는 각 논문 뒤에 우리가 나눴던 토론 내용을 요약해 포함했다. 이후 이 페이지는 확장되어, 서로 다른 벤더에서 유사한 논문이 나온 경우까지 포함해 ‘분리형 OLTP’ 관련 논문 전체를 포괄하도록 보완·재게시되었다.
분리형 OLTP 분야를 빠르게 개괄하고 싶다면 ★ 표시가 있는 논문들만 읽어도 된다.
아래 두 논문은 함께 읽는 것이 좋고, 첫 번째 논문에서 레플리카 간 로그 일관성이나 커밋/리커버리 프로토콜의 세부를 전부 이해하려고 멈춰 서지 않는 편이 낫다. 그 내용은 두 번째 논문에서 더 자세히(그리고 다이어그램과 함께) 다룬다. 오히려 두 번째 논문을 먼저 읽는 것을 권하고 싶을 정도다.
Alexandre Verbitski, Anurag Gupta, Debanjan Saha, Murali Brahmadesam, Kamal Gupta, Raman Mittal, Sailesh Krishnamurthy, Sandor Maurice, Tengiz Kharatishvili, and Xiaofeng Bao. 2017. Amazon Aurora: Design Considerations for High Throughput Cloud-Native Relational Databases. In Proceedings of the 2017 ACM International Conference on Management of Data (SIGMOD/PODS'17), ACM, 1041–1052. [scholar]
Alexandre Verbitski, Anurag Gupta, Debanjan Saha, James Corey, Kamal Gupta, Murali Brahmadesam, Raman Mittal, Sailesh Krishnamurthy, Sandor Maurice, Tengiz Kharatishvilli, and Xiaofeng Bao. 2018. Amazon Aurora: On Avoiding Distributed Consensus for I/Os, Commits, and Membership Changes. In Proceedings of the 2018 International Conference on Management of Data (SIGMOD/PODS '18), ACM. [scholar]
분리형 OLTP 논문의 시초 격인 이 논문들은, 왜 Aurora 같은 시스템을 만들고 싶었는지를 동기로 제시한다. 이전에는 수정하지 않은 MySQL을 EBS 위에서 실행했고, 전송되는 데이터의 양을 살펴보면 같은 데이터가 여러 형태로 여러 번 전송되고 있었다. 로그, binlog, 페이지 쓰기, double-write buffer 쓰기 등이 모두 본질적으로 MySQL에서 스토리지로 튜플을 보내는 동일한 일을 반복하고 있었던 것이다.
MySQL on EBS
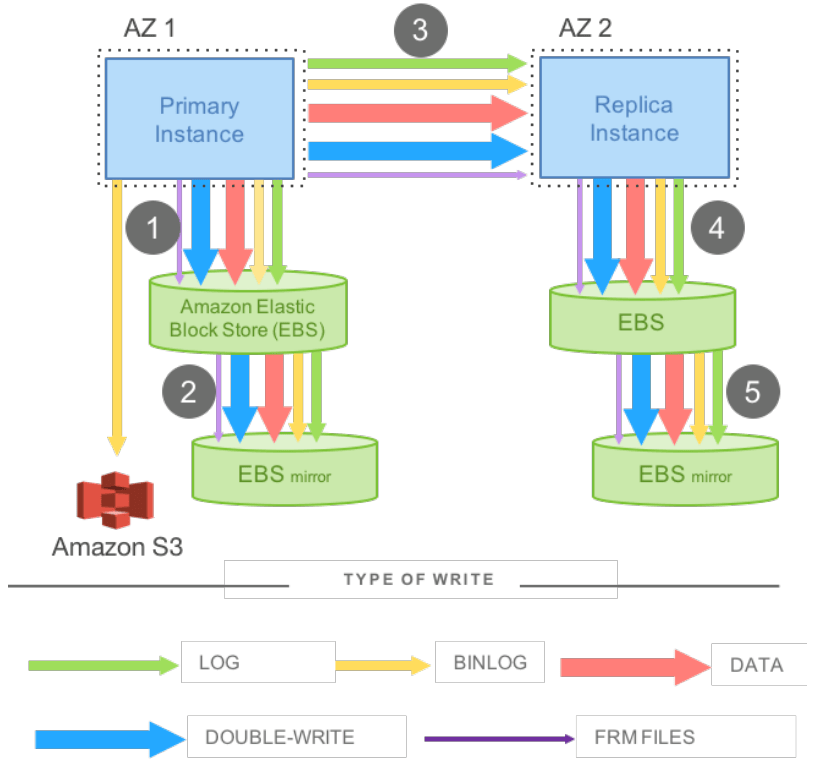
따라서 Aurora는 분리형 시스템에서 컴퓨트와 스토리지 간 프로토콜로 write-ahead log(WAL)을 사용하는 방식을 도입한다. 페이지 쓰기, double-write buffer 등은 모두 제거되고, WAL을 받은 뒤 페이지 구체화(materialization)는 스토리지의 책임이 된다. 우리가 살펴볼 논문들은 대부분 이 모델을 설계의 일부로 “the log is the database”(어떤 형태로든 ‘로그가 곧 데이터베이스’)라는 표현으로 참조한다.
Aurora Architecture
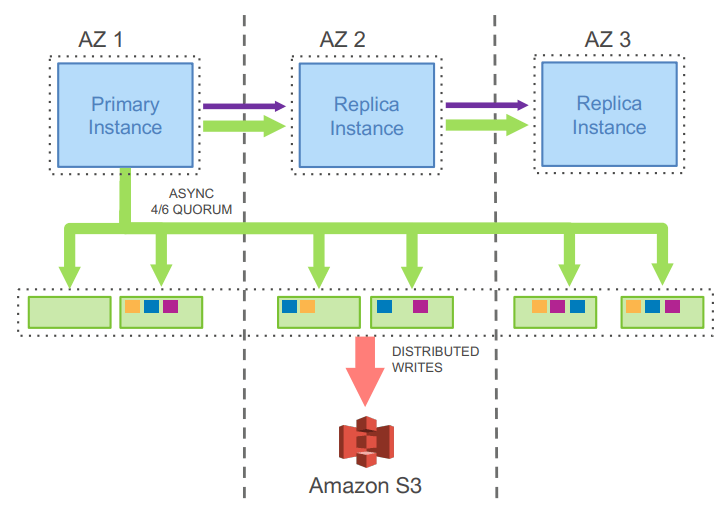
그들이 제시하는 큰 아이디어는, 이렇게 되면 시스템의 병목이 네트워크가 되며, ‘똑똑한 스토리지’가 WAL 업데이트를 페이지 수정으로 처리하는 일을 의미 있게 오프로딩할 수 있고, MVCC 정리(cleanup), 체크포인팅 등도 처리할 수 있다는 점이다. 이를 통해 TPS 35배 증가, 트랜잭션당 I/O 작업 87% 감소를 달성한다. 쿼리 처리 노드에서 스토리지와 복제 책임을 최대한 제거하면 훨씬 더 유능한 데이터베이스가 된다.
Aurora 아키텍처를 시작하기 가장 쉬운 방법은 단일 스토리지 노드로 확대해 보는 것이다:
Aurora Storage Node
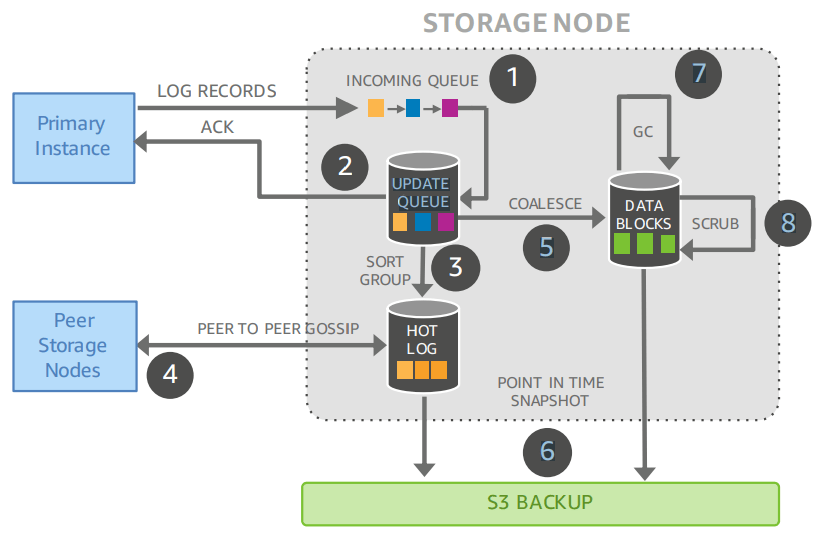
다음 단계를 포함한다:
- 로그 레코드를 수신해 메모리 내 큐에 추가,
- 레코드를 디스크에 영속화하고 ack,
- 레코드를 정리하고(organize) 일부 배치가 유실될 수 있으므로 로그의 갭을 식별,
- 피어와 gossip 하여 갭을 메움,
- 로그 레코드를 합쳐(coalesce) 새로운 데이터 페이지를 생성,
- 주기적으로 로그와 새 페이지를 S3로 스테이징,
- 주기적으로 오래된 버전을 가비지 컬렉션,
- 마지막으로 주기적으로 페이지의 CRC 코드를 검증.
스토리지 노드들은 쿼럼의 일부로 사용되며, 고전적인 “1 AZ + 1 머신 손실을 견딤”은 6노드 쿼럼에서 |W|=4, |R|=3을 의미한다. 쿼럼 덕분에 일시적인 단일 노드 장애(우발적 네트워크 흔들림이든 의도적인 노드 업그레이드든)가 매끄럽게 처리된다. 다만 전통적인 과반수(majority) 쿼럼은 아니다. Primary는 선출된 단일 작성자(sole writer)이며, 이 점이 과반수 쿼럼을 더 일관된 형태로 변환한다. 페이지 서버 쿼럼도 장애가 의심되면 재구성된다. 이 복제 설계는 내 Data Replication Design Spectrum 글의 스펙트럼에도 깔끔하게 들어맞지 않는다.
각 스토리지 쿼럼은 데이터의 한 파티션을 담당하고, WAL은 스토리지 노드 쿼럼들에 동일한 방식으로 파티셔닝된다. 이로 인해 어떤 노드도 전체 WAL을 완전히 보지 못하므로, 로그 상에서 일관된 지점을 추적·식별하는 데 상당한 복잡성이 생긴다. Aurora는 특정 로그 지점을 논의하기 위해 새로운 용어 세트를 도입한다:
LSN: Log Sequence Number. Primary가 WAL 엔트리를 라벨링하기 위해 생성하는 단조 증가 값.
VCL: Volume Complete LSN. 개별 스토리지 노드가, 그 LSN 이하의 모든 이전 로그 레코드 가용성을 보장할 수 있는 가장 높은 LSN.
CPL: Consistency Point LSN. 스토리지 노드가 그 지점 이후의 모든 레코드를 잘라내도(truncate) 안전한 로그 레코드. 리커버리 중 로그 truncation은 이 지점으로 제한된다.
VDL: Volume Durable LSN. VCL 이하이면서 가장 높은 CPL.
SCL: Segment complete LSN. 스토리지 노드가 이전의 모든 로그 레코드를 수신했음을 알고 있는 최대 LSN.
PGCL: Protection Group Complete LSN. 쿼럼 6개 스토리지 노드 중 최소 4개가 내구적으로 저장(durable)한 최대 LSN.
PGMRPL: Protection Group Minimum Read Point LSN. DB 인스턴스에서 활성화된 요청 중 어떤 것이라도 사용하는 가장 낮은 LSN read point. 스토리지 노드는 PGMRPL과 SCL 사이의 읽기 요청만 수용한다.
각 로그 쓰기는 자신의 LSN을 포함하고, 또한 스토리지 그룹으로 마지막으로 보낸 LSN도 포함한다. 모든 쓰기가 트랜잭션 커밋은 아니다. DB 트랜잭션은 일련의 미니 트랜잭션으로 전송되며, 마지막 미니 트랜잭션만이 일관된 트랜잭션 커밋(CPL로 태깅됨)이다. 두 번째 논문에는 Storage Consistency Points에 대한 논의가 길게 이어지며 Volume Complete LSN, Consistency Point LSN, Segment Complete LSN, Protection Group Complete LSN 간 관계를 정확히 파고든다. 여기서의 요지는, 고도로 파티셔닝된 로그로부터 일관된 스냅샷을 복구하는 것은 어렵고, 스토리지 노드들이 다른 스토리지 노드로부터 빠진 로그 엔트리를 채우려 하며, 이는 만만치 않은 메타데이터 추적을 요구한다는 점이다.
노드 쿼럼에 대해 지정된 작성자는 하나뿐이므로, 작성자는 쿼럼 내 어떤 노드가 어느 버전까지 쓰기를 받아들였는지 알고 있다. 따라서 읽기는 쿼럼 읽기가 필요 없고, primary는 올바른 데이터를 갖고 있어야 하는(최소 4개 중) 노드 한 곳에만 읽기 요청을 보낼 수 있다. 읽기 레플리카는 primary와 같은 스토리지 노드를 사용하지만 약 20ms 지연을 두고 Volume Durable LSN까지만 읽는다. 읽기 전용 레플리카(read-only replica)는 primary로부터 binlog를 소비하고 캐시된 페이지만 적용한다. 캐시되지 않은 데이터는 스토리지 그룹에서 가져온다. S3는 백업에 사용된다.
Primary가 실패했을 때를 위한 복구 흐름도 있다. 새 primary는 모든 스토리지 그룹에 연락해, 그 이하에서는 모든 로그 레코드가 알려져 있는 가장 높은 LSN이 무엇인지 찾고, min(max LSN per group)까지 복구해야 한다. 하지만 이는 요약일 뿐 실제는 복잡해 보인다. 다만 redo 로그를 적용해 해당 LSN까지 제대로 복구하는 작업은 이제 많은 스토리지 노드에 병렬화되어 더 빠른 복구로 이어진다.
이것은 ‘쓰기에서 일을 줄이는 대신 읽기에서 일을 늘리는’ 트레이드오프인가? 스토리지를 네트워크 너머로 옮기면 비용이 추가되고, 임의 버전에서 전체 페이지를 재구성하는 것은 싸지 않다. MySQL은 버퍼 캐시에 있는 페이지에 WAL 엔트리를 바로 적용할 수 있지만, 스토리지 노드는 디스크에서 예전 페이지를 가져와야 할 수도 있다. 그러나 많은 작업은 어차피 MySQL이 하던 일이다. undo log를 체이닝해 오래된 튜플 버전을 찾는 것, fuzzy checkpointing 등. 따라서 네트워크를 통해 디스크 페이지를 가져오는 것이 로컬보다 느리더라도, MySQL이 스토리지 관리보다 쿼리 실행과 트랜잭션 처리에 더 집중하도록 해준다는 주장은 설득력이 있다.
Aurora Multi-Master는 2019년 8월에 일반 제공되었고 2023년에 종료(deprecate)되었다. Aurora Multi-Master가 어떻게 동작했는지에 대한 출판 논문은 없지만, AWS Re:Invent 발표와 HPTS 발표에서 내부 구현의 일부가 공유되었다.
다른 멀티 마스터 논문에서 참조되는 주요 설계 결정은, 여러 마스터 간 충돌을 커밋 시점에 낙관적으로(optimistically) 해결했다는 점이다.
Bradley Barnhart, Marc Brooker, Daniil Chinenkov, Tony Hooper, Jihoun Im, Prakash Chandra Jha, Tim Kraska, Ashok Kurakula, Alexey Kuznetsov, Grant McAlister, Arjun Muthukrishnan, Aravinthan Narayanan, Douglas Terry, Bhuvan Urgaonkar, and Jiaming Yan. 2024. Resource Management in Aurora Serverless. Proceedings of the VLDB Endowment 17, 12 (August 2024), 4038–4050. [scholar]
이 논문은 순진한 Aurora Serverless v1(ASv1)에서 Aurora Serverless v2(ASv2)로의 전환을 설명한다. 과금과 최종 사용자 경험이라는 제품 차원의 측면, 그리고 스케일 업/다운 오케스트레이션, 부하 관리, 사용자 워크로드를 최소한의 방해로 이동시키는 방법이라는 내부 기술 측면 모두를 다룬다. ASv1은 스케일을 바꾸기 위해 DB 인스턴스를 재기동(relaunch)하는 방식에 의존했다. 빠르게 재시작되는 DB 인스턴스 사이에서 세션을 옮기기 위해 멀티 테넌트 프록시 프런트엔드를 만들었지만, 세션 전송은 불완전했고(임시 테이블을 옮길 수 없음), 일시적 비가용성으로 인해 방해가 되었으며, 재시작 비용 때문에 (2의 거듭제곱 단위의) 큰 인스턴스 크기 변경에만 의미가 있어 탄력성이 떨어졌다. ASv2의 목표는 더 빠르고, 덜 방해적이며, 주기적(cyclical) 워크로드를 더 잘 추적하는 스케일링이었다.
고객은 Aurora Serverless를 Aurora Capacity Units(ACU) 단위로 구매한다. ACU는 2GB RAM + 0.25 vCPU + (정의되지 않은 양의) 네트워킹 및 블록 디바이스 처리량의 결합이다. 사용자는 DB가 스케일 업/다운할 ACU 상한과 하한을 정의하고, Aurora Serverless는 완전 탄력적이고 사용량 기반의 요금에 가깝게 오토스케일링하려 한다.
Aurora Serverless는 플릿 전체(fleet-wide)의 호스트 간(inter-host) 재균형과, 호스트 로컬(host-local)의 호스트 내(intra-host) 인플레이스 스케일링으로 나뉜다.
Aurora Serverless Architecture
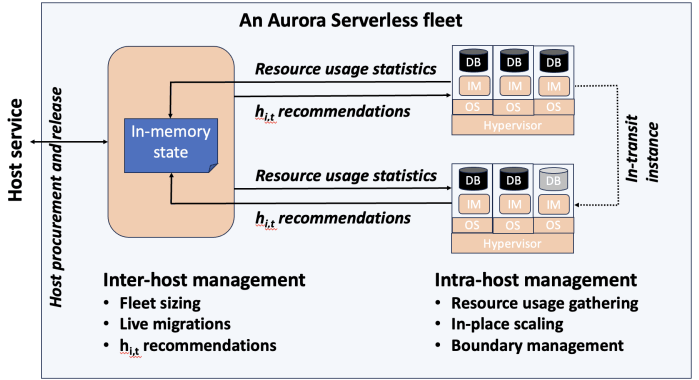
Instance Manager는 한 호스트의 DB 인스턴스들에 대한 리소스 사용 정보를 수집하고, 호스트의 리소스 한도 내에서 인스턴스를 상/하향 스케일링해 필요한 리소스를 맞춘다. Fleet Manager는 DB 인스턴스의 호스트 배치를 제어한다. 호스트 리소스는 오버서브스크라이브되며, 호스트가 리소스 압박을 받으면(CPU, 할당 RAM, 네트워크, 디스크 처리량의 임계 수준) Fleet Manager는 임시 ACU 제한을 부여하고 DB 인스턴스를 라이브 마이그레이션해 클러스터 전체의 ‘열(heat)’을 재분배하고 압박을 완화한다. 스케일 업 속도는 Fleet Manager가 반응할 시간을 주기 위해 Instance Manager가 제한한다. Fleet Manager는 아웃-마이그레이션을 감당할 네트워크 대역폭이 없다고 판단되는 호스트에서는 라이브 마이그레이션을 수행하지 않는다. 새 DB 인스턴스는 최소 ACU 사용을 가정하고 배치된다. Fleet Manager는 예측 및 실제 수요에 따라 플릿 크기도 조정한다.
Fleet Manager는 어떤 인스턴스를 이동할지, 어떤 호스트로 이동할지 선택해야 한다. 인스턴스 선택은 3단계: (1) 부적격 인스턴스 제거, (2) 선호도 점수 계산(예: 자주 이동한 인스턴스는 피하기, 최근 하트비트를 ack한 인스턴스 선호), (3) 수치 점수 계산(얼마나 많은 리소스를 해제하는지 + 이 인스턴스가 가진 미사용 리소스 비율). 선호도 점수가 같으면 수치 점수로 타이브레이크한다. 대상 호스트 선택도 유사하게 진행된다: 부적격 호스트 제거, 선호도 점수(장애 허용 분산, 최근 마이그레이션 실패 없음), 수치 점수(best-fit binpacking 점수 + 가장 사용량이 큰 리소스 비율). 평가에서 이 3단계 접근이 단순 best-fit 대비 더 적은 이동으로 플릿 전체 부하 분산을 더 잘 수행함을 보인다.
DB 인스턴스는 보안 이유로 VM으로 감싸지며, 따라서 리소스 탄력성은 각 VM의 게스트 OS와 협력해서 수행해야 한다. 모든 VM은 최대 128 ACU 인스턴스 크기로 동일하다. 이는 Nitro의 SR-IOV 지원을 통해 효율적인 가상화 I/O를 활용한다. 메모리 탄력성은 여러 변경을 요구했다: 메모리를 오프라인(offline) 처리해 페이지 캐시로 사용되지 않도록 하고 Linux가 모든 페이지에 대한 페이지 테이블 엔트리를 유지하지 않도록 하며, 콜드 페이지는 스왑 아웃하고, 4KB 페이지를 병합해 2MB 크기의 free 페이지를 만들어 하이퍼바이저가 회수할 수 있게 한다. 메모리는 지난 30초 동안의 원하는 버퍼 풀 크기에 기반해 스케일 업, 지난 60초 동안에 기반해 스케일 다운한다. CPU는 지난 30초의 P50에 기반해 스케일 업, 지난 60초의 P70에 기반해 스케일 다운한다. 스케일 업은 둘 중 최대값을, 스케일 다운은 둘 중 최소값을 사용한다.
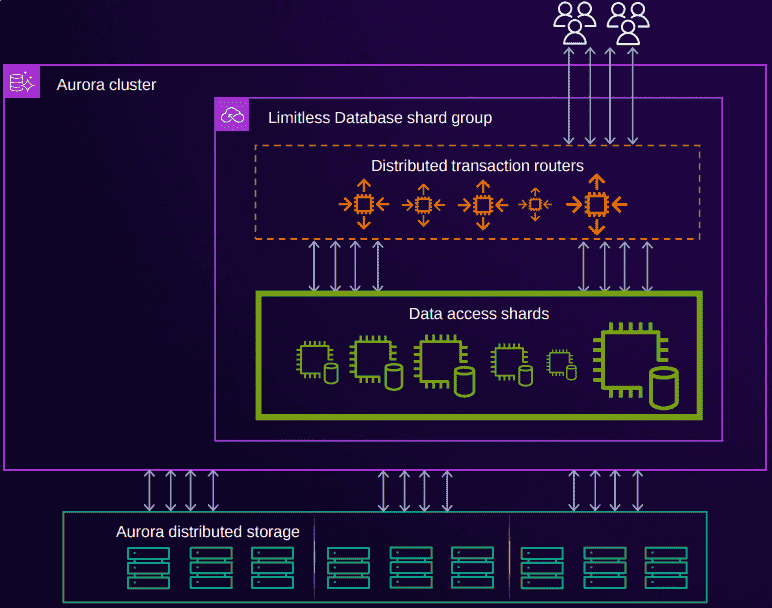
Aurora Limitless는 “Aurora” 브랜드를 재사용하지만, 지금까지 논의해 온 Aurora DB라기보다는 Spanner 같은 shared-nothing 분산 DB에 훨씬 가깝다. Limitless에 관심이 있다면, 공개된 정보는 AWS Re:Invent 발표 자료뿐이다.
Aurora Limitless Architecture
Panagiotis Antonopoulos, Alex Budovski, Cristian Diaconu, Alejandro Hernandez Saenz, Jack Hu, Hanuma Kodavalla, Donald Kossmann, Sandeep Lingam, Umar Farooq Minhas, Naveen Prakash, Vijendra Purohit, Hugh Qu, Chaitanya Sreenivas Ravella, Krystyna Reisteter, Sheetal Shrotri, Dixin Tang, and Vikram Wakade. 2019. Socrates: The New SQL Server in the Cloud. In Proceedings of the 2019 International Conference on Management of Data (SIGMOD/PODS '19), ACM. [scholar]
이 논문은 이전 DR 아키텍처, 관련 동작 및 기능, 그리고 shared-nothing 설계를 설명하는 데 시간을 꽤 쓴다. 기존 RDBMS를 새 아키텍처로 적응시키는 논의도 상당히 있다. 대형 기존 제품에서 큰 아키텍처 변경을 하는 현실적인 이야기라는 점에서 전반적으로 훌륭하지만, 여기서는 분리형 OLTP 개요에만 집중할 것이므로 이 부분에는 집중하지 않겠다.
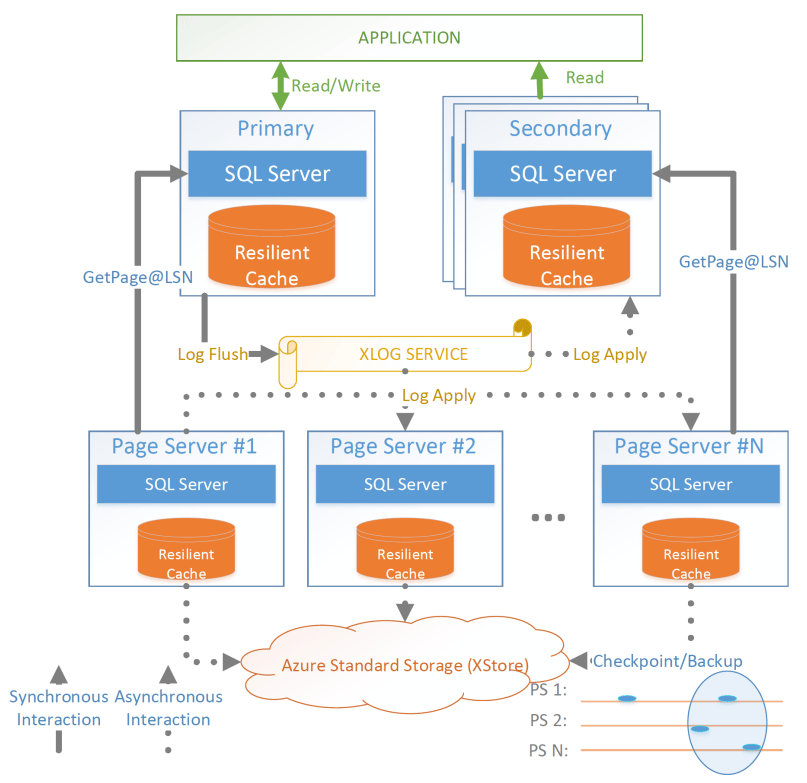
Socrates의 아키텍처는 내구성(durability: 로그가 구현)과 가용성(availability: 스토리지 계층이 구현)을 분리한다. 내구성은 빠른 스토리지에 데이터 복사본을 둘 필요가 없고, 가용성은 고정된 레플리카 수를 필요로 하지 않는다. 두 개념을 분리함으로써 Socrates는 내구성에는 저렴한 HDD를, 스토리지 계층의 가용성에는 더 적은 수의 빠르고 비싼 SSD를 사용할 수 있다.
Socrates Architecture
주요 설계 결정은 다음과 같다:
모든 프로세스는 로컬 디스크 기반 캐시를 가진다. (아래에서 더 설명)
낮은 지연과 높은 내구성 때문에 WAL의 LandingZone(LZ)로 Azure Premium Storage를 사용.
WAL 엔트리의 가용성과 페이지 서버로의 전파(dissemination)를 위한 라우터 XLOG 프로세스.
XStore는 로그 블록의 장기 저장소이며 Azure standard storage.
Primary 컴퓨트 노드는 자신이 분리형 DB의 primary라는 사실을 거의 인지하지 못하며, secondary 읽기 레플리카가 있다는 사실도 모른다. 그저 핵심 기능만 수행한다: 트랜잭션을 실행해 WAL 엔트리를 생성. 나머지 책임은 모두 오프로딩된다. Landing Zone에 대한 쓰기는 가상화된 파일시스템을 통해 수행되며, 스토리지에서 복구 가능한 버퍼 풀(from-storage recoverable buffer pool)이 거의 모든 I/O 가상화에 통합된다. 체크포인팅, 백업/복구, 페이지 수리 등은 하위 스토리지 계층에 위임된다.
장애의 영향을 최소화하기 위해, 컴퓨트 노드는 버퍼 풀을 디스크로 확장하는데 이를 Hekaton(인메모리 스토리지 엔진)의 테이블로 표현한다. SSD에 버퍼 풀을 두는 것은 언뜻 목적에 반하는 듯 보이지만, 그렇지 않으면 콜드 스타트 시 페이지 서버에 수 GB의 페이지 fetch를 한꺼번에 퍼붓게 되고, 워킹 셋이 캐시에 다시 올라오기 전까지 성능이 처참해지기 때문이다.
Socrates XLOG Service
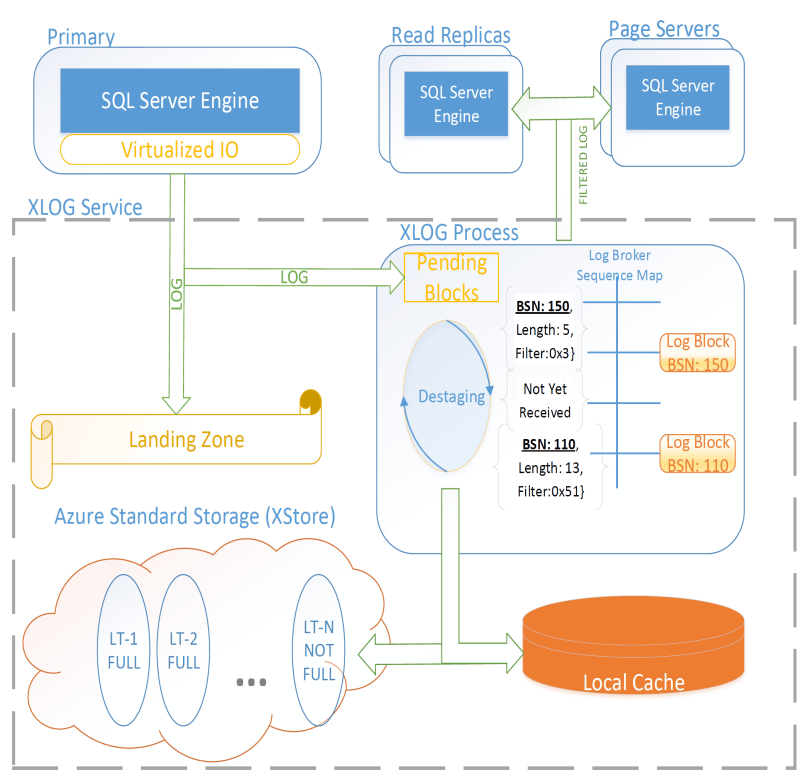
Socrates의 핵심은 WAL을 담당하는 별도의 XLOG 서비스다. Primary는 LZ와 XLOG에 동시에 로그를 전송한다. XLOG는 Primary가 해당 세그먼트가 LZ에 내구적으로 저장되었음을 알려줄 때까지 수신한 WAL 세그먼트를 버퍼링하고, 그 시점에 페이지 서버로 전달한다. 또한 로컬 캐시를 갖고 있으며 시간이 지남에 따라 로그 세그먼트를 blob 스토리지로 옮긴다. (그리고 이것은 Aurora와의 큰 차이: Aurora는 페이지 서버들에 WAL을 파티셔닝하지만, Socrates는 중앙집중형 WAL 서비스를 가진다.)
페이지 서버는 모든 페이지를 저장하지 않는다. 크고(그리고 영속적인) 캐시는 있지만 일부 페이지는 XStore에만 존재한다. 페이지 서버의 역할은 주로 단일 RPC GetPage@LSN을 제공하는 것으로, 지정된 LSN ‘이상’ 버전의 페이지를 제공한다. 따라서 임의 버전에서 페이지를 구체화할 필요가 없고 최신 상태만 유지할 수 있다. 체크포인팅을 위해 페이지 서버는 수정된 페이지를 정기적으로 XStore로 내보낸다. 레플리카의 B-트리 탐색은 leaf 페이지가 부모보다 더 새로운 LSN이면 재시작이 필요할 수 있다. Socrates 팀은 대량 로드, 인덱스 생성, DB 재조직, 깊은 페이지 수리, 테이블 스캔을 페이지 서버로 오프로딩하는 것도 진행 중이다.
백업/복구는 XStore의 Point-In-Time-Restore 기능으로 페이지 데이터의 주기적 스냅샷을 저장한다. 복구는 원하는 시점 이전의 스냅샷과, 스냅샷을 요청 시점까지 끌어올리기 위해 필요한 로그 범위를 식별한다. 그 뒤 스냅샷을 새 blob으로 복사하고 각 blob을 새 페이지 서버 인스턴스에 연결하며, 복사된 로그 위에서 새 SLOG 프로세스를 부트스트랩해 요청된 복구 시점까지의 변경 적용을 돕는다.
Socrates는 2019년 논문치고 WarpStream이나 turbopuffer 같은 ‘현대적인 객체 스토리지 기반 DB’ 느낌이 강하다. Primary의 확장 버퍼 풀 / “Resilient Cache”는 매우 복잡한 mmap() 구현처럼 들린다.
VM 마이그레이션은 캐시를 유지할까? 아마 아닐 것 같다. 플릿에 걸쳐 SQL Server 인스턴스를 빈팩킹하려는 시도가, 특히 모두 영속 캐시에 묶여 있다면, 어렵다는 흥미로운 포인트가 제기됐다. Azure SQL Database는 vCPU와 DTU 모델로 판매되며 예약 기반에 가까운 것 같아서, 그렇게 큰 churn(이동/교체 빈도)이 없을 수도 있다?
캐시는 실제 로컬 SSD인가, 아니면 Azure Managed Disk인가? 대체로 실제 SSD임을 강하게 암시하는 것으로 보인다는 데 의견이 모였다.
Rogerio Ramos, Prashanth Purnananda, Hanuma Kodavalla, Chaitanya Gottipati, Harshil Ambagade, Ankit Anvesh, and Srikanth Sampath. 2025. Hyperscale Resilient Buffer Pool Extension in Azure SQL Database. In 2025 IEEE 41st International Conference on Data Engineering (ICDE), IEEE, 4222–4233. [scholar]
Socrates가 Azure SQL Database Hyperscale이라는 브랜드로 프로덕션에 들어간 뒤 몇 년이 지나, Microsoft 연구진은 프로세스 재시작 시 성능 영향을 최소화하기 위해 인메모리 버퍼 풀을 SSD로 확장하는 Resilient Buffer Pool Extension(RBPEX)에 대한 심층 분석으로 돌아왔다. 전통적으로 버퍼 풀은 메모리에만 있고, SSD 페이지 읽기의 캐싱도 메모리에서 이뤄진다. Hyperscale에서는 버퍼 풀이 메모리와 로컬 SSD에 존재하며, 원격 페이지 서버로부터의 페이지 읽기를 캐시하는 데 사용된다. 동일한 RBPEX는 페이지 서버에서도 객체 스토리지에 있는 페이지의 로컬 저장으로 사용된다. 컴퓨트 노드에서는 불완전한 캐시, 즉 _non-covering RBPEX_이다. 페이지 서버에서는 “캐시”가 객체 스토어의 페이지를 정확히 미러링하는 _covering RBPEX_이다.
RBPEX Architecture
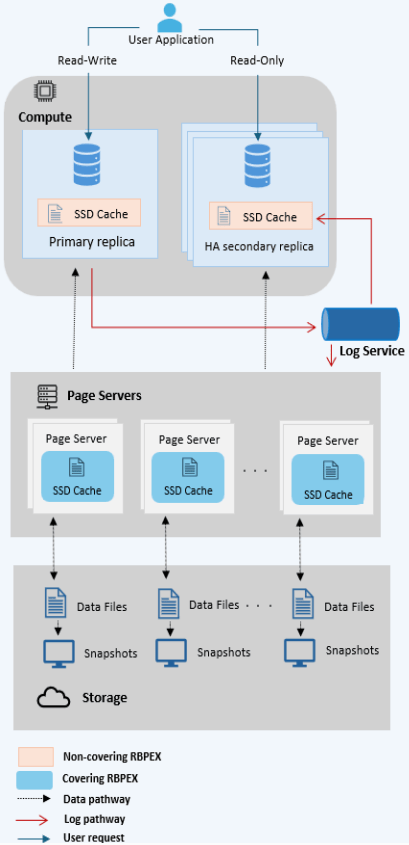
RBPEX File은 RBPEX에 캐시된 데이터 페이지의 백킹 스토어다. 로컬 파일이며 SQL Server 페이지 크기(8KB)의 배수로 크기가 정해지고, 1MB 세그먼트로 나뉘며, 페이지 내용 외에 추가 메타데이터는 저장하지 않는다. 대신 모든 메타데이터는 Hekaton(SQL Server의 인메모리 엔진)을 사용한 SQL 테이블로 추적한다. 해시 기반 테이블 _PageTable_은 <DbId, FileId, PageId> 튜플을 <Offset, Timestamp, State>에 매핑한다. Offset은 RBPEX File 내 오프셋, Timestamp는 페이지가 RBPEX에 마지막으로 쓰이거나 읽힌 시각, State는 {Valid, Invalid, InFlight} 중 하나다. Valid 페이지는 RBPEX File의 데이터가 캐시 대상인 기반 데이터 파일과 동일한 정확한 복사본인 경우다. InFlight 페이지는 쓰기 작업이 진행 중이라 RBPEX File 내용이 오래되었을 수 있는 경우다. 복구 시 PageTable을 스캔해 InFlight와 Invalid 상태의 행을 제거한다. RbpexMetadataTable은 RBPEX File 자체에 대한 메타데이터를 영속화한다.
SQL Server에는 File Control Block(FCB)라는 I/O 추상화 계층이 있으며, Hyperscale에서만 RBPEX의 FCB를 통해 읽기/쓰기를 재라우팅할 수 있게 한다. 페이지를 메모리로 읽어야 할 때 RBPEX FCB가 페이지 읽기를 가로채고, PageTable에 해당 PageId가 Valid로 존재하면 RBPEX File에서 제공한다. 그렇지 않으면 기반 데이터 파일로 읽기가 내려가며(Primary 노드에서는 Page Server GetPage@LSN RPC로 바뀜). 페이지 접근 통계를 추적해 백그라운드 스레드가 자주 쓰이는 페이지를 RBPEX로 옮길 수 있게 한다. RBPEX의 전체 목적은 콜드 스타트 시간을 줄이는 것이므로, 자주 읽히지만 드물게 쓰이는 페이지도 RBPEX에 들어가도록 보장하는 것이 중요하다. 또한 대량 데이터 로드의 쓰기나 대형 분석 테이블 스캔의 읽기를 RBPEX에 넣지 않도록 하는 힌트도 지원한다. 그런 작업은 유용한 페이지를 캐시에서 밀어낼 수 있기 때문이다.
Hyperscale RBPEX Writes
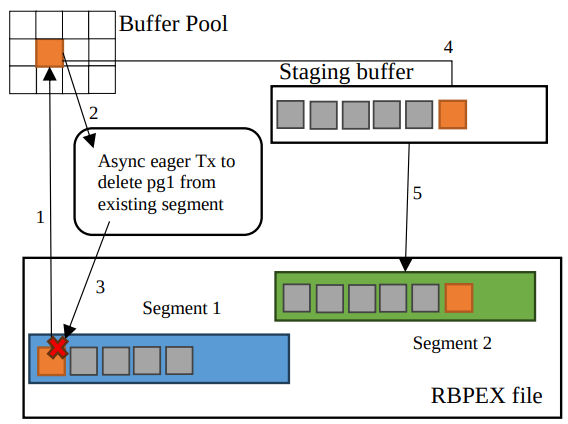
페이지 쓰기에서 기대되는 흐름은: InFlight 표시, RBPEX와 기반 파일에 동시 쓰기, 다시 Valid 표시일 것이다. 하지만 이는 PageTable에 많은 작은 업데이트를 요구해 오버헤드가 크고 랜덤 I/O 요청도 많아진다. 대신 페이지가 버퍼 풀에서 처음 dirty로 표시될 때 PageTable에서 비동기로 삭제된다. dirty 페이지 writeback이 시작되면 RBPEX FCB는 dirty 페이지 쓰기를 스테이징 버퍼에 넣어 버퍼링한다(읽기는 스테이징 버퍼에서도 제공 가능). 스테이징 버퍼는 1MB 세그먼트 단위로 RBPEX File에 플러시된다. 스테이징 버퍼에서 플러시될 때 페이지들은 PageTable에 InFlight로 삽입되고, 세그먼트 전체가 내구화되면 모든 페이지가 Valid로 업데이트된다. 삭제/삽입의 비동기 흐름은 행을 업데이트하는 것보다 낫다. 삭제는 배치할 수 있고 삽입도 지연 내구화가 가능하기 때문이다. 최악의 경우 복구 시 PageTable에 삽입이 누락되더라도 디스크에는 페이지가 있지만 캐시에 있는 것으로 인식되지 않을 뿐이다.
세컨더리는 페일오버 시 성능 영향을 줄이기 위해 DB의 핫 페이지를 프리페치해 캐시를 미리 데울 수 있다. Primary가 핫 페이지를 추적하고 주기적으로 페이지 hit count 샘플을 페이지 서버로 푸시한다. 세컨더리는 페이지 서버를 질의해 어떤 페이지를 가져와 프리웜할지 알 수 있다.
백그라운드 트리머 스레드는 콜드 페이지 처리와 eviction을 담당한다. 마지막 접근 타임스탬프는 세그먼트별로 메모리에서 유지되며, 가장 오래 사용하지 않은(LRU) 세그먼트의 모든 페이지가 축출된다. 업데이트로 이전 페이지가 Invalid가 되어 점유율이 낮아진 세그먼트도 해제되고 페이지가 축출된다.
페이지 서버의 Covering RBPEX는 DB의 연속 페이지로 구성된 16MB 세그먼트로 구성된다. Covering RBPEX는 페이지 단위 정보를 추적할 필요가 없으므로 별도의 SegmentTable에 메타데이터를 둔다. 시작 시 페이지 서버가 담당하는 모든 데이터 페이지는 객체 스토리지에서 로드되어 RBPEX에 삽입된다. 이후 XLOG에서 업데이트를 받아 적용하면 페이지 서버가 페이지 제공 준비가 끝난다. 페이지 업데이트는 위와 유사하지만 DirtyPageBitmap이 세그먼트 내 어떤 페이지가 업데이트되었는지를 추적한다. 페이지 서버도 콜드 세그먼트를 eviction할 수 있으며, Azure SQL 메트릭에 따르면 전체 세그먼트의 약 40%가 최근 7일간 접근되지 않았다.
평가에서는 로컬 RBPEX 읽기 지연 600us, 페이지 서버 읽기 지연 1000us를 보이지만, 뒤에서 컴퓨트 노드의 RBPEX 읽기는 200us라고도 한다. 복구 성능 그래프는 캐시 적중률, 원격 페이지 읽기 QPS, 페이지 래치 대기 시간을 보여주지만, 기대한 전체 시스템 QPS는 없고, 콜드 캐시가 채워지는 데 약 12초가 걸린다.
Jack Hu, Eric Lee, Prashanth Purnananda, and Hanuma Kodavalla. 2025. Scaling and Hardening XLOG: The SQL Azure Hyperscale Log Service. In 2025 IEEE 41st International Conference on Data Engineering (ICDE), IEEE, 4211–4221. [scholar]
Socrates 논문에서 설명된 초기 구현 이후, 세 가지 주요 개선이 있었다: (1) 요청 처리의 블로킹 모델에서 논블로킹으로 전환, (2) 오래된 리더(reader) 그룹에 대한 I/O 병합(coalescing)과 캐싱 개선, (3) 체크섬 검증 계층 추가.
Hyperscale XLOG Architecture
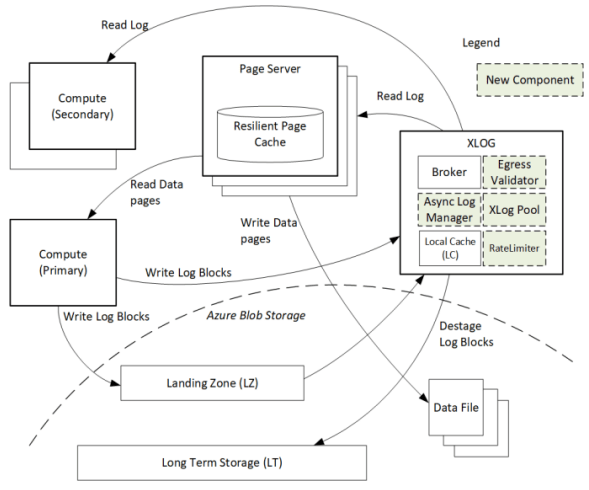
페이지 서버가 XLOG에 GetLogBlocks 요청을 보냈을 때 페이지 서버가 이미 최신 상태라면, XLOG는 새로운 로그 데이터가 생길 때까지 응답을 대기시키며 요청을 롱폴링으로 바꾼다. 이 요청 처리는 대기까지 포함해 동기적으로 수행되어 요청 처리 스레드를 블록했다. 페이지 서버 수가 스레드 수를 넘어서면 신규 요청이 굶주려 지연과 성능이 극도로 나빠졌다. 해결책은 요청 처리 모델을 비동기·논블로킹으로 변경한 것이다. 논문은 이 주제를 자세히 다루지만, 문제와 해결은 어떤 RPC 기반 서비스든 롱러닝 RPC를 처리하거나 스레드풀에서 블로킹 작업을 하는 것과 다를 바 없다.
Hyperscale XLOG Pool
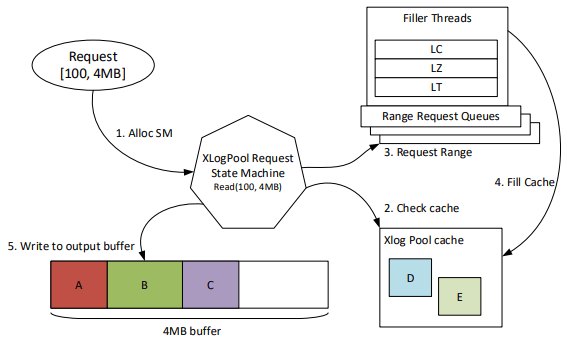
랙 장애, 시스템 업그레이드, 백업 복구 등은 많은 페이지 서버를 한꺼번에 등장시켰고, 이들이 XLOG 로컬 캐시에 더 이상 없는 로그 데이터를 요청하게 했다. XLOG는 이 요청을 독립적으로 처리하며, Azure Storage에 잠재적으로 겹치는 데이터를 여러 번 읽는 요청을 발행했다. 이 읽기 폭주는 Azure Storage의 스로틀링을 유발해 XLOG를 심각하게 벌주고 Landing Zone에 대한 모든 요청에도 영향을 미쳤다. 해결은 두 가지였다. 첫째, XLOG 내부에 레이트 리미터를 두어 190MB/s 읽기를 유지하고, 200MB/s 임계를 넘으면 Azure Storage가 급격히 페널티를 주는 상황을 피했다. (평가에서는 200MB/s를 넘으면 100MB/s로 강제되는 것처럼 보인다.) 둘째, Azure Storage에서 최근에 가져온 로그 블록을 위한 별도 캐시를 추가하고, 모든 outstanding 요청의 범위를 메모리의 자료구조로 유지했다. 새 요청은 기존 요청에 대해 범위를 중복 제거(deduplicate)한다. 전용 filler 스레드가 원하는 범위를 XLOG Pool Cache로 가져오면, 그 범위에 막혀 있던 요청들이 데이터를 소비한다. 요청을 병합하면 동시 요청들이 같은 블록을 반복해서 다시 가져오는 데 대역폭을 낭비하지 않으므로, Azure Storage에서 더 많은 새 로그 블록을 가져올 수 있게 된다.
“유명한 벤더”의 특정 SSD 모델과 연관된 높은 데이터 손상률이 Hyperscale에서 무결성 검증 개선을 촉발한 것으로 보인다. _Egress Validation_이 추가되어, XLOG가 메모리에 Block Sequence Number -> 블록 해시의 작은 해시맵을 유지했다. 블록을 클라이언트에 처음 제공할 때 해시를 저장하고, 이후 같은 BSN 요청에서는 계산된 해시가 저장된 해시와 일치하는지 검증한다. 다르면 손상(corruption)을 의미한다. 엔드-투-엔드 체크섬 검증도 추가됐다. 컴퓨트 노드는 각 블록에 체크섬을 찍고, XLOG가 처음 읽을 때 검증하며, XLOG가 제공하기 전 검증하고, 페이지 서버가 수신할 때 다시 검증한다. 손상된 블록 헤더 해석이 크래시로 이어지지 않도록, 로그 블록을 다루는 코드는 오버플로 감지 정수 연산 라이브러리를 사용하도록 변경됐다. 이 변경들로 중요한 데이터가 온전하다는 보장이 강화됐다.
평가는 각 변경의 영향을 보여준다. 논문 앞에서 이미 충분히 암시된 내용이라 놀라운 점은 없었다. 비동기 요청 처리와 XLOG Pool 변경의 결합은 페이지 서버 수가 증가할수록 로그 블록 처리량을 크게 개선했으며, 이는 작업의 목표와 정확히 일치한다.
큰 맥락에서 Alibaba는 ‘멋진 하드웨어에 돈을 쓰는’ 쪽이다. Modern Database Hardware에서 조금 이야기했지만, Alibaba 논문들은 어려운 소프트웨어 문제를 최신 하드웨어에 상당한 돈을 들여 푸는 데 주저함이 없다는 점을 빠르게 보여준다. 특히 Alibaba는 내부에 RDMA를 폭넓게 배치한 것으로 보이며, Microsoft와 비슷한 수준인 듯하다. 다만 Microsoft는 스택 대부분에 TCP로 폴백할 옵션을 남겨두는 것처럼 보이는 반면, Alibaba는 RDMA의 프리미티브에 결정적으로 의존하는 서비스를 만드는 데도 편안해 보인다.
Wei Cao, Zhenjun Liu, Peng Wang, Sen Chen, Caifeng Zhu, Song Zheng, Yuhui Wang, and Guoqing Ma. 2018. PolarFS: an ultra-low latency and failure resilient distributed file system for shared storage cloud database. Proceedings of the VLDB Endowment 11, 12 (August 2018), 1849–1862. [scholar]
Alibaba는 분리형 OLTP DB를 구축하는 데 있어 특이한 첫 걸음을 택했다. 별도의 페이지 서버를 만들고 DB를 수정해 페이지를 요청하도록 하고 복구를 오프로딩하는 대신, 충분히 빠른 분산 파일시스템을 만드는 데 투자했다. 논문 출판 1년 뒤 Alibaba는 PolarFS를 AsparaDB/PolarDB-FileSystem로 오픈소스했고(PolarDB는 ApsaraDB/PolarDB-for-PostgreSQL
로 오픈소스했으며 PolarFS 사용이 포함됨), 그래서 요약에 링크를 여기저기 뿌려 두었다.
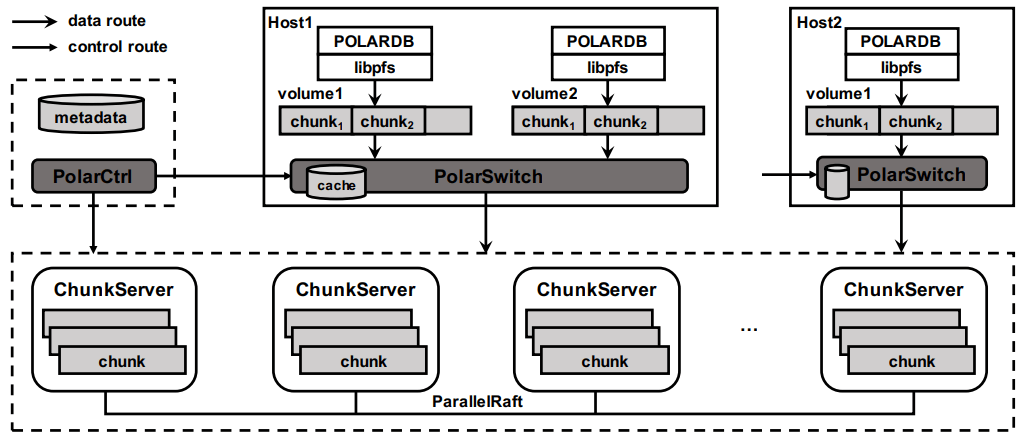
아키텍처 컴포넌트 관점에서: libpfs는 POSIX 유사 파일시스템 API를 노출하는 클라이언트 라이브러리, PolarSwitch는 같은 호스트에서 실행되는 프로세스로 애플리케이션의 I/O 요청을 ChunkServer로 리다이렉트, ChunkServer는 스토리지 노드에 배치되어 I/O 요청을 처리, PolarCtrl은 컨트롤 플레인이다. PolarCtrl의 메타데이터는 MySQL 인스턴스에 저장된다. PolarDB에서 필요한 수정은 파일시스템 호출을 libpfs로 포팅하는 것뿐이었다.
PolarFS Architecture
libpfs API는 다음과 같다:
int pfs_mount(const char *volname, int host_id)
int pfs_umount(const char *volname)
int pfs_mount_growfs(const char *volname)
int pfs_creat(const char *volpath, mode_t mode)
int pfs_open(const char *volpath, int flags, mode_t mode)
int pfs_close(int fd)
ssize_t pfs_read(int fd, void *buf, size_t len)
ssize_t pfs_write(int fd, const void *buf, size_t len)
off_t pfs_lseek(int fd, off_t offset, int whence)
ssize_t pfs_pread(int fd, void *buf, size_t len, off_t offset)
ssize_t pfs_pwrite(int fd, const void *buf, size_t len, off_t offset)
int pfs_stat(const char *volpath, struct stat *buf)
int pfs_fstat(int fd, struct stat *buf)
int pfs_posix_fallocate(int fd, off_t offset, off_t len)
int pfs_unlink(const char *volpath)
int pfs_rename(const char *oldvolpath, const char *newvolpath)
int pfs_truncate(const char *volpath, off_t len)
int pfs_ftruncate(int fd, off_t len)
int pfs_access(const char *volpath, int amode)
int pfs_mkdir(const char *volpath, mode_t mode)
DIR* pfs_opendir(const char *volpath)
struct dirent *pfs_readdir(DIR *dir)
int pfs_readdir_r(DIR *dir, struct dirent *entry,
struct dirent **result)
int pfs_closedir(DIR *dir)
int pfs_rmdir(const char *volpath)
int pfs_chdir(const char *volpath)
int pfs_getcwd(char *buf)
여기에는 흥미로운 미묘함이 몇 가지 있고, OSS 레포의 pfsd_sdk.h에서 이 API를 볼 수 있다. Postgres를 위한 VFS 레이어는 polar_fd.h에 있으며 pfsd_sdk.h에 제시된 API의 약간 상위 집합이다. pfs_fsync()가 없는 것으로 보아 모든 pfs_pwrite()가 즉시 내구적이라고 추정하며, pfsd_sdk.h에는 pfsd_fsync()가 존재하지만 /* mock */ 주석이 붙어 있다. Postgres는 sync_file_range()를 사용하는 것으로 알려져 있는데, 이것도 no-op 처리됐다고 추정한다. 볼륨은 마운트되며 동적으로 확장/축소 가능하지만, 대부분의 파일시스템은 동적 리사이즈와 잘 호환되지 않는다. API에는 표시되지 않지만 direct I/O와 buffered I/O를 모두 지원한다.
주어진 API는 PolarFS의 파일시스템 계층을 설명하며, 이는 마운트된 볼륨 내 블록으로 디렉터리와 파일을 매핑한다. 디렉터리의 내용이나 파일에 연결된 블록은 블록으로 기록되며, 루트 블록이 루트 디렉터리의 메타데이터를 갖는다. 블록 집합을 트랜잭션적으로 업데이트해(읽기 레플리카가 일관된 파일시스템을 보도록) 파일시스템 업데이트를 위한 WAL 역할을 하는 저널 파일이 존재하며, libpfs는 저널에 누가 쓸 수 있는지 레플리카 간 조정하기 위해 disk paxos를 구현한다.
스토리지 계층은 파일시스템 계층을 위한 볼륨 관리/접근 인터페이스를 제공한다. 볼륨은 10GB 청크로 나뉘고 ChunkServer들에 분산된다. 큰 청크 크기는 메타데이터 오버헤드를 줄여 PolarCtrl이 전체 청크-서버 매핑을 메모리에서 유지하는 것이 실용적이도록 선택되었다. 각 ChunkServer는 약 10TB의 청크를 관리하므로, ChunkServer 측의 실용적인 로드밸런싱을 위한 비율도 합리적이다. ChunkServer 내부에서 각 청크는 64KB 블록으로 나뉘고 온디맨드로 할당·매핑된다. 따라서 청크 하나는 청크 LBA -> 블록 위치를 추적하기 위한 메타데이터가 640KB이며, 서버당 1000청크면 총 640MB가 된다.
PolarFS Write Path
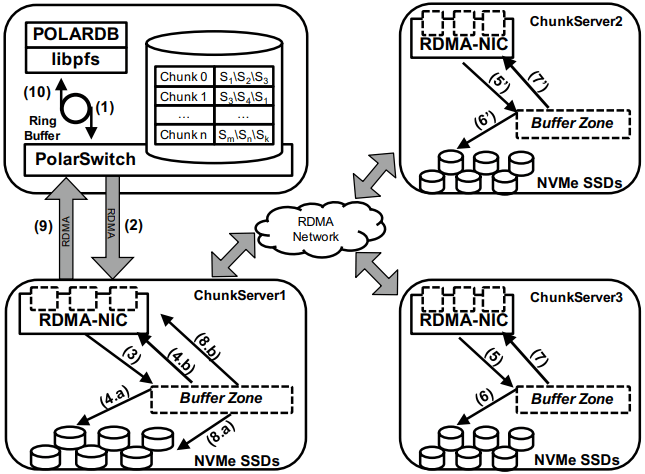
PolarSwitch는 libpfs를 사용하는 애플리케이션 옆에서 실행되는 데몬이다. libpfs는 공유 메모리 링 버퍼로 I/O 요청을 PolarSwitch에 전달하고, PolarSwitch는 I/O 요청을 청크별 요청으로 쪼개며, 청크-서버 인메모리 매핑을 참조해 요청을 전송한다. 완료는 다른 공유 링 버퍼(io_uring과 유사)로 보고된다. 별도 데몬으로 유지하는 이유는 명시되지 않지만, RDMA를 네트워크 전송으로 사용하면 NIC를 한 프로세스만 쓸 수 있거나, vNIC를 쓰더라도 원하는 호스트당 인스턴스 수보다 적은 고정 프로세스 수만 가능하기 때문이라고 추정한다.
ChunkServer는 분리형 스토리지 서버에서 실행되며, SSD당 ChunkServer 1개가 전용 CPU 코어를 사용한다. (즉 SSD가 10TB 이상인 셈인가?) 각 청크는 3D XPoint SSD(인텔 옵테인) 위에 WAL을 유지한다. ChunkServer 간 복제는 순서가 다른 완료(out-of-order completion)를 허용하도록 최적화된 Raft 변형인 ParallelRaft로 수행된다. SPDK는 코어당 IOPS를 극대화하기 위해 사용되며, ChunkServer가 무한 폴링할 수 있도록 전용 코어를 갖는 이유이기도 하다. 큰 청크와 총 데이터 크기 때문에 ChunkServer는 오프라인 허용치가 비교적 높게 설정되는 듯하다.
PolarCtrl은 전용 머신 집합에 배치된 컨트롤 플레인이다. ChunkServer의 멤버십과 라이브니스 관리, 볼륨 및 청크-서버 매핑 유지, ChunkServer에 대한 청크 할당, PolarSwitch 인스턴스로의 메타데이터 배포를 담당한다.
Raft는 모든 연산을 로그로 직렬화하고, 커밋은 순서대로만 한다. 이로 인해 로그에서 뒤에 직렬화된 쓰기 요청은 앞선 모든 쓰기가 커밋될 때까지 응답을 보낼 수 없었다. 이는 쓰기 동시성을 8에서 32로 올릴 때 처리량이 절반으로 떨어지는 문제를 일으켰다. 결과적으로 Raft를 수정해, 응답 및 클라이언트로의 커밋 응답에 대해 out-of-order ack를 허용하고, Raft 로그에 홀(hole)을 허용했다. 그들이 리더 선출과 레플리카 캐치업에 미치는 영향을 상세히 설명한다. 이 새로운 변형은 사실상 Raft를 일반화된 multi-paxos로 바꾸는 셈이며, Raft를 억지로 변형하기보다는 왜 처음부터 그것을 구현하지 않았는지는 설명되지 않는다.
PolarFS는 PolarSwitch가 이후 ChunkServer 요청에 스냅샷 태그를 붙이도록 함으로써 디스크 스냅샷을 지원한다. 새 스냅샷 태그를 받으면 ChunkServer는 LBA->블록 위치 매핑을 복사해 스냅샷을 만들고, 이후에는 copy-on-write로 블록을 수정한다. ChunkServer가 스냅샷을 완료했다고 보고하면, PolarSwitch는 해당 ChunkServer에 대한 요청에 더 이상 스냅샷 태그를 붙이지 않는다.
평가에서는 PolarFS가 로컬 ext4 볼륨 대비 오버헤드가 최소이며, Ceph 대비 지연이 약 10배 낮고 처리량이 2배 높다고 보여준다. 다시 말해, 10TB+ 초대형 SSD, 인텔 옵테인, RDMA, 대량 RAM 등 각각이 비싼 요소를 모두 한 클러스터에 집어넣고, 이를 위한 인프라 스택을 특별 취급(special case)함으로써 얻은 결과다. 싸지 않고, (SPDK와 RDMA를 써봤다는 얘기를 종합하면) 작성·배포·운영도 쉽지 않다.
Wei Cao, Yang Liu, Zhushi Cheng, Ning Zheng, Wei Li, Wenjie Wu, Linqiang Ouyang, Peng Wang, Yijing Wang, Ray Kuan, Zhenjun Liu, Feng Zhu, and Tong Zhang. 2020. POLARDB Meets Computational Storage: Efficiently Support Analytical Workloads in Cloud-Native Relational Database. In 18th USENIX Conference on File and Storage Technologies (FAST 20), USENIX Association, Santa Clara, CA, 29–41. [scholar]
이 논문은 ScaleFlux 제품 형태의 SmartSSD를 DB에 통합하는 ‘컴퓨테이셔널 스토리지’ 측면에 더 초점을 맞추며, 이 작업에서 선택한 DB가 우연히 분리형 DB였다. 하지만 페이지 서버와 컴퓨트의 타이트한 통합을 통한 pushdown을 자세히 다루는 유일한 논문이어서 목록에 포함했다. 이 요약은 실제 논문을 충분히 다루지 못할 것이고, pushdown 측면에만 집중한다.
분리형 아키텍처에서 pushdown의 매력은 매칭되지 않는 데이터에 대해 수행되는 처리를 최소화하는 것이다. 테이블 스캔 필터를 컴퓨트 노드에서 스토리지 노드로 푸시하면, 스토리지 노드가 네트워크로 보내야 하는 행 또는 페이지 수가 줄어든다. 컴퓨테이셔널 스토리지에서는 필터를 SSD 자체까지 푸시해, 매칭되지 않는 행을 PCIe 버스로조차 보내지 않도록 할 수 있다. 하지만 이는 컴퓨트 작업을 컴퓨트 노드에서 스토리지로 이동시키는 것이며, 스토리지의 컴퓨트 자원은 훨씬 제한적이다. Alibaba는 스토리지 노드의 컴퓨트를 키우는 대신 FPGA가 탑재된 SSD를 사용해 스토리지 디바이스 자체의 컴퓨트를 늘리기로 했다.
PolarDB Scan Pushdown Architecture
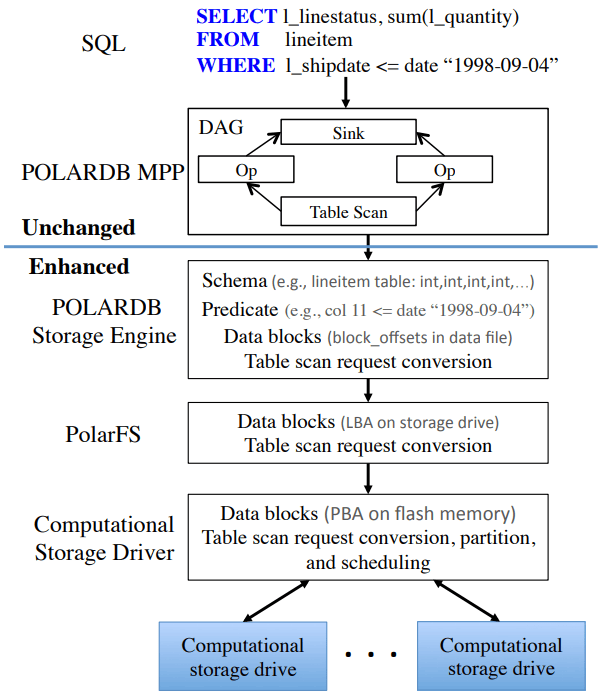
PolarDB의 변경은 스캔 오퍼레이터에서 시작한다. PolarDB는 파일 내 오프셋으로 블록을 요청해 파일에서 데이터를 읽었는데, 이것이 블록 요청에 테이블 스키마와 블록에 적용할 프리디케이트(predicate)도 포함하도록 확장되었다. ChunkServer는 프리디케이트를 FPGA로 푸시할 수 있는 것과 CPU에서 평가해야 하는 것으로 나눈다. PolarFS 논문에서는 ChunkServer가 10TB SSD 1개와 1:1이고 64KB 블록을 추적한다고 했다. 이 논문에서는 ChunkServer가 여러 SmartSSD에 4MB 스트라이프로 데이터를 스트라이핑하며, 4KB 블록은 snappy 압축되어 가변 길이다. ChunkServer는 요청을 스트라이프별로 분할해 해당 SmartSSD로 전달한다.
컴퓨테이셔널 스토리지 디바이스는 Linux에서 드라이버가 블록 디바이스로 노출한다.[1] ChunkServer는 드라이버에 스캔 요청을 보낸다. 드라이버는 하드웨어의 파이프라인 레코드 디코딩에 맞게 필터를 재정렬하고, 논리 블록을 NAND 플래시의 물리 블록으로 변환한다. 또한 드라이버는 큰 스캔을 더 작은 스캔으로 쪼개 동시 요청에서 head-of-line 블로킹이 높은 지연을 유발하는 것을 방지한다.
[1]: SmartSSD<->Host 통합이 어떻게 동작하는지 더 보고 싶다면 NVMe Computational Storage Standardization을 참고.
PolarDB는 프리디케이트를 효율적이고 단순하게 평가할 수 있도록 수정되었다. 키/값 인코딩 포맷을 항상 memcmp()로 정렬 가능(orderable)하도록 바꿔 FPGA가 서로 다른 인코딩과 비교 규칙을 이해할 필요가 없게 했다. 또한 블록을 읽으면서 디코딩할 수 있도록, 메타데이터 풋터를 헤더로 옮겼다.
평가는 TPC-H에서 pushdown 없음, CPU-only pushdown, 컴퓨테이셔널 스토리지(CSD) pushdown을 비교한다. 비압축 데이터에서 CPU pushdown과 CSD pushdown의 쿼리 지연이 모두 2~3배 개선으로 비슷해 보이는데, 이는 대부분의 이득이 한 컴퓨트 인스턴스가 데이터를 받고 필터링한 뒤 버리는 작업에서 벗어나기 때문이므로 놀랍지 않다. 압축 데이터에서는 CSD pushdown이 눈에 띄게 더 낫다. 디컴프레션이 공짜가 아니지만 하드웨어에서 효율적으로 할 수 있기 때문이다. 쿼리별 PCIe 및 네트워크 트래픽 그래프는 pushdown의 각 계층이 네트워크 트래픽(CPU pushdown) 또는 PCIe 트래픽(CSD pushdown)을 또 다른 2~3배씩 줄여준다는 것을 보여준다.
Wei Cao, Yingqiang Zhang, Xinjun Yang, Feifei Li, Sheng Wang, Qingda Hu, Xuntao Cheng, Zongzhi Chen, Zhenjun Liu, Jing Fang, Bo Wang, Yuhui Wang, Haiqing Sun, Ze Yang, Zhushi Cheng, Sen Chen, Jian Wu, Wei Hu, Jianwei Zhao, Yusong Gao, Songlu Cai, Yunyang Zhang, and Jiawang Tong. 2021. PolarDB Serverless: A Cloud Native Database for Disaggregated Data Centers. In Proceedings of the 2021 International Conference on Management of Data (SIGMOD/PODS '21), ACM, 2477–2489. [scholar]
PolarDB Serverless 논문은 RDMA로 구축된 멀티 테넌트 스케일아웃 메모리 풀을 활용하는 내용이다. 결과적으로 메모리까지 분리(disaggregated)된 DB이기도 하다. 이로 인해 메모리와 CPU를 독립적으로 스케일할 수 있고, 평가에서는 PolarDB 테넌트에 할당된 메모리 양을 탄력적으로 바꾸는 모습을 보인다.
하지만 RDMA 위에 페이지 캐시를 구현하는 것은 쉽지 않고, 논문의 상당 부분이 원격 메모리 페이지 래치(latch) 관리와 B-트리 탐색의 정확한 세부를 다루는 데 쓰인다. 특히 B-트리 구조를 바꾸는 연산은 상당한 주의가 필요했다. 또한 복구는 원격 버퍼 캐시에 실패한 RW 노드의 부분 실행 상태가 남아 있다는 점을 처리해야 하므로, 새 RW 노드가 공유 메모리 풀의 래치를 해제하고 부분 수정된 페이지를 버려야 한다. 여기서는 RDMA 특유의 세부는 생략하고, TCP 기반 느린 메모리 분리 아키텍처에도 동일하게 적용될 부분만 다루겠다. 또한 이 논문은 PolarDB와 PolarFS 개선까지 함께 담고 있어 정보량이 많으니 주의.
PolarDB 전체 아키텍처 다이어그램은 다음과 같다:
PolarDB Architecture
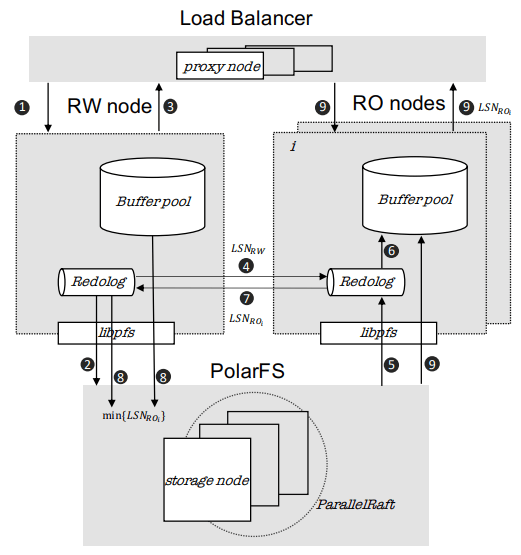
하지만 이 다이어그램이 잘 표현하지 못하는 것들이 있다:
PolarFS는 로그 청크와 페이지 청크를 분리 지원하도록 확장되었다. WAL은 로그 청크에 커밋되며, 설계는 Aurora보다 Socrates XLOG에 가깝다고 직접 말한다.
ParallelRaft 사용 때문에 로그는 페이지 청크의 리더 노드로만 전송되며, 그 노드가 페이지를 구체화하고 다른 레플리카로 업데이트를 전파한다.
또한 RDMA로 빠르고 저렴하게 타임스탬프를 제공하는 타임스탬프 서비스가 있는데 다이어그램에는 없다.
PolarDB Serverless는 원격 메모리 풀을 추가해 RO와 RW가 같은 버퍼 풀을 공유하도록 한다. 원격 메모리 접근은 librmem을 통해 다음 API로 수행된다:
int page_register(PageID page_id,
const Address local_addr,
Address& remote_addr,
Address& pl_addr,
bool& exists);
int page_unregister(PageID page_id);
int page_read(const Address local_addr,
const Address remote_addr);
int page_write(const Address local_addr,
const Address remote_addr);
int page_invalidate(PageID page_id);
최소 할당 단위는 물리적으로 연속된 1GB _slab_이며, 이는 16KB 페이지로 나뉜다(PolarDB는 MySQL 기반이고 MySQL은 16KB 페이지 사용). 슬랩 노드는 여러 슬랩을 보유하고, DB 인스턴스는 시작 시 정의된 버퍼 풀 용량을 맞추기 위해 여러 슬랩 노드에 걸쳐 슬랩을 할당한다. 첫 슬랩은 _home node_로 지정되어 DB 인스턴스의 버퍼 캐시 메타데이터 호스팅 책임을 갖는다. Page Address Table(PAT)은 각 페이지의 슬랩 노드와 물리 주소를 추적한다. Page Invalidation Bitmap(PIB)은 RW 노드가 아직 writeback하지 않은 로컬 수정이 있을 때 업데이트되며(RO 노드가 스테일함을 아는 데 사용), Page Reference Directory(PRD)는 PAT에 기술된 각 페이지에 대해 어떤 인스턴스가 참조를 들고 있는지 추적한다. Page Latch Table(PLT)은 PAT의 각 엔트리에 대한 페이지 래치를 관리한다.
PolarDB Serverless Remote Buffer Pool
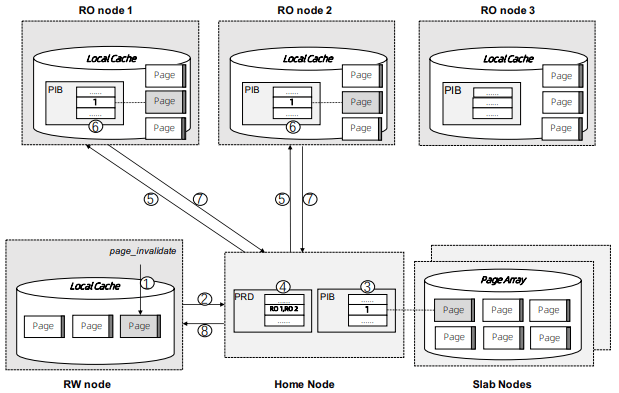
page_register는 home node에 페이지의 refcount를 증가시키고 주소를 반환하거나, 새 페이지를 할당(필요하면 오래된 것을 eviction)하고 주소를 반환하는 요청이다. (스토리지에서 페이지를 읽는 것이 아니라, 슬랩 노드와 PolarFS 사이 직접 통신은 없고 원격 버퍼 풀에 공간을 할당하는 것이다.) page_unregister는 refcount를 감소시켜 필요하면 페이지를 해제할 수 있게 한다. 더티 페이지는 PolarDB가 ChunkServer로부터 온디맨드로 페이지를 구체화할 수 있으므로 즉시 eviction될 수 있다. 버퍼 풀이 확장되면 home node가 PAT/PIB/PRD 메타데이터를 확장하고 슬랩을 선제적으로 할당한다. 버퍼 풀이 축소되면 페이지를 해제해 메모리를 반환하고, 기존 페이지를 디프래그먼트한 뒤 사용하지 않는 슬랩을 반환한다. (디프래그 및 물리 연속 메모리는 원사이드 RDMA를 위해 필요하며, RDMA가 아닌 구현은 더 단순하고 비연속적일 수 있다.)
각 인스턴스는 원격 메모리에 대한 L1/L2/L3 캐시가 없으므로 RAM의 로컬 페이지 캐시를 갖는다. 이 로컬 캐시는 튜닝 가능하며 기본값은 (원문에 값이 누락된 듯하다), TPC-C와 TPC-H 영향을 관찰해 설정되었다. PolarFS에서 읽은 모든 페이지가 원격 메모리로 푸시되는 것은 아니다. 풀 테이블 스캔에서 읽은 페이지는 로컬 캐시에만 읽고 버린다. 페이지 수정은 여전히 로컬 캐시에서만 수행된다. 페이지가 원격 버퍼 풀에 존재한다면 수정 전 먼저 invalidate되어야 하며, 로컬 캐시에서 드롭되기 전 원격 버퍼 풀로 다시 써야 한다(흐름은 위 다이어그램). 삽입/삭제는 락 없이 낙관적으로 트리를 탐색하다 페이지 split/merge가 필요하다고 판단되면 비관적 락 탐색으로 재시작한다. (Socrates는 부모보다 오래된 자식 페이지를 만나면 RO가 B-트리 탐색을 재시작하는 것과 대비된다.)
PolarDB에 대한 몇 가지 개선은 분리형 메모리 아키텍처와 무관해 보이게 제시되지만, 직접적 결과라고 생각한다. 스냅샷 격리 구현은 중앙 타임스탬프 서비스를 사용하도록 바뀌었고, 읽기 타임스탬프와 커밋 타임스탬프 모두를 질의한다. 모든 행은 커밋 타임스탬프가 suffix로 붙어 MVCC 가시성 필터링이 쉬워졌고, 최근 커밋 데이터의 커밋 타임스탬프를 해석하기 위한 Commit Timestamp Log도 추가됐다. 원격 타임스탬프 서비스와 행별 커밋 타임스탬프 추적의 필요성은 RO 레플리카를 RW 리더로 승격할 때 모든 데이터를 스캔하지 않기 위함이다. 다음 유효 커밋 타임스탬프를 복구할 필요가 없고(원격 서비스가 보유), 어떤 트랜잭션들이 동시였는지 등의 메타데이터를 다시 만들 필요도 없다. MVCC 가시성 규칙이 엄격한 타임스탬프 필터이며, 커밋 타임스탬프가 없는 행은 점진적으로 해석할 수 있기 때문이다. (이는 TiDB와 유사한 MVCC/트랜잭션 프로토콜로 이어진다.) 마찬가지로 PolarDB Serverless는 다른 분리형 OLTP 시스템들이 이미 갖고 있던 GetPage@LSN 요청을 PolarFS에 추가해야 할 근거를 제공했다(예: Socrates).
그들이 명시적으로 언급하는 트랜잭션/쿼리 처리 최적화가 몇 가지 있다. RO 노드는 RW 노드가 RO 노드의 마지막 접근 이후 B-트리 구조를 수정했다고 말하지 않는 한 버퍼 풀에서 래치를 획득하지 않는다. 또한 인덱스에 대해 특정 최적화를 구현한다: 프리페칭 인덱스 프로브. 인덱스에서 키를 가져올 때, SQL 실행에서 곧바로 필요할 것으로 가정하고 가리키는 데이터 페이지를 페이지 서버로부터 프리페치한다.
RW 노드가 손실되면 Cluster Manager가 RO 노드를 새 RW 노드로 승격한다. 이는 (원문에 ‘collecting the’ 뒤가 누락된 듯하나) redo 로그를 요청·처리해 모든 청크를 일관된 버전으로 맞추는 과정을 포함한다. 원격 메모리 풀에서 invalidate된 페이지는 PIB를 사용해 eviction되며(수 GB 전체 스캔이 아님), redo로 복구한 버전보다 새로운 페이지도 eviction된다. 실패한 RW 노드가 잡고 있던 모든 락은 해제된다. 활성 트랜잭션은 undo 로그 헤더에서 복구된다. 그 다음 Cluster Manager에 복구 완료를 알리고, 백그라운드에서 활성 트랜잭션을 롤백한다. RW 노드가 자발적으로 다른 노드에 writer 역할을 넘기면, 수정 페이지를 플러시하고 락을 드롭해 RO 노드가 redo 적용 및 페이지 eviction 일을 덜게 할 수 있다. home slab의 모든 레플리카를 잃는 극단 상황에서는 모든 슬랩을 비우고, 모든 DB 노드를 재시작해 복구가 일관된 상태를 복원하도록 한다.
평가는 위 최적화들의 복구 시간 영향을 보여준다. 최적화가 없으면 비가용이 약 85초, 원래 성능으로 회복은 105초 걸린다. PolarFS에서 페이지 구체화를 하면 비가용이 약 15초, 완전 성능은 35초로 줄어든다. 원격 메모리 버퍼 풀이 있으면 비가용은 약 15초, 완전 성능은 23초다. RW 노드의 자발적 핸드오프는 비가용 2초, 완전 성능 6초를 보여준다. 그 밖의 그래프는 메모리를 탄력적으로 스케일할 수 있고, 메모리가 많을수록 성능이 좋아지고 적을수록 나빠지는 것을 보여준다.
그들은 RDMA의 난이도를 여전히 과소평가했다. 이전에 RDMA를 다뤄본 사람이, 읽기/쓰기 레이스와 그룹 멤버십 및 샤드 이동을 맞추는 문제 등 온갖 이슈가 있다고 언급했다. 두 경우 모두, 정보가 갱신되지 않은 클라이언트가 여전히 복제 그룹의 일부라고 생각되는 서버나, 자신이 원하는 샤드를 갖고 있다고 생각되는 서버에 대해 원사이드 RDMA 읽기를 수행할 수 있다.
Wei Cao, Feifei Li, Gui Huang, Jianghang Lou, Jianwei Zhao, Dengcheng He, Mengshi Sun, Yingqiang Zhang, Sheng Wang, Xueqiang Wu, Han Liao, Zilin Chen, Xiaojian Fang, Mo Chen, Chenghui Liang, Yanxin Luo, Huanming Wang, Songlei Wang, Zhanfeng Ma, Xinjun Yang, Xiang Peng, Yubin Ruan, Yuhui Wang, Jie Zhou, Jianying Wang, Qingda Hu, and Junbin Kang. 2022. PolarDB-X: An Elastic Distributed Relational Database for Cloud-Native Applications. In 2022 IEEE 38th International Conference on Data Engineering (ICDE), IEEE, 2859–2872. [scholar]
PolarDB-X는 세 가지 문제를 타겟으로 한다: PolarDB를 한 리전을 넘어 확장하기 위한 cross-DC 트랜잭션, 자동으로 읽기 전용 레플리카를 추가하고 쓰기 책임을 파티셔닝하는 탄력성(elasticity), 그리고 분석/트랜잭션 쿼리를 식별해 서로 다른 레플리카로 조향하는 HTAP. 고수준에서 PolarDB-X는 PolarDB의 Vitess 또는 Citus다. 개별 PolarDB 인스턴스가 더 큰 PolarDB-X 분산 shared-nothing DB의 파티션이 된다. 또한 오픈소스이며 polardb/polardbx에서 제공된다. 대부분 미공개인 Amazon Aurora Limitless와 매우 유사한 결이다.
PolarDB-X Architecture
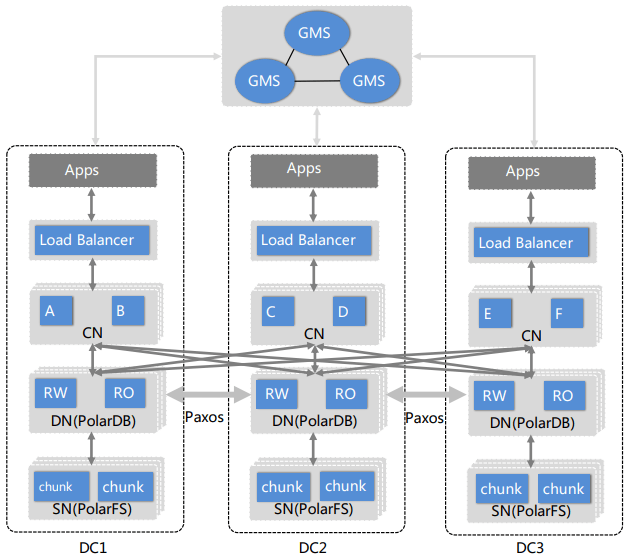
PolarDB 위에서 PolarDB-X는 PolarDB 인스턴스당 Load Balancer와 Computation Node 집합(DN & SN)을 추가하고, 시스템 메타데이터를 위한 Global Meta Service(GMS) 하나를 둔다. GMS는 PolarDB-X의 컨트롤 플레인이며 클러스터 멤버십, 카탈로그 테이블, 테이블/인덱스 파티셔닝 규칙, 샤드 위치, 통계, MySQL 시스템 테이블을 관리한다. Load Balancer는 사용자가 PolarDB-X에 진입하는 지점으로, 지리 인지(geo-aware) 단일 가상 IP로 노출된다. Computation Node는 서로 다른 PolarDB 인스턴스에 저장된 테이블 샤드들에 걸쳐 읽기/쓰기 쿼리를 조정한다. 읽기 쿼리에서는 로컬 스냅샷이 충분히 최신인지 판단해 cross-AZ 리더로 가지 않아도 되는지 결정한다. 쓰기 쿼리에서는 필요 시 cross-shard 트랜잭션을 관리한다. 비용 기반 옵티마이저와 쿼리 실행기를 포함하며, 이를 통해 쿼리를 샤드별 쿼리로 분해하고 최종 결과를 만들기 위한 cross-shard 평가를 수행한다. Database Node(PolarDB)나 Storage Node(PolarFS) 개요는 위의 각 논문 요약을 참고.
PolarDB-X는 기본적으로 기본 키를 해시해 행을 샤드에 할당한다. 논문에는 자세히 없지만, PolarDB-X Partitioned table docs에 따르면 지원 파티셔닝 전략은: SINGLE(샤딩 없음), BROADCAST(각 샤드에 테이블 복제), PARTITION BY HASH/RANGE/LIST(수동 파티셔닝), COHASH(여러 컬럼이 같은 값을 갖는 HASH)이다. 인덱스는 글로벌 또는 로컬로 정의될 수 있으며, 로컬 인덱스는 항상 같은 샤드 내 데이터만 인덱싱한다. 동일한 파티션 키를 가진 테이블들을 테이블 그룹으로 선언하면, 동일한 키 값은 항상 같은 샤드에 저장되어 동등 조인(equi-join)을 예측 가능하게 가속한다.
cross-DC 복제는 PolarDB가 redo 로그를 데이터센터 간으로 전송하는 방식으로 수행한다. 복제는 Paxos 구현과 함께(또는 그 위에서) 리더십과 Durable LSN의 전진을 관리한다. 트랜잭션은 미니 트랜잭션으로 나뉘고, redo 로그 배치로 점진적으로(다른 트랜잭션과 섞여) 전송된다. 사용자의 트랜잭션에서 마지막 미니 트랜잭션이 durable로 표시되면 커밋된다.
cross-shard 트랜잭션을 위해 PolarDB-X는 위에 또 다른 MVCC 및 트랜잭션 프로토콜을 얹는다. Snapshot Isolation을 구현하기 위해 Hybrid Logical Clock(HLC)를 사용한다. HLC는 물리 시계의 강한 동기화를 요구하지 않고 TiDB/Percolator식 중앙 시계 서버를 피할 수 있어 선택되었다. (다만 선형화 가능성(linearizability)은 기술적으로 희생한다.) 인과성 카운터를 bump하는 횟수를 줄이기 위한 최적화들이 있지만, 그 외에는 표준 HLC와 2PC 구현이다. 공개 문서는 대신 Timestamp Oracle 사용을 설명하며, GMS가 Compute Node에 그 기능을 제공한다고 설명한다.
PolarDB-X OSS Architecture
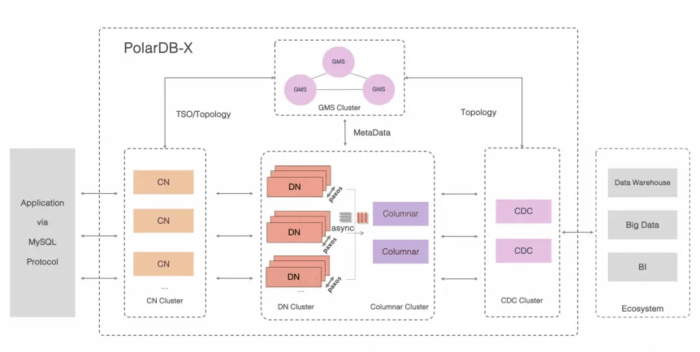
PolarDB-MT는 PolarDB를 멀티 테넌시를 네이티브로 이해하도록 확장한 것이다. 테넌트는 스키마/DB/테이블의 집합이며, 테넌트 간 연산은 허용되지 않는다. 하나의 PolarDB 인스턴스가 여러 테넌트를 지원하며, 모든 연산은 지정된 RW 노드의 redo 로그를 통해 처리된다. 테넌트->RW DB 노드 매핑은 GMS에 저장되며, RW 노드는 자신이 보유한 테넌트에 대해 리스(lease)를 유지한다. 테넌트는 활성 작업을 중단·이동하고 더티 페이지를 플러시한 뒤 리스를 이전함으로써 전송될 수 있다. 장애 시 테넌트는 다른 RW PolarDB 인스턴스들로 분산될 수 있으며, 이들은 실패한 인스턴스의 redo 로그를 테넌트별로 나누고 그에 따라 복구한다. 샤드와 테넌트의 차이는? 논문은 전혀 답하지 않는다. 공개 문서는 테넌트를 사용자와 DB에 대한 성능 격리 컨테이너로 설명한다. Nile처럼 테넌트는 내부적으로 고객을 머신에 더 효율적으로 빈팩킹하는 데 쓰일 가능성도 있어 보인다.
PolarDB-X는 HTAP 솔루션도 제공하는데, 행 지향 RW DB 노드가 비동기로 컬럼 지향 RO DB 노드로 복제한다(티디비/티플래시 스타일). CN의 비용 기반 옵티마이저가 OLAP 쿼리를 식별해 컬럼 노드로 보낸다. 분석 쿼리의 일부는 (PolarDB Computational Storage에서 설명한 작업의 확장으로) Storage Node(PolarFS)로 푸시다운된다. Compute Node는 Query Coordinator가 되어 쿼리를 프래그먼트로 나누고 다른 Compute Node에서 병렬 실행한다. 실행은 500ms 타임슬라이스 작업으로 분할되어 여러 쿼리가 동시에 진척할 수 있다. 분석 처리 스레드풀은 cgroup으로 제한되지만, 트랜잭션 처리는 제한되지 않는다. 분석 엔진 자체의 자세한 내용은 다음 논문 PolarDB-IMCI에 있다.
평가 섹션은 큰 놀라움이 없다. 타임스탬프 오라클 대신 HLC를 쓰면 sysbench 처리량이 19% 높았다. 스케일링 작업은 큰 방해 없이 4~5초 내 완료된다. 컬럼 데이터를 활용하면 컬럼스토어의 이점을 크게 받는 쿼리 실행 시간이 개선된다.
Jianying Wang, Tongliang Li, Haoze Song, Xinjun Yang, Wenchao Zhou, Feifei Li, Baoyue Yan, Qianqian Wu, Yukun Liang, ChengJun Ying, Yujie Wang, Baokai Chen, Chang Cai, Yubin Ruan, Xiaoyi Weng, Shibin Chen, Liang Yin, Chengzhong Yang, Xin Cai, Hongyan Xing, Nanlong Yu, Xiaofei Chen, Dapeng Huang, and Jianling Sun. 2023. PolarDB-IMCI: A Cloud-Native HTAP Database System at Alibaba. Proceedings of the ACM on Management of Data 1, 2 (June 2023), 1–25. [scholar]
PolarDB-IMCI는 PolarDB의 HTAP 솔루션이다. 세 번째 페이지가 되어서야 IMCI가 _in-memory column index_의 약자임을 알게 된다. PolarDB-IMCI의 목표는 신선한 실시간 데이터에 대해, OLTP 성능을 손상시키지 않으면서도 좋은 OLAP 성능을 내는 것이다.
인메모리 컬럼 인덱스는 OLTP 워크로드를 실행하는 노드들과 분리된 읽기 전용 노드 집합에서 유지되어, OLAP과 OLTP가 서로 간섭하지 않게 한다. 업데이트는 redo 로그를 통해 컬럼 레플리카에 적용되며, PolarDB-IMCI는 컬럼 레플리카의 스테일함을 줄이고 변경 파싱을 효율화하기 위해 commit-ahead log shipping(CALS)과 2-Phase conflict-free log replay(2P-COFFER)를 도입한다. 컬럼 인덱스는 append-only 스토리지로 유지되어 RowID 기준 업데이트/룩업이 빠르지만, Primary Key -> RowID 매핑을 위한 두 번째 인덱스(2계층 LSM 트리)를 필요로 한다. IMCI의 체크포인팅은 PolarDB 스토리지 엔진과 통합되어 추가 컬럼 레플리카를 빠르게 띄울 수 있다.
PolarDB-IMCI Architecture
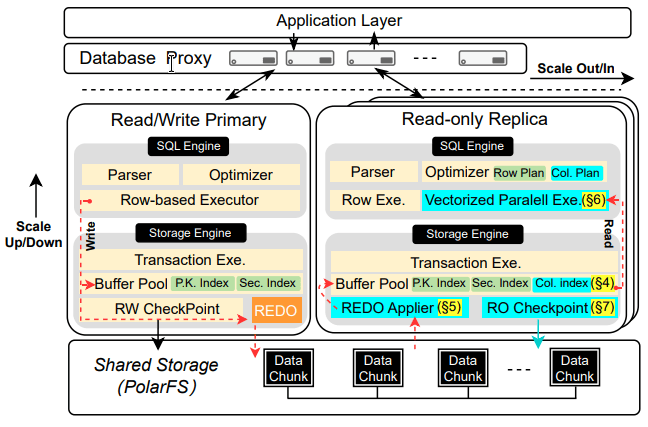
컬럼 인덱스는 DDL의 일부로 정의되며, 테이블의 행 일부만 인메모리 컬럼 인덱스에 담을 수 있다. 테이블은 64K 행 단위 청크로 나뉘고, 각 행 그룹의 인덱싱된 컬럼들은 일부 메타데이터와 함께 압축된 _data pack_으로 구성된다. 남는 행들은 자주 업데이트되므로 압축하지 않은 부분 데이터 팩을 구성한다. 팩 메타데이터는 zonemap 스타일로 삽입된 데이터에 대한 min/max(컬럼별), sum, count, null, distinct 정보를 제공한다. 삭제는 tombstone 삽입으로 처리되며, 삭제 대상 행의 RowID는 기본 키로 룩업한다. 업데이트는 삭제 후 삽입이다. 압축은 표준 컬럼 압축(FOR/delta)이며 deflate/lzma 류가 아니다.
Commit-ahead log shipping은 RW 트랜잭션 노드가 각 DML 문장을 실행한 뒤 WAL 레코드로 기록하는 방식이다. 컬럼 RO 노드는 이 로그 레코드를 적극적으로 가져와 DML 문장으로 파싱해 트랜잭션별 버퍼에 저장한다. RW 노드가 최종 commit/abort 결정을 보내면, 컬럼 노드는 적용(커밋)하거나 폐기(어보트)할 논리 연산 버퍼를 이미 갖고 있다. 버퍼가 넘치는 트랜잭션은 pre-commit되며, MVCC로 데이터가 보이지 않게 한다.
이 작업은 RW 트랜잭션 노드에 추가 부담을 주지 않기 위해 redo WAL만으로 수행된다. 하지만 redo 로그는 물리 페이지 변경을 반영하며 DB/테이블 수준 정보가 부족하고, 페이지 변경에는 B+-Tree split/merge도 포함되며, 전체 업데이트가 아니라 delta만 포함된다. Two-Phase Conflict-Free Parallel Replay는 이 한계를 해결한다. 1단계는 redo 로그를 행 스토어의 인메모리 복사본에 적용해 누락된 데이터/정보를 재구성한다. 2단계는 redo 로그의 LSN에 따른 원래 문장 실행 순서를 존중하면서, 전체 DML을 컬럼 인덱스에 재생(replay)한다.
PolarDB-IMCI의 프록시 계층은 행 기반 비용 모델로 쿼리를 플래닝한다. 비용이 낮으면 트랜잭션 레플리카로 포워딩한다. 비용이 높으면 컬럼 레플리카로 보내고, 컬럼 지향으로 재플래닝한다. 재플래닝은 행 플랜을 베이스로 시작해 새 비용 모델로 조인 오더링을 다시 하고, 표현식 실행을 벡터화 버전으로 변환한다. PolarDB-IMCI는 옵티마이저의 정확한 카디널리티 추정을 위해 랜덤 백그라운드 샘플링으로 테이블 통계를 계산한다.
평가에서는 예상대로, 디스크 기반 B-트리 대비 인메모리 컬럼 인덱스가 OLAP에서 PolarDB 대비 큰 속도 향상을 보인다. Clickhouse와 비슷한 수준의 성능도 보여주고, OLTP 성능에 미치는 영향이 작으며 OLAP 워크로드에 대한 리소스 탄력성을 제공함을 시연한다.
Xinjun Yang, Yingqiang Zhang, Hao Chen, Chuan Sun, Feifei Li, and Wenchao Zhou. 2023. PolarDB-SCC: A Cloud-Native Database Ensuring Low Latency for Strongly Consistent Reads. Proceedings of the VLDB Endowment 16, 12 (August 2023), 3754–3767. [scholar]
SCC는 _Strongly Consistent Cluster_의 약자이며, 이 논문의 초점은 RW 노드가 변경을 커밋한 뒤 RO 노드가 이를 인지하고 읽기를 제공할 수 있게 되기까지의 지연을 최대한 제거하는 것이다. 분리형 DB의 RO 레플리카는 몇 ms의 스테일함을 갖거나, 강한 일관 읽기는 1x~5x의 추가 읽기 지연을 유발한다고 동기를 제시한다. PolarDB-SCC는 세 단계의 타임스탬프(글로벌/테이블/페이지)를 사용해 RO가 더 일찍 변경을 끌어오기 시작할 수 있게 하고, 이를 위한 지연과 오버헤드를 최소화하기 위해 RDMA를 사용한다. 이 추가 지연 때문에 대부분의 DB는 강한 일관 읽기를 리더로 보내라고 권고하며, 이는 로드밸런싱을 무너뜨려 RO 레플리카의 유용성을 떨어뜨린다. PolarDB-SCC가 타겟으로 하는 문제가 바로 이것이다.
PolarDB-SCC Architecture
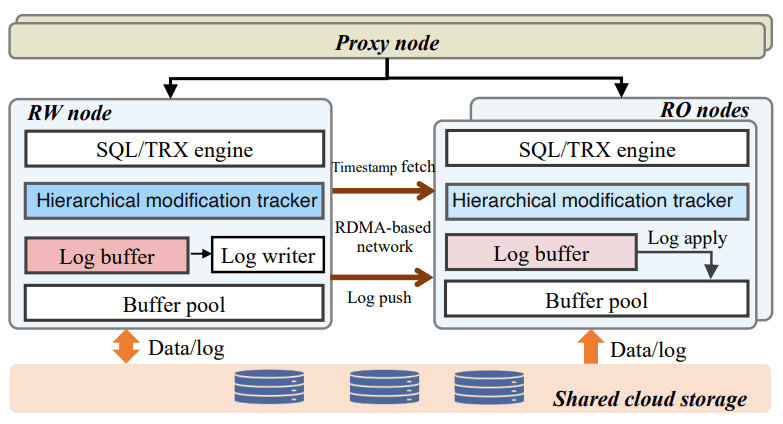
타임스탬핑은 RW 노드를 타임스탬프 오라클로 취급한다. RW 노드는 수정마다 lamport clock을 글로벌/테이블/페이지 수준으로 기록한다. RO 노드는 쿼리 시작 시 현재 타임스탬프를 가져오며, 여러 쿼리에 대해 배치할 수 있다. 쿼리에 타임스탬프가 할당되면, RO 노드는 참조하는 글로벌/테이블/페이지 데이터가 로컬에서 최신이면 읽기를 제공할 수 있다. 계층 구조 때문에, 예를 들어 적용된 테이블 수준 타임스탬프가 쿼리 타임스탬프보다 크면, 모든 페이지가 충분히 최신임이 함의되어 페이지를 개별 체크할 필요가 없다. 글로벌 타임스탬프는 최대 커밋 트랜잭션 타임스탬프다. 페이지별 별도 타임스탬프를 유지하는 오버헤드를 피하기 위해, 페이지의 LSN을 페이지 타임스탬프로 사용한다. RW 노드는 테이블/페이지 타임스탬프를 해시테이블로 유지해 원사이드 RDMA로 빠르게 질의할 수 있다.
논문은 RDMA 기반 로그 쉬핑을 자세히 다루는데, 본질적으로 양쪽의 링버퍼와, 소비되지 않은 로그 데이터가 덮어써지는 것을 안전하게 처리하기 위한 추가 체크들이다. RW 노드는 WAL을 모든 RO 노드로 푸시한다. 어떤 RO가 너무 뒤처지면 스토리지(PolarFS)에서 로그를 읽는다. 기존 로그 버퍼 관리에는 변경이 없다.
트랜잭션 내의 읽기 쿼리도 RO 노드로 보낼 수 있지만, 트랜잭션 앞부분에서 수행된 쓰기의 효과를 포함해야 한다. PolarDB-SCC는 RW 노드가 쓰기 쿼리에서 생성된 최대 LSN을 프록시에 반환하게 한다. 프록시는 이후 같은 트랜잭션의 읽기 쿼리에 그 LSN을 붙여, RO 노드가 해당 트랜잭션의 쓰기가 적용되었음을 확인할 수 있게 한다. 로드밸런서는 최대 쓰기 LSN까지 로컬 적용을 마친 RO 노드에 우선적으로 쿼리를 보낸다.
평가에서는 SysBench 및 프로덕션 워크로드에서 PolarDB-SCC가 PolarDB RO 레플리카의 스테일 읽기보다 약간 나쁜 정도의 지연만을 제공함을 보여준다. 또한 처리량이 스테일 읽기 워크로드와 비슷하게 확장되어, RW 노드에 부담이 더 적다는 것을 보여준다. 그리고 일관 쿼리에서 RO 레플리카를 더 잘 활용해 처리량을 높일 수 있다. (평가에서 프록시/로드밸런서는 언급되지 않지만, PolarDB의 기존 구성 요소였으므로 양쪽에 동일하게 포함됐을 가능성이 높다.)
이 개요에서 ‘PolarDB Elasticity’로 부르는 것은, 논문에서 시스템 이름을 “PolarDB Serverless”라고 부르기 때문이다. 하지만 이것은 이미 PolarDB Serverless라는 이름(메모리 분리 논문)에 쓰였기 때문에, 두 개를 구분하려고 내가 이름을 바꿨다.
Yingqiang Zhang, Xinjun Yang, Hao Chen, Feifei Li, Jiawei Xu, Jie Zhou, Xudong Wu, and Qiang Zhang. 2024. Towards a Shared-Storage-Based Serverless Database Achieving Seamless Scale-Up and Read Scale-Out. In 2024 IEEE 40th International Conference on Data Engineering (ICDE), 5119–5131. [scholar]
서버리스 DB는 물리 리소스 요구가 증가할 때 DB 인스턴스를 매끄럽게 마이그레이션하고, 추가 RO 노드를 동적으로 스케일아웃할 수 있어야 한다. 한 머신에서 다른 머신으로 인스턴스를 옮기는 과정에서 진행 중인 트랜잭션이 중단되면 안 되며, 전환 중 지연 영향도 가능한 최소화되어야 한다. 매끄러운 마이그레이션은 매끄러운 업그레이드도 가능하게 한다. 읽기 확장성에서는 PolarDB-SCC에 의존해, 강한 일관 읽기 작업을 primary에서 오프로딩하면서 복제 지연으로 인한 추가 지연을 최소화한다. 쓰기 확장성에 대한 논의가 빠진 것은 다음 논문(동시에 작성·제출됐을 가능성이 높음)에서 다루기 때문일 가능성이 높다.
PolarDB Elasticity Architecture
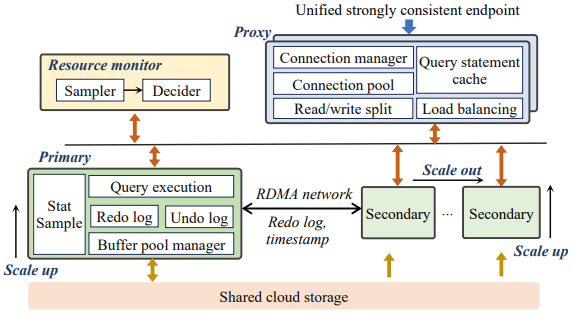
PolarDB Elasticity는 DB 인스턴스 마이그레이션 동안 연결을 유지하기 위한 프록시를 도입한다. 프록시 노드는 모든 애플리케이션이 연결하는 단일 통합 엔드포인트다. (“통합”은 PolarDB-SCC가 없으면 읽기 전용 스테일 엔드포인트와 읽기-쓰기 일관 엔드포인트가 분리되는 설계와 대비되는 의미.) 프록시는 DB의 모든 RO 레플리카에 연결하므로, 애플리케이션의 프록시 연결 1개가 여러 DB 인스턴스 연결로 매핑될 수 있다. 마이그레이션 동안 프록시는 클라이언트 요청을 버퍼링하고, 새 DB 인스턴스에 대한 연결이 성립되면 전달한다.
트랜잭션 마이그레이션은 진행 중 트랜잭션의 undo/redo 로그와 인메모리 트랜잭션 메타데이터를 새 DB 인스턴스로 옮겨, 마이그레이션 시 트랜잭션이 어보트되지 않도록 한다. 마이그레이션이 시작될 때 쿼리가 실행 중이라면, 기존 인스턴스는 쿼리 완료를 ack하기 전에 그 쿼리의 redo 로그를 새 인스턴스로 보내 새 인스턴스가 트랜잭션 실행을 이어받을 수 있게 한다. 인스턴스가 종료되면 undo 로그로 진행 중 쿼리를 롤백할 수 있고, 그 쿼리는 새 노드에서 재실행될 수 있다. 트랜잭션 락은 행이 트랜잭션 ID로 태깅되는 방식으로 표현되며, 따라서 새 DB 인스턴스가 트랜잭션의 소유권을 가져가는 것은 트랜잭션의 모든 락을 가져가는 의미이기도 하다. MySQL binlog는 복구에 필수는 아니지만 많은 고객이 CDC나 후속 처리를 위해 의존하므로, 마이그레이션 동안 binlog도 인스턴스 간으로 이동되어 계속 제대로 방출되도록 한다.
평가는 Aurora Serverless 대비 PolarDB 마이그레이션이 더 빠르고 트랜잭션 어보트가 없음을 보인다. 다만 Aurora Serverless는 이동을 최소화하기 위한 좋은 소스/목적지 쌍 선택에 큰 비중을 두었는데, 이 논문은 범위에 포함하지 않았다. 또한 PolarDB Elasticity는 PolarDB Capacity Units(PCU)로 제공되며, PCU는 1vCPU + 2GB 메모리 및 대응하는 네트워킹/I/O이고, 리소스는 0.5 PCU 단위로 할당/해제된다고 언급한다. 마찬가지로 리소스 한도를 어떻게 모니터링하고 강제하는지에 대한 세부는 없다.
Xinjun Yang, Yingqiang Zhang, Hao Chen, Feifei Li, Bo Wang, Jing Fang, Chuan Sun, and Yuhui Wang. 2024. PolarDB-MP: A Multi-Primary Cloud-Native Database via Disaggregated Shared Memory. In Companion of the 2024 International Conference on Management of Data (SIGMOD/PODS '24), ACM, 295–308. [scholar]
PolarDB-MP는 PolarDB를 둘 이상의 RW 노드를 지원하도록 확장하는 내용을 다룬다. PolarDB는 메모리 분리를 먼저 구현한 점이 독특하며, 따라서 멀티 프라이머리 지원은 RDMA를 통해 모든 레플리카가 접근 가능한 공유 버퍼 풀을 이미 갖고 있다는 사실에 크게 기반한다. 모든 ‘매콤한’ 논문답게, PolarDB-MP는 관련 연구 비판으로 시작한다: Aurora Multi-Master는 OCC를 사용해 어보트율이 높았고, Taurus-MM은 비관적 동시성 제어로 오버헤드가 높았으며(8노드로 처리량 1.8배 증가), IBM pureScale과 Oracle RAC는 전용 맞춤 머신에 의존해 너무 비싸다.
PolarDB-MP Architecture
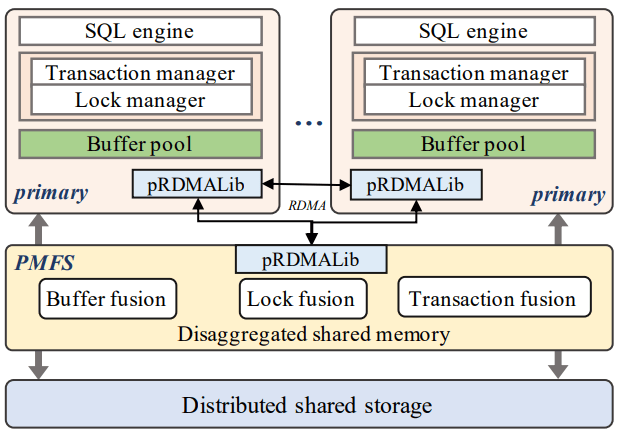
PolarDB-MP의 중심에는 Polar Multi-Primary Fusion Server(PMFS)가 있으며, 이는 Transaction Fusion, Buffer Fusion, _Lock Fusion_으로 구성되고 RDMA 중심성을 더 강화한다. Transaction Fusion은 타임스탬프 오라클을 사용하고, 각 노드의 로컬 트랜잭션 데이터를 위한 공유 메모리를 각 노드에 할당하는데 이 메모리 역시 RDMA로 모든 노드에서 접근 가능하다. Buffer Fusion은 노드들이 공유하는 분산 버퍼 풀이다. Lock Fusion은 페이지 및 행 수준 락을 관리한다. 또한 PolarDB-MP는 LSN을 Logical Log Sequence Number(LLSN)로 확장해 각 노드가 LSN을 생성하면서도 LLSN들 사이에 전역 부분 순서(partial order)가 존재하도록 한다.
PolarDB-MP Transaction Information Table
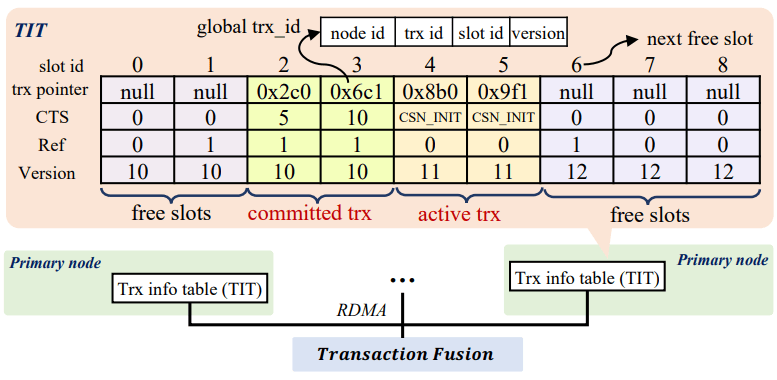
Transaction Fusion은 중앙집중 트랜잭션 정보 관리를 피하기 위한 전역 타임스탬프 오라클 + 노드별 로컬 트랜잭션 정보다. 논문은 흥미롭게도, MVCC가 읽기와 쓰기를 동시에 허용하는 것이 일반적으로 장점이지만 shared-storage 멀티 프라이머리 DB에서는 큰 도전이 된다고 주장한다. 여러 버전 중 올바른 가시 튜플을 결정하려면 전역 트랜잭션 정보가 필요하고 이는 높은 조정 오버헤드를 강제한다. 해결은 트랜잭션 관리를 탈중앙화하는 것: 각 노드는 자신의 로컬 트랜잭션 정보를 Transaction Information Table(TIT)에 유지하며, 이는 RDMA로 다른 노드에서 접근 가능하다. TIT는 트랜잭션 객체 포인터, Commit Timestamp(CTS), 버전(시간에 따라 같은 TIT 슬롯을 재사용하므로 구분용 카운터), 그리고 다른 트랜잭션이 이 락 해제를 기다리는지 나타내는 “ref” 플래그를 유지한다. 트랜잭션은 노드 ID, 노드 로컬 카운터에서 나오는 트랜잭션 ID, 로컬 TIT 내 슬롯 번호, TIT 엔트리 버전 번호를 조합해 전역적으로 식별된다.
튜플을 업데이트할 때 PolarDB-MP는 전역 트랜잭션 ID를 행 메타데이터에 넣는다. 커밋 시점에, 행이 여전히 버퍼에 있으면 CTS가 업데이트되고, 아니면 CSN_INIT로 남는다. PolarDB는 MySQL 파생이므로 MVCC를 위해 undo 로그로 오래된 행 값을 재구성하는데, 읽은 튜플이 주어진 read 버전보다 너무 새로운 경우 이 과정은 변하지 않는다. 행의 CTS가 CSN_INIT라면, 전역 트랜잭션 ID로 해당 트랜잭션의 TIT 엔트리를 가져올 수 있다. 가져온 엔트리가 일치하지 않으면, 트랜잭션은 이미 커밋했고 TIT 슬롯이 재사용되었음을 의미한다. TIT 슬롯은 백그라운드 스레드가 GC하며, 어떤 활성 statement도 그 커밋 트랜잭션보다 더 이전을 읽을 필요가 없을 때만 엔트리가 제거되고, 그 시점에 최소 타임스탬프를 행에 할당해 항상 가시하도록 할 수 있다. 읽기 타임스탬프 요청은 PolarDB-SCC에서 설명한 것처럼 코얼레싱되며 동일한 Linear Lamport Timestamp를 사용한다.
PolarDB-MP Buffer Fusion
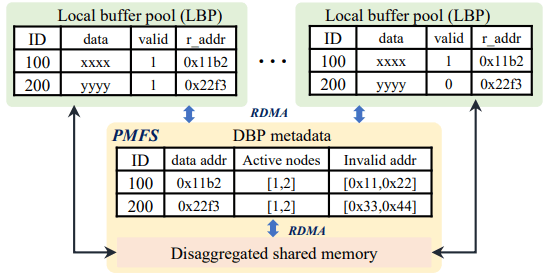
Buffer Fusion은 Distributed Buffer Pool(DBP)에 페이지를 올려 낮은 지연의 페이지 접근을 허용하는 설계다. 각 노드는 DBP의 부분집합인 Local Buffer Pool(LBP)을 유지한다. 각 로컬 버퍼는 원격 버퍼 주소 메타데이터와 로컬 버퍼가 유효한지(valid) 플래그를 가진다. 인스턴스가 DBP에서 페이지를 로컬 버퍼 풀로 가져올 때, DBP 메타데이터를 업데이트해 자신이 그 페이지 복사본을 갖고 있음을 기록한다. 인스턴스가 로컬 버퍼 풀에서 페이지를 업데이트하면, DBP를 조회해 같은 페이지를 LBP에 가진 다른 노드를 찾아 그들의 valid 비트를 끈다. LBP의 더티 페이지는 백그라운드에서 DBP로 플러시되지만, 장애 시 페이지가 복구 가능하도록 먼저 해당 로그를 스토리지에 강제한다.
PolarDB-MP Lock Fusion
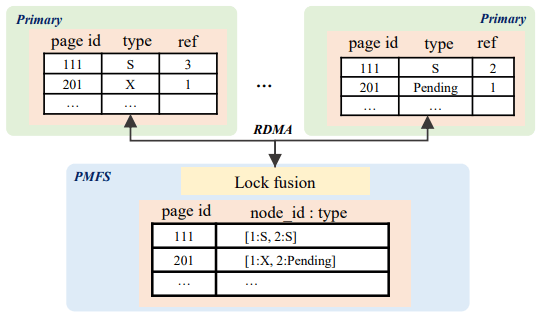
Lock Fusion은 페이지 락(PLock)과 행 락(RLock) 프로토콜을 모두 포함한다. PLock은 B-트리의 원자적 페이지 접근과 구조적 일관성을 유지하기 위해 사용되며, 래치와 유사하다. 페이지를 읽거나 업데이트하기 전, 해당 Shared 또는 eXclusive PLock을 보유해야 한다. 각 노드는 자신이 가진 PLock과 동시에 실행되는 각 트랜잭션별 PLock 참조 카운트를 추적한다. 락은 Fusion Server에서 요청되고, Fusion Server는 PLock이 해제되면 대기자에게 알린다. PLock은 로컬 참조 카운트가 0으로 떨어진 뒤에도, 지역성 때문에 같은 노드가 같은 PLock을 다시 요청할 가능성이 높다는 가정 하에 추측적으로 유지된다. B-트리 구조 변경(split/merge)은 관련 페이지 전체에 대한 X-PLock을 잡고 표준적인 2PL/2PC 조합으로 수행된다.
RLock은 트랜잭션 일관성을 위해 사용된다. 락 정보는 행 자체의 메타데이터로 포함되며, Fusion Server는 대기-그래프 관계(waits-for)만 유지하는데, 아마 데드락 탐지를 위한 것으로 보인다. 행 락은 해당 필드에 트랜잭션 ID를 쓰는 방식으로 획득한다. 행을 업데이트하려면 이미 X-PLock을 보유해야 하므로, 여러 프라이머리가 동시에 같은 행을 업데이트해 락을 잡으려 시도할 수 없다. 이미 트랜잭션 ID가 있으면 충돌이며 트랜잭션은 대기해야 한다. 그런 다음 TIT(로컬 또는 원격)를 조회해 RLock이 활성 트랜잭션에 의해 보유됨을 확인한다. 백그라운드 프로세스가 최소 활성 트랜잭션 ID를 동기화해, 원격 TIT 접근 비용 없이 오래된 트랜잭션이 완료되었음을 확인할 수 있게 한다. PolarDB-MP에서 RLock은 항상 배타적이며(shared RLock 없음), 대부분의 읽기가 MVCC로 락 없이 제공되는 읽기 전용 statement라는 점에 기대고 있다.
각 수정된 페이지에는 LSN이 붙고, 논리 시계처럼 유지된다. 스토리지나 DBP에서 페이지를 읽을 때 로컬 LSN은 읽은 페이지의 기록 LSN 이상이 되도록 업데이트될 수 있다. 이는 서로 다른 프라이머리에서의 페이지 업데이트가 LSN 정렬 시 올바른 순서로 합쳐지도록 보장한다.
평가에서는 워크로드가 완전히 파티셔닝되었을 때 8개 프라이머리로 8배 개선, 파티셔닝이 없을 때 8개 프라이머리로 3배 개선을 보인다. 또한 TPC-C를 think time과 keying time을 0으로 설정해 잘못 실행하여 경합 벤치마크로 만들었다. Aurora Multi-Master와 Taurus Multi-Master와의 직접 비교도 수행하여 동등하거나 더 나은 결과를 보인다. 공유-낫싱 아키텍처에서 글로벌 세컨더리 인덱스를 파티셔닝하는 방식과 비교해 세컨더리 인덱스 업데이트 성능도 비교한다. 지연과 처리량은 주로 RDMA 덕에 더 낫다고 보이는데, 사과-오렌지 비교라 그 의도가 명확하지 않다. 한 프라이머리 손실이 다른 프라이머리의 처리량에 영향을 주지 않음을 보여주는 복구 테스트도 수행한다.
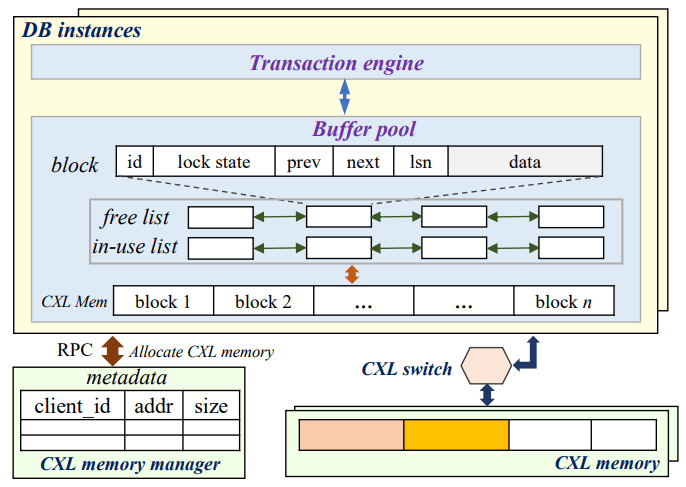
Compute Express Link(CXL)은 프로세서와 디바이스 간 통신을 위한 새로운 인터커넥트 기술이다. 특히 이 작업에서 중요한 점은 CXL이 여러 호스트가 같은 CXL 지원 DRAM 디바이스를 공유할 수 있도록 하는 CXL 스위치(PCIe 디바이스 형태로)를 붙일 수 있다는 것이다. 이는 RDMA와 직접 경쟁 구도이며, 이 논문은 메모리 분리 DB를 구축할 때 CXL과 RDMA를 비교한다. 2.1절은 CXL의(이후 내용을 이해하는 데 필요한) 좋은 개요를 제공하므로, CXL에 익숙하지 않다면 읽을 가치가 크다.
CXL과 RDMA는 DB 맥락 밖에서 먼저 비교된다. CXL 메모리 모듈을 단일 머신과 페어링하면 읽기 지연이 DRAM과 유사하다. 여러 머신이 CXL 메모리 모듈 풀을 공유하려면 CXL 스위치가 필요하고, 이는 로컬 DRAM 대비 3.76배, 원격 NUMA 노드 접근 대비 2.82배 지연을 추가한다. RDMA로 64B 값을 읽는 것은 여전히 약 6배 더 높다. 접근 데이터 크기가 커질수록 CXL의 지연 상승이 RDMA보다 빠르다. DB 용도에서는 로컬 버퍼 풀로 복사해 오기보다, 버퍼 풀을 CXL 위에서 직접 돌리는 것이 더 낫다는 의미다. 많은 DB 연산은 페이지 일부만 접근하며, 작은 페이지 접근은 CXL에서 더 이득이고 읽기 증폭(read amplification)도 줄인다. 그들은 CXL 버퍼 풀과 로컬 DRAM 버퍼 풀을 비교했고, 12개 DB 인스턴스에서 처리량 차이가 7%에 불과했다. 이것이 PolarDB-CXL의 방향을 결정했다.
PolarDB-CXL Architecture
PolarDB-CXL Physical Topology
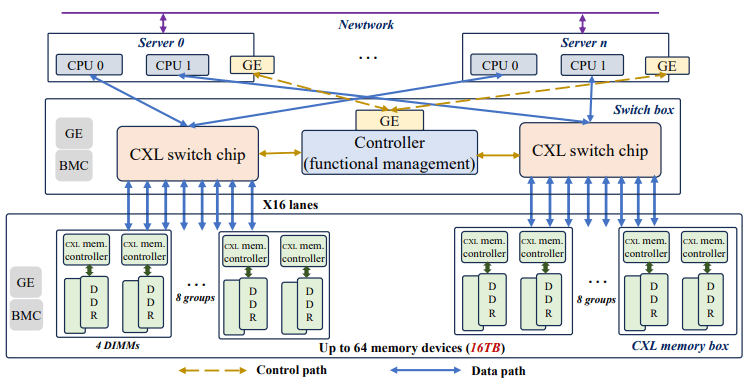
CXL 스위치는 어떤 머신과도 독립적으로 전원이 공급되므로, 개별 머신 장애에도 CXL 메모리의 데이터는 유지된다. 이는 버퍼 풀이 CXL 위에서 직접 실행된다는 점과 결합되어 크래시 후 복구를 가속하는 데 사용되었다. RDMA 기반 분리 메모리 DB는 로컬 메모리에서 페이지를 수정하므로 크래시 시 이를 잃고 redo 로그로부터 페이지를 재구성해야 하며, 빈 로컬 캐시에서 요청 처리를 시작해야 한다. CXL 기반은 로컬 캐시가 없으므로 잃을 것이 없고, 크래시된 노드가 작업하던 더티 페이지의 정확한 복사본이 유지된다. 그러나 이것만으로 즉시 요청 처리를 재개할 수는 없다:
PolarDB-CXL은 (1) 인메모리 자료구조 손실을 해결하기 위해 페이지 래치 상태 같은 메타데이터도 CXL 메모리에 저장한다. 크래시 시점에 write lock되어 있던 페이지는 부분 업데이트(4) 영향을 받았을 수 있으므로 redo 로그로부터 대신 복구할 수 있다. B-트리 구조 수정(3)은 관련 페이지 전체에 대한 래치를 CXL 메모리에서 잡고 수행하며, 래치된 B-트리 페이지도 redo 로그로 재구축된다. LRU 상태에 대한 뮤텍스도 CXL 메모리에 있으며, 복구가 LRU 뮤텍스가 락된 상태를 발견하면(2) 리스트를 재구성한다. 복구 시 PolarDB-CXL은 영속 redo 로그에서 최대 LSN을 가져와 그 LSN보다 새로운 페이지는 버린다(5).
PolarDB-CXL Multi-Primary Data Sharing
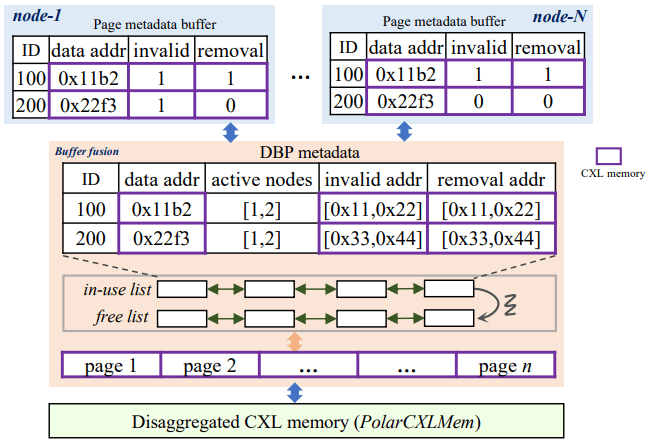
CXL 기반 멀티 프라이머리 DB도 구축할 수 있다. CXL 3.0에는 캐시 일관성(coherency) 프로토콜이 있지만, PolarDB-CXL은 CXL 2.0을 사용하므로 자체 페이지 래칭 및 소유권 프로토콜을 만들었다. 각 DB 노드는 자신이 사용하는 CXL 버퍼 풀의 각 페이지에 대한 메타데이터(주소 등)를 해시테이블로 유지하고, CXL 메모리 자체에 페이지별 invalid 및 removal 플래그를 유지한다. 페이지 접근에는 래치가 필요하고, 수행된 업데이트는 clflush로 CXL 메모리에 플러시돼야 한다. 래치를 드롭할 때 Buffer Fusion Server가 각 노드의 메타데이터 해시테이블에서 해당 페이지에 대해 invalid 플래그를 업데이트한다. 접근 전 removal 플래그로 페이지 주소를 Buffer Fusion Server에서 재요청해야 하는지 확인하고, invalid 플래그로 다른 노드 업데이트를 반영하기 위해 CPU 캐시를 축출해야 하는지 확인한다. 백그라운드 프로세스가 LRU 페이지를 해제해 공간을 만들고, 축출된 페이지에 대해 각 DB 노드에서 removal 플래그를 세팅한다.
다양한 워크로드/구성에서 CXL과 RDMA를 비교한 광범위한 평가가 있으며, CXL이 성능과 복구 시간 모두에서 일관되게 우수하다는 결과를 보인다. 특히 RDMA는 접근마다 페이지 전체를 전송하는 반면, CXL은 필요한 부분만 전송해 메모리 효율이 더 좋다는 점이 확장성 차이의 핵심 이유로 반복 강조된다. CXL은 높은/낮은 경합 모두에서 우수하며, 중간 경합에서 차이가 가장 크다(데이터 공유 효율 때문). 또 한 번, TPC-C는 잘못 실행됐다.
GaussDB는 2020년경 Taurus로 이름이 바뀌었지만, 출판물에서는 두 이름이 계속 사용되었다. 서비스의 대외 이름은 TaurusDB다.
Alex Depoutovitch, Chong Chen, Jin Chen, Paul Larson, Shu Lin, Jack Ng, Wenlin Cui, Qiang Liu, Wei Huang, Yong Xiao, and Yongjun He. 2020. Taurus Database: How to be Fast, Available, and Frugal in the Cloud. In Proceedings of the 2020 ACM SIGMOD International Conference on Management of Data (SIGMOD/PODS '20), ACM, 1463–1478. [scholar]
“Background and Related Work” 섹션 전체가 훌륭하다. 위에서 논의한 시스템들과의 비교를 매우 훌륭하고 간결하게 설정한다. 아주 짧게 요약하면: PolarFS는 스마트 스토리지 없이 파일시스템 추상화를 사용해 효율을 잃고, Aurora는 로그와 페이지 모두에 6노드 쿼럼을 사용해 내구성과 가용성 측면에서 과한 약속을 하며, Socrates는 4계층 Compute/XLOG/Page Server/XSTORE 아키텍처로 복잡성을 너무 많이 추가했다. TaurusDB는 빠른 장애 감지와 재구성을 활용해 쓰기용으로 고가용 3노드 로그를 제공하고, 페이지 데이터는 쉽게 스케일되는 eventual consistent 비동기 복제 Page Store로 제공한다.
Taurus Architecture
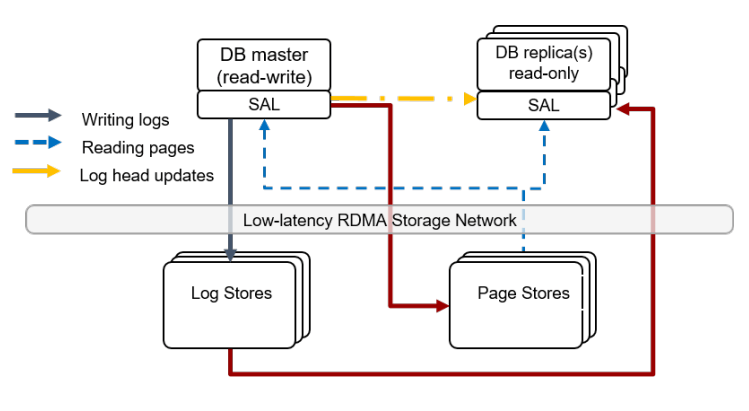
Taurus의 Log Store에서는 WAL 세그먼트가 PLog라는 고정 크기 append-only 동기 복제 스토리지 오브젝트로 전송된다. (P가 무엇인지는 말하지 않는다. Part of a Log?) 배포에는 수백 개의 Log Server가 있고, 그중 3개를 골라 PLog를 구성한다. 세 노드 모두가 쓰기를 ack해야 하며, 그렇지 않으면 새 PLog가 할당된다. (재구성 기반 복제!) DB WAL은 순서가 있는 PLog들의 컬렉션이며, 메타데이터 PLog에 저장된다. 메타데이터 PLog가 크기 한도에 도달하면 새 메타데이터 PLog를 만들고 최신 메타데이터를 거기에 쓴 뒤, 이전 메타데이터 PLog를 삭제한다.
Page Store는 DB primary 또는 읽기 레플리카의 페이지 읽기 요청을 제공하며, 10GB 슬라이스의 데이터를 담당한다. Primary는 모든 페이지 수정에 LSN을 부여하며, Page Server는 읽기 요청을 제공하기 위해 어떤 LSN에서든 페이지를 재구성할 수 있어야 한다. Page Store는 가장 오래된 라이브 트랜잭션(Primary 및 읽기 레플리카 전체)의 가장 오래된 LSN을 통지받고, 그보다 이전 버전은 잊어버릴 수 있다. Page Server는 또한 자신이 제공 가능한 최대 LSN이 무엇인지 응답할 수 있어야 한다. 모든 슬라이스의 모든 레플리카에 대해 최소 persisted LSN이 로그 truncation 임계값이 되며, 로그 레코드가 전부 그 값보다 작은 PLog는 버려도 된다.
Taurus는 Log Store와 Page Store를 다루는 대부분의 로직을 Storage Abstraction Layer(SAL)로 추상화한다. SAL은 WAL 세그먼트->PLog 매핑과 슬라이스->Page Store 매핑을 관리한다. SAL은 Cluster Visible LSN을 유지하는데, 이는 B-트리가 구조적으로 일관되고 redo 로그가 영속화된 가장 높은 LSN이다. SAL은 또한 로그가 Log Store에 영속화된 뒤 Page Server로 로그를 보내는 책임이 있고, Page Store로 작은 쓰기가 조금씩 흘러들어가는 것을 막기 위해 슬라이스별 버퍼를 유지한다. CV-LSN은 슬라이스별 버퍼의 해당 로그 엔트리가 최소 하나의 Page Store에 영속화되었을 때만 전진한다.
Taurus Write Path
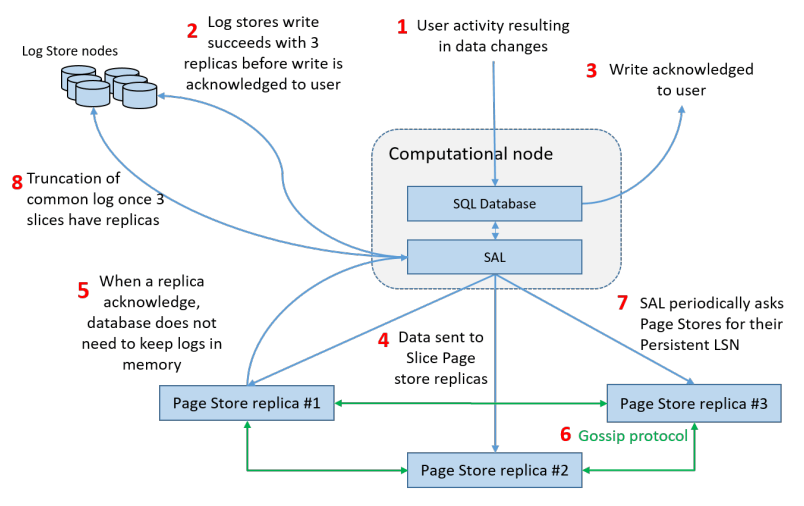
TaurusDB는 쿼럼 기반 복제보다 재구성 기반 복제를 강하게 선호하며, 장점에 대해 대담한 주장을 한다. 비상관 장애(uncorrelated failures)로 인한 쓰기 비가용 확률이 사실상 0이라고 주장하는데, 전역 노드 풀에서 새 샤드를 할당할 Log Store 또는 Page Store가 전부 불가용이어야만 쓰기가 막히기 때문이다. 읽기는 각 Page Store가 독립적으로 제공할 수 있다. 모든 Page Store가 요청 LSN에 비해 너무 오래되었다고 에러를 반환하면, Log Store로부터 수리(repair)된다. 두 경우 모두 낮은 비용으로 높은 가용성을 제공한다.
DB primary가 실패하면, SAL은 먼저 크래시 이전에 Log Store에 영속화된 모든 로그 레코드가 Page Store의 모든 슬라이스에 존재하도록 보장한다. 이는 전통적 ARIES 복구의 redo 단계와 동등하다. 이후 DB 프런트엔드는 undo 로그를 처리해 이전에 진행 중이던 트랜잭션의 효과를 undo하며, 이는 반드시 뒤에 수행돼야 한다. Log Store 노드가 실패하면, 그 노드가 포함된 PLog는 실패로 표시되고 해당 데이터는 일시적이라고 가정하므로 재복제는 수행하지 않는다. Page Server가 실패하면, 기존 Page Server의 데이터를 복사해 새 Page Server를 만든다. SAL이 최근 체인을 가진 Page Server만 실패해 슬라이스의 persisted LSN이 후퇴(regress)했음을 감지하면, Log Store에서 로그 레코드를 가져와 Page Server에 다시 보낸다. Page Store는 슬라이스 레플리카 간에 로그 데이터를 gossip하기도 하여 Log Server의 네트워크 대역폭 부담을 줄인다. gossip은 드물게(약 30분마다) 실행되지만, SAL이 Page Server의 Persisted LSN이 기대대로 증가하지 않는 것을 보면 온디맨드로 트리거할 수 있다.
읽기 전용 레플리카는 WAL 변경이 게시(publish)되면 통지받고 어떤 PLog에 있는지도 알지만, primary 인스턴스가 네트워크 대역폭 세금을 치르지 않도록 데이터를 직접 제공하진 않는다. 읽기 전용 레플리카는 WAL 엔트리를 캐시된 페이지에 적용한다. primary는 결과 최대 LSN이 구조적으로 일관되도록 WAL 레코드 그룹만 게시한다. 읽기 레플리카는 Page Store에 영속화된 것보다 visible LSN을 앞으로 나아가지 않도록 보장하여, 제공된 읽기가 primary에만 존재하는 데이터에 의존하지 않게 한다. 읽기 레플리카의 버퍼 풀은 서로 다른 라이브 트랜잭션에 대응하는 같은 페이지의 여러 버전을 저장할 수도 있다(아마 MySQL undo 로그를 MVCC에 의존하는 대신).
Page Store는 디스크에서 append-only이며, (page,version)->로그 내 슬롯으로 매핑하는 락-프리 해시테이블(Log Directory)을 중심으로 한다. Log Directory는 슬라이스별이며, 복구 시간을 제한하기 위해 주기적으로 스토리지에 저장된다. Page Store는 자체 버퍼 풀도 가지는데, 주로 WAL 엔트리를 적용하기 위해 이전 페이지를 찾을 때 I/O를 피하기 위함이다. 페이지 업데이트 적용은 처음엔 미적용 변경이 가장 많은 페이지를 우선했지만, 핫 페이지만 과도하게 우선시되고 콜드 페이지의 작은 변경을 추적하는 메타데이터가 꾸준히 커지는 문제가 있었다. 대신 ‘가장 오래된 미적용 쓰기 시간’ 기준으로 페이지를 고르고, 배칭을 위해 로그의 꼬리 부분(tail) 캐시를 둔다. Page Store가 로그 레코드를 페이지에 적용하는 속도를 따라가지 못하면, SAL이 쓰기를 스로틀링한다. 2차 캐시에서는 LFU가 더 좋은 교체 정책이라는 흥미로운 언급도 있다.
평가에서는 Taurus가 Aurora 대비 유리한 벤치마킹 결과를 보이며, 이는 Aurora의 쿼럼 기반 복제 대신 재구성 기반 복제 덕분이라고 했다. 복제 지연도 Aurora보다 낮았다. 또한 Socrates가 로컬 SQL Server와 동급 성능에 그쳤던 것과 달리, 분리 덕분에 동일 하드웨어에서 MySQL보다 더 빠르다는 결과도 보였다. 또 한 번, TPC-C는 올바르게 실행되지 않았다.
Shu Lin, Arunprasad P. Marathe, Per-Åke Larson, Chong Chen, Calvin Sun, Paul Lee, Weidong Yu, Jianwei Li, Juncai Meng, Roulin Lin, Xiaoyang Chenxi, and Qingping Zhuxii. 2022. Near Data Processing in Taurus Database. In 2022 IEEE 38th International Conference on Data Engineering (ICDE), 1662–1674. [scholar]
Taurus Near Data Processing은 MySQL 쿼리 처리가 단순 쿼리와 짧은 트랜잭션에 맞춰 설계되어, 많은 데이터를 소비해야 하는 쿼리에서 고전한다는 점에서 출발한다. 초기 필터링은 분리된 스토리지/컴퓨트로 인한 네트워크 부하와 컴퓨트 측 CPU 부하를 모두 줄인다. NDP는 옵티마이저, 스토리지 엔진, Page Store 변경을 필요로 했지만, 스토리지 엔진 계층 위에서 NDP 관련 변경의 영향을 최소화하는 것이 큰 목표였다. 쿼리 플랜에서는 인덱스 스캔 오퍼레이터만 NDP의 존재를 알면 된다.
Taurus NDP Architecture
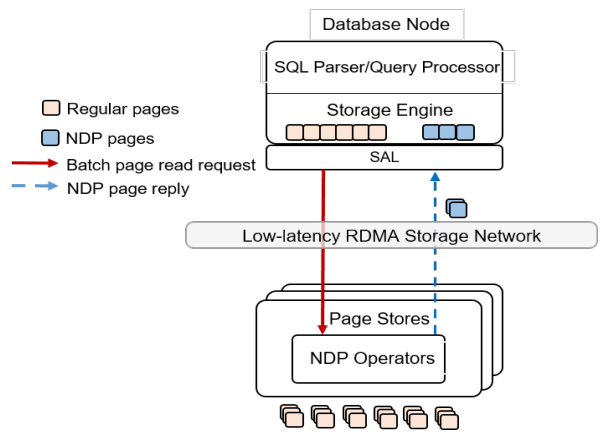
NDP 요청은 쿼리 프로세서가 Page Store에서 평가하기 원하는 필터, 프로젝션, 어그리게이션의 집합이다. NDP 푸시다운은 Page Store에 유휴 CPU가 있을 때만 best-effort로 처리된다. Page Store는 이를 존중하지 않고 원시 DB 페이지를 반환할 수도 있다. 푸시다운을 적용하면 결과는 특수한 NDP Page로 반환되며, 이는 다른 요청에서 재사용되지 않으므로 스토리지 엔진에서 별도로 유지된다. 프리디케이트는 Page Server에서 LLVM으로 JIT 컴파일되어 효율적으로 평가된다. 모든 프리디케이트가 푸시다운되는 것은 아니며, 일부 잔여(residual) 프리디케이트는 MySQL 실행 엔진에서 평가된다. InnoDB의 undo 로그 기반 MVCC는 Page Store가 따라갈 수 없으므로, 쿼리에 가시적이지 않은 일부 행도 반환하여 InnoDB가 올바른 과거 버전을 재구성하고 해당 행에 대해 처리를 수행하도록 한다.
옵티마이저에서 NDP 푸시다운은 최적화가 끝난 뒤 후처리 패스로 적용된다. 이는 NDP를 고려했다면 더 빨랐을 플랜을 놓칠 수 있지만, NDP는 고려해야 할 대안 플랜을 늘려 최적화 시간에 영향을 줄 수 있고, NDP 활성화로 인한 최적화 시간 증가를 최소화한다. MySQL 옵티마이저는 이미 인덱스 스캔 위로 필터/프로젝션을 푸시하는데, NDP는 지원되는 연산자를 더 효율적으로 평가하는 방식일 뿐이다. NDP 프로젝션은 폭(width) 감소가 충분하다고 추정될 때만 켜지며, 가변 길이 컬럼 평균 폭 통계도 확인한다. NDP 필터링은 지원되는 프리디케이트(UDF 제외 등)가 감지될 때만 켜진다. 또한 Page Store가 NDP 요청을 무시할 수 있으므로 최적화는 보장되지 않는다. 중요한 초점은 NDP를 켜도 어떤 쿼리에서도 성능 회귀가 없어야 한다는 점이었다.
InnoDB 내에서는 스키마, 트랜잭션 정보(MVCC 가시성), 수행할 프로젝션/필터/어그리게이션을 포함하는 “NDP descriptor”를 구성한다. Page Store는 NDP 요청과 descriptor를 사용해 InnoDB 페이지(16KB)를 가변 길이 NDP 페이지로 바꾼다. NDP 페이지는 동일한 InnoDB 페이지 헤더를 포함하여 InnoDB 커서를 수정 없이 사용할 수 있지만, “record type” 필드를 설정해 NDP 페이지임을 나타내고 프로젝션/어그리게이션 적용 여부를 나타낸다. 레코드는 인덱스 정렬 순서대로 유지된다. 프로젝션으로 인해 NDP 페이지는 더 좁아질 수 있고, 필터링으로 비어 있으면 빈 결과를 특별히 표시해 빈 페이지를 구체화하지 않도록 한다.
Taurus NDP Parallel Scans
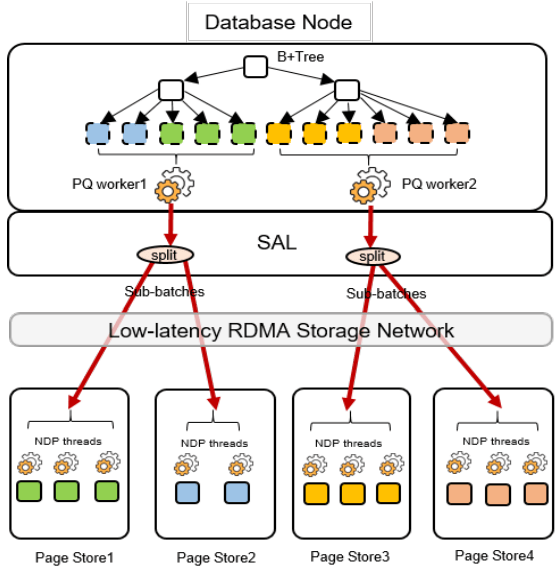
스캔 동안 반환된 NDP 페이지는 InnoDB 버퍼 풀에서 할당되지만, 쿼리 스레드에 프라이빗하게 유지되고, NDP 페이지 할당 수는 일반 쿼리가 버퍼 풀 페이지를 못 쓰게 되는 것을 막도록 제어된다. 스캔에서는 leaf 페이지 ID를 부모 페이지에서 수집해 단일 I/O 요청으로 배치한다. 큰 스캔 동안 트리 구조가 동시에 수정되지 않게 하려면, 루트에서 leaf의 부모까지 공유 락을 잡고, 잠긴 트리 구조에 대응하는 LSN을 생성한다. Page Store는 그 LSN에 맞는 페이지 버전만 반환한다. 이미 버퍼 풀에 있는 페이지는, LSN 기록 후 락을 드롭하면 페이지와 트리 구조가 수정될 수 있으므로, NDP 버퍼 풀 공간으로 복사한다. ~1000개 페이지 읽기를 한 I/O 요청으로 배치하는 것은 InnoDB 측과 Page Store 측 모두에서 큰 병렬성 기회를 제공한다.
Page Store는 MySQL, PostgreSQL, openGauss 프런트엔드를 동시에 지원하는 멀티 테넌트 서비스다. DBMS별 라이브러리는 플러그인으로 로드되며, NDP descriptor는 타입 없는 바이트스트림으로 받아 NDP 플러그인이 해석한다. NDP I/O는 일반 페이지 읽기로 시작해 NDP 플러그인이 NDP 페이지로 변환한다. 테스트에서 NDP descriptor 파싱이 병목으로 확인되어 descriptor 및 LLVM 비트코드 캐시를 추가했다. 많은 요청 웨이브가 보통 같은 descriptor를 공유하기 때문이다. NDP 처리를 위한 전용 스레드풀이 있고, 큐가 자원을 넘으면 페이지를 스킵해 프런트엔드 RDBMS로 넘겨 거기서 처리하도록 한다.
Page Store는 NDP로 비(非)사소한 처리를 수행한다. 프리디케이트는 DB 프런트엔드가 LLVM 비트코드를 생성하고, Page Store가 LLVM MCJIT로 네이티브 코드로 변환한다. JIT 코드가 호출할 수 있는 사전 컴파일된 복잡 함수 라이브러리도 있다. 많은 쿼리 컴파일 연구에서처럼, 사전 컴파일된 프리디케이트 평가는 AST 인터프리팅보다 훨씬 빠르다. Page Store는 테이블이 쿼리의 마지막 테이블일 때 페이지 간 어그리게이션도 수행할 수 있다. GROUP BY가 있으면 논리적으로 인접한 페이지들을, 스칼라 어그리게이션이면 비인접 페이지까지 어그리게이션할 수 있다. 다만 어느 경우든 단일 배치 I/O 요청 내의 페이지에 대해서만 수행한다. 여러 I/O 요청에 걸쳐 쿼리를 상관시키는 것은 훨씬 어렵기 때문이다. InnoDB는 NDP가 부분 평가한 잔여 어그리게이션을 처리한다.
평가는 예시 TPC-H 쿼리에서 네트워크 전송 데이터가 크게 줄어드는 것을 보여주며, 푸시다운 관련 작업에서 기대되는 바와 같다. Primary의 CPU 작업도 예상대로 줄었는데, CPU 작업이 Page Store로 옮겨갔기 때문이다. 또한 단일 스레드 MySQL 스캔 대비 병렬성이 크게 증가해 90% 이상의 속도 향상을 쉽게 얻는다.
Alex Depoutovitch, Chong Chen, Per-Ake Larson, Jack Ng, Shu Lin, Guanzhu Xiong, Paul Lee, Emad Boctor, Samiao Ren, Lengdong Wu, Yuchen Zhang, and Calvin Sun. 2023. Taurus MM: Bringing Multi-Master to the Cloud. Proceedings of the VLDB Endowment 16, 12 (August 2023), 3488–3500. [scholar]
이 논문을 읽으라고 추천하는 것은, 솔직히 말해 분리형 OLTP에서 멀티 마스터 설계를 논의할 핑계가 필요하기 때문이다. Aurora는 멀티 마스터를 구현했으나 이후 되돌렸다. Socrates는 멀티 마스터에 반대했다. PolarDB는 전역 페이지 캐시가 있으면 가능하다고 언급했지만 논문 범위 밖이었다. 그래서 TaurusDB가 이 설계를 볼 기회다.
Taurus Multi-Master Architecture
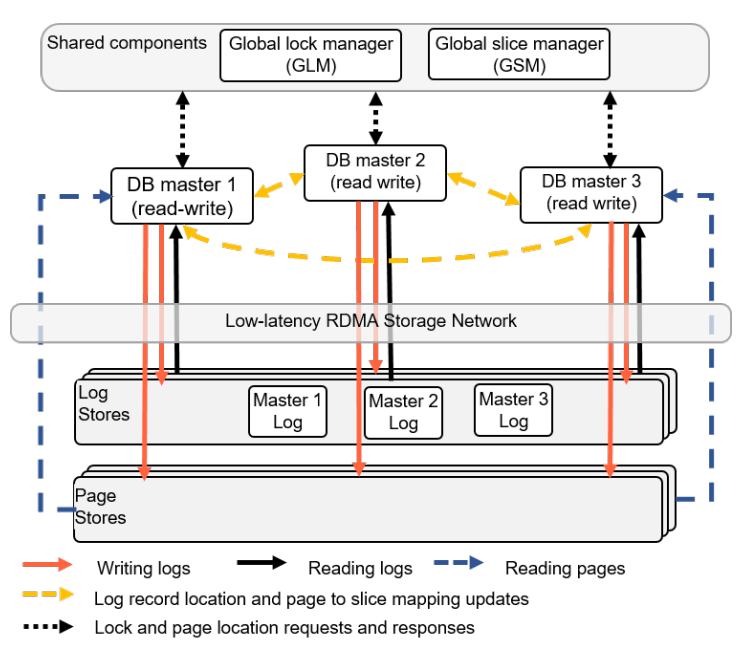
멀티 마스터는 동시 수정(concurrent modification)을 의미하며, 단순하게 보면 LSN이 벡터 클록이 되는 문제로 이어진다. Taurus는 벡터 클록과 스칼라 램포트 클록의 하이브리드인 클록 타입을 도입한다. 예를 들어 서버 3에 대해 clock[3]은 램포트 클록이고 나머지 인덱스는 벡터 클록이다. 이는 서버의 클록이 더 빨리 전진하게 하는 효과가 있는데, 로컬 이벤트가 아니라 인과적으로 관련된 전역 이벤트의 카운터이기 때문이다. 락 경합으로 직렬화되는 연산처럼 인과성이 이미 알려진 경우에는 스칼라 클록을 쓴다. 로그와 페이지는 로컬에서는 스칼라 클록으로 기록되고, Log Service로 보낼 때 벡터 클록으로 전송된다. 페이지 읽기는 스칼라 클록으로 수행된다.
동시 수정의 다른 측면은, 페이지 락을 더 이상 하나의 primary 레플리카 RAM에서 로컬로 할 수 없다는 점이다. 그래서 논문은 락킹을 논의한다. 락은 페이지 단위로 Global Lock Manager(GLM)에서 전역적으로 유지되며 일반적인 Shared/eXclusive 락 스킴을 사용한다. 한 마스터가 페이지 락을 얻으면, 동등하거나 더 약한(row-level) 락을 부여할 수 있다. 다른 마스터가 페이지를 요청하면 페이지는 GLM에 언락되어 반환될 수 있지만, 행 락은 유지된다. (같은 페이지 내 다른 행에 배타 락을 원하는 상황을 상상해 보라.) GLM은 데드락 탐지도 책임진다.
또 다른 컴포넌트: Global Slice Manager가 도입된다. 페이지를 서버에 샤딩하는 결정은 어떤 마스터도 로컬로 할 수 없으므로, 데이터 샤딩 책임은 전역 컴포넌트로 이동한다.
Aurora Multi-Master와 비교하면, Aurora는 마스터 간 충돌 해결을 스토리지 계층으로 미뤘다고 언급된다. 평가에서는 데이터 공유가 없을 때 두 설계가 비슷하지만, 데이터 공유가 늘어날수록 Taurus 설계가 훨씬 더 잘 동작한다.
MariaDB Xpand도 비슷한 것을 했지만, 글로 남기진 않았고 프로젝트는 종료됐다.
멀티 마스터는 업그레이드에도 유용하다. 새 DB 바이너리로 롤링 업그레이드를 하고 트랜잭션을 점진적으로 옮길 수 있는 방법을 주기 때문이다. 하지만 서로 다른 버전의 DB가 동시에 살아있다는 것은 업그레이드/다운그레이드 테스트를 잘 해야 한다는 뜻이기도 하다.
누가 멀티 마스터를 필요로 하나? Aurora는 멀티 마스터를 제거했고, 소문으로는 많이 쓰이지 않았다고 한다. 정말 수요가 있는가? 분리형 OLTP DB에서 쓰기가 너무 많아, 멀티 마스터가 가져오는 복잡성 투자 가치가 있는 고객이 충분한가?
GaussDB는 Huawei에서 개발된 Postgres 파생 RDBMS다. GaussDB for MySQL은 별도 제품이며 혼동을 피하기 위해 Taurus로 이름이 바뀌었다.
이 섹션은 다음 내용을 위한 소개로만 존재한다. 그렇지 않으면 Taurus가 GaussDB로 넘어가면서 왜 두 시스템이 있는지 설명이 없기 때문이다. 이 페이지 대부분은 논문을 시간순으로 정리했지만, GaussDB 작업을 묶기 위해 여기서 순서를 깨겠다.
GaussDB 자체의 배경으로는, 디스크 기반 RDBMS에 인메모리 DB 처리를 도입하려는 동기를 소개하는 다음 출판물이 있다:
Hillel Avni, Alisher Aliev, Oren Amor, Aharon Avitzur, Ilan Bronshtein, Eli Ginot, Shay Goikhman, Eliezer Levy, Idan Levy, Fuyang Lu, Liran Mishali, Yeqin Mo, Nir Pachter, Dima Sivov, Vinoth Veeraraghavan, Vladi Vexler, Lei Wang, and Peng Wang. 2020. Industrial-strength OLTP using main memory and many cores. Proceedings of the VLDB Endowment 13, 12 (August 2020), 3099–3111. [scholar]
이후 지리적으로 분산된 레플리카에서 더 나은 동작을 위해 GaussDB의 복제 지원을 개선한 두 출판물이 있다. 하지만 이 복제는 GaussDB->GaussDB 복제이므로 분리형 OLTP라는 테마에는 맞지 않는다. 그래도 좋은 논문들이다!
Weixing Zhou, Qi Peng, Zijie Zhang, Yanfeng Zhang, Yang Ren, Sihao Li, Guo Fu, Yulong Cui, Qiang Li, Caiyi Wu, Shangjun Han, Shengyi Wang, Guoliang Li, and Ge Yu. 2023. GeoGauss: Strongly Consistent and Light-Coordinated OLTP for Geo-Replicated SQL Database. Proc. ACM Manag. Data 1, 1 (May 2023). [scholar]
Puya Memarzia, Huaxin Zhang, Kelvin Ho, Ronen Grosman, and Jiang Wang. 2024. GaussDB-Global: A Geographically Distributed Database System. In 2024 IEEE 40th International Conference on Data Engineering (ICDE), 5111–5118. [scholar]
이제 분리형 OLTP 내용으로 돌아가자…
Guoliang Li, Wengang Tian, Jinyu Zhang, Ronen Grosman, Zongchao Liu, and Sihao Li. 2024. GaussDB: A Cloud-Native Multi-Primary Database with Compute-Memory-Storage Disaggregation. Proceedings of the VLDB Endowment 17, 12 (August 2024), 3786–3798. [scholar]
GaussDB-MP는 기존 단일 노드 GaussDB에 대해 멀티 프라이머리 컴퓨트/메모리/스토리지 분리를 도입한다. 이전 시스템들과 달리 컴퓨트/스토리지 분리에 대한 별도 논문이 없고, 멀티 프라이머리로 확장하기 전 컴퓨트/메모리/스토리지 분리에 대한 논문도 없다. 대신 전체 스토리를 한 편에 담았고, 아키텍처 설명을 멀티 프라이머리 설계를 논의하기 위한 필요한 설정 정도로만 본다. 이 논문은 Aurora, Taurus, PolarDB의 멀티 프라이머리 설계가 모두 발표된 뒤에 작성됐다. Aurora의 실패는 느린 OCC로 인한 높은 어보트율, TaurusDB-MM은 교차 노드 비관적 락킹으로 인한 높은 동시성 제어 오버헤드, PolarDB-MP는 상태를 가진(stateful) 메모리 레이어라 장애 시 복구가 비효율적이었다. GaussDB-MP는 대신 논리 페이지를 컴퓨트 노드에 파티셔닝하고, Smart Routing Manager가 쿼리를 해당 페이지를 소유한 컴퓨트 노드로 라우팅하며, 트랜잭션에 필요한 모든 페이지를 한 컴퓨트 노드로 가져오기 위한 페이지 소유권 전송(page ownership transfer)을 사용한다.
GaussDB-MP Architecture
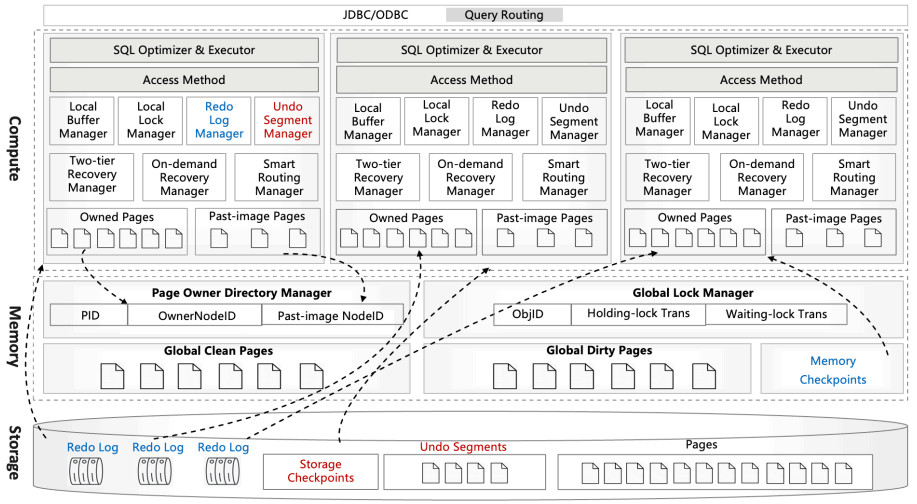
GaussDB는 컴퓨트, 메모리, 스토리지의 3계층을 갖는다. 스토리지 노드는 페이지, redo 로그, undo 세그먼트 영속화에 사용된다는 것 외에는 설명이 적다. Taurus-NDP에서 Taurus와 GaussDB의 페이지 서버가 동일하며, 페이지 내용을 해석하는 플러그인만 다르다고 언급했으므로, 스토리지 노드에 대한 자세한 내용은 Taurus 논문을 참고하라.
컴퓨트 노드는 SQL 최적화, 실행, 트랜잭션 처리, 페이지 소유권 및 할당을 담당한다. 어떤 컴퓨트 노드든 페이지 소유권을 획득하면 그 페이지를 수정할 수 있다. 로컬 버퍼 매니저는 소유 페이지를 로컬 버퍼 풀에 유지하고, 로컬 락 매니저가 페이지 접근을 제어한다. 각 노드는 자신의 WAL을 갖지만(undo 세그먼트는 전역 공유), 각 트랜잭션은 특정 undo 세그먼트 하나에 할당된다. LSN은 램포트 클록 기반이며 페이지 전송 과정 및 백그라운드 스레드로 노드 간 동기화된다. 컴퓨트 노드는 함께 자주 접근되는 페이지를 똑똑하게 같은 곳에 두려고 하며, Smart Routing Manager는 쿼리에 필요한 페이지를 가장 많이 소유한 노드로 쿼리를 라우팅한다.
메모리 노드는 전역 페이지 소유권(어떤 노드가 어떤 페이지를 소유), 전역 버퍼, 전역 락, 그리고 장애 복구 가속을 위한 메모리 체크포인트를 유지한다. 메모리 계층은 무상태(stateless)이며, 컴퓨트 노드 상태로부터 로그 기반 복구 없이 완전히 재구성될 수 있다(PolarDB의 공유 메모리 설계와 대비). Page Owner Directory(POD)는 각 페이지의 소유자를 추적하는 메타데이터를 유지한다. 이 메타데이터는 메모리 노드들에 consistent hash로 샤딩되며, 어떤 노드든 버퍼 풀에 로드된 페이지에 대해서만 엔트리를 가진다. 페이지 락은 POD에서 락을 획득함으로써 수행된다. 튜플은 동시성 제어를 위한 자체 락을 가지며, 페이지 락은 분산 래치에 가깝게 동작한다. 마지막으로 메모리 노드는 워밍 페이지 캐시로 동작하여, 컴퓨트 노드의 클린 페이지가 메모리 노드로 eviction될 수 있고, 이를 통해 스토리지에서 페이지를 재구성할 필요를 줄인다.
3절 GaussDB Transaction Processing은 페이지 소유권과 페이지/튜플 락킹을 포함한 트랜잭션 처리 예시를 한 페이지 분량으로 자세히 워크스루하며, 참고용 다이어그램도 있다. 요약하면 의미가 사라지므로 관심이 있으면 논문을 보라. 다만 몇 가지 최적화는 언급할 만하다. Read Authorization은 다른 노드가 해당 페이지의 읽기를 제공할 수 있도록 하는 리스이며, 페이지 소유자가 페이지를 수정하기 전에 반드시 권한을 회수하겠다는 약속을 포함한다. 이는 읽기 중심 페이지에서 노드 간 통신을 줄인다. 반대로 쓰기가 많은 페이지이고 소유자가 자주 바뀌는 경우, 그런 페이지는 메모리 노드에 두고 컴퓨트 노드들이 원사이드 RDMA로 업데이트한다.
GaussDB-MP Recovery
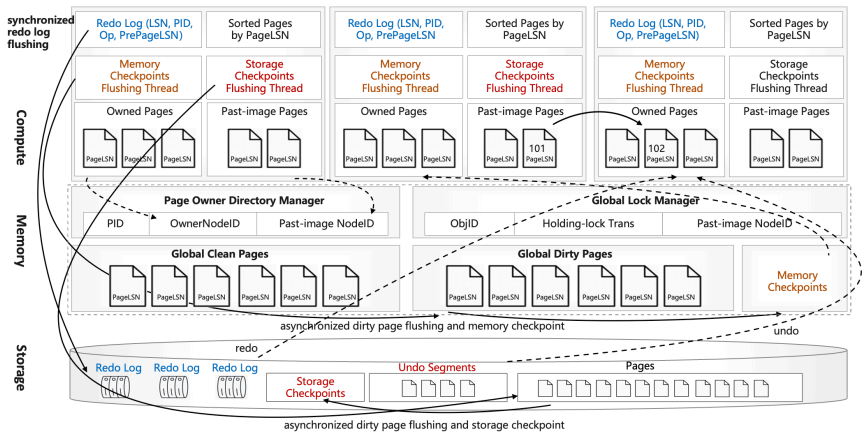
GaussDB-MP는 복구 시간을 최소화하는 데 초점을 강하게 둔다. 전송된 페이지는 이전 소유자에 이전 복사본을 그대로 남기는데, 이는 과거 이미지(past image)로 표시되어 새 소유자가 실패하면 복구 가속에 사용된다. 메모리 계층 장애는 각 컴퓨트 노드의 페이지 소유권/락 관리 로컬 정보를 스캔해 POD와 전역 락 정보를 재구성한다. 컴퓨트 계층 장애는 실패한 컴퓨트 노드가 잡고 있던 페이지 락을 해제하기 위해 전역 락을 스캔해야 한다. 컴퓨트 노드 장애에서 페이지를 복구하기 위해 undo/redo 로그를 최근 체크포인트 위에 적용하는데, 체크포인트는 스토리지, 메모리 계층(자체 체크포인팅), 또는 다른 컴퓨트 노드 버퍼 풀에서 아직 eviction되지 않은 전송 페이지의 “과거 이미지”에서 가져올 수 있다. 페이지가 컴퓨트 노드 간 이동했고 많은 트랜잭션에 관여했다면, 여러 redo 로그와 undo 세그먼트를(램포트 클록 LSN으로) 병합해야 할 수 있다.
Smart Query Router는 쿼리를 미리 실행하지 않고도 쿼리에 필요한 페이지를 예측하기 위해 Multi-Layer Perceptron을 사용한다. 입력은 컬럼명, 연산자, 프리디케이트, distinct 값들이다. 출력은 각 원소가 페이지 그룹의 접근 확률을 나타내는 접근 벡터다. 출력 벡터와 소유한 페이지 그룹 간 코사인 유사도가 가장 큰 노드가 쿼리를 맡는다. 모델 추론은 컴퓨트 노드 위의 JDBC/ODBC 라우팅 레이어에서 수행된다. 학습/훈련 과정에 대한 정보는 없다.
평가는 CockroachDB와 “System-X”(PolarDB, Aurora, IBM PureScale이 아니라고 하니, 사실상 Oracle RAC만 남는다)와 비교한다. 잘못 실행한 TPC-C로 1~6 노드에서 더 나은 성능을 보여준다. 또한 스케일 업이 추가 리소스의 효과를 완전히 내는 데 약 10초가 걸린다고 보여준다. Smart Query Routing은 처리량을 대략 2배로 올린다. 메모리 노드 장애 복구는 약 7초, 컴퓨트 노드 장애 복구는 약 15초가 걸린다.
이 페이지에 대한 토론은 Reddit, Hacker News, Lobsters에서 볼 수 있다.