이 글은 Linux/ARM 환경의 Go 1.24 런타임에서 메모리 할당과 관리 방식을 심층적으로 다루며, 가상 메모리 관점, 힙과 스택 관리, 작은/큰 객체 할당 경로, 할당기 구조(mheap/mcentral/mcache), 스택 성장과 축소, 그리고 사례 연구를 통해 성능 최적화 포인트를 설명합니다.
이 블로그 글은 주로 ARM 아키텍처의 Linux에서 실행되는 Go 1.24 프로그래밍 언어에 초점을 맞춥니다. 다른 운영체제나 하드웨어 아키텍처에 대한 플랫폼별 세부사항은 다루지 않을 수 있습니다.
이 글의 내용은 여러 출처와 필자의 Go에 대한 이해를 바탕으로 작성되었으며, 완전히 정확하지 않을 수도 있습니다. 글 가장 아래의 댓글란에 지적이나 제안을 자유롭게 남겨주세요 😄.
메모리 할당은 모든 프로그래밍 언어 런타임의 핵심이며, Go도 예외가 아닙니다. 메모리를 효율적으로 할당하고 관리하는 것은 Go 애플리케이션의 성능, 확장성, 반응성에 직접적인 영향을 미칩니다. Go는 단순한 API(new(T), &T{}, make)로 대부분의 복잡성을 감추지만, 내부에서 어떤 일이 일어나는지 이해하면 런타임이 어떻게 효율성을 달성하고 어디에서 병목이 생길 수 있는지에 대한 귀중한 통찰을 얻을 수 있습니다.
이 글에서는 Go의 메모리 할당기를 깊이 있게 살펴봅니다. 핵심 구성요소, 서로 다른 크기의 할당을 처리하는 상호작용 방식, 힙 객체와 함께 스택이 어떻게 관리되는지를 다룹니다. 그 과정에서 몇 가지 사례 연구를 통해 Go의 메모리 할당 전략이 실제로 어떤 의미를 갖는지도 살펴봅니다. 글을 다 읽고 나면, Go가 어떻게 메모리 관리를 추상화하면서도 높은 성능을 제공하는지 더 명확하게 이해할 수 있을 것입니다.
Go가 메모리를 어떻게 할당하는지 살펴보기 전에, 일반적인 운영체제에서 메모리가 어떻게 동작하는지에 대한 기본 개념을 이해하는 것이 중요합니다. 먼저 가상 메모리의 기초 글을 읽는 것을 추천합니다. 이미 익숙하다면 건너뛰어도 됩니다. 이제 Go의 가상 메모리 관점을 살펴보겠습니다.
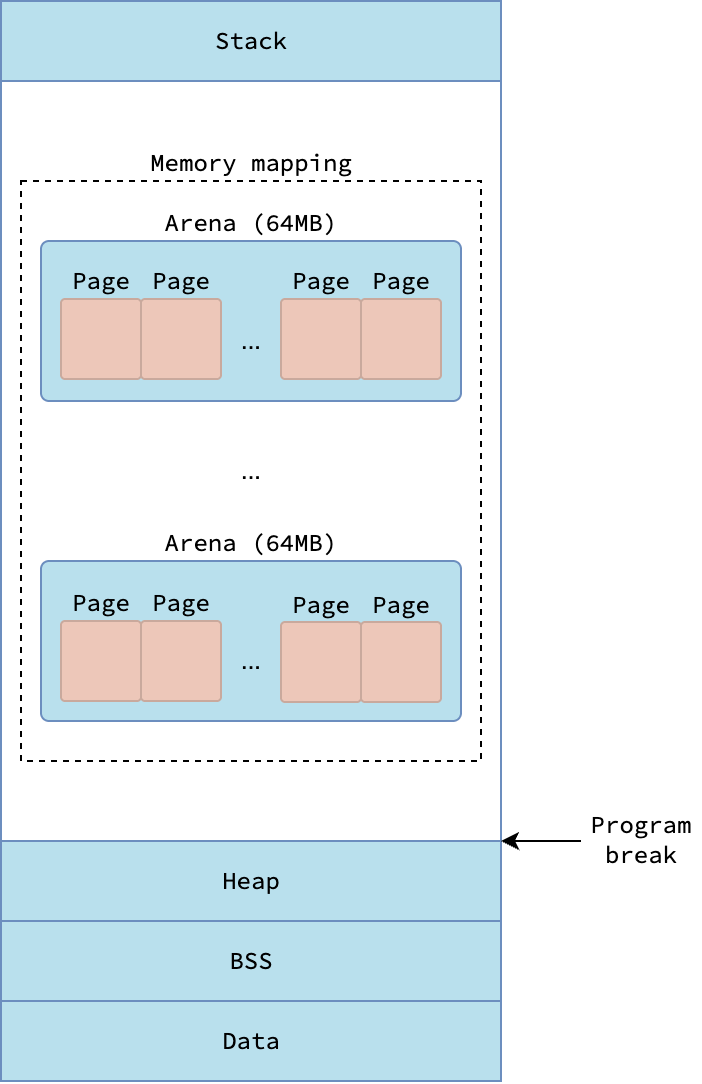
Go 프로세스는 단순한 사용자 공간 애플리케이션이므로, 기초 글에서 설명한 표준 가상 메모리 레이아웃을 따릅니다. 특히, 프로세스의 스택(Stack) 구간은 Go 런타임의 메인 스레드 m0에 연결된 g0 스택(일명 시스템 스택)입니다. 초기화된(즉, 0이 아닌 값) 전역 변수는 데이터(Data) 구간에 저장되고, 초기화되지 않은 전역 변수는 BSS 구간에 저장됩니다.
전통적인 힙(Heap) 구간은 프로그램 브레이크(program break) 아래에 위치하지만, Go 런타임은 이 구간을 힙 객체 할당에 사용하지 않습니다. 대신, Go 런타임은 힙 객체와 고루틴 스택을 할당하기 위해 메모리 매핑된 구간에 크게 의존합니다. 이후로는 Go가 동적 할당에 사용하는 이 메모리 매핑 구간을 힙(Heap)이라고 부르겠습니다. 이는 프로그램 브레이크 아래의 전통적인 프로세스 힙과 혼동하면 안 됩니다.
 |
|---|
| Go 런타임 관점의 가상 메모리 레이아웃 |
이 메모리를 효율적으로 관리하기 위해, Go 런타임은 메모리 매핑 구간을 거칠게에서 세밀하게 이르는 계층적 단위로 분할합니다. 가장 거친 단위는 아레나(arena)이며, 고정 크기 64 MB 영역입니다. mmap 시스템 호출의 특성상 요청한 주소와 다른 주소를 반환할 수 있기 때문에, 아레나들은 연속적일 필요가 없습니다.
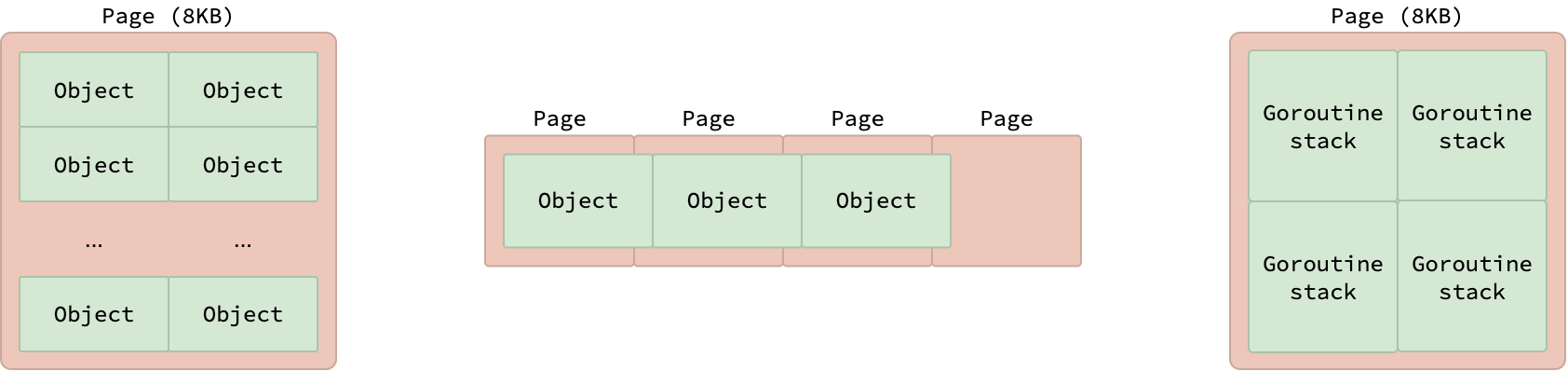
각 아레나는 다시 더 작은 고정 크기 단위인 페이지(page)로 나뉘며, 각 페이지의 크기는 8 KB입니다. 여기서 말하는 런타임 관리 페이지는 기초 글에서 설명한 일반적인 OS 페이지(보통 4 KB)와 다르다는 점에 유의하세요. 객체가 8 KB보다 작으면 각 페이지에는 같은 크기의 여러 객체가 담기고, 정확히 8 KB이면 한 개 객체만 담깁니다. 8 KB보다 큰 객체는 여러 페이지에 걸쳐 배치됩니다.
 |
|---|
| Go 런타임의 메모리 페이지 |
이 페이지들은 고루틴 스택 할당에도 사용됩니다. 이전 Go 스케줄러 글에서 설명했듯, 각 고루틴 스택은 처음에 2 KB를 차지하므로, 하나의 8 KB 페이지에는 최대 4개의 고루틴 스택을 담을 수 있습니다.
Go의 메모리 관리에서 또 하나의 핵심 개념은 스팬(span)입니다. 스팬은 하나 이상의 연속된 페이지로 구성된 메모리 단위입니다. 각 스팬은 동일한 크기의 여러 객체로 다시 분할됩니다. 스팬을 동일한 크기의 객체들로 나누는 것은, 사실상 segregated fit 메모리 할당 전략을 사용하는 것입니다. 이 전략은 다양한 크기의 객체에 대해 효율적으로 메모리를 할당하면서 단편화를 최소화하는 데 도움을 줍니다.
Go 런타임은 스팬의 메타데이터(첫 페이지의 시작 주소, 페이지 수, 할당된 객체 수 등)를 보관하기 위해 mspan 구조체를 사용합니다. 이 글에서 _스팬_이라고 하면 그 스팬이 대표하는 메모리 영역을 의미하고, mspan이라고 하면 그 영역을 기술하는 구조체를 의미합니다.
Go 런타임은 객체 크기를 사이즈 클래스(size class) 라는 사전 정의된 그룹으로 조직합니다. 모든 스팬은 자신이 담는 객체의 크기에 따라 정확히 하나의 사이즈 클래스에 속합니다. Go는 총 68개의 서로 다른 사이즈 클래스를 정의하며, 0부터 67까지 번호가 매겨져 있습니다. 자세한 내용은 사이즈 클래스 테이블을 참고하세요. 사이즈 클래스 0은 대형 객체(32 KB보다 큼)를 처리하는 데 예약되어 있고, 클래스 1부터 67까지는 초소형(tiny) 및 소형(small) 객체에 사용됩니다.
 |
|---|
| 서로 다른 사이즈 클래스를 가진 두 스팬 |
특정 사이즈 클래스에 속하는 스팬은 테이블의 bytes/span과 objects 열에 의해 정해지는 고정된 페이지 수와 객체 수를 갖습니다. 위 그림은 사이즈 클래스 38(2048바이트 객체)에서 온 스팬 하나와, 사이즈 클래스 55(10880바이트 객체)에서 온 또 하나의 스팬을 보여줍니다. 8 KB 페이지 하나에 정확히 네 개의 2048바이트 객체가 들어가므로, 클래스 38의 스팬은 한 페이지 안에 8개의 객체를 담습니다. 반대로, 10880바이트 객체는 한 페이지를 초과하므로, 클래스 55의 스팬은 4 페이지에 걸쳐 3개의 객체를 담습니다.
그런데 왜 사이즈 클래스 55의 스팬이 아래 그림처럼 2 페이지에 걸쳐 객체 1개만 담지 않을까요? 이유는 메모리 단편화를 줄이기 위해서입니다. 스팬 내 객체들이 연속적이므로, 마지막 객체와 스팬의 끝 사이에는 빈 공간이 생길 수 있습니다. 이를 테일 낭비(tail waste) 라고 하며, 공식 (페이지 수)*8192-(객체 수)*(객체 크기)로 쉽게 계산할 수 있습니다. 만약 스팬을 2 페이지로만 할당했다면 테일 낭비는 2*8192-10880*1=5504 바이트가 되지만, 4 페이지로 할당하면 4*8192-10880*3=128 바이트로 크게 줄어듭니다.
 |
|---|
| 스팬의 테일 낭비 |
사용자 Go 애플리케이션은 다양한 크기의 객체를 할당할 수 있는데, 왜 Go는 소형 객체에 대해 단 67개의 사이즈 클래스만 가질까요? 예를 들어 300바이트 크기의 소형 객체를 할당하면 사이즈 클래스 테이블에 정확히 일치하는 항목이 없습니다. 이런 경우, Go 런타임은 요청된 객체 크기를 다음 사이즈 클래스로 올림합니다. 이 예에서는 320바이트가 됩니다. 지금까지 그림에 나타난 초록색 객체는 사용자가 실제로 할당한 객체가 아니라, Go 런타임이 관리하는 사이즈 클래스 객체 입니다.
 |
|---|
| 사용자 객체와 사이즈 클래스 객체 |
사용자 애플리케이션이 할당한 객체(이하 사용자 객체)는 사이즈 클래스 객체 내부에 담깁니다. 사용자 객체의 크기는 다양할 수 있지만, 반드시 자신이 속한 사이즈 클래스 객체의 크기보다 작아야 합니다. 이 때문에 사용자 객체 크기와 사이즈 클래스 객체 크기 사이에는 낭비가 생길 수 있습니다. 모든 사이즈 클래스 객체에서 발생한 이러한 낭비와 테일 낭비를 합친 것이 스팬의 총 낭비(total waste) 입니다.
⚠️ 사이즈 클래스 객체가 항상 사용자 객체 1개만 담는 것은 아닙니다. 소형 및 대형 사용자 객체의 경우 보통 사이즈 클래스 객체 1개에 사용자 객체 1개가 들어가지만, 초소형(tiny) 사용자 객체는 하나의 사이즈 클래스 객체에 여럿이 포장될 수 있습니다. 초소형 객체 할당기를 참고하세요.
최악의 경우를 가정해 사이즈 클래스 55의 스팬이 각각 10241바이트(해당 클래스의 최소 크기)의 사용자 객체 3개를 담는다면, 3개의 사이즈 클래스 객체 낭비는 3*(10880-10241)=1917 바이트이고, 테일 낭비는 4*8192-10880*3=128 바이트입니다. 따라서 총 낭비는 1917+128=2045 바이트이고, 스팬 크기는 4*8192=32768 바이트이므로 최대 총 낭비 비율은 2045/32768=6.24%입니다. 이는 Go의 사이즈 클래스 테이블에서 클래스 55의 6번째 열에 표시된 값과 일치합니다.
Go가 단편화를 최소화하려는 segregated fit 전략을 사용하더라도, 메모리 낭비는 완전히 사라지지 않습니다. 스팬의 총 낭비는 스팬마다 외부 단편화가 얼마나 되는지를 반영합니다.
Go의 가비지 컬렉터는 트레이싱 기반으로, 수집 사이클 동안 객체 그래프를 순회해 도달 가능한 객체를 식별합니다. 그런데 어떤 타입이 포인터를 전혀 포함하지 않는다고(직접적으로든, 필드를 통해서든) 컴파일 타임에 알 수 있다면—예: 여러 필드를 가진 구조체인데 그 필드들 중 어떤 것도 다른 객체를 가리키는 포인터를 담지 않음—그 타입의 객체는 스캔을 건너뛸 수 있으니 오버헤드를 줄이고 성능을 높일 수 있겠죠? 포인터 존재 여부는 컴파일 타임에 결정되므로 이 최적화는 런타임 비용이 들지 않습니다.
이 동작을 돕기 위해 Go 런타임은 스팬 클래스(span class) 개념을 도입했습니다. 스팬 클래스는 스팬이 담는 객체의 사이즈 클래스와 그 객체가 포인터를 포함하는지 여부, 두 속성으로 스팬을 분류합니다. 포인터를 포함하면 scan 클래스, 포함하지 않으면 noscan 클래스로 분류됩니다.
포인터의 존재 여부는 이진적 속성(있거나 없거나)이므로, 스팬 클래스의 총 개수는 사이즈 클래스의 두 배입니다. Go는 총 68*2=136개의 스팬 클래스를 정의합니다. 스팬 클래스는 0부터 135 사이의 정수로 표현되며, 짝수면 scan, 홀수면 noscan 클래스입니다.
앞서 모든 스팬은 정확히 하나의 사이즈 클래스에 속한다고 했지만, 더 정확히는 모든 스팬은 정확히 하나의 스팬 클래스 에 속합니다. 연결된 사이즈 클래스는 스팬 클래스 번호를 2로 나누어 구할 수 있습니다. 또 스팬이 scan인지 noscan인지는 스팬 클래스 번호의 짝홀로 알 수 있습니다. 짝수면 scan, 홀수면 noscan입니다.
스팬을 효율적으로 관리하기 위해, Go 런타임은 스팬 셋(span set)이라는 자료구조로 스팬을 조직합니다. 스팬 셋은 동일한 스팬 클래스에 속하는 여러 mspan 객체들의 모음으로, 아래 그림과 같습니다.
 |
|---|
| 스팬 셋의 레이아웃 |
본질적으로 스팬 셋은 배열들의 슬라이스입니다. 슬라이스는 필요에 따라 동적으로 자라고, 각 배열의 크기는 512 항목으로 고정입니다. 배열의 각 요소는 스팬의 메타데이터를 담는 mspan 객체이며, null일 수 있습니다. 위 그림에서 보라색 요소는 non-null, 흰색 요소는 null을 의미합니다.
스팬 셋에는 head와 tail이라는 두 필드가 더 있는데, 각각 스팬 셋의 첫 번째와 마지막 non-null 요소를 추적합니다. 팝(pop)은 head에서 시작하여, 상위 배열부터 하위 배열로(top-down), 각 배열에서는 왼쪽에서 오른쪽으로 순서대로 진행합니다. 푸시(push)도 tail에서 시작해 같은 방식으로 진행하며, 배열을 왼쪽에서 오른쪽으로 채웁니다. 푸시/팝으로 인해 배열이 비게 되면, 해당 배열은 스팬 셋에서 제거되어 향후 재사용을 위한 빈 배열 풀에 들어갑니다.
head와 tail은 원자적(atomic) 변수이므로, 여러 고루틴이 동시에 스팬을 추가/삭제해도 추가적인 락 없이 안전하게 동작합니다.
필드가 1000개나 되는 큰 구조체에서 일부 필드는 포인터일 때, Go의 가비지 컬렉터는 어떤 필드가 포인터인지 어떻게 알아서 객체 그래프를 정확히 순회할까요? 만약 런타임에 모든 객체의 모든 필드를 검사해야 한다면, 특히 크거나 중첩이 깊은 자료구조에서는 지나치게 비효율적일 것입니다. 이를 해결하기 위해, Go는 포인터 위치를 모두 스캔하지 않고도 효율적으로 식별할 수 있게 메타데이터를 사용합니다. 핵심 구조는 힙 비트(heap bits)와 malloc 헤더입니다.
512바이트보다 작은 객체는 스팬 안에서 할당되며, 스팬의 어떤 워드(보통 8바이트)가 포인터를 담는지 추적하기 위해 힙 비트맵을 사용합니다. 비트맵의 각 비트는 하나의 워드를 나타내며, 1은 포인터, 0은 비포인터 데이터를 의미합니다. 비트맵은 스팬 끝에 저장되며, 해당 스팬의 모든 객체가 공유합니다. 스팬이 생성될 때 런타임은 비트맵을 위한 공간을 예약하고, 남은 공간에 가능한 많은 객체를 채워 넣습니다.
 |
|---|
| 스팬 안의 힙 비트 |
512바이트보다 큰 객체에 대해 큰 비트맵을 유지하는 것은 비효율적이므로, 각 객체 앞에는 8바이트의 malloc 헤더(객체의 타입 정보에 대한 포인터)가 붙습니다. 이 타입 메타데이터에는 해당 타입의 포인터 레이아웃을 인코딩한 GCData 필드가 포함되어 있습니다. 가비지 컬렉터는 이 데이터를 이용하여 객체 그래프를 순회할 때 포인터가 들어 있는 필드만 정확하고 효율적으로 찾아냅니다.
 |
|---|
| 객체의 malloc 헤더 |
Go는 전역 mheap 객체를 통해 메모리 매핑 구간 위에 자체 힙 추상화를 구축합니다. mheap은 새로운 스팬을 할당하고 사용되지 않는 스팬을 스위핑하며, 고루틴 스택까지 관리합니다.
mheap.allocGo 런타임은 거대한 가상 주소 공간에서 동작하기 때문에, 특히 높은 동시성 하에서 스팬을 할당할 때 연속된 빈 페이지를 효율적으로 찾는 것이 어렵습니다. 초기 Go 버전에서는 Scaling the Go Page Allocator 제안서에 자세히 설명된 것처럼 모든 mheap 작업이 전역적으로 동기화되었습니다. 이 설계는 치열한 할당 워크로드에서 처리량 저하와 꼬리 지연 증가 를 야기했습니다. 현재 Go 메모리 할당기는 해당 제안의 확장 가능한 설계를 구현합니다. 이제 그 병목을 어떻게 극복하고 높은 동시성 환경에서도 효율적으로 메모리를 관리하는지 살펴보겠습니다.
가상 주소 공간이 크고, 각 페이지의 상태(사용 중/비어 있음)가 이진 속성이므로, 이를 비트맵으로 저장하는 것이 효율적입니다. 여기서 1은 사용 중, 0은 비어 있음을 의미합니다. 이때의 사용/비어 있음은 사용자 Go 애플리케이션이 아니라, 페이지가 mcentral에 넘겨졌는지 여부를 뜻합니다. 각 비트맵은 8개의 uint64 값(총 64바이트)으로 이루어져 있으며, 연속된 512개의 페이지 상태를 표현합니다.
아레나가 64 MB, 페이지가 8 KB이므로 한 아레나에는 64MB/8KB=8192 페이지가 있습니다. 각 비트맵이 512 페이지를 커버하므로, 아레나마다 8192/512=16개의 비트맵이 필요합니다. 비트맵 하나가 64바이트이므로, 아레나당 모든 비트맵의 총 크기는 16×64=1024 바이트, 즉 1 KB입니다.
그러나 비트맵을 순회하며 빈 페이지 구간을 찾는 것은 여전히 비효율적이고, 비트맵에 빈 페이지가 전혀 없다면 더더욱 낭비입니다. 따라서 빈 페이지를 빠르게 찾을 수 있도록 요약(summary) 을 도입합니다. 요약은 start, end, max 세 필드를 갖습니다. start는 비트맵 시작 부분의 연속된 0 비트 수, end는 끝 부분의 연속된 0 비트 수를 의미합니다. max는 비트맵 내부에서 가장 긴 0 비트 연속 구간의 길이입니다. 비트맵이 수정될 때(페이지를 할당/해제할 때) 요약은 즉시 갱신됩니다.
아래 그림은 비트맵 요약의 예시입니다. 시작 부분에 연속 3개의 빈 페이지, 끝 부분에 연속 7개의 빈 페이지가 있고, 내부에서 가장 긴 빈 페이지 구간은 10입니다. 화살표는 주소가 증가하는 방향을 나타냅니다. 즉, 낮은 주소에 3개, 높은 주소에 7개의 빈 페이지가 있습니다.
 |
|---|
| 비트맵 요약 시각화 |
이 세 필드로, Go는 단일 아레나 내부 또는 인접한 여러 아레나에 걸쳐 충분히 큰 연속 빈 메모리 조각을 찾을 수 있습니다. 인접한 두 청크 S1과 S2(각각 512 페이지)를 생각해 봅시다. S1의 요약은 start=3, end=7, max=10, S2는 start=5, end=2, max=8입니다. 이 둘은 연속적이므로 합쳐 1024 페이지를 커버하는 하나의 요약으로 만들 수 있습니다. 합친 결과는 start=S1.start=3, end=S2.end=2, max=max(S1.max, S2.max, S1.end+S2.start)=max(10, 8, 7+5)=12입니다.
 |
|---|
| 인접 메모리 청크 두 개의 요약 병합 |
낮은 레벨의 요약을 병합함으로써, Go는 연속 빈 페이지를 효율적으로 추적할 수 있는 계층적 구조를 암묵적으로 구축합니다. 런타임은 아래 그림처럼 전체 가상 주소 공간에 대해 단일 전역 라딕스 트리(radix tree) 형태의 요약을 관리합니다. 파란 박스는 연속 메모리 청크에 대한 요약을 나타내고, 점선은 상위 레벨의 어느 부분을 커버하는지를 보여줍니다. 녹색 박스는 리프 노드 요약이 가리키는 512 페이지의 비트맵입니다.
 |
|---|
| 전체 주소 공간을 위한 요약의 라딕스 트리 |
linux/amd64 아키텍처에서 Go는 48비트 가상 주소 공간(= 2^48 바이트, 256 TB)을 사용합니다. 이 설정에서 라딕스 트리 높이는 5입니다. 내부 노드(레벨 0~3)는 각 8개의 자식 노드에서 병합한 요약을 저장합니다. 각 리프 노드(레벨 4)는 단일 비트맵(512 페이지)의 요약에 대응합니다.
레벨 0에는 16384개의 엔트리가 있고, 레벨 1에는 16384*8, 레벨 2에는 16384*8^2, 레벨 3에는 16384*8^3, 레벨 4에는 16384*8^4개의 엔트리가 있습니다. 리프 엔트리 하나가 512 페이지를 요약하므로, 레벨 0의 각 엔트리는 512*8^4=2097152 연속 페이지를 요약합니다. 이는 2097152*8KB=16GB의 메모리를 수용합니다. 이 수치는 최대값이며, 실제 각 레벨의 엔트리 수는 힙이 커짐에 따라 점진적으로 증가합니다.
 |
|---|
| 요약 라딕스 트리 상세 보기 |
앞서 언급했듯 레벨 0의 각 엔트리는 209715=2^21 연속 페이지를 요약하므로, start, end, max는 최대 2^21까지 커질 수 있습니다. 따라서 세 필드를 합쳐 저장하려면 최대 21*3=63 비트가 필요합니다. 이는 하나의 uint64에 요약을 담을 수 있음을 의미하며, 이를 pallocSum이라 합니다. 처음 21비트에 start, 다음 21비트에 end, 그 다음 21비트에 max를 저장합니다.
특수 케이스가 하나 있습니다. max=2^21이면 전체 청크가 비어 있다는 뜻입니다. 이때 start와 end도 2^21이 되며, 요약 값은 2^63으로 인코딩됩니다. 반대로, 빈 페이지가 전혀 없으면—즉 start, end, max가 모두 0이면—요약 값은 0입니다.
요약 라딕스 트리는 슬라이스들의 배열로 구현되어 있고, 배열의 각 슬라이스는 트리의 한 레벨을 나타냅니다. 배열은 트리의 레벨 수를 고정하고, 각 슬라이스는 힙이 커짐에 따라 동적으로 확장됩니다. 낮은 주소의 요약은 슬라이스의 앞쪽에, 높은 주소의 요약은 뒤쪽에 추가됩니다. 해당 레벨의 요약 슬라이스는 예약된 주소 공간 전체를 커버하므로, 슬라이스에서 요약의 인덱스는 그 요약이 나타내는 메모리 영역을 직접 결정합니다.
pageAlloc.findGo는 깊이 우선 탐색(DFS)으로 충분히 긴 연속 빈 페이지 구간을 찾습니다. 라딕스 트리의 레벨 0에서 최대 16,384개의 엔트리를 스캔하는 것부터 시작합니다. 요약이 0(빈 페이지 없음)이면 다음 엔트리로 이동합니다. 만약 인접한 두 엔트리의 경계, 첫 엔트리의 시작, 마지막 엔트리의 끝에서 충분한 연속 구간을 발견하면, 요약이 가리키는 주소를 바탕으로 즉시 그 주소를 반환합니다.
그 외의 경우, 현재 요약의 max가 요청을 만족하면 다음 레벨의 8개 자식 엔트리로 내려갑니다. 리프 레벨에 도달했는데도 충분한 연속 구간을 찾지 못하면, max 값이 충분히 큰 엔트리 내부의 비트맵을 스캔해 정확한 빈 페이지 구간을 찾습니다. 레벨 0의 모든 엔트리를 다 훑고도 적당한 구간을 못 찾으면 0을 반환합니다(즉, 빈 페이지가 없음).
이 알고리즘의 단점 하나는, 레벨 0의 앞쪽 엔트리들이 이미 대부분 사용 중이면, 할당마다 라딕스 트리에서 같은 경로를 반복적으로 순회하게 되어 비효율적이라는 점입니다. Go는 이를 해결하기 위해 searchAddr라는 힌트 를 유지합니다. 이 힌트는 그 주소 이전에는 빈 페이지가 없다는 표시입니다. 덕분에 할당기는 매번 처음부터가 아니라 이 힌트부터 탐색을 시작할 수 있습니다.
힙 할당이 낮은 주소에서 높은 주소로 진행되므로, 탐색 후에는 힌트를 앞으로 당겨 검색 공간을 줄일 수 있고, 메모리가 해제되기 전까지는 대부분의 할당이 힌트 근처에서 이뤄집니다.
mheap.growpageAlloc.find가 0을 반환해 라딕스 트리에 빈 페이지가 없으면, Go 런타임은 커널에 mmap 시스템 호출을 통해 가상 주소 공간 확장을 요청해야 합니다. 확장 크기는 요청된 페이지 수만큼이 아니라 아레나 크기(64 MB) 단위로 올림되어 이뤄집니다. 페이지 1개만 필요해도, 가상 메모리 공간은 64 MB만큼(물리 메모리는 요청 페이징 덕분에 즉시 소진되지 않음) 확장됩니다.
런타임은 커널이 새 할당에 사용하길 원하는 주소들을 담은 힌트 주소 목록 arenaHints를 유지합니다. 이 목록은 main이 실행되기 전에 초기화되며 값들은 여기에서 볼 수 있습니다. 힙 확장 중 Go는 이 힌트들을 순회하며, 각 주소를 mmap 첫 번째 인자로 넣어 그 위치에 메모리를 할당해 달라고 요청합니다.
하지만 커널은 다른 위치를 선택할 수 있습니다. 그런 경우 Go는 다음 힌트로 넘어갑니다. 모든 힌트가 실패하면, 아레나 크기에 맞춰 정렬된 임의의 주소에 메모리를 요청하고, 이후 확장이 새로 할당된 아레나와 연속되도록 힌트 목록을 갱신합니다.
이 과정으로 메모리 구간은 None 에서 Reserved 로 전이합니다. 아레나가 런타임에 등록(즉, 전체 아레나 목록에 추가)되면, 구간은 Reserved 에서 Prepared 로 전이합니다. 이 시점에서 요약 라딕스 트리는 새 아레나를 포함하도록 갱신되고, 각 레벨의 요약 슬라이스가 확장되며, 새 페이지들의 비트맵을 비어 있음으로 표시하고 요약을 갱신합니다. 이 새 메모리 구간은 또한 in-use로 추적됩니다.
mheap.haveSpan요청한 페이지 런(run)을 찾으면, 런타임은 해당 메모리 범위를 관리할 mspan 객체를 설정합니다. 다른 Go 객체와 마찬가지로 mspan 자체도 메모리에 존재해야 합니다. 이 객체들은 mmap으로 커널에서 직접 메모리를 요청하는 fixalloc슬랩 할당기로 할당됩니다.
이후 스팬의 사이즈 클래스, 페이지 수, 첫 페이지 주소를 설정하고, 연관된 메모리 구간은 Prepared 에서 Ready 로 전이하여 mcentral이 사용할 준비가 됩니다.
mheap.allocToCache불행히도 pageAlloc.find와 mheap.grow는 전역 락에 의존하므로, 높은 동시성 할당 워크로드에서 병목이 될 수 있습니다. Go 프로그램은 프로세서 P의 수만큼 동시 실행되므로, 각 P에 빈 페이지를 로컬 캐싱하면 전역 락 경합을 피할 수 있습니다.
Go는 프로세서별 pageCache로 이를 구현합니다. pageCache는 64페이지 정렬된 메모리 청크의 기준 주소와, 그 중 어떤 페이지가 비어 있는지 추적하는 64비트 비트맵으로 구성됩니다. 각 페이지가 8 KB이므로, 하나의 P가 가진 pageCache에는 최대 512 KB의 빈 메모리를 담을 수 있습니다.
고루틴이 mheap에 스팬을 요청하면, 런타임은 먼저 현재 P의 pageCache를 확인합니다. 충분한 빈 페이지가 있으면 즉시 그 페이지들로 스팬을 설정합니다. 없으면 pageAlloc.find로 돌아가 적절한 연속 구간을 찾습니다.
pageCache가 비어 있으면, 새 캐시를 할당합니다. 먼저 현재 힌트 주소인 searchAddr 근처에서 페이지를 얻으려 시도합니다(상세는 Finding Free Pages 참조). 힌트가 부정확할 수 있으므로, 라딕스 트리를 걸어가며 빈 페이지를 찾아야 할 수도 있습니다.
pageCache는 최대 64페이지까지 담을 수 있으므로, N이 64에 가까워질수록 N개의 빈 페이지를 캐시에 보유할 확률은 내려갑니다. 이런 경우 캐시 미스가 잦아져 pageAlloc.find로 자주 되돌아가야 합니다. 그래서 N이 16 이상이면 굳이 캐시를 확인하지 않고 곧바로 pageAlloc.find로 넘어갑니다.
아래 다이어그램은 스팬 할당을 위한 빈 페이지 탐색 로직을 요약합니다. 회색 상자 _Find pages_는 Finding Free Pages에서, 초록 상자 _Grow the heap_은 Growing the heap에서, 파란 상자 _Set up a span_은 Set up a Span에서 설명했습니다.
flowchart LR
style O fill:#d6e8d5 style G fill:#a7c7e7 style P rx:20,ry:20
0((Start)) --> A A{N < 16} --> |No|B[Acquire lock] B --> C[Find free pages at hint address] subgraph P[Find pages] C --> D{Free pages found?} D --> |No|F[Find free pages by walking summary radix tree] end D --> |Yes|E[Release lock] F --> N{Free pages found?} N --> |Yes|E N --> |No|O[Grow the heap] O --> E E --> G[Set up a span] A --> |Yes|H{Is P's
page cache
empty?} H --> |Yes|I[Acquire lock] I --> J[Allocate a new
page cache
for P] J --> K[Release lock] K --> L[Find free pages in the page cache] H --> |No|L L --> M{Free pages found?} M --> |Yes|G M --> |No|B G --> 1(((End))) Logic for finding free pages for span allocation
새 페이지를 확보하면, 다른 P들이 차지하지 못하도록 요약 라딕스 트리에서 해당 페이지들을 사용 중으로 표시하고, 다음 힙 확장에서 재사용되지 않게 합니다. 또한 이후 할당에서 이 페이지들을 건너뛰도록 힌트도 갱신합니다.
mheap.allocMSpanLockedSet up a Span에서 논의했듯, 페이지 런을 표현하고 관리하려면 mspan 객체를 할당해야 합니다. 이를 매번 mheap에서 직접 가져오면 전역 락을 잡아야 하므로 병목이 됩니다. 이를 피하기 위해, Go 런타임은 페이지와 마찬가지로 각 P별로 사용 가능한 mspan 객체를 캐시합니다.
pageCache에서 빈 페이지를 찾으면, 런타임은 먼저 현재 P에 캐시된 mspan이 있는지 확인합니다. 있다면 전역 락 없이 즉시 재사용합니다. 없다면, 여러 개의 mspan을 mheap에서 할당해 P의 프리 리스트에 캐시하고, 그중 하나를 새 페이지 런을 관리하도록 지정합니다.
mcentralmheap은 주로 페이지나 큰 스팬 같은 거친 단위의 메모리를 관리하므로, 초소형/소형 객체를 효율적으로 할당/해제하는 데에는 적합하지 않습니다. 이 역할은 mcentral이 맡으며, 동시에 mheap과 프로세서별 할당기인 mcache 사이를 잇는 다리 역할을 합니다(자세한 내용은 Processor’s Memory Allocator 참조).
각 mcentral은 특정 스팬 클래스에 속하는 스팬을 관리합니다. 전체적으로 mheap은 클래스당 하나씩 총 136개의 mcentral 인스턴스를 유지합니다. 각 mcentral 내부에는 두 종류의 스팬 셋이 있습니다. full(빈 객체 없음)과 partial(일부 빈 객체 있음)입니다. 각 종류는 다시 _swept_와 _unswept_로 나뉩니다.
flowchart A[mcentral] --> B[Full
span sets] A --> C[Partial
span sets] B --> D[Unswept
span set] B --> E[Swept
span set] C --> F[Unswept
span set] C --> G[Swept
span set]
Span sets in a mcentral instance
스팬이 swept 되었다는 것은 무엇일까요? Go의 가비지 컬렉터는 mark-and-sweep 방식으로 작동합니다. 먼저 도달 가능한 객체를 마킹하고, 이후 도달 불가능한 객체를 쓸어(sweep)내어 런타임에 재사용시키거나 경우에 따라 프로세스의 메모리 사용량을 줄이기 위해 커널에 다시 돌려줍니다. 스위핑은 복잡하지만 본질적으로 세 단계를 포함합니다. unswept 셋에서 스팬을 팝하고, 그 스팬 안에서 도달 불가능으로 표시된 객체를 해제하고, 스팬을 swept 셋으로 푸시합니다.
스팬이 partial과 full 사이를 오가는 전이는 할당 또는 스위핑 중에 빈 객체 수의 증감에 따라 결정됩니다. 스팬의 빈 객체 수가 0이 되면 partial에서 full로 옮겨지고, 반대로 빈 객체가 생기면 full에서 partial로 옮겨집니다.
스팬 셋은 Span Set에서 설명했듯 스레드 안전하므로, mcentral은 추가적인 락 없이 여러 고루틴이 동시에 접근할 수 있습니다. 이는 Go 프로그램의 스팬 할당 처리량을 높여줍니다.
mcentral.cacheSpanmheap과 mcache 사이의 중간자 역할을 하는 mcentral은, 자신의 스팬 셋에서 스팬을 꺼내거나 mheap에서 스팬을 새로 요청하여, 요청한 mcache에 넘길 수 있도록 스팬을 준비합니다. 아래 플로우차트에 그 로직이 정리되어 있습니다. 초록 상자 _Request mheap to allocate a span_의 세부는 Span Allocation에서 설명했습니다.
flowchart LR
style I fill:#d6e8d5
0((Start)) --> A[Sweep to prepare available memory for allocation if needed] A --> B{Any span
in partial
swept span set?} B --> |Yes|Z[Return the span] B --> |No|C{Any span
in partial
unswept span set?}
C --> |Yes|D[Sweep the span]
D --> Z
C --> |No|E{Any span in full unswept span set?}
E --> |Yes|F[Sweep the span]
F --> G{Does span have any free object?}
G --> |Yes|Z
G --> |No|H[Move the span to full swept span set]
H --> E
E --> |No|I[Request mheap to allocate a span]
I --> Z
Z --> 1(((End)))
Logic for preparing a span by mcentral
mcentral.uncacheSpanmcache이 스팬을 mcentral로 반환해야 할 때, mcentral.uncacheSpan을 호출합니다. 스팬이 아직 스위핑되지 않았다면 먼저 스위핑하여 도달 불가능한 객체를 회수합니다. 스위핑 여부와 관계없이, 스팬의 빈 객체 수에 따라 full 또는 partial swept 셋에 배치됩니다.
mcacheGo 스케줄러 글에서 논의했듯, 각 프로세서 P는 고루틴의 실행 컨텍스트입니다. 고루틴이 메모리를 할당할 수 있으므로, 각 P는 자체 메모리 할당기인 mcache를 유지합니다. 이는 초소형/소형 힙 할당과 고루틴 스택 세그먼트 할당에 최적화되어 있습니다.
mcache라는 이름은, 스팬 클래스별로 빈 객체가 있는 스팬을 alloc 필드에 캐시하기 때문에 붙었습니다. mcache 인스턴스가 초기화될 때 각 스팬 클래스에는 빈 객체가 전혀 없는 emptymspan이 설정됩니다. 고루틴이 특정 스팬 클래스의 사용자 객체를 할당해야 하면, mcache는 캐시된 스팬에서 빈 사이즈 클래스 객체를 찾거나, 없다면 mcentral에서 새 스팬을 요청해 캐시에 넣은 뒤 빈 객체를 제공합니다. 아래 도식에 그 로직이 나와 있습니다.
flowchart LR
style C fill:#d6e8d5 style D fill:#b1ddf0
0((Start)) --> A{Any free size class
object in
the cached
span?} A --> |Yes|Z[Return the free
size class
object]
A --> |No|B{Is the cached span equal emptymspan?}
B --> |No|C[Return the cached span to mcentral]
B --> |Yes|D[Request mcentral for a new span]
C --> D
D --> E[Cache the new span]
E --> Z
Z --> 1(((End)))
Logic for requesting a free size class object from mcache
초록 상자 _Return the cached span to mcentral_는 Collecting a Span에서, 파란 상자 _Request mcentral for a new span_은 Preparing a Span에서 설명했습니다.
16바이트보다 작은 모든 사용자 초소형(tiny) 객체는 스팬 클래스 5(또는 사이즈 클래스 2)의 스팬에서 할당됩니다. 각 mcache 인스턴스는 스팬 내 tiny 할당을 다음 세 필드로 추적합니다.
tiny: 현재 할당 가능한 여유 공간이 남아 있는 사이즈 클래스 객체의 시작 주소tinyoffset: 마지막으로 할당된 사용자 객체의 끝 위치(tiny로부터의 상대 위치)tinyalloc: 현재 스팬에서 지금까지 할당된 사용자 tiny 객체 수 |
|---|
| 초소형 사용자 객체 할당에 사용되는 스팬의 예 |
위 그림은 tiny 객체 할당에 사용되는 스팬을 보여주며, 0x30은 사이즈 클래스 객체의 예시 시작 주소입니다. 자세한 할당 로직은 Tiny Objects: mallocgcTiny에서 설명합니다.
지금까지 살펴본 바와 같이, Go의 메모리 할당기는 mheap, mcentral, mcache 세 구성요소가 협력하여 메모리를 효율적으로 관리하는 복합 시스템입니다. 아래 그림은 이 구성요소들이 Go 프로그램의 메모리를 어떻게 할당하는지 요약합니다. 다음 섹션에서 힙 할당 로직의 세부를 보기 전에 한 번 훑어보세요.
 |
|---|
| Go 메모리 할당기 요약 |
Go에서 객체를 힙에 할당하려면 반드시 new(T)나 &T{}를 써야 한다고 흔히 오해합니다. 하지만 꼭 그렇지는 않습니다. 첫째, 객체가 충분히 작고 함수 스코프 안에서만 살며 그 밖에서 참조되지 않으면, 컴파일러가 힙 대신 스택에 배치할 수 있습니다. 둘째, var n int처럼 보이는 원시 타입도 escape analysis 결과에 따라 힙에 놓일 수 있습니다. 셋째, make로 슬라이스/맵/채널 같은 합성 타입을 만들면, 그 내부 자료구조는 대개 힙에 할당됩니다.
어떤 객체를 힙에 올릴지는 컴파일러가 결정하며, 이는 Stack or Heap?에서 설명합니다. 이 섹션은 Go 런타임이 힙 객체를 할당할 때 사용하는 함수인 mallocgc에만 집중합니다. 이 함수는 new, make, &T{} 같은 다양한 내장 함수/연산자에 의해 간접 호출됩니다.
mallocgc는 크기에 따라 객체를 세 부류로 나눕니다. 초소형(16바이트 미만), 소형(16바이트~32760바이트), 대형(32760바이트 초과)입니다. 또한 타입에 포인터가 포함되는지 여부도 고려합니다. 이 기준에 따라 서로 다른 할당 경로를 선택하며, 아래 도식과 같습니다.
flowchart LR A((Start)) --> B{size ≤ 32760 bytes?} B -- Yes --> C{type doesn't contain pointer} C -- Yes --> D{size <
16 bytes?} D -- Yes --> E[mallocgcTiny:
Allocate
tiny object] D -- No --> F[mallocgcSmallNoscan:
Allocate small object of noscan span class] C -- No --> G{size ≤ 512 bytes?} G -- Yes --> H[mallocgcSmallScanNoHeader:
Allocate small object of scan span class with
heap bits] G -- No --> I[mallocgcSmallScanHeader:
Allocate small object of scan span class with malloc header] B -- No --> J[mallocgcLarge:
Allocate
large object]
E --> Z(((End)))
F --> Z
H --> Z
I --> Z
J --> Z
How mallocgc determines which allocation path to take
mallocgcTiny초소형 객체는 각 프로세서 P의 mcache가 Tiny Objects Allocator에서 설명한 세 속성을 사용해 할당합니다. 아래 도식에 할당 로직이 나와 있습니다.
flowchart LR
style C fill:#b1ddf0 style G fill:#d6e8d5
A((Start)) --> B[Align mcache.tinyoffset based on the requested size] B --> C{mcache.tinyoffset + size ≤ 16 bytes?} C -- Yes --> D[Allocate user object at mcache.tiny + mcache.tinyoffset] D --> K[Increase mcache.tinyoffset by requested size] K --> M[Return the address of the allocated object] C -- No --> E{Any free
size class
object in mcache's cached span of
span class
5?} E -- Yes --> F[Allocate user object
at the
beginning of the size class
object]
E -- No --> G[Request a new span of span class 5 from mcentral]
G --> H[Cache the new span in mcache]
H --> L[Return the first free size class object in the new span]
L --> F
F --> J[Set mcache.tiny to the starting address of the size class object, and mcache.tinyoffset to requested size]
J --> M
M --> Z(((End)))
Overview logic for mallocgcTiny
tinyoffset는 요청한 크기에 맞춰 정렬됩니다. 8의 배수면 8바이트 정렬, 4의 배수면 4바이트, 2의 배수면 2바이트, 그 외에는 정렬 없음입니다. 파란 다이아몬드의 검사는 요청 크기 size의 사용자 객체를 현재 tinyoffset에서 시작해 현재 사이즈 클래스 객체 안에 담을 수 있는지를 의미합니다. 가능하면 그 안에 새 사용자 객체를 배치합니다. 초록 상자 _Request a new span of span class 5 from mcentral_의 세부는 Preparing a Span에서 설명했습니다.
 |
|---|
| 초소형 객체 할당 |
초소형 객체 할당은 각 프로세서 P에 로컬인 mcache가 담당합니다. 따라서 스팬을 새로 요청해야 하는 경우(즉 mcentral이 mheap에서 받아올 때)를 제외하면, 락 없는 스레드 안전한 할당이 가능합니다.
tiny 할당에 쓰이는 스팬은 스팬 클래스 5, 즉 사이즈 클래스 2입니다. 사이즈 클래스 테이블에 따르면, 사이즈 클래스 2의 스팬은 512개의 사이즈 클래스 객체를 담습니다. 사이즈 클래스 객체 하나가 tiny 사용자 객체 여러 개를 담을 수 있으므로, 단 하나의 스팬으로도 락 없이 최소 512번의 tiny 사용자 객체 할당을 처리할 수 있습니다.
가비지 컬렉터가 살아있는 객체를 효율적으로 식별하고, 다른 객체를 참조하지 않는 객체에 대한 추적을 건너뛰기 위해, Go는 소형 객체를 타입에 포인터 포함 여부에 따라 scan 과 noscan 스팬 클래스로 분류합니다(Span Class 참조). 또한 scan 스팬 클래스는 힙 비트와 malloc 헤더의 유무에 따라 다시 둘로 나뉩니다. Go는 이러한 분류에 따라 서로 다른 함수로 소형 객체를 할당합니다.
mallocgcSmallNoscan포인터를 포함하지 않는 소형 객체는 mallocgcSmallNoscan이 할당합니다. 요청된 size는 먼저 해당 사이즈 클래스 객체에 정확히 맞도록 올림됩니다. 할당이 noscan 이므로 스팬 클래스는 2*sizeclass+1로 계산됩니다. 예를 들어 365바이트 객체를 요청하면 384바이트로 올림되어 사이즈 클래스 22가 됩니다. 대응하는 스팬 클래스는 45(2*22+1)입니다.
그 다음 현재 프로세서 P의 mcache에 해당 스팬 클래스의 캐시된 스팬 안에 빈 객체가 있는지 확인합니다. 없으면 mcentral에서 새 스팬을 요청해 mcache에 캐시한 뒤 빈 사이즈 클래스 객체를 얻습니다. 이후 가비지 컬렉터와 프로파일러를 위한 정보를 갱신하고, 할당된 객체의 주소를 반환합니다.
mallocgcSmallScanNoHeader and mallocgcSmallScanHeader포인터를 포함하는 소형 객체는 크기에 따라 mallocgcSmallScanNoHeader 또는 mallocgcSmallScanHeader가 할당합니다. 요청된 size가 512바이트 이하이면 전자가, 초과하면 후자가 담당합니다. 기본 로직은 mallocgcSmallNoscan과 유사하나, 스팬 클래스, 스팬의 레이아웃, 스팬 내부의 사이즈 클래스 객체 레이아웃이 다릅니다.
mallocgcSmallScanNoHeader에서 사용하는 스팬은 mallocgcSmallNoscan에서 사용하는 스팬과 달리 끝부분에 힙 비트(자세한 내용은 Heap Bits and Malloc Header)를 보관합니다. 이 공간을 예약해야 하므로, 해당 스팬은 사이즈 클래스 테이블에 표기된 것보다 적은 개수의 사이즈 클래스 객체만 담을 수 있습니다. 예약 로직은 mheap.initSpan에 구현되어 있습니다.
mallocgcSmallScanHeader가 사용하는 스팬 내부의 사이즈 클래스 객체 레이아웃도 특이합니다. 각 사이즈 클래스 객체 앞에 malloc 헤더(자세한 내용은 Heap Bits and Malloc Header)가 붙습니다. 따라서 사용자 객체와 malloc 헤더가 사이즈 클래스 객체 하나에 정확히 들어가도록, 요청된 size에 8바이트를 더한 뒤 다음 사이즈 클래스로 올림합니다. 예를 들어 포인터를 포함하는 636바이트 객체를 요청하면 보통은 사이즈 클래스 28(640바이트)에 들어가지만, malloc 헤더 때문에 644바이트가 되어 사이즈 클래스 29(704바이트)로 올라갑니다.
mcache와 mcentral은 최대 32 KB 사이즈 클래스의 스팬만 관리하므로, 32760바이트를 넘는 대형 객체는 mcache나 mcentral을 거치지 않고 Span Allocation에서 설명한 대로 mheap에서 직접 할당합니다. 대형 객체를 담는 스팬도 scan 또는 _noscan_일 수 있습니다. 소형 객체와 달리 대형 객체는 스팬 클래스가 다양하지 않고, _scan_이면 항상 0, _noscan_이면 항상 1입니다.
예를 들어 대형 구조체 100만 개를 담는 슬라이스 같은 큰 객체를 할당하더라도, 커널은 즉시 물리 메모리를 커밋하지 않습니다. 대신 그 할당에 필요한 가상 주소 공간만 예약합니다. 물리 페이지는 요청 페이징 덕분에, 프로그램이 처음 그 영역에 쓸 때에만 비로소 할당됩니다.
Go 스케줄러 글에서 논의했듯, Go 런타임 코드와 사용자 코드는 모두 커널이 관리하는 스레드에서 실행됩니다. 각 스레드는 자신의 스택을 가지며, 스택은 함수 파라미터, 지역 변수, 리턴 주소를 담는 스택 프레임들의 연속된 메모리 블록입니다. 스택 할당은 단순히 스택 포인터 조정이므로, 여기서는 Go에서 스택을 어떻게 할당하고 관리하는지에 집중합니다.
Go에서는 스레드의 스택을 _시스템 스택_이라고 부르고, 고루틴의 스택은 그냥 _스택_이라고 부릅니다. 실행 컨텍스트 관리를 위해 런타임은 m(스레드)과 g(고루틴) 추상화를 도입합니다. 모든 g는 자신의 스택 시작/끝 주소를 담는 stack 필드를 가집니다. 각 m에는 특별한 고루틴 g0가 있으며, 그 스택이 시스템 스택을 나타냅니다. 런타임은 고루틴 스택이 아닌 시스템 스택에서 실행해야 하는 작업(예: 고루틴 스택 성장/축소 수행)을 할 때 g0를 사용합니다.
메인 스레드의 시스템 스택은 Go 프로세스 시작 시 커널이 할당합니다. 메인이 아닌 스레드의 시스템 스택은 운영체제와 CGO 사용 여부에 따라 커널 또는 Go 런타임이 할당합니다. 다윈과 윈도우에서는 비메인 스레드의 시스템 스택을 항상 커널이 할당합니다. 리눅스에서는 CGO를 사용하지 않는 경우 Go 런타임이 비메인 스레드의 시스템 스택을 할당합니다.
 |  |
|---|---|
| 다윈/윈도우의 프로세스 가상 메모리 레이아웃 | 리눅스의 프로세스 가상 메모리 레이아웃 |
커널이 할당한 시스템 스택은 Go가 관리하는 가상 메모리 공간 바깥에 존재하고, 런타임이 할당한 시스템 스택은 그 안에서 생성됩니다. 커널은 자신의 시스템 스택이 Go 관리 메모리와 충돌하지 않도록 보장합니다. 커널이 할당한 시스템 스택의 크기는 보통 512 KB에서 수 MB 사이이고, Go가 할당한 시스템 스택은 16 KB로 고정입니다. 반면 고루틴 스택은 2 KB로 시작해 필요에 따라 동적으로 커지거나 줄어듭니다.
stackallocGo 런타임이 관리하는 스택(시스템/고루틴 스택)은 스팬 안에 수용됩니다. 스택은 런타임 또는 사용자 코드 실행 중 지역 변수와 호출 프레임을 담는 특수한 힙 객체로 생각할 수 있습니다.
스택은 보통 현재 P의 mcache에서 할당됩니다. 가비지 컬렉션이 진행 중이거나, 프로세서 P의 개수가 변하거나, 현재 스레드가 시스템 호출 중에 P에서 분리(detach)된 경우에는 전역 풀에서 할당합니다. 전역 풀은 두 가지가 있습니다. 32 KB 미만을 위한 small 풀과, 32 KB 이상을 위한 large 풀입니다.
고루틴은 작은 스택으로 시작하므로 작은 스택 풀에서 할당되지만, 함수 호출이 많아지거나 스택 변수들이 늘어 32 KB를 넘게 되면 큰 스택 풀을 사용합니다. 이 동작은 Stack Growth에서 설명합니다.
작은 스택 풀은 mspan 이중 연결 리스트 4개로 이루어진 배열입니다. 각 스팬은 연속 가상 메모리 블록을 관리하는 메타데이터를 담고, 모두 스팬 클래스 0이며 연속 4페이지(=32 KB)를 커버합니다. 배열의 각 엔트리는 스택 오더(order) 에 대응하며, 오더에 따라 스택 크기가 결정됩니다. 오더 0 → 스택 2 KB, 오더 1 → 4 KB, 오더 2 → 8 KB, 오더 3 → 16 KB입니다.
왜 이런 방식으로 스택을 오더/크기로 나눌까요? 고루틴 스택은 연속된 메모리이며, 커질 때마다 크기를 두 배로 늘리기 때문입니다. 자세한 내용은 Stack Growth에서 설명합니다.
 |
|---|
| 작은 스택 풀 |
32 KB 미만 스택이 요청되면, 런타임은 먼저 요청 크기에 맞는 오더를 결정합니다. 그런 다음 해당 오더의 리스트 헤드에서 사용 가능한 스팬을 찾습니다. 없으면 mheap에서 스팬을 받아(자세한 내용은 Span Allocation) 필요한 오더의 스택들로 쪼갭니다. 스팬이 준비되면, 첫 번째 사용 가능한 스택을 가져와 스팬의 메타데이터를 갱신하고 반환합니다.
큰 스택 풀은 다양한 크기의 스택들로 이루어진 단순 연결 리스트이며, 각 스택은 스팬 클래스 0의 mspan 하나에 담깁니다. 32 KB 이상 스택이 요청되면 리스트의 첫 스택을 꺼내 반환합니다. 리스트가 비어 있으면 mheap에서 새 스팬을 요청합니다(자세한 내용은 Span Allocation).
스택 풀은 전역적이며 여러 스레드가 동시에 접근할 수 있으므로, 뮤텍스로 보호되어야 합니다. 이는 락 경합으로 처리량이 낮아질 수 있음을 의미합니다.
스택 할당 시 락 경합을 줄이기 위해, 각 프로세서 P는 자신의 mcache 안에 스택 캐시를 유지합니다. 작은 스택 풀과 유사하게, 스택 캐시는 스택 오더마다 하나씩 네 개의 단일 연결 리스트로 구성됩니다.
작은 스택 할당을 처리할 때, 런타임은 먼저 현재 P의 스택 캐시에 사용 가능한 스택이 있는지 확인합니다. 없으면 작은 스택 풀에서 여러 개를 받아 캐시에 채워 넣은 뒤 첫 번째 것을 반환합니다. 큰 스택은 캐시에서 제공하지 않고 항상 큰 스택 풀에서 직접 할당합니다.
morestack과거 Go는 분절 스택(segmented stack) 접근 방식을 사용했습니다. 각 고루틴은 작은 스택으로 시작했습니다. 어떤 함수 호출이 현재 스택의 여유보다 더 많은 공간을 필요로 하면, 새 스택을 할당해 이전 스택에 연결했습니다. 함수가 반환되면 새 스택을 해제하고 이전 스택에서 계속 실행했습니다. 이를 스택 분할(stack split) 이라고 불렀습니다.
아래 코드와 그림은 ingest 함수가 파일에서 한 줄씩 데이터를 처리하는 상황을 보여줍니다. read의 스택 프레임이 두 스택에 걸쳐 흩어질 수 있습니다. 스택 포인터가 어떤 한계(이른바 스택 가드(stack guard), 아래에서 설명)에 닿으면, read나 process 호출이 스택 분할을 일으킬 수 있습니다. 이 방식에서는 고루틴 스택이 연속적이지 않을 수도 있음을 유의하세요.
func ingest(path string) {
...
for {
line, err := read(file) // Causes stack split.
if err == io.EOF {
break
}
process(line)
}
...
}
 |
|---|
| 분절 스택 전략의 스택 분할 |
하지만 이 분절 스택은 _hot stack split_이라는 성능 문제를 낳았습니다. 루프 안에서 자주 호출되는 함수가 매번 스택 할당/해제를 반복하면 큰 성능 저하가 발생했습니다. 함수가 반환될 때 새 스택을 매번 해제해야 했기 때문입니다. 스택 분할 하나가 60ns 정도 걸리므로, 루프 매 반복마다 발생하면 누적 오버헤드가 큽니다.
이를 피하기 위한 꼼수로, 루프 안에서 자주 호출되는 함수의 스택 프레임에 패딩 을 넣어 스택 분할 가능성을 낮추기도 했습니다. 더미 지역 변수를 늘려 스택 프레임 크기를 키우는 방식입니다. 하지만 프로그래머 입장에서는 오류를 유발하기 쉽고 가독성을 해칩니다.
hot stack split 문제를 완화하기 위해, Go는 1.4 이후 연속 스택(contiguous stacks) 접근으로 전환했습니다. 고루틴 스택이 커져야 하면, 현재의 두 배 크기를 갖는 새 스택을 할당합니다. 현재 스택의 내용을 새 스택으로 복사하고, 고루틴은 새 스택을 사용합니다.
 |
|---|
| 연속 스택 전략의 스택 복사 |
위 그림은 연속 스택을 보여주며, (예: 첫 반복이 끝난 뒤처럼) 활용도가 낮아졌다고 해서 즉시 줄이지는 않음을 보여줍니다. 이 동작은 hot-split 문제를 완화합니다.
그렇다고 고루틴 스택을 전혀 줄이지 않으면, 피크 시 크게 늘어난 뒤 대부분이 유휴 상태로 남아 메모리 낭비가 생길 수 있습니다. 실제로 연속 스택 체계에서는, 함수 반환 시점이 아니라 가비지 컬렉터 사이클 동안 스택을 줄입니다. 사용 중인 스택 총합이 현재 스택의 1/4 미만이면, 현재의 절반 크기인 더 작은 새 스택을 할당합니다. 현재 스택의 내용을 복사하고, 고루틴은 새 스택을 사용합니다. 자세한 내용은 shrinkstack을 참고하세요.
Go 스케줄러 글에서 언급했듯, 고루틴 스택이 커지려면 함수 프롤로그에 몇 가지 검사 코드를 삽입해야 합니다. 이 검사는 CPU 명령이며 호출될 때마다 사이클을 소비합니다. 자주 호출되는 작은 함수에서는 이 오버헤드가 무시 못 할 수 있습니다. 이를 줄이기 위해, 작은 함수에는 //go:nosplit 지시어를 붙여 프롤로그에 스택 성장 검사 코드를 넣지 않도록 합니다.
⚠️ 헷갈리지 마세요.
//go:nosplit의 split은 분절 스택의 split을 떠올리게 하지만, 연속 스택에서의 "스택 성장 검사"도 가리킵니다.
함수가 호출되면, 스택 포인터는 그 함수의 스택 프레임 크기만큼 감소합니다. 그리고 고루틴의 스택 가드(stack guard)와 비교되어 스택 성장이 필요한지 판단합니다. 스택 가드는 StackNosplitBase와 StackSmall 두 부분으로 구성됩니다. 리눅스에서는 스택 바닥에서 928바이트 위에 가드가 놓이는데, StackNosplitBase가 800바이트, StackSmall가 128바이트입니다.
 |
|---|
| 고루틴 스택에서 스택 가드의 위치 |
스택 오버플로우는 스택 포인터가 스택 바닥을 넘어서는 상황이니, 왜 스택 바닥이 아니라 스택 가드와 비교할까요? 그 이유는 Go 런타임 소스의 이 주석에 설명되어 있습니다. 간단히 다시 풀어보겠습니다.
첫째, //go:nosplit로 표시되어 스택 성장 검사를 생략하는 함수들이 안전하게 실행되려면, 그 함수들이 잘못된 주소를 참조하지 않고 실행할 수 있도록 StackNosplitBase만큼의 여유 공간을 반드시 남겨야 합니다. 예를 들어 스택 성장을 담당하는 함수인 morestack 자체의 스택 프레임은 반드시 할당된 스택 안에 온전히 들어가야 합니다.
둘째, 스택 프레임이 StackSmall보다 작은 작은 함수들에 대한 최적화를 위해서입니다. 이런 함수가 호출될 때는 굳이 스택 포인터를 감소시키고 스택 가드와 비교하지 않습니다. 대신 현재 스택 포인터가 스택 가드 아래인지 여부만 확인합니다. 이로써 함수 호출마다 스택 포인터 조정 한 번을 생략해 CPU 명령 하나를 절약합니다.
stackfree고루틴이 실행을 마치거나, 여유 공간이 너무 커서 스택이 줄어들었거나, Go 런타임이 관리하는 시스템 스레드가 종료되면, 그 스택은 재사용 가능 상태로 표시됩니다. 고루틴이 현재 어떤 P에 붙어 있고 그 P의 스택 캐시 크기가 충분히 작다면, 스택은 해당 P의 스택 캐시로 돌아갑니다. 그렇지 않으면 스택은 크기에 따라 전역 풀로 돌아갑니다. 작은 스택이면 해당 오더의 작은 스택 풀로, 크거나 같으면 큰 스택 풀로 돌아갑니다.
스택이 전역 풀로 돌아갈 때, 가비지 컬렉션이 진행 중이 아니라면 해당 페이지 메모리는 커널로 반환됩니다. 자세한 내용은 Go 런타임 소스의 이 주석을 참고하세요.
var n T는 항상 스택에, new(T)나 &T{}는 항상 힙에 할당된다고 생각할 수 있지만, Go에서는 항상 그렇지 않습니다. 몇 가지 가상의 예를 통해 문제의 본질과 Go의 대응을 살펴보겠습니다.
다음 프로그램은 getUserByID 함수가 식별자로 사용자를 조회한다고 가정합니다. 가정상 getUserByID는 스택에 User 구조체를 할당하고, DB에서 데이터를 채워 넣은 뒤 그 주소(포인터)를 반환합니다.
func getUserByID(id int64) *User {
var user User
user = db.FindUserByID(id)
return &user
}
func main() {
var userID int64 = 1
var user *User = getUserByID(userID)
var userAge = user.age
user.age = userAge + 1
}
 |
|---|
| 댕글링 포인터 문제 |
getUserByID가 호출되면, 지역 변수 user는 그 스택 프레임의 0xe0 주소에 놓입니다. 함수가 반환된 뒤에도 user 포인터는 0xe0을 가리키지만, getUserByID의 스택 프레임이 팝되어 더 이상 유효하지 않은 주소입니다. 이후 main에서 user.age에 접근하면 잘못된 주소를 역참조하게 되어 댕글링 포인터 문제와 정의되지 않은 동작을 초래합니다.
이런 문제를 막기 위해 Go는 컴파일 타임에 escape analysis를 수행합니다. escape analysis는 var n T, new(T), &T{}, make(T)로 선언된 변수가 고루틴 스택에 안전하게 할당될 수 있는지, 아니면 힙으로 도망(escape) 가야 하는지를 결정합니다. 변수가 자신을 선언한 함수 밖에서 참조되는 것으로 판단되면, 함수가 반환된 뒤에도 안전하게 접근할 수 있도록 힙에 할당됩니다.
위 코드에서 user는 주소가 반환되어 main에서 사용되므로 힙으로 도망가는 것으로 판정됩니다. 따라서 컴파일러는 user를 힙에 할당해 댕글링 포인터 문제를 방지합니다.
escape analysis는 또한 보통 힙에 할당될 객체(new(T), &T{}, make(T) 등)라도, 함수 스코프 안에서만 사용되고 컴파일 타임에 크기가 MaxImplicitStackVarSize를 넘지 않음이 증명되면 스택에 남겨두려고 시도합니다.
컴파일러 최적화(escape 결과 포함)를 출력하게 하는 -gcflags="-m" 옵션으로 다음 프로그램을 빌드해 위 동작을 확인해 보세요.
package main
type User struct { ID int64 }
func newUser(id int64) *User {
user := User{ID: id}
return &user
}
func main() {
_ = newUser(20250603)
_ = make([]User, 100)
}
// $ go build -gcflags="-m" main.go
// ./main.go:6:2: moved to heap: user
// ./main.go:12:10: make([]User, 100) does not escape
user는 힙으로 이동했지만, make([]User, 100)으로 만든 슬라이스는 main 내부에서만 쓰이고 크기도 MaxImplicitStackVarSize보다 작으므로 스택을 벗어나지 않습니다.
이제 슬라이스 길이를 1,000,000으로 바꾸고 같은 옵션으로 다시 빌드해 보세요. user는 여전히 힙으로 도망가지만, 이번에는 make([]User, 1000000)도 MaxImplicitStackVarSize를 초과해 스택에 담기엔 너무 커서 힙으로 도망갑니다.
// $ go build -gcflags="-m" main.go
// ./main.go:6:2: moved to heap: user
// ./main.go:12:10: make([]User, 1000000) escapes to heap
이제 Go가 힙 객체와 스택을 어떻게 할당하는지 이해했으니, 실제 사례를 통해 Go가 실제로 어떻게 메모리를 할당하고, 힙 할당을 어떻게 최적화할 수 있는지 살펴보겠습니다.
Go의 슬라이스는 기반 배열에 대한 포인터, 길이, 용량(capacity)을 담는 디스크립터입니다. make([]T, length, capacity)로 새 슬라이스를 만들면, 컴파일러는 make를 Go 런타임의 makeslice 호출로 바꿉니다. makeslice는 기반 배열을 힙에 할당하기 위해 capacity*sizeof(T) 크기로 mallocgc를 호출합니다. 즉, capacity는 기반 배열의 크기를, length는 배열에서 사용 중인 요소 수를 나타냅니다.
append는 슬라이스 끝에 새 요소를 붙여 길이를 늘립니다. 새 길이가 현재 용량을 넘으면, append는 두 배 크기의 새 기반 배열을 할당하기 위해 mallocgc를 호출하고, 기존 요소를 복사하며, 슬라이스 디스크립터가 새 배열을 가리키도록 갱신합니다.
슬라이스는 [start:end] 문법으로 리슬라이스할 수 있습니다. 리슬라이스는 원본과 같은 기반 배열 안의 하위 범위를 가리키는 새로운 슬라이스 헤더를 만듭니다. 중요한 점은, 이 동작은 데이터 복사나 추가 메모리 할당을 하지 않는다는 것입니다. 새 슬라이스는 기존 배열을 그대로 재사용합니다. 자세한 내용은 Slice Intro를 보세요.
이 리슬라이스 동작을 이용하면, 새로운 슬라이스를 만들지 않고 기반 배열을 재사용하여 힙 할당을 최적화할 수 있습니다. 아래 프로그램은 CSV 파일을 파싱해 각 행을 순차 처리하며, 각 행은 많은 필드를 가질 수 있습니다.
package main
import (
"bufio"
"os"
)
func parse(line string) []string {
start := 0
var row []string
for i := 0; i < len(line); i++ {
if line[i] == ',' {
row = append(row, line[start:i])
start = i + 1
}
}
row = append(row, line[start:])
return row
}
func process(row []string) {
// Process the line.
}
func main() {
file, _ := os.Open("input.csv")
defer file.Close()
scanner := bufio.NewScanner(file)
for scanner.Scan() {
line := scanner.Text()
row := parse(line)
process(row)
}
}
parse가 각 줄마다 빈 슬라이스를 만들기 때문에, 호출될 때마다 힙에 새 기반 배열이 할당됩니다. 또한 각 필드마다 append가 호출되므로, 초기 용량을 초과하면 여러 번의 힙 할당이 발생합니다. 결국 mallocgc의 동일 경로가 반복 실행되어 많은 낭비를 낳습니다.
이제 row 슬라이스의 기반 배열을 재사용하도록 최적화해 봅시다. row[:0]로 리슬라이스하면 길이만 0으로 리셋되고 용량은 유지됩니다. 힙 할당은 parse의 첫 호출(즉, 첫 줄을 파싱할 때)만 발생합니다. 1,024개 필드, 1,000,000줄짜리 CSV 파일이라면, 힙 할당 횟수는 단순 리슬라이스만으로 1000000*log₂(1024)=10⁷에서 log₂(1024)=10으로 줄어듭니다.
package main
import (
"bufio"
"os"
)
func parse(line string, row []string) []string {
start := 0
for i := 0; i < len(line); i++ {
if line[i] == ',' {
row = append(row, line[start:i])
start = i + 1
}
}
row = append(row, line[start:])
return row
}
func process(row []string) {
// Process the line.
}
func main() {
file, _ := os.Open("input.csv")
defer file.Close()
var row []string
scanner := bufio.NewScanner(file)
for scanner.Scan() {
line := scanner.Text()
row = row[:0] // 기반 배열 재사용
row = parse(line, row)
process(row)
}
}
최근 iter 패키지에서 여러 스칼라 변수를 하나의 구조체로 묶는 커밋이 있었습니다.
 |
|---|
| 여러 변수를 하나의 구조체로 묶기 |
원래는 이 7개 변수가 함수 스코프를 넘어 살아남기 때문에, 각각이 별도로 힙에 할당되어 mallocgc가 7번 호출됩니다. 이 중 일부는 16바이트보다 작아 초소형 객체 할당기가 처리할 수 있더라도, Pull이 자주 호출되면 mallocgc 7회 호출 오버헤드는 여전히 큽니다.
이 변수들을 하나의 구조체로 묶으면, 구조체 하나를 힙에 할당하기 위한 mallocgc 한 번만 필요하므로 메모리 할당 효율이 좋아집니다. 단점은 관련 없는 객체들이 서로 결합되어, 더 이상 필요 없는 개별 객체를 가비지 컬렉터가 세밀하게 회수하지 못하게 될 수 있다는 점입니다. 하지만 이 사례에서는 대부분의 변수가 함께 사용되므로, 트레이드오프가 수용 가능했습니다.
원 PR의 벤치마크 결과(아래 복사)에서 힙 할당 횟수가 11에서 5로 줄었음을 볼 수 있습니다. 이는 위 분석과 같이 7개 변수를 하나로 묶어 mallocgc 호출 6회를 절약한 것과 부합합니다. 또한 메모리 사용량과 할당 시간도 약 1/3 감소했습니다.
│ /tmp/bench.old │ /tmp/bench.new │
│ sec/op │ sec/op vs base │
Pull-12 218.6n ± 7% 146.1n ± 0% -33.19% (p=0.000 n=10)
│ /tmp/bench.old │ /tmp/bench.new │
│ B/op │ B/op vs base │
Pull-12 288.0 ± 0% 176.0 ± 0% -38.89% (p=0.000 n=10)
│ /tmp/bench.old │ /tmp/bench.new │
│ allocs/op │ allocs/op vs base │
Pull-12 11.000 ± 0% 5.000 ± 0% -54.55% (p=0.000 n=10)
sync.Pool로 객체 재사용하기일부 애플리케이션에서는 동일 타입의 수명이 짧고 상태 없는 객체를 매우 자주 만들었다가 곧바로 버리는 패턴이 나타납니다. 전형적인 예가 fmt 패키스의 문자열 포매팅에서 널리 쓰이는 pp 프린터 객체입니다. Fprintf, Sprintf 같은 함수들이 그렇습니다.
이 함수들이 매번 새 pp를 할당해 포매팅에 쓰고 버린다면, 초당 10,000개의 로그를 쓰는 애플리케이션은 초당 10,000개의 pp를 할당하고 가비지 컬렉터가 스캔하게 만드는 셈입니다. 잦은 힙 할당과 GC 스캔으로 큰 오버헤드를 낳습니다.
이 오버헤드를 줄이기 위해 Go는 동일 타입의 객체를 캐시/재사용하는 sync.Pool을 제공합니다. Get 요청을 처리할 때, 풀에 사용 가능한 객체가 있으면 이를 반환합니다. 없으면 사용자 정의 New 함수를 호출해 하나를 생성하는데, 궁극적으로는 힙에 할당하기 위해 mallocgc를 호출합니다. 사용을 마친 객체는 Put으로 다시 풀에 돌려보냅니다. 이렇게 재활용하면 힙 할당 횟수와 GC가 스캔해야 할 객체 수를 줄여 성능을 높일 수 있습니다.
실제로 Fprintf와 Sprintf는 풀에서 pp를 가져와 포매팅에 사용한 뒤 다시 풀에 반납합니다. ppFree 풀은 fmt 패키지가 import될 때 초기화됩니다.
sync.Pool은 높은 동시성에서도 락 없이 효율적으로 동작하도록 설계되었습니다. 이를 위해 pinning 기법을 사용합니다. pinning은 풀에서 가져오거나 반납하는 동안 고루틴이 선점(preempt)되지 않도록 보장합니다. sync.Pool은 각 프로세서 P에 로컬이므로, pinning은 연산 중 고루틴이 같은 P에 머물게 해줍니다.
Go의 메모리 할당기는 분명한 목표를 갖고 설계되었습니다. 높은 동시성 애플리케이션에서 효율적일 것. mheap/mcentral/mcache 층을 나누어 전역 조율과 P별 캐싱을 균형 있게 결합함으로써 락 경합을 줄이고 빠른 할당을 달성합니다. 스택은 힙 객체와는 다르지만, 효율적 할당과 적응적 성장이라는 유사한 원칙을 따릅니다.
대부분의 Go 개발자에게 이러한 세부사항은 &T{}, new(T), make(T) 같은 단순한 구문 뒤에 숨겨져 있습니다. 그럼에도 내부를 이해하면 왜 어떤 패턴이 더 성능이 좋은지, 가비지 컬렉터가 할당과 어떻게 상호작용하는지, 런타임이 저지연 대규모 동시성을 위해 어떤 트레이드오프를 하는지를 알 수 있습니다. Go 애플리케이션을 만들고 최적화할 때, 여러분이 만드는 모든 변수와 고루틴 뒤에는 결국 이런 메커니즘이 있음을 기억하세요.
이 글이 더 효율적이고 신뢰할 수 있는 Go 프로그램을 작성하는 데 도움이 되길 바랍니다. 궁금한 점이 있으면 언제든 댓글로 남겨 주세요. 내용이 유익했다면  로 응원도 부탁드립니다! 😄
로 응원도 부탁드립니다! 😄