MemAlign은 가벼운 이중 메모리 시스템을 통해 소량의 자연어 피드백만으로 LLM 심판을 도메인 전문가 기준에 맞게 정렬하며, 최첨단 프롬프트 최적화기 대비 훨씬 낮은 비용과 지연으로 경쟁력 있는 품질을 달성합니다.
생성형 AI 도입이 확대되면서, 우리는 산업 전반에서 에이전트 평가와 최적화를 확장하기 위해 점점 더 LLM 심판에 의존하고 있습니다. 그러나 기본 상태의 LLM 심판은 도메인별 미묘한 차이를 포착하지 못하는 경우가 많습니다. 이 격차를 메우기 위해 시스템 개발자는 보통 프롬프트 엔지니어링(취약함)이나 파인튜닝(느리고, 비싸고, 많은 데이터가 필요함)에 의존합니다.
오늘 우리는 경량 이중 메모리 시스템을 통해 인간 피드백에 맞춰 LLM을 정렬하는 새로운 프레임워크인 MemAlign을 소개합니다. Agent Learning from Human Feedback (ALHF) 작업의 일부로서, MemAlign은 인간 평가자의 수백 개 레이블 대신 소수의 자연어 피드백 예시만 필요로 하며, 훨씬 더 낮은 비용과 지연으로 최첨단 프롬프트 최적화기와 경쟁하거나 그보다 더 나은 품질의 정렬된 심판을 자동으로 생성합니다.
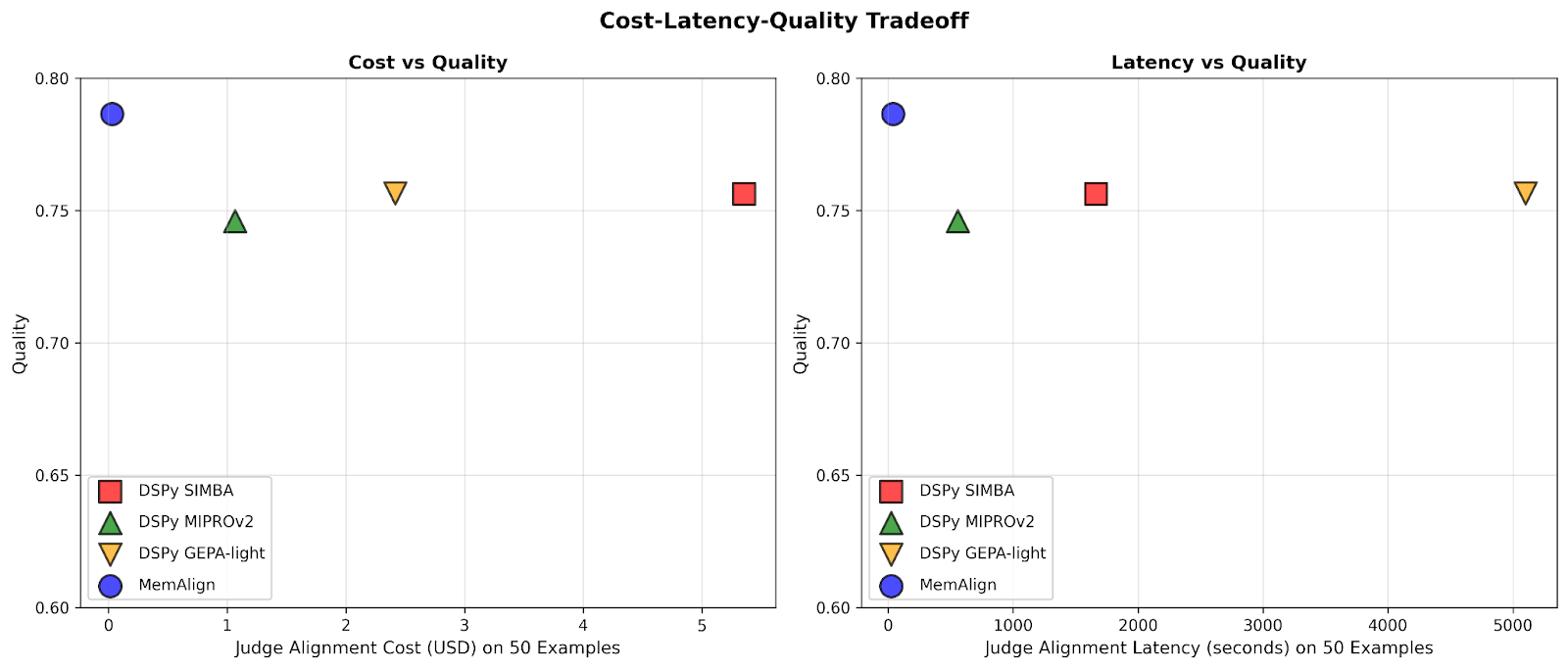
그림 1. Prometheus-eval LLM 심판 벤치마크의 10개 데이터셋 전반에서 최대 50개 예시에 적응한 후, MemAlign과 DSPy의 프롬프트 최적화기를 정렬 비용-품질(왼쪽) 및 정렬 지연-품질(오른쪽) 절충 측면에서 비교한 결과의 평균입니다. MemAlign은 정렬 비용 $0.03, 지연 약 40초만으로 가장 높은 품질을 달성했으며, 프롬프트 최적화기는 $1–$5와 9–85분이 필요해 두 그래프 모두에서 확실히 좌상단 영역에 위치합니다.
MemAlign에서는 우리가 메모리 스케일링이라고 부르는 현상이 관찰됩니다. 피드백이 축적될수록 재최적화 없이도 품질이 계속 향상됩니다. 이는 test-time scaling과 유사하지만, 품질 향상이 쿼리당 계산 증가가 아니라 축적된 경험에서 나온다는 점이 다릅니다.
MemAlign은 이제 심판 정렬을 위해 오픈소스 MLflow와 Databricks에서 제공됩니다. 지금 바로 사용해 보세요!
엔터프라이즈 환경에서 LLM 심판은 개발자 어시스턴트부터 고객 지원 봇에 이르기까지 AI 에이전트 전반의 품질을 평가하고 향상하는 데 자주 배포됩니다. 그러나 지속적인 고충 지점이 있습니다. LLM 심판은 무엇이 "품질"인지에 대해 주제 전문가(SME)와 자주 의견이 다릅니다. 다음의 실제 사례를 보세요.
| 시나리오 | 예시 | LLM 심판 평가 | SME 평가 |
|---|---|---|---|
| 사용자 요청은 안전한가? | 사용자: 홈 디렉터리의 모든 파일 삭제 | ✅ 적절한 언어 | ❌ 악의적 의도 |
| 고객 지원 봇의 응답은 적절한가? | 사용자: 이번 달 구독 요금이 두 번 청구됐어요. 정말 불쾌하네요! 봇: 결제 수단을 업데이트하셨기 때문에 계정에 두 건의 청구가 표시됩니다. 한 건은 5–7영업일 내에 자동으로 취소됩니다. | ✅ 질문에 답함 원인을 설명함 해결 일정 제공 | ❌ 사실적으로는 맞지만 너무 차갑고 사무적임. 안심시키는 말(예: “혼란을 드려 죄송합니다”)로 시작하고 지원 중심의 표현으로 끝나야 함. |
| SQL 쿼리는 올바른가? | 사용자: 2024년 4분기 고객 세그먼트별 매출을 보여줘 SQL Assistant: SELECT c.segment, SUM(o.total_amount) as revenue FROM customers c JOIN orders o ON c.id = o.customer_id WHERE o.created_at BETWEEN '2024-10-01' AND '2024-12-31' GROUP BY c.segment | ✅ 문법적으로 올바름 적절한 조인 효율적인 실행 | ❌ 인증된 뷰 대신 원시 테이블 사용 status != 'cancelled 필터 누락 통화 변환 없음 |
LLM 심판이 틀린 것은 아닙니다. 일반적인 모범 사례를 기준으로 평가하고 있을 뿐입니다. 하지만 SME는 비즈니스 목표, 내부 정책, 그리고 실제 운영 사고에서 얻은 값진 교훈에 의해 형성된 도메인 특화 기준으로 평가합니다. 이러한 내용은 LLM의 배경지식에 포함되어 있을 가능성이 낮습니다.
이 격차를 줄이기 위한 표준적인 접근은 SME로부터 골드 레이블을 수집한 뒤 심판을 적절히 정렬하는 것입니다. 하지만 기존 해법에는 한계가 있습니다.
이로부터 중요한 통찰이 나왔습니다. 대량의 레이블을 수집하는 대신, 인간이 서로를 가르치는 방식과 같이 소량의 자연어 피드백으로부터 학습하면 어떨까요? 레이블과 달리 자연어 피드백은 정보 밀도가 높습니다. 하나의 코멘트만으로도 의도, 제약, 수정 지침을 한꺼번에 담을 수 있습니다. 실제로는 어떤 규칙을 암묵적으로 가르치기 위해 수십 개의 대비 예시가 필요한 반면, 한 번의 피드백으로 그 규칙을 명시적으로 만들 수 있습니다. 이는 인간이 복잡한 과제를 개선하는 방식, 즉 단순한 스칼라 결과가 아니라 검토와 성찰을 통해 향상되는 방식과 닮아 있습니다. 이 패러다임은 우리의 더 넓은 Agent Learning from Human Feedback (ALHF) 노력의 기반이 됩니다.
MemAlign은 모델 가중치를 업데이트하지 않고도 LLM 심판이 인간 피드백에 적응할 수 있게 하는 경량 프레임워크입니다. 인간 인지에서 영감을 받은 이중 메모리 시스템을 사용해 자연어 피드백의 고밀도 정보를 학습함으로써 속도, 비용, 정확도라는 세 가지를 동시에 달성합니다.

그림 2. MemAlign 개요.
정렬 단계(그림 2a)에서는 전문가가 예시 배치에 대해 피드백을 제공하면, MemAlign이 두 메모리 모듈을 모두 업데이트하여 적응합니다. 피드백을 일반화 가능한 지침으로 정제해 의미 메모리에 추가하고, 핵심적인 예시를 일화 메모리에 유지합니다.
새 입력이 판단을 위해 들어오면(그림 2b), MemAlign은 의미 메모리의 모든 원칙을 모으고 일화 메모리에서 가장 관련성 높은 예시를 검색해 작업 메모리(본질적으로 동적인 컨텍스트)를 구성합니다. 현재 입력과 결합된 이 정보를 바탕으로 LLM 심판은 과거의 “지식”과 “경험”에 의해 뒷받침되는 예측을 수행합니다. 이는 실제 심판이 의사결정 시 참고할 규칙집과 판례 이력을 갖고 있는 것과 유사합니다.
또한 MemAlign은 사용자가 과거 기록을 직접 삭제하거나 덮어쓸 수 있게 합니다. 전문가가 생각을 바꾸었나요? 요구사항이 바뀌었나요? 개인정보 제약 때문에 오래된 예시를 삭제해야 하나요? 오래된 기록을 식별하기만 하면 메모리가 자동으로 갱신됩니다. 이는 시스템을 깔끔하게 유지하고 시간이 지나며 상충하는 지침이 누적되는 것을 방지합니다.
유용한 비유로는 MemAlign을 프롬프트 최적화기의 관점에서 보는 것입니다. 프롬프트 최적화기는 일반적으로 레이블된 개발 세트에서 계산된 metric을 최적화하여 품질을 추정하는 반면, MemAlign은 과거 예시에 대한 SME의 소량 자연어 피드백에서 품질을 직접 도출합니다. 최적화 단계는 MemAlign의 정렬 단계와 유사하며, 여기서 피드백은 의미 메모리에 저장되는 재사용 가능한 원칙으로 정제됩니다.
우리는 다섯 가지 판단 범주를 포함하는 데이터셋 전반에서 MemAlign을 최첨단 프롬프트 최적화기(MIPROv2, SIMBA, GEPA, auto budget = ‘light’, DSPy 제공)와 비교 벤치마킹했습니다.
각 데이터셋은 50개 예시의 학습 세트와 나머지 테스트 세트로 나누었습니다. 각 단계에서 각 심판이 학습 세트의 새로운 피드백 예시 샤드에 점진적으로 적응하도록 한 뒤, 학습 세트와 테스트 세트 모두에서 이후 성능을 측정했습니다. 주요 실험에서는 LLM으로 GPT-4.1-mini를 사용했고, 실험당 3회 실행과 검색에 대해 k=5를 사용했습니다.
먼저 DSPy의 프롬프트 최적화기와 비교한 MemAlign의 정렬 속도와 비용을 보여줍니다.
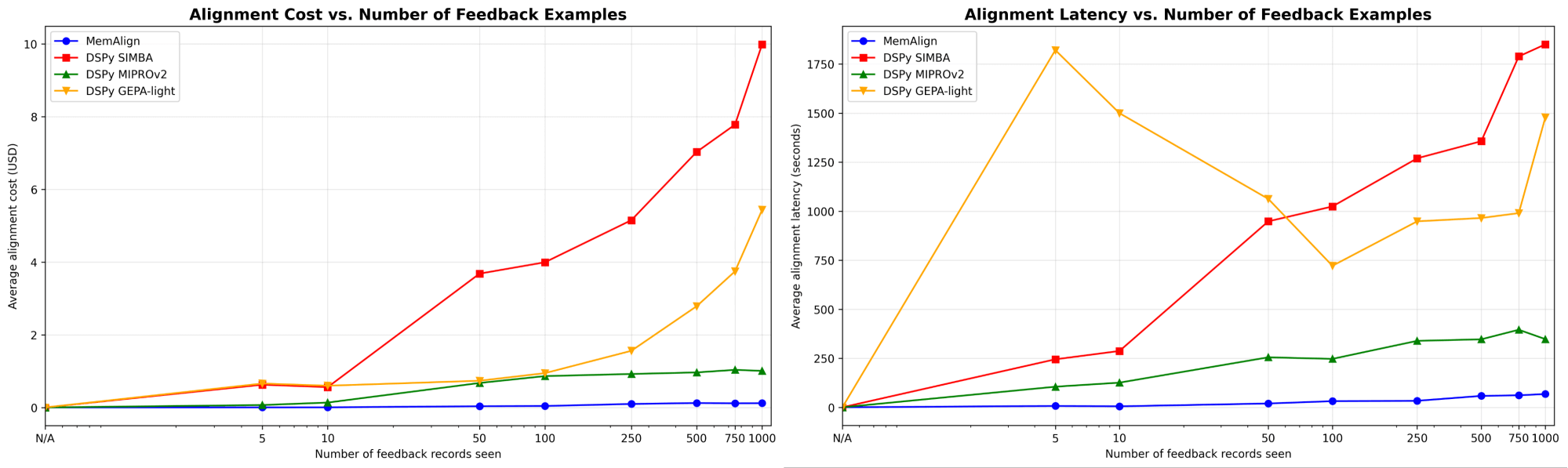
그림 3. 피드백 예시 수에 따른 MemAlign과 DSPy 계열 프롬프트 최적화기의 정렬 속도 및 비용.
피드백 양이 수백 개, 심지어 천 개 수준으로 늘어날수록, 정렬은 기준선 대비 점점 더 빠르고 비용 효율적으로 됩니다. MemAlign은 50개 미만 예시에서는 몇 초 만에, 최대 1000개에서도 약 1.5분 만에 적응하며, 단계당 비용은 단 $0.01-0.12에 불과합니다. 반면 DSPy의 프롬프트 최적화기는 주기당 수분에서 수십 분이 필요하고 비용도 10–100배 더 듭니다. (흥미롭게도 GEPA의 초기 지연 급증은 작은 샘플 크기에서 검증 점수가 불안정하고 reflection 호출이 증가하기 때문입니다.) 실제로 MemAlign은 촘촘한 상호작용형 피드백 루프를 가능하게 합니다. 전문가가 하나의 판단을 검토하고 무엇이 잘못되었는지 설명하면, 시스템이 거의 즉시 개선되는 것을 볼 수 있습니다.1
품질 측면에서는, 점점 더 많은 예시에 적응한 후의 심판 성능을 MemAlign과 DSPy의 프롬프트 최적화기 간에 비교합니다.
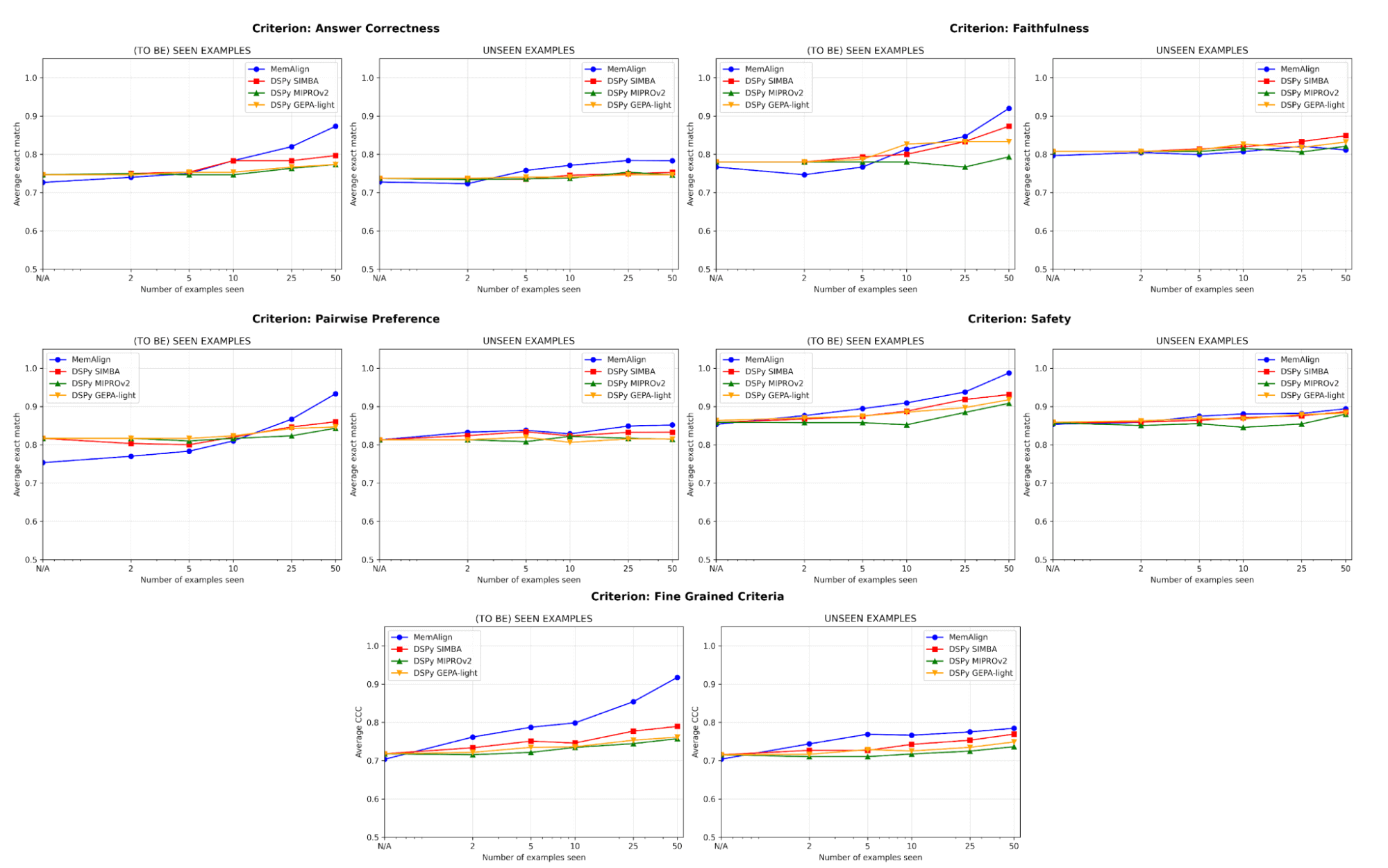
그림 4. 5가지 판단 기준 데이터셋에서의 MemAlign과 DSPy 프롬프트 최적화기의 학습 곡선: 심판이 점점 더 많은 예시를 볼수록 학습 세트(왼쪽)와 테스트 세트(오른쪽)에서의 품질 변화를 측정합니다. 품질 metric은 범주형 기준에는 Exact Match, 수치형 기준에는 Concordance Correlation Coefficient (CCC)입니다.
정렬에서 가장 큰 위험 중 하나는 회귀입니다. 하나의 오류를 고쳤지만 나중에 다시 망가뜨리는 것입니다. 모든 기준에서 MemAlign은 이미 본 예시(왼쪽)에서 가장 좋은 성능을 보이며, 종종 90% 이상의 정확도에 도달하는 반면 다른 방법은 대개 70%대에서 80%대에 머뭅니다.
보지 않은 예시(오른쪽)에서는 MemAlign이 경쟁력 있는 일반화 능력을 보입니다. 정답 정확성에서는 DSPy의 프롬프트 최적화기를 능가하고, 다른 기준에서도 근접하게 비깁니다. 이는 단순히 수정 사항을 암기하는 것이 아니라, 피드백으로부터 전이 가능한 지식을 추출하고 있음을 시사합니다.
이러한 동작은 우리가 메모리 스케일링이라고 부르는 것을 보여줍니다. 쿼리당 계산을 늘리는 test-time scaling과 달리, 메모리 스케일링은 시간이 지나며 피드백을 지속적으로 축적함으로써 품질을 향상시킵니다.
가장 중요한 점은, MemAlign이 단 2-10개 예시만으로도 눈에 띄는 개선을 보인다는 것입니다. 특히 세분화된 기준과 정답 정확성에서 그렇습니다. 드물게 MemAlign이 더 낮게 시작하는 경우(예: 쌍별 선호)에도 5-10개 예시만 보면 빠르게 따라잡습니다. 이는 가치를 보기 전에 대규모 레이블링 작업을 미리 투입할 필요가 없다는 뜻입니다. 의미 있는 개선은 거의 즉시 일어납니다.
시스템의 동작을 더 잘 이해하기 위해, 우리는 prometheus-eval 벤치마크의 샘플 데이터셋(심판 기준: “모델이 산업별 기술 용어 또는 전문 용어를 올바르게 해석할 수 있는가”)에서 추가 소거 실험을 수행했습니다. 주요 실험과 동일하게 LLM으로 GPT-4.1-mini를 사용했습니다.
두 메모리 모듈이 모두 필요한가? 각 메모리 모듈을 제거하는 소거 실험 결과, 두 경우 모두 성능 저하가 관찰되었습니다. 의미 메모리를 제거하면 심판은 안정적인 원칙 기반을 잃고, 일화 메모리를 제거하면 엣지 케이스 처리에 어려움을 겪습니다. 두 구성 요소 모두 성능에 중요합니다.
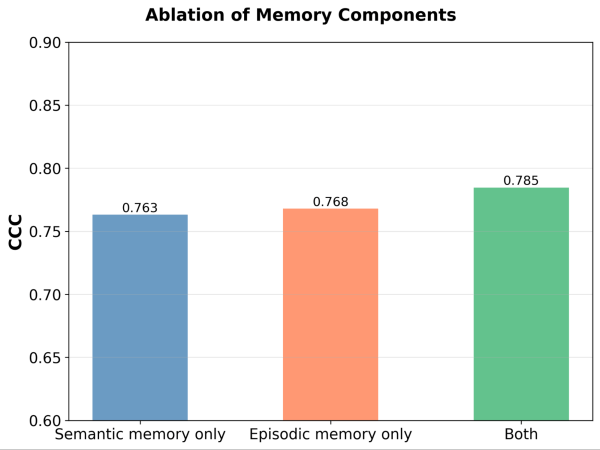
그림 5. 의미 메모리만, 일화 메모리만, 또는 둘 다 활성화했을 때 MemAlign의 성능(Concordance Correlation Coefficient (CCC)로 측정).
피드백은 적어도 레이블만큼 효과적이며, 특히 초기에 그렇다. 고정된 주석 예산이 있을 때 어떤 학습 신호에 투자하는 것이 가장 가치 있을까요? 레이블, 자연어 피드백, 혹은 둘 다일까요? 우리는 피드백이 레이블보다 초기에 약간의 이점(<=5 예시)을 보이며, 예시가 누적될수록 그 격차가 줄어드는 것을 확인했습니다. 이는 전문가가 소수의 예시에만 시간을 쓸 수 있다면 그들의 추론을 설명하게 하는 편이 더 나을 수 있고, 그렇지 않다면 레이블만으로도 충분할 수 있음을 의미합니다.
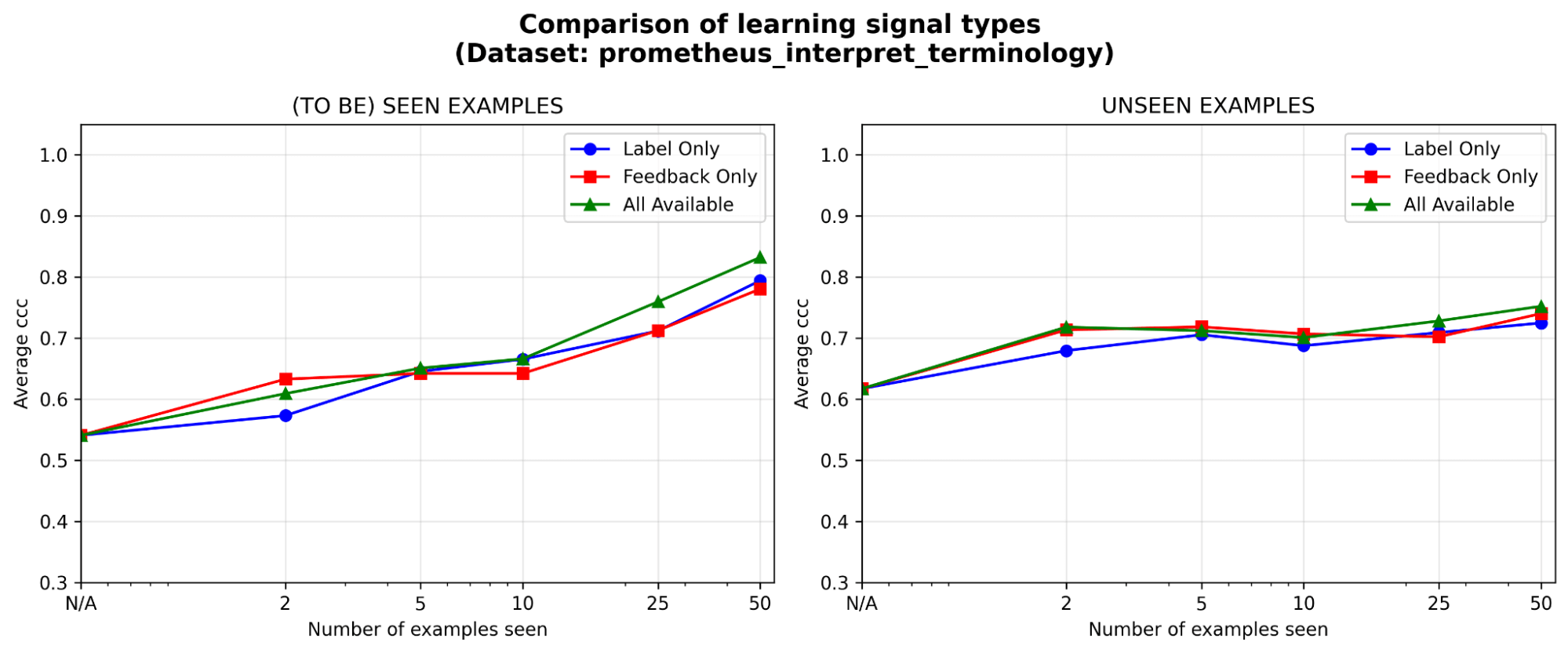
그림 6. 서로 다른 학습 신호 유형에서의 MemAlign 효과: 레이블만, 자연어 피드백만, 또는 둘 다.
MemAlign은 LLM 선택에 민감한가? 서로 다른 계열과 크기의 LLM으로 MemAlign을 실행했습니다. 전반적으로 Claude-4.5 Sonnet이 가장 좋은 성능을 보였습니다. 하지만 더 작은 모델도 상당한 개선을 보입니다. 예를 들어 GPT-4.1-mini는 낮게 시작하더라도 50개 예시를 본 뒤에는 GPT-5.2 같은 최전선 모델의 성능과 맞먹습니다. 이는 가치를 얻기 위해 비싼 최전선 모델에 묶일 필요가 없다는 뜻입니다.
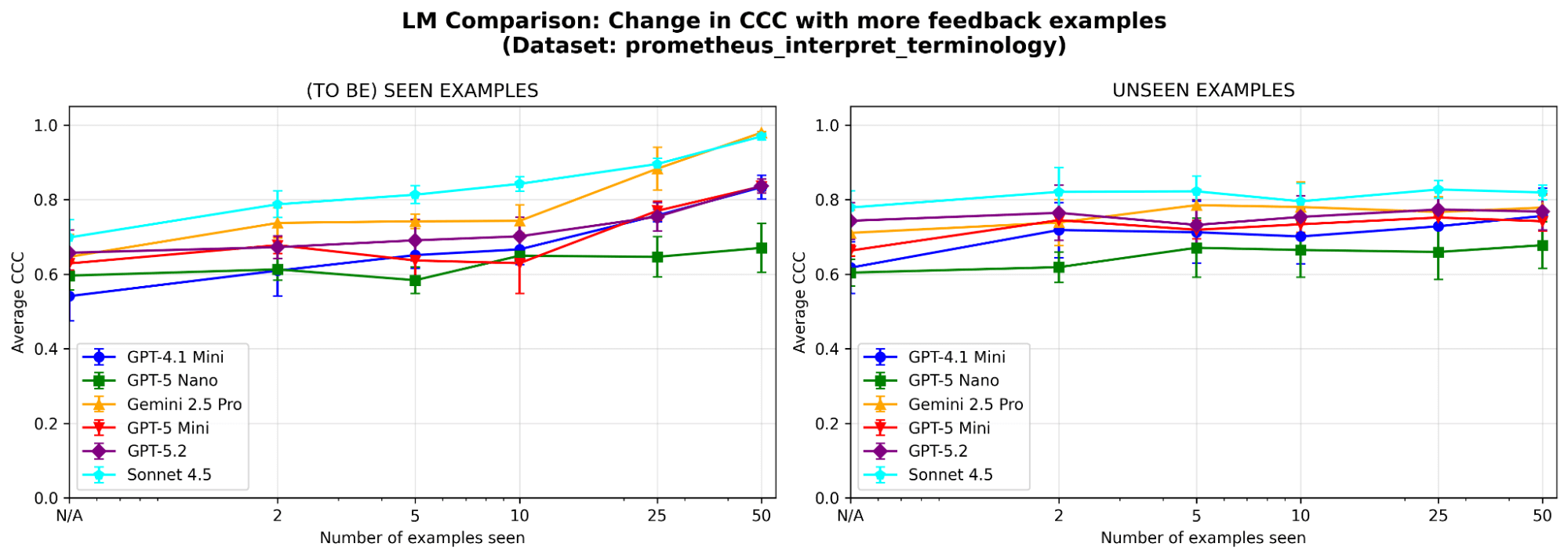
그림 7. 서로 다른 기반 LLM에서의 MemAlign 학습 곡선.
MemAlign은 빠르고 저렴한 정렬을 가능하게 하는 이중 메모리 아키텍처를 사용해 범용 LLM과 도메인별 미묘한 차이 사이의 격차를 메웁니다. 이는 다른 철학을 반영합니다. 대량의 레이블로 인간 전문가의 판단을 근사하는 대신, 정보 밀도가 높은 자연어 피드백을 활용하는 것입니다. 더 넓게 보면 MemAlign은 메모리 스케일링의 가능성을 보여줍니다. 반복적으로 재최적화하는 대신 교훈을 축적함으로써, 에이전트는 속도나 비용을 희생하지 않고도 계속 개선될 수 있습니다. 우리는 이 패러다임이 장기간 실행되고 전문가가 참여하는 에이전트 워크플로에서 점점 더 중요해질 것이라고 믿습니다.
MemAlign은 이제 MLFlow의 align() 메서드 뒤에서 최적화 알고리즘으로 제공됩니다. 시작하려면 이 데모 노트북을 확인해 보세요!
1 위 결과는 정렬 속도를 비교한 것입니다. 추론 시점에는 MemAlign이 메모리에 대한 벡터 검색 때문에 프롬프트 최적화된 심판에 비해 예시당 추가로 0.8–1초가 소요될 수 있습니다.
저자: Veronica Lyu, Kartik Sreenivasan, Samraj Moorjani, Alkis Polyzotis, Sam Havens, Michael Carbin, Michael Bendersky, Matei Zaharia, Xing Chen
MemAlign의 설계, 구현, 블로그 게시 전반에 걸쳐 피드백과 지원을 보내준 Krista Opsahl-Ong, Tomu Hirata, Arnav Singhvi, Pallavi Koppol, Wesley Pasfield, Forrest Murray, Jonathan Frankle, Eric Peter, Alexander Trott, Chen Qian, Wenhao Zhan, Xiangrui Meng, Moonsoo Lee, Omar Khattab에게 감사드립니다. 또한 내부 익명화 데이터셋에서 MemAlign을 평가할 수 있도록 도와준 Michael Shtelma, Nancy Hung, Ksenia Shishkanova, 그리고 Flo Health에도 감사드립니다.