이 장은 고급 제어 구조(예외, 연속, 사용자 정의 효과)를 안전하게 다루기 위해 단순 타입 시스템을 확장하는 방법과, 제어 흐름에 대한 안전 보장을 위해 제어 효과를 추적하는 타입·효과 시스템을 다룬다.
URL: https://xavierleroy.org/control-structures/book/main015.html
Title: Chapter 13 Type and effect systems



타입 시스템은 프로그램의 신뢰성과 명확성을 높이기 위해 프로그래밍 언어에 자주 적용된다. 이는 여러 가지 흔한 프로그래밍 오류를 방지하고, 프로그램 구성 요소의 인터페이스를 기술한다.
타입 시스템은 “배열의 모든 원소는 같은 타입을 가진다”나 “함수는 기대한 타입의 인자에만 적용된다”와 같은 데이터 무결성 보장을 제공한다. 또한 제어 흐름에 대한 보장도 제공할 수 있다. 예를 들어, 어떤 타입 시스템은 프로그램의 종료를 보장하고, 다른 타입 시스템은 프로그램이 발생시킬 수 있는 모든 예외가 프로그램 내부에서 처리되도록 보장하여, 9.4절에서 설명한 미처리 예외 문제를 방지한다.
이 장은 타입 시스템과 제어 구조의 상호작용을 두 관점에서 살펴본다. 첫째, 순수 언어를 위한 단순 타입 시스템을 확장하여 고급 제어 구조(예외, 연속, 사용자 정의 효과)를 지원하면서도 데이터 무결성을 보장하는 방법을 탐구한다. 둘째, 타입·효과 시스템이 제어 효과를 추적하여 미처리 예외나 미처리 효과의 부재와 같은 제어 흐름 안전 보장을 달성하는 방법을 논의한다.
타입 시스템._타입 규율(type discipline)_은 프로그램이 다루는 값을 _타입_으로 조직한다. 이 타입에는 다음이 포함된다.
_타입 시스템_은 프로그램이 조작하는 값들에 타입을 부여하고 이 타입들이 일관적인지 보장한다. 예를 들어, 타입이 bool → int인 함수는 문자열이 아니라 불리언에만 적용될 수 있다. 마찬가지로, 정수는 마치 함수인 것처럼 적용될 수 없다.
FUN과 같은 식(expression) 언어에서는, 보통 타이핑 규칙 집합으로 타입 시스템을 정의한다. 이는 “가정 Γ 하에서, 식 e는 타입 τ를 가진다”를 의미하는 술어 Γ ⊢ e : τ를 공리와 추론 규칙으로 정의한다. 환경 Γ는 변수 x_i에서 그 타입 τ_i로의 부분 사상이다.
타입: τ, σ ::= bool ∣ int ∣ … 기저 타입들 ∣ σ → τ 함수 타입
Γ(x) = τ (var)
Γ ⊢ x : τ
c ∈ {true, false} (const)
Γ ⊢ c : bool
Γ, x : σ ⊢ e : τ (abstr)
Γ ⊢ λ x . e : σ → τ
Γ ⊢ e₁ : σ → τ Γ ⊢ e₂ : σ (app)
Γ ⊢ e₁ e₂ : τ
Γ ⊢ e₁ : bool Γ ⊢ e₂ : τ Γ ⊢ e₃ : τ (cond)
Γ ⊢ if e₁ then e₂ else e₃ : τ
그림 13.1: FUN 언어를 위한 타입 대수와 타이핑 규칙.
그림13.1은 FUN 언어의 타이핑 규칙을 보여준다. 규칙 (var)은 변수 x의 타입이 타이핑 환경에서 x에 연관된 타입임을 말한다. 규칙 (const)은 true와 false가 bool 타입임을 말한다. 규칙 (abstr)은, x가 타입 σ를 가진다고 가정했을 때, 본문 e가 타입 τ를 가지면 함수 λ x . e가 타입 σ → τ를 가진다고 말한다. 규칙 (app)은 타입 σ → τ의 함수는 타입 σ의 인자에 적용되어 타입 τ의 결과를 만든다고 말한다. 마지막으로 규칙 (cond)은, 조건식 e₁이 bool 타입이고 두 분기 e₂와 e₃가 모두 타입 τ일 때 조건식 if e₁ then e₂ else e₃의 타입이 τ임을 말한다.
타입 검사.타입은 프로그램 실행 중에 _동적_으로 검사될 수도 있지만, 프로그램 실행 전에 컴파일 시 분석을 통해 _정적_으로 검사하는 편이 더 강한 보장을 제공한다. 이 분석을 _타입 체커_라고 하며, 식과 변수에 타입을 부여하고 타이핑 규칙이 지켜지는지 검증한다. FUN과 같은 단순 타입 시스템에서는 주석 없는 프로그램에서도 모든 타입을 추론할 수 있다. 더 풍부한 타입 시스템에서는 프로그램에 일부 타입 정보를 제공해야 하는데, 예를 들어 함수 매개변수의 타입을 λ x : τ . e처럼 명시해야 한다.
타입 안전성은 잘-타이핑된 프로그램이 “잘못되지 않는다”(does not go wrong)라는 성질이다(Milner, 1978). 즉, “true false”(불리언 true를 마치 함수인 것처럼 불리언 false에 적용하는 것)와 같은 미정의 연산을 수행하지 않는다. 대신, 잘-타이핑된 프로그램은 값으로 정상 종료하거나 안전하게 발산(diverge)한다.
타입 안전성을 증명하는 한 방법은 Wright and Felleisen (1994)가 도입했으며, 언어의 축약(reduction) 의미론에 대해 다음 두 속성을 보이는 것이다.
자세한 내용과 이 방법에 따른 FUN의 타입 안전성 증명은 Pierce (2002) 8.3절과 9.3절을 보라.
예외.예외의 타이핑에서 핵심 이슈는 예외를 발생시키는 코드와 이를 포착하는 코드가 예외 값의 타입에 합의하는지를 보장하는 것이다. 간단한 해결책은 예외 값에 대해 고정된 타입 exn을 사용하는 것이다. 이는 다음과 같은 타이핑 규칙으로 이어진다.
Γ ⊢ e : exn
Γ ⊢ raise e : τ
Γ ⊢ e₁ : τ Γ, x : exn ⊢ e₂ : τ
Γ ⊢ try e₁ with x → e₂ : τ
식 raise e는 결코 값을 만들지 않으므로, 모든 가능한 타입 τ를 가진다. 또는, 다형적 타입 시스템(13.3절)에서는 raise를 다형적 타입 ∀ α, exn → α를 가진 미리 정의된 함수로 볼 수 있다.
OCaml과 ML 계열의 다른 함수형 언어에서 exn 타입은 확장 가능한 데이터 타입이며, 예외 선언은 타입 exn에 생성자를 추가하는 것과 같다. 예를 들어, 다음 선언
exception Error of string
은 다음과 동일하고
type exn += Error of string
Error라는 생성자를 타입 string → exn으로 도입한다.
Java와 같은 객체지향 언어에서는 exn 타입의 역할을 Throwable 클래스가 맡는다. 예외 선언은 Throwable의 서브클래스를 정의하는 것과 같다.
예외에 대한 타입 안전성은 9.2절의 예외에 대한 축약 의미론을 사용하고 보존성과 진행성에 의한 증명으로 직접 보일 수 있다. (증명은 Wright and Felleisen (1994) 참조.) 더 간단한 방법은 9.3절의 ERS(exception-returning style) 변환이 의미만 보존하는 것이 아니라 다음 의미에서 타이핑도 보존함을 관찰하는 것이다.
if Γ ⊢ e : τ then Γ ⊢ ℰ(e) : τ + exn
ERS 변환 후 τ 타입의 값의 타입을 τ̄로 쓰며, 이는 다음과 같다.
ῑ = ι for all base types ι (bool, exn, etc.) σ̄ → τ̄ = σ̄ → τ̄ + exn
결과적으로, e가 기저 타입 ι의 폐쇄 프로그램이면, 그 ERS 변환 ℰ(e)는 타입 ι + exn을 가지며 발산하거나 ι + exn 타입의 값으로 종료한다. 이는 e가 발산하거나, ι 타입 값으로 정상 종료하거나, 미처리 예외로 종료한다는 뜻이다. 이 타이핑은 e가 “잘못될” 수 없다는 의미에서 안전하지만, e가 예외를 발생시키고 이를 처리하지 않은 채 잊어버리는 것을 막지는 못한다.
효과 핸들러.위의 예외에 대한 단순 타이핑은 사용자 정의 효과와 효과 핸들러로 쉽게 확장할 수 있으며, 타입 안전성은 보장하지만 미처리 효과의 부재는 보장하지 않는다. 주요 차이는 예외 발생과 달리, 효과 수행은 값을 반환할 수 있다는 점이다.
OCaml과 같이, τ eff라는 “τ 타입의 값을 반환하는 효과”의 매개변수화된 타입을 도입한다. 효과 선언은 10.1절에서 본 것처럼 eff 타입을 새 생성자로 확장하는 것이다. 10.5절의 perform과 handle 구성의 타이핑 규칙은 다음과 같다.
Γ ⊢ e : τ eff
Γ ⊢ perform e : τ
Γ ⊢ e : σ Γ ⊢ e_ret : σ → τ Γ ⊢ e_eff : ∀ α, α eff → (α → τ) → τ
Γ ⊢ handle e with e_ret, e_eff : τ
perform은 τ eff 타입의 효과를 인자로 받아 τ 타입의 결과를 반환한다. handle e with e_ret, e_eff에서 정상 핸들러 e_ret은 σ → τ 타입인데, 이는 e의 값(타입 σ)을 인자로 받아 handle 전체의 반환값(타입 τ)을 만들기 때문이다. 효과 핸들러 e_eff의 타입은 더 미묘하다. 첫 번째 인자로 임의 타입 α의 α eff 효과를 받아야 하므로 “모든 타입 α에 대해”라는 전칭이 필요하다. 두 번째 인자는 한정된 연속으로, α 타입의 인자(해당 perform의 반환값)를 받아 τ 타입의 결과를 만든다. e_eff의 결과 타입은 핸들러의 결과 타입 τ이다.
위의 타이핑은 “깊은(deep)” 핸들러의 것이다. “얕은(shallow)” 핸들러에서는, 연속의 타입이 핸들러의 범위 밖이므로 α → τ가 아니라 α → σ가 되며, 따라서 처리되는 계산 e와 같은 타입 σ의 값을 만든다.
현재 연속 호출(call-with-current-continuation, callcc). 8.2절의 callcc와 throw 연산자는 다음처럼 타이핑할 수 있다.
Γ, k : τ cont ⊢ e : τ
Γ ⊢ callcc(λ k . e) : τ
Γ ⊢ e₁ : τ cont Γ ⊢ e₂ : τ
Γ ⊢ throw e₁ e₂ : σ
타입 τ cont는 τ 타입의 인자를 기대하는 연속의 타입이다. 함수로서의 연속과 throw를 단순한 함수 적용으로 보는 Scheme의 call/cc 표현에서는, τ cont는 τ → ∀ α . α 같은 함수 타입이 된다. (연속은 반환하지 않으므로, 예외 발생과 마찬가지로 결과 타입에 대해 무엇이든 가정할 수 있다.)
위 표현에서 throw는 τ cont 타입의 연속에 τ 타입의 인자를 적용하는 연산자이다. callcc(λ k . e)에서는 k가 τ cont 연속에 바인딩되는데, 여기서 τ는 e와 callcc 전체의 타입이다.
SML/NJ에서 callcc와 throw는 언어 구문이 아니라 다음과 같은 다형적 타입을 가진 라이브러리의 미리 정의된 함수이다.
callcc: ∀ α, (α cont → α) → α
throw: ∀ α β, α cont → α → β
callcc의 타입 안전성.callcc와 throw에 대해 8.4절의 축약 의미론을 사용하여 보존성과 진행성에 의한 증명으로 타입 안전성을 보일 수 있다(Wright and Felleisen, 1994). 또 다른 증명은 6.5절의 호출-기반(call-by-value) CPS 변환이 다음 의미에서 타입을 보존한다는 사실을 이용한다.
if Γ ⊢ e : τ then Γ ⊢ 𝒞(e) : (τ → R) → R
여기서 R은 “결과 타입”, 즉 전체 프로그램의 타입이고, CPS 변환 후 τ 타입 값의 타입 τ̄은 다음과 같다.
ῑ = ι for all base types ι
σ̄ → τ̄ = σ̄ → (τ̄ → R) → R
τ cont = τ → R
특히 전체 프로그램 p에 대해 ⊢ p : R이고 R이 기저 타입이면, ⊢ 𝒞(p)(λ x . x) : R 이다. 이는 변환된 프로그램 𝒞(p)를 초기 연속 λ x . x에 적용했을 때 잘못되지 않고 실행됨을 보장한다.
다중 프롬프트 한정(델리미트) 연속.한정 연속을 위한 제어 연산자는, 그 연속을 한정하는 “프롬프트”의 타입이 고정되고 정적으로 알려져 있는 한 타입 검사가 쉽다. 여러 프롬프트를 지원할 때는 필요한 각 연속 타입마다 새 프롬프트를 만들 수 있으므로 문제가 되지 않는다. Gunter et al. (1995)를 따라, 타입 τ prompt를 도입한다. 이는 타입 τ의 계산을 한정할 수 있는 프롬프트의 타입이며, 다음 세 가지 미리 정의된 연산을 갖는다.
new_prompt: ∀ α, unit → α prompt
delim: ∀ α, α prompt → (unit → α) → α
capture: ∀ α β, α prompt → ((β → α) → α) → β
delim p f는 Gunter et al. (1995)에서는 set p f로 쓰며, delim 식이 반환되는 프로그램 지점에 프롬프트 p를 설정하고 f()를 평가한다. 프롬프트의 타입 α prompt는 f()의 타입 α와 일치해야 한다.
capture p(λ k . e)는 cupto p(λ k . e)라고도 쓰며, 현재 프로그램 지점에서 동일한 프롬프트 p의 가장 가까운 델리미터 delim p까지의 한정된 연속을 포착한다. 이 연속을 k에 바인딩하고, delim p 지점으로 돌아간 다음 e를 평가한다. capture 식의 타입이 β이고 프롬프트 p가 α prompt 타입이면, 가장 가까운 delim p의 타입은 α이다. 따라서 한정된 연속의 타입은 β → α이다. e가 정상적으로 반환하면 그 값은 delim 식의 값이 되며, 이때 타입은 α여야 한다.
단일 프롬프트 한정 연속의 미세한 타이핑.일부 한정 연속 제어 연산자는 하나의 프롬프트만 지원한다. control/prompt(Felleisen, 1988)와 shift/reset(Danvy and Filinski, 1990)가 그 예다. 이 경우 프롬프트에 고정 타입을 쓰는 것은 비현실적이다. 대신, Danvy and Filinski (1989)는 shift/reset을 위한 타입 시스템을 제시하는데, 이는 현재 변수와 식의 타입뿐 아니라 프롬프트의 타입도 추적한다. shift 식은 프롬프트를 이동시키고 그 타입을 바꿀 수 있으므로, 프롬프트의 타입은 식 실행 전후의 두 타입이 기록된다. 따라서 타이핑 관계는
Γ ; α ⊢ e : τ ; β
가 되며, 여기서 τ는 e가 반환하는 값의 타입, α는 e가 평가되기 전의 원래 결과 타입, β는 e가 평가된 후의 새로운 결과 타입이다. “결과 타입”은 둘러싼 평가 컨텍스트, 즉 가장 가까운 프롬프트의 타입이다. α와 β 두 결과 타입을 이해하는 한 가지 방법은 e의 한정 CPS 변환의 타입이 (τ → α) → β가 됨을 관찰하는 것이다.
함수 타입 σ → τ는 적용 전후의 결과 타입을 추적하기 위해 σ ; α → τ ; β가 된다. CPS로 변환되면 위 타입을 가진 함수는 σ → (τ → α) → β 타입이 된다.
(Γ, x : σ); α ⊢ e : τ; β
Γ; δ ⊢ λ x . e : (σ; α → τ; β); δ
Γ; δ ⊢ e₁ : (σ; α → τ; ε); β Γ; ε ⊢ e₂ : σ; δ
Γ; α ⊢ e₁ e₂ : τ; β
함수 적용에 대한 타이핑 규칙은 결과 타입이 왼쪽에서 오른쪽으로 변화하는 평가 순서를 반영한다. e₁을 평가할 때 β에서 δ로, e₂를 평가할 때 δ에서 ε로, 마지막으로 함수 적용 시 ε에서 α로 변화한다.
Γ; σ ⊢ e : σ; τ
Γ; α ⊢ reset e : τ; α
(Γ, k : τ; δ → α; δ); σ ⊢ e : σ; β
Γ; α ⊢ shift(λ k . e) : τ; β
reset 델리미터는 새로운 결과 타입 σ를 설치하는데, 이는 한정된 식 e의 타입이기도 하며, reset e의 평가 동안 현재 결과 타입 α가 변하지 않도록 보장한다.
shift 연산자는 shift 식 평가의 끝(타입 τ)에서 결과 타입이 α인 델리미터까지의 연속을 포착한다. 연속은 프롬프트를 이동시키지 않음을 주목하라. 따라서 결과 타입이 동일한 δ를 갖는 τ에서 α로의 함수가 된다.
매개변수 다형성.일부 FUN 식은 여러 다른 타입을 가진다. 예를 들어 λ x . x는 임의의 타입 τ에 대해 τ → τ 타입을 가진다. 이러한 모든 타입을 한 번에 표현하기 위해 타입 변수 α와 다형적 타입 ∀ α, τ를 도입할 수 있다.
타입: τ, σ ::= bool ∣ int ∣ … 기저 타입들
∣ σ → τ 함수 타입
∣ α 타입 변수
∣ ∀ α , τ 다형적 타입
그렇다면 λ x . x는 ∀ α, α → α 타입을 가지며, 이 다형적 타입의 모든 인스턴스, 즉 어떤 타입 τ에 대해서도 τ → τ 타입으로 사용할 수 있다. 다음 두 가지 타이핑 규칙이 이러한 매개변수 다형성 스타일을 포착한다.
Γ ⊢ e : τ α가 Γ에 자유롭지 않음 (gen)
Γ ⊢ e : ∀ α, τ
Γ ⊢ e : ∀ α, τ (inst)
Γ ⊢ e : τ [α := σ]
타입 추론상의 이유로 Haskell, OCaml, SML과 같은 언어는 (gen) 규칙을 let에 의해 바인딩된 식으로 제한한다. 이는 이후 논의에는 중요하지 않다.
다형적 참조 문제.위 (gen)과 (inst) 규칙을 사용하는 매개변수 다형성은 순수 함수형 언어에서는 완전히 타입 안전하지만, ML 스타일 언어의 참조 등 가변 데이터 구조가 존재하면 불완전해진다. 다음을 보자.
let f = ref (fun x -> x) in f := (fun x -> x + 1); !f "hello"
만약 f에 규칙 (gen)에 따라 ∀ α, (α → α) ref 타입을 부여하면, 먼저 f를 (int → int) ref 타입으로 사용해 후속 함수(successor)를 f에 저장하고, 이어서 f를 (string → string) ref 타입으로 사용해 문자열에 대한 후속 함수로 읽어 올 수 있다. 그러나 프로그램은 "hello" + 1을 평가할 때 잘못된다.
이 불완전성을 피하기 위해 매개변수 다형성에 대한 여러 제한이 제안되었다. SML 97과 OCaml(일부 확장 포함)에서 사용하는 것은 _값 제한(value restriction)_이다. 이는 타입을 일반화할 수 있는 표현식을 구문적 값으로만 제한한다. 구문적 값이란 상수, 변수, 함수 추상, 그리고 값에 적용된 생성자를 말한다. 이는 다음과 같은 일반화 제한 규칙로 포착된다.
구문적 값: v ::= c ∣ x ∣ λ x . e ∣ C v₁ … vₙ
Γ ⊢ v : τ α가 Γ에 자유롭지 않음 v는 구문적 값 (gen-val)
Γ ⊢ v : ∀ α , τ
값 제한 하에서는, 위 예의 참조 f는 ref (fun x -> x)가 구문적 값이 아니므로 다형적 타입을 받을 수 없다. 오직 (int → int) ref나 (string → string) ref 같은 단형(monotype)만 받을 수 있으며, 둘 다로는 사용할 수 없다. 반면 대부분의 유용한 다형적 정의는 다음과 같은 함수 정의다.
let compose f g = fun x -> f (g x)
이러한 정의는 구문적 값이며 여전히 다형적 타입을 부여할 수 있다.
다형적 callcc 문제.위 매개변수 다형성 문제는 1991년까지는 참조와 같은 가변 데이터 구조에 특유한 것으로 여겨졌다. 그해 Harper와 Lillibridge는 callcc가 있지만 가변 데이터는 없는 상황에서도 유사한 문제가 있음을 보였다. 다음을 보자.
type 'a attempt = { current: 'a; retry: 'a -> unit } let r = callcc (fun k -> let rec retry f = throw k { current = f; retry = retry } in { current = (fun x -> x); retry = retry }) in r.current "hello"; r.retry (fun x -> x + 1)
이 예에서 callcc는 r의 정의로 되돌아가서 r.current "hello"를 두 번, 서로 다른 r.current 함수로 실행하는 데 사용된다. 좀 더 정확히는, callcc가 먼저 정상 반환하여 r.current를 항등 함수에 바인딩한다. r.current "hello"의 적용은 안전하다. 다음으로 r.retry를 호출하여 포착된 연속 k를 재시작하면 callcc가 다시 반환하면서 r.current를 후속 함수에 바인딩한다. 그러고 나서 r.current "hello"를 적용하면, "hello" + 1을 평가하는 동안 잘못된다.
값 제한이 없다면 이 예는 잘-타이핑된다. 13.2절의 callcc와 throw 타입을 사용하면 r을 정의하는 식은 임의 타입 α에 대해 (α → α) attempt 타입을 가진다. (gen) 규칙은 r에 ∀ α, (α → α) attempt라는 다형적 타입을 부여할 수 있게 해 주며, r.current "hello"와 r.retry (fun x -> x + 1) 두 호출 모두 잘-타이핑된다. 값 제한 하에서는 callcc (…)가 값이 아니므로 r의 타입은 단형으로 남는다. 따라서 이 예는 잘-타이핑되지 않는다.
CPS 변환은 이 현상을 설명해 준다. 제한 없는 (gen) 규칙이 있을 때, CPS 변환의 타입 보존은 만약 e : τ이고 𝒞(e) : (τ → R) → R이라면, 𝒞(e)가 ((∀ α, τ) → R) → R 타입도 가져야 함을 요구한다. 이는 위와 유사한 반례로 보이듯 callcc의 적용에서는 사실이 아니다(Harper and Lillibridge, 1993). 그러나 e가 구문적 값 v인 경우에는 𝒞(e) = λ k . k Ψ(v)이며, Ψ(v)는 타입 τ의 구문적 값이므로 (gen-val) 규칙에 의해 ∀ α, τ 타입도 가진다.
타입·효과 시스템은 식을 평가할 때 수행될 수 있는 _효과(effect)_를 추적하는 능력을 기존 타입 시스템에 확장한 것이다. 이는 FX-87 언어의 맥락에서 Lucassen and Gifford (1988)에 의해 도입되었는데, 서로의 효과가 간섭하지 않기 때문에 병렬로 평가할 수 있는 부분식을 검출하는 방법이었다. 타입·효과 시스템은 또한 미처리 예외와 같은 바람직하지 않은 효과의 부재를 증명하여 소프트웨어 신뢰성을 향상시키는 데 쓸 수 있다.
타입·효과 시스템은 네 자리 타이핑 관계 Γ ⊢ e : τ ! ϕ를 정의하는데, 이는 가정 Γ하에서 식 e가 값 타입 τ와 효과 타입 ϕ를 가진다는 뜻이다. 값 타입은 식이 반환하는 값을 기술한다. 이는 int나 bool → bool처럼 값의 집합을 기술하는 친숙한 타입 식이다. 효과 타입은 e의 평가 중 발생할 수 있는 효과를 기술한다. 우선 “완전히 순수(pure)”(평가가 어떤 효과도 수행하지 않음)와 “불순수(impure)”(평가가 어떤 효과는 수행할 수 있음) 두 효과 타입만 고려한다. 더 정밀한 효과 타입은 13.5절에서 논한다.
타입·효과 시스템으로 순수성 추적.이제 FUN + 예외를 위한 단순 타입·효과 시스템을 제시한다. 값 타입과 효과 타입은 다음과 같다.
값 타입: τ, σ ::= bool ∣ … 기저 타입들
∣ exn 예외의 타입
∣ σ –[ϕ]→ τ 함수 타입(ϕ = 잠재(latent) 효과)
효과 타입: ϕ ::= 0 순수 계산(예외 없음)
∣ 1 불순수 계산(예외 발생 가능)
효과 시스템의 특징은 σ –[ϕ]→ τ로 확장된 함수 타입이다. 여기서 σ는 인자 값의 타입, τ는 결과 값의 타입, ϕ는 함수의 잠재 효과 즉, 함수 적용 시 수행될 수 있는 효과다. 이는 함수 추상에 대한 타이핑 규칙에서 분명하다.
Γ, x : σ ⊢ e : τ ! ϕ (abstr)
Γ ⊢ λ x . e : σ –[ϕ]→ τ ! 0
함수 본문 e의 효과 ϕ는 함수 추상 λ x . e의 잠재 효과가 된다. λ x . e 자체는 값이므로 평가가 어떤 효과도 수행하지 않는 순수 식이다.
Γ(x) = τ (var)
Γ ⊢ x : τ ! 0
c ∈ {true, false} (const)
Γ ⊢ c : bool ! 0
함수 추상과 마찬가지로 변수와 상수는 순수하다고 본다.
Γ ⊢ e : τ ! 0 (sub)
Γ ⊢ e : τ ! 1
어떤 식이 순수하면, 그 식을 맥락에 맞추기 위해 필요하다면 불순수로도 볼 수 있다.
Γ ⊢ e₁ : bool ! ϕ Γ ⊢ e₂ : τ ! ϕ Γ ⊢ e₃ : τ ! ϕ (cond)
Γ ⊢ if e₁ then e₂ else e₃ : τ ! ϕ
조건식 if e₁ then e₂ else e₃는 e₁, e₂, e₃가 모두 순수한 경우에만 순수하다. 이들 중 하나라도 예외를 발생시킬 수 있다면 조건식도 그럴 수 있다. 이를 포착하기 위해 세 식과 조건식 모두에 같은 효과 ϕ를 부여한다. (sub) 규칙으로 순수 식은 언제든 효과 1을 줄 수 있으므로, (cond) 규칙은 세 식 중 일부만 순수한 경우도 올바르게 다룬다.
Γ ⊢ e₁ : σ –[ϕ]→ τ ! ϕ Γ ⊢ e₂ : σ ! ϕ (app)
Γ ⊢ e₁ e₂ : τ ! ϕ
마찬가지로, 함수 적용 e₁ e₂가 순수하려면 e₁과 e₂가 순수해야 하고, e₁을 평가해 얻은 함수의 잠재 효과도 0이어야 한다. 이를 포착하기 위해 e₁, e₂, 함수의 잠재 효과, 적용 e₁ e₂에 모두 같은 ϕ를 부여한다.
Γ ⊢ e : exn ! ϕ (raise)
Γ ⊢ raise e : τ ! 1
예외 발생은 효과이므로, raise e는 효과 타입이 1인 불순수 식이다.
Γ ⊢ e₁ : τ ! 1 Γ, x : exn ⊢ e₂ : τ ! ϕ (try)
Γ ⊢ try e₁ with x → e₂ : τ ! ϕ
Γ ⊢ e₁ : τ ! 0 Γ, x : exn ⊢ e₂ : τ ! ϕ (try-pure)
Γ ⊢ try e₁ with x → e₂ : τ ! 0
예외 처리 try e₁ with x → e₂는 e₁이 발생시킬 수 있는 모든 예외를 잡는다. 빠져나갈 수 있는 예외는 e₂가 발생시키는 것뿐이다. 따라서 e₁의 효과는 무시되며, try의 효과는 e₂의 효과가 된다. 또한 e₁이 효과 0으로 타이핑될 수 있다면 e₁이 순수함을 안다. 이 경우 e₂는 평가되지 않으며 try 전체가 순수하다.
타입 안전성과 검사된 예외.위 타입·효과 시스템을 사용하면 미처리 예외의 부재를 증명할 수 있다. 즉, 프로그램 p가 효과 0으로 타이핑될 수 있다(⊢ p : τ ! 0)면, p의 실행은 미처리 예외로 중단될 수 없다. p가 발생시킬 수 있는 모든 예외는 p 내부에서 처리된다. 이를 보이려면 먼저 다음 보존성을 보인다.
보존성: 만약 ⊢ e : τ ! ϕ이고 e → e′이면 ⊢ e′ : τ ! ϕ
이제 ⊢ p : τ ! ϕ이고 p가 미처리 예외로 중단된다고 하자. 즉 p →* raise v (어떤 예외 값 v)에 이른다. 보존성에 의해 ⊢ raise v : τ ! ϕ이다. (raise) 규칙에 의해 ϕ는 1이어야 한다. 따라서 ⊢ p : τ ! 0이면, p는 미처리 예외로 중단될 수 없다.
단순 타입·효과의 한계. (abstr)와 (sub) 규칙에 따르면, λ x . x + 1 같은 순수 함수는 어떤 잠재 효과 ϕ도 가질 수 있다. 그러나 ϕ = 0이면 이 함수는 순수한 맥락에서만 호출될 수 있고, ϕ = 1이면 불순수한 맥락에서만 호출될 수 있다. 이는 제약적일 수 있다. 다음을 보자.
let use_pure (f: int –[0]→ int) = f 2 + f 3 let use_impure (f: int –[1]→ int) = if ... then f 4 else raise E
그러면 함수 λ f . use_pure f + use_impure f는 잘-타이핑되지 않는다. f에 int –[0]→ int를 주면 use_impure 호출이 잘못되고, f에 int –[1]→ int를 주면 use_pure 호출이 잘못된다.
이 단순화된 예는 함수의 잠재 효과에 대한 다형성을 지원하는 타입·효과 시스템이 필요함을 보여준다. 이는 13.5절과 13.6절에서 설명하듯 서브타입 다형성이나 매개변수 다형성으로 달성할 수 있다.
효과의 격자.효과 타입은 “효과가 더 적음”에서 “효과가 더 많음”으로 자연스럽게 순서화된다. 효과 타입 사이의 부분순서를 ⊆로 표기하자. 순수성, 즉 효과의 부재는 이 부분순서의 최소 원소다. 예를 들어 13.4절의 ϕ ::= 0 ∣ 1에서는 0 ⊆ 1이며 최소 원소는 0이다.
많은 타입·효과 시스템에서 효과 타입 ϕ는 원자적 효과의 유한 집합 {F₁, …, Fₙ}이며, 집합 포함으로 순서화된다. 공집합 ∅는 효과의 부재를 의미한다. 원자 효과 F는 여러 형태를 취할 수 있다.
포섭에서 서브타이핑으로.13.4절의 단순 타입·효과 시스템에서 (sub) 규칙은 순수 식은 언제든 불순수로 간주할 수 있음을 말한다. 더 일반적으로, 효과가 ϕ인 식은 항상 더 큰 효과 ϕ′ ⊇ ϕ로 간주할 수 있다.
Γ ⊢ e : τ ! ϕ ϕ ⊆ ϕ′ (sub1)
Γ ⊢ e : τ ! ϕ′
13.4절 끝의 예에서 보듯 이 타이핑 규칙만으로는 유연성이 부족하다. 때로는 함수의 잠재 효과를 “확장”하고 싶다. 예를 들어 순수 함수를 불순수 함수를 기대하는 맥락에서 사용하고 싶을 수 있다. 이를 위해 값 타입 τ, τ′ 사이에 서브타입 관계 τ <: τ′를 도입하고, 다음처럼 더 강한 규칙을 사용한다.
Γ ⊢ e : τ ! ϕ τ <: τ′ ϕ ⊆ ϕ′ (sub)
Γ ⊢ e : τ′ ! ϕ′
서브타이핑 관계 <:
τ <: τ
σ′ <: σ ϕ ⊆ ϕ′ τ <: τ′
σ –[ϕ]→ τ <: σ′ –[ϕ′]→ τ′
인자 타입에서는 반변(σ′ <: σ), 결과 타입과 잠재 효과에서는 공변(τ <: τ′, ϕ ⊆ ϕ′)임을 주목하라. 예를 들어 다음이 성립한다.
int –[0]→ int <: int –[1]→ int
순수 함수는 불순수로 볼 수 있으므로, 그리고
int –[1]→ (int –[0]→ int) <: int –[1]→ (int –[1]→ int)
순수 함수를 반환하는 함수는 불순수 함수를 반환하는 함수로 볼 수 있으므로. 하지만 다음도 성립한다.
(int –[1]→ int) –[1]→ int <: (int –[0]→ int) –[1]→ int
불순수 함수를 인자로 받는 함수는 그 인자를 순수 함수로 제한할 수 있으므로.
(sub) 규칙을 사용하면 이제 고차 함수 use_impure : (int –[1]→ int) –[1]→ int를 순수 함수 f : int –[0]→ int에 적용할 수 있다. f를 상위타입 int –[1]→ int로 보거나, use_impure를 상위타입 (int –[0]→ int) –[1]→ int로 보면 된다.
고차 함수에서의 서브타이핑 한계.자료구조에 대한 내부 이터레이터를 생각하자. 예를 들어 리스트에 대한 map 이터레이터.
let rec map f l = match l with [] -> [] | x :: l -> f x :: map f l
map 자체는 효과가 없다. map f l이 수행하는 효과는 f가 수행하는 효과다. 따라서 f가 순수하면 map f도 순수 함수로, 그렇지 않으면 불순수 함수로 타이핑되길 기대한다.
map: (σ –[0]→ τ) –[0]→ (σ list –[0]→ τ list) (i)
map: (σ –[1]→ τ) –[0]→ (σ list –[1]→ τ list) (ii)
그러나 이 둘은 서로의 서브타입이 아니며, 그 공통 서브타입 (σ –[1]→ τ) –[0]→ (σ list –[0]→ τ list)는 map의 올바른 타입이 아니다. 결과적으로 map 정의를 두 사본으로 나누어야 한다. (i)를 받는 map_pure와 (ii)를 받는 map_impure.
효과 타입에 대한 매개변수 다형성은 이 문제의 더 나은 해법을 제공한다. 효과 타입에 대한 변수 ρ를 추가하고, 13.3절의 값 타입 변수 α처럼 사용, 일반화, 인스턴스화할 수 있다. 특히 map 함수에 다음과 같은 고도로 다형적인 타입을 줄 수 있다.
map : ∀ α β ρ, (α –[ρ]→ β) –[0]→ (α list –[ρ]→ β list)
이 타입은 map 함수를, 매핑되는 함수의 인자 타입 α와 결과 타입 β뿐 아니라 그 잠재 효과 ρ에 대해서도 제네릭하게 만든다. 위 (i), (ii) 타입은 α = σ, β = τ, ρ = 0 또는 ρ = 1로 취한 이 다형적 타입의 인스턴스다.
매개변수 다형성과 효과 집합. “순수/불순수”보다 풍부한 13.5절의 원자 효과 집합에 대해서도 효과 다형성의 혜택을 누릴 수 있을까? 예를 들어 다음 함수를 생각하자.
let use f x = if x < 0 then raise Error else f x
이상적으로 use f x의 타입은, 이 표현이 f가 발생시킬 수 있는 모든 예외에 더해 Error 예외도 발생시킬 수 있음을 말해야 한다. 이를 위해 원자 효과의 확장 가능한 집합 {F₁, …, Fₙ} ∪ ρ를 도입한다. 이는 F₁, …, Fₙ과 더불어 효과 변수 ρ의 모든 효과를 포함한다. use의 원하는 타입은 다음과 같다.
use : ∀ α ρ, (int –[ρ]→ α) –[0]→ int –[{Error} ⋃ ρ]→ α
확장 가능한 집합은 포섭과 유사한 흥미로운 성질을 가진다. 확장 변수 ρ를 인스턴스화함으로써 더 많은 원자 효과를 집합에 추가할 수 있다.
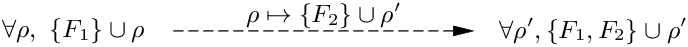
마찬가지로, 두 집합의 확장 변수를 인스턴스화하여 합집합을 취할 수 있다.
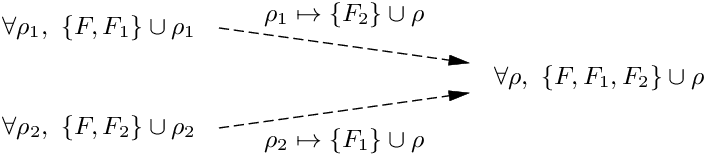
13.5절의 서브타이핑은 함수 인자 위치에서 반변이었지만, 효과 변수 인스턴스화에 기반한 이 포섭 개념은 모든 위치에서 공변이다. 13.7절의 시스템처럼, 어떤 타입·효과 시스템은 서브타이핑 규칙이 없고 포섭을 전적으로 효과 변수 인스턴스화로만 표현한다.
행(rows)과 행 다형성.타입의 행은 레코드와 객체에 대한 정밀한 타이핑과 타입 추론을 지원하기 위해 Wand (1987)이 도입하고 Rémy (1989)이 발전시켰다. 이는 확장 가능한 효과 집합의 아이디어를 엄밀하게 정식화해 준다. 행의 특징은, 집합의 어떤 원소가 “있음”뿐 아니라 “없음”도 표현할 수 있다는 점이다.
행: ϕ ::= ρ 행 변수
∣ ∅ 빈 행
∣ F: π; ϕ ϕ에 원소 F가 존재 여부 π로 추가됨
존재성: π ::= θ 존재성 변수
∣ Abs 부재
∣ Pre(τ) τ 타입으로 존재
행은 _치환(permutation)_과 _흡수(absorption)_에 대해 다음과 같이 다룬다.
F₁: π₁; F₂: π₂; ϕ = F₂: π₂; F₁: π₁; ϕ (permutation)
F: Abs; ∅ = ∅ (absorption)
행 변수 ρ에 대한 kind 시스템을 사용하여 행에 동일 원소 F가 중복 포함되지 않도록 보장할 수 있다. 이는 같은 원소 F에 대한 모순된 정보를 배제하고, 유니피케이션을 잘 정의하도록 만든다. 확장 가능한 집합 대신 행을 사용하면, 위 use 함수의 타입은 다음과 같다.
use : ∀ α ρ θ, (int –[Error: θ; ρ]→ α) –[0]→ int –[Error: Pre(unit); ρ]→ α
use에 넘기는 함수 f는 Error 효과가 있을 수도 없을 수도 있다(존재성 변수 θ로 표현). 그러나 use의 전체 적용은 확실히 Error 효과를 가지며(Pre(unit)), 인자로 받은 f가 가진 나머지 효과 ρ도 가진다.
이제 12.7절의 소규모 대수적 효과와 핸들러 언어를 위한 타입·효과 시스템을 발전시킨다. 이 시스템은 타입 안전성을 보장하고 “미처리 효과” 오류를 방지하는 것을 목표로 한다. Hillerström and Lindley (2016)에 기반하며, 효과 타입을 행으로 표현하고 서브타이핑 없이 행 다형성을 사용한다. 문법은 12.7절에서 약간 단순화했다.
Values: v ::= x ∣ c ∣ λ x.M
Computations: M, N ::= v v′ 적용(application)
∣ if v then M else N 조건식
∣ val v 사소한 계산
∣ do x ⇐ M in N 계산의 순서화
∣ perform F(v) 효과 수행
∣ with H handle M 효과 처리
Handlers: H ::= { val(x) → M_val;
F₁(x; k) → M₁;
⋮
Fₙ(x; k) → Mₙ }
값 타입과 효과 타입은 다음과 같다.
값 타입: τ, σ ::= α 변수
∣ int ∣ bool 기저 타입
∣ σ –[ϕ]→ τ 함수 타입
∣ ∀ α, τ ∣ ∀ ρ, τ ∣ ∀ θ, τ 다형성
효과 타입: ϕ ::= ρ ∣ ∅ ∣ F: π; ϕ 효과 F의 행
존재성 타입: π ::= θ ∣ Abs ∣ Pre(σ ↠ τ)
효과 타입에서 F: Pre(σ ↠ τ) 표기는, 이름이 F인 효과가 인자 타입 σ를 지니고 결과 타입 τ를 만드는 것으로 “존재함”을 의미한다. 13.2절과 달리, 효과 값에 대한 확장 가능한 데이터타입 τ eff는 없다. 효과 F는 단지 이름이며 사전에 정해진 고정 타입을 둘 필요가 없다. 수행자와 핸들러 사이의 타입 합의는 효과 타입이 담고 있는 Pre(σ ↠ τ) 정보가 보장한다.
값의 타이핑: Γ ⊢ v : τ
Γ(x) = τ (var)
Γ ⊢ x : τ
c ∈ {true, false} (const)
Γ ⊢ c : bool
Γ, x : σ ⊢ M : τ ! ϕ (abstr)
Γ ⊢ λ x . M : σ –[ϕ]→ τ
계산의 타이핑: Γ ⊢ M : τ ! ϕ
Γ ⊢ v₁ : σ –[ϕ]→ τ Γ ⊢ v₂ : σ (app)
Γ ⊢ v₁ v₂ : τ ! ϕ
Γ ⊢ v : bool Γ ⊢ M : τ ! ϕ Γ ⊢ N : τ ! ϕ (cond)
Γ ⊢ if v then M else N : τ ! ϕ
Γ ⊢ v : τ (ret)
Γ ⊢ val v : τ ! ϕ
Γ ⊢ M : σ ! ϕ Γ, x : σ ⊢ N : τ ! ϕ (bind)
Γ ⊢ do x ⇐ M in N : τ ! ϕ
Γ ⊢ v : σ (perform)
Γ ⊢ perform F(v) : τ ! (F : Pre(σ ↠ τ); ϕ)
Γ ⊢ M : σ ! ψ Γ ⊢ H : σ ! ψ ⇒ τ ! ϕ (handle)
Γ ⊢ with H handle M : τ ! ϕ
추가: α, ρ, θ 타입 변수의 일반화/인스턴스화 규칙.
핸들러의 타이핑: Γ ⊢ H : σ ! ψ ⇒ τ ! ϕ
ψ = F₁ : Pre(σ₁ ↠ τ₁); …; Fₙ : Pre(σₙ ↠ τₙ); ω
ϕ = F₁ : π₁; …; Fₙ : πₙ; ω
Γ, x : σ ⊢ M_val : τ ! ϕ Γ, x : σᵢ, k : τᵢ –[ϕ]→ τ ⊢ Mᵢ : τ ! ϕ for i = 1,…,n (deep)Γ ⊢ { val(x) → M_val; F₁(x, k) → M₁; …; Fₙ(x, k) → Mₙ } : σ ! ψ ⇒ τ ! ϕ
그림 13.2: 대수적 효과와 핸들러를 가진 언어를 위한 타입·효과 시스템.
그림13.2는 값, 계산, 핸들러에 대한 타이핑 규칙을 나열한다. “값은 있고(values are), 계산은 한다(computations do)”(P. Blain Levy)라는 말처럼, 값은 값 타입만 가지며(Γ ⊢ v : τ), 계산은 값 타입과 효과 타입을 함께 가진다(Γ ⊢ M : τ ! ϕ). 핸들러는 값/효과 타입 변환자로 타이핑된다(Γ ⊢ H : σ ! ψ ⇒ τ ! ϕ).
값에 대한 규칙은 놀랄 것 없다. (abstr) 규칙에서 함수 본문 M의 효과가 함수 추상 λ x . M의 잠재 효과가 된다.
값 v는 우리가 선택한 어떤 효과 타입 ϕ와 함께 사소한 계산 val v로 사용할 수 있다((ret) 규칙). 흔히 ϕ는 ∅나 효과 변수 ρ로, 효과의 부재를 표현하지만, 다른 타이핑 제약을 만족시키려면 다른 선택이 필요할 수도 있다. (bind) 규칙이 그런 예인데, do x ⇐ M in N으로 순서화되는 두 계산 M과 N 모두에 같은 효과 ϕ가 부여되어야 한다.
적용(app)과 조건(cond)에 대한 규칙은 13.4절의 대응 규칙의 단순화 버전이다. 처음으로 비자명한 행 타입을 사용하는 규칙은 효과 수행에 대한 것이다.
Γ ⊢ v : σ (perform)
Γ ⊢ perform F(v) : τ ! (F : Pre(σ ↠ τ); ϕ)
perform F(v)의 효과 타입은 공집합이 아니어야 하며, 인자 v의 타입 σ와 perform 식 결과의 타입 τ로 F가 존재함(Pre)으로 포함되어야 한다. 타입 σ와 τ는 F의 사전 선언에 붙는 것이 아니며, perform F 표현마다 다르게 사용할 수 있다.
with H handle M에 대한 규칙은 직관적이지만, 핸들러 H에 대한 규칙은 그렇지 않다.
Γ ⊢ M : σ ! ψ Γ ⊢ H : σ ! ψ ⇒ τ ! ϕ (handle)
Γ ⊢ with H handle M : τ ! ϕ
ψ = F₁ : Pre(σ₁ ↠ τ₁); …; Fₙ : Pre(σₙ ↠ τₙ); ω
ϕ = F₁ : π₁; …; Fₙ : πₙ; ω
Γ, x : σ ⊢ M_val : τ ! ϕ Γ, x : σᵢ, k : τᵢ –[ϕ]→ τ ⊢ Mᵢ : τ ! ϕ for i = 1,…,n (deep)
Γ ⊢ { val(x) → M_val; F₁(x, k) → M₁; …; Fₙ(x, k) → Mₙ } : σ ! ψ ⇒ τ ! ϕ
핸들러는 값/효과 타입 σ ! ψ를 τ ! ϕ로 변환한다. “이전”(ψ)과 “이후”(ϕ)의 두 행은 공통 접미사 ω를 공유하는데, 이는 처리되는 F₁,…,Fₙ 외의 다른 효과를 기술한다. Fᵢ는 ψ에 반드시 σᵢ ↠ τᵢ 타입으로 존재해야 하지만, ϕ에서는 우리가 선택한 아무 존재성 πᵢ나 가질 수 있다. 만약 핸들러의 각 분기 M_val, M₁,…,Mₙ이 Fᵢ를 수행하지 않는다면, πᵢ = Abs로 두어 해당 효과 Fᵢ가 완전히 처리되었음을 나타낼 수 있다.
핸들러의 모든 분기는 같은 타입 τ ! ϕ를 가져야 한다. 값 분기 val(x) → M_val은 처리되는 표현의 값 타입이 σ이므로 x: σ를 가정하고 타이핑된다. 각 효과 분기 Fᵢ(x, k) → Mᵢ는 x가 Fᵢ의 인자 타입 σᵢ를, k가 τᵢ –[ϕ]→ τ 타입(즉, Fᵢ의 결과 타입 τᵢ를 받아 τ를 만드는 연속)임을 가정하고 타이핑된다.
위 타이핑은 깊은(deep) 핸들러의 것이다. 얕은(shallow) 핸들러에서는 연속 k의 타입이 τᵢ –[ψ]→ σ로 바뀐다. 얕은 경우 연속은 핸들러의 범위 밖이므로, 그 타입과 효과는 처리되는 표현의 것(σ ! ψ)과 같다. 깊은 경우 연속은 처리되므로 핸들러의 것(τ ! ϕ)과 같다.
Hillerström and Lindley (2016)은 보존성과 진행성에 의한 논증으로 이 타입·효과 시스템의 정당성(soundness)을 보였다.
행 다형성은 타입·효과 시스템에 잘 들어맞는다. 이는 내부 이터레이터 같은 제네릭 고차 함수에 정밀한 타입을 부여할 뿐 아니라, Haskell, OCaml, SML 등에 있는 유니피케이션 기반 Hindley–Milner 타입 추론(Milner, 1978)도 지원한다. 그러나 Hindley–Milner 타입 추론은 서브타이핑과 양립하지 않으며, 모든 포섭을 행 변수 인스턴스화로만 표현해야 한다. 이는 이론적/실무적 한계를 갖는데, 이제 이를 논한다.
효과 타이핑의 부정확성. 행 다형성은 효과가 전파되는 방향을 고려하지 않는다. 이는 부정확한 타이핑을 낳을 수 있다. 다음을 보자.
g = λf: int –[ϕ]→ int. λb: bool.
handle (if b then f 0 else perform E ())
with { val(x) -> ret x; E(_, _) -> f 1 }
함수 f가 효과 E를 수행하는 것과 같은 조건식 안에서 호출되므로, f의 잠재 효과 ϕ는 E의 존재를 인정해야 한다.
ϕ = E: Pre(int ↠ int); ψ
그러나 핸들러에서의 f 1 적용은 ϕ 효과를 가지며, handle…with 전체도 마찬가지다. 그 결과, f가 E를 수행하지 않는 경우에도 E 효과가 항상 핸들러를 빠져나갈 수 있는 것처럼 보인다.
f에 τ₁ = ∀ ρ, int –[ρ]→ int나 τ₂ = ∀ θ, int –[E: θ; ϕ]→ int 같은 다형적 타입을 줄 수도 있다. 이 경우 핸들러의 효과 타입은 더 이상 E의 존재를 언급하지 않겠지만, 전체 함수 g는 (τ₁의 경우) 순수 함수나 (τ₂의 경우) E 효과를 수행하지 않는 함수에만 적용될 수 있다. f가 무엇을 하든 f와 정확히 같은 효과만을 갖는다는 것을 지정하는 g의 유효한 타입은 없다.
효과 타입의 장황함. 행은 많은 정보를 담는다. 이는 특히 타입 오류 메시지에서 읽기 어렵게 만든다. 소스 코드에서 직접 쓰는 것은 더 어렵다. Hindley–Milner 타입 추론은 값 타입과 함께 많은 효과 타입을 자동으로 추론해 주어 이 부담을 덜어줄 수 있다. 그러나 데이터 타입 정의나 모듈 인터페이스 등에서는 여전히 수동으로 타입을 써야 한다.
타입을 표시할 때, 타입의 전체 의미를 바꾸지 않는 효과 타입은 생략할 수 있다. 예를 들어 ∀ ρ, σ –[ρ]→ τ에서 ρ가 σ나 τ에 나타나지 않으면 순수 함수 타입 σ → τ로 표시할 수 있다. 마찬가지로, θ가 전칭되고 어디에도 나타나지 않는 행 F: θ; ϕ는 ϕ로 표시할 수 있다.
타입 선언을 직접 작성할 때, 평범한 함수 화살표 →는 순수 함수 타입으로 읽을 수 있다.
f: σ → τ ≡ f: ∀ ρ, σ –[ρ]→ τ
타입에 평범한 화살표가 여러 개 있으면, 보통 그 모두가 같은 행 변수 ρ를 공유하도록 해도 안전하다. 예를 들어:
f: (σ → bool) → (σ → τ) → σ list → τ list
≡ f: ∀ ρ, (σ –[ρ]→ bool) –[ρ]→ (σ –[ρ]→ τ) –[ρ]→ σ list –[ρ]→ τ list
드물게 이러한 해석이 함수 f의 실제 구현에 너무 제한적일 수도 있다. 예를 들어 구현이 σ → bool 인자를 결코 호출하지 않는다면 그렇다. 이 경우 선언에 더 정밀한 효과 타입을 명시할 수 있다.
행 타입 닫기와 다시 열기.13.7절의 시스템에서, 행 변수 ρ로 끝나는 “열린(open)” 행 타입은, 공집합 ∅로 끝나는 “닫힌(closed)” 행 타입보다 더 유연하다. 그러나 닫힌 행 타입은 이해하기 쉽고 표시가 간단하다.
Leijen (2017)은 함수의 잠재 효과에 대해 “열린” 행과 “닫힌” 행 사이를 변환할 수 있음을 관찰한다. 변수 ρ로 끝나는 행을 닫으려면, 먼저 ρ를 일반화한 뒤 ∅로 인스턴스화하면 된다.
Γ ⊢ e : σ –[F₁: π₁; …; Fₙ: πₙ; ρ]→ τ ! ϕ ρ ∉ FV(σ, τ, π₁,…, πₙ) (close)
Γ ⊢ e : σ –[F₁: π₁; …; Fₙ: πₙ; ∅]→ τ ! ϕ
반대로, 닫힌 행의 마지막 ∅를 행 변수 ρ, 또는 더 일반적으로 임의의 행 ψ로 바꾸어 다시 열 수 있는 다음 타이핑 규칙을 추가할 수 있다.
Γ ⊢ e : σ –[F₁: π₁; …; Fₙ: πₙ; ∅]→ τ ! ϕ (open)
Γ ⊢ e : σ –[F₁: π₁; …; Fₙ: πₙ; ψ]→ τ ! ϕ
Leijen (2017)은 let 바인딩을 타이핑할 때 (close) 규칙을 사용해, 타입 일반화 전에 가능한 한 많은 행 변수를 제거하고, let으로 바인딩된 변수를 사용할 때 (open) 규칙으로 열린 행의 유연성을 되찾을 것을 제안한다.
타입·효과 시스템에 대한 보다 추상적인 소개는 타입 시스템 관점의 Henglein et al. (2005)와 정적 분석 관점의 Nielson et al. (1999)에 있다. 타입 추론에 관한 참고서로 Pottier and Rémy (2005)가 있으며, 행 타입에 대한 장을 포함한다.
값 제한은 가변 상태와 제어 연산자를 매개변수 다형성과 조화시키는 데 핵심적이다. Garrigue (2004)의 완화된 값 제한(relaxed value restriction)처럼 서브타입 다형성의 아이디어와 결합해 더 유연하게 만들 수 있으며, 이는 OCaml에서 사용된다. 다형적 참조 문제에 대한 초기 해법으로는 참조 할당 효과를 추적하는 타입·효과 시스템(Talpin and Jouvelot, 1994)이 있으나, 값 제한보다 훨씬 복잡하다.
실험적 언어 Koka(https://koka-lang.github.io)는 행 다형성을 갖춘 타입·효과 시스템을 사용해 대수적 효과를 정적으로 제어한다(Leijen, 2014, Leijen, 2017). 오늘날 사용 가능한 타입·효과 시스템 구현 중 가장 진보되고 실용적인 사례라 할 수 있다.
Wadler and Thiemann (2003)은 단순 효과 시스템과 모나드 계층 사이의 대응을 구축한다. F* 언어(Swamy et al., 2016)는 이러한 모나드 계층을 효과의 타이핑에 사용한다.