넷플릭스가 kubelet+containerd 런타임으로 현대화하는 과정에서 커널 마운트 락 경합과 CPU 아키텍처 특성(특히 NUMA·하이퍼스레딩·캐시 구조)이 컨테이너 대량 기동 성능에 미치는 영향을 분석하고, 마운트 연산을 O(n)에서 O(1)로 줄여 병목을 해소한 이야기.

11 min read
Nov 7, 2025
Authors: Harshad Sane, Andrew Halaney
이렇게 상상해 보세요. 금요일 밤 넷플릭스에서 재생 버튼을 누르는 순간, 보이지 않는 곳에서 수백 개의 컨테이너가 몇 초 만에 동작을 시작해 요청을 처리합니다. 넷플릭스에서는 전 세계 수백만 회원에게 끊김 없는 스트리밍 경험을 제공하기 위해 컨테이너를 효율적으로 스케일링하는 것이 핵심입니다. 이 규모에서의 응답성을 따라가기 위해 컨테이너 런타임을 현대화했는데, 뜻밖의 병목에 부딪혔습니다. 바로 CPU 아키텍처 자체였습니다.
하드웨어 수준에서 컨테이너 스케일링을 이해하기 위해 어떤 방식으로 문제를 진단했고 무엇을 배웠는지, 그 과정을 함께 살펴보겠습니다.
애플리케이션 수요로 인해 서버를 스케일 업해야 할 때, 우리는 AWS에서 새 인스턴스를 받습니다. 이 새로운 용량을 효율적으로 사용하기 위해, 리소스가 완전히 할당되었다고 간주될 때까지 노드에 파드가 배치됩니다. 노드는 애플리케이션이 하나도 없는 상태에서, 애플리케이션을 받을 준비가 되자마자 순식간에 포화 상태가 될 수 있습니다.
기존 컨테이너 플랫폼에서 새로운 컨테이너 플랫폼으로의 마이그레이션이 진행될수록, 우려스러운 추세가 보이기 시작했습니다. 일부 노드가 장시간 멈춘 듯한 상태가 되었고, 간단한 헬스 체크가 30초 후 타임아웃이 나기도 했습니다. 초기 조사에서 이런 상황에서 마운트 테이블 길이가 급격히 증가하며, 그것을 읽는 것만으로도 30초 이상 걸릴 수 있다는 점이 드러났습니다. systemd의 스택을 보면 마운트 이벤트 처리로 바쁘게 돌아가고 있었고, 결국 시스템 전체가 락업될 수 있었습니다. 이 기간 동안 kubelet도 containerd와 통신하다가 자주 타임아웃이 발생했습니다. 마운트 테이블을 살펴보니, 이 마운트들이 컨테이너 생성과 관련되어 있음을 알 수 있었습니다.
영향을 받은 노드는 거의 모두 r5.metal 인스턴스였고, 레이어가 많은(50개 이상) 컨테이너 이미지를 포함한 애플리케이션을 시작하고 있었습니다.
그림 1의 플레임그래프는 containerd가 시간을 어디에 쓰는지 명확히 보여줍니다. 컨테이너의 루트 파일시스템을 조립하는 과정에서 다양한 마운트 관련 작업을 수행하며 커널 수준 락을 잡으려는 시도에 거의 모든 시간이 소비됩니다!
Press enter or click to view image in full size
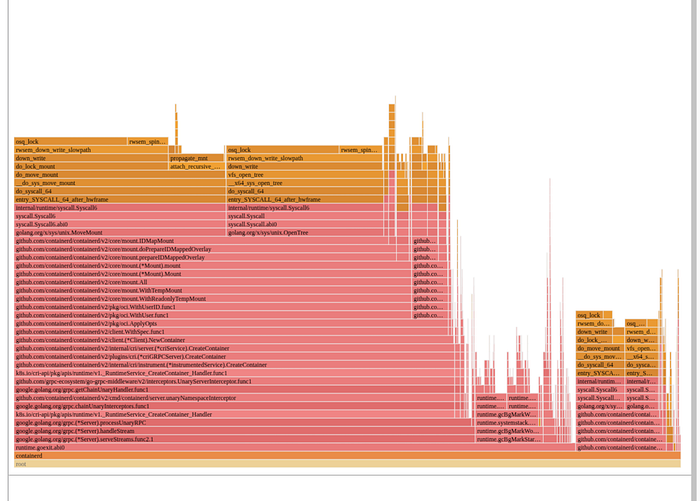
Figure 1: Flamegraph depicting lock contention
더 자세히 보면, user namespace를 사용하는 경우 containerd는 각 레이어마다 다음 호출을 실행합니다:
이 바인드 마운트는 컨테이너의 사용자 범위 소유가 되며, 이후 컨테이너의 overlayfs 기반 rootfs를 만들기 위한 lowerdir로 사용됩니다. overlayfs rootfs가 마운트되면, overlayfs가 구성된 이후에는 유지할 필요가 없기 때문에 해당 바인드 마운트들은 언마운트됩니다.
노드가 동시에 많은 컨테이너를 시작하면, 모든 CPU가 이러한 mount와 umount를 실행하느라 바빠집니다. 커널 VFS에는 마운트 테이블과 관련된 여러 전역 락이 있으며, 각 마운트는 플레임그래프 상단에서 보듯 그 락을 획득해야 합니다. 많은 컨테이너를 빠르게 설정하려는 시스템은 이런 문제에 취약하며, 이는 컨테이너 이미지의 레이어 수에 비례합니다.
예를 들어, 한 노드가 100개의 컨테이너를 시작하고 각 컨테이너 이미지가 50개 레이어를 가진다고 가정해 봅시다. 각 컨테이너는 레이어마다 idmap을 적용하기 위해 50개의 바인드 마운트가 필요합니다. 컨테이너의 overlayfs 마운트는 이 바인드 마운트들을 lower 디렉터리로 사용해 생성되고, 이후 50개 바인드 마운트는 umount로 정리할 수 있습니다. containerd는 실제로 이 과정을 두 번 수행합니다. 한 번은 이미지 내 일부 사용자 정보를 확인하기 위해, 또 한 번은 실제 rootfs를 만들기 위해서입니다. 즉, 100개 컨테이너의 시작 경로에서 수행되는 마운트 연산 총수는 100 * 2 * (1 + 50 + 50) = 20200회이며, 이들 모두는 여러 전역 마운트 관련 락을 획득해야 합니다!
서론에서 언급했듯, 넷플릭스는 컨테이너 런타임 현대화를 진행 중입니다. 과거에는 virtual kubelet + docker 솔루션을 사용했지만, 이제는 kubelet + containerd 솔루션을 사용합니다. 기존 런타임과 새 런타임 모두 user namespace를 사용했는데, 그렇다면 차이는 무엇일까요?
모든 컨테이너가 단일 호스트 사용자 범위를 공유했습니다. 이미지 레이어의 UID는 untar 시점에 이동(shift)되어, 컨테이너가 파일에 접근할 때 파일 권한이 일치하도록 했습니다. 모든 컨테이너가 동일한 호스트 사용자를 사용했기 때문에 가능한 방식이었습니다. 2. New Runtime:
각 컨테이너는 고유한 호스트 사용자 범위를 부여받아 보안이 향상됩니다. 컨테이너가 탈출하더라도 자기 파일에만 영향을 줄 수 있습니다. 각 컨테이너마다 untar하고 UID를 이동시키는 비용이 큰 과정을 피하기 위해, 새 런타임은 커널의 idmap 기능을 사용합니다. 이를 통해 파일을 복사하거나 소유권을 변경하지 않고도 컨테이너별 UID 매핑을 효율적으로 할 수 있으며, 이것이 containerd가 많은 마운트를 수행하는 이유입니다.
아래 그림 2는 이 idmap 기능이 어떤 모습인지 단순화해 보여줍니다:
Press enter or click to view image in full size
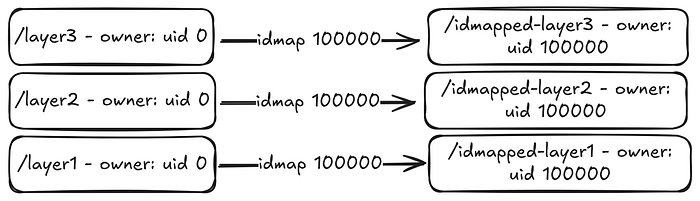
Figure 2: idmap feature
앞서 언급했듯, 이 문제는 주로 r5.metal 인스턴스에서 발생했습니다. 근본 원인을 파악한 뒤에는 레이어가 많은 컨테이너 이미지를 만들고, 해당 이미지를 사용하는 수백 개 워크로드를 테스트 노드로 보내 쉽게 재현할 수 있었습니다.
이 작성자의 업데이트를 받으려면 Medium에 무료로 가입하세요.
더 빠른 로그인을 위해 나를 기억하기
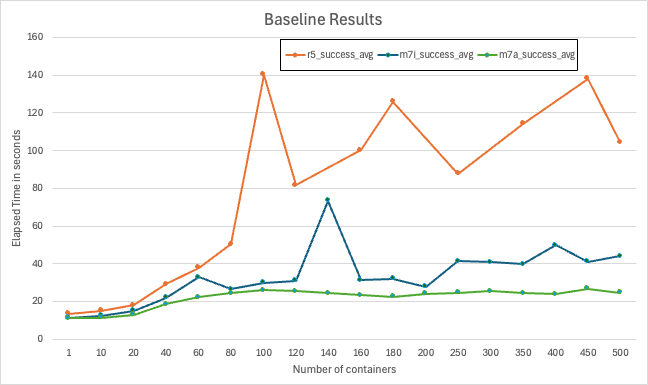
어떤 인스턴스에서는 이 병목이 더 두드러지는 이유를 이해하기 위해, 서로 다른 AWS 인스턴스 타입에서 컨테이너 기동을 벤치마크했습니다:
그림 3은 각 인스턴스 타입에서 컨테이너를 스케일링한 베이스라인 결과를 보여줍니다.
perf record와 커스텀 마이크로벤치마크를 사용해 보면, 가장 뜨거운 코드 경로는 Linux 커널의 Virtual Filesystem(VFS) 경로 탐색(path lookup) 코드에 있었습니다. 구체적으로는 path_init()에서 시퀀스 락(sequence lock)을 기다리는 타이트한 스핀 루프입니다. CPU는 대부분의 시간을 pause 명령을 실행하는 데 썼는데, 이는 많은 스레드가 전역 락을 기다리며 스핀하고 있음을 의미합니다. 아래 디스어셈블리 스니펫에서 확인할 수 있습니다.
path_init():
…
mov mount_lock,%eax
test $0x1,%al
je 7 c
pause
…
Intel의 Topdown Microarchitecture Analysis (TMA)를 사용해 다음을 관측했습니다:
경합 접근에 매우 많은 시간이 소비되는 것을 고려할 때, 하드웨어 차이 관점에서 자연스럽게 NUMA와 Hyperthreading이 이 하위 집합에 미치는 아키텍처 영향에 대한 조사가 이어졌습니다.
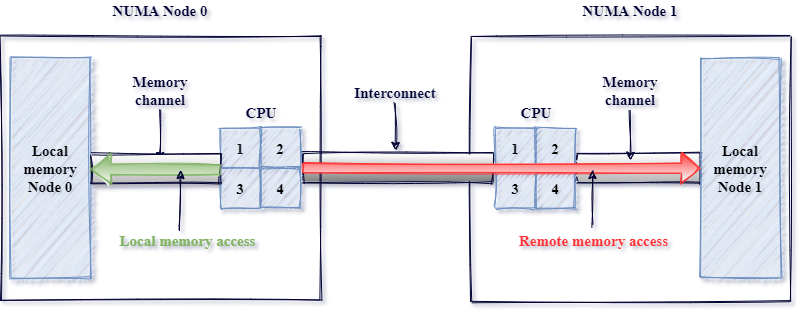
Non-Uniform Memory Access(NUM A)는 각 프로세서가 빠른 접근을 위한 로컬 메모리를 가지되, 다른 프로세서에 연결된 메모리에 접근하려면 인터커넥트를 통해야 하는 시스템 설계입니다. 1990년대에 다중 프로세서 시스템에서 확장성을 높이기 위해 도입된 NUMA는 성능을 개선하지만, CPU가 다른 프로세서에 붙은 메모리에 접근해야 할 때 더 높은 지연 시간을 유발합니다. 그림 4는 NUMA 아키텍처에서 로컬 접근과 원격 접근 패턴을 단순하게 설명한 이미지입니다.
Press enter or click to view image in full size
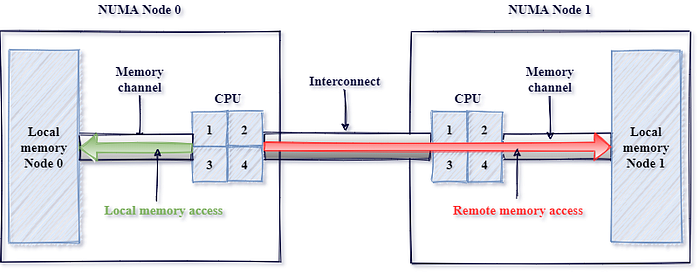
Figure 4:Source:https://pmem.io/images/posts/numa_overview.png
AWS 인스턴스는 매우 다양한 형태와 크기로 제공됩니다. 가장 큰 코어 수를 얻기 위해, 우리는 2소켓 5세대 metal 인스턴스(r5.metal)를 테스트했으며, 이 인스턴스에서는 titus agent가 컨테이너를 오케스트레이션했습니다. 현대 듀얼 소켓 아키텍처는 NUMA 설계를 채택해 로컬 접근은 빠르지만 원격 접근 지연은 높습니다. 컨테이너 오케스트레이션이 지역성을 유지할 수는 있지만, 전역 락은 원격 동기화로 인해 높은 지연 효과에 쉽게 부딪힐 수 있습니다. NUMA의 영향을 테스트하기 위해, 2개의 NUMA 노드(또는 소켓)를 가진 AWS 48xl 크기 인스턴스와, 단일 NUMA 노드(또는 소켓)를 나타내는 AWS 24xl 크기 인스턴스를 비교했습니다. 그림 5에서 보듯, 추가 홉이 높은 지연 시간을 유발하며 매우 빠르게 실패로 이어집니다.
Press enter or click to view image in full size
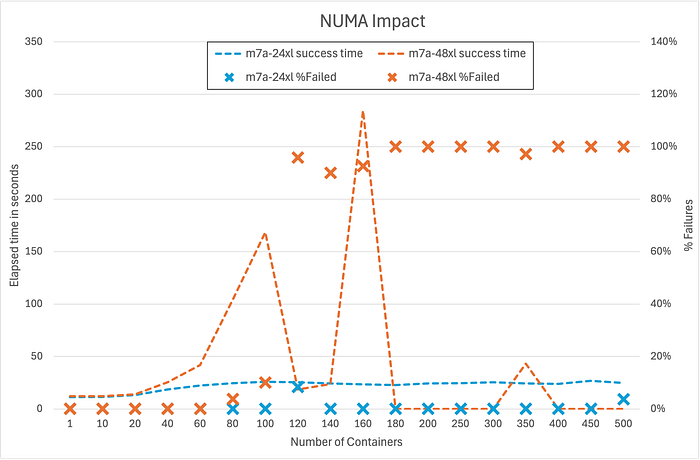
Figure 5: Numa Impact
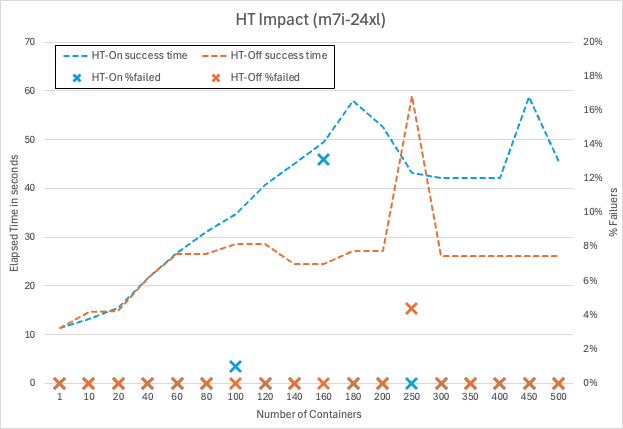
Figure 6: Hyperthreading impact
일부 현대 서버 CPU는 코어와 캐시 슬라이스를 메시(mesh) 형태의 인터커넥트로 연결하며, 각 교차점이 특정 메모리 주소 부분집합에 대한 캐시 일관성을 관리합니다. 이러한 설계에서는 모든 통신이 중앙의 큐잉 구조를 통과하며, 해당 구조는 특정 주소에 대해 한 번에 하나의 요청만 처리할 수 있습니다. 전역 락(예: mount lock)에 심한 경합이 걸리면, 그 락을 대상으로 하는 모든 원자적(atomic) 연산이 이 단일 큐로 집중되어 요청이 쌓이고, 그 결과 메모리 스톨과 지연 시간 스파이크가 발생합니다.
그림 7에 나온 몇몇 잘 알려진 메시 기반 아키텍처에서는 이 중앙 큐를 “Table of Requests”(TOR)라고 부르며, 많은 스레드가 동일한 락을 두고 싸울 때 놀라운 병목이 될 수 있습니다. 높은 경합에서 특정 CPU가 마치 “숨을 고르는 듯” 멈칫하는 이유가 궁금했다면, 종종 이것이 원인입니다.
Press enter or click to view image in full size
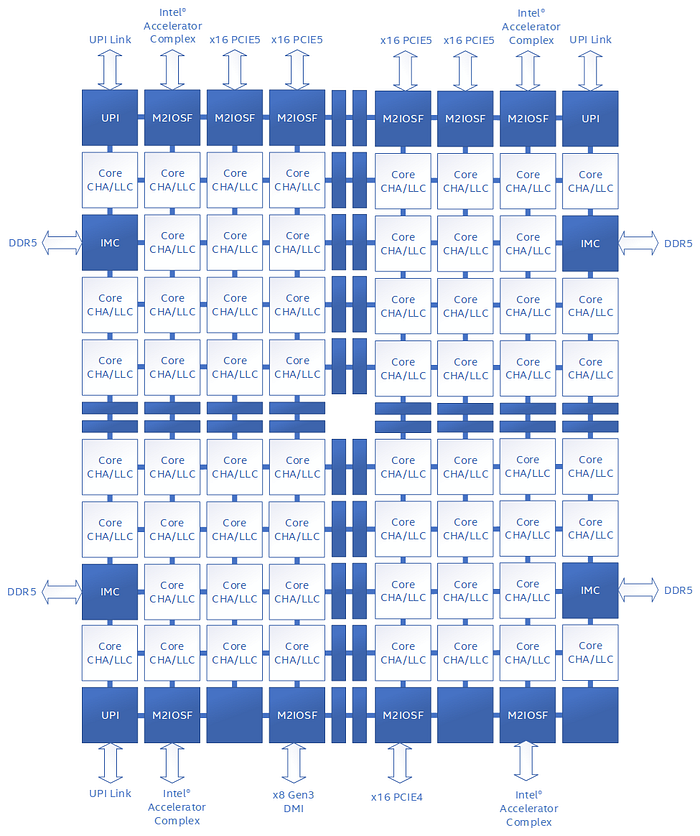
Figure 7: Public document from one of the major CPU vendors Source:https://www.intel.com/content/dam/developer/articles/technical/ddio-analysis-performance-monitoring/Figure1.png
일부 현대 서버 CPU는 분산된 칩릿(chiplet) 기반 아키텍처(그림 8)를 사용합니다. 여기서 여러 코어 컴플렉스가 각각 자신의 로컬 last-level cache를 가지며, 고속 인터커넥트 패브릭으로 연결됩니다. 이러한 설계에서는 캐시 일관성이 각 코어 컴플렉스 내부에서 관리되고, 컴플렉스 간 트래픽은 확장 가능한 제어 패브릭이 처리합니다. 중앙집중식 큐잉 구조를 가진 메시 기반 아키텍처와 달리, 이 분산 접근 방식은 여러 도메인에 걸쳐 경합을 분산시키므로 전역 락 경합으로 인한 심각한 스톨이 발생할 가능성이 낮습니다. 기술적 세부 사항에 관심이 있는 분들은, 주요 CPU 벤더가 공개한 문서를 통해 이러한 분산 캐시 및 칩릿 설계에 대한 더 깊은 통찰을 얻을 수 있습니다.
Press enter or click to view image in full size
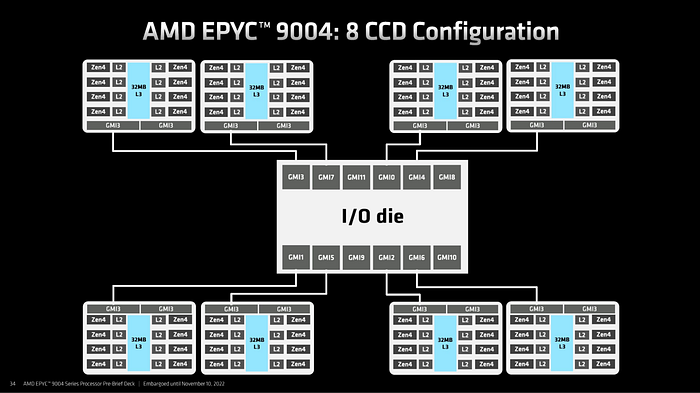
Figure 8: Public document from one of the major CPU vendors, Source: (AMD EPYC 9004 Genoa Chiplet Architecture 8x CCD — ServeTheHome)
아래는 동일한 워크로드를 m7i(중앙집중식 캐시 아키텍처)와 m7a(분산 캐시 아키텍처)에서 실행한 비교입니다. 가능한 한 공정하게 비교하기 위해, 그림 6에서 보인 이전의 회귀를 고려해 m7i에서는 Hyperthreading(HT)을 비활성화했고, 같은 코어 수로 실험을 수행했습니다. 결과는 그림 9에서 보듯 약 20%의 성능 차이가 비교적 일관되게 나타남을 분명히 보여줍니다.
Press enter or click to view image in full size
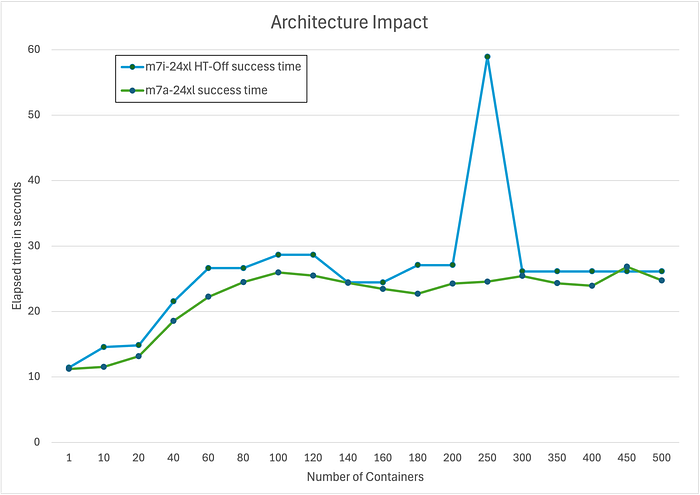
Figure 9: Architectural impact between m7i and m7a
위의 NUMA, HT, 마이크로아키텍처 관련 이론을 검증하기 위해, 우리는 주어진 수의 스레드를 생성한 뒤 전역적으로 경합되는 락에서 스핀하는 작은 microbenchmark를 개발했습니다. 스레드 수를 늘리며 벤치마크를 실행하면, 서로 다른 시나리오에서 시스템의 지연 시간 특성을 드러낼 수 있습니다. 예를 들어, 아래 그림 10은 NUMA, HT, 그리고 서로 다른 마이크로아키텍처에서의 마이크로벤치마크 결과입니다.
Press enter or click to view image in full size
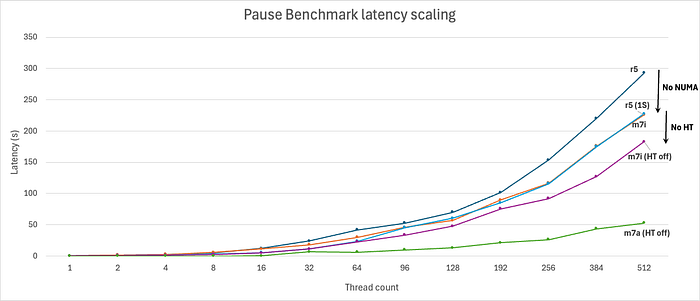
Figure 10: Global lock contention benchmark results
이 커스텀 합성 벤치마크(pause_bench)의 결과는 다음을 확인해 주었습니다:
하드웨어 아키텍처의 영향을 이해하는 것은 가능한 완화책을 평가하는 데 중요하지만, 근본 원인은 전역 락에 대한 경합입니다. containerd 업스트림과 함께 작업하며 두 가지 가능한 해결책에 도달했습니다:
새 API를 사용하려면 새 커널이 필요했기 때문에, 더 많은 커뮤니티가 혜택을 볼 수 있도록 후자의 change를 선택했습니다. 이를 적용한 뒤에는 containerd의 플레임그래프가 더 이상 마운트 관련 작업에 지배되지 않습니다. 실제로 아래 그림 11에서 보듯, 마운트 관련 부분을 보이게 하려고 아래에서 보라색으로 강조해야 할 정도였습니다!
Press enter or click to view image in full size
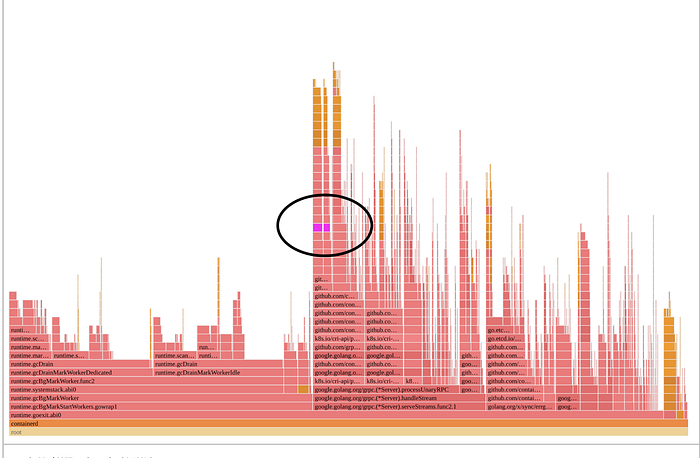
Figure 11: Optimized solution
넷플릭스에서 modern kubelet + containerd 런타임으로 마이그레이션하는 여정은, 대규모 환경에서 소프트웨어와 하드웨어 아키텍처가 얼마나 깊게 얽힐 수 있는지를 보여주었습니다. kubelet/containerd가 컨테이너별 고유 사용자를 사용하는 방식은 큰 보안 이점을 가져왔지만, 동시에 커널과 CPU 아키텍처에 뿌리를 둔 새로운 병목을 드러냈습니다. 특히 레이어가 많은 컨테이너 이미지를 수백 개 단위로 병렬 기동할 때 두드러졌습니다. 우리의 조사는 이 워크로드에 대해 모든 하드웨어가 동일하지 않다는 점을 강조했습니다. 중앙집중식 캐시 관리는 캐시 경합을 증폭시켰고, 분산 캐시 설계는 부하가 커져도 부드럽게 스케일했습니다.
궁극적으로 최선의 해법은 하드웨어에 대한 인식과 소프트웨어 개선을 결합하는 것이었습니다. 즉각적인 완화책으로는 이러한 조건에서 더 잘 스케일하는 CPU 아키텍처로 워크로드를 라우팅했습니다. 또한 소프트웨어 설계를 바꿔 레이어별 마운트 연산을 최소화함으로써, 전역 락을 기동 시간 병목에서 제거해 기반 CPU 아키텍처와 무관하게 더 빠르고 더 신뢰할 수 있는 스케일링을 가능하게 했습니다. 이 경험은 전반적(holistic) 성능 엔지니어링의 중요성을 다시 한 번 보여줍니다. 넷플릭스 규모에서 끊김 없는 사용자 경험을 제공하려면 소프트웨어 스택과 그 위에서 실행되는 하드웨어 모두를 이해하고 최적화하는 것이 핵심입니다.
이 통찰이 변화하는 컨테이너 생태계 속에서 다른 이들이 길을 찾는 데 도움이 되길 바라며, 잠재적 도전 과제를 견고하고 고성능인 플랫폼을 구축할 기회로 바꾸는 데 보탬이 되길 바랍니다.
Special thanks to the Titus and Performance Engineering teams at Netflix.
{kind=link}
{kind=link}