1980년대에 머문 CPU에 대한 멘탈 모델을 현대 x86/Linux의 관점에서 업데이트하며, 메모리 계층·TLB·OoO·동시성·SIMD·전력 관리·GPU·가상화와 향후 동향까지 훑는다.
이 글은 David Albert의 다음 질문에 대한 답변이다:
내 CPU에 대한 멘탈 모델은 1980년대에 멈춰 있다: 기본적으로 산술, 논리, 비트 조작과 시프트, 그리고 메모리에서 로드/스토어를 하는 상자 같은 것. 벡터 명령(SIMD) 같은 비교적 새로운 발전과, 최신 CPU가 가상화를 지원한다는 아이디어(하지만 실제로 무슨 뜻인지는 모름) 정도는 어렴풋이 알고 있다.
내가 놓치고 있는 멋진 발전은 뭐가 있을까? 오늘날의 CPU는 작년의 CPU가 못 하던 무엇을 할 수 있을까? 2년 전, 5년 전, 10년 전의 CPU는? 내가 특히 관심 있는 건 프로그래머가 직접 활용해야(혹은 이를 활용하기 위해 프로그래밍 환경이 재설계돼야) 해서, 그래서 아직 사용하지 못하고 있을지도 모르는 것들이다. 이 기준이면 Hyper-threading/SMT 같은 건 제외되는 것 같은데, 솔직히 확신은 없다. 또한 아직 CPU가 못 하지만 가까운 미래에 할 수 있게 될 것들도 궁금하다.
아래 내용은 별도 언급이 없으면 x86과 linux를 기준으로 한다. 역사는 반복되는 경향이 있고, x86에서 새로웠던 것들 중 상당수는 슈퍼컴퓨팅/메인프레임/워크스테이션 쪽에서는 이미 익숙한 것들이었다.
우선 칩은 레지스터 폭이 넓어졌고 더 많은 메모리를 주소 지정할 수 있다. 80년대에는 8비트 CPU를 썼을 수도 있지만, 지금은 거의 확실히 여러분의 머신에 64비트 CPU가 들어 있다. 64비트 머신 프로그래밍에는 익숙하다고 가정하므로 이 얘기는 많이 하지 않겠다. 주소 공간을 늘려주는 것 외에도, 64비트 모드는 레지스터를 더 많이 제공하고( x87 부동소수점 때문에 32/64비트 연산에서 의사-무작위로 80비트 정밀도를 얻는 일을 피함으로써) 더 일관된 부동소수점 결과를 제공한다. 80년대 초 이후 x86에 도입되어 여러분이 거의 확실히 쓰고 있는 다른 것들로는 페이징/가상 메모리, 파이프라이닝, 부동소수점 등이 있다.
이제는 무의미해진 것들(A20M 같은 것)과, 여러분이 드라이버를 쓰거나 BIOS 코드를 쓰거나 보안 감사를 하거나 그 밖의 유난히 로우레벨 작업을 할 때만 삶에 영향을 주는 것들(APIC/x2APIC, SMM, NX, SGX 같은 것)은 다루지 않겠다.
남은 주제들 중 일상적인 프로그래밍에 가장 큰 영향을 주는 것은 메모리가 동작하는 방식이다. 내 첫 컴퓨터는 286이었다. 그 머신에서는 메모리 접근이 몇 사이클 걸릴 수 있었다. 몇 년 전에는 메모리 접근이 400사이클 이상 걸리는 Pentium 4 시스템을 쓴 적이 있다. 프로세서는 메모리보다 훨씬 더 빠르게 발전했다. 상대적으로 느린 메모리 문제의 해법은 캐시(자주 쓰는 데이터에 빠른 접근 제공)와 프리페치(접근 패턴이 예측 가능하면 데이터를 캐시에 미리 로드) 추가였다.
몇 사이클 대 400+ 사이클은 정말 나빠 보인다; 100배 이상 느리다. 하지만 내가 64비트(8바이트) 값의 큰 블록을 읽고 연산하는 멍청한 루프를 작성하더라도, CPU는 내가 필요로 하기 전에 올바른 데이터를 프리페치할 만큼 똑똑해서 3GHz 프로세서에서 약 22 GB/s로 처리할 수 있다. 3GHz에서 매 사이클 8바이트를 소비할 수 있는 계산은 24GB/s이므로 22GB/s면 나쁘지 않다. 메인 메모리에 가야 해서 성능을 100배 잃는 게 아니라 대략 8% 정도 손해를 보는 셈이다.
1차 근사로는 예측 가능한 메모리 접근 패턴을 쓰고 CPU 캐시보다 작은 데이터 덩어리에서 작업하면 최신 캐시의 이점을 대부분 얻는다. 최대한 성능을 쥐어짜고 싶다면 이 문서가 좋은 출발점이다. 100페이지짜리 PDF를 소화한 뒤에는 최적화 대상 시스템의 마이크로아키텍처와 메모리 서브시스템을 익히고, likwid 같은 것으로 애플리케이션 성능을 프로파일링하는 법을 배워야 한다.
칩에는 메인 메모리 외에도 각종 작은 캐시가 잔뜩 있다. 디코드된 명령 캐시 같은 이상한 작은 캐시들은 마이크로 최적화를 극한으로 하지 않는 한 몰라도 된다. 큰 예외가 TLB인데, 이는 가상 메모리 조회( x86에서는 4레벨 페이지 테이블 구조로 수행)용 캐시다. 페이지 테이블이 l1 데이터 캐시에 들어 있더라도 조회당 4사이클, 즉 매번 가상 주소 조회 전체를 하려면 16사이클이 든다. 모든 사용자 모드 메모리 접근에 필요하니 도저히 받아들일 수 없고, 그래서 가상 주소 조회용으로 작고 빠른 캐시가 있다.
1레벨 TLB 캐시는 빨라야 하므로 크기가 심하게 제한된다(현대 칩에서 64 엔트리 정도일 수 있다). 4k 페이지를 쓰면 TLB 미스를 내지 않고 주소 지정할 수 있는 메모리 양이 제한된다. x86은 2MB, 1GB 페이지도 지원하며, 더 큰 페이지 크기를 쓰면 큰 이득을 보는 애플리케이션도 있다. 메모리를 많이 쓰는 장기 실행 애플리케이션이 있다면 검토해볼 만하다.
또한 1레벨 캐시는 보통 페이지 크기와 캐시의 연관도의 곱으로 제한된다. 캐시가 그보다 작으면, 캐시 인덱싱에 쓰는 비트가 가상 주소든 물리 주소든 동일하므로 캐시를 인덱싱하기 전에 가상→물리 변환을 할 필요가 없다. 캐시가 그보다 크면 캐시를 인덱싱하기 위해 먼저 TLB 조회를 해야(최소 1사이클 추가 비용) 하거나, 가상 인덱스 캐시를 만들어야 하는데(가능하지만) 복잡성과 소프트웨어 결합도가 커진다. 현대 칩에서 이 한계를 볼 수 있다. Haswell은 8-way 연관도 캐시와 4kB 페이지를 가지며 l1 데이터 캐시는 8 * 4kB = 32kB다.
20년 넘게 x86 칩은 추측 실행과 실행 재정렬(하나의 정체 자원 때문에 전체가 막히지 않도록)을 할 수 있었다. 이는 때때로 이상한 성능 딸꾹질을 만든다. 하지만 x86은 단일 CPU에 대해 레지스터와 메모리 같은 외부에서 보이는 상태가 모든 것이 순서대로 실행된 것처럼 업데이트되어야 한다는 요구가 꽤 엄격하다. 구현은 의존성이 있는 임의의 두 명령에 대해 그 둘이 서로에 대해 올바른 순서로 실행되도록 보장하는 방식으로 이뤄진다.
겉으로 보기에는 순서대로 실행된 것처럼 보여야 한다는 제약 덕분에, 최상의 성능을 쥐어짜려는 경우가 아니라면 OoO 실행의 존재를 대부분 무시할 수 있다. 큰 예외는 어떤 것이 외부적으로 순서대로 보이기만 하는 게 아니라 내부적으로도 실제로 순서대로 실행되었음을 보장해야 할 때다.
예를 들어 rdtsc로 특정 명령 시퀀스의 실행 시간을 측정하려는 경우를 생각해보자. rdtsc는 숨겨진 내부 카운터를 읽어서 결과를 외부에서 보이는 레지스터 edx와 eax에 넣는다.
다음과 같은 코드를 보자:
foo
rdtsc
bar
mov %eax, [%ebx]
baz
여기서 foo, bar, baz는 eax, edx, [%ebx]를 건드리지 않는다고 하자. rdtsc 다음의 mov는 eax 값을 메모리 위치에 쓸 것이고, eax는 외부에서 보이는 레지스터이므로 CPU는 모든 것이 순서대로 일어난 것처럼 보이게 하기 위해 mov가 rdtsc가 실행된 뒤에만 실행되도록 보장한다.
하지만 rdtsc와 foo나 bar 사이에는 명시적 의존성이 없으므로, rdtsc는 foo보다 먼저, foo와 bar 사이, 또는 bar 뒤에 실행될 수 있다. 심지어 baz가 rdtsc보다 먼저 실행되는 것도 가능하다(단 baz가 mov 명령에 어떤 영향도 주지 않는다면). 어떤 상황에서는 괜찮지만, rdtsc가 foo의 실행 시간을 재려는 목적이라면 괜찮지 않다.
rdtsc를 다른 명령에 대해 정확히 순서대로 배치하려면 실행을 직렬화하는 명령이 필요하다. 정확히 어떻게 해야 하는지는 Intel의 이 문서에 나와 있다.
위의 순서 제약(동일 위치에 대한 load/store는 서로에 대해 재정렬될 수 없다는 의미) 외에도 x86의 load/store에는 다른 제약이 있다. 특히 단일 CPU에 대해 store는 다른 store와 재정렬되지 않고, store는 (같은 위치 여부와 무관하게) 더 이른 load와도 재정렬되지 않는다.
하지만 load는 더 이른 store와 재정렬될 수 있다. 예를 들어 다음을 작성하면:
mov 1, [%esp]
mov [%ebx], %eax
이는 다음처럼 실행될 수 있다:
mov [%ebx], %eax
mov 1, [%esp]
하지만 반대는 성립하지 않는다 — 후자를 작성하면 전자처럼 실행될 수는 없다.
첫 번째 예제를 작성한 순서대로 실행되게 하려면 직렬화 명령을 끼워 넣을 수 있다. 하지만 그건 CPU가 모든 명령을 직렬화해야 한다는 뜻이다. 이는 느리다. 직렬화 명령 이전의 모든 명령이 끝날 때까지 이후의 어떤 것도 실행하지 못하게 만들기 때문이다. load/store 순서만 중요하다면 load/store만 직렬화하는 mfence도 있다.
다른 메모리 펜스인 lfence와 sfence는 다루지 않겠지만, 여기서 더 읽을 수 있다.
지금까지는 단일 코어 내 순서(대부분 load/store가 순서화됨)를 봤지만, 멀티코어 순서도 있다. 위의 제약은 모두 적용된다; core0가 core1을 관찰한다면 core1의 load/store는 단일 코어 규칙을 모두 지키는 것으로 보인다. 하지만 core0와 core1이 상호작용할 때 그 상호작용이 순서화된다는 보장은 없다.
예를 들어 core0와 core1이 시작할 때 eax와 edx가 0이고, core0가 다음을 실행한다고 하자:
mov 1, [_foo]
mov [_foo], %eax
mov [_bar], %edx
core1은 다음을 실행한다:
mov 1, [_bar]
mov [_bar], %eax
mov [_foo], %edx
두 코어 모두에서 첫 번째와 두 번째 명령 사이의 코어 내 의존성 때문에 eax는 반드시 1이어야 한다. 하지만 core0의 3행은 core0가 core1의 무엇이든 보기 전에 실행될 수 있고, 반대도 마찬가지이므로, 두 코어 모두에서 edx가 0일 수도 있다.
여기까지가 메모리 배리어로, 코어 내 메모리 접근을 직렬화한다. store는 코어들 사이에서 일관된 순서로 관측되어야 하므로, 배리어는 코어 간 동시성에도 영향이 있긴 하지만, 그걸 올바르게 추론하기는 꽤 어렵다. Linus는 락 대신 메모리 배리어를 쓰는 것에 대해 이렇게 말한다:
락을 안 쓰는 것의 진짜 비용은 종종 피할 수 없는 버그로 귀결된다. 메모리 배리어로 영리한 일을 하는 건 거의 항상 버그가 터지기 직전인 경우가 많다. 서로 다른 메모리 순서를 가진 10가지 아키텍처에서 일어날 수 있는 모든 일을, 그리고 배리어 하나가 빠졌을 때를 머릿속에 담아내는 건 그냥 정말 어렵다. … 사실 누구든 새로운 락킹 메커니즘을 만들면, 그들은 항상 틀린다. 하지 마라.
그리고 현대 x86 CPU에서는 동시성 프리미티브를 구현할 때 메모리 배리어를 쓰는 것보다 락을 쓰는 것이 종종 더 싸다. 그러니 락을 보자.
_foo를 0으로 두고 두 스레드가 각각 incl (_foo)를 10000번씩 실행하면, 동일 위치를 단일 명령으로 20000번 증가시키는 셈인데 결과는 20000을 넘지 않는 것이 보장되지만 (이론적으로) 최소 2까지도 내려갈 수 있다. 이론적 최소가 왜 10000이 아니라 2인지 바로 떠오르지 않는다면 그걸 알아내는 건 좋은 연습문제다. 바로 떠오른다면 보너스 문제로, 어떤 그럴듯한 CPU 구현이 실제로 그 결과를 만들 수 있는지, 아니면 스펙이 허용하지만 절대 일어나지 않는 헛소리인지 생각해보라. 이 글만으로 보너스 문제 답을 내기엔 정보가 부족하지만, 충분한 정보를 링크했다고 믿는다.
간단한 코드로 시험해볼 수 있다:
#include <stdlib.h>
#include <thread>
#define NUM_ITERS 10000
#define NUM_THREADS 2
int counter = 0;
int *p_counter = &counter;
void asm_inc() {
int *p_counter = &counter;
for (int i = 0; i < NUM_ITERS; ++i) {
__asm__("incl (%0) \n\t" : : "r" (p_counter));
}
}
int main () {
std::thread t[NUM_THREADS];
for (int i = 0; i < NUM_THREADS; ++i) {
t[i] = std::thread(asm_inc);
}
for (int i = 0; i < NUM_THREADS; ++i) {
t[i].join();
}
printf("Counter value: %i\n", counter);
return 0;
}
위 코드를 clang++ -std=c++11 -pthread로 컴파일하면 내 두 머신에서 다음과 같은 결과 분포를 얻는다:
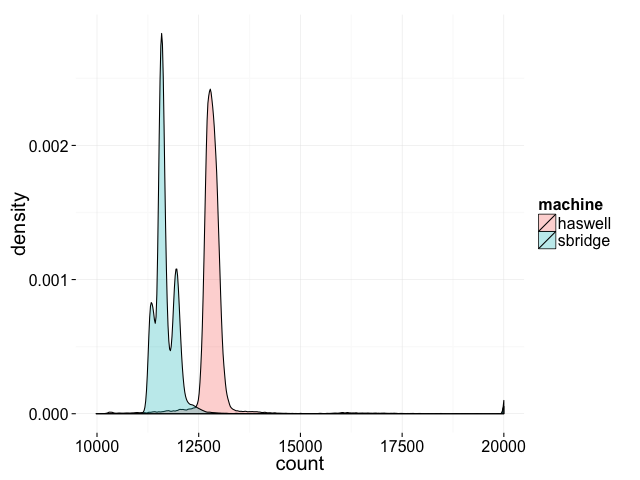
결과가 실행마다 달라질 뿐 아니라, 분포 자체가 머신마다 다르다. 이론적 최소 2는 물론이고 10000 아래도 한 번도 나오지 않지만, 최종 결과가 10000과 20000 사이 어디든 나올 가능성이 있다.
incl이 단일 명령이긴 해도 원자적이라고 보장되진 않는다. 내부적으로 incl은 load 후 add 후 store로 구현된다. cpu0의 증가가 cpu1의 load와 store 사이에 끼어들어 실행될 수도 있고, 반대도 마찬가지다.
Intel의 해법은 lock 프리픽스인데, 몇몇 명령 앞에 붙여 원자적으로 만든다. 위 코드에서 incl을 lock incl로 바꾸면 결과는 항상 20000이 된다.
이렇게 단일 명령을 원자적으로 만든다. 시퀀스를 원자적으로 만들려면 xchg나 cmpxchg를 쓸 수 있는데, 이들은 비교-교환 프리미티브로서 항상 락이 걸린다. 작동 방식은 자세히 다루지 않겠지만 궁금하면 David Dalrymple의 글을 보라..
메모리 트랜잭션을 원자적으로 만드는 것 외에도, 락은 전역적으로 서로에 대해 순서가 정해져 있으며, load/store는 락에 대해 재정렬되지 않는다.
메모리 순서에 대한 엄밀한 모델은 x86 TSO 문서를 보라.
지금까지 논의는 하드웨어에서 동시성이 어떻게 동작하는지였다. x86이 무엇을 재정렬할 수 있는지에 제한이 있긴 하지만, 컴파일러가 동일한 제한을 갖는 것은 아니다. C나 C++에서는 컴파일러가 재정렬하지 않도록 적절한 프리미티브를 넣어야 한다. Linus가 여기서 지적하듯 다음 같은 코드가 있으면:
local_cpu_lock = 1;
// .. do something critical ..
local_cpu_lock = 0;
컴파일러는 local_cpu_lock = 0이 크리티컬 섹션 중간으로 밀려 들어가면 안 된다는 걸 모른다. 컴파일러 배리어는 CPU 메모리 배리어와 별개다. x86 메모리 모델이 비교적 엄격하므로, 어떤 컴파일러 배리어는 하드웨어 레벨에서는 아무것도 하지 않는(no-op) 대신 컴파일러에게 재정렬하지 말라고만 알려준다. 마이크로코드/어셈블리/C/C++보다 높은 수준의 언어를 쓰고 있다면, 컴파일러가 별도 주석 없이도 대체로 이걸 처리해줄 것이다.
다른 아키텍처로 코드를 포팅한다면, x86이 요즘 마주칠 만한 아키텍처 중 가장 강한 메모리 모델을 가진 편이라는 점이 중요하다. 아무 생각 없이 그냥 동작하던 코드를 더 약한 보장(PPC, ARM, Alpha)을 가진 아키텍처로 포팅하면 버그가 거의 확실히 생긴다.
다음 예를 보자:
Initial
-----
x = 1;
y = 0;
p = &x;
CPU1 CPU2
---- ----
i = *p; y = 1;
MB;
p = &y;
MB는 메모리 배리어다. Alpha 21264 시스템에서는 이게 i = 0이 될 수 있다.
Kourosh Gharachorloo는 그 이유를 이렇게 설명한다:
CPU2는 y=1을 수행하면서 "invalidate y"를 CPU1에 보낸다. 이 invalidate는 CPU1의 incoming "probe queue"로 들어가는데; 문제는 CPU1에서 MB를 하지 않으면 이 invalidate가 이론적으로 probe queue에 그대로 머물 수 있다는 점에서 발생한다. 이 시점에서 invalidate는 즉시 acknowledge된다(즉, CPU1의 캐시에서 실제로 무효화될 때까지 기다리지 않고 acknowledge를 보낸다). 따라서 CPU2는 MB를 통과할 수 있다. 그리고 p에 대한 write를 수행한다. 이제 CPU1은 p를 읽는다. read p에 대한 reply는 CPU1의 incoming 경로에서 probe queue를 우회하는 것이 허용된다(이는 이전에 들어온 probe들이 서비스되기를 기다리지 않고도 reply/data가 21264로 빨리 돌아오도록 하기 위함이다). 이제 CPU1은 캐시에 남아 있는 y의 옛 값을 읽기 위해 p를 역참조할 수 있다(CPU1의 probe queue에 있는 invalidate y는 아직 거기 앉아 있다).
CPU1에서 MB가 이걸 어떻게 고치나? 21264는 모든 MB에서 incoming probe queue를 flush한다(즉, 그 안에 대기 중인 메시지를 서비스한다). 따라서 p를 읽은 뒤 MB를 하면 y에 대한 invalidate가 확실히 들어오게 된다. 그 결과 y에 대한 오래된 캐시 값을 더 이상 볼 수 없다.
위 시나리오는 이론적으로 가능하지만, 그로 인한 문제를 관측할 확률은 극히 작다. 이유는 캐싱을 적절히 설정해도 CPU1은 "read p"에 대한 데이터 reply를 받기 전에 probe queue의 메시지(invalidate)를 서비스할 기회를 충분히 가질 가능성이 높기 때문이다. 그럼에도 CPU1의 probe queue에 y에 대한 invalidate 앞에 많은 것들을 쌓아둔 상황이라면, p에 대한 reply가 돌아오면서 이 invalidate를 우회할 가능성이 있다. 다만 그 시나리오를 설정하고 실제로 이상 현상을 관측하는 것은 어려울 것이다.
다른 아키텍처 얘기까지 하면 너무 길어지니 자세히 다루지 않겠다. 다만 왜 누가 이런 최적화를 허용하는 스펙을 만들었는지 궁금하다면, DEC가 상승하는 팹 비용에 짓눌리기 전에는 그들의 칩이 너무 빨라서 에뮬레이션으로 업계 표준 x86 실제 워크로드 벤치마크를 x86 칩이 네이티브로 돌리는 것보다 더 빨리 돌릴 수 있었다는 점을 생각해보라. 당시 가장 RISC다운 아키텍처가 왜 그런 결정을 했는지에 대한 더 많은 설명은 Alpha 아키텍처의 동기에 관한 이 논문을 보라.
참고로, 이건 내가 Mill 아키텍처에 회의적인 큰 이유다. 성능 주장대로 될지 여부를 떠나, 기술적으로 뛰어난 것만으로는 그것 자체가 비즈니스 모델이 아니다.
이전 섹션에서 나열한 제약은 캐시 가능한(즉 “write-back” 또는 WB) 메모리에 적용된다. 이것 자체도 한때는 “새로운” 것이었다. 그 이전에는 캐시 불가능(UC) 메모리만 있었다.
UC 메모리의 흥미로운 점 중 하나는 모든 load/store가 버스로 나가야 한다고 기대된다는 점이다. 캐시가 없고 온보드 버퍼링이 거의 없는 프로세서에서는 완전히 합리적이다. 그 결과, 메모리에 접근할 수 있는 장치는 UC 메모리 영역에 대한 모든 접근이 각각의 버스 트랜잭션을, 순서대로, 발생시킨다는 점에 의존할 수 있다(일부 장치는 메모리 read/write 자체를 트리거로 무언가를 수행하기 때문이다). 1982년에는 잘 동작했지만, 비디오 카드가 최신 업데이트를 그냥 쭉 빨아들이고 싶을 때는 그다지 좋지 않다. 같은 UC 위치(또는 같은 워드의 다른 바이트)에 여러 번 쓰기가 일어나면, 비디오 카드는 중간 결과를 모두 볼 필요가 없는데도 CPU는 각 write마다 별도의 버스 트랜잭션을 발행해야 한다.
해법은 write combine(WC)이라는 메모리 타입을 만드는 것이었다. WC는 일종의 eventual consistent UC다. write는 결국 메모리에 도달해야 하지만 내부적으로 버퍼링될 수 있다. WC 메모리는 UC보다 더 약한 순서 보장도 갖는다.
대부분의 경우 장치와 직접 대화하지 않는 한 이를 다룰 필요가 없다. 예외는 “non-temporal” load/store 연산이다. 이는 주소가 WB로 표시된 메모리 영역에 있더라도 특정 load/store를 WC 메모리에 대한 접근처럼 동작하게 만든다.
캐시에 어떤 것을 오염시키고 싶지 않을 때 유용하다. 이는 특정 데이터를 한 번 이상 쓰지 않을 것을 아는 스트리밍 계산을 할 때 종종 유용하다.
메모리 지연과 대역폭이 프로세서마다 다른 비균일 메모리 접근(NUMA)은 너무 흔해져서, 이제는 너무 흔하다는 이유로 NUMA나 ccNUMA를 거의 말하지 않고 기본값이라고 가정한다.
여기서의 요점은 메모리를 공유하는 스레드는 같은 소켓에 있어야 하고, 메모리 매핑 I/O를 많이 하는 스레드는 대화하는 I/O 장치에 가장 가까운 소켓에 있어야 한다는 것이다.
왜 그런지에 대한 설명은 글을 최소 한 자릿수 더 길게 만들 것이기 때문에 대부분 피했지만, NUMA는 비교적 자족적이고 설명하기 쉬운 주제이기도 하고, ‘왜’가 ‘무엇’에 비해 얼마나 긴지를 보여주기 위해 엄청 단순화한 설명을 해보겠다.
옛날엔 그냥 메모리만 있었다. 그러다 CPU가 메모리 대비 충분히 빨라져서 캐시를 넣고 싶어졌다. 캐시가 백킹 스토어(메모리)와 불일치하면 큰일이므로, 캐시는 자신이 무엇을 들고 있는지에 대한 정보를 유지해서 언제/어떻게 백킹 스토어에 써야 하는지 알아야 한다.
이건 그리 나쁘지 않다. 하지만 각자 캐시를 가진 코어 2개가 생기면 조금 더 복잡해진다. 캐시 없는 경우와 같은 프로그래밍 모델을 유지하려면, 캐시들은 서로 및 백킹 스토어와 일관돼야 한다. 기존 load/store 명령 API에는 미안! 다른 CPU가 네가 원하는 주소를 들고 있어서 이 load가 실패했어 같은 말을 할 수 있는 수단이 없으므로, 가장 단순한 방법은 CPU가 load/store를 하고 싶을 때마다 버스에 메시지를 뿌리게 하는 것이었다. 두 CPU가 연결된 메모리 버스가 이미 있으니, 다른 CPU가 해당 데이터를 수정된 형태로 캐시에 가지고 있으면 데이터를 응답하고(적절한 캐시 라인을 무효화하며) 보내도록 요구하면 된다.
이건 어느 정도 잘 된다. 대부분의 시간에는 각 CPU가 다른 CPU가 신경 쓰지 않는 데이터를 만지므로 버스 트래픽이 낭비되긴 하지만, CPU가 안녕! 내가 이 주소를 가져가서 수정할 거야라고 메시지를 보내면 다른 CPU가 요청하기 전까지는 그 주소를 완전히 소유한다고 가정할 수 있고(대개 그런 요청은 일어나지 않을 것이다), 단일 메모리 주소가 아니라 예를 들어 64바이트짜리 캐시 라인 단위로 작업할 수 있으므로 전체 오버헤드는 낮다.
4 CPU까지도 괜찮긴 하지만 오버헤드는 좀 더 나빠진다. 하지만 모든 CPU가 다른 모든 CPU의 메시지에 응답해야 하는 방식은 4 CPU를 크게 넘어서면 확장되지 않는다. 버스가 포화될 뿐 아니라 캐시도 포화되기 때문이다(캐시의 물리적 크기/비용은 동시에 지원하는 read/write 수의 O(n^2)이고 속도는 크기와 반비례한다).
이 문제에 대한 “단순한” 해법은 N-way P2P 브로드캐스트 대신, 상태를 추적하는 단일 중앙 디렉터리를 두는 것이다. 어차피 이제 칩(소켓) 하나에 2~16코어를 집어넣고 있으니, 칩당 하나의 디렉터리가 칩 내 모든 코어의 캐시 상태를 추적하도록 하는 것이 자연스럽다.
이건 칩 단위 문제만 해결한다. 칩끼리 대화하는 방법이 필요하다. 불행히도 시스템을 확장하는 동안 버스 속도가 충분히 빨라져서, 작은 시스템조차도 여러 칩과 메모리를 하나의 버스로 길게 연결할 만큼 멀리 신호를 보내기가 어렵다. 가장 단순한 해법은 각 소켓이 메모리의 한 영역을 소유하게 만들어 모든 소켓이 메모리의 모든 부분에 연결될 필요가 없게 하는 것이다. 이는 디렉터리의 디렉터리 같은 상위 레벨 디렉터리가 필요해지는 복잡성도 피한다. 어떤 메모리 조각을 어떤 디렉터리가 소유하는지가 명확하기 때문이다.
단점은 한 소켓에 앉아서 다른 소켓이 소유한 메모리를 원하면 큰 성능 페널티가 있다는 점이다. 단순성을 위해 대부분의 “작은”(< 128코어) 시스템은 링 같은 버스를 쓰므로, 페널티는 추가 홉을 거쳐 메모리로 가는 직접적인 지연/대역폭 페널티뿐 아니라, 유한한 자원(링 버스)을 소모해 다른 소켓 간 접근도 느리게 만든다.
이론상 OS가 이를 투명하게 처리하지만, 실제로는 종종 비효율적이다.
여기서 syscall은 linux 시스템 콜을 의미하며, x86의 SYSCALL이나 SYSENTER 명령을 의미하진 않는다.
현대 코어가 가진 캐싱의 부작용 중 하나는 컨텍스트 스위치가 비싸다는 점이고, 이 때문에 시스템 콜도 비싸다. Livio Soares와 Michael Stumm이 그 비용을 논문에서 매우 자세히 논의한다. 아래에서 그들의 그림 몇 개를 쓰겠다. 먼저 SPEC CPU의 하위 벤치마크인 Xalan에서 Core i7이 달성하는 IPC(클록당 명령 수) 그래프다.
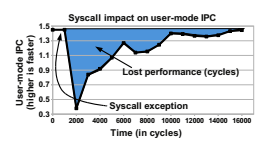
시스템 콜 이후 14,000사이클이 지나도 코드는 여전히 완전한 속도로는 돌지 않는다.
다음은 몇 가지 시스템 콜의 풋프린트 표로, 직접 비용(명령 수/사이클)과 간접 비용(캐시와 TLB 축출 수)을 모두 보여준다.
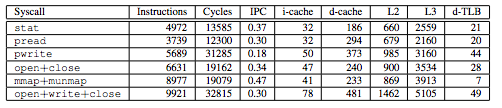
어떤 시스템 콜은 40+ TLB 축출을 일으킨다! d-TLB가 64 엔트리인 칩에서는 TLB를 거의 쓸어버리는 수준이다. 캐시 축출도 공짜가 아니다.
시스템 콜 비용이 큰 것이, 고성능 코드에서 배치 버전 시스템 콜(예: epoll, recvmmsg)로 옮겨간 이유이자, 아주 높은 성능 I/O가 필요한 사람들이 종종 유저 공간 I/O 스택을 쓰는 이유다. 더 일반적으로는 컨텍스트 스위치 비용 때문에 고성능 코드는 종종 코어당 스레드(thread-per-core)(혹은 핀 고정한 단일 스레드) 형태이고, 논리적 태스크당 스레드(thread-per-logical-task)가 아니다.
이 높은 비용은 또한 vDSO의 동인이기도 했다. vDSO는 권한 상승이 필요 없는 단순한 시스템 콜 일부를 유저 공간 라이브러리 호출로 바꾼다.
현대 x86 CPU는 사실상 모두 SSE(128비트 벡터 레지스터 및 명령)를 지원한다. 같은 연산을 여러 번 하고 싶을 때가 흔하기 때문에 Intel은 128비트 데이터 덩어리를 2개의 64비트, 4개의 32비트, 8개의 16비트 등으로 보고 연산할 수 있는 명령을 추가했다. ARM도 다른 이름(NEON)으로 같은 것을 지원하며, 지원되는 명령도 꽤 비슷하다.
SIMD 명령을 쓰면 2x~4x 가속을 얻는 것이 흔하다; 계산량이 큰 워크로드라면 꼭 알아볼 가치가 있다.
컴파일러는 벡터화 가능한 흔한 패턴을 인식할 만큼 충분히 좋아져서, 다음 같은 단순 코드는 현대 컴파일러에서 자동으로 벡터 명령을 사용한다.
for (int i = 0; i < n; ++i) {
sum += a[i];
}
하지만 특히 SIMD 코드에서는, 어셈블리를 직접 쓰지 않으면 컴파일러가 종종 비최적 코드를 생성하므로, 최상의 성능이 정말 중요하다면 디스어셈블리를 보고 컴파일러 최적화 버그를 확인하고 싶을 것이다.
현대 CPU에는 다양한 시나리오에서 전력 사용을 최적화하는 멋진 전력 관리 기능이 많다. 그 결과 “race to idle”, 즉 가능한 한 빨리 일을 끝내고 CPU가 다시 잠들게 하는 것이 가장 전력 효율적인 작업 방식이다.
특정 마이크로 최적화가 전력 소모에 도움이 된다는 연구가 많이 있었지만, 실제 워크로드에 적용하면 기대만큼 이득이 크지 않은 경우가 많다.
나는 이 주제에 대해 다른 것들보다도 덜 자격이 된다. 다행히 Cliff Burdick이 GPU 섹션을 써주겠다고 했고, 아래가 그 내용이다.
2000년대 중반 이전에는 GPU(Graphical Processing Unit)가 하드웨어에 대한 제어를 극히 제한적으로만 허용하는 API에 묶여 있었다. 라이브러리가 더 유연해지면서 프로그래머들은 선형대수 루틴 같은 보다 범용적인 작업에 프로세서를 사용하기 시작했다. GPU의 병렬 아키텍처는 수백 개의 동시 스레드를 запуск하여 행렬의 큰 덩어리를 처리할 수 있었다. 하지만 코드는 전통적인 그래픽 API를 사용해야 했고, 하드웨어를 어느 정도까지 제어할 수 있는지도 여전히 제한적이었다. Nvidia와 ATI는 이를 주목하고 그래픽 업계 밖의 사람들에게도 익숙한 API로 더 많은 하드웨어에 접근할 수 있게 하는 프레임워크를 출시했다. 라이브러리는 인기를 얻었고, 오늘날 GPU는 CPU와 함께 고성능 컴퓨팅(HPC)에서 널리 사용된다.
CPU와 비교했을 때 GPU 하드웨어는 아래와 같은 주요 차이가 있다.
최상위 수준에서 GPU 프로세서는 하나 또는 여러 개의 스트리밍 멀티프로세서(SM)를 포함한다. 현대 GPU의 각 SM에는 보통 100개가 넘는 부동소수점 유닛이 들어 있는데, GPU 세계에서는 흔히 이를 코어라고 부른다. 각 코어는 보통 800MHz 정도로 클록되지만, CPU처럼 더 높은 클록에 더 적은 코어를 가진 프로세서도 있다. GPU 프로세서는 대형 캐시나 분기 예측 등 CPU에 있는 많은 기능이 없다. 코어, SM, 그리고 전체 프로세서의 층을 오갈수록 통신은 점점 더 느려진다. 그래서 GPU에서 잘 수행되는 문제는 보통 높은 병렬성을 가지면서도 소수 스레드 사이에서 공유될 수 있는 데이터가 어느 정도 있는 경우다. 왜 그런지는 아래 메모리 섹션에서 다룬다.
현대 GPU의 메모리는 전역 메모리(global), 공유 메모리(shared), 레지스터(register)라는 3가지 주요 범주로 나뉜다. 전역 메모리는 GPU 박스에 적혀 있는 GDDR 메모리로, 보통 2~12GB 정도이며 처리량은 300~400GB/s다. 전역 메모리는 프로세서의 모든 SM에 걸친 모든 스레드가 접근할 수 있으며, 카드에서 가장 느린 메모리 유형이기도 하다. 공유 메모리는 이름 그대로 동일 SM 내 모든 스레드가 공유하는 메모리다. 보통 전역 메모리보다 최소 2배 빠르지만, 서로 다른 SM의 스레드 사이에서는 접근할 수 없다. 레지스터는 CPU의 레지스터처럼 GPU에서 데이터에 접근하는 가장 빠른 방법이지만, 스레드별 로컬이며 데이터는 다른 실행 중인 스레드에게 보이지 않는다. 공유 메모리와 전역 메모리는 접근 규칙이 매우 엄격하며 이를 따르지 않으면 심각한 성능 페널티가 있다. 위에서 언급한 처리량을 달성하려면 동일 스레드 그룹 내 스레드들 사이에서 메모리 접근이 완전히 coalesced되어야 한다. CPU가 하나의 캐시 라인으로 읽어들이는 것과 유사하게, GPU도 단일 접근이 정렬만 잘 되면 그룹의 모든 스레드를 обслуж할 수 있도록 캐시 라인 크기가 잡혀 있다. 하지만 최악의 경우 그룹의 모든 스레드가 서로 다른 캐시 라인에 접근하면, 스레드마다 별도의 메모리 read가 필요하다. 이는 대개 캐시 라인의 대부분 데이터가 해당 스레드에 의해 사용되지 않는다는 뜻이고, 결과적으로 메모리의 유효 처리량이 떨어진다. 공유 메모리에도 유사한 규칙이 적용되며, 여기서 다루지 않을 예외가 몇 가지 있다.
GPU 스레드는 SIMT(Single Instruction Multiple Thread) 방식으로 실행되며, 각 스레드는 하드웨어에서 사전에 정해진 크기(보통 32)로 그룹을 이뤄 실행된다. 이 마지막 부분은 많은 함의를 가진다; 그 그룹의 모든 스레드는 같은 시점에 같은 명령을 수행해야 한다. 그룹 내 어떤 스레드가 다른 스레드와 다른 분기 경로(예: if 문)를 타야 한다면, 분기에 속하지 않은 모든 스레드는 분기가 끝날 때까지 실행이 중단된다. 아주 단순한 예:
if (threadId < 5) {
// Do something
}
// Do More
위 코드에서는 이 분기 때문에 그룹의 32 스레드 중 27 스레드가 분기가 끝날 때까지 실행을 멈춘다. 많은 스레드 그룹이 이 코드를 실행한다면, 대부분의 코어가 놀고 있는 동안 전체 성능이 크게 떨어질 수 있다는 걸 상상할 수 있을 것이다. 하드웨어가 다른 그룹을 해당 코어에 스왑 인할 수 있는 것은 전체 그룹이 스톨되었을 때뿐이다.
현대 GPU는 CPU가 필요하다. CPU는 CPU 메모리와 GPU 메모리 사이에 데이터를 복사하고, GPU에서 실행할 작업을 시작하며, GPU 코드를 실행(launch)한다. 최고 처리량에서 PCIe 3.0 16레인 버스는 약 13~14GB/s 정도의 속도를 낼 수 있다. 이는 높아 보이지만 GPU 내부 메모리 속도와 비교하면 한 자릿수 이상 느리다. 사실 GPU가 더 강력해질수록 PCIe 버스는 점점 병목이 되고 있다. GPU가 CPU보다 가지는 성능 이점을 보려면 GPU에 충분히 큰 작업을 적재해, GPU가 잡을 실행하는 시간이 데이터 복사에 드는 시간보다 유의미하게 커야 한다.
새로운 GPU는 CPU로 돌아가지 않고도 GPU 코드에서 동적으로 작업을 запуска할 수 있는 기능이 있지만, 현 시점에서는 활용이 꽤 제한적이다.
CPU와 GPU의 주요 아키텍처 차이 때문에 어느 하나가 다른 하나를 완전히 대체할 것이라고 상상하긴 어렵다. 사실 GPU는 병렬 작업에서 CPU를 잘 보완하며, GPU가 실행되는 동안 CPU가 다른 작업을 독립적으로 수행할 수 있게 한다. AMD는 "Heterogeneous System Architecture"(HSA)로 두 기술을 융합하려 시도하고 있지만, 기존 CPU 코드를 가져와 CPU 부분과 GPU 부분 사이에서 어떻게 나눌지 결정하는 것은 프로세서뿐 아니라 컴파일러에게도 큰 도전이 될 것이다.
가상화를 언급했으니 조금 얘기하겠다. 하지만 Intel의 가상화 명령 구현은 일반적으로, 가상화를 직접 다루는 매우 로우레벨 코드를 쓰지 않는 한 신경 쓸 필요가 없는 것들이다.
그런 것들을 다루는 일은 꽤 지저분하다. 이 코드를 보면 알 수 있다. Intel의 VT 명령을 사용해 VM 게스트를 띄우도록 설정하는 것은, 거기서 보이는 매우 단순한 경우조차도 로우레벨 코드가 약 1000줄 필요하다.
Vish의 VT 코드를 보면 페이지 테이블/가상 메모리에 할애된 코드가 꽤 많다는 걸 알 수 있다. 이것도 OS나 다른 로우레벨 시스템 코드를 쓰지 않는 한 신경 쓸 필요 없는 또 다른 “새로운” 기능이다. 가상 메모리를 쓰는 것은 세그먼트 메모리를 쓰는 것보다 훨씬 단순하지만, 요즘엔 관련이 없으니 여기서는 이 정도로만 하겠다.
얘기가 나왔으니 SMT도 언급하겠다. 말했듯이 이는 대부분 프로그래머에게 투명하다. 단일 코어에서 SMT를 켜면 전형적으로 약 25%의 속도 향상이 있다. 전체 처리량엔 좋지만 각 스레드는 원래 성능의 60% 정도만 얻을 수도 있다. 단일 스레드 성능이 매우 중요한 애플리케이션이라면 SMT를 끄는 편이 나을 수도 있다. 다만 워크로드에 따라 크게 달라지고, 다른 어떤 변경과 마찬가지로 정확한 워크로드에서 벤치마크를 돌려 무엇이 최선인지 보는 게 좋다.
칩(과 소프트웨어)에 추가된 복잡성의 부작용 중 하나는, 예전보다 성능 예측이 훨씬 어려워졌다는 점이다; 따라서 실제로 실행될 특정 하드웨어에서 정확한 워크로드를 벤치마킹하는 중요성이 커졌다.
예를 들어, 사람들은 Computer Languages Benchmarks Game의 벤치마크를 언어가 서로 더 빠르다는 증거로 자주 든다. 나는 직접 결과를 재현해보려 했는데, 내 모바일 Haswell(결과에 쓰인 서버 Kentsfield가 아니라)에서는 상대 속도가 최대 2배까지 다르게 나온다. 같은 머신에서 같은 벤치마크를 돌려도, Nathan Kurz가 최근 gcc -O3가 gcc -O2보다 25% 느린 사례를 알려줬다. C++ 프로그램은 링크 순서를 바꾸는 것만으로도 15% 성능 변화가 날 수 있다. 벤치마킹은 어려운 문제다.
옛날식 통념은 분기가 비싸며 어떤(혹은 대부분) 대가를 치르더라도 피해야 한다는 것이다. Haswell에서 분기 예측 실패 페널티는 14사이클이다. 분기 예측 실패율은 워크로드에 따라 다르다. perf stat로 몇 가지(bzip2, top, mysqld, 내 블로그 재생성)를 재보면 분기 예측 실패율이 0.5%~4% 사이로 나온다. 올바르게 예측된 분기의 비용을 1사이클이라고 하면, 평균 비용은 .995 * 1 + .005 * 14 = 1.065 cycles에서 .96 * 1 + .04 * 14 = 1.52 cycles 사이다. 나쁘지 않다.
이건 1995년 이후로는 페널티를 과대평가한 것이다. Intel이 조건부 이동 명령을 추가해 분기 없이도 조건적으로 데이터를 이동할 수 있게 했기 때문이다. 이 명령은 Linus가 통렬히 깠던 것이라 나쁜 평판이 있지만, 분기 대비 cmov를 사용해 유의미한 가속을 얻는 경우는 꽤 흔하다
분기가 더 늘어나는 실제 사례로는 정수 오버플로 검사 활성화가 있다. bzip2로 특정 파일을 압축할 때, 오버플로 검사를 켜면 명령 수가 약 30% 증가하는데(증가분은 전부 추가 분기 명령에서 비롯됨), 그 결과 성능은 1%만 떨어진다.
예측 불가능한 분기는 나쁘지만 대부분의 분기는 예측 가능하다. 프로파일러가 핫스팟을 가리킬 때까지 분기 비용을 무시하는 건 요즘 합리적이다. 지난 10년간 CPU는 최적화되지 않은 코드를 실행하는 데 훨씬 좋아졌고, 컴파일러도 더 잘 최적화하게 되었으므로, 절대적인 최선의 성능을 쥐어짜려는 것이 아니라면 분기 최적화는 시간 대비 효율이 좋지 않다.
정말로 그게 필요하다면, 손으로 이걸 주물럭거리는 것보다 프로파일 유도 최적화를 쓰는 편이 나을 가능성이 크다.
정말 손으로 해야 한다면, 어떤 분기가 자주 타일지 아닐지를 알려주는 컴파일러 지시문이 있다. 현대 CPU는 분기 힌트 명령을 무시하지만, 컴파일러가 코드 레이아웃을 더 잘 잡는 데는 도움될 수 있다.
옛날식 통념은 struct에 패딩을 넣고 정렬을 맞추라는 것이다. 하지만 Haswell에서는 페이지 경계를 넘지 않는 거의 모든 단일 스레드 작업에서 mis-alignment 페널티가 0이다. 차이를 만드는 경우도 있지만, 일반적으로 이는 CPU가 나쁜 코드를 실행하는 데 훨씬 좋아져서 대체로 무의미해진 또 다른 최적화 유형이다. 또한 아무 이득 없이 메모리 풋프린트만 늘리는 경우에는 약간 해롭기도 하다.
그리고 페이지 정렬이나 큰 경계에 맞춘 정렬을 하지 마라. 캐시 성능을 망칠 수 있다.
이것도 이제는 별로 말이 안 되는 최적화다. 코드 크기를 줄이거나 성능을 올리기 위해 자기 수정 코드를 쓰는 것이 예전에는 의미가 있었지만, 현대 캐시는 l1 명령 캐시와 데이터 캐시를 분리하는 경향이 있어, 실행 중인 코드를 수정하려면 칩의 l1 캐시들 사이에 비싼 통신이 필요하다.
덜 추측적인 것부터 더 추측적인 것까지 가능한 변화 몇 가지를 소개한다.
더 많은 컴퓨트가 대형 데이터센터로 이동한다는 것은 이제 очевид하다. VM에서 돌리기도 하고, 컨테이너 같은 것에서 돌리기도 하고, 베어메탈에서 돌리기도 하지만, 어떤 경우든 개별 머신이 여러 다양한 워크로드를 실행하도록 멀티플렉싱되는 경우가 많다. 이상적으로는 SLA가 있는 지연 민감 워크로드에 영향을 주지 않으면서, 남는 자원을 흡수하도록 best effort 워크로드를 스케줄링할 수 있으면 좋겠다. 실제로 이는 상대적으로 단순한 하드웨어 변경으로 가능하다.
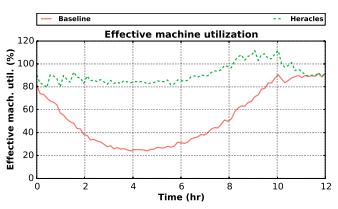
캐시를 파티셔닝해 best effort 워크로드가 지연 민감 워크로드에 영향을 주지 않게 할 수 있다면, David Lo 등은 지연 SLA에 영향을 주지 않으면서도 약 90%의 머신 이용률을 얻을 수 있음을 보였다. 실선 빨간색은 일반적인 Google 웹 검색 클러스터의 부하고, 점선 녹색은 적절한 최적화를 했을 때 얻는 것이다. 술집 대화로는, 실선 빨간색이 이미 Google 경쟁사 대부분이 달성할 수 있는 것보다 더 좋다(더 높다)는 인상이다. 90% 최적화 이용률과 전형적인 서버 이용률 10%~90%를 비교하면, 순진하고 최적화되지 않은 설정으로 운영할 때와 비교해 작업 단위당 비용에서 엄청난 차이가 난다. Google은 상당한 하드웨어 노력으로 간섭을 피할 수 있었지만, 추가적인 격리 기능이 있으면 더 적은 노력으로 더 높은 효율로 이를 할 수 있다.
IBM은 이미 POWER 칩에 이런 기능을 갖고 있다. Intel은 Haswell에 추가하려 했지만 버그 때문에 비활성화되었다. 일반적으로 현대 CPU는 꽤 복잡하므로 예전보다 훨씬 많은 버그가 있을 것이라 예상해야 한다.
트랜잭셔널 메모리 지원은 말 그대로 하드웨어 차원의 트랜잭션 지원이다. 이를 위해 xbegin, xend, xabort라는 세 가지 새 명령이 있다.
xbegin은 새 트랜잭션을 시작한다. 충돌(또는 xabort)이 발생하면 프로세서의 아키텍처 상태(메모리 포함)는 xbegin 직전 상태로 롤백된다. 라이브러리나 언어 지원을 통해 트랜잭셔널 메모리를 사용한다면 여러분에게는 투명해야 한다. 라이브러리 지원을 구현하는 쪽이라면, 하드웨어 버퍼 크기가 제한된 이 하드웨어 지원을 임의 크기의 트랜잭션을 처리할 수 있게 어떻게 변환할지 고민해야 한다.
Hardware Lock Elision은 자세히 다루지 않겠다. 다만 내부적으로는 트랜잭셔널 메모리를 구현하는 메커니즘과 매우 유사한 메커니즘으로 구현되며, 락 기반 코드를 빠르게 하도록 설계되었다는 점만 말하겠다. HLE를 활용하려면 이 문서를 보라.
스토리지와 네트워킹 모두에서 I/O 대역폭은 올라가고 지연은 내려가고 있다. 문제는 I/O가 보통 시스템 콜로 수행된다는 점이다. 앞서 봤듯 시스템 콜의 상대적 오버헤드는 커지고 있다. 스토리지와 네트워킹 모두에서 답은 유저 모드 I/O 스택으로 이동하는 것이다(모든 걸 커널 모드로 두는 것도 되긴 하지만 더 팔기 어렵다). 스토리지 쪽은 아직은 대체로 괴상한 연구 주제에 가깝지만, HPC와 HFT 분야는 네트워킹에서 오래전부터 이를 해왔다. 오래전이라는 게 몇 달이 아니라는 뜻이다. 2005년 논문에서 내가 여기서 다룰 네트워킹 내용과, 다루지 않을 내용(DCA)까지도 언급한다.
이제 이게 슈퍼컴퓨팅이 아닌 세계로도 스며들고 있다. MS는 1년 넘게 Azure에서 가상화된 RDMA를 가진 infiniband 네트워킹을 광고해왔고, Cloudflare는 Solarflare NIC로 동일한 기능을 얻는 이야기를 했다 등. 결국 온보드 고속 이더넷을 가진 SoC도 보게 될 것이고, 그것이 Xeon급 장치로만 제한되지 않는다면 모든 디바이스로 내려올 것이다. ARM 장치들의 경쟁은 적어도 한 ARM SoC 제조사가 상품 SoC에 고속 이더넷을 넣도록 만들 가능성이 높고, 그건 Intel을 움직이게 할지도 모른다.
RDMA 부분은 중요하다; CPU를 완전히 우회하고 NIC가 원격 요청에 응답하게 해준다. 몇 달 전 Stanford/Coursera의 Mining Massive Data Sets 수업을 들었다. 초기 강의 중 하나에서 1Gb top-of-rack 스위치를 가진 “전형적인” 데이터센터 설정 예를 든다. 커널 TCP를 비-RDMA NIC로 돌린다면 “거대한” 데이터를 처리하는 데 그 설정은 크게 무리 없는데, linux TCP 스택으로 1Gb/s를 밀어 넣는 데 코어 하나를 바닥까지 써버릴 수 있기 때문이다. 하지만 Azure에서는 단일 머신에서 40Gb를 얻는다고 말한다; 이는 랙 전체에서 기대할 대역폭의 40배를 한 머신이 내는 것이다. 또한 2us 미만 지연을 언급하는데, 이는 커널 TCP로 얻을 수 있는 것보다 여러 자릿수 낮다. 이건 새로운 아이디어가 아니다. 2011년 논문은 지금까지 네트워크 측에서 일어난 모든 일을 예측했고, 아직 좀 더 먼 일도 일부 예측했다.
이 MS 발표는 이런 대역폭과 지연을 네트워크 스토리지에 어떻게 활용할 수 있는지 논의한다. 링크를 안 눌러도 되는 구체적 예는 Amazon의 EBS다. EBS는 AWS 노드 어디서나 임의 크기의 “탄력적” 디스크를 쓰게 해준다. 회전 디스크의 시크 지연이 커널 TCP를 통한 RPC보다 더 큰 경우가 있으니, 거의 투명하게 무한 스토리지를 얻을 수 있다. 예를 들어 네트워크에서 100us (.1ms) 지연을 얻고 디스크 시크가 8ms라면, 원격 디스크 접근은 8ms 대신 8.1ms가 된다. 오버헤드가 크지 않다. 하지만 SSD에서는 잘 안 맞는다. SSD에서는 20 us (.02ms) 같은 지연을 얻을 수 있기 때문이다. 하지만 RDMA 지연은 충분히 낮아서 SSD에서도 투명한 EBS 유사 레이어가 가능하다.
여기까지가 네트워크 I/O다. 다음 세대 스토리지 기술이 플래시보다 더 빠르게 배치되기 시작하면 디스크 쪽 성능 이득은 더 커질 수도 있다. 성능 차이가 너무 커서 Intel은 차세대 저지연 스토리지 기술을 따라가기 위해 새 명령을 추가하고 있다. 누구에게 묻느냐에 따라 그 기술들은 10~20년 동안 “몇 년 뒤”였다; 네트워킹보다 더 불확실하다. 하지만 플래시만 놓고도, 단일 마이크로초 범위 지연을 낼 수 있는 장치를 과시하는 사람들이 있으며, 이는 상당한 개선이다.
고속 네트워크 I/O처럼 이것도 이미 일부 틈새에서는 존재한다. DESRES는 계산 화학에서 100x~1000x 가속을 얻기 위해 수년간 ASIC을 해왔다. Microsoft는 FPGA로 검색을 가속하는 이야기를 했다. memcached 같은 시스템을 가속하는 연구도 오래전부터 있었다. Toshiba와 Stanford의 연구자들은 한참 전에 실제 구현을 демон스트레이션했다. 그리고 나는 최근 Berkeley의 같은 주제 프리프린트도 봤다. 비트코인 채굴 ASIC을 만드는 회사는 여러 곳이다. 다른응용영역에서도 마찬가지다.
CPU에서 전력/성능 향상을 얻기가 점점 어려워지니 이런 것을 더 보게 될 듯하다. 프로그래밍을 소프트웨어 중심의 노력으로만 생각하면 이건 질문을 회피하는 것처럼 느낄 수도 있다. 하지만 다른 관점으로는 ‘무언가를 프로그래밍한다’는 의미 자체가 바뀔 것이다. 미래에는 소프트웨어를 쓰는 것과 결합해 FPGA나 ASIC 같은 하드웨어를 설계하는 것을 의미할 수도 있다.
이 글이 처음 게시된 뒤 1년이 지난 2016년이 된 지금, 기업들이 하드웨어 가속기에 투자하는 것을 볼 수 있다. Microsoft는 이전의 FPGA 가속 검색 작업에 더해, FPGA로 네트워킹을 가속하고 있다고 발표했다. Google은 그들답게 인프라에 대해 함구하지만, Tensorflow의 초기 릴리스를 보면 FPGA를 명확히 참조하는 코드 조각을 볼 수 있다. 예를 들면:
enum class PlatformKind {
kInvalid,
kCuda,
kOpenCL,
kOpenCLAltera, // Altera FPGA OpenCL platform.
// See documentation: go/fpgaopencl
// (StreamExecutor integration)
kHost,
kMock,
kSize,
};
그리고:
string PlatformKindString(PlatformKind kind) {
switch (kind) {
case PlatformKind::kCuda:
return "CUDA";
case PlatformKind::kOpenCL:
return "OpenCL";
case PlatformKind::kOpenCLAltera:
return "OpenCL+Altera";
case PlatformKind::kHost:
return "Host";
case PlatformKind::kMock:
return "Mock";
default:
return port::StrCat("InvalidPlatformKind(", static_cast<int>(kind), ")");
}
}
이 글을 쓰는 시점에서 Google은 +google +kOpenClAltera에 대해 어떤 결과도 반환하지 않으므로, 널리 관측된 것 같지는 않다. Altera OpenCL에 익숙하지 않고 Google에서 일한다면, 주석에 제안된 내부 go 링크 go/fpgaopencl를试해볼 수 있다. 나처럼 Google에서 일하지 않는다면, 음, Altera 문서가 여기 있다. 기본 아이디어는 GPU에서 실행할 법한 OpenCL 코드를 가져와 FPGA에서 대신 실행할 수 있다는 것이고, 주석으로 미루어 Google은 FPGA가 달린 노드로 데이터를 스트리밍 인/아웃할 수 있는 어떤 설정이 있는 것으로 보인다.
이 FPGA 전용 코드는 ddd4aaf5286de24ba70402ee0ec8b836d3aed8c7에서 제거되었는데, 커밋 메시지는 “TensorFlow: upstream changes to git.”로 시작하고 내부 Google 커밋들의 리스트(각 내부 커밋 설명 포함)가 뒤따른다. 이상하게도 FPGA 지원 제거에 대한 내용은 없는데, 그 정도면 설명이 있을 법한 큰 변화처럼 보이기 때문에, 의도적으로 삭제(redact)된 것이 아닌가 싶다. Amazon도 인프라 계획에 대해 꽤 비밀스러운데, 하드웨어 인재를 빨아들이는 양상을 보면 합리적인 추측을 할 수 있다. 다른 몇몇 회사도 하드웨어 가속기에 꽤 크게 베팅하고 있지만, 그건 내가 공개 소스나 공개 정보가 아니라 사적인 대화로 알게 된 것이므로 어떤 회사인지는 여러분이 추측해보라.
트랜지스터 스케일링이 전개된 방식의 재미있는 부작용 중 하나는, 칩에 엄청난 수의 트랜지스터를 집적할 수는 있지만 발열이 너무 커서 칩이 녹지 않게 하려면 평균 트랜지스터는 대부분의 시간 동안 스위칭할 수 없다는 점이다.
그 결과, 대부분의 시간에 쓰이지 않는 전용 하드웨어를 포함시키는 편이 더 말이 된다. 이는 PCMP나 ADX 같은 온갖 특수 명령이 나오는 이유 중 하나다. 또한 과거에는 오프칩에 있던 전체 장치가 칩에 통합되는 흐름이 있다. 여기에는 GPU나(모바일 장치의 경우) 무선 라디오 같은 것들이 포함된다.
하드웨어 가속 트렌드와 결합하면, 기업들이 자체 칩(또는 최소한 자체 칩의 일부)을 설계하는 것이 더 말이 된다. Apple은 PA Semi를 인수해 큰 이득을 봤다. 처음에는 표준적인 ARM 아키텍처에 작은 커스텀 가속기를 더했고, 다음에는 자체 커스텀 아키텍처에 커스텀 가속기를 더했다. 적절한 커스텀 하드웨어와 잘 설계된 벤치마킹 및 시스템 설계의 조합 덕분에, iPhone 4는 내 플래그십 Android 폰보다 약간 더 반응성이 좋다. 내 Android 폰은 몇 년 더 최신이고 프로세서도 훨씬 빠르며 RAM도 더 많은데도 말이다.
Amazon은 옛 Calxeda 팀의 상당 부분을 데려왔고, 충분히 많이 채용해서 꽤 큰 하드웨어 설계 팀을 만들고 있다. Facebook은 ARM SoC 인력을 소수 데려왔고 Qualcomm과 뭔가를 하고 있다. Linus는 여기저기에서 더 많은 전용 하드웨어를 보게 될 거라고 말한 바 있다. 기타 등등.
x86 칩에는 많은 새 기능과 온갖 번쩍이는 장치가 추가되었다. 대부분은 그것이 무엇인지 몰라도 이점을 취할 수 있다. 1차 근사로는 코드를 예측 가능하게 만들고 메모리 지역성을 염두에 두는 것만으로도 꽤 잘 먹힌다. 정말 로우레벨인 것들은 보통 라이브러리나 드라이버가 숨기고, 컴파일러는 나머지를 처리하려 한다. 예외는 여러분이 정말 로우레벨 코드를 작성하는 경우인데, 그땐 세상이 훨씬 더 지저분해졌다. 또는 여러분이 코드에서 절대적인 최선의 성능을 쥐어짜려는 경우인데, 그땐 세상이 훨씬 더 기괴해졌다.
그리고 미래에는 뭔가가 일어날 것이다. 하지만 대부분의 예측은 틀리니, 누가 알겠는가?
구현 세부를 많이 다루는 Matt Godbolt의 발표가 있다. 한 단계 더 내려가고 싶다면 Shen과 Lipasti의 Modern Processor Design를 보라. Amazon에 표시된 날짜(2013)에도 불구하고 이 책은 꽤 오래됐지만, 프로세서 내부에 관해 내가 찾은 책 중 여전히 최고다. P6 시대의 고성능 CPU를 만들기 위해 구현해야 하는 것들을 상당히 자세하게 설명한다. 또한 서로 다른 가정 하에서 이론적 성능 한계를 도출하고, 다양한 엔지니어링 트레이드오프에 대해, 왜 그런지에 대한 설명까지 곁들여 많이 이야기한다.
“왜”에 대해 한 단계 더 깊이 들어가려면 VLSI 교재가 필요할 텐데, 이는 소자와 인터커넥트가 어떻게 스케일링되고 그게 회로 설계에, 더 나아가 아키텍처에 어떤 영향을 주는지 설명해준다. 나는 Weste & Harris를 좋아하는데 설명이 명확하고, 온라인에서 해답을 찾을 수 있는 좋은 연습문제가 있기 때문이다. 하지만 문제를 풀 생각이 아니라면 대체로 어떤 VLSI 교재든 상관없다. “왜”를 한 단계 더 들어가려면 고체 소자 교재와, 전송선/인터커넥트가 어떻게 동작하는지 설명하는 무언가가 필요하다. 소자 쪽은 나는 Pierret의책들을 좋아한다. E-mag 쪽은 Ramo, Whinnery & Van Duzer를 통해 처음 접했지만, Ida가 더 나은 입문서다.
현 세대 CPU의 구체 사항과 최적화 기법은 Agner Fog의 사이트를 보라. 미래의 최적화 도구에 대해서는 이 글을 보라. What Every Programmer Should Know About Memory도 좋은 배경지식이다. 이 문서들은 중요한 내용을 많이 다루지만, 더 높은 수준의 언어로 작성한다면 염두에 둘 다른 것들도 많다. Intel CPU 역사에 대해서는 Xao-Feng Li의 좋은 개요가 있다.
좀 엉뚱한 것으로는 CPU 백도어 가능성에 관한 이 글을 보라. 덜 엉뚱한 것으로는, 현대 CPU의 복잡성이 온갖 흥미로운 버그를 가능하게 하는 방식에 관한 이 글을 보라.
락킹 벤치마크를 더 보려면 Aleksey Shipilev의 이 글, Paul Khuong의 이 글, 그리고 그들의 아카이브를 보라.
일반적인 벤치마킹에 대해서는 작년 Strange Loop의 Aysylu Greenberg의 벤치마킹 발표가 흔한 함정들에 대한 좋은 입문이다. 더 고급이면서 더 구체적인 것으로는 Gil Tene의 지연 관련 발표가 훌륭하다.
내가 언급한 것들보다 훨씬 이전의 역사적 컴퓨팅은 IBM's Early Computers와, CDC 6600 설계를 설명하는 Design of a Computer를 보라. Readings in Computer Architecture도 많은 아이디어의 원래 출처를 보는 데 좋다.
미안하지만 이 목록은 꽤 불완전하다. 제안 환영!
내가 많은 것을 빠뜨리고 있다는 건 의심의 여지가 없다. 중요한 것을 빠뜨렸다고 생각하면 알려달라. 그러면 업데이트하겠다. 가능한 한 단순하게 유지하면서도 무슨 일이 벌어지는지의 감을 담으려 했지만, 어떤 경우에는 과도하게 단순화했을 것이고, 완전히 잊고 언급하지 못한 것도 있을 것이다. 그리고 물론 내가 한 일반화는 정말 엄밀하게 따지면 거의 전부 틀린다. 첫 몇 문장만 꼬집어도, A20M이 언제나 어디서나 무의미한 것은 아니고(커리어의 약 0.2%를 그걸 다루는 데 쓴 것 같다), x86-64가 x86보다 항상 우월한 것도 아니다(내가 다뤄야 했던 어떤 워크로드에서는 추가 레지스터의 이득이 더 긴 명령의 비용에 의해 상쇄되고도 남았다; 워크로드에서 명령 스트림과 icache 미스가 병목이 되는 경우는 드물지만 있긴 하다) 등등. 아마 가장 큰 문제는 내 NUMA 설명일 텐데, P6 버스가 요청에 대해 defer나 retry로 응답하는 것이 실제로 가능하기 때문이다. 유사한 메커니즘을 coherency 강제에 쓰지 않는 것이 합리적이긴 하지만, 여러 단계의 설명 없이 왜 그렇다고 납득할 만하게 설명할 수 있는 방법이 떠오르지 않았다. 정말로, 충분히 깊게 파고들면 거의 모든 일반화가 무너진다. 내가 말하는 모든 추상화는 새는(leaky) 것이다. 한 단계 더 깊게 들어가는 문서 링크를 포함하려 했지만, 아마 빠진 영역도 있을 것이다.
Leah Hanson과 Nathan Kurz의 코멘트 덕분에 큰 편집이 있었고, Nicholas Radcliffe, Stefan Kanthak, Garret Reid, Matt Godbolt, Nikos Patsiouras, Aleksey Shipilev, Oscar R Moll의 코멘트는 작은 편집으로 이어졌다. 또한 David Albert가 그의 글을 인용하도록 허락해준 것과, 예전에 이 주제에 대해 이야기했을 때 흥미로운 후속 질문을 해준 것에 감사한다. GPU 섹션을 써준 Cliff Burdick과, TensorFlow에서 Google kOpenCLAltera 코드를 찾아준 Hari Angepat에게도 감사한다.