30년 경력의 그래픽스 프로그래머가 현대 GPU의 ‘완전 바인드리스’ 하드웨어 현실에 맞춰, 지속 객체(PSO·디스크립터 세트·리소스 상태 추적)를 대폭 줄인 최소한의 그래픽 API와 셰이딩 모델을 제안한다.
URL: https://www.sebastianaaltonen.com/blog/no-graphics-api
내 이름은 Sebastian Aaltonen이다. 나는 30년 동안 그래픽 코드를 써 왔다. 1999년에 첫 3D 가속 게임을 출시했다. 그 이후로 거의 모든 게임 콘솔 세대(Nokia N-Gage, Nintendo DS/Switch, Sony Playstation/Portable, Microsoft Xbox)와 모든 PC 그래픽 API(DirectX, OpenGL, Vulkan)를 다뤘다. 지난 4년 동안은 WebGPU, Metal(Mac & iOS), Vulkan(Android)을 타겟으로 하는 HypeHype용 새 렌더러를 만들고 있다. 커리어 동안 여러 Ubisoft 내부 엔진을 만들었고, Unreal Engine 4를 최적화했으며, Unity DOTS 그래픽 팀을 이끌었다. 나는 Vulkan Advisory Panel 멤버이며 Arm Ambassador다.
이 글에는 저수준 하드웨어 디테일이 많이 포함되어 있다. 이 글을 쓸 때 나는 “GPT5 Thinking” AI 모델을 사용해 공개된 Linux 오픈소스 드라이버를 교차 참조하여 내 지식을 확인하고, 이 글에 NDA 정보가 포함되지 않도록 했다. 출처: AMD RDNA ISA 문서 및 GPUOpen, Nvidia PTX ISA 문서, Intel PRM, Linux 오픈소스 GPU 드라이버(Mesa, Freedreno, Turnip, Asahi) 및 벤더 최적화 가이드/발표 자료. 이 글은 공개 전 여러 업계 내부자들이 검토했다.
10년 전, 새로운 저수준 PC 그래픽 API의 도입으로 실시간 컴퓨터 그래픽스에 큰 변화가 일어났다. AMD는 Xbox One(2013)과 Playstation 4(2013) 계약을 모두 따냈다. 그들의 새로운 Graphics Core Next(GCN) 아키텍처는 AAA 게임의 사실상 선도 개발 플랫폼이 되었다. 당시 PC 그래픽 API인 DirectX 11과 OpenGL 4.5는 드라이버 오버헤드가 컸고 단일 스레드 렌더링을 전제로 설계되어 있었다. AAA 개발자들은 PC에서 더 높은 성능의 API를 요구했다. DICE는 AMD와 함께 PC용 AMD GCN 특화 저수준 API인 Mantle을 만들었다. 이에 대한 대응으로 Microsoft, Khronos, Apple이 각각 저수준 API 개발을 시작했고, DirectX 12, Vulkan, Metal이 탄생했다.
초기의 반응은 엇갈렸다. 합성 벤치마크와 데모에서는 큰 성능 향상이 보였지만, Unreal과 Unity 같은 주요 게임 엔진에서는 성능 이득이 보이지 않았다. Ubisoft에서 우리 팀은 기존 DirectX 11 렌더러를 DirectX 12로 포팅하면 오히려 성능이 떨어지는 경우가 많다는 것을 확인했다. 뭔가 이상했다.
기존의 고수준 API는 지속 상태(persistent state)가 거의 없었고, 매우 세분화된 상태 설정자(state setter)와 개별 데이터 입력을 드로우콜 직전에 셰이더에 바인딩했다. 반면 새 저수준 API는 드로우콜 비용을 낮추기 위해 셰이더 파이프라인 상태와 바인딩을 사전( ahead-of-time )에 묶어 지속 객체로 만들었다. 당시 GPU 아키텍처는 매우 이질적이었다. 데이터 리매핑, 검증, 업로드를 미리 하는 것이 큰 이득이었다. 하지만 기존 게임 엔진의 렌더링 하드웨어 인터페이스(RHI)는 세분화된 즉시 모드(immediate mode) 렌더링을 전제로 했고, 새 저수준 API는 데이터를 지속 객체로 묶어야 했다.
이 비호환을 해결하기 위해 RHI 아래에 새로운 저수준 그래픽 리매핑 레이어가 생겨났다. 이 레이어는 OpenGL과 DirectX 11 드라이버가 하던 복잡성을 떠안아, 리소스를 추적하고 사용자 영역의 세분화된 동적 상태와 지속되는 저수준 GPU 상태 사이의 매핑을 관리했다. 그래픽 프로그래머는 두 역할로 분화되기 시작했다. 새 저수준 “드라이버” 레이어와 RHI에 집중하는 저수준 그래픽 프로그래머, 그리고 RHI 위에서 시각적 그래픽 알고리즘을 구축하는 고수준 그래픽 프로그래머. 시각 프로그래밍 역시 물리 기반 조명, 컴퓨트 셰이더, 이후 레이트레이싱으로 더 복잡해졌다.
DirectX 12, Vulkan, Metal은 흔히 “모던 API”로 불린다. 하지만 이 API들은 이제 10년이 되었다. 이들은 처음 설계될 때 지금 기준으로 13년 된 GPU를 지원하도록 만들어졌는데, GPU 역사에서 13년은 엄청나게 긴 시간이다. 구형 GPU 아키텍처는 오늘날 흔한 컴퓨트 집약적 범용 워크로드가 아니라 전통적인 버텍스/픽셀 셰이더 작업에 최적화되어 있었다. 벤더별 바인딩 모델과 데이터 경로를 가졌고, 하드웨어 차이는 하나의 API 아래로 포장되어야 했다. 사전 생성된 지속 객체는 매핑/업로드/검증/바인딩 비용을 오프로딩하는 데 핵심이었다.
반면 콘솔 API와 Mantle은 AMD GCN 아키텍처만을 위해 설계되었고, 당시로서는 미래지향적이었다. GCN은 완전한 읽기/쓰기 캐시 계층과 텍스처/버퍼 디스크립터를 저장할 수 있는 스칼라 레지스터를 갖추어, 사실상 모든 것을 메모리처럼 취급했다. 복잡한 데이터 리매핑 API가 필요 없었고 사전 작업도 훨씬 적었다. 단일 현대 GPU 아키텍처를 타겟으로 했기 때문에 콘솔 API와 Mantle은 API 복잡성이 훨씬 낮았다.
10년이 지난 지금 GPU는 크게 진화했다. 모든 현대 GPU 아키텍처는 일관된 마지막 레벨 캐시(coherent LLC)를 포함한 완전한 캐시 계층을 갖춘다. CPU는 PCIe REBAR 또는 UMA로 GPU 메모리에 직접 쓸 수 있고, 64비트 GPU 포인터를 셰이더에서 직접 지원한다. 텍스처 샘플러는 바인드리스(bindless)이며, CPU 드라이버가 디스크립터 바인딩을 구성할 필요가 없다. 텍스처 디스크립터는 GPU 메모리 내 배열(흔히 descriptor heap)에 직접 저장될 수 있다. 오늘날의 현대 GPU만을 위해 API를 설계한다면, 이러한 지속 “리텐드 모드(retained mode)” 객체 대부분이 필요 없다. DirectX 12.0, Metal 1, Vulkan 1.0이 해야 했던 타협은 더 이상 필요하지 않다. 우리는 API를 대폭 단순화할 수 있다.
지난 10년은 모던 API의 약점을 드러냈다. PSO 퍼뮤테이션 폭발이 가장 큰 문제다. 벤더(Valve, Nvidia 등)는 아키텍처/드라이버 조합별 PSO를 테라바이트 단위로 저장하는 대형 클라우드 서버를 운영한다. 사용자의 로컬 PSO 캐시가 100GB를 넘기도 한다. 로딩이 오래 걸리고 스터터가 곳곳에서 발생한다고 게이머들이 불평하는 것도 무리가 아니다.
API 표면을 벗겨내기 전에, 그래픽 API가 역사적으로 왜 이런 형태로 설계되었는지 이해해야 한다. OpenGL이 의도적으로 느렸던 것도 아니고, Vulkan이 의도적으로 복잡했던 것도 아니다. 10~20년 전 GPU 하드웨어는 매우 다양했고 빠르게 진화하고 있었다. 이렇게 다양한 하드웨어를 대상으로 크로스 플랫폼 API를 설계하려면 타협이 필요했다.
고전적인 사례부터 시작하자: 3dFX Voodoo 2 12MB(1998)는 3칩 설계였다. 단일 래스터라이저 칩이 4MB 프레임버퍼 메모리에 연결되고, 두 개의 텍스처 샘플링 칩은 각각 자기 4MB 텍스처 메모리에 연결되어 있었다. 지오메트리 파이프라인도 없고 프로그래머블 셰이더도 없었다. CPU는 변환된 삼각형 정점을 래스터라이저로 보냈다. 래스터라이저는 버텍스 컬러와 두 텍스처 샘플 결과를 어떻게 섞을지 제어하는 블렌딩 방정식을 구성할 수 있었다. 텍스처 샘플러는 서로의 메모리나 프레임버퍼를 읽을 수 없었기에 멀티 패스 렌더링이 불가능했다. 윈도 합성이 불가능했기 때문에 전용 2D 비디오 카드에 연결하는 루프백 케이블을 갖고 있었고, 3D 렌더링은 독점 풀스크린에서만 동작했다. 이 시대의 3D 그래픽 카드는 현재 GPU의 거대한 프로그래머블 SIMD 배열과는 거의 공통점이 없는, 매우 특화된 하드웨어였다. 이런 하드웨어는 DirectX(1995)와 OpenGL(1992) 설계에 큰 영향을 주었다. 하위 호환성은 매우 중요했고, API는 점진적으로 개선되었다. 30년 된 이 API 설계는 지금도 우리가 소프트웨어를 쓰는 방식에 영향을 준다.

3dFX Voodoo 2 12MB (1998): 개별 프로세서와 그 사이의 트레이스, 그리고 각자의 메모리 칩(프로세서당 1MB 칩 4개)이 선명히 보인다. Image © TechPowerUp.
Nvidia의 Geforce 256은 GPU라는 용어를 만들었다. 래스터라이저 외에 지오메트리 프로세서를 포함했다. 지오메트리 프로세서, 래스터라이저, 텍스처 샘플링 유닛은 같은 다이에 통합되었고 메모리를 공유했다. DirectX 7은 두 가지 새 개념을 도입했다: 렌더 타깃 텍스처와 유니폼 상수. 멀티패스 렌더링은 텍스처 샘플러가 래스터라이저 출력물을 읽을 수 있게 했고, 이는 3dFX Voodoo 2의 분리 메모리 설계를 무효화했다.
지오메트리 프로세서 API는 변환 행렬(float4x4), 라이트 위치/색(float4)을 위한 유니폼 입력을 제공했다. 제조사마다 GPU 구현은 달랐고, 많은 경우 지오메트리 엔진 내부에 작은 상수 메모리 블록을 넣었다. 하지만 이것만이 유일한 방식은 아니었다. OpenGL에서는 각 셰이더가 자기 지속 유니폼을 갖는다. 이 설계 덕분에 드라이버가 상수를 셰이더 명령 스트림에 직접 삽입할 수 있었고, 이 API 특성은 지금도 OpenGL 4.6과 ES 3.2에 남아 있다.
당시 GPU에는 범용 읽기/쓰기 캐시가 없었다. 래스터라이저는 블렌딩/뎁스 버퍼링을 위한 화면 로컬 캐시가 있었고, 텍스처 샘플러는 선형 보간된 버텍스 UV를 이용한 프리페치에 의존했다. DirectX 8 셰이더 모델 1.0(SM 1.0)에서 셰이더가 도입되었을 때 픽셀 셰이더 단계는 텍스처 UV 계산을 지원하지 않았다. UV는 버텍스 단위로 계산되어 하드웨어가 보간한 뒤 텍스처 샘플러로 바로 전달되었다.
DirectX 9는 셰이더 명령 한도를 크게 늘렸지만, 셰이더 모델 2.0은 새 데이터 경로를 노출하지 않았다. 버텍스/픽셀 셰이더는 여전히 1:1 입력:출력 기계로 동작했고, 사용자는 버텍스 위치/속성 변환 수학과 픽셀 컬러만 커스터마이즈할 수 있었다. 프로그래머블 로드/스토어는 지원하지 않았다. 고정 기능 입력 블록(버텍스 페치, 유니폼(상수) 메모리, 텍스처 샘플러)은 그대로였다. 버텍스 셰이더는 별도 실행 유닛이었고, 상수 인덱싱(제한적인 float4 배열)을 얻었지만 텍스처 샘플링은 여전히 없었다.
DirectX 9 셰이더 모델 3.0은 명령 한도를 65536까지 늘려 사람이 셰이더 어셈블리를 쓰고 유지하기 어려워졌다. 고수준 셰이딩 언어가 탄생했다: HLSL(2002)과 GLSL(2002~2004). 이 언어들은 1:1 요소별 변환 설계를 채택했다. 각 셰이더 호출은 단일 데이터 요소(버텍스 또는 픽셀)를 처리한다. 프레임워크 스타일 셰이더 설계는 이후 API 설계에 큰 영향을 주었다. 당시에는 하드웨어 차이를 추상화하기 좋았지만, 오늘날에는 스케일링 문제가 드러나고 있다.
DirectX 11은 데이터 모델을 크게 바꿔 컴퓨트 셰이더, 범용 읽기-쓰기 버퍼, 인다이렉트 드로잉을 도입했다. GPU는 이제 스스로를 완전히 먹여 살릴 수 있게 되었다. 범용 버퍼의 도입은 셰이더 프로그램이 프로그래머블 메모리 위치에 접근/수정할 수 있게 했고, 이는 하드웨어 벤더가 범용 캐시 계층을 구현하도록 강제했다. 셰이더는 단순한 1:1 변환을 넘어섰고, 특화된 하드코딩 데이터 경로의 시대가 끝났다. GPU 하드웨어는 범용 SIMD 설계로 이동했다. SIMD 유닛이 이제 버텍스/픽셀/지오메트리/헐/도메인/컴퓨트를 모두 실행한다. 오늘날 프레임워크에는 16개의 셰이더 엔트리 포인트가 있다. 이는 API 표면을 크게 늘리고 조합을 어렵게 만든다. 그 결과 GLSL과 HLSL은 여전히 풍부한 라이브러리 생태계를 갖지 못한다.
DirectX 11에는 하드웨어 데이터 경로의 특성을 수용하기 위해 설계된 온갖 종류의 버퍼 타입이 존재했다: typed SRV & UAV, byte address SRV & UAV, structured SRV & UAV, append & consume(카운터 포함), constant, vertex, index 버퍼. 텍스처처럼 DirectX의 버퍼도 불투명 디스크립터를 사용한다. 디스크립터는 하드웨어 특화(보통 128~256비트) 데이터 블롭으로, 리소스의 크기/포맷/속성/GPU 메모리 주소를 인코딩한다. DirectX 11 GPU는 버퍼 로드(gather) 연산에 텍스처 샘플러를 활용했다. 샘플러에는 타입 변환 하드웨어와 작은 읽기 전용 캐시가 이미 있었기 때문이다. typed 버퍼는 텍스처와 같은 포맷을 지원했고, DirectX는 텍스처와 버퍼 둘 다에 SRV(Shader Resource View) 추상화를 사용했다.
불투명 디스크립터를 사용하면 버퍼 포맷이 셰이더 컴파일 타임에 알려지지 않는다. 읽기 전용 버퍼는 텍스처 샘플러가 처리하니 괜찮았다. 하지만 읽기-쓰기 버퍼(DirectX의 UAV)는 초기에는 32비트와 128비트(vec4) 타입으로 제한되었다. 이후 API/하드웨어 개정으로 typed UAV 로드 제한이 점차 해결되었지만, 근본 문제는 남았다: 디스크립터는 간접 참조(포인터 포함)가 필요하고, 컴파일러 최적화가 제한되며(데이터 타입이 런타임에만 확정), 포맷 변환 하드웨어는 지연을 늘리고(vs raw L1$load), 로드 시 확장은 레지스터를 더 오래 점유하며(vs 사용 시 확장), 디스크립터 관리는 CPU 드라이버 복잡성을 늘리고, API는 복잡하다(버퍼 타입 10개).
DirectX 11에서 structured buffer는 사용자 정의 struct 타입을 허용하는 유일한 버퍼 타입이었다. 다른 버퍼 타입은 단순 스칼라/벡터 요소의 균질 배열을 나타냈다. 불행히도 structured buffer는 다른 버퍼 타입과 레이아웃 호환이 되지 않았다. typed/byte address/vertex/index 버퍼에 대한 structured view가 허용되지 않았다. 이유는 structured buffer가 내부적으로 특수 AoSoA 스위즐 최적화를 사용했기 때문이며, 이는 오래된 vec4 아키텍처에 중요했다. 이런 하드웨어 특화 최적화가 structured buffer의 활용을 제한했다.
DirectX 12는 모든 버퍼를 메모리에서 선형으로 만들어 서로 호환되게 했다. SM 6.2는 byte address buffer에 load<T> 문법 설탕을 추가해 임의 오프셋에서 깔끔한 struct 로딩 문법을 허용했다. 하지만 하위 호환성 때문에 옛 버퍼 타입을 여전히 지원하고, 모든 버퍼는 여전히 불투명 디스크립터를 사용한다. HLSL에는 여전히 64비트 GPU 포인터 지원이 없다. 반면 Nvidia CUDA 컴퓨팅 플랫폼(2007)은 처음부터 64비트 포인터에 전적으로 의존했지만, 초기에는 학술 용도에 인기가 제한적이었다. 오늘날 CUDA는 AI 플랫폼의 선두이며 하드웨어 설계에 큰 영향을 끼치고 있다.
DirectX 12 출시 당시 16비트 레지스터와 16비트 수학 지원은 혼란스러웠다. Microsoft는 DirectX 12를 Windows 7에 백포트하지 않는 questionable한 결정을 내렸다. Windows 8 대상 셰이더 바이너리는 16비트 타입을 지원했지만, 대부분 게이머는 Windows 7을 계속 사용했다. 개발자들은 셰이더를 두 세트로 내고 싶지 않았다. OpenGL의 lowp/mediump 스펙도 엉망이었다. 비트 깊이가 제대로 표준화되지 않았다. mediump는 모바일 게임에서 인기 있는 최적화였지만, 대부분 PC 드라이버가 이를 무시해 개발자를 괴롭혔다. AAA 게임은 2016년 PS4 Pro가 더블 레이트 fp16을 지원하기 전까지 대부분 16비트 수학을 무시했다.
AI, 레이트레이싱, GPU-드리븐 렌더링의 부상으로 GPU 벤더는 원시 데이터 로드 경로 최적화와 더 크고 빠른 범용 캐시에 집중하기 시작했다. 텍스처 샘플러(타입 변환)를 경유하는 로드는 지연이 너무 컸는데, 현대 셰이더에서는 종속 로드 체인이 흔하기 때문이다. 하드웨어는 8/16/64비트 타입과 포인터를 네이티브로 지원하게 되었다.
대부분 벤더는 고정 기능 버텍스 페치 하드웨어를 버리고, 버텍스 셰이더에서 표준 raw load 명령을 내보내기 시작했다. 완전 프로그래머블 버텍스 페치는 클러스터드 GPU-드리븐 렌더링 같은 새 알고리즘을 가능하게 했다. 고정 기능 하드웨어에 쓰이던 트랜지스터 예산을 다른 곳에 쓸 수 있었다.
메시 셰이더는 래스터라이저 진화의 정점으로, 인덱스 중복 제거 하드웨어와 포스트-트랜스폼 캐시를 제거한다. 이 패러다임에서는 모든 입력이 raw 메모리로 취급된다. 사용자는 메시를 내부적으로 정점을 공유하는 자급자족(meshlet)으로 분할해야 한다. 이는 보통 오프라인에서 수행된다. GPU는 드로우콜마다 병렬 인덱스 중복 제거를 할 필요가 없어 전력과 트랜지스터를 절약한다. 오늘날 Nvidia 매출에서 게임은 10%에 불과하고 AI가 90%이며 레이트레이싱도 계속 성장하므로, 고정 기능 지오메트리 하드웨어가 최소한으로 줄어들고 드라이버가 자동으로 버텍스 셰이더를 메시 셰이더로 변환하는 것도 시간 문제일 가능성이 크다.
모바일 GPU는 타일 기반 렌더러다. 타일러는 개별 삼각형을 작은 타일(보통 16x16~64x64 픽셀)에 빈닝한다. 메시 셰이더는 이 목적에는 너무 거친 그레인이다. 메시렛을 작은 타일에 빈닝하면 지오메트리 오버셰이딩이 커진다. 명확한 수렴 경로가 없다. 우리는 여전히 버텍스 셰이더 경로를 지원해야 한다.
10년 전 DirectX 12.0, Vulkan 1.0, Metal 1.0이 도착했을 때 기존 GPU 하드웨어는 바인드리스 리소스를 널리 지원하지 않았다. API는 하드웨어 차이를 추상화하기 위해 복잡한 바인딩 모델을 채택했다. DirectX는 스테이지당 최대 128 리소스 인덱싱을 허용했지만 Vulkan과 Metal은 초기에는 디스크립터 인덱싱을 전혀 지원하지 않았다. 개발자는 텍스처 아틀라스에 패킹하거나 메시를 합치는 등 바인딩 변경 오버헤드를 줄이는 전통적 우회책을 계속 사용해야 했다. GPU 하드웨어는 지난 10년 동안 크게 진화해 범용 바인드리스 SIMD 설계로 수렴했다.
이제 현대 바인드리스 하드웨어만을 위해 API와 셰이딩 언어를 설계하면 얼마나 단순해지는지 살펴보자.
메모리 관리부터 시작하자. 레거시 그래픽 API는 GPU 메모리 관리를 완전히 추상화했다. 과거 GPU는 분리 메모리와/또는 캐시 일관성 문제가 있는 특수 데이터 경로를 가졌기 때문에 추상화가 필요했다. DirectX 12와 Vulkan이 10년 전 도착했을 때 GPU 하드웨어는 사용자에게 placement heap을 노출할 만큼 성숙했다. 콘솔은 이미 몇 세대 전부터 메모리를 노출했고, 개발자는 PC/모바일에도 비슷한 유연성을 원했다. Apple은 Vulkan/DirectX 12보다 4년 늦게 Metal 2에서 placement heap을 도입했다.
모던 API는 사용자가 힙 타입을 열거해 드라이버가 제공하는 메모리 종류를 파악하도록 요구한다. 큰 덩어리로 미리 할당하고 사용자 영역 할당기에서 서브할당하는 것이 좋은 관행이다. 하지만 Vulkan에는 설계 결함이 있다. 텍스처/버퍼 객체를 먼저 만든 다음, 새 리소스와 호환되는 힙 타입을 질의해야 한다. 이는 사용자를 게으른(lazy) 할당 패턴으로 몰아, 런타임에서 성능 히치와 메모리 스파이크를 유발할 수 있다. 또한 GPU 메모리 할당을 크로스 플랫폼 라이브러리로 감싸기 어렵다. 예를 들어 AMD VMA는 Vulkan 버퍼/텍스처 객체를 만들고 메모리도 할당한다. 우리는 관심사를 완전히 분리하고 싶다.
오늘날 CPU는 GPU 메모리를 완전히 볼 수 있다. iGPU는 UMA를 가지며, 현대 dGPU는 PCIe Resizable BAR를 가진다. 전체 GPU 힙을 매핑할 수 있다. Vulkan의 힙 API는 자연스럽게 CPU 매핑 GPU 힙을 지원한다. DirectX 12는 2023년에 지원을 얻었다(HEAP_TYPE_GPU_UPLOAD).
CUDA는 GPU 메모리 할당을 단순하게 설계했다. GPU malloc API는 크기를 입력받아 매핑된 CPU 포인터를 반환한다. GPU free는 메모리를 해제한다. CUDA는 CPU 매핑 GPU 메모리를 지원하지 않는다. GPU는 PCIe 버스를 통해 CPU 메모리를 읽는다. CUDA는 GPU 메모리 할당도 지원하지만 CPU가 직접 쓸 수는 없다.
우리는 CUDA malloc의 단순함과 CPU 매핑 GPU 메모리(UMA/ReBAR)를 결합한다. 두 세계의 장점을 취한다: CPU가 쓰기 빠르고 GPU가 읽기 빠르며, 설계도 깔끔하고 사용하기 쉽다.
// 1024 uint32 배열을 위한 GPU 메모리 할당
uint32* numbers = gpuMalloc(1024 * sizeof(uint32));
// 직접 초기화(CPU 매핑 GPU 포인터)
for (int i = 0; i < 1024; i++) numbers[i] = random();
gpuFree(numbers);
기본 gpuMalloc 정렬은 16바이트(vec4 정렬)이다. 더 넓은 정렬이 필요하면 gpuMalloc(size, alignment) 오버로드를 사용한다. 예제 코드는 gpuMalloc<T> 래퍼를 사용하며, gpuMalloc(elements * sizeof(T), alignof(T))를 수행한다.
드로우 인자, 유니폼, 디스크립터 같은 작은 데이터는 GPU 메모리에 직접 쓰는 것이 최적이다. 큰 지속 데이터는 여전히 복사를 수행하고 싶다. GPU는 캐시 지역성을 높이기 위해 Morton-order와 비슷한 스위즐 레이아웃으로 텍스처를 저장한다. DirectX 11.3과 12는 스위즐 레이아웃 표준화를 시도했지만 모든 제조사를 설득하지 못했다. 텍스처 스위즐의 일반적인 방법은 드라이버 제공 복사 명령을 사용하는 것이다. 복사 명령은 CPU 매핑 “업로드” 힙에서 선형 텍스처 데이터를 읽고, 프라이빗 GPU 힙에서 스위즐된 레이아웃으로 쓴다. 모든 현대 GPU에는 무손실 델타 컬러 압축(DCC)도 있다. 현대 GPU의 복사 엔진은 DCC 압축/해제를 할 수 있다. DCC와 Morton 스위즐이 텍스처를 프라이빗 GPU 힙으로 복사하고 싶은 주요 이유다. 최근 GPU는 버퍼 데이터에 대해서도 범용 무손실 메모리 압축을 추가했다. 힙이 CPU 매핑이면, CPU는 그 압축 포맷을 읽고 쓸 방법을 모르므로 GPU가 벤더 특화 무손실 압축을 활성화할 수 없다. 데이터를 압축하려면 복사 명령이 필요하다.
따라서 gpuMalloc에 메모리 타입 파라미터가 필요하다. 표준 메모리 타입은 CPU 매핑 GPU 메모리(쓰기 결합 CPU 접근)여야 한다. GPU가 읽기 빠르고, CPU가 일반 포인터처럼 직접 쓸 수 있다. GPU 전용 메모리는 텍스처와 큰 GPU 전용 버퍼에 사용한다. CPU는 이 GPU 포인터에 직접 쓸 수 없다. 사용자는 먼저 CPU 매핑 GPU 메모리에 데이터를 쓴 후, 복사 명령을 발행해 최적 압축 포맷으로 변환한다. 현대 텍스처 샘플러와 디스플레이 엔진은 압축된 GPU 데이터를 직접 읽을 수 있으므로 이후 레이아웃 변환이 필요 없다(“현대 배리어” 장 참고). 업로드된 데이터는 즉시 사용 가능하다.
우리는 두 종류의 GPU 포인터를 갖는다: CPU 매핑 가상 주소와 GPU 가상 주소. GPU는 GPU 주소만 역참조할 수 있다. GPU 데이터 구조 내부의 모든 포인터는 GPU 주소여야 한다. CPU 매핑 주소는 CPU 쓰기용으로만 사용한다. CUDA에는 CPU 매핑 주소를 GPU 주소로 변환하는 API(cudaHostGetDevicePointer)가 있다. Metal 4의 버퍼 객체는 두 getter를 제공한다: .contents(CPU 매핑 주소)와 .gpuAddress(GPU 주소). gpuMalloc API는 Metal처럼 관리 객체 핸들이 아니라 포인터를 반환하므로, 우리는 CUDA 접근(gpuHostToDevicePointer)을 선택한다. 이 호출은 공짜가 아니다. 드라이버는 보통 해시맵(기저 주소 외에도 변환이 필요하면 트리)을 사용해 구현할 것이다. 이상적으로는 할당당 한 번 주소 변환을 하고 사용자 영역 구조체(void* cpu, void* gpu)에 캐시한다. 이것이 내 userland GPUBumpAllocator(부록에 전체 구현) 방식이다.
// 3rd party 라이브러리로 메쉬 로드
auto mesh = createMesh("mesh.obj");
auto upload = uploadBumpAllocator.allocate(mesh.byteSize); // 커스텀 범프 할당기(gpuMalloc ptr 래핑)
mesh.load(upload.cpu);
// GPU 전용 메모리 할당 후 복사
void* meshGpu = gpuMalloc(mesh.byteSize, MEMORY_GPU);
gpuMemCpy(commandBuffer, meshGpu, upload.gpu);
Vulkan은 최근 VK_EXT_host_image_copy라는 새 확장을 얻었다. 드라이버가 CPU→GPU 이미지 직접 복사를 구현하고, 하드웨어 특화 텍스처 스위즐을 CPU에서 수행한다. 이 확장은 현재 UMA 아키텍처에서만 제공되지만, PCIe ReBAR에서도 기술적 이유로 불가능한 것은 아니다. 불행히도 이 API는 DCC를 지원하지 않는다. CPU에서 DCC 압축을 수행하는 것은 너무 비싸다. 이 확장은 주로 블록 압축 텍스처에 유용하다(DCC가 필요 없기 때문). 하드웨어 복사를 통한 GPU 프라이빗 메모리 업로드를 보편적으로 대체할 수는 없다.
또한 읽기백을 위한 세 번째 메모리 타입(CPU 캐시됨)이 필요하다. 이 타입은 CPU와의 캐시 일관성 때문에 GPU 쓰기 속도가 느리다. 게임은 읽기백을 드물게만 사용한다. 대표적 사용처는 스크린샷과 가상 텍스처링 읽기백이다. AI 학습/추론 같은 GPGPU 알고리즘은 CPU-GPU 간 효율적 통신에 의존한다.
CUDA malloc의 단순함과 CPU 매핑 GPU 메모리를 섞으면, 최소한의 API 표면으로 유연하고 빠른 GPU 메모리 할당 시스템을 얻는다. 이는 미니멀한 현대 그래픽 API의 훌륭한 출발점이다.
CUDA, Metal, OpenCL은 64비트 포인터 시맨틱을 가진 C/C++ 셰이더 언어를 활용한다. 이 언어들은 정렬이 맞는 어떤 GPU 메모리 위치에서든 struct를 로드/스토어할 수 있다. 컴파일러는 와이드 로드(결합), 레지스터 매핑, 비트 추출 같은 최적화를 뒤에서 처리한다. 많은 현대 GPU는 레지스터의 8/16비트 부분을 추출하는 데 무료 명령 수정자(modifier)를 제공하여, 컴파일러가 8/16비트 값을 하나의 레지스터에 패킹할 수 있게 한다. 덕분에 셰이더 코드는 깔끔하고 효율적이다.
8개의 32비트 값을 가진 struct를 로드하면 컴파일러는 대부분 128비트 와이드 로드 두 번(각각 4레지스터를 채움)을 내보낼 것이다. 이는 로드 명령 수를 4배 줄인다. 와이드 로드는 특히 좁은 8/16비트 필드가 있는 struct에서 더 빠르다. GPU는 ALU가 밀집되어 있고 큰 레지스터 파일을 갖지만, CPU에 비해 메모리 경로는 상대적으로 느리다. CPU는 종종 두 개의 로드 포트로 사이클당 로드를 수행한다. 현대 GPU에서는 4사이클당 1 SIMD 로드 정도가 가능하다. 와이드 로드 + 셰이더 내 언팩은 데이터를 다루는 가장 효율적인 방식인 경우가 많다.
DirectX 게임에서 8~16비트의 컴팩트 데이터는 전통적으로 텍셀 버퍼(Buffer<T>)에 저장되었다. 하지만 현대 GPU는 컴퓨트 워크로드에 최적화되어 있다. 요즘 raw 버퍼 로드 명령은 텍셀 버퍼보다 최대 2배 처리량이 높고 최대 3배 낮은 지연을 갖는다. 텍셀 버퍼는 더 이상 현대 GPU에서 최적 선택이 아니다. 텍셀 버퍼는 구조화 데이터를 지원하지 않으므로, 사용자는 데이터를 여러 텍셀 버퍼로 SoA 레이아웃으로 쪼개야 한다. 각 텍셀 버퍼는 별도 디스크립터를 갖고, 데이터 접근 전에 디스크립터를 로드해야 한다. 이는 리소스(SGPR, 디스크립터 캐시 슬롯)를 소모하고, 단일 64비트 raw 포인터보다 스타트업 지연이 크다. SoA는 비선형 인덱스 조회(예: 머티리얼, 텍스처, 트라이앵글, 인스턴스, 본 ID)에서 캐시 미스를 크게 늘린다. 텍셀 버퍼는 정규화 타입([0,1], [-1,1])을 부동소수 레지스터로 무료 변환해 주지만, 와이드 로드를 잃고 느린 텍스처 샘플러 경로를 통과해야 한다. 좁은 텍셀 버퍼 로드는 레지스터 팽창도 유발한다. RGBA8_UNORM을 vec4로 로드하면 즉시 네 개의 벡터 레지스터가 할당되고, 샘플러 하드웨어가 나중에 값을 쓴다. 컴파일러는 로드→사용 거리를 늘리기 위해 셰이더 앞부분으로 로드를 끌어올려 지연을 숨긴다. 반면 와이드 raw 로드를 쓰면 uint8x4는 단 하나의 32비트 레지스터만 차지하고, 사용할 때 8비트 채널을 언팩한다. 레지스터 수명도 더 짧다. 현대 GPU는 레지스터의 16비트 하위/상위 절반에 직접 접근할 수 있고, 일부는 8비트(AMD SDWA modifier)도 가능하다. 패킹된 더블 레이트 수학은 2x16비트 변환 명령을 더 빠르게 한다. 일부 아키텍처(Nvidia, AMD)는 64비트 포인터 raw 로드를 VRAM에서 groupshared 메모리로 직접 수행해 지연 숨김에 필요한 레지스터 팽창을 더 줄인다. 64비트 포인터를 사용하면 게임 엔진은 AI 하드웨어 최적화의 이득도 얻는다.
포인터 기반 시스템은 정렬을 명시적으로 만든다. DirectX나 Vulkan에서 버퍼 객체를 할당할 때는 정렬을 API에 질의해야 한다. 버퍼 바인드 오프셋도 적절히 정렬되어야 한다. 정렬 계약은 저수준 셰이더 컴파일러가 최적 코드(예: 정렬된 4x32바이트 와이드 로드)를 내도록 해준다. DirectX ByteAddressBuffer 추상화에는 설계 결함이 있다. load2/load3/load4는 4바이트 정렬만 요구한다. 새 SM 6.2 load<T>도 요소 단위 정렬(half4=2, float4=4)만 요구한다. 일부 벤더(예: Nvidia)는 ByteAddressBuffer.load4를 네 개의 개별 로드로 쪼개야 한다. 버퍼 추상화는 항상 나쁜 코드젠을 막아주지 못하며, 나쁜 코드젠을 고치기도 어렵다. C/C++ 기반 언어(CUDA, Metal)는 alignas 속성으로 struct 정렬을 명시할 수 있다. 예제 코드의 루트 struct는 모두 alignas(16)을 사용한다.
기본적으로 GPU 쓰기는 동일 스레드 그룹(= 같은 컴퓨트 유닛) 내부 스레드에게만 보인다. 이는 비일관 L1$ 설계를 허용한다. 가시성은 보통 배리어로 제공된다. 한 디스패치 내에서 그룹 간 가시성이 필요하면 버퍼 바인딩에 [globallycoherent]를 붙이고, 컴파일러는 그 버퍼 접근에 대해 일관(coherent) 로드/스토어 명령을 내보낸다. 우리는 버퍼 객체 대신 64비트 포인터를 쓰므로, 명시적 coherent 로드/스토어 명령을 제공한다(atomic load/store와 유사한 문법). 마찬가지로 캐시 계층을 우회하는 non-temporal 로드/스토어도 제공할 수 있다.
Vulkan은 (2019) VK_KHR_buffer_device_address 확장으로 64비트 포인터를 지원한다(https://docs.vulkan.org/samples/latest/samples/extensions/buffer_device_address/README.html). 이 확장은 모바일을 포함한 모든 벤더에서 널리 지원되지만 Vulkan 1.4 코어에는 포함되지 않았다. BDA의 주된 문제는 GLSL/HLSL 셰이딩 언어에 포인터 지원이 없다는 점이다. 사용자는 raw 64비트 정수로 대신해야 한다. 64비트 정수는 struct로 캐스트할 수 있지만, struct는 커스텀 BDA 문법으로 정의된다. 배열 인덱싱은 컴파일러가 주소 계산을 생성하도록 하려면 배열을 가진 추가 BDA struct 타입 선언이 필요하다. 디버깅 지원도 제한적이다. 사용성은 매우 중요하며, HLSL/GLSL이 포인터를 네이티브로 지원하기 전까지 BDA는 틈새로 남을 것이다. 이는 포인터가 언어의 핵심 기둥이고 디버깅이 완벽한 CUDA/OpenCL/Metal과 대조적이다.
DirectX 12는 셰이더에서 포인터를 지원하지 않는다. 그 결과 HLSL은 배열을 함수 파라미터로 전달할 수 없다. UBO/SSBO 안에 머티리얼 배열 같은 단순한 것도 매크로 해킹이 필요하다. groupshared 메모리 배열을 함수 사이에 전달할 수 없어, 리덕션(prefix sum, sort 등) 같은 재사용 함수를 만들기 어렵다. 물론 유틸 헤더마다 전역 배열을 선언할 수는 있지만, 컴파일러가 각자 groupshared 메모리를 따로 할당해 점유율(occupancy)을 낮춘다. groupshared 메모리를 alias하는 쉬운 방법도 없다. GLSL도 동일한 문제를 가진다. CUDA/Metal MSL 같은 포인터 기반 언어는 배열에서 이런 문제가 없다. CUDA는 방대한 3rd party 라이브러리 생태계를 갖고 있고, 이 생태계는 Nvidia를 지구에서 가장 가치 있는 회사로 만들었다. 그래픽 셰이딩 언어도 현대 표준을 충족하도록 진화해야 한다. 우리도 라이브러리 생태계가 필요하다.
이후 예제에서는 CUDA와 Metal MSL과 유사한 C/C++ 스타일 셰이딩 언어를 사용하되, 그래픽 특화 요소를 위해 일부 HLSL 스타일의 시스템 값(SV) 시맨틱을 섞어 쓸 것이다.
운영체제 스레딩 API는 흔히 스레드 함수에 단 하나의 64비트 void 포인터를 제공한다. OS는 사용자의 데이터 입력 레이아웃에 관심이 없다. 같은 철학을 GPU 커널 데이터 입력에 적용해 보자. 셰이더 커널은 단 하나의 64비트 포인터를 받으며, 커널 함수 시그니처에서 원하는 struct로 캐스트한다. 개발자는 CPU와 GPU 양쪽에서 같은 C/C++ 헤더를 공유할 수 있다.
// 공통 헤더...
struct alignas(16) Data
{
// 유니폼 데이터
float16x4 color; // 16비트 float 벡터
uint16x2 offset; // 16비트 int 벡터
const uint8* lut; // 8비트 데이터 배열 포인터
// 입력/출력 데이터 배열 포인터
const uint32* input;
uint32* output;
};
// CPU 코드...
gpuSetPipeline(commandBuffer, computePipeline);
auto data = myBumpAllocator.allocate<Data>(); // 커스텀 범프 할당기(gpuMalloc ptr 래핑, 부록 참고)
data.cpu->color = {1.0f, 0.0f, 0.0f, 1.0f};
data.cpu->offset = {16, 0};
data.cpu->lut = luts.gpu + 64; // GPU 포인터는 포인터 연산 지원(오프셋 API 불필요)
data.cpu->input = input.gpu;
data.cpu->output = output.gpu;
gpuDispatch(commandBuffer, data.gpu, uvec3(128, 1, 1));
// GPU 커널...
[groupsize = (64, 1, 1)]
void main(uint32x3 threadId : SV_ThreadID, const Data* data)
{
uint32 value = data->input[threadId.x];
// TODO: color, offset, lut 등을 사용하는 코드...
data->output[threadId.x] = value;
}
예제에서 우리는 GPU 인자 할당을 위해 단순 선형 범프 할당기(myBumpAllocator)를 사용한다(부록 참고). 이는 {void* cpu, void* gpu}를 반환한다. CPU 포인터는 영구 매핑 GPU 메모리에 직접 쓰는 데 사용하고, GPU 포인터는 GPU 데이터 구조에 저장하거나 디스패치 인자로 넘길 수 있다.
대부분 GPU는 웨이브를 시작하기 직전에 루트 유니폼(64비트 포인터 포함)을 상수/스칼라 레지스터에 프리로드한다. 이 최적화는 여전히 유효하다. 드로우/디스패치 명령은 베이스 데이터 포인터를 싣고, 모든 입력 유니폼(다른 데이터 포인터 포함)은 베이스 포인터에서 작은 고정 오프셋에 있다. 셰이더는 미리 컴파일되고 PSO 생성 중에 디바이스 특화 마이크로코드로 추가 최적화되므로, 드라이버는 레지스터 프리로드 같은 루트 데이터 최적화를 설정할 충분한 기회를 가진다. 사용자는 루트 struct의 앞부분에 가장 중요한 데이터를 두는 것이 좋다(일부 아키텍처에서 루트 데이터 크기가 제한되기 때문). 우리 루트 struct에는 하드 제한이 없다. 나머지 필드는 셰이더 컴파일러가 표준(스칼라/유니폼) 메모리 로드를 내보낸다.
셰이더에 제공되는 루트 데이터 포인터는 const다. 셰이더는 루트 입력 데이터를 수정할 수 없다. 명령 프로세서가 새 웨이브에 데이터를 프리로드하기 위해 여전히 사용할 수 있기 때문이다. 출력은 non-const 포인터를 통해 수행한다(위 예제의 Data::output). 루트 데이터를 const로 강제하면, 드라이버가 특별한 유니폼 데이터 경로 최적화를 수행할 자유도 준다.
특별한 유니폼 버퍼 타입이 필요할까? 현대 셰이더 컴파일러는 자동 유니포미티(uniformity) 분석을 수행한다. 어떤 명령의 모든 입력이 유니폼이면 출력도 유니폼이다. 유니포미티는 셰이더 전반에 전파된다. 현대 아키텍처는 스칼라 레지스터/로드(또는 Intel의 SIMD1 같은 개념)를 갖고 있다. 유니포미티 분석은 벡터 로드를 스칼라 로드로 변환해 레지스터를 절약하고 지연을 줄인다. 이는 버퍼 타입(UBO vs SSBO)에 의존하지 않는다. 리소스는 읽기 전용이어야 한다(그래서 GLSL에서는 SSBO에 readonly를 붙이거나 DirectX 12에서는 UAV보다 SRV를 선호해야 한다). 컴파일러는 포인터가 alias되지 않는다는 것도 증명해야 한다. C/C++ const는 해당 포인터를 통해 수정할 수 없다는 뜻이지, 다른 읽기-쓰기 포인터가 같은 메모리 영역을 alias하지 않는다는 보장은 아니다. C99는 이를 위해 restrict 키워드를 추가했고, CUDA 커널은 이를 자주 사용한다. Metal의 루트 포인터는 기본적으로 no-alias(restrict)이며, Vulkan과 DirectX 12의 버퍼 객체도 마찬가지다. 우리는 같은 관례를 채택해 컴파일러에 더 많은 최적화 자유도를 줘야 한다.
컴파일 타임에 주소 유니포미티를 증명하지 못하는 경우도 있다. 현대 GPU는 동적으로 유니폼한 주소 로드를 기회적으로 최적화한다. 메모리 컨트롤러가 벡터 로드 명령의 모든 레인이 같은 주소를 쓰는 것을 감지하면, SIMD 와이드 gather 대신 단일 레인 로드를 수행하고 결과를 모든 레인에 복제한다. 이는 투명하며 셰이더 코드 생성이나 레지스터 할당에 영향을 주지 않는다. 동적으로 유니폼한 데이터는 과거보다 성능 타격이 훨씬 작고, 빠른 raw 로드 경로와 결합하면 더더욱 그렇다.
일부 벤더(ARM Mali, Qualcomm Adreno)는 유니포미티 분석을 더 발전시켰다. 셰이더 컴파일러는 유니폼 로드와 유니폼 수학을 추출해 스칼라 프리앰블을 만든다. 프리앰블은 셰이더 전에 실행되어, 유니폼 메모리 로드와 수학을 드로우/디스패치당 한 번만 수행하고 결과를 특수 하드웨어 상수 레지스터(루트 상수에 쓰이는 것과 동일)에 저장한다.
이 모든 최적화는 고전적인 16KB/64KB 유니폼/상수 버퍼 추상화보다 더 나은 유니폼 처리 방법을 제공한다. 많은 GPU는 여전히 루트 상수, 시스템 값, 프리앰블을 위한 특수 유니폼 레지스터를 갖는다.
이상적으로는 텍스처 디스크립터도 GPU 메모리의 다른 데이터처럼 동작해 struct 안에서 다른 데이터와 자유롭게 섞일 수 있어야 한다. 하지만 이런 수준의 유연성은 모든 현대 GPU에서 보편적으로 지원되지는 않는다. 다행히 바인드리스 텍스처 샘플러 설계는 지난 10년 동안 수렴해, 현재는 두 가지 주요 방법만 남았다: 256비트 raw 디스크립터와 인덱스드 디스크립터 힙.
AMD의 raw 디스크립터 방식은 256비트 디스크립터를 GPU 메모리에서 컴퓨트 유닛의 스칼라 레지스터로 직접 로드한다. 연속된 8개의 32비트 스칼라 레지스터가 하나의 디스크립터를 담는다. SIMD 텍스처 샘플 명령 동안 셰이더 코어는 256비트 텍스처 디스크립터와 레인별 UV를 샘플러 유닛에 보낸다. 샘플러는 추가 간접 없이 텍셀을 주소 계산/로드할 모든 정보를 가진다. 단점은 256비트 디스크립터가 레지스터 공간을 많이 차지하며, 샘플 명령마다 샘플러로 다시 보내야 한다는 점이다.
인덱스드 디스크립터 힙 방식은 32비트 인덱스(구형 Intel iGPU는 20비트)를 사용한다. 32비트 인덱스는 struct에 저장하기 쉽고, 표준 SIMD 레지스터에 로드할 수 있으며, 전달 비용도 낮다. SIMD 샘플 명령 동안 셰이더 코어는 텍스처 인덱스와 레인별 UV를 샘플러 유닛에 보낸다. 샘플러는 디스크립터 힙에서 디스크립터를 가져온다: 힙 베이스 주소 + 텍스처 인덱스 * 스트라이드(현대 GPU에서는 256비트). 텍스처 힙 베이스 주소는 Vulkan/Metal에서는 드라이버가 추상화하거나, DirectX 12에서는 사용자가 SetDescriptorHeaps로 제공한다. 텍스처 힙 베이스 변경은 (구형 하드웨어에서) 내부 파이프라인 배리어를 유발할 수 있다. 현대 GPU에서는 텍스처 힙 64비트 베이스 주소가 샘플 명령 데이터의 일부인 경우가 많아, 여러 힙에서의 샘플링을 자연스럽게 한다(64비트 베이스 + 레인별 32비트 오프셋). 샘플러 유닛에는 첫 접근 이후 간접 읽기를 피하기 위한 작은 디스크립터 캐시가 있다. 디스크립터 힙이 수정되면 디스크립터 캐시는 무효화되어야 한다.
몇 년 전까지만 해도 AMD의 스칼라 레지스터 기반 텍스처 디스크립터가 장기적으로 승자가 될 것처럼 보였다. 스칼라 레지스터가 디스크립터 힙보다 더 유연해, 디스크립터를 GPU 데이터 구조 안에 직접 내장할 수 있기 때문이다. 하지만 단점이 있다. 레이트레이싱과 디퍼드 텍스처링(Nanite) 같은 현대 워크로드는 비유니폼 텍스처 인덱스에 의존한다. 텍스처 힙 인덱스는 SIMD 웨이브에서 유니폼하지 않다. 32비트 힙 인덱스는 4바이트라 레인마다 보내기 쉽다. 반면 256비트 디스크립터는 32바이트다. 레인마다 256비트 디스크립터를 가져오고 보내는 것은 비현실적이다. 현대 Nvidia, Apple, Qualcomm GPU는 샘플 명령에서 레인별 디스크립터 인덱스 모드를 지원해 비유니폼 케이스가 더 효율적이다. 필요하면 샘플러가 내부 루프를 수행한다. 샘플러 유닛과의 입출력은 힙 인덱스의 일관성과 무관하게 한 번만 전송된다. AMD의 스칼라 레지스터 기반 디스크립터 아키텍처는 셰이더 컴파일러가 텍스처 샘플 명령 주변에 스칼라화 루프를 생성해야 한다. 이는 추가 ALU 사이클을 요구하고, 샘플러 데이터 전송을 여러 번(부분 마스킹 포함) 해야 한다. 이것이 Nvidia가 레이트레이싱에서 AMD보다 빠른 이유 중 하나다. ARM과 Intel도 32비트 힙 인덱스를 사용하지만, 최신 아키텍처는 아직 레인별 힙 인덱스 모드를 갖지 않아 AMD와 비슷한 스칼라화 루프를 생성한다.
이 차이는 통합된 텍스처 디스크립터 힙 추상화로 감쌀 수 있다. 사실상 텍스처 디스크립터 크기는 256비트(Apple은 텍스처 디스크립터 192비트 + 샘플러 32비트)다. 텍스처 힙은 256비트 디스크립터 블롭의 균질 배열로 제시될 수 있다. 인덱싱도 쉽다.
DirectX 12 셰이더 모델 6.6은 이런 텍스처 힙 추상화를 제공하지만, CPU나 컴퓨트 셰이더가 디스크립터 힙 메모리에 직접 쓰는 것을 허용하지 않는다. CPU에서 디스크립터를 만들고 GPU로 복사하기 위해 별도의 API 세트를 사용하며, GPU는 디스크립터를 쓸 수 없다. 이제 우리는 이 API 추상화를 완전히 없애고, CPU와 GPU가 디스크립터 힙에 직접 쓸 수 있도록 할 수 있다. 필요한 것은 256비트(uint64[4]) 하드웨어 특화 디스크립터 블롭을 만드는 간단한(user-land) 드라이버 헬퍼 함수뿐이다. 현대 GPU는 UMA 또는 PCIe ReBAR이므로 CPU가 GPU 메모리에 직접 디스크립터 블롭을 쓸 수 있다. 사용자는 컴퓨트 셰이더로 디스크립터를 복사하거나 생성할 수도 있다. 셰이딩 언어에도 디스크립터 생성 intrinsic을 제공한다. 이는 하드웨어 특화 uint64x4 디스크립터 블롭을 반환한다(CPU API와 유사). 이는 DirectX 12의 디스크립터 업데이트 모델보다 훨씬 빠르고 유연하며 API 복잡성을 크게 줄인다. Vulkan의 VK_EXT_descriptor_buffer 확장(2022)은 내 제안과 유사하게 CPU/GPU 직접 쓰기를 허용하지만, 불행히도 Vulkan 1.4 코어 스펙에는 포함되지 않았다.
// 앱 시작: 텍스처 디스크립터 힙 할당(예: 65536 디스크립터)
GpuTextureDescriptor *textureHeap = gpuMalloc<GpuTextureDescriptor>(65536);
// 3rd party 라이브러리로 이미지 로드
auto pngImage = pngLoad("cat.png");
auto uploadMemory = uploadBumpAllocator.allocate(pngImage.byteSize); // 커스텀 범프 할당기(gpuMalloc ptr 래핑)
pngImage.load(uploadMemory.cpu);
// 텍스처용 GPU 메모리 할당(메타데이터 포함 최적 레이아웃)
GpuTextureDesc textureDesc { .dimensions = pngImage.dimensions, .format = FORMAT_RGBA8_UNORM, .usage = SAMPLED };
GpuTextureSizeAlign textureSizeAlign = gpuTextureSizeAlign(textureDesc);
void *texturePtr = gpuMalloc(textureSizeAlign.size, textureSizeAlign.align, MEMORY_GPU);
GpuTexture texture = gpuCreateTexture(textureDesc, texturePtr);
// 256비트 텍스처 뷰 디스크립터 생성 후 저장
textureHeap[0] = gpuTextureViewDescriptor(texture, { .format = FORMAT_RGBA8_UNORM });
// 배치 업로드: begin
GpuCommandBuffer uploadCommandBuffer = gpuStartCommandRecording(queue);
// 여기서 모든 텍스처 복사!
gpuCopyToTexture(uploadCommandBuffer, texturePtr, uploadMemory.gpu, texture);
// TODO 다른 텍스처...
// 배치 업로드: end
gpuBarrier(uploadCommandBuffer, STAGE_TRANSFER, STAGE_ALL, HAZARD_DESCRIPTORS);
gpuSubmit(queue, { uploadCommandBuffer });
// 이후 렌더링...
gpuSetActiveTextureHeapPtr(commandBuffer, gpuHostToDevicePointer(textureHeap));
CPU 측 텍스처 객체(GpuTexture)를 완전히 없애는 것도 거의 가능하다. 하지만 불행히도 모든 현대 GPU의 삼각형 래스터라이저 유닛은 아직 바인드리스가 아니다. CPU 드라이버는 렌더 타깃/뎁스-스텐실 바인딩, 클리어, 리졸브를 위한 커맨드 패킷을 준비해야 한다. 이 API들은 256비트 GPU 텍스처 디스크립터를 쓰지 않는다. 따라서 드라이버 특화 추가 CPU 데이터( GpuTexture 객체에 저장)가 필요하다.
셰이더에서 텍스처를 참조하는 가장 단순한 방법은 32비트 인덱스를 쓰는 것이다. 단일 인덱스는 디스크립터 범위의 시작 오프셋을 나타낼 수도 있다. 이는 DirectX 12의 디스크립터 테이블과 Vulkan의 디스크립터 세트 추상화를 API 없이 구현하는 간단한 방법을 제공한다. 또한 빠른 머티리얼 스위치에도 우아한 해법을 준다. 필요한 것은 단 하나의 64비트 GPU 포인터뿐이다. 머티리얼 데이터 struct(머티리얼 속성 + 32비트 텍스처 힙 시작 인덱스 포함)를 가리키면 된다. Vulkan의 vkCmdBindDescriptorSets와 DirectX 12의 SetGraphicsRootDescriptorTable은 비교적 빠르지만, 영구 매핑 GPU 메모리에 단 하나의 64비트 포인터를 쓰는 것만큼 빠르지 않다. 리소스 바인딩 API 객체를 생성/업데이트/삭제할 필요가 없어 복잡성이 크게 줄고, 즉시 vs 리텐드 모드 불일치를 해결하기 위해 흔히 쓰는 디스크립터 세트 해시맵 유지 비용도 사라져 CPU 시간이 절약된다.
// 공통 헤더...
struct alignas(16) Data
{
uint32 srcTextureBase;
uint32 dstTexture;
float32x2 invDimensions;
};
// GPU 커널...
const Texture textureHeap[];
[groupsize = (8, 8, 1)]
void main(uint32x3 threadId : SV_ThreadID, const Data* data)
{
Texture textureColor = textureHeap[data->srcTextureBase + 0];
Texture textureNormal = textureHeap[data->srcTextureBase + 1];
Texture texturePBR = textureHeap[data->srcTextureBase + 2];
Sampler sampler = {.minFilter = LINEAR, .magFilter = LINEAR}; // 내장 샘플러(Metal 스타일)
float32x2 uv = float32x2(threadId.xy) * data->invDimensions;
float32x4 color = sample(textureColor, sampler, uv);
float32x4 normal = sample(textureNormal, sampler, uv);
float32x4 pbr = sample(texturePBR, sampler, uv);
float32x4 lit = calculateLighting(color, normal, pbr);
TextureRW dstTexture = TextureRW(textureHeap[data->dstTexture]);
dstTexture[threadId.xy] = lit;
}
Metal 4는 텍스처 디스크립터 힙을 자동으로 관리한다. 텍스처 객체에는 .gpuResourceID가 있으며 이는 64비트 힙 인덱스다(Xcode GPU 디버거는 0x3 같은 작은 값을 보여준다). 텍스처 ID를 DirectX SM 6.6이나 Vulkan(디스크립터 버퍼 확장)의 텍스처 인덱스처럼 GPU struct에 직접 쓸 수 있다. 하지만 Metal의 힙 관리는 자동이라 사용자는 텍스처 디스크립터를 연속 범위로 할당할 수 없다. 흔한 관행은 범위의 첫 텍스처에 대한 32비트 인덱스를 저장하고 나머지 텍스처 인덱스를 계산하는 것이다(위 코드 예제처럼). Metal은 이를 지원하지 않는다. 사용자는 각 텍스처마다 64비트 핸들을 따로 써야 한다. 텍스처 5개 세트를 주소 지정하려면 Metal에서는 40바이트(564비트)가 필요하지만, Vulkan/DirectX 12는 4바이트(132비트)면 된다. Apple GPU 하드웨어는 SM 6.6 텍스처 힙을 구현할 수 있지만 제한은 Metal API(소프트웨어)다.
텍셀 버퍼는 하위 호환성을 위해 여전히 지원할 수 있다. DirectX 12는 텍셀 버퍼 디스크립터를 텍스처 디스크립터와 같은 힙에 저장한다. 텍셀 버퍼는 1D 텍스처(필터 없는 tfetch 경로)처럼 동작한다. 텍셀 버퍼는 주로 하위 호환성 용도이므로, 드라이버 벤더가 이를 백그라운드에서 raw 로드로 교체하는 등 복잡한 일을 할 필요는 없다. 나는 드라이버 백그라운드 스레드와 셰이더 교체를 좋아하지 않는다.
비유니폼 텍스처 인덱스는 GLSL/HLSL의 NonUniformResourceIndex 표기와 유사한 표기를 사용해야 한다. 이는 저수준 GPU 셰이더 컴파일러에 레인별 힙 인덱스를 가진 특수 텍스처 명령(또는 유니폼 디스크립터만 지원하는 GPU에서는 스칼라화 루프)을 내도록 지시한다. 버퍼는 디스크립터가 아니므로 버퍼에는 NonUniformResourceIndex가 필요 없다. 우리는 레인당 64비트 포인터를 그냥 전달하면 된다. 이는 모든 현대 GPU에서 동작한다. 스칼라화 루프도 없고, 혼란도 없다. 또한 언어는 ptr[index] 문법으로 32비트 인덱스를 가진 메모리 로드를 네이티브로 지원해야 한다. 일부 GPU는 32비트 레인별 오프셋을 가진 raw 메모리 로드 명령을 지원하며, 이는 레지스터 압력을 줄인다. GPU 벤더에게 피드백: 아키텍처에 아직 없다면 “64비트 공유 베이스 + 32비트 레인별 오프셋” raw 로드 명령과 16비트 uv(w) 텍스처 로드 명령을 추가해 달라.
const Texture textureHeap[];
[groupsize = (8, 8, 1)]
void main(uint32x3 threadId : SV_ThreadID, const Data* data)
{
// 포인터 시맨틱에서는 비유니폼 "버퍼 데이터"가 문제되지 않는다!
Material* material = data->materialMap[threadId.xy];
// 비유니폼 텍스처 힙 인덱스
uint32 textureBase = NonUniformResourceIndex(material.textureBase);
Texture textureColor = textureHeap[textureBase + 0];
Texture textureNormal = textureHeap[textureBase + 1];
Texture texturePBR = textureHeap[textureBase + 2];
Sampler sampler = {.minFilter = LINEAR, .magFilter = LINEAR};
float32x2 uv = float32x2(threadId.xy) * data->invDimensions;
float32x4 color = sample(textureColor, sampler, uv);
float32x4 normal = sample(textureNormal, sampler, uv);
float32x4 pbr = sample(texturePBR, sampler, uv);
color *= material.color;
pbr *= material.pbr;
// 나머지 셰이더
}
현대 바인드리스 텍스처링은 모든 텍스처 바인딩 API를 제거하게 해준다. 전역 인덱싱 가능한 텍스처 힙은 모든 텍스처를 모든 셰이더에 보이게 한다. 텍스처 데이터는 여전히 DCC와 Morton 스위즐을 활성화하기 위해 복사 명령으로 GPU 메모리에 로드되어야 한다. 텍스처 디스크립터 생성은 얇은 GPU 특화 user-land API가 여전히 필요하다. 텍스처 힙은 CPU와 GPU 모두에 raw GPU 메모리 배열로 직접 노출될 수 있어, DirectX 12 SM 6.6 대비 텍스처 힙 API 복잡성을 크게 줄인다.
우리의 셰이더 루트 데이터가 단일 64비트 포인터이고 텍스처는 32비트 인덱스이므로, 셰이더 파이프라인 생성은 극도로 단순해진다. 텍스처 바인딩, 버퍼 바인딩, 바인드 그룹(디스크립터 세트, argument buffer)이나 루트 시그니처를 정의할 필요가 없다.
auto shaderIR = loadFile("computeShader.ir");
GpuPipeline computePipeline = gpuCreateComputePipeline(shaderIR);
DirectX 12와 Vulkan은 루트 시그니처, 푸시 디스크립터, 푸시 상수, 디스크립터 세트 등을 바인딩하기 위한 복잡한 API를 사용한다. 하지만 현대 GPU 드라이버는 본질적으로 하나의 struct를 GPU 메모리에 구성하고 그 포인터를 커맨드 프로세서에 전달한다. 우리는 그 정도의 API 복잡성이 불필요함을 보였다. 사용자는 루트 struct를 영구 매핑 GPU 메모리에 쓰고, 64비트 GPU 포인터를 드로우/디스패치 함수에 직접 전달하면 된다. 사용자는 struct 안에 64비트 포인터와 32비트 텍스처 힙 인덱스를 넣어 필요에 맞는 어떤 간접 데이터 레이아웃도 구성할 수 있다. 루트 바인딩 API와 DX12의 버퍼 “동물원”은 64비트 포인터로 효율적으로 대체될 수 있다. 이는 셰이더 파이프라인 생성을 대폭 단순화한다. 데이터 레이아웃을 정의할 필요도 없다. 사용자에게 더 큰 유연성을 주면서 API 복잡성의 거대한 덩어리를 제거했다.
Vulkan, Metal, WebGPU에는 파이프라인 생성 시 고정되는 정적(스페셜라이제이션) 상수 개념이 있다. 드라이버의 내부 셰이더 컴파일러는 이 상수를 입력 셰이더 IR의 리터럴로 적용하고 이후 상수 전파 및 데드 코드 제거를 수행한다. 이는 파이프라인 생성 시 동일 셰이더의 여러 퍼뮤테이션을 만들 수 있게 하여, 오프라인 컴파일의 시간과 저장 공간을 줄인다.
Vulkan과 Metal은 스페셜라이제이션 상수와 값을 설명하는 API 세트와 특수 셰이더 문법을 갖는다. 하지만 셰이더 측에 정의된 상수 struct와 매칭되는 C struct를 그냥 제공하는 편이 더 낫다. 최소한의 API 표면으로 중요한 개선을 가져온다.
Vulkan의 스페셜라이제이션 상수에는 설계 결함이 있다. 스페셜라이제이션 상수는 디스크립터 세트 레이아웃을 수정할 수 없다. 입력/출력이 고정된다. 사용자가 가능한 모든 입출력을 포함한 “우버 레이아웃”을 만들고 사용하지 않는 디스크립터 업데이트를 건너뛰는 식으로 해킹할 수는 있지만 번거롭고 최적이 아니다. 우리의 설계는 같은 문제가 없다. 상수로 분기하고(반대쪽은 데드 코드 제거) 셰이더 데이터 입력 포인터를 다른 struct로 재해석하면 된다. C++ 상속 레이아웃도 흉내 낼 수 있다. 입력 struct의 앞부분은 공통 레이아웃으로 두고, 특화 데이터는 끝에 둔다. 정적 다형성(static polymorphism)을 깔끔히 달성할 수 있다. 런타임 성능은 손수 최적화한 셰이더와 동일하다. 스페셜라이제이션 struct에는 GPU 포인터도 포함할 수 있어 런타임 메모리 위치를 하드코딩해 간접을 피할 수 있다. 이는 기존 셰이더 언어에서는 불가능했다. 대신 GPU 벤더는 런타임에서 셰이더를 분석해 비슷한 교체 최적화를 수행하는 백그라운드 스레드를 써야 했고, 이는 CPU 비용과 드라이버 복잡성을 크게 늘렸다.
// 공통 헤더...
struct alignas(16) Constants
{
int32 qualityLevel;
uint8* blueNoiseLUT;
};
// CPU 코드...
Constants constants { .qualityLevel = 2, blueNoiseLUT = blueNoiseLUT.gpu };
auto shaderIR = loadFile("computeShader.ir");
GpuPipeline computePipeline = gpuCreateComputePipeline(shaderIR, &constants);
// GPU 커널...
[groupsize = (8, 8, 1)]
void main(uint32x3 threadId : SV_ThreadID, const Data* data, const Constants constants)
{
if (constants.qualityLevel == 3)
{
// 데드 코드 제거
}
}
셰이더 퍼뮤테이션 지옥은 현대 그래픽스의 가장 큰 문제 중 하나다. 게이머는 스터터를 불평하고, 개발자는 오프라인 셰이더 컴파일이 몇 시간 걸린다고 불평한다. 이 설계는 사용자에게 유연성을 추가한다. 셰이더 내부에서 정적/동적 동작을 쉽게 전환할 수 있어, 일반적 폴백과 필요 시 스페셜라이제이션을 함께 쓰기 쉽다. 이는 셰이더 퍼뮤테이션 수를 줄이고 파이프라인 생성으로 인한 런타임 스톨도 줄인다.
모던 그래픽 API에서 가장 미움받는 기능은 배리어일 것이다. 배리어는 두 가지 목적을 가진다: 생산자→소비자 실행 의존성 강제, 그리고 텍스처 레이아웃 전환.
많은 그래픽 프로그래머는 GPU 동기화에 대해 잘못된 멘탈 모델을 갖는다. 흔한 믿음은 GPU 동기화가 개별 텍스처/버퍼 의존성에 기반한다는 것이다. 현실에서 현대 GPU 하드웨어는 개별 리소스에 그다지 관심이 없다. 우리는 사용자 영역에서 개별 리소스 목록과 레이아웃 변화를 준비하는 데 많은 CPU 사이클을 쓰지만, 현대 드라이버는 عملي상 그 목록을 버린다. 추상화가 현실과 맞지 않는다.
현대 바인드리스 아키텍처는 GPU에 많은 자유를 준다. 셰이더는 어떤 64비트 포인터나 전역 디스크립터 힙의 어떤 텍스처에도 쓸 수 있다. CPU는 GPU가 어떤 결정을 내릴지 모른다. 그러면 CPU가 영향을 받는 각 리소스에 대해 전환 배리어를 어떻게 내야 할까? 이는 바인드리스 아키텍처와 오늘날의 고전적인 CPU-드리븐 렌더링 API 사이의 명백한 불일치다. 10년 전 API가 왜 그렇게 설계되었는지 살펴보자.
AMD GCN은 모던 그래픽 API 설계에 큰 영향을 주었다. GCN은 비동기 컴퓨트와 바인드리스 텍스처링(스칼라 레지스터에 디스크립터 저장)에서 앞서갔지만, DCC와 캐시 설계에는 중요한 제한이 있었다. 이는 오늘날 배리어 모델이 왜 그렇게 복잡한지 보여주는 좋은 예다. GCN에는 일관된 마지막 레벨 캐시가 없었다. ROP(픽셀 셰이더 출력)는 VRAM에 직접 연결된 특수 비일관 캐시를 가졌다. 드라이버는 먼저 ROP 캐시를 메모리로 플러시한 뒤, 픽셀 셰이더 쓰기가 셰이더와 샘플러에 보이도록 L2$를 무효화해야 했다. 커맨드 프로세서도 L2$의 클라이언트가 아니었다. 컴퓨트 셰이더가 쓴 인다이렉트 인자는 전체 L2$를 무효화하고 더티 라인을 VRAM으로 플러시하기 전에는 커맨드 프로세서에 보이지 않았다. GCN 3는 ROP용 DCC를 도입했지만, AMD 텍스처 샘플러는 DCC 압축된 텍스처나 압축된 뎁스 버퍼를 직접 읽을 수 없었다. 드라이버는 내부 디컴프레스 컴퓨트 셰이더를 수행해 압축을 제거해야 했다. 디스플레이 엔진도 DCC 텍스처를 읽을 수 없었다. 렌더 타깃을 샘플링하는 흔한 케이스는 내부 배리어 두 개와 모든 캐시 플러시를 요구했다(ROP 대기, ROP 캐시와 L2$ 플러시, 디컴프레스 컴퓨트 실행, 컴퓨트 대기).
AMD의 RDNA 아키텍처는 중요한 개선을 했다: 모든 메모리 연산을 커버하는 일관된 L2$를 갖고, ROP와 커맨드 프로세서는 L2$의 클라이언트다. 비일관 캐시는 컴퓨트 유닛 내부의 작은 L0$와 K$(스칼라 캐시)뿐이다. 배리어는 이제 작은 캐시의 미완료 쓰기를 상위 캐시에 플러시하는 것만으로 충분하다. 드라이버는 마지막 레벨(L2) 캐시를 VRAM으로 플러시할 필요가 없어 배리어가 훨씬 빨라진다. RDNA의 개선된 디스플레이 엔진은 DCC 압축 텍스처를 읽을 수 있고, (디)컴프레서가 L2$와 L0$ 텍스처 캐시 사이에 있다. 샘플링 전에 텍스처를 VRAM으로 디컴프레스할 필요가 없어, 텍스처 레이아웃 전환(압축/비압축)이 사라진다. 모든 데스크톱/모바일 GPU 벤더가 비슷한 결론에 도달했다: 오늘날 병목은 대역폭이다. 리소스를 VRAM으로 디코딩하며 대역폭을 낭비하면 안 된다. 레이아웃 전환은 더 이상 필요 없다.

AMD RDNA (2019): RDNA 아키텍처의 개선된 캐시 계층, DCC, 디스플레이 엔진. L2$는 DCC 압축 데이터를 포함한다. (디)컴프레서는 L2$와 하위 레벨 사이에 위치한다. L0$(텍스처)는 디컴프레스된다. Image © AMD.
리소스 리스트는 DirectX 12와 Vulkan 배리어에서 가장 짜증나는 부분이다. 사용자는 각 리소스 상태를 개별 추적하고, 배리어마다 이전/다음 상태를 API에 알려야 한다. 이는 10년 된 GPU에서 벤더가 배리어 API 아래에 다양한 디컴프레스 명령을 숨겼기 때문에 필요했다. 배리어 명령이 디컴프레스 명령 역할을 했으므로 어떤 리소스가 디컴프레스를 요구하는지 알아야 했다.
오늘날 하드웨어는 텍스처 레이아웃이나 디컴프레스 단계가 필요 없다. Vulkan은 2025년 VK_KHR_unified_image_layouts 확장으로 배리어에서 이미지 레이아웃 전환을 제거했다(https://www.khronos.org/blog/so-long-image-layouts-simplifying-vulkan-synchronisation). 하지만 여전히 개별 텍스처/버퍼를 나열해야 한다. 왜일까?
주된 이유는 레거시 API와 툴링 호환성이다. 사람들은 리소스 의존성으로 생각하는 데 익숙하고, Vulkan/DirectX 12 검증 레이어가 그 방식으로 설계되어 있다. 그러나 GPU가 실행하는 배리어 명령은 텍스처나 버퍼 정보가 전혀 없다. 리소스 리스트는 오로지 드라이버가 소비한다.
현대 드라이버는 리소스 리스트를 루프하며 플래그 집합을 채운다. 드라이버는 더 이상 레이아웃이나 LLC 일관성을 걱정하지 않지만, 여전히 특수 케이스에서 플러시가 필요한 작은 비일관 캐시가 있다. 현대 GPU는 대부분의 비일관 캐시를 모든 배리어에서 자동으로 플러시한다. 예를 들어 AMD의 L0$와 K$(스칼라 캐시)는 항상 플러시된다. 모든 패스가 어떤 출력이든 쓰며, 그 출력은 이런 캐시 어딘가에 살기 때문이다. 모든 쓰기 주소를 세밀하게 추적하는 것은 너무 비싸다. 작은 비일관 캐시는 대개 inclusive라 수정된 라인이 다음 캐시 레벨로 플러시된다. 이는 빠르고 VRAM 트래픽을 만들지 않는다.
일부 아키텍처에는 자동으로 플러시되지 않는 특수 캐시가 있다. 예: 텍스처 샘플러의 디스크립터 캐시(앞 절 참고), 래스터라이저 ROP 캐시, HiZ 캐시. 커맨드 프로세서는 웨이브 스폰 지연을 줄이기 위해 보통 앞서 달린다. 셰이더에서 인다이렉트 인자를 쓴다면, 경쟁을 피하기 위해 커맨드 프로세서 프리페처를 스톨하도록 GPU에 알려야 한다. 하지만 GPU는 컴퓨트 셰이더가 인다이렉트 인자 버퍼에 썼는지 알 수 없다. DirectX 12에서는 버퍼를 D3D12_RESOURCE_STATE_INDIRECT_ARGUMENT로 전환하고, Vulkan에서는 소비자 의존성을 VK_PIPELINE_STAGE_DRAW_INDIRECT_BIT 같은 스테이지로 표현한다. 이런 전환/의존성이 배리어에 포함되면, 드라이버는 커맨드 프로세서 프리페처 스톨 플래그를 배리어에 포함한다.
현대 배리어 설계는 리소스 리스트 대신, 이런 특수 비일관 캐시에서 무엇이 일어나는지 설명하는 단일 비트필드를 사용한다. 특수 케이스에는 디스크립터 무효화, 드로우 인자 무효화, 뎁스 캐시 무효화 등이 있다. 우리는 드로우 인자를 생성하거나, 디스크립터 힙에 쓰거나, 컴퓨트 셰이더로 뎁스 버퍼에 쓸 때 이런 플래그가 필요하다. 대부분 배리어는 특별한 캐시 무효화 플래그가 필요 없다.
일부 GPU는 특수 케이스에서 여전히 디컴프레스가 필요할 수 있다. 예: 복사나 클리어 명령(클리어 컬러가 바뀌면 fast clear eliminate). 복사/클리어 명령은 영향을 받는 리소스를 파라미터로 받으므로, 드라이버는 필요하면 데이터를 디코드하는 조치를 취할 수 있다. 이런 특수 케이스를 위해 배리어에 리소스 리스트가 필요하지 않다. 모든 포맷/사용 플래그가 압축을 지원하는 것도 아니다. 드라이버는 이런 경우 데이터를 압축하지 않고 유지해, 전환을 반복하며 대역폭을 낭비하지 않는다.
표준 UAV 배리어(컴퓨트→컴퓨트)는 사소하다.
gpuBarrier(commandBuffer, STAGE_COMPUTE, STAGE_COMPUTE);
텍스처 디스크립터 힙에 쓰는(드문) 경우 특별 플래그를 추가한다.
gpuBarrier(commandBuffer, STAGE_COMPUTE, STAGE_COMPUTE, HAZARD_DESCRIPTORS);
래스터라이저 출력과 픽셀 셰이더 사이 배리어는 오프스크린 렌더 타깃→샘플링에서 흔하다. 예제는 배리어가 버텍스 셰이더를 막지 않도록 스테이지 의존성을 설정해, 버텍스 셰이딩(모바일에서는 타일 빈닝)이 이전 패스와 오버랩될 수 있다. 래스터 출력 스테이지(또는 그 이후)를 생산자로 가진 배리어는, 아키텍처가 필요하면 비일관 ROP 캐시를 자동으로 플러시한다. 이를 위한 명시적 플래그가 필요 없다.
gpuBarrier(commandBuffer, STAGE_RASTER_COLOR_OUT | STAGE_RASTER_DEPTH_OUT, STAGE_PIXEL_SHADER);
사용자는 큐 실행 의존성(생산자/소비자 스테이지 마스크)만 기술한다. 개별 텍스처/버퍼 리소스 상태를 추적할 필요가 없어 복잡성이 크게 줄고, 현재 DirectX 12/Vulkan 설계 대비 CPU 시간을 상당히 절약한다. Metal 2는 이미 이런 현대 배리어 설계를 갖고 있으며 리소스 리스트를 사용하지 않는다.
많은 GPU는 커스텀 스크래치패드 메모리를 갖는다: 각 컴퓨트 유닛 내부의 groupshared 메모리, 타일 메모리, Qualcomm GMEM 같은 큰 공유 스크래치패드. 이 메모리는 드라이버가 자동 관리한다. groupshared 같은 임시 스크래치패드는 메모리에 저장되지 않는다. 타일 메모리는 타일 래스터라이저가 자동으로 저장한다(store op == store). 유니폼 레지스터는 읽기 전용이며 드로우콜마다 미리 채워진다. 스크래치패드와 유니폼 레지스터는 캐시 일관성 프로토콜이 없고 배리어와 직접 상호작용하지 않는다.
현대 GPU는 셰이더 스테이지가 끝났을 때 메모리에 값을 쓰는 동기화 명령과, 어떤 스테이지가 시작하기 전에 메모리 위치에 값이 나타날 때까지 기다리는 명령(대기에는 선택적 캐시 플러시 시맨틱 포함)을 지원한다. 이는 배리어를 생산자/소비자 두 개로 쪼갠 것과 같다. DirectX 12의 split barrier와 Vulkan의 event→wait가 이런 설계다. 배리어를 분리하면 사이에 독립 작업을 넣어 GPU를 비우지 않고(stall 없이) 진행할 수 있다.
하지만 Vulkan event→wait(DX12 split barrier) 사용은 거의 없다. 주된 이유는 일반 배리어 자체가 이미 너무 복잡해 개발자가 추가 복잡성을 피하기 때문이다. 과거에는 split barrier 드라이버 지원도 완벽하지 않았다. 리소스 리스트를 제거하면 split barrier는 훨씬 단순해진다.
또한 split barrier를 타임라인 세마포어와 비슷하게 만들 수 있다: signal 명령은 단조 증가 64비트 값(atomic max)에 기록하고, wait 명령은 그 값이 >= N이 될 때까지 기다린다. 카운터는 GPU 메모리 포인터일 뿐, 지속 API 객체가 필요 없다. 이는 훨씬 단순한 event→wait API를 제공한다.
gpuSignalAfter(commandBuffer, STAGE_RASTER_COLOR_OUT, gpuPtr, counter, SIGNAL_ATOMIC_MAX);
// 여기 독립 작업 삽입
gpuWaitBefore(commandBuffer, STAGE_PIXEL_SHADER, gpuPtr, counter++, OP_GREATER_EQUAL);
이 API는 기존 VkEvent보다 훨씬 단순하면서 더 유연하다. 위 예제는 타임라인 세마포어 시맨틱을 구현했지만, 예를 들어 비트마스크로 여러 생산자를 기다리는 패턴도 가능하다: SIGNAL_ATOMIC_OR로 비트를 설정하고, gpuWaitBefore에서 마스크의 모든 비트가 set될 때까지 기다린다(마스크는 선택 파라미터).
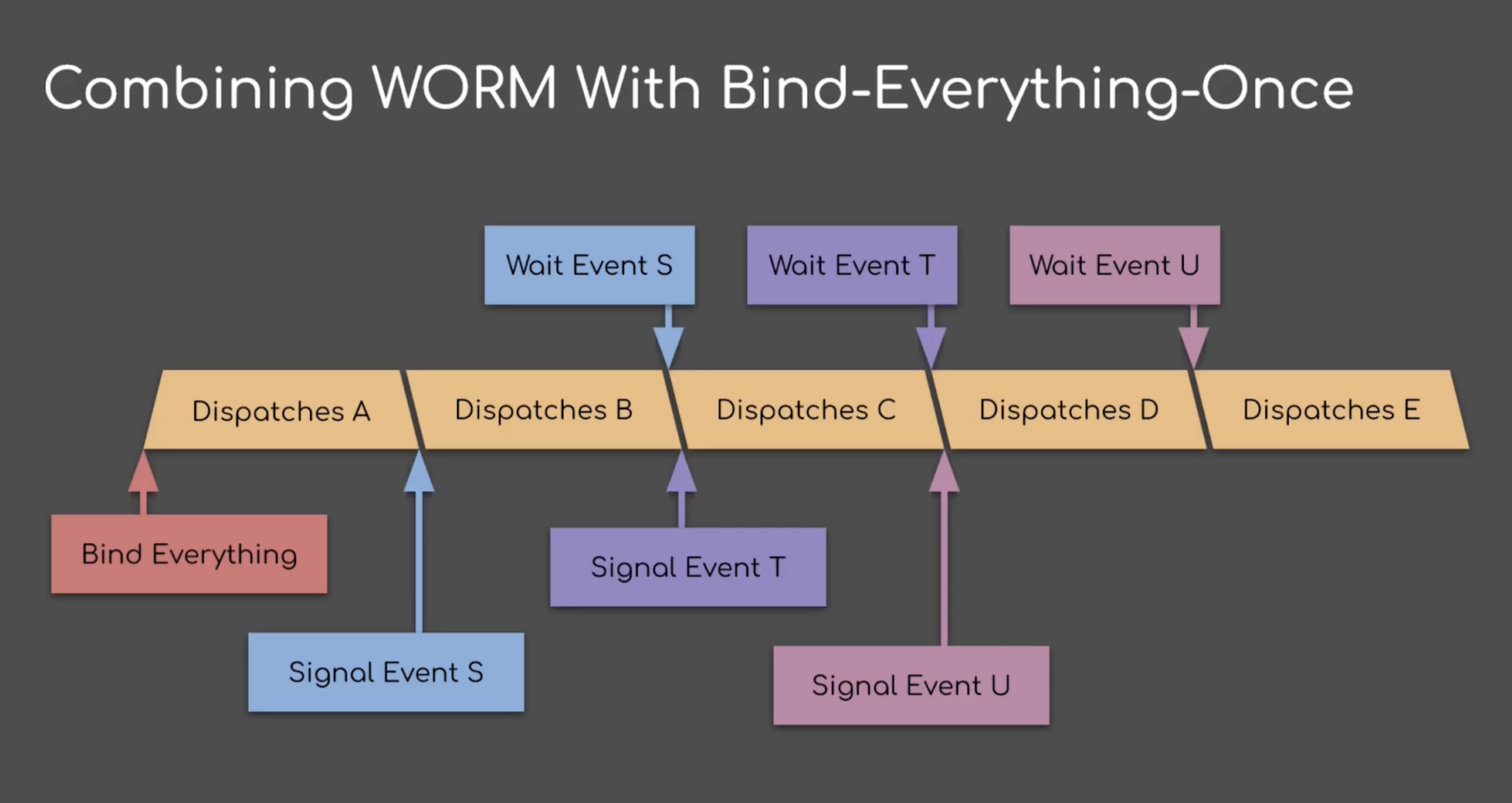
독립 작업을 생산자→소비자 사이에 넣는 캐스케이딩 signal→wait는 GPU 스톨을 피한다. Image © Timothy Lottes.
GPU→CPU 동기화도 초기 Vulkan/Metal에서 지저분했다. 제출마다 별도 펜스 객체가 필요했고, N-버퍼링으로 객체를 재사용하는 것이 흔했다. 이는 위 VkEvent와 유사한 사용성 문제다. DirectX 12는 타임라인 세마포어로 GPU→CPU 동기화를 처음 깔끔하게 해결했다. Vulkan 1.2와 Metal 2는 이후 같은 설계를 채택했다. 타임라인 세마포어는 단조 증가 64비트 카운터 하나만 필요하다. 이는 많은 엔진이 여전히 쓰는 옛 Vulkan/Metal 펜스 API보다 복잡성을 줄인다.
#define FRAMES_IN_FLIGHT 2
GpuSemaphore frameSemaphore = gpuCreateSemaphore(0);
uint64 nextFrame = 1;
while (running)
{
if (nextFrame > FRAMES_IN_FLIGHT)
{
gpuWaitSemaphore(frameSemaphore, nextFrame - FRAMES_IN_FLIGHT);
}
// 여기서 프레임 렌더링
gpuSubmit(queue, {commandBuffer}, frameSemaphore, nextFrame++);
}
gpuDestroySemaphore(frameSemaphore);
제안하는 배리어 설계는 DirectX 12/Vulkan 대비 큰 개선이다. API 복잡성을 대폭 줄이고, 사용자가 개별 리소스를 추적할 필요를 없앤다. 간단한 해저드 추적은 큐+스테이지 그레인으로 작동하며, 이는 현대 하드웨어가 실제로 하는 방식과 맞는다. 엔진 그래픽 백엔드는 단순해지고 CPU 사이클을 절약한다.
Vulkan과 DirectX 12는 리소스의 사전 생성과 재사용을 장려하도록 설계되었다. 초기 Vulkan 예제는 시작 시 커맨드 버퍼 하나를 기록해 매 프레임 재생했다. 개발자는 곧 커맨드 버퍼 재사용이 비현실적이라는 것을 깨달았다. 실제 게임 환경은 동적이고 카메라는 계속 움직이며, 가시 오브젝트 세트도 자주 바뀐다.
엔진들은 사전 기록 커맨드 버퍼를 사실상 무시했다. Metal과 WebGPU는 프레임 직전에 만들고 GPU 완료 후 사라지는 트랜지언트 커맨드 버퍼를 제공한다. 이는 커맨드 버퍼 관리 필요를 없애고 같은 커맨드를 여러 번 제출하는 것도 방지한다. GPU 벤더도 Vulkan에서 원샷 커맨드 버퍼(프레임 인플라이트당 리셋 가능한 커맨드 풀)를 권장한다. 이는 드라이버 내부 메모리 관리(힙 할당기 vs 범프 할당기)를 단순화하기 때문이다. 모범 사례는 Metal/WebGPU 설계와 일치한다. 지속 커맨드 버퍼 객체는 제거 가능하며, 그 복잡성은 쓸모 있는 이점을 제공하지 못했다.
while (running)
`
GpuCommandBuffer commandBuffer = gpuStartCommandRecording(queue);
// 여기서 프레임 렌더링
}
불타는 질문부터 시작하자: 그래픽 셰이더가 이제도 필요한가? UE5 Nanite는 64비트 원자 연산으로 픽셀을 “찍는” 컴퓨트 셰이더를 사용한다. 상위 비트는 픽셀 깊이, 하위 비트는 페이로드. atomic-min은 가장 가까운 표면이 남도록 한다. 이 기법은 SIGGRAPH 2015의 Media Molecule Dreams(Alex Evans)에서 처음 발표되었다. 하드웨어 래스터라이저는 계층/이른 뎁스-스텐실 테스트 같은 장점이 있다. Nanite는 거친 클러스터 컬링에만 의존하므로 키트배시 콘텐츠에서 오버드로우가 늘어난다. Ubisoft(나와 Ulrich Haar)는 SIGGRAPH 2015에서 2패스 클러스터 컬링 알고리즘을 발표했다. Ubisoft는 클러스터 컬링과 하드웨어 래스터라이저를 결합해 더 세밀한 컬링을 했다. 오늘날 GPU는 바인드리스이고 이런 GPU-드리븐 워크로드에 훨씬 적합하다. 10년 전 Ubisoft는 바인드리스 텍스처링 대신 가상 텍스처링(모든 텍스처를 같은 아틀라스)에 의존해야 했다.
오늘날 컴퓨트 전용 래스터라이저(Nanite, SDF 구체 트레이싱, DDA 복셀 트레이싱)가 많지만, 게임에서 삼각형 렌더링에 가장 널리 쓰이는 기술은 여전히 하드웨어 래스터라이저다. 따라서 래스터 파이프라인을 더 유연하고 사용하기 쉽게 만드는 방법을 논의할 가치가 충분하다.
현대 셰이더 프레임워크는 16개의 엔트리 포인트로 성장했다. 래스터화에는 8개(픽셀, 버텍스, 지오메트리, 헐, 도메인, 패치 상수, 메시, 앰플리피케이션), 레이트레이싱에는 6개(레이 제너레이션, 미스, 클로지스트 히트, 애니 히트, 인터섹션, 콜러블)가 있다. 반면 CUDA는 엔트리 포인트가 하나뿐이다: 커널. 이것이 CUDA의 조합성을 만든다. CUDA는 건강한 3rd party 라이브러리 생태계를 갖는다. 텐서 코어(AI) 같은 새 하드웨어 블록은 intrinsic 함수로 노출된다.
그래픽스에서도 원래는 이렇게 시작했다. 텍스처 샘플링이 우리의 첫 intrinsic이었다. 오늘날 텍스처 샘플링은 완전히 바인드리스이며 드라이버 설정조차 필요 없다. 개발자가 선호하는 설계는 이것이다: 단순하고, 조합 가능하며, 확장 가능한 것.
최근에는 인라인 레이트레이싱과 cooperative matrix(DirectX 12의 wave matrix, Metal의 subgroup matrix) 같은 intrinsic도 추가되었다. 이것이 새로운 방향이길 바란다. 거대한 16-셰이더 프레임워크를 분해하고, 유연하게 조합 가능한 intrinsic로 대체하기 시작해야 한다.
셰이더 프레임워크 복잡성을 해결하는 것은 큰 주제다. 이 글의 범위를 통제하기 위해, 오늘은 컴퓨트 셰이더와 래스터 파이프라인만 다룬다. 레이트레이싱, SER(Shader Execution Reordering), 동적 레지스터 할당 확장, Apple의 새로운 L1$ 기반 레지스터 파일(동적 캐싱) 같은 주제를 포함해 셰이더 프레임워크 단순화를 다루는 후속 글을 쓸 예정이다.
현재 관련 있는 래스터 파이프라인은 두 가지다: 버텍스+픽셀, 메시+픽셀. 타일 기반 디퍼드 렌더링(TBDR)을 사용하는 모바일 GPU는 삼각형 단위로 빈닝을 수행한다. 타일 크기는 보통 16x16~64x64 픽셀로, 메시렛은 빈닝에 너무 거친 프리미티브다. 메시렛은 레인↔버텍스의 1:1 매핑이 없고, 선택된 삼각형만을 위해 메시 셰이더 웨이브를 부분 실행하는 쉬운 방법도 없다. 이것이 모바일 GPU 벤더가 Nvidia/AMD가 설계한 데스크톱 중심 메시 셰이더 API를 채택하는 데 소극적이었던 주된 이유다. 버텍스 셰이더는 모바일에서 여전히 중요하다.
지오메트리, 헐, 도메인, 패치 상수(테셀레이션) 셰이더는 논의하지 않는다. 그래픽 커뮤니티는 이 셰이더 타입들을 실패한 실험으로 널리 본다. 설계에 성능 문제들이 많다. 관련 사용처에서는 인덱스 버퍼를 생성하는 컴퓨트 프리패스를 실행하면 이 스테이지들을 능가한다. 또한 메시 셰이더는 온칩 메모리에 컴팩트한 8비트 인덱스 버퍼를 생성할 수 있어, 레거시 스테이지 대비 성능 격차를 더 벌린다.
우리 목표는 baked state가 최소인 현대 PSO 추상화를 만드는 것이다. Vulkan/DirectX 12에 대한 주된 비판 중 하나는 파이프라인 퍼뮤테이션 폭발이다. PSO 안의 상태가 적을수록 파이프라인 퍼뮤테이션도 줄어든다. 개선할 영역은 두 가지: 그래픽 셰이더 데이터 바인딩과 래스터라이저 상태.
버텍스+픽셀 파이프라인은 컴퓨트 커널보다 추가 입력이 필요하다: 버텍스 버퍼, 인덱스 버퍼, 래스터라이저 상태, 렌더 타깃 뷰, 뎁스-스텐실 뷰. 먼저 셰이더에서 보이는 데이터 바인딩을 논의하자.
버텍스 버퍼 바인딩은 쉽게 해결된다: 제거하면 된다. 현대 GPU는 빠른 raw 로드 경로를 갖는다. 대부분 벤더는 몇 세대 전부터 버텍스 페치 하드웨어를 에뮬레이트해 왔다. 저수준 셰이더 컴파일러는 사용자 정의 버텍스 레이아웃을 읽고, 버텍스 셰이더 시작 부분에 적절한 raw load 명령을 생성한다.
버텍스 바인딩 선언은 struct 메모리 레이아웃을 정의하기 위한 특수 C/C++ API의 또 다른 예다. 이는 복잡성을 늘리고, 레이아웃마다 PSO 퍼뮤테이션을 컴파일하게 한다. 우리는 버텍스 버퍼를 표준 C/C++ struct로 대체한다. API가 필요 없다.
// 공통 헤더...
struct Vertex
{
float32x4 position;
uint8x4 normal;
uint8x4 tangent;
uint16x2 uv;
};
struct alignas(16) Data
{
float32x4x4 matrixMVP;
const Vertex *vertices;
};
// CPU 코드...
gpuSetPipeline(commandBuffer, graphicsPipeline);
auto data = myBumpAllocator.allocate<Data>();
data.cpu->matrixMVP = camera.viewProjection * modelMatrix;
data.cpu->vertices = mesh.vertices;
gpuDrawIndexed(commandBuffer, data.gpu, mesh.indices, mesh.indexCount);
// 버텍스 셰이더...
struct VertexOut
{
float32x4 position : SV_Position;
float16x4 normal;
float32x2 uv;
};
VertexOut main(uint32 vertexIndex : SV_VertexID, const Data* data)
{
Vertex vertex = data->vertices[vertexIndex];
float32x4 position = data->matrixMVP * vertex.position;
// TODO: 노멀 변환
return { .position = position, .normal = normal, .uv = vertex.uv };
}
인스턴스 데이터와 다중 버텍스 스트림도 마찬가지다. raw 메모리 로드로 효율적으로 구현할 수 있다. raw 로드를 쓰면 버텍스 스트라이드를 동적으로 조정하고, 보조 버텍스 버퍼 로드를 조건 분기하고, 커스텀 수식으로 버텍스 인덱스를 계산해 클러스터드 GPU-드리븐 렌더링, 파티클 쿼드 확장, 고차 곡면, 효율적 지형 렌더링 등 많은 알고리즘을 구현할 수 있다. 추가 셰이더 엔트리 포인트나 바인딩 API가 필요 없다. 새 정적 상수 시스템으로 파이프라인 생성 시 버텍스 스트림을 데드 코드 제거하거나, 정적 버텍스 스트라이드를 제공할 수도 있다. 옛 최적화 전략은 여전히 존재하지만, 이제는 렌더러 요구에 맞게 기법을 자유롭게 조합할 수 있다.
// 공통 헤더...
struct VertexPosition
{
float32x4 position;
};
struct VertexAttributes
{
uint8x4 normal;
uint8x4 tangent;
uint16x2 uv;
};
struct alignas(16) Instance
{
float32x4x4 matrixModel;
}
struct alignas(16) Data
{
float32x4x4 matrixViewProjection;
const VertexPosition *vertexPositions;
const VertexAttributes *vertexAttribues;
const Instance *instances;
};
// CPU 코드...
gpuSetPipeline(commandBuffer, graphicsPipeline);
auto data = myBumpAllocator.allocate<Data>();
data.cpu->matrixViewProjection = camera.viewProjection;
data.cpu->vertexPositions = mesh.positions;
data.cpu->vertexAttributes = mesh.attributes;
data.cpu->instances = batcher.instancePool + instanceOffset; // 포인터 연산이 편리
gpuDrawIndexedInstanced(commandBuffer, data.gpu, mesh.indices, mesh.indexCount, instanceCount);
// 버텍스 셰이더...
struct VertexOut
{
float32x4 position : SV_Position; // SV 값은 실제 struct 필드가 아님(레이아웃에 영향 없음)
float16x4 normal;
float32x2 uv;
};
VertexOut main(uint32 vertexIndex : SV_VertexID, uint32 instanceIndex : SV_InstanceID, const Data* data)
{
Instance instance = data->instances[SV_InstanceIndex];
// NOTE: positions/attributes 분리는 TBDR GPU에 유리(버텍스 셰이더를 두 부분으로 분할)
VertexPosition vertexPosition = data->vertexPositions[SV_VertexIndex];
VertexAttributes vertexAttributes = data->vertexAttributes[SV_VertexIndex];
float32x4x4 matrix = data->matrixViewProjection * instance.matrixModel;
float32x4 position = matrix * vertexPosition.position;
// TODO: 노멀 변환
return { .position = position, .normal = normal, .uv = vertexAttributes.uv };
}
인덱스 버퍼 바인딩은 여전히 특별하다. GPU에는 인덱스 중복 제거 하드웨어가 있다. 같은 버텍스를 두 번 셰이딩하고 싶지 않다. 인덱스 중복 제거 하드웨어는 버텍스 웨이브를 패킹해 중복을 제거한다. 인덱스 버퍼링은 오늘날도 중요한 최적화다. 비인덱스 지오메트리는 삼각형당 3개의 버텍스 셰이더 호출(레인)을 실행한다. 완벽한 그리드는 셀당 두 삼각형이므로, 마지막 행/열을 무시하면 두 삼각형당 한 번의 버텍스 셰이더 호출만 필요하다. 현대 오프라인 버텍스 캐시 최적화기는 트라이앵글당 약 0.7 버텍스 효율의 메시를 출력한다. 현실에서 인덱스 버퍼로 버텍스 셰이딩 비용을 4~6배 줄일 수 있다.
현대 인덱스 버퍼 하드웨어는 다른 GPU 유닛과 같은 캐시 계층에 연결된다. 인덱스 버퍼는 drawIndexed 호출에 들어가는 추가 GPU 포인터일 뿐이다. 인덱스 버퍼를 위한 API 표면은 그 정도면 충분하다.
메시 셰이더는 오프라인 버텍스 중복 제거에 의존한다. 흔한 구현은 레인당 하나의 버텍스를 셰이딩해 온칩 메모리에 출력한다. 8비트 로컬 인덱스 버퍼는 각 삼각형이 어떤 3개 버텍스를 쓰는지 래스터라이저에 알려준다. 메시렛 출력이 한 번에 모두 제공되고 이미 온칩 저장소에서 변환되어 있으므로, 삼각형 셋업 후 버텍스를 중복 제거하거나 패킹할 필요가 없다. 이것이 메시 셰이더에 인덱스 중복 제거 하드웨어나 포스트-트랜스폼 캐시가 필요 없는 이유다. 메시 셰이더 입력은 모두 raw 데이터다. gpuDrawMeshlets 명령 외 추가 API 표면이 필요 없다.
예제 메시 셰이더는 128 레인 스레드 그룹을 사용한다. Nvidia는 출력 메시렛당 최대 126 버텍스와 64 트라이앵글을 지원하고, AMD는 256 버텍스와 128 트라이앵글을 지원한다. 셰이더는 초과 레인을 마스크한다. 삼각형은 64개를 넘지 않으므로, 64 레인 스레드 그룹을 써 삼각형 레인 활용을 최적화하고 버텍스 셰이딩을 2회 반복하는 선택도 가능하다. 내 삼각형 페치 로직은 단일 메모리 로드 명령이라 레인의 절반을 낭비해도 문제되지 않는다. 나는 대신 버텍스 셰이딩 병렬성을 택했다. 최적 선택은 워크로드와 타겟 하드웨어에 따라 다르다.
// 공통 헤더...
struct Vertex
{
float32x4 position;
uint8x4 normal;
uint8x4 tangent;
uint16x2 uv;
};
struct alignas(16) Meshlet
{
uint32 vertexOffset;
uint32 triangleOffset;
uint32 vertexCount;
uint32 triangleCount;
};
struct alignas(16) Data
{
float32x4x4 matrixMVP;
const Meshlet *meshlets;
const Vertex *vertices;
const uint8x4 *triangles;
};
// CPU 코드...
gpuSetPipeline(commandBuffer, graphicsMeshPipeline);
auto data = myBumpAllocator.allocate<Data>();
data.cpu->matrixMVP = camera.viewProjection * modelMatrix;
data.cpu->meshlets = mesh.meshlets;
data.cpu->vertices = mesh.vertices;
data.cpu->triangles = mesh.triangles;
gpuDrawMeshlets(commandBuffer, data.gpu, uvec3(mesh.meshletCount, 1, 1));
// 메시 셰이더...
struct VertexOut
{
float32x4 position : SV_Position;
float16x4 normal;
float32x2 uv;
};
[groupsize = (128, 1, 1)]
void main(uint32x3 groupThreadId : SV_GroupThreadID, uint32x3 groupId : SV_GroupID, const Data* data)
{
Meshlet meshlet = data->meshlets[groupId.x];
// 메시렛 출력 할당 intrinsic
VertexOut* outVertices = allocateMeshVertices<VertexOut>(meshlet.vertexCount);
uint8x3* outIndices = allocateMeshIndices(meshlet.triangleCount);
// 트라이앵글 인덱스(3x 8비트)
if (groupThreadId.x < meshlet.triangleCount)
{
outIndices[groupThreadId.x] = triangles[meshlet.triangleOffset + groupThreadId.x].xyz;
}
// 버텍스
if (groupThreadId.x < meshlet.vertexCount)
{
Vertex vertex = data->vertices[meshlet.vertexOffset + groupThreadId.x];
float32x4 position = data->matrixMVP * vertex.position;
// TODO: 노멀 변환
outVertices[groupThreadId.x] = { .position = position, .normal = normal, .uv = vertex.uv };
}
}
버텍스 셰이더와 메시 셰이더 모두 픽셀 셰이더를 사용한다. 래스터라이저는 삼각형 픽셀 커버리지, HiZ, 이른 뎁스/스텐실 테스트 결과에 기반해 픽셀 셰이더 작업을 생성한다. 하드웨어는 하나의 픽셀 셰이더 웨이브에 여러 삼각형/인스턴스를 패킹할 수 있다. 픽셀 셰이더는 요즘 그렇게 특별하지 않다. 픽셀 셰이더는 다른 셰이더 타입과 같은 SIMD 코어에서 실행된다. 다만 보간된 버텍스 출력, 화면 위치, 샘플 인덱스/커버리지 마스크, 트라이앵글 ID, 페이싱 등 특수 입력이 있다. 특수 입력은 기존 API와 비슷하게 시스템 값(:SV) 시맨틱으로 커널 함수 파라미터로 선언한다.
// 픽셀 셰이더...
const Texture textureHeap[];
struct VertexIn // 버텍스 셰이더 출력 struct 레이아웃과 매칭
{
float16x4 normal;
float32x2 uv;
};
struct PixelOut
{
float16x4 color : SV_Color0;
};
PixelOut main(const VertexIn &vertex, const DataPixel* data)
{
Texture texture = textureHeap[data->textureIndex];
Sampler sampler = {.minFilter = LINEAR, .magFilter = LINEAR};
float32x4 color = sample(texture, sampler, vertex.uv);
return { .color = color };
}
데이터 바인딩 제거는 버텍스/픽셀 셰이더 사용을 단순하게 만든다. 복잡한 데이터 바인딩 API는 64비트 GPU 포인터 하나로 대체된다. 사용자는 버텍스 레이아웃마다 PSO 퍼뮤테이션을 만들지 않고도 유연한 버텍스 페치를 쓸 수 있다.
레거시 API(OpenGL, DirectX 9)는 셰이더 입력과 래스터라이저 상태를 설정하는 세분화된 명령을 제공했다. 드라이버는 필요 시 셰이더 파이프라인을 구성해야 했다. 하드웨어 특화 래스터라이저/블렌더/입력 어셈블러 커맨드 패킷은 개별 상태를 결합한 섀도 상태(shadow state)로부터 구성되었다. Vulkan 1.0과 DirectX 12는 정반대 설계를 택했다. 모든 상태를 PSO에 사전 bake하고, 뷰포트/시저/스텐실 값 같은 일부만 동적으로 바꿀 수 있게 했다. 결과는 PSO 퍼뮤테이션 폭발이었다.
PSO 생성은 드라이버의 저수준 셰이더 컴파일러 호출이 필요해 비싸다. PSO 퍼뮤테이션은 저장 공간과 RAM을 많이 먹는다. PSO 변경은 가장 비싼 상태 변화다. 일부 벤더가 렌더 상태를 셰이더 마이크로코드에 직접 넣어 얻은 작은 성능 이점은, 크게 증폭된 파이프라인 생성/바인딩/데이터 관리 비용이 곳곳에서 유발하는 성능 문제에 가려졌다. 추는 반대편으로 너무 멀리 움직였다.
현대 GPU는 ALU 밀도가 높다. Nvidia/AMD는 최근 추가 파이프라인으로 ALU 레이트를 두 배로 늘렸고, Apple도 M 시리즈에서 fp32 파이프라인을 두 배로 늘렸다. 셰이더에서 단순히 상수를 대체하는 정도의 상태는, ALU 명령 하나가 늘거나 유니폼 레지스터를 낭비하더라도 파이프라인 중복을 요구해서는 안 된다. 오늘날 많은 셰이더는 ALU 바운드가 아니다. 비용이 측정 불가능한 경우도 많지만, 퍼뮤테이션 감소의 이점은 크다. Vulkan 1.3은 올바른 방향으로 큰 진전을 했다. 많은 baked PSO 상태를 이제 동적으로 설정할 수 있다.
더 깊게 보면, 모든 GPU는 래스터라이저/뎁스-스텐실 유닛을 구성하는 커맨드 패킷을 사용한다. 이 패킷은 셰이더 마이크로코드와 직접 연결되지 않는다. 상태 변경을 위해 셰이더 마이크로코드를 수정할 필요는 없다. Metal은 뎁스-스텐실 상태 객체를 별도로 두고, 적용하는 별도 명령을 갖는다. 별도 상태 객체는 PSO 퍼뮤테이션을 줄이고 비싼 셰이더 바인딩 호출을 줄인다. Vulkan 1.3의 동적 상태도 비슷한 퍼뮤테이션 감소를 달성하지만 더 세분화되어 있다. Metal의 설계가 실제 하드웨어 커맨드 패킷과 더 잘 맞는다. 큰 패킷은 API 부풀림과 오버헤드를 줄인다. DirectX 12는 불행히도 대부분 뎁스-스텐실 상태를 PSO에 묶어 둔다(스텐실 ref와 뎁스 바이어스만 동적). 우리의 설계에서는 뎁스-스텐실 상태는 별도 객체다.
GpuDepthStencilDesc depthStencilDesc =
{
.depthMode = DEPTH_READ | DEPTH_WRITE,
.depthTest = OP_LESS_EQUAL,
.depthBias = 0.0f,
.depthBiasSlopeFactor = 0.0f,
.depthBiasClamp = 0.0f,
.stencilReadMask = 0xff,
.stencilWriteMask = 0xff,
.stencilFront =
{
.test = OP_ALWAYS,
.failOp = OP_KEEP,
.passOp = OP_KEEP,
.depthFailOp = OP_KEEP,
.reference = 0
},
.stencilBack =
{
.test = COMPARE_ALWAYS,
.failOp = OP_KEEP,
.passOp = OP_KEEP,
.depthFailOp = OP_KEEP,
.reference = 0
}
};
// 위를 더 간단히 표현(C++ API struct 기본값 사용):
GpuDepthStencilDesc depthStencilDesc =
{
.depthMode = DEPTH_READ | DEPTH_WRITE,
.depthTest = OP_LESS_EQUAL,
};
GpuDepthStencilState depthStencilState = gpuCreateDepthStencilState(depthStencilDesc);
즉시 모드(데스크톱) GPU는 알파 블렌더 유닛을 구성하는 유사한 커맨드 패킷을 가진다. DirectX 13을 설계한다면 블렌드 상태 객체를 PSO에서 분리하면 끝이다. 하지만 우리는 크로스 플랫폼 API를 설계하고 있고, 블렌딩은 모바일에서 완전히 다르게 동작한다.
모바일 GPU(TBDR)는 오래전부터 프로그래머블 블렌딩을 지원했다. 렌더 타일은 컴퓨트 유닛에 가까운 스크래치패드 메모리(예: groupshared)에 들어가, 픽셀 셰이더가 이전 픽셀 색을 직접 저지연으로 읽고 쓸 수 있다. 대부분 모바일 GPU에는 고정 기능 블렌딩 하드웨어가 없다. 전통적 그래픽 API를 사용하면, 드라이버의 저수준 셰이더 컴파일러가 셰이더 끝에 블렌딩 명령을 추가한다. 이는 버텍스 페치 코드 생성과 유사하다. 모바일 GPU만을 위한 API를 설계한다면, 버텍스 버퍼처럼 블렌드 상태 API를 없애고 프레임버퍼 페치 intrinsic을 노출했을 것이다. 사용자는 원하는 블렌딩 공식을 어떤 것이든 쓸 수 있고, 순서 독립 투명도 같은 고급 알고리즘도 구현할 수 있다. 또한 파라미터화된 일반 공식을 써 PSO 퍼뮤테이션 폭발을 줄일 수도 있다. 데스크톱/모바일 모두 블렌딩 퍼뮤테이션을 줄이는 방법이 존재하지만, 제한은 현재 API다.
Vulkan의 서브패스는 프레임버퍼 페치를 크로스 플랫폼 API로 감싸려는 시도였다. 이것은 Vulkan 설계의 또 다른 실수였다. Vulkan은 Mantle에서 단순한 저수준 설계를 물려받았지만, OpenGL 대체를 목표로 모바일과 데스크톱 모든 아키텍처를 타겟해야 했다. 두 완전히 다른 아키텍처를 같은 API로 감싸는 것은 쉽지 않다. 서브패스는 저수준 API 안에 고수준 개념으로 들어왔고, 단일 렌더패스인 척하면서 전체 렌더패스 체인을 정의할 수 있었다. 이는 드라이버 복잡성을 늘리고 셰이더/렌더패스 API를 불필요하게 복잡하게 했다. 사용자는 복잡한 지속 멀티 렌더패스 객체를 미리 만들고, 이를 파이프라인 생성에 넘겨야 했다. 셰이더 파이프라인은 내부적으로 멀티 파이프라인(서브패스당 하나)이 되었다. Vulkan은 프레임버퍼 페치 intrinsic을 셰이더 언어에 노출하는 것을 피하려고 이런 복잡성을 추가했다. 더 나쁜 점은, 서브패스는 프로그래머블 블렌딩을 해결하기에도 부족했다. 픽셀 순서는 패스 경계에서만 보장된다. 서브패스는 좁은 1:1 멀티패스 용도에만 유용했다. Vulkan 1.3은 서브패스를 사실상 버리고 “동적 렌더링”을 도입했다. 이제 Metal/DirectX 12/WebGPU처럼 지속 렌더패스 객체를 만들 필요가 없다. 이는 복잡한 프레임워크가 API 디자이너에게는 매력적일 수 있지만, 개발자는 단순한 셰이더 intrinsic을 선호한다는 좋은 مثال이다. 엔진은 이미 플랫폼별로 다른 셰이더를 빌드할 수 있다. Apple의 Metal 예제도 iOS에서는 프레임버퍼 페치를 쓰고, Mac에서는 전통적 멀티패스를 쓴다.
블렌딩과 프레임버퍼 페치의 하드웨어 차이는 추상화할 수 없다는 것이 분명하다. Vulkan 1.0은 이를 시도했고 실패했다. 올바른 해법은 사용자에게 선택권을 주는 것이다. 사용자는 블렌드 상태를 PSO에 내장할 수 있다. 이는 모든 플랫폼에서 동작하며, 블렌드 상태 관련 퍼뮤테이션 문제가 없는 셰이더에는 완벽한 접근이다. 모바일 GPU의 내부 셰이더 컴파일러는 usual대로 픽셀 셰이더 끝에 블렌딩 명령을 추가한다. 즉시 모드(데스크톱) GPU(및 일부 모바일 GPU)에서는 별도의 블렌드 상태 객체를 선택할 수 있다. 이는 PSO 퍼뮤테이션을 줄이고, 전체 파이프라인 변경 없이 블렌드 상태 구성 패킷만 보내면 되므로 런타임 블렌드 변경이 빨라진다.
GpuBlendDesc blendDesc =
{
.colorOp = OP_ONE,
.srcColorFactor = FACTOR_SRC_ALPHA,
.dstColorFactor = FACTOR_ONE_MINUS_SRC_ALPHA,
.alphaOp = OP_ONE,
.srcAlphaFactor = FACTOR_SRC_ALPHA,
.dstAlphaFactor = FACTOR_ONE_MINUS_SRC_ALPHA,
.colorWriteMask = 0xf
};
// 블렌드 상태 객체 생성(피처 플래그 필요)
GpuBlendState blendState = gpuCreateBlendState(blendDesc);
// 동적 블렌드 상태 설정(피처 플래그 필요)
gpuSetBlendState(commandBuffer, blendState);
모바일 GPU에서는 블렌드 상태를 PSO에 내장하거나, 프레임버퍼 페치로 커스텀 블렌딩 공식을 쓸 수 있다. 모바일 개발자가 다양한 알파 블렌딩 모드마다 PSO 퍼뮤테이션을 컴파일하기 싫다면, 동적 드로우 struct 입력으로 파라미터화된 일반 공식을 쓸 수 있다.
// 표준 퍼센티지 블렌드 공식(내부 셰이더 컴파일러가 자동 추가)
dst.rgb = src.rgb * src.a + dst.rgb * (1.0 - src.a);
dst.a = src.a * src.a + dst.a * (1.0 - src.a);
// HypeHype가 사용하는 모든 블렌드 모드를 지원하는 커스텀 공식
const BlendParameters& p = data->blendParameters;
vec4 fs = src.a * vec4(p.sc_sa.xxx + p.sc_one.xxx, p.sa_sa + p.sa_one) + dst.rgba * vec4(p.sc_dc.xxx, sa_da);
vec4 fd = (1.0 - src.a) * vec4(p.dc_1msa.xxx, p.da_1msa) + vec4(p.dc_one.xxx, p.da_one);
dst.rgb = src.rgb * fs.rgb + dst.rgb * fd.rgb;
dst.a = src.a * fs.a + dst.a * fd.a;블렌드 상태를 PSO에서 분리하면 일부 자동 데드 코드 최적화를 잃을 수 있다. 사용자가 색 출력 비활성화를 위해 전통적으로 블렌드 상태의 colorWriteMask를 쓴다. 블렌드 상태가 PSO에 baked되어 있으면 컴파일러가 이를 기반으로 데드 코드 제거를 할 수 있다. 비슷한 최적화를 위해 우리는 PSO에 각 컬러 타깃의 writeMask를 둔다.
듀얼 소스 블렌딩은 픽셀 셰이더에서 두 개의 색 출력을 요구하는 특수 모드다. 듀얼 소스 블렌딩은 단일 렌더 타깃만 지원한다. 블렌드 상태가 분리 가능하므로, PSO desc에 supportDualSourceBlending 필드가 필요하다. 이를 켜면 컴파일러는 두 번째 출력이 듀얼 소스 블렌딩용임을 안다. 검증 레이어는 출력이 없으면 경고한다. 두 색을 내보내는 픽셀 셰이더는 듀얼 소스 블렌딩 없이도 사용할 수 있지만(두 번째 색은 무시), 두 색을 내보내는 데 약간의 비용이 있다.
PSO에 남는 렌더 상태는 최소다: 프리미티브 토폴로지, 렌더 타깃 및 뎁스-스텐실 타깃 포맷, MSAA 샘플 수, 알파 투 커버리지. 이 상태는 생성되는 셰이더 마이크로코드에 영향을 주므로 PSO에 남아야 한다. 상태 변경 때문에 PSO 마이크로코드를 다시 빌드하고 싶지는 않다. 내장 블렌드 상태를 쓰면 그것도 PSO에 baked된다. 결과적으로 PSO 생성용 래스터 상태 struct는 간단해진다.
GpuRasterDesc rasterDesc =
{
.topology = TOPOLOGY_TRIANGLE_LIST,
.cull = CULL_CCW,
.alphaToCoverage = false,
.supportDualSourceBlending = false,
.sampleCount = 1`
.depthFormat = FORMAT_D32_FLOAT,
.stencilFormat = FORMAT_NONE,
.colorTargets =
{
{ .format = FORMAT_RG11B10_FLOAT }, // 3 렌더 타깃 G-buffer
{ .format = FORMAT_RGB10_A2_UNORM },
{ .format = FORMAT_RGBA8_UNORM }
},
.blendstate = GpuBlendDesc { ... } // 선택(내장 블렌드 상태, 아니면 동적)
};
// 위를 더 간단히 표현(C++ API struct 기본값 사용):
GpuRasterDesc rasterDesc =
{
.depthFormat = FORMAT_D32_FLOAT,
.colorTargets =
{
{ .format = FORMAT_RG11B10_FLOAT },
{ .format = FORMAT_RGB10_A2_UNORM },
{ .format = FORMAT_RGBA8_UNORM }
},
};
// 픽셀 + 버텍스 셰이더
auto vertexIR = loadFile("vertexShader.ir");
auto pixelIR = loadFile("pixelShader.ir");
GpuPipeline graphicsPipeline = gpuCreateGraphicsPipeline(vertexIR, pixelIR, rasterDesc);
// 메시 셰이더
auto meshletIR = loadFile("meshShader.ir");
auto pixelIR = loadFile("pixelShader.ir");
GpuPipeline graphicsMeshletPipeline = gpuCreateGraphicsMeshletPipeline(meshletIR, pixelIR, rasterDesc);
HypeHype의 Vulkan 셰이더 PSO 초기화 백엔드 코드는 400줄이며, 다른 엔진과 비교하면 꽤 컴팩트한 편이다. 여기서는 픽셀+버텍스 셰이더를 단 18줄로 초기화했다. 읽기 쉽고 이해하기 쉽다. 성능 타협도 없다.
래스터 파이프라인의 렌더링은 컴퓨트 파이프라인과 비슷하다. 컴퓨트는 데이터 포인터 하나를 제공하지만, 래스터는 커널 엔트리 포인트가 두 개(버텍스, 픽셀)이므로 포인터도 두 개를 제공한다. Metal은 버텍스/픽셀에 별도 바인딩 슬롯 세트를 갖는다. DirectX/Vulkan/WebGPU는 각 바인딩에 가시성 마스크(버텍스, 픽셀, 컴퓨트 등)를 둔다. 많은 엔진은 같은 데이터를 버텍스/픽셀에 모두 바인딩하는데, DirectX/Vulkan/WebGPU에서는 마스크 비트를 합칠 수 있어 괜찮지만 Metal에서는 바인딩 호출이 두 배가 된다. 두 데이터 포인터 접근은 양쪽 장점을 모두 갖는다. 같은 데이터를 쓰고 싶으면 같은 포인터를 두 번 전달하면 되고, 완전 분리를 원하면 서로 다른 포인터를 주면 된다. 셰이더 컴파일러는 버텍스/픽셀 각각에 대해 데드 코드 제거와 상수/스칼라 프리로드 최적화를 따로 수행한다. 공유/중복 어느 쪽도 성능을 나쁘게 만들지 않는다. 사용자는 설계에 맞게 선택하면 된다.
// 공통 헤더...
struct Vertex
{
float32x4 position;
uint16x2 uv;
};
struct alignas(16) DataVertex
{
float32x4x4 matrixMVP;
const Vertex *vertices;
};
struct alignas(16) DataPixel
{
float32x4 color;
uint32 textureIndex;
};
// CPU 코드...
gpuSetDepthStencilState(commandBuffer, depthStencilState);
gpuSetPipeline(commandBuffer, graphicsPipeline);
auto dataVertex = myBumpAllocator.allocate<DataVertex>();
dataVertex.cpu->matrixMVP = camera.viewProjection * modelMatrix;
dataVertex.cpu->vertices = mesh.vertices;
auto dataPixel = myBumpAllocator.allocate<DataPixel>();
dataPixel.cpu->color = material.color;
dataPixel.cpu->textureIndex = material.textureIndex;
gpuDrawIndexed(commandBuffer, dataVertex.gpu, dataPixel.gpu, mesh.indices, mesh.indexCount);
// 버텍스 셰이더...
struct VertexOut
{
float32x4 position : SV_Position; // SV 값은 실제 struct 필드가 아님(레이아웃에 영향 없음)
float32x2 uv;
};
VertexOut main(uint32 vertexIndex : SV_VertexID, const DataVertex* data)
{
Vertex vertex = data.vertices[vertexIndex];
float32x4 position = data->matrixMVP * vertex.position;
return { .position = position, .uv = vertex.uv };
}
// 픽셀 셰이더...
const Texture textureHeap[];
struct VertexIn // 버텍스 셰이더 출력 struct 레이아웃과 매칭
{
float32x2 uv;
};
PixelOut main(const VertexIn &vertex, const DataPixel* data)
{
Texture texture = textureHeap[data->textureIndex];
Sampler sampler = {.minFilter = LINEAR, .magFilter = LINEAR};
float32x4 color = sample(texture, sampler, vertex.uv);
return { .color = color };
}
우리는 PSO 안의 상태를 최소화해 PSO 퍼뮤테이션 폭발을 줄이는 것이 목표였다. 뎁스-스텐실은 모든 아키텍처에서 분리 가능하다. 블렌드 상태 분리는 데스크톱에서 가능하지만, 대부분 모바일은 블렌드 방정식을 픽셀 셰이더 마이크로코드 끝에 굽는다. 프레임버퍼 페치 intrinsic을 직접 노출하는 것이 Vulkan의 실패한 서브패스 접근보다 훨씬 낫다. 사용자는 자신만의 블렌드 공식을 써 새로운 알고리즘을 열 수도 있고, 파라미터화된 일반 공식을 써 PSO 수를 줄일 수도 있다.
표준 드로우/디스패치 명령은 스레드 그룹 차원, 인덱스 수, 인스턴스 수 등의 인자를 C/C++ 함수 파라미터로 제공한다. 인다이렉트 드로우는 GPU 버퍼+오프셋 쌍을 인자 소스로 사용하게 하며, GPU-드리븐 렌더링을 가능하게 하는 중요한 기능이다. 우리의 버전은 usual 버퍼 객체+오프셋 대신 단일 GPU 포인터를 사용해 API를 약간 단순화한다.
gpuDispatchIndirect(commandBuffer, data.gpu, arguments.gpu);
gpuDrawIndexedInstancedIndirect(commandBuffer, dataVertex.gpu, dataPixel.gpu, arguments.gpu);
우리의 인자는 모두 GPU 포인터다. 데이터와 인자 모두 간접이다. 이는 기존 API 대비 큰 개선이다. DirectX 12/Vulkan/Metal은 인다이렉트 루트 인자를 지원하지 않는다. CPU가 제공해야 한다.
인다이렉트 멀티드로우(MDI)도 지원해야 한다. 드로우 카운트는 GPU 주소에서 온다. MDI 파라미터는: 루트 데이터 배열(버텍스/픽셀용 GPU 포인터), 드로우 인자 배열(GPU 포인터), 루트 데이터 배열 스트라이드(버텍스/픽셀 각각). 스트라이드=0은 같은 루트 데이터를 각 드로우에 복제함을 의미한다.
gpuDrawIndexedInstancedIndirectMulti(commandBuffer, dataVertex.gpu, sizeof(DataVertex), dataPixel.gpu, sizeof(DataPixel), arguments.gpu, drawCount.gpu);
Vulkan의 멀티드로우는 드로우콜마다 바인딩을 바꿀 수 없다. gl_DrawID로 드로우 데이터 struct를 담은 버퍼를 인덱싱하는 방식이 흔하다. 이는 셰이더에서 간접을 하나 추가한다. 텍스처를 가져오려면 디스크립터 인덱싱이나 디스크립터 버퍼 확장을 써야 한다. DirectX 12 ExecuteIndirect는 구성 가능한 커맨드 시그니처로 드로우마다 루트 상수를 설정할 수 있지만, 모든 커맨드 프로세서에서 빠른 경로를 타지 않는다. ExecuteIndirect tier 1.1(2024)은 D3D12_INDIRECT_ARGUMENT_TYPE_INCREMENTING_CONSTANT라는 새 옵션 카운터 증가 기능을 추가해 draw ID를 구현할 수 있게 했다. SM6.8(2024)은 SV_StartInstanceLocation을 추가해 인다이렉트 드로우 인자에 상수를 직접 내장할 수 있게 했다. 이는 SV_InstanceID와 달리 드로우 전체에서 유니폼이어서, 인덱싱 로드에서 최적 코드젠(유니폼/스칼라 경로)을 제공한다. 하지만 데이터 페치는 여전히 간접이 필요하다. GPU가 생성한 루트 데이터는 지원되지 않는다.
GPU에서 드로우 인자나 루트 데이터를 생성한다면 커맨드 프로세서가 디스패치가 끝날 때까지 기다리도록 해야 한다. 현대 커맨드 프로세서는 지연을 숨기기 위해 커맨드와 인자를 프리페치한다. 우리는 이를 막는 플래그를 배리어에 둔다. 모범 사례는 미세한 배리어를 피하기 위해 드로우 인자와 루트 데이터 업데이트를 배치하는 것이다.
gpuBarrier(commandBuffer, STAGE_COMPUTE, STAGE_COMPUTE, HAZARD_DRAW_ARGUMENTS);
현재 PC/모바일 그래픽 API에서 인다이렉트 셰이더 선택이 없는 것은 큰 한계다. 인다이렉트 셰이더 선택은 레이트레이싱과 유사한 멀티 파이프라인으로 구현할 수 있다. Metal도 인다이렉트 커맨드 생성( Vulkan에는 Nvidia 유사 확장)을 지원한다. 드로우콜을 스킵하는 효율적 방법은 가치 있는 부분집합이다. DirectX 워크 그래프와 CUDA 동적 병렬성은 셰이더가 필요 시 더 많은 웨이브를 스폰하게 한다. 불행히도 이런 하드웨어 개선 접근 API는 플랫폼 특화로 흩어져 있고 여러 셰이더 엔트리 포인트에 분산되어 있다. 표준화 경로가 명확하지 않다. 후속 글에서 셰이더 프레임워크와 함께 이 주제를 깊게 다룰 것이다.
제안 설계는 인다이렉트 드로잉을 매우 강력하게 만든다. 셰이더 루트 데이터와 드로우 파라미터 모두 GPU가 간접 제공할 수 있다. 이는 멀티드로우를 강화해, 해킹 없이 깔끔하고 효율적인 드로우별 데이터 바인딩을 가능하게 한다. 인다이렉트 드로잉과 셰이더 프레임워크의 미래는 후속 글에서 다루겠다.
래스터라이저 하드웨어는 드로우를 시작하기 전에 렌더링 준비가 필요하다. 흔한 작업은 렌더 타깃/뎁스-스텐실 뷰 바인딩과 컬러/뎁스 클리어다. 클리어는 클리어 컬러가 바뀌면 fast clear eliminate를 트리거할 수 있으며, 이는 클리어 명령이 투명하게 처리한다. 모바일 GPU에서는 타일이 렌더링 중 온칩 저장소에서 VRAM으로 저장된다. Vulkan/Metal/WebGPU는 렌더 패스 추상화를 사용해 렌더 타깃 로드/클리어/스토어를 표현한다. DirectX 12도 2018 업데이트에서 최신 Intel(Gen11) 및 Qualcomm(Adreno 630) GPU 최적화를 위해 렌더 패스 지원을 추가했다. 렌더 패스 추상화는 API 복잡성을 크게 늘리지 않으므로 현대 크로스 플랫폼 API에서 쉽게 선택할 수 있다.
DirectX 12에는 RTV/DSV와 이를 저장하는 별도 디스크립터 힙이 있다. 하지만 이는 API 추상화일 뿐이다. 이 힙은 드라이버가 할당한 CPU 메모리다. RTV/DSV는 GPU 디스크립터가 아니다. 래스터라이저 API는 바인드리스가 아니다. CPU 드라이버가 커맨드 패킷으로 래스터라이저를 설정한다. Vulkan/Metal에서는 beginRenderPass에 기존 텍스처/뷰 객체를 직접 전달하고, 드라이버는 텍스처 객체에서 필요한 정보를 얻는다. 우리의 GpuTexture 객체는 이 역할을 수행한다. 래스터 출력이 우리가 CPU 측 텍스처 객체를 여전히 필요로 하는 주된 이유다. 텍스처 디스크립터는 GPU 메모리에 직접 쓰지만, CPU 드라이버는 그 GPU 메모리에 접근할 수 없다.
GpuRenderPassDesc renderPassDesc =
{
.depthTarget = {.texture = deptStencilTexture, .loadOp = CLEAR, .storeOp = DONT_CARE, .clearValue = 1.0f},
.stencilTarget = {.texture = deptStencilTexture, .loadOp = CLEAR, .storeOp = DONT_CARE, .clearValue = 0},
.colorTargets =
{
{.texture = gBufferColor, .loadOp = LOAD, .storeOp = STORE, .clearColor = {0,0,0,0}},
{.texture = gBufferNormal, .loadOp = LOAD, .storeOp = STORE, .clearColor = {0,0,0,0}},
{.texture = gBufferPBR, .loadOp = LOAD, .storeOp = STORE, .clearColor = {0,0,0,0}}
}
};
gpuBeginRenderPass(commandBuffer, renderPassDesc);
// 드로우콜 추가!
gpuEndRenderPass(commandBuffer);
바인드리스 렌더 패스, 바인드리스/인다이렉트 (멀티-)클리어, 인다이렉트 시저/뷰포트(rect 배열) 등이 있으면 좋겠지만, 많은 GPU는 여전히 CPU 드라이버가 래스터라이저 설정을 해야 한다.
배리어 관련 주의: 렌더 패스 begin/end는 자동으로 배리어를 내지 않는다. 사용자는 서로 다른 렌더 타깃에 쓰는 여러 렌더 패스를 동시에 진행할 수 있다. 래스터 출력 스테이지(또는 이후)와 소비자 스테이지 사이 배리어는 아키텍처가 필요하면 작은 ROP 캐시를 플러시한다. 렌더 패스 사이에 자동 배리어가 없다는 것은 효율적 뎁스 프리패스 구현에도 중요하다(ROP 캐시를 불필요하게 플러시하지 않음).

Claybook(GDC 2018, Sebastian Aaltonen)의 GPU 기반 점토 시뮬레이션 및 레이트레이싱 기술: 나는 Unreal Engine 4 콘솔 배리어 구현(Xbox One, PS4)을 최적화해 렌더 타깃 오버랩을 가능하게 했다. 배리어 스톨이 회피된다.
내 프로토타입 API는 한 화면에 들어간다: 150줄 코드. 이 글의 제목은 “그래픽 API는 필요 없다”지만, 오늘날 이는 명백히 불가능한 목표다. 그래도 꽤 근접했다. WebGPU는 기능 세트가 더 작고 ~2700줄 API(Emscripten C 헤더)를 가진다. Vulkan 헤더는 ~20,000줄이지만 레이트레이싱 등 더 많은 기능을 지원한다. 우리의 미니멀 API는 아직 그런 기능을 포함하지 않는다. 우리는 API 복잡성을 줄이기 위해 성능을 희생할 필요가 없었다. 이 기능 세트에서 우리의 API는 기존 API보다 더 유연하다. 완전히 확장된 2025년 여름 Vulkan 1.4는 실제로 같은 일을 할 수 있지만 사용이 훨씬 복잡하고 API 오버헤드가 크다.
// Opaque handles
struct GpuPipeline;
struct GpuTexture;
struct GpuDepthStencilState;
struct GpuBlendState;
struct GpuQueue;
struct GpuCommandBuffer;
struct GpuSemaphore;
// Enums
enum MEMORY { MEMORY_DEFAULT, MEMORY_GPU, MEMORY_READBACK };
enum CULL { CULL_CCW, CULL_CW, CULL_ALL, CULL_NONE };
enum DEPTH_FLAGS { DEPTH_READ = 0x1, DEPTH_WRITE = 0x2 };
enum OP { OP_NEVER, OP_LESS, OP_EQUAL, OP_LESS_EQUAL, OP_GREATER, OP_NOT_EQUAL, OP_GREATER_EQUAL, OP_ALWAYS };
enum BLEND { BLEND_ADD, BLEND_SUBTRACT, BLEND_REV_SUBTRACT, BLEND_MIN, BLEND_MAX };
enum FACTOR { FACTOR_ZERO, FACTOR_ONE, FACTOR_SRC_COLOR, FACTOR_DST_COLOR, FACTOR_SRC_ALPHA, ... };
enum TOPOLOGY { TOPOLOGY_TRIANGLE_LIST, TOPOLOGY_TRIANGLE_STRIP, TOPOLOGY_TRIANGLE_FAN };
enum TEXTURE { TEXTURE_1D, TEXTURE_2D, TEXTURE_3D, TEXTURE_CUBE, TEXTURE_2D_ARRAY, TEXTURE_CUBE_ARRAY };
enum FORMAT { FORMAT_NONE, FORMAT_RGBA8_UNORM, FORMAT_D32_FLOAT, FORMAT_RG11B10_FLOAT, FORMAT_RGB10_A2_UNORM, ... };
enum USAGE_FLAGS { USAGE_SAMPLED, USAGE_STORAGE, USAGE_COLOR_ATTACHMENT, USAGE_DEPTH_STENCIL_ATTACHMENT, ... };
enum STAGE { STAGE_TRANSFER, STAGE_COMPUTE, STAGE_RASTER_COLOR_OUT, STAGE_PIXEL_SHADER, STAGE_VERTEX_SHADER, ... };
enum HAZARD_FLAGS { HAZARD_DRAW_ARGUMENTS = 0x1, HAZARD_DESCRIPTORS = 0x2, , HAZARD_DEPTH_STENCIL = 0x4 };
enum SIGNAL { SIGNAL_ATOMIC_SET, SIGNAL_ATOMIC_MAX, SIGNAL_ATOMIC_OR, ... };
// Structs
struct Stencil
{
OP test = OP_ALWAYS,
OP failOp = OP_KEEP;
OP passOp = OP_KEEP;
OP depthFailOp = OP_KEEP;
uint8 reference = 0;
};
struct GpuDepthStencilDesc
{
DEPTH_FLAGS depthMode = 0;
OP depthTest = OP_ALWAYS;
float depthBias = 0.0f;
float depthBiasSlopeFactor = 0.0f;
float depthBiasClamp = 0.0f;
uint8 stencilReadMask = 0xff;
uint8 stencilWriteMask = 0xff;
Stencil stencilFront;
Stencil stencilBack;
};
struct GpuBlendDesc
{
BLEND colorOp = BLEND_ADD,
FACTOR srcColorFactor = FACTOR_ONE;
FACTOR dstColorFactor = FACTOR_ZERO;
BLEND alphaOp = BLEND_ADD;
FACTOR srcAlphaFactor = FACTOR_ONE;
FACTOR dstAlphaFactor = FACTOR_ZERO;
uint8 colorWriteMask = 0xf;
};
struct ColorTarget {
FORMAT format = FORMAT_NONE;
uint8 writeMask = 0xf;
};
struct GpuRasterDesc
{
TOPOLOGY topology = TOPOLOGY_TRIANGLE_LIST;
CULL cull = CULL_NONE;
bool alphaToCoverage = false;
bool supportDualSourceBlending = false;
uint8 sampleCount = 1;
FORMAT depthFormat = FORMAT_NONE;
FORMAT stencilFormat = FORMAT_NONE;
Span<ColorTarget> colorTargets = {};
GpuBlendDesc* blendstate = nullptr; // 선택적 내장 블렌드 상태
};
struct GpuTextureDesc
{
TEXTURE type = TEXTURE_2D;
uint32x3 dimensions;
uint32 mipCount = 1;
uint32 layerCount = 1;
uint32 sampleCount = 1;
FORMAT format = FORMAT_NONE;
USAGE_FLAGS usage = 0;
};
struct GpuViewDesc
{
FORMAT format = FORMAT_NONE;
uint8 baseMip = 0;
uint8 mipCount = ALL_MIPS;
uint16 baseLayer = 0;
uint16 layerCount = ALL_LAYERS;
};
struct GpuTextureSizeAlign { size_t size; size_t align; };
struct GpuTextureDescriptor { uint64[4] data; };
// Memory
void* gpuMalloc(size_t bytes, MEMORY memory = MEMORY_DEFAULT);
void* gpuMalloc(size_t bytes, size_t align, MEMORY memory = MEMORY_DEFAULT);
void gpuFree(void *ptr);
void* gpuHostToDevicePointer(void *ptr);
// Textures
GpuTextureSizeAlign gpuTextureSizeAlign(GpuTextureDesc desc);
GpuTexture gpuCreateTexture(GpuTextureDesc desc, void* ptrGpu);
GpuTextureDescriptor gpuTextureViewDescriptor(GpuTexture texture, GpuViewDesc desc);
GpuTextureDescriptor gpuRWTextureViewDescriptor(GpuTexture texture, GpuViewDesc desc);
// Pipelines
GpuPipeline gpuCreateComputePipeline(ByteSpan computeIR);
GpuPipeline gpuCreateGraphicsPipeline(ByteSpan vertexIR, ByteSpan pixelIR, GpuRasterDesc desc);
GpuPipeline gpuCreateGraphicsMeshletPipeline(ByteSpan meshletIR, ByteSpan pixelIR, GpuRasterDesc desc);
void gpuFreePipeline(GpuPipeline pipeline);
// State objects
GpuDepthStencilState gpuCreateDepthStencilState(GpuDepthStencilDesc desc);
GpuBlendState gpuCreateBlendState(GpuBlendDesc desc);
void gpuFreeDepthStencilState(GpuDepthStencilState state);
void gpuFreeBlendState(GpuBlendState state);
// Queue
GpuQueue gpuCreateQueue(/* DEVICE & QUEUE CREATION DETAILS OMITTED */);
GpuCommandBuffer gpuStartCommandRecording(GpuQueue queue);
void gpuSubmit(GpuQueue queue, Span<GpuCommandBuffer> commandBuffers);
// Semaphores
GpuSemaphore gpuCreateSemaphore(uint64 initValue);
void gpuWaitSemaphore(GpuSemaphore sema, uint64 value);
void gpuDestroySemaphore(GpuSemaphore sema);
// Commands
void gpuMemCpy(GpuCommandBuffer cb, void* destGpu, void* srcGpu,);
void gpuCopyToTexture(GpuCommandBuffer cb, void* destGpu, void* srcGpu, GpuTexture texture);
void gpuCopyFromTexture(GpuCommandBuffer cb, void* destGpu, void* srcGpu, GpuTexture texture);
void gpuSetActiveTextureHeapPtr(GpuCommandBuffer cb, void *ptrGpu);
void gpuBarrier(GpuCommandBuffer cb, STAGE before, STAGE after, HAZARD_FLAGS hazards = 0);
void gpuSignalAfter(GpuCommandBuffer cb, STAGE before, void *ptrGpu, uint64 value, SIGNAL signal);
void gpuWaitBefore(GpuCommandBuffer cb, STAGE after, void *ptrGpu, uint64 value, OP op, HAZARD_FLAGS hazards = 0, uint64 mask = ~0);
void gpuSetPipeline(GpuCommandBuffer cb, GpuPipeline pipeline);
void gpuSetDepthStencilState(GpuCommandBuffer cb, GpuDepthStencilState state);
void gpuSetBlendState(GpuCommandBuffer cb, GpuBlendState state);
void gpuDispatch(GpuCommandBuffer cb, void* dataGpu, uvec3 gridDimensions);
void gpuDispatchIndirect(GpuCommandBuffer cb, void* dataGpu, void* gridDimensionsGpu);
void gpuBeginRenderPass(GpuCommandBuffer cb, GpuRenderPassDesc desc);
void gpuEndRenderPass(GpuCommandBuffer cb);
void gpuDrawIndexedInstanced(GpuCommandBuffer cb, void* vertexDataGpu, void* pixelDataGpu, void* indicesGpu, uint32 indexCount, uint32 instanceCount);
void gpuDrawIndexedInstancedIndirect(GpuCommandBuffer cb, void* vertexDataGpu, void* pixelDataGpu, void* indicesGpu, void* argsGpu);
void gpuDrawIndexedInstancedIndirectMulti(GpuCommandBuffer cb, void* dataVxGpu, uint32 vxStride, void* dataPxGpu, uint32 pxStride, void* argsGpu, void* drawCountGpu);
void gpuDrawMeshlets(GpuCommandBuffer cb, void* meshletDataGpu, void* pixelDataGpu, uvec3 dim);
void gpuDrawMeshletsIndirect(GpuCommandBuffer cb, void* meshletDataGpu, void* pixelDataGpu, void *dimGpu);버퍼/텍스처 객체를 바인딩하지 않고, 메모리 레이아웃을 명시적으로 기술하는 API도 호출하지 않는 코드를 어떻게 디버깅할까? C/C++ 디버거는 수십 년 동안 그런 일을 해 왔다. 소프트웨어의 메모리 레이아웃을 기술하는 특별한 OS API는 없다. 디버거는 64비트 포인터 체인을 따라가며 컴파일러가 제공하는 디버그 심볼 데이터를 사용한다. 여기에는 struct와 클래스의 메모리 레이아웃이 포함된다. CUDA와 Metal은 완전한 64비트 포인터 시맨틱을 가진 C/C++ 기반 셰이딩 언어를 사용하며, 둘 다 포인터 체인을 문제 없이 따라가는 강력한 디버거를 갖는다.
텍스처 디스크립터 힙은 그냥 GPU 메모리다. 디버거는 이를 인덱싱해 텍스처 디스크립터를 로드하고, 디스크립터 데이터를 보여주며, 텍셀을 시각화할 수 있다. 이것은 Xcode Metal 디버거에서 이미 작동한다. 어떤 GPU 주소의 어떤 struct 안에서든 텍스처나 샘플러 핸들을 클릭하면 디버거가 시각화한다.
현대 GPU는 메모리를 가상화한다. 각 프로세스는 자기 페이지 테이블을 가진다. GPU 캡처에는 자체 가상 주소 공간을 가진 별도의 리플레이어 프로세스가 있다. 리플레이어가 모든 할당을 순진하게 재생하면, 각 메모리 할당에 대해 다른 GPU 가상 주소를 받는다. 레거시 API에서는 GPU 주소를 데이터 구조에 직접 저장할 수 없었으니 괜찮았다. 하지만 현대 API는 리플레이어가 정확한 GPU 가상 메모리 레이아웃을 미러링하도록 강제하는 특별한 리플레이 메모리 할당 API가 필요하다. DX12와 Vulkan BDA에는 이를 위한 공개 API가 있다: RecreateAt와 VkMemoryOpaqueCaptureAddressAllocateInfo. Metal과 CUDA 디버거도 내부 비공개 API로 같은 일을 한다. RenderDoc 같은 오픈소스 툴을 위해서는 공개 API가 바람직하다.
raw 포인터는 보안 문제를 가져오지 않을까? 다른 앱 메모리를 읽고 쓸 수 있지 않을까? 가상 메모리 때문에 불가능하다. 자신의 메모리 페이지만 접근할 수 있다. 실수로 스테일 포인터를 쓰거나 오버플로우하면 페이지 폴트가 나고 앱이 크래시한다. 페이지 폴트는 기존 버퍼 기반 API에서도 가능하다. DirectX 12와 Vulkan은 storage(byteaddress/structured) 버퍼 주소를 클램프하지 않는다. OOB는 페이지 폴트를 유발한다. 사용자가 메모리 힙을 해제하고 스테일 버퍼/텍스처 디스크립터를 계속 쓰는 실수도 페이지 폴트로 이어진다. 본질적으로 달라지는 것은 없다. 매핑되지 않은 영역 접근은 페이지 폴트이며 앱이 크래시한다. 이는 C/C++ 프로그래머에게 익숙한 모델이다. 견고성을 원한다면 ptr+size 쌍을 사용하면 된다. WebGPU가 바로 그렇게 구현된다. WebGPU 셰이더 컴파일러(Tint 또는 Naga)는 각 버퍼 접근마다 추가 클램프 명령을 내보낸다(버텍스 접근과 인덱스 버퍼 값 OOB 포함). 웹사이트가 오동작해도 브라우저를 크래시시키면 안 되기 때문이다. WebGL은 인덱스 버퍼 데이터를 다른 데이터로 셰이딩하는 것을 허용하지 않았다. WebGL은 CPU에서 인덱스를 스캔했기 때문에 인덱스 버퍼 업데이트가 매우 느렸다. 당시에는 커스텀 버텍스 페치가 불가능했고, 하드웨어는 셰이더 실행 전 이미 페이지 폴트를 냈다.
기존 소프트웨어 실행은 매우 중요하다. ANGLE, Proton, MoltenVK 같은 번역 레이어는 레거시 API의 이식성과 디프리케이션 과정에 중요한 역할을 한다. DirectX 12, Vulkan, Metal을 우리의 새 API로 번역하는 것을 논의해 보자.
MoltenVK(Vulkan→Metal 번역 레이어)는 Vulkan의 버퍼 중심 API를 Metal의 64비트 포인터 생태계로 번역할 수 있음을 증명한다. MoltenVK는 Vulkan 디스크립터 세트를 Metal argument buffer로 번역한다. 생성된 argument buffer는 버퍼 바인딩마다 64비트 GPU 포인터, 텍스처 바인딩마다 64비트 텍스처 ID를 가진 표준 GPU struct다. 우리는 디스크립터 세트마다 텍스처 힙에서 연속 범위를 할당해, 각 텍스처 바인딩마다 64비트 텍스처 ID 대신 단일 32비트 베이스 인덱스를 저장함으로써 더 개선할 수 있다. 이는 Metal과 달리 우리의 API가 사용자 관리 텍스처 힙을 제공하기 때문에 가능하다.
MoltenVK는 디스크립터 세트를 Metal API 루트 바인딩 슬롯으로 매핑한다. 우리는 최대 8개의 64비트 포인터 필드를 가진 루트 struct를 생성하고, 각 필드는 디스크립터 세트 struct를 가리킨다. 루트 상수는 값 필드로, 루트 디스크립터(루트 버퍼)는 64비트 포인터로 번역한다. GPU 드라이버가 우리의 루트 struct 필드를 유니폼/스칼라 레지스터에 프리로드한다면(루트 인자 장에서 논의), 효율은 동일할 것이다.
우리 API는 Metal과 같은 64비트 포인터 시맨틱을 사용한다. MoltenVK가 쓰는 동일한 기법으로 셰이더의 버퍼 로드/스토어 명령을 번역할 수 있다. MoltenVK는 Vulkan의 buffer device address 확장 번역도 지원한다.
Proton(DX12→Vulkan 번역 레이어)은 DirectX 12 SM 6.6 디스크립터 힙을 Vulkan의 디스크립터 버퍼 확장으로 번역할 수 있음을 증명한다. Proton은 다른 DirectX 12 기능도 Vulkan으로 번역한다. 우리는 이미 MoltenVK로 Vulkan→Metal 번역이 가능함을 보였고, 이는 전이적으로 DirectX 12→Metal 번역도 가능함을 의미한다. MoltenVK에서 가장 큰 결핍은 SM 6.6 스타일 디스크립터 힙(Vulkan 디스크립터 버퍼 확장)이다. Metal은 디스크립터 힙을 사용자에게 직접 노출하지 않는다. 우리의 새 API는 그런 제한이 없다. 우리의 디스크립터 힙 시맨틱은 SM 6.6 텍스처 힙의 상위 집합이며 Vulkan 디스크립터 버퍼 확장과도 근접히 맞는다. 번역은 직관적이다. Vulkan 확장은 디스크립터 무효화 플래그도 추가하는데, 이는 우리의 HAZARD_DESCRIPTORS와 매칭된다. DirectX 12 디스크립터 힙 API는 GPU 메모리의 raw 디스크립터 배열 위에 얇은 래퍼이므로 번역이 쉽다.
Metal 4.0을 지원하려면 Metal의 드라이버 관리 텍스처 디스크립터 힙을 구현해야 한다. 이는 우리 텍스처 힙 위에 간단한 프리리스트로 구현 가능하다. Metal은 64비트 텍스처 핸들을 사용하며, 이는 최신 Apple Silicon에서 직접 힙 인덱스로 구현된다. Metal은 셰이더에서 텍스처 핸들을 텍스처처럼 직접 쓸 수 있는데, 이는 textureHeap[uint64(handle)]에 대한 문법 설탕이다. Metal 텍스처 핸들은 우리의 셰이더 번역기에서 uint64로 번역되어 동일한 GPU 메모리 레이아웃을 유지한다.
우리 API는 버텍스 버퍼를 지원하지 않는다. WebGPU도 하드웨어 버텍스 버퍼를 쓰지 않지만 고전적 버텍스 버퍼 추상화를 구현한다. WGSL 셰이더 번역기(Tint 또는 Naga)는 버텍스 스트림마다 storage buffer 바인딩을 하나 추가하고, 버텍스 셰이더 시작 부분에 버텍스 로드 명령을 생성한다. 커스텀 버텍스 페치는 OOB를 피하기 위한 클램프 명령 생성도 가능해, 오동작 웹사이트가 브라우저를 크래시시키지 못한다. 우리의 셰이더 번역기는 각 버텍스 스트림에 대해 루트 struct에 64비트 포인터를 추가하고, 레이아웃에 맞는 struct를 생성하며, 버텍스 struct 로드 명령을 버텍스 셰이더 앞부분에 생성한다.
우리는 DirectX 12, Vulkan, Metal 앱을 새 API 위에서 실행하는 번역 레이어를 만들 수 있음을 보였다. WebGPU는 브라우저가 이 API들 위에 구현하므로, WebGPU 앱도 실행 가능하다.
Nvidia Turing(RTX 2000 시리즈, 2018)은 레이트레이싱, 텐서 코어, 메시 셰이더, 저지연 raw 메모리 경로, 더 크고 빠른 캐시, 스칼라 유닛, 보조 정수 파이프라인 등 많은 미래지향 기능을 도입했다. 공식적으로 PCIe ReBAR 지원은 RTX 3000 시리즈에서 출시되었지만, ReBAR을 지원하는 해킹된 Turing 드라이버가 존재해 하드웨어가 가능함을 시사한다. 7년 된 이 GPU는 우리가 필요한 모든 것을 지원한다. Nvidia는 2025년 가을 GTX 1000 시리즈 드라이버 지원을 종료했다. 현재 지원되는 Nvidia GPU는 모두 새 API로 지원될 수 있다.
AMD RDNA2(RX 6000 시리즈, 2020)은 레이트레이싱과 메시 셰이더로 Nvidia 기능 세트에 맞췄다. 1년 전 RDNA 1은 일관된 L2$, 새 L1$ 레벨, 빠른 L0$, 범용 DCC 읽기/쓰기 경로, 빠른 언필터드 로드, 현대 SIMD32 아키텍처를 도입했다. PCIe ReBAR은 “Smart Access Memory” 브랜드로 공식 지원된다. 5년 된 이 GPU는 우리가 필요한 모든 것을 지원한다. AMD는 2021년에 이미 GCN 드라이버 지원을 종료했다. 현재 RDNA 1/2는 버그/보안 업데이트만 받고, RDNA 3가 게임 최적화를 받는 가장 오래된 GPU다. 현재 지원되는 AMD GPU는 모두 우리 API로 지원 가능하다.
Intel Alchemist / Xe1(2022)은 SM 6.6 전역 인덱싱 가능한 힙을 지원한 최초의 Intel 칩이다. 레이트레이싱, 메시 셰이더, PCIe ReBAR(dGPU), UMA(iGPU)도 지원한다. 3년 된 이 GPU는 우리가 필요한 모든 것을 지원한다.
Apple M1 / A14(MacBook M1, iPhone 12, 2020)은 Metal 4.0을 지원한다. Metal 4.0은 CPU에 대한 GPU 메모리 가시성(폰/컴퓨터 모두 UMA)을 보장하고, 사용자가 64비트 포인터와 64비트 텍스처 핸들을 GPU 메모리에 직접 쓸 수 있게 한다. Metal 4.0은 또한 새 residency set API를 제공하여, 예전 useResource/useHeap API에서의 바인드리스 리소스 관리 사용성 문제를 해결한다. iOS 26은 iPhone 11을 여전히 지원한다. 개발자는 아직 Metal 4.0을 요구하는 앱을 출시할 수 없다. iOS 27에서 iPhone 11 지원이 내년에 디프리케이트될 가능성이 높다. Mac에서는 Intel Mac을 버리면 Metal 4.0을 보장받는다. M1~M5 = 5세대 = 5년.
ARM Mali-G710(2021)은 ARM의 첫 현대 아키텍처다. 새 command stream frontend(CSF)를 도입해 드로우콜 빌딩의 CPU 의존성을 줄이고, 멀티드로우 인다이렉트와 컴퓨트 큐 같은 핵심 기능을 추가했다. 비유니폼 인덱스 텍스처 샘플링이 크게 빨라졌고, AFBC 무손실 압축기는 16비트 부동 타깃도 지원한다. G710은 Vulkan BDA와 디스크립터 버퍼 확장을 지원하며, 향후 드라이버로 2025년 unified image layout 확장도 지원 가능하다. Mali-G715(2022)는 레이트레이싱 지원을 추가했다.
Qualcomm Adreno 650(2019)은 최신 Turnip 오픈소스 드라이버로 Vulkan BDA, 디스크립터 버퍼, unified image layout 확장, 16비트 스토리지/수학, 동적 렌더링, 확장 동적 상태를 지원한다. Adreno 740(2022)는 레이트레이싱을 도입했다.
PowerVR DXT(Pixel 10, 2025)는 PowerVR 최초로 Vulkan 디스크립터 버퍼와 buffer device address 확장을 지원하는 아키텍처다. 또한 64비트 원자, 8/16비트 스토리지/수학, 동적 렌더링, 확장 동적 상태 및 우리가 요구하는 모든 기능을 지원한다.
모던 그래픽 API는 지난 10년 동안 점진적으로 개선되어 왔다. DirectX 12 출시 6년 후, SM 6.6(2021)은 현대 전역 텍스처 힙을 도입해 완전 바인드리스 렌더러 설계를 가능하게 했다. Metal 4.0(2025)과 CUDA는 깔끔한 64비트 포인터 기반 셰이더 아키텍처를 가지며 바인딩 API 표면이 작다. Vulkan은 가장 제한적인 표준이지만 buffer device address(2020), descriptor buffer(2022), unified image layouts(2025) 같은 확장이 현대 바인드리스 인프라 지원을 추가한다. 하지만 툴링은 여전히 뒤처져 있다. 현재 단일 API가 모든 요구를 만족하지는 못하지만, 각 API의 최고 요소를 조합하면 현대 하드웨어를 위한 완벽한 API를 만들 수 있다.
10년 전 모던 API는 CPU-드리븐 바인딩 모델을 위해 설계되었다. 새 바인드리스 기능은 선택적 기능/확장으로 제공되었다. 완전한 단절(clean break)은 사용성을 개선하고 API 부풀림과 드라이버 복잡성을 크게 줄일 것이다. 산업 전체가 완전히 새로운 API에 동의하게 하는 것은 매우 어렵다. 벤더들이 새 메이저 버전(Vulkan 2.0, DirectX 13)에서는 하위 호환성을 내려놓고, 오늘날의 완전 바인드리스 GPU 아키텍처를 수용하길 바란다. 새 바인드리스 API 설계는 API와 엔진 RHI 사이의 불일치를 해결해, 해시맵과 세분화된 리소스 추적을 제거할 수 있게 한다. Metal 4.0은 이 목표에 가깝지만 전역 인덱싱 가능한 텍스처 힙이 없다. 64비트 텍스처 핸들은 텍스처 범위를 표현할 수 없다.
HLSL과 GLSL은 20년 전 1:1 요소별 변환 함수 프레임워크(버텍스, 픽셀, 지오메트리, 헐, 도메인 등)로 설계되었다. 메모리 접근은 추상화되어 있고 포인터 지원이 없어 배열 처리가 번거롭다. 20년 동안 존재했음에도 HLSL/GLSL은 라이브러리 생태계를 쌓지 못했다. 반면 CUDA는 메모리를 직접 노출하는 조합 가능한 언어이며, AI 텐서 코어 같은 새 기능을 intrinsic로 제공한다. CUDA는 광범위한 라이브러리 생태계를 갖고 있고, 이는 Nvidia를 4T 달러 가치로 끌어올렸다. 우리는 여기서 배워야 한다.
WebGPU 노트: WebGPU 설계는 10년 된 코어 Vulkan 1.0을 기반으로 추가 제한을 더한 것이다. WebGPU는 바인드리스 리소스, 64비트 GPU 포인터, 영구 매핑 GPU 메모리를 지원하지 않는다. DirectX 11과 Vulkan 1.0의 혼합처럼 느껴진다. 웹 그래픽에 큰 개선이지만, 현대 바인드리스 API 기준에는 못 미친다. WebGPU는 별도 글에서 다룰 것이다.
내 프로토타입 API는 최신 GPU 아키텍처에서 무엇이 가능한지 보여준다. 최신 API의 최고 요소를 조합하면, DirectX 11과 Metal 1.0보다 사용이 단순하면서도 DirectX 12와 Vulkan보다 더 높은 성능과 유연성을 제공하는 API를 만들 수 있다. 우리는 현대 바인드리스 하드웨어를 받아들여야 한다.
예제 코드 전반에서 사용한 간단한 user-land GPU 범프 할당기. temp allocator 생성자에서 gpuHostToDevicePointer를 한 번 호출한다. GPU 포인터에 대해 표준 포인터 산술(오프셋 등)을 수행할 수 있다. 전통적 Vulkan/DX12 버퍼 API는 별도 오프셋이 필요하다. 이는 API와 사용자 코드(ptr vs 핸들+오프셋 쌍)를 단순화한다. 실사용 수준의 temp allocator는 오버플로우 처리(확장, 플러시 등)를 구현해야 한다.
template<typename T>
struct GPUTempAllocation<T>
{
T* cpu;
T* gpu;
}
struct GPUBumpAllocator
{
uint8 *cpu;
uint8 *gpu;
uint32 offset = 0;
uint32 size;
TempBumpAllocator(uint32 size) : size(size)
{
cpu = gpuMalloc(size);
gpu = gpuHostToDevicePointer(cpu);
}
TempAllocation<uint8> alloc(int bytes, int align = 16)
{
offset = alignRoundUp(offset, align);
if (offset + bytes > size) offset = 0; // 단순 링 랩(오버플로우 검출 없음)
TempAllocation<uint8> alloc = { .cpu = cpu + offset, . gpu = gpu + offset };
offset += bytes;
return alloc;
}
template<typename T>
T* alloc(int count = 1)
{
TempAllocation<uint8> mem = alloc(sizeof(T) * count, alignof(T));
return TempAllocation<T> { .cpu = (T*)mem.cpu, . gpu = (T*)mem.gpu };
}
};